1 econometria financeira - iseg lisbonpascal.iseg.utl.pt/~nicolau/ef_mmf/1-210.pdf · 2 1...
TRANSCRIPT

1
Econometria Financeira
2011/2012
João Nicolau

2
1 Introdução
1.1 Objecto e Método
“Financial econometrics is simply the application of econometric tools to financial data”(Engle, 2001).
Vamos estudar alguns métodos econométricos para séries temporais financeiras. Estes méto-dos servem de suporte a variadíssimos estudos:
• Modelação dos retornos e previsão da volatilidade;• Avaliação do risco (por exemplo, através do Value at Risk);• Avaliação de opções, etc.;• Selecção e gestão de portfolios;• Análise da previsibilidade e eficiência dos mercados, etc.;

3
1.2 Séries Financeiras versus Séries Macroeconómicas
Principais diferenças entre as séries financeiras e séries macroeconómicas:• dados de natureza macroeconómica (consumo, produto, taxa de desemprego) podemser observados mensalmente, trimestralmente ou anualmente; dados financeiros, como porexemplo, retornos de acções ou taxas de câmbio podem ser observados com uma frequênciamuito superior; nalguns casos, com intervalos de minutos ou segundos entre duas observaçõesconsecutivas;• o número de observações disponíveis é muito maior com séries financeiras;• os dados macroeconómicos são menos fiáveis• as séries financeiras exibem habitualmente fortes efeitos não lineares e distribuições nãonormais.

4
1.3 Preços e Retornos
Ponto de partida:
P1, P2, ..., Pn
(por exemplo, a série das cotações de fecho do BCP num certo intervalo de tempo).
Depois: calculam-se os retornos.
Duas formas de calcular os retornos:
Rt =Pt − Pt−1
Pt−1rt = logPt − logPt−1

5
Relação entre Rt e rt :
rt = logPt − logPt−1
= logPt
Pt−1
= log
(1 +
Pt − Pt−1
Pt−1
)= log (1 +Rt) .
Mas, em geral,
rt ' Rt
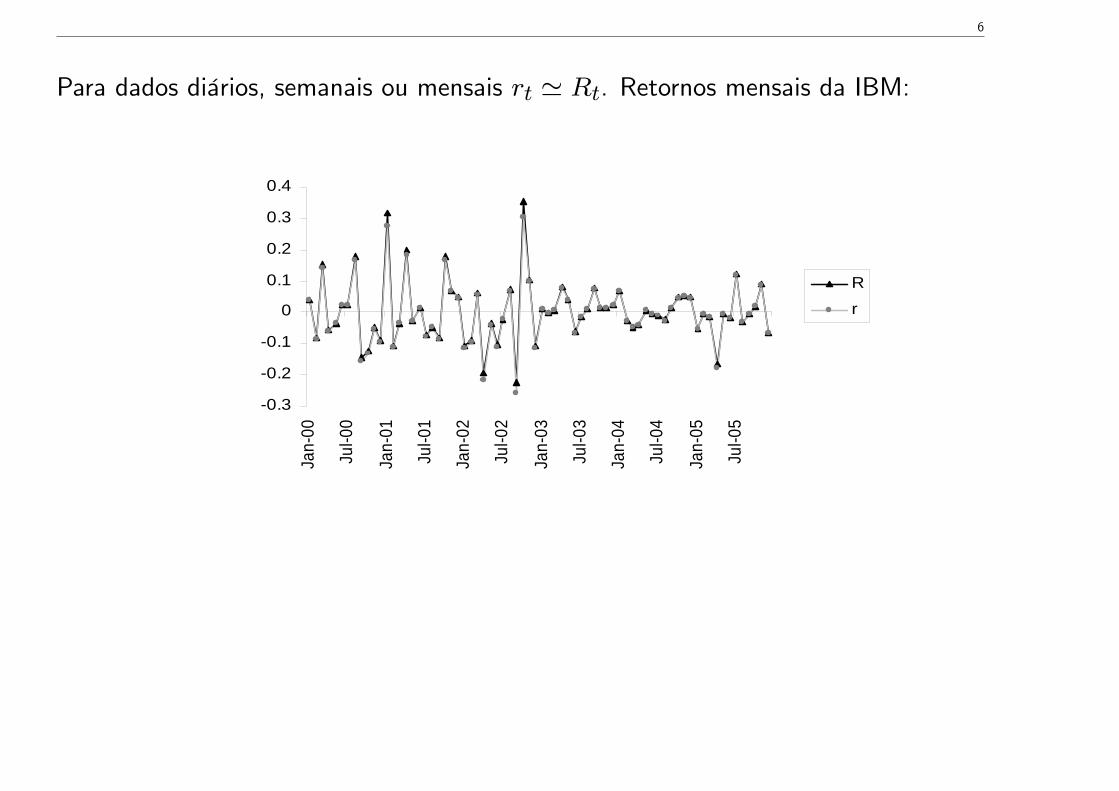
6
Para dados diários, semanais ou mensais rt ' Rt. Retornos mensais da IBM:
0.3
0.2
0.1
0
0.1
0.2
0.3
0.4
Jan
00
Jul0
0
Jan
01
Jul0
1
Jan
02
Jul0
2
Jan
03
Jul0
3
Jan
04
Jul0
4
Jan
05
Jul0
5
R
r
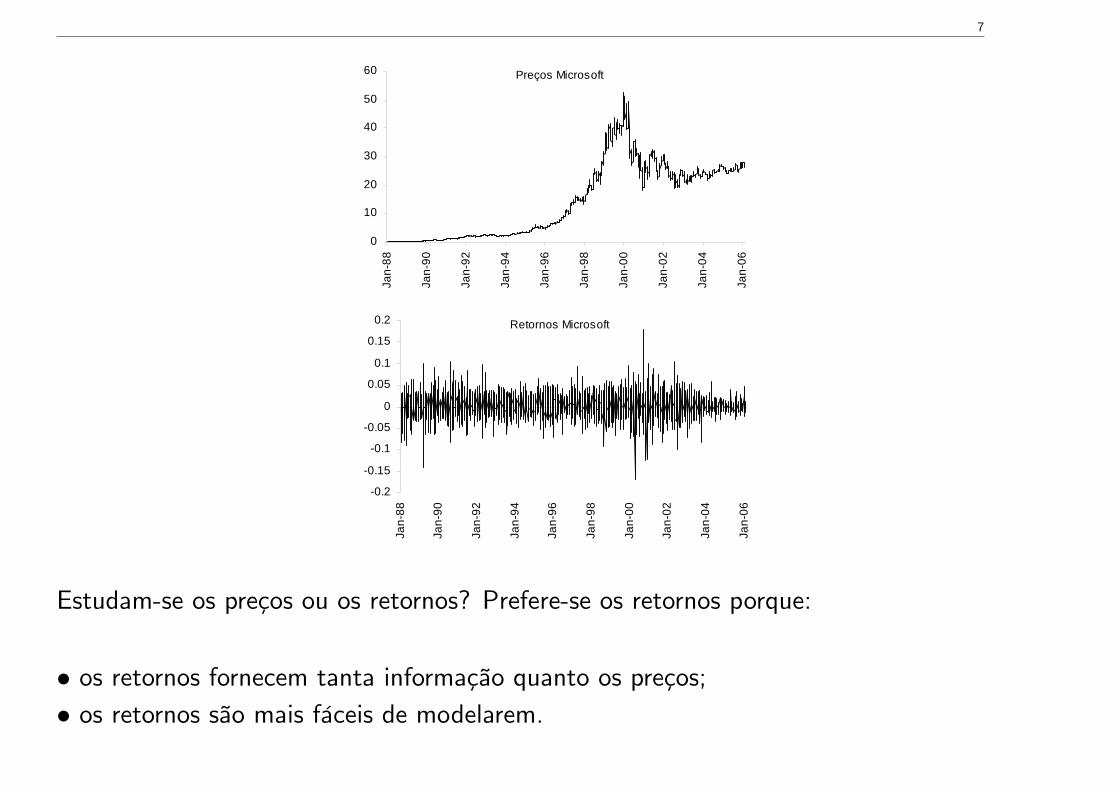
7
Preços Microsoft
0
10
20
30
40
50
60
Jan
88
Jan
90
Jan
92
Jan
94
Jan
96
Jan
98
Jan
00
Jan
02
Jan
04
Jan
06
Retornos Microsoft
0.2
0.15
0.1
0.05
0
0.05
0.1
0.15
0.2
Jan
88
Jan
90
Jan
92
Jan
94
Jan
96
Jan
98
Jan
00
Jan
02
Jan
04
Jan
06
Estudam-se os preços ou os retornos? Prefere-se os retornos porque:
• os retornos fornecem tanta informação quanto os preços;• os retornos são mais fáceis de modelarem.

8
Estuda-se rt ou Rt? Prefere-se geralmente rt .
Retornos Anualizados
Qual é a taxa de rendibilidade anual, rA, tal que, aplicada a um investimento P0 permite aofim de T anos obter o investimento Pn? Ou seja, qual é o valor rA que resolve a equação
P0erAT = Pn ?⇒ rA =
1
Tlog
(Pn
P0
).
Se os preços P0, P1, ...Pn são diários e se admitirmos que num ano se observam 250 preços,então deduz-se a relação T = n/250. Nestas condições,
rA =250
nlog
(Pn
P0
).
Em termos gerais, se num ano se observamN preços (por exemplo,N = 12 se as observaçõessão mensais) e dispomos de n observações sobre os preços, então T = n/N e
rA = ... = Nr.

9
Volatilidade Anualizada
Retorno anual
X = logPN − logP0 =N∑t=1
rt.
Supondo E (r1) = E (r2) = ... = E (rN) , tem-se que o retorno médio anual é dado por
E (X) = N E (rt) .
Estimativa de E (X) é, precisamente, rA = Nr .
Suponha-se que a sucessão {rt} é não autocorrelacionada e que Var (rt) = σ2. Nestascondições, a variância anualizada é dada por
Var (X) = Var
N∑t=1
rt
= Nσ2.

10
Entre os investidadores fala-se numa “volatilidade anualizada”dada por√Nσ
onde σ é o desvio padrão associado a um medida intra anual.
Dados diários, vol. anualizada√
250σd (σd é o dp associado aos dados diários);
Dados mensais, vol. anualizada√
12σm (σm é o dp associado aos dados mensais).
A informação anualizada pode ser dada em percentagem:
Nr × 100%,√Nσ × 100%.

11
1.4 Retorno Multi-Períodos
{P1, P2, ..., Pn} → preços diários. Retorno semanal (supondo 1 semana = 5 dias)? Bastaconsiderar
rt (5) = log
(Pt
Pt−5
)De uma forma geral,
rt (m) = log
(Pt
Pt−m
)= log (Pt)− log (Pt−m) .
Como calcular rt (m) a partir dos retornos em t = 1, 2, ...? Para exemplificar, suponha-seque se têm retornos diários e procura-se o retorno semanal, i.e., admita-se o seguinte:
retorno 2a feira r1 = logP1 − logP0retorno 3a feira r2 = logP2 − logP1retorno 4a feira r3 = logP3 − logP2retorno 5a feira r4 = logP4 − logP3retorno 6a feira r5 = logP5 − logP4retorno da semana logP5 − logP0 = r1 + r2 + ...+ r5

12
A tabela anterior sugere que o retorno da semana é igual à soma dos retornos diários dasemana. Com efeito,
logP5 − logP0 = logP5 − logP4︸ ︷︷ ︸r5
+ logP4 − logP3︸ ︷︷ ︸r4
+ logP3 − logP2︸ ︷︷ ︸r3
+logP2 − logP1︸ ︷︷ ︸r2
+ logP1 − logP0︸ ︷︷ ︸r1
Conclui-se:
rt (m) = rt + rt−1 + ...+ rt−m+1.

13
2 Revisões: Modelos ARMA
A variável dependente é y (pode ser um retorno, uma taxa de juro, etc.).
Começaremos por admitir que a única informação que dispomos sobre y é a própria série:
Como explicar yt a partir da informação Ft−1 = {yt−1, yt−2, ...}?
Se yt não está correlacionado de alguma forma com os seus valores passados yt−1, yt−2, ... aabordagem de séries temporais é inútil. Pelo contrário, se existe evidência de autocorrelação,então os valores passados da série podem explicar parcialmente o comportamento futuro dey.

14
2.1 Definições Preliminares
2.1.1 Autocorrelação de Ordem s (FAC)
Suponha-se que y é um processo estacionário de segunda ordem (E2O). Para medir a asso-ciação linear entre yt e yt−s considera-se o coeficiente de autocorrelação de ordem s,
ρs =Cov(yt, yt−s)√
Var (yt) Var (yt−s).
Como Var (yt) = Var (yt−s) escrevemos Var (yt) = Var (yt−s) = γ0.
ρs =Cov(yt, yt−s)√Var (yt) Var (yt)
=γs√γ2
0
=γsγ0.
Naturalmente,
|ρs| ≤ 1.

15
Em geral, devemos esperar (sem contar com sazonalidade):
• |ρs| > |ρk| para s < k. Os eventos remotos, por estarem mais afastados no tempo, devemestar menos correlacionados com os eventos contemporâneos.
• |ρs| → 0 quando s→ +∞. O passado muito remoto não deve estar correlacionado como presente.
2.1.2 Autocorrelação Parcial de Ordem s (FACP)
Quando se calcula a correlação entre, por exemplo, yt e yt−2, por vezes sucede que acorrelação detectada se deve ao facto de yt estar correlacionado com yt−1, e yt−1, porsua vez, estar correlacionado com yt−2. Com a autocorrelação parcial procura-se medir acorrelação entre yt e yt−s eliminando o efeito das variáveis intermédias, yt−1, ..., yt−s+1. Aanálise desta forma de autocorrelação é importante na medida em que permite, juntamentecom a FAC, identificar o processo linear subjacente.

16
Considere-se:
yt = c+ φ11yt−1 + ξt
yt = c+ φ21yt−1 + φ22yt−2 + ξt
yt = c+ φ31yt−1 + φ32yt−2 + φ33yt−3 + ξt
...
yt = c+ φs1yt−1 + φs2yt−2 + ...+ φssyt−s + ξt
A autocorrelação parcial de ordem i é dada pelo coeficiente φii. Por exemplo, a autocorre-lação parcial de ordem 2 é dada pelo coeficiente φ22 na regressão
yt = c+ φ21yt−1 + φ22yt−2 + ξt.
Podemos usar o OLS para obter φ22. Este coeficiente mede a relação entre yt e yt−2 depoisdo efeito de yt−1 ter sido removido.

17
Exemplo
0
4
8
12
16
20
1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005 2010
Y FEDERAL FUNDS RATE

18
2.2 Processos Lineares Estacionários
2.2.1 Processos Média Móvel
Processo MA (1)
yt = µ+ θut−1 + ut
onde ut é um ruído branco, Var (ut) = σ2. Interpretação:• yt é uma combinação linear de choques aleatórios (ut−1 e ut);• .yt resulta de um mecanismo de correcção: utilizamos o erro cometido no período anterior,ut−1, como “regressor ” (i.e., como variável explicativa);• Modelo indicado para modelar fenómenos de memória muito curta (veremos que a auto-correlação de y extingue-se muito rapidamente).
Para sabermos alguma coisa sobre as propriedades estatísticas de yt é necessário calcularmomentos, covariâncias, correlações, etc.

19
Momentos Marginais
Os primeiros momentos marginais (ou não condicionais) são
E (yt) = E (µ+ θut−1 + ut) = µ
Var (yt) = Var (µ+ θut−1 + ut) = θ2σ2 + σ2
Covariâncias
γ1 = Cov (yt, yt−1) = E [(yt − µ) (yt−1 − µ)]
= E [(θut−1 + ut) (θut−2 + ut−1)]
= θσ2
Pode-se provar
γs = 0 para s > 1.
O processo yt é E2O pois:
• E (yt) e Var (yt) são constantes;• γs não depende de t.

20
FAC e FACP
Conclui-se agora que as autocorrelações são dadas por
ρ1 =γ1
γ0=
θσ2
θ2σ2 + σ2=
θ
θ2 + 1ρk = 0 para k > 1.
Só o primeiro coeficiente de autocorrelação, ρ1, é diferente de zero ⇒ Memória curta (oque se passou há dois períodos atrás não está associado com o valor corrente).
Relativamente às autocorrelações parciais tem-se
φ11 = ρ1 =θ
θ2 + 1
e (pode-se provar)
φkk 6= 0, mas φkk → 0, quando k →∞.

21
Momentos Condicionais
Considere-ne novamente:
yt = µ+ θut−1 + ut.
Momentos condicionais:
E (yt| Ft−1) = µ+ θut−1
Var (yt| Ft−1) = σ2
Se ut é um ruído branco Gaussiano então
yt| Ft−1 ∼ N(µ+ θut−1, σ
2).

22
Processo MA (q)
yt = µ+ θ1ut−1 + θ2ut−2 + ...+ θqut−q + ut,
O processo yt continua a representar-se como uma combinação linear de choques aleatórios.
Pode-se provar:
E (yt) = µ
Var (yt) = σ2(
1 + θ21 + ...+ θ2
q
)ρk =
{6= 0 se k = 1, 2, ..., q0 se k = q + 1, q + 2, ...
Pode-se provar ainda:
φkk 6= 0, mas φkk → 0, quando k → +∞.

23
2.2.2 Processos Autoregressivos
Agora, em vez de yt ser explicado pelos erros passados, yt é explicado pelos seus própriosvalores passados.
Processo AR (1)
yt = c+ φyt−1 + ut
onde ut é ruído branco.
Este modelo é muito importante porque reproduz razoavelmente a dinâmica de muitas sérieseconómicas e financeiras.

24
Momentos Marginais
Comece-se por calcular a média marginal
E (yt) = E (c+ φyt−1 + ut) = c+ φE (yt−1) .
Se assumirmos à partida a condição de E2O (implicando E (yt) = E (yt−1) = E (y)) vem
E (y) = c+ φE (y)⇒ E (y) = c1−φ
Seguindo um raciocínio idêntico vem:
Var (yt) = Var [c+ φyt−1 + ut] = φ2 Var (yt−1) + Var [ut]
= φ2 Var (yt−1) + σ2
Sob a hipótese de E2O, tem-se Var (yt) = Var (yt−1) = Var (y) e, portanto,
Var (y) = φ2 Var (y) + σ2 ⇒ Var (y) = σ2
1−φ2 .

25
FAC e FACP
Pode-se provar:
ρk = φk.
Por outro lado, tendo em conta a definição de autocorrelação parcial, tem-se:
yt = c+ φ11yt−1 + ut ⇒ φ11 = ρ1
yt = c+ φ21yt−1 + φ22yt−2 + ut ⇒ φ22 = 0
Assim,
φkk =
{ρ1 se k = 10 se k > 1

26
Os dois primeiros momentos condicionais são
E (yt| Ft−1) = E (yt| yt−1) = E [c+ φyt−1 + ut| yt−1] = c+ φyt−1,
Var (yt| Ft−1) = E[(yt − c− φyt−1)2
∣∣∣ yt−1
]= E
[u2t
∣∣∣ yt−1
]= σ2.
Se ut é um ruído branco Gaussiano então
yt| Ft−1 ∼ N(c+ φyt−1, σ
2).
Pode-se provar que a condição de estacionaridade do processo AR(1) é
|φ| < 1.
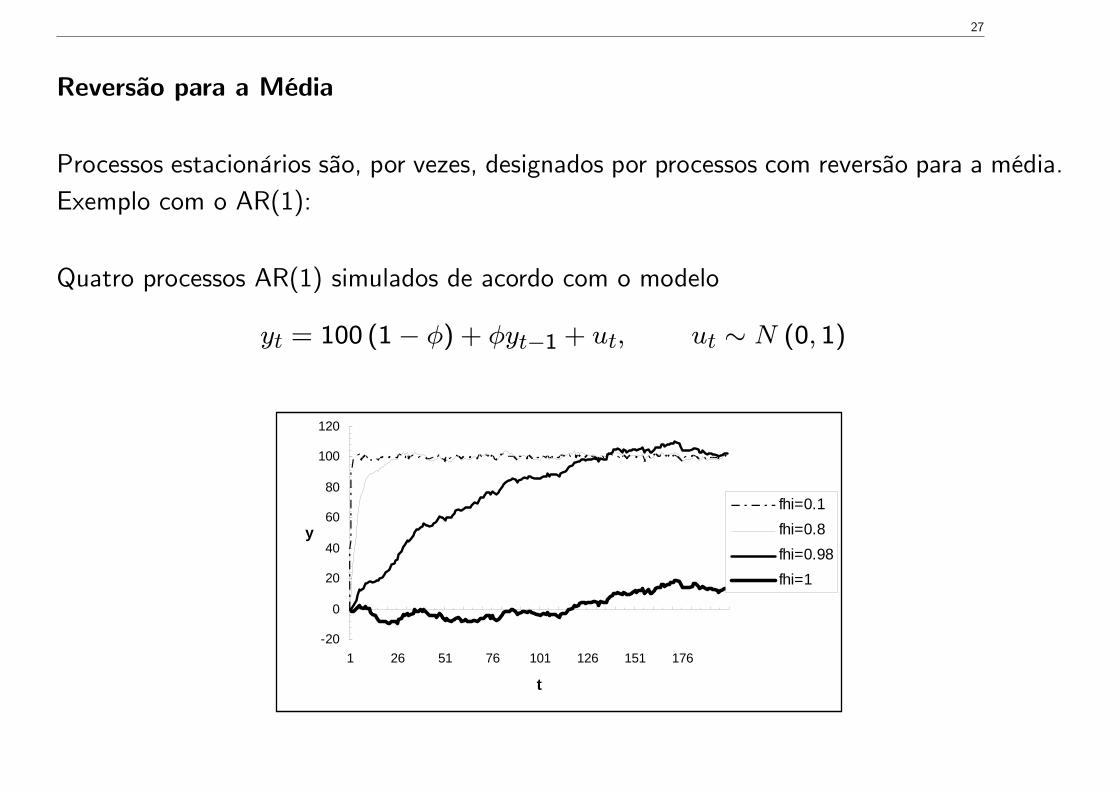
27
Reversão para a Média
Processos estacionários são, por vezes, designados por processos com reversão para a média.Exemplo com o AR(1):
Quatro processos AR(1) simulados de acordo com o modelo
yt = 100 (1− φ) + φyt−1 + ut, ut ∼ N (0, 1)
20
0
20
40
60
80
100
120
1 26 51 76 101 126 151 176
t
y
fhi=0.1fhi=0.8fhi=0.98fhi=1

28
Processo AR (p)
yt = c+ φ1yt−1 + ...+ φpyt−p + ut
Estacionaridade
Proposição O processo AR(p) é estacionário sse as raízes da equação(1− φ1L− φ2L
2 − ...φpLp)
= 0
são em módulo superiores a um.
AR(1), φp (L) = (1− φL)
AR(2), φp (L) =(
1− φ1L− φ2L2), etc.

29
FAC e FACP
Suponha-se que y é E2O. Nestas condições, pode-se provar:
ρk não se anulam mas ρk → 0 quando k →∞.
φkk =
{6= 0 se k = 1, 2, ..., p0 se k = p+ 1, p+ 2, ...
É óbvio que φkk = 0 se k > p. Por exemplo φp+1,p+1 = 0 porque
yt = φ1yt−1 + ...+ φpyt−p + 0yt−p−1 + ut
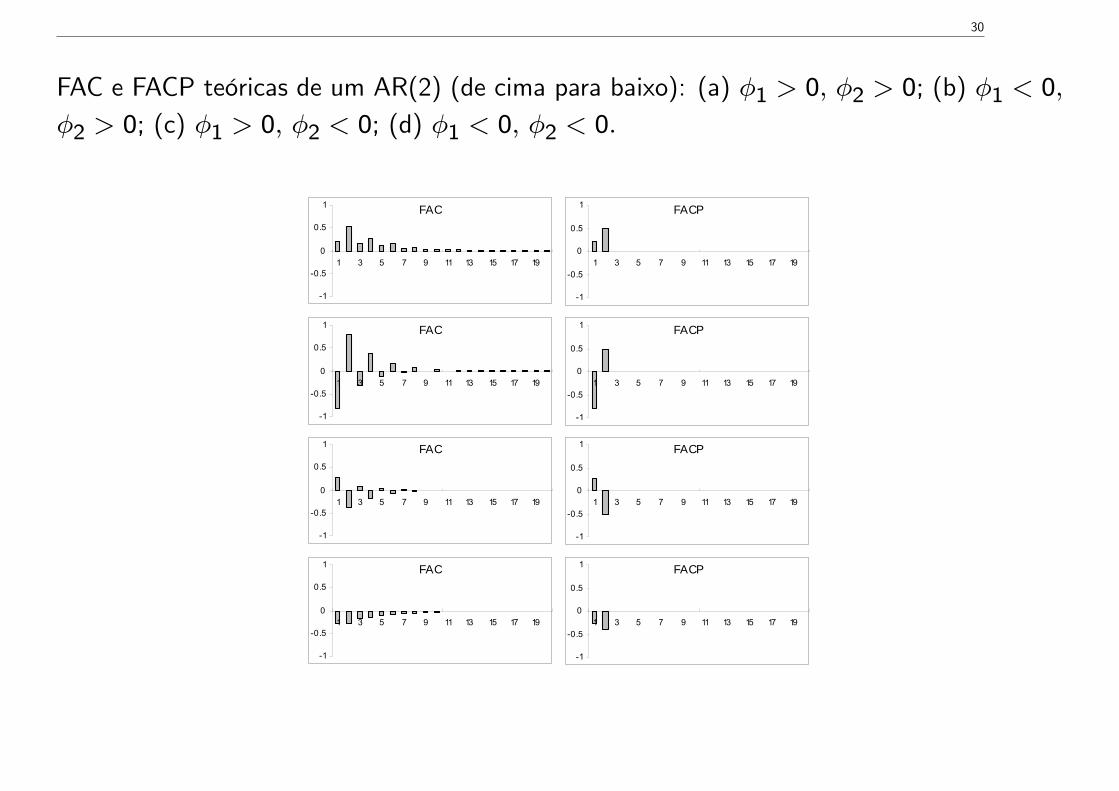
30
FAC e FACP teóricas de um AR(2) (de cima para baixo): (a) φ1 > 0, φ2 > 0; (b) φ1 < 0,
φ2 > 0; (c) φ1 > 0, φ2 < 0; (d) φ1 < 0, φ2 < 0.
FAC
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FACP
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FAC
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FACP
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FAC
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FACP
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FAC
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19
FACP
1
0.5
0
0.5
1
1 3 5 7 9 11 13 15 17 19

31
2.2.3 Processos ARMA
Por que não combinar os dois processos AR e MA? Modelo ARMA(p,q):
yt = φ1yt−1 + ...+ φpyt−p + θ1ut−1 + ...+ θqut−q + ut
Resumo:
AR(p) MA(q) ARMA(p,q)Estac. Raízes φp (L) = 0 Sempre Raízes φp (L) = 0
fora do círc. unitár. estacionários fora do círc. unitár.FAC Decaimento expo- Decaimento brusco Decaimento expo-
nencial e/ou sinu- para zero a partir de nencial e/ou sinu-soidal para zero k = q + 1 soidal para zero
FACP Decaimento brusco Decaimento expo- Decaimento expo-para zero a partir de nencial e/ou sinu- nencial e/ou sinu-k = p+ 1 soidal para zero soidal para zero
Fonte: Murteira et al. (1993), pág. 69

32
Exercício Na figuras seguintes traçam-se as FAC e FACP de vários processos lineares simu-lados (n = 50000). Procure identificá-los.
FAC
0.3
0.2
0.1
0
0.1
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.3
0.2
0.1
0
0.1
1 2 3 4 5 6 7 8 9 10
FAC
00.10.20.30.40.50.6
1 2 3 4 5 6 7 8 9 10
FACP
0.10
0.10.20.30.40.50.6
1 2 3 4 5 6 7 8 9 10
FAC
0.40.30.20.1
00.10.2
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.3
0.2
0.1
0
0.1
1 2 3 4 5 6 7 8 9 10
FAC
0.10
0.10.20.30.40.5
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.2
0
0.2
0.4
0.6
1 2 3 4 5 6 7 8 9 10
FAC
0.99880.999
0.99920.99940.99960.9998
1
1 2 3 4 5 6 7 8 9 10
FACP
0.20
0.20.40.60.8
11.2
1 2 3 4 5 6 7 8 9 10
FAC
0.10
0.10.20.30.40.50.6
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.2
0
0.2
0.4
0.6
1 2 3 4 5 6 7 8 9 10
FAC
0.10
0.10.20.30.40.5
1 2 3 4 5 6 7 8 9 10
FACP
0.30.20.1
00.10.20.30.40.5
1 2 3 4 5 6 7 8 9 10
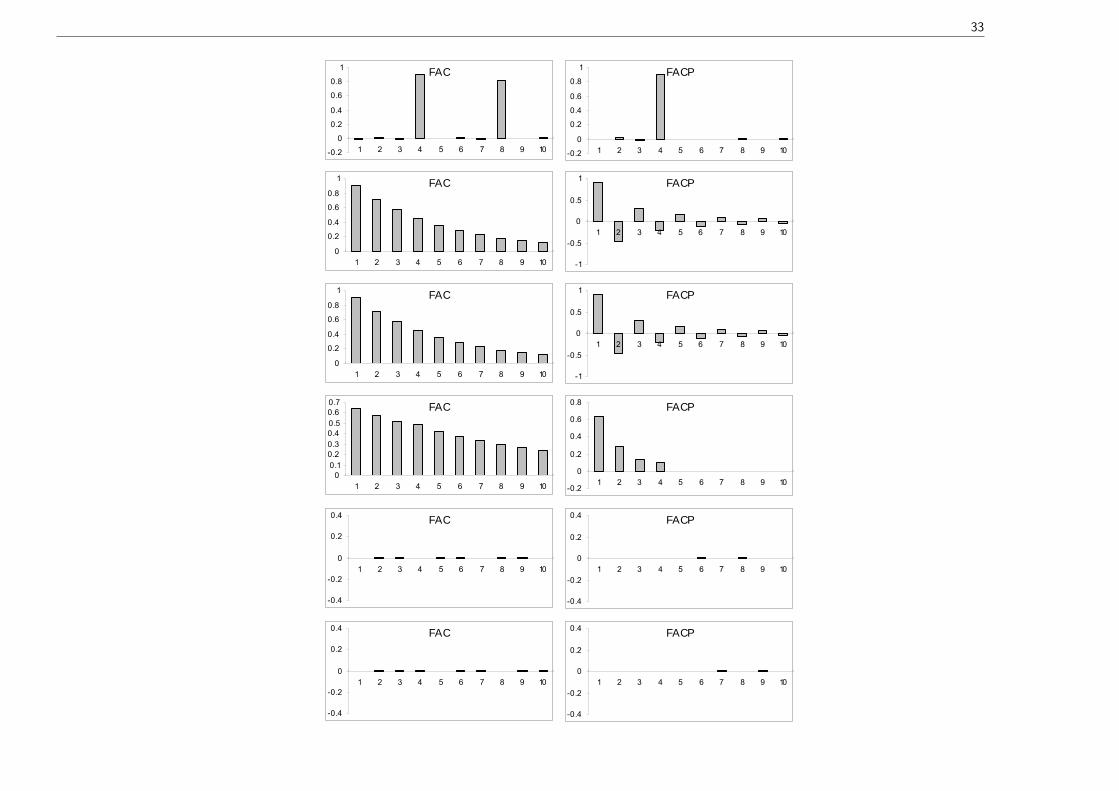
33
FAC
0.2
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8 9 10
FACP
0.2
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8 9 10
FAC
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8 9 10
FACP
1
0.5
0
0.5
1
1 2 3 4 5 6 7 8 9 10
FAC
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8 9 10
FACP
1
0.5
0
0.5
1
1 2 3 4 5 6 7 8 9 10
FAC
00.10.20.30.40.50.60.7
1 2 3 4 5 6 7 8 9 10
FACP
0.2
0
0.2
0.4
0.6
0.8
1 2 3 4 5 6 7 8 9 10
FAC
0.4
0.2
0
0.2
0.4
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.2
0
0.2
0.4
1 2 3 4 5 6 7 8 9 10
FAC
0.4
0.2
0
0.2
0.4
1 2 3 4 5 6 7 8 9 10
FACP
0.4
0.2
0
0.2
0.4
1 2 3 4 5 6 7 8 9 10
34
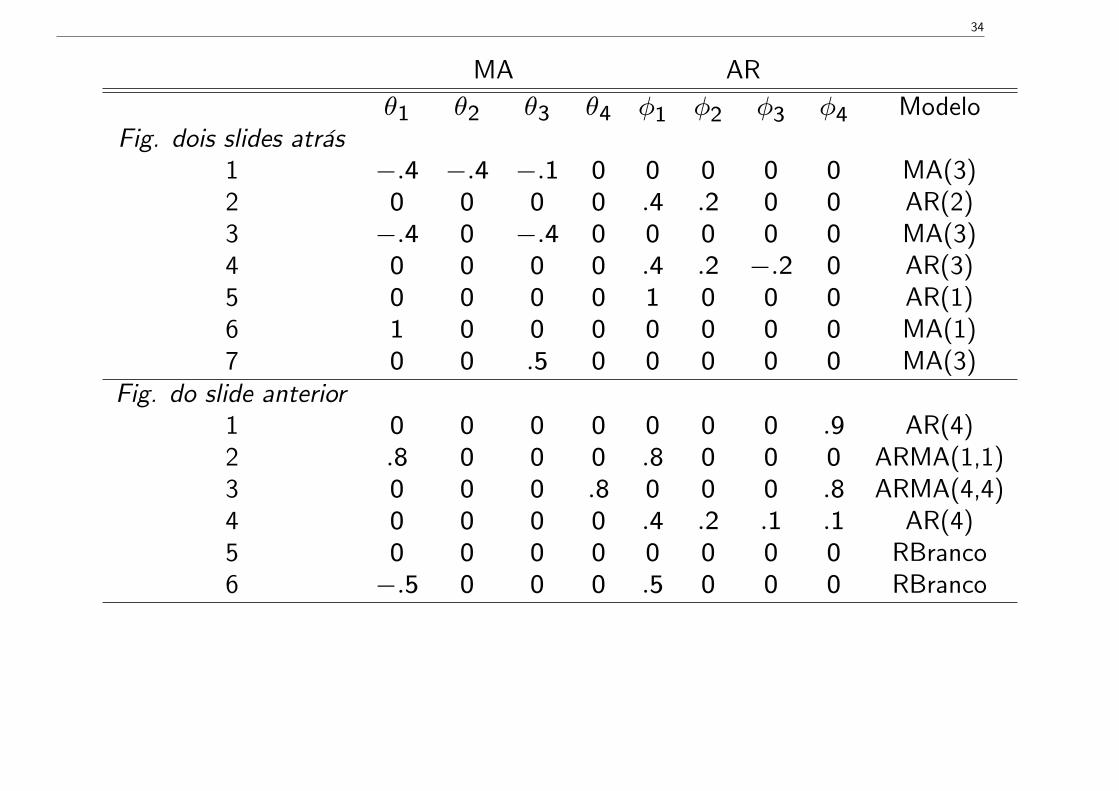
MA ARθ1 θ2 θ3 θ4 φ1 φ2 φ3 φ4 Modelo
Fig. dois slides atrás1 −.4 −.4 −.1 0 0 0 0 0 MA(3)2 0 0 0 0 .4 .2 0 0 AR(2)3 −.4 0 −.4 0 0 0 0 0 MA(3)4 0 0 0 0 .4 .2 −.2 0 AR(3)5 0 0 0 0 1 0 0 0 AR(1)6 1 0 0 0 0 0 0 0 MA(1)7 0 0 .5 0 0 0 0 0 MA(3)
Fig. do slide anterior1 0 0 0 0 0 0 0 .9 AR(4)2 .8 0 0 0 .8 0 0 0 ARMA(1,1)3 0 0 0 .8 0 0 0 .8 ARMA(4,4)4 0 0 0 0 .4 .2 .1 .1 AR(4)5 0 0 0 0 0 0 0 0 RBranco6 −.5 0 0 0 .5 0 0 0 RBranco

35
2.3 Modelação ARMA
Procura-se:
• definir um modelo parcimonioso (em termos de parâmetros);
• que apresente boas propriedades estatísticas;
• e descreva bem a série em estudo.
Para alcançarmos estes objectivos seguimos a metodologia de Box-Jenkins. Propõe trêsetapas: identificação, estimação e avaliação do diagnóstico.
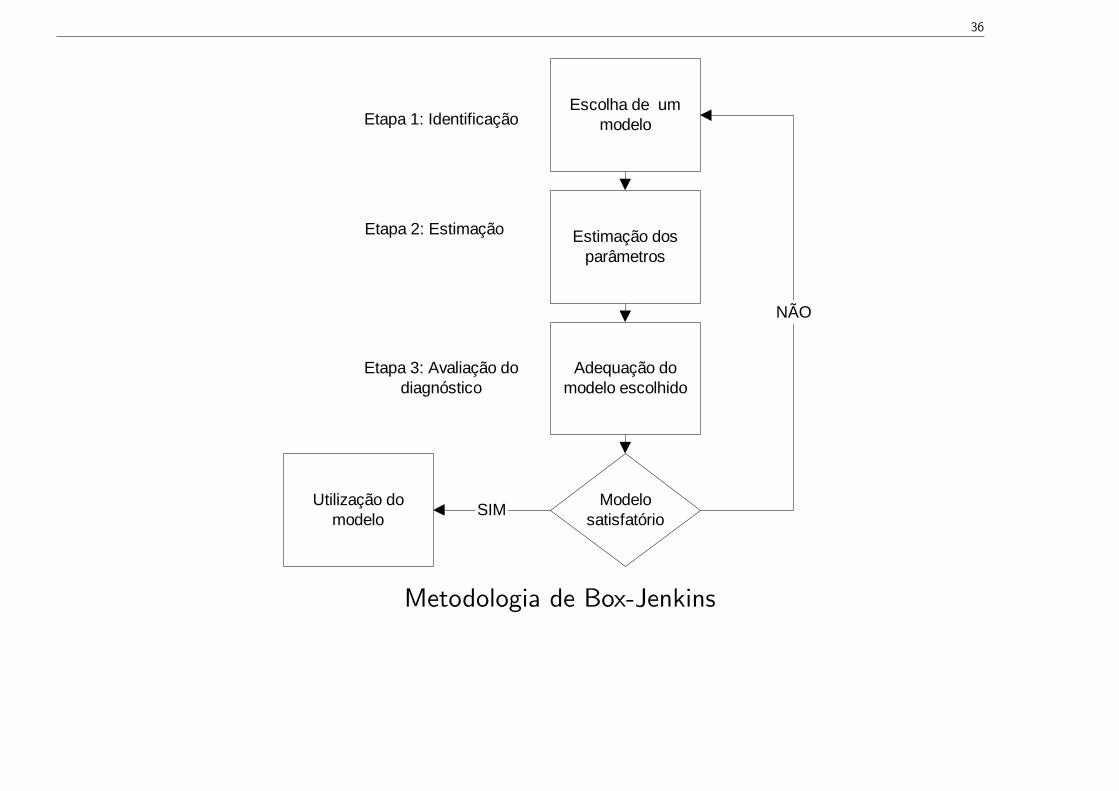
36
Escolha de ummodelo
Estimação dosparâmetros
Adequação domodelo escolhido
Modelosatisfatório
NÃO
Utilização domodelo
Etapa 1: Identificação
Etapa 2: Estimação
Etapa 3: Avaliação dodiagnóstico
SIM
Metodologia de Box-Jenkins

37
Etapa 1: Identificação
• Estacionarização da série;
• Identificação da ordem p e q através da FAC e FACP.
Etapa 2: Estimação
Estimador de Máxima Verosimilhança.
No caso AR(p) pode ser usado o estimador OLS que é consistente mesmo que a distribuiçãodos erros não seja Gaussiana.

38
Etapa 3: Avaliação do Diagnóstico
É necessário analisar os seguintes aspectos:
• significância estatística dos parâmetros;• invertibilidade e estacionaridade;• análise da matriz de correlação dos estimadores;• redundância entre as estimativas;• branqueamento dos resíduos;• se existir mais do que um modelo que cumpra as condições anteriores é necessário selec-cionar o melhor (à luz de determinado critério).

39
Analise-se a questão do Branqueamento dos Resíduos
Considere-se o ARMA(1,1)
yt = φyt−1 + θ1ut−1 + ut.
Suponha-se que se estima (por engano) o AR(1)
yt = φyt−1 + ηt
onde ηt representa o erro da equação anterior. Como detectar o erro de especificação? Comoηt = θ1ut−1+ut ∼MA(1) é natural esperar que os resíduos ηt venham autocorrelacionados.
É muito importante que os resíduos venham branqueados, i.e. não exibam autocorrelações(caso contrário, parte da média condicional não foi modelada).

40
Análise da FAC e FACP dos resíduos:
Teste Kendal e Stuart H0: ρk (u) = 0
√nρk (u)
d−→ N (0, 1)
Teste Ljung-Box H0: ρ1 (u) = ... = ρm (u) = 0
Q = n (n+ 2)m∑k=1
1
n− kρ2k (u)
d−→ χ2(m−p−q)
Teste Jenkis e Daniels H0: φkk (u) = 0
√nφkk (u)
d−→ N (0, 1)

41
Finalmente, discuta-se a última questão. Pode suceder que dois ou mais modelos cumpramas condições anteriores. Como seleccionar o ‘melhor’?
• O objectivo último é a previsão → avaliar a qualidade preditiva dos vários modelosconcorrentes;
• Outra abordagem: escolher o modelo mais preciso (melhor ajustamento) com o menor node parâmetros (parcimónia). Há certamente um trade-off a resolver: maior precisão implicamenor parcimónia.
O coeficiente de determinação ajustado é, provavelmente, o indicador mais utilizado. É umbom indicador no âmbito do modelo de regressão linear clássico, com distribuição normal.Mais gerais são os critérios de informação de Akaike e de Schwarz porque se baseiam novalor da função de verosimilhança.

42
O critério de informação de Akaike (AIC) é dado pela expressão
AIC = −2logLn
n+
2k
n.
O critério de Schwarz é dado pela expressão
SC = −2logLn
n+k
nlogn.
• Valor alto de logLn (função log verosimilhança) ⇒ ↑ precisão;• no parâmetros, k é baixo ⇒ modelo parcimonioso
Logo: minimizar as estatísticas AIC e SC.
Em certos casos, um modelo pode minimizar apenas um dos critérios. Como proceder nestescasos? Vários estudos têm revelado o seguinte:• o critério SC, em grandes amostras tende a escolher o modelo correcto; em peque-nas/médias amostras pode seleccionar um modelo muito afastado do modelo correcto;• o critério AIC, mesmo em grande amostras tende a seleccionar o modelo errado, emboranão seleccione modelos muito afastados do correcto.

43
3 Factos Empíricos Estilizados das Séries Financeiras
3.1 Regularidade Empíricas relacionadas com a Distribuição Marginal
Comece-se por considerar a fdp marginal f de um certo retorno rt. Estamos interessadosem saber algo sobre f (que é geralmente desconhecida). Obtém-se alguma informação sobref calculando vários momentos da amostra. Pelo método dos momentos, os parâmetrospopulacionais desconhecidos,
µ = E (r) , σ =√
Var (r), sk =E(
(r − µ)3)
σ3, k =
E(
(r − µ)4)
σ4
podem ser estimados de forma consistente, respectivamente, pelos estimadores
r =
∑nt=1 rt
n, σ =
√∑nt=1 (rt − r)2
n,
sk =n−1∑n
t=1 (rt − r)3
σ3 , k =n−1∑n
t=1 (rt − r)4
σ4 .

44
Os factos empíricos estilizados que descreveremos a seguir envolvem explicitamente estesmomentos. Concretamente, mostraremos a seguir que• r tende a ser maior do que o retorno do investimento sem risco;• σ depende da natureza do activo;• sk tende a ser negativo;• k tende a ser superior a 3.
3.1.1 Prémio de Risco Positivo
PR ou Equity Risk Premia
valor esperado do retorno de um investimento no mercado de capitais - o retorno doinvestimento sem risco.
De acordo com a teoria financeira este prémio deve ser positivo...
Dimson, Marsh e Staunton (2002) fizeram o seguinte exercício:
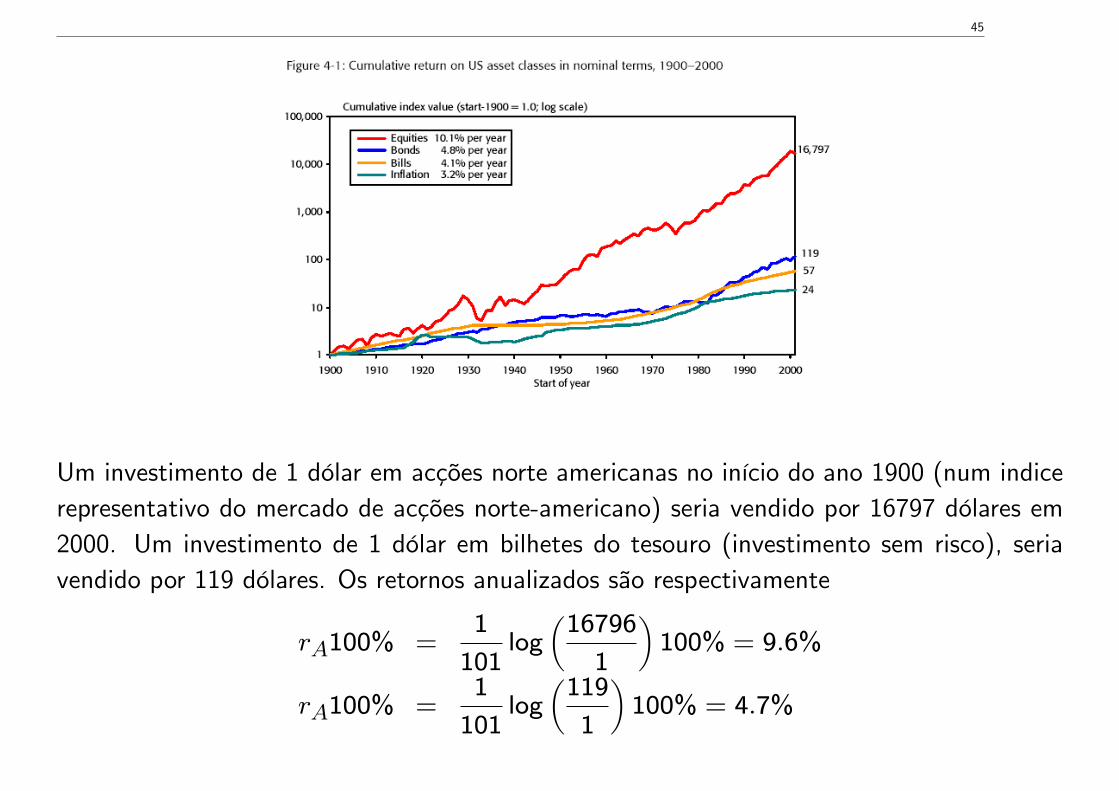
45
Um investimento de 1 dólar em acções norte americanas no início do ano 1900 (num indicerepresentativo do mercado de acções norte-americano) seria vendido por 16797 dólares em2000. Um investimento de 1 dólar em bilhetes do tesouro (investimento sem risco), seriavendido por 119 dólares. Os retornos anualizados são respectivamente
rA100% =1
101log
(16796
1
)100% = 9.6%
rA100% =1
101log
(119
1
)100% = 4.7%
46
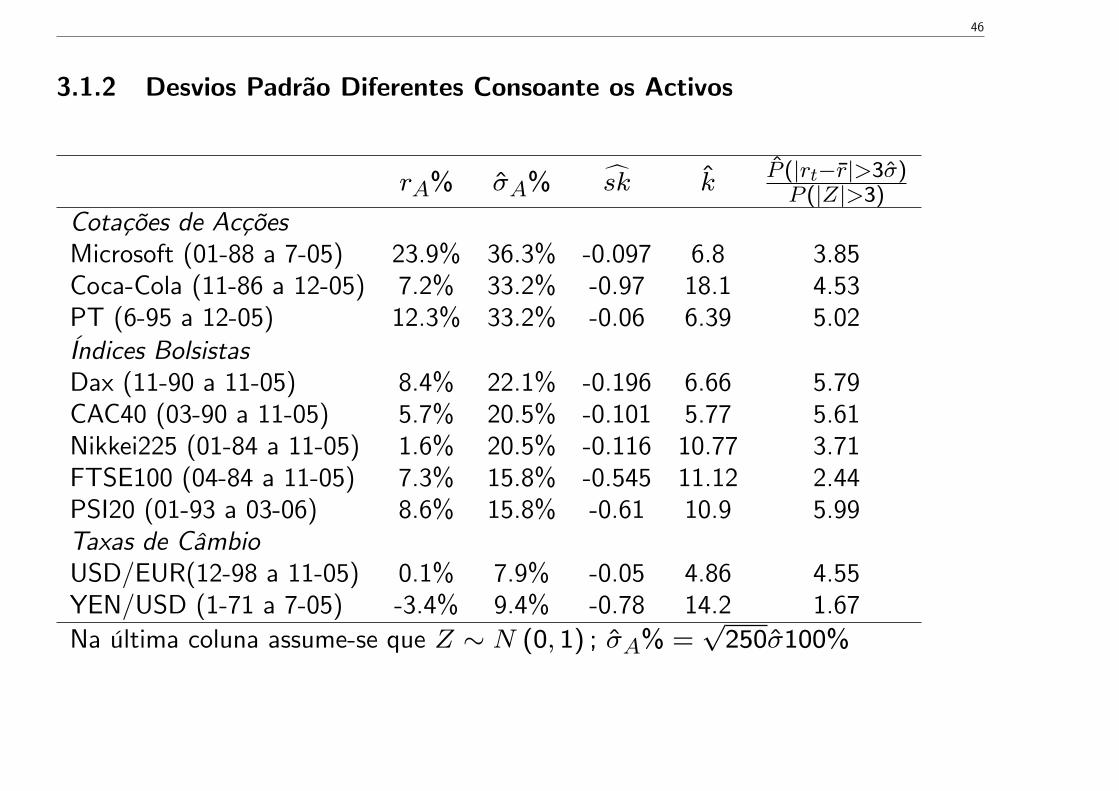
3.1.2 Desvios Padrão Diferentes Consoante os Activos
rA% σA% sk kP (|rt−r|>3σ)P (|Z|>3)
Cotações de AcçõesMicrosoft (01-88 a 7-05) 23.9% 36.3% -0.097 6.8 3.85Coca-Cola (11-86 a 12-05) 7.2% 33.2% -0.97 18.1 4.53PT (6-95 a 12-05) 12.3% 33.2% -0.06 6.39 5.02Índices BolsistasDax (11-90 a 11-05) 8.4% 22.1% -0.196 6.66 5.79CAC40 (03-90 a 11-05) 5.7% 20.5% -0.101 5.77 5.61Nikkei225 (01-84 a 11-05) 1.6% 20.5% -0.116 10.77 3.71FTSE100 (04-84 a 11-05) 7.3% 15.8% -0.545 11.12 2.44PSI20 (01-93 a 03-06) 8.6% 15.8% -0.61 10.9 5.99Taxas de CâmbioUSD/EUR(12-98 a 11-05) 0.1% 7.9% -0.05 4.86 4.55YEN/USD (1-71 a 7-05) -3.4% 9.4% -0.78 14.2 1.67Na última coluna assume-se que Z ∼ N (0, 1) ; σA% =
√250σ100%

47
• Os activos com maior variabilidade (e, portanto com maior risco associado) são os títulos deempresas, seguidos dos índices bolsistas e taxas de câmbio (bilhetes do tesouro - resultadosnão apresentados - apresentam a menor variabilidade).• Vários estudos indicam que a variabilidade dos retornos tende a diminuir à medida que adimensão das empresas aumenta.
3.1.3 Retornos de Acções e de Índices tendem a Apresentar Assimetria Negativa
A distribuição de r é assimétrica negativa (positiva) se sk < 0 (> 0). Se sk = 0 adistribuição é simétrica.
Podemos ter uma estimativa sk negativa se as variações negativas fortes forem mais acen-tuadas do que as variações positivas fortes. Ver a tabela anterior. As distribuições dasrendibilidades de acções e índice bolsistas tendem a ser assimétricas negativas. As fortesvariações dos preços são maioritariamente de sinal negativo. Estas variações são obviamentecrashes bolsistas.

48
Sob certas hipóteses, incluindo {rt} é uma sequência de v.a. homocedásticas com dis-tribuição normal, a estatística de teste
Z1 =√nsk√
6
tem distribuição assimptótica N (0, 1) . A hipótese nula H0: sk = 0 pode ser testada apartir deste resultado.
Mas as hipóteses de partida, normalidade e homocedasticidade, são relativamente severas.
O estimador sk é por vezes criticado por não ser robusto face à presença de valores extremos.
Para as taxas de câmbio não há razão especial para esperar sk > 0 ou sk < 0
49
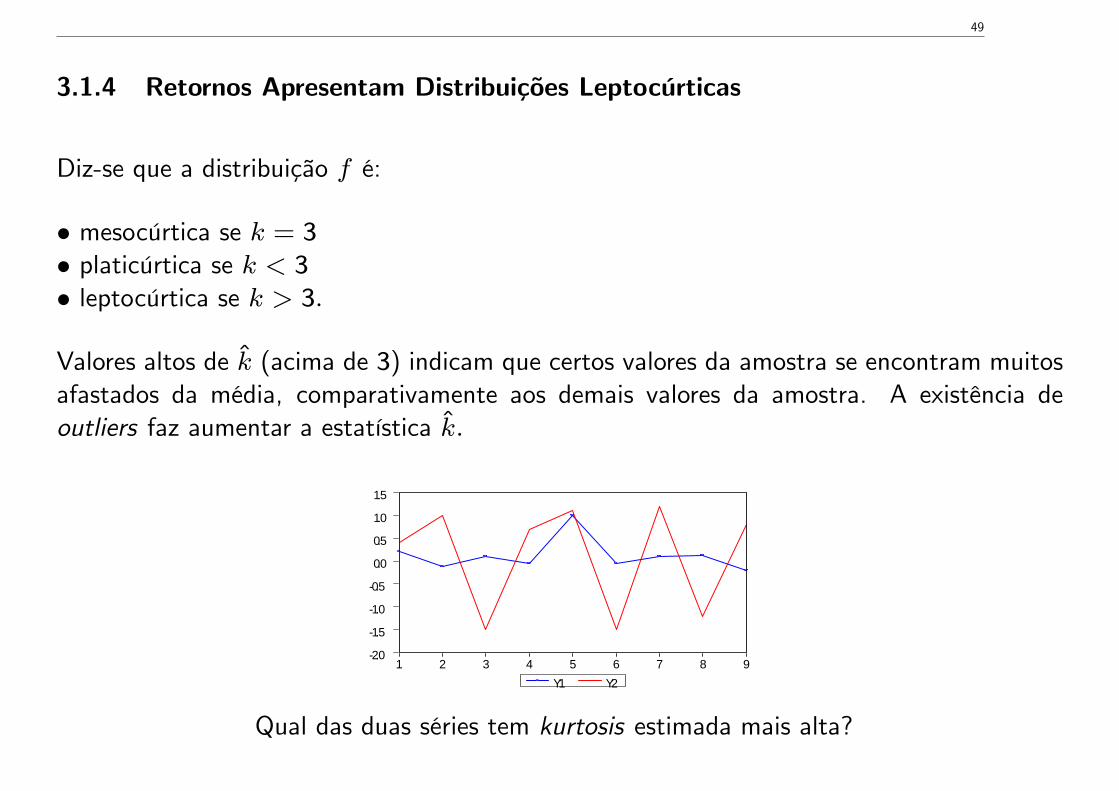
3.1.4 Retornos Apresentam Distribuições Leptocúrticas
Diz-se que a distribuição f é:
• mesocúrtica se k = 3• platicúrtica se k < 3• leptocúrtica se k > 3.
Valores altos de k (acima de 3) indicam que certos valores da amostra se encontram muitosafastados da média, comparativamente aos demais valores da amostra. A existência deoutliers faz aumentar a estatística k.
2.0
1.5
1.0
0.5
0.0
0.5
1.0
1.5
1 2 3 4 5 6 7 8 9Y1 Y2
Qual das duas séries tem kurtosis estimada mais alta?
50
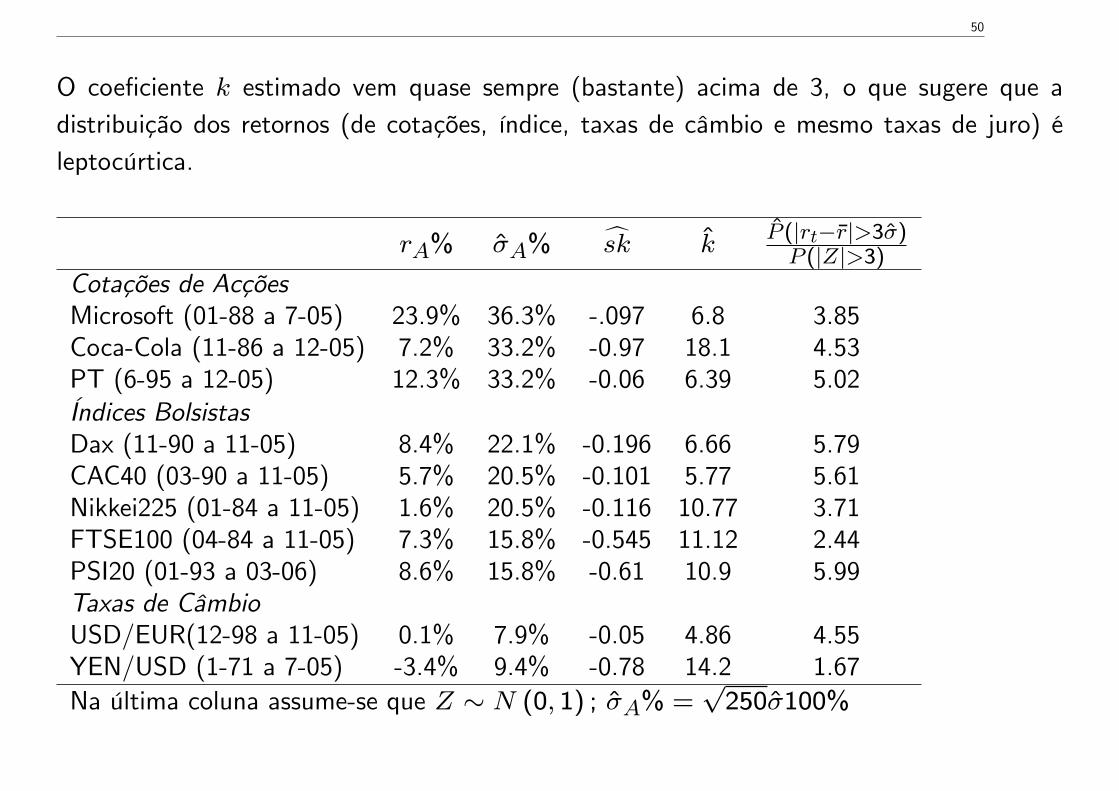
O coeficiente k estimado vem quase sempre (bastante) acima de 3, o que sugere que adistribuição dos retornos (de cotações, índice, taxas de câmbio e mesmo taxas de juro) éleptocúrtica.
rA% σA% sk kP (|rt−r|>3σ)P (|Z|>3)
Cotações de AcçõesMicrosoft (01-88 a 7-05) 23.9% 36.3% -.097 6.8 3.85Coca-Cola (11-86 a 12-05) 7.2% 33.2% -0.97 18.1 4.53PT (6-95 a 12-05) 12.3% 33.2% -0.06 6.39 5.02Índices BolsistasDax (11-90 a 11-05) 8.4% 22.1% -0.196 6.66 5.79CAC40 (03-90 a 11-05) 5.7% 20.5% -0.101 5.77 5.61Nikkei225 (01-84 a 11-05) 1.6% 20.5% -0.116 10.77 3.71FTSE100 (04-84 a 11-05) 7.3% 15.8% -0.545 11.12 2.44PSI20 (01-93 a 03-06) 8.6% 15.8% -0.61 10.9 5.99Taxas de CâmbioUSD/EUR(12-98 a 11-05) 0.1% 7.9% -0.05 4.86 4.55YEN/USD (1-71 a 7-05) -3.4% 9.4% -0.78 14.2 1.67Na última coluna assume-se que Z ∼ N (0, 1) ; σA% =
√250σ100%
51
.3
.2
.1
.0
.1
.2
30 40 50 60 70 80 90 00 10
R
30
20
10
0
10
20
30 40 50 60 70 80 90 00 10
Z
Bandas (3,3)
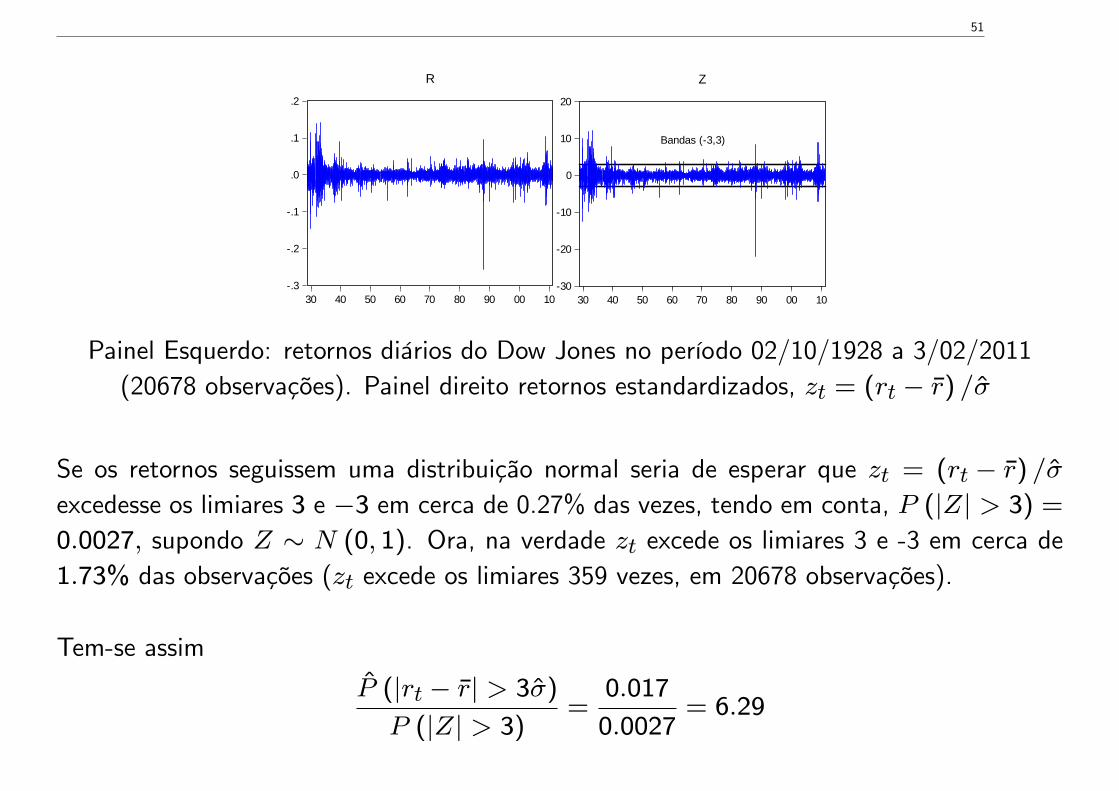
Painel Esquerdo: retornos diários do Dow Jones no período 02/10/1928 a 3/02/2011(20678 observações). Painel direito retornos estandardizados, zt = (rt − r) /σ
Se os retornos seguissem uma distribuição normal seria de esperar que zt = (rt − r) /σ
excedesse os limiares 3 e −3 em cerca de 0.27% das vezes, tendo em conta, P (|Z| > 3) =
0.0027, supondo Z ∼ N (0, 1). Ora, na verdade zt excede os limiares 3 e -3 em cerca de1.73% das observações (zt excede os limiares 359 vezes, em 20678 observações).
Tem-se assim
P (|rt − r| > 3σ)
P (|Z| > 3)=
0.017
0.0027= 6.29

52
Por que razão a distribuição leptocúrtica se designa habitualmente de “distribuição de caudaspesadas”?
0
0.1
0.2
0.3
0.4
0.5
7 4.5 2 0.5 3 5.5
Normal
Leptoc.
0
0.002
0.004
0.006
0.008
0.01
7 4.5 2 0.5 3 5.5
Normal
Leptoc.

53
O ensaio H0: k = 3 [y ∼ Normal & y é i.i.d] pode ser conduzido pela estatística de teste
Z1 =√n
(k − 3
)√
24
d−→ N (0, 1) .
Por exemplo, para a Microsoft e sabendo que no período considerado se observaram 4415
dados diários (n = 4415) tem-se
z1 =√
4415(6.8− 3)√
24= 51.54.
O valor-p é P (|Z1| > 51.54) ≈ 0. Existe forte evidência contra H0.
Podemos ainda testar a hipótese conjunta H0: k = 3 & sk = 0 [assumindo r ∼ Normal
& r é i.i.d] através da estatística de Bera-Jarque
Z21 + Z2
2 = n
(k − 3
)2
24+sk
2
6
d−→ χ2(2)
54
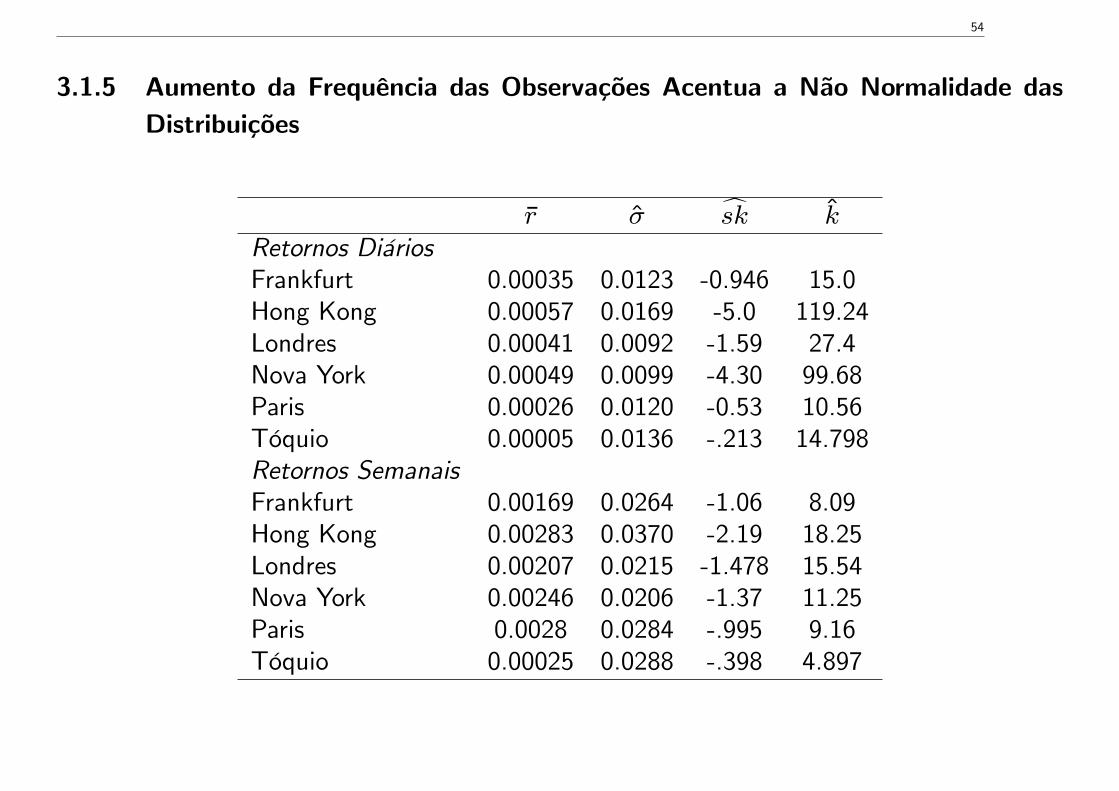
3.1.5 Aumento da Frequência das Observações Acentua a Não Normalidade dasDistribuições
r σ sk kRetornos DiáriosFrankfurt 0.00035 0.0123 -0.946 15.0Hong Kong 0.00057 0.0169 -5.0 119.24Londres 0.00041 0.0092 -1.59 27.4Nova York 0.00049 0.0099 -4.30 99.68Paris 0.00026 0.0120 -0.53 10.56Tóquio 0.00005 0.0136 -.213 14.798Retornos SemanaisFrankfurt 0.00169 0.0264 -1.06 8.09Hong Kong 0.00283 0.0370 -2.19 18.25Londres 0.00207 0.0215 -1.478 15.54Nova York 0.00246 0.0206 -1.37 11.25Paris 0.0028 0.0284 -.995 9.16Tóquio 0.00025 0.0288 -.398 4.897

55
A diminuição da frequência das observações atenua o problema da não normalidade - Expli-cação Teórica:
P0, P1, P2, ... preços diários.
P0, P5, P10, ... preços semanais (5 dias úteis).
Retornos semanais são:
logP5 − logP0︸ ︷︷ ︸retorno 1a semana
, logP10 − logP5︸ ︷︷ ︸retorno 2a semana
, ...
Para h geral, o primeiro retorno observado é r1 = logPh − logP0. Tem-se
r1 (h) = logPh − logP0 = r1 + r2 + ...+ rh =h∑i=1
ri
(ri são os retornos diários). Pelo TLC (sob certas condições)∑hi=1 ri − E
(∑hi=1 ri
)√
Var(∑h
i=1 ri) =
√h (r − E (ri))
σ
d−→ N (0, 1) quando h→∞.

56
3.1.6 Efeitos de Calendário
“Efeitos de calendário”: quando a rendibilidade e/ou a volatilidade varia com o calendário.
Por exemplo, se certo título regista maior rendibilidade e/ou volatilidade às segundas-feiras,temos um efeito de calendário.
Serão estes efeitos de calendário anomalias?
Dia da Semana
“Efeito de segunda-feira”
• Rendibilidade mais alta?• Volatilidade mais alta?

57
Testar este e outros efeitos:
rt = β + δ1tert + δ2quat + δ3quit + δ4sext + ut
onde ter, qua, etc. são variáveis dummy ... “Grupo base”= segunda-feira.
Ensaio: H0: δ1 = δ2 = ... = δ4 = 0 corresponde a testar a não existência de diferençasnas médias dos retornos dos vários dias da semana. A estatística habitual:
F =R2/ (k − 1)(
1−R2)/(n− k)
∼ F (k − 1, n− k) sob H0.
Na presença de heterocedasticidade, os teste t e F são inválidos. Uma solução passa pelautilização de erros padrão robustos (ou da estatística F robusta) contra a presença de hete-rocedasticidade .
58
3.1.7 Distribuições Leptocúrticas para Retornos
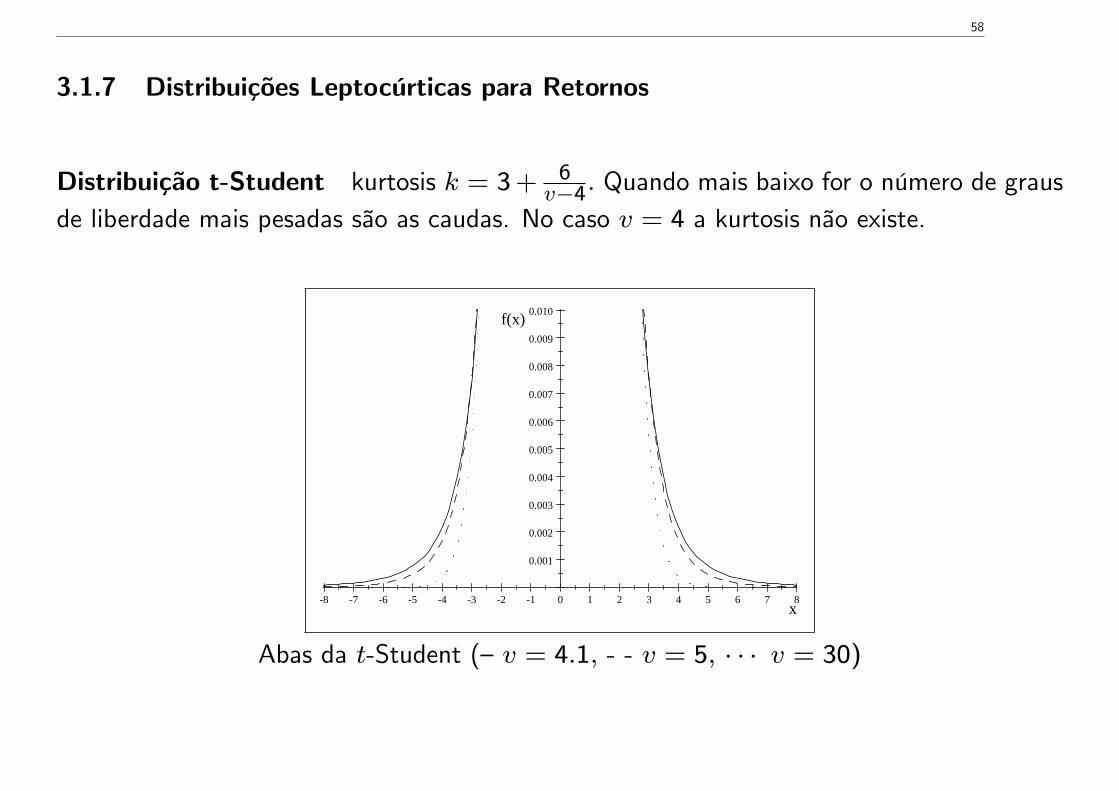
Distribuição t-Student kurtosis k = 3 + 6v−4. Quando mais baixo for o número de graus
de liberdade mais pesadas são as caudas. No caso v = 4 a kurtosis não existe.
8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8
0.001
0.002
0.003
0.004
0.005
0.006
0.007
0.008
0.009
0.010
x
f(x)
Abas da t-Student (—v = 4.1, - - v = 5, · · · v = 30)

59
Mistura de Normais A variável X, que representa a mistura de normais, pode escrever-seda seguinte forma:
X = (1− U)X1 + UX2,
U ∼ Bernoulli, X1 ∼ N(µ1, σ
21
), X2 ∼ N
(µ2, σ
22
).
Pode-se mostrar que,
• E (X) = αµ1 + (1− α)µ2;
• Var (X) = ασ21 + (1− α)σ2
2 + α (1− α) (µ1 − µ2)2 ;
• E(
(X − E (X))3)
= α (1− α) (µ1 − µ2)(
(1− 2α) (µ1 − µ2)2 + 3(σ2
1 + σ22
));
• k = 3 +3α(1−α)(σ2
1−σ22)
2
(ασ21+(1−α)σ2
2)2 > 3 supondo, para simplificar, que µ1 = µ2 = 0.
60
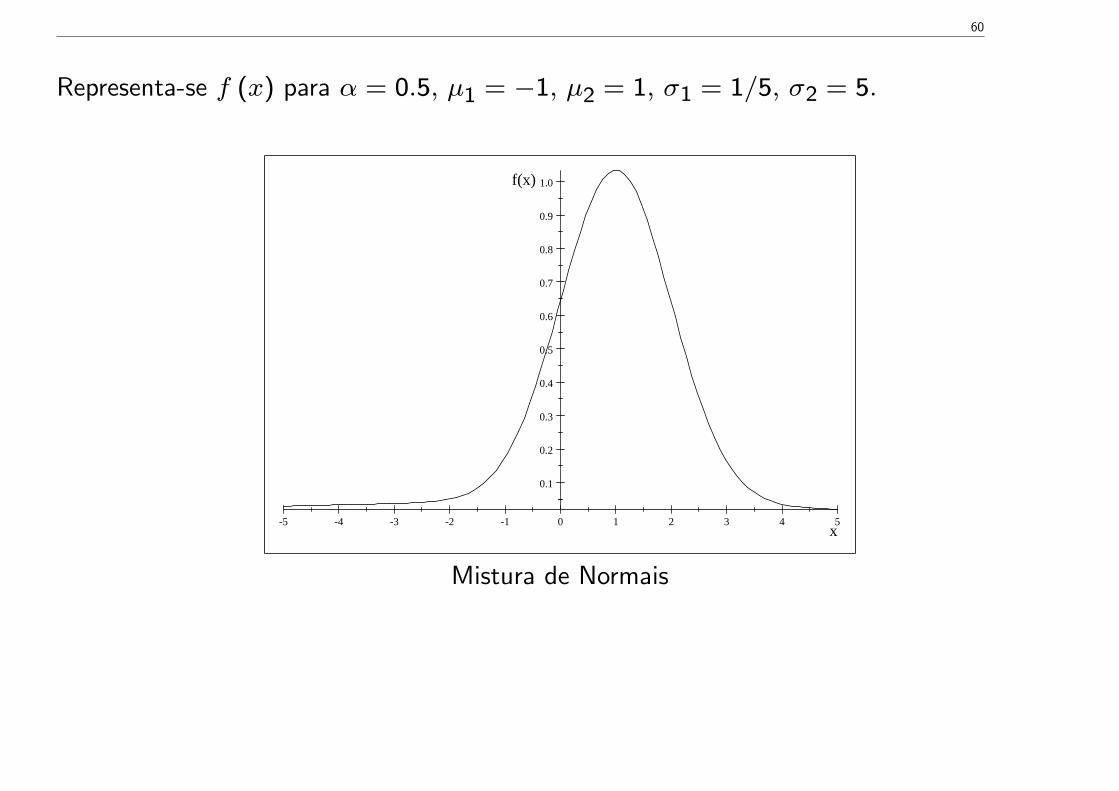
Representa-se f (x) para α = 0.5, µ1 = −1, µ2 = 1, σ1 = 1/5, σ2 = 5.
5 4 3 2 1 0 1 2 3 4 5
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
x
f(x)
Mistura de Normais

61
Distribuição com Caudas de Pareto A fdp de Pareto é
g (y) = αcαy−(α+1), y > c.
À primeira vista pode parecer que esta distribuição não serve... Porquê?
Diz-se que uma fdp f (y) tem distribuição com caudas de Pareto (mesmo que não seja umadistribuição de Pareto) se
f (y) ∼ Cy−(α+1), α > 0
(C é uma constante). O sinal “∼”significa aqui que
limy→∞ f (y) /Cy−(α+1) = 1.
f (y) tem um decaimento polinomial para zero (decaimento lento para zero) e, portanto,caudas pesadas. As caudas são tanto mais mais pesadas quanto menor for o valor de α.

62
2.0 2.5 3.0 3.5 4.0 4.5 5.00.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
x
fdp
Cauda de Pareto vs. Cauda Gaussiana
Estimador de Hill
Suponha-se f (y) ∼ Cy−(α+1). Como estimar α?
Passo 1: admita-se um cenário mais simples: f (y) tem distribuição (exacta) de Pareto,y ∼ Pareto (c, α) , ou seja
f (y) =αcα
yα+1, y > c.

63
Resulta:
α =n∑n
t=1 log (yt/c),
√n (αn − α)
d−→ N(
0, α2)
Passo 2: retome-se agora a hipótese f (y) ∼ Cy−(α+1). Se só para valores grandes de yse tem f (y) ' Cy−(α+1) então devemos considerar apenas os dados yt tais que yt > q
(onde q pode ser interpretado como um quantil de y, geralmente um quantil ordem superiora 0.95).
O estimador para α (designado por estimador de Hill) é agora
α (q) =n (q)∑n
t=1 log (yt/q) I{yt>q}, n (q) =
n∑t=1
I{yt>q}.
Pode-se mostrar √n (q) (α (q)− α (q))
d−→ N(
0, α2)
quando n→∞, n (q)→∞ e n (q) /n→ 0. Observe-se
Var (α (q)) =α2
n (q), Var (α (q)) =
α2
n (q)

64
Exemplo Resulta do quadro seguinte que α (0.01) = 3/5.193 = 0.577
yt I{yt>0.01} log (yt/0.01) I{yt>0.01}-0.110 0 00.090 1 2.1970.100 1 2.303-0.100 0 00.020 1 0.6930.005 0 0∑
3 5.193
Qual é o valor do threshold q que devemos escolher? Temos um dilema de enviesamentoversus variância:
• se q é alto a estimação de α (q) é baseada em poucas observações, i.e., n (q) é baixo,pelo que a variância de α (q) é alta (observe-se Var (α (q)) = α2/n (q));
• se q é baixo, perde-se a hipótese f (y) ∼ Cy−(α+1) e, como consequência, o estimadorα (q) é enviesado e mesmo inconsistente (recorde-se que α (q) é baseado na hipótese f (y) ∼Cy−(α+1)).

65
Exemplo Estimação do índice de cauda (dentro de parênteses encontram-se o número deobservações efectivamente utilizadas para estimar α).
Retornos α (q0.96) α (q0.97) α (q0.98) α (q0.99)
ORACLE 3.0(153)
3.23(115)
3.3(73)
4.17(39)
DOWJONES 2.67(1114)
2.74(835)
2.85(557)
3.0(279)
EURO/DÓLAR 4.70(65)
5.12(49)
5.33(33)
5.14(17)
• Em todos os casos é razoável admitir-se que a variância existe. Porquê?• A distribuição dos retornos do DOWJONES parece ter as caudas mais pesadas; o quartomomento pode não existir.

66
3.1.8 Estimação Não Paramétrica da Função Densidade de Probabilidade
A forma mais simples de estimar f (x) consiste em obter o histograma das frequênciasrelativas. Existem, no entanto, estimadores preferíveis. Uma estimativa não paramétrica def (x) pode ser dada por
f (x) =1
nh
n∑i=1
K
(x− xih
)onde K (u) é uma fdp. Sob certas condições, incluindo h→ 0, n→∞, nh→∞ pode-seprovar
f (x)p−→ f (x) .
67
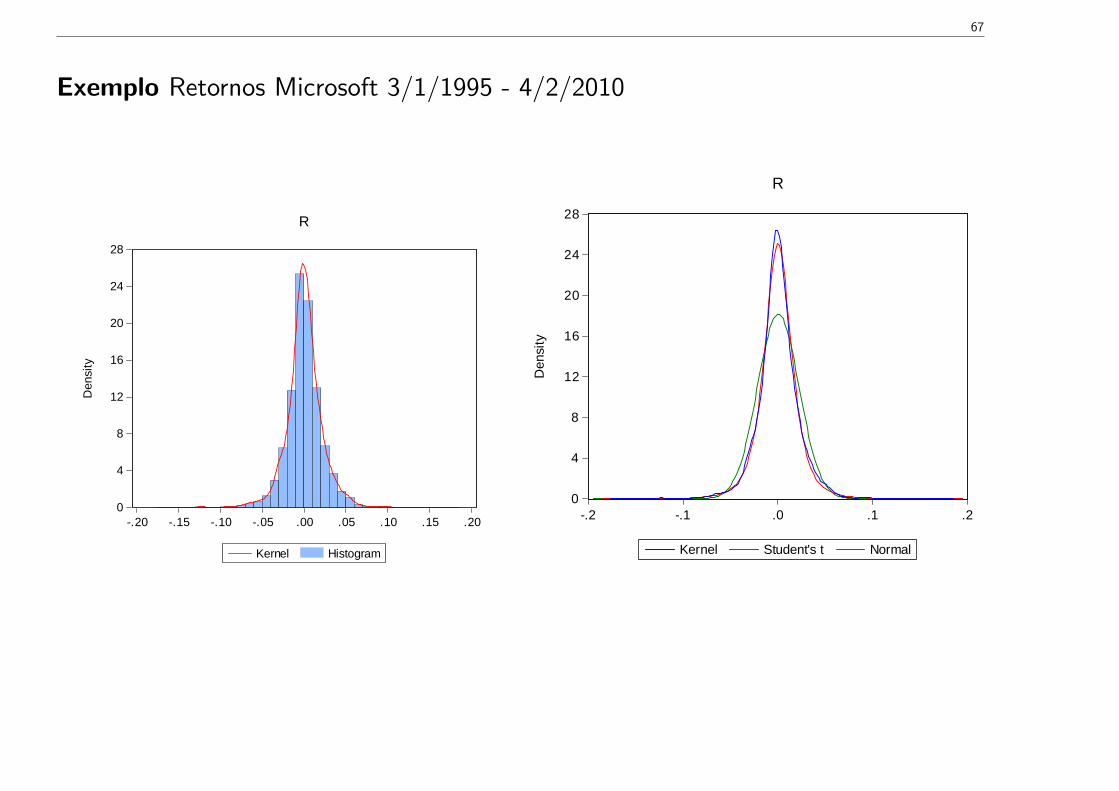
Exemplo Retornos Microsoft 3/1/1995 - 4/2/2010
0
4
8
12
16
20
24
28
.20 .15 .10 .05 .00 .05 .10 .15 .20
Kernel Histogram
Den
sity
R
0
4
8
12
16
20
24
28
.2 .1 .0 .1 .2
Kernel Student's t NormalD
ensi
ty
R

68
3.2 Regularidade Empíricas relacionadas com a Distribuição Condi-
cional
Neste ponto discutimos regularidades que envolvem especificações dinâmicas (por exemplo,veremos como o retorno depende dos seus valores passados, ou como o quadrado dos retornosdepende do quadrado dos retornos passados, entre outras especificações condicionais).
3.2.1 Autocorrelações Lineares Baixas entre os Retornos
Em geral os coeficientes de autocorrelação dos retornos são baixos. Por exemplo:.
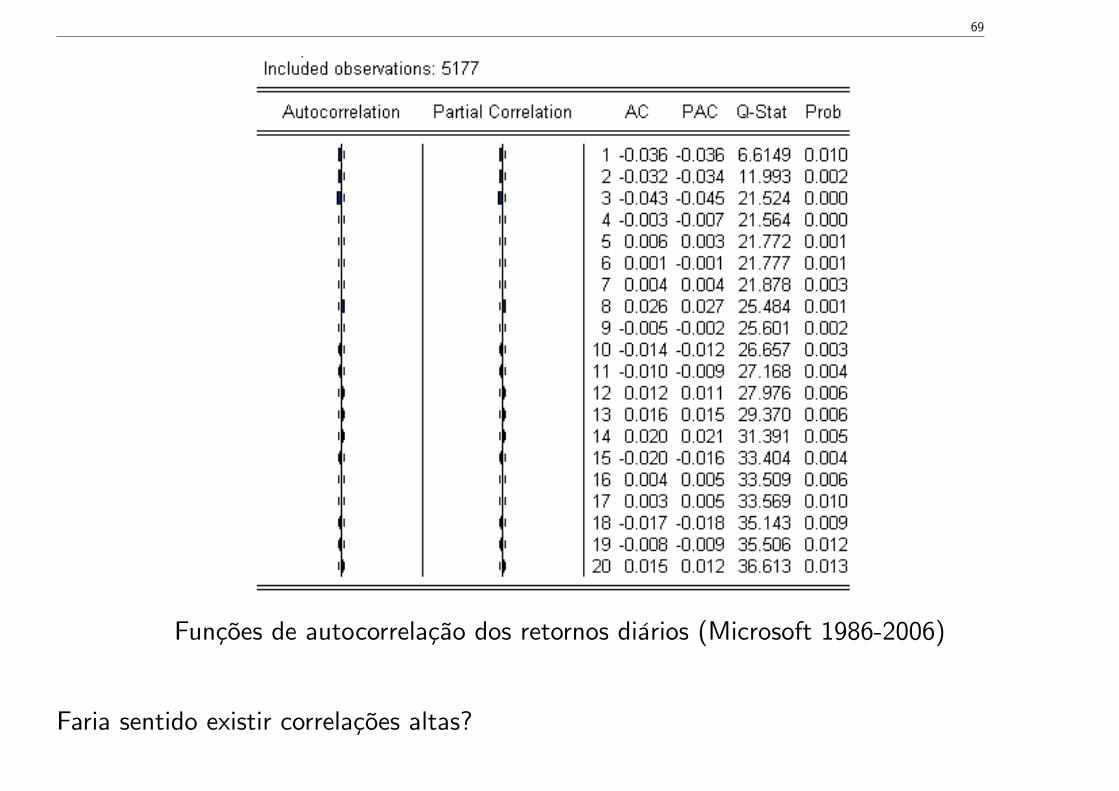
69
Funções de autocorrelação dos retornos diários (Microsoft 1986-2006)
Faria sentido existir correlações altas?

70
Teste Kendal e Stuart H0: ρk = 0
√n (ρk + 1/n)
d−→ N (0, 1) , ρk ≈ N(−1
n,
1√n
)
Teste Ljung-Box H0: ρ1 = ... = ρm = 0
Qm = n (n+ 2)m∑k=1
1
n− kρ2k
d−→ χ2(m)
Analise-se H0: ρ1 = ... = ρ20 = 0. Fixe-se por exemplo, m = 20. Tem-se Q20 = 36.613.
valor-p= 0.013. Existe evidência estatística contra a hipótese nula H0: ρ1 = ... = ρ20 = 0.
Esta conclusão parece contraditória com a ideia de baixas autocorrelações dos retornos.
Há explicação?

71
Uma forma de mitigar a presença de heterocedasticidade consiste em estandardizar os re-tornos pelo padrão de heterocedasticidade:
r∗t =rt − rσt
onde σt é uma estimativa da volatilidade no momento t (r∗t pode ser encarado como os“retornos” expurgados de heterocedasticidade).
Como obter σt? Solução (“subóptima”):
σ2t = (1− λ) r2
t−1 + λσ2t−1, λ = 0.96
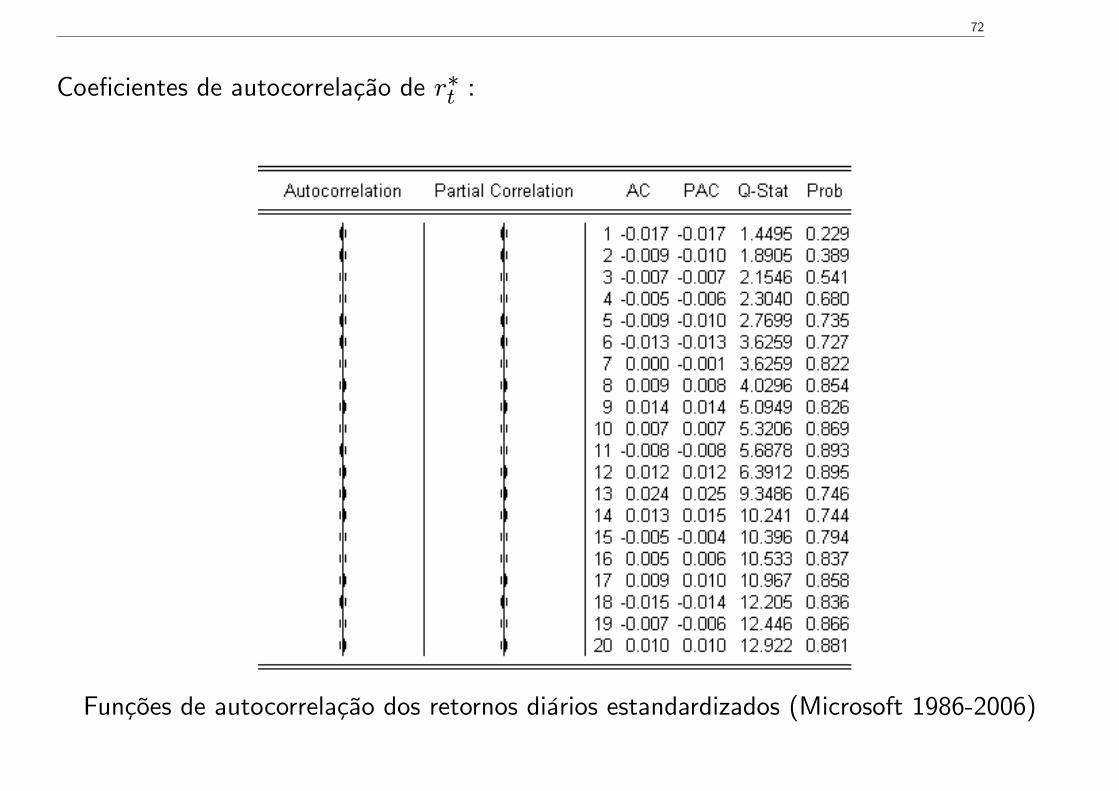
72
Coeficientes de autocorrelação de r∗t :
Funções de autocorrelação dos retornos diários estandardizados (Microsoft 1986-2006)
73
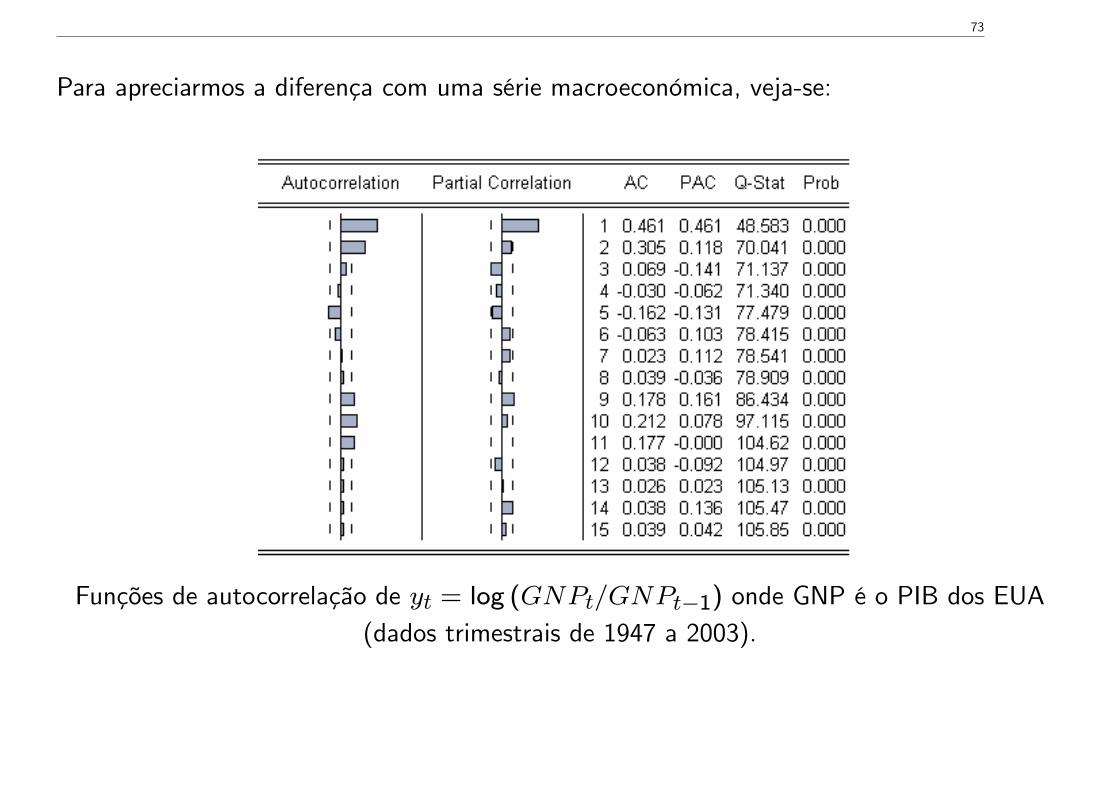
Para apreciarmos a diferença com uma série macroeconómica, veja-se:
Funções de autocorrelação de yt = log (GNPt/GNPt−1) onde GNP é o PIB dos EUA(dados trimestrais de 1947 a 2003).

74
3.2.2 Volatility Clustering
Vimos: valores muitos altos e muito baixos ocorrem frequentemente. Este valores extremosnão ocorrem isoladamente: tendem a ocorrer de forma seguida (volatility clustering).
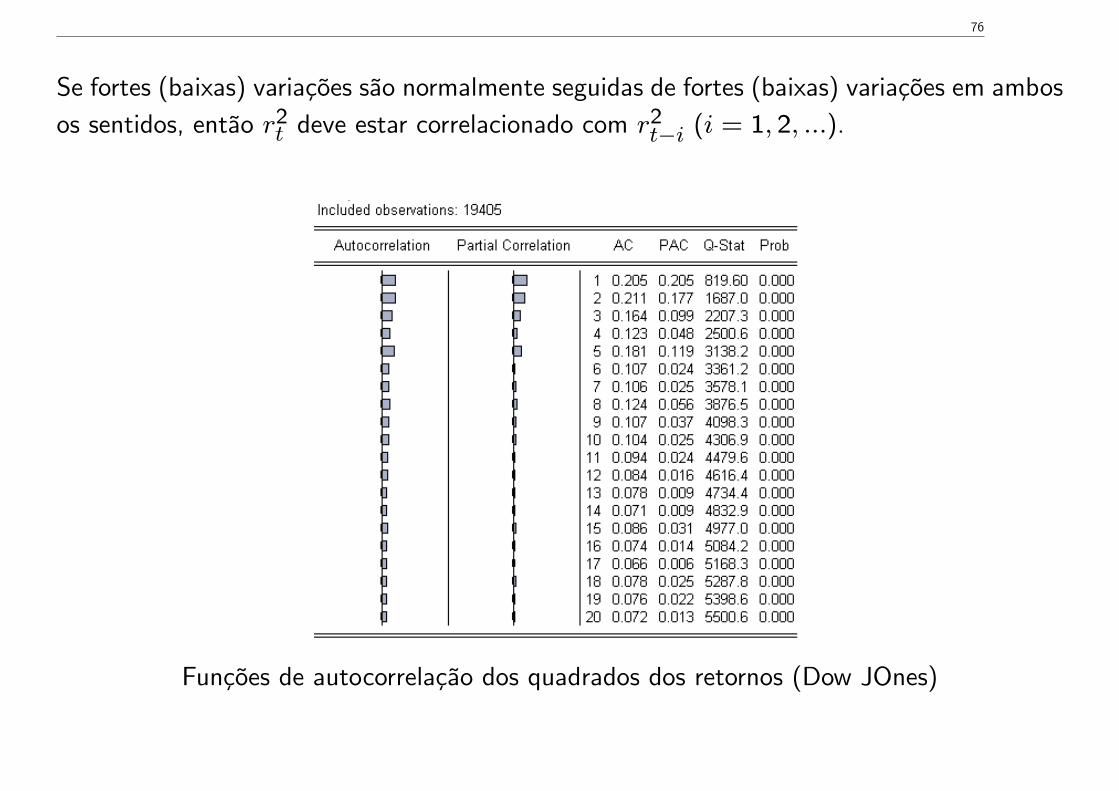
Uma das propriedades mais importantes: fortes (baixas) variações são normalmente seguidasde fortes (baixas) variações em ambos os sentidos.

75
0.30.250.2
0.150.1
0.050
0.050.1
0.150.2
Oct
28
May
32
Dec
35
Jul3
9
Feb
43
Sep
46
Apr
50
Nov
53
Jun
57
Jan
61
Aug
64
Mar
68
Oct
71
May
75
Dec
78
Jul8
2
Feb
86
Sep
89
Apr
93
Nov
96
Jun
00
Jan
04
Retornos diários do Dow Jones (1928-2006)
0.3
0.25
0.2
0.15
0.1
0.05
0
0.05
0.1
0.15
0.2
Retornos diários do Dow Jones dispostos por ordem aleatória
76
Se fortes (baixas) variações são normalmente seguidas de fortes (baixas) variações em ambosos sentidos, então r2
t deve estar correlacionado com r2t−i (i = 1, 2, ...).
Funções de autocorrelação dos quadrados dos retornos (Dow JOnes)
77
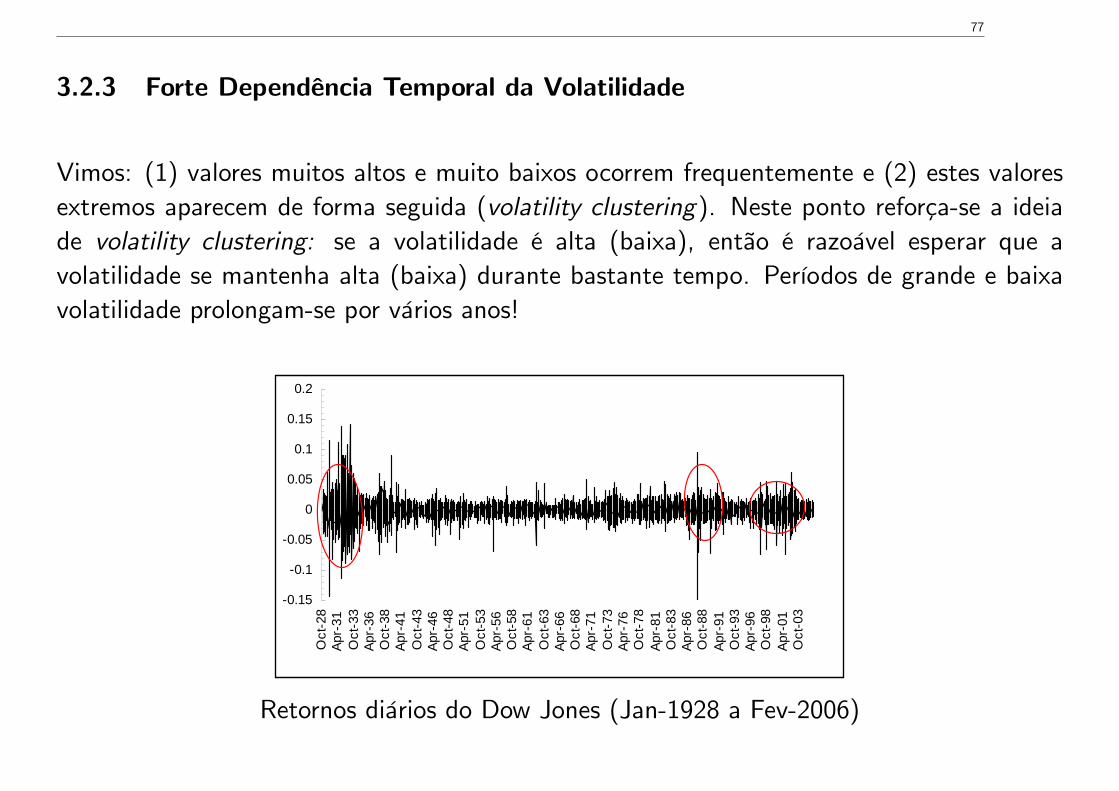
3.2.3 Forte Dependência Temporal da Volatilidade
Vimos: (1) valores muitos altos e muito baixos ocorrem frequentemente e (2) estes valoresextremos aparecem de forma seguida (volatility clustering). Neste ponto reforça-se a ideiade volatility clustering: se a volatilidade é alta (baixa), então é razoável esperar que avolatilidade se mantenha alta (baixa) durante bastante tempo. Períodos de grande e baixavolatilidade prolongam-se por vários anos!
0.15
0.1
0.05
0
0.05
0.1
0.15
0.2
Oct
28
Apr
31O
ct3
3Ap
r36
Oct
38
Apr
41O
ct4
3Ap
r46
Oct
48
Apr
51O
ct5
3Ap
r56
Oct
58
Apr
61O
ct6
3Ap
r66
Oct
68
Apr
71O
ct7
3Ap
r76
Oct
78
Apr
81O
ct8
3Ap
r86
Oct
88
Apr
91O
ct9
3Ap
r96
Oct
98
Apr
01O
ct0
3
Retornos diários do Dow Jones (Jan-1928 a Fev-2006)
78
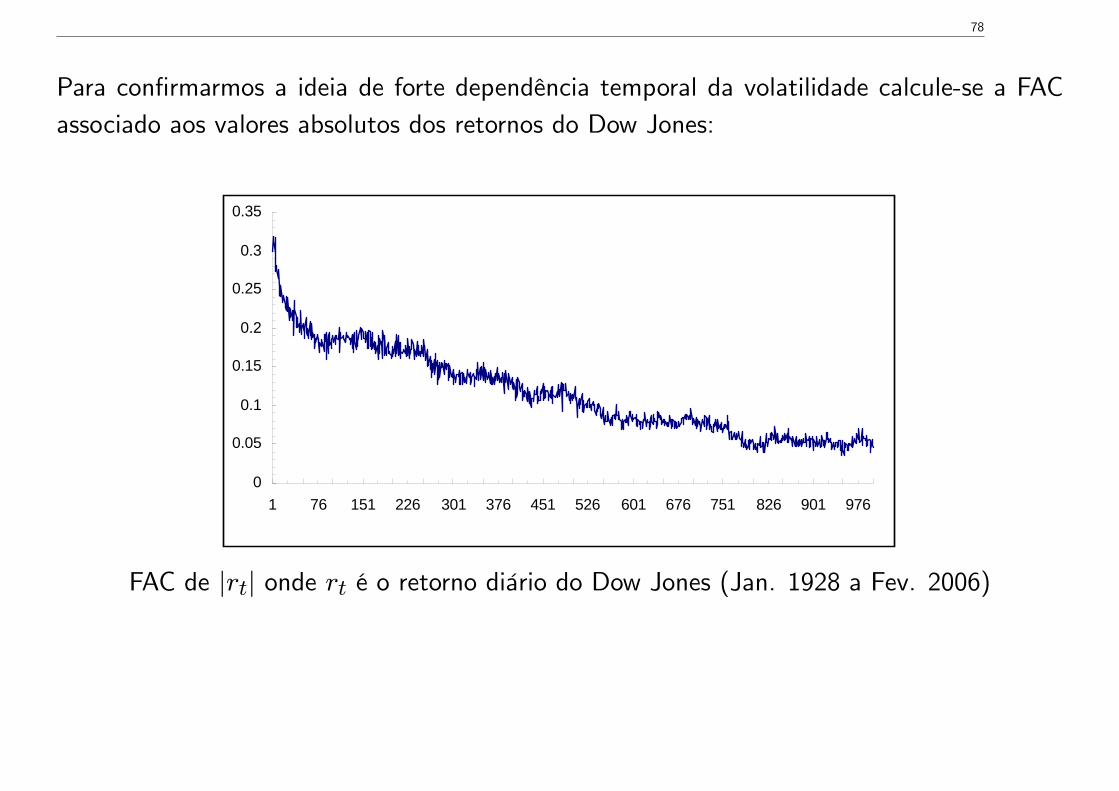
Para confirmarmos a ideia de forte dependência temporal da volatilidade calcule-se a FACassociado aos valores absolutos dos retornos do Dow Jones:
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 76 151 226 301 376 451 526 601 676 751 826 901 976
FAC de |rt| onde rt é o retorno diário do Dow Jones (Jan. 1928 a Fev. 2006)
79
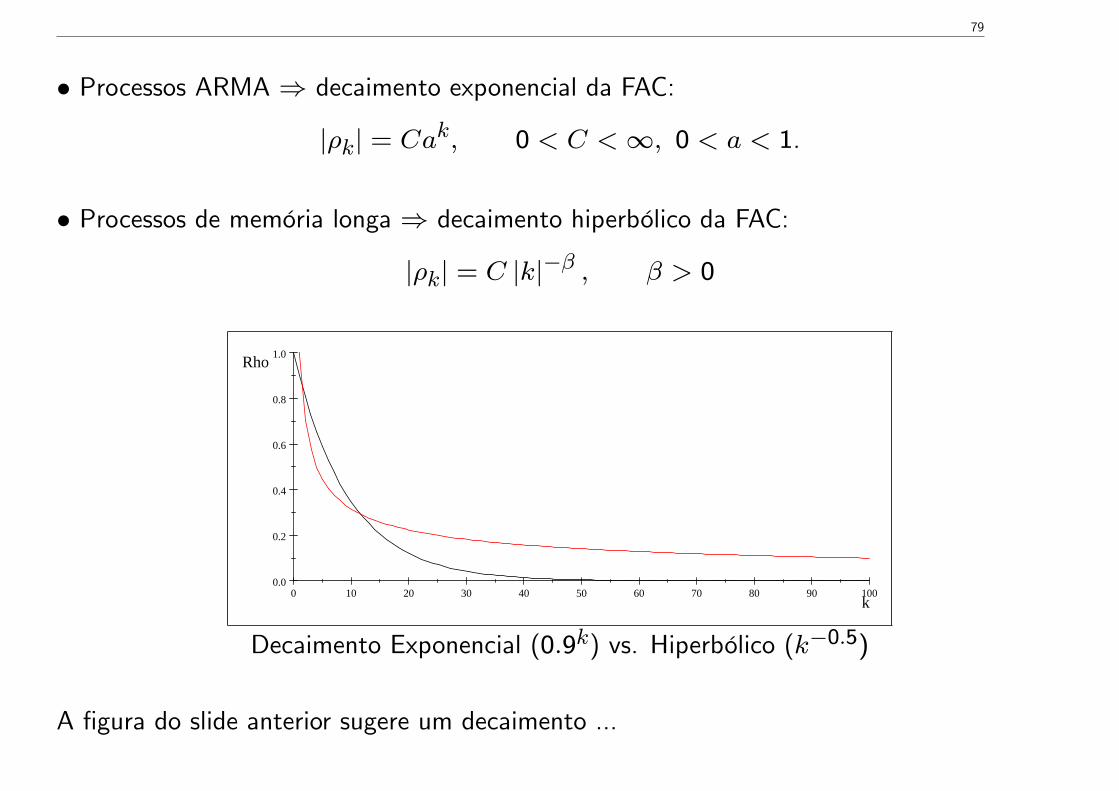
• Processos ARMA ⇒ decaimento exponencial da FAC:
|ρk| = Cak, 0 < C <∞, 0 < a < 1.
• Processos de memória longa ⇒ decaimento hiperbólico da FAC:
|ρk| = C |k|−β , β > 0
0 10 20 30 40 50 60 70 80 90 1000.0
0.2
0.4
0.6
0.8
1.0
k
Rho
Decaimento Exponencial (0.9k) vs. Hiperbólico (k−0.5)
A figura do slide anterior sugere um decaimento ...

80
3.2.4 Efeito Assimétrico
Correlação entre a volatilidade e a ocorrência de perdas significativas nos mercados de cap-itais.
Índices Bolsistas Corr(rt−1, r
2t
)Amesterdão -0.049Frankfurt -0.095Hong Kong -0.081Nova York -0.199Taxas de CâmbioLibra Britânica 0.074Dólar Canadiano 0.041Yen -0.008Franco Suíço 0.014
Como verificar se as estimativas são estatisticamente significativas?

81
3.2.5 Aumento da Frequência das Observações Acentua a Não Linearidade
Vários estudos indicam que os coeficientes de autocorrelações de r2t e de |rt| tendem a
aumentar com o aumento da frequência das observações.
3.2.6 Co-Movimentos de Rendibilidade e Volatilidade
Ao se analisarem duas ou mais séries financeiras de retornos ao longo do tempo, geralmenteobservam-se co-movimentos de rendibilidade e volatilidade, isto é, quando a rendibilidade ea volatilidade de uma série aumenta (diminui), a rendibilidade e a volatilidade das outrastende, em geral, a aumentar (diminuir).

82
1000
2000
3000
4000
5000
6000
7000
1990 1992 1994 1996 1998 2000 2002 2004 2006
CAC
1000
2000
3000
4000
5000
6000
7000
8000
9000
1990 1992 1994 1996 1998 2000 2002 2004 2006
DAX
0
1000
2000
3000
4000
5000
6000
1990 1992 1994 1996 1998 2000 2002 2004 2006
DJ EURO STOXX 50
1000
2000
3000
4000
5000
6000
7000
1990 1992 1994 1996 1998 2000 2002 2004 2006
FTSE 100
2000
4000
6000
8000
10000
12000
14000
16000
1990 1992 1994 1996 1998 2000 2002 2004 2006
PSI20
200
400
600
800
1000
1200
1400
1600
1990 1992 1994 1996 1998 2000 2002 2004 2006
S&P 500
Índices Bolsistas
.08
.04
.00
.04
.08
1990 1992 1994 1996 1998 2000 2002 2004 2006
CAC
.12
.08
.04
.00
.04
.08
1990 1992 1994 1996 1998 2000 2002 2004 2006
DAX
.08
.04
.00
.04
.08
1990 1992 1994 1996 1998 2000 2002 2004 2006
DJ EURO STOXX 50
.06
.04
.02
.00
.02
.04
.06
1990 1992 1994 1996 1998 2000 2002 2004 2006
FTSE 100
.12
.08
.04
.00
.04
.08
1990 1992 1994 1996 1998 2000 2002 2004 2006
PSI20
.08
.06
.04
.02
.00
.02
.04
.06
1990 1992 1994 1996 1998 2000 2002 2004 2006
S&P 500
Retornos de Índices
83
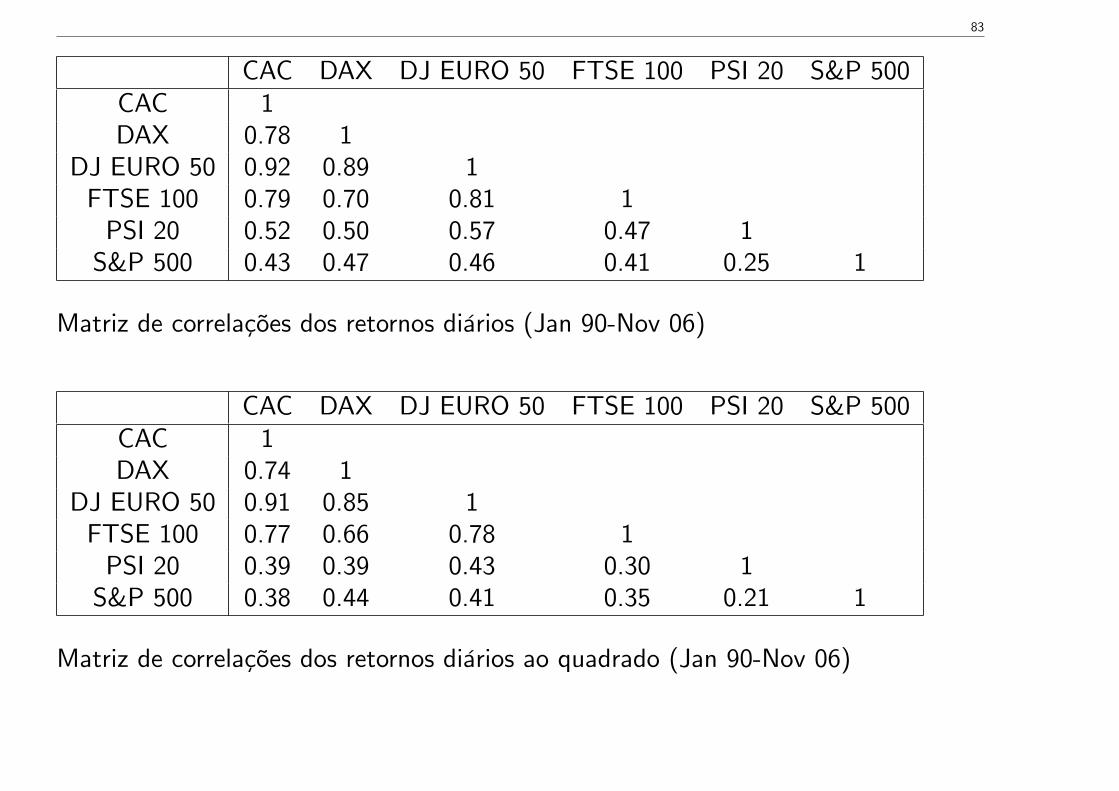
CAC DAX DJ EURO 50 FTSE 100 PSI 20 S&P 500CAC 1DAX 0.78 1
DJ EURO 50 0.92 0.89 1FTSE 100 0.79 0.70 0.81 1PSI 20 0.52 0.50 0.57 0.47 1S&P 500 0.43 0.47 0.46 0.41 0.25 1
Matriz de correlações dos retornos diários (Jan 90-Nov 06)
CAC DAX DJ EURO 50 FTSE 100 PSI 20 S&P 500CAC 1DAX 0.74 1
DJ EURO 50 0.91 0.85 1FTSE 100 0.77 0.66 0.78 1PSI 20 0.39 0.39 0.43 0.30 1S&P 500 0.38 0.44 0.41 0.35 0.21 1
Matriz de correlações dos retornos diários ao quadrado (Jan 90-Nov 06)

84
4 Modelação da Heterocedasticidade Condicionada: Caso
Univariado
4.1 Introdução
0.15
0.1
0.05
0
0.05
0.1
0.15
0.2
Oct2
8Ap
r31
Oct3
3Ap
r36
Oct3
8Ap
r41
Oct4
3Ap
r46
Oct4
8Ap
r51
Oct5
3Ap
r56
Oct5
8Ap
r61
Oct6
3Ap
r66
Oct6
8Ap
r71
Oct7
3Ap
r76
Oct7
8Ap
r81
Oct8
3Ap
r86
Oct8
8Ap
r91
Oct9
3Ap
r96
Oct9
8Ap
r01
Oct0
3

85
Por que razão a volatilidade não é constante?
• Uma parte da volatilidade pode ser relacionada com a especulação.
• Episódios de extrema volatilidade ocorrem quando uma “bolha especulativa” rebenta.
• Graves crises económicas e políticas também explicam momentos de alta volatilidade.
• Conceito "chegada de informação".

86
Replicar o fenómeno de volatilidade não constante a partir do conceito de chegada de infor-mação.
Seja Nt o número de notícias no dia t.
Nt = 1 ⇒ variação do preço numa quantidade aleatória dada por ε1,t
logPt = logPt−1 + µ+ ε1,t
Nt = 2 ⇒ variação do preço numa quantidade aleatória dada por ε1,t + ε2,t
logPt = logPt−1 + µ+ ε1,t + ε2,t
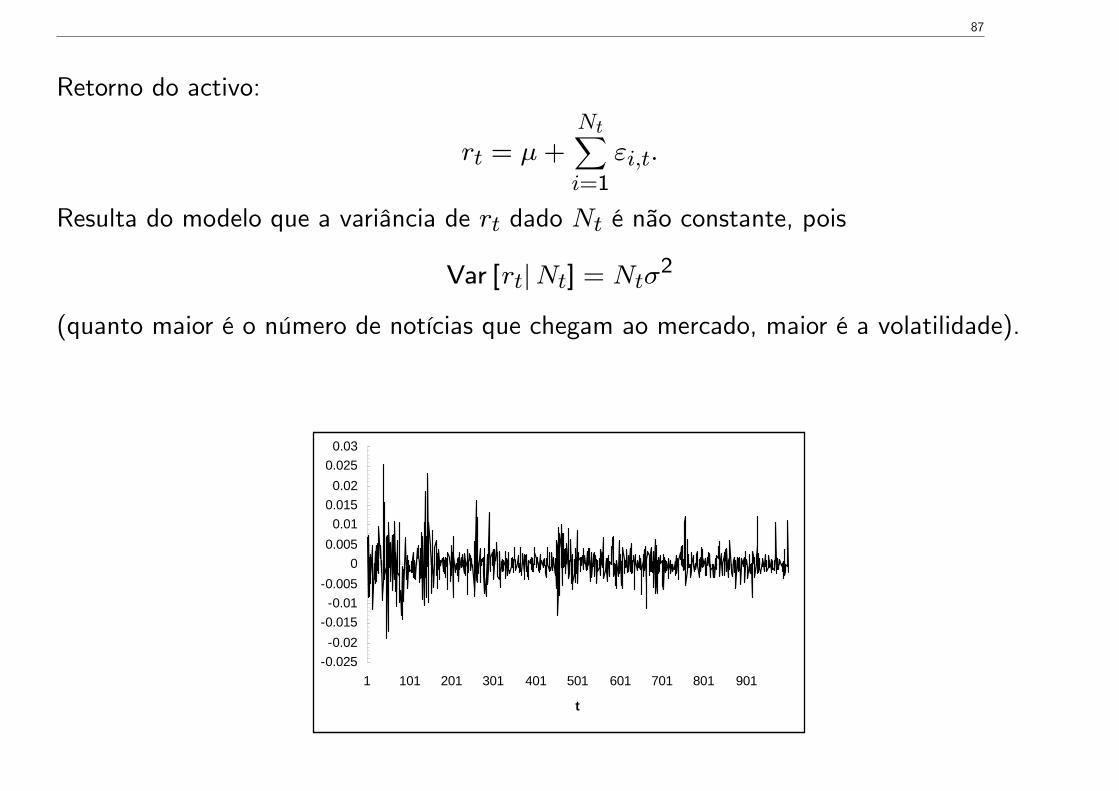
87
Retorno do activo:
rt = µ+Nt∑i=1
εi,t.
Resulta do modelo que a variância de rt dado Nt é não constante, pois
Var [rt|Nt] = Ntσ2
(quanto maior é o número de notícias que chegam ao mercado, maior é a volatilidade).
0.0250.02
0.0150.01
0.0050
0.0050.01
0.0150.02
0.0250.03
1 101 201 301 401 501 601 701 801 901
t

88
O modelo anterior sugere a especificação
rt = µ+ ut, ut = σtεt.
ut tem variância condicional σ2t não constante.
Processos Multiplicativos
Considere-se
ut = σtεt
e as seguintes hipóteses:
H1: {εt} é uma sequência de v.a. i.i.d. com E [εt] = 0 e Var [εt] = 1;H2: εt é independente de ut−k, k ∈ N;
H3: σt é Ft−1 mensurável.
Calcule-se E [ut| Ft−1] e Var [ut| Ft−1] e conclua:
Processos multiplicativos do tipo ut = σtεt (H1-H3) são processos heterocedásticos (var-iância não constante) mas não autocorrelacionados.

89
Que função especificar para σt ou σ2t?
Volatility clustering : fortes variações são normalmente seguidas de fortes variações em ambosos sentidos ⇒ Corr
(r2t , r
2t−1
)> 0 ⇒ Corr
(u2t , u
2t−1
)> 0. Se u2
t−1 é um valor alto
(baixo), u2t tenderá também a ser um valor alto (baixo).
Faz sentido escrever o seguinte modelo para σ2t :
σ2t = ω + α1u
2t−1, ω > 0, α1 ≥ 0.
Com efeito,
u2t−1 é “alto” ⇒ σ2
t é “alto” ⇒ u2t é “alto”.

90
Distribuições de Caudas Pesada
Seja ut = σtεt sob as hipóteses H1-H3. Admita-se εt ∼ N (0, 1) . Tem-se
E (ut) = 0
Var (ut) = E(u2t
)= E
[σ2t
]E(u3t
)= 0 ⇒ skweness = 0 (Verifique)
ku =E(u4t
)E(u2t
)2 > 3 [quadro]
Este resultado sugere que um modelo de HC pode ser adequado para modelar retornos ...

91
Vantagens dos modelos de HC
Iremos ver que os modelos de HC permitem:
• modelar a volatilidade (e as covariâncias condicionais, no caso multivariado); como se sabe,a volatilidade é uma variável fundamental na análise do risco de mercado, na construção deportfolios dinâmicos, na valorização de opções, etc.;• estimar de forma mais eficiente os parâmetros definidos na média condicional;• estabelecer intervalos de confiança correctos para y. Isto é, se y exibe HC e esta é neg-ligenciada, os intervalos de previsão para y são incorrectos. Observe-se, com efeito, queos intervalos de confiança dependem da variância do erro de previsão e o erro de previsãodepende (entre outros aspectos) da variância (condicional) da v.a. residual.

92
4.2 Modelo ARCH
Considere-se o seguinte modelo
yt = µt + ut,
µt = E (yt| Ft−1) média condicional
ut = σtεt
Assumam-se as hipóteses H1-H3.
Definição ut segue um modelo ARCH(q) (ou tem representação ARCH(q)) se
ut = σtεt
σ2t = ω + α1u
2t−1 + ...+ αqu
2t−q, ω > 0, αi ≥ 0
É importante constatar que σ2t ∈ Ft−1.
Como a vol. exibe forte dependência temporal, raramente se considera q = 1.

93
Exercício de simulação:
rt = ut, (µt = 0)
ut = σtεt, εt RB Gaussiano com variância 1
σ2t = ω + α1u
2t−1 + ...+ α8u
2t−8.
Painel (a) ARCH(0) α1 = α2 = ... = α8 = 0
Painel (b) ARCH(1) α1 = 0.8, α2 = ... = α8 = 0;Painel (c) ARCH(3) α1 = 0.3, α2 = 0.3, α3 = 0.2, α4 = ... = α8 = 0;Painel (d) ARCH(8) α1 = 0.2, α2 = ... = α8 = 0.1
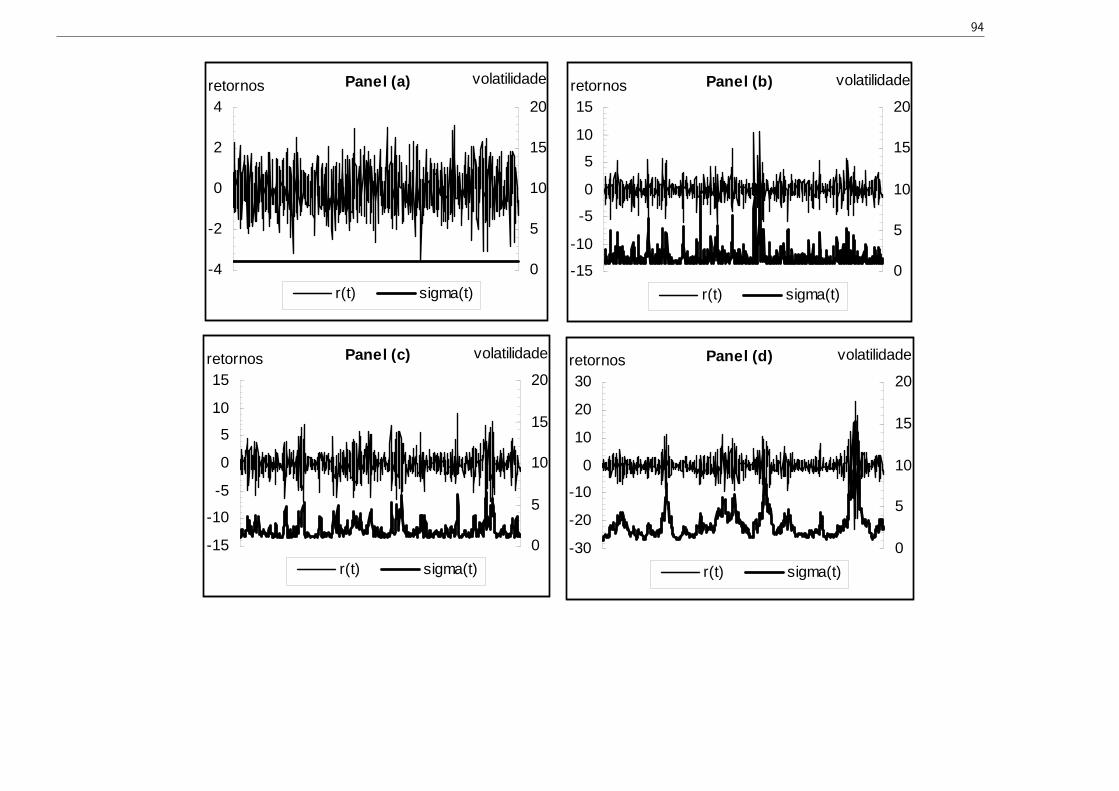
94
Panel (a)
4
2
0
2
4retornos
0
5
10
15
20
volatilidade
r(t) sigma(t)
Panel (b)
15
10
5
0
5
10
15retornos
0
5
10
15
20
volatilidade
r(t) sigma(t)
Panel (c)
15
10
5
0
5
10
15retornos
0
5
10
15
20
volatilidade
r(t) sigma(t)
Panel (d)
30
20
10
0
10
20
30retornos
0
5
10
15
20
volatilidade
r(t) sigma(t)

95
4.2.1 Dois Primeiros Momentos de ut
Como εt é independente de ut−k, k > 0, segue-se que σ2t (que é uma função de ut−k) é
independente de εt. Prove-se:
E (ut) = 0,
Var (ut) = E(σ2t
)Cov
(ut, ut−k
)= 0, k ∈ N.

96
4.2.2 Representação AR de um ARCH
Existem dependências no segundo momento do processo. A representação autoregressiva doprocesso ARCH mostra exactamente esse aspecto. Prove-se:
u2t = ω + α1u
2t−1 + vt, α1 ≥ 0.
Como E (vt) = 0 e Cov(vt, vt−k
)= 0 conclui-se
ut ∼ ARCH(1)⇒ u2t ∼ AR(1).
Logo o processo u2t é autocorrelacionado (se α1 > 0) e apresenta as características básicas
de um processo AR(1). De igual forma se conclui:
ut ∼ ARCH(q)⇒ u2t ∼ AR(q).

97
4.2.3 Estacionaridade Segunda Ordem no ARCH(q)
Estude-se a ESO de ut. Vimos que E (ut) e Cov(ut, ut−k
)são finitos e não dependem de
t; só falta estudar Var (ut) . O ARCH(1) na sua representação autoregressiva:
u2t = ω + α1u
2t−1 + vt, α1 ≥ 0.
Da estrutura autoregressiva resulta que a condição de ESO é 0 ≤ α < 1. Se ut é ESO vem
E(u2t
)=
ω
1− α1
No caso geral, ARCH(q). Condição de ESO:
α1 + α2 + ...+ αq < 1, (αi ≥ 0).
Neste caso, depois de algumas contas, obtém-se
Var (ut) = E(u2t
)=
ω
1− (α1 + α2 + ...+ αq).

98
Observação: Embora a expressão Var [ut| Ft−1] seja variável, Var (ut) é constante. Assim:ut é condicionalmente heterocedástico (heterocedasticidade condicional) mas em termos nãocondicionais ou marginais, ut é homocedástico. De forma análoga, também num processoestacionário, a média condicional é variável e a não condicional é constante. Por exemplo,num processo AR(1) estacionário, a média condicional é variável ao longo do tempo e dadapor µt = c+ φyt−1; no entanto, a média marginal c/ (1− φ) é constante.
4.2.4 FAC e FACP de um u2t e Identificação do Processo ARCH(q)
Suponha-se que os quatro primeiros momentos de u são finitos não dependem de t. Vimosut ∼ARCH(q)⇒ u2
t ∼AR(q). Assim a FAC e a FACP de u2 exibem o comportamento típicode um AR: [completar]• ρk• φkk =
{não se anula se
se• Em particular, tem-se num ARCH(1)
ρk = αk1, k ≥ 1, φ11 = α e φkk = 0, k ≥ 2.

99
Passos para a identificação da ordem q de um processo ARCH(q)
1. Estima-se o modelo yt = µt + ut supondo σ2t constante;
2. Obtêm-se os resíduos ut = yt − µt, t = 1, ..., n;
3. Calcula-se u2t , t = 1, ..., n;
4. Calcula-se a FAC e a FACP de u2t e identifica-se a ordem q.
Na figura seguinte simulou-se um ARCH(q), n = 5000 observações. Qual a ordem de q?
FAC de u^2
0.1
0
0.1
0.2
0.3
0.4
0.5
1 5 9 13 17 21 25 29
FACP de u^2
0.1
0
0.1
0.2
0.3
0.4
0.5
1 5 9 13 17 21 25 29

100
4.2.5 Características da Distribuição Marginal de ut
Suponha-se que εti.i.d.∼ N (0, 1) . Então a distribuição condicional de ut é N
(0, σ2
). MAS
f (ut) não é normal! Sabe-se:
E (ut) = 0
Var (ut) = E(u2t
)=
ω
1− (α1 + ...+ αq)
E(u3t
)= 0⇒ skweness = 0
ku =E(u4t
)E(u2t
)2 > kε = 3 (já vimos).
f tem caudas de Pareto
Podemos obter uma expressão exacta para ku. Suponha-se ut ∼ ARCH(1), εti.i.d.∼ N (0, 1)
e 3α21 < 1. Pode-se mostrar:
ku = 3 +6α2
1
1− 3α21
> 3 [fazer gráfico]

101
Algumas conclusões:
• Embora {ut} seja um processo não autocorrelacionado, {ut} não é uma sequênciade variáveis independentes (basta observar, por exemplo, Cov
(u2tu
2t−1
)6= 0 ou que
E(u2t
∣∣∣Ft−1
)depende de u2
t−1);
• Mesmo que ut seja condicionalmente Gaussiano a distribuição marginal não é Gaussiana.Em particular, se ut é condicionalmente Gaussiano então a distribuição marginal éleptocúrtica.

102
4.2.6 Momentos e Distribuição de y
Seja yt = µt + ut, ut = σtεt (assumam-se as hipóteses habituais para εt). Então [comple-tar]:
• E (yt| Ft−1) =
• Var (yt| Ft−1) =
• Se εt é Gaussiano então yt| Ft−1 ∼• E (yt) =
• Var (yt) =
103
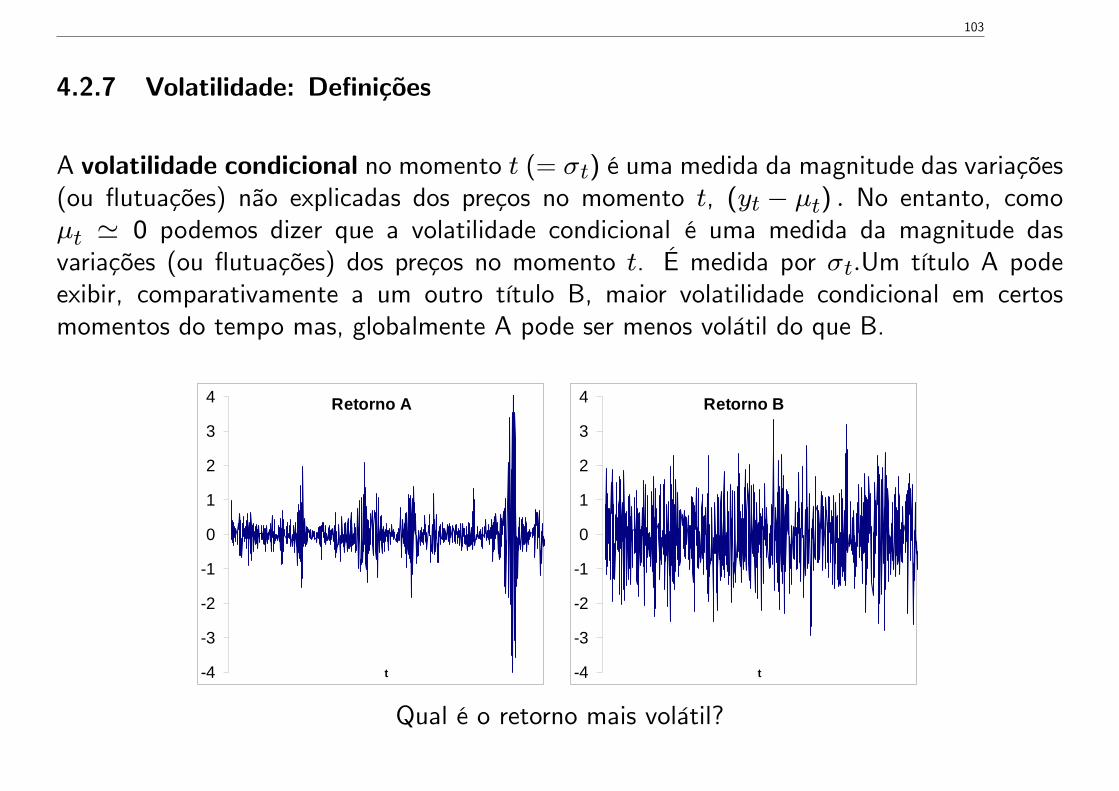
4.2.7 Volatilidade: Definições
A volatilidade condicional no momento t (= σt) é uma medida da magnitude das variações(ou flutuações) não explicadas dos preços no momento t, (yt − µt) . No entanto, comoµt ' 0 podemos dizer que a volatilidade condicional é uma medida da magnitude dasvariações (ou flutuações) dos preços no momento t. É medida por σt.Um título A podeexibir, comparativamente a um outro título B, maior volatilidade condicional em certosmomentos do tempo mas, globalmente A pode ser menos volátil do que B.
Retorno B
4
3
2
1
0
1
2
3
4
t
Retorno A
4
3
2
1
0
1
2
3
4
t
Qual é o retorno mais volátil?

104
Falamos neste caso de volatilidade não condicional que é uma medida da magnitude dasvariações (ou flutuações) dos preços num hiato de tempo (meses ou anos) (que não sãoexplicadas). Pode ser medida através das estatísticas
Var (ut) =
∑nt=1 ut
2
nou Var (ut) =
ω
1− (α1 + ...+ αq).
No exemplo acima, o retorno B apresenta volatilidade constante.Também se pode usar
σ2y =
1
n
∑(yt − y)2
mas σ2y ≥ Var (ut) .

105
4.3 Modelo GARCH
Tendo em conta a forte dependência temporal da volatilidade, era usual, nas primeirasaplicações (ainda na década de 80) considerar-se um ARCH de ordem elevada. Um ARCHde ordem elevada levanta problemas de estimação. A melhor solução apareceu com o modeloGARCH.
Definição ut segue um modelo GARCH(p,q) se
ut = σtεt
σ2t = ω + α1u
2t−1 + ...+ αqu
2t−q + β1σ
2t−1 + ..+ βpσ
2t−p
ω > 0, αi ≥ 0, β ≥ 0.
Surpreendentemente, o modelo mais simples GARCH(1,1),
σ2t = ω + α1u
2t−1 + β1σ
2t−1
veio a revelar-se suficiente em muitas aplicações.

106
4.3.1 GARCH(p,q) representa um ARCH(∞)
Mostrar para o GARCH(1,1).
4.3.2 Representação ARMA de um GARCH
Mostrar para o GARCH(1,1).

107
Concluir: u2t ∼ ARMA(1, 1). No caso geral pode-se mostrar
ut ∼ GARCH(p,q)⇒ u2t ∼ ARMA(max {p, q} , p).
Por exemplo,
ut ∼ GARCH(1,2)⇒ u2t ∼ ARMA(2,1)
ut ∼ GARCH(2,1)⇒ u2t ∼ ARMA(2,2)
ut ∼ GARCH(2,2)⇒ u2t ∼ ARMA(2,2)
Em geral é problemático identificar o GARCH a partir das FAC e FACP de u2t . Por duas
razões: 1) o GARCH implica uma estrutura ARMA para u2t e, como se sabe, no ARMA,
nenhuma das funções de autocorrelação (FAC ou FACP) é nula a partir de certa ordem; 2)não existe uma correspondência perfeita entre a estruturas ARMA e GARCH.

108
As funções de autocorrelação não são interessantes nesta fase? De forma alguma, por duasrazões: 1) se FAC e a FACP de u2
t não apresentarem coeficientes significativos então
2) a existência de vários coeficientes de autocorrelação e de autocorrelação parcial significa-tivos é indício
Como regra geral, não devemos usar o ARCH; o GARCH é preferível. A identificação dasordens p e q do GARCH faz-se na fase da estimação.

109
4.3.3 Estacionaridade de Segunda Ordem num GARCH(p,q)
Como se sabe E (ut) = Cov(ut, ut−k
)= 0, ∀k ∈ N. Assim, para discutir a ESO do
processo u, basta analisar E(u2t
). Pode-se provar que a condição de ESO é
q∑i=1
αi +p∑i=1
βi < 1.
No caso GARCH(1,1):
α1 + β1 < 1.

110
4.4 Modelo IGARCH
Vamos analisar apenas o IGARCH(1,1):
σ2t = ω + α1u
2t−1 + β1σ
2t−1, α1 + β1 = 1.
A designação Integrated GARCH resulta do facto de u2t possuir uma raiz unitária:
u2t = ω + (α1 + β1)︸ ︷︷ ︸
1
u2t−1 − β1vt−1 + vt
u2t = ω + u2
t−1 − β1vt−1 + vt
(1− L)u2t = ω − β1vt−1 + vt
Nestas condições, ut não é ESO. Durante algum tempo pensou-se que ut seria também nãoestacionário em sentido estrito. Isso é falso. Pode-se mostrar:
1) a condição necessária e suficiente para que ut seja EE é E[log
(β1 + α1ε
2t
)]< 0;
2) e que esta condição acaba por ser menos exigente que a condição de ESO, α1 + β1 < 1.

111
4.4.1 Alterações de Estrutura e o IGARCH
Modelos aparentemente IGARCH podem também dever-se a alterações de estrutura (talcomo processos aparentemente do tipo yt = yt−1 + ut podem dever-se a alterações deestrutura). Por exemplo, considere-se a seguinte simulação de Monte Carlo:
yt = ut, t = 1, 2, ..., 1000
ut = σtεt
σ2t = ω + αu2
t−1 + βσ2t−1,
α = 0.1, β = 0.6, ω =
{0.5 t = 1, 2, ..., 5001.5 t = 501, 502, ..., 1000
Este modelo foi simulado 500 vezes. Na figura seguinte representa-se uma das 500 trajec-tórias simuladas
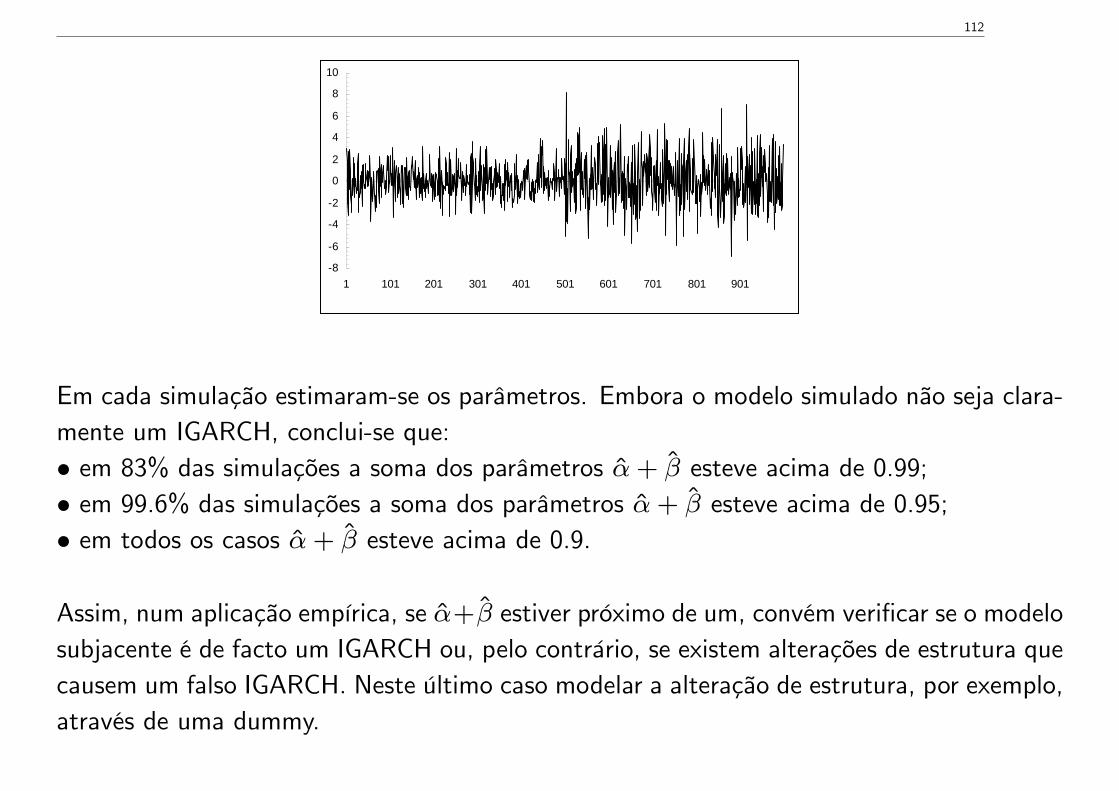
112
8
6
4
2
0
2
4
6
8
10
1 101 201 301 401 501 601 701 801 901
Em cada simulação estimaram-se os parâmetros. Embora o modelo simulado não seja clara-mente um IGARCH, conclui-se que:• em 83% das simulações a soma dos parâmetros α+ β esteve acima de 0.99;• em 99.6% das simulações a soma dos parâmetros α+ β esteve acima de 0.95;• em todos os casos α+ β esteve acima de 0.9.
Assim, num aplicação empírica, se α+β estiver próximo de um, convém verificar se o modelosubjacente é de facto um IGARCH ou, pelo contrário, se existem alterações de estrutura quecausem um falso IGARCH. Neste último caso modelar a alteração de estrutura, por exemplo,através de uma dummy.

113
4.5 Modelo GJR-GARCH
O modelo GJR-GARCH é devido a Glosten, Jagannathan e Runkle.
Leverage Effect (i.e. momentos de maior volatilidade são despoletados por variações nega-tivas nos preços). Vimos a medida (naive) Cov
(y2t , yt−1
)< 0.
Veremos agora uma forma bastante mais eficiente de estimar esse efeito. O modelo ARCH/GARCHapenas detecta o chamado “efeito magnitude”. Isto é, a volatilidade só responde à magnitudedo valor de ut. Em esquema:
↑ u2t−1 ⇒ ↑ σ2
t (efeito magnitude)
Para modelar o efeito assimétrico é necessário que a volatilidade responda assimetricamenteao sinal de ut. Mais precisamente, a volatilidade deve aumentar mais quando ut < 0 (“mánotícia”) do que quando ut > 0 (“boa notícia”).

114
Modelo GJR-GARCH → modela não só o efeito magnitude como também o efeito as-simétrico. A especificação mais simples:
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + γ1u
2t−1I{ut−1<0},
I{ut−1<0} =
{1 se ut−1 < 00 se ut−1 ≥ 0.
De acordo com o efeito assimétrico devemos esperar γ1 > 0. Para ensaiar o efeito assimétricopodemos considerar o ensaio H0: γ1 = 0.
Pode-se provar que a condição de ESO (no caso em que a distribuição de ε é simétrica) éα1 + γ1/2 + β1 < 1. Nesta circunstâncias,
Var (ut) = E[σ2t
]=
ω
1− (α1 + γ1/2 + β1)

115
4.6 Modelo de Het. Cond. com Variáveis Explicativas
Considere-se um modelo GARCH(1,1) (poderia ser outro modelo qualquer) com variáveisexplicativas:
yt = µt + ut
ut = σtεt
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + g (xt)
onde ω+ g : R→ R+ (exigimos que g (xt) +ω > 0). Que variáveis poderemos considerarpara xt? Vejamos alguns exemplos:
• Dias da semana (ou qualquer outro efeito de calendário):
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + δ1St + δ2Tt + δ3Q
at + δ5Q
ut
onde St = 1 se t é uma segunda-feira, etc. (deverá ter-se ω + min {δi} > 0⇒ σ2t > 0).

116
• Ocorrência de factos, notícias significativas. Por exemplo,
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + δ1goodt + δ2badt
goodt =
{1 t = são divulgados resultados da empresa ABC acima do esperado0 0
badt =
{1 t = são divulgados resultados da empresa ABC abaixo do esperado0 0
• Variação do preço do crude.• Medida de volatilidade de outro activo/mercado.• Volume de transacções:
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + δ1vol
∗t−1
onde vol∗t−1 =volt−1σvol
ou vol∗t−1 = log (volt−1) ou vol∗t−1 = volt−1/volt−2. Observe-seque o volume pode ser considerado como uma variável proxy da variável não observadachegada de informação.• Qualquer outra variável (estacionária) que supostamente afecte a volatilidade.

117
Exemplo A literatura dos modelos de taxas de juro (a um factor) sugere que a volatilidadeda taxa de juro depende do nível da taxa de juro:
rt = c+ φrt−1 + ut
ut = σtεt
σ2t = ω + α1u
2t−1 + βσ2
t−1 + γrt−1.
O ensaio H0: γ = 0 vs. H1 : γ > 0 permite analisar se a nível da taxa de juro influenciapositivamente a volatilidade. Geralmente conclui-se γ > 0. A figura sugere (claramente)γ > 0.
0
2
4
6
8
10
12
14
16
18
Jan
54
May
56
Sep
58
Jan
61
May
63
Sep
65
Jan
68
May
70
Sep
72
Jan
75
May
77
Sep
79
Jan
82
May
84
Sep
86
Jan
89
May
91
Sep
93
Jan
96
May
98
Sep
00
Jan
03
May
05
Taxa de Juro (Bilhetes do Tesouro a 3 meses -EUA)

118
4.7 Estimação
Considere-se
yt = µt (θ) + ut
ut = σt (θ) εt, εt ∼ D (0, 1)
A v.a. εt tem distribuição conhecida D (normal, t-Student ou outra) de média zero evariância um.
Por exemplo,
yt = γ0 + γ1xt + φ1yt−1 + ut
ut = σtεt, εt ∼ N (0, 1)
σ2t = ω + α1u
2t−1 + β1σ
2t−1 + δsegt
θ = (γ0, γ1, φ1, ω α1, β1, δ)′

119
4.7.1 Estimador de Máxima Verosimilhança
O estimador de máxima verosimilhança é
θn = arg maxθ
n∑t=1
log f (yt| It; θ) , It = {yt−1, yt−2, ...; xt,xt−1, ...} .
Escreva-se log f (yt| It; θ) no caso εti.i.d∼ N (0, 1) .
Pode-se mostrar:√n(θn − θ0
)d−→ N
(0, I (θ0)−1
)onde I (θ0) = A (θ0) = B (θ0) é a matriz de informação de Fisher e
A (θ) = −E
(∂2lt (θ)
∂θ∂θ′
), B (θ) = E
(∂lt (θ)
∂θ
∂lt (θ)
∂θ′
)
Ver EVIEWS

120
4.7.2 Estimador de Pseudo (ou Quase) Máxima Verosimilhança
Na prática, a distribuição de εt não é conhecida. Podemos ainda assim supor, por exemplo,εt ∼ N (0, 1) ou εt ∼ t (n)? A resposta é afirmativa.
Suponhamos que a verdadeira mas desconhecida fdp condicional de y é f . O estimador demáxima verosimilhança
θn = arg maxθ
n∑t=1
log f (yt| It; θ)
não pode ser implementado, pois a função f é desconhecida.
O estimador de pseudo máxima verosimilhança usa como pseudo verdadeira fdp a função h(que na generalidade dos casos é diferente de f),
θpmvn = arg max
θ
n∑t=1
log h (yt| It; θ) .

121
Sob certas condições, mesmo que h 6= f, o estimador de pseudo máxima verosimilhançaapresenta boas propriedades. As condições são:
• h pertence à família das densidades exponenciais quadráticas (a normal e a t-Student,entre muitas outras distribuições, pertencem a esta família);• a média condicional está bem especificada;• a variância condicional está bem especificada.
Pode-se provar, sob estas condições:
θpmvn
p−→ θ0√n(θpmvn − θ0
)d−→ N
(0, A (θ0)−1B (θ0)A (θ0)−1
)Se, por acaso, a função h é a própria função f , i.e., f = h, então o estimador de pseudomáxima verosimilhança é o estimador de máxima verosimilhança e A (θ0) = B (θ0) .

122
Em suma, mesmo que a distribuição de εt não seja conhecida podemos supor, por exemplo,εt ∼ N (0, 1) (ou εt ∼ D tal que a densidade h satisfaça as condições estabelecidas),porque θ
pmvn é ainda assim um estimador consistente (embora não assimptoticamente efi-
ciente) e tem distribuição assimptótica normal. O único cuidado adicional é tomar comomatriz de variâncias-covariâncias (assimptótica) a expressão A (θ0)−1B (θ0)A (θ0)−1 enão I (θ0)−1. Como fazer isto no EVIEWS? Basta escolher a opção “heteroskedasticityconsistent covariance (Bollerslev-Wooldrige)”no menu “options”da estimação. Esta opçãoconvém estar sempre activa.

123
4.7.3 Método da Máxima Verosimilhança Revisitado: Distribuições Não Normais
No âmbito do método da máxima (ou da pseudo máxima) verosimilhança, normalmenteassume-se εt ∼ N (0, 1). Contudo, verifica-se habitualmente que os resíduos estandard-izados, ε = ut/σt apresentam um valor de kurtosis quase sempre acima do valor 3, i.e.,kε > 3. Este resultado é, até certo ponto, inesperado. Porquê? Também a distribuiçãocondicional ut| Ft−1 (e não só a marginal) é leptocúrtica.
Já vimos uma forma de lidar com este problema: basta tomar o estimador de pseudo máximaverosimilhança. Uma alternativa consiste em formular uma distribuição leptocúrtica para εttal que E [εt] = 0 e Var [εt] = 1.

124
Hipótese: εt ∼ t-Student(v)
Estima-se também v, no de graus de liberdade. Se v é baixo (abaixo de 10)⇒ evidência decaudas pesadas para a dist. condicional
4 6 8 10 12 14 16 18 200
2
4
6
8
10
12
14
16
graus de liberdade
kurtosis
Kurosis kε = 3 + 6v−4
125
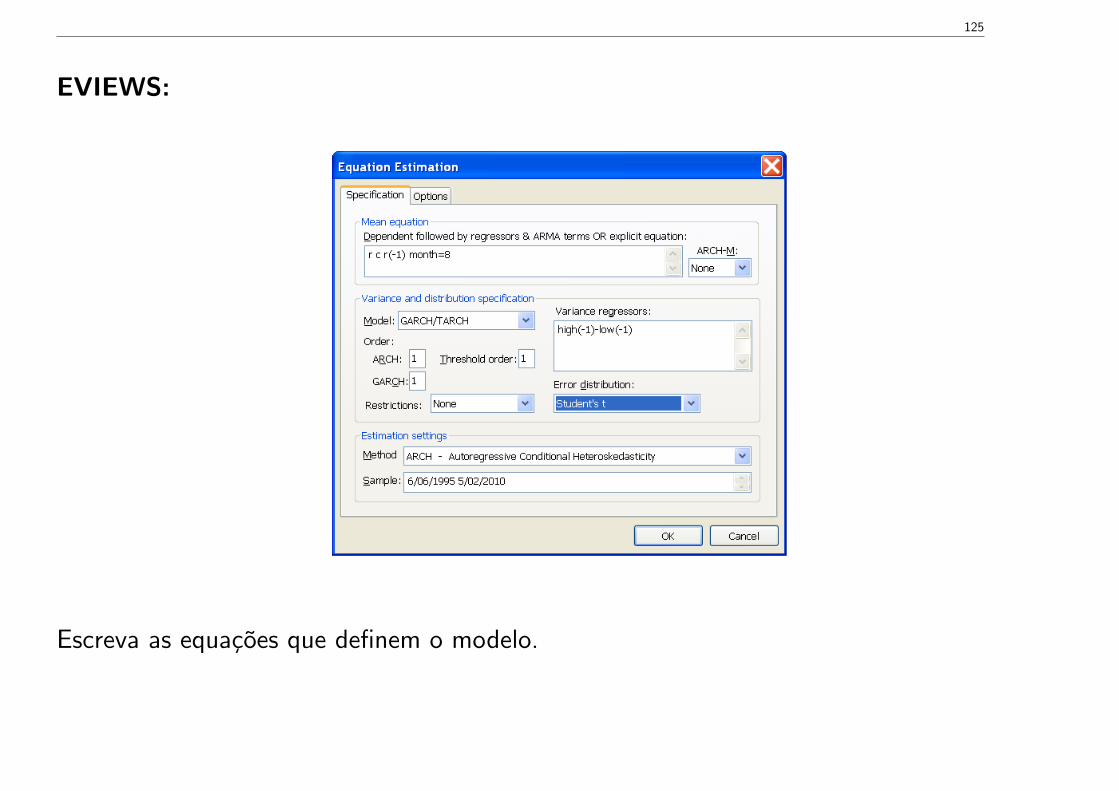
EVIEWS:
Escreva as equações que definem o modelo.
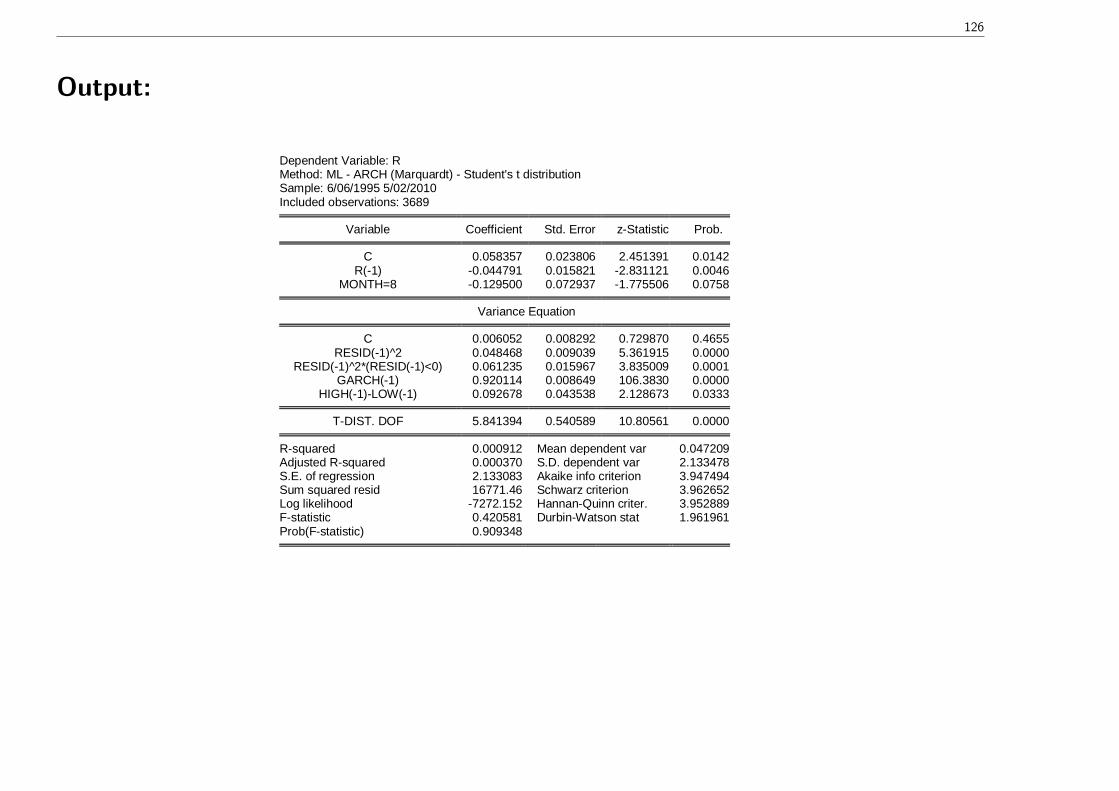
126
Output:
Dependent Variable: RMethod: ML ARCH (Marquardt) Student's t distributionSample: 6/06/1995 5/02/2010Included observations: 3689
Variable Coefficient Std. Error zStatistic Prob.
C 0.058357 0.023806 2.451391 0.0142R(1) 0.044791 0.015821 2.831121 0.0046
MONTH=8 0.129500 0.072937 1.775506 0.0758
Variance Equation
C 0.006052 0.008292 0.729870 0.4655RESID(1)^2 0.048468 0.009039 5.361915 0.0000
RESID(1)^2*(RESID(1)<0) 0.061235 0.015967 3.835009 0.0001GARCH(1) 0.920114 0.008649 106.3830 0.0000
HIGH(1)LOW(1) 0.092678 0.043538 2.128673 0.0333
TDIST. DOF 5.841394 0.540589 10.80561 0.0000
Rsquared 0.000912 Mean dependent var 0.047209Adjusted Rsquared 0.000370 S.D. dependent var 2.133478S.E. of regression 2.133083 Akaike info criterion 3.947494Sum squared resid 16771.46 Schwarz criterion 3.962652Log likelihood 7272.152 HannanQuinn criter. 3.952889Fstatistic 0.420581 DurbinWatson stat 1.961961Prob(Fstatistic) 0.909348

127
4.8 Ensaios Estatísticos
Há basicamente dois momentos de interesse na realização de ensaios estatísticos.
Num primeiro momento, interessa verificar se existe evidência do efeito ARCH.
Posteriormente, depois da estimação, haverá que analisar a adequabilidade do modelo esti-mado.

128
4.8.1 Ensaios Pré-Estimação ARCH
Teste ARCH (teste multiplicador de Lagrange)
Considere-se
yt = µt + ut
ut = σtε
σ2t = ω + α1u
2t−1 + ...+ αqu
2t−q.
Existe efeito ARCH se pelo menos um parâmetro αi for diferente de zero. Se todos foremzero, não existe efeito ARCH.
Pode-se provar, sob a hipótese H0: α1 = α2 = ... = αq = 0 que
nR2 d−→ χ2(q)
onde R2 é o coeficiente de determinação da regressão de u2t sobre as variáveis[
1 u2t−1 ... u2
t−q].

129
Para a realização do teste os passos são:1. Estima-se o modelo yt = µt + ut supondo σ2
t = σ2 constante;2. Obtêm-se os resíduos ut = yt − µt, t = 1, ..., n;
3. regressão OLS de u2t sobre
[1 u2
t−1 ... u2t−q
];
4. obtenção de R2 da equação anterior e cálculo do valor-p

130
FAC de u2t
Como se viu, a existência de um processo GARCH implica a correlação das variáveis u2t e
u2t−k. O teste Ljung-Box é assimptoticamente equivalente ao teste ARCH. A sua hipótese
nula é H0: ρ1
(u2t
)= ... = ρm
(u2t
)= 0, sendo ρi
(u2t
)o coeficiente de autocorrelação
entre u2t e u
2t−i.
Q = n (n+ 2)m∑i=1
1
n− iρ2i
(u2t
)d−→ χ2
(m−k)
onde k é o número de parâmetros estimados. Evidência contra a hipótese nula sugere aexistência de um efeito ARCH.

131
EVIEWS
Dependent Variable: RMethod: Least SquaresSample: 6/06/1995 5/02/2010Included observations: 3689
Variable Coefficient Std. Error tStatistic Prob.
C 0.069015 0.036806 1.875110 0.0609R(1) 0.024767 0.016468 1.503933 0.1327
MONTH=8 0.231417 0.123256 1.877532 0.0605
Rsquared 0.001518 Mean dependent var 0.047209Adjusted Rsquared 0.000976 S.D. dependent var 2.133478S.E. of regression 2.132436 Akaike info criterion 4.353220Sum squared resid 16761.28 Schwarz criterion 4.358273Log likelihood 8026.514 HannanQuinn criter. 4.355018Fstatistic 2.801919 DurbinWatson stat 2.001065Prob(Fstatistic) 0.060823
Heteroskedasticity Test: ARCH
Fstatistic 56.94060 Prob. F(10,3668) 0.0000Obs*Rsquared 494.3696 Prob. ChiSquare(10) 0.0000
Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 21/02/10 Time: 23:59Sample (adjusted): 20/06/1995 5/02/2010Included observations: 3679 after adjustments
Variable Coefficient Std. Error tStatistic Prob.
C 1.509621 0.227111 6.647061 0.0000RESID^2(1) 0.161080 0.016481 9.773582 0.0000RESID^2(2) 0.064220 0.016649 3.857279 0.0001RESID^2(3) 0.058670 0.016681 3.517210 0.0004RESID^2(4) 0.058059 0.016614 3.494605 0.0005RESID^2(5) 0.026900 0.016605 1.620025 0.1053RESID^2(6) 0.066473 0.016605 4.003208 0.0001RESID^2(7) 0.107843 0.016616 6.490505 0.0000RESID^2(8) 0.015260 0.016683 0.914662 0.3604RESID^2(9) 0.080552 0.016652 4.837491 0.0000RESID^2(10) 0.061323 0.016490 3.718813 0.0002
Rsquared 0.134376 Mean dependent var 4.553870Adjusted Rsquared 0.132016 S.D. dependent var 11.92536S.E. of regression 11.11034 Akaike info criterion 7.656615Sum squared resid 452776.6 Schwarz criterion 7.675184Log likelihood 14073.34 HannanQuinn criter. 7.663225Fstatistic 56.94060 DurbinWatson stat 2.005539Prob(Fstatistic) 0.000000
O teste Ljung-Box corrobora as conclusões do teste ARCH:
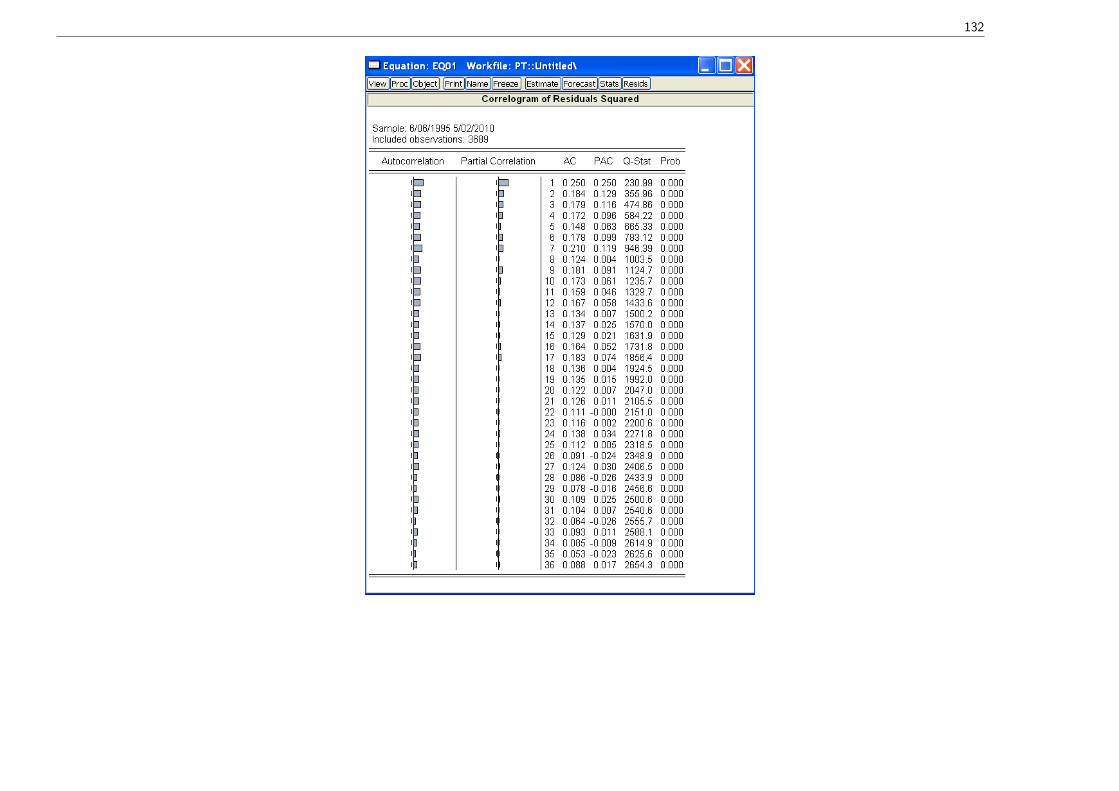
132

133
4.8.2 Ensaios Pós-Estimação
Depois do modelo estimado (pelo método da máxima (ou da pseudo) verosimilhança) háinteresse em testar determinada suposição envolvendo os parâmetros ou em analisar a ade-quabilidade do modelo.
Teste de Wald
O teste de Wald baseia-se no resultado conhecido:√n(θn − θ0
)d−→ N (0, V0) .
Permite analisar: 1) a significância das estimativas; 2) hipóteses envolvendo vários parâmet-ros e combinações lineares entre eles.
Ver EVIEWS

134
Testes de Diagnóstico
O modelo em análise é yt = µt + ut, ut = σtεt e as hipóteses são: {εt} é um processodiferença de martingala ou ruído branco e {εt} é um processo homocedástico. Nestascircunstância, se o modelo está bem especificado, deve ter-se: {εt} deve ser não autocor-relacionado e {εt} deve ser condicionalmente homocedástico. Assim, se
(a) y é, por exemplo, um ARMA e a média condicional não captar esta estrutura, os processos{ut} e {εt} exibirão autocorrelação;(b) de igual forma, se y segue um GARCH e a variância condicional não captar esta estruturaε2t = u2
t/σ2t exibirá autocorrelação;
(c) finalmente, se ε segue uma distribuição leptocúrtica então kε > 3.
Para analisar (a), (b) e (c) devemos:
1. estimar um modelo ARMAX+GARCH;2. obter os resíduos ut;3. obter os resíduos estandardizados εt = ut/σt;

135
Análise da questão (a). Efectuar o teste Ljung-Box tomando como hipótese nula, H0:ρ1 (εt) = ... = ρm (εt) = 0 (ρi (εt) é o coeficiente de autocorrelação entre εt e εt−i)e estatística de teste
Q = n (n+ 2)m∑i=1
1
n− iρ2i (εt)
d−→ χ2(m−k)
onde k é o número de parâmetros estimados. Evidência contra a hipótese nula sugere queεt é autocorrelacionado. Neste caso é necessário rever a especificação da média condicional.
Análise da questão (b). Efectuar o teste Ljung-Box tomando como hipótese nula, H0:
ρ1
(ε2t
)= ... = ρm
(ε2t
)= 0 (ρi
(ε2t
)é o coeficiente de autocorrelação entre ε2
t e ε2t−i) e
estatística de teste
Q = n (n+ 2)m∑i=1
1
n− iρ2i
(ε2t
)d−→ χ2
(m−k)
onde k é o número de parâmetros estimados. Evidência contra a hipótese nula sugere que ε2t
é autocorrelacionado. Neste caso é necessário rever a especificação da variância condicional.

136
4.9 Previsão
Suponha-se que y segue um modelo do tipo ARMA+GARCH. Temos {y1, y2, ..., yn} eprocura-se:
• prever yn+1, yn+2, ...;
• estabelecer ICs para yn+1, yn+2, ...;
• prever σ2n+1, σ
2n+2, ...;
• estabelecer ICs para σ2n+1, σ
2n+2, ...;

137
4.9.1 Previsão da Variância Condicional
Previsor com EQM mínimo para σ2n+h (dada a informação em Fn):
E(σ2n+h
∣∣∣Fn) .Note-se que E
(u2n+h
∣∣∣Fn) = E(σ2n+hε
2n+h
∣∣∣Fn) = E(σ2n+h
∣∣∣Fn).Para facilitar a notação considere-se σ2
n+h,n := E(σ2n+h
∣∣∣Fn) . Vejam-se os exemplosseguintes.

138
Modelo GARCH(1,1) σ2t = ω + α1u
2t−1 + β1σ
2t−1
h = 1 σ2n+1,n = ... = ω + α1u
2n + β1σ
2n
h = 2 σ2n+2,n = ... = ω + (α1 + β1)σ2
n+1,n
h geral σ2n+h,n = ... = ω + (α1 + β1)σ2
n+h−1,n
Pode-se provar, sob a condição 0 ≤ α1 + β1 < 1:
σ2n+h,n =
ω(
1− (α1 + β1)h)
1− α1 − β1+ (α1 + β1)h−1
(α1u
2n + β1σ
2n
).
Assim, no caso α1 + β1 < 1, tem-se
σ2n+h,n →
ω
1− α1 − β1= Var (ut) (quando h→∞).
No caso α1 + β1 = 1 (IGARCH(1,1)) vem
σ2n+h,n = σ2
n+1,n, se ω = 0
σ2n+h,n → ∞, se ω > 0 (quando h→∞).

139
4.9.2 A Previsão da Variável Dependente y
A previsão pontual de yn+h não envolve qualquer novidade ...
Todavia, a estimação por intervalos deve agora reflectir a presença de HC.
IC a (1− α) 100% para yn+h:
E(yn+h
∣∣Fn)± q1−α/2
√Var
(yn+h
∣∣Fn)Supondo normalidade, o IC a 95% para yn+h é
E(yn+h
∣∣Fn)± 1.96√
Var(yn+h
∣∣Fn).Infelizmente esta expressão só pode ser usada para h = 1. Veremos um procedimento debootstrap que permite obter IC correctos para yn+h, com h finito.
No limite, quando h→∞, o IC a (1− α) 100% para a previsão de longo prazo é
E (y)± ζ1−α/2
√Var (y)

140
Exemplo Considere-se o modelo AR(1)+GARCH(1,1)
yt = c+ φyt−1 + ut,
σ2t = ω + α1u
2t−1 + β1σ
2t−1.
Sabendo ut| Ft−1 ∼ N(
0, σ2t
), obtenha então um IC a 95% para yn+1.
141
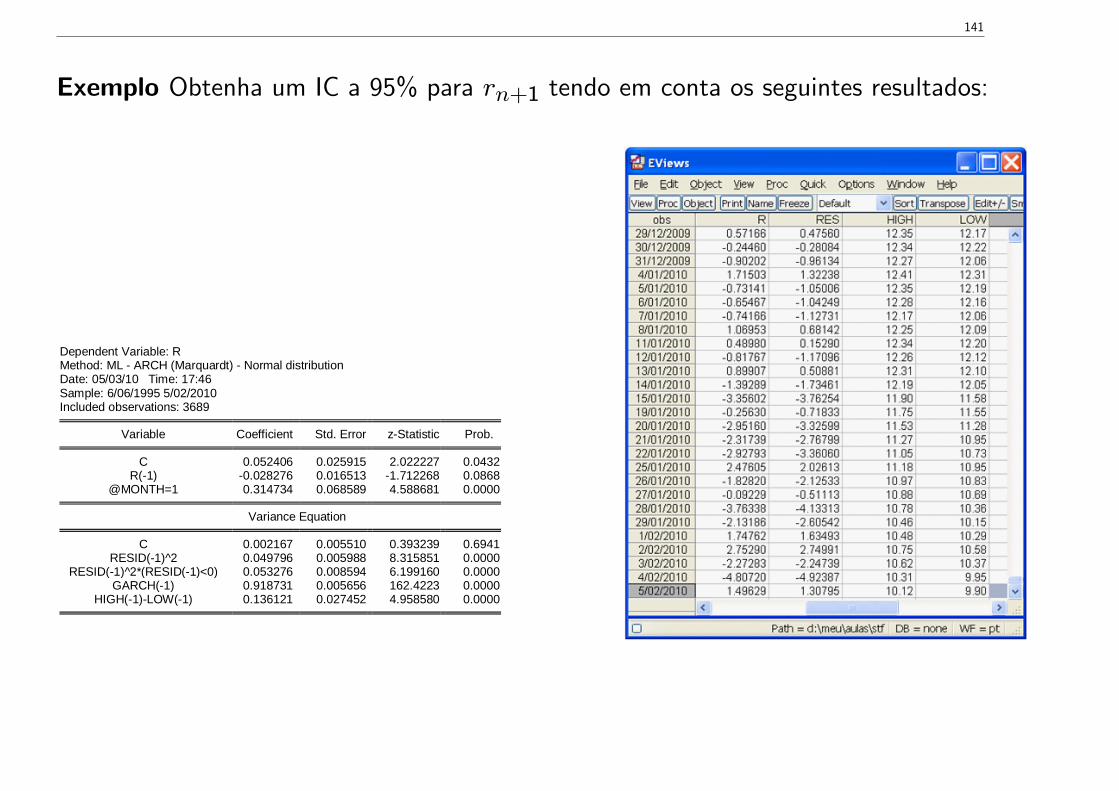
Exemplo Obtenha um IC a 95% para rn+1 tendo em conta os seguintes resultados:
Dependent Variable: RMethod: ML ARCH (Marquardt) Normal distributionDate: 05/03/10 Time: 17:46Sample: 6/06/1995 5/02/2010Included observations: 3689
Variable Coefficient Std. Error zStatistic Prob.
C 0.052406 0.025915 2.022227 0.0432R(1) 0.028276 0.016513 1.712268 0.0868
@MONTH=1 0.314734 0.068589 4.588681 0.0000
Variance Equation
C 0.002167 0.005510 0.393239 0.6941RESID(1)^2 0.049796 0.005988 8.315851 0.0000
RESID(1)^2*(RESID(1)<0) 0.053276 0.008594 6.199160 0.0000GARCH(1) 0.918731 0.005656 162.4223 0.0000
HIGH(1)LOW(1) 0.136121 0.027452 4.958580 0.0000

142
4.9.3 Intervalos de Confiança para y e para a Volatilidade baseados em Boostrap
Vimos até agora as seguintes questões:
• intervalos de confiança para yn+1;
• previsão de σ2t para os períodos n+ 1, n+ 2, ...;
Estas questões são relativamente simples tratar. Já a obtenção de intervalos de confiançapara yn+h, h > 1 e para σ2
n+h, h ≥ 1 é problemática, pois não são conhecidas as dis-tribuições de interesse. Estas questões resolvem-se de forma muito satisfatória recorrendoao bootstrap.
Para exemplificar considere-se o modeloyt = c+ φyt−1 + utut = σtεtσ2t = ω + αu2
t−1 + βσ2t−1.
(1)
onde ε tem distribuição desconhecida de média nula e variância um. O algoritmo é o seguinte:

143
1. Estimar o modelo (1) e obter
{εt, t = 1, ..., n} , onde εt =ut
σt
σ2 =ω
1− α− β, µ =
c
1− φθ =
(c, φ, ω, α, β
)′
2. Simular o modelo y∗t = c+ φy∗t−1 + u∗tu∗t = σ∗t ε
∗t
σ∗2t = ω + αu∗2t−1 + βσ∗2t−1
(2)
com os seguintes valores iniciais: σ∗20 = σ2 e y∗0 = µ. Os valores de ε∗t são retiradosaleatoriamente com reposição do conjunto {ε1, ..., εn} .

144
3. Estimar o modelo (2) e obter as seguintes previsões: y∗n+h = c∗ + φ∗y∗n+h−1
σ∗2n+h = ω∗ + α∗u∗2n+h−1 + β∗σ∗2n+h−1
Note-se que θ∗=(c∗, φ
∗, ω∗, α∗, β
∗)′é o vector das estimativas obtidas no contexto
do modelo simulado (2).
4. Repetir os passos 2 e 3 B vezes. Com este procedimento obtêm-se as seguintes séries:{y∗(1)n+j, y
∗(2)n+j, ..., y
∗(B)n+j
}, j = 1, ..., h,{
σ∗2 (1)n+j , σ
∗2 (2)n+j , ..., σ
∗2 (B)n+j
}, j = 1, ..., h.
5. Um intervalo de previsão a (1− α) 100% para yn+j é[qα
2, q1−α2
]onde qα
2e q1−α2
são os quantis empíricos da amostra{y∗(1)n+j, y
∗(2)n+j, ..., y
∗(B)n+j
}.

145
6. Um intervalo de previsão a (1− α) 100% para σ2n+j é[
qσ∗2
α2, qσ
∗21−α2
]onde agora qα
2e q1−α2
são os quantis empíricos da amostra{σ∗2 (1)n+j , σ
∗2 (2)n+j , ..., σ
∗2 (B)n+j
}.

146
5 Modelação da Heterocedasticidade Condicionada: Caso
Multivariado
5.1 Introdução
Estimação multivariada:• relevante na selecção de portfolios, da gestão do risco, etc.• estimação dos co-movimentos de rendibilidade e volatilidade. Por exemplo, como se trans-mite a volatilidade de um mercado aos demais mercados? qual a magnitude do impacto davolatilidade de um mercado sobre outro?
Para tratar estas questões vai considerar-se um modelo genérico, envolvendo m equações:
y1t = µ1t + u1t,
...
ymt = µmt + umt

147
Notação mais compacta:
yt =
y1t...ymt
, µt =
µ1t...µmt
, ut =
u1t...
umt
.Assim
yt = µt + ut.
Modelo para µt. Por exemplo VAR(1), m = 2 :(y1ty2t
)=
(φ11 φ120 φ22
)(y1,t−1y2,t−1
)︸ ︷︷ ︸
µt
+
(u1tu2t
)

148
Modelo de heterocedasticidade condicional multivariado:
ut = H1/2t εt
• εt vector de v.a. i.i.d. (condicionalmente homocedástico) tal que
E (εt) = 0, Var (εt) = Im.
• Ht é uma matriz quadrada de ordemm, simétrica, definida positiva e Ft−1 mensurável.
H1/2t é uma matriz quadrada ordem m tal que H
1/2t
(H
1/2t
)′= Ht.
Dadas as hipóteses, tem-se
Var (yt| Ft−1) = ... = Ht

149
5.2 Densidade e Verosimilhança
Assuma-se normalidade dos erros: εt ∼ N (0, Im) . Tem-se:
εt ∼ N (0, Im)⇒ ut| Ft−1 ∼ N (0,Ht)⇒ yt| Ft−1 ∼ N (µt,Ht) .
Assim, a densidade conjunta condicional de yt é
f (yt| Ft−1) = (2π)−m/2 |Ht|−1/2 exp{−1
2(yt − µt)′H−1
t (yt − µt)}.
A função log-verosimilhança é então
logLn (θ) =n∑t=1
log f (yt| Ft−1)
= ... = −nm2
log (2π)− 1
2
n∑t=1
log |Ht (θ)|
−1
2
n∑t=1
(yt − µt (θ))′H−1t (θ) (yt − µt (θ)) .
É necessário definir uma hipótese sobre a estrutura de µt e de Ht.

150
5.3 Modelo VECH (ou VEC)
Modelo VECH (ou VEC) GARCH(1,1):
vech (Ht) = w + A1 vech(ut−1u′t−1
)+ B1 vech (Ht−1) .
No caso m = 2 (processo bivariado) e GARCH(1,1):
vech (Ht) =
h11,th12,th22,t
=
w11w12w22
+
α11 α12 α13α21 α22 α23α31 α32 α33
u21,t−1
u1,t−1u2,t−1
u22,t−1
+
β11 β12 β13β21 β22 β23β31 β32 β33
h11,t−1h12,t−1h22,t−1
.
Por exemplo,
h12,t = E (u1tu2t| Ft−1) = w12 + α21u21,t−1 + α23u
22,t−1
+α22u1,t−1u2,t−1 + β21h11,t−1 + β22h12,t−1 + β23h22,t−1

151
Correlações condicionais:
ρij,t =hij,t√hii,thjj,t
, i, j = 1, ...,m.
{ut} é ESO se todos os valores próprios de A + B forem em módulo menores do que um.
Nestas condições:
E(
vech(utu′t
))= E (vech (Ht)) = (I−A1−B1)−1 w.

152
Vantagem do modelo VEC: grande flexibilidade, todos os elementos de Ht dependam detodos os produtos cruzados de vech
(ut−1u′t−1
)e de todos os elementos de Ht−1.
Desvantagens (superam largamente as suas vantagens):
• O número de parâmetros a estimar é excessivamente alto. No GARCH(1,1) multivariadocom m equações, o número de parâmetros a estimar é
m (m (m+ 1) /2) (1 + (m (m+ 1)))
2 213 784 210
• Por definição a matriz Ht deve ser definida positiva, mas não é fácil garantir isso apartir das matrizes A1 e B1. Se Ht não é definida positiva, é possível, por exemplo,que ρij,t > 1 ou ht,ii < 0.

153
Exemplo Existem efeitos de rendimento e de volatilidade do PSI20 que possam ser antecipa-dos através do Dow Jones (DJ)? Seja y1t e y2t o retorno diário associado, respectivamente,aos índices, PSI20 e DJ. As variáveis y1t e y2t foram previamente centradas (razão?). Depoisde vários ensaios, definiu-se o seguinte modelo(
y1ty2t
)=
(φ11 φ120 φ22
)(y1,t−1y2,t−1
)+ H
1/2t εt
onde
vech (Ht) =
h11,th12,th22,t
=
00w22
+
α11 0 α130 0 00 0 α33
u21,t−1
u1,t−1u2,t−1
u22,t−1
+
β11 0 00 0 00 0 β33
h11,t−1h12,t−1h22,t−1
+
γvolt−100
.

154
Usando os dados no período 31/12/92 a 15/03/99 (1496 observações) obteve-se,
y1t = .2343(.028)
y1t−1 + .1430(.023)
y2t−1, y2t = .0753(.023)
y2t−1
h1t = .3132(.0466)
u21t−1 + .0466
(.0151)u2
2t−1 + .6053(.0459)
h1t−1 + .0254(.0062)
volt−1
h2t = 1.25× 10−6
(5.2×10−7)+ .0903
(.0195)u2
2t−1 + .897(.0227)
h2t−1, h12,t = 0.
Escreva A1 e B1 e analise os resultados.

155
5.4 Modelo Diagonal VECH
Podem obter-se modelos VECH com menos parâmetros impondo que as matrizes A1 e B1
sejam diagonais. Por exemplo, no caso m = 2, vem
vech (Ht) =
h11,th12,th22,t
=
w11w12w22
+
α11 0 00 α22 00 0 α33
u21,t−1
u1,t−1u2,t−1
u22,t−1
+
β11 0 00 β22 00 0 β33
h11,t−1h12,t−1h22,t−1
(este princípio aplica-se naturalmente no caso de modelos multivariados GARCH(p,q)).

156
Com matrizes A1 e B1 diagonais pode optar por escrever o modelo diagonal VECH naforma equivalente
Ht = ω + a1 ◦ ut−1u′t−1 + b1 ◦Ht−1
onde ω, a1 e b1 são matrizes simétricas de tipo m ×m e “◦” é o produto de Hadamard.Por exemplo, no caso m = 2, o modelo anterior escreve-se(h11,t h12,th12,t h22,t
)=
(w11 w12w12 w22
)+
(a11 a12a12 a22
)◦(
u21,t−1 u1,t−1u2,t−1
u1,t−1u2,t−1 u22,t−1
)+(
b11 b12b12 b22
)◦(h11,t−1 h12,t−1h12,t−1 h22,t−1
)onde a11 = α11, a12 = α22, a22 = α33, etc. Note-se, portanto, que
h11,t = ω11 + a11u21,t−1 + b11h11,t−1
h12,t = ω12 + a12u1,t−1u2,t−1 + b12h12,t−1
h22,t = ω22 + a22u22,t−1 + b22h22,t−1.

157
A vantagem do modelo: menos parâmetros a estimar 3m (m+ 1) /2.
Desvantagem: Considere-se o caso m = 2 e GARCH(1,1). hii,t só depende dos termosu2i,t−1 e hii,t−1, e h12,t só depende dos termos u1,t−1u2,t−1 e h12,t−1, A especificaçãoDiagonal VECH elimina a possibilidade de interacção entre as diferentes variâncias e covar-iâncias condicionais.
Por outro lado, a matriz Ht, por construção, não resulta definida positiva.
Há várias formas de ultrapassar este último problema. Por exemplo:
Ht = ω1 (ω1)′ + a1 (a1)′ ◦ ut−1u′t−1 + b1
(b1
)′ ◦Ht−1
com ω = ω1 (ω1)′, a1 = a1 (a1)′ e b1 = b1
(b1
)′e ω1, a1 e b1 são matrizes quadradas
de ordem m. As matrizes ω, a1 e b1 assim construídas implicam uma matriz Ht definidapositiva.
Ver EVIEWS

158
Um modelo ainda mais restritivo (mas que é usado com algum sucesso na modelação desistemas com muitas equações) foi desenvolvido pela J.P. Morgan (1996): h11,th12,th22,t
=
1− λ 0 00 1− λ 00 0 1− λ
u21,t−1
u1,t−1u2,t−1
u22,t−1
+
λ 0 00 λ 00 0 λ
h11,t−1h12,t−1h22,t−1
.Existe uma redução dramática do número de parâmetros a estimar (passamos para apenas1, qualquer que seja o número de equações do modelo).

159
5.5 Modelo “Triangular”
5.5.1 Introdução e Formalização do Modelo
Em certas aplicações é admissível supor:
E(y1t| F
y1t−1 ∪ F
y2t−1
)= E
(y1t| F
y1t−1
)(*)
Var(y1t| F
y1t−1 ∪ F
y2t−1
)= Var
(y1t| F
y1t−1
)
A equação (*) implica que y2 não causa à Granger y1.
Exemplo: y1t é o retorno do NASDAQ e y2t é o retorno do PSI20.
Para processos y1 e y2 com as características acima descritas, é possível definirem-se proces-sos multivariados simplificados.

160
Considere-se o processo y = (y1, y2, y3) e suponham-se as seguintes relações: y1 � y2 �y3 onde “y1 � y2”significa y1 influencia y2 dado F
y2t−1 e y2 não influencia y1 dado F
y1t−1.
Suponha-se y ∼ VAR(1). Tem-se: y1ty2ty3t
=
c1c2c3
+
φ11 0 0φ21 φ22 0φ31 φ32 φ33
y1,t−1y2,t−1y3,t−1
+
u1tu2tu3t
.A matriz dos coeficientes autoregressivos é triangular, porque na média condicional y1,t
apenas depende de y1,t−1, y2t depende de y1,t−1 e y2,t−1 e y3t depende de y1,t−1, y2,t−1
e y3,t−1.

161
Estrutura de dependências do segundo momento condicional:u1t = e1tu2t = ae1t + e2tu3t = be1t + ce2t + e3t
⇔
u1tu2tu3t
︸ ︷︷ ︸
ut
=
1 0 0a 1 0b c 1
︸ ︷︷ ︸
Ψ
e1te2te3t
︸ ︷︷ ︸
et
onde:
• (e1t, e2t, e3t) são independentes entre si;
• eit| Ft−1 ∼ N(
0, σ2it
), σ2
it = ωi + αie2i,t−1 + βiσ
2i,t−1.
u2t depende de e2t (efeitos idiossincrásicos) e ainda dos choques e1t (volatility spillover).
u3t depende de e3t (efeitos idiossincrásicos) e ainda dos choques e1t e e2t.
A designação “modelo triangular” é agora óbvia:
yt = c + Φyt−1 + Ψet
sendo Φ e Ψ matrizes triangulares inferiores.

162
Dadas as hipótese sobre o vector et, defina-se
Σt := Var (et| Ft−1) =
σ2
1,t 0 0
0 σ22,t 0
0 0 σ23,t
.Logo,
Ht = Var (ut| Ft−1) = Var (Ψet| Ft−1) = Ψ Var (et| Ft−1) Ψ′ = ΨΣtΨ′.
Pode-se provar que a condição de ESO do processo {ut} é αi + βi < 1, i = 1, 2, 3.
Ht como função dos termos ut−1u′t−1 e Ht−1
Ht = ... = ΨWΨ′ + Ψ(A ◦Ψ−1ut−1u′t−1
(Ψ−1
)′)Ψ′+Ψ
(B ◦Ψ−1Ht−1
(Ψ−1
)′)Ψ′.
Resulta, por exemplo, que
h22,t = a2ω1 + ω2 + a2 (α1 + α2)u21,t−1
−2aα2u1,t−1u2,t−1 + a2 (β1 + β2)h11,t−1 − 2aβ2h12,t−1 + β2h22,t−1

163
Ht como função de σ21,t, σ
22,t e σ
23,t
Ht = ΨΣtΨ′
=
1 0 0a 1 0b c 1
σ2
1,t 0 0
0 σ22,t 0
0 0 σ23,t
1 a b
0 1 c0 0 1
=
σ2
1,t aσ21,t bσ2
1,t
aσ21,t a2σ2
1,t + σ22,t abσ2
1,t + cσ22,t
bσ21,t abσ2
1,t + cσ22,t b2σ2
1,t + c2σ22,t + σ2
3,t
.Resulta:
h11,t = Var (y1t| Ft−1) = Var (u1t| Ft−1) = σ21,t
h22,t = Var (y2t| Ft−1) = Var (u2t| Ft−1) = a2σ21,t + σ2
2,t
h33,t = Var (y3t| Ft−1) = Var (u3t| Ft−1) = b2σ21,t + c2σ2
2,t + σ23,t
h12,t = Cov (y1t, y2t| Ft−1) = aσ21,t
h13,t = Cov (y1t, y3t| Ft−1) = bσ21,t
h23,t = Cov (y2t, y3t| Ft−1) = abσ21,t + cσ2
2,t

164
Coeficientes de correlação condicionados:
ρ12,t =aσ2
1,t√σ2
1,t
√a2σ2
1,t + σ22,t
=aσ1,t√
a2σ21,t + σ2
2,t
ρ13,t =bσ2
1,t√σ2
1,t
√b2σ2
1,t + c2σ22,t + σ2
3,t
=bσ1,t√
b2σ21,t + c2σ2
2,t + σ23,t
ρ23,t =abσ2
1,t + cσ22,t√
a2σ21,t + σ2
2,t
√b2σ2
1,t + c2σ22,t + σ2
3,t
.
Os sinais dos coeficientes a, b e c são decisivos nos sinais dos coeficientes de correlaçãocondicionados.

165
Rácios de Variância e Transmissão da Volatilidade ao longo do Tempo
Análise do mercado 2
Tendo em conta
a2σ21,t + σ2
2,t
h22,t= 1
tem-se
RV1,2t =
a2σ21t
h22,t,
RV2,2t =
σ22,t
h22,t= 1−
a2σ21t
h22,t
RV1,2t a proporção da variância do mercado 2 que é causada pelo efeito de volatility spillover
do mercado 1 (efeito do mercado 1 para 2).

166
Análise do mercado 3
Tendo em conta
b2σ21,t + c2σ2
2,t + σ23,t
h33,t= 1
tem-se
RV1,3t =
b2σ21t
h33,t,
RV2,3t =
c2σ22t
h33,t,
RV3,3t = 1−
b2σ21t
h33,t−c2σ2
2t
h33,t.

167
5.5.2 Estimação
Considere a representação yt = c + Φyt−1 + Ψet, isto é,
y1t = c1 + φ11y1,t−1 + e1t (1)
y2t = c2 + φ21y1,t−1 + φ22y2,t−1 + ae1t + e2t (2)
y3t = c3 + φ31y1,t−1 + φ32y2,t−1 + φ33y3,t−1 + be1t + ce2t + e3t (3)
onde eit| Ft−1 ∼ N(
0, σ2it
), σ2
it = ωi + αie2i,t−1 + βiσ
2i,t−1.
Passos:
1. Estimar a eq. (1), pelo método da máxima verosimilhança, e obter os resíduos {e1t} .
2. Substituir, na eq. (2), e1t por e1t e estimar o modelo. Obter os resíduos {e2t} .
3. Substituir, na eq. (3), e1t por e1t e e2t por e2t e estimar o modelo.

168
5.5.3 Exemplo
Pinto (2010) analisou a transmissão de volatilidade do mercado Norte-Americano (US) parao mercado Europeu (EU) e, em particular, as repercussões destes dois mercados no mercadoPortuguês (PT), através de um modelo triangular. Período: 4 de Janeiro de 1993 - 4 deSetembro de 2009.
r1t - retorno do SP500, r2t - retorno do DJ Euro 50, r3t - retorno do PSI 20.
Passo 1
Dependent Variable: R1Method: ML ARCHSample (adjusted): 6/01/1993 4/09/2009Included observations: 4055 after adjustments
Variable Coefficient Std. Error zStatistic Prob.
C 0.052202 0.013247 3.940658 0.0001R1(1) 0.017161 0.017808 0.963644 0.3352
Variance Equation
C 0.007049 0.001077 6.546092 0.0000RESID(1)^2 0.066257 0.004820 13.74617 0.0000GARCH(1) 0.929667 0.005114 181.7812 0.0000
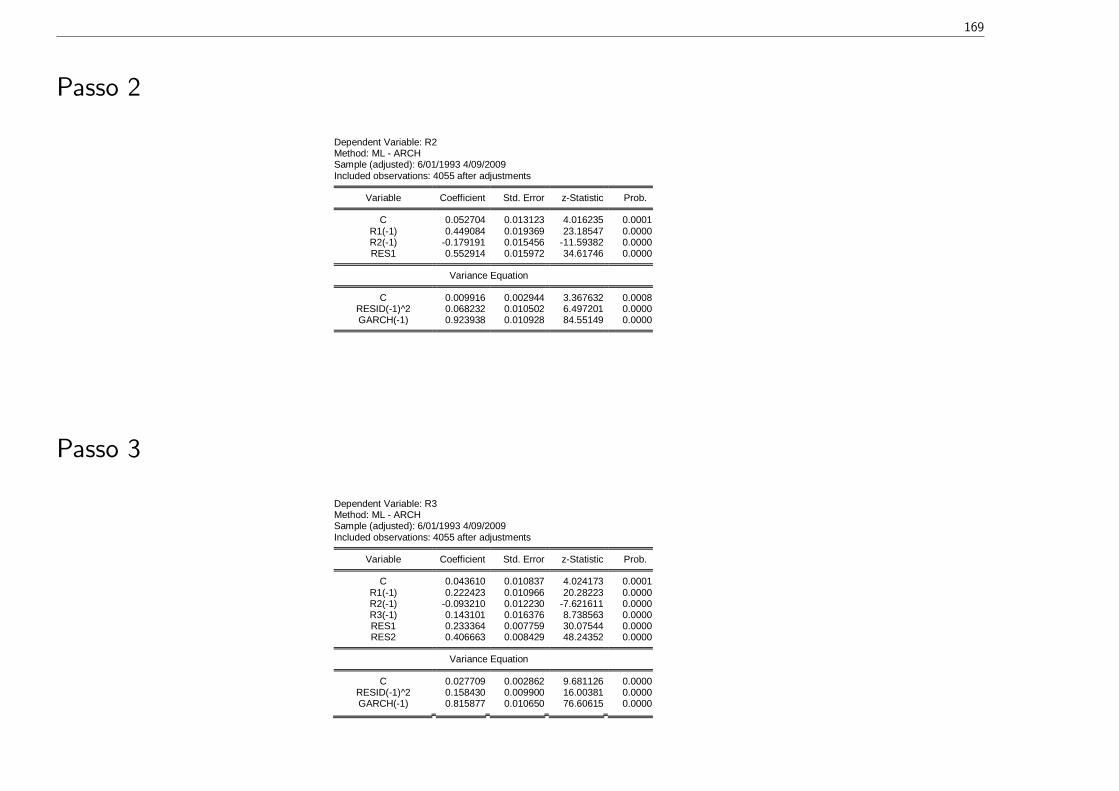
169
Passo 2
Dependent Variable: R2Method: ML ARCHSample (adjusted): 6/01/1993 4/09/2009Included observations: 4055 after adjustments
Variable Coefficient Std. Error zStatistic Prob.
C 0.052704 0.013123 4.016235 0.0001R1(1) 0.449084 0.019369 23.18547 0.0000R2(1) 0.179191 0.015456 11.59382 0.0000RES1 0.552914 0.015972 34.61746 0.0000
Variance Equation
C 0.009916 0.002944 3.367632 0.0008RESID(1)^2 0.068232 0.010502 6.497201 0.0000GARCH(1) 0.923938 0.010928 84.55149 0.0000
Passo 3
Dependent Variable: R3Method: ML ARCHSample (adjusted): 6/01/1993 4/09/2009Included observations: 4055 after adjustments
Variable Coefficient Std. Error zStatistic Prob.
C 0.043610 0.010837 4.024173 0.0001R1(1) 0.222423 0.010966 20.28223 0.0000R2(1) 0.093210 0.012230 7.621611 0.0000R3(1) 0.143101 0.016376 8.738563 0.0000RES1 0.233364 0.007759 30.07544 0.0000RES2 0.406663 0.008429 48.24352 0.0000
Variance Equation
C 0.027709 0.002862 9.681126 0.0000RESID(1)^2 0.158430 0.009900 16.00381 0.0000GARCH(1) 0.815877 0.010650 76.60615 0.0000
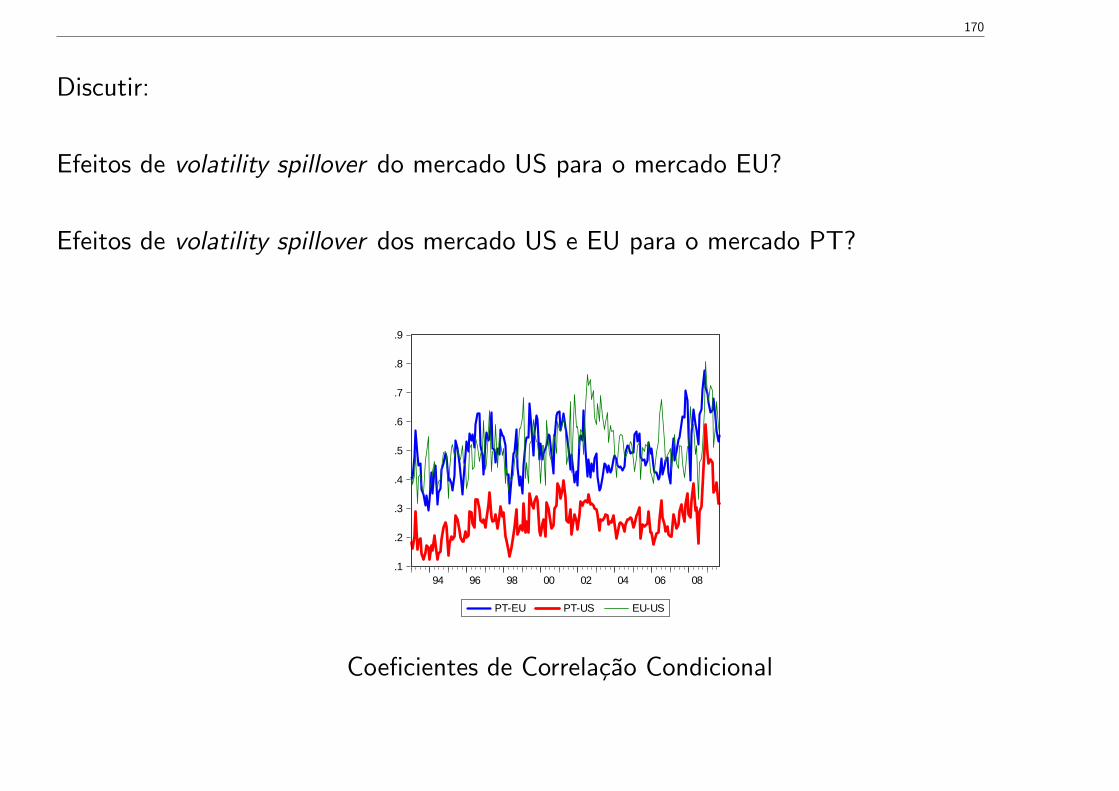
170
Discutir:
Efeitos de volatility spillover do mercado US para o mercado EU?
Efeitos de volatility spillover dos mercado US e EU para o mercado PT?
.1
.2
.3
.4
.5
.6
.7
.8
.9
94 96 98 00 02 04 06 08
PTEU PTUS EUUS
Coeficientes de Correlação Condicional
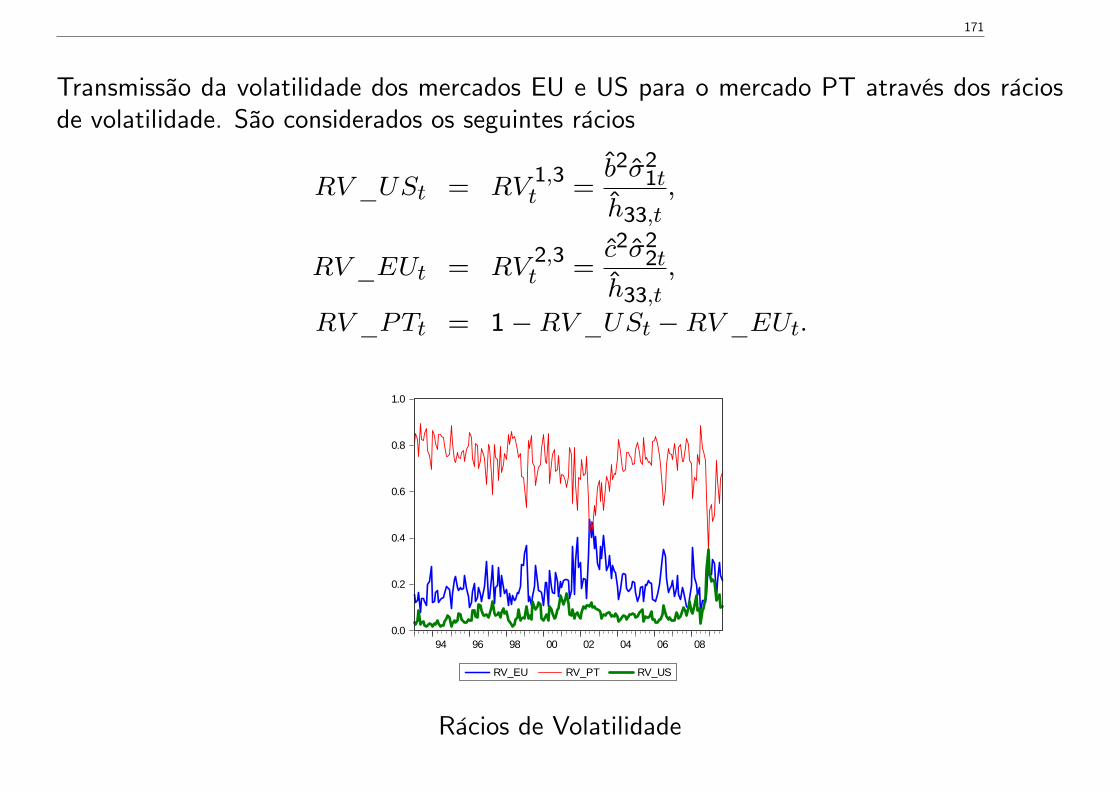
171
Transmissão da volatilidade dos mercados EU e US para o mercado PT através dos ráciosde volatilidade. São considerados os seguintes rácios
RV _USt = RV1,3t =
b2σ21t
h33,t,
RV _EUt = RV2,3t =
c2σ22t
h33,t,
RV _PTt = 1−RV _USt −RV _EUt.
0.0
0.2
0.4
0.6
0.8
1.0
94 96 98 00 02 04 06 08
RV_EU RV_PT RV_US
Rácios de Volatilidade

172
5.6 Testes de Diagnóstico
A hipótese de partida é ut = H1/2t εt onde εt ∼ N (0, Im) . Se o modelo estiver correcta-
mente especificado, {εt} deve ser uma sucessão de vectores i.i.d., com matriz de variâncias-covariâcias (contemporânea) dada por Im. Naturalmente que εt é desconhecido, mas podeser estimado da seguinte forma
εt = H−1/2t ut.
εt é o vector dos resíduos estandardizados (e ut é o vector dos resíduos). A matriz H−1/2t
pode obter-se a partir da decomposição Cholesky. Por exemplo, considere-se um sistema deduas equações (m = 2)
Ht =
[σ2
1t σ12,t
σ12,t σ22t
]=
[σ2
1t ρtσ1tσ2tρtσ1tσ2t σ2
2t
].
A decomposição de Cholesky fornece
H1/2t =
[σ1t 0
ρtσ2t σ2t
√1− ρ2
t
].

173
Assim,
H−1/2t =
1σ1t
0
− ρt
σ1t
√1−ρ2
t
1
σ2t
√1−ρ2
t
.e [
ε1tε2t
]=
1σ1t
0
− ρt
σ1t
√1−ρ2
t
1
σ2t
√1−ρ2
t
[u1tu2t
]=
u1tσ1t
u2t
σ2t
√1−ρ2
t
− u1tρt
σ1t
√1−ρ2
t
.
Para avaliar se os efeitos de heterocedasticidades estão convenientemente modelados:
Primeiro passo: regressão de ε21t sobre as seguintes variáveis (para além de um termo con-
stante):
• resíduos quadráticos ε2i,t−k, com i = 1, ...,m e k = 1, ..., L (L desfasamentos) e
• termos cruzados εi,t−kεj,t−k, com i, j = 1, ...,m e k = 1, ..., L.

174
Segundo passo: teste F de nulidade de todos os parâmetros com excepção do do termoindependente. Se existir evidência estatística contra a hipótese nula, podemos suspeitar quea matriz Ht não foi convenientemente modelada.
Nos passos seguintes repete-se o procedimento, tomando sucessivamente ε2i,t i = 2, ...,m
como variável dependente na regressão auxiliar.

175
Aplicação Selecção de Portfolios: problema da determinação dos pesos óptimos de umacarteira constituída por m activos com risco.
Por exemplo, suponha-se que o valor da carteira de um investidor é de 1 mihão de Euros eestá assim distribuída: 176000 Euros em A1, 104000 em A2 e 720000 em A3. Logo m = 3
e o vector de pesos da carteira é
ω =
0.1760.1040.720
.Considere-se
vector do valor esperado condic. dos retornos:
µt = (E (R1t| Ft−1) , ...,E (Rmt| Ft−1))′ ;
Matriz das variâncias-covariâncias condicionais dos retornos:
Var (rt| Ft−1) = Ht;

176
Vector dos pesos da carteira no momento t:
ωt = (ω1t, ..., ωmt)′ ;
Retorno do portfolio:
Rpt =m∑i=1
ωitRit = ω′trt;
Valor esperado condicional do portfolio:
E(Rpt
∣∣∣Ft−1
)= E
(ω′trt
∣∣∣Ft−1
)= ω′tµt;
Variância condicional do portfolio
Vpt = Var(Rpt
∣∣∣Ft−1
)= Var
(ω′trt
∣∣∣Ft−1
)= ω′tVar (rt| Ft−1)ωt = ω′tHtωt.

177
O problema de optimização (horizonte de investimento h = 1): minωn+1 Var(Rp,n+1
∣∣∣Fn)s.a E
(Rp,n+1
∣∣∣Fn) = µp e∑mi=1 ωi,n+1 = 1
⇔{
minωi ω′n+1Hn+1ωn+1
s.a ω′n+1µn+1 = µp e ω′n+11 = 1

178
6 Risco de Mercado e o Valor em Risco
6.1 Introdução
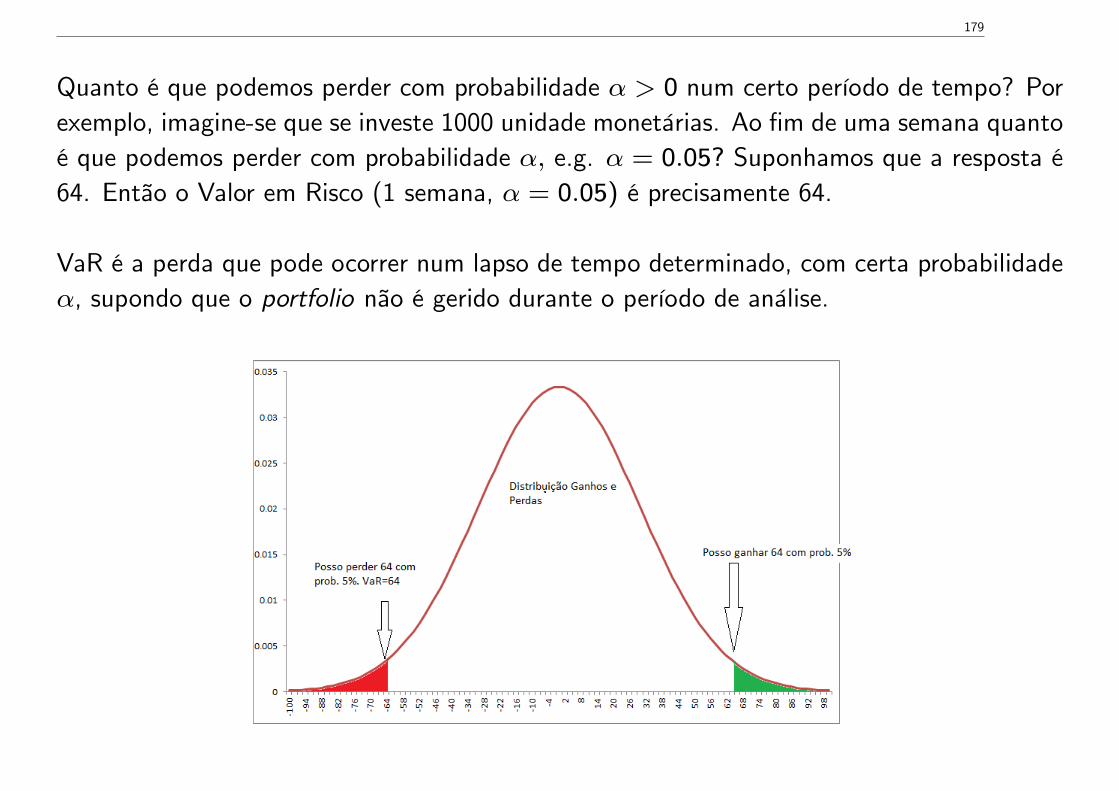
179
Quanto é que podemos perder com probabilidade α > 0 num certo período de tempo? Porexemplo, imagine-se que se investe 1000 unidade monetárias. Ao fim de uma semana quantoé que podemos perder com probabilidade α, e.g. α = 0.05? Suponhamos que a resposta é64. Então o Valor em Risco (1 semana, α = 0.05) é precisamente 64.
VaR é a perda que pode ocorrer num lapso de tempo determinado, com certa probabilidadeα, supondo que o portfolio não é gerido durante o período de análise.

180
Em termos probabilísticos, o VaR é o quantil de ordem α (em módulo) da distribuição teóricade ganhos e perdas (ou variação do capital)
Vn+h − Vn = ∆Vn+1 =∆Vn+h
VnVn = Rn+hVn
Onde:
• Vn é o valor do investimento no momento presente
• Vn+h é o valor do investimento no futuro (h períodos à frente)
• Rn+h =∆Vn+hVn
retorno do investimento.

181
Exemplo Considere-se a compra de 200,000 acções de um título no período n , ao preço dePn = 5 Euros. O investimento é de Vn = 5 × 200, 000 = 1, 000, 000 Euros. Suponha-seque no momento n + h o preço do título passa para Pn+h = 5.5 Euros. A variação docapital é de ∆Vn+h = 1, 100, 000−1, 000, 000 = 100, 000. O retorno (em tempo discreto)é Rn+h =
(Pn+h − Pn
)/Pn = 0.1. É importante notar que o retorno pode também ser
obtido através da expressão Rn+h = ∆Vn+h/Vn.
Os valores que V vier a assumir no período n+ 1, n+ 2, ..., n+h dizem respeito ao períodode investimento e, portanto, Vn+h, é desconhecido para h ≥ 1.
O VaR a 100α% baseado na distribuição marginal de ganhos e perdas é o valor VaR tal que
P(∆Vn+h < −V aR
)= α.
O VaR a 100α% baseado na distribuição condicional é o valor VaR tal que
P(∆Vn+h < −V aR
∣∣Fn) = α.
O VaR deve ser baseado na distribuição de ganhos e perdas marginal ou condicional?

182
Em princípio deve ser baseado na distribuição condicional. Por que não usar Fn se estamelhora a previsão?
Exemplo Determine o VaR a 5% a dois dias sabendo que ∆Vn+2| Fn ∼ N (10, 225) .
Resposta: 14.67
Exemplo Determine o VaR a 5% a dois dias sabendo que Rn+2| Fn ∼ N (0.01, 0.000225)
e Vn = 1000. Resposta: 14.67
Na prática estas distribuições são desconhecidas.

183
6.2 Abordagem Não Paramétrica
Método 1 (directamente a partir da série ∆Vn+1)
Tendo em conta
P (∆Vn+1 < −V aR) = α
tem-se
V aRn,n+1,α = −q∆Vα
V aRn,n+1,α = −q∆Vα
q∆Vα é o quantil (estimado) de ordem α da distribuição de ∆Vn+1.
Exemplo Ver ficheiro VaR.XLS.

184
Método 2 (a partir dos retornos)
Por definição tem-se
P(
∆Vn+1 < −V aRn,n+1,α
)= α
ou, como ∆Vn+1 =∆Vn+1Vn
Vn = Rn+1Vn,
P(Rn+1Vn < −V aRn,n+1,α
)= α,
P
(Rn+1 < −
V aRn,n+1,α
Vn
)= α,
P(Rn+1 < qRα
)= α.
Resulta
V aRn,n+1,α = −qRαVnV aRn,n+1,α = −qRαVn
onde qRα é o quantil de ordem α da distribuição de Rn+1.

185
Exercício Considere a série que se encontra no ficheiro petroleo.wk1 (Crude Oil WTI CushingU$/BBL). Calcule o VaR a 5% a um dia para um investimento de 1000 u.m. Use o métodonão paramétrico.
No caso h > 1 ver o manual.
Se a análise incide sobre um portfolio linear, na construção da série histórica dos retornos
Rp,t = ω1R1,t + ω2R2,t + ...+ ωnRn,t,
onde ωi são os pesos do capital investido no activo i (∑ni=1 ωi = 1), os pesos devem
permanecer fixos durante todo o período histórico.

186
Abordagem não paramétrica - desvantagens:
• A distribuição relevante para obter o VaR é a distribuição condicional de Rn+h e nãoa distribuição marginal.
• Quando α é muito baixo por exemplo α = 0.01 ou inferior o estimador qRα é muitoimpreciso.Justificação teórica: sob certas condições o quantil empírico qα (isto, é aestatística de ordem [nα]) tem distribuição assimptótica dada por
√n (qα − qα)
d−→ N
(0,α (1− α)
(f (qα))2
).
A variância assimptótica de qα “explode”quando α é muito alto (perto de 1) ou muitobaixo (perto de zero).
• Até onde coligir os dados? Considerar todo o passado disponível? Ou só o passadorecente? A metodologia exposta atribui o mesmo peso a todas as observações.

187
6.3 Abordagem Paramétrica
Considere-se novamente a expressão para o caso h = 1:
∆Vn+1 =∆Vn+1
VnVn = Rn+1Vn ' rn+1Vn.
Esta expressão mostra que a distribuição condicional de rn+1Vn apenas depende da dis-tribuição de rn+1 (no momento n, Vn é conhecido). Podemos assim concentrar-nos apenassobre a distribuição de rn+1.

188
Assuma-se
rn+1| Fn ∼ N(µn+1, σ
2n+1
)Tem-se
P(
∆Vn+1 < −V aRn,n+1,α
∣∣∣Fn) = α
P
(rn+1 < −
V aRn,n+1,α
Vn
∣∣∣∣∣Fn)
= α.
Estandardizando rn+1
Zn+1 =rn+1 − µn+1
σn+1
vem
P
Zn+1 <−V aRn,n+1,α
Vn− µn+1
σn+1
∣∣∣∣∣∣∣Fn = α
−V aRVn − µn+1
σn+1= qZα ⇒ V aRn,n+1,α = −
(µn+1 + qZασn+1
)Vn
(qZα é o quantil de ordem α da distribuição da variável Zn+1).

189
No caso h > 1 tem-se
∆Vn+h =∆Vn+h
VnVn
= Rn+h (h)Vn
≈ rn+h (h)Vn.
=(rn+1 + rn+2 + ...+ rn+h
)Vn, rn+i = log (Pn+i/Pn+i−1)
Pode-se mostrar
V aRn,n+h,α = −(
E(rn+h (h)
∣∣Fn) + qZα
√Var
(rn+h (h)
∣∣Fn))Vnonde qZα é o quantil de ordem α da distribuição de
Z =rn+h (h)− E
(rn+h (h)
∣∣Fn)√Var
(rn+h (h)
∣∣Fn) .
Exemplo Determine o VaR a 5% a dois dias sabendo que Rn+2| Fn ∼ N (0.01, 0.000225)e Vn = 1000. Resposta: 14.67
Na prática é necessário definir um modelo econométrico que nos permita obter uma estima-tiva de E
(rn+h (h)
∣∣Fn) e de Var(rn+h (h)
∣∣Fn) .

190
6.3.1 Modelo Gaussiano Simples
O caso mais simples consiste em assumir
rt = c+ ut,
onde {ut} é um ruído branco Gaussiano, ut ∼ N(
0, σ2). Assim, rn+1 ∼ N
(c, σ2
).
No caso h = 1, tem-se, pela fórmula anterior
V aRn,n+1,α = −(c+ qZασ
)Vn
onde qZα é o quantil de ordem α da distribuição N (0, 1) . No excel: qZα = NORM.S.INV(α)
α 0.001 0.01 0.05qZα -3.09 -2.33 -1.64
Estimação:
V aRn,n+1,α = −(c+ qZα σr
)Vn.

191
Exercício Considere a série que se encontra no ficheiro petroleo.wk1 (Crude Oil WTI CushingU$/BBL). Calcule o VaR a 5% a um dia para um investimento de 1000 u.m. Use o métodoparamétrico baseado no modelo Gaussiano simples.
Caso h > 1. É necessário deduzir-se a distribuição condicional de rn+h (h). Como, porhipótese, rn+h (h) não depende Fn, a distribuição condicional coincide com a distribuiçãomarginal. Pelas propriedades habituais da distribuição normal vem
rn+h (h) = rn+1 + rn+2 + ...+ rn+h ∼ N(ch, σ2h
)e, portanto, pela aplicação da fórmula vem
V aRn,n+h,α = −(ch+
√hσqZα
)Vn,
V aRn,n+h,α = −(ch+
√hσqZα
)Vn.
Exercício Considere a série que se encontra no ficheiro petroleo.wk1 (Crude Oil WTI CushingU$/BBL). Calcule o VaR a 5% a cinco dias para um investimento de 1000 u.m. Use o métodoparamétrico baseado no modelo Gaussiano simples.

192
6.3.2 Modelo RiskMetrics
As hipóteses de normalidade e variância condicional constante, assumidas no modelo anterior,são, como se sabe, bastante limitativas. Modelo RiskMetrics desenvolvido pela J.P. Morganpara o cálculo do VaR:
rt = c+ σtεt, σ2t = (1− λ)u2
t−1 + λσ2t−1
O modelo assenta na hipótese IGARCH(1,1) com termo constante nulo, ω = 0, e médiacondicional µt = c.
No caso h ≥ 1 temos de aplicar a fórmula:
V aRn,n+h,α = −(
E(rn+h (h)
∣∣Fn) + qZα
√Var
(rn+h (h)
∣∣Fn))Vn.Temos de calcular E
(rn+h (h)
∣∣Fn) e Var(rn+h (h)
∣∣Fn) .

193
Caso h ≥ 1,
E(rn+h (h)
∣∣Fn) = ch
Var(rn+h (h)
∣∣Fn) = Var(rn+1 + ...+ rn+h
∣∣Fn)= Var (rn+1| Fn) + ...+ Var
(rn+h
∣∣Fn)= E
(σ2n+1
∣∣∣Fn) + ...+ E(σ2n+h
∣∣∣Fn)= hσ2
n+1.
Assim, pela fórmula V aRn,n+h,α = −(
E(rn+h (h)
∣∣Fn) + qZα
√Var
(rn+h (h)
∣∣Fn))Vnvem
V aRn,n+h,α = −(ch+ qZα
√hσn+1
)Vn.
Estimativa:
V aRn,n+h,α = −(ch+ qZα
√hσn+1
)Vn.
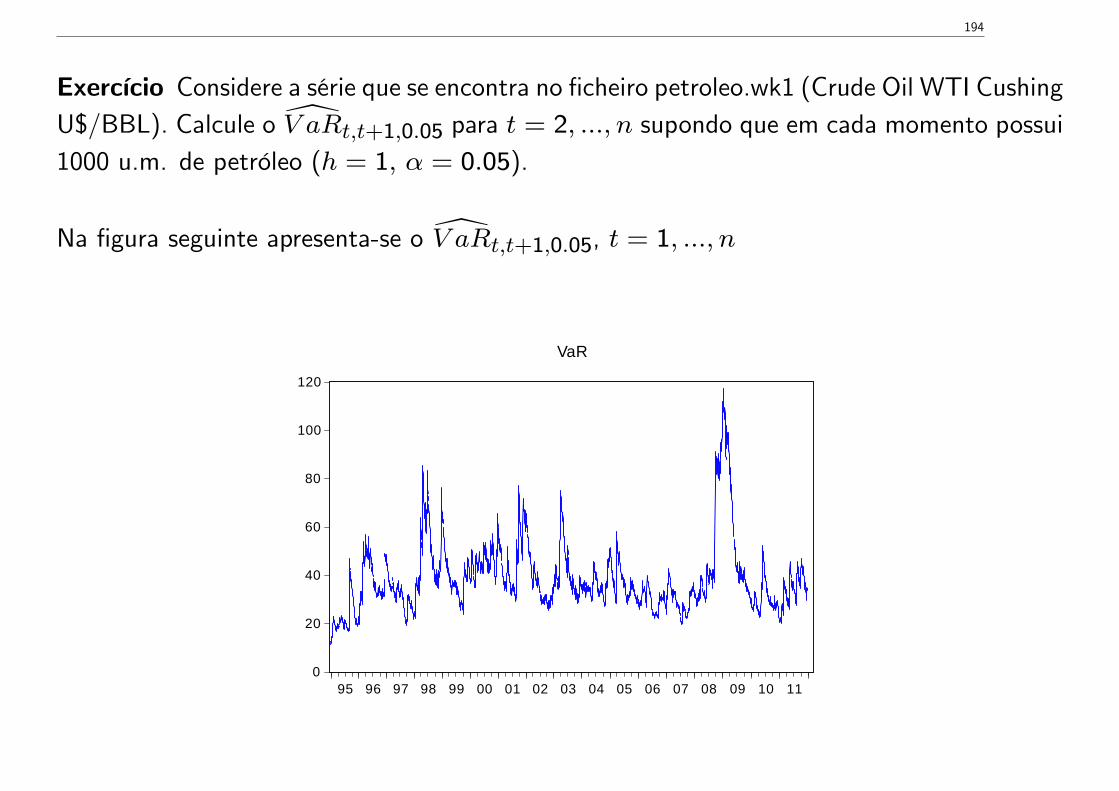
194
Exercício Considere a série que se encontra no ficheiro petroleo.wk1 (Crude Oil WTI CushingU$/BBL). Calcule o V aRt,t+1,0.05 para t = 2, ..., n supondo que em cada momento possui1000 u.m. de petróleo (h = 1, α = 0.05).
Na figura seguinte apresenta-se o V aRt,t+1,0.05, t = 1, ..., n
0
20
40
60
80
100
120
95 96 97 98 99 00 01 02 03 04 05 06 07 08 09 10 11
VaR

195
6.3.3 Modelo GARCH (média condicional constante)
Assuma-se agora
rt = c+ ut
ut = σtεt, ut ∼ GARCH.
Tal como no caso anterior, temos de obter a distribuição de rn+h (h)∣∣Fn. Tem-se
E(rn+h (h)
∣∣Fn) = ch
Para obter Var(rn+h (h)
∣∣Fn) considere-seVar
(rn+h (h)
∣∣Fn)= Var (rn+1| Fn) + ...+ Var
(rn+h
∣∣Fn)=
h∑k=1
σ2n+k,n

196
Tem-se
V aRn,n+h,α = −
ch+ qZα
√√√√√ h∑k=1
σ2n+k,n
Vn
Exemplo Considere-se o modelo
rt = c+ σtεt, σ2t = ω + α1u
2t−1 + β1σ
2t−1.
Tendo em conta que
σ2n+k,n =
ω
1− α1 − β1+ (α1 + β1)k−1
(α1u
2n + β1σ
2n
),

197
resulta
Var(rn+h (h)
∣∣Fn)=
h∑k=1
σ2n+k,n
=h∑k=1
(ω
1− α1 − β1+ (α1 + β1)k−1
(α1u
2n + β1σ
2n
))
=1
1− α1 − β1
(hω −
(α1u
2n + β1σ
2n
) ((α1 + β1)h − 1
)).
Vem
V aRn,n+h,α
= −(ch+ qZα
√1
1− α1 − β1
(hω −
(α1u2
n + β1σ2n
) ((α1 + β1)h − 1
)))Vn.

198
Resultados da estimação GARCH dos retornos do Dow Jones (28317 observações diárias).
Dependent Variable: retornos do Dow JOnesMethod: ML ARCHIncluded observations: 28317 after adjusting endpoints
Coefficient Std. Error zStatistic Prob.C 0.000416 4.54E05 9.155216 0.0000
Variance EquationC 1.17E06 5.17E08 22.67097 0.0000
ARCH(1) 0.085080 0.001263 67.38911 0.0000GARCH(1) 0.905903 0.001542 587.6203 0.0000
Rsquared 0.000450 Mean dependent var 0.000188Adjusted Rsquared 0.000556 S.D. dependent var 0.010753S.E. of regression 0.010756 Akaike info criterion 6.640694Sum squared resid 3.275823 Schwarz criterion 6.639529Log likelihood 94026.27 DurbinWatson stat 1.921149
Sabe-se que rn = −0.0101, σ2n = 0.00014.
V aRn,n+h,α estimado, supondo Vn = 1, corresponde à expressão:
−(ch+ qZα
√1
1− α1 − β1
(hω −
(α1u2
n + β1σ2n
) ((α1 + β1
)h − 1)))
onde un = rn − c = −0.0101− 0.000416 = −.01051.
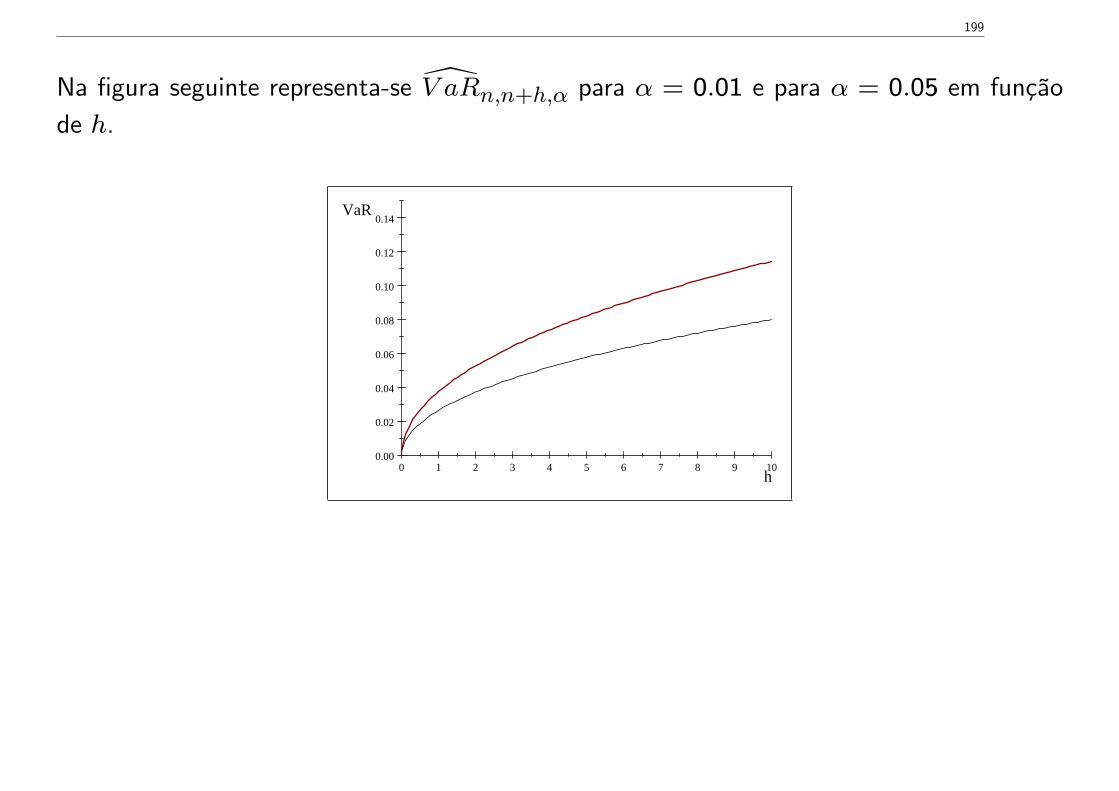
199
Na figura seguinte representa-se V aRn,n+h,α para α = 0.01 e para α = 0.05 em funçãode h.
0 1 2 3 4 5 6 7 8 9 100.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
h
VaR

200
6.4 Generalização: Portfolio com m Activos
Obtenha-se agora o VaR supondo que o portfolio é constituído porm acções. Para simplificarassuma-se que
rt = (R1t, ..., Rmt)′∣∣∣Ft−1 ∼ N (µt,Ht)
onde µt := E (rt| Ft−1) e Var (rt| Ft−1) := Ht. No momento n o portfolio vale Vn, porexemplo, uma alocação de 1 milhão de Euros no título 1 e 2 milhões no título 2, traduz-sepor um investimento no valor de Vn = 3 milhões, sendo ω1 = 1/3 desse valor investido notítulo 1 e ω2 = 2/3 investido no título 2. A obtenção do VaR é similar ao do caso de umportfolio com apenas 1 activo:
P(
∆Vn+1 < −V aRn,n+1,α
∣∣∣Fn) = α
P
(∆Vn+1
VnVn < −V aRn,n+1,α
∣∣∣∣Fn) = α
P
(Rp,n+1 < −
V aRn,n+1,α
Vn
∣∣∣∣∣Fn)
= α.

201
Estandardizando Rp,n+1, isto é, considerando
Zn+1 =Rp,n+1 − E
(Rp,n+1
∣∣∣Fn)√Var
(Rp,n+1
∣∣∣Fn)vem
P
Zn+1 <−V aRn,n+1,α
Vn− E
(Rp,n+1
∣∣∣Fn)√Var
(Rp,n+1
∣∣∣Fn)∣∣∣∣∣∣∣∣∣Fn
= α
−V aRn,n+1,αVn
− E(Rp,n+1
∣∣∣Fn)√Var
(Rp,n+1
∣∣∣Fn) = qZα
⇒ V aRn,n+1,α = −(
E(Rp,n+1
∣∣∣Fn) + qZα
√Var
(Rp,n+1
∣∣∣Fn))Vn

202
Tendo em conta que Rp,n+1 =∑mi=1 ωiRi,n+1 = ω′rn+1 tem-se
Rp,n+1 = E(Rp,n+1
∣∣∣Fn) = ω′µn+1,
e
Var(Rp,n+1
∣∣∣Fn) = ω′Hn+1ω.
Finalmente
V aRn,n+1,α = −(ω′µn+1 + qZα
√ω′Hn+1ω
)Vn
onde qZα é o quantil de ordem α da distribuição de Zn+1| Fn.

203
Exemplo Considere-se um portfolio, no momento n, constituído por de 1 milhão de Eurosno título 1 e 2 milhões no título 2. Admita-se a seguinte distribuição(
R1,n+1R2,n+1
)∣∣∣∣∣Fn ∼ N((
00
),
(0.01 0.002
0.002 0.005
)).
Tem-se para α = 0.05
V aRn,n+1,α = 1.645
√√√√( 1/3 2/3)( 0.01 0.002
0.002 0.005
)(1/32/3
)× 3 = 0.32 milhões.
O valor em risco com uma probabilidade de 0.05 para um horizonte temporal de h = 1
período é de cerca de 0.32 milhões de euros.
Se considerássemos os dois activos separadamente teríamos:
V aR do título 1 = 1.645√
0.01× 1 = 0.164
V aR do título 2 = 1.645√
0.005× 2 = 0.232.
Observa-se que a soma dos VaR individuais, 0.164 + 0.232 = 0.396, é maior do que o VaRdo portfolio.

204
6.5 Avaliação do VaR (Backtesting)
Neste ponto avalia-se a qualidade da estimativa proposta para o VaR. Esta avaliação é impor-tante por várias razões. As empresas (sobretudo bancos) que usam o VaR são pressionadasinterna e externamente (por directores, auditores, reguladores, investidores) para produziremVaR precisos. Um VaR preciso é fundamental na gestão e controle do risco e na alocaçãode capital. Por essa razão é essencial que empresa teste regularmente as suas medidas derisco, na linha das recomendações adoptadas em acordo internacionais. Por outro lado,embora a definição de VaR seja muito precisa e objectiva, existem diferentes métodos deestimação do VaR, que produzem diferentes estimativas (algumas bastante díspares); porisso, é importante identificar a melhor abordagem para o problema concreto em análise.

205
6.5.1 Cobertura Marginal e Condicional
Como V aRt−1,t,α é construído no período t−1 não se sabe, antecipadamente, se no período
t se tem ou não ∆Vt < −V aRt−1,t,α. Intuitivamente, é natural esperar que a desigualdade
∆Vt < −V aRt−1,t,α ⇔ rt < −V aRt−1,t,α
Vt−1
ocorra α100% das vezes. Por outras palavras, seja
It =
1 se ∆Vt < −V aRt−1,t,α ou rt < −V aRt−1,t,α
Vt−1
0 no caso contrário.
É natural esperar que a % de uns da sequência It seja de α100%.
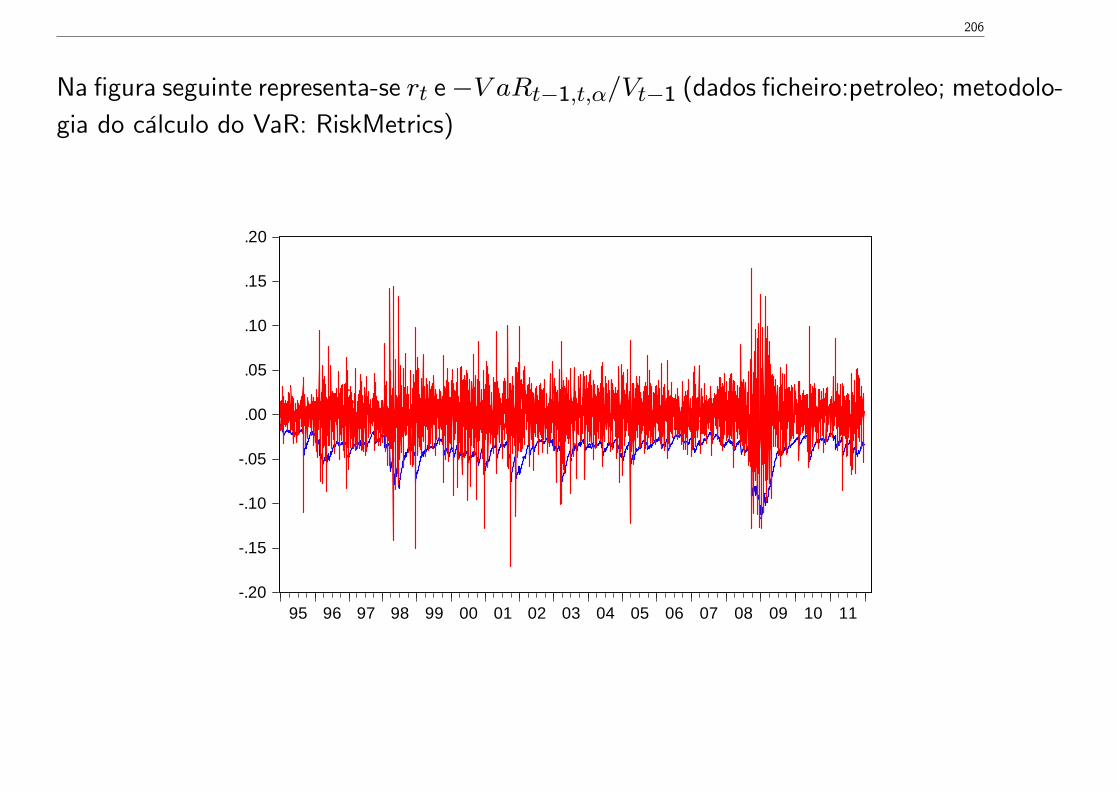
206
Na figura seguinte representa-se rt e−V aRt−1,t,α/Vt−1 (dados ficheiro:petroleo; metodolo-gia do cálculo do VaR: RiskMetrics)
.20
.15
.10
.05
.00
.05
.10
.15
.20
95 96 97 98 99 00 01 02 03 04 05 06 07 08 09 10 11

207
A previsão do VaR produz uma cobertura marginal correcta se
P (It = 1) = α⇔ E (It) = α.
A previsão do VaR produz uma cobertura condicional correcta se
P (It = 1| Ft−1) = α⇔ E (It| Ft−1) = α.
Nota: E (It| Ft−1) = α⇒ Cov(It, It−k
)= 0.
Por que razão a cobertura condicional é importante?

208
6.5.2 Teste Estatístico
Suponha-se que It segue uma cadeia de Markov com a seguinte matriz de probabilidades detransição
P =
(1− p01 p011− p11 p11
)onde pij = P (It = j| It−1 = i) .
Se p01 = p11 ⇒ {It} é uma sucessão de v.a. i.i.d. (com distribuição de Bernoulli). Logo ahipótese a testar é
H0: p01 = p11 = α [A previsão do VaR produz uma cobertura condicional e marginalcorrecta]. Sob H0 pode-se provar:
RV = −2 log(1− α)n00+n10 αn01+n11
(1− p01)n00 pn0101 (1− p11)n10 p
n1111
d−→ χ2(2).
nij é o número de vezes em que I passou de i para j

209
Exemplo Estimou-se o V aRt−1,t,α, com α = 0.05 (dados ficheiro:petroleo; metodologiado cálculo do VaR: RiskMetrics). Teste
H0 : p01 = p11 = 0.05
Sabe-se:
Freq. Absolutas ItIt = 0 It = 1 Total
It−1 = 0 3772 218 3990It−1 = 1 218 16 234Total 3990 234 4224
PIt = 0 It = 1
It−1 = 0 37723990 = 0.945 218
3990 = 0.055
It−1 = 1 218234 = 0.932 16
234 = 0.068
RVobs = −2 log(1− α)n00+n10 αn01+n11
(1− p01)n00 pn0101 (1− p11)n10 p
n1111
= −2 log(1− 0.05)3990 0.05234
(1− 0.055)3772 (0.055)218 (1− 0.068)218 (0.068)16
= 3.244
pvalue = P (RV > 3.244|H0) = 0.197

210
Os testes baseados na cadeia de Markov baseiam-se em dependências de primeira ordem.Ora, pode suceder que It dado It−1 dependa ainda de It−2. Neste caso, os testes baseadosno modelo da cadeia de Markov, podem perder bastante potência.
A hipótese E (It| Ft−1) = α sugere que It dado Ft−1 apenas depende de uma constante,α. Assim, se It depende de alguma variável Ft−1 mensurável, a hipótese E (It| Ft−1) = α
deve ser rejeitada. Procedimento alternativo aos testes anteriores:
It = α0 +k∑i=1
αiIt−i + x′t−1β + ut
onde x′t−1 é um vector 1×m de variáveis Ft−1 mensuráveis e β é um vector de parâmetrosm× 1. A hipótese de correcta cobertura marginal e condicional envolve o ensaio H0 : α1 =
0, ..., αk = 0, β = 0, α0 = α. Naturalmente a estatística F pode ser usada.