Алексей Рылко, iprospect — «seo-инсайды, которые вы можете...
TRANSCRIPT

SEO-инсайды, которые вы можете достать из логов сервераАлексей Рылко, iProspect Paris для 8p 2016: Бизнес в сети

Для владельцев интернет-проектов
Которые также как и Джанлуиджи хотят держать все под контролем
Для руководителей SEO-компаний
Которые также как и Дэвид хотят работать с Европой

Для SEO-специалистов
Которые любят правильные цифры и не любят « сломанный телефон »

Для SEO-специалистов
Которые слишком дорожат своими клиентами, чтобы делать не очень правильные вещи

Прежде чем начать
6
Все примеры на следующих слайдах
реальны.
Все возможные совпадения, совершенно
случайны.
“ “
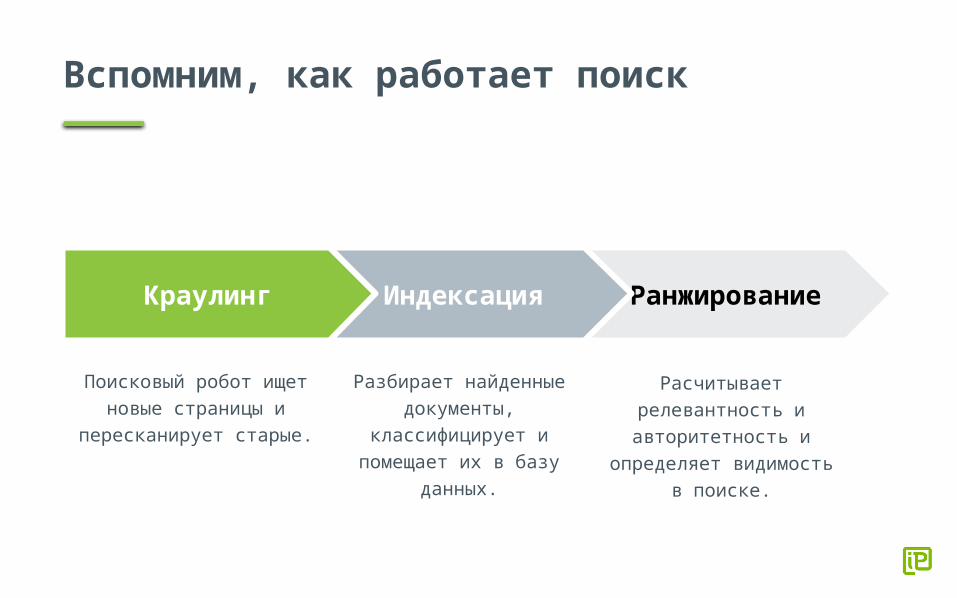
Вспомним, как работает поиск
Поисковый робот ищет новые страницы и
пересканирует старые.
РанжированиеИндексацияКраулинг
Разбирает найденные документы,
классифицирует и помещает их в базу
данных.
Расчитывает релевантность и авторитетность и
определяет видимость в поиске.

Что собой представляют логи?
site.com 66.249.64.117 - - [27/Jul/2015:12:45:21 +0300] "GET /your-page.html / HTTP/1.0" 200 77032 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Абсолютно любое обращение к сайту фиксируется на сервере в специальных файлах – логах сервера – в виде таких строк:
IP-адрес Дата и время
Посещенная
страница
Код ответа
сервера
Размер страницы в
байтахUser-agent
Домен

А все в месте они образуют это:

СПОЙЛЕР: Есть много удобных инструментов

Где искать серверные логи?
/var/log/apache/access.log
/var/log/nginx/access.log
%SystemDrive%\inetpub\logs\LogFiles
Apache
Nginx
IIS

ИзучаемповедениеGooglebot’а
самостоятельно

Googlebot и неактивные ссылки

Googlebot и robots.txt
1. Googlebot следует инструкциям в файле robots.txt.
2. Googlebot блокирует доступ, но не управляет индексацией.
3. Иногда Googlebot может показывать в результатах поиска страницы, закрытые в robots.txt, притом, что он никогда их не посещал, ни индексировал.
«Googlebot не будет напрямую индексировать содержимое, указанное в файле robots.txt, однако сможет найти эти страницы по ссылкам с других сайтов.
Таким образом, URL, а также другие общедоступные сведения, например текст ссылок на сайт, могут появиться в результатах поиска Google.
Чтобы полностью исключить появление URL в результатах поиска Google, используйте другие способы: парольную защиту файлов на сервере или метатеги с директивами по индексированию».
https://support.google.com/webmasters/answer/6062608?hl=ru&rd=1

Googlebot и robots.txt
Задача: удалить из индекса много ненужных страниц.Частая ошибка: robots.txt + meta name=“robots” “noindex”.Правильный вариант: robots.txt + meta name=“robots” “noindex”.
4. Ошибки в названии файла, в инструкциях, в хронологии.
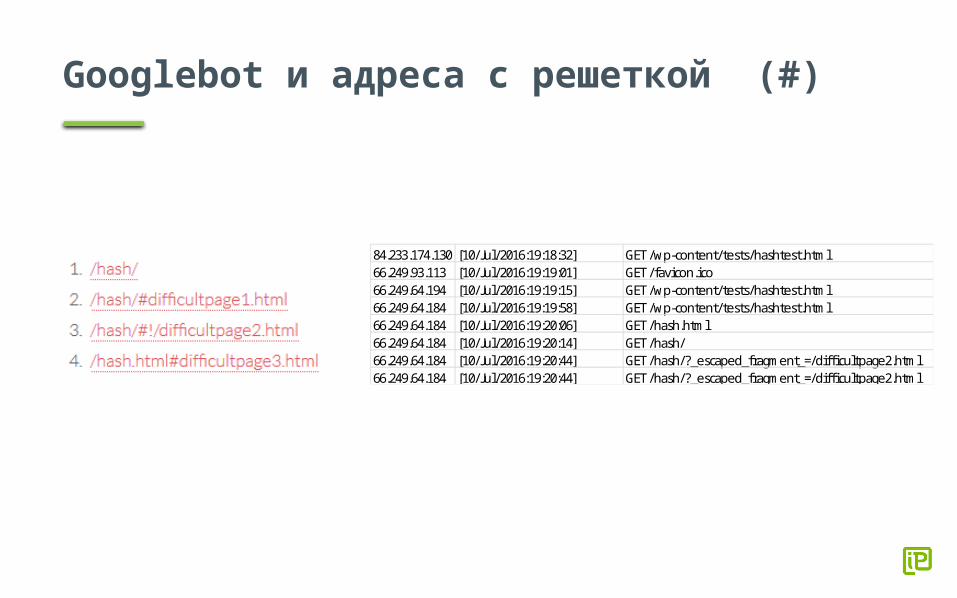
Googlebot и адреса с решеткой (#)
84.233.174.130 [10/Jul/2016:19:18:32] GET /wp-content/tests/hashtest.html66.249.93.113 [10/Jul/2016:19:19:01] GET /favicon.ico66.249.64.194 [10/Jul/2016:19:19:15] GET /wp-content/tests/hashtest.html66.249.64.184 [10/Jul/2016:19:19:58] GET /wp-content/tests/hashtest.html66.249.64.184 [10/Jul/2016:19:20:06] GET /hash.html66.249.64.184 [10/Jul/2016:19:20:14] GET /hash/66.249.64.184 [10/Jul/2016:19:20:44] GET /hash/?_escaped_fragment_=/diffi cultpage2.html66.249.64.184 [10/Jul/2016:19:20:44] GET /hash/?_escaped_fragment_=/diffi cultpage2.html

Google против всего интернета
17
60 000 000 000 000СТРАНИЦ В СЕТИ, КОТОРЫЕ НУЖНО НАХОДИТЬ И ПОДДЕРЖИВАТЬ В АКТУАЛЬНОМ СОСТОЯНИИ
77 160 494СТРАНИЦ В СЕКУНДУ НУЖНО СКАНИРОВАТЬ GOOGLE,
ЧТОБЫ ОБХОДИТЬ ВСЕ СТРАНИЦЫ ХОТЯ БЫ 1 РАЗ В 3 МЕСЯЦА.
Краулинговый бюджет
Краулинговый бюджет – процессорное время, выделяемое поисковой системой для сканирования определенного сайта за единицу времени.
Основной фактор влияния: Pagerank.
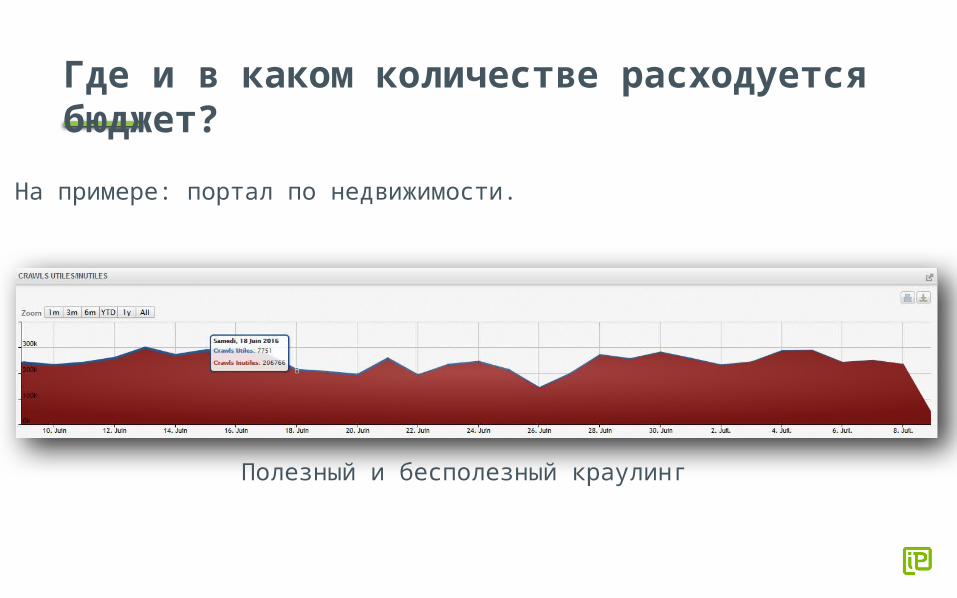
Где и в каком количестве расходуется бюджет?
На примере: портал по недвижимости.
Полезный и бесполезный краулинг
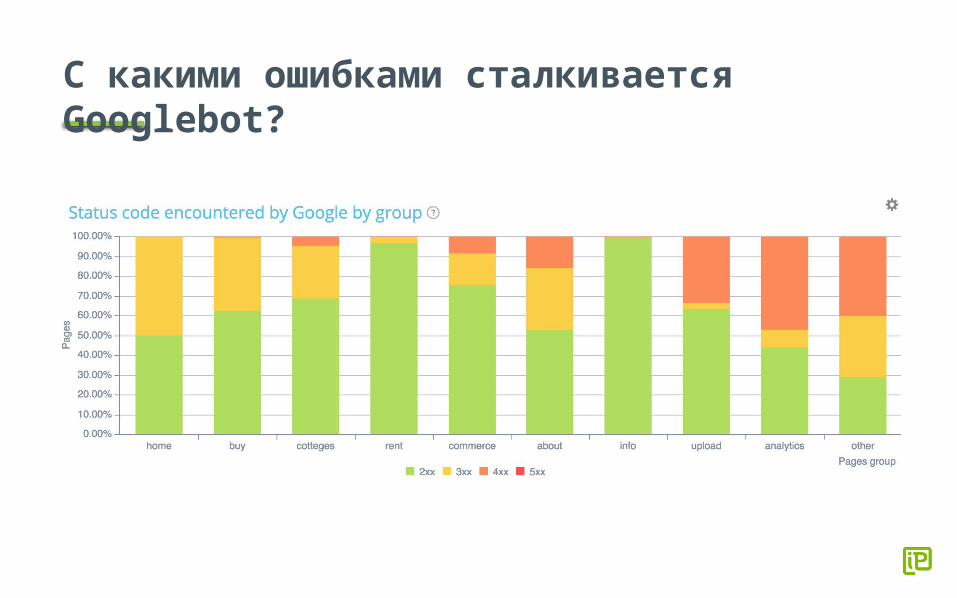
С какими ошибками сталкивается Googlebot?
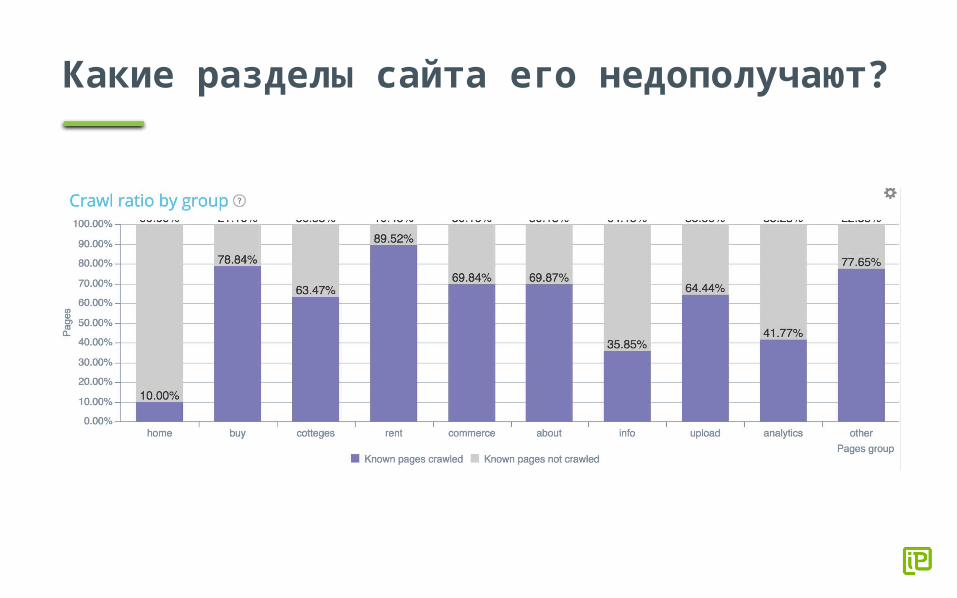
Какие разделы сайта его недополучают?
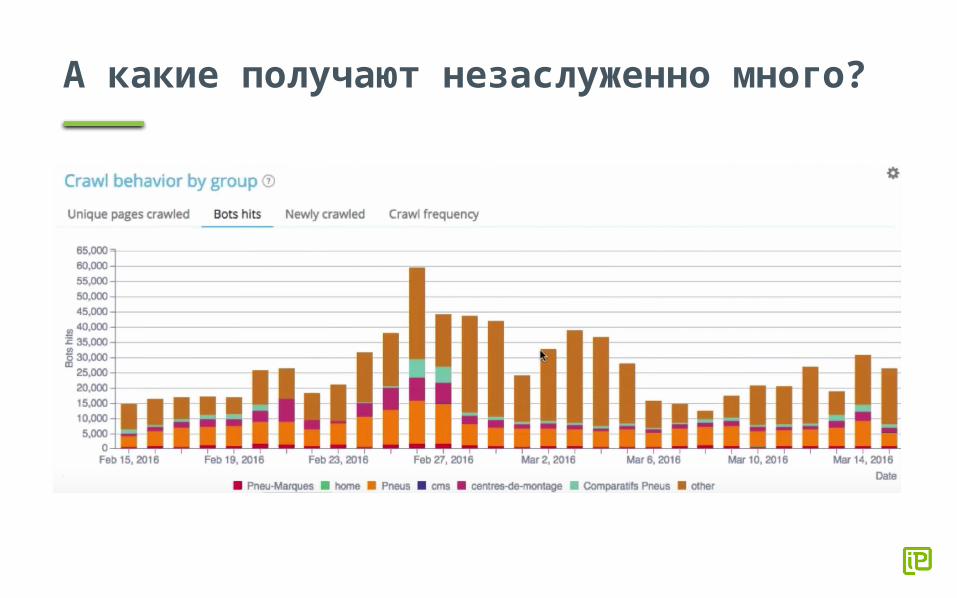
А какие получают незаслуженно много?

Сколько страниц у вас на сайте?
Пример: крупный онлайн-ритейлер (~10 млн переходов из поиска в месяц). Сканирование сайта обнаружило 5,3 миллиона страниц.

Страницы-сироты (orphan pages)
Страницы-сироты – страницы, о которых знает поисковая система, но которые не присутствуют в структуре сайта.

Страницы-сироты (orphan pages)
Откуда они берутся?
• Страницы, на которые ведут внешние ссылки, но нет внутренних.
• Страницы с исправленными ошибками, но в базе Googlebot.• Более неактуальные страницы с кодом 200OK.• Оставшиеся после переезда страницы.• Ошибки в rel=«canonical» и sitemap.xml.

Активные страницы (active pages)
Активные страницы – страницы, которые принесли хотя бы 1 визит из органического поиска за заданный период (30-60 дней).
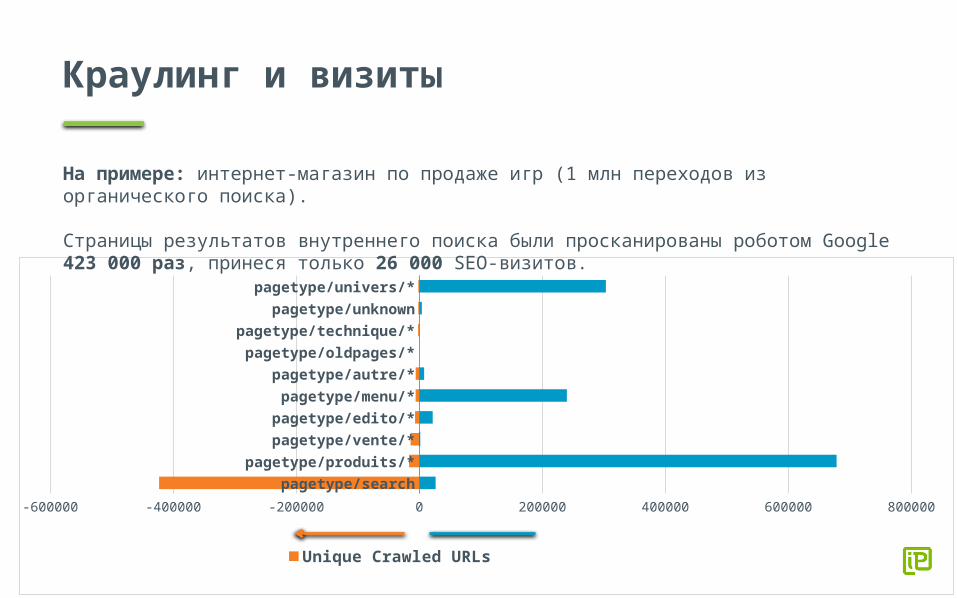
Краулинг и визиты
pagetype/searchpagetype/produits/*
pagetype/vente/*pagetype/edito/*pagetype/menu/*pagetype/autre/*
pagetype/oldpages/*pagetype/technique/*
pagetype/unknownpagetype/univers/*
-600000 -400000 -200000 0 200000 400000 600000 800000
Unique Crawled URLs
На примере: интернет-магазин по продаже игр (1 млн переходов из органического поиска).
Страницы результатов внутреннего поиска были просканированы роботом Google 423 000 раз, принеся только 26 000 SEO-визитов.
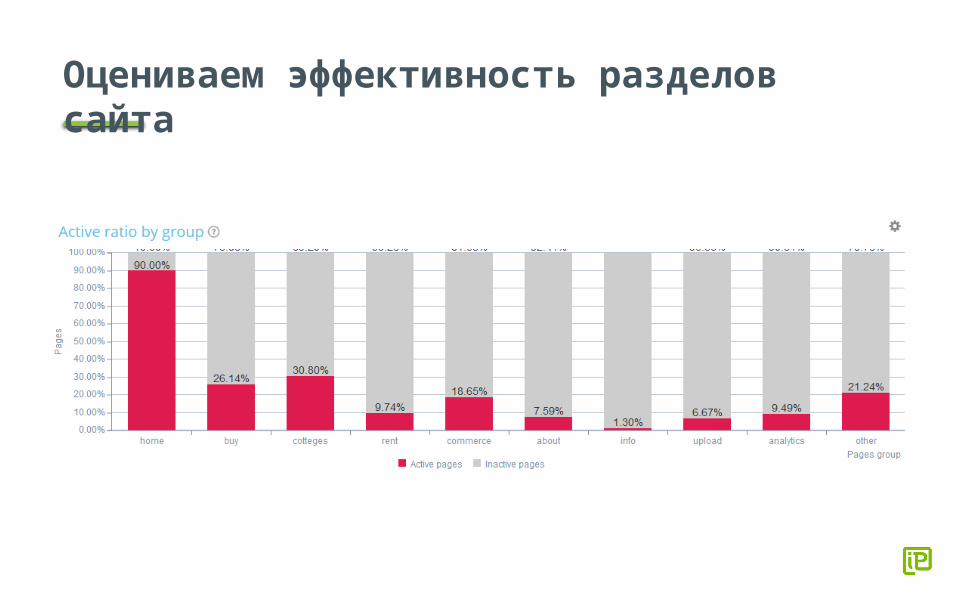
Оцениваем эффективность разделов сайта
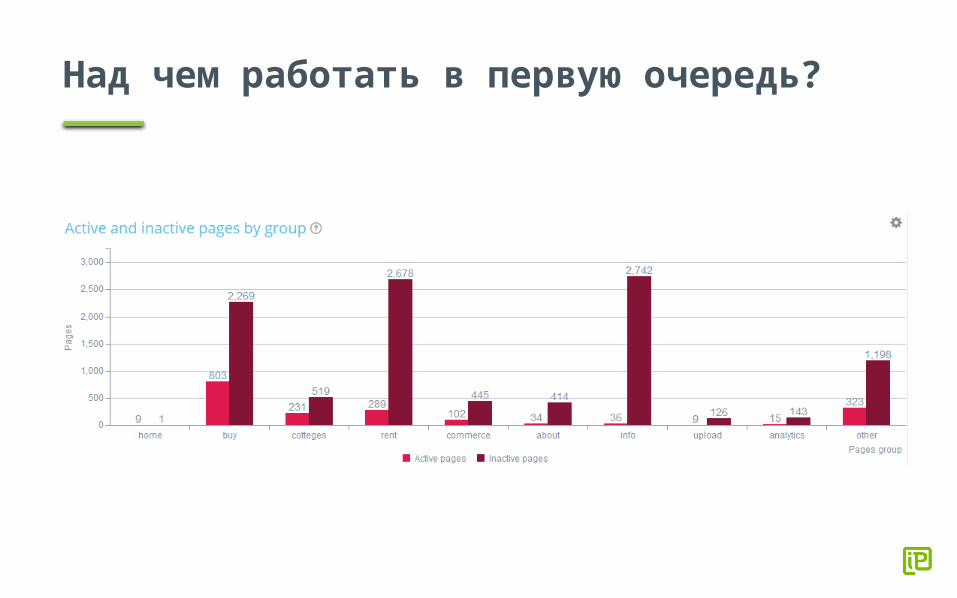
Над чем работать в первую очередь?
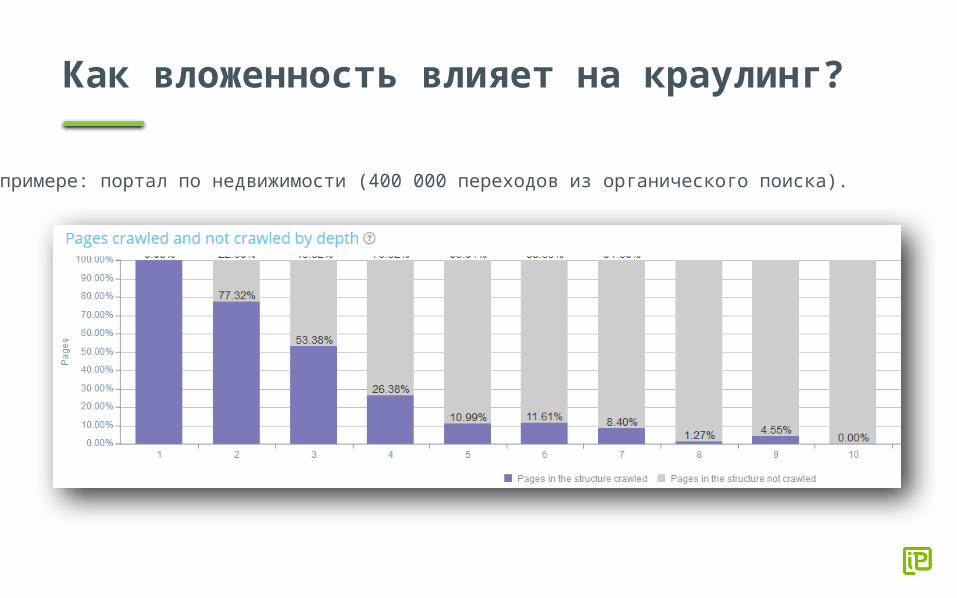
Как вложенность влияет на краулинг?
На примере: портал по недвижимости (400 000 переходов из органического поиска).
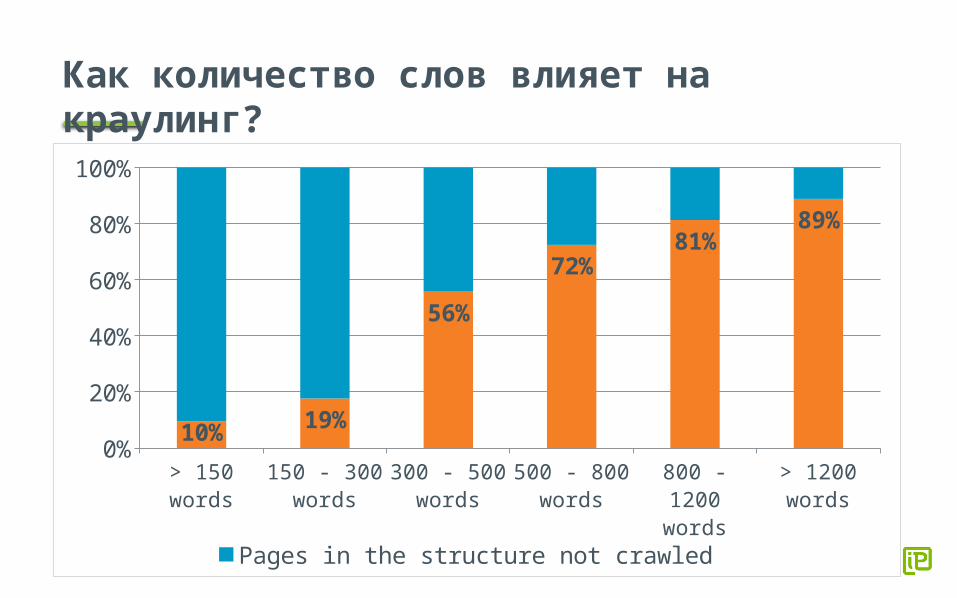
Как количество слов влияет на краулинг?
> 150 words
150 - 300 words
300 - 500 words
500 - 800 words
800 - 1200 words
> 1200 words
0%10%20%30%40%50%60%70%80%90%
100%
10% 19%
56%72%
81%89%
Pages in the structure not crawled Pages in the structure crawled
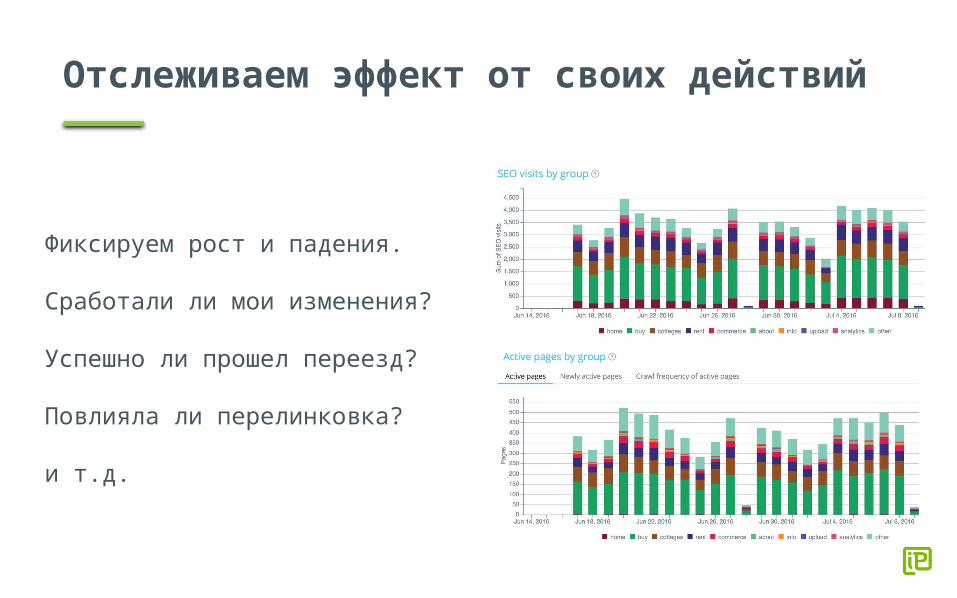
Отслеживаем эффект от своих действий
Фиксируем рост и падения.
Сработали ли мои изменения?
Успешно ли прошел переезд?
Повлияла ли перелинковка?
и т.д.
Аргументируем доработки
Обычный программист
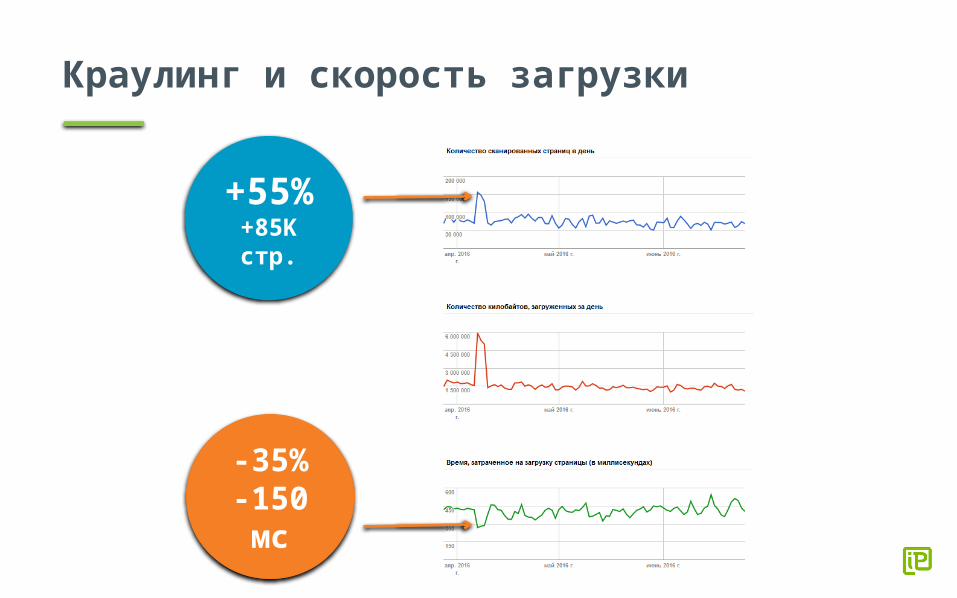
Краулинг и скорость загрузки
-35%-150 мс
+55%
+85K стр.
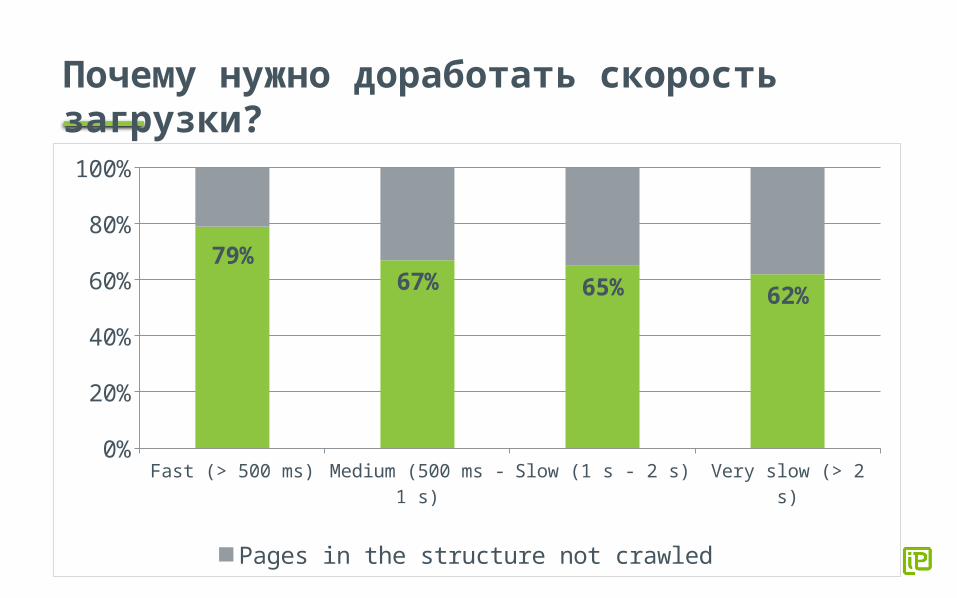
Почему нужно доработать скорость загрузки?
Fast (> 500 ms) Medium (500 ms - 1 s)
Slow (1 s - 2 s) Very slow (> 2 s)0%
10%20%30%40%50%60%70%80%90%
100%
79%67% 65% 62%
Pages in the structure not crawled Pages in the structure crawled
Аргументируем доработки
Понимающий и сочувствующий программист

Инструменты для работы с
логами

2 подхода в работе с логами сервера
Аудит Мониторинг
1. Логи за 30-60 дней (размер и тематика).
2. Кросс-аналитика: Краулинг + Логи + Google Analytics.
3. Диагностика полезных и бесполезных страниц, зон сайта, о которых Google знает и нет.
Сбор логов в режиме реального времени.
Обязателен при редизайне / переезде сайта.
Оповещения:
• Ошибки• Объем краулинга• Атаки• Новые страницы

Инструменты для работы с логами
Google Search Console
Десктопные программы
Apache log viewerScreaming Frog
SplunkPower BI
SaaS Решения
BotifyOncrawlLogs.ioQbox
Logentries
Ручная обработка
Командная строка
Notepad++Excel
Open Sourceпакеты
ELKLogalizeGraylog
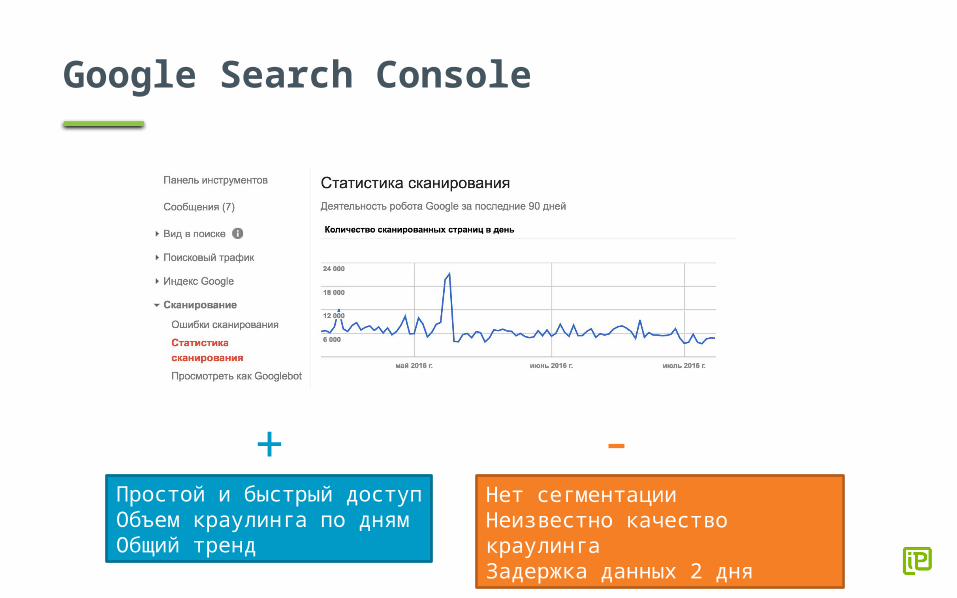
Google Search Console
+ -Простой и быстрый доступОбъем краулинга по днямОбщий тренд
Нет сегментацииНеизвестно качество краулингаЗадержка данных 2 дня

Excel / Notepad++ / Консоль
cat file1.log file2.log > output_file.logсat file1.log | grep 'googlebot' >> file-googlebots.log
Объединить несколько файлов в одинОставить только визиты Googlebot’а
Полезные команды для работы с логами
Max: 1 млн строк. Max: 500 мб. Max: НетExcel Notepad++ Terminal, Cygwin
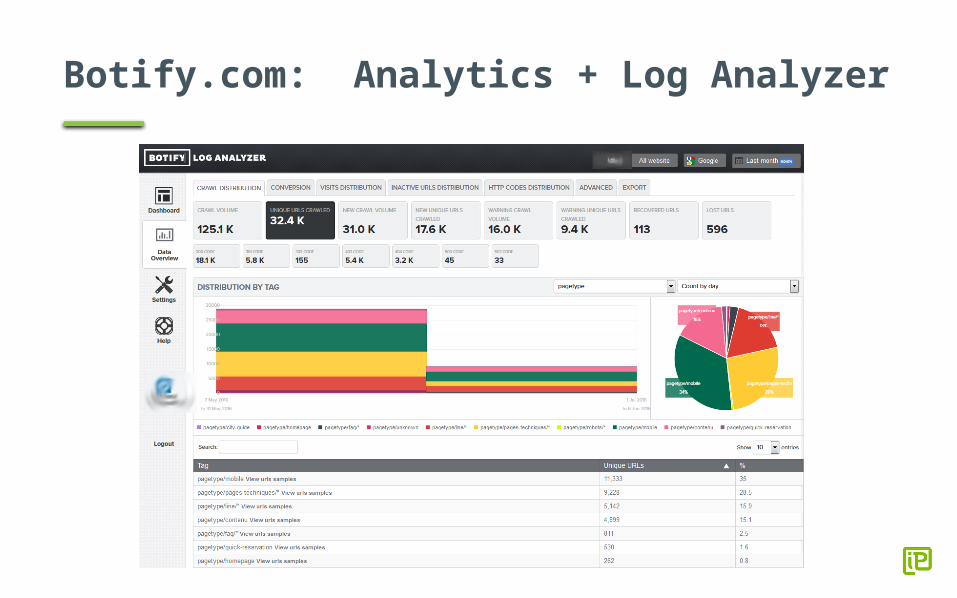
Botify.com: Analytics + Log Analyzer
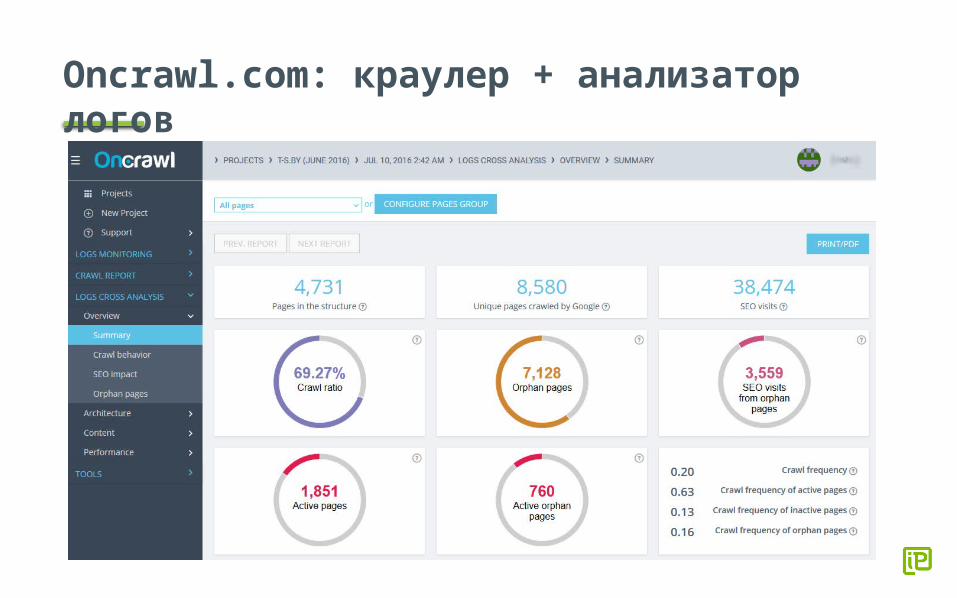
Oncrawl.com: краулер + анализатор логов

ELK: Elasticsearch + Logstash + Kibana
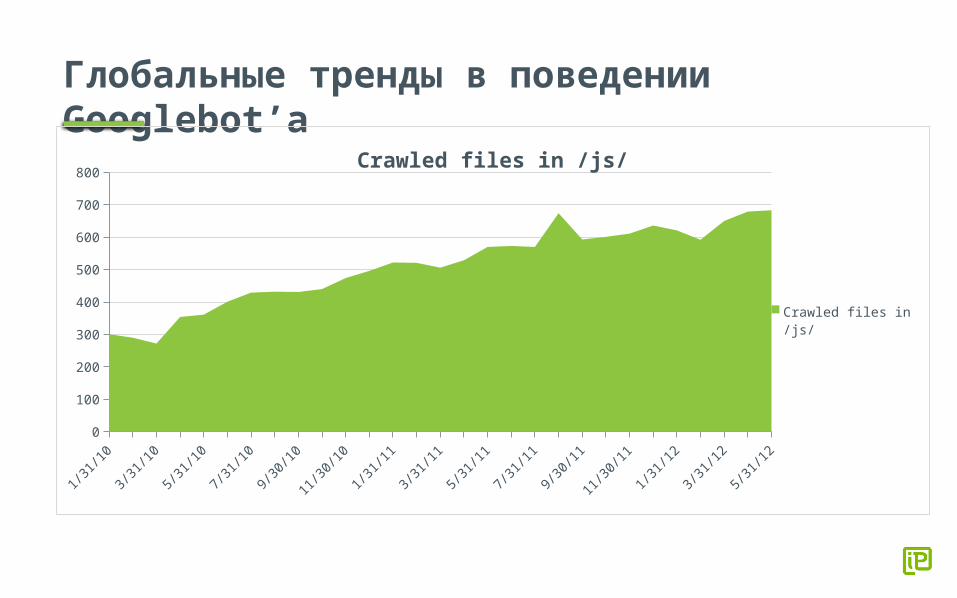
Глобальные тренды в поведении Googlebot’а
1/1/10
2/1/10
3/1/10
4/1/10
5/1/10
6/1/10
7/1/10
8/1/10
9/1/1010/
1/10
11/1/1
012/
1/101/1
/112/1
/113/1
/114/1
/115/1
/116/1
/117/1
/118/1
/119/1
/1110/
1/11
11/1/1
112/
1/111/1
/122/1
/123/1
/124/1
/125/1
/120
100
200
300
400
500
600
700
800Crawled files in /js/
Crawled files in /js/

Подведем итог
1. Логи сервера – самый надежный и точный источник информации о поведении поисковых роботов.
2. Появилось много инструментов для удобной работы с ними. Можно легко подобрать под свои задачи и бюджет.
3. Изучение логов позволяет проверить многие гипотезы, мифы, особенности работы поиска.
4. Полезный источник информации для поиска точек роста, применения усилий, проверки своей работы.
5. Неограниченные возможности по внутрисайтовой кросс-аналитике, например, можно сопоставить страницы, посещаемые роботом Google со страницами, приносящими доход.
6. Для тех, кто хочет идти дальше:1. Оценка ссылочных кампаний на основе роста краулингового бюджета
и частоты краулинга.2. Определение наложения антиспам фильтров типа « Google Panda ».

Merci! Вопросы?Алексей Рылко / [email protected] / fb.com/rylko