© 2007 elsevier lecture 6: embedded processors embedded computing systems mikko lipasti, adapted...
TRANSCRIPT

© 2007 Elsevier
Lecture 6: Embedded Processors
Embedded Computing Systems
Mikko Lipasti, adapted from M. Schulte
Based on slides and textbook from Wayne Wolf

High Performance Embedded Computing
© 2007 Elsevier
Topics
Embedded microprocessor market. Categories of CPUs. RISC, DSP, and Multimedia processors. CPU mechanisms.

High Performance Embedded Computing
© 2007 Elsevier
Demand for Embedded Processors
Embedded processors account for Over 97% of total
processors sold Over 60% of total sales from
processors Sales expected to
increase by roughly 15% each year

High Performance Embedded Computing
© 2007 Elsevier
Flynn’s taxonomy of processors Single-instruction single-data (SISD) Single-instruction multiple-data (SIMD) Multiple-instruction multiple-data (MIMD) Multiple-instruction single data (MISD)
What is an example of each? Which would you expect to see in embedded
systems?

High Performance Embedded Computing
© 2007 Elsevier
Other axes of comparison
RISC vs. CISC---Instruction set style. Instruction issue width. Static vs. dynamic scheduling for multiple-
issue machines. Scalar vs. vector processing. Single-threaded vs. multithreading. A single CPU can fit into multiple categories.

High Performance Embedded Computing
© 2007 Elsevier
Embedded vs. general-purpose processors Embedded processors may be customized
for a category of applications. Customization may be narrow or broad.
We may judge embedded processors using different metrics: Code size. Energy efficiency. Memory system performance. Predictability.

High Performance Embedded Computing
© 2007 Elsevier
Embedded RISC processors RISC processors often
have simple, highly-pipelinable instructions
Pipelines of embedded RISC processors have grown over time: ARM7 has 3-stage
pipeline. ARM9 has 5-stage
pipeline ARM11 has 8-stage
pipeline.
ARM11 pipeline [ARM05].

High Performance Embedded Computing
© 2007 Elsevier
RISC processor families ARM:
ARM7 has in-order execution, and no memory management or branch prediction;
ARM9 ARM11 has out of order execution, memory management, and branch prediction,
MIPS: MIPS32 4K has 5-stage pipeline; 4KE family has DSP extension; 4KS is designed for security.
PowerPC: PowerPC 400 series includes several embedded processors; Motorola and IBM offer superscalar versions of the PowerPC

High Performance Embedded Computing
© 2007 Elsevier
Embedded DSP Processors
DSP processors feature Deterministic execution times Fast multiply-accumulate instructions Multiple data accesses per cycle Specialized addressing modes Efficient support for loops and interrupts Efficient processing of “streaming” data
Embedded DSP processors are optimized to perform DSP algorithms; speech coding, filtering, convolution, fast Fourier transforms, discrete cosine transforms
y b xk n k nn
N
0

High Performance Embedded Computing
© 2007 Elsevier
Example: TI C55x/C54x DSPs 40-bit arithmetic (32-bit values + 8 guard bits). Barrel shifter. 17 x 17 multiplier. Two address generators. Lots of special purpose registers and
addressing modes Coprocessors for compute-intensive functions
including pixel interpolation, motion estimation, and DCT/IDCT computations

High Performance Embedded Computing
© 2007 Elsevier
TI C55x microarchitecture

High Performance Embedded Computing
© 2007 Elsevier
Parallelism extraction
Static: Use compiler to
analyze program. Simpler CPU. Can’t depend on data
values. VLIW
Dynamic: Use hardware to
identify opportunities. More complex CPU. Can make use of data
values. Superscalar

High Performance Embedded Computing
© 2007 Elsevier
VLIW architectures
Each very long instruction word (VLIW) erforms multiple operations in parallel
Needs a good compiler that understands the architecture Allows deterministic execution times Code growth can be reduced by allowing
Operations within an instruction to be performed sequentially
A given field to specify different types of operations
Branch Memory Memory Arithmetic Logic Vector
Branch/Mem Mem/Arith VectorArith/LogicSeq

High Performance Embedded Computing
© 2007 Elsevier
Simple VLIW architecture Large register file feeds multiple function
units.
Register file
E boxAdd r1,r2,r3; Sub r4,r5,r6; Ld r7,foo; St r8,baz; NOP
ALU ALU Load/store Load/store FU

High Performance Embedded Computing
© 2007 Elsevier
Clustered VLIW architecture Register file, function units divided into clusters. What are advantages/disadvantages of having clusters in
VLIW architectures?
Execution
Register file
Execution
Register file
Cluster bus

High Performance Embedded Computing
© 2007 Elsevier
TI C62x/C67x DSPs VLIW with up to 8 instructions/cycle. 32 32-bit registers. Function units:
Two multipliers. Six ALUs.
All instructions execute conditionally.

High Performance Embedded Computing
© 2007 Elsevier
TI C6x data operations
8/16/32-bit arithmetic. 40-bit operations. Bit manipulation operations. C67x processors add floating-point
arithmetic.

High Performance Embedded Computing
© 2007 Elsevier
C6x block diagram
Data path 1/Reg file 1
Data path 2/Reg file 2
Execute DMA
timers
Serial
Program RAM/cache512K bits
Data RAM512K bits
JTAG
PLL
bus

High Performance Embedded Computing
© 2007 Elsevier
Texas Instruments C62x
N. Seshan, “High VelociTI processing [Texas Instruments VLIW DSP architecture]”, IEEE Signal Processing Magazine, v. 15, no. 2, pp. 86-101, 117, 1998.

High Performance Embedded Computing
© 2007 Elsevier
Emerging DSP Architectures
Parallelism at multiple levels Multiple processors
System-on-a-chip designs Multiple simultaneous tasks
Multithreaded processors Multiple instruction per cycle
Very Long Instruction Word (VLIW) architectures Multiple operation per instruction
Single Instruction Multiple Data (SIMD) instructions Architecture/compiler pairs improve performance
and help manage application complexity

High Performance Embedded Computing
© 2007 Elsevier
Superscalar processors Instructions are dynamically scheduled.
Dependencies are checked at run time in hardware.
Used to some extent in embedded processors. Embedded Pentium is two-issue in-order. Some PowerPCs are superscalar
What advantages/disadvantages do VLIW processors compared to superscalar?

High Performance Embedded Computing
© 2007 Elsevier
SIMD and subword parallelism Many special-purpose SIMD machines
All processors perform same operation on different data
Subword parallelism is widely used for video. ALU is divided into subwords for independent
operations on small operands. Vector processing is another form of SIMD
processing Lots of times these terms are interchanged

High Performance Embedded Computing
© 2007 Elsevier
SIMD Instructions
Recent multimedia processors commonly support Single Instruction Multiple data (SIMD) instructions
The same operation is performed on multiple data operands using a single instruction
Exploits low precision and high data parallelism of multimedia applications
A3 A2 A1 A0
B3 B2 B1 B0
A3+B3 A2+B2 A1+B1 A0+B0

High Performance Embedded Computing
© 2007 Elsevier
Operand characteristics in MediaBench

High Performance Embedded Computing
© 2007 Elsevier
Dynamic behavior of loops in MediaBench The loops of media
applications in many cases are not very deep
Path ratio = (instructions executed per iteration) / (total number of loop instructions).
What does the path ratio reveal?

High Performance Embedded Computing
© 2007 Elsevier
TriMedia TM-1 characteristics
Characteristics Floating point support Sub-word parallelism
support VLIW Additional custom
operations

High Performance Embedded Computing
© 2007 Elsevier
Trimedia TM-1memory interface
video in
audio in
I2C
timers
image co-p
PCI
video out
audio out
serial
VLD co-p
VLIW CPU
High Performance Embedded Computing
© 2007 Elsevier
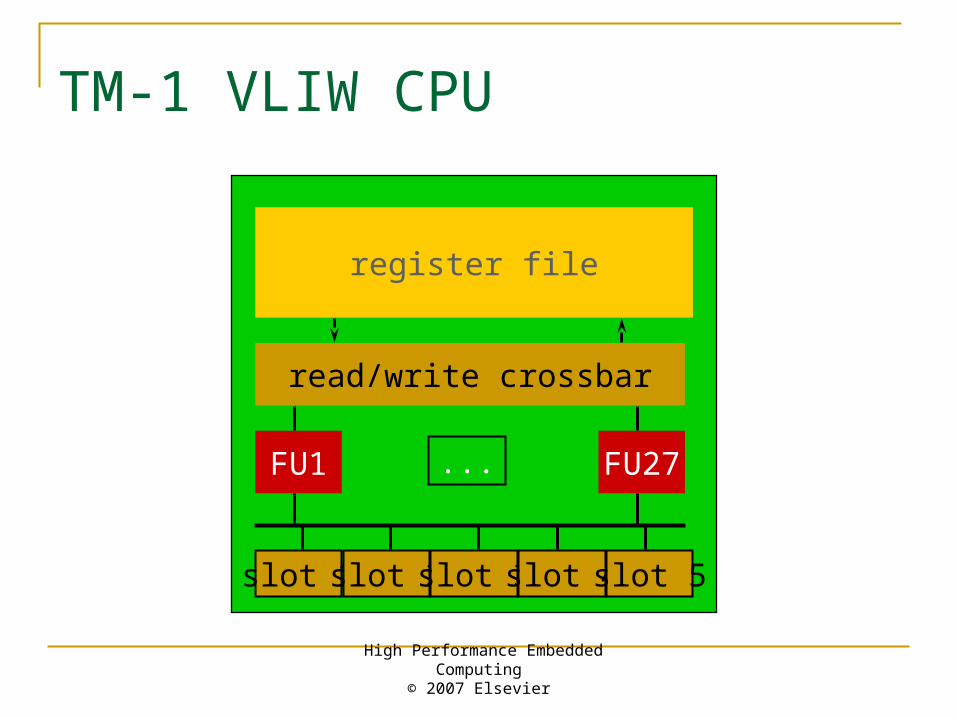
TM-1 VLIW CPU
register file
read/write crossbar
FU1 FU27
slot 1 slot 2 slot 3 slot 4 slot 5
...

High Performance Embedded Computing
© 2007 Elsevier
Multithreading Low-level parallelism mechanism. Interleaved multithreading (IMT) alternately
fetches instructions from separate threads. Often used with VLIW and vector processors
Simultaneous multithreading (SMT) fetches instructions from several threads on each cycle. Often used with superscalar processors
What advantages/disadvantages does IMT have relative to SMT?

High Performance Embedded Computing
© 2007 Elsevier
Dynamic voltage scaling (DVS) Power scales with V2
while performance scales roughly as V.
Reduce operating voltage, add parallel operating units to make up for lower clock speed.
DVS doesn’t work well in processors with high-leakage power.

High Performance Embedded Computing
© 2007 Elsevier
Dynamic voltage and frequency scaling (DVFS) Scale both voltage and
clock frequency. Can use control
algorithms to match performance to application, reduce power.

High Performance Embedded Computing
© 2007 Elsevier
Razor architecture
Razor runs clock faster than worst case allows
Used specialized latch to detect errors.
Recovers only on errors, gains average-case performance.