- presented by anita nagarajan
DESCRIPTION
A Dynamic Tracing Mechanism For Performance Analysis of OpenMP Applications - Caubet, Gimenez, Labarta, DeRose, Vetter (WOMPAT 2001). - Presented by Anita Nagarajan. Introduction. OpenMP Standard for shared memory parallel programming - PowerPoint PPT PresentationTRANSCRIPT

A Dynamic Tracing Mechanism For Performance Analysis of OpenMP
Applications
- Caubet, Gimenez, Labarta, DeRose, Vetter (WOMPAT 2001)
- Presented by Anita Nagarajan

Introduction
OpenMP– Standard for shared memory parallel programming– Set of directives and library routines for Fortran and C/C++
Performance Tools– Need: Analyse parallel behaviour. Determine causes for
OpenMP application performance problems.– Properties: Minimize intrusion cost, maximize performance
data captured

Introduction(Contd.)…
Dynamic Instrumentation– Instrument application while it is executing, recompilation
not required.
Dynamic Probe Class Library(DPCL)– Developed at IBM, built on top of the Dyninst API.– Using DPCL, performance tool “attaches” to application,
“inserts code patches” into the binary, “starts/continues” its execution
– Program instrumentation can be done at “function entry points”, “exit points” and “call sites”.

DPCL
DPCL consists of– Client library– Runtime library– Daemon– Super-daemon

OMPtrace
Built on top of DPCL IBM compiler translates OpenMP directives
into function calls.

Translation of OpenMP Directives

OMPtrace

OMPtrace(Contd.)…

OMPtrace(Contd.)…
Hardware Counters– OMPtrace can access hardware counters, and
provide statistics of the hardware events. Eg.L1/L2 hits, L1/L2 misses, number of instructions
Paraver– Computes “Derived Metrics” from hardware
events. Eg. L1 misses per second

Case Study: Sweep3D
Multidimensional wavefront algorithm for “discrete ordinates” deterministic particle transport simulation.

Sweep3D(Contd.)…
diag - original version of Sweep3D mkj – “do idiag” and “do jkm” loops replaced by a
triple nested loop (“do m”, “do k”, “do j”) ccrit - based on “mkj”, outer loop parallelized,
synchronization implemented using the “CRITICAL” directive.
cpipe – based on “mkj”, outer loop parallelized, synchronization implemented using shared arrays and busy waiting.

Results from Experiments
version 1 2 3 4 5 6 12
Ccrit 28.26 24.41 26.84 26.47 29.28 30.34 30.43
Cpipe 25.63 18.45 13.01 12.53 10.06 7.67 7.76
Diag 17.28 13.09 11.40 9.64 8.50 7.78 6.55
Elapsed time in seconds for the different OpenMP versions

Analysis of Results using Paraver
Ccrit– Not scalable
Overhead of mutex lock and unlock, contention
Red: Trying to obtain lock
Blue: Using lock
Green – Release lock
Light Blue – Execution outside critical section

Cpipe– Better performance than ccrit.– Poor locality because the “m” loop has an
iteration count of 6.
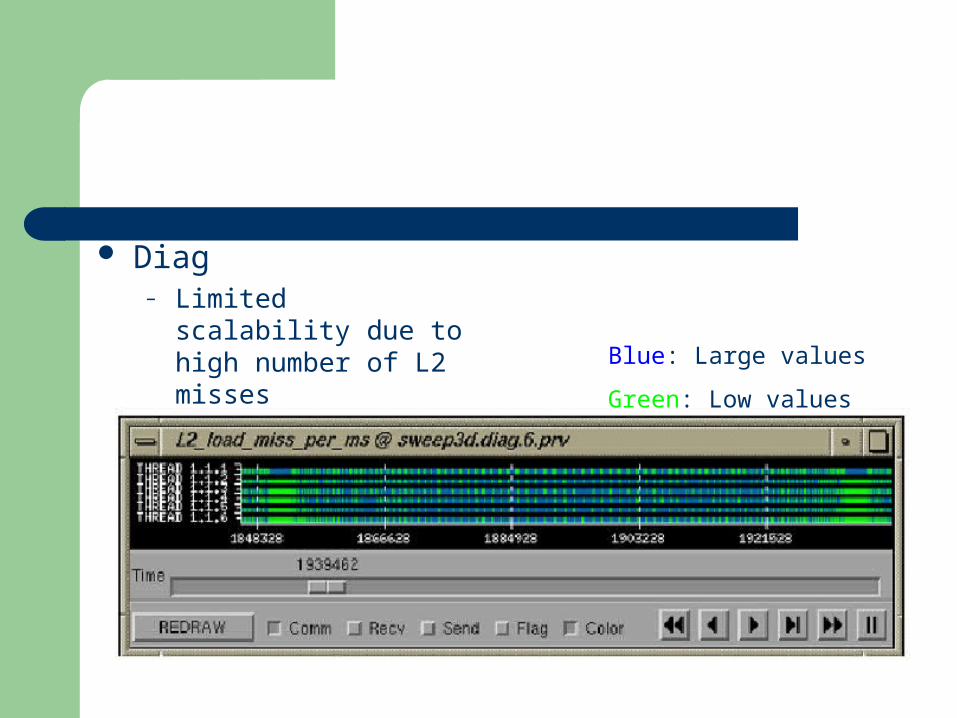
Diag– Limited scalability due to
high number of L2 misses Blue: Large values
Green: Low values

Optimization
kjmi– Interchange loops – Good performance,
better scalability
1 2 3 4 5 6 12
kjmi 14.86 10.01 7.35 5.82 4.89 3.62 2.88

Conclusions
OMPtrace and Paraver form a useful tool for performance analysis and optimization of OpenMP applications.