1 improving value communication…steffan carnegie mellon improving value communication for...
TRANSCRIPT

1Improving Value Communication… SteffanCarnegie Mellon
Improving Value Communication for Improving Value Communication for Thread-Level SpeculationThread-Level Speculation
Greg Steffan, Chris Colohan, Greg Steffan, Chris Colohan,
Antonia Zhai, and Todd MowryAntonia Zhai, and Todd Mowry
School of Computer ScienceSchool of Computer Science
Carnegie Mellon UniversityCarnegie Mellon University

2Improving Value Communication… SteffanCarnegie Mellon
Multithreaded Machines Are EverywhereMultithreaded Machines Are Everywhere
How can we use them? Parallelism!
C
P
C
SUN MAJC, IBM Power4,Sibyte SB-1250
ALPHA 21464,Intel Xeon
Threads
C
C
P
C
P

3Improving Value Communication… SteffanCarnegie Mellon
Automatic ParallelizationAutomatic Parallelization
Proving independence of threads is hard:Proving independence of threads is hard:
– complex control flowcomplex control flow
– complex data structurescomplex data structures
– pointers, pointers, pointerspointers, pointers, pointers
– run-time inputsrun-time inputs
How can we make the compiler’s job feasible?How can we make the compiler’s job feasible?
Thread-Level Speculation (TLS)

4Improving Value Communication… SteffanCarnegie Mellon
Retry
TLS
E1 E2 E3
Load
Thread-Level SpeculationThread-Level Speculation
Epoch1
Epoch2
Epoch3
exploit available thread-level parallelism
Load
StoreTime
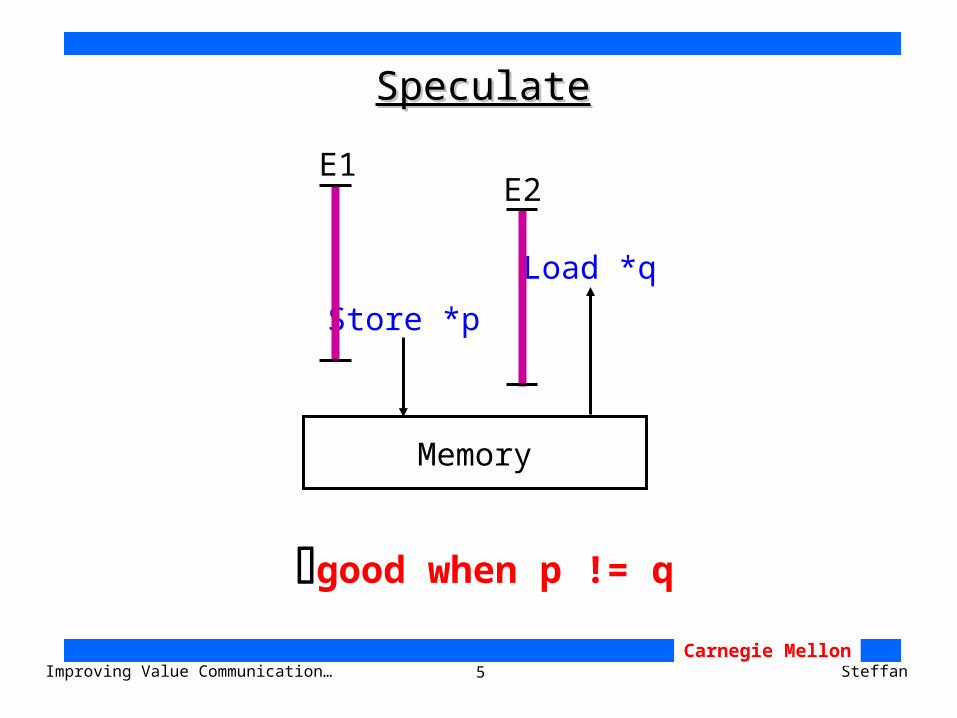
5Improving Value Communication… SteffanCarnegie Mellon
SpeculateSpeculate
good when p != q
Store *p
Load *q
E1E2
Memory

6Improving Value Communication… SteffanCarnegie Mellon
Synchronize (and forward)Synchronize (and forward)
good when p == q
Store *p
Load *q
E1E2
Memory
Signal
Wait(stall)
Store *pLoad *q
E1E2
Memory
(Speculate)

7Improving Value Communication… SteffanCarnegie Mellon
Reduce the Critical Forwarding PathReduce the Critical Forwarding Path
Wait
Load X
Store X
Signal
Overview Big Critical Path Small Critical Path
decreases execution time
critical
path
stall execution time
execution time

8Improving Value Communication… SteffanCarnegie Mellon
PredictPredict
good when p == q and
*q is predictable
Store *p
Load *q
E1E2
Memory
Value
Predictor
Store *p
Load *q
E1E2
Memory
SignalWait(stall)
(Synchronize)
Store *pLoad *q
E1E2
Memory
(Speculate)

9Improving Value Communication… SteffanCarnegie Mellon
Improving on Compile-Time DecisionsImproving on Compile-Time Decisions
Predict
Speculate
Synchronize
Compiler
Speculate
Synchronize
Hardware
reduce critical
forwarding path
reduce critical
forwarding path
is there any potential benefit?

10Improving Value Communication… SteffanCarnegie Mellon
Potential for Improving Value CommunicationPotential for Improving Value Communication
efficient value communication is key
U=Un-optimized, P=Perfect Prediction (4 Processors)

11Improving Value Communication… SteffanCarnegie Mellon
OutlineOutline
Our Support for Thread-Level SpeculationOur Support for Thread-Level Speculation
– Compiler SupportCompiler Support
– Experimental FrameworkExperimental Framework
– Baseline PerformanceBaseline Performance
• Techniques for Improving Value CommunicationTechniques for Improving Value Communication
• Combining the TechniquesCombining the Techniques
• ConclusionsConclusions

12Improving Value Communication… SteffanCarnegie Mellon
Compiler Support (SUIF1.3 and gcc)Compiler Support (SUIF1.3 and gcc)
1) Where to speculate1) Where to speculate
– use profile information, heuristics, loop unrollinguse profile information, heuristics, loop unrolling
2) Transforming to exploit TLS2) Transforming to exploit TLS
– insert new TLS-specific instructionsinsert new TLS-specific instructions
– synchronizes/forwards register valuessynchronizes/forwards register values
3) Optimization3) Optimization
– eliminate dependences due to loop induction variableseliminate dependences due to loop induction variables
– algorithm to schedule the critical forwarding pathalgorithm to schedule the critical forwarding path
compiler plays a crucial role
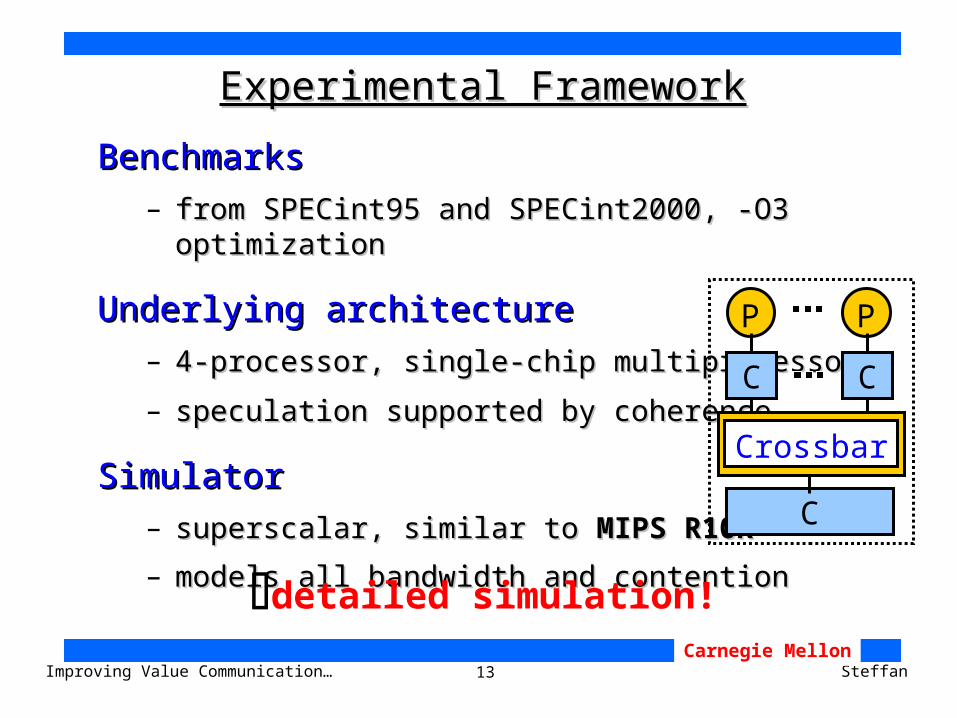
13Improving Value Communication… SteffanCarnegie Mellon
Experimental FrameworkExperimental Framework
BenchmarksBenchmarks
– from SPECint95 and SPECint2000, -O3 optimizationfrom SPECint95 and SPECint2000, -O3 optimization
Underlying architectureUnderlying architecture
– 4-processor, single-chip multiprocessor4-processor, single-chip multiprocessor
– speculation supported by coherencespeculation supported by coherence
SimulatorSimulator
– superscalar, similar to superscalar, similar to MIPS R10KMIPS R10K
– models all bandwidth and contentionmodels all bandwidth and contention
detailed simulation!
C
C
P
C
P
Crossbar

14Improving Value Communication… SteffanCarnegie Mellon
Compiler PerformanceCompiler Performance
S=Sequential

15Improving Value Communication… SteffanCarnegie Mellon
Compiler PerformanceCompiler Performance
overheads of TLS compilation can be significant
S=Sequential, T=TLS Run Sequentially

16Improving Value Communication… SteffanCarnegie Mellon
Compiler PerformanceCompiler Performance
much failed speculation and sync. stall
S=Seq., T=TLS Seq., U=Un-optimized

17Improving Value Communication… SteffanCarnegie Mellon
Compiler PerformanceCompiler Performance
compiler optimization is effective
S=Seq., T=TLS Seq., U=Un-optimized, B=Compiler Optimized

18Improving Value Communication… SteffanCarnegie Mellon
OutlineOutline
Our Support for Thread-Level SpeculationOur Support for Thread-Level Speculation
Techniques for Improving Value CommunicationTechniques for Improving Value Communication
– When Prediction is BestWhen Prediction is Best
• Memory Value PredictionMemory Value Prediction
• Forwarded Value PredictionForwarded Value Prediction
• Silent StoresSilent Stores
– When Synchronization is BestWhen Synchronization is Best
• Combining the TechniquesCombining the Techniques
• ConclusionsConclusions

19Improving Value Communication… SteffanCarnegie Mellon
Memory Value PredictionMemory Value Prediction
Store *pLoad *q
E1E2
Memory
avoid failed speculation if *q is predictable
Store *pLoad *q
E1E2
Memory
Value
Predictor
PredictionWith Value

20Improving Value Communication… SteffanCarnegie Mellon
Value Predictor ConfigurationValue Predictor Configuration
Context
Stride
Confidence
Confidence
Aggressive hybrid predictorAggressive hybrid predictor
– 1K x 3-entry context and 1K-entry stride 1K x 3-entry context and 1K-entry stride
– 2-bit, up/down, saturating confidence counters2-bit, up/down, saturating confidence counters
predict only when confident
no prediction
>?
load PC
predicted value
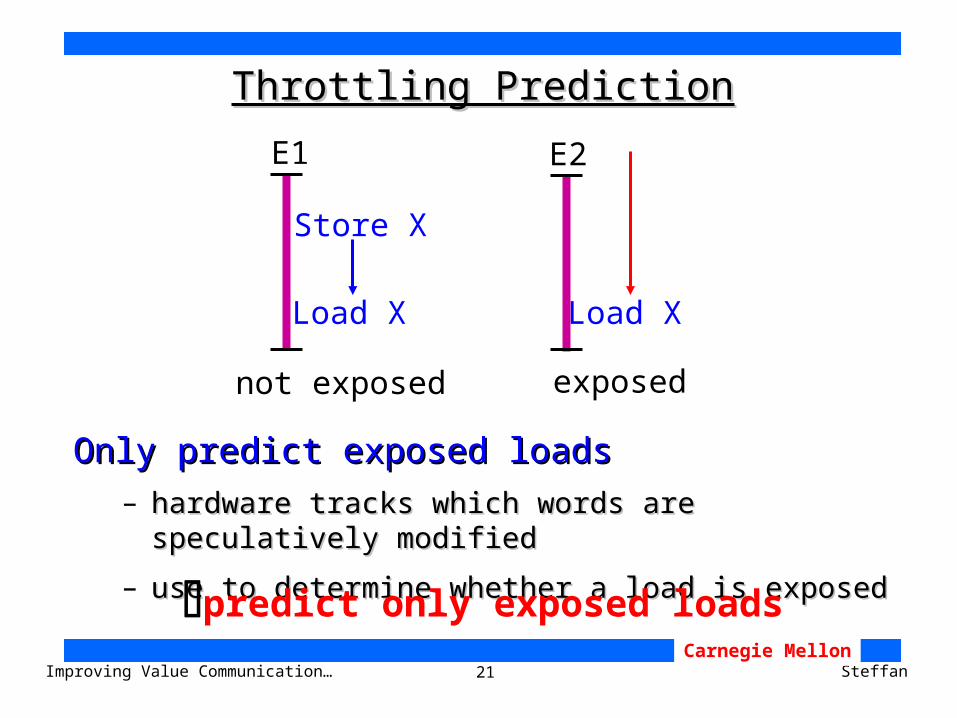
21Improving Value Communication… SteffanCarnegie Mellon
Throttling PredictionThrottling Prediction
Only predict exposed loadsOnly predict exposed loads
– hardware tracks which words are speculatively modifiedhardware tracks which words are speculatively modified
– use to determine whether a load is exposed use to determine whether a load is exposed
predict only exposed loads
Store X
E1
Load X Load X
E2
not exposed exposed

22Improving Value Communication… SteffanCarnegie Mellon
Memory Value PredictionMemory Value Prediction
exposed loads are fairly predictable

23Improving Value Communication… SteffanCarnegie Mellon
Memory Value PredictionMemory Value Prediction
must throttle further
B=Baseline, E=Predict Exposed Loads

24Improving Value Communication… SteffanCarnegie Mellon
Memory Value PredictionMemory Value Prediction
effective if properly throttled
B=Baseline, E=Predict Exposed Lds, V=Predict Violating Loads

25Improving Value Communication… SteffanCarnegie Mellon
Forwarded Value PredictionForwarded Value Prediction
Store X
Load X
E1E2
SignalWait
avoid synchronization stall if X is predictable
Store XLoad X
E1E2
Value
Predictor
PredictionWith Value
(stall)
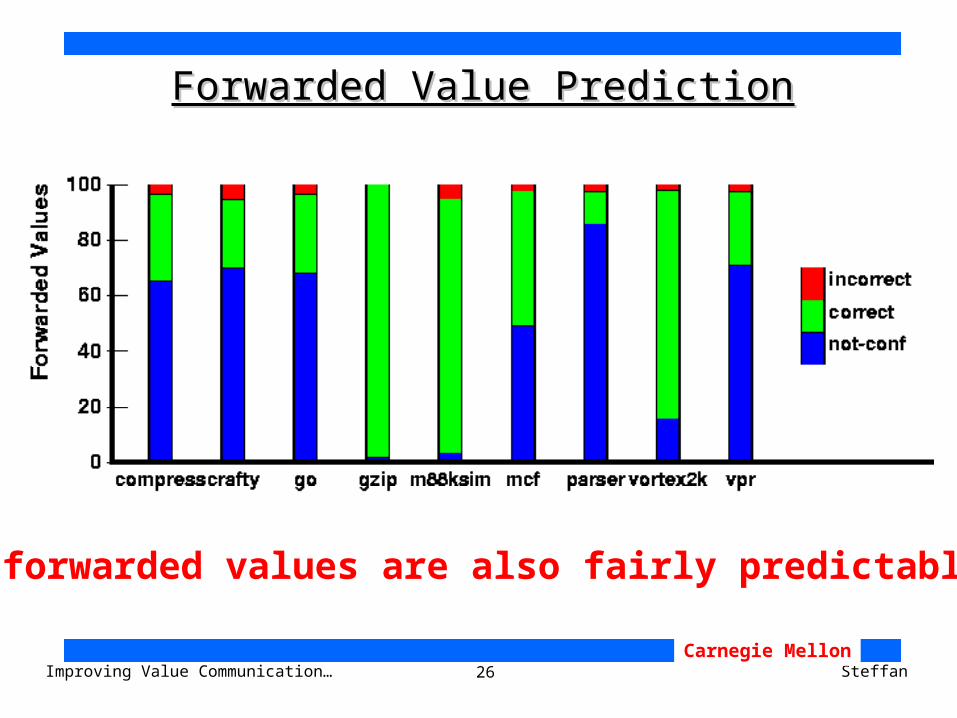
26Improving Value Communication… SteffanCarnegie Mellon
Forwarded Value PredictionForwarded Value Prediction
forwarded values are also fairly predictable

27Improving Value Communication… SteffanCarnegie Mellon
Forwarded Value PredictionForwarded Value Prediction
B=Baseline, F=Predict Forwarded Values
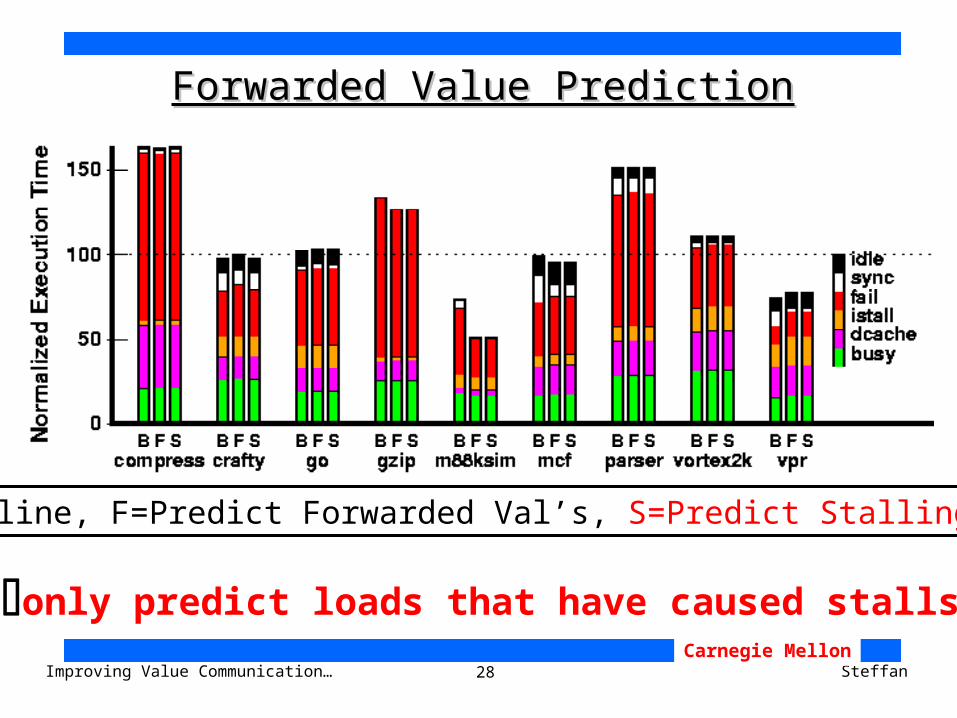
28Improving Value Communication… SteffanCarnegie Mellon
Forwarded Value PredictionForwarded Value Prediction
only predict loads that have caused stalls
B=Baseline, F=Predict Forwarded Val’s, S=Predict Stalling Val’s

29Improving Value Communication… SteffanCarnegie Mellon
Silent StoresSilent Stores
Store X=5Load X
E1E2
Memory (X=5)
(Store X=5) Load X
E1E2
Memory (X=5)
ExploitingSilentStores
avoid failed speculation if store is silent
Load X==5?

30Improving Value Communication… SteffanCarnegie Mellon
Silent StoresSilent Stores
silent stores are prevalent

31Improving Value Communication… SteffanCarnegie Mellon
Impact of Exploiting Silent StoresImpact of Exploiting Silent Stores
most of the benefits of memory value prediction
B=Baseline, SS=Exploit Silent Stores

32Improving Value Communication… SteffanCarnegie Mellon
OutlineOutline
Our Support for Thread-Level SpeculationOur Support for Thread-Level Speculation
Techniques for Improving Value CommunicationTechniques for Improving Value Communication
When Prediction is BestWhen Prediction is Best
– When Synchronization is BestWhen Synchronization is Best
• Hardware-Inserted Dynamic SynchronizationHardware-Inserted Dynamic Synchronization
• Reducing the Critical Forwarding PathReducing the Critical Forwarding Path
• Combining the TechniquesCombining the Techniques
• ConclusionsConclusions

33Improving Value Communication… SteffanCarnegie Mellon
Hardware-Inserted Dynamic SynchronizationHardware-Inserted Dynamic Synchronization
Store *pLoad *q
E1E2
Memory
avoid failed speculation
WithDynamic
Sync.
Store *p
Load *q
E2
E1
(stall)
Memory

34Improving Value Communication… SteffanCarnegie Mellon
Hardware-Inserted Dynamic SynchronizationHardware-Inserted Dynamic Synchronization
B=Baseline, D=Synchronize Violating Loads

35Improving Value Communication… SteffanCarnegie Mellon
Hardware-Inserted Dynamic SynchronizationHardware-Inserted Dynamic Synchronization
B=Baseline, D=Sync. Violating Ld.s, R=D+Reset
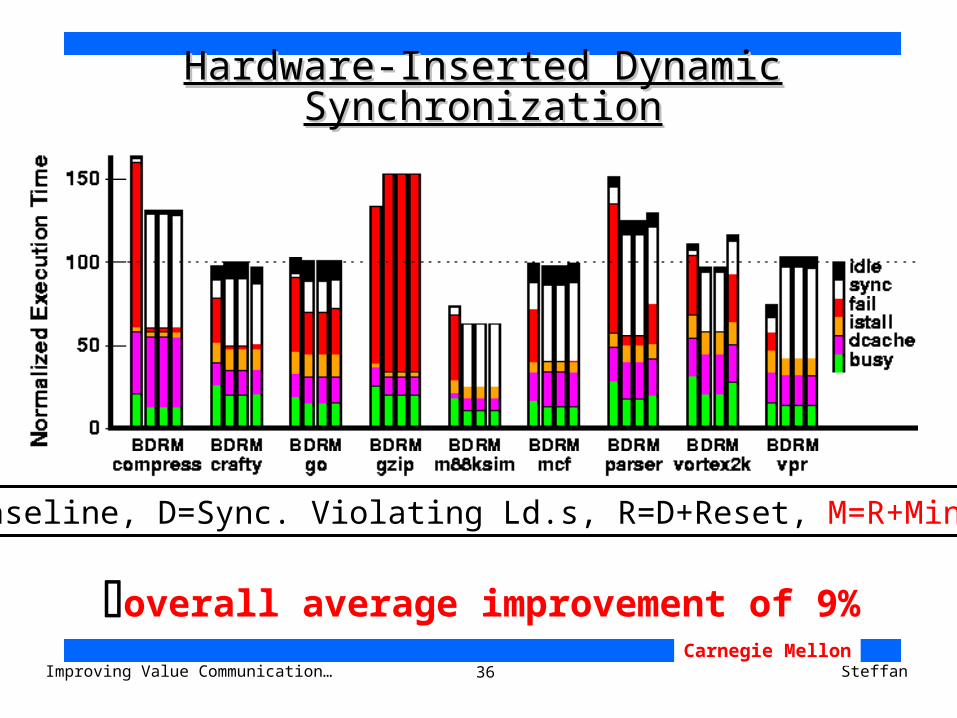
36Improving Value Communication… SteffanCarnegie Mellon
Hardware-Inserted Dynamic SynchronizationHardware-Inserted Dynamic Synchronization
overall average improvement of 9%
B=Baseline, D=Sync. Violating Ld.s, R=D+Reset, M=R+Minimum

37Improving Value Communication… SteffanCarnegie Mellon
Reduce the Critical Forwarding PathReduce the Critical Forwarding Path
Wait
Load X
Store X
Signal
Overview Big Critical Path Small Critical Path
decreases execution time
critical
path
stall execution time
execution time
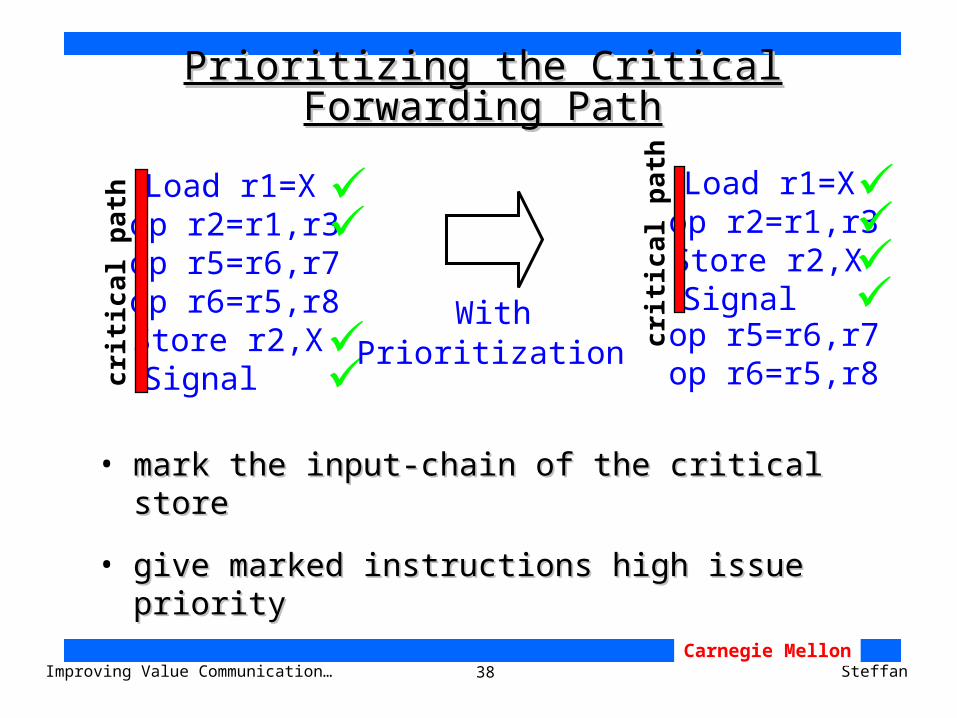
38Improving Value Communication… SteffanCarnegie Mellon
Prioritizing the Critical Forwarding PathPrioritizing the Critical Forwarding Path
Load r1=X
Store r2,XSignal
op r2=r1,r3op r5=r6,r7op r6=r5,r8
cri
tic
al p
ath
• mark the input-chain of the critical storemark the input-chain of the critical store
• give marked instructions high issue prioritygive marked instructions high issue priority
Load r1=X
Store r2,XSignal
op r2=r1,r3
op r5=r6,r7op r6=r5,r8
cri
tic
al p
ath
PrioritizationWith
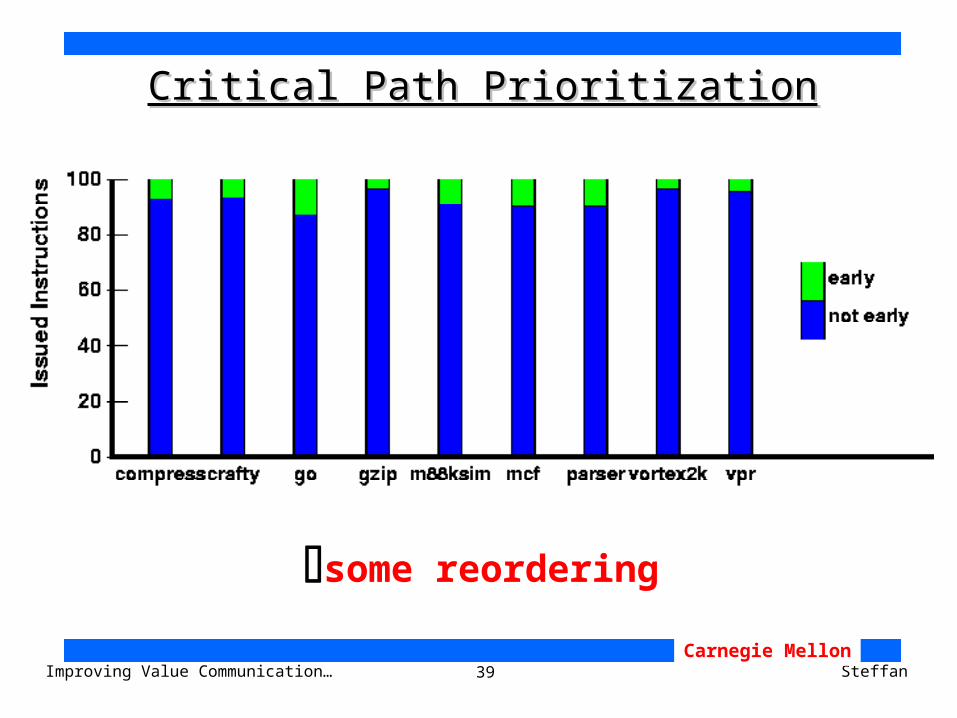
39Improving Value Communication… SteffanCarnegie Mellon
Critical Path PrioritizationCritical Path Prioritization
some reordering

40Improving Value Communication… SteffanCarnegie Mellon
Impact of Prioritizing the Critical PathImpact of Prioritizing the Critical Path
not much benefit, given the complexity
B=Baseline, S=Prioritizing Critical Path

41Improving Value Communication… SteffanCarnegie Mellon
OutlineOutline
Our Support for Thread-Level SpeculationOur Support for Thread-Level Speculation
Techniques for Improving Value CommunicationTechniques for Improving Value Communication
Combining the TechniquesCombining the Techniques
• ConclusionsConclusions

42Improving Value Communication… SteffanCarnegie Mellon
Combining the TechniquesCombining the Techniques
Techniques are orthogonal with one exception:Techniques are orthogonal with one exception:
Memory value prediction and dynamic sync.Memory value prediction and dynamic sync.
– only synchronize memory values that are unpredictableonly synchronize memory values that are unpredictable
– dynamic sync. logic checks prediction confidencedynamic sync. logic checks prediction confidence
– synchronize if not confidentsynchronize if not confident

43Improving Value Communication… SteffanCarnegie Mellon
Combining the TechniquesCombining the Techniques
B=Baseline

44Improving Value Communication… SteffanCarnegie Mellon
Combining the TechniquesCombining the Techniques
B=Baseline, A=All But Dynamic Synchronization
significant improvement

45Improving Value Communication… SteffanCarnegie Mellon
Combining the TechniquesCombining the Techniques
B=Baseline, A=All But Dynamic Synchronization, D=All
good for some, bad for others

46Improving Value Communication… SteffanCarnegie Mellon
Combining the TechniquesCombining the Techniques
close to ideal for m88ksim and vpr
B=Baseline, A=All But Dyn. Sync., D=All, P=Perfect Prediction

47Improving Value Communication… SteffanCarnegie Mellon
ConclusionsConclusions
Prediction Prediction
– memory value predictionmemory value prediction: effective when throttled: effective when throttled
– forwarded value predictionforwarded value prediction: effective when throttled: effective when throttled
– silent storessilent stores: prevalent and effective: prevalent and effective
SynchronizationSynchronization
– dynamic synchronizationdynamic synchronization: can help or hurt: can help or hurt
– hardware prioritizationhardware prioritization: ineffective, if compiler is good: ineffective, if compiler is good
prediction is effective
synchronization has mixed results

48Improving Value Communication… SteffanCarnegie Mellon
BACKUPSBACKUPS

49Improving Value Communication… SteffanCarnegie Mellon
GoalsGoals
1) Parallelize general-purpose programs1) Parallelize general-purpose programs
– difficult problemdifficult problem
2) Keep hardware support simple and minimal2) Keep hardware support simple and minimal
– avoid large, specialized structuresavoid large, specialized structures
– preserve the performance of non-TLS workloadspreserve the performance of non-TLS workloads
3) 3) Take full advantage of the compilerTake full advantage of the compiler
– region selection, synchronization, optimizationregion selection, synchronization, optimization
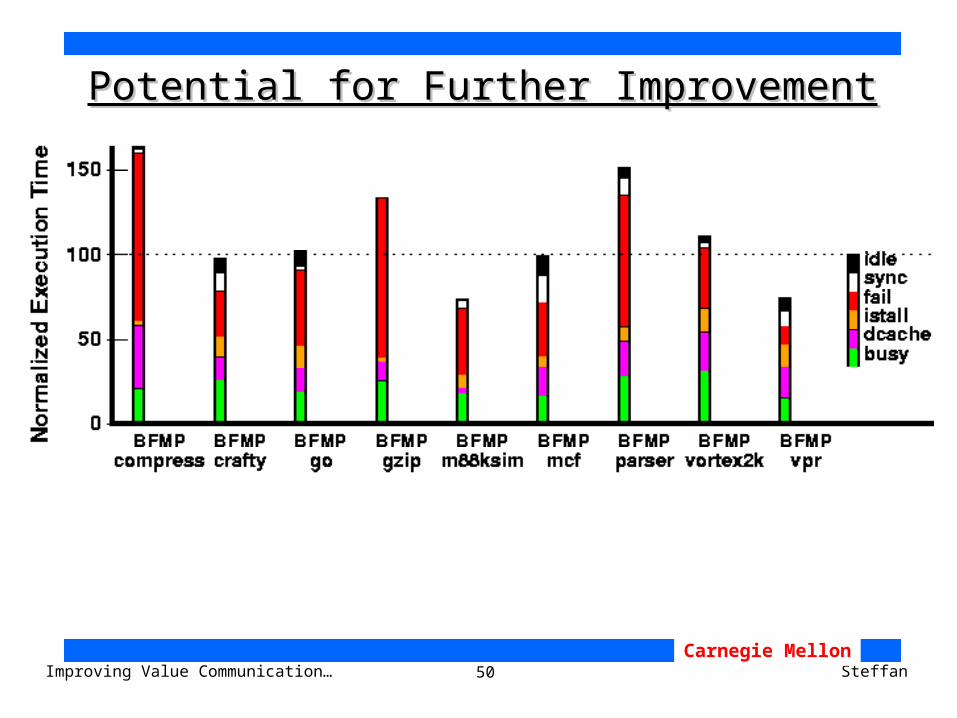
50Improving Value Communication… SteffanCarnegie Mellon
Potential for Further ImprovementPotential for Further Improvement
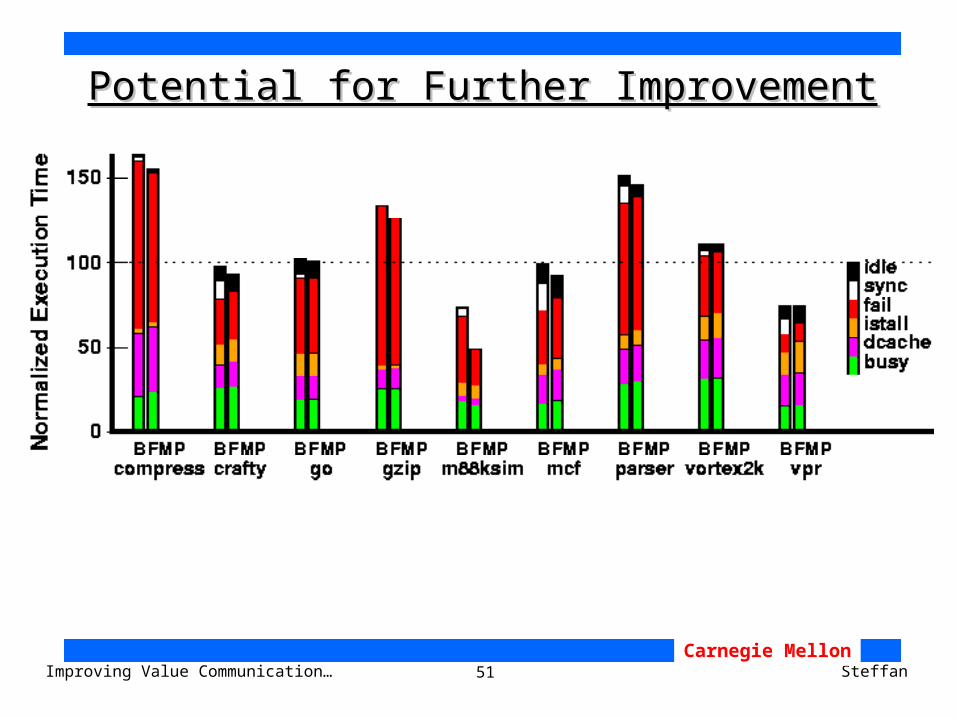
51Improving Value Communication… SteffanCarnegie Mellon
Potential for Further ImprovementPotential for Further Improvement

52Improving Value Communication… SteffanCarnegie Mellon
Potential for Further ImprovementPotential for Further Improvement
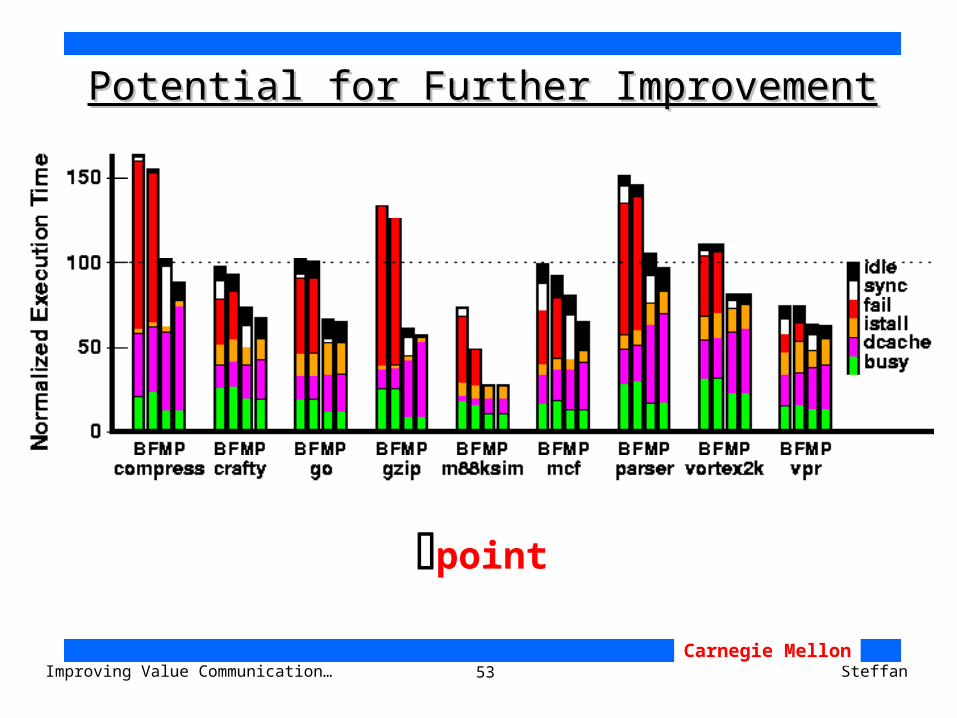
53Improving Value Communication… SteffanCarnegie Mellon
Potential for Further ImprovementPotential for Further Improvement
point

54Improving Value Communication… SteffanCarnegie Mellon
Pipeline ParametersPipeline Parameters
Issue WidthIssue Width 44
Functional UnitsFunctional Units 2Int, 2FP, 1Mem, 1Bra2Int, 2FP, 1Mem, 1Bra
Reorder Buffer SizeReorder Buffer Size 128128
Integer MultiplyInteger Multiply 12 cycles12 cycles
Integer DivideInteger Divide 76 cycles76 cycles
All Other IntegerAll Other Integer 1 cycle1 cycle
FP DivideFP Divide 15 cycles15 cycles
FP Square RootFP Square Root 20 cycles20 cycles
All Other FPAll Other FP 2 cycles2 cycles
Branch PredictionBranch Prediction GShare (16KB, 8 history bits)GShare (16KB, 8 history bits)

55Improving Value Communication… SteffanCarnegie Mellon
Memory ParametersMemory Parameters
Cache Line SizeCache Line Size 32B32B
Instruction CacheInstruction Cache 32KB, 4-way set-assoc32KB, 4-way set-assoc
Data CacheData Cache 32KB, 2-way set-assoc, 2 banks32KB, 2-way set-assoc, 2 banks
Unified Secondary CacheUnified Secondary Cache 2MB, 4-way set-assoc, 4 banks 2MB, 4-way set-assoc, 4 banks
Miss HandlersMiss Handlers 16 for data, 2 for insts16 for data, 2 for insts
Crossbar InterconnectCrossbar Interconnect 8B per cycle per bank8B per cycle per bank
Minimum Miss Latency to Minimum Miss Latency to Secondary CacheSecondary Cache
10 cycles10 cycles
Minimum Miss Latency to Local Minimum Miss Latency to Local MemoryMemory
75 cycles75 cycles
Main Memory BandwidthMain Memory Bandwidth 1 access per 20 cycles1 access per 20 cycles

56Improving Value Communication… SteffanCarnegie Mellon
When Prediction is BestWhen Prediction is Best
Predicting under TLSPredicting under TLS
– only update predictor for successful epochsonly update predictor for successful epochs
– cost of misprediction is high: must re-execute epochcost of misprediction is high: must re-execute epoch
– each epoch requires a logically-separate predictoreach epoch requires a logically-separate predictor
Differentiation from previous work:Differentiation from previous work:
– loop induction variables optimized by compilerloop induction variables optimized by compiler
– larger regions of code, hence larger number of larger regions of code, hence larger number of memory dependences between epochsmemory dependences between epochs

57Improving Value Communication… SteffanCarnegie Mellon
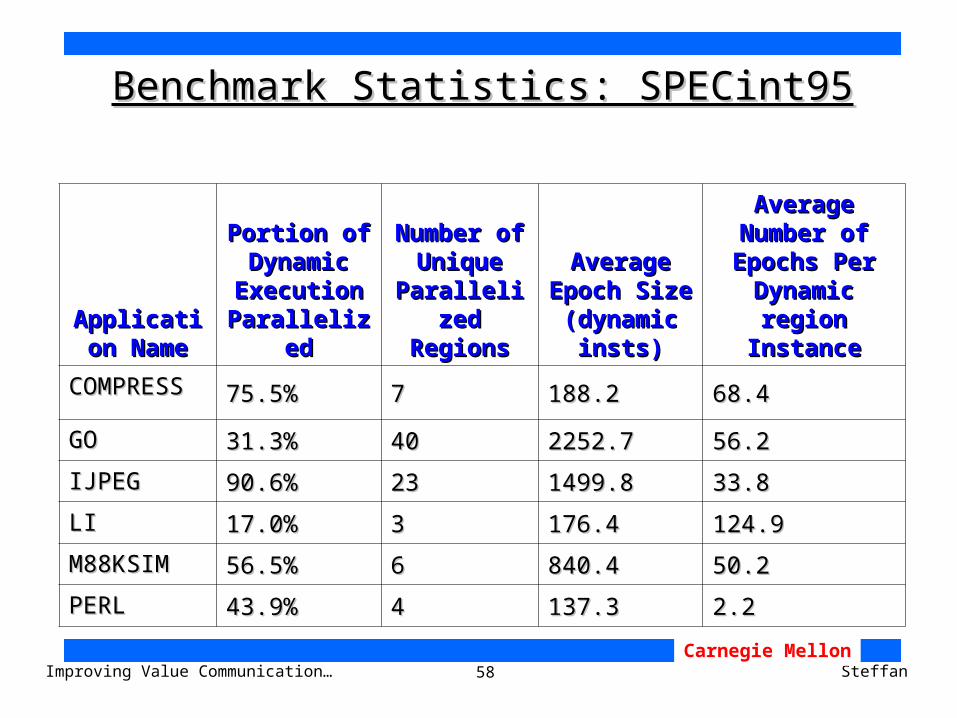
Benchmark Statistics: SPECint2000Benchmark Statistics: SPECint2000
Application Application
NameName
Portion of Portion of Dynamic Dynamic
Execution Execution ParallelizedParallelized
Number of Number of Unique Unique
Parallelized Parallelized RegionsRegions
Average Average Epoch Epoch Size Size
(dynamic (dynamic insts)insts)
Average Average Number of Number of Epochs Per Epochs Per
Dynamic region Dynamic region InstanceInstance
BZIP2BZIP2 98.1%98.1% 11 251.5251.5 451596.0451596.0
CRAFTYCRAFTY 36.1%36.1% 3434 30.830.8 1315.71315.7
GZIPGZIP 70.4%70.4% 11 1307.01307.0 2064.82064.8
MCFMCF 61.0%61.0% 99 206.2206.2 198.9198.9
PARSERPARSER 36.4%36.4% 4141 271.1271.1 19.419.4
PERLBMKPERLBMK 10.3%10.3% 1010 65.165.1 2.42.4
VORTEX2KVORTEX2K 12.7%12.7% 66 1994.31994.3 3.43.4
VPRVPR 80.1%80.1% 66 90.290.2 6.36.3
58Improving Value Communication… SteffanCarnegie Mellon
Benchmark Statistics: SPECint95Benchmark Statistics: SPECint95
Application Application NameName
Portion of Portion of Dynamic Dynamic
Execution Execution ParallelizedParallelized
Number of Number of Unique Unique
Parallelized Parallelized RegionsRegions
Average Average Epoch Size Epoch Size (dynamic (dynamic
insts)insts)
Average Average Number of Number of Epochs Per Epochs Per
Dynamic region Dynamic region InstanceInstance
COMPRESSCOMPRESS 75.5%75.5% 77 188.2188.2 68.468.4
GOGO 31.3%31.3% 4040 2252.72252.7 56.256.2
IJPEGIJPEG 90.6%90.6% 2323 1499.81499.8 33.833.8
LILI 17.0%17.0% 33 176.4176.4 124.9124.9
M88KSIMM88KSIM 56.5%56.5% 66 840.4840.4 50.250.2
PERLPERL 43.9%43.9% 44 137.3137.3 2.22.2

59Improving Value Communication… SteffanCarnegie Mellon
Memory Value PredictionMemory Value Prediction
Application Application NameName
Avg. Exposed Avg. Exposed Loads per EpochLoads per Epoch IncorrectIncorrect CorrectCorrect
Not Not ConfidentConfident
COMPRESSCOMPRESS 12.012.0 0.3%0.3% 31.8%31.8% 67.9%67.9%
CRAFTYCRAFTY 4.54.5 3.0%3.0% 48.6%48.6% 48.3%48.3%
GOGO 7.87.8 2.5%2.5% 41.2%41.2% 56.2%56.2%
GZIPGZIP 66.666.6 1.4%1.4% 52.8%52.8% 45.7%45.7%
M88KSIMM88KSIM 7.57.5 1.2%1.2% 90.9%90.9% 7.7%7.7%
MCFMCF 2.52.5 1.7%1.7% 34.9%34.9% 63.3%63.3%
PARSERPARSER 3.63.6 3.2%3.2% 48.7%48.7% 48.0%48.0%
VORTEX2KVORTEX2K 25.425.4 2.8%2.8% 64.9%64.9% 32.2%32.2%
VPRVPR 6.36.3 3.6%3.6% 49.8%49.8% 46.4%46.4%
exposed loads are quite predictable

60Improving Value Communication… SteffanCarnegie Mellon
Throttling Prediction FurtherThrottling Prediction Further
cache
tag
Load PC
Load PC
Load PC
Load PC
Exposed
Load Table
On an exposed load:
only predict violating loads
Load PC
Load PC
On a dependence violation:
Load PC
Load PC
Load PC
Load PC
Exposed
Load Table
cache
tag
Violating
Loads List
61Improving Value Communication… SteffanCarnegie Mellon
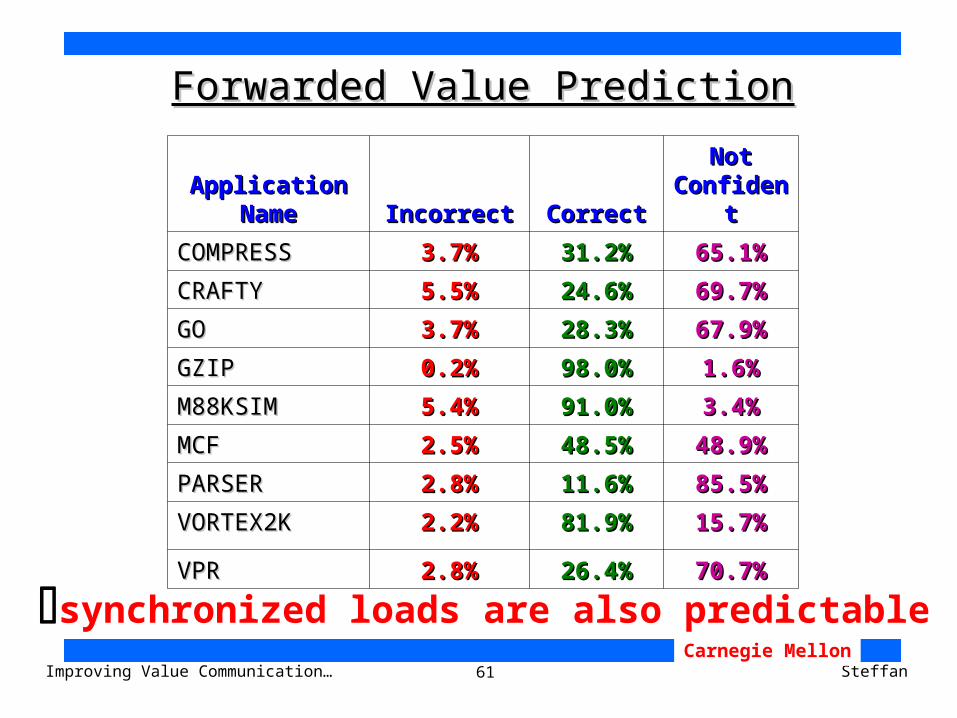
Forwarded Value PredictionForwarded Value Prediction
Application Application NameName IncorrectIncorrect CorrectCorrect
Not Not ConfidentConfident
COMPRESSCOMPRESS 3.7%3.7% 31.2%31.2% 65.1%65.1%
CRAFTYCRAFTY 5.5%5.5% 24.6%24.6% 69.7%69.7%
GOGO 3.7%3.7% 28.3%28.3% 67.9%67.9%
GZIPGZIP 0.2%0.2% 98.0%98.0% 1.6%1.6%
M88KSIMM88KSIM 5.4%5.4% 91.0%91.0% 3.4%3.4%
MCFMCF 2.5%2.5% 48.5%48.5% 48.9%48.9%
PARSERPARSER 2.8%2.8% 11.6%11.6% 85.5%85.5%
VORTEX2KVORTEX2K 2.2%2.2% 81.9%81.9% 15.7%15.7%
VPRVPR 2.8%2.8% 26.4%26.4% 70.7%70.7%
synchronized loads are also predictable

62Improving Value Communication… SteffanCarnegie Mellon
Silent StoresSilent Stores
Application NameApplication NameDynamic, Non-Stack, Dynamic, Non-Stack,
Silent StoresSilent Stores
COMPRESSCOMPRESS 80%80%
CRAFTYCRAFTY 16%16%
GOGO 16%16%
GZIPGZIP 4%4%
M88KSIMM88KSIM 57%57%
MCFMCF 19%19%
PARSERPARSER 12%12%
VORTEX2KVORTEX2K 84%84%
VPRVPR 26%26%
silent stores are prevalent

63Improving Value Communication… SteffanCarnegie Mellon
Critical Path PrioritizationCritical Path Prioritization
Application Application NameName
Issued Insts That Are High Issued Insts That Are High Priority and Issued EarlyPriority and Issued Early
COMPRESSCOMPRESS 7.1%7.1%
CRAFTYCRAFTY 6.8%6.8%
GOGO 12.9%12.9%
GZIPGZIP 3.6%3.6%
M88KSIMM88KSIM 9.1%9.1%
MCFMCF 9.9%9.9%
PARSERPARSER 9.7%9.7%
VORTEX2KVORTEX2K 3.6%3.6%
VPRVPR 4.7%4.7%
significant reordering