1 beehive: a framework for graph data analytics on cloud computing platforms anand tripathi, vinit...
TRANSCRIPT

1
Beehive: A Framework for Graph Data Analytics on Cloud Computing
Platforms•Anand Tripathi, Vinit Padhye, Tara Sasank Sunkara
Department of Computer Science
University of Minnesota
Presentation by
Tara Sasank Sunkara
eBay Inc.
•Acknowledgements: This work was partly supported by NSF award 1319333•and by the computing resources of Minnesota Supercomputing Institute (MSI)

2
Outline
• Project Goals • Beehive Computation Model• Beehive System Architecture• Beehive Programming framework• Architectural mechanisms and optimizations• Experimental evaluation• Algorithmic techniques for performance improvement• Conclusion and future work
2

3
Project Goals
• Many data analytics applications require processing of large scale graph data
• Analysis of such large scale graph data requires parallel processing utilizing a cluster computing environment.
• Parallelism in many graph problems tends to be fine-grained and irregular, and it is not easy to extract parallelism through static analysis and data partitioning.• This is called amorphous parallelism.

4
Project Goals
• Problem: How to extract amorphous parallelism in large-scale graph problems?
• Graph problems with amorphous parallelism cannot be easily partitioned for programming using the MapReduce model.
• The Beehive framework has been developed to address this problem, providing an alternate programming model.

5
Project Goals
The design of the Beehive framework has been driven by the following goals:– Provide a programming model which enables extraction of
amorphous parallelism using a speculative execution model based on optimistic concurrency control.
– Provide simple abstractions and programming primitives that eliminate complex message-passing paradigms
– Provide support for fault-tolerance and recovery• This aspect is the focus of our on-going work.

6
Beehive Computation Model
It has three key elements:1. A distributed key-value based storage system which
maintains graph data in the memory of cluster computing nodes.
2. A task-pool model for parallel execution of tasks on cluster nodes
3. Worker threads executing tasks as atomic transactions in parallel.– A transaction model which ensures atomicity and isolation
of the tasks– In case of any read-write or write-write conflicts among
parallel tasks, one of them commits and the others are aborted.– Speculatively harness amorphous parallelism using optimistic
concurrency control techniques.

7
Beehive System Architecture
• Beehive system executes on a collection of computing nodes in a cluster
• A Beehive process (called Beehive Node ) executing on a cluster node contains the following components:• Local workpool of tasks to be executed• A pool of worker threads• A component of the global key-value based data storage
service
• The system contains a Global Transaction Validation Service for optimistic concurrency control
7

8

9
Beehive computation model
• Computation Model: Task and Transaction• Task – Computation for a task is specific to the application
problem and the algorithm • A task reads and updates some vertices• A task can create new tasks on its completion
• Transaction – Every task is executed as a transaction. • Transaction is validated by the ‘global validator’• On an abort, the task is re-executed as a new transaction• On commit the updates are written to the Beehive storage
9

10
Distributed Key-Value Based Storage
• Graph data is stored as a collection of key-value based items in a distributed storage across cluster nodes– Typically each vertex is stored with vertex-id as key
• Data is maintained in-memory at cluster nodes • A task can access any item with location-transparency• Key-value items can be relocated dynamically, for
example for graph clustering, to improve locality of data with tasks
• Relieves programmer from the burden of explicitly using message-passing primitives.

11
Task-pool Model
• A distributed pool of ready-to-run tasks is maintained across the cluster nodes.
• Each cluster node contains a pool of worker threads– The size of this pool is declared by the application program
• A worker thread’s function is to repeatedly pick a task from the local pool and execute it as a transaction using optimistic concurrency control methods:– On commitment of the transaction-task, it updates the
global storage and possibly creates new tasks– On abortion, the worker repeats the task execution as a
new transaction

12
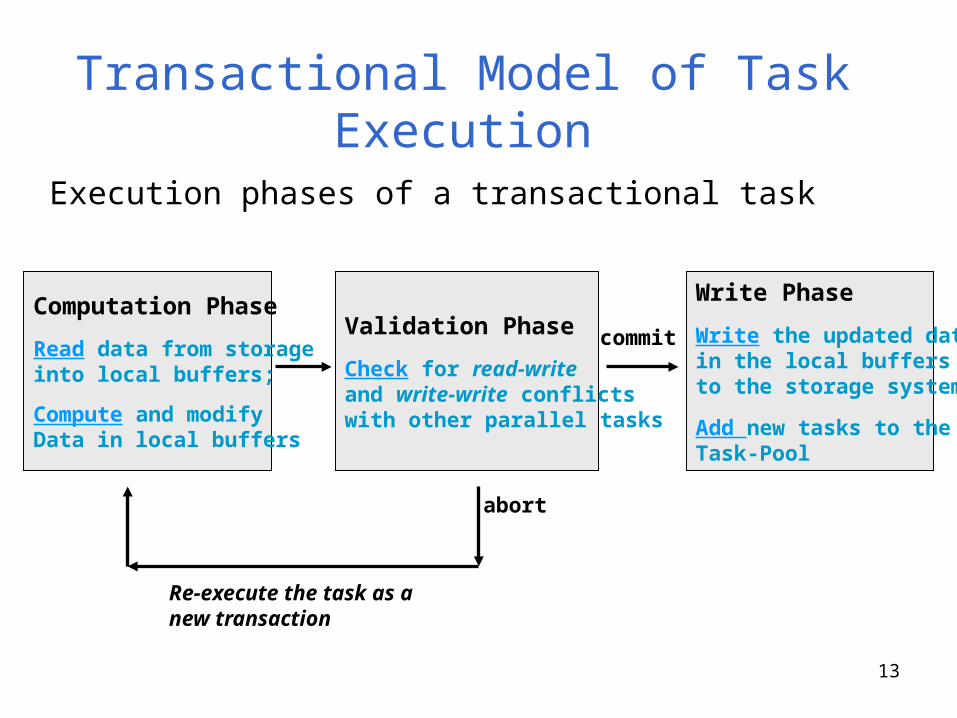
Transactional Model of Task Execution
• Computation tasks in a graph analytics program are executed as transactions.
• The transaction execution model is based on optimistic concurrency control methods [Kung-Robinson]:– A transaction (task) reads required graph data from the
key-value storage system in its local buffer– Performs all updates on the buffered data– After computation phase, it goes into validation phase to
detect any read-write and write-write conflicts with any other concurrent transactional tasks
– On commitment, it writes the updated data items into the key-value storage, and it may create new tasks which are inserted into the task pool
13
Transactional Model of Task Execution
Execution phases of a transactional task
Computation Phase
Read data from storageinto local buffers;
Compute and modifyData in local buffers
Validation Phase
Check for read-write and write-write conflictswith other parallel tasks
Write Phase
Write the updated datain the local buffersto the storage system
Add new tasks to theTask-Pool
commit
abort
Re-execute the task as a new transaction

14
Why optimistic model?
• Initially we investigated a conflict-free transactional task scheduling model– No two tasks with overlapping working sets (read/write set items)
can be executed concurrently
• Major disadvantages of conflict-free scheduling approach:– the read/write sets of the tasks may not be known a-priori.– Highly pessimistic.
• We also considered a locking based approach but it was not adopted due to the complexity of issues such as lock management and deadlocks.
14

15
Transaction Model
1. Transaction (task) acquires ‘Start-Timestamp” when it begins execution
2. Read and Compute Phase
3. Validation service checks that no concurrent transaction committed after the start-timestamp has any read-write or write-write conflicts.
4. Validation service commits the transaction and assigns it a Commit-Timestamp.
5. Transaction writes the updates to the global key-value storage.
6. Reports completion to the global validation service.

16
Transaction Validation ModelValidation Service maintains two counters:• Last assigned Commit Timestamp (CTS)– Once a transaction is validated it will be assigned a
timestamp(counter)
• Stable Timestamp (STS)– Updates of all committed transactions up to this commit
timestamp value have been pushed to the global storage.– STS is used as the start timestamp of any new transaction.
STS CTS
100 101 105103 104102 106
Updates written to the global storage
Updates NOT yet written to the global storage

17
Example problem
• Max-flow problem - Pre-flow Push algorithm • For each vertex with excess flow, push the excess flow
to neighbor vertex who are at a lower height. • If there is no neighbor vertex of lower height with
available edge capacity, lift the height of the vertex.• Keep doing this till the flow of all vertices except the
source and the sink are balanced.
17

Max-flow algorithm
18
T
H=6
H=4H=4
H=3
H=5
T Task Vertex
T
H=6
H=4H=4
H=3
H=5
TT

19
Beehive Programming Framework
• Framework provides Worker thread class.• This class can be suitably inherited by an application-
defined worker class.• A worker thread picks a task from the local workpool and
executes the doTask() method.– This method can be overridden by an application when
inheriting from the worker class.
• Framework provides mechanisms for executing a task’s computation as a transaction.

20
An illustration of programming in Beehive Framework
20

21
Research Problems
• Architectural Mechanisms• Task distribution strategies – sender initiated vs. receiver-
initiated• Task placement – Locality aware vs. Load aware• Task validation - Single Global validation vs. Hierarchical
validation• Support barrier synchronous model for phased execution
• Non-transactional task execution
• Algorithmic techniques for performance improvement by reducing remote data access costs.• Task Granularity• Caching
21

22
Task Distribution Model
• A task completion may result in creation of new tasks• The new tasks are distributed across different Beehive
nodes in two ways:1. Locality-aware: Affinity of a task to execute at a particular
Beehive node based either on data locality or task functionAffinity may be one of the following three types:– Strong: Must execute at a designated node
– For example some initialization task
– Weak: Prefer to execute at the designated node.– No-Affinity: Can be executed at any node
2. Load-aware: Balancing of load at different Beehive nodes

23
Load Distribution Models
• Load distribution strategies for new tasks created.• K-way split : Local work-pool invokes load distributor on
every task completion, split new generated tasks to K peers (inclusive local node).
• Random – any K-1 other peers• Round Robin – next K-1 peers• Load Aware – K-1 least loaded peers
• Beehive framework provides mechanism to obtain load information of other Beehive nodes.
23

24
Task Validation Approaches
• Single Global Validation:• Global validator at Global Task Management Service• Every transaction has to get validated to commit and
update the shared storage.
• Hierarchical Validation:• A local validator at every Beehive node additional to global
validator.• Filters requests to global validator by aborting transactions
that conflict with locally executed concurrent transactions• Reduced the load on the global validator by more than
60% in our experiments.
24
25
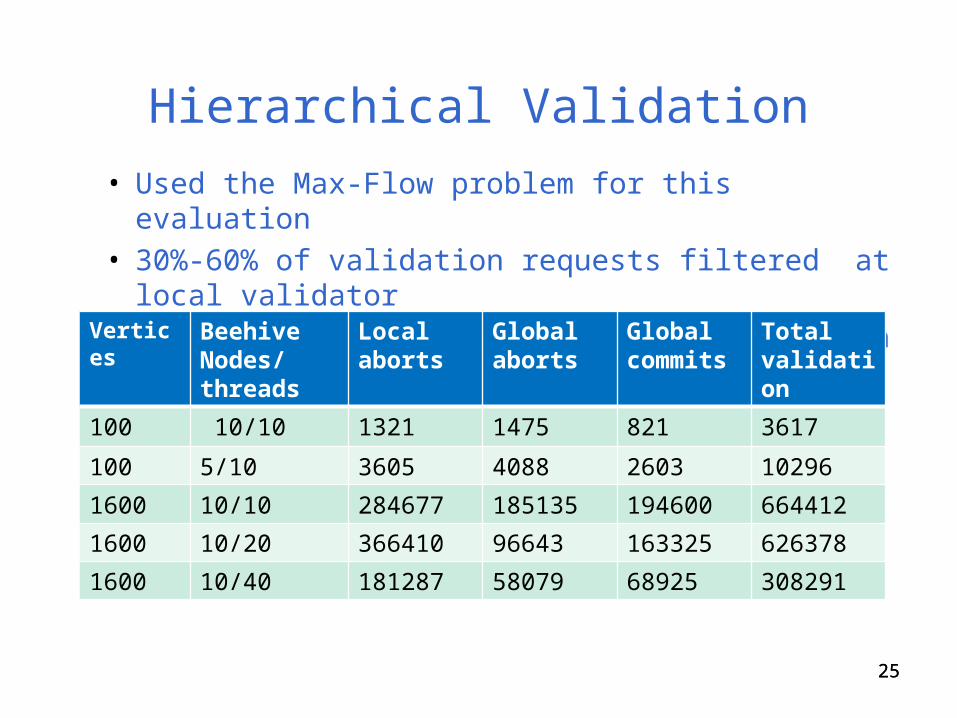
Hierarchical Validation
• Used the Max-Flow problem for this evaluation• 30%-60% of validation requests filtered at local validator• More significant gains in bigger graph with more threads
25
Vertices Beehive Nodes/ threads
Local aborts
Global aborts
Global commits
Total validation requests
100 10/10 1321 1475 821 3617
100 5/10 3605 4088 2603 10296
1600 10/10 284677 185135 194600 664412
1600 10/20 366410 96643 163325 626378
1600 10/40 181287 58079 68925 308291

26
Two models of parallel execution
• Many problems with structured parallelism can be executed using the Barrier synchronization model, without requiring the transactional task execution model.
• A application can specify the execution mode as either TRANSACTION MODE or BARRIER MODE
• Barrier model is useful for problems with structured parallelism and BSP based programming models.– Ex: Pagerank

27
Experimental Evaluation
• We programmed several graph problems to evaluate the performance of the Beehive framework and its mechanisms1. Max-Flow Problem using Preflow-Push Algorithms
2. Minimum Weight Spanning Tree problem using Gallgher-Humblet-Spira Algorithm
3. Graph-Coloring problem
4. PageRank problem • This problem was programmed using the Barrier model of
execution
• Experiments were conducted on the Itasca cluster of Minnesota Supercomputing Institute:– Each cluster node has 8 cores, 2.8 GHz, 22 GB memory

28
Max-Flow Problem• Implemented Preflow-Push Algorithm
• Evaluation with graphs of different sizes and edge capacities
• Graphs generated using Washington Graph Generator–Used Random-Level Graphs
Vertices Edges Beehive Nodes
Time (secs)
1600 4760 10 336
2500 7450 10 622
5000 14900 10 2254
10,000 29800 20 5878

Impact of Affinity levels
• We have evaluated graphs with setting different affinity levels.
• With strong affinity set the execution took more time.• Weak or No affinity performed almost similar.
29
# of vertices Computation time (secs) - Strong Affinity
Computation time (secs) – Weak Affinity / No Affinity
1600 964 471

30
Task granularity
Fine grained task
T T
T
Coarse grained tasksk
Task Vertex SetTask Vertex

31
Performance improvement techniques
• Increased task granularity • In the Max-flow problem• Increasing the task size to vertex and its neighborhood• It may increase number of aborts per transaction as
Read/Write sets are bigger.• Advantages:
• Reduces number of tasks• Reduced network access costs by parallel reads and writes
31
# of vertices Time (secs) with increased task size
Time (secs) with simple task
100 18 25
1600 379 471

32
Improvement with increased task granularity
• Max-flow problem for a 1600 vertex graph.• Reduced number of tasks to 1/3rd • No significant increase in the fraction of aborts• Data below is for a graph of 1600 vertices
32
Granularity # of machines/threads
# of Local Aborts
# of Global Aborts
# of Global commits
Single vertex task
10/10 284677 185135 194600
Vertex +neighborhood
10/10 70511 60921 60304

33
Performance improvement through caching
• When a task is re-executed because of an abort, we avoid re-fetching the working set data items which have not been modified.
• This required us to include additional functionality in the validator:– Validator indicates which data items have been modified.– Task re-fetches only those modified items.
33

34
Minimum Spanning Tree Probelm
• Given is undirected graph with edge weights.• Implemented Gallagher-Humblet-Spira Algorithm• A vertex merges with its nearest neighbor to form a
cluster, and becomes cluster-head.• Successively, a cluster merges with its nearest node
outside its cluster or nearest other cluster.• Computation stops when no more merging is possible.• The number of clusters finally left are the connected
components of the graph.

35
Data access patterns
Problem in merging clusters: • Identifying the cluster head of the target cluster may
require following cluster head pointers on a chain of vertices.
• This may introduce significant remote data access cost
Solution: 1. Update the cluster head pointers of vertices in a cluster
to directly point to the cluster head while merging.• This can be performed asynchronously as a background
task
2. Push some of this computation into the storage service.
35

36
Minimum Weight Spanning Tree
36
Vertices Edges Beehive Nodes
Time (secs)
1000 16827 10 16
2000 65971 10 24
5000 84679 10 32
10000 337,842 10 96
20000 672,725 10 728
50000 1,682,659 10 7138

37
Graph Coloring• A coloring task is executed for each vertex.
–It reads the colors, if any assigned, of all its neighbors.–Chooses the lowest numbered unused color for the vertex
Vertices Edges Beehive Nodes Time (secs)
100,000 3,373,321 10 110200,000 6,724,266 10 208300,000 10,089,422 10 308400,000 14,459,419 10 425500,000 16,818,073 10 541
1,000,000 33,642,660 10 12532,000,000 67,265,322 10 43042,000,000 67,265,322 20 14622,000,000 67,265,322 30 1406

38
PageRank Problem• Barrier model for phased execution.
• Non-transactional execution.
38
Vertices Edges Beehive Nodes Time (secs)
100,000 3,373,321 10 93200,000 6,724,266 10 181
1,000,000 33,642,660 10 17461,000,000 33,642,660 20 7211,000,000 33,642,660 30 6352,000,000 67,265,322 20 2072

Amount of parallelismProblem Completed Tasks Aborts Time(secs)
Max-flow 9716609 71685675 5878
Graph coloring 10003 299 19.6
39
• Abort rates for a 10000 vertex graph.– Ratio of abort/commit close to 7.3 for the max-flow
problem.– Signifies low parallelism achievable for this particular
problem.
• Graph coloring problem has just 10003 tasks.– One task per vertex– Three bookkeeping tasks

40
Related Work
• Distributed GraphLab [Low et al] is closest to our work but that system does not support optimistic execution model and dynamic graph structures. It expects either graph colored for parallel execution or provides a locking engine to acquire locks on the vertices and its neighborhood.
• Piccolo [Power] provides a programming model based on shared data store but does not provide transactional semantics for multi-item updates. And run time resolves conflicts using user-defined accumulation functions.
• Pregel [Malewicz] – bulk synchronous message passing abstraction with messages between vertices for communication. May not be suitable for all types of graph processing.
• Dryad [Isard] is based on data-flow model.
• Parallel BGL [Gregor] is a C++ based library for distributed memory multi-processors, using the notion of active messages and executes in BSP like phases.

41
Conclusion• Optimistic task scheduling methods can be effectively used for exploiting
amorphous parallelism in graph problems.
• Relieves programmer from the burden of explicit message passing and synchronizations,
• But implementation of the algorithm should be driven towards amortizing or reducing remote data access costs.
• Hierarchical validation helps filtering around 30%-60% of validation requests
• Performance improvement can be achieved using data caching, increasing task granularity, and algorithm re-design to reduce remote data access costs.
• Load aware task placement is more efficient than locality aware task placement.
• Optimal cluster size for better performance.
• Because of the remote data latencies start dominating execution times.
41

42
Current and Future Work
• Fault tolerance• Checkpointing and recovery on failures
• Efficient clustering methods and initial loading of data• This can significantly improve data locality for tasks
• Adaptive methods to control the degree of optimistic execution to reduce the abort rate.
• Hybrid scheduling mechanisms to shift dynamically from optimistic execution to conflict-free scheduling.
• Optimizing algorithm implementation to reduce data access/computations if possible.
• Programming of application problems from social networking domain, ML/DM algorithms.
42

Thank you!
43

Questions?
44