1 exercise: bioinformatic databases and blast. 2 outline ncbi and entrez pubmed google scholar ...
Post on 19-Dec-2015
226 views
TRANSCRIPT

11
Exercise:Exercise:BIOINFORMATIC DATABASESBIOINFORMATIC DATABASES
andandBLASTBLAST

22
OutlineOutline
NCBI and EntrezNCBI and Entrez PubmedPubmed Google scholarGoogle scholar RefSeqRefSeq SwissprotSwissprot Fasta formatFasta format PDBPDB:: Protein Data Bank Protein Data Bank Organism specific databasesOrganism specific databases SummarySummary Pairwise Sequence Alignment and BLASTPairwise Sequence Alignment and BLAST OverviewOverview Query type: DNA or ProteinQuery type: DNA or Protein

33
What’s in a database?What’s in a database? Sequences – genes, proteins, etcSequences – genes, proteins, etc
Full genomesFull genomes
Annotation – information about genes/proteins:Annotation – information about genes/proteins:- function- function- cellular location- cellular location- chromosomal location- chromosomal location- introns/exons- introns/exons- protein structure- protein structure- phenotypes, diseases- phenotypes, diseases
PublicationsPublications
44
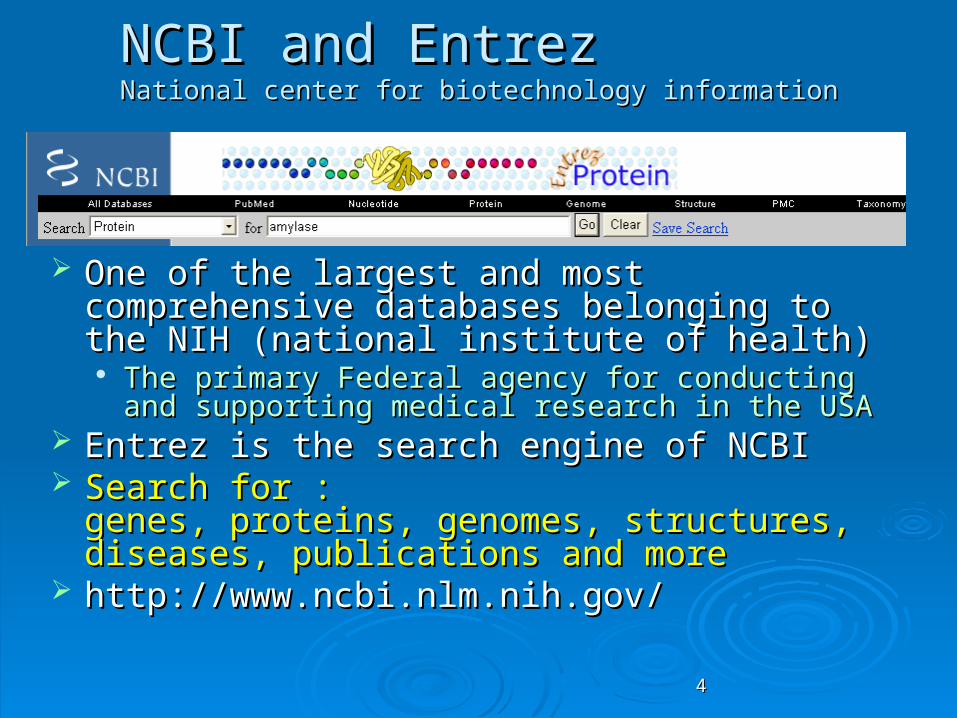
NCBI and EntrezNCBI and EntrezNational center for biotechnology informationNational center for biotechnology information
One of the largest and most comprehensive One of the largest and most comprehensive databases belonging to the NIH (national databases belonging to the NIH (national institute of health)institute of health) The primary Federal agency for conducting and The primary Federal agency for conducting and
supporting medical research in the USAsupporting medical research in the USA Entrez is the search engine of NCBIEntrez is the search engine of NCBI Search for :Search for :
genes, proteins, genomes, structures, diseases, genes, proteins, genomes, structures, diseases, publications and morepublications and more
httphttp://://wwwwww..ncbincbi..nlmnlm..nihnih..govgov//
55
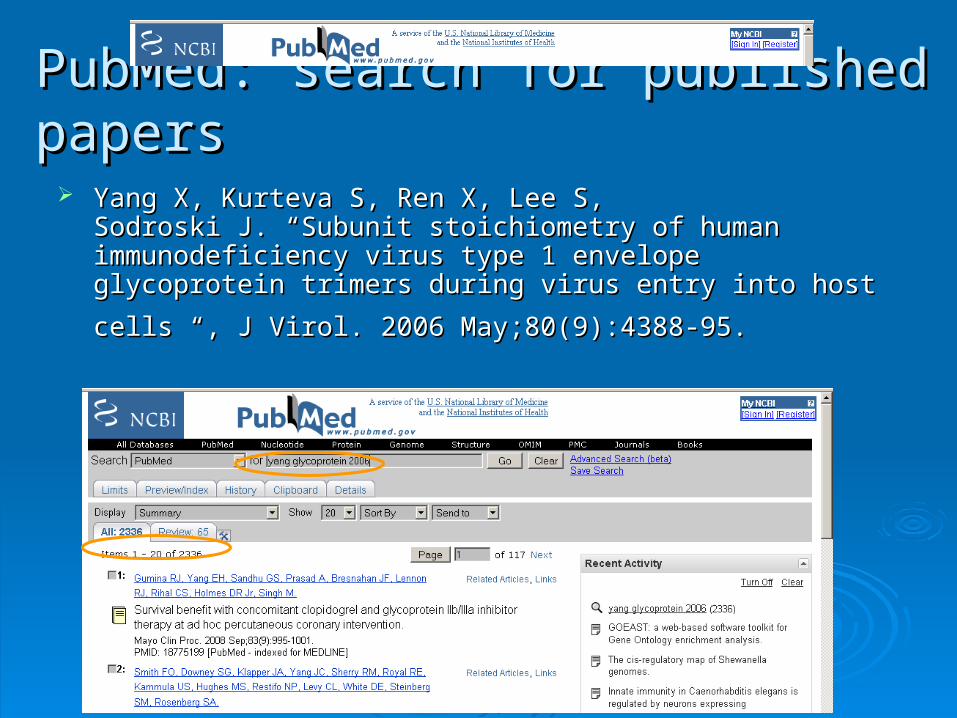
PubMed: search for published papersPubMed: search for published papers
Yang X, Kurteva S, Ren X, Lee S,Yang X, Kurteva S, Ren X, Lee S,Sodroski JSodroski J.. “Subunit stoichiometry of human immunodeficiency virus “Subunit stoichiometry of human immunodeficiency virus type 1 envelope glycoprotein trimers during virus entry into host type 1 envelope glycoprotein trimers during virus entry into host
cells “, J Virolcells “, J Virol.. 2006 May;80(9):4388-95. 2006 May;80(9):4388-95.
66
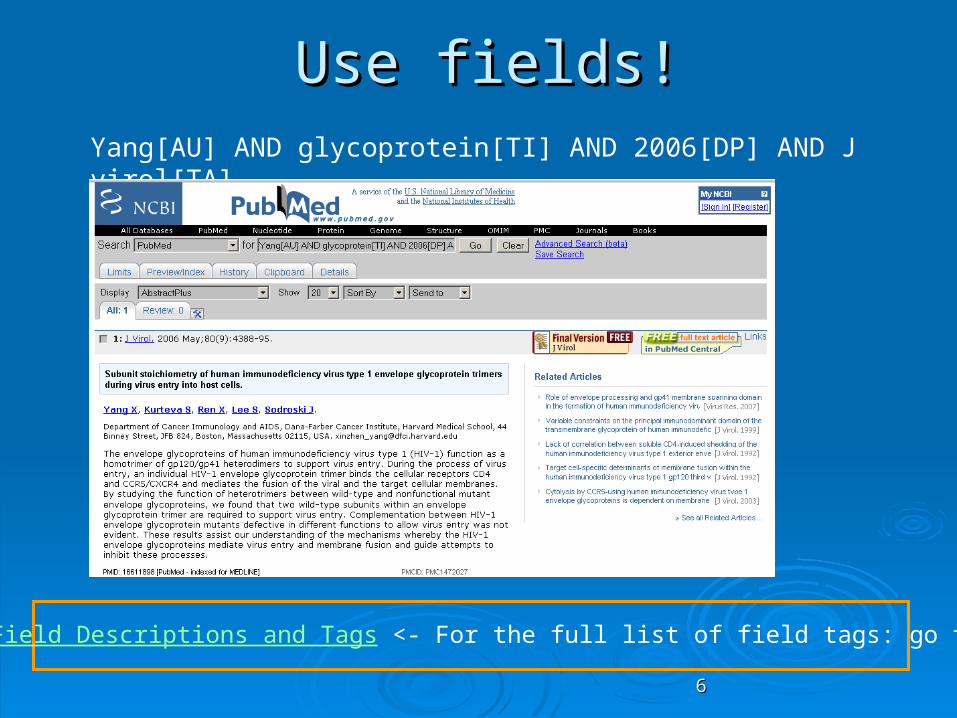
Use fields!Use fields!Yang[AU] AND glycoprotein[TI] AND 2006[DP] AND J virol[TA]
For the full list of field tags: go to help >- Search Field Descriptions and Tags

77
ExerciseExercise
Retrieve all publications in which the Retrieve all publications in which the first first author is:author is: Pe'er I Pe'er I and the and the last author is:last author is: Shamir RShamir R
88
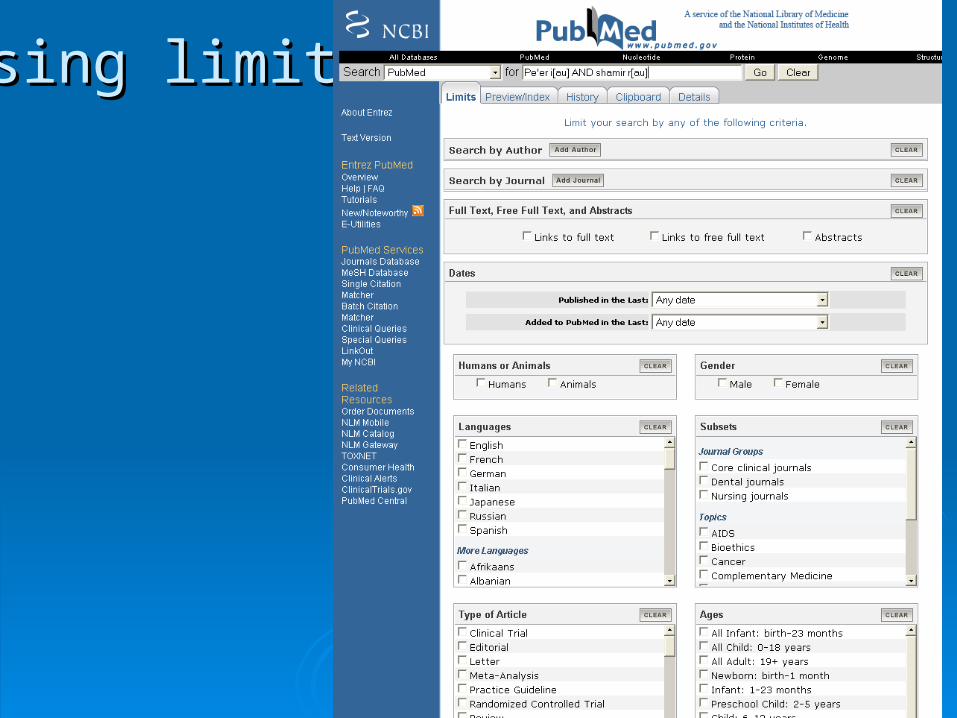
Using limitsUsing limits

99
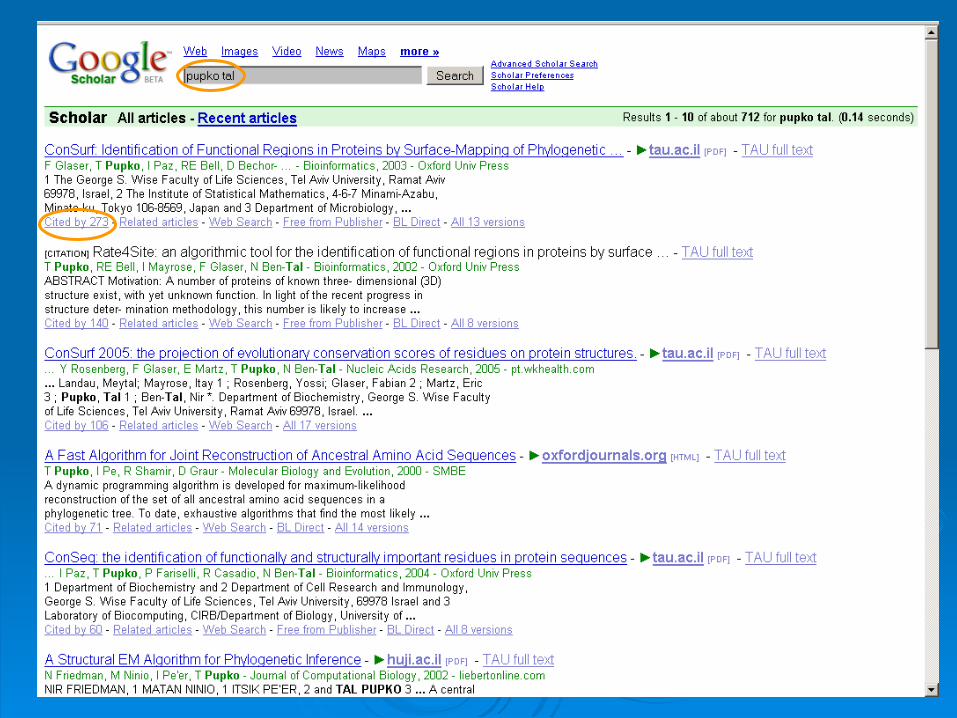
Google scholarGoogle scholarhttp://scholar.google.com/
1010

1111
NCBI gene & protein databases: NCBI gene & protein databases: GenBankGenBank
GenBankGenBank is an annotated collection of all is an annotated collection of all publicly available DNA sequences (and publicly available DNA sequences (and their amino-acid translations)their amino-acid translations)
Holds over Holds over 148148 billionbillion bases (2009)bases (2009)

1212
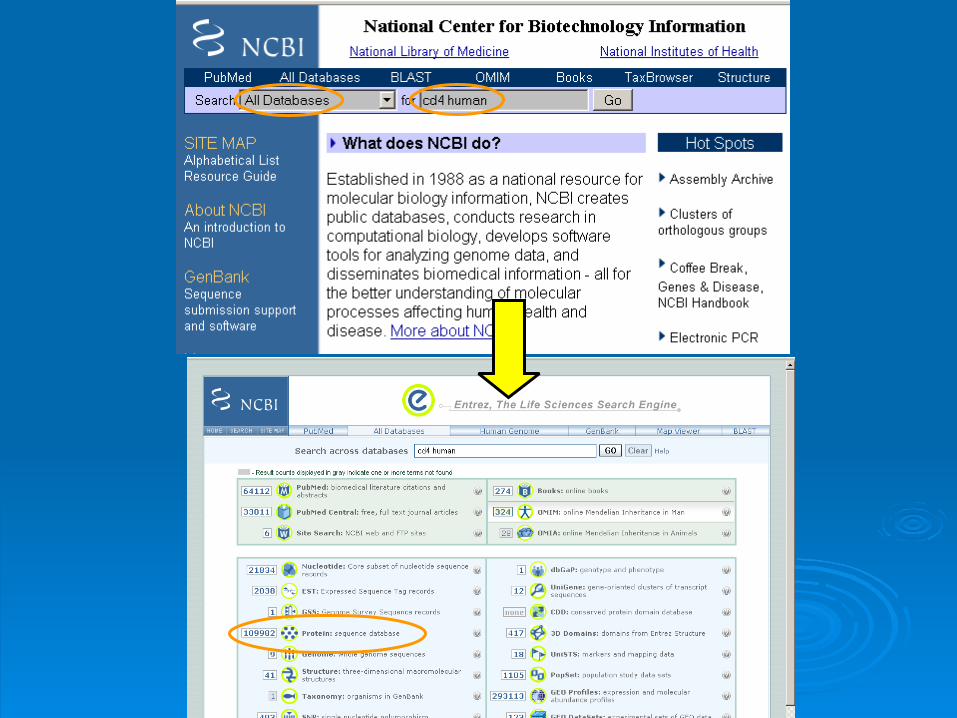
Searching NCBI for the protein Searching NCBI for the protein human CD4human CD4
Search demonstrationSearch demonstration
1313
1414
Using field descriptions, qualifiers, Using field descriptions, qualifiers, and boolean operatorsand boolean operators
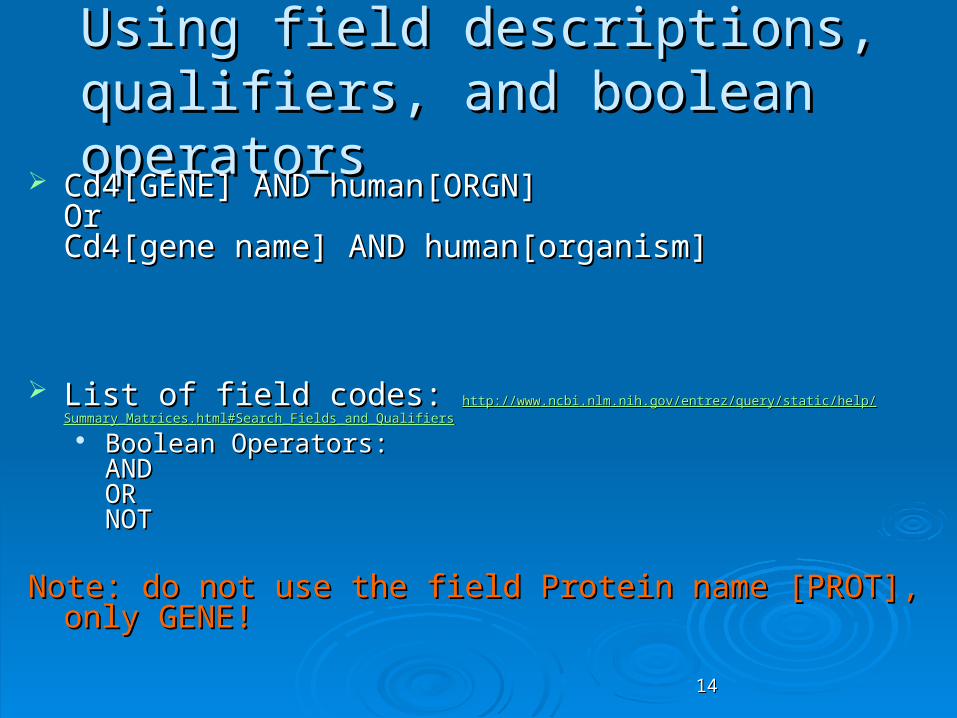
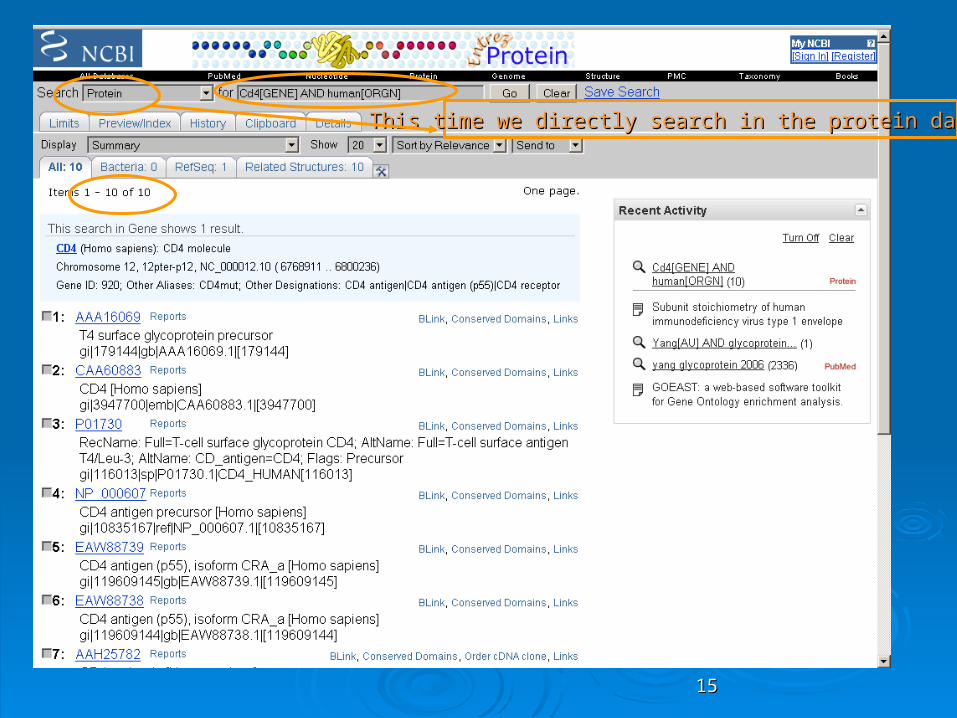
Cd4[GENE] AND human[ORGN] Cd4[GENE] AND human[ORGN] Or Or Cd4[gene name] AND human[organism]Cd4[gene name] AND human[organism]
List of field codes: List of field codes: httphttp://://wwwwww..ncbincbi..nlmnlm..nihnih..govgov//entrezentrez//queryquery//staticstatic//helphelp//Summary_MatricesSummary_Matrices..html#Search_Fields_and_Qualifiershtml#Search_Fields_and_Qualifiers
Boolean Operators:Boolean Operators:ANDANDORORNOTNOT
Note: do not use the field Protein name [PROT], only GENE!Note: do not use the field Protein name [PROT], only GENE!
1515
This time we directly search in the protein databaseThis time we directly search in the protein database
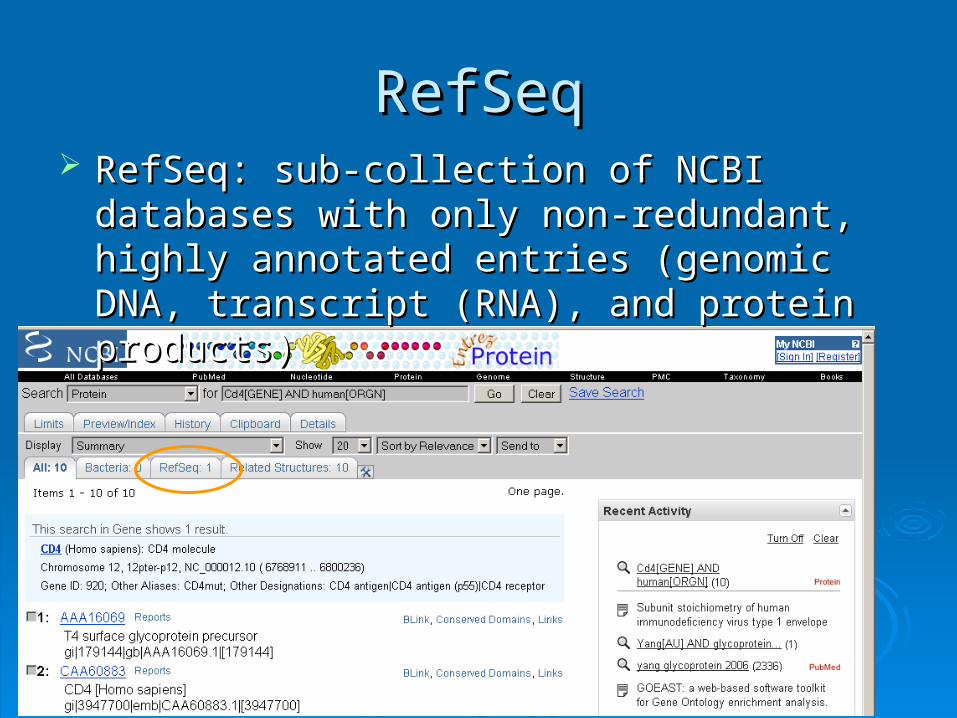
1616
RefSeqRefSeq RefSeq: sub-collection of NCBI databases with RefSeq: sub-collection of NCBI databases with
only non-redundant, highly annotated entries only non-redundant, highly annotated entries (genomic DNA, transcript (RNA), and protein (genomic DNA, transcript (RNA), and protein products)products)
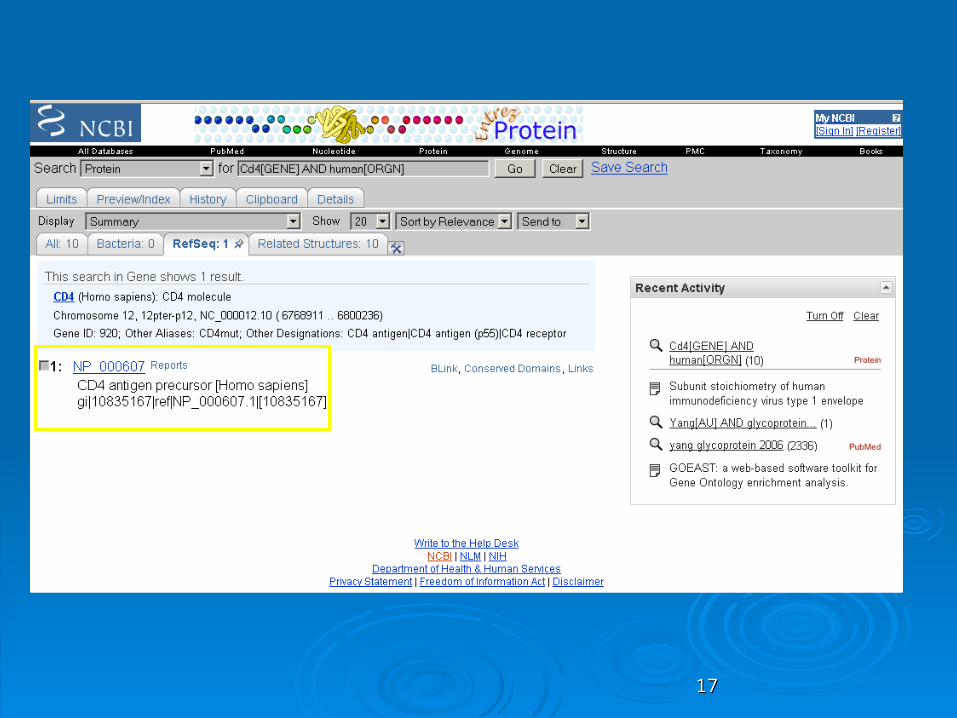
1717
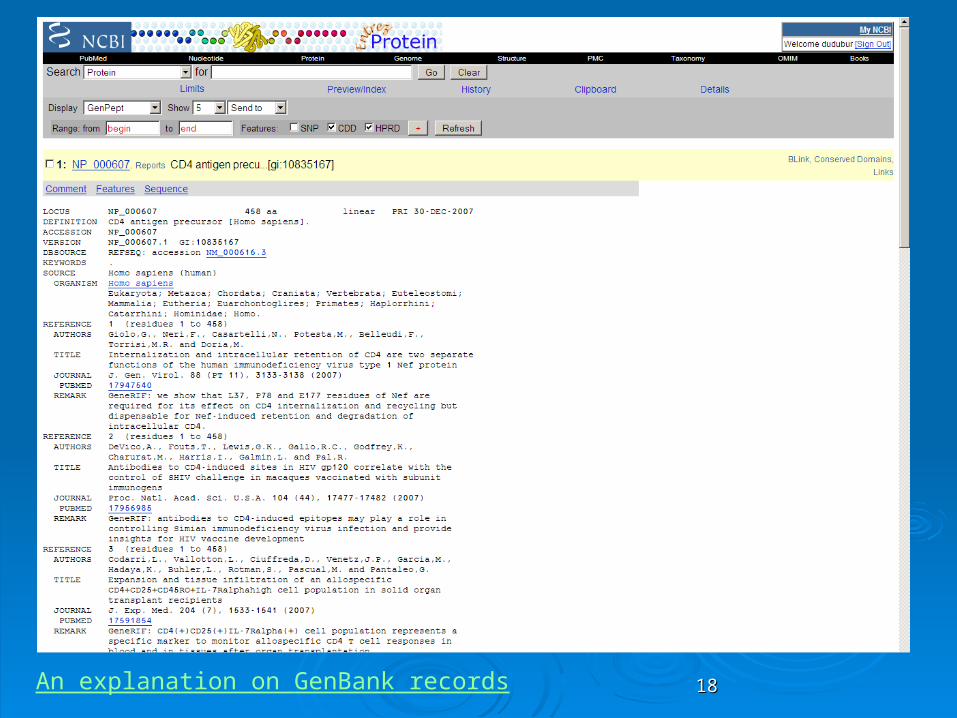
1818An explanation on GenBank records

1919
SwissprotSwissprot
A protein sequence database which A protein sequence database which strives to provide a high level of strives to provide a high level of annotation:annotation:* the function of a protein* the function of a protein* domains structure* domains structure* post* post--translational modificationstranslational modifications* variants* variants
One entry for each proteinOne entry for each protein
2020
UniProtUniProt
2121
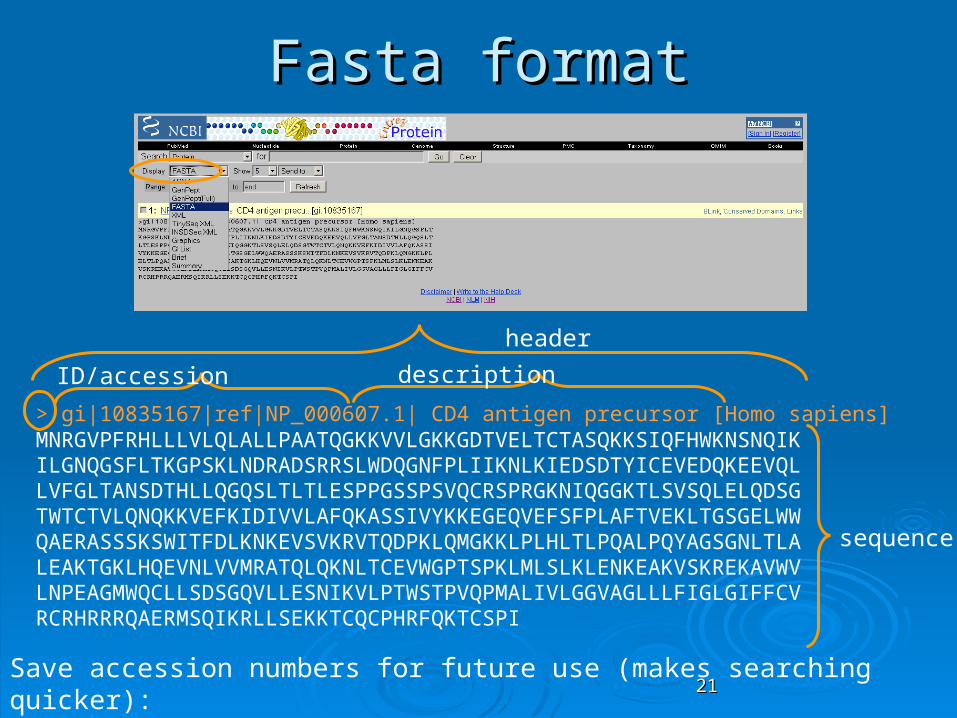
Fasta formatFasta format
> gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLTKGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLTLTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSIVYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
Save accession numbers for future use (makes searching quicker):RefSeq accession number: NP_000607.1
header
ID/accession description
sequence
2222
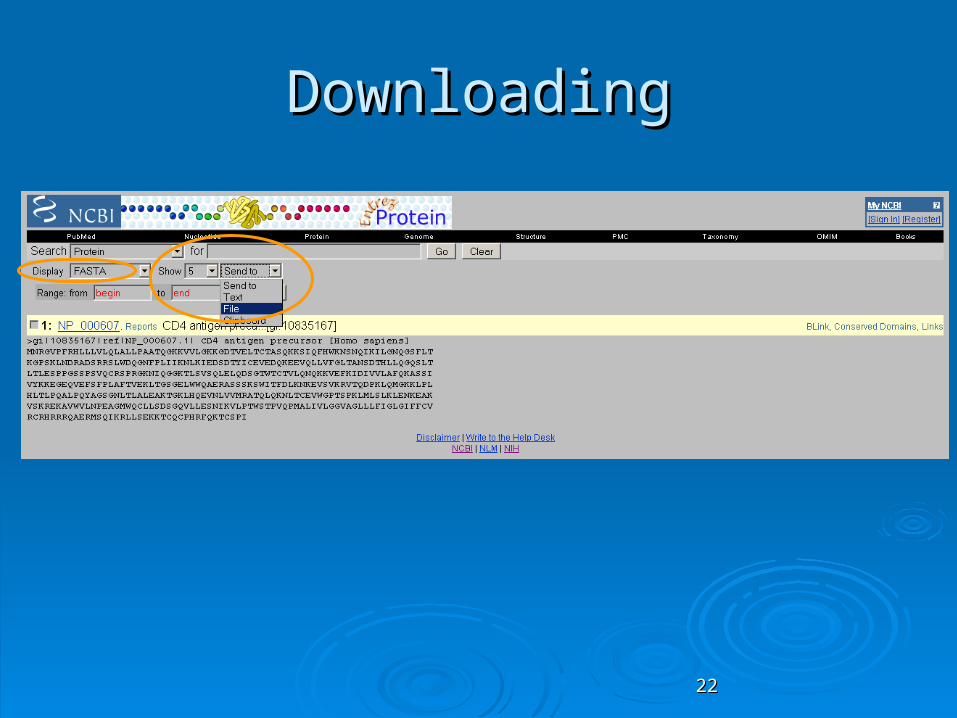
DownloadingDownloading

2323
PDBPDB:: Protein Data Bank Protein Data Bank
Main database of 3D structuresMain database of 3D structures Includes ~56,000 entries (Includes ~56,000 entries (proteinsproteins, ,
nucleic acids, others)nucleic acids, others) Proteins organized in groups, families etcProteins organized in groups, families etc Is highly redundant Is highly redundant
different conformations (e.g., ligand different conformations (e.g., ligand dependent)dependent)
http://www.rcsb.orghttp://www.rcsb.org
2424
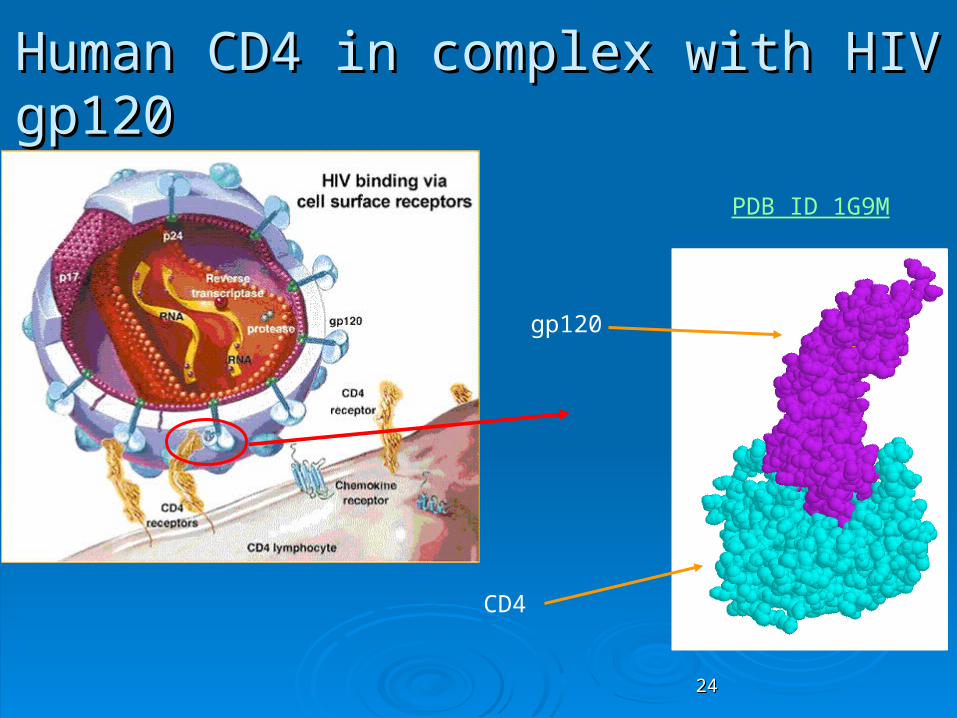
Human CD4 in complex with HIV gp120Human CD4 in complex with HIV gp120
gp120
CD4
PDB ID 1G9M

2525
Model organisms have independent databases:Model organisms have independent databases:
Organism specific databasesOrganism specific databases
HIV database http://hiv-web.lanl.gov/content/index
http://gmod.org/wiki/Main_Page?q=node/71

2626
SummarySummary
General and comprehensive databases:General and comprehensive databases: NCBI, EMBL, DDBJNCBI, EMBL, DDBJ
Genome specific databases:Genome specific databases: ENSEMBL, UCSC genome browserENSEMBL, UCSC genome browser
Highly annotated databases:Highly annotated databases: Proteins:Proteins:
• Swissprot, RefSeqSwissprot, RefSeq Structures:Structures:
• PDBPDB

2727
And always remember:And always remember:
1.1.GoogleGoogle (or any search engine) (or any search engine)
2.2.RTFM -RTFM -
Read the manual!!! (/help/FAQ)Read the manual!!! (/help/FAQ)

2828
Pairwise Pairwise Sequence Sequence
Alignment and Alignment and BLASTBLAST

2929
What is sequence alignment?What is sequence alignment?
Alignment: Alignment: Comparing two (pairwise) or Comparing two (pairwise) or more (multiple) sequences. Searching for more (multiple) sequences. Searching for a series of identical or similar characters in a series of identical or similar characters in the sequences.the sequences.
MVNLTSDEKTAVLALWNKVDVEDCGGE|| || ||||| ||| || || ||MVHLTPEEKTAVNALWGKVNVDAVGGE

3030
Local vs. GlobalLocal vs. Global Global alignmentGlobal alignment – finds the best – finds the best
alignment across the alignment across the wholewhole two two sequences.sequences.
Local alignmentLocal alignment – finds regions of – finds regions of high similarity in high similarity in partsparts of the of the sequences.sequences.
ADLGAVFALCDRYFQ|||| |||| |ADLGRTQN-CDRYYQ
ADLG CDRYFQ|||| |||| |ADLG CDRYYQ

3131
In the course of evolution, the sequences In the course of evolution, the sequences changed from the ancestral sequence by changed from the ancestral sequence by random mutationsrandom mutations
Three types of mutations:Three types of mutations:
1.1. InsertionInsertion - AAGA - AAGA AAG AAGTTAA
2.2. DeletionDeletion - A - AAAGAGA AGA AGA
3.3. SubstitutionSubstitution -- AA AAGGAA AA AACCAA
Evolutionary changes in sequencesEvolutionary changes in sequences
InsertionInsertion + + DeletionDeletion IndelIndel

3232
Scoring schemeScoring scheme
Match/mismatch scores: substitution matricesMatch/mismatch scores: substitution matrices Nucleic acids:Nucleic acids:
• Transition-transversionTransition-transversion Amino acids:Amino acids:
• Evolution (empirical data) based: (PAM, BLOSUM)Evolution (empirical data) based: (PAM, BLOSUM)• Physico-chemical properties based (Grantham, Physico-chemical properties based (Grantham,
McLachlan)McLachlan)
Gap penaltyGap penalty
3333
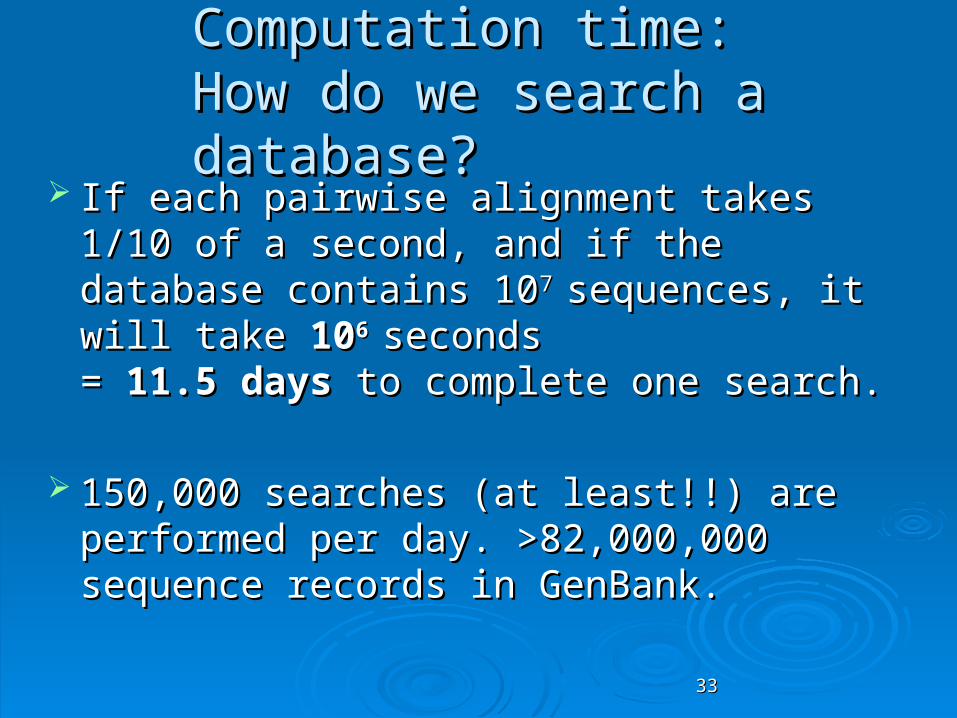
Computation time:Computation time:How do we search a database?How do we search a database?
If each pairwise alignment takes 1/10 of a If each pairwise alignment takes 1/10 of a second, and if the database contains 10second, and if the database contains 107 7
sequences, it will take sequences, it will take 101066 seconds seconds = = 11.511.5 daysdays to complete one search. to complete one search.
150,000 searches (at least!!) are 150,000 searches (at least!!) are performed per day. >82,000,000 sequence performed per day. >82,000,000 sequence records in GenBank.records in GenBank.

3434
ConclusionConclusion
Using the exact comparison pairwise Using the exact comparison pairwise alignment algorithm between the query alignment algorithm between the query and all DB entries – too slowand all DB entries – too slow

3535
HeuristicHeuristic
Definition:Definition: a heuristic is a a heuristic is a design to solve a problem that design to solve a problem that does not provide an exact does not provide an exact solution (but is not too bad) but solution (but is not too bad) but reduces the time complexity of reduces the time complexity of the exact solutionthe exact solution

3636
BLASTBLAST
BLAST - BLAST - BBasic asic LLocal ocal AAlignment and lignment and SSearch earch TToolool
A heuristic for searching a database for A heuristic for searching a database for similar sequencessimilar sequences
The heuristic based on restrictions of the The heuristic based on restrictions of the similarity (such as using similarity (such as using ungapped word ungapped word matching instead of single character matching instead of single character matching).matching).

3737
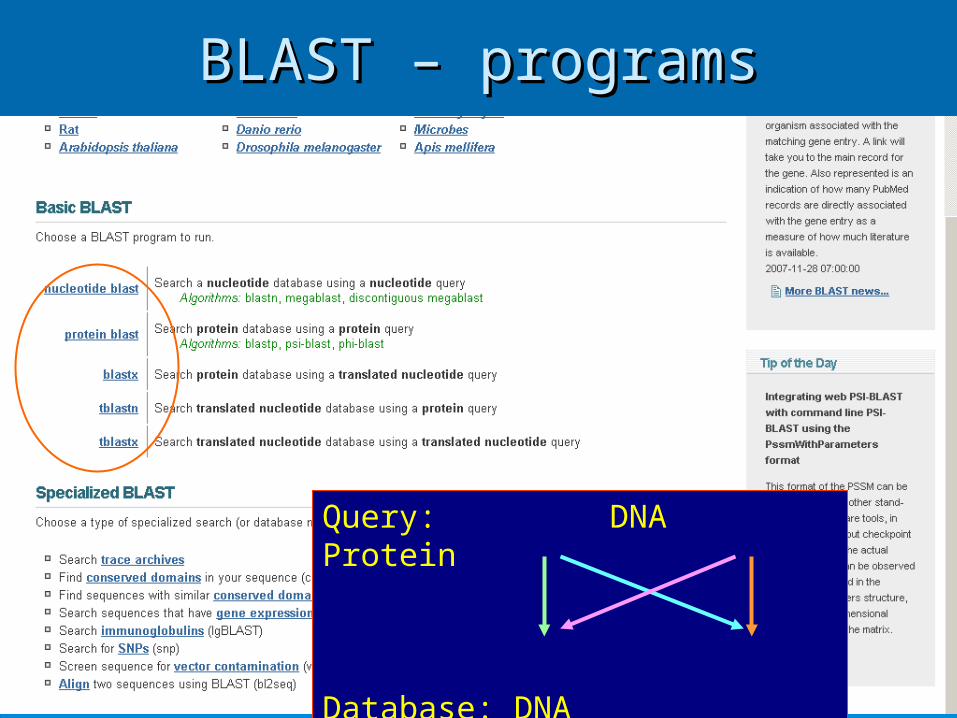
Query: DNA Protein
Database: DNA Protein
Query type: DNA or ProteinQuery type: DNA or Protein All types of searches are possibleAll types of searches are possible
blastn – nuc vs. nucblastp – prot vs. prot
blastx – translated query vs. protein database
tblastn – protein vs. translated nuc. DB
tblastx – translated query vs. translated database

3838
Query typeQuery type
Information content in the letters:Information content in the letters: Nucleotides: 4 letter alphabetNucleotides: 4 letter alphabet Amino acids: 20 letter alphabetAmino acids: 20 letter alphabet
• Two random DNA sequences will, on average, have 25% identity• Two random protein sequences will, on average, have 5% identity
The amino-acid sequence is often preferable for homology search
Selection (and hence conservation) works (mostly) at Selection (and hence conservation) works (mostly) at the protein levelthe protein level

3939
E-valueE-value The number of times we will theoretically The number of times we will theoretically
find an alignment with a score ≥ find an alignment with a score ≥ YY of a of a random sequence vs. a random databaserandom sequence vs. a random database
Theoretically, we could trust
any result with an
E-value ≤ 1
In practice – BLAST uses estimations. E-values of 10-4 and lower indicate a
significant homology.E-values between 10-4 and 10-2 should be checked (similar domains, maybe
non-homologous).E-values between 10-2 and 1 do not
indicate a good homology

4040
Filtering low complexityFiltering low complexity
Low complexity regionsLow complexity regions : e.g., Proline rich : e.g., Proline rich areas (in proteins), Alu repeats (in DNA)areas (in proteins), Alu repeats (in DNA)
Regions of low complexity generate high Regions of low complexity generate high scores of alignment, BUT – this does not scores of alignment, BUT – this does not indicate homologyindicate homology

4141
BLAST 2 sequences at NCBI BLAST 2 sequences at NCBI
Produces the Produces the locallocal alignment of two given alignment of two given sequences using sequences using BLASTBLAST (Basic Local (Basic Local Alignment Search Tool)Alignment Search Tool) engine for local engine for local alignmentalignment
Does not use an optimal algorithm but a Does not use an optimal algorithm but a heuristicheuristic

4242
Back to NCBIBack to NCBI
4343
BLAST – bl2seqBLAST – bl2seq
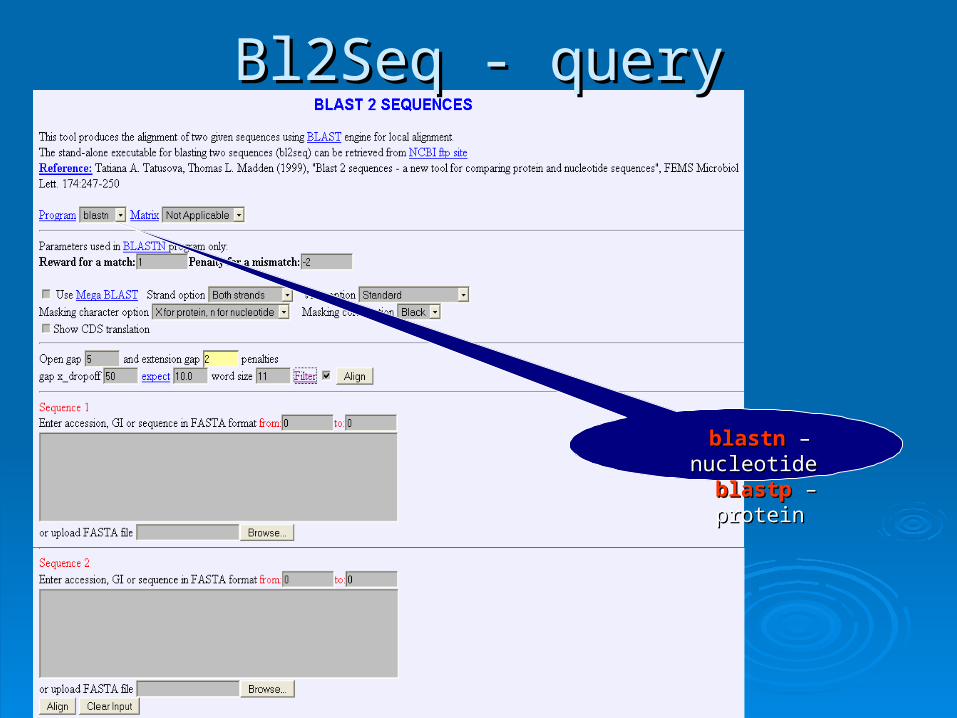
4444
blastnblastn – nucleotide – nucleotide
blastpblastp – protein – protein
Bl2Seq - queryBl2Seq - query

4545
Bl2seq resultsBl2seq results

4646
Bl2seq resultsBl2seq results
MatchMatch DissimilarityDissimilarity GapsGaps SimilaritySimilarity Low Low
complexitycomplexity
4747
BLAST – programsBLAST – programs
Query: DNA Protein
Database: DNA Protein
4848
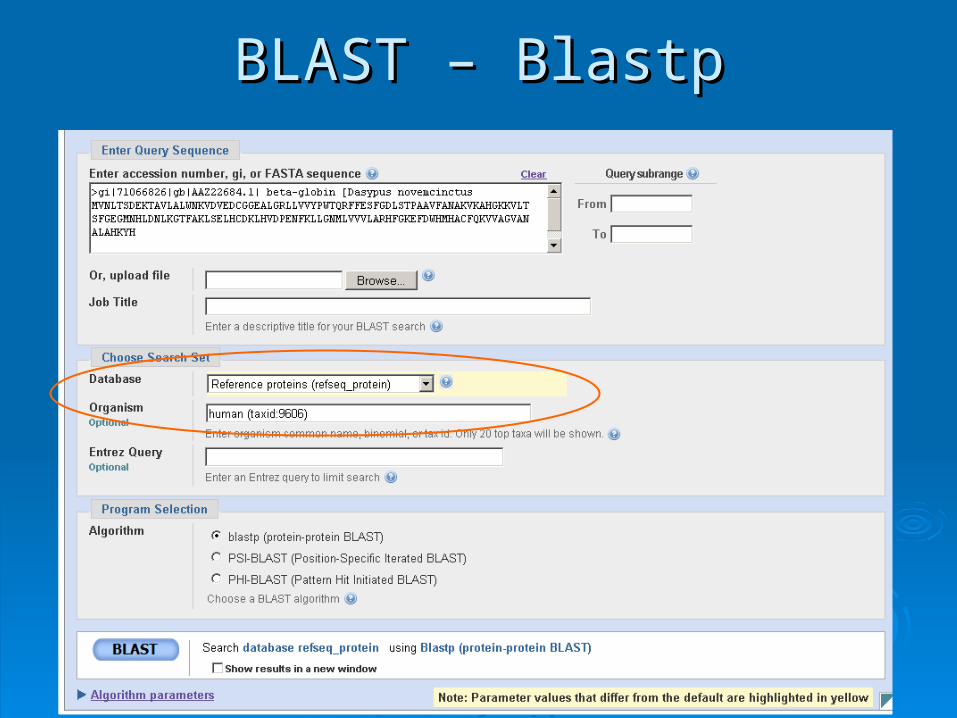
BLAST – BlastpBLAST – Blastp
4949
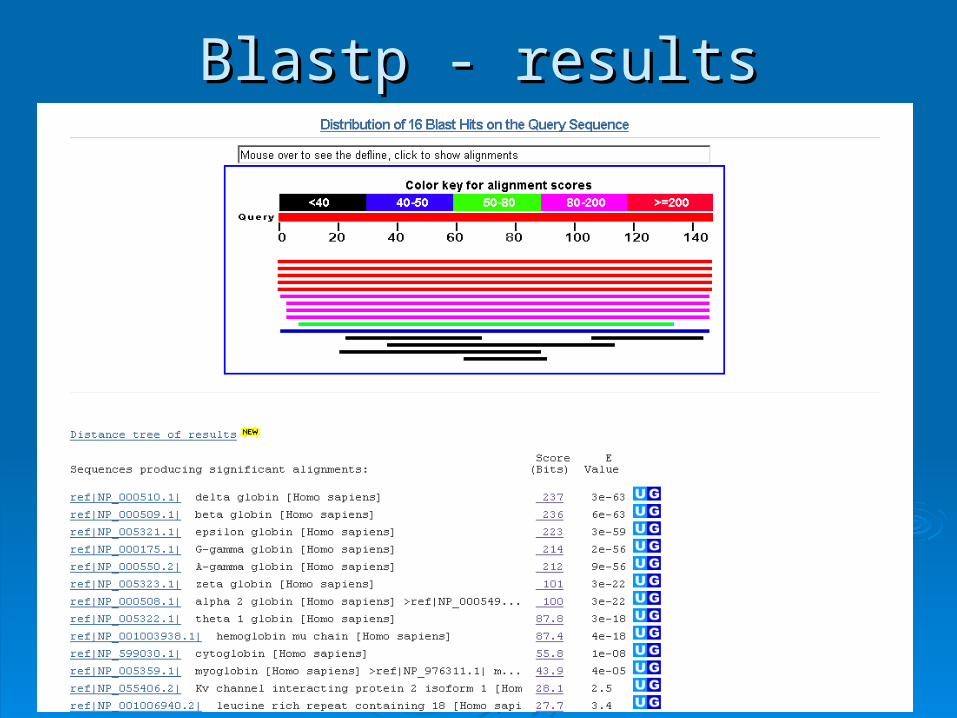
Blastp - resultsBlastp - results
5050
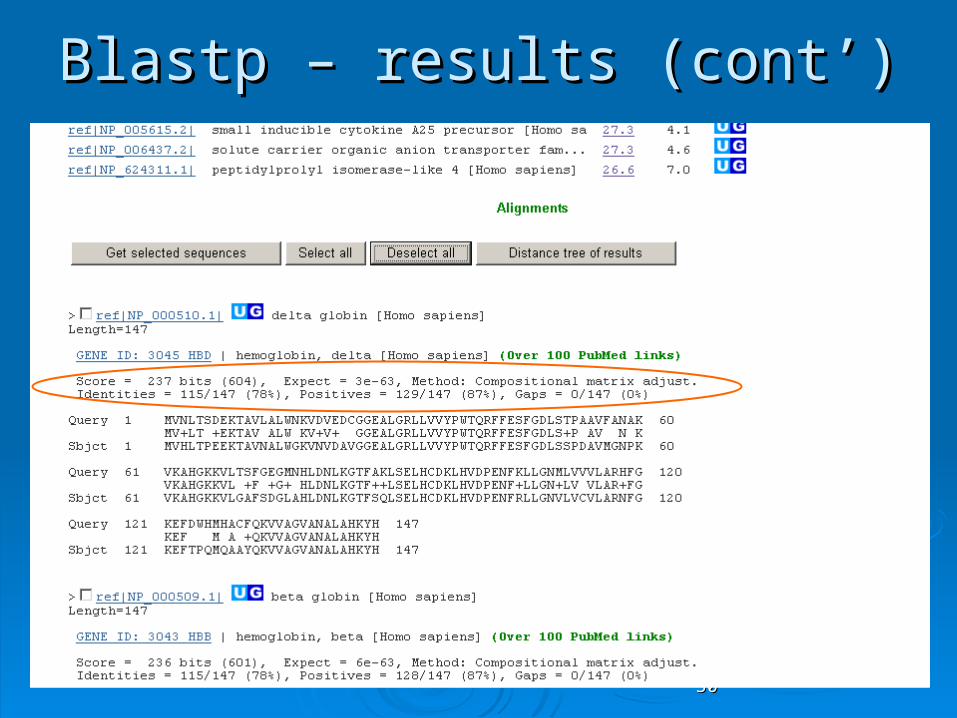
Blastp – results (cont’)Blastp – results (cont’)
5151
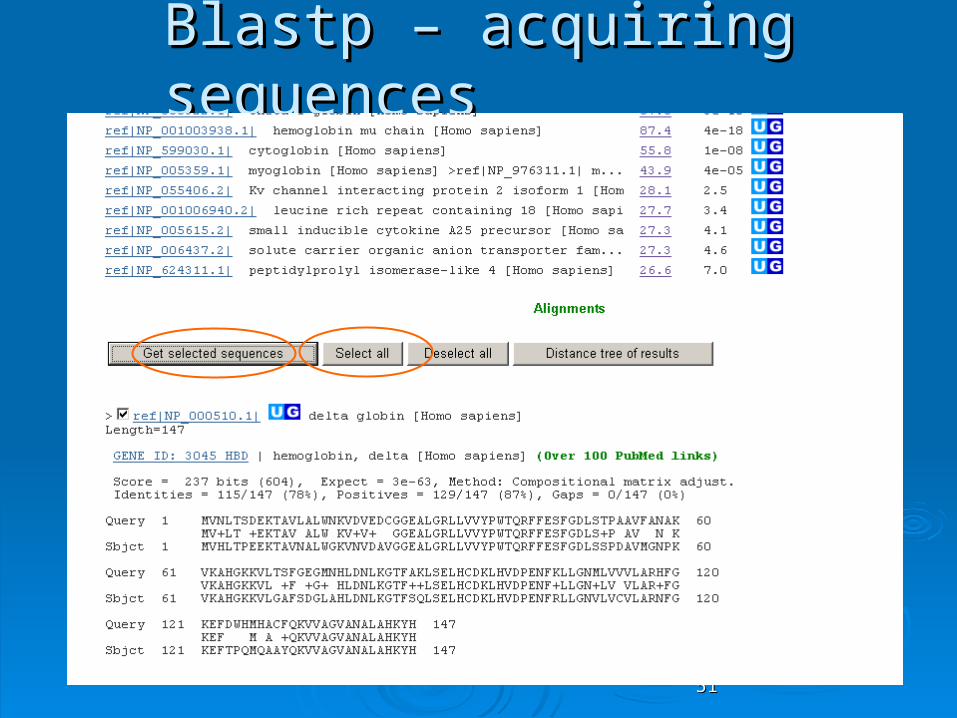
Blastp – acquiring sequencesBlastp – acquiring sequences
5252
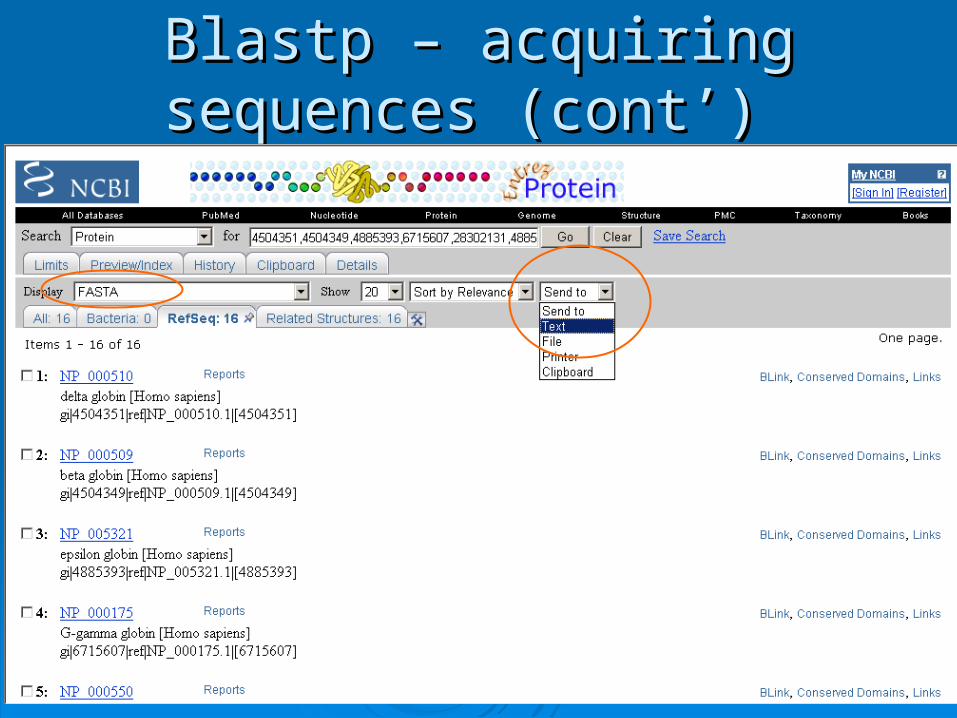
Blastp – acquiring sequences Blastp – acquiring sequences (cont’)(cont’)