1 high-performance grid computing and research networking presented by xing hang instructor: s....
TRANSCRIPT

1
High-Performance Grid Computing and High-Performance Grid Computing and Research NetworkingResearch Networking
Presented by Xing Hang
Instructor: S. Masoud Sadjadihttp://www.cs.fiu.edu/~sadjadi/Teaching/
sadjadi At cs Dot fiu Dot edu
Algorithms on a Grid of ProcessorsAlgorithms on a Grid of Processors

2
Acknowledgements
The content of many of the slides in this lecture notes have been adopted from the online resources prepared previously by the people listed below. Many thanks!
Henri Casanova Principles of High Performance Computing http://navet.ics.hawaii.edu/~casanova [email protected]

3
2-D Torus topology We’ve looked at a ring, but for some applications it’s convenient to
look at a 2-D grid topology
A 2-D grid with “wrap-around” is called a 2-D torus. Advanced parallel linear algebra libraries/languages allow to
combine arbitrary data distribution strategies with arbitrary topologies (ScaLAPACK, HPF)
1-D block to a ring 2-D block to a 2-D grid cyclic or non-cyclic (more on this later)
We can go through all the algorithms we saw on a ring and make them work on a grid
In practice, for many linear algebra kernel, using a 2-D block-cyclic on a 2-D grid seems to work best in most situations
we’ve seen that blocks are good for locality we’ve seen that cyclic is good for load-balancing
√p
√p

4
Semantics of a parallel linear algebra routine?
Centralized when calling a function (e.g., LU)
the input data is available on a single “master” machine the input data must then be distributed among workers the output data must be undistributed and returned to the “master” machine
More natural/easy for the user Allows for the library to make data distribution decisions transparently to
the user Prohibitively expensive if one does sequences of operations
and one almost always does so Distributed
when calling a function (e.g., LU) Assume that the input is already distributed Leave the output distributed
May lead to having to “redistributed” data in between calls so that distributions match, which is harder for the user and may be costly as well
For instance one may want to change the block size between calls, or go from a non-cyclic to a cyclic distribution
Most current software adopt distributed more work for the user more flexibility and control

5
Matrix-matrix multiply Many people have thought of doing a matrix-multiply on a 2-D torus Assume that we have three matrices A, B, and C, of size NxN Assume that we have p processors, so that p=q2 is a perfect square and our processor grid is qxq We’re looking at a 2-D block distribution, but not cyclic
again, that would obfuscate the code too much
We’re going to look at three “classic” algorithms: Cannon, Fox, SnyderA00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33

6
Cannon’s Algorithm (1969)
Very simple (from systolic arrays) Starts with a data redistribution for matrices A and B
goal is to have only neighbor-to-neighbor communications A is circularly shifted/rotated “horizontally” so that its
diagonal is on the first column of processors B is circularly shifted/rotated “vertically” so that its diagonal
is on the first row of processors Called preskewing
A00 A01 A02 A03
A11 A12 A13 A10
A22 A23 A20 A21
A33 A30 A31 A32
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B11 B22 B33
B10 B21 B32 B03
B20 B31 B02 B13
B30 B01 B12 B23

7
Cannon’s Algorithm
Preskewing of A and B
For k = 1 to q in parallel
Local C = C + A*B
Vertical shift of B
Horizontal shift of A
Postskewing of A and B
Of course, computation and communication could be done in an overlapped fashion locally at each processor

8
Execution Steps...
A00 A01 A02 A03
A11 A12 A13 A10
A22 A23 A20 A21
A33 A30 A31 A32
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B11 B22 B33
B10 B21 B32 B03
B20 B31 B02 B13
B30 B01 B12 B23
local computationon proc (0,0)
A01 A02 A03 A00
A12 A13 A10 A11
A23 A20 A21 A22
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B10 B21 B32 B03
B20 B31 B02 B13
B30 B01 B12 B23
B00 B11 B22 B33
Shifts
A01 A02 A03 A00
A12 A13 A10 A11
A23 A20 A21 A22
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B10 B21 B32 B03
B20 B31 B02 B13
B30 B01 B12 B23
B00 B11 B22 B33
local computationon proc (0,0)

9
Fox’s Algorithm(1987)
Originally developed for CalTech’s Hypercube
Uses broadcasts and is also called broadcast-multiply-roll algorithm broadcasts diagonals of matrix A
Uses a shift of matrix B No preskewing step
first diagonalsecond diagonalthird diagonal...

10
Execution Steps...
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
initialstate
A00 A00 A00 A00
A11 A11 A11 A11
A22 A22 A22 A22
A33 A33 A33 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
Broadcast of A’s 1st diagonal
Localcomputation
A00 A00 A00 A00
A11 A11 A11 A11
A22 A22 A22 A22
A33 A33 A33 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33

11
Execution Steps...
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
B00 B01 B02 B03
Shift of B
A01 A01 A01 A01
A12 A12 A12 A12
A23 A23 A23 A23
A30 A30 A30 A30
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
Broadcast of A’s 2nd diagonal
Localcomputation
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
B00 B01 B02 B03
A01 A01 A01 A01
A12 A12 A12 A12
A23 A23 A23 A23
A30 A30 A30 A30
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
B00 B01 B02 B03

12
Fox’s Algorithm
// No initial data movementfor k = 1 to q-1 in parallel Broadcast A’s kth diagonal Local C = C + A*B Vertical shift of B// No final data movement
Note that there is an additional array to store incoming diagonal block

13
Snyder’s Algorithm (1992)
More complex than Cannon’s or
Fox’s
First transposes matrix B
Uses reduction operations (sums) on
the rows of matrix C
Shifts matrix B
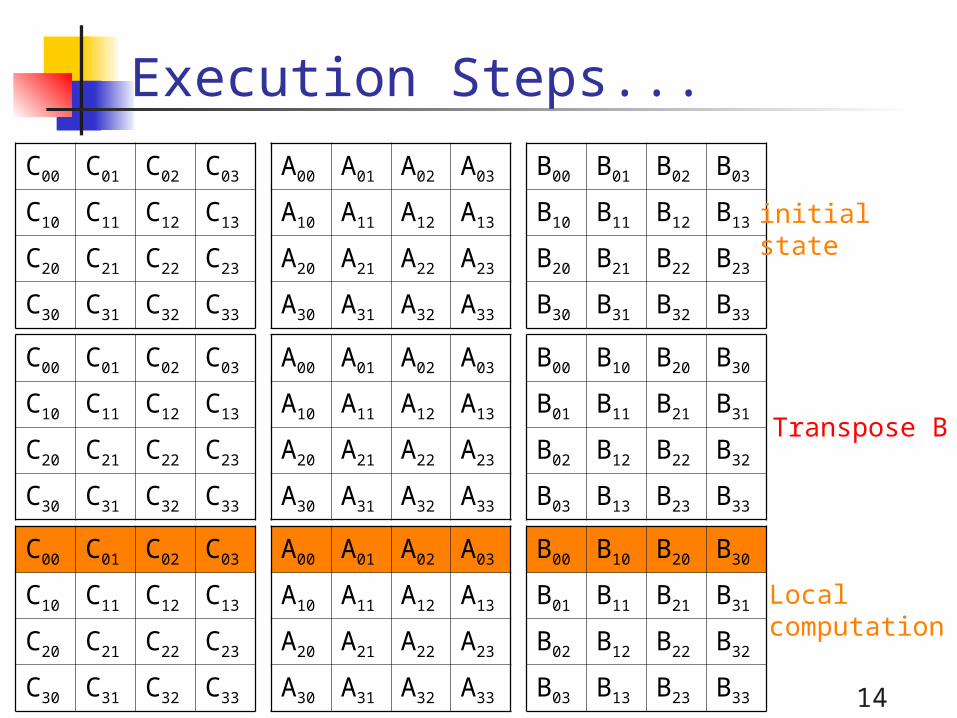
14
Execution Steps...
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
initialstate
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
Transpose B
Localcomputation
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B10 B20 B30
B01 B11 B21 B31
B02 B12 B22 B32
B03 B13 B23 B33
B00 B10 B20 B30
B01 B11 B21 B31
B02 B12 B22 B32
B03 B13 B23 B33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33

15
Execution Steps...
Shift B
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B01 B11 B21 B31
B02 B12 B22 B32
B03 B13 B23 B32
B00 B10 B20 B30
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B01 B11 B21 B31
B02 B12 B22 B32
B03 B13 B23 B32
B00 B10 B20 B30
Global sumon the rowsof C
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B01 B11 B21 B31
B02 B12 B22 B32
B03 B13 B23 B32
B00 B10 B20 B30
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
Localcomputation
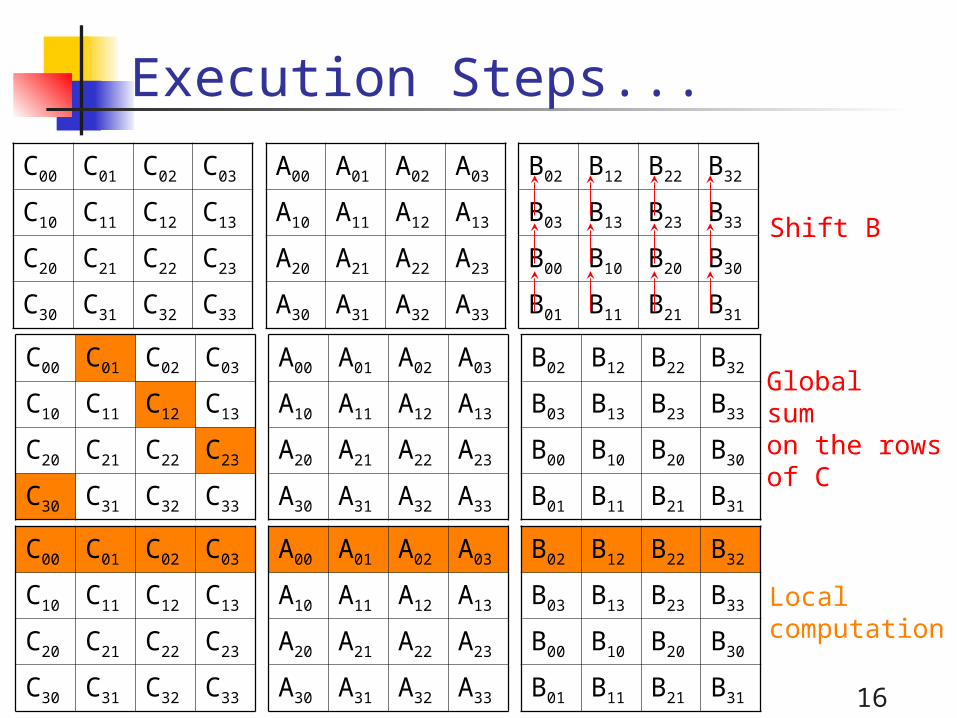
16
Execution Steps...
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
Shift B
B02 B12 B22 B32
B03 B13 B23 B33
B00 B10 B20 B30
B01 B11 B21 B31
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
B02 B12 B22 B32
B03 B13 B23 B33
B00 B10 B20 B30
B01 B11 B21 B31
Global sumon the rowsof C
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
B02 B12 B22 B32
B03 B13 B23 B33
B00 B10 B20 B30
B01 B11 B21 B31
Localcomputation

17
Complexity Analysis
Very cumbersome Two models
4-port model: every processor can communicate with its 4 neighbors in one step
Can match underlying architectures like the Intel Paragon
1-port model: only one single communication at a time for each processor
Both models are assumed bi-directional communication

18
One-port results
Cannon
Fox
Snyder

19
Complexity Results
m in these expressions is the block size Expressions for the 4-port model are MUCH more
complicated Remember that this is all for non-cyclic distributions
formulae and code become very complicated for a full-fledge implementation (nothing divides anything, nothing’s a perfect square, etc.)
Performance analysis of real code is known to be hard
It is done in a few restricted cases An interesting approach is to use simulation
Done in ScaLAPACK (Scalable Linear Algebra PACKage) for instance
Essentially: you have written a code so complex you just run a simulation of it to figure out how fast it goes in different cases

20
So What?
Are we stuck with these rather cumbersome algorithms?
Fortunately, there is a much simpler algorithm that’s not as clever about as good in practice anyway
That’s the one you’ll implement in your programming assignment

21
The Outer-Product Algorithm
Remember the sequential matrix multiplyfor i = 1 to n
for j = 1 to n for k = 1 to n
Cij = Cij + Aik * Bkj
The first two loops are completely parallel, but the third one isn’t i.e., in shared memory, would require a mutex to
protect the writing of shared variable Cij
One solution: view the algorithm as “n sequential steps”for k = 1 to n // done in sequence
for i = 1 to n // done in parallel for j = 1 to n // done in parallel
Cij = Cij + Aik * Bkj

22
The Outer-Product Algorithm
for k = 1 to n // done in sequence
for i = 1 to n // done in parallel
for j = 1 to n // done in parallel
Cij = Cij + Aik * Bkj
During the kth step, the processor who “owns” Cij needs Aik and Bkj
Therefore, at the kth step, the kth column on A and the kth row of B must be broadcasted over all processors
Let us assume a 2-D block distribution

23
2-D Block distribution
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
C00 C01 C02 C03
C10 C11 C12 C13
C20 C21 C22 C23
C30 C31 C32 C33
B00 B01 B02 B03
B10 B11 B12 B13
B20 B21 B22 B23
B30 B31 B32 B33
k
k
At each step, n-q processors receive a piece of the kth column and n-q processors receive a piece of the kth row (n=q2 processors)

24
Outer-Product Algorithm
Once everybody has received a piece of row k, everybody can add to the Cij’s they are responsible for
And this is repeated n times In your programming assignment:
Implement the outer-product algorithm Do the “theoretical” performance
analysis with assumptions similar to the ones we
have used in class so far

25
Further Optimizations
Send blocks of rows/column to avoid too many small transfers What is the optimal granularity?
Overlap communication and computation by using asynchronous communication How much can be gained?
This is a simple and effective algorithm that is not too cumbersome

26
Cyclic 2-D distributions
What if I want to run on 6 processors? It’s not a perfect square
In practice, one makes distributions cyclic to accommodate various numbers of processors
How do we do this in 2-D? i.e, how do we do a 2-D block cyclic
distribution?

27
The 2-D block cyclic distribution
Goal: try to have all the advantages of both the horizontal and the vertical 1-D block cyclic distribution Works whichever way the computation
“progresses” left-to-right, top-to-bottom, wavefront, etc.
Consider a number of processors p = r * c arranged in a rxc matrix
Consider a 2-D matrix of size NxN Consider a block size b (which divides
N)

28
The 2-D block cyclic distribution
b
b
N
P0 P1 P2
P5P4P3

29
The 2-D block cyclic distribution
P2
P5
P1
P4
P0
P3
b
b
N
P0 P1 P2
P5P4P3

30
The 2-D block cyclic distribution
P2 P0 P1 P2 P0 P1
P5 P3 P4 P5 P3 P4
P1
P4
P0
P3
b
b
N
P0 P1 P2
P5P4P3
P2 P0 P1 P2 P0 P1
P5 P3 P4 P5 P3 P4
P1
P4
P0
P3
P2 P0 P1 P2 P0 P1
P5 P3 P4 P5 P3 P4
P1
P4
P0
P3
P2 P0 P1 P2 P0 P1P1P0
Slight load imbalance Becomes negligible with
many blocks Index computations had
better be implemented in separate functions
Also: functions that tell a process who its neighbors are
Overall, requires a whole infrastructure, but many think you can’t go wrong with this distribution