† saarland university, germany ‡ university of utah, usa estimating performance of a ray-tracing...
TRANSCRIPT

† Saarland University, Germany‡ University of Utah, USA
Estimating Performance of aRay-Tracing ASIC Design
Estimating Performance of aRay-Tracing ASIC Design
Sven Woop† Erik Brunvand‡
Philipp Slusallek†

Ray Tracing in Car IndustryRay Tracing in Car Industry

Ray Tracing GamesRay Tracing Games

Previous WorkPrevious Work
• Ray Tracers for Static Scenes
• CPU based: [OpenRT], [MLRT SIGGRAPH05]
• GPU based: Purcell (Grids) [SIGGRAPH02], Foley et al. (KD Trees) [GH05]
• Custom Hardware: Commercial Hardware (ART-VPS) Schmittler (KD Trees) [GH04] RPU (KD Trees) [SIGGRAPH05]
• Ray Tracers for Dynamic Scenes
• CPU based: Wald (Grids) [SIGGRAPH06] Wald (AABVHs) [TOG / Tech. Rep. 2006]
• Custom Hardware: Woop (B-KD Trees) [GH06]

OutlineOutline
• Previous Work
• DRPU Architecture
• B-KD Trees
• Traversal Processor
• Prototype Implementations
• DRPU-FPGA
• DRPU-ASICs
• Conclusion

Definition of B-KD TreesDefinition of B-KD Trees
B-KD Tree (Bounded KD-Tree)
• Binary Tree
• 1D bounding intervalls for each child
• Leaf nodes point to a single primitive
split axisT1
T T
T 0
10

B-KD Tree SubdivisionB-KD Tree Subdivision• Bounding Volume Hierarchy (partially unbounded)
• Each node can be associated with a full bounding box
• Bounds may overlap
Primitives in single leaf nodes
More traversal steps as for KD Tree
Support for dynamic scenes
T T10
T01T00 T11T10
T1T 0
10T
11T
00T
01T

B-KD Tree SubdivisionB-KD Tree Subdivision• Bounding Volume Hierarchy (partially unbounded)
• Each node can be associated with a full bounding box
• Bounds may overlap
Primitives in single leaf nodes
More traversal steps as for KD Tree
Support for dynamic scenes
T T10
T01T00 T11T10
T1T 0
10T
11T
00T
01T

B-KD Tree SubdivisionB-KD Tree Subdivision• Bounding Volume Hierarchy (partially unbounded)
• Each node can be associated with a full bounding box
• Bounds may overlap
Primitives in single leaf nodes
More traversal steps as for KD Tree
Support for dynamic scenes
T T10
T01T00 T11T10
T1T 0
10T
11T
00T
01T

B-KD Tree SubdivisionB-KD Tree Subdivision• Bounding Volume Hierarchy (partially unbounded)
• Each node can be associated with a full bounding box
• Bounds may overlap
Primitives in single leaf nodes
More traversal steps as for KD Tree
Support for dynamic scenes
T T10
T01T00 T11T10
T1T 0
10T
11T
00T
01T

B-KD Tree SubdivisionB-KD Tree Subdivision• Bounding Volume Hierarchy (partially unbounded)
• Each node can be associated with a full bounding box
• Bounds may overlap
Primitives in single leaf nodes
More traversal steps as for KD Tree
Support for dynamic scenes
T T10
T01T00 T11T10
T1T 0
10T
11T
00T
01T

Update of B-KD TreesUpdate of B-KD Trees
Update Procedure
• Bounds updated on changed geometry
• B-KD tree structure remains constant
Linear updating complexity
split axisT1
T T
T 0
10

DRPU ArchitectureDRPU Architecture
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor
vertices from memory

DRPU ArchitectureDRPU Architecture
• Rendering Units
• Highly multi-threaded
• Higher hardware usage
• Synchronous execution of packets of 4 rays
• Memory bandwidth reduction
• First level caches
• Memory bandwidth reduction
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Processor
• Design similar to fragment processors on GPUs
• Improved Programming Model
• Add highly efficient recursion
• Add flexible memory access
• Programming Model
• Ray generation tasks
• Material shading
• Calls Ray Casting Units to cast rays
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Unit
• Ray Casting Units
• High-performance traversal and intersection
• Support for continous dynamic scenes
• B-KD Trees approach
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Unit
• Ray Casting Units
• Traversal Processor
• Efficient traversal of B-KD trees
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Unit
• Ray Casting Units
• Traversal Processor
• Efficient traversal of B-KD trees
• Geometry Unit
• Ray transformations
• Vertex-based ray/triangle intersection [Möller Trumbore]
• Shared vertices save memory 6x
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Unit
• Ray Casting Units
• Scene Changes
• Skinning Processor
• Skeleton Subspace Deformation
• Re-uses Geometry Unit
• Pure stream architecture
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
• Programmable Shading Unit
• Ray Casting Units
• Scene Changes
• Skinning Processor (see paper)
• Skeleton Subspace Deformation
• Re-uses Geometry Unit
• Pure stream architecture
• Update Processor
• Stream-like architecture
• Partial breadth-first execution
• One B-KD node update per clock cycle peak
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

DRPU ArchitectureDRPU Architecture
vertices from memory
TraversalProcessing
Unit
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
from memory
Shading Unit
to framebuffer
from memory
Shader Cache128 Bit wide
from memory
Skinning Processor
instructions from memory
nodes tomemory
instructions from memory
vertices tomemory
Update Processor

Traversal of B-KD TreesTraversal of B-KD Trees
Traversal of B-KD Trees
• Early ray termination
• Clipping of near/far interval against both bounding intervalls
• Take closer child, push farther child to stack
• Traversal order does not affect correctness
Complexity
• 4x computational cost of KD tree traversal step
• 2x stack memory
near
I
R
Tcloser ch ild
Tfarther ch ild
far
I 1 0
10

Traversal ProcessorTraversal Processor
• Stack control computes next address
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty
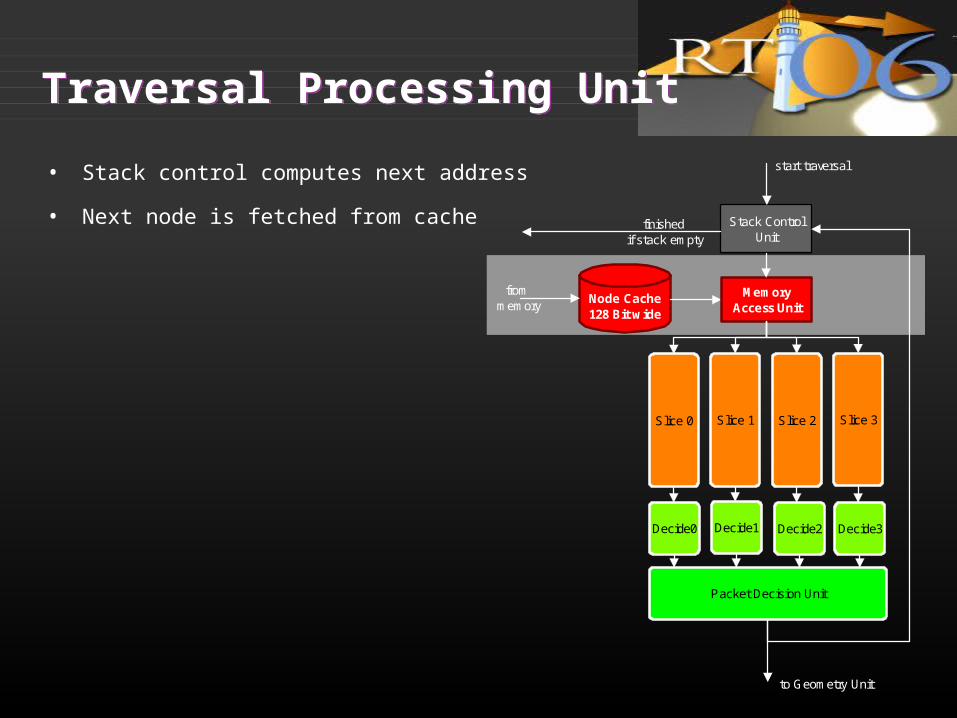
Traversal Processing UnitTraversal Processing Unit
• Stack control computes next address
• Next node is fetched from cache
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty

Traversal Processing UnitTraversal Processing Unit
• Stack control computes next address
• Next node is fetched from cache
• 4 traversal slices compute 4x4 distances to bounding planes
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty

Traversal Processing UnitTraversal Processing Unit
• Stack control computes next address
• Next node is fetched from cache
• 4 traversal slices compute 4x4 distances to bounding planes
• 4 Decision Units compute per ray traversal decision
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty

Traversal Processing UnitTraversal Processing Unit
• Stack control computes next address
• Next node is fetched from cache
• 4 traversal slices compute 4x4 distances to bounding planes
• 4 Decision Units compute per ray traversal decision
• Packet Decision Unit computes packet traversal decision
• Packet goes left if exists a that ray goes left
• Packet goes right if exists a ray that goes right
• Packet goes from left to right if exists a ray that goes into both children from left to right
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty

Traversal Processing UnitTraversal Processing Unit
• Stack control computes next address
• Next node is fetched from cache
• 4 traversal slices compute 4x4 distances to bounding planes
• 4 Decision Units compute per ray traversal decision
• Packet Decision Unit computes packet traversal decision
• Packet goes left if exists a that ray goes left
• Packet goes right if exists a ray that goes right
• Packet goes from left to right if exists a ray that goes into both children from left to right
Incoherent packets possible
Node Cache128 Bit wide
from memory
Stack Control Unit
Memory Access Unit
Slice 0 Slice 1 Slice 2 Slice 3
Decide0 Decide1 Decide2 Decide3
Packet Decision Unit
to Geometry Unit
start traversal
finished if stack empty

FPGA ImplementationFPGA Implementation
Hardware
• Xilinx Virtex4 LX160
• 66 MHz
• 1.0 GB/s (limited to 0.5 GB/s)
• 7.5 Gflops
• 2,3 Gflops programmable
• 5,2 Gflops fixed function
Implementation
• Packets of 4 rays
• 32 packets of rays
• 3x 8 KB caches, direct mapped
• 24 bit floating point
Virtex4 Board

ASIC DesignASIC Design
• Synthesis
• Synopsys Synthesis
• UMC 130nm CMOS process
• Place & Route
• Cadence Encounter
• Some manual placements to achieve good results
• Only DRPU Core
• No chip interface designed (PCI Express, DRAM, ...)
• No power estimation
DRPU-ASIC

DRPU-ASICDRPU-ASIC
Hardware
• UMC 130nm process
• Die size: 49 mm2
• 266 MHz clock
• 2.1 GB/s bandwidth
• 30 Gflops
Implementation Differences
• Larger caches (3x 16 KB, 4-way associative)
• 32 bit floating point
7mm
7mm

GPU ComplexityGPU Complexity
ATI R520 (October, 2005)
• 90nm process
• 288 mm2 die
• 600 MHz clock speed
• 170 GFlops programmable?
• 44,8 GB/s memory bandwidth
Implementation
• Packets of 4 fragments
• 16 fragment pipelines
• 8 vertex piplines
• 32 bit floating point
7mm
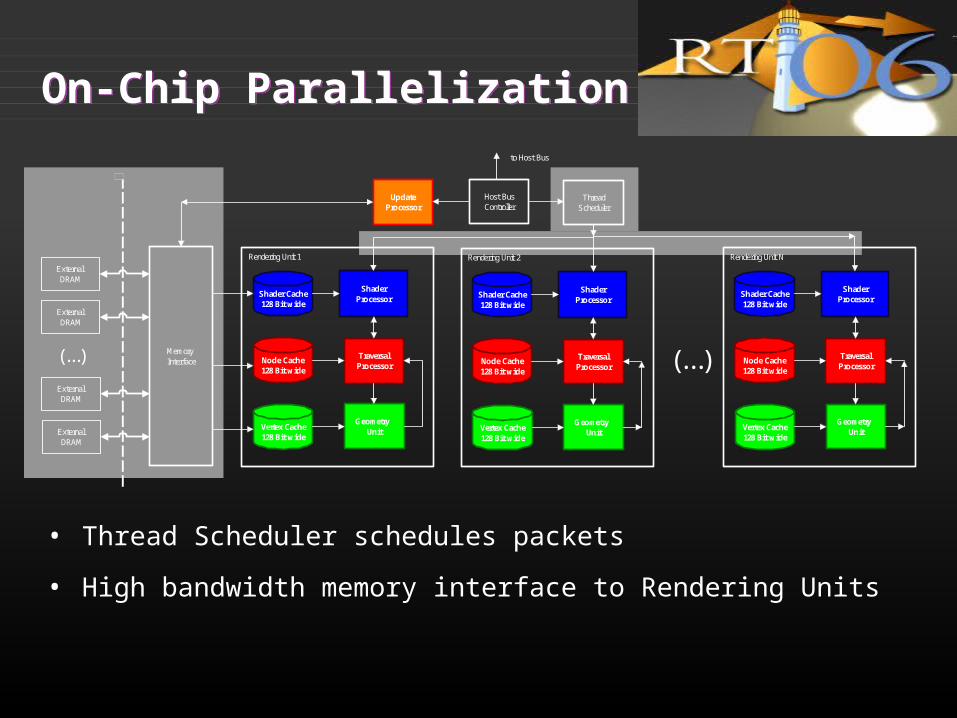
On-Chip ParallelizationOn-Chip Parallelization
• Thread Scheduler schedules packets
• High bandwidth memory interface to Rendering Units
Update Processor
Traversal Processor
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
Shader Processor
Shader Cache128 Bit wide
Rendering Unit 2
Traversal Processor
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
Shader Processor
Shader Cache128 Bit wide
Rendering Unit 1
(...)
Thread Scheduler
Host Bus Controller
to Host Bus
Memory Interface
External DRAM
External DRAM
(...)
External DRAM
External DRAM
Traversal Processor
Geometry Unit
Node Cache128 Bit wide
Vertex Cache128 Bit wide
Shader Processor
Shader Cache128 Bit wide
Rendering Unit N

DRPU4 ASICDRPU4 ASIC
Hardware
• UMC 130nm process
• 196 mm2 die (4 x 49 mm2)
• 266 MHz clock
• 8,5 GB/s
• 120 GFlops
Implementation Differences
• 4x DRPU ASIC
• No high level control
14mm
14mm

DRPU8-ASICDRPU8-ASIC
Hardware
• 90nm process (extrapolated using constant field scaling)
• 186 mm2 die
• 400 MHz clock speed
• 25,6 GB/s bandwidth
• 361 Gflops
• 110 Gflops programmable
• 471 Gflops fixed function
Implementation Differences
• 8x DRPU-ASIC
9,6 mm
19,3 mm

ResultsResults 1024x768, shadows

ResultsResults 1024x768, shadows

Results for DRPU8Results for DRPU8
Performance sufficient for game play
Room for improving image quality
Gael 91.2 fps DynGael 96.0 fps

Conclusions and Future WorkConclusions and Future Work
• Ray Tracing Hardware Design
• Support for programmable recursive shading
• Coherent scene changes
• Working Prototype Implementation
• Post layout ASIC Results
• Still no power results
• No direct performance comparison against GPU

Questions?Questions?
• Project Homepage:http://www.saarcor.de
• Computer Graphics Lab at Saarland University:http://graphics.cs.uni-sb.de