1 fast algorithms for mining association rules rakesh agrawal ramakrishnan srikant
Post on 18-Dec-2015
224 views
TRANSCRIPT

1
Fast Algorithms for Mining Fast Algorithms for Mining Association RulesAssociation Rules
Rakesh AgrawalRamakrishnan Srikant

©Ofer Pasternak
Data Mining Seminar 2003
2
OutlineOutline
IntroductionFormal statementApriori AlgorithmAprioriTid AlgorithmComparisonAprioriHybrid AlgorithmConclusions

©Ofer Pasternak
Data Mining Seminar 2003
3
IntroductionIntroduction
Bar-Code technologyMining Association Rules over
basket data (93)Tires ^ accessories automotive
serviceCross market, Attached mail.Very large databases.

©Ofer Pasternak
Data Mining Seminar 2003
4
NotationNotation
Items – I = {i1,i2,…,im}Transaction – set of items
– Items are sorted lexicographicallyTID – unique identifier for each
transaction
IT

©Ofer Pasternak
Data Mining Seminar 2003
5
NotationNotation
Association Rule – X Y
YXIYIX and ,

©Ofer Pasternak
Data Mining Seminar 2003
6
Confidence and SupportConfidence and Support
Association rule XY has confidence c, c% of transactions in D that contain X also contain Y.
Association rule XY has support s,s% of transactions in D contain X and Y.

©Ofer Pasternak
Data Mining Seminar 2003
7
NoticeNotice
X A doesn’t mean X+YA– May not have minimum support
X A and A Z doesn’t mean X Z
– May not have minimum confidence

©Ofer Pasternak
Data Mining Seminar 2003
8
Define the ProblemDefine the Problem
Given a set of transactions D, generate all association rules that have support and confidence greater than the user-specified minimum support and minimum confidence.

©Ofer Pasternak
Data Mining Seminar 2003
9
Previous AlgorithmsPrevious Algorithms
AISSETMKnowledge DiscoveryInduction of Classification RulesDiscovery of causal rulesFitting of function to dataKID3 – machine learning

©Ofer Pasternak
Data Mining Seminar 2003
10
Discovering all Association Discovering all Association RulesRules
Find all Large itemsets– itemsets with support above
minimum support.Use Large itemsets to generate the
rules.

©Ofer Pasternak
Data Mining Seminar 2003
11
General ideaGeneral idea
Say ABCD and AB are large itemsets
Computeconf = support(ABCD) / support(AB)
If conf >= minconfAB CD holds.

©Ofer Pasternak
Data Mining Seminar 2003
12
Discovering Large Discovering Large ItemsetsItemsets
Multiple passes over the data First pass – count the support of individual
items. Subsequent pass
– Generate Candidates using previous pass’s large itemset.
– Go over the data and check the actual support of the candidates.
Stop when no new large itemsets are found.

©Ofer Pasternak
Data Mining Seminar 2003
13
The TrickThe Trick
Any subset of large itemset is large.Therefore
To find large k-itemset– Create candidates by combining large
k-1 itemsets.– Delete those that contain any subset
that is not large.

©Ofer Pasternak
Data Mining Seminar 2003
14
Algorithm AprioriAlgorithm Apriori
k
k
kk
t
kt
k-k
k-1
;L Answer
minsup}|c.countC { c L
c.count
Cc
,t)(C C
Dt
)(L C
); k 2; L( k
itemsets} {large 1- L
end
end
end
;
do candidates forall
subset
begin do ons transactiforall
;genapriori-
begin do For
1
1
Count item occurrences
Generate new k-itemsets candidates
Find the support of all the candidates
Take only those with support over minsup

©Ofer Pasternak
Data Mining Seminar 2003
15
Candidate generationCandidate generation
Join step
Prune step
1k1k2k2k11
1k1k
1k1k1
k
q.itemp.item,q.itemp.item,...,q.itemp.item
qp,LL
itemqitempitempp.item
C
where
from
.,.,.,select
intoinsert
2
k
k-1
k
c from C
) L(s
ets s of c(k-1)-subs
C itemsets c
delete
then if
do forall
do forall
P and q are 2 k-1 large itemsets identical in all k-2 first items.
Join by adding the last item of q to p
Check all the subsets, remove a candidate with “small” subset

©Ofer Pasternak
Data Mining Seminar 2003
16
ExampleExample
L3 = { {1 2 3}, {1 2 4}, {1 3 4}, {1 3 5}, {2 3 4} }
After joining
{ {1 2 3 4}, {1 3 4 5} }
After pruning
{1 2 3 4}
{1 4 5} and {3 4 5}
Are not in L3

©Ofer Pasternak
Data Mining Seminar 2003
17
CorrectnessCorrectness
1k1k2k2k11
1k1k
1k1k1
k
q.itemp.item,q.itemp.item,...,q.itemp.item
qp,LL
itemqitempitempp.item
C
where
from
.,.,.,select
intoinsert
2
k
k-1
k
c from C
) L(s
ets s of c(k-1)-subs
C itemsets c
delete
then if
do forall
do forall
Show that kk LC
Join is equivalent to extending Lk-1 with all items and removing those whose (k-1) subsets are not in Lk-1
Prevents duplications
Any subset of large itemset must also be large

©Ofer Pasternak
Data Mining Seminar 2003
18
Subset FunctionSubset Function
Candidate itemsets - Ck
are stored in a hash-tree Finds in O(k) time whether
a candidate itemset of size k is contained in transaction t.
Total time O(max(k,size(t))
k
k
kk
t
kt
k-k
k-1
;L Answer
minsup}|c.countC { c L
c.count
Cc
,t)(C C
Dt
)(L C
); k 2; L( k
itemsets} {large 1- L
end
end
end
;
do candidates forall
subset
begin do ons transactiforall
;genapriori-
begin do For
1
1

©Ofer Pasternak
Data Mining Seminar 2003
19
ProblemProblem??
Every pass goes over the whole data.
k
k
kk
t
kt
k-k
k-1
;L Answer
minsup}|c.countC { c L
c.count
Cc
,t)(C C
Dt
)(L C
); k 2; L( k
itemsets} {large 1- L
end
end
end
;
do candidates forall
subset
begin do ons transactiforall
;genapriori-
begin do For
1
1

©Ofer Pasternak
Data Mining Seminar 2003
20
Algorithm AprioriTidAlgorithm AprioriTid
Uses the database only once.Builds a storage set C^k
– Members has the form < TID, {Xk} > Xk are potentially large k-items in
transaction TID. For k=1, C^1 is the database.
Uses C^k in pass k+1.
Each item is replaced by an itemset of size 1

©Ofer Pasternak
Data Mining Seminar 2003
21
AdvantageAdvantage
C^k could be smaller than the database.– If a transaction does not contain k-
itemset candidates, than it will be excluded from C^k .
For large k, each entry may be smaller than the transaction– The transaction might contain only
few candidates.

©Ofer Pasternak
Data Mining Seminar 2003
22
DisadvantageDisadvantage
For small k, each entry may be larger than the corresponding transaction.– An entry includes all k-itemsets
contained in the transaction.

©Ofer Pasternak
Data Mining Seminar 2003
23
Algorithm AprioriTidAlgorithm AprioriTid
k
k
kk
t^kt
t
kt
^k-1
^k
k-k
k-1
^1
;L Answer
minsup}|c.countC { c L
;t.TID,CCthenφ)(C
c.count
Cc
items};oft.set1])c[k(c
itemsoft.setc[k]|(cC {c C
Centries t
;C
)(L C
); k 2; L( k
;database DC
itemsets} {large 1- L
end
end
end
if
;
do candidates forall
begin do forall
;genapriori-
begin do For
1
1
Count item occurrences
Generate new k-itemsets candidates
Find the support of all the candidates
Take only those with support over minsup
The storage set is initialized with the database
Build a new storage set
Determine candidate itemsets which are containted in
transaction TID
Remove empty entries

©Ofer Pasternak
Data Mining Seminar 2003
24
TIDItems
1001 3 4
2002 3 5
3001 2 3 5
4002 5
TIDSet-of-itemsets
100{ {1},{3},{4} }
200{ {2},{3},{5} }
300{ {1},{2},{3},{5} }
400{ {2},{5} }
ItemsetSupport
{1}2
{2}3
{3}3
{5}3
itemset
{1 2}
{1 3}
{1 5}
{2 3}
{2 5}
{3 5}
TIDSet-of-itemsets
100{ {1 3} }
200{ {2 3},{2 5} {3 5} }
300{ {1 2},{1 3},{1 5},{2 3}, {2 5}, {3 5} }
400{ {2 5} }
ItemsetSupport
{1 3}2
{2 3}3
{2 5}3
{3 5}2
itemset
{2 3 5}
TIDSet-of-itemsets
200{ {2 3 5} }
300{ {2 3 5} }
ItemsetSupport
{2 3 5}2
Database C^1
L2
C2 C^2
C^3
L1
L3C3

©Ofer Pasternak
Data Mining Seminar 2003
25
CorrectnessCorrectness
Show that Ct
generated in the kth pass is the same as set of candidate k-itemsets in Ck
contained in transaction with t.TID
k
k
kk
t^kt
t
kt
^k-1
^k
k-k
k-1
^1
;L Answer
minsup}|c.countC { c L
;t.TID,CCthenφ)(C
c.count
Cc
items};oft.set1])c[k(c
itemsoft.setc[k]|(cC {c C
Centries t
;C
)(L C
); k 2; L( k
;database DC
itemsets} {large 1- L
end
end
end
if
;
do candidates forall
begin do forall
;genapriori-
begin do For
1
1

©Ofer Pasternak
Data Mining Seminar 2003
26
CorrectnessCorrectness
Lemma 1k >1, if C^k-1 is correct and
complete, and Lk-1 is correct,
Then the set Ct generated at the kth pass is the same as the set of candidate k-itemsets in Ck contained in transaction with t.TID
t of C^k t.set-of-itemsets
includes all large k-itemsets contained in transaction with t.TID
t of C^k t.set-of-itemsets
doesn’t include any k-itemsets not contained in transaction with t.TID
Same as the set of all large k-itemsets

©Ofer Pasternak
Data Mining Seminar 2003
27
ProofProofSuppose a candidate itemset c = c[1]c[2]…c[k] is in transaction t.TID
c1 = (c-c[k]) and c2=(c-c[k-1]) were in transaction t.TID
c1 and c2 must be large
c1 and c2 were members of t.set-of-items
c will be a member of Ct
Ck was built using apriori-gen(Lk-1) all subsets of c of Ck must be large
C^k-1 is complete

©Ofer Pasternak
Data Mining Seminar 2003
28
ProofProof
Suppose c1 (c2) is not in transaction t.TID
c1 (c2) is not in t.set-of-itemsets c of Ck is not in transaction t.TID
c will not be a member of Ct
C^k-1 is correct

©Ofer Pasternak
Data Mining Seminar 2003
29
CorrectnessCorrectness
Lemma 2
k >1, if Lk-1 is correct and the set Ct generated in the kth step is the same as the set of candidate k-itemsets in Ck in transaction t.TID, then the set C^k is correct and complete.

©Ofer Pasternak
Data Mining Seminar 2003
30
ProofProof
Apriori-gen guarantees Ct includes all
large k-itemsets in t.TID, which are added to C^k
C^k is complete.
Ct includes only itemsets in t.TID, only items in Ct are added to C^k
C^k is correct. k
k
kk
t^kt
t
kt
^k-1
^k
k-k
k-1
^1
;L Answer
minsup}|c.countC { c L
;t.TID,CCthenφ)(C
c.count
Cc
items};oft.set1])c[k(c
itemsoft.setc[k]|(cC {c C
Centries t
;C
)(L C
); k 2; L( k
;database DC
itemsets} {large 1- L
end
end
end
if
;
do candidates forall
begin do forall
;genapriori-
begin do For
1
1
kk LC

©Ofer Pasternak
Data Mining Seminar 2003
31
CorrectnessCorrectness
Theorem 1
k >1, the set Ct generated in the kth pass is the same as the set of candidate k-itemsets in Ck contained in transaction t.TID
Show:C^k is correct and complete and Lk is
correct for all k>=1.

©Ofer Pasternak
Data Mining Seminar 2003
32
Proof (by induction on k)Proof (by induction on k)
K=1 – C^1 is the database. Assume it holds for k=n.
– Ct generated in pass n+1 consists of exactly those itemsets in Cn+1 contained in transaction t.TID.
– Apriori-gen guaranteesand Ct is correct Ln+1 is correctC^n+1 will be correct and complete C^k is correct and complete for all k>=1 The theorem holds
1n1n LC Lemma 2
Lemma 1

©Ofer Pasternak
Data Mining Seminar 2003
33
General idea (reminder)General idea (reminder)
Say ABCD and AB are large itemsets
Computeconf = support(ABCD) / support(AB)
If conf >= minconfAB CD holds.

©Ofer Pasternak
Data Mining Seminar 2003
34
Discovering RulesDiscovering Rules
For every large itemset l– Find all non-empty subsets of l.– For every subset a
Produce rule a (l-a) Accept if support(l) / support(a) >=
minconf

©Ofer Pasternak
Data Mining Seminar 2003
35
Checking the subsetsChecking the subsets
For efficiency, generate subsets using recursive DFS. If a subset ‘a’ doesn’t produce a rule, we don’t need to check for subsets of ‘a’.
ExampleGiven itemset : ABCD If ABC D doesn’t have enough
confidence then surely AB CD won’t hold

©Ofer Pasternak
Data Mining Seminar 2003
36
WhyWhy??
For any subset a^ of a:Support(a^) >= support(a) Confidence ( a^ (l-a^) ) =support(l) / support(a^) <=support(l) / support(a) =confidence ( a (l-a) )

©Ofer Pasternak
Data Mining Seminar 2003
37
Simple AlgorithmSimple Algorithm
end
end
call
then if
output
beginthen if
begin do forall
genrules procedure
forall
);,agenrules(l
1)1(m
); a(lthe rule a
minconf) (conf
)a)/support( support(lconf
Aa
};a| aemset a {(m-1)-itA
emset)large m-it: emset, alarge k-it:(l
),lgenrules(l
2 dok,sets llarge item
m-1k
m-1km-1
m-1k
m-1
mm-1m-1
mk
kk
k
Check all the subsets
Check all the large itemsets
Output the rule
Continue the DFS over the subsets.
If there is no confidence the DFS branch cuts here
Check confidence of new rule

©Ofer Pasternak
Data Mining Seminar 2003
38
Faster AlgorithmFaster Algorithm
Idea:
If (l-c) c holds than all the rules(l-c^) c^ must hold Example:
If AB CD holds, then so do ABC D and ABD C
C^ is a non empty subset of c

©Ofer Pasternak
Data Mining Seminar 2003
39
Faster AlgorithmFaster Algorithm
From a large itemset l, – Generate all rules with one item in it’s
consequent. Use those consequents and Apriori-gen
to generate all possible 2 item consequents.
Etc. The candidate set of the faster
algorithm is a subset of the candidate set of the simple algorithm.

©Ofer Pasternak
Data Mining Seminar 2003
40
Faster algorithmFaster algorithm
end
call
end
delete
else
output
then if
begin do forall
begin then if
genrules-ap procedure
end
call
begin do , forall
);,hs(lap-genrule
from Hh
) support(lsupport conf and dence with confi
h)hlthe rule (
minconf)(conf
);hl)/support( support(lconf
H h
);en(H apriori-gH
1)m(k
equents)-item cons: set of mtemset , H:large k-i(l
);,Hs(lap-genrule
nt };e consequeitem in th with one from ls derived ts of rule{consequenH
2kemsets llarge k-it
1mk
1m1m
k
1m1mk
1mkk
1m1m
m1m
mk
1k
k1
k
Find all 1 item
consequents (using 1 pass of the simple algorithm)
Generate new (m+1)-consequents
Check the support of the new rule
Continue for bigger consequents
If a consq. Doesn’t hold, don’t look for
bigger.

©Ofer Pasternak
Data Mining Seminar 2003
41
AdvantageAdvantage
Example
Large itemset : ABCDEOne item conseq. : ACDEB ABCEDSimple algorithm will check:ABCDE, ABECD, BCEAD and ACEBD. Faster algorithm will check:ACEBD which is also the only rule that
holds.

©Ofer Pasternak
Data Mining Seminar 2003
42
ABCDE
ACDEB
ABCED
ACDBE
ADEBCCDEAB
ACEBD
BCEAD
ACEBD
ABECD
ABCED
Large itemset
Rules with minsup
Simple algorithm:
Fast algorithm:
ACEBD
ABCDE
ACDEB
ABCED
Example

©Ofer Pasternak
Data Mining Seminar 2003
43
ResultsResults
Compare Apriori, and AprioriTid performances to each other, and to previous known algorithms:– AIS– SETM
The algorithms differ in the method of generating all large itemsets.
Both methods generate candidates “on-the-fly”
Designed for use over SQL

©Ofer Pasternak
Data Mining Seminar 2003
44
MethodMethod
Check the algorithms on the same databases– Synthetic data– Real data

©Ofer Pasternak
Data Mining Seminar 2003
45
Synthetic DataSynthetic Data
Choose the parameters to be compared.– Transaction sizes, and large itemsets sizes
are each clustered around a mean.– Parameters for data generation
D – Number of transactions T – Average size of the transaction I – Average size of the maximal potentially large
itemsets L – Number of maximal potentially large itemsets N – Number of Items.

©Ofer Pasternak
Data Mining Seminar 2003
46
Synthetic DataSynthetic Data
Expriment values:– N = 1000– L = 2000
T5.I2.D100k T10.I2.D100k T10.I4.D100k T20.I2.D100k T20.I4.D100k T20.I6.D100k
D – Number of transactionsT – Average size of the transactionI – Average size of the maximal
potentially large itemsetsL – Number of maximal potentially
large itemsetsN – Number of Items.
T=5, I=2, D=100,000

©Ofer Pasternak
Data Mining Seminar 2003
47
•SETM values are too big to fit the graphs.
•Apriori always beats AIS
D – Number of transactionsT – Average size of the transactionI – Average size of the maximal
potentially large itemsets
•Apriori is better than AprioriTid in large problems

©Ofer Pasternak
Data Mining Seminar 2003
48
Explaining the ResultsExplaining the Results
AprioriTid uses C^k instead of the database. If C^k fits in memory AprioriTid is faster than Apriori.
When C^k is too big it cannot sit in memory, and the computation time is much longer. Thus Apriori is faster than AprioriTid.

©Ofer Pasternak
Data Mining Seminar 2003
49
Reality CheckReality Check
Retail sales– 63 departments– 46873
transactions (avg. size 2.47)
Small database, C^k fits in memory.

©Ofer Pasternak
Data Mining Seminar 2003
50
Reality CheckReality CheckMail Order
15836 items
2.9 million transactions (avg size 2.62)
Mail Customer
15836 items
213972 transactions (avg size 31)

©Ofer Pasternak
Data Mining Seminar 2003
51
So who is betterSo who is better??
Look At the Passes.
At final stages, C^k is small enough to fit in memory

©Ofer Pasternak
Data Mining Seminar 2003
52
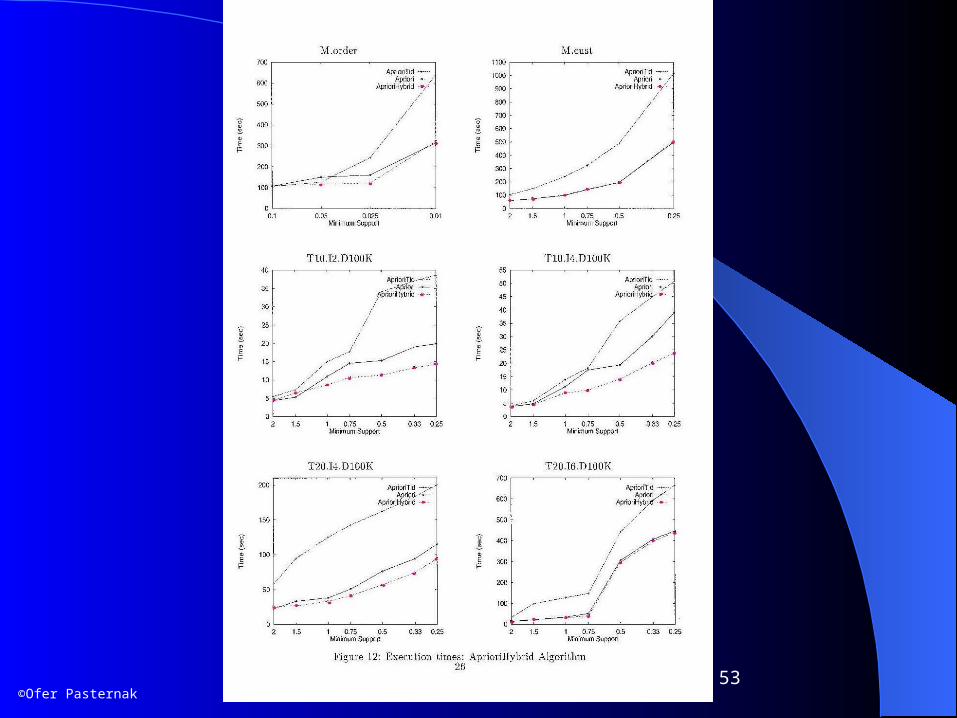
Algorithm AprioriHybridAlgorithm AprioriHybrid
Use Apriori in initial passesEstimate the size of C^k
Switch to AprioriTid when C^k is expected to fit in memory
The switch takes time, but it is still better in most cases.
kCc candidates
ons transactiofnumber support(c)
©Ofer Pasternak
Data Mining Seminar 2003
53

©Ofer Pasternak
Data Mining Seminar 2003
54
Scale up experimentScale up experiment

©Ofer Pasternak
Data Mining Seminar 2003
55
ConclusionsConclusions
The Apriori algorithms are better than the previous algorithms.– For small problems by factors– For large problems by orders of
magnitudes.The algorithms are best combined.The algorithm shows good results
in scale-up experiments.

©Ofer Pasternak
Data Mining Seminar 2003
56
SummarySummary
Association rules are an important tool in analyzing databases.
We’ve seen an algorithm which finds all association rules in a database.
The algorithm has better time results then previous algorithms.
The algorithm maintains it’s performances for large databases.

©Ofer Pasternak
Data Mining Seminar 2003
57
EndEnd