1 blog mining – market research made easy? bettina berendt, k.u.leuven,
Post on 19-Dec-2015
214 views
TRANSCRIPT

1
Blog Mining – Market Research made easy?
Bettina Berendt, K.U.Leuven, www.berendt.de
Blog Mining – Market Research made easy?
Bettina Berendt, K.U.Leuven, www.berendt.de

2
About me ...

3
Motivation / Excecutive summary
Dem Volk aufs Maul sehen :

4
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

5
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

6
What‘s a blog?
a (more or less) frequently updated publication on the Web, sorted in (usually reverse) chronological order of the constituent blog posts.
The content may reflect any interests including personal, journalistic or corporate.
Usually textual, but multimedia forms exist (photoblog, vblog, …)

7
Blogs and other social media (“Web 2.0“)
Blogs(e.g., Livejournal; Huffington Post)Sharing / linking by:Hyperlinks, comments, blogroll, trackback links
Social network sites(e.g., MySpace)
Microblogging(e.g., Twitter)
Wikis(e.g., Wikipedia)
“Annotation platforms“(e.g., del.icio.us)

8
Blogs and other social media,and some of their origins in older media
Blogs(e.g., Livejournal; Huffington Post)Sharing / linking by:Hyperlinks, comments, blogroll, trackback links
Diaries (Often political) journalism PR; press releases
Social network sites(e.g., MySpace)
Dating sites
Chatrooms
Microblogging(e.g., Twitter)
Wikis(e.g., Wikipedia)
Computer-supportedcooperative work
“Annotation platforms“(e.g., del.icio.us)
Bookmarks www.dmoz.org
Usenet

9
What‘s market research?
identification, collection, analysis, and dissemination of information
for the purpose of assisting management in decision making related to the identification and solution of problems and opportunities in marketing

10
Traditional methods of (consumer) market research
Based on questioning: Focus groups, surveys, questionnaires, ...
Based on observations: Ethnographic studies - observe social phenomena in their natural
setting - observations can occur cross-sectionally or longitudinally - examples include product-use analysis and computer cookie traces.
Experimental techniques - create a quasi-artificial environment to try to control spurious factors, then manipulates at least one of the variables - examples include purchase laboratories and test markets

11
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...
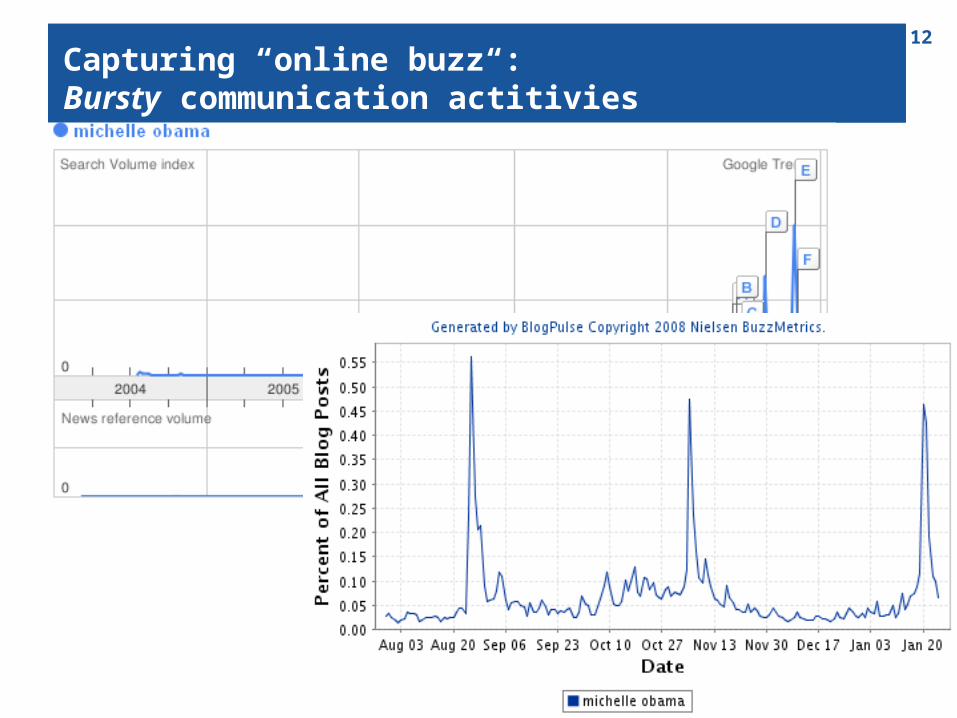
12
Capturing “online buzz“Capturing “online buzz“:Bursty communication actitivies
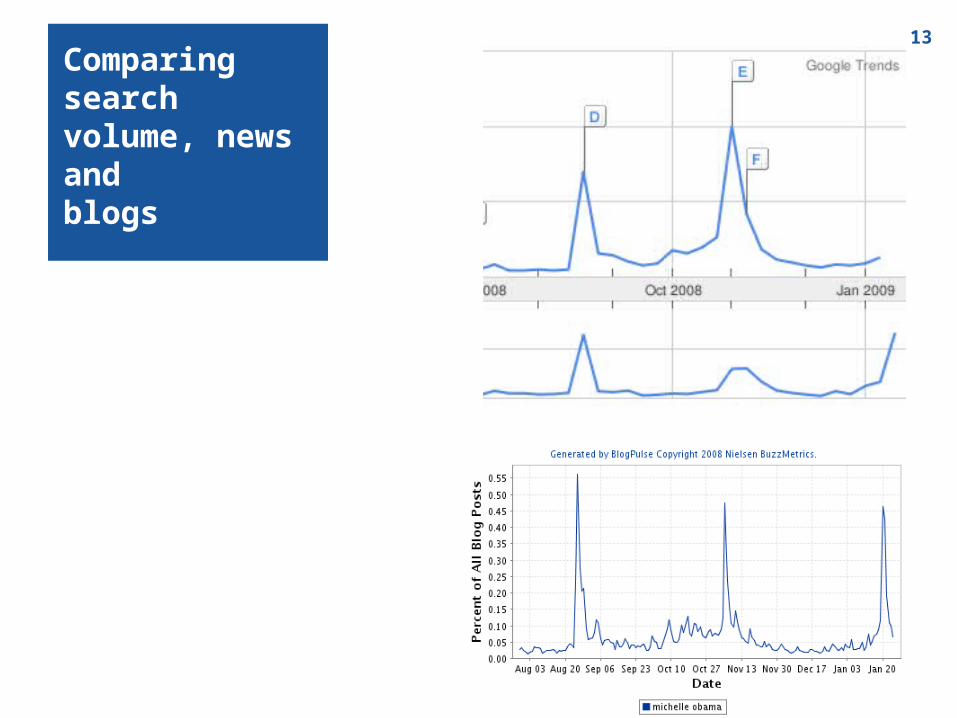
13
Comparing search volume, news and blogs

14
The idea of text mining ...
... is to go beyond frequency-counting
... is to go beyond the search-for-documents framework
... is to find patterns (of meaning) within and across documents
(yes, there is text mining behind some of the things the above tools do!)

15
The steps of text mining
1. Application understanding
2. Corpus generation
3. Data understanding
4. Text preprocessing
5. Search for patterns / modelling
Topical analysis
Sentiment analysis / opinion mining
6. Evaluation
7. Deployment

16
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

17
Application understanding; Corpus generation
What is the question?
What is the context?
What could be interesting sources, and where can they be found?
Crawl
Use a search engine and/or archive Google blogs search
Technorati
Blogdigger
...

18
Preprocessing (1)
Data cleaning
Goal: get clean ASCII text
Remove HTML markup*, pictures, advertisements, ...
Automate this: wrapper induction
* Note: HTML markup may carry information too (e.g., <b> or <h1> marks something important), which can be extracted! (Depends on the application)

19
Preprocessing (2)
Further text preprocessing Goal: get processable lexical / syntactical units Tokenize (find word boundaries) Lemmatize / stem
ex. buyers, buyer buyer / buyer, buying, ... buy
Remove stopwords Find Named Entities (people, places, companies, ...); filtering Resolve polysemy and homonymy: word sense disambiguation;
“synonym unification“ Part-of-speech tagging; filtering of nouns, verbs, adjectives, ... ...
Most steps are optional and application-dependent! Many steps are language-dependent; coverage of non-English varies Free and/or open-source tools or Web APIs exist for most steps

20
Preprocessing (3)
Creation of text representation
Goal: a representation that the modelling algorithm can work on
Most common forms: A text as
a set or (more usually) bag of words / vector-space representation: term-document matrix with weights reflecting occurrence, importance, ...
a sequence of words
a tree (parse trees)

21
An important part of preprocessing:Named-entity recognition (1)

22
An important part of preprocessing:Named-entity recognition (2)
Technique: Lexica, heuristic rules, syntax parsing
Re-use lexica and/or develop your own
configurable tools such as GATE
A challenge: multi-document named-entity recognition
See proposal in Subašić & Berendt (Proc. ICDM 2008)

23
The simplest form of content analysis is based on NER
Berendt, Schlegel und KochIn Zerfaß et al. (Hrsg.) Kommunikation, Partizipation und Wirkungen im Social Web, 2008

24
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...
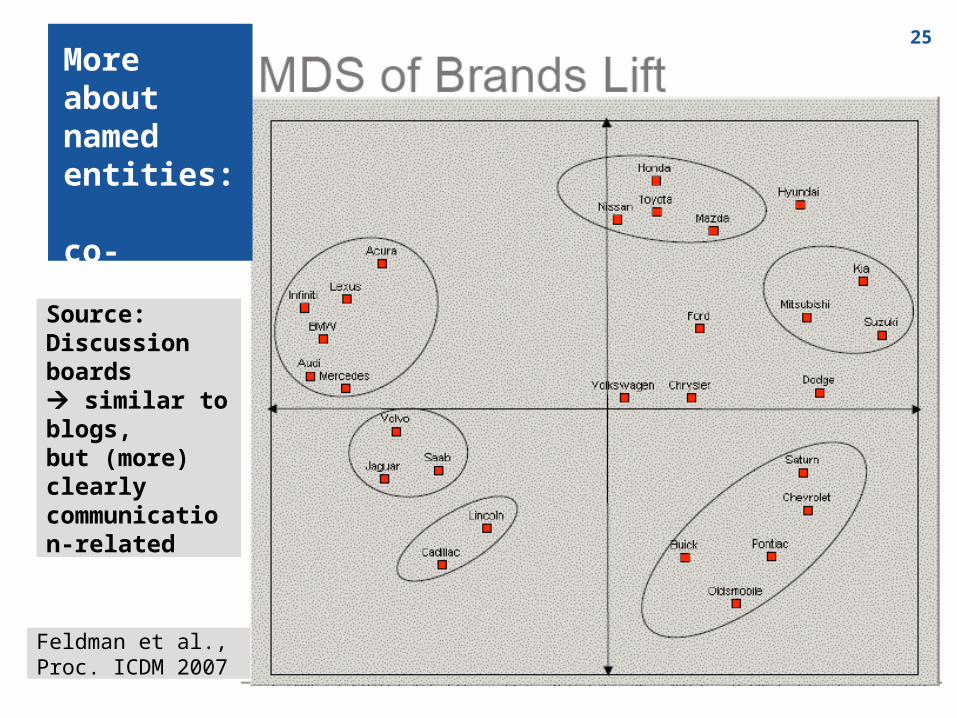
25
Feldman et al., Proc. ICDM 2007
More about named entities: co-occurrence
Source:Discussion boards similar to blogs,but (more) clearly communication-related

26
Co-occurrence of brands and attributes
Feldman et al., Proc. ICDM 2007

27
Recall “Michelle Obama“
Google Trends, Blogpulse etc. associate documents / document sets with “bursts“
But: this means the user has to read the documents!
Can we do better and create a concise summary of what was discussed in that period?
Can we allow the user to ask as much detail as s/he is interested in?
More advanced text modelling: Summarization – of time-indexed documents
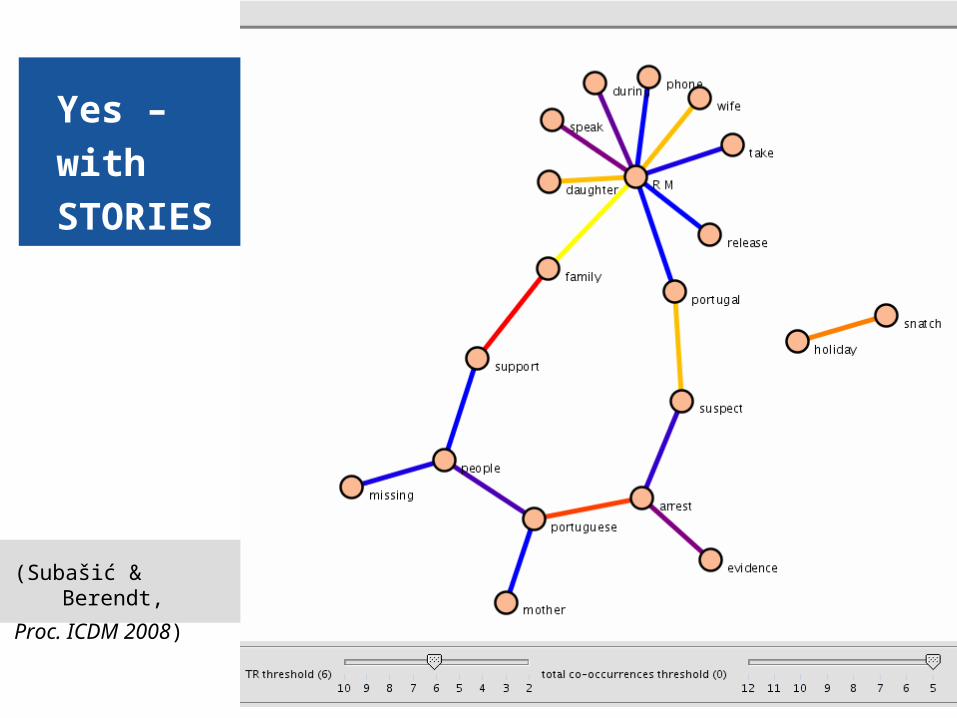
28
Yes –
with
STORIES
(Subašić & Berendt,
Proc. ICDM 2008)

29
Salient story elements
1. Identify content-bearing terms (e.g. 150 top-TF.IDF over whole corpus)
2. Split whole corpus T by atomic time period (e.g., week)
3. For each time period (atomic or moving-average) Compute the weights for corpus t for this period Weight =
Support of co-occurrence of 2 content-bearing terms w1, w2 in t =
(# articles from t containing both w1, w2 in window) / (# all articles in t)
4. Threshold Number of occurrences of co-occurrence(w1, w2) in t ≥ θ1 (e.g., 5)
Time-relevance TR of co-occurrence(w1, w2) =
support(co-occurrence(w1, w2)) in t / support(co-occurrence(w1, w2)) in T ≥ θ2 (e.g., 2)
Thresholds are set dynamically + interactively by the user
5. Story elements = relationships = all these edges
Story basics = terms = all nodes connected by these edges

30
Salient story stages, and story evolution
6. Story stage = the story graph made of basics and elements in t
7. Story evolution = how story stages evolve over the t in T

31
An event: a missing child
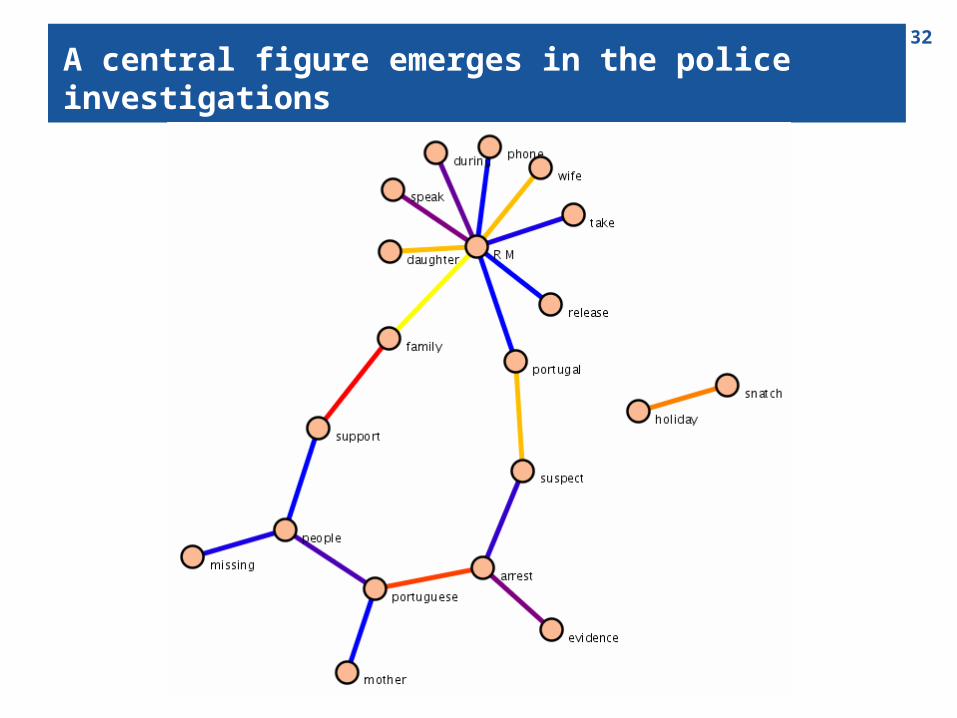
32
A central figure emerges in the police investigations

33
Uncovering more details

34
Uncovering more details

35
An eventless time

36
The story and the underlying documents

37
(Berendt & Trümper, in press)
Navigating between documents; relating different source types to one another

38A simple form of opinion mining:Feature-based Summary (Hu and Liu, Proc. SIGKDD’04)
GREAT Camera., Jun 3, 2004
Reviewer: jprice174 from Atlanta, Ga.
I did a lot of research last year before I bought this camera... It kinda hurt to leave behind my beloved nikon 35mm SLR, but I was going to Italy, and I needed something smaller, and digital.
The pictures coming out of this camera are amazing. The 'auto' feature takes great pictures most of the time. And with digital, you're not wasting film if the picture doesn't come out. …….
Feature1: picture
Positive: 12
The pictures coming out of this camera are amazing.
Overall this is a good camera with a really good picture clarity.
…
Negative: 2
The pictures come out hazy if your hands shake even for a moment during the entire process of taking a picture.
Focusing on a display rack about 20 feet away in a brightly lit room during day time, pictures produced by this camera were blurry and in a shade of orange.
Feature2: battery life
…
Source: Product reviews similar to blogs, but (more) clearly product-related

39
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

40
An application: Crisis PR – Step 1:Use blogs to observe public discussions
Detect products about which there is controversial discussion
sentiment mining from text
and/or
use the structure of blogs (e.g., structure of blog post + comments; Mishne & Glance, Proc. WWW 2006)
and/or
discussion in the mainstream media (may be later though)

41
An application: Crisis PR – Step 2: Use blogs to communicate facts + own concerns
Example Dell‘s “exploding laptops“ – product recall and aftermath
Dell launched a blog at that time (much maligned at first, but they learned ...)
Evaluation of „all English-language consumer commentary on the Web“ before and after (methodology based on Reichhold 1996, The Loyalty Effect):
Market sentinel, 2007

42
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

43
First ...
... the imperfect nature of automatic text analysis presents a challenge
But: human inter-rater agreement on various aspects of texts also tends to be rather low!

44
Some findings
Only a fraction of the population blog (8% of adult Internet users - Pew Internet & American Life Project July 2006)
Most blogs are personal
US survey (Business Week July 2006)
German-language blogosphere is less “mature“, esp. Less politicized, than the US blogosphere (Berendt, Schlegel & Koch, 2008)
This includes fewer mentions of companies
But what about those personal blogs ...?

45
What makes people happy?

46
Happiness in blogosphere

47
Well kids, I had an awesome birthday thanks to you. =D Just wanted to so thank you for coming and thanks for the gifts and junk. =) I have many pictures and I will post them later. hearts
Well kids, I had an awesome birthday thanks to you. =D Just wanted to so thank you for coming and thanks for the gifts and junk. =) I have many pictures and I will post them later. hearts
current mood:
Home alone for too many hours, all week long ... screaming child, headache, tears that just won’t let themselves loose.... and now I’ve lost my wedding band. I hate this.
Home alone for too many hours, all week long ... screaming child, headache, tears that just won’t let themselves loose.... and now I’ve lost my wedding band. I hate this.
current mood:
What are the characteristic words of these two moods?
[Mihalcea, R. & Liu, H. (2006). In Proc. AAAI Spring Symposium CAAW.]
Slides based on Rada Mihalcea‘s presentation.

48
Data, data preparation and learning
LiveJournal.com – optional mood annotation
10,000 blogs:
5,000 happyhappy entries / 5,000 sadsad entries
average size 175 words / entry
post-processing – remove SGML tags, tokenization, part-of-speech tagging
quality of automatic “mood separation”
naïve bayes text classifier five-fold cross validation
Accuracy: 79.13% (>> 50% baseline)

49
Results: Corpus-derived happiness factors
yay 86.67
shopping 79.56
awesome 79.71
birthday 78.37
lovely 77.39
concert 74.85
cool 73.72
cute 73.20
lunch 73.02
books 73.02
goodbye 18.81hurt 17.39tears 14.35cried 11.39upset 11.12sad 11.11cry 10.56died 10.07lonely 9.50crying 5.50
happiness factor of a word = the number of occurrences in the happy blogposts / the total frequency in the corpus

50
Agenda
Concepts
The representativeness challenge
Text mining: first steps
Text mining: going deeper
Closing the loop: from blogs to blogs
From “online buzz“ to text mining
So ...

51
Conclusion
[A brief glance given:] (Semi-)automated forms of text analysis, applied to blogs, can produce useful insights
[Only briefly mentioned today:] It can profit from the simultaneous analysis of link structures and/or tags
It is the only way of analysing large-scale corpora; mining methods are improving continuously
However, machine language understanding is not human language understanding
Also, representativeness is questionable
Need to combine blog mining with other forms of market research!
NB: These forms include Web usage mining, query mining, ...
But mining remains exploratory analysis

52

53
Literature and other sources
URLs of pictures are given in the “Comments“ of the slides.
Literature (Please note: Most of our papers are available at http://www.cs.kuleuven.be/~berendt):
pp. 22, 28-36: Subašić, I. & Berendt, B. (2008). Web mining for understanding stories through graph visualisation. In Proc. of the 2008 Eighth IEEE International Conference on Data Mining (pp. 570–579). Los Alamitos, CA: IEEE Computer Society Press.
pp. 23, 44: Berendt, B., Schlegel, M., & Koch, R. (2008). Die deutschsprachige Blogosphäre: Reifegrad, Politisierung, Themen und Bezug zu Nachrichtenmedien. In A. Zerfaß, M. Welker, & J. Schmidt (Eds.), Kommunikation, Partizipation und Wirkungen im Social Web (Band 2:Strategien und Anwendungen: Perspektiven für Wirtschaft, Politik, Publizistik) (pp. 72–96). Köln, Germany: Herbert von Halem Verlag.
pp. 25f: R. Feldman, M. Fresko, J. Goldenberg, O. Netzer, and L. H. Ungar (2007). Extracting product comparisons from discussion boards. In Proc. ICDM 2007, pp. 469–474. IEEE Computer Society, 2007. http://ieeexplore.ieee.org/iel5/4470209/4470210/04470275.pdf?arnumber=4470275
p. 37: Berendt, B. & Trümper, D. (in press). Semantics-based analysis and navigation of heterogeneous text corpora: the porpoise news and blogs engine. In I.-H. Ting (Ed.), Web Mining Applications in E-commerce and E-services, Berlin etc.: Springer.
p. 38: Minqing Hu and Bing Liu (2004). Mining and summarizing customer reviews. In Proc. SIGKDD’04 (pp. 168-177). http://portal.acm.org/citation.cfm?doid=1014052.1014073
p. 40: Gilad Mishne and Natalie Glance (2006). Leave a Reply: An Analysis of Weblog Comments. In Proc. WWE 2006. http://www.blogpulse.com/www2006-workshop/papers/wwe2006-discovery-lin-final.pdf
p. 41: market sentinel (2007). Responding to crisis using social media Updating the “Dell Hell” case study - are Dell turning opinion round? http://www.marketsentinel.com/files/Crisisresponseusingsocialmedia.pdf
p. 44: BusinessWeek - Jul 19 2006. A Survey: Majority of blogs are personal. (not online any more)
pp. 47-49: Mihalcea, R. & Liu, H. (2006). A corpus-based approach to finding happiness, In Proc. AAAI Spring Symposium on Computational Approaches to Analyzing Weblogs. http://www.cs.unt.edu/%7Erada/papers/mihalcea.aaaiss06.pdf
See http://wiki.esi.ac.uk/Current_Approaches_to_Data_Mining_Blogs for more articles on the subject.