СУБД 2013 Лекция №5 "Определение узких мест"
TRANSCRIPT

СУБД
Лекция 5
Павел Щербинин

Подсистемы хранения
MyISAM
• Блокировка и конкуренция
• Автоматическое исправление
• Ручное исправление
CHECK TABLE mytable и REPAIR TABLE mytable
• Особенности индексирования
Полнотекстовый индекс
• Отложенная запись ключей
DELAY_KEY_WRITE

Подсистемы хранения
InnoDB
• Транзакции
• Блокировки на уровне строк
• Кластерные индексы
• Внешние ключи
• Возможны Deadlocks

Подсистемы хранения
Memory
• Данные хранятся в памяти и теряются при
перезапуске
• Поддерживают индексы типа HASH
• Не поддерживают TEXT, BLOB, VARCHAR => CHAR
• Используется для
промежуточных таблиц

Подсистемы хранения
Критерии выбора
• Транзакции
• Конкурентный доступ
• Резервное копирование
• Восстановление после сбоя
• Специальные возможности
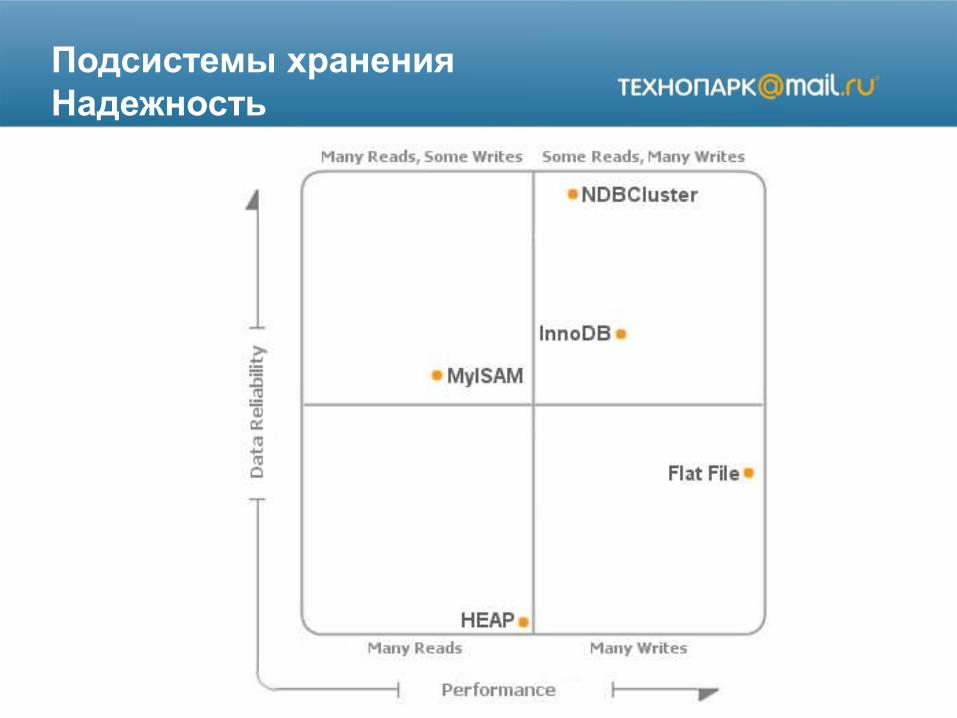
Подсистемы хранения
Надежность

Подсистемы хранения
Практические примеры
• Протоколирование
MyISAM, Archive
Отчеты?: репликация, Merge
• Чтение, или в основном чтение
MyISAM
• Обработка заказов
InnoDB
• Распространение на дисках
MyISAM, Compressed MyISAM
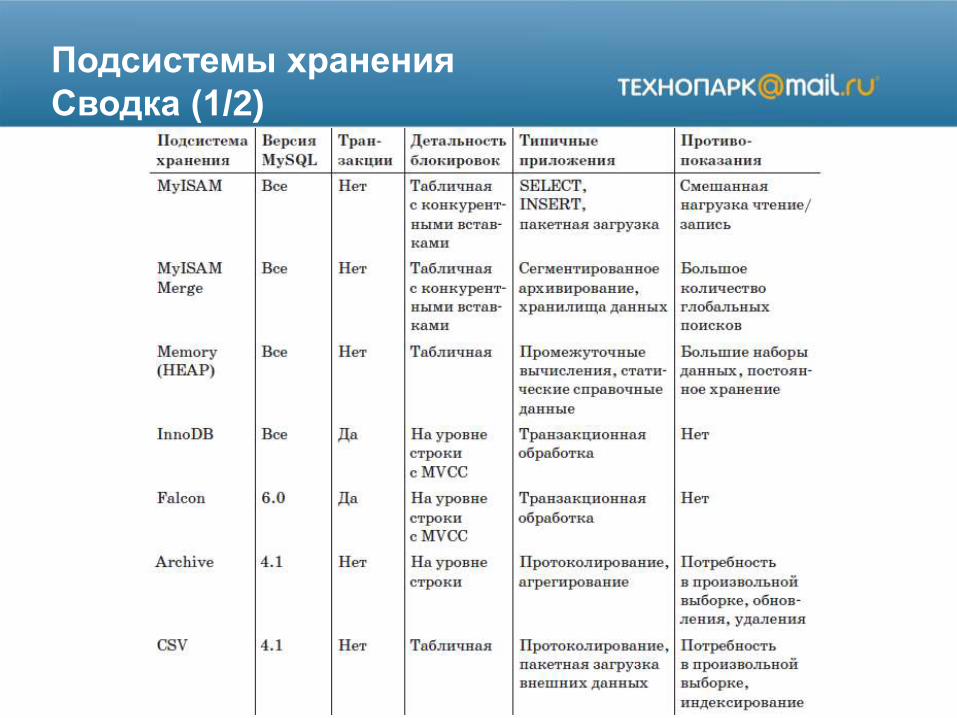
Подсистемы хранения
Сводка (1/2)
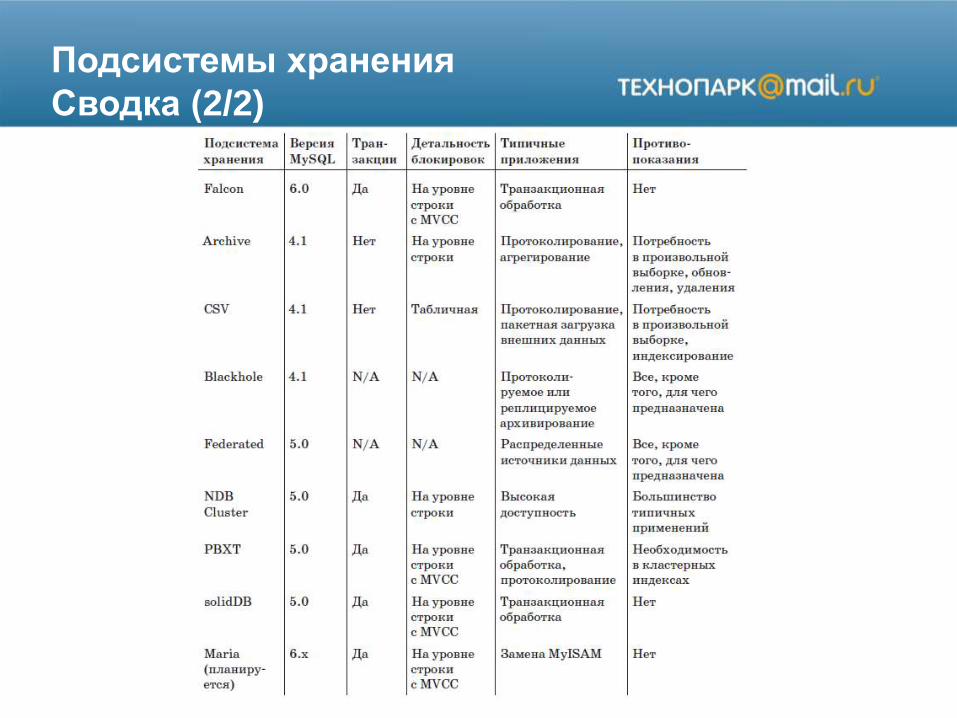
Подсистемы хранения
Сводка (2/2)

Индексирование
Индексы используются для:• Быстрого поиска записей по условию WHERE;
• Для объединения таблиц с посредством JOIN. Необходимо использовать одинаковые типы сравниваемых полей. Если для сравнения необходимо произвести преобразование типов, то индексы использоваться не будут;
• Для выбора наименьшего количества совпадений. Если есть множественный индекс, то использоваться будет тот индекс, который находит самое маленький число строк.
• Поиска MAX и MIN значений для ключевых полей ;
• Для сортировки и группировки таблиц (……ORDER BY и GROUP BY);
• Для извлечения данных не из таблицы с данными, а из индексного файла. Это возможно только в некоторых случаях, например, когда все извлекаемые поля проиндексированы.
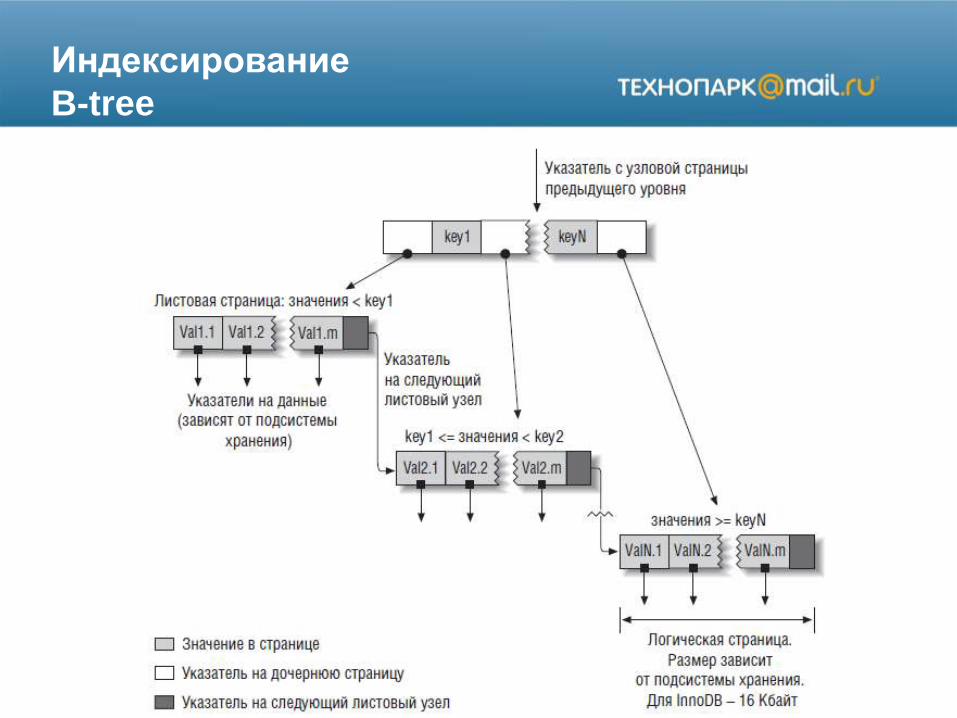
Индексирование
B-tree
Индексирование
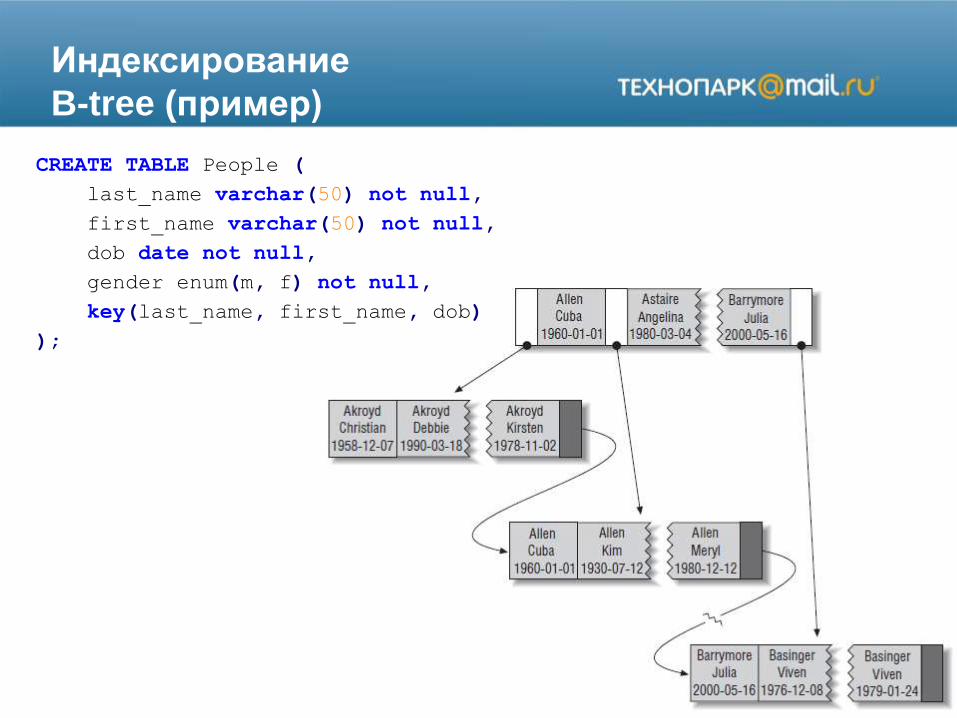
B-tree (пример)
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum(m, f) not null,
key(last_name, first_name, dob)
);

Индексирование
B-tree (особенности)
Можно:• Поиск по полному значению• Поиск по самому левому префиксу• Поиск по префиксу столбца• Поиск по диапазону значений• Поиск по полному совпадению одной части и
диапазону в другой части• Запросы только по индексуНельзя:• Поиск без использования левой части ключа• Нельзя пропускать столбцы• Оптимизация после поиска в диапазоне
Индексирование
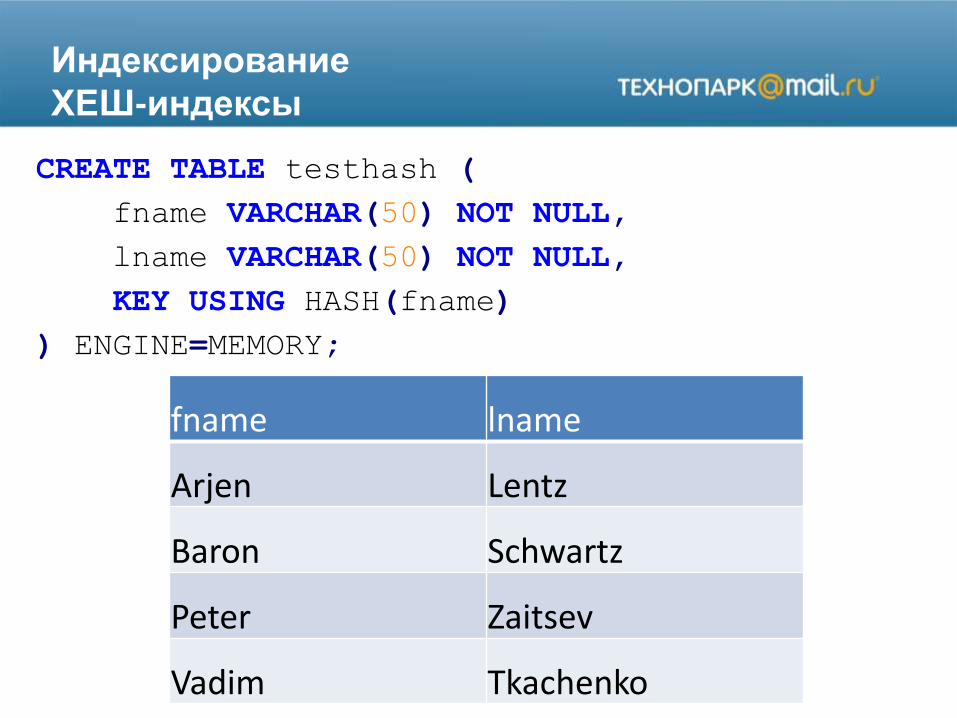
ХЕШ-индексы
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
fname lname
Arjen Lentz
Baron Schwartz
Peter Zaitsev
Vadim Tkachenko

Индексирование
ХЕШ-индексы
f(‘Arjen’) = 2323f(‘Baron’) = 7437f(‘Peter’) = 8784f(‘Vadim’) = 2458
Ячейка Значение
2323Указатель на строку 1
2458Указатель на строку 4
7437Указатель на строку 2
8784Указатель на строку 3
SELECT lname FROM testhash WHERE fname=Peter;

Индексирование
ХЕШ-индексы (особенности)
• MySQL не может использовать данные в индексе, чтобы избежать чтения строк
• MySQL не может использовать хеш-индексы для сортировки, поскольку строки в нем не хранятся в отсортированном порядке
• Хеш-индексы не поддерживают поиск по частичному ключу, так как хеш-коды вычисляются для всего индексируемого значения
• Хеш-индексы поддерживают только сравнения на равенство, использующие операторы =, IN() и <=>
• Доступ к данным в хеш-индексе очень быстр, если нет большого количества коллизий
• Некоторые операции обслуживания индекса могут оказаться медленными, если количество коллизий велико

Профилирование
• К каким данным MySQL обращается чаще всего
• Какие типы запросов MySQL выполняет чаще всего
• В каких состояниях преимущественно находятся потоки (threads) MySQL
• Какие подсистемы MySQL чаще всего использует для выполнения запросов
• Какие виды обращения к данным встречаются наиболее часто
• Сколько различных видов действий, например просмотра индексов, выполняет MySQL
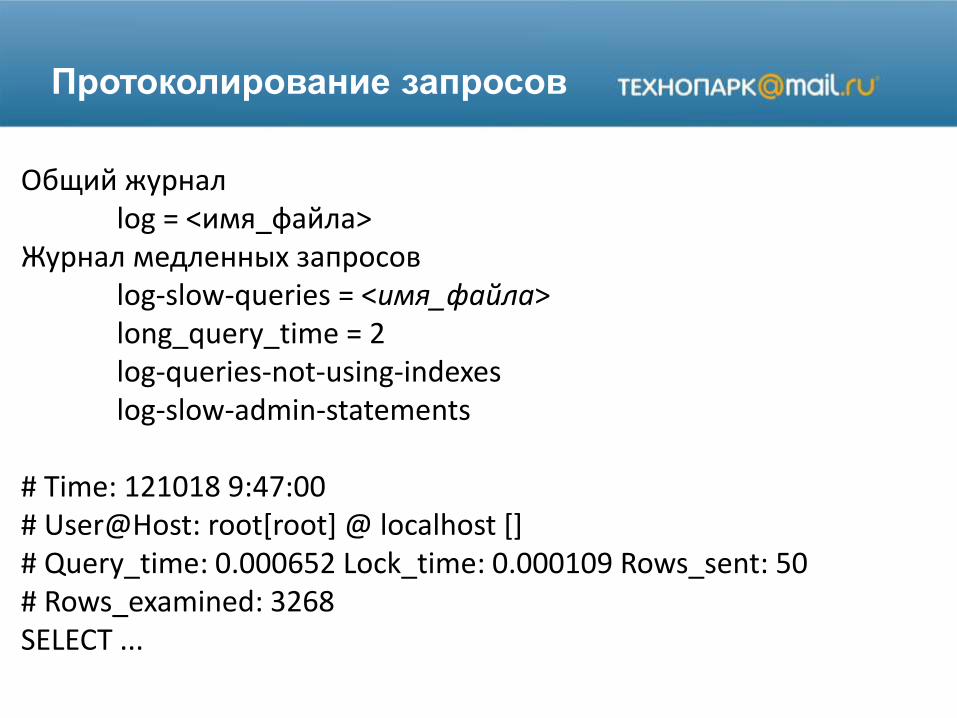
Протоколирование запросов
Общий журналlog = <имя_файла>
Журнал медленных запросовlog-slow-queries = <имя_файла>long_query_time = 2log-queries-not-using-indexeslog-slow-admin-statements
# Time: 121018 9:47:00# User@Host: root[root] @ localhost []# Query_time: 0.000652 Lock_time: 0.000109 Rows_sent: 50# Rows_examined: 3268SELECT ...

Протоколирование запросов
• Таблица могла быть заблокирована, поэтому запрос был вынужден ждать. Величина Lock_time показывает, как долго запрос ждал освобождения блокировки.
• Данные или индексы могли к тому моменту еще отсутствовать в кэше. Это обычный случай, когда сервер MySQL только запущен или не настроен должным образом.
• Мог идти ночной процесс резервного копирования, из-за чего все операции дискового ввода/вывода замедлялись.
• Сервер мог обрабатывать в тот момент другие запросы, поэтому данный выполнялся медленнее.

Протоколирование запросов
Долго выполняющиеся запросыПериодические выполняемые пакетные задания действительно могут запускать долго выполняющиеся запросы, но обычные запросы не должны занимать много времени.
Запросы, больше всего нагружающие серверИщите запросы, которые потребляют большую часть времени сервера. Напомним, что короткие запросы, выполняемые очень часто, тоже могут занимать много времени.
Новые запросыИщите запросы, которых вчера не было в первой сотне, а сегодня они появились. Это могут быть новые запросы или запросы, которые обычно выполнялись быстро, а теперь замедлились из-за изменившейся схемы индексации. Либо произошли еще какие-то изменения.

Профилирование сервера
SHOW STATUSBytes_received и Bytes_sent
Количество байтов, соответственно полученных и отправленных сервером.
Com_*Команды, которые сервер выполняет
Created_*Временные таблицы и файлы, созданные во время выполнения запроса
Handler_*Операции подсистемы хранения
Select_*Различные типы планов выполнения операции соединения
Sort_*Разнообразная информация о сортировке
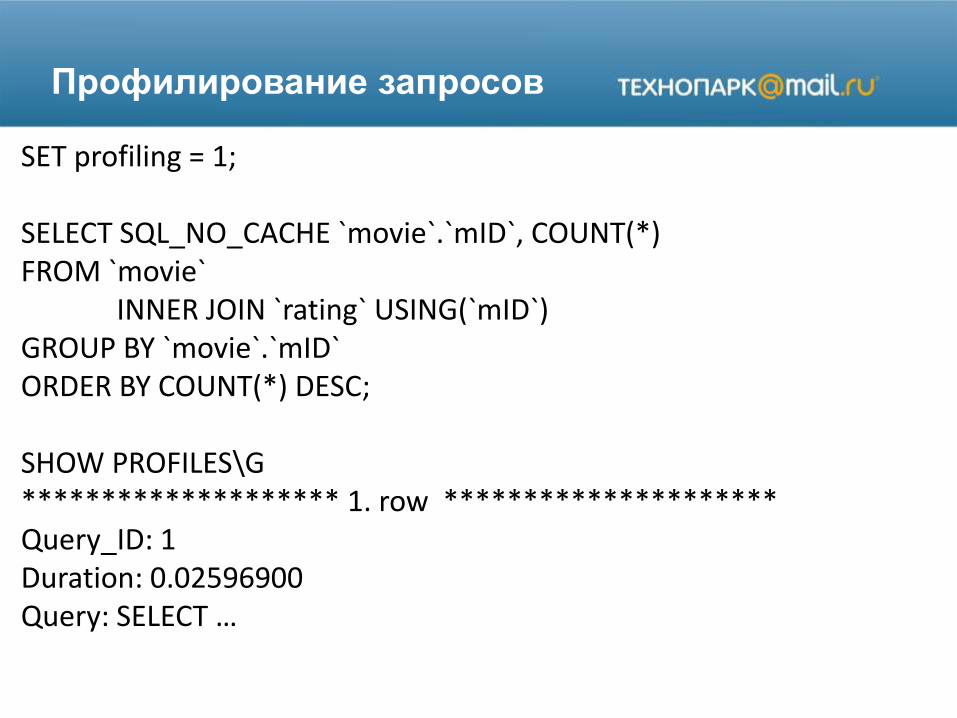
Профилирование запросов
SET profiling = 1;
SELECT SQL_NO_CACHE `movie`.`mID`, COUNT(*)FROM `movie`
INNER JOIN `rating` USING(`mID`)GROUP BY `movie`.`mID`ORDER BY COUNT(*) DESC;
SHOW PROFILES\G******************** 1. row *********************Query_ID: 1Duration: 0.02596900Query: SELECT …

EXPLAIN
• EXPLAIN ничего не говорит о том, как влияют на запрос триггеры, хранимые и пользовательские (UDF) функции.
• Она не работает с хранимыми процедурами, хотя можно разложить процедуру на отдельные запросы и вызвать EXPLAIN для каждого из них.
• Она ничего не говорит об оптимизациях, которые MySQLпроизводит уже на этапе выполнения запроса.
• Часть отображаемой статистической информации – всего лишь оценка, иногда очень неточная.
• Она не показывает все, что можно было бы сообщить о плане выполнения запроса
• Она не делает различий между некоторыми операциями, называя их одинаково.
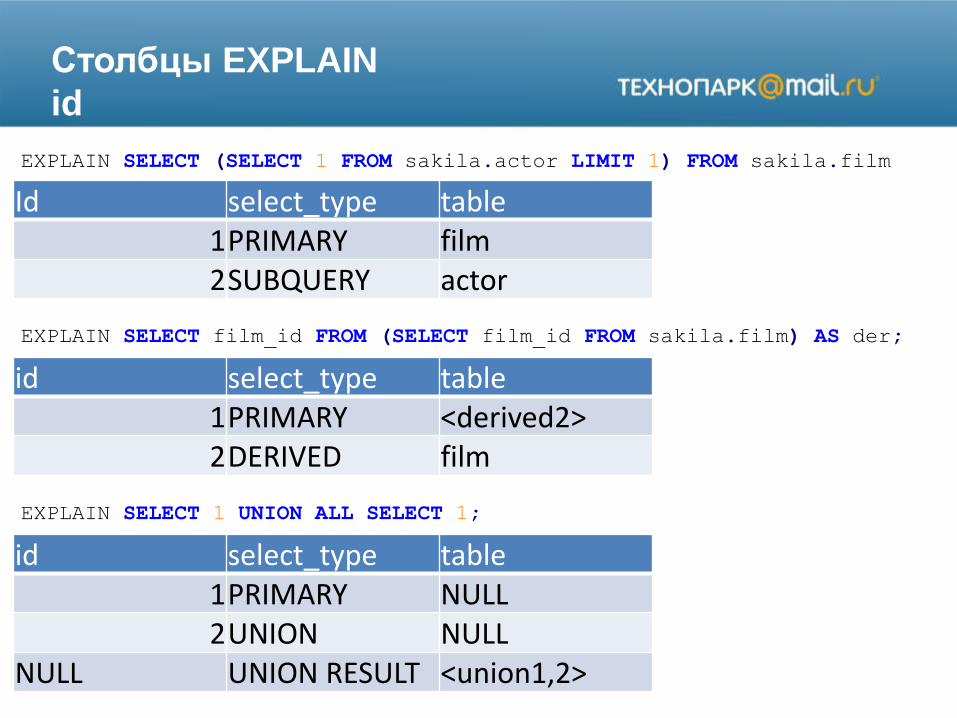
Столбцы EXPLAIN
id
EXPLAIN SELECT (SELECT 1 FROM sakila.actor LIMIT 1) FROM sakila.film
Id select_type table1PRIMARY film2SUBQUERY actor
EXPLAIN SELECT film_id FROM (SELECT film_id FROM sakila.film) AS der;
id select_type table1PRIMARY <derived2>2DERIVED film
EXPLAIN SELECT 1 UNION ALL SELECT 1;
id select_type table1PRIMARY NULL2UNION NULL
NULL UNION RESULT <union1,2>

Столбцы EXPLAIN
select_type
PRIMARYСамый внешний запрос
SUBQUERYЗапрос SELECT, который содержится в подзапросе, находящемся вофразе SELECT (иными словами, не во фразе FROM
DERIVEDЗначение DERIVED означает, что данный запрос SELECT является подзапросом во фразе FROM.
UNIONВторой и последующий запросы SELECT, входящие в объединениеUNION, помечаются признаком UNION.
UNION RESULTЗапрос SELECT, применяемый для выборки результатов из временнойтаблицы, созданной в ходе выполнения UNION.
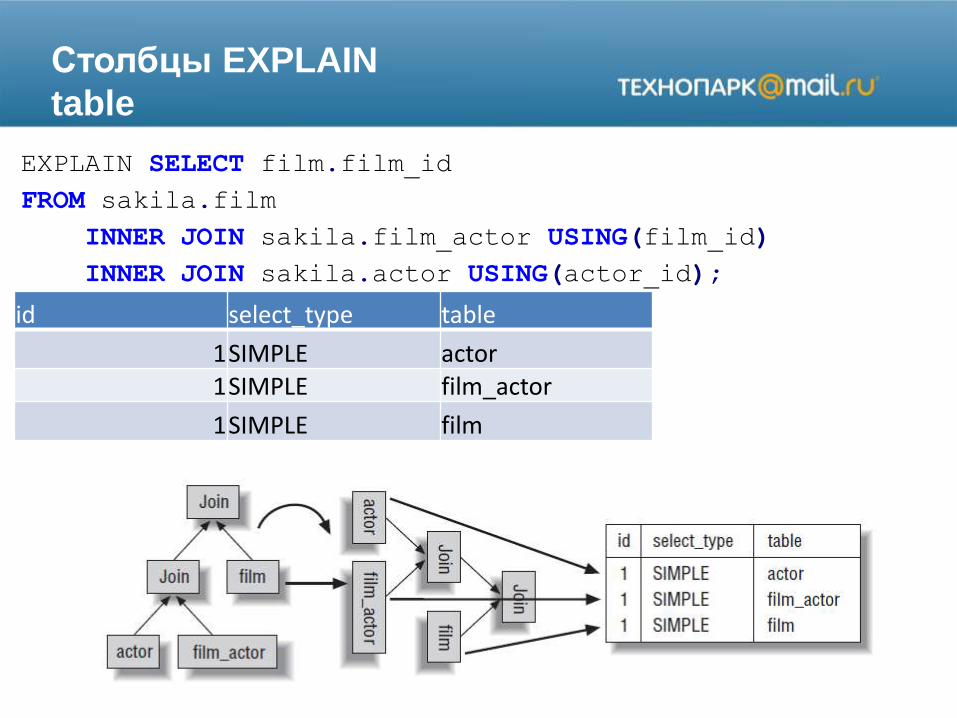
Столбцы EXPLAIN
table
EXPLAIN SELECT film.film_id
FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
INNER JOIN sakila.actor USING(actor_id);
id select_type table
1SIMPLE actor1SIMPLE film_actor
1SIMPLE film

Столбцы EXPLAIN
table
EXPLAIN SELECT actor_id,
(SELECT 1 FROM sakila.film_actor WHERE
film_actor.actor_id = der_1.actor_id LIMIT 1)
FROM (
SELECT actor_id
FROM sakila.actor LIMIT 5
) AS der_1
UNION ALL
SELECT film_id,
(SELECT @var1 FROM sakila.rental LIMIT 1)
FROM (
SELECT film_id,
(SELECT 1 FROM sakila.store LIMIT 1)
FROM sakila.film LIMIT 5
) AS der_2;
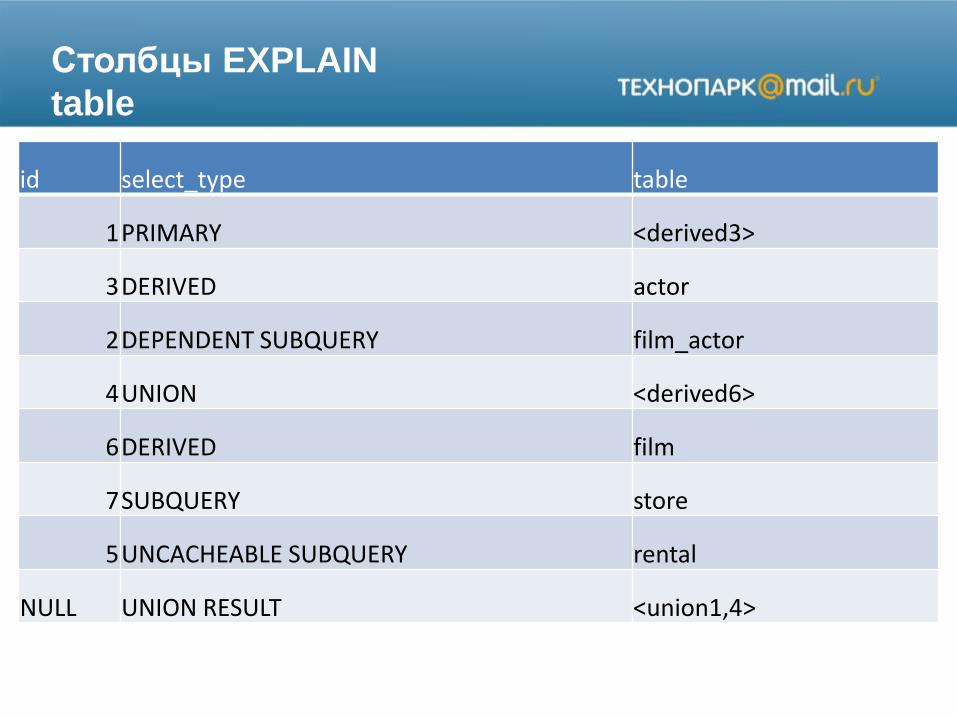
Столбцы EXPLAIN
table
id select_type table
1PRIMARY <derived3>
3DERIVED actor
2DEPENDENT SUBQUERY film_actor
4UNION <derived6>
6DERIVED film
7SUBQUERY store
5UNCACHEABLE SUBQUERY rental
NULL UNION RESULT <union1,4>

Столбцы EXPLAIN
type
ALLЭтот подход обычно называют сканированием таблицы.
indexТо же, что сканирование таблицы, только MySQL просматривает ее в порядке, задаваемом индексом, а не в порядке следования строк.
rangeПросмотр диапазона – это ограниченная форма сканирования индекса. Просмотр начинается в определенной точке индекса и возвращает строки в некотором диапазоне значений.
refЭто доступ по индексу (иногда он называется поиском по индексу (index lookup)), в результате которого возвращаются строки, соответствующие единственному заданному значению.
eq_refЭто поиск по индексу в случае, когда MySQL точно знает, что будет возвращено не более одного значения.
const, systemЭти типы доступа MySQL применяет, когда в процессе оптимизации какую-то часть запроса можно преобразовать в константу.
NULLЭтот метод означает, что MySQL сумела разрешить запрос на фазе оптимизации, так что в ходе выполнения вообще не потребуется обращаться к таблице или индексу.

Столбцы EXPLAIN
possible_keys, key
EXPLAIN SELECT actor_id, film_id FROM sakila.film_actor\G
************************* 1. row *************************id: 1select_type: SIMPLEtable: film_actortype: indexpossible_keys: NULLkey: idx_fk_film_idkey_len: 2ref: NULLrows: 5143Extra: Using index

Столбцы EXPLAIN
key_len
EXPLAIN SELECT actor_id, film_id FROM sakila.film_actor
WHERE actor_id=4;
...| type | possible_keys | key | key_len |...
...| ref | PRIMARY | PRIMARY | 2 |...

Столбцы EXPLAIN
key_len
EXPLAIN SELECT actor_id, film_id FROM sakila.film_actor
WHERE actor_id=4;
...| type | possible_keys | key | key_len |...
...| ref | PRIMARY | PRIMARY | 2 |...
CREATE TABLE t (
a char(3) NOT NULL,
b int(11) NOT NULL,
c char(1) NOT NULL,
PRIMARY KEY (a,b,c)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
EXPLAIN SELECT a FROM t WHERE a=sak AND b = 112;

Столбцы EXPLAIN
key_len
EXPLAIN SELECT actor_id, film_id FROM sakila.film_actor
WHERE actor_id=4;
...| type | possible_keys | key | key_len |...
...| ref | PRIMARY | PRIMARY | 2 |...
CREATE TABLE t (
a char(3) NOT NULL,
b int(11) NOT NULL,
c char(1) NOT NULL,
PRIMARY KEY (a,b,c)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
EXPLAIN SELECT a FROM t WHERE a=sak AND b = 112;
... |type | possible_keys | key | key_len |...
... | ref | PRIMARY | PRIMARY | 13 |...

Столбцы EXPLAIN
ref
EXPLAIN SELECT STRAIGHT_JOIN f.film_id
FROM sakila.film AS f
INNER JOIN sakila.film_actor AS fa
ON f.film_id=fa.film_id AND fa.actor_id = 1
INNER JOIN sakila.actor AS a USING(actor_id);
...| table |...| key | key_len | ref |...
...| a |...| PRIMARY | 2 | const |...
...| f |...| idx_fk_language_id | 1 | NULL |...
...| fa |...| PRIMARY | 4 | const,sakila.f.film_id |...

Столбцы EXPLAIN
rows
EXPLAIN SELECT f.film_id
FROM sakila.film AS f
INNER JOIN sakila.film_actor AS fa USING(film_id)
INNER JOIN sakila.actor AS a USING(actor_id);
...| rows |...
...| 200 |...
...| 13 |...
...| 1 |...

Столбцы EXPLAIN
extra
Using indexОзначает, что MySQL воспользуется покрывающим индексом, чтобыизбежать доступа к самой таблице.
Using whereОзначает, что сервер произведет дополнительную фильтрацию строк,отобранных подсистемой хранения.
Using temporaryОзначает, что MySQL будет применять временную таблицу для сортировки результатов запроса.
Using filesortОзначает, что MySQL прибегнет к обычной сортировке для упорядочения результатов, а не станет читать строки из таблицы в порядке, задаваемом индексом.
range checked for each recordОзначает, что подходящего индекса не нашлось, поэтому сервер будет заново искать индекс при обработке каждой строки в операциисоединения.
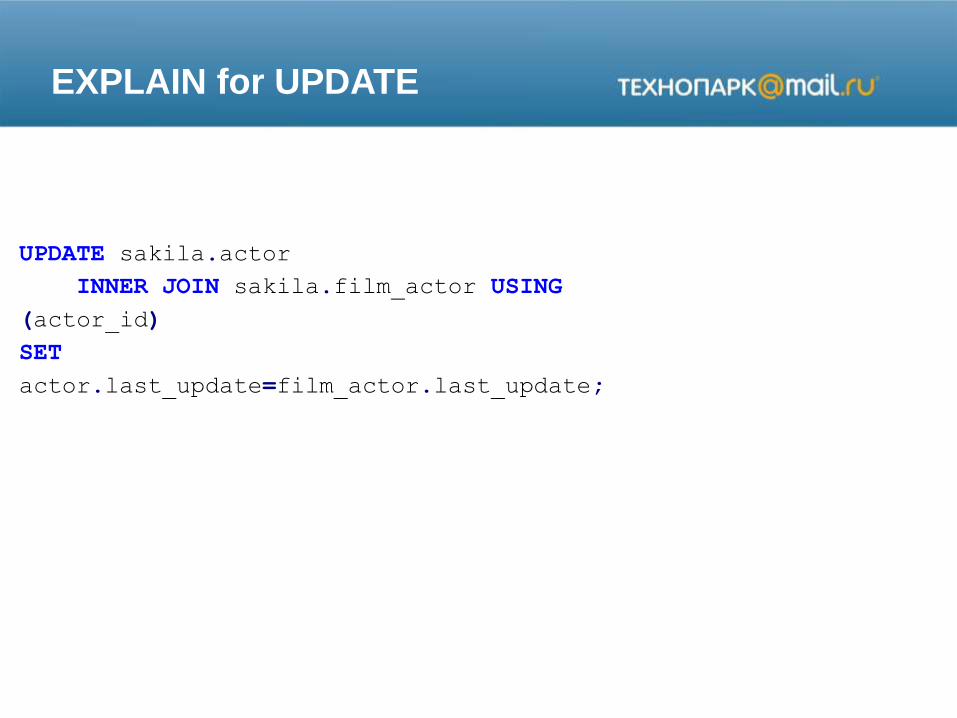
EXPLAIN for UPDATE
UPDATE sakila.actor
INNER JOIN sakila.film_actor USING
(actor_id)
SET
actor.last_update=film_actor.last_update;

EXPLAIN for UPDATE
UPDATE sakila.actor
INNER JOIN sakila.film_actor USING
(actor_id)
SET
actor.last_update=film_actor.last_update;
EXPLAIN
SELECT film_actor.actor_id
FROM sakila.actor
INNER JOIN sakila.film_actor
USING (actor_id)\G
***** 1. row *****id: 1select_type: SIMPLEtable: actortype: indexpossible_keys: PRIMARYkey: PRIMARYkey_len: 2ref: NULLrows: 200Extra: Using index***** 2. row *****id: 1select_type: SIMPLEtable: film_actortype: refpossible_keys: PRIMARYkey: PRIMARYkey_len: 2ref: sakila.actor.actor_idrows: 13Extra: Using index
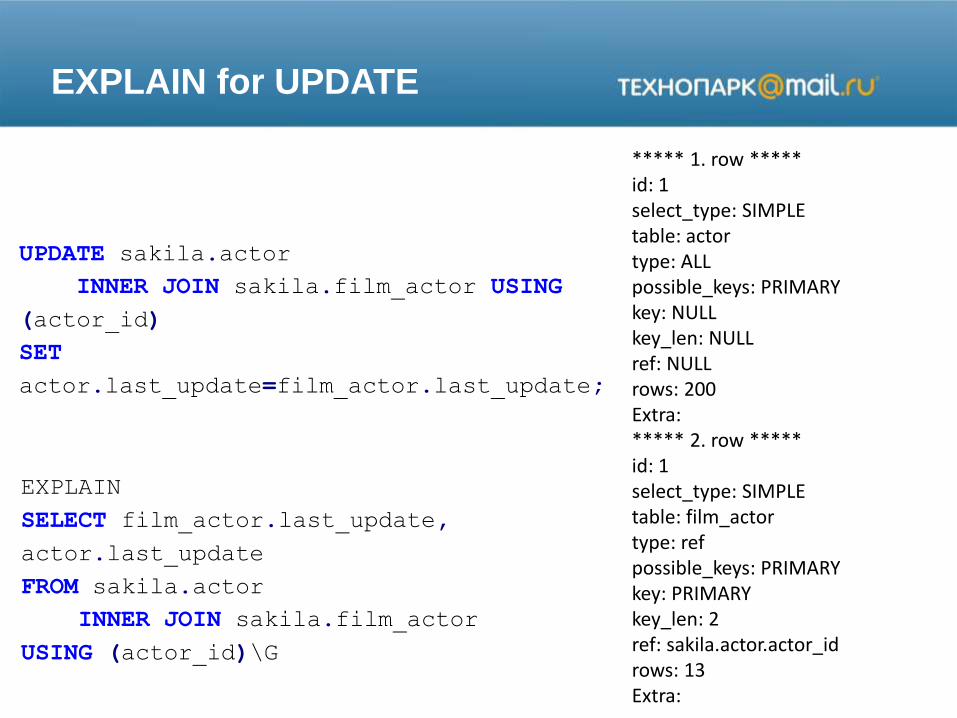
EXPLAIN for UPDATE
UPDATE sakila.actor
INNER JOIN sakila.film_actor USING
(actor_id)
SET
actor.last_update=film_actor.last_update;
EXPLAIN
SELECT film_actor.last_update,
actor.last_update
FROM sakila.actor
INNER JOIN sakila.film_actor
USING (actor_id)\G
***** 1. row *****id: 1select_type: SIMPLEtable: actortype: ALLpossible_keys: PRIMARYkey: NULLkey_len: NULLref: NULLrows: 200Extra:***** 2. row *****id: 1select_type: SIMPLEtable: film_actortype: refpossible_keys: PRIMARYkey: PRIMARYkey_len: 2ref: sakila.actor.actor_idrows: 13Extra:
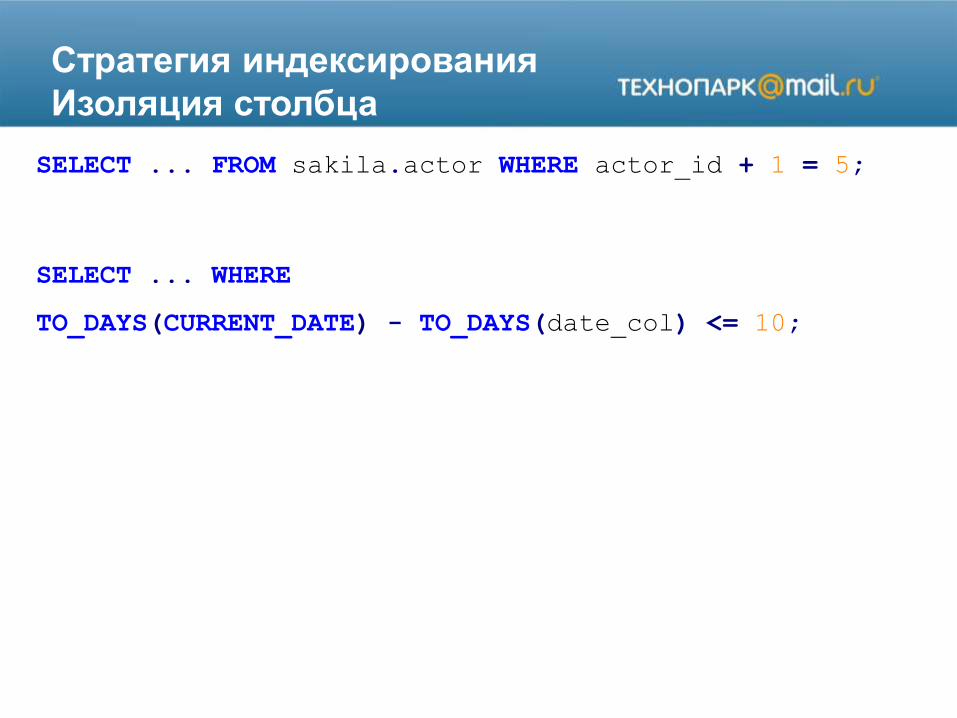
Стратегия индексирования
Изоляция столбца
SELECT ... FROM sakila.actor WHERE actor_id + 1 = 5;
SELECT ... WHERE
TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
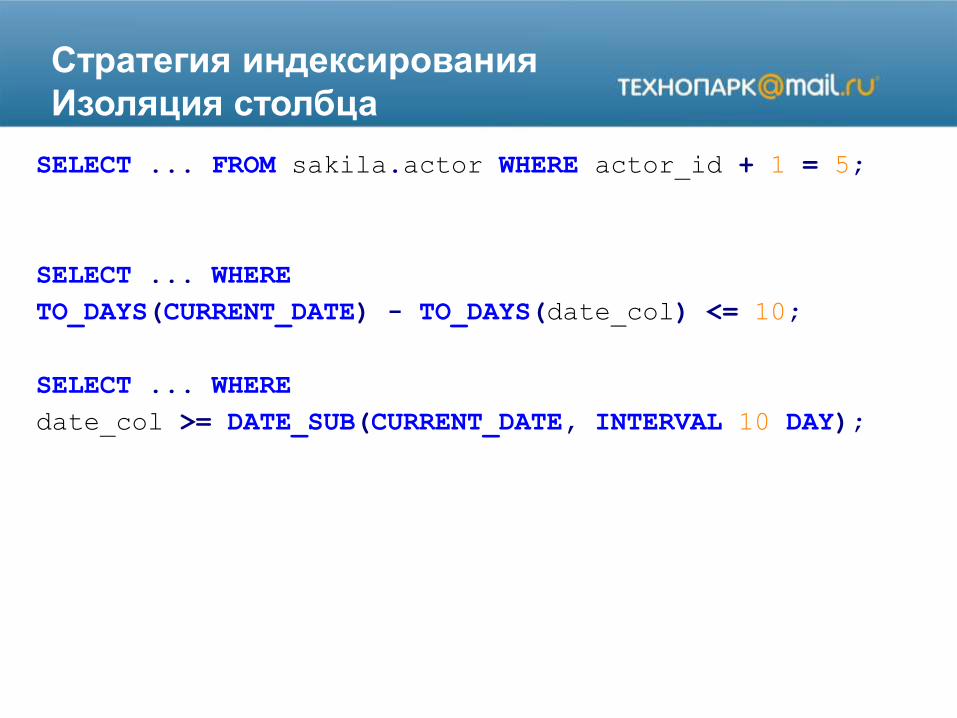
Стратегия индексирования
Изоляция столбца
SELECT ... FROM sakila.actor WHERE actor_id + 1 = 5;
SELECT ... WHERE
TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
SELECT ... WHERE
date_col >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
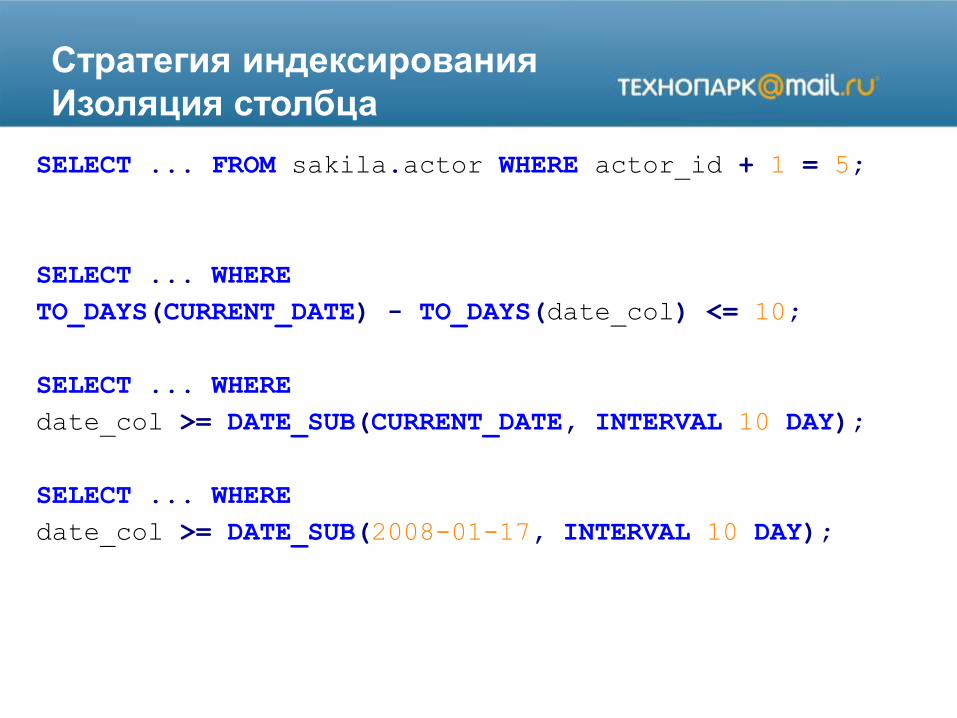
Стратегия индексирования
Изоляция столбца
SELECT ... FROM sakila.actor WHERE actor_id + 1 = 5;
SELECT ... WHERE
TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
SELECT ... WHERE
date_col >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
SELECT ... WHERE
date_col >= DATE_SUB(2008-01-17, INTERVAL 10 DAY);
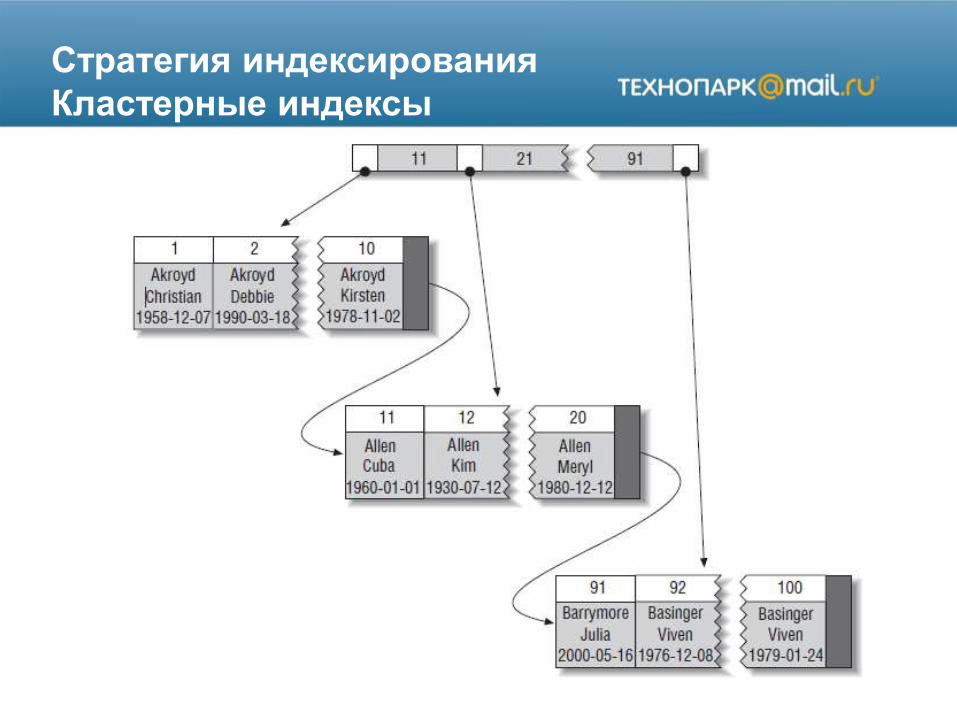
Стратегия индексирования
Кластерные индексы

Стратегия индексирования
Кластерные индексы (+)
• Вы можете хранить связанные данные рядом.
• Быстрый доступ к данным. Кластерный индекс хранит и индекс, и данные вместе в одной B-Treeструктуре, поэтому извлечение строк из кластерного индекса обычно происходит быстрее, чем сопоставимый поиск в некластерном индексе.
• Использующие покрывающие индексы запросы могут получить значение первичного ключа из листового узла.

Стратегия индексирования
Кластерные индексы (-)
• Если данные помещаются в памяти, то порядок доступа к ним не имеет значения, и тогда кластерные индексы не принесут большой пользы.
• Если вы загружаете большое количество данных в другом порядке, то по окончании загрузки имеет смысл реорганизовать таблицу с помощью команды OPTIMIZE TABLE.
• Обновление столбцов кластерного индекса обходится дорого, поскольку InnoDB вынуждена перемещать каждую обновленную строку в новое место.
• Для таблиц с кластерным индексом вставка новых строк или обновление первичного ключа, требующее перемещения строки, может приводить к расщеплению страницы.
• Полное сканирование кластерных таблиц может оказаться более медленным, особенно если строки упакованы менее плотно или хранятся непоследовательно из-за расщепления страниц.
• Вторичные (некластерные) индексы могут оказаться больше, чем вы ожидаете, поскольку в листовых узлах хранятся значения столбцов, составляющих первичный ключ.
• Для доступа к данным по вторичному индексу требуется просмотр двух индексов вместо одного.
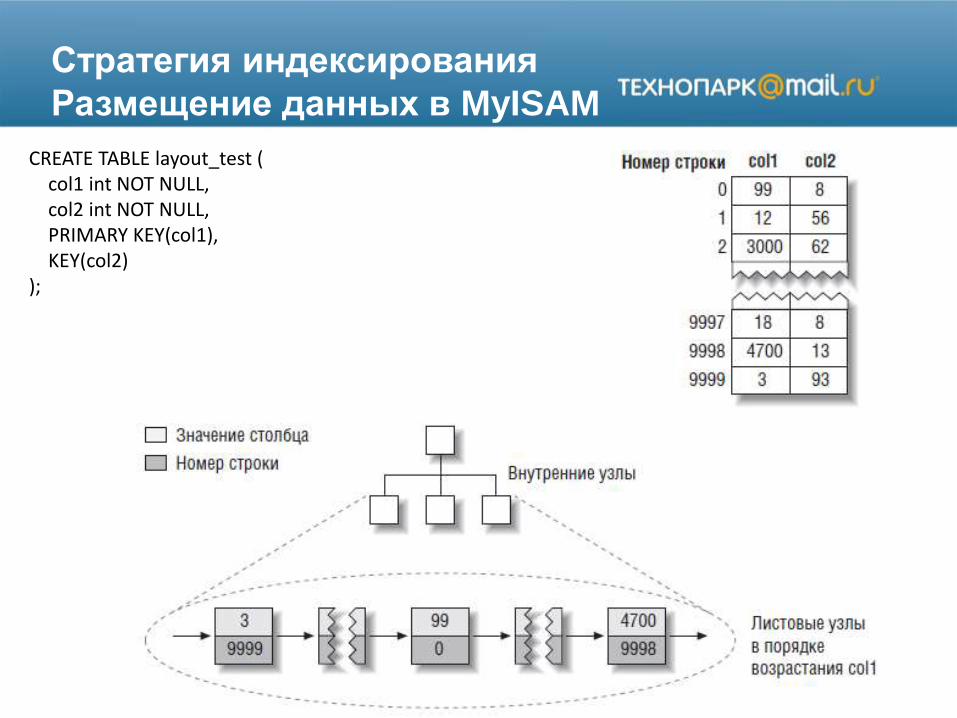
Стратегия индексирования
Размещение данных в MyISAM
CREATE TABLE layout_test (col1 int NOT NULL,col2 int NOT NULL,PRIMARY KEY(col1),KEY(col2)
);
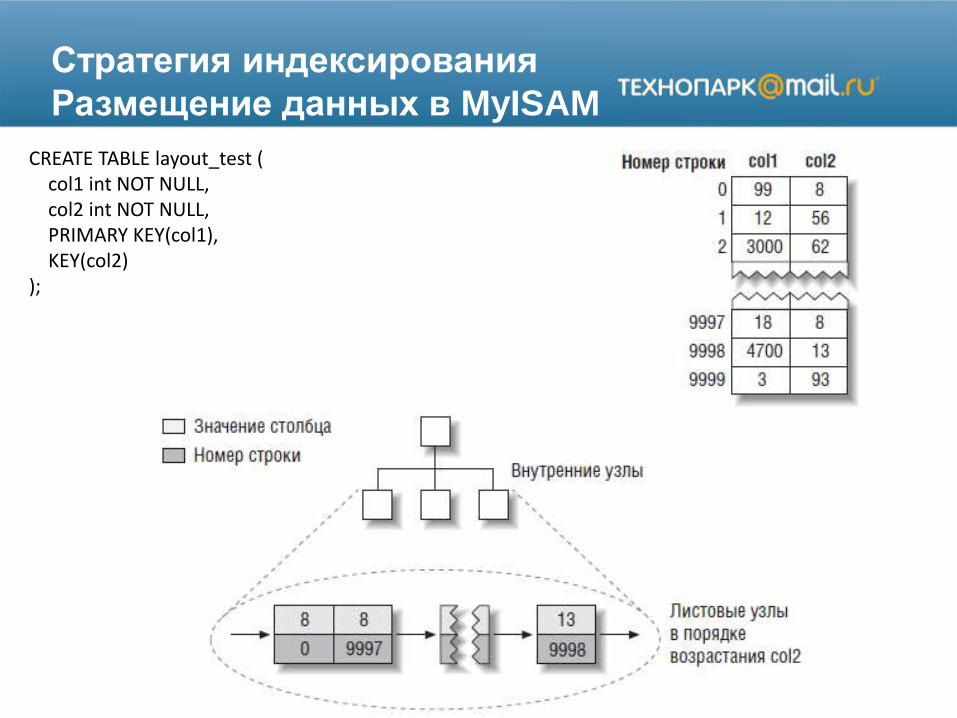
Стратегия индексирования
Размещение данных в MyISAM
CREATE TABLE layout_test (col1 int NOT NULL,col2 int NOT NULL,PRIMARY KEY(col1),KEY(col2)
);
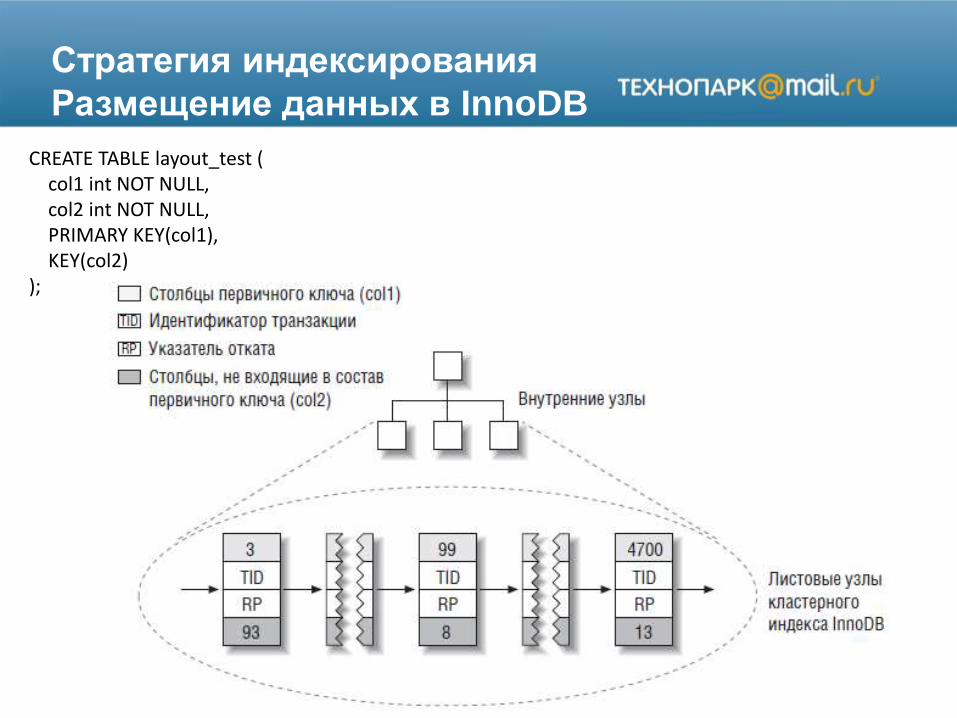
Стратегия индексирования
Размещение данных в InnoDB
CREATE TABLE layout_test (col1 int NOT NULL,col2 int NOT NULL,PRIMARY KEY(col1),KEY(col2)
);
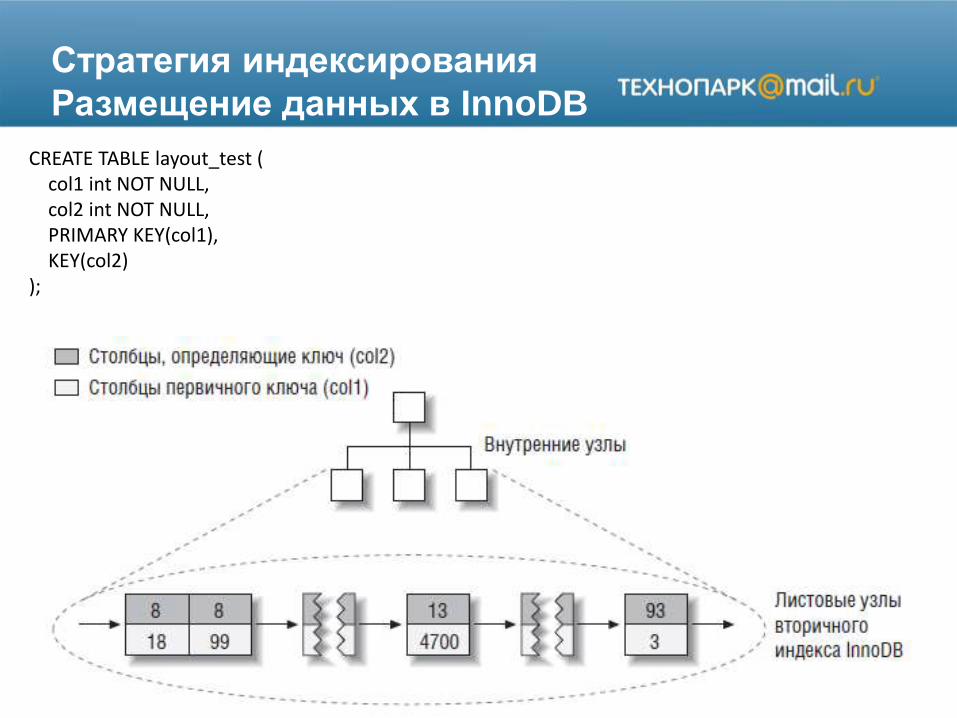
Стратегия индексирования
Размещение данных в InnoDB
CREATE TABLE layout_test (col1 int NOT NULL,col2 int NOT NULL,PRIMARY KEY(col1),KEY(col2)
);
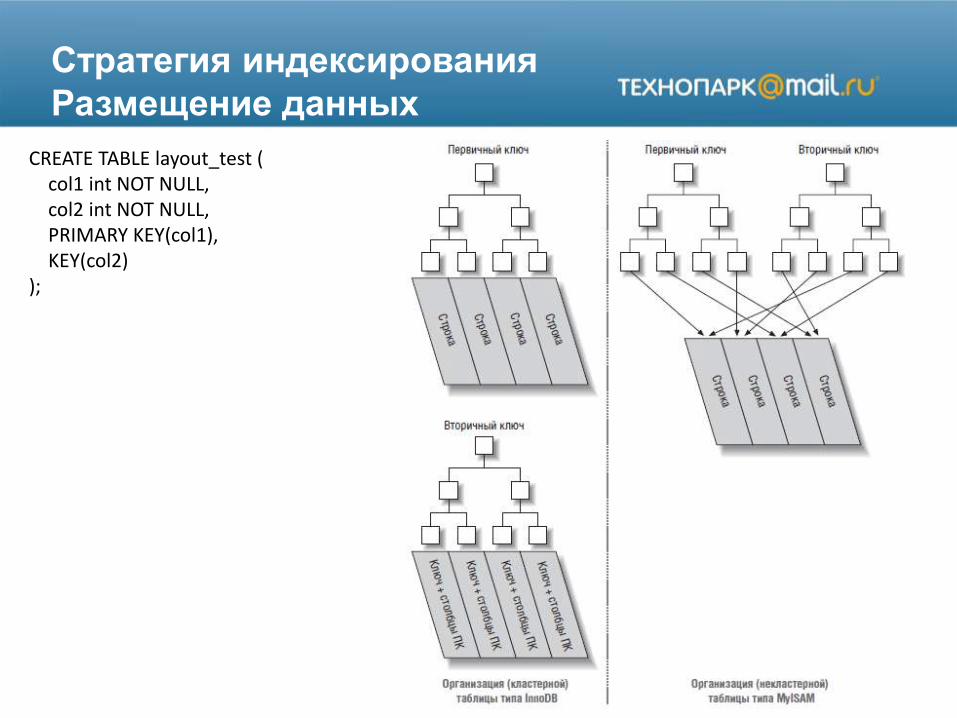
Стратегия индексирования
Размещение данных
CREATE TABLE layout_test (col1 int NOT NULL,col2 int NOT NULL,PRIMARY KEY(col1),KEY(col2)
);
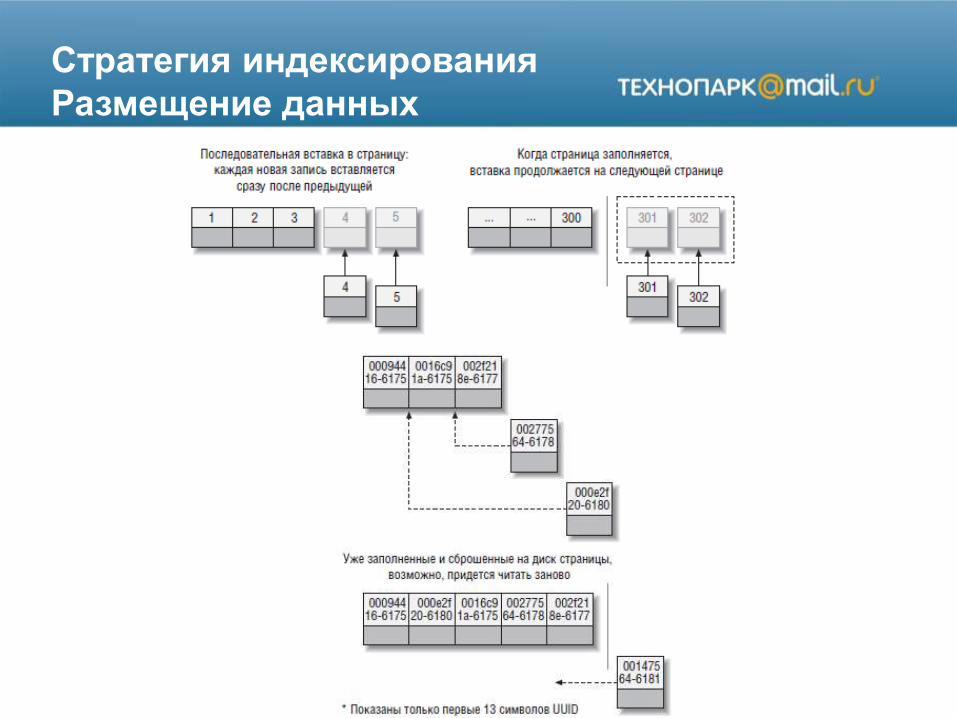
Стратегия индексирования
Размещение данных

Покрывающие индексы
• Записи индекса обычно компактнее полной строки, поэтому, если MySQL читает только индекс, то обращается к значительно меньшему объему данных.
• Индексы отсортированы по индексируемым значениям (по крайней мере, внутри страницы), поэтому для поиска по диапазону, характеризуемому большим объемом ввода/вывода, потребуется меньше операций обращения к диску.
• Большинство подсистем хранения кэширует индексы лучше, чем сами данные.
• Покрывающие индексы особенно полезны в случае таблиц InnoDB из-за кластерных индексов. Вторичные индексы InnoDB хранят значения первичного ключа строки в листовых узлах. Таким образом, вторичный индекс, который «покрывает» запрос, позволяет избежать еще одного поиска по первичному индексу.

Покрывающие индексы
EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G************************** 1. row **************************id: 1select_type: SIMPLEtable: inventorytype: indexpossible_keys: NULLkey: idx_store_id_film_idkey_len: 3ref: NULLrows: 4673Extra: Using index

Покрывающие индексы
EXPLAIN SELECT actor_id, last_nameFROM sakila.actor WHERE last_name = ‘HOPPER’\G************************** 1. row **************************id: 1select_type: SIMPLEtable: actortype: refpossible_keys: idx_actor_last_namekey: idx_actor_last_namekey_len: 137ref: constrows: 2Extra: Using where; Using index

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ORDER BY inventory_id, customer_id\G************************** 1. row **************************type: refpossible_keys: rental_datekey: rental_daterows: 1Extra: Using where

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id DESC;

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id DESC, customer_id ASC;

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id, staff_id;

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date > ‘2005-05-25’ ORDER BY rental_date, inventory_id;

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ ORDER BY customer_id;

Покрывающие индексы
CREATE TABLE rental (...PRIMARY KEY (rental_id),UNIQUE KEY rental_date (rental_date,inventory_id,customer_id),KEY idx_fk_inventory_id (inventory_id),KEY idx_fk_customer_id (customer_id),KEY idx_fk_staff_id (staff_id),...);
EXPLAIN SELECT rental_id, staff_id FROM sakila.rentalWHERE rental_date = ‘2005-05-25’ AND inventory_id IN(1,2) ORDER BY customer_id;
