© 2008 ibm corporation regular expression learning for information extraction yunyao li *,...
TRANSCRIPT

© 2008 IBM Corporation
Regular Expression Learning for Information Extraction
Yunyao Li*, Rajasekar Krishnamurthy*, Sriram Raghavan*, Shivakumar Vaithyanathan*, H. V. Jagadish○
*IBM Almaden Research Center
○ University of Michigan
http://www.almaden.ibm.com/cs/projects/avatar/

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
Importance of Regular Expression (Regex)
Regex is essential to many information extraction (IE) tasks
Email addresses
Software names
Credit card numbers
Social security numbers
Gene and Protein names
….
But … writing regexes for an IE task is not straightforward
Web collections
Email compliance
bioinformatics

© 2008 IBM Corporation
Phone Number Extraction
A simple pattern:
blocks of digits separated by non-word character:
R0 = (\d+\W)+\d+
Identifies valid phone numbers (e.g. 800-865-1125, 725-1234)
Produces invalid matches (e.g. 123-45-6789, 10/19/2002, 1.25 …)
Misses valid phone numbers (e.g. (800) 865-CARE)

© 2008 IBM Corporation
Software Name Extraction
A simple pattern:
blocks of capitalized words followed by version number:
R0 = ([A-Z]\w*\s*)+[Vv]?(\d+\.?)+
Identifies valid software names (e.g. Eclipse 3.2, Windows 2000)
Produces invalid matches (e.g. English 123, Room 301, Chapter 1.2)
Misses valid software names (e.g. Windows XP)

© 2008 IBM Corporation
Conventional Regex Writing Process for IE
Regex0
SampleDocuments
Match 1Match 2
…
Good Enough?
N
YRegexfinal
(\d+\W)+\d+(\d+\W)+\d{4}
800-865-1125725-1234…123-45-678910/19/20021.25…
Regex1Regex2Regex3 (\d+[\.\s\-])+\d{4}(\d{3}[\.\s\-])+\d{4}

© 2008 IBM Corporation
Our goal - Learning Regexfinal automatically
Regex0
SampleDocuments
Match 1Match 2
…
NegMatch 1…
NegMatch m0
PosMatch 1…
PosMatch n0
Labeled Matches ReLIERegexfinal

© 2008 IBM Corporation
Intuition
R0 ([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\ [a-zA-Z] {0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,2}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
…
([A-Z][a-zA-Z]{1,10}\s){2,4}\s*(\w{0,2}\d[\.]?){1,4}
…
Compute F-measure
F1
F7
F8
F34
F48
…
((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4} F35
R’
([A-Z] [a-z] {1,10}\s){1,5}\s*( [a-zA-z] {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s) {1,2} \s*(\\w{0,2}\d[\.]?){1,4}
(((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
……
([A-Z] [a-z] {1,10}\s){1,5} \s*( \d {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5} \s*(\\w{0,2}\d[\.]?){1,3}
……
([A-Z] [a-z] {1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
…………..
……
…
……
…
• Generate candidate regular expressions by modifying current regular expression• Select the “best candidate” R’• If R’ has better than current regular expression, repeat the process

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
Regex Learning Problem
Ideally:
find the best Rf among all possible regexes
How do we define the best?
Highest F-measure over a document collection D.
We can only compute F-measure based on the labeled data
Must limited Rf such that any match of Rf is also a match of R0

© 2008 IBM Corporation
Regex Learning as a Search Problem
+ ++
+
+
+
+
+
+
+
+
+
+
+
+
+
+
++
+
+
+
+
+
+
+
+
+
++
+++
++
++
+
+
+
+
+
+
++
+
++
+
+ ++
+
++
+
++
++
+
++
+
+
++
--
-
-
-
--
--
-
--
-
--
--
--
--
-
--
--
-
-
-
---
-
-
--
--
--
-
--
-
-
-
--
--
--
---
-- --
- --
- --
--
-
- --
+ +--- --
-
--
-
-
-
---
--M(R0, D)M(Rf, D)
M(R, D): Matches of R over document collection D.

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
Two Regex Transformations
Drop-disjunct Transformation:
R = Ra(R1| R2|… Ri| Ri+1|…| Rn) Rb R’ = Ra (R1| … Ri|…) Rb
Include-Intersect Transformation
R = RaXRb R’ = Ra(XY) Rb
where Y

© 2008 IBM Corporation
(\d+\W)+\d+ (\d{3}\W)+\d+
Applying Drop-Disjunct Transformation
Character Class Restriction
E.g. To restrict the matching of non-word characters
(\d+\W)+\d+ (\d+[\.\s\-])+\d+
Quantifier Restriction
E.g. To restrict the number of digits in a block

© 2008 IBM Corporation
Applying Include-Intersect Transformation
Negative Dictionaries
Disallow certain words from matching specific portions of the regex
E.g. a simple pattern for software name extraction:
blocks of capitalized words followed by version number:
R0 = ([A-Z]\w*\s*)+[Vv]?(\d+\.?)+
Identifies valid software name (e.g. Eclipse 3.2, Windows 2000)
Produces invalid matches (e.g. ENGLISH 123, Room 301, Chapter 1.2)
([A-Z]\w*\s*)+[Vv]?(\d+\.?)+ ( [A-Z]\w*\s*)+[Vv]?(\d+\.?)+((?! ENGLISH|Room|Chapter)

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
ReLIE Algorithm
Chara
cter c
lass
restr
iction
s
Quantifierrestrictions
Negativedictionary
R0 ([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\ [a-zA-Z] {0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,2}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
…
([A-Z][a-zA-Z]{1,10}\s){2,4}\s*(\w{0,2}\d[\.]?){1,4}
…
Compute F-measure
F1
F7
F8
F34
F48
…
((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4}
Chara
cter c
lass
restr
iction
s
Quantifierrestrictions
Negativedictionary
F35
R’
([A-Z] [a-z] {1,10}\s){1,5}\s*( [a-zA-z] {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s) {1,2} \s*(\\w{0,2}\d[\.]?){1,4}
(((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
……
([A-Z] [a-z] {1,10}\s){1,5} \s*( \d {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5} \s*(\\w{0,2}\d[\.]?){1,3}
……
([A-Z] [a-z] {1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
…………..
……
…
……
…
• Generate candidate regular expressions by applying a single transformation• Select the “best candidate” R’ based on F-measure on training corpus • If R’ has better F-measure than current regular expression, repeat the process• Use validation set to avoid over-fitting

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
Experimental Set Up
Data Set
EWeb: 50K web pages from IBM intranet
AWeb: 50K web pages from University of Michigan web site.
• AWeb-S: subset of 10K pages from AWeb
Email: 10K emails from Enron collection
Extraction TasksSoftwareNameTask CourseNumberTask
PhoneNumberTask URLTask
Comparison Study
ReLIE
Conditional Random Fields (CRF):
• Base feature set– matches corresponding to the input regex
– three adjacent words to each side of the matches
© 2008 IBM Corporation
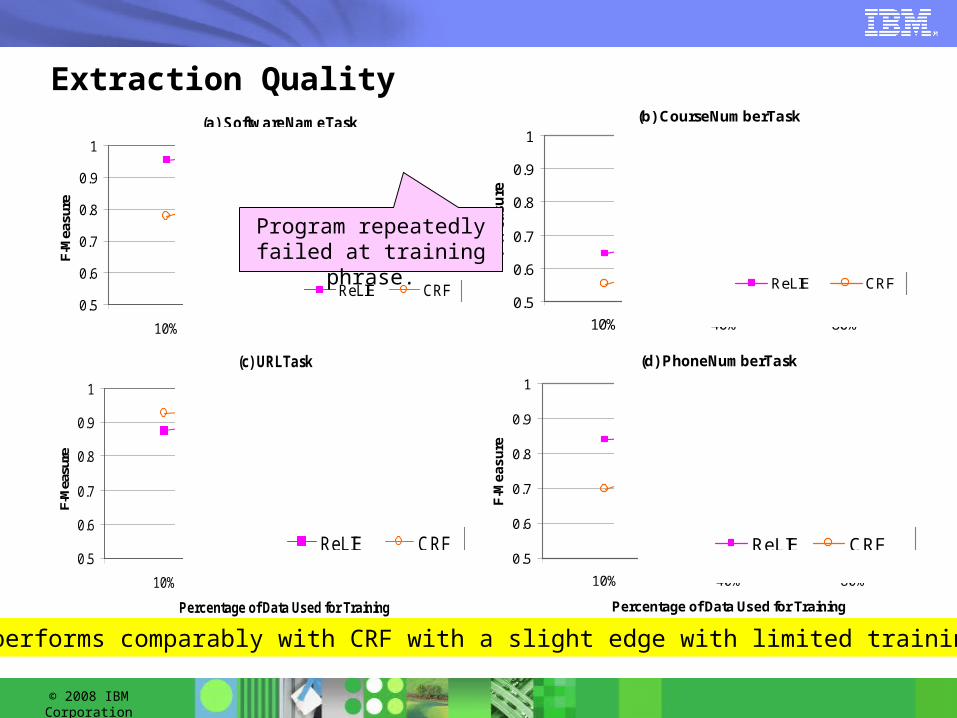
Extraction Quality(a) SoftwareNameTask
0.5
0.6
0.7
0.8
0.9
1
10% 40% 80%
Percentage of Data Used for Training
F-M
easu
re
ReLIE CRF
(b) CourseNumberTask
0.5
0.6
0.7
0.8
0.9
1
10% 40% 80%
Percentage of Data Used for Training
F-M
easu
re
ReLIE CRF
(c) URLTask
0.5
0.6
0.7
0.8
0.9
1
10% 40% 80%
Percentage of Data Used for Training
F-M
easu
re
ReLIE CRF
(d) PhoneNumberTask
0.5
0.6
0.7
0.8
0.9
1
10% 40% 80%
Percentage of Data Used for Training
F-M
ea
su
re
ReLIE CRF
ReLIE performs comparably with CRF with a slight edge with limited training data
Program repeatedly failed at training phrase.

© 2008 IBM Corporation
(a) SoftwareNameTask training: EWeb, testing: AWeb
0
0.2
0.4
0.6
0.8
1
10% 40% 80%
F-M
easu
re
ReLIE CRF
Cross-domain Evaluation
(c) URLTask training: Aweb-S, testing: Email
0
0.2
0.4
0.6
0.8
1
10% 40% 80%Percentage of Data Used for Training
F-M
ea
su
re
ReLIE CRF
(d) PhoneNumberTask training: Email testing: AWeb
0
0.2
0.4
0.6
0.8
1
10% 40% 80%Percentage of Data Used for Training
F-M
easu
re
ReLIE CRF
ReLIE significantly outperforms CRF for all three tasks
(b) CourseNameTask is not tested, as course names exist only in AWeb.

© 2008 IBM Corporation
Performance
ReLIE is an order of magnitude faster than CRF for both training and testing
Average Training/Testing Time (sec)(with 40% data for training)

© 2008 IBM Corporation
What has ReLIE learned?
Patterns learned by ReLIE are similar to features manually given to CRF

© 2008 IBM Corporation
ReLIE as Feature Extractor for CRF
C+RL: CRF + features learned by ReLIE
• Token level features learned by ReLIE• helpful when the training data is small
• Character level features learned by ReLIE• always helpful

© 2008 IBM Corporation
Outline
Motivation
Regex Learning Problem
Regex Transformations
ReLIE Search Algorithm
Experiments
Summary

© 2008 IBM Corporation
ReLIE
Effective for learning regexes for certain classes of IE
Particularly useful when
cross-domain, or
limited training data
Potentially becoming a powerful feature extractor for CRF and other machine learning algorithms.

© 2008 IBM Corporation
http://www.almaden.ibm.com/cs/projects/avatar/