1 efficient massive sharing of content among peers by peter triantafillou, chryssani xiruhaki and...
Post on 20-Dec-2015
217 views
TRANSCRIPT

1
Efficient Massive Sharing of Content among Peers
by Peter Triantafillou, Chryssani Xiruhaki and Manolis Koubarakis
Dept. of Electronics and Computer Engineering Technical University of Crete Chania, 73100
Greece

2
Outline
Background Aim System Architecture Experimental Result

3
Background
Internet content sharing system has become very popular recently(e.g. Napster)
Content sharing systems could consists of very large number of nodes, offering resources and content(documents).

4
Background
The central control of information at special nodes is undesirable– Central points of failure– Peformance bottleneck
Need to create a P2P system Architecture in which nodes can collaborate with each other.

5
Aim
Ensuring high performance in large-scale P2P content sharing systems.
This paper focus on two particular sub-goals:– Ensuring load balancing across all nodes of such a
system.– Ensuring short response times to user requests.

6
System Architecture
Divide documents into a number of semantic categories. It uniquely maps each document to a semantic category
Category 1 Category 2
Document 1
Document 2
Document 3
Document 4
Document 5Document 6
……..

7
System Architecture
The nodes will be divided into a number of clusters.
Node 2Node 1
Node 7Node 6Node 5
Node 4
Node 3
Cluster 1 Cluster 2

8
System Architecture
Each semantic category can only be found in one and only one clusters
Cluster 1 Cluster 2
Category 1
Category 3
Category 2
Category 4

9
System Architecture
Each node store the cluster metadata describing which category of documents are stored by which cluster nodes
Global load balance if– Inter-cluster load balance– Intra-cluster load balance

10
User Request Processing
Request can be either to publish(contribute) or to retrieve(download) documents.– Identified the semantic category of the document.– The request will be forwarded to the proper clusters– the request will be forwarded to one randomly
chosen node of the cluster– If the node does/could not store the requested
documents, it will forward the request to some other nodes of the same cluster.

11
User Request Processing
With this approach, the paper claims that– The load is balanced within a cluster– The response time is low and it is bounded by the
number of nodes in the cluster.

12
Inter-cluster Load Balance
Assumption:– Each node contribute documents belonging to a
single semantic category– The content has known popularity, with document
popularities following the Zipf distribution – Each node have the same storage and processing
power
The system contain N nodes

13
Inter-cluster Load Balance
Question: Is there a partition of N nodes into k(given) clusters N1, N2,…, Nk such that the following two constraint are satisfied?– If two documents belong to the same semantic
category, then the nodes that contributed/store these documents belongs to the same cluster
– Clusters have equal normalized popularities
Formally, p(Ni)/| Ni | = p(Nj)/| Nj | ,for all 1<=i,j <=k

14
Inter-cluster Load Balance
Cluster 3
Cluster 1 Cluster 2

15
Inter-cluster Load Balance
Cluster 1 Cluster 2
Cluster 3

16
Inter-cluster Load Balance
The problem is NP-complete Consider partitioning the given set of nodes N
into clusters with nearly equal normalized popularities
Minimizing the following quantity:

17
Inter-cluster Load Balance
The paper proposed a greedy algorithm, called MinDiff– Initially all cluster are empty– The MinDiff considers each semantic category in
turn– It assign the category to the cluster of nodes which
minimize the quantity of the above equation

18
Inter-cluster Load Balance
MinDiff is incomplete(it might miss the optimal solution)
MinDiff runs in polynomial time and achieves very good results.

19
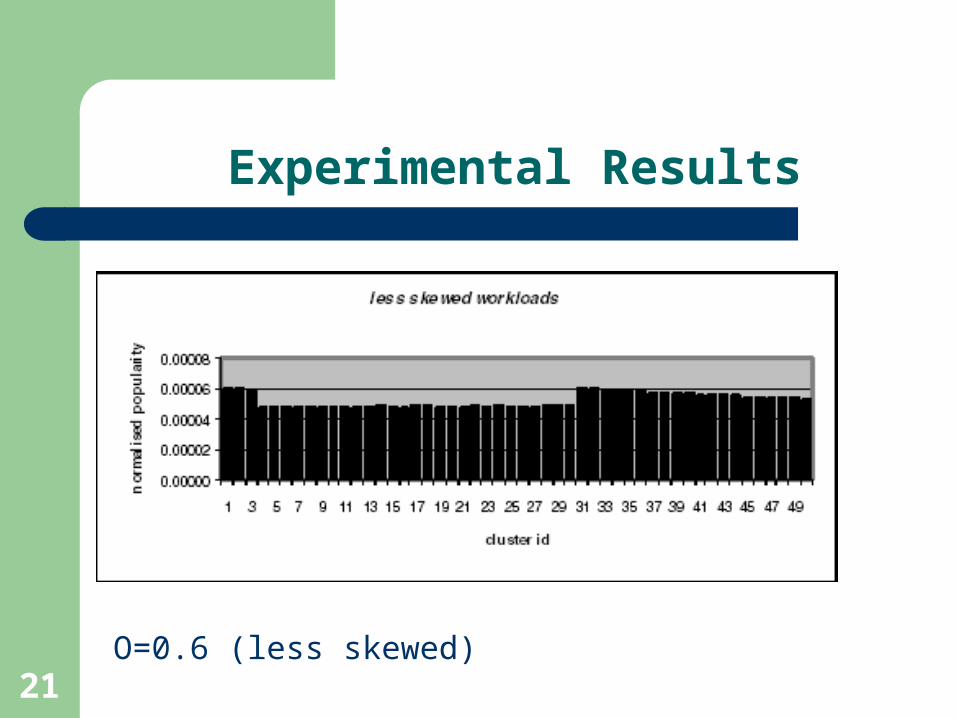
Experimental Results
Documents: 19800
Semantic categories: 300
Clusters: 50
Popularity distribution of documents are Zipf-like
with parameter O = 0.3 and O = 0.7

20
Experimental Results
O=0.3 (more skewed)
21
Experimental Results
O=0.6 (less skewed)