0 0 c x 0$À 6 8 aÔ. ún´#{@ ã é# ÙË w - cda.cn · hbase mapreduce zook eeper hdfs...
TRANSCRIPT

主 题
13:30 14:10 Linux on Power助力大数据解决方案的介绍与案例分享
14:10 14:50 赢在开源 - 全堆栈Hadoop计算 认知及预测解决方法
14:50 15:30 赢在极速 - 探究Linux on Power的NoSQL解决方案
15:30 16:10 赢在高效管理 - MongoDB数据库技术实验分享
16:10 16:50 赢在敏捷洞察 - 重新定义DB2 BLU数据管理
时 间


大数据平台的演进
•2003-2006 年 Google 发表三篇论文 : GFS, MapReduce, BigTable
•2006 年 Yahoo 启动 Apache Hadoop 项目•2011 年麦肯锡提出 “大数据时代” 概念。总结:
大数据具有 4V 特点: Volume (大量)、 Velocity (高速)、Variety (多样)、 Value (价值)。
核心思想:海量数据存储、分析、查询、预测。核心技术:分布式、 Hadoop 。
•2000 年 Symphony SOA 网格计算中间件诞生, 2008 年支持 MapReduce。•1993 年 GPFS 并行文件系统诞生, 2010 年支持 Hadoop。
Google, Hadoop 和企业级大数据平台技术架构的比较 :
Google 云计算应用
©2015 IBM Corporation
Hadoop云计算应用 商业应用,Hadoop云计算应用
BigTable MapReduce
Chu
bbyGFS
HBase MapReduce
Zook
eeperHDFS
HBase增强Symphony
MapReduce
GPFS-FPO
Google论文 Hadoop开源实现 企业级大数据解决方案

加快决策在影响点提供洞察
预测成果以更智慧的方式开展更广泛的预测
针对数据调优根据信息调整业务
IBM 大数据解决方案,帮助客户
利用大数据和分析基础架构实现业务转型,在关键时刻提升的洞察层次
支持以高度安全的共享方式访问数据IBM 提供范围广泛的大数据和分析解决方案,这些解决方案可轻松扩展以提供安全的共享访问。
加深理解IBM 可帮助您对趋势建模,模拟各种场景,预测潜在威胁和商机并监控业绩。
分析从后台“走到”前台IBM 可帮助您选择能够最大程度提高信息可用性的大数据基础架构,使您能够快速发现商机,自信地开展行动。
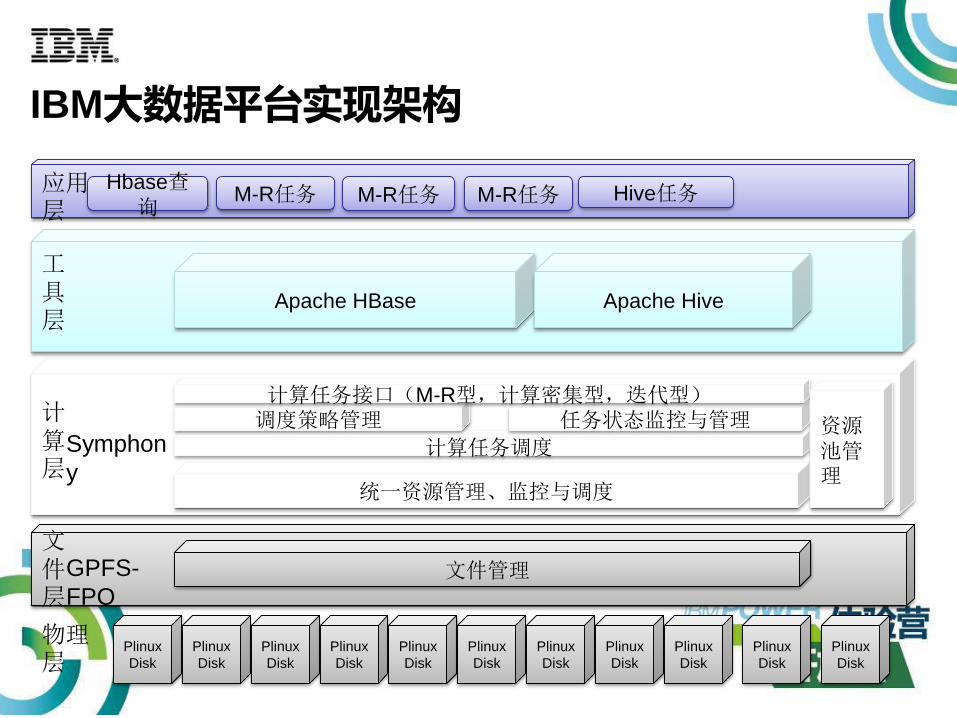
物理层
文件管理
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
Plinux
Disk
IBM大数据平台实现架构
计算层
应用层
M-R任务 M-R任务
计算任务调度
调度策略管理 任务状态监控与管理计算任务接口(M-R型,计算密集型,迭代型)
M-R任务 Hive任务Hbase查
询
GPFS-
FPO
统一资源管理、监控与调度
Apache HBase Apache Hive
工具层
Symphon
y
文件层
资源池管理
6

7

8
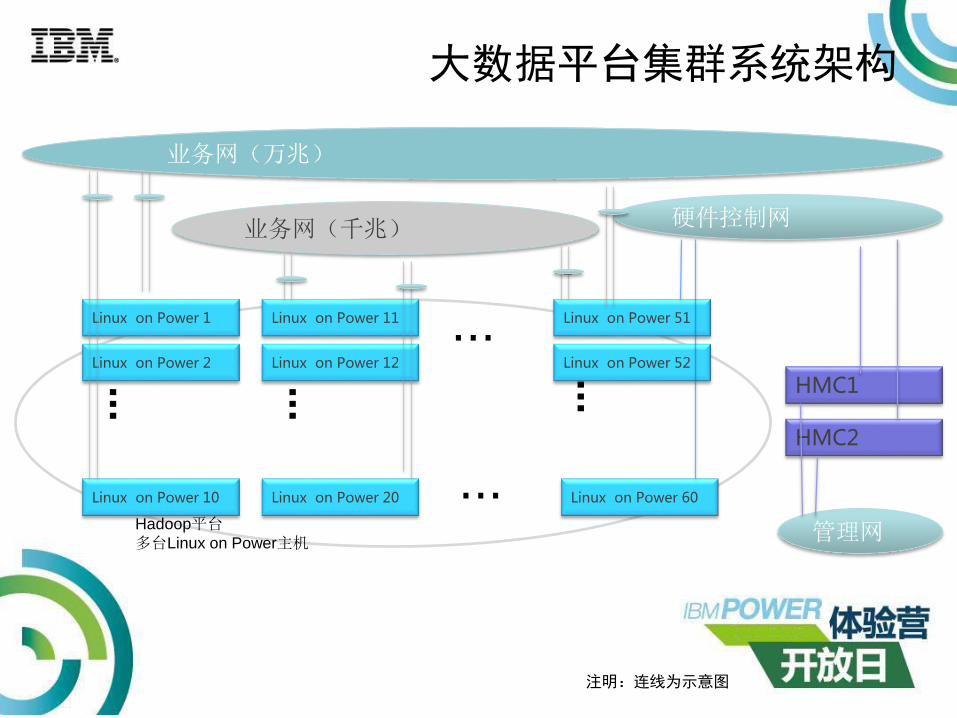
Hadoop平台多台Linux on Power主机
大数据平台集群系统架构
Linux on Power 1
...
业务网(万兆)
Linux on Power 2
Linux on Power 10
Linux on Power 51
Linux on Power 52
Linux on Power 60
HMC1
HMC2
硬件控制网
Linux on Power 11
Linux on Power 12...
Linux on Power 20
......
...
业务网(千兆)
管理网
注明:连线为示意图

7R2-2 node27R2-1 node1
Data
HBase
Region
Zoo
Keeper
HBase
Master
Data
HBase
Region
Zoo
Keeper
Symphony
node
Symphony
Master
Hive
GPFS-Connector 1.0 or 2.0
测试架构图(基元)
GPFS-FPO
IBM Platform Symphony 大数据解决方案
Hadoop MapReduce apps,Oozie,Pig,Hive and so on
Hadoop MapReduce API
org.apche.hadoop.fs
org.apche.hadoop.io
org.apache.hadoop.util
org.apche.hadoop.mapreduce
org.apche.hadoop.mapred
Platform Symphony
Hadoop MapReduce app adapter
Platform Symphony APIs
Platform Symphony
Hadoop common libraries
HDFS file system connector GPFS file system connector
HDFS GPFS

GPFS-FPO +OpenSource Hadoop
%pool: pool=system layoutMap=cluster blocksize=256K
%pool: pool=fpodata blocksize=1024K allowWriteAffinity=yes writeAffinityDepth=1 blockGroupFactor=128
%nsd: device=/dev/sdd servers=node1 usage=metadataOnly failureGroup=101 pool=system
%nsd: device=/dev/sde servers=node2 usage=dataOnly failureGroup=1,0,1 pool=fpodata
==========================================================
Installation on pcc64 with GPFS411 (on all hosts)
# ln -s /usr/lpp/mmfs/fpo/hadoop-2.4/hadoop-gpfs-2.4.jar $HADOOP_HOME/share/hadoop/common
# ln -s /usr/lpp/mmfs/fpo/hadoop-2.4/libgpfshadoop.64.so $HADOOP_HOME/lib/native/libgpfshadoop.so
# ln -s /usr/lpp/mmfs/lib/libgpfs.so $HADOOP_HOME/lib/native/libgpfs.so
# cp /usr/lpp/mmfs/fpo/hadoop-2.4/gpfs-connector-daemon /var/mmfs/etc/
# cp /usr/lpp/mmfs/fpo/hadoop-2.4/install_script/gpfs-callback_start_connector_daemon.sh /var/mmfs/etc/
# cp /usr/lpp/mmfs/fpo/hadoop-2.4/install_script/gpfs-callback_stop_connector_daemon.sh /var/mmfs/etc/
Configuration (on one host is enough)
# cd /usr/lpp/mmfs/fpo/hadoop-2.4/install_script/
# ./gpfs-callbacks.sh --add
# ./gpfs-callbacks.sh --list
<property>
<name>hadoop.tmp.dir</name>
<value>/gpfs/bigfs/tmp/[hostname]</value>
</property>
<property>
<name>fs.default.name</name>
<value>gpfs:///</value>
</property>
<property>
<name>fs.gpfs.impl</name>
<value>org.apache.hadoop.fs.gpfs.GeneralParallelFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.gpfs.impl</name>
<value>org.apache.hadoop.fs.gpfs.GeneralParallelFs</value>
</property>
<property>
<name>gpfs.mount.dir</name>
<value>/mnt/gpfs</value>
</property>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://rhel1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/root/tmp/hadoop-${user.name}</value>
<description>Abase for other
temporary directories.</description>
</property>
</configuration>

GPFS 与GPFS-FPO区别
share disk VS share nothing

• 基于Symphony构建多租户的大数据平台,实现资源共享和统一管理,多应
用并发资源调度,应用的SLA管理
• Symphony+GPFS-FPO方案兼容开源Hadoop标准,能够很好地与支持开
源Apache Hadoop版本HBase/M-R/Hive应用的运行,避免客户应用迁移和
重新开发
• 利用开源Hadoop标准,统一不同应用不同ISV的开发版本,实现开放的企
业大数据平台
• Powerlinux通过增加磁盘扩展柜,以满足客户的数据容量需求
• IBM的售前和售后技术服务支持,帮助客户梳理需求,规划方案架构,解决
项目实施和部署中的各种技术难题,对客户有很大的帮助
基于Symphony+GPFS 大数据解决方案的特点
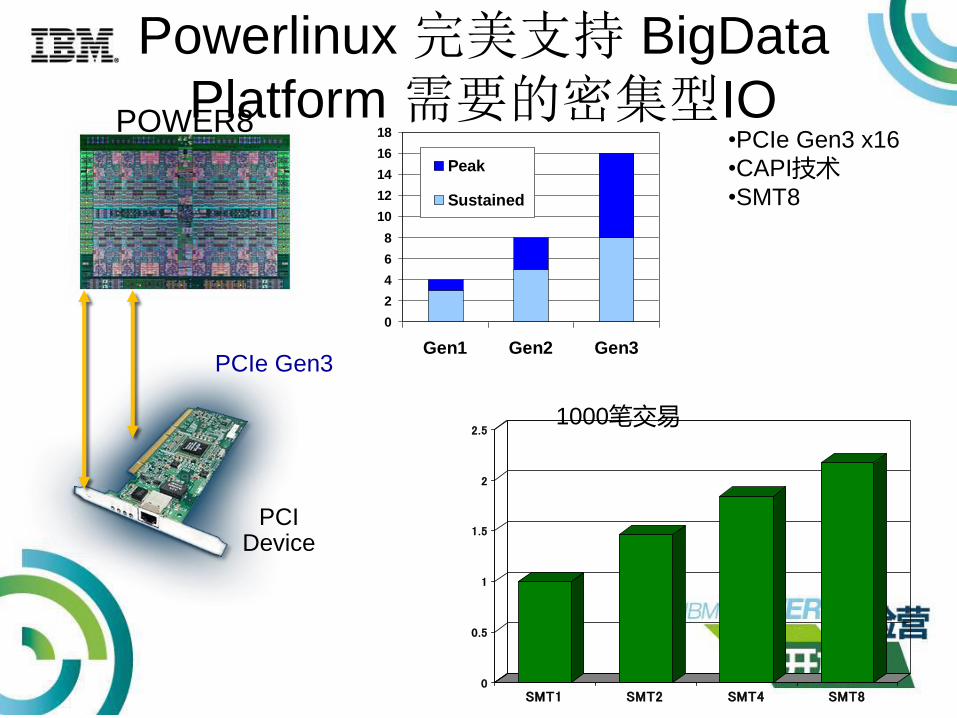
Powerlinux 完美支持 BigData
Platform 需要的密集型IO
PCIe Gen3
PCIDevice
POWER8
0
0.5
1
1.5
2
2.5
SMT1 SMT2 SMT4 SMT8
0
2
4
6
8
10
12
14
16
18
Gen1 Gen2 Gen3
Peak
Sustained
•PCIe Gen3 x16
•CAPI技术•SMT8
1000笔交易
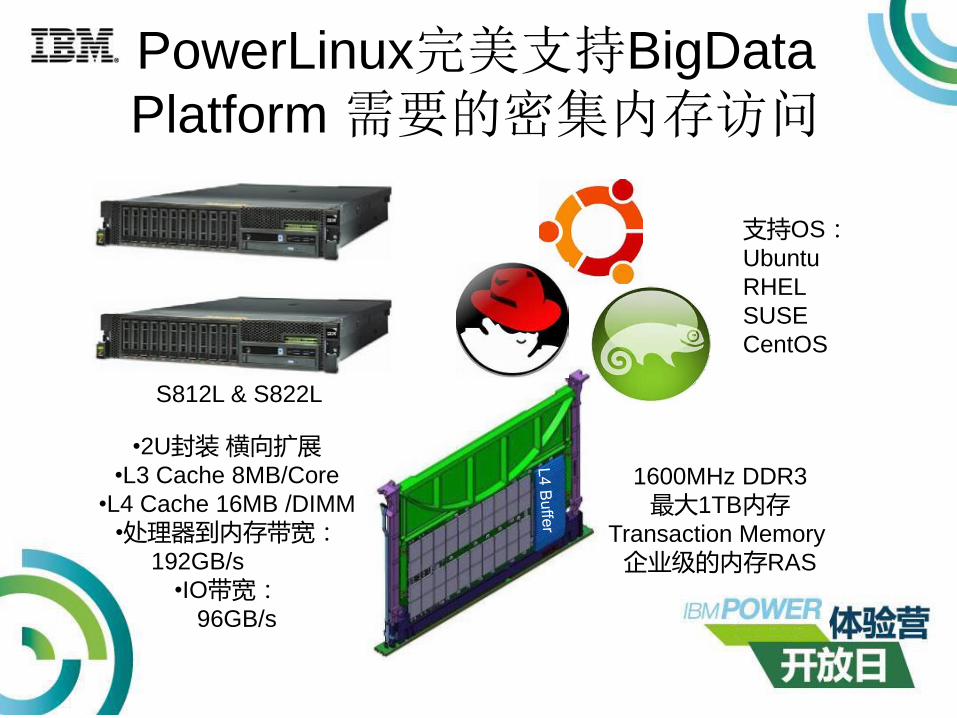
PowerLinux完美支持BigData
Platform 需要的密集内存访问
1600MHz DDR3
最大1TB内存Transaction Memory
企业级的内存RAS
S812L & S822L
•2U封装 横向扩展•L3 Cache 8MB/Core
•L4 Cache 16MB /DIMM
•处理器到内存带宽:192GB/s
•IO带宽:96GB/s
支持OS:Ubuntu
RHEL
SUSE
CentOS

Powerlinux 完美兼容开源Appache
Hadoop ProjectAppche Hadoop 组件 支持情况
Hadoop1.x&2.XTM
HDFSTM
HbaseTM
ZookeeperTM
SparkTM
HiveTM
MongoDBTM
...
Y
Y
Y
Y
Y
Y
Y
Powerlinux上Java优化为应用提速
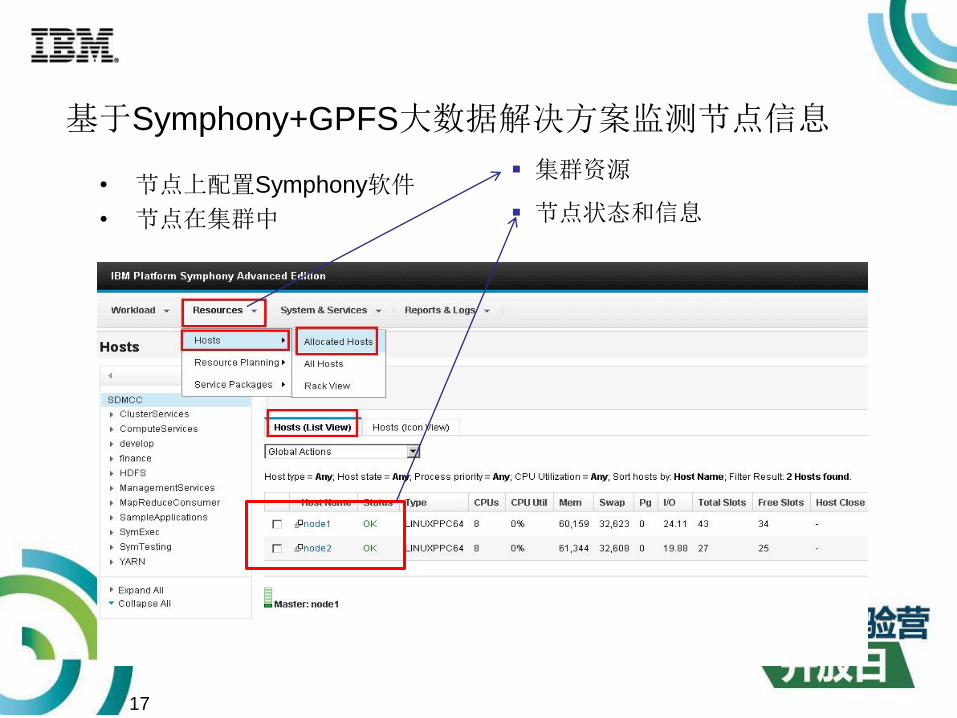
基于Symphony+GPFS大数据解决方案监测节点信息
• 节点上配置Symphony软件
• 节点在集群中
17
集群资源
节点状态和信息

基于Symphony+GPFS大数据解决方案POSIX特性
• 配置GPFS-FPO
• 添加NSD到GPFS集群中
18
只需要运行OS命令,即可实现文件系统操作
文件系统NSD清晰呈现Network Shared Disk

基于Symphony+GPFS大数据解决方案出现后作业的调度
• 打开Symphony的管理平台页面
19
作业挂起、恢复、
停掉、改变优先级
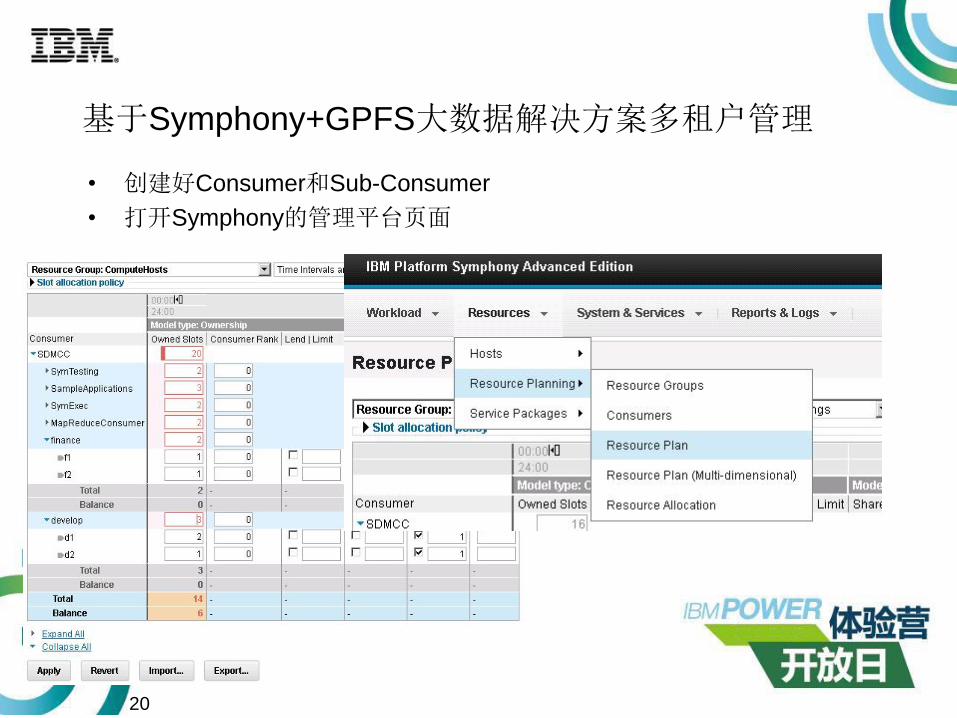
基于Symphony+GPFS大数据解决方案多租户管理
• 创建好Consumer和Sub-Consumer
• 打开Symphony的管理平台页面
20
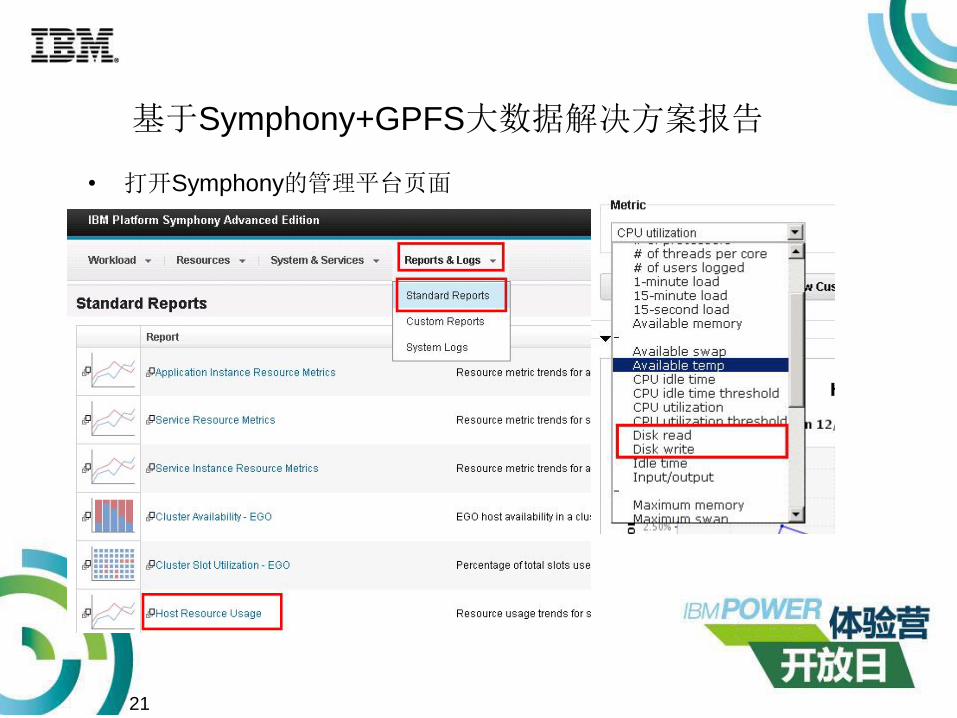
基于Symphony+GPFS大数据解决方案报告
• 打开Symphony的管理平台页面
21

Comments
• 结合强大Power处理能力和Linux架构的Powerlinux为系统提供独特性能。
• Powerlinux完美兼容Appache开源架构套件
• Powerlinux完美支持Symphony+GPFS-FPO大数据解决方案
Open source(Hadoop)
GPFS+SymphonyPowerlinux

Thanks

主 题
13:30 14:10 Linux on Power助力大数据解决方案的介绍与案例分享
14:10 14:50 赢在开源 - 全堆栈Hadoop计算 认知及预测解决方法
14:50 15:30 赢在极速 - 探究Linux on Power的NoSQL解决方案
15:30 16:10 赢在高效管理 - MongoDB数据库技术实验分享
16:10 16:50 赢在敏捷洞察 - 重新定义DB2 BLU数据管理
时 间

贾子轩
IBM服务器解决方案售前技术支持专家
基于Linux on Power与Redis的NoSQL
解决方案实践

Agenda
1.Redis介绍2.CAPI介绍3.方案介绍

• NoSQL 及 Redis 广泛应用于中国互联网企业
1. The newest NoSQL for KVS(Key-Value Store)
2. The fastest data store (served entirely from RAM)
3. Among the top 3 DBs chosen by developers
4. The most requested add-on in Heroku*
5. Much more than a simple key/value - Strings, Hashes, Lists, Sets, Sorted Set, LUA, transactions, Bits operations
6. Strong use cases, dynamic community, large eco-system
• 行业技术的进步,尤其互联网技术的发展,促进了分布式计算和应用的极速发展,技术架构演进促进了数据类型的演化
• 大数据类型的多元化急剧增长,传统关系型SQL不满足技术架构的适用性,NoSQL应运而生
非关系型简单数据类型
处理快速易于扩展可用性高
Redis

• Redis 键值数据库在分布式架构的应用场景
• Redis服务器可以作为OLTP数据库的前端,承载高响应的压力
–读: Redis处理海量的读请求,未命中再流转到后台数据库。
–写: 直接写到后台数据库,异步更新到Redis
–适用于”读多写少”且数据实时性要求相对不高的数据应用场景
Rea
d
Writ
e
• 高负载OLTP数据库的应用前端配置Redis服务器, 来配合高响应,简单数据关系,较低实时性和准确性要求的工作负载 :
–广泛应用于Web 2.0领域 : 社交,网页,视频等等
–电商及搜索领域也有应用
–延伸应用到移动互联的应用

Open source, in-memory NoSQL. The world’s fastest database
A data structures engine – includes Strings, Hashes, Lists, Sets, Sorted Set, LUA, transactions, Bits operations
Strong use cases, dynamic community, large eco-system
Ranked 12 out of 50 Top Developer Tools & Services of 2014
The world’s fastest growing database
Redis factsheet

Agenda
1.Redis介绍2.CAPI介绍3.方案介绍
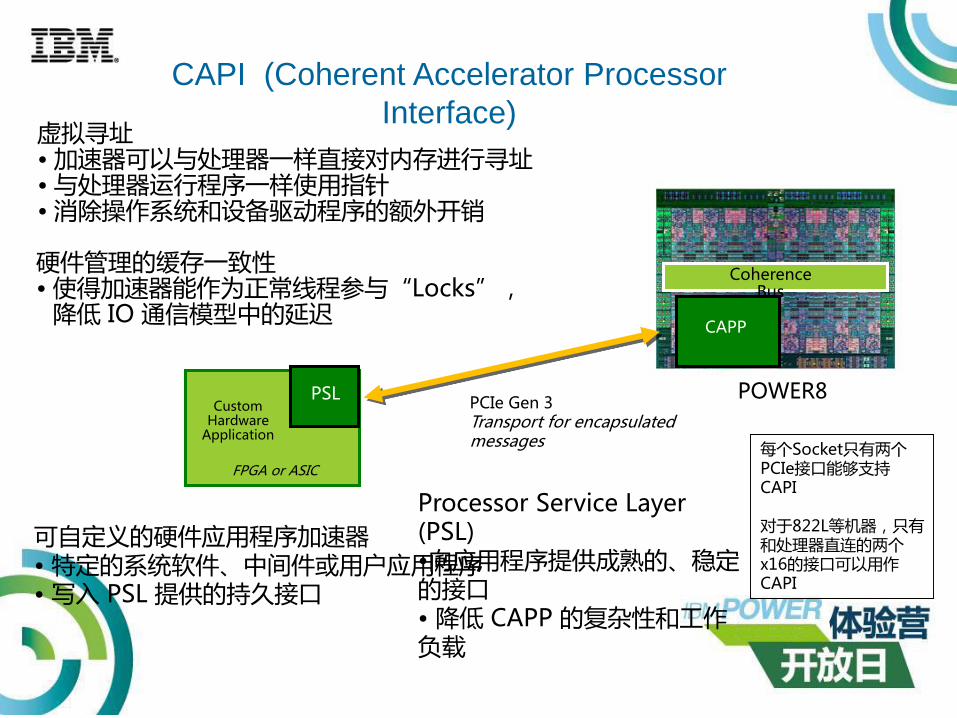
CustomHardware
Application
POWER8
CAPP
Coherence Bus
PSL
FPGA or ASIC
可自定义的硬件应用程序加速器• 特定的系统软件、中间件或用户应用程序• 写入 PSL 提供的持久接口
POWER8PCIe Gen 3Transport for encapsulated messages
Processor Service Layer (PSL)•向应用程序提供成熟的、稳定的接口• 降低 CAPP 的复杂性和工作负载
虚拟寻址• 加速器可以与处理器一样直接对内存进行寻址• 与处理器运行程序一样使用指针• 消除操作系统和设备驱动程序的额外开销
CAPI (Coherent Accelerator Processor
Interface)
硬件管理的缓存一致性• 使得加速器能作为正常线程参与“Locks”,
降低 IO 通信模型中的延迟
每个Socket只有两个PCIe接口能够支持CAPI
对于822L等机器,只有和处理器直连的两个x16的接口可以用作CAPI

• What is CAPI?
• CAPI is an innovative method to add a processing engine to a POWER8 system
CAPI
– The new processing engine can be configured to do… ….ANYTHING!• A Specialty Engine such as MonteCarlo, Vision Processing• An Extended Storage or Flash Device• Or Edge of Network Processing
Customize a processor to fit your
business need

FPGA
POWE
R8
Core
CA
PP
PC
Ie
• Proprietary hardware to enable coherent acceleration
• Operating system enablement
• Ubuntu LE
• Libcxl function calls
• Customer application and accelerator
• Application sets up data and calls theaccelerator functional unit (AFU)
• AFU reads and writes coherent data across the PCIe and communicates with the application
• PSL cache holds coherent data for quick AFU access
POWER8
Processor
OS
App
Memory (Coherent)
AFU
IBM Supplied
PSL
CAPI technology connections
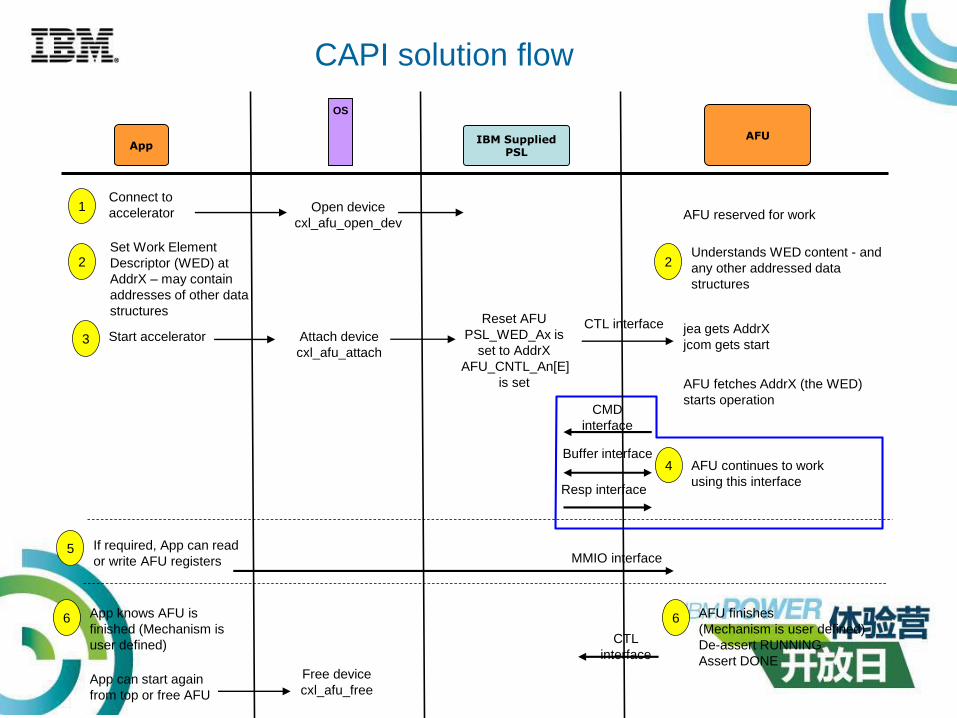
2 2Set Work Element
Descriptor (WED) at
AddrX – may contain
addresses of other data
structures
Understands WED content - and
any other addressed data
structures
AFU reserved for workOpen device
cxl_afu_open_dev
1Connect to
accelerator
App
OS
IBM Supplied PSL
AFU
If required, App can read
or write AFU registers5
MMIO interface
AFU continues to work
using this interface
Reset AFU
PSL_WED_Ax is
set to AddrX
AFU_CNTL_An[E]
is set
jea gets AddrX
jcom gets start
CTL interfaceStart accelerator3 Attach device
cxl_afu_attach
6 6 AFU finishes
(Mechanism is user defined)
De-assert RUNNING
Assert DONE
App knows AFU is
finished (Mechanism is
user defined)
App can start again
from top or free AFU
CTL
interface
Free device
cxl_afu_free
CAPI solution flow
Resp interface
CMD
interface
Buffer interface4
AFU fetches AddrX (the WED)
starts operation

Agenda
1.Redis介绍2.CAPI介绍3.方案介绍

客户价值 :• 性能的提升 : 用内存+闪存替代,降低内存成本• 高可用性 : Power RAS vs x86• 可扩展性 : CAPI技术将内存使用扩展到缓存系统• TCO : 更少的管理成本,电力消耗,空间占用
Power Solution for NoSQL
Power S822L/S812L
Ubuntu 14.10
FlashSystem 900
2~57 TB Flash
WWW
4 U
传统NoSQL架构面临的挑战:
• Scale-out x86服务器内存容量的限制
• 性能提升的瓶颈和集群可靠性的缺失
• 大规模横向扩展带来的成本不可控及复杂架构的可用性
• 处理能力及负载密度提升带来的高成本
Load Balancer
500GB Cache Node
WWW
500GB Cache Node500GB Cache Node500GB Cache Node1U x86 server (24)
512 GB memory
24U
CAPI+Flash+Redis业界极速NoSQL解决方案
36
极速三剑客 :CAPI + Flash + Redis

只有IBM能够提供采用POWER8和闪存技术的创新型NoSQL/KVS集成式内存解决方案
负载均衡器
500GB Cache Node
10Gb上行链路
IBM POWER8服务器
FlashSystem840
全新的差分性NoSQL平台(POWER8 CAPI + FlashSystem)
WWW10Gb上行链路
WWW
备用节点
500GB Cache Node500GB Cache Node500GB缓存节点
500GB缓存节点
IBM Data Engine for
NoSQL - Power Systems Edition
24:1的物理服务器整合率
节省6倍机柜空间(2U服务器 + 2U
FlashSystem vs. 24个1U服务器)
24U
4U
昨天的NoSQL内存(x86)
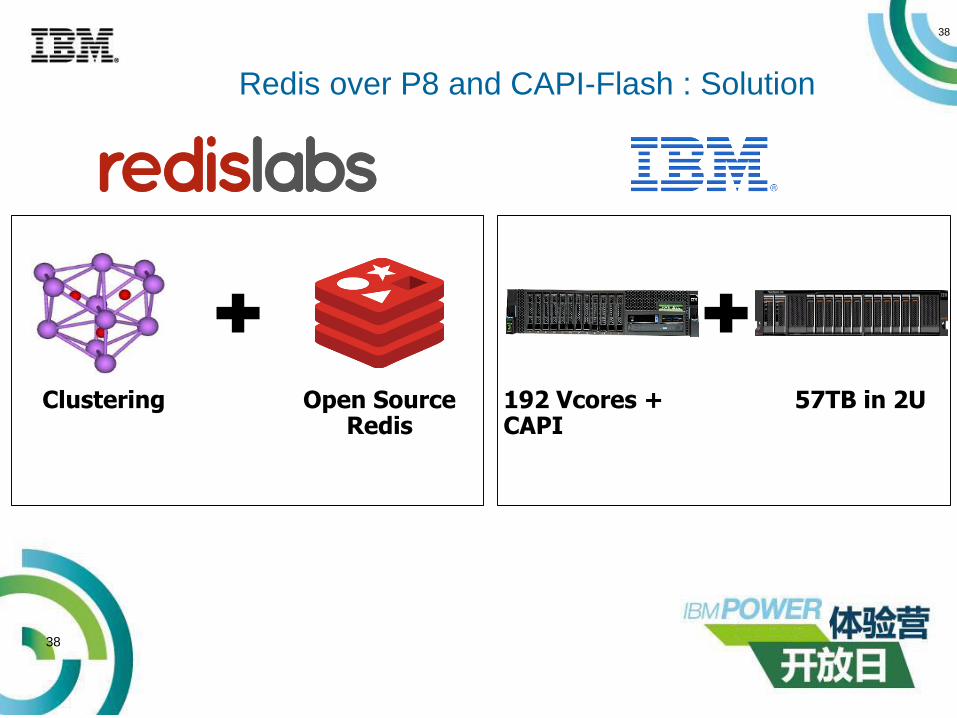
38
Open Source Redis
Clustering
Redis over P8 and CAPI-Flash : Solution
192 Vcores + CAPI
57TB in 2U
38

Redis Labs VS. OSS Redis (highlights)
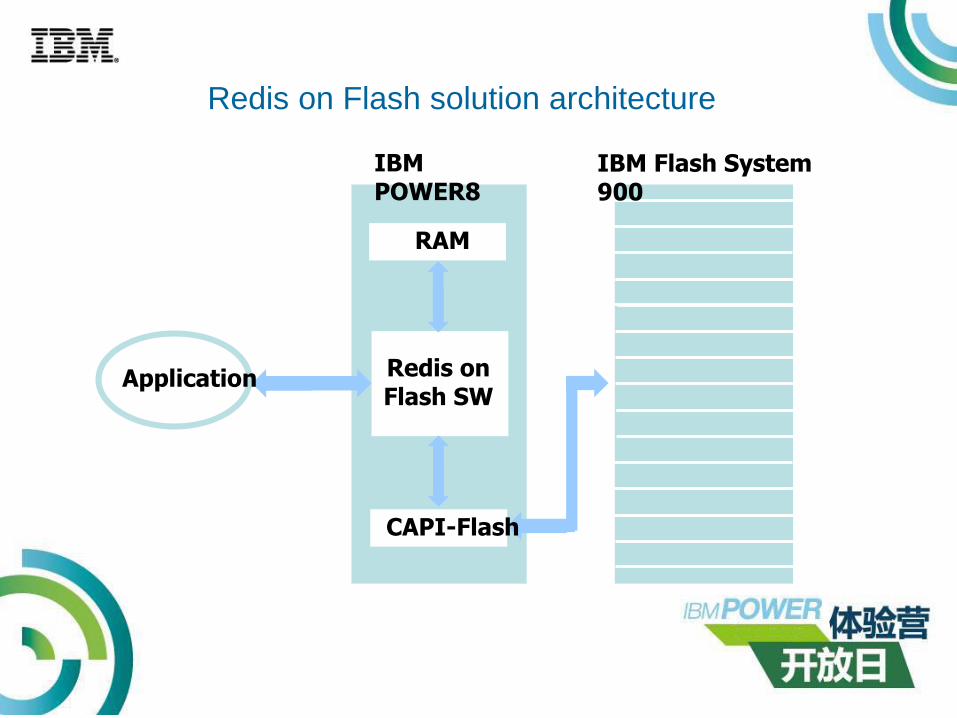
Application
IBM POWER8
RAM
Redis on Flash SW
CAPI-Flash
IBM Flash System 900
Redis on Flash solution architecture
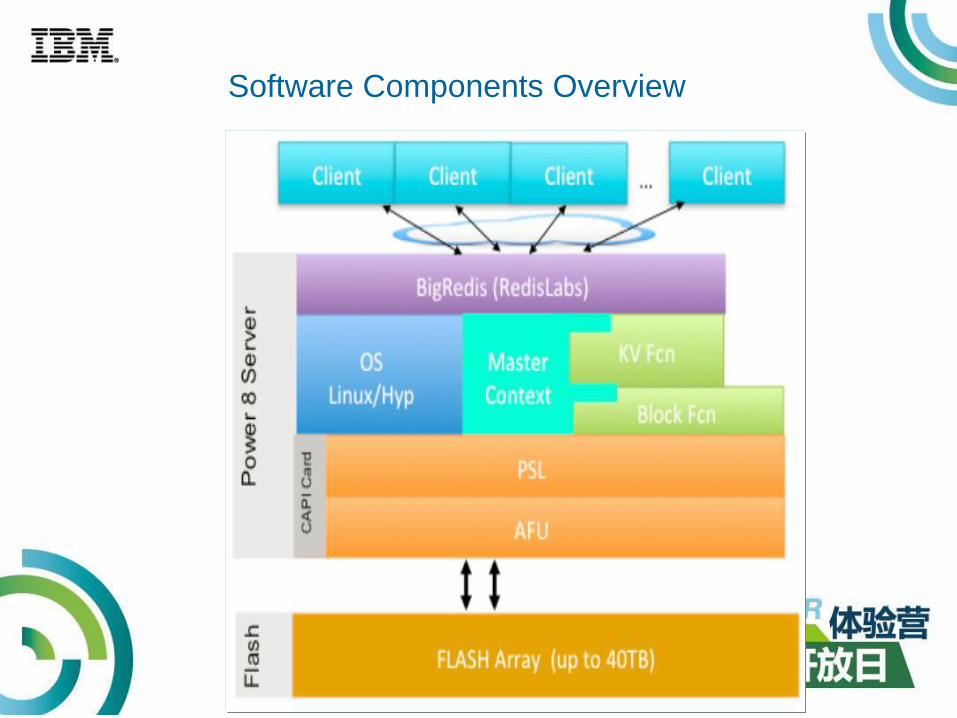
Software Components Overview

Redis on Flash - a new concept
Flash used as RAM extender and NOT as a persistent
storage
RAM
4410 GB590 GB
88.2%11.8%
FLASH
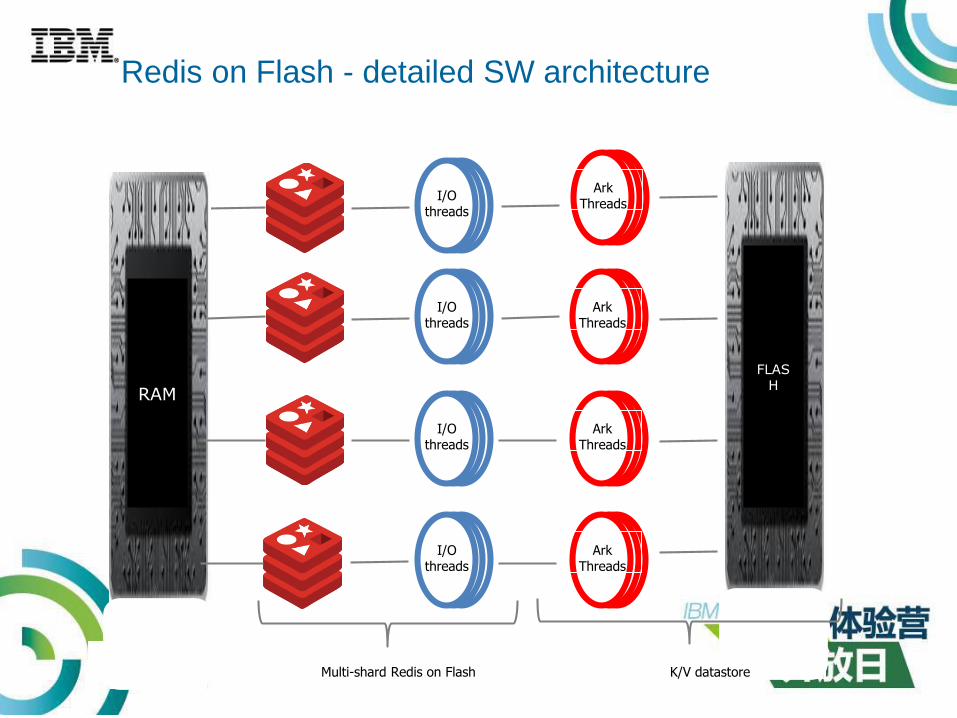
Redis on Flash - detailed SW architecture
RAM
I/O threads
Multi-shard Redis on Flash
I/O threads
I/O threads
I/O threads
ArkThreads
ArkThreads
ArkThreads
ArkThreads
K/V datastore
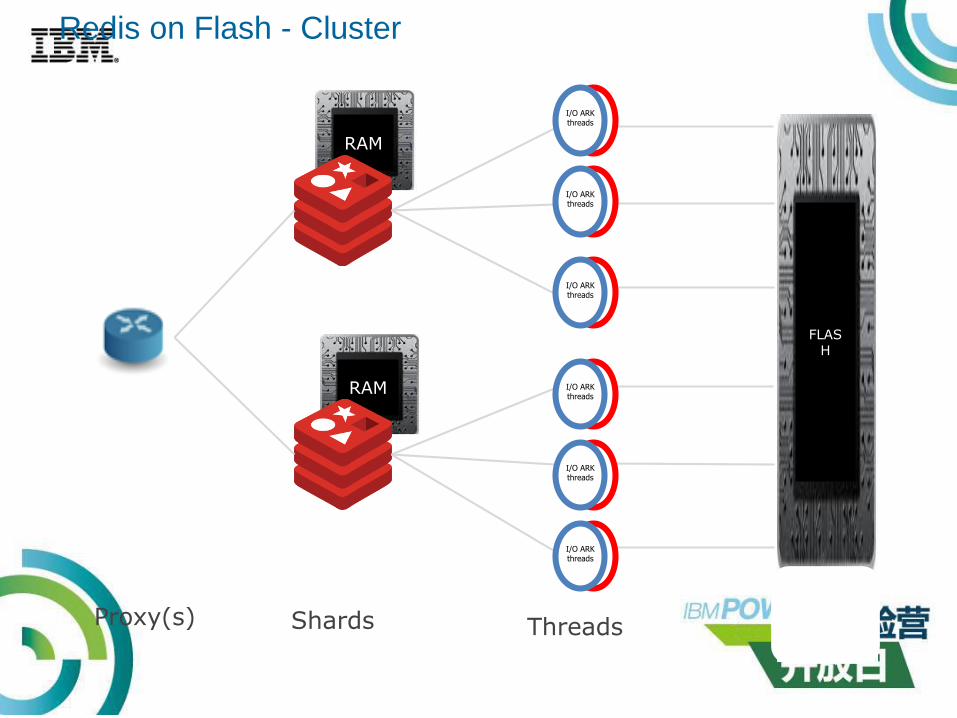
RAM
RAM
Redis on Flash - Cluster
Proxy(s) Shards Threads
I/O ARK threads
I/O ARK threads
I/O ARK threads
I/O ARK threads
I/O ARK threads
I/O ARK threads
FLASH

Redis on Power 8 - 40TB Deployment
4x 8247-22L
• 40TB• 1M IOPS• 4GBps• 16 FC
ports
Each server:--------------• 1xCAPI• 2x FC ports• 350K-400K IOPS
Each 8247-22L server:-------------------------•Access to 6TB flash•16TB persistent storage•768GB RAM•192 Vcores (HW threads)•4x10Gbps Ethernet
FlashSystem 900
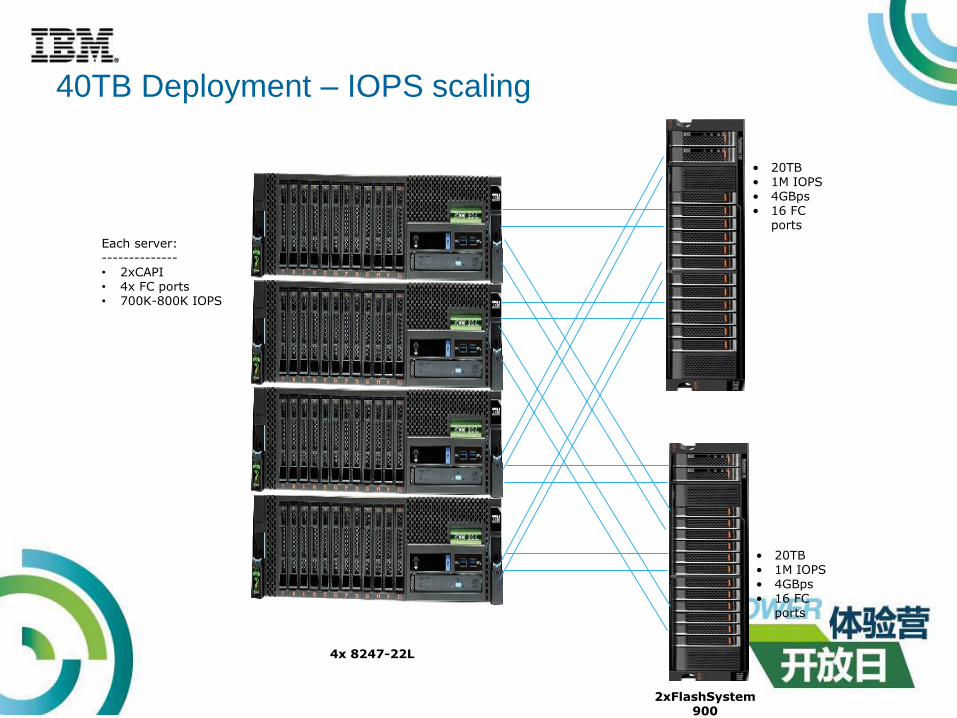
40TB Deployment – IOPS scaling
4x 8247-22L
• 20TB• 1M IOPS• 4GBps• 16 FC
ports
• 20TB• 1M IOPS• 4GBps• 16 FC
ports
2xFlashSystem 900
Each server:--------------• 2xCAPI• 4x FC ports• 700K-800K IOPS
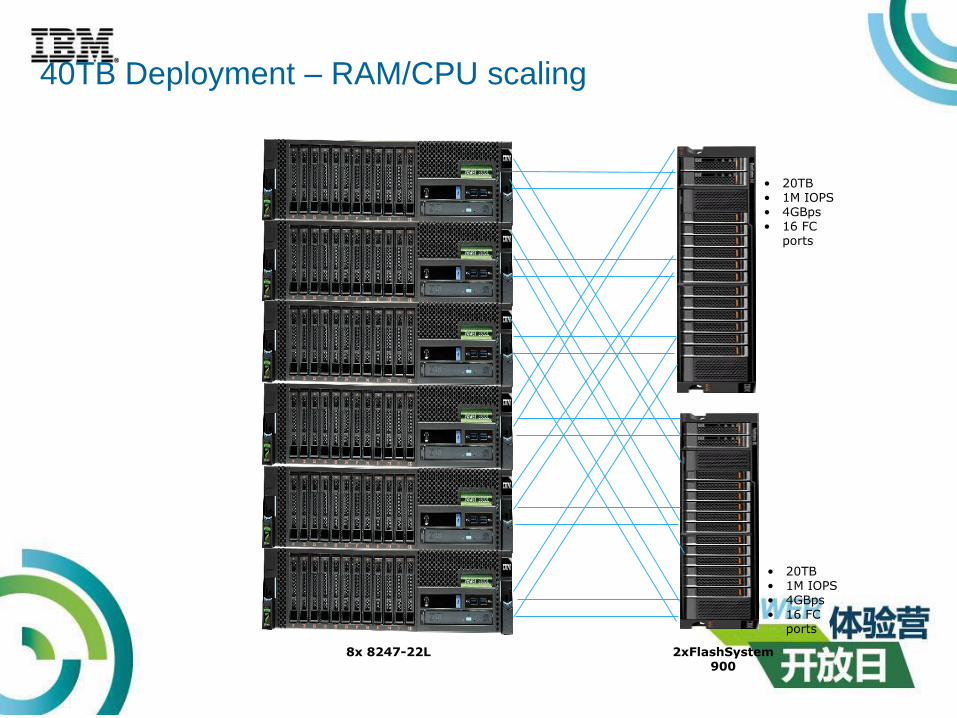
40TB Deployment – RAM/CPU scaling
8x 8247-22L
• 20TB• 1M IOPS• 4GBps• 16 FC
ports
• 20TB• 1M IOPS• 4GBps• 16 FC
ports
2xFlashSystem 900

Redis on Power 8 - Scaling
Linearly scale, easy to manage

IBM NoSQL解决方案场景演示
• 演示环境及方案部署 :– 1x S822L (20 Core 3.69GHz w/ 2xCAPI Adapter each)
– RLEC 0.99 (Redis Enterprise Code Optimized for Power)
– FlashSystem 840
– Ubuntu 14.10
• 场景演示 :– Redis on RAM
– Redis on RAM+Flash

场景一:Redis on RAM
• Redis on RAM
– DB size : 50GB with 15 Shards
– Set : Get = 1 : 1
• Scenario :
– Pure RAM
• Result :
– Throughput : 2M OPS/s
– Latency : 2.4-2.5ms
– CPU Utilization : 73%

场景二:Redis on RAM+Flash
• Redis on Flash
– DB size : 50~60GB RAM with 15 Shards
– Set : Get = 1 : 1
• Scenario :
– RAM : Flash = 1 : 9
– 80% RAM Hit Ratio
– 50% RAM Hit Ratio
– 20% RAM Hit Ratio
• Result :
– Higher the RAM hit ratio, higher the throughput & lower the
latency

Thanks

主 题
13:30 14:10 Linux on Power助力大数据解决方案的介绍与案例分享
14:10 14:50 赢在开源 - 全堆栈Hadoop计算 认知及预测解决方法
14:50 15:30 赢在极速 - 探究Linux on Power的NoSQL解决方案
15:30 16:10 赢在高效管理 - MongoDB数据库技术实验分享
16:10 16:50 赢在敏捷洞察 - 重新定义DB2 BLU数据管理
时 间

MongoDB on PowerLinux
孙建

DataBase is evolving !
Relational-SQL
关系型数据库 oracle/DB2/MySQL
NO-SQL
非关系型数据库,一般不提供事务处理能力
New-SQL
新式的关系型数据库管理系统,针对OLTP(读-写)工作负载,追求提供和NoSQL系统相同的扩展性能,且仍然保
持ACID和SQL等特性(scalable and ACID and (relational and/or sql -access))
MongoDB V2.0

DataBase is evolving!
MongoDB v2.0

NO-SQL
MongoDB V2.0

NO-SQL 特点
开源
大数据量
高并发
弱事务
易扩展
灵活的数据模型
解决特定问题
MongoDB V2.0

NO-SQL DataBase
MongoDB V2.0
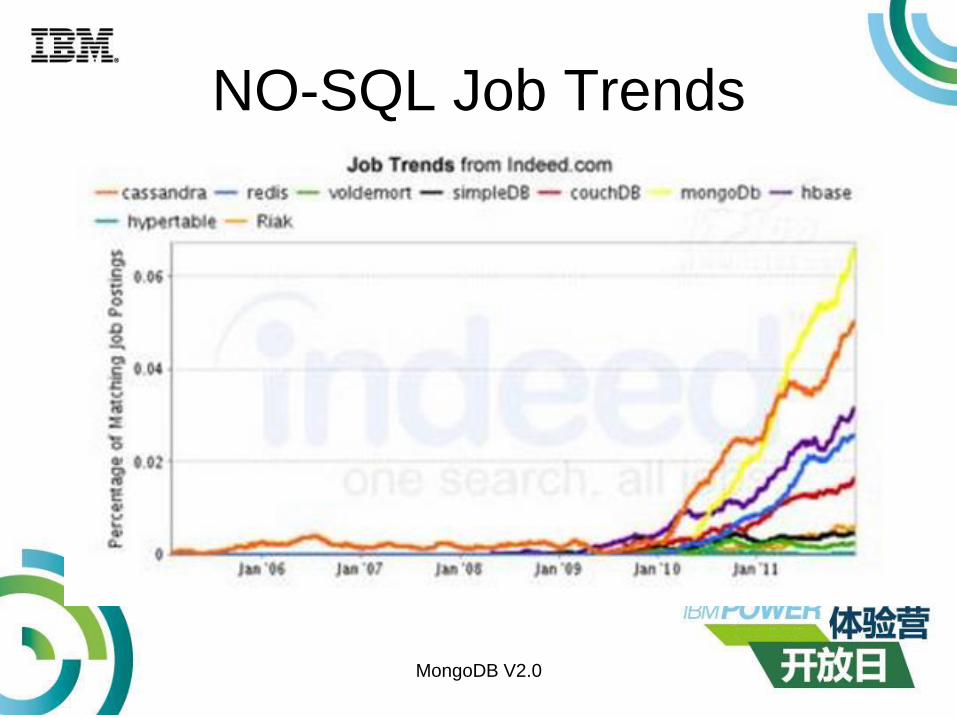
NO-SQL Job Trends
MongoDB V2.0

MongoDB V2.0

Open Source
开源软件的编译安装 ?字节序还是障碍吗?
Power8 LE 横空出世
redhat
suse
ubuntu
centos
MongoDB V2.0

Data Volume
• 大数据量
S822L 12块内置盘 7R2 6块内置盘
S822L 1TB 内存 7R2 256G内存
MongoDB V2.0

High Performance
• Power8
SMT2/SMT4/SMT8 per core
10 core per socket
CAPI
on chip L3 cahce
L4 cache and memory buffer
MongoDB V2.0

High Performance
• 高并发
S822L 20Core * SMT8 = 160 Threads
X86 80Core * SMT2 = 160 Threads
MongoDB V2.0

High Performance
• 高并发
MongoDB 经典的架构 3节点 replica set 主从节点间一直在复制数据
从节点间有心跳
都对并发执行的性能提出了高要求 !!!
主节点的单机RAS越高当然越好!!
MongoDB V2.0

High Performance
• 低延迟
mongoDB CAPI + Flash System -----In
Progress
Redis CAPI + Flash System ---- GA
MongoDB V2.0
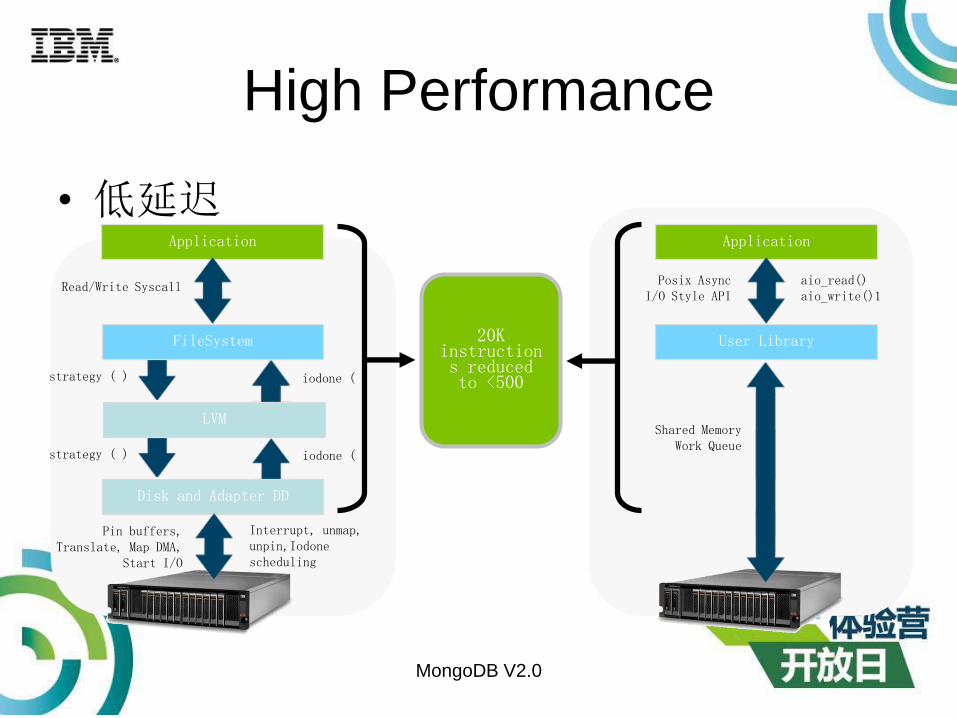
High Performance
• 低延迟
MongoDB V2.0
strategy ( )
Pin buffers, Translate, Map DMA,
Start I/O
Application
Read/Write Syscall
Interrupt, unmap, unpin,Iodone scheduling
20K instructions reduced to <500
Disk and Adapter DD
strategy ( ) iodone ( )
FileSystem
Application
User Library
Posix AsyncI/O Style API
Shared Memory Work Queue
aio_read()aio_write()1
iodone ( )
LVM

High Performance• 低延迟
MongoDB V2.0
Identical hardware with 2 different paths to
data
Power S822
Flash System 840
ConventionalPCIe I/O CAPI
0
20000
40000
60000
80000
100000
120000
PCIe I/O CAPI
0
50
100
150
200
250
300
350
400
450
500
PCIe I/O CAPI
IOPs per HW Thread Latency (us)
108,438466
16,150
199

High Performance
• Advanced ToolChain 通用的编译器 gcc
优化过的系统库
免费 !!!!
MongoDB V2.0

Easy Scale Out
• 裸机
• 虚拟化
PowerVM
PowerKVM
Docker
虚拟化全部免费!!!
MongoDB V2.0

MongoDB V2.0

MongoDB V2.0

MongoDB V2.0
MongoDB在PowerLinux调优案例

最终结果主机 主机
\CPU\内存进程部署 存储占比 平均处理
效率(条/秒)
CPU使用情况(使用占比-
top抓屏数据)
内存使用情况(内存使用量 -top抓屏
数据)
X86 4*X86 24C,128GB
查 重 的Mongodb采用3复本集(3复本)部署,共60 个数据库(DB) , 启 动16个查重进程
共测试话单约26亿条,存储占用约360G
35553 40 128G
PowerLinux
4*PowerLinux8C,128GB
服务器端1
台客户端2台
查 重 的Mongodb采用3复本集(3复本)部署,共60 个数据库(DB) , 启 动16个查重进程
共测试话单约26亿条 ,
存储占用约360G
52717 40 128G
MongoDB V2.0

业务分析测试数据
硬件平台 Power
速率(条/秒)每进程:724/秒
总处理:14418/秒
CPU利用率 82%
内存使用 111G
IO 平均30%Busy/最大80%
网络 平均15M
数据量:全省一天1/10的数据
调整IO前编译前

性能瓶颈分析
IO存在瓶颈,计费应用主要是以文件的方式交互
问题分析:1.磁盘数量少,只有5块用来存储数据2.Raid5要比Raid0慢
Disk total KB/s PLtest2
Disk Read KB/s
Disk Write KB/s
IO/sec
17:00:11 776.8 0 1217:00:21 6.4 37377 5066.417:00:31 0.2 17590 1926.217:00:41 6.4 24691 3166.417:00:51 0.2 19320 2809.917:01:01 0 17735 1940.317:01:11 0.2 28258 3797.317:01:21 0 12438 1437.617:01:31 0.2 22063 2810.617:01:41 0 27984 3559.617:01:51 0.2 22251 2829.717:02:01 19.2 11513 1576.917:02:11 6.6 24751 3104.117:02:21 0 32682 4391.917:02:31 0.2 17459 1984.717:02:41 0 13434 2229.617:02:51 0.2 31821 3586.3
nmon Sar -d
调整IO前编译前
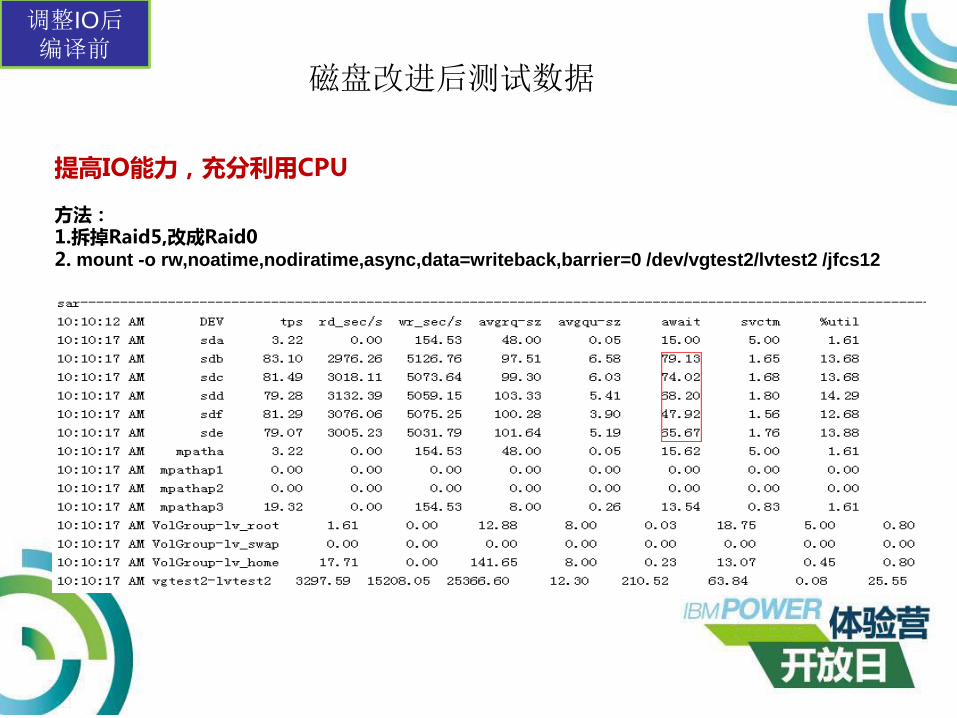
磁盘改进后测试数据
提高IO能力,充分利用CPU
方法:1.拆掉Raid5,改成Raid02. mount -o rw,noatime,nodiratime,async,data=writeback,barrier=0 /dev/vgtest2/lvtest2 /jfcs12
调整IO后编译前

业务分析测试数据
硬件平台 Power
速率(条/秒)每进程:745/秒
总处理:14917/秒
CPU利用率 90%
内存使用 111G
IO 平均3%Busy/最大6%
网络 平均17M
数据量:全省一天1/10的数据
调整IO后编译前

第二轮瓶颈分析
提高IO能力后,Iowait%低于1%,CPU利用率达到90%,但是测试结果提升不大,观察后台iostat提升不大,因为await 和svctm两者的数值差距较大,继续优化IO
方法:减少预读,默认128:echo '16' > /sys/block/sda/queue/read_ahead_kb
增大队列,默认128:echo '512' > /sys/block/sda/queue/nr_requests
尽量不使用交换区,默认60:echo '0' > /proc/sys/vm/swappiness
IO调度,默认cfq:echo 'deadline' > /sys/block/sdx/queue/scheduler
调整IO后编译前

上面针对IO的优化没有太多的提升,后根据x86测试时的对比,并且通过Perf 工具抓取的运行时数据,发现大量STD模板库占用过多的CPU,尝试通过优化代码来提升性能。
第三轮瓶颈分析
调整IO后编译后

优化方法介绍编译工具:
AT 7.0
优化后的编译选项:CCFLAGS=-fpic -ftemplate-depth-64 -fpeel-loops -funroll-loops -ftree-vectorize -
fvect-cost-model -O3 -mcpu=power7 -mtune=power7 -maltivec -mvsx -mhot-
level=1 -mcmodel=medium -Wl,-q
THRDEFS=-D_REENTRANT -D_THREAD_SAFE -DPTHREADS -DTHREAD -
D_RWSTD_MULTI_THREAD -D_GNU_SOURCE
LDFLAGS=-lpthread -ldl
SHLDFLAGS=-shared –lpthread
优化前的编译选项:AT(Advance ToolChain7.0):
CCFLAGS=-fpic -ftemplate-depth-64 -O3 -qarch=pwr7 -qtune=pwr7 -qaltivec -
qhot=level=1 -Wl,-q
THRDEFS=-D_REENTRANT -D_THREAD_SAFE -DPTHREADS -DTHREAD -
D_RWSTD_MULTI_THREAD -D_GNU_SOUORCE
LDFLAGS=-lpthread -ldl
SHLDFLAGS=-shared -lpthread
调整IO后编译后

优化工具介绍AT (IBM Advanced Toolchain for PowerLinux)7.0
是一组开源开发工具和运行时库,它使用户能够在 Linux 上利用 IBM 最新的Power 硬件特性。
CCFLAGS=-fpic -ftemplate-depth-64 -fpeel-loops -funroll-loops -ftree-vectorize -fvect-cost-
model -O3 -mcpu=power7 -mtune=power7 -maltivec -mvsx -mhot-level=1 -mcmodel=medium -
Wl,-q
fpic --生成共享库中使用的 Position-Independent Code
ftemplate-depth-64 –控制模板递归深度fpeel-loops --减少无用的循环次数funroll-loops --仅对循环次数能够在编译时或运行时确定的循环进行展开,生成的代码尺寸将变大ftree-vectorize --开启向量化fvect-cost-model --向量成本模型mcpu=power7 --基于Power7CPU的架构来编译mtune=power7 --基于Power7CPU的架构来优化maltivec --在Power平台 上开户向量化还需要这个开关mvsx --生成可以使用向量和无向量指令的代码mhot-level=1 --热点代码1级mcmodel=medium –产生power平台64代码,静态数据可以达到 4Gb
调整IO后编译后

业务分析测试数据
硬件平台 Power
速率(条/秒)每进程:1229/秒总处理:24584/秒
CPU利用率 63%
内存使用 100G
IO 平均1%Busy
网络 平均25M
数据量:全省一天1/10的数据
调整IO后编译后

优化后的代码热点调整IO后编译后

Thanks

主 题
13:30 14:10 Linux on Power助力大数据解决方案的介绍与案例分享
14:10 14:50 赢在开源 - 全堆栈Hadoop计算 认知及预测解决方法
14:50 15:30 赢在极速 - 探究Linux on Power的NoSQL解决方案
15:30 16:10 赢在高效管理 - MongoDB数据库技术实验分享
16:10 16:50 赢在敏捷洞察 - 重新定义DB2 BLU数据管理
时 间

赢在敏捷洞察 重新定义DB2 BLU数据管理
胡云飞
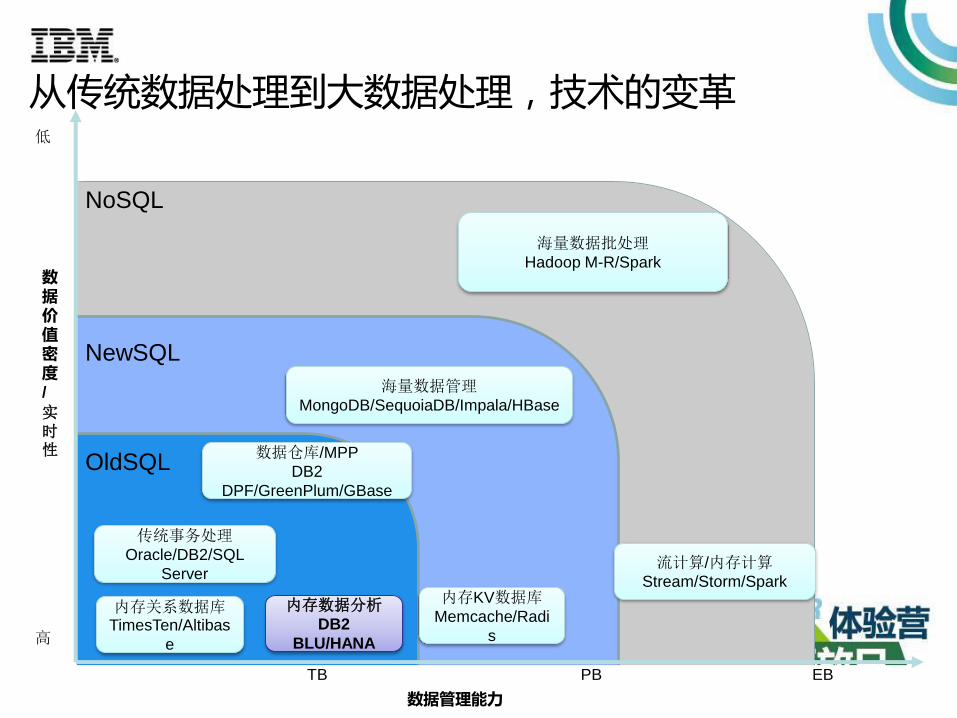
从传统数据处理到大数据处理,技术的变革
数据管理能力
TB PB EB
数据价值密度/
实时性
高
低
OldSQL
NewSQL
NoSQL
流计算/内存计算Stream/Storm/Spark
内存关系数据库TimesTen/Altibas
e
内存KV数据库Memcache/Radi
s
内存数据分析DB2
BLU/HANA
海量数据批处理Hadoop M-R/Spark
海量数据管理MongoDB/SequoiaDB/Impala/HBase
数据仓库/MPP
DB2
DPF/GreenPlum/GBase
传统事务处理Oracle/DB2/SQL
Server

©2013 IBM Corporation 90
DB2 BLU概述
DB2应对分析查询(OLAP)类业务的新技术– OLAP的特性:海量数据,多表关联,更关注查询
– DB2 BLU为DB2数据库添加列式功能
• 表数据的存储是按列组织的,而不是按行
• 使用矢量处理引擎
• 使用这种表的格式与星型模式数据集市可以显著改善存储、查询性能、易用性和实现价值的速度
– 独特的新运行时技术,它充分利用了 CPU 架构,
并直接内置在 DB2 内核中
–独特的新编码,实现了高速度和压缩
• 这一新功能经过了主内存优化、CPU 优化和I/O 优化
经典 DMS
(适用于非 BLU 表)
BLU DMS
(适用于 BLU 表)
经典 DB2 缓冲池
支持 SIMD的 CPU
(经典的行结构表)压缩的、编码的列式内容
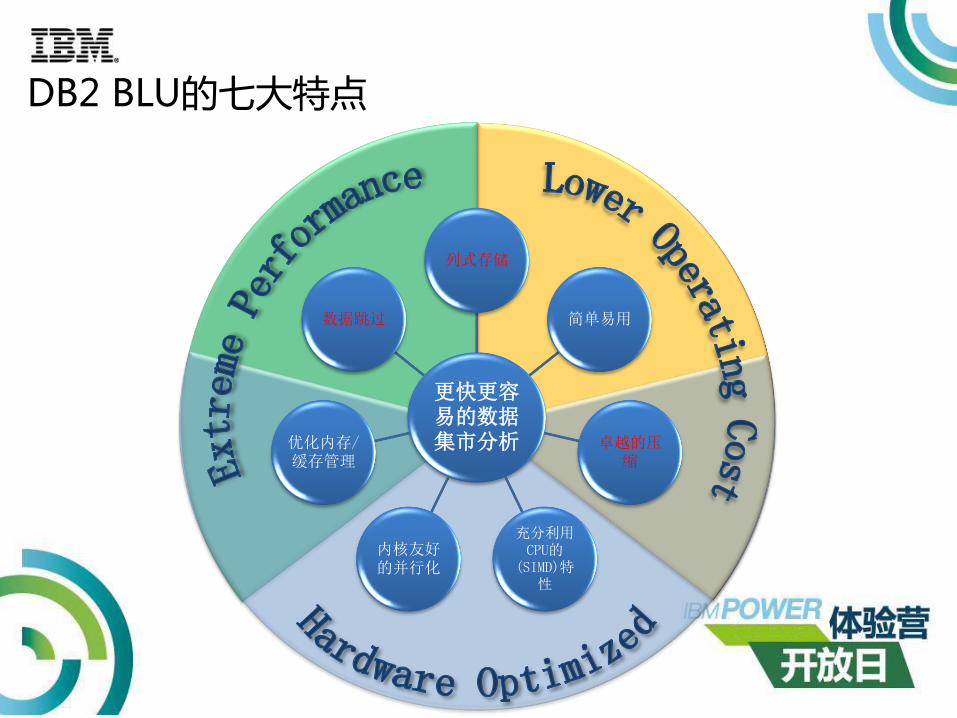
DB2 BLU的七大特点
更快更容易的数据集市分析
列式存储
简单易用
卓越的压缩
充分利用CPU的
(SIMD)特性
内核友好的并行化
优化内存/缓存管理
数据跳过

©2013 IBM Corporation 92
DB2 BLU七大特点之一 :简单易用
运营–只需加载数据就可以启动
–像所宣称的那样易于评估和执行
BI 开发人员和 DBA - 更快地交付成果
–无需配置或物理建模
–无需索引或调优 - 开箱即用的性能
–数据架构师/DBA 可专注于业务价值,而不是物理设计
ETL 开发人员
–无需聚合各个表 - 更简单的 ETL 逻辑
–更快的加载和转换速度
业务分析师
–真正的即席查询 - 无调优,无索引
–针对大型数据集提出复杂的查询
© 2013 IBM Corporation 93
© 2013 IBM Corporation
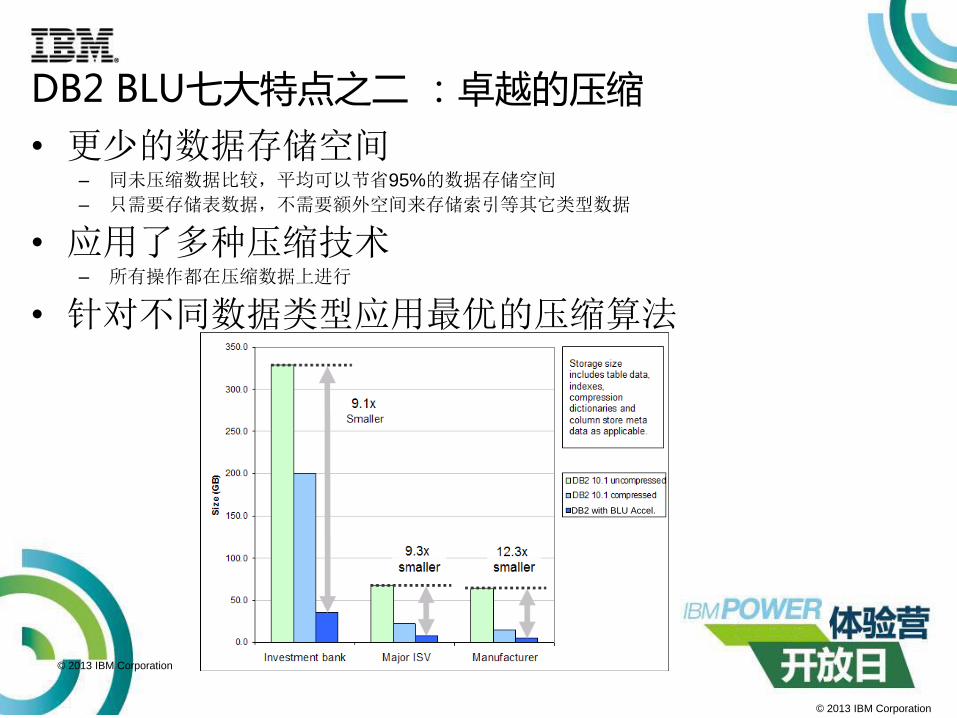
DB2 BLU七大特点之二 :卓越的压缩
DB2 with BLU Accel.DB2 with BLU Accel.
• 更少的数据存储空间– 同未压缩数据比较,平均可以节省95%的数据存储空间
– 只需要存储表数据,不需要额外空间来存储索引等其它类型数据
• 应用了多种压缩技术– 所有操作都在压缩数据上进行
• 针对不同数据类型应用最优的压缩算法

© 2013 IBM Corporation 94
© 2013 IBM Corporation94
没用SIMD 技术的CPU每条指令只能处理一个数据
DB2 BLU七大特点之三 :充分利用CPU的SIMD特性
利用Single Instruction Multiple Data (SIMD)特性增加性能 DB2 BLU 能够在一个指令中同时对多个数据进行操作
– 包括比较,Join, 分组和数学计算
Compare
= 2005
Compare
= 2005
Compare
= 2005
2001
指令
结果
数据
2002 2003 2004
2005
2005 2006 2007 20082009 2010 2011 2012
Processor
CoreCompare
= 2005
2001
指令
结果
数据200220032004200520062007
Compare
= 2005
Compare
= 2005
Compare
= 2005
Compare
= 2005
Compare
= 2005
Compare
= 2005 2005
Processor
Core

© 2013 IBM Corporation 95
© 2013 IBM Corporation95
DB2 BLU七大特点之四 :内核友好的并行化
© 2013 IBM Corporation95
更加关注于服务器的硬件设计因素– DB2 BLU中对表的查询将自动以并行化的方式处理
将CPU缓存,高速缓存块(cacheline)的效率最大化

© 2013 IBM Corporation 96
© 2013 IBM Corporation96
DB2 BLU七大特点之五 :列式存储
© 2013 IBM Corporation96 © 2013 IBM Corporation96
减少I/O– 只处理查询关注的列中的数据
直接对相关列进行运算– 所有的运算,Join仅对关注列进行– 在必须返回结果集前,数据将不会组合成行的形式
提高内存中的数据密度– 列中的数据在内存和存储中始终保持着压缩的形态
卓越的压缩– 提供更高的压缩比10:1(DB2 BLU)
高效的缓存– 数据被组合成利于缓存和寄存器处理的格式
C1 C2 C3 C4 C5 C6 C7 C8C1 C2 C3 C4 C5 C6 C7 C8
© 2013 IBM Corporation 97
© 2013 IBM Corporation97
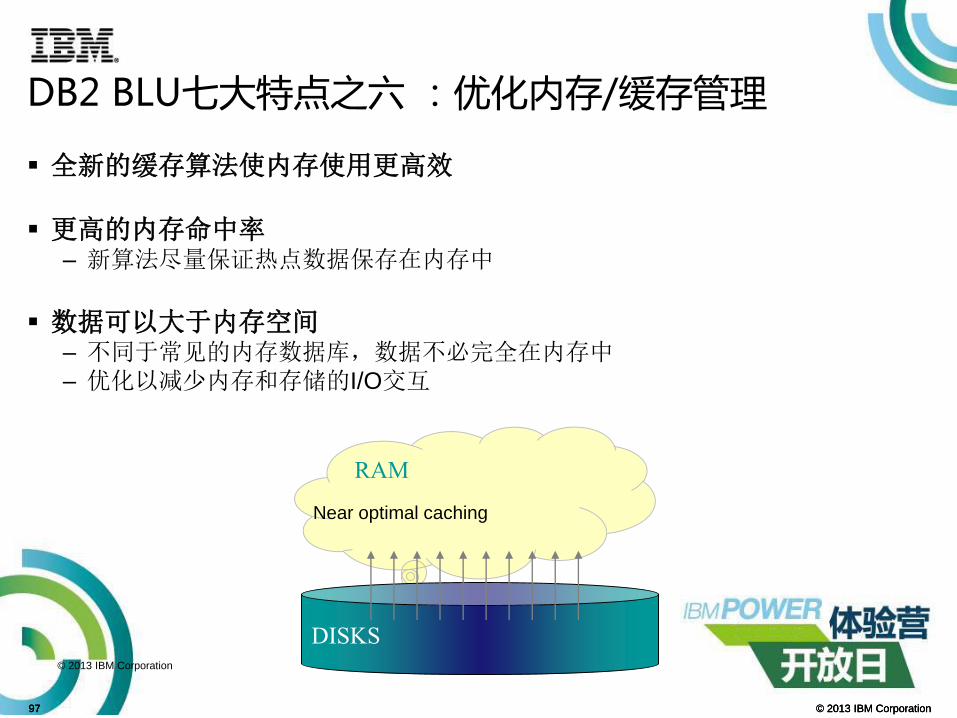
DB2 BLU七大特点之六 :优化内存/缓存管理
© 2013 IBM Corporation97 © 2013 IBM Corporation97
全新的缓存算法使内存使用更高效
更高的内存命中率– 新算法尽量保证热点数据保存在内存中
数据可以大于内存空间– 不同于常见的内存数据库,数据不必完全在内存中– 优化以减少内存和存储的I/O交互
RAM
DISKS
Near optimal caching
© 2013 IBM Corporation 98
© 2013 IBM Corporation98
DB2 BLU七大特点之七 :数据跳过
© 2013 IBM Corporation98
自动监测一段数据是否符合查询的忽略条件
能够节省大量的I/O,内存和CPU资源
不需要数据库管理员进行任何定义
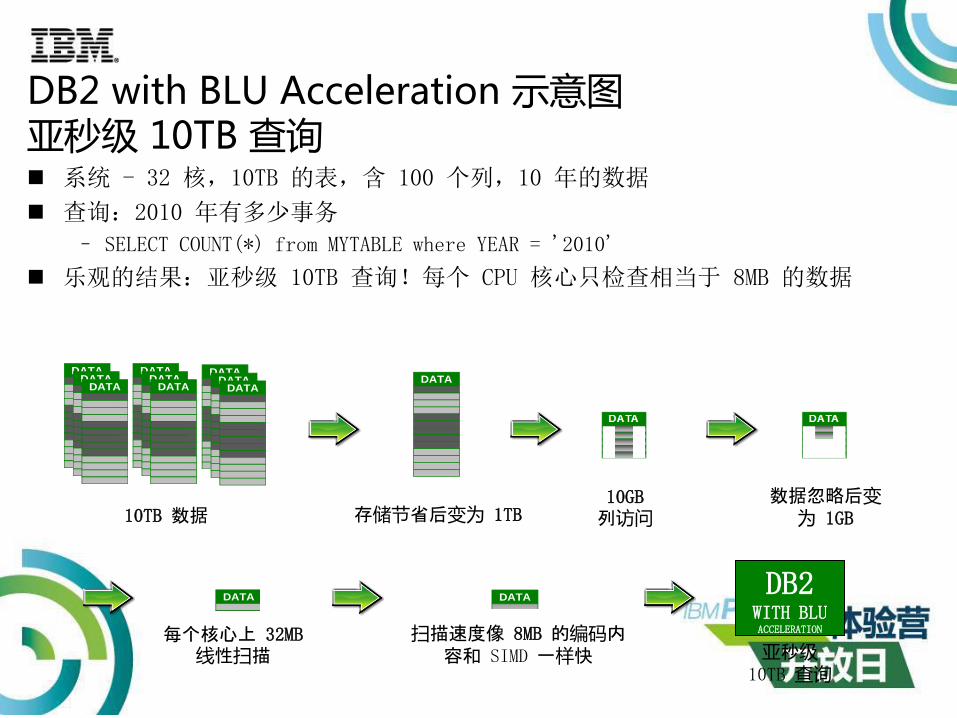
DB2 with BLU Acceleration 示意图亚秒级 10TB 查询 系统 - 32 核,10TB 的表,含 100 个列,10 年的数据
查询:2010 年有多少事务
– SELECT COUNT(*) from MYTABLE where YEAR = '2010'
乐观的结果:亚秒级 10TB 查询!每个 CPU 核心只检查相当于 8MB 的数据
DATADATA
DATA
DATADATA
DATA
DATADATA
DATA
10TB 数据
DATA
存储节省后变为 1TB
DATA
每个核心上 32MB线性扫描
扫描速度像 8MB 的编码内容和 SIMD 一样快
DATA
亚秒级10TB 查询
DB2WITH BLUACCELERATION
10GB列访问
数据忽略后变为 1GB
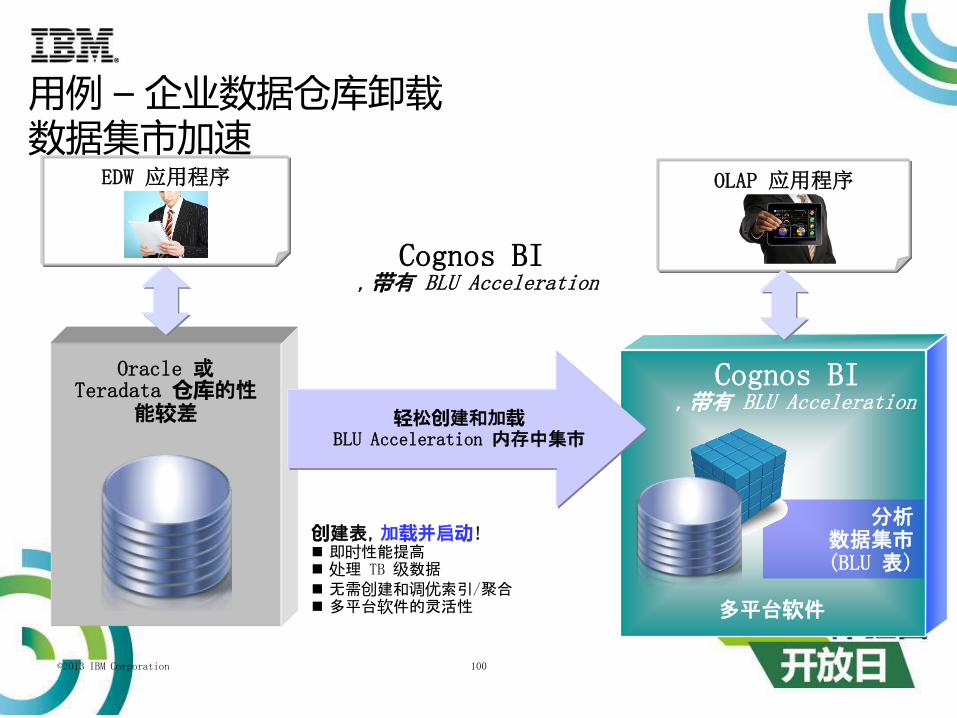
©2013 IBM Corporation 100
Cognos BI ,带有 BLU Acceleration
多平台软件
分析数据集市(BLU 表)
Oracle 或Teradata 仓库的性
能较差
创建表,加载并启动! 即时性能提高 处理 TB 级数据 无需创建和调优索引/聚合 多平台软件的灵活性
Cognos BI,带有 BLU Acceleration
用例 – 企业数据仓库卸载数据集市加速
EDW 应用程序 OLAP 应用程序
轻松创建和加载BLU Acceleration 内存中集市
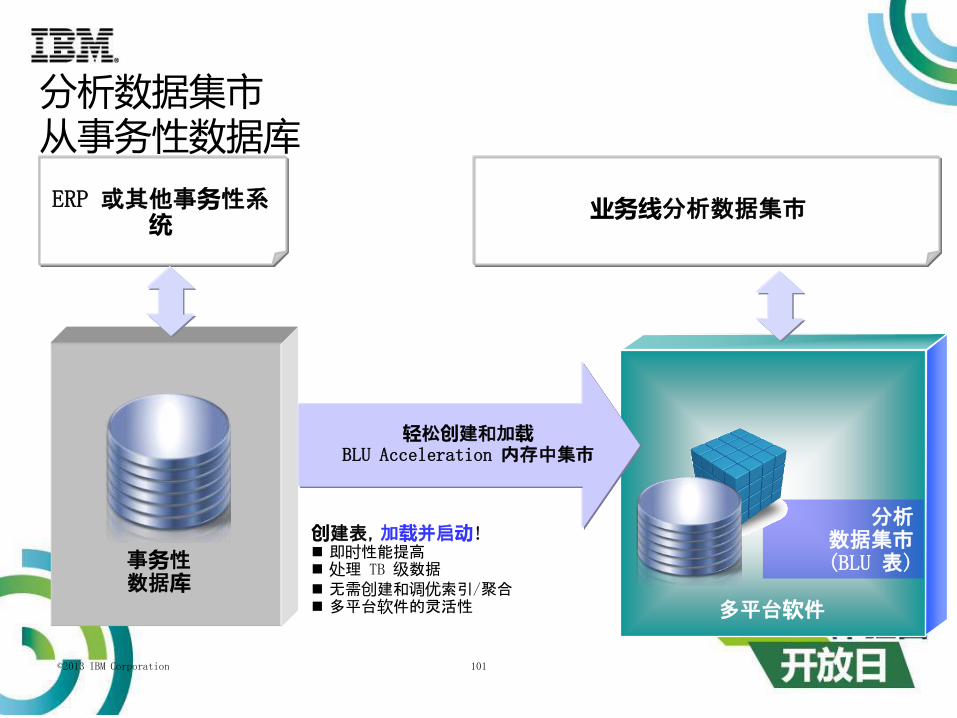
©2013 IBM Corporation 101
多平台软件
分析数据集市(BLU 表)
ERP 或其他事务性系统
轻松创建和加载BLU Acceleration 内存中集市
事务性数据库
分析数据集市从事务性数据库
创建表,加载并启动! 即时性能提高 处理 TB 级数据 无需创建和调优索引/聚合 多平台软件的灵活性
业务线分析数据集市

© 2013 IBM Corporation 102
© 2013 IBM Corporation10
2
DB2 10.5 BLU 针对Power服务器的优化
列压缩后的数据在存储的时候会充分考虑寄存器的大小– Power7+比Intel芯片拥有更多的寄存器 (64 vs. 16)
– 越多的数据存放在寄存器中以为着越高的性能
DB2 BLU 利用SIMD 处理指令获得更好的性能– 利用上面的寄存器能够在一个时钟周期内执行更多的比较操作– 通过利用Power7的SIMD特性获得更高的性能
DB2针对Power的架构会使用一个为Power特别优化过的单独动态链接库

© 2013 IBM Corporation 103
© 2013 IBM Corporation
DB2 10.5 Beta同DB2 10.1查询速度测试比较结果
客户 查询速度提高
某大型金融服务公司 46.8倍
某第三方软件供应商 37.4倍
某分析软件业务公司 13.0倍
某全球零售公司 6.1倍
某大型欧洲银行 5.6倍
分析查询速度
平均提高
10-25 倍
“It was amazing to see the faster query times compared to the performance
results with our row-organized tables. The performance of four of our
queries improved by over 100-fold! The best outcome was a query that
finished 137x faster by using BLU Acceleration.” - Kent Collins, Database Solutions Architect, BNSF Railway
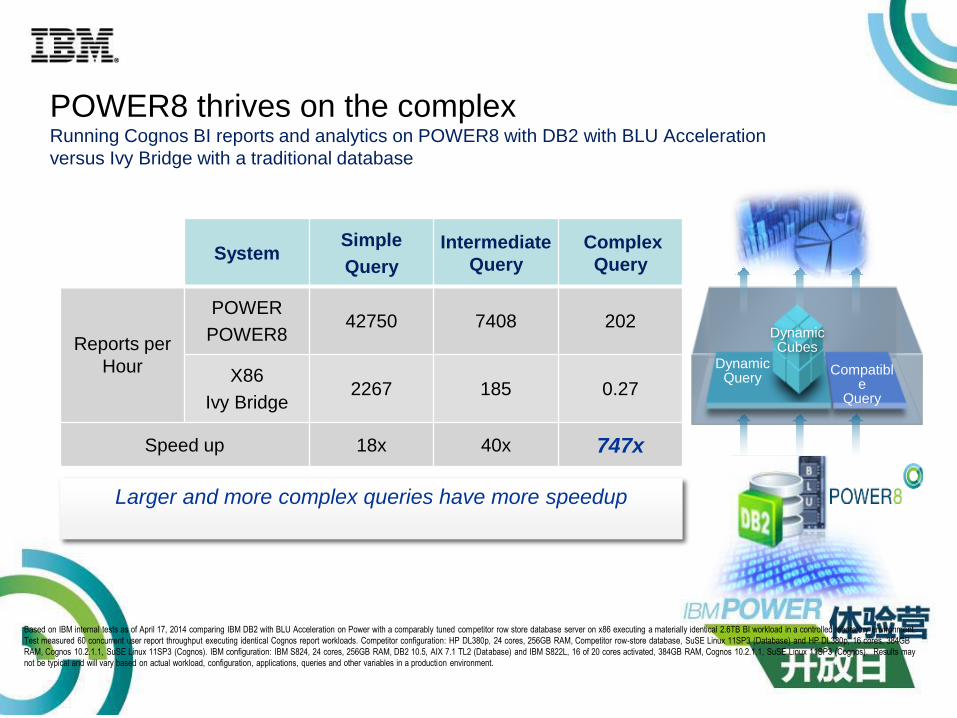
System Simple
Query
Intermediate
Query
Complex
Query
Reports per
Hour
POWER
POWER842750 7408 202
X86
Ivy Bridge2267 185 0.27
Speed up 18x 40x 747x
Larger and more complex queries have more speedup
DynamicQuery
Compatible
Query
DynamicCubes
POWER8 thrives on the complex Running Cognos BI reports and analytics on POWER8 with DB2 with BLU Acceleration
versus Ivy Bridge with a traditional database
Based on IBM internal tests as of April 17, 2014 comparing IBM DB2 with BLU Acceleration on Power with a comparably tuned competitor row store database server on x86 executing a materially identical 2.6TB BI workload in a controlled laboratory environment.
Test measured 60 concurrent user report throughput executing identical Cognos report workloads. Competitor configuration: HP DL380p, 24 cores, 256GB RAM, Competitor row-store database, SuSE Linux 11SP3 (Database) and HP DL380p, 16 cores, 384GB
RAM, Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). IBM configuration: IBM S824, 24 cores, 256GB RAM, DB2 10.5, AIX 7.1 TL2 (Database) and IBM S822L, 16 of 20 cores activated, 384GB RAM, Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). Results may
not be typical and will vary based on actual workload, configuration, applications, queries and other variables in a production environment.

Projections are based on IBM internal tests as of April 17, 2014 comparing IBM DB2 with BLU Acceleration on Power with a comparably tuned competitor row store database server on x86 executing a materially identical 2.6TB BI workload in a
controlled laboratory environment. Test measured 60 concurrent user report throughput executing identical Cognos report workloads. Competitor configuration: HP DL380p, 24 cores, 256GB RAM, Competitor row-store database, SuSE Linux 11SP3
(Database) and HP DL380p, 16 cores, 384GB RAM, Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). IBM configuration: IBM S824, 24 cores, 256GB RAM, DB2 10.5, AIX 7.1 TL2 (Database) and IBM S822L, 16 of 20 cores activated, 384GB RAM,
Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). S824 results were extrapolated to an C812L-M based 10c@ 3.4 GHz / 1-socket / 256 GB memory / 2x4TB drive system. The HP DL380p results were extrapolated to E5-2620: 12c @ 2.0 Ghz / 2 socket
/ 256 GB memory / 2x4TB drives. The results were obtained under laboratory conditions, and not in an actual customer environment. IBM's internal workload studies are not benchmark applications, nor are they based on any benchmark standard. As
such, customer applications, differences in the stack deployed, and other systems variations or testing conditions may produce different results and may vary based on actual configuration, applications, specific queries and other variables in a
production environment.
Running Cognos BI reports and analytics on Softlayer POWER8 systems with DB2 with BLU
Acceleration versus x86 E5-2620 Softlayer offerings running a traditional database
Enable 73X faster business decisions through complex analytics
on POWER8 running Linux compared to x86

Power+DB2 BLU内存分析案例
企业ETL应用
DB2 BLU加速原来Row数据库中需要执行2小时20分的ETL过程缩减到3分30秒即可完成,整体提升性能30倍,
硬件环境: Power7 16Cores;128GB
Our BI solution is built on a Cognos/DB2,
With BLU Acceleration, we have been able to reduce the
time spent on pre-aggregation from one hour to two
minutes. BLU Acceleration is truly amazing.
–Yong Zhou, Sr. Manager of Data Warehouse &
Business Intelligence Department, Taikang Life
Insurance
企业数据仓库应用,承担全行报表表查询,数据供给
•作为企业入门级数据仓库系统与Row
数据库相比性能提升15倍。
•节省70%的存储空间,90%的表压缩率达到90%以上,其中最大的单表120G压缩后为15GB
•一张1400万记录的表与一张400万记录的表做left join,3秒内显示结果.*
硬件环境: Power7 4Cores; 32 GB

XX电信运行商内存数据库测试报告
2015.2

场景一:查询SQL语句 客户测试数据(59秒) VS. BLU(20秒)
Table name: DW_PRODUCT_MULTICARD_MM
Table records: 21079541 rows
Result set: 586243 rows
Test SQL :
SELECT a.*,to_char(op_time, 'yyyyMM') as op_time_fm, to_char(mark_time, 'yyyyMM') as mark_time_fm FROM DW_PRODUCT_MULTICARD_MM
where 1 = 1 and to_char(op_time, 'yyyyMM') = '201301' and city_id in(1, 2, 3, 4, 5, 6, 7, 8, 9);
该场景主要测试内存数据库产品在应对大数据量即席查询应用时的性能情况,我们选择了一人多卡明细查询这个场景,涉及数据量约2700万

数载装试测 : Load 约13亿行数据 38分钟
Load Table name: DMW_CDR_CI_M_201304
Table records: 1299662283 rows
Complete Load time: ≈ 38 min

场景二: 算计圈往交 客户测试数据9h VS. BLU FP6
16m46.571s
Base Table name: DMW_CDR_CI_M_201304 Result Table name: dmw_cdr_sphere_201304
Table records: 1299662283 rows Result set: 457542331 rows
Test SQL : insert into
sesion.DMW_CDR_SPHERE_201304( PRODUCT_NO ,OPPOSITE_REGULAR_NO ,CITY_ID ,CALL_COUNTS ,CALL_DURATION ,CALL_FEE ,IN_CALL_COUNTS ,I
N_CALL_DURATION ,IN_CALL_FEE ,OUT_CALL_COUNTS ,OUT_CALL_DURATION ,OUT_CALL_FEE ,fw_CALL_COUNTS ,
fw_CALL_DURATION ,fw_CALL_FEE ) select product_no, opposite_regular_no, city_id, sum(call_counts), sum(call_duration), sum(call_fee), sum(case when calltype_id
= 1 then call_counts else 0 end), sum(case when calltype_id = 1 then call_duration else 0 end), sum(case when calltype_id = 1 then call_fee else 0 end), sum(case
when calltype_id <> 1 then call_counts else 0 end), sum(case when calltype_id <> 1 then call_duration else 0 end), sum(case when calltype_id <> 1 then call_fee else 0
end) , sum(case when calltype_id = 3 then call_counts else 0 end), sum(case when calltype_id = 3 then call_duration else 0 end), sum(case when calltype_id = 3
then call_fee else 0 end) from DMW_CDR_CI_M_201304 b group by product_no,opposite_regular_no,city_id
注: 所有测试均基于单台机器,预计布署至多台服务器性能会有较大幅度提升
该场景主要测试内存数据库产品在处理海量基础数据生成计算结果时的性能情况,本次测试数据量为一个月的语音详单,数据量约21亿条,100G。

Thanks