いまさら聞けない “モデル” の話 @dsirnlp#5
DESCRIPTION
DSIRNLP#5 の 松田の発表ですTRANSCRIPT

いまさら聞けない “モデル” の話
DSIRNLP #5 (ゆるふわ枠) 2014/01/11 @スマートニュース株式会社
Koji Matsuda a.k.a @condiAonal
1
※発表スライドは後ほどslideshareに公開します

自己紹介タイム
• 学生でも教員でも無いですが,大学にお世話になっています • すずかけ論文読み会という勉強会で月イチくらいで発表して
ます – 多摩川以西(?)の機械学習屋さん(ファン)で小規模に – 現在のところクローズド.発表資料の多くは参加者により公開されて
います.
• 求職中です!!!!
2

ことの始まり
3
2013年初夏:研究室(自然言語処理メイン)の メンバーと草津温泉に行きました.その車中にて.
先生から「モデルを考えよう」というアドバイスを頂くのですが,具体的に何をしたらいいのでしょう?
とりあえず,「問題の性質」を考えるのがいいんじゃない?
うーん問題の性質,と言われても,ただの分類問題のように思えます.「こういう特徴量が効く」というだけでは,研究としてちょっとつまらないですよね?
学生 さん
学生 さん
私
ぐぬぬ〜(気持ちはたいへん分かるが,うまいアドバイスが思いつかない) 私

4
わきみちです

5
解読
“Unsupervised TranscripAon of Historical Documents” [Kirkpatrick+, ACL 2013]
「さまざまな要因を考慮しながら確率モデルを組み上げる」 という意味で,お手本のような論文なのでおすすめです

言われてみれば
• 「モデルを考える」といわれても,具体的な方法論を教わったことはあまり無いように思えます – そもそも「モデル」って何でしょう???
• そこそこ長く研究に携わっている方なら,自然に理解している概念も,研究を始めたばかりの学生さんにはなかなか難しい – これは「モデル」の話に限りませんが・・・
• この問題意識を共有したい!! – そうだ 勉強会で話してみよう!
6

このトークの主旨
• 「モデル」とは何か,をいくつかの例から帰納的に明らかにすることを試みます
• 同時に,「モデルを考える」とはどのような営みかを考えてみます
願わくば,悩める大学院生/新入社員のための幽かな希望の光とならんことを
研究者の皆様にはあまりにも自明な話であり,退屈かもしれません
7
「自分だったらどう説明するか」ということを考えながらお聞き頂ければ幸いです
※フィードバック歓迎です!

「モデル」という言葉の意味
• 人によってさまざま. – アプリケーション屋さんが使う「モデル」 – 数理屋さんが使う「モデル」
• これほど多義な言葉もそうそう無い • この多義性が,「つかめなさ」を生んでいる一因
• 天下り的に「モデル」とはこういう意味だ!と定義するのは難しい(というか,議論が終わらない)
• そこで今回は,自然言語処理においてよく用いられる幾つかのモデルから共通の特徴を抜き出すことができないか考えてみます
8

NLP まわりの色々なモデル
• 言語モデル:単語列に確率を割り当てるためのモデル – n-‐gram言語モデル, RNN言語モデル,…
• 言語の背後にある「構造」のためのモデル – 隠れマルコフモデル(HMM),マルコフ確率場(MRF/CRF),…
• 分類モデル – ナイーブベイズ,SVM, …
9

言語モデルの例 (n-‐gram言語モデル)
• ある文(単語列)の確率を求めたい – P( I can fly )
• ある単語の出現確率は,直前n-‐1個の単語にしか依存しない,と仮定 – 2-‐gramモデルなら,,, – P(I can fly) = P(I|<S>)P(can|I)P(fly|can)
• それ以前の文脈や,統語的な特徴は全て捨象
10

構造モデルの例 (隠れマルコフモデル)
11
• ある文の確率を求めたい/文のそれぞれの単語に品詞を付与したい – 品詞: 名詞,形容詞,副詞等
• 単語の出現確率は品詞(隠れ変数)にのみ依存,品詞は一つ前の語の品詞にのみ依存と仮定 – 離れた位置にある語についての情報は捨象

文書分類モデルの例 (ナイーブベイズモデル)
• ある文書が予め決められたどのカテゴリーに属するかを判定したい – ポジティブ/ネガティブ etc… – スポーツ/政治/芸能/経済 etc…
• すべての単語は(カテゴリーが決まった条件のもとで)お互いに独立に生起する,と仮定 – ある単語が出現すると,他の単語も出現しやすく
なる,といった現象は捨象
12

「モデル」の本質/仮定・捨象
• 三つのモデルを駆け足で眺めてみましたが,以上に共通する要素は何だったでしょうか – n-‐gramモデル:単語の生起確率は直前の単語にしか依
存しないと <仮定> – 隠れマルコフモデル:単語の生起確率は品詞と一つ前の
語の品詞にしか依存しないと <仮定> – ナイーブベイズモデル:単語の生起確率はカテゴリが決
まったもとでお互いに独立であると <仮定> • <仮定> を行い,大勢に影響しない要素を <捨象>
することこそ,「モデル」の本質(キリッ – 言い切って進めます
13

「モデル」の本質/パラメータ
• <仮定>(ストーリーの骨組み) を決めた上で,その詳細はデータに「語らせる」 – n-‐gramモデル: ある語が出現したもとでの,直後の
語の出現確率 • 回数をカウントするだけ
– 隠れマルコフモデル: ある品詞から他の品詞への遷移確率,ある品詞がある語を出力する確率 • 複数の変数(品詞,語の出現回数)が絡み合っているので
ちょっと複雑 – ナイーブベイズモデル:あるカテゴリのもとでの,ある
語の出現確率 • 回数をカウントするだけ
14

(脇道)複雑さと信頼性のトレードオフ
• しかし,その <仮定>/<捨象> は,正しいですか? • できることなら,捨象をできるだけ行わず,用い
ることのできる情報をすべて使いたい – しかし,モデルが複雑性を増せば増すほど,「稀な」
事象に対応するパラメータが増えていきます • n-‐gramモデルにおいて n を大きくした場合 • サイコロを一度だけふって「このサイコロは6しか出ない」と
言っているようなもの
• 何を用い何を捨てるか,というのは腕の見せ所 – ただし,比較的ロバストな学習モデルもあります
15
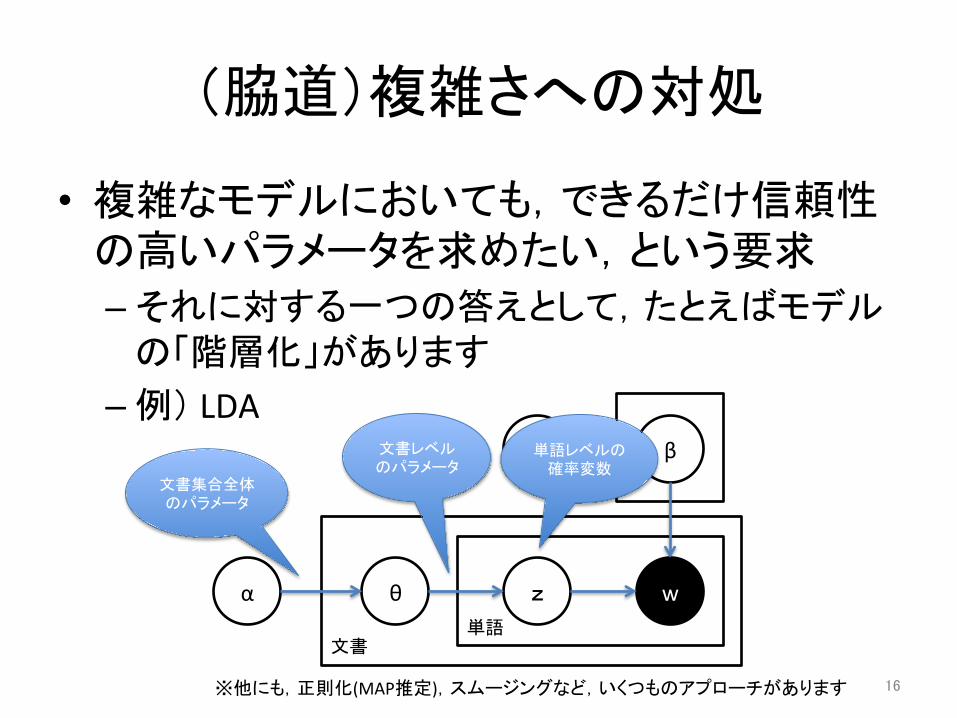
(脇道)複雑さへの対処
• 複雑なモデルにおいても,できるだけ信頼性の高いパラメータを求めたい,という要求 – それに対する一つの答えとして,たとえばモデル
の「階層化」があります – 例) LDA
16
θ z w α
β 文書レベルのパラメータ
単語レベルの確率変数
文書集合全体のパラメータ
※他にも,正則化(MAP推定),スムージングなど,いくつものアプローチがあります
単語 文書

モデル?アルゴリズム?
• 「モデル」と同様にさまざまな使われ方をする言葉として「アルゴリズム」があります
• モデルとアルゴリズムは,異なるものであると考えたほうが良いように思えます – ただし,境界線はあいまい
• 私の理解 – 「モデル」はあくまで,<目的>の数理的な表現 – その<目的>にいかに到達するか,が「アルゴリズム」
の領分 • 匠の技
17
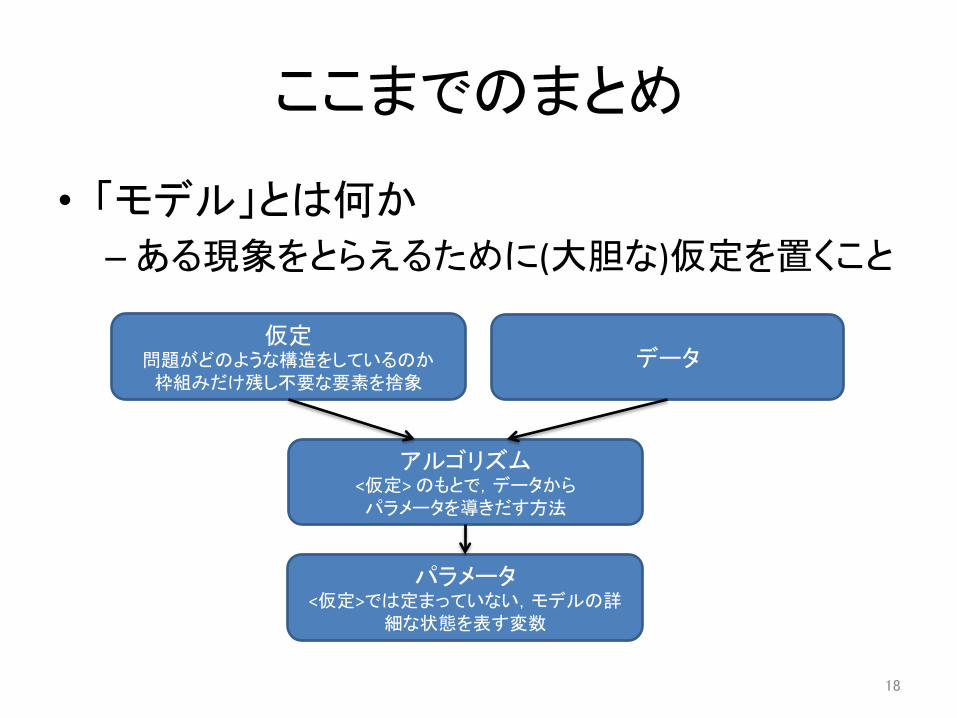
ここまでのまとめ
• 「モデル」とは何か – ある現象をとらえるために(大胆な)仮定を置くこと
18
仮定 問題がどのような構造をしているのか
枠組みだけ残し不要な要素を捨象 データ
パラメータ <仮定>では定まっていない,モデルの詳
細な状態を表す変数
アルゴリズム <仮定> のもとで,データから パラメータを導きだす方法

モデルを考えよう/ Playing with your Problem
• 問題の性質を考えましょう – その問題は「分類」で表すのが本当に適切ですか?
• じつは「選好関係」ではないか?「回帰」ではないか?
– ある事例に対するラベルが,他の事例のラベルに影響を与える場合,構造を扱えるモデルを検討 • 例)品詞ラベルは,周囲の語の品詞に依存する
– モデルの内部の状態を他のモデルへ渡すようなことを考えているなら,確率モデルが有用かもしれません • 全体を一つの確率モデルとして記述することができれば,
見通しが良くなるかも
19

(脇道)確率モデルを組み上げる時は
• 推論が効率的にできる構造になっているか – 鎖状(クリークの数え上げが楽)
• ループがあると,ちょっと難しくなる
– 仮定する分布が共役ペアになっているか • Dirichlet / MulAnomialなど
• 条件付き確率のモデル化で十分ではないか – 同時確率より表現能力は劣るが,リッチな素性を
入れ込める – HMM(同時確率)に対するCRF(条件付き確率)
20

「モデル」を中心に据えた論文を いっぱい読みましょう
• 結局のところ,自分の中に「モデルのモデル/モデルの索引」をつくり上げることが必要になる
• 確率モデルを扱った論文は難しい,と言われますが,コツさえつかめば何とかなる – その論文は「何をモデル化しているか」 – それぞれの変数について
• 何を表しているか:現実世界の何と対応しているか • ドメインはなにか:スカラーか,ベクトルか,確率分布か
– どういう <仮定> を置いているか • 何を <捨象> しているか,それは重要ではないのか
21 背景のグラフィカルモデルは “Joint Modeling of a Matrix with Associated Text via Latent Binary Features” [Zhang and Carin, NIPS 2012] より

モデルを「実装」する
• 「仮定」「データ」「アルゴリズム」の三本柱のうち,最も実装がたいへんなのは「アルゴリズム」の部分
• 多くの場合は <目的関数> に対する <最適化問題> に落とすことができます – 非常に研究が進んでいる分野
• この部分をある程度サボるためのツールキットが出てきています – 確率モデル : infer.net,BUGS/Stan, HBC, … – ニューラルネット : Pylearn2, Torch, … – 組み合わせ最適化:CPLEXなどのLPソルバー – 連続最適化: libLBFGS(準ニュートン法のパッケージ)など
22

モデルを「実装」する (確率モデルの例)
• ProbabilisAc Programming – 確率モデルの <仮定> を記述して,データを与えるとよし
なに推論してくれる枠組み – See also : hpp://probabilisAc-‐programming.org/ – 例) HBC: Hierarchical Bayes Compiler による LDA
23
alpha ~ Gam(0.1,1)!eta ~ Gam(0.1,1)!beta_{k} ~ DirSym(eta, V) , k \in [1,K]!theta_{d} ~ DirSym(alpha, K) , d \in [1,D]!z_{d,n} ~ Mult(theta_{d}) , d \in [1,D] , n \in [1,N_{d}]!w_{d,n} ~ Mult(beta_{z_{d,n}}), d \in [1,D] , n \in [1,N_{d}]
HBCは現在メンテナンスされていないので,あまりおすすめはできません 実際に使うなら, BUGS, Stan, infer.net(非商用のみ)がホットなようです BUGS/Stan は勉強会があるそうです [検索]
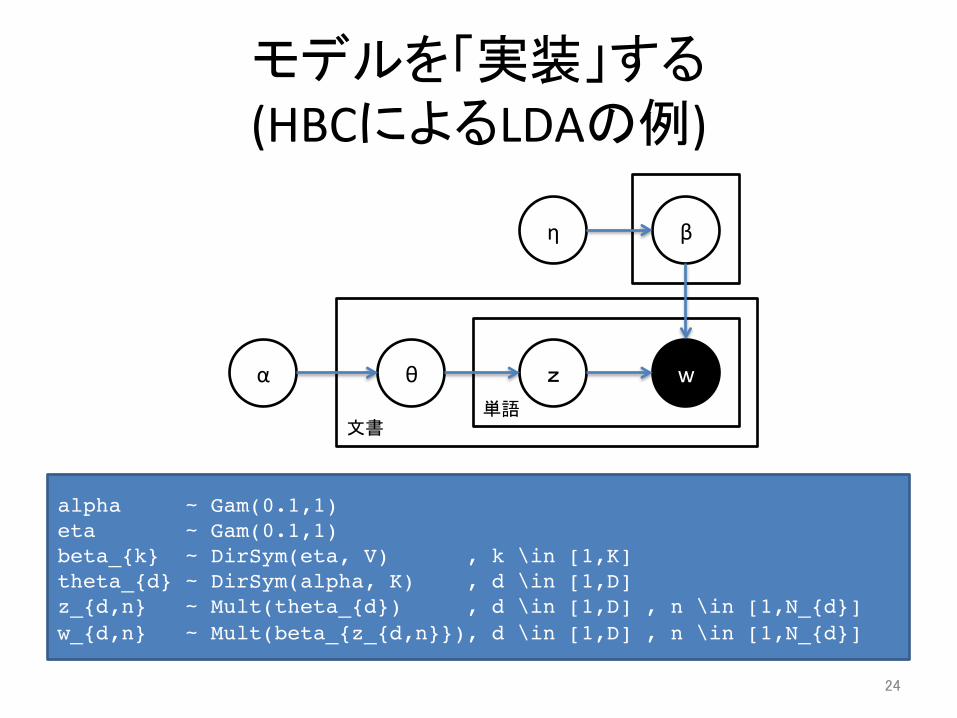
モデルを「実装」する (HBCによるLDAの例)
24
θ z w α
β η
単語 文書
alpha ~ Gam(0.1,1)!eta ~ Gam(0.1,1)!beta_{k} ~ DirSym(eta, V) , k \in [1,K]!theta_{d} ~ DirSym(alpha, K) , d \in [1,D]!z_{d,n} ~ Mult(theta_{d}) , d \in [1,D] , n \in [1,N_{d}]!w_{d,n} ~ Mult(beta_{z_{d,n}}), d \in [1,D] , n \in [1,N_{d}]

モデルを「実装」する (ニューラルネットの例)
• Torch7 ( hpp://torch.ch/ ) の例
25
require "nn”!mlp = nn.Sequential() -- 多層のネットワーク!mlp:add( nn.Linear(100, 25) ) – 入力100ユニット -> 中間25ユニット!mlp:add( nn.Tanh() ) – 活性化関数は tanh!mlp:add( nn.Linear(25, 50) ) – 出力層は50クラス!mlp:add( nn.SoftMax() )!criterion = nn.ClassNLLCriterion()!trainer = nn.StochasticGradient(mlp, criterion) – 最適化はSGD!trainer:train(dataset)
100U 25U 50U
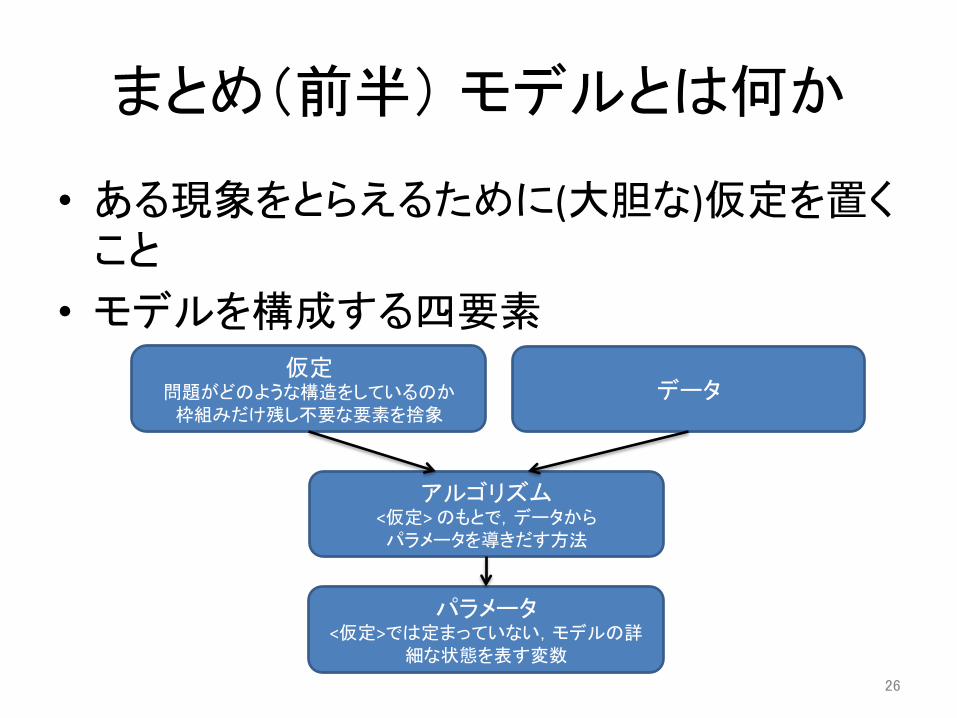
まとめ(前半) モデルとは何か
• ある現象をとらえるために(大胆な)仮定を置くこと
• モデルを構成する四要素 仮定
問題がどのような構造をしているのか 枠組みだけ残し不要な要素を捨象
データ
パラメータ <仮定>では定まっていない,モデルの詳
細な状態を表す変数
アルゴリズム <仮定> のもとで,データから パラメータを導きだす方法
26

まとめ(後半) Playing with your Model
• 「モデルを考える」ときには, – 直面している問題の性質を考えましょう
• 分類で表すことが適切な問題なのか • 構造(他の変数との絡み)を考慮する必要があるのか
– 「アルゴリズム」については先人の知恵を借りることが可能か,時間を割いて調べてみる価値がありそうです
27
というようなことを,研究を始めたばかり(始めるつもり) の人に伝えたいです