download.microsoft.comdownload.microsoft.com/.../filestreamstorage.docx · web viewartículo...
TRANSCRIPT

Artículo técnico de SQL Server
Autor: Paul S. Randal (SQLskills.com)
Revisores técnicos: Alexandru Chirica, Arkadi Brjazovski, Prem Mehra, Joanna Omel, Mike Ruthruff, Robin Dhamankar
Fecha de publicación: octubre de 2008
Se aplica a: SQL Server 2008
Resumen: en estas notas del producto se describe la característica FILESTREAM de SQL Server 2008, que permite el almacenamiento y el acceso eficiente a datos BLOB mediante una combinación de SQL Server 2008 y el sistema de archivos NTFS. También se explican las distintas opciones de almacenamiento de BLOB, la configuración de Windows y SQL Server para usar datos de FILESTREAM, los aspectos que hay que tener en cuenta a la hora de combinar FILESTREAM con otras características, y detalles de implementación como la creación de particiones y el rendimiento.
Estas notas del producto están destinadas a arquitectos, profesionales de TI y DBA encargados de la evaluación o implementación de FILESTREAM. Se da por supuesto que el lector está familiarizado con Windows y SQL Server, y que tiene al menos unos conocimientos rudimentarios de conceptos de base de datos como las transacciones.
IntroducciónEn la sociedad actual se generan datos a unas velocidades increíbles y a menudo es necesario almacenarlos y obtener acceso a ellos de manera controlada y eficiente. Existen distintas tecnologías para ello y la elección de la tecnología suele depender de la naturaleza de los datos que se van a almacenar: estructurados, semiestructurados o no estructurados:
Los datos estructurados son aquellos que se pueden almacenar fácilmente en un esquema relacional, como los que representan datos de ventas de una empresa. Se pueden almacenar en una base de datos con una tabla de información para los productos que la compañía vende, otra tabla con información sobre los clientes y otra tabla con los detalles de ventas de los productos a los clientes. El acceso a los datos y su manipulación se realiza mediante un lenguaje de consultas enriquecido como Transact-SQL.

Los datos semiestructurados son aquellos que se ajustan a un esquema flexible pero que no se suelen almacenar bien en un conjunto de tablas de base de datos, como aquellos en los que cada punto de datos puede tener atributos radicalmente diferentes. Los datos semiestructurados suelen almacenarse con el tipo de datos xml en el software de base de datos Microsoft® SQL Server® y normalmente se obtiene acceso a ellos mediante un lenguaje de consultas basado en elementos como XQuery.
Los datos no estructurados pueden no tener ningún esquema (por ejemplo, un fragmento de datos cifrados) o pueden ser grandes cantidades de datos binarios (muchos megabytes o incluso gigabytes) que parecen no tener ningún esquema pero en realidad tienen un esquema muy simple inherente, como los archivos de imagen, vídeo de transmisión por secuencias o clips de sonido. En este caso, los datos binarios se refieren a datos que pueden tener cualquier valor, no solo los que se pueden escribir con un teclado. Estos valores de datos se conocen comúnmente como objetos binarios grandes, o simplemente blobs.
En estas notas del producto se describe la característica FILESTREAM de SQL Server 2008, que permite el almacenamiento y el acceso eficiente a datos BLOB mediante una combinación de SQL Server 2008 y el sistema de archivos NTFS. Se explica la característica FILESTREAM propiamente dicha, las opciones de almacenamiento de BLOB, la configuración del sistema operativo Windows® y SQL Server para usar datos de FILESTREAM, los aspectos que hay que tener en cuenta a la hora de combinar FILESTREAM con otras características, y detalles de implementación como las particiones y el rendimiento.
Opciones para el almacenamiento de blobsSi bien los datos estructurados y semiestructurados se pueden almacenar fácilmente en una base de datos relacional, la elección de dónde almacenar los datos no estructurados o BLOB es más complicada. A la hora de decidir dónde almacenar los datos BLOB, tenga en cuenta los siguientes requisitos:
Rendimiento: la manera en que se van a usar los datos es un factor fundamental. Si se necesita acceso de transmisión por secuencias, el almacenamiento de los datos dentro de una base de datos de SQL Server puede ser más lento que almacenarlos externamente en una ubicación como el sistema de archivos NTFS. Cuando se usa el almacenamiento del sistema de archivos, los datos se leen del archivo y se pasan a la aplicación cliente (directamente o con un almacenamiento en búfer adicional). Cuando los datos BLOB se almacenan en una base de datos de SQL Server, primero se deben leer en la memoria de SQL Server (el grupo de búferes) y después se devuelven a la aplicación cliente a través de una conexión de cliente. Esto no solo significa que los datos pasan por una fase de procesamiento adicional; también significa que la memoria de SQL Server está "contaminada" innecesariamente con datos BLOB, lo que puede causar problemas de rendimiento en operaciones posteriores de SQL Server.
Seguridad: los datos confidenciales cuyo acceso se debe administrar estrechamente se pueden almacenar en una base de datos y se puede supervisar la seguridad mediante los controles de acceso habituales de SQL Server. Si se almacenan los mismos datos en el sistema de archivos, es necesario implementar distintos métodos de seguridad como las listas de control de acceso (ACL).
Tamaño de los datos: según el estudio que se cita más adelante en estas notas del producto, es mejor almacenar los blob de menos de 256 kilobytes (kB) (como los iconos de widget) en una base de datos y los blobs de más de 1 megabyte (MB) fuera de la base de datos. En el caso de datos cuyo tamaño está comprendido entre 256 kB y 1 MB, la solución de almacenamiento más eficiente depende de la proporción de lectura y escritura de los datos, y de la tasa de "sobrescritura". El almacenamiento de datos BLOB exclusivamente dentro de la base de datos (por ejemplo, usando el tipo de datos varbinary (max)) está limitado a 2 gigabytes (GB) por BLOB.
2

Acceso de cliente: el protocolo que el cliente emplea para obtener acceso a datos de SQL Server, como ODBC, quizás no sea el adecuado para aplicaciones como la transmisión por secuencias de archivos de vídeo grandes. En este caso, puede ser necesario almacenar los datos en el sistema de archivos.
Semántica transaccional: si los datos BLOB tienen asociados datos estructurados que se almacenarán en la base de datos, los cambios en los datos BLOB necesitarán ajustarse a la semántica transaccional para que los dos conjuntos de datos estén sincronizados. Por ejemplo, si una transacción crea datos BLOB y una fila en una tabla de base de datos pero después hace una reversión, se debe revertir la creación de los datos BLOB y la creación de la fila de la tabla. Esto puede resultar muy complejo si los datos BLOB se almacenan en el sistema de archivos sin ningún vínculo a la base de datos.
Fragmentación de datos: las actualizaciones y sobrescrituras frecuentes harán que los BLOB se muevan, ya sea dentro de los archivos de base de datos de SQL Server o dentro del sistema de archivos, en función de dónde se almacenen los datos. En este caso, si los BLOB son grandes, se pueden fragmentar (es decir, pueden no almacenarse en una parte contigua del disco). Es más fácil resolver esta fragmentación si se usa el sistema de archivos en lugar de SQL Server.
Facilidad de uso: es más difícil y costoso administrar una solución que emplea varias tecnologías no integradas que una solución integrada.
Costo: el costo de la solución de almacenamiento varía en función de la tecnología que se emplea.
Las explicaciones anteriores sobre el tamaño y la fragmentación se basan en el conocido documento de Microsoft Research BLOB o no BLOB: ¿almacenamiento de objetos grandes en una base de datos o en un sistema de archivos? (Gray, Van Ingen y Sears). Este documento contiene más información sobre las ventajas y desventajas de ambos modelos y se puede descargar desde aquí:
http://research.microsoft.com/research/pubs/view.aspx?msr_tr_id=MSR-TR-2006-45
Existen diversas soluciones para el almacenamiento de BLOB, y cada una de ellas tiene sus pros y sus contras, según los requisitos indicados anteriormente. En la tabla siguiente se comparan tres opciones frecuentes para almacenar datos BLOB, incluido FILESTREAM, en SQL Server 2008.
Punto de comparación
Solución de almacenamientoServidor de archivos/sistema de archivos
SQL Server (con varbinary (max))
FILESTREAM
Tamaño máximo de BLOB
Tamaño del volumen NTFS
2 GB - 1 bytes Tamaño del volumen NTFS
Rendimiento de la transmisión por secuencias de BLOB grandes
Excelente Deficiente Excelente
Seguridad ACL manuales Integrada Integrada + ACL automáticas
Costo por GB Bajo Alto BajoFacilidad de uso Difícil Integrada IntegradaIntegración con datos estructurados
Difícil Coherencia en el nivel de datos
Coherencia en el nivel de datos
Desarrollo e implementación de aplicaciones
Más complejos Más sencillos Más sencillos
Recuperación de la fragmentación
Excelente Deficiente Excelente
3

Punto de comparación
Solución de almacenamientoServidor de archivos/sistema de archivos
SQL Server (con varbinary (max))
FILESTREAM
de datosRendimiento de pequeñas actualizaciones frecuentes
Excelente Moderado Deficiente
Tabla 1: comparación de las tecnologías de almacenamiento de BLOB anteriores a SQL Server 2008
FILESTREAM es la única solución que proporciona coherencia transaccional de los datos estructurados y no estructurados, así como administración integrada, seguridad, bajo costo y excelente rendimiento de transmisión de datos por secuencias. Para lograrlo, almacena los datos estructurados en los archivos de base de datos y los datos BLOB no estructurados en el sistema de archivos, al tiempo que mantiene la coherencia transaccional entre los dos almacenamientos. En la sección "Información general de FILESTREAM" más adelante en estas notas del producto se proporcionan más detalles sobre la arquitectura de FILESTREAM.
Información general de FILESTREAMFILESTREAM es una característica nueva de SQL Server 2008. Permite almacenar los datos estructurados en la base de datos y almacenar directamente en el sistema de archivos NTFS los datos no estructurados asociados (es decir, los BLOB). El acceso a los datos BLOB se realiza mediante las API de transmisión por secuencias de Win32® de alto rendimiento, lo que evita la penalización de rendimiento que supone el acceso a los datos BLOB a través de SQL Server.
FILESTREAM mantiene en todo momento la coherencia transaccional entre los datos estructurados y no estructurados, e incluso permite la recuperación a un momento dado de los datos de FILESTREAM mediante copias de seguridad de registros. SQL Server mantiene automáticamente la coherencia y no se necesita ninguna lógica personalizada en la aplicación. Para ello, el mecanismo de FILESTREAM mantiene el equivalente de un registro de transacciones de la base de datos, que comparte muchos requisitos de administración (se describen con más detalle en la sección "Configurar la recolección de elementos no utilizados de FILESTREAM", más adelante en estas notas del producto). La combinación del registro de transacciones de la base de datos y el registro de transacciones de FILESTREAM permite la correcta recuperación transaccional de los datos estructurados y de FILESTREAM.
En lugar de ser un tipo de datos completamente nuevo, FILESTREAM es un atributo de almacenamiento del tipo de datos varbinary (max) existente. FILESTREAM mantiene gran parte del comportamiento existente del tipo de datos varbinary (max). Cambia la forma en que se almacenan los datos BLOB: en el sistema de archivos en lugar de en archivos de datos de SQL Server. Puesto que FILESTREAM se implementa como una columna varbinary (max) y se integra directamente en el motor de base de datos, la mayoría de las funciones y herramientas de administración de SQL Server funcionan para los datos de FILESTREAM sin necesidad de realizar modificación alguna.
Hay que destacar que el comportamiento del tipo de datos varbinary (max) normal no ha cambiado en SQL Server 2008, incluido el límite de tamaño de 2 GB. La incorporación del atributo FILESTREAM hace que una columna varbinary (max) tenga básicamente un tamaño ilimitado (en realidad, el tamaño está limitado al del volumen NTFS subyacente).
Los datos de FILESTREAM se almacenan en el sistema de archivos en un conjunto de directorios NTFS denominados contenedores de datos, que corresponden a los grupos de archivos especiales de la base
4

de datos. El acceso transaccional a los datos de FILESTREAM está controlado por SQL Server y por un controlador del filtro del sistema de archivos que se instala como parte de la habilitación de FILESTREAM en el nivel de Windows. El uso de un controlador del filtro del sistema de archivos también permite el acceso remoto a los datos de FILESTREAM a través de una ruta de acceso UNC. SQL Server mantiene un vínculo de ordenaciones de filas de tabla a los archivos FILESTREAM asociados. Esto significa que si se elimina o se cambia el nombre de algún archivo de FILESTREAM directamente a través del sistema de archivos se dañará la base de datos.
El uso de FILESTREAM requiere varias modificaciones del esquema en las tablas de datos (especialmente, el requisito de que cada fila debe tener un identificador de fila único) y tiene también algunas restricciones cuando se combina con otras características (como la imposibilidad de cifrar datos de FILESTREAM). Todo esto se describe con detalle en la sección "Configurar SQL Server para FILESTREAM", más adelante en estas notas del producto.
Hay dos formas de obtener acceso a datos de FILESTREAM y manipularlos: con el modelo de programación Transact-SQL estándar o mediante las API de transmisión por secuencias de Win32. Ambos mecanismos reconocen totalmente las transacciones y admiten la mayoría de las operaciones DML, incluidas la inserción, actualización, eliminación y selección. También se admiten datos de FILESTREAM para operaciones de mantenimiento como copia de seguridad, restauración y comprobación de coherencia. La principal excepción es que no se admiten actualizaciones parciales de los datos de FILESTREAM. Cualquier actualización de un valor de datos de FILESTREAM se traduce en la creación de una nueva copia del archivo de datos de FILESTREAM. El archivo anterior se quita de forma asincrónica, como se describe en la sección "Configurar la recolección de elementos no utilizados de FILESTREAM", más adelante en estas notas del producto.
Acceso a datos BLOB mediante el modelo de programación dualDespués de almacenar los datos en una columna FILESTREAM, se puede obtener acceso a ellos mediante transacciones Transact-SQL o a través de las API de Win32. Esta sección ofrece algunos detalles generales sobre los modelos de programación y su uso.
Acceso a Transact-SQL
Con Transact-SQL, es posible insertar, actualizar y eliminar datos de FILESTREAM de la manera siguiente:
Se pueden rellenar previamente campos de FILESTREAM mediante una operación de inserción (con un valor vacío o un valor pequeño distinto de NULL). Sin embargo, las interfaces de Win32 constituyen una manera más eficiente de transmitir por secuencias una gran cantidad de datos.
Al actualizar datos de FILESTREAM, se modifican los datos BLOB subyacentes en el sistema de archivos. Cuando un campo FILESTREAM está establecido en NULL, se eliminan los datos BLOB asociados al campo. No se pueden usar actualizaciones fragmentadas de Transact-SQL implementadas como UPDATE.Write() para realizar actualizaciones parciales en los datos de FILESTREAM.
Cuando se elimina una fila que contiene datos de FILESTREAM, o cuando se elimina o se trunca una tabla que contiene datos de FILESTREAM, también se eliminan los datos BLOB subyacentes del sistema de archivos. La eliminación física real de los archivos de FILESTREAM es un proceso asincrónico en segundo plano, como se explica en la sección "Configurar la recolección de elementos no utilizados de FILESTREAM", más adelante en estas notas del producto.
5

Para obtener más información y ejemplos del uso de Transact-SQL para obtener acceso a datos de FILESTREAM, vea el tema "Obtener acceso a datos FILESTREAM con Transact-SQL" (http://msdn.microsoft.com/es-es/library/cc645962.aspx) en los Libros en pantalla de SQL Server 2008.
Acceso de transmisión por secuencias de Win32
Para permitir el acceso transaccional del sistema de archivos a los datos de FILESTREAM, una nueva función intrínseca, GET_FILESTREAM_TRANSACTION_CONTEXT(), proporciona el token que representa la transacción actual a la que está asociada la sesión. Se debe haber iniciado la transacción y no haberse confirmado ni revertido todavía. Al obtener un token, la aplicación enlaza las operaciones de transmisión por secuencias del sistema de archivos de FILESTREAM con una transacción iniciada. La función devuelve NULL en caso de que se no haya iniciado explícitamente ninguna transacción. Se debe obtener un token para poder obtener acceso a archivos de FILESTREAM.
En FILESTREAM, el motor de base de datos controla el espacio de nombres del sistema de archivos físico de BLOB. Una nueva función intrínseca, PathName, proporciona la ruta de acceso UNC lógica del BLOB correspondiente a cada campo de FILESTREAM de la tabla. La aplicación usa esta ruta de acceso lógica para obtener el identificador de Win32 y actuar sobre los datos BLOB mediante las interfaces normales del sistema de archivos de Win32. La función devuelve NULL si el valor de la columna FILESTREAM es NULL. Por tanto, se debe crear previamente un archivo de FILESTREAM para poder obtener acceso a él en el nivel de Win32. Esto se hace como se ha descrito anteriormente.
La compatibilidad con la transmisión por secuencias de Win32 funciona en el contexto de una transacción de SQL Server. Después de obtener un token de transacción y un nombre de ruta de acceso, se emplea la API OpenSqlFilestream de Win32 para obtener un identificador de archivo de Win32. O bien, se puede usar la API administrada SqlFileStream. Después, las interfaces de transmisión por secuencias de Win32, como ReadFile() y WriteFile(), pueden usar este identificador para obtener acceso al archivo y actualizarlo mediante el sistema de archivos. Una vez más, tenga en cuenta que los archivos de FILESTREAM no se pueden eliminar directamente y no se puede cambiar su nombre con el sistema de archivos. De lo contrario, se perderá la coherencia de nivel de vínculo entre la base de datos y el sistema de archivos (es decir, la base de datos resultará dañada).
El acceso del sistema de archivos de FILESTREAM modela una instrucción Transact-SQL mediante la apertura y el cierre de archivos. La instrucción se inicia cuando se abre un identificador de archivo y finaliza cuando se cierra el identificador. Por ejemplo, cuando se cierra un identificador de escritura, se desencadenan todos los posibles desencadenadores AFTER que estén registrados en la tabla como si se hubiera completado una instrucción UPDATE.
Para obtener más información y ejemplos del uso de las API de Win32 para obtener acceso a datos de FILESTREAM, vea el tema "Crear aplicaciones cliente para datos FILESTREAM" (http://msdn.microsoft.com/es-es/library/cc645940.aspx) en los Libros en pantalla de SQL Server 2008.
6

Semántica de transacciones
Se deben cerrar todos los identificadores de archivo antes de que la transacción se confirme o se revierta. Si se queda abierto un identificador cuando se confirma una transacción, se produce un error en la confirmación y todas las lecturas y escrituras adicionales del identificador provocan un error, como cabría esperar. Entonces se debe revertir la transacción. Del mismo modo, si la base de datos o la instancia del motor de base de datos se cierra, se invalidan todos los identificadores abiertos.
Siempre que se abre un archivo de FILESTREAM para una operación de escritura, se crea un nuevo archivo de longitud cero y se escribe en él todo el valor de los datos actualizados de FILESTREAM. El archivo anterior se quita de forma asincrónica, como se describe en la sección "Configurar la recolección de elementos no utilizados de FILESTREAM", más adelante en estas notas del producto.
Con FILESTREAM, el motor de base de datos asegura la durabilidad de la transacción en la confirmación de los datos BLOB de FILESTREAM que se modifican desde el acceso de transmisión por secuencias del sistema de archivos. Para ello se emplea el registro de FILESTREAM mencionado anteriormente y un vaciado explícito del contenido del archivo de FILESTREAM en el disco.
Semántica de aislamiento
La semántica de aislamiento se rige por los niveles de aislamiento de transacción del motor de base de datos. Cuando se obtiene acceso a datos de FILESTREAM mediante las API de Win32, solo se admite el nivel de aislamiento de lectura confirmada. El acceso a Transact-SQL también permite los niveles de aislamiento de lectura repetible y serializable. Además, mediante el acceso a Transact-SQL, se permiten lecturas de datos sucios en el nivel de aislamiento de lectura no confirmada, o la sugerencia de consulta NOLOCK, pero dicho acceso no mostrará las actualizaciones en curso de datos de FILESTREAM.
Las operaciones de apertura de acceso al sistema de archivos no esperan ningún bloqueo. En su lugar, se produce un error inmediato de las operaciones de apertura si no pueden obtener acceso a los datos debido al aislamiento de transacción. Se produce un error en las llamadas de API de transmisión por secuencias con ERROR_SHARING_VIOLATION si la operación de apertura no puede continuar debido a la infracción de aislamiento.
Actualizaciones parciales
Para permitir que se realicen actualizaciones parciales, la aplicación puede emitir un control FS de dispositivo (FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT) para capturar el contenido anterior en el archivo al que hace referencia el identificador abierto. También se puede hacer mediante la API administrada SqlFileStream con la marca ReadWrite. Esto desencadenará una copia del contenido anterior en el lado servidor, como se ha explicado anteriormente. Para mejorar el rendimiento de la aplicación y evitar posibles tiempos de espera mientras trabaja con archivos muy grandes, debe usar E/S asincrónica.
Si se emite el FSCTL una vez que se ha escrito en el identificador, se conservará la última operación de escritura y se perderán las escrituras anteriores realizadas en el identificador.
Para obtener más información sobre las actualizaciones parciales, vea el tema "Realizar actualizaciones parciales de los datos FILESTREAM" (http://technet.microsoft.com/es-es/library/cc627407.aspx) en los Libros en pantalla de SQL Server 2008.
7

Escritura continua desde clientes remotos
El acceso remoto del sistema de archivos a datos de FILESTREAM está habilitado a través del protocolo Bloque de mensajes del servidor (SMB). Si el cliente es remoto, el almacenamiento en caché de las operaciones de escritura depende de las opciones especificadas y de la API usada. Por ejemplo, el valor predeterminado para las API de código nativo es realizar una escritura continua, mientras que en las API administradas el valor predeterminado es usar el almacenamiento en búfer. Esta diferencia refleja los comentarios de los clientes sobre las distintas API y sus usos en las versiones CTP de vista previa de SQL Server 2008.
Se recomienda que las aplicaciones que se ejecutan en clientes remotos consoliden las pequeñas operaciones de escritura (mediante almacenamiento en búfer) para realizar menos operaciones de escritura con un tamaño de datos mayor. Además, si se emplea el almacenamiento en búfer, el cliente debe emitir un vaciado explícito antes de que se confirme la transacción.
No se admite la creación de vistas asignadas a la memoria (E/S asignada a la memoria) usando un identificador FILESTREAM. Si se usa la asignación en memoria para datos de FILESTREAM, el motor de base de datos no puede garantizar la coherencia y la durabilidad de los datos o la integridad de la base de datos.
Cuándo se debe usar FILESTREAMAunque la tecnología FILESTREAM cuenta con muchas características atractivas, quizás no sea la opción óptima en todas las situaciones. Como se ha mencionado anteriormente, el tamaño de los datos BLOB y los patrones de acceso son los factores más importantes a la hora de decidir si los datos BLOB se deben almacenar totalmente dentro de la base de datos o mediante FILESTREAM.
El tamaño afecta a lo siguiente:
Eficiencia del acceso a los datos BLOB mediante cualquier mecanismo de almacenamiento. Como se ha mencionado anteriormente, el acceso de transmisión por secuencias a datos BLOB grandes es más eficiente con FILESTREAM, pero las actualizaciones parciales son (potencialmente mucho) más lentas.
Eficiencia de la copia de seguridad de los datos estructurados y BLOB combinados mediante cualquier mecanismo de almacenamiento. Una copia de seguridad que combine archivos de base de datos de SQL Server y un gran número de archivos de FILESTREAM será más lenta que una copia de seguridad exclusivamente de archivos de base de datos de SQL Server de un tamaño total equivalente. Esto se debe a la sobrecarga adicional que supone realizar una copia de seguridad de cada archivo NTFS (una por cada valor de datos de FILESTREAM). Esta sobrecarga es más evidente cuando los archivos de FILESTREAM son menores (ya que la sobrecarga de tiempo se convierte en un porcentaje mayor del tiempo total de copia de seguridad por MB de datos).
A modo de ejemplo, el gráfico siguiente muestra el rendimiento relativo de lecturas locales de diferentes tamaños de datos de BLOB mediante varbinary(max), FILESTREAM mediante Transact-SQL y FILESTREAM mediante NTFS. Se puede ver (en la línea azul) que el acceso Win32 de los datos de FILESTREAM es varias veces más rápido que el acceso a Transact-SQL de datos varbinary(max) a medida que el tamaño de los datos aumenta. Tenga en cuenta que las medidas de rendimiento están en megabits por segundo (Mbps).
8

Ilustración 1: rendimiento de lectura de diferentes tamaños de BLOB
Las cifras de NTFS incluyen el tiempo necesario para iniciar una transacción, recuperar el nombre de la ruta de acceso y el contexto de la transacción de SQL Server, y abrir un identificador de Win32 para los datos de FILESTREAM. Todas las pruebas se realizaron usando el mismo equipo con cuatro núcleos de procesador y un grupo de búferes activo de SQL Server.
El otro factor que hay que tener en cuenta es si se puede escribir en el cliente o en el nivel intermedio (o si se puede modificar) para usar las API de transmisión por secuencias de Win32 y el acceso normal a SQL Server. Si no se puede, FILESTREAM no resultará adecuado, ya que el máximo rendimiento se obtiene cuando se usan las API de transmisión por secuencias de Win32.
Configurar Windows para FILESTREAMComo ocurre con cualquier otra implementación, antes de implementar una aplicación que usa FILESTREAM es importante preparar el servidor Windows que hospedará la base de datos de SQL Server y los contenedores de datos de FILESTREAM asociados. En esta sección se explica cómo configurar el hardware de almacenamiento y el sistema de archivos NTFS como preparación para el uso de FILESTREAM. Después se muestra cómo habilitar FILESTREAM en el nivel de Windows.
Selección y configuración de hardwareUna de las causas más frecuentes de una carga de trabajo con un rendimiento bajo es una configuración de hardware inadecuada. A veces la causa es una memoria insuficiente, lo que conduce a "paginar excesivamente" el grupo de búferes de SQL Server, y en otras ocasiones es simplemente que el hardware de almacenamiento no tiene la capacidad de rendimiento de E/S que la carga de trabajo necesita. En el caso de las aplicaciones que usarán FILESTREAM para la transmisión por secuencias de alto rendimiento de datos BLOB mediante las API de Win32, la elección y la configuración del hardware de almacenamiento son fundamentales.
9

En las próximas secciones se describen algunas prácticas recomendadas para la elección y el diseño del almacenamiento. Para obtener una explicación más detallada al respecto, vea las notas del producto de TechNet "Diseño del almacenamiento de la base de datos física" (http://www.microsoft.com/technet/prodtechnol/sql/2005/physdbstor.mspx). Después de realizar un diseño óptimo, es conveniente realizar pruebas de carga para validar la capacidad de rendimiento del subsistema de E/S. Esto se describe en detalle en el artículo de prácticas recomendadas de SQL Server en TechNet "Prácticas recomendadas de E/S antes de la implementación" (http://www.microsoft.com/technet/prodtechnol/sql/bestpractice/pdpliobp.mspx).
Diseño del almacenamiento físicoAsegúrese de tener en cuenta la carga de trabajo prevista en un contenedor de datos de FILESTREAM cuando decida dónde se debe colocar, así como las cargas de trabajo de los contenedores de datos o los archivos de SQL Server colocados. Puede que cada contenedor de datos de FILESTREAM necesite estar en su propio volumen, ya que el hecho de tener varios contenedores de datos con cargas de trabajo elevadas en un único volumen puede producir contención.
Lo importante aquí es que si no se piensa en las cargas de trabajo implicadas, poner todo en un mismo volumen puede producir problemas de rendimiento. El grado de separación necesario variará de un cliente a otro.
También es posible crear un esquema de tabla dentro de SQL Server que permita el equilibrio de carga de los datos de FILESTREAM entre varios volúmenes. Esto se describe en la sección "Equilibrio de carga de datos de FILESTREAM".
Elección del nivel RAIDLas ventajas de emplear la tecnología RAID son ampliamente conocidas, y se ha escrito mucho sobre la elección de un nivel RAID adecuado para los requisitos de la aplicación, por lo que estas notas del producto no intentarán repetir toda esa información. Las notas del producto "Diseño del almacenamiento de la base de datos física" mencionadas anteriormente incluyen una sección excelente sobre los niveles RAID y la elección del nivel RAID. A continuación se ofrece información general simple sobre los factores que hay que tener en cuenta.
Los niveles RAID difieren de diversas maneras, especialmente en cuanto a rendimiento de lectura y escritura, resistencia a errores y costo. Por ejemplo, RAID 5 es relativamente económico, puede controlar el error de solo una unidad de la matriz RAID y puede resultar inadecuado para cargas de trabajo con muchas escrituras. Por otra parte, RAID 10 proporciona un rendimiento excelente de lectura y escritura, y puede controlar errores en varias unidades (en función del grado de creación de reflejo presente), pero es más costoso, ya que al menos el 50 por ciento de las unidades de la matriz RAID son redundantes. Estos son los tres factores principales que influyen en la elección de un nivel RAID. El nivel RAID elegido puede ser diferente para el volumen en el que se almacenan todas las bases de datos de usuario, y puede ser distinto incluso entre el volumen que almacena los archivos de datos y el que almacena los archivos de registro para una sola base de datos.
Si la carga de trabajo va a implicar transmisión por secuencias de alto rendimiento de datos de FILESTREAM, la elección inmediata puede ser que el volumen del contenedor de datos de FILESTREAM use el nivel RAID que proporciona el mayor rendimiento de lectura. Sin embargo, esto quizás no proporcione un alto grado de resistencia ante errores. Por otra parte, la elección inmediata puede ser usar el mismo nivel RAID que para los demás volúmenes que almacenan los datos para la base de datos, pero esto quizás no proporcione los niveles de rendimiento que la carga de trabajo demanda.
10

En estas notas del producto, queremos destacar que se debe realizar una elección consciente del nivel RAID para los volúmenes de contenedores de datos de FILESTREAM después de evaluar las ventajas y las desventajas, no decidir basándose en un único factor.
Elección de la interfaz de unidadEn las bases de datos típicas que tienen datos BLOB, el tamaño total de los datos BLOB puede ser muchas veces mayor que el tamaño total de los datos estructurados. Al implementar una solución que implica almacenar los datos de FILESTREAM en volúmenes diferentes, quizás desee usar un almacenamiento más barato para el volumen, como IDE o SATA (en lo sucesivo denominado simplemente "SATA"), en lugar de un almacenamiento SCSI más costoso. Antes de tomar esta decisión, hay que entender las ventajas y desventajas que ello implica. Esta sección proporciona información general de las distintas características de SCSI frente a IDE/SATA para que pueda tomar una decisión informada basándose en el rendimiento, la confiabilidad y el costo.
Capacidad y rendimiento
Las unidades SATA suelen tener más capacidad que las unidades SCSI, pero tienen una velocidad de giro (RPM) menor que las unidades SCSI. Si bien hay algunas unidades SATA de 10.000 RPM, la mayoría son de 5.400 o 7.200 RPM. Existen unidades SCSI de alto rendimiento de 10.000 y hasta 15.000 RPM. Aunque RPM puede ser una métrica de comparación útil, las dos cifras que se deben usar realmente para realizar una comparación son la latencia (el tiempo que transcurre hasta que el cabezal del disco se encuentra en la posición adecuada sobre la superficie del disco) y las velocidades de transferencia medias (cuántos datos se puede transferir hacia y desde la superficie del disco por segundo). También es importante que las unidades puedan procesar patrones complejos de E/S de forma eficiente. A la hora de elegir las unidades, asegúrese de que las unidades SATA admitan Native Command Queue (NCQ) y las unidades SCSI admitan Command Tag Queue (CTQ), lo que les permite procesar varias E/S de disco intercaladas para lograr un mejor rendimiento.
En resumen, las unidades SCSI suelen tener mejor latencia y velocidades de transferencia, por lo que proporcionarán mejor rendimiento de transmisión de datos, pero posiblemente a un costo mayor.
Confiabilidad
SQL Server emplea la ordenación de escritura garantizada y la durabilidad para proporcionar confiabilidad y capacidad de recuperación gracias a su mecanismo de registro de escritura previa. Para obtener más información sobre estos requisitos de E/S, vea las notas del producto de TechNet "Conceptos básicos de E/S de SQL Server" (http://www.microsoft.com/technet/prodtechnol/sql/2005/iobasics.mspx).
En cuanto a confiabilidad, SCSI suele ser mejor que SATA porque admite de forma uniforme la escritura forzada de datos en el disco mientras que SATA no lo admite. Esto se consigue admitiendo la escritura continua, donde los datos que se van a escribir no se almacenan en memoria caché, o admitiendo el vaciado forzoso del contenido de la memoria caché en el disco. La falta de cualquiera de estos mecanismos puede afectar a la capacidad de recuperación después de un error de hardware, de software o de alimentación. Todos los tipos de interfaces pueden admitir el intercambio en caliente para permitir reparaciones mientras se mantiene la disponibilidad.
La característica FILESTREAM se basa en dos garantías de ordenación de escritura y durabilidad:
Durabilidad de los datos en tiempo de confirmación de la transacción Registro de escritura previa para la creación y eliminación de archivos de FILESTREAM
11

Para lograr durabilidad de los datos, el controlador del sistema de archivos de FILESTREAM emite un vaciado explícito de los archivos que se han modificado antes de que se confirme una transacción (los detalles del mecanismo quedan fuera del ámbito de estas notas del producto). Esto garantiza que en caso de que se produzca un error de alimentación, los discos que no tienen suficiente memoria caché alimentada por batería no perderán los datos de FILESTREAM confirmados pero sin vaciar. Si las unidades SATA no admiten una operación de vaciado forzado, se puede ver afectada la capacidad de recuperación y se pueden perder datos.
El registro de escritura previa se basa en la coherencia de los metadatos NTFS. Esto por sí solo depende de la confiabilidad de las unidades subyacentes. No hay ningún problema con SCSI, pero si las unidades SATA no admiten el vaciado forzado, se pueden perder algunos cambios en los metadatos NTFS si se produce una situación de error de alimentación. Esto puede dar lugar a varios escenarios:
NTFS no puede recuperarse y el volumen no se puede montar (es decir, el contenedor de datos de FILESTREAM está básicamente sin conexión).
NTFS se recupera pero los cambios de los metadatos NTFS se pierden y SQL Server no puede revertir una transacción sin confirmar que realiza una inserción de datos de FILESTREAM (es decir, los datos de FILESTREAM se "pierden").
NTFS se recupera pero los cambios de los metadatos NTFS se pierden y SQL Server no puede revertir una transacción sin confirmar que realiza una eliminación de datos de FILESTREAM (es decir, los datos de FILESTREAM se pierden).
Hay que destacar que estos tres escenarios no son peores que si los datos BLOB se almacenaran fuera de la base de datos en un volumen NTFS con unidades SATA subyacentes que no admitieran el almacenamiento forzado de datos en el disco. El uso de FILESTREAM en un volumen con unidades SATA subyacentes en este caso es realmente mejor que almacenar los datos BLOB en archivos NTFS sin formato en el mismo volumen, ya que la coherencia del nivel de vínculo de FILESTREAM proporciona un mecanismo para detectar cuándo se han producido esos "daños" (mediante la ejecución de DBCC CHECKDB en la base de datos).
En resumen, los datos de FILESTREAM se pueden almacenar de forma confiable en volúmenes con almacenamiento SATA subyacente, siempre y cuando las unidades SATA admitan el almacenamiento forzado de datos en el disco mediante el vaciado de la memoria caché.
Configuración de NTFSIncluso el subsistema de E/S mejor diseñado, cuando se ejecuta en hardware de alto rendimiento, puede que no funcione de la manera deseada si el sistema de archivos (en este caso, NTFS) no está configurado correctamente. En esta sección se describen algunas de las opciones de configuración que pueden afectar a una carga de trabajo en la que participan datos de FILESTREAM.
Para obtener información general más completa sobre NTFS, vea los artículos de TechNet Library "Referencia técnica de NTFS" (http://technet.microsoft.com/es-es/library/cc758691.aspx) y "Trabajar con sistemas de archivos" (http://technet.microsoft.com/es-es/library/bb457112.aspx).
12

Optimizar el rendimiento de NTFS
De forma predeterminada, NTFS no está configurado para controlar una carga de trabajo de alto rendimiento con decenas de miles de archivos en un directorio individual del sistema de archivos (es decir, el escenario de FILESTREAM). Hay dos opciones de NTFS que es necesario configurar para facilitar el rendimiento de FILESTREAM. Es especialmente importante establecer estas opciones correctamente antes de iniciar cualquier simulación de rendimiento; de lo contrario, los resultados no serán representativos del rendimiento real de FILESTREAM.
La primera opción de configuración consiste en deshabilitar la generación de nombres 8.3 cuando se crean nuevos archivos (o se cambian de nombre). Este proceso genera un nombre secundario para cada archivo que solo sirve por compatibilidad con versiones anteriores para las aplicaciones de 16 bits. El algoritmo genera un nuevo nombre 8.3 y después tiene que examinar todos los nombres de archivo con formato 8.3 existentes en el directorio para asegurarse de que el nuevo nombre es único. A medida que el número de archivos del directorio aumenta (normalmente por encima de 300.000), este proceso lleva cada vez más tiempo. El tiempo necesario para crear un archivo aumenta y el rendimiento disminuye, por lo que desactivar este proceso puede mejorar considerablemente el rendimiento. Para desactivar este proceso, escriba lo siguiente en un símbolo del sistema y reinicie el equipo:
fsutil behavior set disable8dot3 1
Nota: esta opción deshabilita la generación de nombres 8.3 en todos los volúmenes NTFS del servidor. Si hay aplicaciones de 16 bits que usan algunos volúmenes, pueden experimentar problemas después de cambiar este comportamiento.
La segunda opción que hay que desactivar es la actualización de la hora de último acceso a un archivo cuando se obtiene acceso al mismo. Si la carga de trabajo tiene acceso brevemente a muchos archivos, se dedica una cantidad de tiempo desproporcionada actualizando simplemente la hora de último acceso de cada archivo. Al desactivar esta opción también aumenta considerablemente el rendimiento. Para desactivar este proceso, escriba lo siguiente en un símbolo del sistema y reinicie el equipo:
fsutil behavior set disablelastaccess 1
Tamaño de clúster
Todos los sistemas de archivos de Windows tienen el concepto de "clúster", que es la unidad de asignación cuando se asigna espacio en disco. Como un clúster es la menor cantidad de espacio en disco que se puede asignar, si un archivo es muy pequeño, parte del clúster puede quedar sin utilizar (se desperdicia). Por tanto, el tamaño de clúster suele ser bastante reducido para que los archivos pequeños no desaprovechen espacio en disco.
Los archivos grandes pueden tener asignados muchos clústeres o los archivos pueden crecer con el tiempo y asignárseles clústeres a medida que crecen. Si un archivo crece mucho, pero en fragmentos pequeños, es probable que los clústeres asignados no sean contiguos en el disco (es decir, sean "fragmentos"). Esto significa que cuanto menores sean los clústeres y cuanto más crezca un archivo, más "fragmentado" estará.
Por tanto, el tamaño de clúster es un compromiso entre desaprovechar espacio en disco y reducir la fragmentación. Puede encontrar información más detallada sobre los diversos tamaños de clúster de los sistemas de archivos de Windows en el artículo de Knowledge Base "Tamaño de clúster predeterminado para FAT y NTFS" (http://support.microsoft.com/kb/140365).
13

La recomendación para usar FILESTREAM es que las unidades individuales de datos BLOB tengan un tamaño de 1 MB o superior. Si es así, se recomienda que el tamaño de clúster de NTFS para el volumen del contenedor de datos de FILESTREAM se establezca en 64 kB para reducir la fragmentación. Se debe hacer manualmente porque el valor predeterminado para los volúmenes NTFS de hasta 2 terabytes (TB) es de 4 kB. Para ello se usa la opción /A del comando format. Por ejemplo, escriba lo siguiente en un símbolo del sistema:
format F: /FS:NTFS /V:MyFILESTREAMContainer /A:64K
Este valor se debe combinar con tamaños de búfer grandes, como se describe en la sección "Consideraciones sobre la optimización del rendimiento y las simulaciones", más adelante en estas notas del producto.
Administrar la fragmentación
Como se ha descrito anteriormente, cuando muchos archivos de un volumen crecen, se fragmentan. Esto significa que la colección de clústeres asignados al archivo no es contigua. Cuando el archivo se lee secuencialmente, los cabezales del disco necesitan leer todos los clústeres en orden, lo que puede significar que tienen que leer partes diferentes del disco. Aunque los archivos no crezcan una vez creados, si se crearon en un volumen en el que el espacio disponible no está en un único fragmento contiguo, se pueden fragmentar inmediatamente, ya que los clústeres necesarios para alojarlos no están disponibles de forma contigua.
Esta fragmentación hace que el rendimiento de lectura secuencial sea menor que cuando no hay fragmentación (o cuando hay poca). El problema es muy similar al de la fragmentación de índices dentro de una base de datos que disminuye el rendimiento del recorrido de intervalos de consulta.
Por tanto, es esencial quitar periódicamente la fragmentación mediante una herramienta de desfragmentación de disco para mantener el rendimiento de lectura secuencial. Además, si el volumen que se va a usar para hospedar el contenedor de datos de FILESTREAM se usó previamente, o si todavía contiene otros datos, se debe comprobar el nivel de fragmentación y corregir en caso de que sea necesario.
Compresión
Los datos almacenados en NTFS se pueden comprimir para ahorrar espacio en disco, pero a costa de un uso adicional de la CPU para comprimir y descomprimir los datos cuando se escriben o se leen, respectivamente. La compresión tampoco es útil si los datos no se pueden comprimir. Por ejemplo, los datos aleatorios, los datos cifrados o los datos que ya se han comprimido no se comprimen bien, pero aun así se deben seguir pasando por el algoritmo de compresión de NTFS, lo que produce una sobrecarga de la CPU.
Por estos motivos, solo tiene sentido habilitar la compresión cuando los datos se puedan comprimir mucho y cuando la CPU adicional necesaria no haga que disminuya el rendimiento de la carga de trabajo. También hay que tener en cuenta que la compresión solo se pueden habilitar cuando el tamaño de clúster de NTFS es 4.096 bytes o menos.
La compresión se puede habilitar en el volumen del contenedor de datos de FILESTREAM cuando se formatea, mediante la opción /C del comando format. Por ejemplo:
format F: /FS:NTFS /V:MyFILESTREAMContainer /A:4096 /C
14

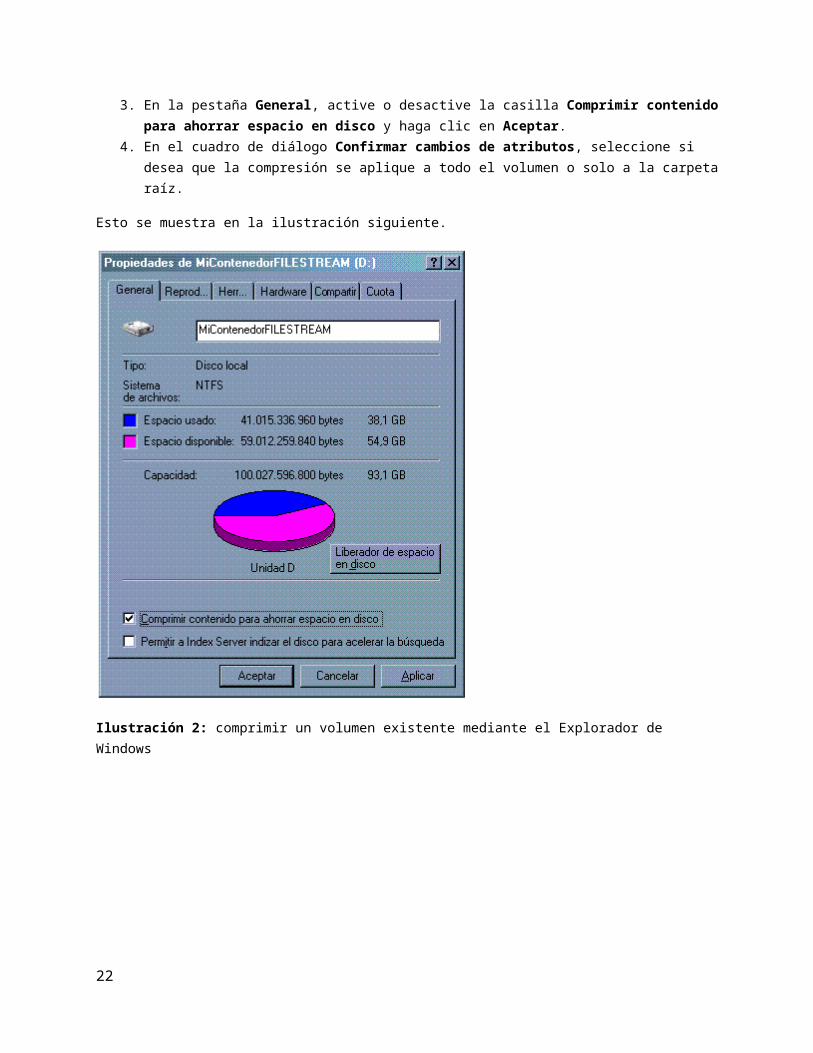
También se puede habilitar la compresión en un volumen existente siguiendo estos pasos:
1. En Mi PC o en el Explorador de Windows, haga clic con el botón secundario en el volumen que desee comprimir o descomprimir.
2. Haga clic en Propiedades para ver el cuadro de diálogo Propiedades.3. En la pestaña General, active o desactive la casilla Comprimir contenido para ahorrar
espacio en disco y haga clic en Aceptar.4. En el cuadro de diálogo Confirmar cambios de atributos, seleccione si desea que la
compresión se aplique a todo el volumen o solo a la carpeta raíz.
Esto se muestra en la ilustración siguiente.
Ilustración 2: comprimir un volumen existente mediante el Explorador de Windows
15

Administración del espacio
Si bien es posible colocar varios contenedores de datos de FILESTREAM en un único volumen NTFS, hay motivos para tener una asignación 1:1 entre los contenedores de datos y los volúmenes NTFS. Aparte de la posible contención dependiente de la carga de trabajo, no hay ninguna manera de administrar el uso del espacio del contenedor de datos de FILESTREAM desde dentro de SQL Server, por lo que hay que usar cuotas de disco de NTFS si es necesario. El seguimiento de las cuotas de disco se realiza por usuario y por volumen, por lo que si se tienen varios contenedores de datos de FILESTREAM en un único volumen resulta difícil saber qué contenedor de datos usa más espacio en disco. Todos los archivos de FILESTREAM se crearán bajo la cuenta de servicio de SQL Server. Si se cambia esto, el espacio en disco empezará a cargarse a la nueva cuenta de servicio.
Hay un único controlador del filtro del sistema de archivos de FILESTREAM para cada volumen NTFS que tiene un contenedor de datos de FILESTREAM, y también hay uno para cada versión de SQL Server que tiene un contenedor de datos de FILESTREAM en el volumen. Cada controlador del filtro es responsable de administrar todos los contenedores de datos de FILESTREAM de ese volumen, para todas las instancias que usan una versión específica de SQL Server.
Por ejemplo, un volumen NTFS que hospeda tres contenedores de datos de FILESTREAM, uno para cada una de tres instancias de SQL Server 2008, solo tendrá un controlador del filtro del sistema de archivos de FILESTREAM de SQL Server 2008.
Seguridad
Existen dos requisitos de seguridad para usar la característica FILESTREAM. En primer lugar, se debe configurar SQL Server para la seguridad integrada. En segundo lugar, si se va a usar acceso remoto, se debe habilitar el puerto SMB (445) a través de cualquier sistema de firewall. Esto también es necesario para el acceso normal a recursos compartidos remotos. Para obtener más información, vea el artículo de Knowledge Base "Información general de los servicios y los requisitos de puerto de red para Windows Server System" (http://support.microsoft.com/kb/832017).
Consideraciones sobre software antivirusEl software antivirus es ubicuo en el entorno de hoy en día. FILESTREAM no puede impedir que el software antivirus examine los archivos del contenedor de datos de FILESTREAM (esto crearía problemas de seguridad). El software normalmente tiene una configuración de directiva sobre lo que se debe hacer con un archivo sospechoso de estar contaminado con un virus: eliminar el archivo o restringir el acceso al mismo (lo que se conoce como poner el archivo en "cuarentena"). En ambos casos, se impedirá el acceso a los datos BLOB del archivo afectado y SQL Server pensará que el archivo se ha eliminado.
Se recomienda que configure el software antivirus para que ponga en cuarentena los archivos, no para que los elimine. Se puede usar DBCC CHECKDB dentro de SQL Server para averiguar qué archivos parecen faltar y el administrador de Windows puede correlacionar los nombres de archivo con el registro del software antivirus y realizar la acción necesaria.
16

Habilitar FILESTREAM en WindowsFILESTREAM es una característica híbrida que requiere que tanto el administrador de Windows como el administrador de SQL Server realicen algunas acciones antes de que se habilite la característica. Esto es necesario para mantener la separación de tareas entre los dos administradores, especialmente si el administrador de SQL Server no es también el administrador de Windows. Al habilitar FILESTREAM en el nivel de Windows se instala un controlador del filtro del sistema de archivos, que es algo para lo que solo un administrador de Windows tiene privilegios.
En el nivel de Windows, FILESTREAM se habilita durante la instalación de SQL Server 2008 o mediante la ejecución del Administrador de configuración de SQL Server. He aquí los pasos que hay que seguir:
1. En el menú Inicio, seleccione Todos los programas, seleccione Microsoft SQL Server 2008, seleccione Herramientas de configuración y, a continuación, haga clic en Administrador de configuración de SQL Server.
2. En la lista de servicios, haga clic con el botón secundario en Servicios de SQL Server y, a continuación, haga clic en Abrir.
3. En el complemento Administrador de configuración de SQL Server, busque la instancia de SQL Server en la que desee habilitar FILESTREAM.
4. Haga clic con el botón secundario en la instancia y, a continuación, haga clic en Propiedades.5. En el cuadro de diálogo Propiedades de SQL Server, haga clic en la pestaña FILESTREAM.6. Active la casilla Habilitar FILESTREAM para acceso a Transact-SQL.7. Si desea leer y escribir datos de FILESTREAM desde Windows, haga clic en Habilitar
FILESTREAM para el acceso de transmisión por secuencias de E/S de archivos. Escriba el nombre del recurso compartido de Windows en el cuadro Nombre de recurso compartido de Windows.
8. Si los clientes remotos deben tener acceso a los datos de FILESTREAM que están almacenados en este recurso compartido, seleccione Permitir que los clientes remotos tengan acceso de transmisión por secuencias a los datos de FILESTREAM.
9. Haga clic en Aplicar.
En la ilustración siguiente se muestra la pestaña FILESTREAM como se describe en el procedimiento.
17

Ilustración 3: configurar FILESTREAM mediante el Administrador de configuración de SQL Server
Este procedimiento debe realizarse para cada instancia de SQL Server que vaya a usar la característica FILESTREAM antes de que la pueda usar SQL Server. No hay ningún especificación del contenedor de datos de FILESTREAM en esta fase; esto se realiza cuando se crea un grupo de archivos de FILESTREAM en una base de datos después de que se haya habilitado FILESTREAM dentro de SQL Server.
Tenga en cuenta que es posible deshabilitar el acceso de FILESTREAM en el nivel de Windows incluso aunque SQL Server lo haya habilitado. En ese caso, después de reiniciar la instancia de SQL Server, todos los datos de FILESTREAM no estarán disponibles. Se mostrará la advertencia siguiente.
Ilustración 4: advertencia que se muestra al deshabilitar FILESTREAM con el Administrador de configuración de SQL Server
18

Configurar SQL Server para FILESTREAMCada instancia de SQL Server que vaya a usar la característica FILESTREAM se debe configurar por separado, tanto en el nivel de Windows como en el de SQL Server. Después de habilitar FILESTREAM, se debe configurar una base de datos para almacenar datos de FILESTREAM y solo entonces se pueden definir las tablas que incluyen columnas FILESTREAM. En esta sección se describe cómo configurar FILESTREAM en el nivel de SQL Server y cómo crear bases de datos y tablas habilitadas para FILESTREAM, y se explica la interacción de FILESTREAM con otras características de SQL Server 2008.
Consideraciones sobre la seguridadFILESTREAM requiere el uso de seguridad integrada (es decir, autenticación de Windows). Cuando una aplicación que usa Win32 intenta obtener acceso a datos de FILESTREAM, el usuario de Windows se valida mediante SQL Server. Si el usuario tiene acceso de Transact-SQL a los datos de FILESTREAM, el acceso se concederá también en el nivel de Win32, siempre y cuando el token de transacción se obtenga en el contexto de seguridad del usuario de Windows que está abriendo el archivo.
El requisito de la autenticación de Windows procede de la naturaleza de las API de E/S de archivos de Windows. La única manera de pasar la identidad del cliente desde la aplicación cliente a SQL Server durante una operación de E/S de archivos es usar el token de Windows asociado al subproceso del cliente.
Cuando se crea el contenedor de datos de FILESTREAM, se protege automáticamente de forma que solo la cuenta de servicio de SQL Server y los miembros del grupo BUILTIN/Administradores puedan obtener acceso al árbol de directorios del contenedor de datos. Hay que tener cuidado de que el contenido del contenedor de datos nunca cambie excepto mediante métodos transaccionales admitidos, ya que el cambio mediante otros métodos hará que el contenedor resulte dañado.
Habilitar FILESTREAM en SQL ServerEl segundo paso para habilitar FILESTREAM se realiza dentro de la instancia de SQL Server 2008. No se debe hacer hasta que FILESTREAM se haya habilitado en el nivel de Windows y el volumen NTFS que almacenará los datos de FILESTREAM se haya preparado correctamente (como se ha descrito en la sección "Configurar Windows para FILESTREAM" anteriormente).
El acceso a FILESTREAM se controla dentro de SQL Server mediante sp_configure para establecer la opción de configuración filestream_access_level en uno de tres valores posibles. Los valores posibles son:
0: deshabilitar la compatibilidad de FILESTREAM con esta instancia 1: habilitar FILESTREAM para el acceso a Transact-SQL solamente 2: habilitar FILESTREAM para el acceso a Transact-SQL y de transmisión por secuencias de Win32
En el ejemplo siguiente se muestra cómo habilitar FILESTREAM para el acceso a Transact-SQL y de transmisión por secuencias de Win32.
EXEC sp_configure filestream_access_level, 2;
GO
RECONFIGURE;
GO
19

La instrucción RECONFIGURE es necesaria para que el valor recién configurado surta efecto. Tenga en cuenta que si FILESTREAM no se ha habilitado en el nivel de Windows, no se habilitará en el nivel de SQL Server cuando se ejecute el código anterior. El valor configurado actual se puede averiguar mediante el código siguiente.
EXEC sp_configure filestream_access_level;
GO
Si FILESTREAM no está configurado en el nivel de Windows, el "config_value" (valor de configuración) del resultado de sp_configure será diferente (es decir, 0) del "run_value" (valor de ejecución) después de haberse ejecutado la instrucción RECONFIGURE.
Crear una base de datos habilitada para FILESTREAMUna vez que FILESTREAM está habilitado en los niveles de Windows y SQL Server, se puede definir un contenedor de datos de FILESTREAM. Para ello se define un grupo de archivos de FILESTREAM en una base de datos. Hay una asignación 1:1 entre los grupos de archivos de FILESTREAM y los contenedores de datos de FILESTREAM.
Un grupo de archivos de FILESTREAM se puede definir cuando se crea una base de datos o se puede crear por separado mediante una instrucción ALTER DATABASE. En el ejemplo siguiente se crea un grupo de archivos de FILESTREAM en una base de datos existente.
ALTER DATABASE Production ADD
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM;
GO
La cláusula CONTAINS FILESTREAM es necesaria para diferenciar el nuevo grupo de archivos de los grupos de archivos normales de la base de datos. Si la característica FILESTREAM está deshabilitada, esta instrucción producirá el error siguiente.
Mensaje 5591, nivel 16, estado 3, línea 1
La característica FILESTREAM está deshabilitada.
20

Suponiendo que FILESTREAM esté habilitado en los niveles de Windows y de SQL Server, se creará el grupo de archivos. En este momento, el contenedor de datos de FILESTREAM se define agregando un único archivo al grupo de archivos. El nombre de la ruta de acceso especificado es el nombre de la ruta de acceso del directorio que se creará como raíz del contenedor de datos. El nombre completo de la ruta de acceso hasta el nombre del directorio final, sin incluirlo, debe existir ya. En el ejemplo siguiente se define el contenedor de datos para el grupo de archivos FileStreamGroup1 creado anteriormente.
ALTER DATABASE Production ADD FILE (
NAME = FSGroup1File,
FILENAME = 'F:\Production\FSDATA')
TO FILEGROUP FileStreamGroup1;
GO
Ahora se creará el directorio FSDATA. Solo contendrá dos elementos:
El archivo filestream.hdr. Son los metadatos de FILESTREAM para el contenedor de datos. El directorio $FSLOG. Es el equivalente en FILESTREAM del registro de transacciones de una
base de datos.
Hay que tener en cuenta que una base de datos puede tener varios grupos de archivos de FILESTREAM. Esto puede resultar útil para separar el almacenamiento de BLOB para varias tablas de la base de datos.
Crear una tabla para almacenar datos de FILESTREAMUna vez que la base de datos tiene un grupo de archivos de FILESTREAM, se pueden crear tablas que contengan columnas FILESTREAM. Como se ha mencionado anteriormente, una columna FILESTREAM se define como una columna varbinary(max) que tiene el atributo FILESTREAM. En el código siguiente se crea una tabla con una sola columna FILESTREAM.
USE Production;
GO
CREATE TABLE DocumentStore (
DocumentID INT IDENTITY PRIMARY KEY,
Document VARBINARY (MAX) FILESTREAM NULL,
DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL
UNIQUE DEFAULT NEWID ())
21
FILESTREAM_ON FileStreamGroup1;
GO
Una tabla puede tener varias columnas FILESTREAM, pero los datos de todas las columnas FILESTREAM de una tabla deben almacenarse en el mismo grupo de archivos de FILESTREAM. Si no se especifica la cláusula FILESTREAM_ON, se usará el grupo de archivos de FILESTREAM que esté configurado como el predeterminado. Esto podría no ser la configuración deseada y producir problemas de rendimiento.
Una vez creada la tabla, el contenedor de datos de FILESTREAM contendrá otro directorio, correspondiente a la tabla, con un subdirectorio que corresponde a la columna FILESTREAM de la tabla. Este subdirectorio contendrá los archivos de datos una vez introducidos los datos en la tabla. La estructura de directorios variará según el número de columnas FILESTREAM que tenga una tabla y si la tabla está particionada o no.
Tenga en cuenta que para que una tabla tenga una o varias columnas FILESTREAM, debe tener también una columna del tipo de datos uniqueidentifier con el atributo ROWGUIDCOL. Esta columna no debe permitir valores NULL y debe tener una restricción de columna única UNIQUE o PRIMARY KEY . El valor GUID de la columna lo suministrar una aplicación al insertar datos o una restricción DEFAULT que use la función NEWID() (o NEWSEQUENTIALID() si se ha configurado la replicación de mezcla, como se indica en la sección "Combinaciones de características y restricciones" más adelante).
Para obtener más información sobre los detalles y las restricciones del esquema de tabla y las opciones necesarias, vea el tema "CREATE TABLE (Transact-SQL)" (http://msdn.microsoft.com/es-es/library/ms174979.aspx) en los Libros pantalla de SQL Server 2008.
Configurar la recolección de elementos no utilizados de FILESTREAMLos archivos de datos de FILESTREAM del contenedor de datos de FILESTREAM no se pueden actualizar parcialmente. Esto significa que cualquier cambio realizado en los datos BLOB de la columna FILESTREAM creará un archivo de datos de FILESTREAM nuevo. El archivo "anterior" se conservará hasta que ya no sea necesario para recuperar la base de datos. Los archivos que representan datos de FILESTREAM eliminados, o inserciones revertidas de datos de FILESTREAM, se conservan de manera similar.
El proceso de recolección de elementos no utilizados quita los archivos que ya no se necesitan. Este proceso es automático, a diferencia de lo que ocurre en Windows SharePoint® Services, donde la recolección de elementos no utilizados se debe implementar manualmente en el almacén externo de BLOB.
A todas las operaciones de archivos de FILESTREAM se les asigna un número de secuencia de registro (LSN) en el registro de transacciones de la base de datos. Siempre y cuando el registro de transacciones se trunque más allá del LSN de la operación de FILESTREAM, el archivo ya no será necesario y puede ser objeto de la recolección de elementos no utilizados. Por tanto, todo lo que pueda evitar el truncamiento del registro de transacciones también puede impedir la eliminación física de un archivo de FILESTREAM. He aquí algunos ejemplos:
No se han realizado copias de seguridad de registros en el modelo de recuperación FULL o BULK_LOGGED.
Hay una transacción activa de ejecución prolongada. El trabajo del lector del registro de replicación no se ha ejecutado.
22

La recolección de elementos no utilizados de FILESTREAM es una tarea en segundo plano desencadenada por el proceso de punto de comprobación de la base de datos. Se ejecuta automáticamente un punto de comprobación cuando se ha generado una cantidad suficiente de registros de transacciones. Para obtener más información, vea el tema "Puntos de comprobación de base de datos (SQL Server)" (http://msdn.microsoft.com/es-es/library/ms189573.aspx) en los Libros en pantalla de SQL Server 2008. Puesto que las operaciones de archivos de FILESTREAM se graban mínimamente en el registro de transacciones de la base de datos, puede pasar bastante tiempo hasta que el número de entradas del registro de transacciones generadas desencadene un proceso de punto de comprobación y se produzca la recolección de elementos no utilizados. Si esto supone algún problema, puede forzar la recolección de elementos no utilizados mediante la instrucción CHECKPOINT.
Consideraciones sobre la creación de particionesSi la tabla que contiene datos de FILESTREAM tiene particiones, la cláusula FILESTREAM_ON debe especificar un esquema de partición para los grupos de archivos de FILESTREAM basado en la función de partición de la tabla. Esto es necesario porque el esquema de partición normal implicará los grupos de archivos normales que no se pueden usar para almacenar datos de FILESTREAM. La definición de la tabla (en una instrucción CREATE TABLE o CREATE CLUSTERED INDEX…WITH DROP_EXISTING) especifica después ambos esquemas de partición.
El esquema de partición de FILESTREAM puede especificar que todas las particiones se asignen a un único grupo de archivos, pero no se recomienda porque puede causar problemas de rendimiento.
En el ejemplo siguiente se muestra esta sintaxis.
CREATE PARTITION FUNCTION DocPartFunction (INT)
AS RANGE RIGHT FOR VALUES (100000, 200000);
GO
CREATE PARTITION SCHEME DocPartScheme AS
PARTITION DocPartFunction TO (Data_FG1, Data_FG2, Data_FG3);
GO
CREATE PARTITION SCHEME DocFSPartScheme AS
PARTITION DocPartFunction TO (FS_FG1, FS_FG2, FS_FG3);
GO
CREATE TABLE DocumentStore (
DocumentID INT IDENTITY PRIMARY KEY,
23

Document VARBINARY (MAX) FILESTREAM NULL,
DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL
UNIQUE DEFAULT NEWID () ON Data_FG1)
ON DocPartScheme (DocumentID)
FILESTREAM_ON DocFSPartScheme;
GO
Observe que para usar la columna DocumentID como columna de partición, el índice no clúster subyacente que aplica la restricción UNIQUE en el DocGUID se debe colocar explícitamente en un grupo de archivos para que la columna DocumentID puede ser la columna de partición. Esto significa que el cambio de partición solo es posible si se deshabilitan las restricciones UNIQUE antes de realizar el cambio de partición, ya que son índices no alineados y, a continuación, se vuelven a habilitar.
Continuando con el ejemplo anterior, en el código siguiente se crea una tabla y después se intenta un cambio de partición.
CREATE TABLE NonPartitionedDocumentStore (
DocumentID INT IDENTITY PRIMARY KEY,
Document VARBINARY (MAX) FILESTREAM NULL,
DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL
UNIQUE DEFAULT NEWID ());
GO
ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore;
GO
Se produce un error en el cambio de partición y se genera el mensaje siguiente.
Mensaje 7733, nivel 16, estado 4, línea 1
Error de la instrucción 'ALTER TABLE SWITCH'. La tabla 'FileStreamTestDB.dbo.DocumentStore' tiene particiones, mientras que el índice 'UQ_Document_8CC1617F60ED59' no las tiene.
Al deshabilitar el índice único en la tabla de origen e intentarlo de nuevo se obtiene el código siguiente.
24

ALTER INDEX [UQ__Document__8CC331617F60ED59] ON DocumentStore DISABLE;
GO
ALTER TABLE FileStreamTest3 SWITCH PARTITION 2 TO NonPartitionedFileStreamTest3;
GO
Esto también produce un error y se muestra el mensaje siguiente.
Mensaje 4947, Nivel 16, Estado 1, Línea 1
Error de la instrucción ALTER TABLE SWITCH. El índice de la tabla de origen 'FileStreamTestDB.dbo.DocumentStore' no es idéntico al índice 'UQ_NonParti_8CC3316103317E3D' de la tabla de destino 'FileStreamTestDB.dbo.NonPartitionedDocumentStore'.
Se deben deshabilitar los índices únicos de las tablas con particiones y sin particiones antes de que el modificador pueda continuar.
ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON NonPartitionedDocumentStore DISABLE;
GO
ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore;
GO
ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON
NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON);
ALTER INDEX [UQ__Document__8CC331617F60ED59] ON
NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON);
GO
25

Se incluirá más información sobre la creación de particiones de datos de FILESTREAM en unas notas del producto futuras sobre la creación de particiones en SQL Server 2008.
Equilibrio de carga de datos de FILESTREAMTambién se puede usar la creación de particiones para crear un esquema de tabla que permita el equilibrio de carga de los datos de FILESTREAM entre varios volúmenes. Puede resultar conveniente por diversas razones como limitaciones del hardware o para permitir el almacenamiento de zonas activas de una tabla en volúmenes diferentes.
En el código siguiente se muestra una función y un esquema de partición según la columna uniqueidentifier que reparte eficazmente los datos de FILESTREAM en 16 volúmenes y crea bandas de los datos estructurados en dos grupos de archivos.
USE master;
GO
-- Crear la base de datos
CREATE DATABASE Production ON PRIMARY
(NAME = 'Production', FILENAME = 'E:\Production\Production.mdf'),
FILEGROUP DataFilegroup1
(NAME = 'Data_FG1', FILENAME = 'F:\Production\Data_FG1.ndf'),
FILEGROUP DataFilegroup2
(NAME = 'Data_FG2', FILENAME = 'G:\Production\Data_FG2.ndf'),
FILEGROUP FSFilegroup0 CONTAINS FILESTREAM
(NAME = 'FS_FG0', FILENAME = 'H:\Production\FS_FG0'),
FILEGROUP FSFilegroup1 CONTAINS FILESTREAM
(NAME = 'FS_FG1', FILENAME = 'I:\Production\FS_FG1'),
FILEGROUP FSFilegroup2 CONTAINS FILESTREAM
(NAME = 'FS_FG2', FILENAME = 'J:\Production\FS_FG2'),
FILEGROUP FSFilegroup3 CONTAINS FILESTREAM
(NAME = 'FS_FG3', FILENAME = 'K:\Production\FS_FG3'),
FILEGROUP FSFilegroup4 CONTAINS FILESTREAM
(NAME = 'FS_FG4', FILENAME = 'L:\Production\FS_FG4'),
26

FILEGROUP FSFilegroup5 CONTAINS FILESTREAM
(NAME = 'FS_FG5', FILENAME = 'M:\Production\FS_FG5'),
FILEGROUP FSFilegroup6 CONTAINS FILESTREAM
(NAME = 'FS_FG6', FILENAME = 'N:\Production\FS_FG6'),
FILEGROUP FSFilegroup7 CONTAINS FILESTREAM
(NAME = 'FS_FG7', FILENAME = 'O:\Production\FS_FG7'),
FILEGROUP FSFilegroup8 CONTAINS FILESTREAM
(NAME = 'FS_FG8', FILENAME = 'P:\Production\FS_FG8'),
FILEGROUP FSFilegroup9 CONTAINS FILESTREAM
(NAME = 'FS_FG9', FILENAME = 'Q:\Production\FS_FG9'),
FILEGROUP FSFilegroupA CONTAINS FILESTREAM
(NAME = 'FS_FGA', FILENAME = 'R:\Production\FS_FGA'),
FILEGROUP FSFilegroupB CONTAINS FILESTREAM
(NAME = 'FS_FGB', FILENAME = 'S:\Production\FS_FGB'),
FILEGROUP FSFilegroupC CONTAINS FILESTREAM
(NAME = 'FS_FGC', FILENAME = 'T:\Production\FS_FGC'),
FILEGROUP FSFilegroupD CONTAINS FILESTREAM
(NAME = 'FS_FGD', FILENAME = 'U:\Production\FS_FGD'),
FILEGROUP FSFilegroupE CONTAINS FILESTREAM
(NAME = 'FS_FGE', FILENAME = 'V:\Production\FS_FGE'),
FILEGROUP FSFilegroupF CONTAINS FILESTREAM
(NAME = 'FS_FGF', FILENAME = 'W:\Production\FS_FGF');
GO
USE Production;
GO
-- Crear una función de partición basada en los 6 últimos bytes del GUID
27

CREATE PARTITION FUNCTION LoadBalance_PF (UNIQUEIDENTIFIER)
AS RANGE LEFT FOR VALUES (
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-100000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-200000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-300000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-400000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-500000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-600000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-700000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-800000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-900000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-a00000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-b00000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-c00000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-d00000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-e00000000000'),
CONVERT (uniqueidentifier, '00000000-0000-0000-0000-f00000000000'));
GO
-- Crear un esquema de partición de FILESTREAM que permita la asignación a 16 grupos de archivos de FILESTREAM
CREATE PARTITION SCHEME LoadBalance_FS_PS
AS PARTITION LoadBalance_PF TO (
FSFileGroup0, FSFileGroup1, FSFileGroup2, FSFileGroup3,
FSFileGroup4, FSFileGroup5, FSFileGroup6, FSFileGroup7,
FSFileGroup8, FSFileGroup9, FSFileGroupA, FSFileGroupB,
FSFileGroupC, FSFileGroupD, FSFileGroupE, FSFileGroupF);
GO
28

-- Crear un esquema de partición de datos para aplicar la técnica round-robin entre dos grupos de archivos
CREATE PARTITION SCHEME LoadBalance_Data_PS
AS PARTITION LoadBalance_PF TO (
DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2,
DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2,
DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2,
DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2);
GO
-- Crear la tabla con particiones
CREATE TABLE DocumentStore (
DocumentID INT IDENTITY,
Document VARBINARY (MAX) FILESTREAM NULL,
DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL
DEFAULT NEWID (),
CONSTRAINT DocStorePK PRIMARY KEY CLUSTERED (DocGUID),
CONSTRAINT DocStoreU UNIQUE (DocGUID))
ON LoadBalance_Data_PS (DocGUID)
FILESTREAM_ON LoadBalance_FS_PS;
GO
El equilibrio de carga se puede probar fácilmente mediante el código siguiente.
SET NOCOUNT ON;
GO
29

-- Insertar 10000 filas para probar el equilibrio de carga
DECLARE @count INT = 0;
WHILE (@count < 10000)
BEGIN
INSERT INTO DocumentStore DEFAULT VALUES;
SET @count = @count + 1;
END;
GO
-- Comprobar la distribución
SELECT COUNT ($PARTITION.LoadBalance_PF (DocGUID))
FROM DocumentStore
GROUP BY $PARTITION.LoadBalance_PF (DocGUID);
GO
Los resultados de una ejecución de ejemplo de esta prueba fueron de 631, 641, 661, 640, 649, 637, 618, 618, 576, 608, 595, 645, 640, 616, 602 y 623 filas en cada uno de los grupos de archivos de FILESTREAM FS_FG0 a FS_FGF.
Combinaciones de características y restriccionesPuesto que la característica FILESTREAM almacena datos dentro del sistema de archivos, hay algunas restricciones y consideraciones sobre la combinación de FILESTREAM con otras características de SQL Server. Esta sección proporciona información general sobre las combinaciones de características que debe conocer. Para obtener más información, vea el tema "Compatibilidad de FILESTREAM con otras características de SQL Server" (http://msdn.microsoft.com/es-es/library/bb895334.aspx) en los Libros en pantalla de SQL Server 2008.
Replicación
Tanto la replicación transaccional como la replicación de mezcla admiten datos de FILESTREAM, pero hay que tener en cuenta muchos aspectos como los siguientes:
Cuando la topología de replicación incluye instancias que usan versiones diferentes de SQL Server, existen limitaciones en cuanto al tamaño de los datos que se pueden enviar a instancias de nivel inferior.
Las opciones de filtro de replicación determinan si el atributo FILESTREAM se replica o no mediante replicación transaccional.
30

El tamaño del valor máximo de datos varbinary(max) que se puede replicar en la replicación transaccional sin replicar el atributo FILESTREAM es 2 GB.
Cuando se usa la replicación de mezcla, tanto ella como FILESTREAM necesitan una columna uniqueidentifier. Hay que tener cuidado con el esquema de la tabla cuando se usa la replicación de mezcla para que los GUID sean secuenciales (es decir, use NEWSEQUENTIALID() en lugar de NEWID()).
Creación de reflejo de la base de datos
La creación de reflejo de la base de datos no admite FILESTREAM. No se puede crear un grupo de archivos FILESTREAM en el servidor principal. La creación de reflejo de la base de datos no se puede configurar para una base de datos que contiene grupos de archivos de FILESTREAM.
Cifrado
Los datos de FILESTREAM no se pueden cifrar mediante los métodos de cifrado de SQL Server. Si el cifrado de datos transparente está habilitado, los datos de FILESTREAM no se cifran.
Clústeres de conmutación por error
FILESTREAM se admite totalmente con clústeres de conmutación por error. Todos los nodos del clúster deben tener habilitado FILESTREAM en el nivel de Windows y los contenedores de datos de FILESTREAM se deben colocar en almacenamiento compartido para que los datos estén disponibles en todos los nodos. Para obtener más información, vea en los Libros en pantalla de SQL Server 2008 el tema: "Configurar FILESTREAM en un clúster de conmutación por error" (http://msdn.microsoft.com/es-es/library/cc645886.aspx).
Texto completo
La indización de texto completo funciona con una columna FILESTREAM exactamente igual que con una columna varbinary(max). La tabla debe tener una columna adicional que contenga la extensión de nombre de archivo para los datos BLOB que se almacenan en la columna FILESTREAM.
Instantáneas de base de datos
SQL Server no admite instantáneas de base de datos para los contenedores de datos de FILESTREAM. Si se incluye un archivo de datos de FILESTREAM en una cláusula CREATE DATABASE ON, se producirá un error en la instrucción y se generará el mensaje correspondiente.
Si una base de datos contiene datos de FILESTREAM, todavía se puede crear una instantánea de base de datos de los grupos de archivos normales. En este caso, se devolverá un mensaje de advertencia y los grupos de archivos de FILESTREAM se marcarán como sin conexión en la instantánea de base de datos. Las consultas funcionarán de la manera esperada en la instantánea de base de datos a menos que intenten obtener acceso a los datos de FILESTREAM. Si esto ocurre, se producirá un error.
Una base de datos que contiene datos FILESTREAM no se puede revertir a una instantánea, ya que no hay ninguna manera de saber en qué estado estaban los datos de FILESTREAM en el momento representado por la instantánea de base de datos.
Vistas, índices, estadísticas, desencadenadores y restricciones
Las columnas FILESTREAM no pueden formar parte de una clave de índice ni especificarse como una columna INCLUDE en un índice no clúster. Es posible definir una columna calculada que haga referencia a una columna FILESTREAM, pero la columna calculada no se puede indizar.
31

No se pueden crear estadísticas de columnas FILESTREAM.
No se pueden crear restricciones PRIMARY KEY, FOREIGN KEY y UNIQUE en columnas FILESTREAM.
Las vistas indizadas no pueden contener columnas FILESTREAM; sin embargo, las vistas no indizadas sí pueden contenerlas.
No se pueden definir desencadenadores INSTEAD OF en tablas que contienen columnas FILESTREAM.
Niveles de aislamiento
Cuando se obtiene acceso a datos de FILESTREAM mediante las API de Win32, solo se admite el nivel de aislamiento de lectura confirmada. El acceso a Transact-SQL también permite los niveles de aislamiento de lectura repetible y serializable. Además, mediante el acceso a Transact-SQL, se permiten lecturas de datos sucios en el nivel de aislamiento de lectura no confirmada, o la sugerencia de consulta NOLOCK, pero dicho acceso no mostrará las actualizaciones en curso de datos de FILESTREAM.
Copias de seguridad y restauración
FILESTREAM funciona con todos los modelos de recuperación y todas las formas de copias de seguridad y restauración (completa, diferencial y de registros). En una situación de desastre, si se especifica la opción CONTINUE_AFTER_ERROR en una opción BACKUP o RESTORE, los datos de FILESTREAM pueden no recuperarse sin pérdida de datos (similar a la recuperación de datos normales cuando se especifica CONTINUE_AFTER_ERROR).
Seguridad
La instancia de SQL Server debe estar configurada para usar seguridad integrada si se necesita el acceso de Win32 a los datos de FILESTREAM.
Trasvase de registros
El trasvase de registros admite FILESTREAM. Los servidores principal y secundario deben ejecutar SQL Server 2008, o una versión posterior, y deben tener habilitado FILESTREAM en el nivel de Windows.
SQL Server Express
SQL Server Express admite FILESTREAM. El límite de tamaño de base de datos de 4 GB no incluye el contenedor de datos de FILESTREAM.
Sin embargo, si se envían datos de FILESTREAM hacia o desde la instancia de SQL Server Express mediante Service Broker, hay que tener cuidado porque Service Broker no admite el almacenamiento de datos como FILESTREAM en las colas de transmisión ni de destino. Esto significa que si se forma una cola, se puede alcanzar el límite de tamaño de base de datos de 4 GB.
En este caso, una alternativa consiste en usar un esquema donde la conversación de Service Broker envíe las notificaciones que los datos de FILESTREAM deben enviar o recibir. A continuación, la transmisión real de los datos de FILESTREAM se realiza mediante acceso remoto a través del recurso compartido de FILESTREAM del contenedor de datos de FILESTREAM de la instancia de SQL Server Express.
32

Consideraciones sobre la optimización del rendimiento y las simulacionesHay varias consideraciones importantes a la hora de optimizar una carga de trabajo de FILESTREAM:
Asegúrese de que el hardware esté configurado correctamente para FILESTREAM. Asegúrese de que la generación de nombres 8.3 esté deshabilitada en NTFS. Asegúrese de que el seguimiento de la última hora de acceso esté deshabilitado en NTFS. Asegúrese de que el contenedor de datos de FILESTREAM no se encuentre en un volumen
fragmentado. Asegúrese de que el tamaño de datos BLOB sea adecuado para el almacenamiento con
FILESTREAM. Asegúrese de que los contenedores de datos de FILESTREAM tengan sus propios volúmenes
dedicados.
Un factor importante que hay que destacar es el tamaño de búfer usado por el protocolo SMB que se emplea para almacenar en búfer las lecturas de datos de FILESTREAM. En las pruebas con el sistema operativo Windows Server® 2003, los tamaños de búfer mayores suelen lograr un mejor rendimiento, con tamaños de búfer de un múltiplo de aproximadamente 60 kB. Los tamaños de búfer mayores pueden ser más eficientes en otros sistemas operativos.
Hay otras consideraciones adicionales cuando se compara una carga de trabajo de FILESTREAM con otras opciones de almacenamiento (una vez optimizada la carga de trabajo de FILESTREAM):
Asegúrese de que el hardware de almacenamiento y el nivel RAID sean los mismos en ambos casos. Asegúrese de que la configuración de compresión del volumen sea la misma en ambos casos. Tenga en cuenta si FILESTREAM va a realizar escritura continua según la API en uso y las
opciones especificadas.
Consideraciones sobre la migración de datosUn escenario habitual con SQL Server 2008 será la migración de datos BLOB existentes al almacenamiento de FILESTREAM. Si bien proporcionar una herramienta completa o un conjunto de código para realizar esas migraciones queda fuera del ámbito de estas notas del producto, a continuación se muestra un flujo de trabajo simple que se puede seguir:
Revisar las consideraciones de tamaño de datos para usar FILESTREAM con el fin de asegurarse de que los tamaños de datos promedio implicados son tales que el almacenamiento de FILESTREAM resulta adecuado.
Revisar la información disponible sobre las combinaciones de características y las limitaciones para asegurarse de que el almacenamiento de FILESTREAM funcionará con todos los demás requisitos de la aplicación.
Seguir las recomendaciones de la sección "Consideraciones sobre la optimización del rendimiento y las simulaciones" anterior.
Asegurarse de que la instancia de SQL Server usa seguridad integrada y que FILESTREAM se ha habilitado en los niveles de Windows y SQL Server.
Asegurarse de que la ubicación del contenedor de datos de FILESTREAM de destino tiene suficiente espacio en disco para almacenar los datos BLOB migrados.
Crear los grupos de archivos de FILESTREAM necesarios.
33

Duplicar los esquemas de tabla implicados, cambiando las columnas BLOB necesarias para que sean FILESTREAM.
Migrar al nuevo esquema todos los datos que no sean BLOB. Migrar todos los datos BLOB a las nuevas columnas FILESTREAM.
Prácticas recomendadas para el uso de FILESTREAMEsta sección es una colección de prácticas recomendadas que han surgido del uso de FILESTREAM durante las pruebas internas y públicas de la versión preliminar de la característica. Como ocurre con todas las prácticas recomendadas, se trata de generalizaciones y quizás no sean aplicables a todas las situaciones y todos los escenarios. Las prácticas recomendadas son las siguientes, sin ningún orden concreto:
Se deben evitar varias anexiones pequeñas un archivo de FILESTREAM siempre que sea posible, ya que cada anexión crea un archivo de FILESTREAM nuevo. Esto puede ser muy costoso en el caso de archivos de FILESTREAM grandes. Si es posible, se deben agrupar varias anexiones en una sola columna varbinary(max) y después anexarlas a la columna FILESTREAM cuando se alcance un umbral de tamaño.
En el caso de una carga de trabajo con muchas escrituras multiproceso, considere la posibilidad de configurar el parámetro AllocationSize para las API OpenSqlFilestream o SqlFilestream. Unos tamaños de asignación iniciales mayores limitarán la posibilidad de fragmentación en el nivel del sistema de archivos, especialmente cuando se combinan con un tamaño de clúster NTFS grande como se ha descrito anteriormente.
Si los archivos de FILESTREAM son grandes, evite actualizaciones de Transact-SQL que anexen o antepongan datos a un archivo. Esto (normalmente) pondrá en cola datos en tempdb y de nuevo en un nuevo archivo físico, lo que afectará al rendimiento.
Cuando se lea un valor de FILESTREAM, tenga en cuenta lo siguiente:o Si las lecturas solo necesitan leer los primeros bytes, use la funcionalidad de subcadena.o Si se va a leer todo el archivo, use el acceso de Win32.o Si se van a leer partes aleatorias del archivo, abra el identificador de archivo mediante
SetFilePointer. o Cuando se lea un archivo completo, especifique la marca FILE_SEQUENTIAL_ONLY.o Use búferes cuyo tamaño sea múltiplos de 60 kB (como se ha descrito anteriormente).
El tamaño de un archivo de FILESTREAM se puede obtener sin necesidad de abrir un identificador para el archivo: agregue una columna calculada persistente a la tabla que almacena el tamaño de archivo de FILESTREAM. La columna calculada se actualiza mientras el archivo ya está abierto para operaciones de escritura.
ConclusiónEn estas notas del producto se ha descrito la característica FILESTREAM de SQL Server 2008 que permite el almacenamiento y el acceso eficiente a datos BLOB mediante una combinación de SQL Server 2008 y el sistema de archivos NTFS. Para concluir, merece la pena reiterar los puntos principales destacados en este documento.
34

El almacenamiento de FILESTREAM no resulta adecuado en todos los casos. Según estudios anteriores y el comportamiento de la característica FILESTREAM, es mejor almacenar como datos FILESTREAM los datos BLOB con un tamaño de 1 MB o más a los que no se va a obtener acceso mediante Transact-SQL.
También hay que tener en cuenta la carga de trabajo de actualización, ya que cualquier actualización parcial de un archivo de FILESTREAM generará una copia completa del archivo. Con una carga de trabajo en la que haya muchas actualizaciones, el rendimiento puede disminuir tanto que FILESTREAM no resulte adecuado.
Se deben estudiar los detalles de las combinaciones de características para asegurarse de que la implementación se realiza correctamente. Por ejemplo, en SQL Server 2008 RTM, la creación de reflejo de la base de datos no puede usar datos de FILESTREAM ni aislamiento de instantánea. Se admiten la mayoría de las demás combinaciones de características, pero algunas pueden tener ciertas limitaciones (como la replicación). Estas notas del producto no proporcionan una taxonomía exhaustiva de las características y su interacción, por lo que se deben consultar las secciones más recientes de los Libros en pantalla de SQL Server antes de la implementación, especialmente porque es posible que algunas limitaciones aumenten en futuras versiones.
Por último, si FILESTREAM se implementa sin configurar correctamente Windows y SQL Server, quizás no se alcancen los niveles de rendimiento previstos. Se deben usar las prácticas recomendadas y los detalles de configuración descritos anteriormente como ayuda para evitar problemas de rendimiento.
Para obtener más información:
http://www.microsoft.com/sqlserver/: Sitio web de SQL Server
http://technet.microsoft.com/es-es/sqlserver/: SQL Server TechCenter
http://msdn.microsoft.com/es-es/sqlserver/: Centro para desarrolladores de SQL Server
¿Le sirvió de ayuda este documento? Proporciónenos su opinión. Díganos, en una escala de 1 (poco útil) a 5 (excelente), cómo calificaría este documento y por qué lo valora con esta puntuación. Por ejemplo:
¿Lo valora alto debido a que tiene buenos ejemplos, capturas de pantalla excelentes, una redacción comprensible u otra razón?
¿Lo valora bajo debido a que sus ejemplos son escasos, las capturas de pantalla son borrosas o su redacción es poco clara?
Esta información nos ayudará a mejorar la calidad de las notas del producto que publicamos.
Enviar comentarios.
35