クラシックな機械学習の入門 6. 最適化と学習アルゴリズム
DESCRIPTION
学習データから分類器を学習するアルゴリズムの理論的基礎である最適化のアルゴリズムについて説明する。TRANSCRIPT

6. 最適化と学習アルゴリズム
勾配降下法 直線探索
劣勾配降下法 ニュートン法
確率的勾配降下法
クラシックな機械学習の入門

学習における計算効率の問題
既に説明した回帰、識別(分類)の解法で得た閉じた式は逆行列計算が必要。例えば、線形回帰の場合の正規方程式の解である重みベクトルは w=(XTX)-1XTy
学習データが高次元になると(XTX)の次元も大きくなり、逆行列の計算はコストが高い(次元数の3乗)
要は損失(=Loss)を最小化したい
正規方程式の場合は2乗誤差だった。
逆行列計算を避けて最適化する方法が実用上重要。

記法:損失(Loss)
zz
ym
L
ym
ym
L
ylossm
L
my
D
m
i
ii
m
i
ii
m
i
ii
m
i
ii
ii
i
,0max
,11
,1
,1
2
,on 1
1) or 1(
,
1
1
2
1
2
2
1
ここで
ヒンジ損失の場合
乗損失の場合
例:
個あるとするただしデータは に対する分類の正解:
次元ベクトルとするは重みベクトル:入力データ:
xww
xwxww
xww
x
wx

記法: 勾配(Gradient)とヘッセ行列(Hessian)
のヘッセ行列における
の勾配における
ノルム:
次元ベクトルとするは
1
1
kDD
kkDD
kDD
kk
kDD
k
wwDDwwwwD
wwwwDwwk
k
wwnww
k
k
p
D
pp
p
pp
D
p
p
ww
L
ww
L
ww
L
ww
L
L
L
w
L
w
LL
L
wwwwp
D
ww
ww
w
ww
www
ww
ww
w
2
,
2
,1
2
1
2
T
1
1
1
1
11
1111
11
H
,....,

勾配降下法
右図で分るようにL(w)が凸の場合は、勾配▽L(w)の
逆方向に進むとW*=argmin L(W)に向かって進む。
図は1次元だが実際は多次元なので、勾配の方向が大切なことに注意
L(w)
min L(w)
W* w ▽L(W*)=0
勾配 =▽L(W)

定式化
• 勾配降下法(Gradient Descent)の定式化する
となる
けば閉じた解が求まり損失を微分して0と置
:2乗損失だと
:重みベクトルの更新式
となる。方向に進むので下の式を求めるには勾配の逆
最適な重みベクトル
ル更新された重みベクト回目の繰り返し結果の
のときの損失:重みベクトル:重みベクトル
kkkk
kkkk
kkkk
k
L
LL
LL
L
k
L
www
wwvw
wwvw
ww
w
www
v
v
w
1
2
2
12
2
1
*
minarg**
minarg
minarg:
:
2乗損失でないとこう簡単な式ではない

最急降下法アルゴリズム • L(w)を最小化するようなwを求めるために、wの現在の値w(k)から勾配▽L(w)の逆方向に進むアルゴリズム
)())(,(
2)(,)(
11:4
)size step()(:3
)(:2
:1
);(minarg;0;
)()()1(
2
2
)()()1(
)(
)1()(
*)(
*)0(
nn
k
n
kkk
nn
kkkkk
k
kk
k
y
yL
stepkkstep
Lstep
Lstep
step
Lk
xxwww
xww
www
w
ww
ww
www
乗損失なら つまり
へ として
は進む幅
を計算
)に十分近くて収束したがは (具体的に
に十分近いなら終了が
初期値

最急降下法の収束の評価
前提条件
凸 & ▽2L(w) positive
Lipschitz条件:
テイラー展開により近似
1
0
2
2
12
2
2
2
1
2
2
2
22
2
22
2
1
11
kkkk
kkkk
k
kkk
kkkk
kkkkk
LLL
LLL
L
LLLLL
LL
www
www
w
wwwww
wwww
+
+
+
により
と次のテイラー近似するをとし、
GL
GLL
k
kkkk
2
2
11
w
wwww

直観的説明
min L(w)
W(k+1) w(k)
GL
GLLL
GLipshitz
GLL
k
kkkkkkk
kkkk
2
2
1
2
1
2
1
2
11
w
wwwwwww
wwww
がある条件より以下のような
凸かつ▽2L(w)≥0なので、minLに近づく
につれてこの差は小さくなる
適当なGで上から抑えられる

最急降下法の収束の評価:つづき
以下に収束回の更新で誤差
として:以下にするのはオーダ誤差を
より条件
とおくを選び、というここで
ないし等しいとするとに十分近い(が +
2
22
2*
2
2
*
*2
2
*1*1
12
2
Lipschitz
,
)
1
GBO
k
BGOO
k
BGG
kG
BLL
GL
kG
BBB
LLL
LLL
k
k
k
kkk
kk
kkkk
ww
w
w
www
wwww
www

捕捉
という雰囲気
とおくを選び、というこのあたりを想定して
くらいにはなるだろう
と無意味!をやたらと大きくする
kG
BB
GBGLL
BB
GLL
k
kk
k
kk
k
2
**
2
*
2
*
2
**
wwww
www
wwww

step size αを決める:直線探索
α(k)が小さすぎると収束が遅々として進まず、
大きすぎると最悪の場合最適値を飛び 越す
最適なα(k) を求める問題:直線探索
厳密に解くのは困難
0 subject to
(min
k
kkk LLk
単位ベクトル の
方向)つまり降下方向は wddw

直線探索の代案
kの減少関数にする i.e.
しかし、あまりにもヒューリスティック
もう少し客観的な基準として
Armijo基準とWolfe基準がある
kk 1

Armijo基準とWolfe基準
α
L(W+α▽L(W))-L(W)
α▽L(W)
ξα▽L(W): 0<ξ<1 予め決まった値
ξ=0
この不等式を満たすようにαを選ぶ:Armijo基準
L(W+αd)-L(W) ≤ ξα▽L(W)Td Wolfe基準: α が小さくなりすぎないため。 α =0だと明らかに成立しない(!▽L(W)Td<0)
1
TT
ddWdW LL
最適値
行き過ぎ
α=0

直線探索の代案:2分割法
k回目の繰り返しにおいて以下のアルゴリズムでα(k)を減少させる
Step1 t=1, αt(k)=α(k)
Step2 if 停止基準(Armijo基準等)が満たされる
then return αt(k)
else αt(k)=α(k)/2
Step3 k k+1
Step4 Step 2へ

微分可能でない場合: 劣勾配(sub-gradient)の利用
gwvwvvgwT
LLL
L
0|
tsubgradien:convext:
の凸関数
w v
...|gw L

例
10
0,1
11
1
01
1,1
01
1
1
wwL
wL
wwL
wwL
losshinge
wwL
wL
wwL
wwwL
lossL

劣勾配降下法 Sub-Gradient Descent
へ として
を計算
)に十分近くて収束したがは (具体的に
に十分近いなら終了が
初期値
11:4
minarg:3
0|
:gradient-sub 2 step
:1
);(minarg;0;
,
1
)1()(
*)(
*)0(
stepkkstep
Lstep
LL
L
step
Lk
kk
L
k
kk
k
gwvw
gwvwvvg
w
ww
ww
www
wgv

最急降下法がうまくいかない場合
• ジグザグに動きながら最適解に近づくので収束する速度が遅い(効率が良くない)
• 勾配以外の情報も使ってみるニュートン法

ニュートン法
最小化したいのは損失 L(w) ただし、直接には最適化できない場合を考えている
今wの現在値w(k)が与えられていて、dを加えることによってより最適値に近いw(k+1)を得たい。
ここでw(k)が定数でdを変数と思って
L(w(k+1))= L(w(k)+ d)
の左辺を直接最適化する代わりに右辺を最小にする d を求める。
この結果をd(k)とし、よりよいLをL(w(k)+ d(k))として、繰り返すことによって真の最適値に近づこうとする
ここでL(w(k)+ d)を2次のテーラー近似する場合がニュートン法

kkk
kkkk
LL
LLLL
wwd
dwddwwdw
d
1
TT
Hminarg
H2
1
右辺
2次のテーラー展開
右辺をdの関数と見て最小化しニュートン方向d(t)を求める
ニュートン法のアルゴリズム
よいは直線探索で決めても
へ として
は
を計算 ニュートン方向
に十分近いなら終了が
初期値
k
kkkkkk
kkk
k
stepkkstep
LLstep
LLstep
step
Lkstep
11:4
size stepH:3
H:2
:1
);(minarg;;0:0
1)()1(
1
*)(
*0
wwww
wwd
ww
www

ニュートン法の直感的な解釈
この辺りは▽の変化すなわちヘッセ行列 HL(W)が小さ
いので大きく進む方が効率がよい
HL(W)-1:大
この辺りは▽の変化すなわちヘッセ行列 HL(W)が
大きいので大きく進むと不味い方向に行ってしまう。
HL(W)-1 :小

ニュートン法の問題点
ニュートン法は勾配降下法より多くの場合で性能がよいが、ヘッセ行列の逆行列を繰り返しの度に計算しなければならない
N×Nの行列の逆行列の計算にはO(N3)のコストがかかる。Nが大きくなると実用的でなくなる
ヘッセ行列の逆行列を近似する行列を行列のかけ算だけによる更新式を使ってO(N2)で計算する方法もある。 BFGS公式のヘッセ逆行列版(cf. 共立出版「最適化法」p.122)

確率的勾配降下法 Stochastic Gradient Descent(SGD)
ここまで述べてきた方法は全データを一挙に学習に用いるバッチ処理
1データないし少数のデータ毎に重みベクトルw学習する方法:オンライン学習に近い 最終結果としては、1ないし少数データ毎の学習で得られたwの平均
メモリに全データを展開しなくてよい可能性もある省メモリしかし、全データを何回も繰り返し使うなら省メモリにならない-
1つのデータは1回しか見ないストリームマイニング的
2種類のSGD Sample Approximation(SA):1データ毎の学習
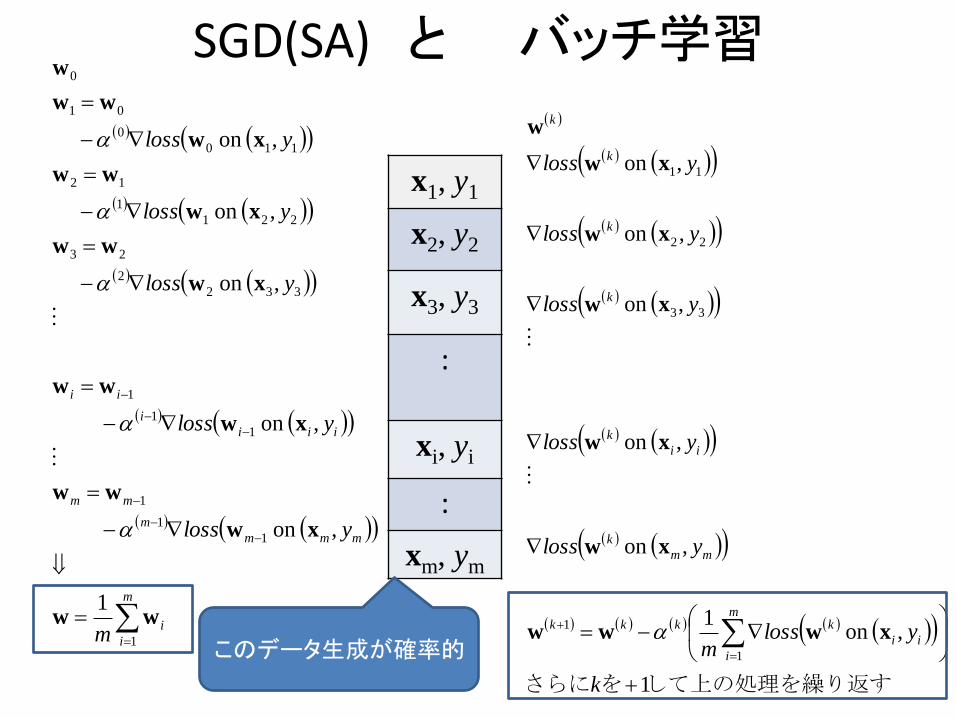
SGD(SA) と バッチ学習
x1, y1
x2, y2
x3, y3
:
xi, yi
:
xm, ym
m
i
i
mmm
m
mm
iii
i
ii
m
yloss
yloss
yloss
yloss
yloss
1
1
1
1
1
1
1
332
2
23
221
1
12
110
0
01
0
1
,on
,on
,on
,on
,on
ww
xw
ww
xw
ww
xw
ww
xw
ww
xw
ww
w
すして上の処理を繰り返をさらに 1
,on 1
,on
,on
,on
,on
,on
1
1
33
22
11
k
ylossm
yloss
yloss
yloss
yloss
yloss
m
i
ii
kkkk
mm
k
ii
k
k
k
k
k
xwww
xw
xw
xw
xw
xw
w
このデータ生成が確率的

Sample Average Approximation(SAA)
SA inside SAA
全データからランダムにm個のデータをサンプルしてm個のデータからなるデータ集合を作る。
このようにして異なるデータ集合をk個作る。
データ集合(i)にSGD(SA)を適用して学習し、重みベクトルw(i)を計算
最終結果
m
i
im 1
1ww

例:SGDによるサポートベクターマシン
k
BB
yy
ni
n
ym
ym
sum
sumsum
iii
T
i
m
i
i
T
i
m
i
i
T
iB
ww
www
wwww
xwwxw
w
wxwxwWW
結果:
}
からランダムに生成 を {
回繰り返す以下を
全データ数初期値:
は以下のようになるに注意すると
then if
then 1 if
..1
k
:,
SVD
21
1min1
1min
22
0
2
2112