資料分析的前奏曲 談資料收集的挑戰
TRANSCRIPT

資料分析的前奏曲 : 談資料收集的挑戰
周世恩 @ Datasci.tw 2016/7/16
1

About Me
- 台大工程科學與海洋工程研究所碩士班畢
- 參與奈米科技、天文物理、海洋工程相關數據處理
- 前 QSearch 礦工 (資料工程師、資料分析師、資料科學家)
- 剩下個資 ...... 留給台下各位當做資料收集的練習吧
2

資料收集踩雷分享時間夠還有一些乾貨分享...
3

人力分配
技術挑戰
今日地雷分享比例
4

回顧 FAQ
對於心理學、金融、社會科學研究,當必須研究特定社會現象,
必須用「問卷」來收集資料
(1) 缺乏規模化
(2) 無法測試收集
(3) 無法確認資料是否收集完全
機密性、個資法、缺乏有經驗前輩來給予指引 ...
5

資料工程師能幫什麼忙
透過有技術能力的夥伴、員工,能更有效率地根據資料使用者的需求,操控
電腦、機器人等工具來加速資料的抓取,並再將抓取的原始資料變成
”乾淨”的資料。
6

新手轉職為資料工程師
- 寫程式的能力,著重於 I/O 處理
- 資料庫運用有操作經驗
- 能耐的性子,當程式無法運作時,展現工人智慧
- 熟悉各常見的資料格式與讀取方式
7
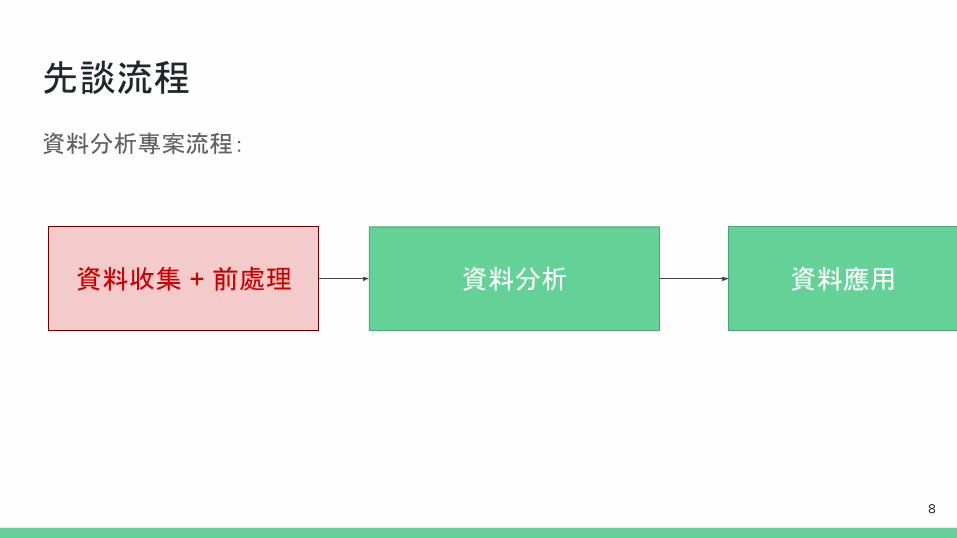
資料分析專案流程:
先談流程
8
資料收集 + 前處理 資料分析 資料應用

先談流程
資料分析專案流程:
Data Collection Schema Matching Record Linkage
Data Cleansing
Classification
Data Mining
NER / NLP
Reporting
Ope
ratio
n
9

今日重點
Data Collection Schema Matching
10
資料分析專案流程:
Record Linkage
Data Cleansing
Classification
Data Mining
NER / NLP
Reporting
Ope
ratio
n

拜科技之賜
我們擁有先進資料收集工具:
Data Collection Schema Matching Record Linkage
Data Cleansing
Classification
Data Mining
NER / NLP
Reporting
Ope
ratio
n
IoT Sensor Web Crawler Open Data
11

回歸問題面 - Why?
資料運用方向:
優化(節省人力物力能源 ) 尋找機會(風險控管)
提升工作效率 市場調查
降低生產成本 加強行銷
提昇回購率 打壓競爭對手
12

我們要收集什麼資料 - What?
需要PM、銷售端、業務端等資料受惠端提供問題
並與資料工程師討論資料收集來源
13

資料工程師下重手前
1. 資料工程師必須測試資料來源穩定性
2. PM等資料需求者必須要確認資料潛在價值
彼此是否合作愉快:
1. 取決於資料工程師對PM的產業經驗的信任度
2. 以及PM對資料工程師執行力的信賴感
14

你就是那條龍。↑ 結合PM 與工程師於一身
15

以上是人的問題終於可以來到技術端...
16

今日技術重點
資料分析流程:
Data Collection Schema Matching Record Linkage
Data Cleansing
Classification
Data Mining
NER / NLP
Reporting
Ope
ratio
n
17

Technical Challenge
1. Challenges of basic web crawling
2. Challenges of large scale web crawling
3. Challenges of advanced web crawling
- Image/Video data crawling- Revisit policy- Collaborative crawling- Real-time crawling- Coverage estimation- Friendly crawler design
18

Foundation of Web Crawling
- 熟悉 http protocol 等基本網路知識
- 至少熟悉一程式語言
- 能實作基本 Crawler- 熟悉 <html> 格式
- 有效運用 HTML parser (必要時撰寫 regex)
- 多半 Web Crawling 的問題是...萬事起頭難
19

20

Challenges of Web Crawling
1. 網路問題 (IP 被封鎖、Proxy 沒開啟、Timeout)2. 對方 Server 有限制 User-Agent3. Deep web 問題 (你完全忘了需要登入才能看到)4. <html> parser 寫錯?
5. 回傳格式找不到 Repeated content6. Database 哪種適合?
- Non-relational and schema-less data model- Low latency and high performance- Highly scalable
21

只是收個資料而已...
我們有捷徑:
1. 運用 Sensor Data (各種感測器)2. 運用 API3. 一起鼓吹政府 Open Data
22

學術圈的挑戰
隨著大家胃口被越養越大,做個研究而已,
卻可能在資料採集就花上80%以上的時間,
- 要學術圈養人處理 Web Crawling 實在是太辛苦了
- 有時候也只為了一次性專案
長時間下來學術圈越來越無法負荷大量資料處理能力
23

Technical Challenge
1. Challenges of basic web crawling
2. Challenges of large scale web crawling
3. Challenges of advanced web crawling
- Image/Video data crawling- Revisit policy- Collaborative crawling- Real-time crawling- Coverage estimation- Friendly crawler design
24

Large-Scale Web Crawling
- 基本架構
- 實作細節
- 限制與開發考量
25

Large-Scale Web Crawling - 基本架構
Initial Seeds Initialize frontier
Done
frontiers
26

Large-Scale Web Crawling - 追求方向
方向
1. 提升涵蓋度
2. 提升即時性
3. 提升新鮮度
4. 提升抓取效率
務實管理要求
1. 機器數量控制
2. 網路速度(上下傳)提升
3. 內容變動程度預測
4. 錯誤處理與管理
27

Large ?
28
每日傳輸量 設計考量
< 1 GB 一台機器從頭到尾完成
< 10 GB 分散式爬蟲 + 集中儲存
10 GB+ 分散式爬蟲 + 分散式儲存

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- 使用 PAAS 或用 IAAS + AutoScaling 架設爬蟲叢集- 用 IAAS 雲端服務可能會出現 External IP 不足的問題 ↳ 選一台可對外連線 Instance 架設 Squid
- 其餘機器再設定 Proxy
29

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- AutoScaling 與 Scheduler 有密切的關係,調整爬蟲資源。- Scheduler 主要工作:(1) 調整抓取順序 (Ordering policy)(2) 調整同步抓取數量 (Concurrent Issue)(3) 確認Instances 是否健康
30

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- Scheduler 設計注意細節:(1) In-memory or Disk-based Request queue?(2) 插隊機制?(3) 有效壓縮 Queue System 資源使用量(4) 以 Hash Table 取代掉 FIFO queue (5) 重複抓取 (Duplicate Seed Filtering)
31

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- Scrape 設計注意細節:(1) 建議Scheduler 與寫入資料的機器是獨立的(2) 定時重開或回收未用的資源(3) 需要裝設即時Monitoring Agent (ganglia) 資料傳輸工具建議:Apache Flume, Apache Kafka, Pub/Sub Messaging System
32

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- Extract Structured Data 設計注意細節:(1) 運用現成的 Parser (xmlparser, json parser,
pyQuery, Apache Tika,...)(2) 建議在 Scheduler 端每送一 Request就夾帶一
flag,以便統計 Missing Rate. (3) 結合 Task Queue System ,當 Scheduler 比較空閒
時將新抓取 Request 加入排程中33

Challenges of Large-Scale Web Crawling - 實作細節
Initial Seeds Initialize frontier
Done
frontiers
- Store Data 設計注意細節:(1) 設計資源統一管理的儲存系統(GFS, HDFS, ...)(2) 建議批次塞入資料來降低網路資源使用
34

海量資料處理工程師
- 熟練雲端運算服務、分散式系統建構
- 分散式資料庫運用有操作經驗
- 網路架構設計或網路性能調教
- 協調管理能力
35

Large-Scale Web Crawling - 限制與開發考量
* 網路問題
(1) 我方下載快,不代表對方上傳快
(2) 網路速度是否不穩定?
(3) 對方是否會因大量 Request 被判定為”DDOS”?(4) IP 被封鎖,如何有效率的準備 IP Pools(5) 資料傳輸成本 ?
36

Large-Scale Web Crawling - 限制與開發考量
* 機器管理問題
(1) 運用 Docker ?(2) 機器效能要求 ? (3) 機器資源管理 (4) Scheduler 穩定性
37
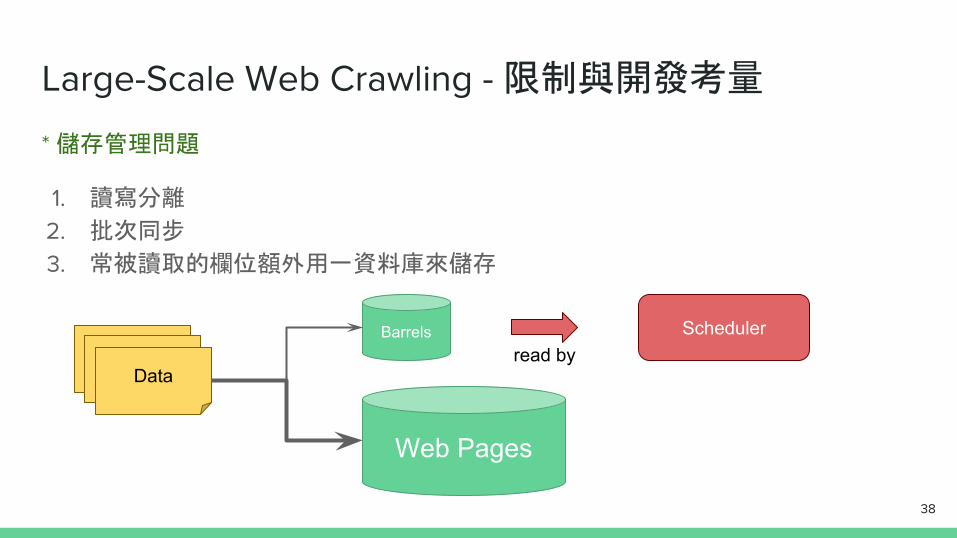
Large-Scale Web Crawling - 限制與開發考量
* 儲存管理問題
1. 讀寫分離
2. 批次同步
3. 常被讀取的欄位額外用一資料庫來儲存
38
DataDataData
Web Pages
Barrels Schedulerread by

Large-Scale Web Crawling - 限制與開發考量
* Seeds 選擇與 Infinite loop detection 問題
(1) 觀察新抓取的文章量與抓取深度的關係
(2) 運用其他公開統計來輔助
39

Technical Challenge
1. Challenges of basic web crawling
2. Challenges of large scale web crawling
3. Challenges of advanced web crawling
- Image/Video data crawling- Revisit policy- Collaborative crawling- Real-time crawling- Coverage estimation- Friendly crawler design
40

- Image/Video Data Crawling: 資料量更大、網路更吃重
- Collaborative Crawling: 多層次的資料收集
- Re-visit Policy: 維持資料新鮮度,怎麼辦?- Real-time Crawling: 維持資料即時性,又沒無限資源,怎麼辦?- Coverage Estimation: 已收集資料有多完整?- Friendly Crawler Design: 你是一個惡意的 Crawler 嗎?
The challenge of advanced web crawling
41

Image/video Crawling
考量到更龐大的網路與儲存資源需求 (圖片傳輸量約為文字~ 28倍),資源的運用與選
擇更為重要
設計上的考量
(1) 盡可能透過現有 Text Data 來決定此 Image/Video 值得被收集
(2) 根據重要性進行排序,重要的先抓
(3) 用縮圖取代原圖
(4) 盡可能用 Push 取代 Pull (有特定目的才觸發圖片收集,例:圖片上傳)
42

Re-visit Policy
一個連結打開的內容,每次打開時內容可能有變化。為了維持自家資料庫的新鮮度,
必須再訪網頁。相關挑戰:
- 如果我收集了 2 億個網頁,每個都必須再訪更新?
- 多久要再訪一次?- 可否微量更新 (Atomic Update)?
43

Re-visit Policy - 執行方案
從空間上找變化程度
從時間上找變化程度
44
統計各網頁變化量用機器學習工具建立模型
將模型用於預測各網頁變化量
統計各網頁變化頻率用機器學習工具建立模型
將模型用於預測各網頁頻率
Re-visit policy
整合

Collaborative Crawling
原本要爬特別的主題,透視透過 URL +原文相似性探勘,來深度把特定主題的文章抓
下來。但可能這樣的探勘方式得到一堆雜訊。資料需求者增加
- Location- Browsing behaviors- ...
來提升特定主題資料的精準度
45

Collaborative Crawling - 問題面
1. 需要的部份很少很少,但為了追求精準的資料,要求很大很大。Redundant Data 很多
2. 為了加速篩選,篩選器 (Filter) 可能做在 Downloader 元件上
3. 篩選速度要快
其實很難,
最後可能回歸一家抓取團隊統籌負責,再分送給需求者。
46

Real-Time Crawling
通常在媒體、即時交易系統內特別重視。
大家可參考 Google News 的發跡原因。
網頁或目標物的點擊量、閱覽量越高,越可能是潛在 Crawling 對象
透過 URL pattern 或 Text Mining 可預測該網頁或目標物是否是即時分析需要的資
料。
47

Coverage Estimation
48

Friendly Crawler Design
1. Follow robots.txt- Allow or Unallowed? - 是否符合User-Agent 規範
2. 不要故意超過規範的流量 ( e.g., 對方誤判為DDOS )3. 要遵守 API 協定規範或 Protocol 規範
49
要當個友善爬蟲工程師


Reference:
1. Pant, Gautam, Padmini Srinivasan, and Filippo Menczer. "Crawling the web." Web Dynamics. Springer Berlin Heidelberg, 2004. 153-177.
2. Ferrara, Emilio, et al. "Web data extraction, applications and techniques: a survey." Knowledge-based systems 70 (2014): 301-323.
3. “Crawling”, http://slideplayer.com/slide/7572783/
51