1 hybrid mpi+openmp yao-yuan chuang. 2 most modern high performance computing (hpc) systems are...
TRANSCRIPT

1
Hybrid MPI+OpenMP
Yao-Yuan Chuang
2
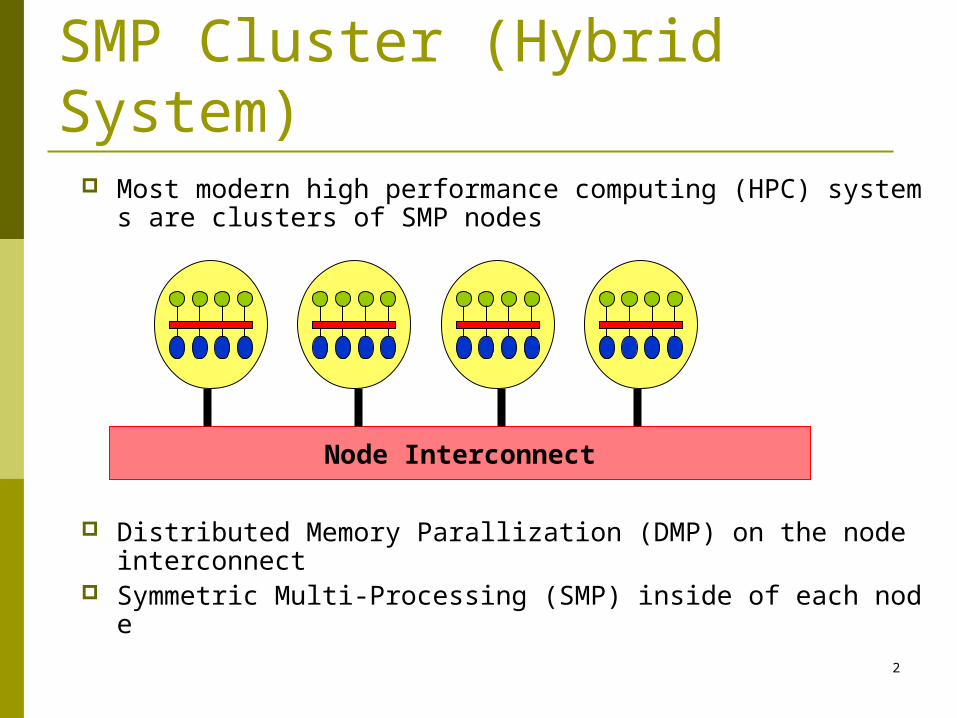
Most modern high performance computing (HPC) systems are clusters of SMP nodes
Distributed Memory Parallization (DMP) on the node interconnect
Symmetric Multi-Processing (SMP) inside of each node
SMP Cluster (Hybrid System)
Node Interconnect

3
Current Solutions for Programming MPI based:
MPP model Massively parallel processing Each CPU = one MPI process
Hybrid MPI + OpenMP Each SMP node = one MPI process MPI communication on the node interconnect OpenMP inside of each SMP node DMP with MPI and SMP with OpenMP
OpenMP based: Cluster OpenMP
Other models: High Performance Fortran Node Interconnect

4
MPI + OpenMP on SMP Clusters Could provide highest performance? Advantages
Could be effective utilizing heavyweight communications between nodes and lightweight threads within a node
Less communication packets and uses larger communication packets than pure MPI on SMP Clusters
Disadvantages Very difficult to start with OpenMP and modify for MPI Very difficult to program, debug, modify and maintain Generally, cannot do MPI calls within OpenMP parallel regions Only people very experienced in both should use this mixed program
ming model Single node and single CPU performance suffers

5
Hybrid MPI + OpenMP programming Each MPI process spawns multiple OpenMP threads
mpirun
rank0
rank1

6
omphello.c#include <stdio.h>#include <omp.h>
int main(int argc, char *argv[]) { int iam = 0, np = 1;
#pragma omp parallel default(shared) private(iam, np) { #if defined (_OPENMP) np = omp_get_num_threads(); iam = omp_get_thread_num(); #endif printf("Hello from thread %d out of %d\n", iam, np); }}

7
omphello.f program ompf ! hello from OMP_threads implicit none
integer nthreads, myrank, omp_get_num_threads
integer omp_get_thread_num
!$OMP PARALLEL PRIVATE(myrank) SHARED(nthreads)
nthreads = omp_get_num_threads()
myrank = omp_get_thread_num()
if (myrank.eq.0) print *, 'Num threads = ', nthreads
print *, ' HELLO ....I am thread # ', myrank
!$OMP END PARALLEL
end

8
mpihello.c#include <stdio.h>#include <mpi.h>
int main(int argc, char *argv[]) { int numprocs, rank, namelen; char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Get_processor_name(processor_name, &namelen);
printf("Process %d on %s out of %d\n", rank, processor_name, numprocs);
MPI_Finalize();}

9
mpihello.fprogram f1 !Hello World MPI/F90 styleimplicit noneinclude 'mpif.h'integer::myrank, numprocs, ierr, comm = MPI_COMM_WORLDcharacter(80)::strcall mpi_init(ierr)call mpi_comm_size(comm, numprocs, ierr)call mpi_comm_rank(comm, myrank, ierr)if (myrank .EQ. 0) print *, 'Num procs ', numprocscall mpi_get_processor_name(str, 80, ierr)print *, 'Hello world : I am processor ', myrank, ':', strcall mpi_finalize(ierr)end

10
Hybrid MPI + OpenMP: mixhello.c#include <stdio.h>#include "mpi.h"#include <omp.h>
int main(int argc, char *argv[]) { int numprocs, rank, namelen; char processor_name[MPI_MAX_PROCESSOR_NAME]; int iam = 0, np = 1;
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Get_processor_name(processor_name, &namelen);
#pragma omp parallel default(shared) private(iam, np) { np = omp_get_num_threads(); iam = omp_get_thread_num(); printf("Hello from thread %d out of %d from process %d out of %d on %s\n", iam, np, rank, numprocs, processor_name); }
MPI_Finalize();}

11
Compile and Execution Compile OPENMP hello
% pgCC omphello.c -o omphello -mp% setenv OMP_NUM_THREADS 4 % ./omphello
Compile MPI hello% pgcc mpihello.c -o mpihello -Mmpi % /opt/pgi/linux86/6.2/mpi/mpich/bin/mpirun -np 4 mpihello
Compile Hybrid MPI + OpenMP Hello% pgcc mixhello.c -o mixhello -Mmpi
% /opt/pgi/linux86/6.2/mpi/mpich/bin/mpirun -np 4 mixhello
How about if we forget the –Mmpi ?

12
Hybrid MPI + OpenMP Calculate Each MPI process integrates over a r
ange of width 1/nproc, as a discrete sum of nbin bins each of width step
Within each MPI process, nthreads OpenMP threads perform part of the sum as in OPENMP alone.

13
omppi.c#include <omp.h>static long num_steps = 100000; double step;#define NUM_THREADS 2void main (){ int i; double x, pi, sum = 0.0; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS);#pragma omp parallel for reduction(+:sum) private(x) for (i=1;i<= num_steps; i++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = step * sum;}

14
mpipi.c#include <mpi.h>void main (int argc, char *argv[]){ int i, my_id, numprocs; double x, pi, step, sum = 0.0 ; step = 1.0/(double) num_steps ; MPI_Init(&argc, &argv) ; MPI_Comm_Rank(MPI_COMM_WORLD, &my_id) ; MPI_Comm_Size(MPI_COMM_WORLD, &numprocs) ; my_steps = num_steps/numprocs ; for (i=my_id*my_steps; i<(my_id+1)*my_steps ; i++) { x = (i+0.5)*step; sum += 4.0/(1.0+x*x); } sum *= step ; MPI_Reduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD) ;}

15
mixpi.c#include <mpi.h>#include “omp.h”void main (int argc, char *argv[]){ int i, my_id, numprocs; double x, pi, step, sum = 0.0 ; step = 1.0/(double) num_steps ; MPI_Init(&argc, &argv) ; MPI_Comm_Rank(MPI_COMM_WORLD, &my_id) ; MPI_Comm_Size(MPI_COMM_WORLD, &numprocs) ; my_steps = num_steps/numprocs ;#pragma omp parallel for private(x) reduction(+:sum) for (i=myrank*my_steps; i<(myrank+1)*my_steps ; i++) { x = (i+0.5)*step; sum += 4.0/(1.0+x*x); } sum *= step ; MPI_Reduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD) ;}
Get the MPI partdone first, thenadd OpenMP pragma

16
Hybrid MPI + OpenMP Calculate #include <stdio.h>#include <mpi.h>#include <omp.h>#define NBIN 100000#define MAX_THREADS 8void main(int argc,char **argv) { int nbin,myid,nproc,nthreads,tid; double step,sum[MAX_THREADS]={0.0},pi=0.0,pig; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Comm_size(MPI_COMM_WORLD,&nproc); nbin = NBIN/nproc; step = 1.0/(nbin*nproc);#pragma omp parallel private(tid) { int i; double x; nthreads = omp_get_num_threads(); tid = omp_get_thread_num(); for (i=nbin*myid+tid; i<nbin*(myid+1); i+=nthreads) { x = (i+0.5)*step; sum[tid] += 4.0/(1.0+x*x);} printf("rank tid sum = %d %d %e\n",myid,tid,sum[tid]); } for(tid=0; tid<nthreads; tid++) pi += sum[tid]*step; MPI_Allreduce(&pi,&pig,1,MPI_DOUBLE,MPI_SUM,MPI_COMM_WORLD); if (myid==0) printf("PI = %f\n",pig); MPI_Finalize();}

17
Hybrid MPI + OpenMP Calculate Compilation
% mpicc –o hpi hpi.c -openmp
Execution % mpirun –np 2 hpi
Outputrank tid sum = 1 1 6.434981e+04
rank tid sum = 1 0 6.435041e+04
rank tid sum = 0 0 9.272972e+04
rank tid sum = 0 1 9.272932e+04
PI = 3.141593

18
Comparison From “MPI versus MPI+OpenMP on the IBM SP for the NAS Benchmark
s” by F. Cappello and D. Etiemble (2000)The hybrid memory model of clusters of multiprocessorsraises two issues: programming model and performance.Many parallel programs have been written by using theMPI standard. To evaluate the pertinence of hybrid modelsfor existing MPI codes, we compare a unified model (MPI)and a hybrid one (OpenMP fine grain parallelization afterprofiling) for the NAS 2.3 benchmarks on two IBM SP systems.The superiority of one model depends on 1) the levelof shared memory model parallelization, 2) the communicationpatterns and 3) the memory access patterns. Therelative speeds of the main architecture components (CPU,memory, and network) are of tremendous importance forselecting one model. With the used hybrid model, our resultsshow that a unified MPI approach is better for most ofthe benchmarks. The hybrid approach becomes better onlywhen fast processors make the communication performancesignificant and the level of parallelization is sufficient.

19
Comparison From “Comparing the OpenMP, MPI, and Hybrid Programming
Paradigms on an SMP Cluster” byt G. Jost and H. Jin, NASA Ames Research Center (2003).
We have run several implementations of the same CFD benchmark code employingdifferent parallelization paradigms on a cluster of SMP nodes. When using the high-speedinterconnect or shared memory, the pure MPI paradigm turned out to be the most efficient. Aslow network lead to a decrease in the performance of the pure MPI implementation. Thehybrid implementations showed different sensitivity to network speed, depending on theparallelization strategy employed. The benefit of the hybrid implementations was visible on aslow network.
The hybrid parallelization approach is suitable for large applications with an inherentmultilevel structure, such as multi-zone codes. For codes like the BT benchmark, whereparallelization occurs only on one or more of the spatial dimensions, the use of either processlevel parallelization or OpenMP is, in general, more appropriate. We plan to conduct a studyusing multi-zone versions of the NAS Parallel Benchmarks [12], which are more suitable forthe exploitation of multilevel parallelism.

20
Cluster OpenMPYao-Yuan Chuang

21
What is OpenMP OpenMP is a language for annotating sequenti
al in C, C++, and Fortran Creation of tread teams
Redundant execution Cooperative execution
Synchronization between threads Barriers, locks, critical sections, single threaded regions
Creation of variables private to a thread Implemented through compiler support and a
run-time library

22
Cluster OpenMP Cluster OpenMP is a run-time library tht supports running an Ope
nMP program on a cluster
It is released with the Intel compilers (starting from 9.1) and requires an extra license.
Suitable Programs: Programs that scale successfully with OpenMP Programs that have good data locality Programs that use synchronization sparingly

23
Why Cluster OpenMP? You need higher performance that can achieved using a single no
de
You want to use a cluster programming model easier than using MPI
Your program gets excellent speedup with ordinary OpenMP
Your program has reasonably good locality of reference and little synchronization

24
A Simple Cluster OpenMP Program#include <omp.h>static int x;#pragma intel omp sharable (x)
int main() {
x = 0;#pragma omp parallel
{#pragma omp critical
x++;}
Printf (“%d should equal %d\n”,omp_get_max_threads(),x);}

25
Compiling and Running the Program Compilation
% icc test.c –o test –cluster-openmp% icc test.c –o test –cluster-openmp-profile
Assume there are two nodes, node254 and node1, and we run one process per node with 4 threads each% cat kmp_cluster.ini--hostlist=node254,node1 –processes=2 –process_threads=4
The Cluster OpenMP runtime reads kmp_cluster.ini and determines the parameters: hostnames, number of processes, and number of threads per processShould be 8 for previous example
26
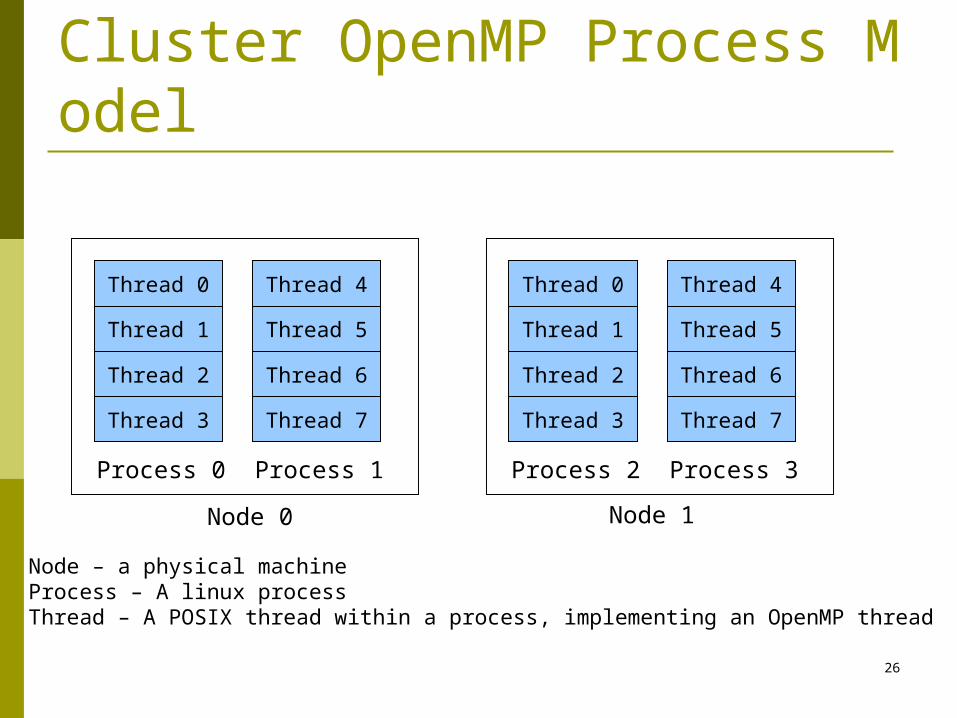
Cluster OpenMP Process Model
Thread 0
Thread 1
Thread 2
Thread 3
Process 0
Node 0 Node 1
Node – a physical machineProcess – A linux processThread – A POSIX thread within a process, implementing an OpenMP thread
Thread 4
Thread 5
Thread 6
Thread 7
Process 1
Thread 0
Thread 1
Thread 2
Thread 3
Process 2
Thread 4
Thread 5
Thread 6
Thread 7
Process 3

27
Cluster OpenMP Memory Model If multiple OpenMP threads access a variable, it must be sharable
!
Cluster OpenMPSharable memory
Privatememory
Cluster OpenMPSharable memory
SharableVariables
Process 0 address space Process 1 address space
Note: Process sharable memory can be shared between threads in a process Private memory is accessible by a single thread Cluster OpenMP does not provide a single system image
Process sharable memory
Process sharable memory
Privatememory

28
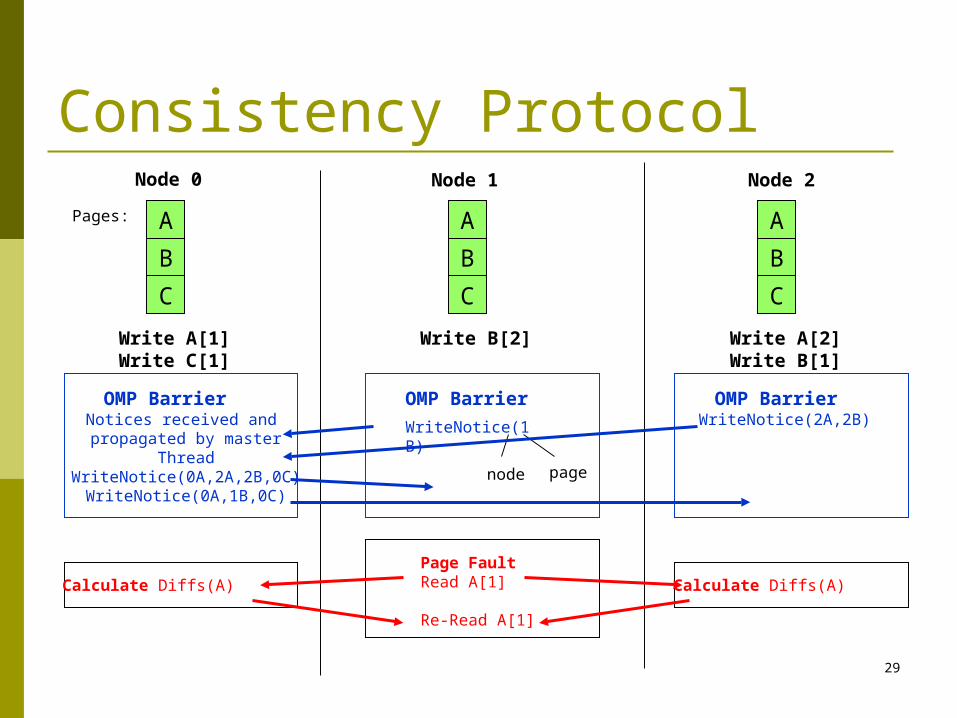
How Cluster OpenMP Program Works Consistency Protocol is designed to manage memory in Cluster
OpenMP. The basic idea:
Between OpenMP barriers, data exchange is not necessary, i.e., visibility of data modifications to other threads only after synchronization.
When a page of sharable memory is no up-to-date, it becomes protected.
Any access then faults (SIGSEGV) into Cluster OpenMP runtime library, which requires information from remote nodes and updates the page.
Protection is removed from page. Instruction causing the fault is re-started, this time successfully acce
ssing the data.
29
Consistency Protocol
A
B
C
Pages:
Node 0
Write A[1]Write C[1]
OMP BarrierNotices received and propagated by master
ThreadWriteNotice(0A,2A,2B,0C)
WriteNotice(0A,1B,0C)
Calculate Diffs(A)
A
B
C
Write B[2]
OMP Barrier
WriteNotice(1B)
Page FaultRead A[1]
Re-Read A[1]
A
B
C
Write A[2]Write B[1]
OMP BarrierWriteNotice(2A,2B)
Calculate Diffs(A)
Node 1 Node 2
node page

30
MPI Based Parallelization vs. DSM MPI based: (hybrid MPI + OpenMP)
Potential of boundary exchange between two domains in one large message, dominated by bandwidth of the network
DSM based: (OpenMP only) Additional latency based overhead in each barrier Communication of updated data of pages
Not all of this data may be needed Packages may be too small Significant latency
Communication not oriented on boundaries of a domain decomposition
Probably more data must be transferred than necessary
Communication might be 10 times slower than with MPI

31
Sharable VariablesOpenMP Cluster OpenMP
All variables are sharable except threadprivate variables
Sharable variables are variables that either:
a. Are used in a shared way in a parallel region and allocated in an enclosing scope in the same routine
b. Appear in a sharable directive
The compiler automatically applies these assumptions when –cluster-openmp or –cluster-openmp-profile is specified. It automatically makes the indicated variables sharable. All other variables are nonsharable by default.

32
Sharable Variables All variables in a shared clause or implicitly shared must be made
sharable, except for system variables
Sharable variable can be specified by#pragma intel omp sharable (var) //C, C++
!dir$ omp sharable (var) ! Fortran

33
Before Porting Verify that your code works correctly with OpenMP
Try running with the –cluster-openmp option
Use –clomp-sharable-propagation option to identify the sharable variables
Compile all source files using –clomp-sharable-propagation and –ipo
Insert the indicated sharable directives in your code
Rebuild and execute the program.

34
Example: pi.f and pi2.fpi.f pi2.f double precision pi
integer nsteps
nsteps = 1000000
call compute (nsteps, pi)
print *, nsteps, pi
end
subroutine calcpi(nsteps,pi,sum)
double precision pi,sum,step
integer nsteps
double precision x
step= 1.0d0/nsteps
sum = 0.0d0
!$omp parallel private(x)
!$omp do reduction (+:sum)
do i = 1, nsteps
x = (i – 0.5d0)*step
sum = sum + 4.0d0/(1.0d0 + x*x)
end do
!$omp end do
!$omp end parallel
pi = step * sum
end
subroutine compute(nsteps,pi)
double precision pi,sum
integer nsteps
call calcpi(nsteps,pi,sum)
end

35
Example: pi.f and pi2.f To find the variables that must be declared sharable, use the following c
ommand% ifort –cluster-openmp –clomp-sharable –propagation pi.f
pi2.f –ipo
The resulting compiler warnings IPO: perform multi-file optimizationsIPO: generating object file /tmp/ipo-ifortqKrZN4.ofortcom: Warning: Sharable directive should be inserted by user as ‘!dir$ omp sharable(nsteps)’in file pi.f, line 2, column 16fortcom: Warning: Sharaable directive should be inserted by users as ‘!dir$ imp sharable(sum)’in file pi2.f line 2, column 29pi.f(18) : (col. 6) remark: OpenMP DEFINED LOOP WAS PARALLELIZED.pi2.f(17) : (col. 6) remark: OpenMP DEFINED REGION WAS PARALLELIZED.

36
Example: pi.f and pi2.fpi.f pi2.f double precision pi
integer nsteps
!dir$ omp sharable(nsteps)
nsteps = 1000000
call compute (nsteps, pi)
print *, nsteps, pi
end
subroutine calcpi(nsteps,pi,sum)
double precision pi,sum,step
integer nsteps
double precision x
step= 1.0d0/nsteps
sum = 0.0d0
!$omp parallel private(x)
!$omp do reduction (+:sum)
do i = 1, nsteps
x = (I – 0.5d0)*step
sum = sum + 4.0d0/(1.0d0 + x*x)
end do
!$omp end do
!$omp end parallel
pi = step * sum
end
subroutine compute(nsteps,pi)
double precision pi,sum
integer nsteps
!dir$ omp sharable(sum)
call calcpi(nsteps,pi,sum)
end
37
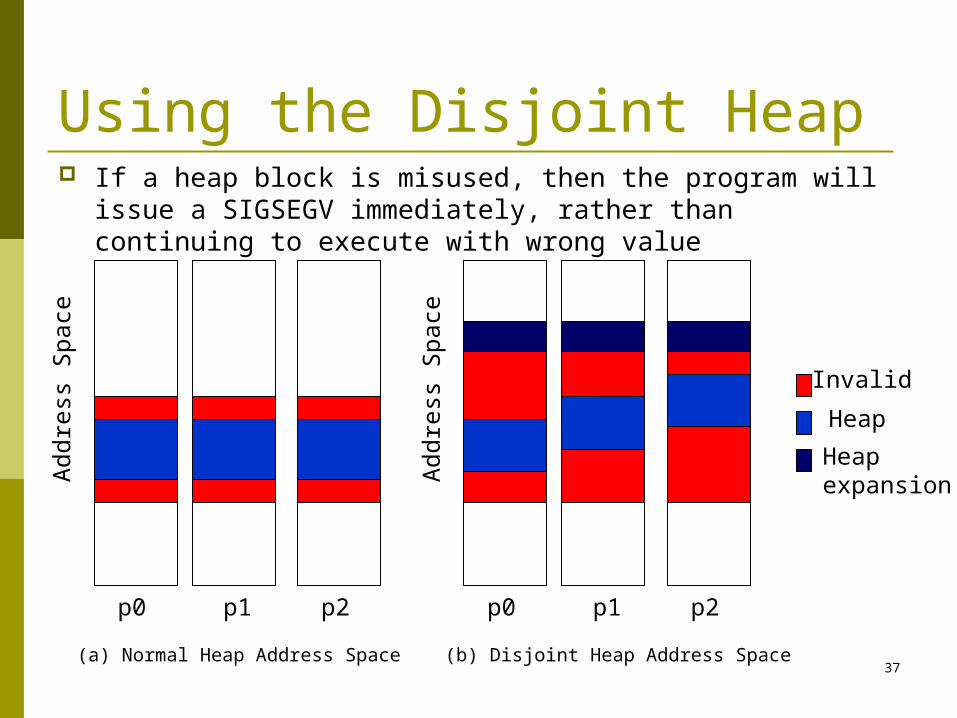
Using the Disjoint Heap If a heap block is misused, then the program will issue a
SIGSEGV immediately, rather than continuing to execute with wrong value
p0 p1 p2
Invalid
Heap
Addre
ss S
pace
(a) Normal Heap Address Space
p0 p1 p2
Addre
ss S
pace
(b) Disjoint Heap Address Space
Heapexpansion

38
Disjoint Heap To enable the disjoin heap by setting environment variable KMP_
DISJOINT_HEAPSIZE to a size with ‘K’ for 1024 bytes, M for 1024*1024 bytes. The minimum is 2MB. compile with “-g” % setenv KMP_DISJOINT_HEAP 128M run program, if you get an error (segmenttion fault ip=0x400c2f) Use addr2line to find the source line
% addr2line –e switch.exe 0x400c2f Add kmp_sharable_malloc to the variable in that line
The total address space consumed by the disjoint heap is the size you set for KMP_DISJOINT_HEAPSIZE multiply by the number of threads.
If any process in your program uses more heap space than is allocated for the disjoint heap, an error message appears.

39
Language Specific Porting Steps For each language, it is important to check for the share d use of
dynamically allocated memory. Fortran Code
Use –clomp-sharable-commons, -clomp-sharable-localsaves, and –clomp-sharable-argexprs to isolate the offending variables.
The ALLOCATABLE variable can be shared defined in a sharable directive
C and C++ Code Use kmp_sharable_malloc instead of malloc, use kmp_sharable_fre
e instead of free

40
Use default(none) clause to find sharable variable If your program does not function correctly, use default (none) cl
ause to find variable that need to be made sharable. Place a default(none) clause on a parallel directive that seems to ref
erence a non-sharable variable in a shared way. Add variable mentioned in the messages to a private or shared claus
e for the parallel region and recompile. Use the –clomp-sharable-info option to report all variables automati
cally and promoted to sharable. Verify all variables in the shared clause are either in a –clomp-sharab
le-info message or in an explicit sharable directive. For C/C++ program, verify that data shared by dereferencing a point
er is made sharable.

41
Fortran Consideration In Fortran, the sharable directive
must be placed in the declaration part of a routine.
Common block cannot appear in the sharable directive variable list. But the common block name can.!dir$ omp sharable (/cname/)
Variables in an EQUIVALENCE statement cannot appear in the sharable directive list.
Option Description
-clomp-sharable-argexprs An argument to any subroutine or function call is assigned to a temporary value located in the sharable memory.
-clomp-sharable-commons All common blocks are placed in the sharable memory.
-clomp-sharable-localsaves All variables declared in the subroutines or functions with SAVE attribute are placed in the sharable memory
-clomp-sharable-modvars All variables declared in modules are placed in sharable memory.
Defaults values:-no-clomp-sharable-argexprs-no-clomp-sharable-commons-no-clomp-sharable-localsaves-no-clomp-sharable-modvars

42
Fortran ConsiderationOriginal code Use Option Change to
common /blk/ a(100)
-clomp-sharable-commons
common /blk/ a(100)!dir$ omp sharable (/blk/)
real a(100)save a
-clomp-shrable-localsaves
real a(100)save a!dir$ omp sharable (a)
module mreal a(100)
-clomp-shrable-modvars
module mReal a(100)!dir$ omp sharable (a)

43
Running a Cluster OpenMP Program Verify that a kmp_cluster.ini file exists in the current director
y
Run the configuration checker script % clomp_configchecker.pl program_name
Check kmp_cluster.ini file Ping each node and test the rsh/ssh command Confirms the existence of the executable on each node Verifies the library compatibility Send warning messages if any inconsistency Creates a log file, clomp_configchecker.log
Type the name of the executable to execute the program

44
Cluster OpenMP Initialization File The kmp_cluster.ini file consists of
Option line, Environment variable section, and Comments The PATH, SHELL, and LD_LIBRARY_PATH are not allowed
Option Default Description
processes=integer if value omp_num_threads is set then it is equal to omp_num_threads/process_threads, otherwise equal to number of hosts
Number of processes to use
process_threads=integer 1 Number of threads per process
omp_num_threads=integer process * process_threads Number of OpenMP threads
hostlist=host1,host2… master node List of hosts
hostfile=filename master node List of hosts in file
launch=keyword rsh Rsh or ssh
sharable_heap=integer [K/M/G]
256M Size of sharable memory
startup_timeout= 30 Num of Sec. for remote node starts
[no-]heartbeat Heartbeat Check remote alive
45
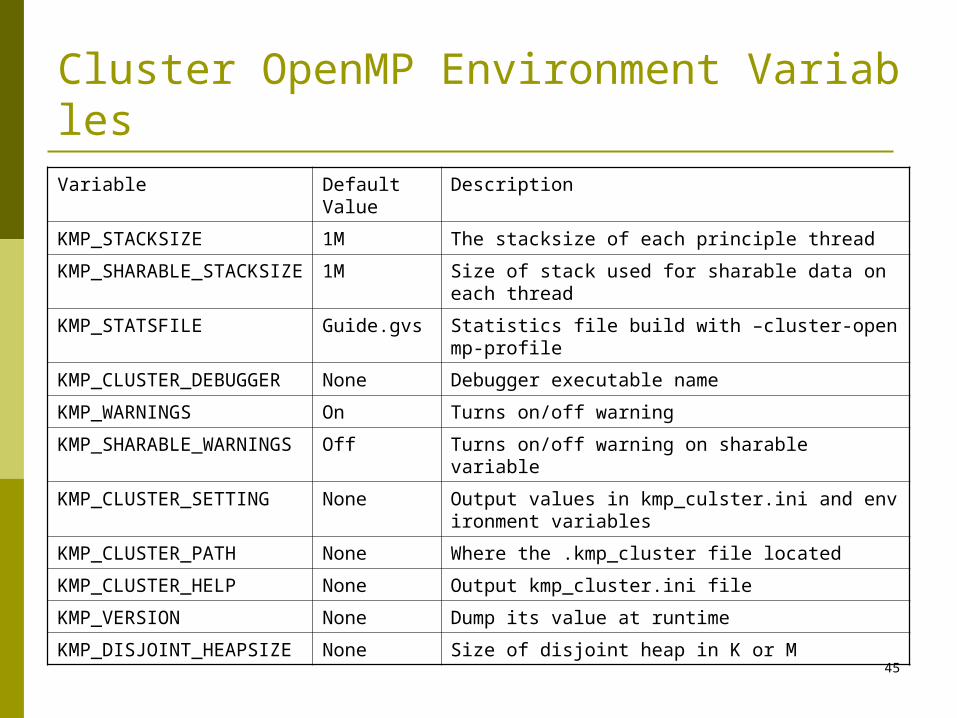
Cluster OpenMP Environment VariablesVariable Default
ValueDescription
KMP_STACKSIZE 1M The stacksize of each principle thread
KMP_SHARABLE_STACKSIZE 1M Size of stack used for sharable data on each thread
KMP_STATSFILE Guide.gvs Statistics file build with –cluster-openmp-profile
KMP_CLUSTER_DEBUGGER None Debugger executable name
KMP_WARNINGS On Turns on/off warning
KMP_SHARABLE_WARNINGS Off Turns on/off warning on sharable variable
KMP_CLUSTER_SETTING None Output values in kmp_culster.ini and environment variables
KMP_CLUSTER_PATH None Where the .kmp_cluster file located
KMP_CLUSTER_HELP None Output kmp_cluster.ini file
KMP_VERSION None Dump its value at runtime
KMP_DISJOINT_HEAPSIZE None Size of disjoint heap in K or M

46
Cluster OpenMP API RoutinesAPI Description
void *kmo_sharable_malloc(size_t size) Allocate sharable memory
void *kmo_aligned_sharabl_malloc(size_t size) Allocate sharable memory in a page boundary
void *kmp_sharable_realloc(void *ptr, size_t size) De-allocate previously allocated memory
void kmp_sharable_free (void *ptr) Free sharable memory
void kmp_set_warnings_on(void) Enable rin-time warnings
void kmp_set_warnings_off(void) Disable run-time warnings
omp_int_t kmp_get_process_num(void) Return the proces number of the current process
omp_int_t kmo_get_num_processes(void) Return the number of processes
omp_int_t kmp_get_process_thread_num(void) Return the thread number of the current thread with respect to current process

47
Allocating Sharable Memory at Run-Time C
void *kmp_sharable_malloc(int size);void *kmp_aligned_sharable_malloc(int size);void kmp_sharable_free (void *ptr)
C++#include <kmp_sharable.h>foo *fp = new kmp_sharable foo(10); //class fooclass foo : public foo_base, public kmp_sharable_base{}
Fortraninteger, allocatable :: x(:)!dir$ omp sharable (x)
allocate(x(500)) ! Allocates x in sharable memory

48
Tools for Use with Cluster OpenMP Correctness Tools:
Intel Thread Checker – find variables that should be made sharable Intel Compiler – find variables that should be made sharable Inted Debugger – debugger
Performance Tools: Segvprof – shows where SEGV hot spots Intel Trace Analyzer – displays message trafic between nodes Cluster OpenMP dashboard – real-time view of page Intel Thread Profiler – displays OpenMP performance information

49
Intel Thread Checker Support in version 3.1 Used as follows:
% setenv TC_PREVIEW 1 % setenv TC_OPTIONS [verbose,] shared % setenv KMP_FOR_TCHECK 1 setup kmp_cluster.ini with “--process=1 --process_threads=4” compile the application with –g % tcheck_cl [-c] <executable> <executable args>
-c to clear the instumentation cache

50
Intel Debugger % setenv IDB_PARALLEL_SHELL <path yo your ssh>
% setenv IDB_PARALLEL_SHELL /usr/bin/ssh Source the idbvars.csh script in /opt/intel/idb/<platform>/idbvar
s.csh Add the following to kmp_cluster.ini
--no_heartbeat --IO=system --startup_timeout=60000 Compile the application with –g
Setup IDB_HOME to be the directory where idb resides % setenv IDB_HOME /opt/intel/idb/<platform>/
Use –clomp and full pathname to executable % idb –clomp /home/ychuang/test.exe

51
IDB Tips The program begins running automatically when you enter IDB
When it prints a prompt, that means it stopped at an automatic breakpoint, use “continue”
“print” is available for printing values of sharable variables
“break” is available
Showing the OpenMP team information is not supported

52
Segvprof.pl Compile with –g to get line level profiles
Set the environment variable KMP_CLUSTER_PROFILE to 1
Run the code
Analyze the *.gmon files with segvprof.pl% segvprof.pl –e <executable> *.gmon
Reports shows the number of SEGVs which occurred at each line
Sorted by region if –cluster-openmp-profile was used at compile time otherwise for the whole program

53
Intel Trace Analyzer/Collector % setenv KMP_TRACE 1 Run application % traceanalyzer <application>.stf
Add user events to your code: VT_funcdef(char *name,0,int *handle);
ex: VT_funcdef(“INIT”,0,&init_handle); VT_begin(int handle);
ex: VT_begin(init_handle); VT_end(int handle);
ex: VT_end(init_handle);
Show the event timeline and then ungroup the application thread to reveal the user-defined functions on the timeline and see the time listed in the thread window

54
Intel Trace Analyzer/Collector

55
Cluster OpenMP Dashboard % setenv KMP_CLUSTER_DISPLAY :0.0 Add the fillowing to the kmp_cluster.ini file:
KMP_CLUSTER_DISPLAY=:0.0 For example:
--processes=2 –process_threads=4 –launch=ssh KMP_CLUSTER_DISPLAY=:0.0
Run the application as normal

56
Intel Thread Profiler Compile with –cluster-openmp-profile Creates a file guide.gvs Open that file using the Windows* GUI Use –p with clomp_forcaster.pl to create a sorted, summarized C
SV file from the .gvs file, for use with a spreadsheet

57
Cluster OpenMP Resources Example programs and tools can be found at Intel devloper site a
t http://premier.intel.com, the clomp_tools.tar.gz contains under Intel C++ Compiler, Linux* Cluster OpenMP Intel Fortran Compiler, Linux* Cluster OpenMP Contains serveral perl scripts:
clomp_getlatency.pl – measure latency to remote node clomp_configchecker.pl- check configuration clomp_forecaster.pl – estimate program performance segvprof.pl – display per line/function profile information Example codes and kmp_cluster.ini file

58
References “OpenMP on MPPs and clusters of SMP nodes using Intel Compil
ers with Cluster OpenMP” by R. Rabenseifner, B. Krammer, 2006.
“Cluster OpenMP* user’s guide version 9.1”, Intel Corporation, 2005.
“Intel Cluster OpenMP*” L. Meadows, Intel, 2007.