1 comp3503 semi-supervised learning comp3503 semi-supervised learning daniel l. silver
TRANSCRIPT

1
COMP3503COMP3503 Semi-Supervised Learning Semi-Supervised Learning
Daniel L. SilverDaniel L. Silver

2
AgendaAgenda Unsupervised + Supervised = Unsupervised + Supervised =
Semi-supervisedSemi-supervised Semi-supervised approachesSemi-supervised approaches Co-TrainingCo-Training SoftwareSoftware

3
Stanford’s Sebastian Thrun holds a $2M check on top of Stanley, a Stanford’s Sebastian Thrun holds a $2M check on top of Stanley, a robotic Volkswagen Touareg R5robotic Volkswagen Touareg R5
212 km autonomus vehicle race, Nevada 212 km autonomus vehicle race, Nevada Stanley completed in 6h 54mStanley completed in 6h 54m Four other teams also finishedFour other teams also finished Great Great TED talk by him on Driverless carsby him on Driverless cars Further Further background on Sebastian
DARPA Grand DARPA Grand Challenge 2005Challenge 2005

4Unsupervised + Unsupervised + Supervised = Semi-Supervised = Semi-supervisedsupervised Sebastian Thrun on
Supervised, Unsupervised and Semi-supervised learning
http://www.youtube.com/watch?v=qkcFRr7LqAw

5
Labeled data is expensive Labeled data is expensive ……

6
6
Semisupervised learningSemisupervised learning● Semisupervised learningSemisupervised learning: attempts to use : attempts to use
unlabeled data as well as labeled dataunlabeled data as well as labeled data The aim is to improve classification The aim is to improve classification
performanceperformance● Why try to do this? Unlabeled data is often Why try to do this? Unlabeled data is often
plentiful and labeling data can be plentiful and labeling data can be expensiveexpensive
Web mining: classifying web pagesWeb mining: classifying web pages Text mining: identifying names in textText mining: identifying names in text Video mining: classifying people in the newsVideo mining: classifying people in the news
● Leveraging the large pool of unlabeled Leveraging the large pool of unlabeled examples would be very attractiveexamples would be very attractive
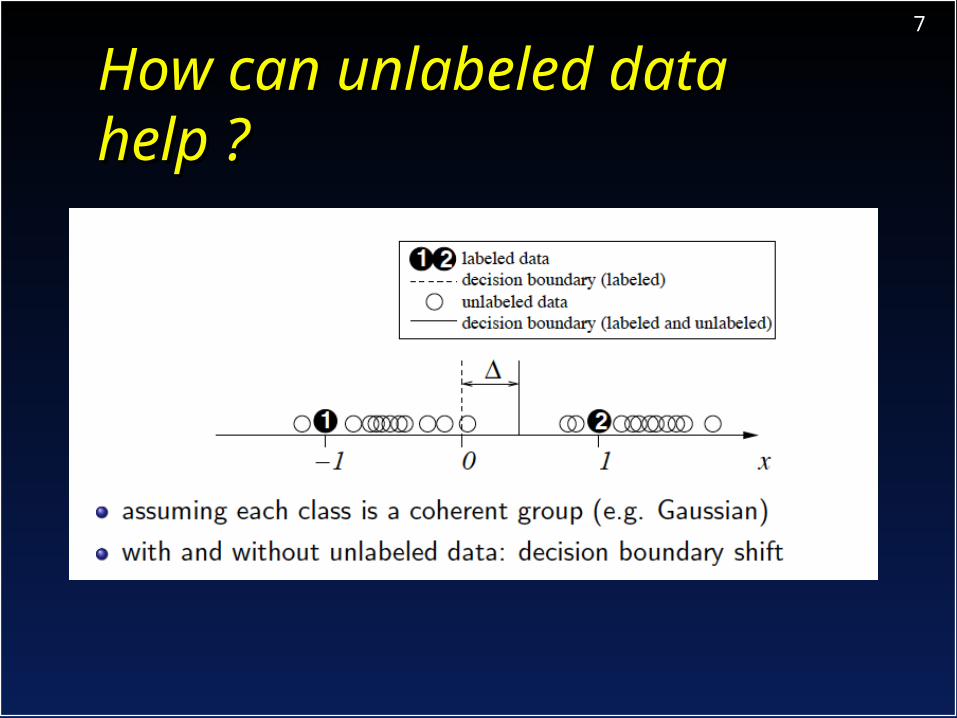
7
How can unlabeled data How can unlabeled data help ?help ?

8
8
Clustering for Clustering for classificationclassification
● Idea: use naïve Bayes on labeled Idea: use naïve Bayes on labeled examples and then apply EMexamples and then apply EM
1. Build naïve Bayes model on labeled data1. Build naïve Bayes model on labeled data
2. Label unlabeled data based on class probabilities 2. Label unlabeled data based on class probabilities (“expectation” step)(“expectation” step)
3. Train new naïve Bayes model based on all the data 3. Train new naïve Bayes model based on all the data (“maximization” step)(“maximization” step)
4. Repeat 24. Repeat 2ndnd and 3 and 3rdrd step until convergence step until convergence
● Essentially the same as EM for clustering Essentially the same as EM for clustering with fixed cluster membership probabilities for labeled data and with fixed cluster membership probabilities for labeled data and #clusters = #classes#clusters = #classes
● Ensures finding model parameters Ensures finding model parameters that have that have equal or greater likelihood after each iterationequal or greater likelihood after each iteration

9
9
Clustering for Clustering for classificationclassification
● Has been applied successfully to Has been applied successfully to document classificationdocument classification
● Certain phrases are indicative of classesCertain phrases are indicative of classes●e.g “supervisor” and “PhD topic” in graduate student webpagee.g “supervisor” and “PhD topic” in graduate student webpage
● Some of these phrases occur only in the unlabeled Some of these phrases occur only in the unlabeled data, some in both setsdata, some in both sets●EM can generalize the model by taking advantage EM can generalize the model by taking advantage of co-occurrence of these phrasesof co-occurrence of these phrases
● Has been shown to work quite wellHas been shown to work quite well● A bootstrappng procedure A bootstrappng procedure from unlabeled to from unlabeled to labeledlabeled
● Must take care to ensure feedback is Must take care to ensure feedback is positivepositive

10
Also known as Self-training Also known as Self-training ....

11
Also known as Self-training Also known as Self-training ....

12
12
Clustering for Clustering for classificationclassification
● Refinement 1: Refinement 1: Reduce weight of unlabeled data to increase Reduce weight of unlabeled data to increase power of more accuracte labeled datapower of more accuracte labeled data During Maximization step, maximize During Maximization step, maximize weighting of labeled examplesweighting of labeled examples
●Refinement 2: Refinement 2: Allow multiple clusters per classAllow multiple clusters per class Number of clusters per class can be set by Number of clusters per class can be set by cross-validation .. What does this mean ??cross-validation .. What does this mean ??

13
Generative ModelsGenerative Models
See Xiaojin Zhu slides – p. 28Xiaojin Zhu slides – p. 28

14
14
Co-trainingCo-training● Method for learning from Method for learning from multiple viewsmultiple views (multiple sets of attributes), (multiple sets of attributes), eg: classifying eg: classifying webpageswebpages
●First set of attributes describes content of web pageFirst set of attributes describes content of web page●Second set of attributes describes links from other pagesSecond set of attributes describes links from other pages
● Procedure:Procedure:1.1.Build a model from each view using available labeled Build a model from each view using available labeled datadata
2.2.Use each model to assign labels to unlabeled dataUse each model to assign labels to unlabeled data
3.3.Select those unlabeled examples that were most Select those unlabeled examples that were most confidently predicted by both models (ideally, preserving confidently predicted by both models (ideally, preserving ratio of classes)ratio of classes)
4.4.Add those examples to the training setAdd those examples to the training set
5.5.Go to Step 1 until data exhaustedGo to Step 1 until data exhausted● Assumption: views are independent – Assumption: views are independent – this this reduces the probability of the models agreeing on reduces the probability of the models agreeing on incorrect labelsincorrect labels

15
15
Co-trainingCo-training● Assumption: views are independent – Assumption: views are independent – this this reduces the probability of the models agreeing on reduces the probability of the models agreeing on incorrect labelsincorrect labels● On datasets where independence holds On datasets where independence holds experiments have shown that co-training gives experiments have shown that co-training gives better results than using a standard semi-better results than using a standard semi-supervised EM approachsupervised EM approach● Whys is this ?Whys is this ?

16
16
Co-EM: EM + Co-trainingCo-EM: EM + Co-training
● Like EM for semisupervised learning, Like EM for semisupervised learning, but view is switched in each iteration of but view is switched in each iteration of EMEM
●Uses all the unlabeled data (probabilistically labeled) Uses all the unlabeled data (probabilistically labeled) for trainingfor training
● Has also been used successfully with Has also been used successfully with neural networks and support vector neural networks and support vector machinesmachines Co-training also seems to work when Co-training also seems to work when views are chosen randomly!views are chosen randomly!
●Why? Possibly because co-trained combined Why? Possibly because co-trained combined classifier is more robust than the assumptions made classifier is more robust than the assumptions made per each underlying classifierper each underlying classifier

17Unsupervised + Unsupervised + Supervised = Semi-Supervised = Semi-supervisedsupervised Sebastian Thrun on
Supervised, Unsupervised and Semi-supervised learning
http://www.youtube.com/watch?v=qkcFRr7LqAw

18
Example: Object recognition results from tracking-based semi-supervised learning http://www.youtube.com/watch?v=9i7gK3-UknU http://www.youtube.com/watch?v=N_spEOiI550 Video accompanies the RSS2011 paper "Tracking-based semi-
supervised learning". The classifier used to generate these results was trained using 3
hand-labeled training tracks of each object class plus a large quantity of unlabeled data.
Gray boxes are objects that were tracked in the laser and classified as neither pedestrian, bicyclist, nor car.
The object recognition problem is broken down into segmentation, tracking, and track classification components. Segmentation and tracking are by far the largest sources of error.
Camera data is used only for visualization of results; all object recognition is done using the laser range finder.

19
Software …Software …
WEKA version that does semi-supervised learning • http://www.youtube.com/watch?v=sWxcIjZFGNM• https://sites.google.com/a/deusto.es/xabier-ugarte/
downloads/weka-37-modification LLGC - Learning with Local and Global
Consistency• http://research.microsoft.com/en-us/um/people/
denzho/papers/LLGC.pdf

20
References:References:
Introduction to Semi-Supervised LearningIntroduction to Semi-Supervised Learning• http://pages.cs.wisc.edu/~jerryzhu/pub/sslicml07.pdf http://pages.cs.wisc.edu/~jerryzhu/pub/sslicml07.pdf
Introduction to Semi-Supervised LearningIntroduction to Semi-Supervised Learning• http://mitpress.mit.edu/sites/default/files/titles/http://mitpress.mit.edu/sites/default/files/titles/
content/9780262033589_sch_0001.pdfcontent/9780262033589_sch_0001.pdf
