© 2009 vmware inc. all rights reserved vmware vcenter operation manager karoly szalai, technical...
TRANSCRIPT

© 2009 VMware Inc. All rights reserved
VMware vCenter Operation Manager
Karoly Szalai, Technical Support Engineer
CCNP, VCP 3/4/5, VCAP4-DCA

2
Agenda
What is vCOPs and why is it good for me?
An example scenario
Counters and badges

3
Managing Performance/Capacity in vSphere: the basics
Is it optimised?
• Which VMs need adjustment?
• What are my keyratios?
• How much can I claim back from “fat” VMs?
• How many more VMs can I put without impacting performance?
Is it healthy?
• Every VM & ESX performing well? CPU, RAM, Network, Disk?
• Are they behaving expectedly?
• Any fault on any component?
Is it enough?
• Enough CPU, RAM, Network, Disk? Future risk?
• Time remaining?
• Capacity remaining?
• Where are the “Stress points”in time?
What is vCOPs? Is this just an another monitoring system? Boring! We already have the best (nagios, zabbix, HP openview, etc.)
No, it’s more than just a monitoring system!

4
vCOPs is built to complement vCenter
Is it healthy = Health
• Workload
• Anomalies
• Faults
Is it enough = Risk
• Time remaining
• Capacity remaining
• Stress period
Is it optimised = Efficiency
• What we can reclaim?
• Density, key ratio!
Daily update at midnight!

5
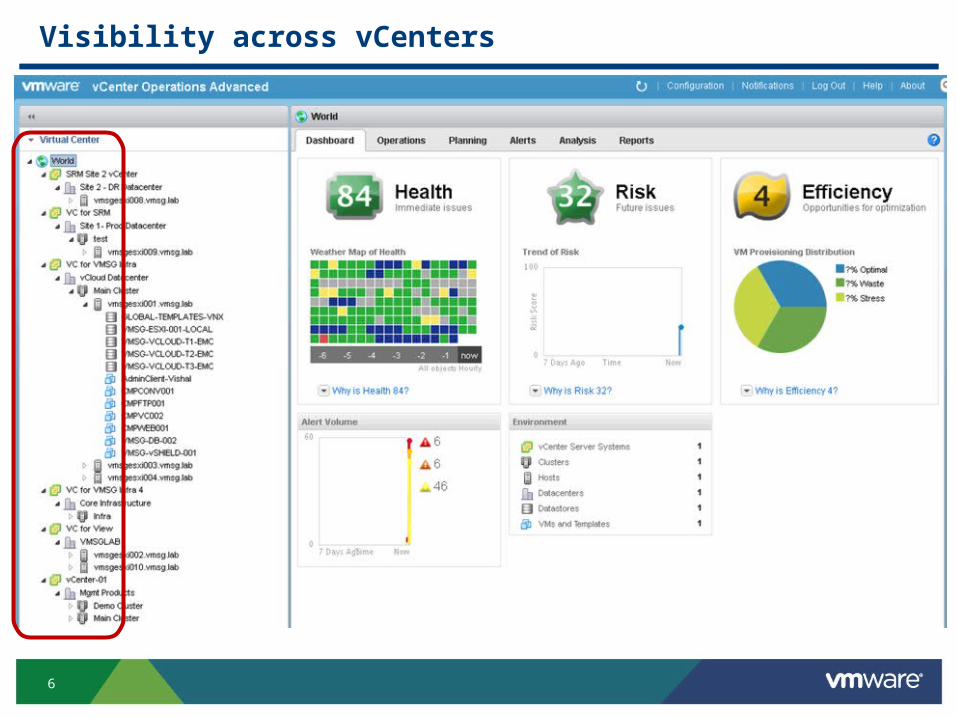
Bird-eye view
This is a small environment 1 vCenter
1 Datacenter
2 clusters
4 hosts
9 VMs (including off)
2 datastore
6
Visibility across vCenters

7
Everyday task: performance troubleshooting
You got an email from the app team, saying the main intranet application was slow
• The email was 1 hour ago. The email stated it was slow for about 1 hour and it was ok after that
• (So it was slow between 1-2 hours ago, but it’s ok now. Helpful, isn’t it?)
• You just checked. Everything is indeed ok in the past 1 hour.
• The application spans 10 VMs in 2 different clusters, 4 datastores and 1 RDM
• You are not familiar with the applications. You don’t know what apps runs on each VM as you have no access to
the Guest OS
• Your environment: 1 VC, 4 clusters, 35 hosts 500+ VM, 30 datastores, 1 midrange array, 10GE FCoE
How do you approach/solve this with just vCenter?
What do you do? A: smile, as this will be a nice challenge for your TAM/BCS/MCS engineer
B: no sweat, you’re VCDX,CCIE, ITIL master + you can fix your storage fw with a hex editor. You’re born for this
C: send a text: “Honey, this evening is cancelled, I got a better offer”
D: Buy a dinner to app team, and tell them to keep quiet.

8
Everyday task: performance troubleshooting
The minimum you need to prove
• Performance problem is not caused by your infrastructure, not by your VMware
• Infrastructure: VMware + Storage + Network
• Application: VM + App inside the VMs
What you should be able to prove
• For each VM, the following was ok during the incident: CPU, RAM, Disk, network
• The shared infrastructure was also healthy: ESXi, datastore, overall platform
Ideally you can prove
• Show the exact application level counter that are slow, with the underlying infrastructure-level counter that caused it = Root Cause Analysis

9
Challenge 1: details are lost after 1 hour
The first problem is: vCenter stores only 1 hour worth of data in depth. After an hour, a lot of details are no longer available!
In real time performance we have 2 cores info + 16 different counters
In past day stats we have only CPU info of VM and 6 counters only! A typical ESX host has 12-24 cores. What if the problem with vSMP?

10
Challenge 1: details are lost after 1 hour
<1 hour >1 hour
Memory Counters
<1 hour >1 hour
Disk Counters

11
In the meantime in vCOPs

12
Challenge 2: vSphere and applications
Here is the second challenge: vSphere has no application-awareness! You have a little idea what the 10 VMs make up the application
What services are running on each VM
Only thing you can do is to group them via vAPP like vCOPs:

13
In the meantime in vCOPs
Same application
• Health is 89, so it’s good
• It’s been good in the past 6 hours
• The app consists 4 components: distribution, analysis, collection and presentation
• We know there are only 2 VMs. So you’re getting app-level data here!
• You can double click on each metric to dig deeper, but full HD resolution recommended
• You can configure your tab as you like it.

14
Another plus is Infrastructure navigator
Infrastructure navigator is a separate component in vCOPs (enterprise or higher level)
VIN can answer for the following questions:
• How many VMs make up this application?
• What services are running on each VM?
• Who are talking to who? Using what ports?
• Which VMs are protected with DR? You can even tell which SRM protection group and SRM protection plan are involved.
VIN requires vCenter 5, as it relies on web client (new UI standards)

15
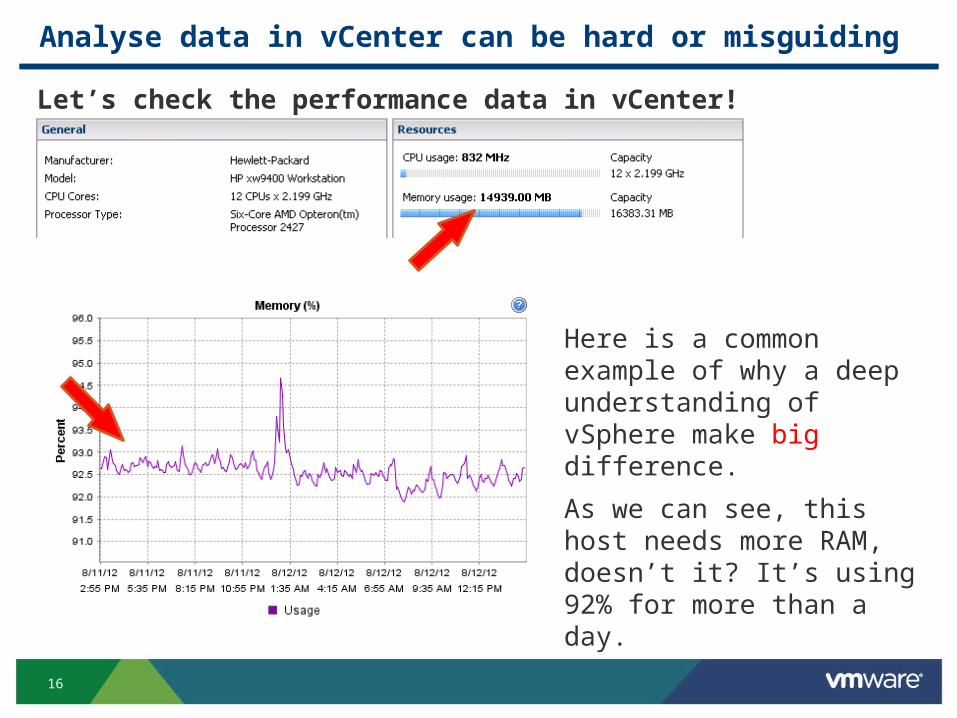
Analyse data in vCenter can be hard or misguiding
Hey! There is an
alarm with high
memory usage!
It’s above 90% for
more than 5 mins!
THIS IS BAD! WE NEED TO BUY MORE RAM! NOW!
16
Analyse data in vCenter can be hard or misguiding
Let’s check the performance data in vCenter!
Here is a common example of why a deep understanding of vSphere make big difference.
As we can see, this host needs more RAM, doesn’t it? It’s using 92% for more than a day.

17
In the meantime in vCOPs
Configured memory: 16.383 MB
Demand: 5.574 MB (36% of Usable)
Usage: 15.147MB (98% of Usable)
Usable: 15.43 MB
Normal demand: 4.672 – 8.843 MB
Plenty of headroom! It just saves us from a costly RAM upgrade project!

18
Counters and badges
A vCenter farm with only 50 ESXi host and 500 VM will have 10000< counters!
• It is impossible to look at them, so let vCOPS to analyse them.
vCenter presents raw counters
• i.e. what does Ready time of 1500 in Real Time chart mean? Is value of 2000 in Real Time chart better than value of 75000 in Daily chart?
• Is memory usage at 90% at ESXi level good or bad?
• Is IOPs of 300 good or bad for datastore XYZ?
Single counter can be misleading
• Low CPU usage does not mean VM is getting the CPU, if there is limit, contention and co-stop.
• Disk performance measured with different counters at multiple layers (VM, kernel, physical)
Different counters have different units
• GHz, %, MB, kbps, IO/s, ms
• This make analysis even more complex
Derived countersStandardises the scale into 0 - 100
1 universal unit, minimse the “translation” in our head
Can be >100 if demand is unmet
Universal. Apply to CPU, RAM, Disk, Net etc.
Counters derived using sophisticated formula, not just aggregated.
For the same counter, different objects use different formula

19
Thresholds: vCOPs does differently
vCenter sets static threshold, which can be misleading
• During peak time, it is common for VM to reach high utilisation
• Static threshold will generate alerts when it should not
• vSphere admins quickly learn to ignore them, defeating the purpose of alert to begin with
• During non-peak, it might be abnormal for VM to reach even 50% utilisation
• Static threshold will not generate alerts when it should have
vCenter only sets high threshold
• Do you have any threshold when CPU or RAM utilisation drops below 5%?
• A drop in entire array storage IOPs might be a sign of terrible day ahead
• Will not alert when:
• Utilisation drops from 75% to 1% when it should not
• Utilisation change from 5% to 75% when it should not
• We need to plots both upper and lower range!
Each VM differs. The same VM differs depending on day/time
• Intelligence required to analyse each metrics and their expected “normal” behaviour

20
Dynamic threshold & alerts
vCenter Operations uses dynamic threshold
• It is dynamic and personalized down to individual metric.
• Varies from object to object. 1000 VM will have their own threshold.
• Varies from time to time. The same CPU Usage counter has different threshold at different time. This cater for
peak. See the chart below.
• Varies from metric to metric. An ESX with 12 cores, each core can have its own CPU Usage threshold.
• You can fix hard thresholds if you need to.
• This needs Enterprise edition. It comes with no static threshold defined.
• Steps http://virtual-red-dot.blogspot.com/2012/01/vcenter-operations-5-hard-threshold.html
Notice the range varies in size

21
Badges – Health
Answers complex questions like:• How is the entire virtual data center doing?
• For every cluster, host, datastore, what’s their health?
Health is the current operational state• It represents what is wrong now and should be
addressed within 1 day. Thus Health needs to be scored
such that if it’s red, then it really needs attention.
Weather Map
• Simple way to check that entire farm is healthy
• Shows health of all parent and child objects
• Each square can be VM, ESX, datastore, cluster datacenter,
vCenter
Value Explanation
75 – 100 Normal behaviour
50 – 75 The object experience some problems.
25 – 50 The object might have serious problems. Check, and take action as soon as possible
0 – 25 The object is either not functioning properly or will stop functioning soon

22
Badges – Workload
Answers complex questions like:• For every object how is Demand vs Spply?
• For every single VM, is CPU/Memory/Disk/Network
bound?
• Any VM is not getting what they are entitled/required?
• What’s the normal workload range for every object in
our vDC?
Workload is not utilisation or usage
• More accurate than utilisation as it takes many factors
than just utilisation
Workload = (Demand/Entitlement)
• Entitlement is dynamic. Affected by shares, limit, etc.
• Demand ≠ Usage
• Usage may mean passive usage (RAM page is there but no
write/read at all
• Score is Max(CPU, RAM, Disk IO, Net IO)
Value Explanation
0 – 80 Workload is not high.
80 – 90 The object is experiencing somehigh resource workloads.
90 – 95 Workload on the object isapproaching its capacity in ≥1 areas.
>95 Workload on the object is at or over its capacity in ≥1 areas.

23
Badges – Anomalies
Answers complex questions like:• Is our vDC doing as usual? Are there any unexpected
changes (as we have dynamic environment)?
• Which VMs, ESX, cluster, datastore etc are behaving
abnormally?
• … and exactly which counters are the culprits?
Identifying metric abnormalities
• It needs to learn dynamic ranges of “Normal” for each
metric, so give it >3 cycle per metric
• A month-end job means it needs 3 months
• Normal range changes after configuration or application
changes
Anomalies score
• High number of anomalies:
• Usually an indication of problem
• Demand change
• Application team changed code/app
• KPI (Key performance Indicator) metrics impacts the
anomalies more than non KPI metrics
Value Explanation
0 – 50 Normal Anomaly range
50 – 75 The score exceeds the normal range.
75 – 90 The score is very high.
> 90Most of the metrics are beyond their thresholds. This object might not be working properly or will stop working soon.

24
Badges – Faults
Answers complex questions like:• What fault do we experience in our vDC?
• For every object, what faults does it have?
Specific knowledge of which vCenter events
• Which events affect Availability and Performance of
which object?
• Pulled from active vCenter events
• Example:
• Loss of redundancy in NICs or HBAs
• Memory checksum errors
• HA failover problems.
• Each fault has a default score
• Highest individual Fault Score drives the Fault object
score
Best Practices
• Do not change Fault Threshold
• Use Alerts View to manage Faults. You can Filter it to
just show Faults.
Value Explanation
0 – 25 No fault is registered on the object
25 – 50 Faults of low importance happens on object.
50 – 75 Faults of high importance happens on object.
> 75 Faults of critical importance happens on object

25
Badges – Risk
Answers complex questions like:• Do we have risk from performance or capacity in our
vDC? If yes, where are they and how serious?
• Which objects are at risk? What is the specific risk?
Risk Score takes into account
• Time Remaining
• Capacity Remaining
• Stress
Risk is an early warning system
• Identifies potential problems that could eventually hurt
the performance
• The Risk Chart shows Risk score over the last 7 days,
giving a view of trend
Value Explanation
0 – 50 No problems are expected in the future.
50 – 75 There is a low chance of future problems or a potential problem might occur in the far future.
75 – 100 There is a chance of a more serious problem or a problem might occur in the medium-term future.
100 The chances of a serious future problem are high or a problem might occur in the near future

26
Badges – Time remaining
Answer complex questions like:• How much time do we have before we need to buy
more server, storage, network before performance
starts to degrade or we run out of capacity?
• For every cluster, VM, datastore, how much time do we
have?
Measures time remaining before each
resource type reaches its capacity• CPU
• Memory
• Disk (IOPS & Space)
• Network I/O
Early warning of upcoming provisioning
needs• Based on Score Provisioning buffer. Default value is 30
days.
• Set in “Capacity & Time Remaining” section
Value Time remaining
50 – 100 > 2x SP Buffer (60 days)
25 – 50 < 2x SP Buffer
<25 Near SP Buffer
0 < SP buffer (30 days)

27
Badges – Capacity remaining
Answer complex questions like:• How many more VM can we put without impacting
performance or using up capacity?
• For every cluster, VM, datastore, which components (CPU,
RAM, Disk, Network) would run out first?
Early warning system• A low score of 1 mean you still have >30 days.
• Measures how many more VMs can be placed on the
object
Percentage of Total VM “Slots” Remaining• Based on the average size of the VM on the object (e.g.
VM profile)
• Each object has its OWN VM profile size: Host, Cluster,
Datacenter, Etc.
From the table, notice value is not linear
• It is also not the same with Time Remaining threshold.
• A value of 30 means >120 days for capacity but around 40
days for time.
Value Capacity remaining
>10 >120 days
5 – 10 60 – 120 days
2 – 5 30 – 60 days
1 <30 days

28
Capacity remaining calculation
Determine capacity constraint resources
Deployed or Powered On VMs• Powered off VMs only use disk space resources
• Powered off VMs use ALL of the 4 resources
Calculation example:
• The limit is 40 more VMs
• We have 9 deployed VMs
• 40/(40+9) = 81%
You can drill down to see details
• You can check all 9 components as shown on right
• This helps to answer the question which components have
how many days or VM left
• Summary = min (all 9 components)

29
Badges – Stress
Answer complex questions like:
• In our vDC, do we have stress points or periods? How bad is it?
• For every cluster, VM, datastore, which ones are experiencing
stress and how bad is it?
Measures long-term or chronic workload (6
weeks)
• Chart shows weeks break down of Stress for each day/hour
averaged over the last 6 Weeks
• Workloads > 70% = “Stressed”
• Threshold Configurable as per screenshot below Value Explanation
0 – 1 Normal score. No action needed
1 – 5 Some of the object resources arenot enough to meet the demands.
5 – 30 The object is experiencing regular resource shortage.
>30Most of the resources on the object are constantly insufficient. The object might stop functioning properly.

30
Stress Calculation
Stress Score is a % and is based on area of Workload Above “Stress Line”
Threshold compared to the Total Capacity of the object• Stress Score = (Stress area / Stress Zone) *100
• But max value can be > 100% as the workload can be >100.
Example• Stress Line is 70% Workload
• 12% of the area is above the 70% threshold
• Stress Score is 12
0
100
70
Stress Zone
Workload Line
12%

31
Badges – Efficiency
Answer complex questions like:
• Are there optimization opportunities in our vDC?
• How well do we do in terms of VM provisioning? Do
we get them right?
Efficiency Score factors
• Reclaimable waste
• Density ratio
Graph Depicts VMs by Percent
• Optimal – Optimally Provisioned VMs
• Waste – Over Provisioned VMs
• Stress – Under Provisioned VMs
• Not used in Efficiency Calculation (see Risk)
Value Explanation
>25 The efficiency is good. The resource use on the selected object is optimal.
10 – 25 The efficiency is good, but can be improved. Some resources are not fully used.
0 – 10 The resources on the selected object are not used in the most optimal way.
0 The efficiency is bad. Many resources are wasted.

32
Badges – Reclaimable waste
Answer complex questions like:
• Do we over provisioned the VMs in terms of CPU, RAM and
Disk? If yes, what’s the degree of over provisioning?
• For every cluster, VM, datastore, what can we reclaim?
It identifies the amount of reclaimable
resources
• CPU
• Memory
• Disk
Reclaimable Waste = Reclaimable Capacity /
Deployed Capacity
• Waste Score = Max(CPU Waste Score, RAM Waste Score,
Disk Space Waste Score)
• Disk calculation can also include old snapshots and
templates
Value Explanation
0 – 50 No resources are wasted on theselected object.
50 – 75 Some resource can be used better.
75 – 100 Many resources are underused
100 Most of the resources on the selected object are wasted.

33
Badges – Density
Answer complex questions like:
• How high can we push our consolidation ratio before we experience performance problem?
• Now that’s a million dollar question!
• For every datacenter, cluster, ESXi, what are our key ratios and how much head room do we have?
Contrasts Actual vs Ideal Density
• Identify Optimal Resource Deployment Before Contention Occurs
• Ideal is based on demand, not simple
configuration.
• High Density is good. 100 is not too high.
Value Explanation
>25 Good consolidation
10 – 25 Some resources are not fully consolidated
0 – 10 The consolidation for many resources is low
0 The resource consolidation is extremely low.

34
Badge thresholds
There are 2 different threshold: VM and Infra (ESXi, Cluster, Datastore, etc)
Notice that Major badge has different threshold to its minor badges
Even “similar” badges have different threshold. Notice Time remaining and Capacity remaining have very different thresholds.
35
Using badges together
Workload High & Anomalies Low & Stress High
• Workload – Object is Running Hot. Potentially Starving
for Resources
• Anomalies – Normal Behavior for this timeframe
• Stress – Object is often running under high Workload.
Workload High & Anomalies Low & Stress Low
• Workload – Object is Running Hot. Potentially Starving
for Resources
• Anomalies – Normal Behavior for this timeframe
• Stress – Object usually has enough resources
Workload High & Anomalies High
• Workload – Object is Running Hot. Potentially Starving
for Resources
• Anomalies – Abnormal behavior for this timeframe
If there are Alert and Fault too, then it is a sign
of major issue
Add resources
Not likely a big problem…
a cyclical workload spike?
Something is a miss! Immediate attention.

36
… at the end
This is not all! We are just scratching the surface.
• Heat map / Cold map: 2 dimensional chart, great way to show a lot of info on 1 screen about all cluster/host/VM
• Planning: gives visibility for the next 6 month. CPU/memory demand, Disk I/O, Network I/O
• Alerts: normal vs smart alert
• Smart alert relies on the advanced analytics instead of simple raw counters. Not static, based on Dynamic Threshold. Can do SNMP, SMTP, file.
• Performance chart!
• Capacity management
• Historical utilization trends, resources have been requested vs. needed, how many VMs fit in my farm?
• Forecast: when will I run out of capacity? What if I add/remove/reconfigure capacity?
• Change events correlated with Performance: enable operations to quickly understand and resolve performance issues

37
Questions?