1 ling 696b: phonotactics wrap-up, ot, stochastic ot
TRANSCRIPT

1
LING 696B: Phonotactics wrap-up, OT, Stochastic OT

2
Remaining topics 4 weeks to go (including the day
before thanksgiving): Maximum-entropy as an alternative to
OT (Jaime) Rule induction (Mans) + decision tree Morpho-phonological learning (Emily)
and multiple generalizations (LouAnn’s lecture)
Learning and self-organization (Andy’s lecture)

3
Towards a parametric model of phonotactics
Last time: simple sequence models with some simple variations
Phonological generalization needs much more than this Different levels:
Natural classes: Bach +ed= ?; onset sl/*sr, *shl/shr Also: position, stress, syllable, …
Different ranges: seems to be unbounded Hungarian (Hayes & Londe): ablak-nak / kert-nek; paller-nak / mutagen-nek English: *sCVC, *sNVN (skok? spab? smin?)

4
Towards a parametric model of phonotactics Parameter explosion seems unavoidable
Searching over all possible natural classes? Searching over unbounded ranges?
Data sparsity problem serious Esp. if counting type rather than token
frequency Isolate generalization at specific
positions/configurations with templates Need theory for templates (why sCVC?) Templates for everything? Non-parametric/parametric boundary blurred

5
Towards a parametric model of phonotactics Critical survey of literature needed
How can phonological theory constrain parametric models of phonotactics?
Homework assignment (count as 2-3): a phonotactics literature review E.g. V-V, C-C, V-C interaction, natural
classes, positions, templates, … Extra credit if also present ideas about
how they are related to modeling

6
OT and phonological acquisition
Isn’t data sparsity already a familiar issue? Old friend: “poverty of stimulus” -- training
data vastly insufficient for learning the distribution (recall: the limit sample size 0)
+
-

7
OT and phonological acquisition
Isn’t data sparsity already a familiar issue? Old friend: “poverty of stimulus” -- training
data vastly insufficient for learning the distribution (recall: the limit sample size 0)
+
-

8
OT and phonological acquisition
Isn’t data sparsity already a familiar issue? Old friend: “poverty of stimulus” -- training
data vastly insufficient for learning the distribution (recall: the limit sample size 0)
Maybe the view is wrong: forget distribution in a certain language, focus on universals

9
OT and phonological acquisition
Isn’t data sparsity already a familiar issue? Old friend: “poverty of stimulus” -- training
data vastly insufficient for learning the distribution (recall: the limit sample size 0)
Maybe the view is wrong: forget distribution in a certain language, focus on universals
Standard OT: generalization hard-coded, abandon the huge parameter space Justification: only consider the ones that are
plausible/attested Learning problem made easier?

10
OT learning: constraint demotion
Example: English (sibilant+liquid) onset Somewhat motivated constraints: *sh+C,
*sr, Ident(s), Ident(sh). Starting equal. Demote constraints that prefer the wrong
guysSri Lanka *sr *shC Ident(s) Ident(sh
)
shri
*sri
*Example adapted from A. Albright

11
OT learning: constraint demotion Now, pass shleez/sleez to the learner
No negative evidence: shl never appeared in English
Conservative strategy: underlying form same as the surface by default (richness of the base)
/shleez/
*sr *shC Ident(s) Ident(sh)
shleez
sleez

12
Biased constraint demotion(Hayes, Prince & Tesar) Why the wrong generalization?
Faithfulness -- Ident(sh) is high, therefore allowing underlying sh to appear everywhere
In general: faithfulness high leads to “too much” generalization in OT
C.f. the subset principle Recipe: keep faithfulness as low as
possible, unless evidence suggests otherwise Hope: learn the “most restrictive” language What kind of evidence?

13
Remarks on OT approaches to phonotactics The issues are never-ending
Not enough to put all F low, which F is low also matters (Hayes)
Mission accomplished? -- Are we almost getting the universal set of F and M?
Even with hard-coded generalization, still takes considerable work to fill all the gaps (e.g. sC/shC, *tl/*dl) Why does bwa sounds better than tla
(Moreton)

14
Two worlds Statistical model and OT seem to ask
different questions about learning OT/UG: what is possible/impossible?
Hard-coded generalizations Combinatorial optimization (sorting)
Statistical: among the things that are possible, what is likely/unlikely? Soft-coded generalizations Numerical optimization
Marriage of the two?

15
OT and variation Motivation: systematic variation
that leads to conflicting generalizations Example: Hungarian again (Hayes &
Londe)

16
Proposals on getting OT to deal with variation Partial order rather than total order of
constraints (Antilla) Don’t predict what’s more likely than others
Floating constraints (historical OT people) Can’t really tell what the range is
Stochastic OT (Boersma, Hayes) Does produce a distribution Moreover, a generative model Somewhat unexpected complexity

17
Stochastic OT Want to set up a distribution to learn. But
distribution over what? GEN? -- This does not lead to conflicting
generalizations from a fixed ranking One idea: distribution over all grammars (also
see Yang’s P&P framework) How many OT grammars? --(N!)
Lots of distributions are junk, e.g. (1,2,…N)~0.5, (N,N-1,…,1)~0.5; everything else zero
Idea: constrain the distribution over N! grammars with (N-1) ranking values

18
Stochastic Optimality Theory:Generation Canonical OT
Stochastic OT C1 C3 C2 Sample and evaluate
ordering
C1<<C3<<C2

19
What is the nature of the data? Unlike previous generative models, here
the data is relational Candidates have been “pre-digested” as
violation vectors Candidate pairs (+ frequency) contain
information about the distribution over grammars
Similar scenario: estimating numerical (0-100) grades from letter grades (A-F).

20
Stochastic Optimality Theory:Learning Canonical OT
Stochastic OT
(C1>>C3) (C2>>C3)
max {C1, C2} > C3 ~ .77max {C1, C2} < C3 ~ .23
“ranking values”: G = (1, … , N) RN
???Ordinal data (D)

21
Gradual Learning Algorithm (Boersma & Hayes) Two goals
A robust method for learning standard OT(note: arbitrary noise-polluted OT ranking is a graph cut problem -- NP)
A heuristic for learning Stochastic OT Example: mini grammar with
variation/ba/ P(.) *[+voice]
Ident(voice)
ba 0.5 *
pa 0.5 *

22
How does GLA work Repeat for many times (forced to stop)
Pick a winner by throwing a dice according to P(.) Adjust constraints with a small value if the
prediction doesn’t match the picked winner Similar to training neural nets
“Propogate” error to the ranking values Some randomness is involved in getting the error
/ba/ P(.) *[+voice]
Ident(voice)
ba 0.5 *
pa 0.5 *

23
GLA is stochastic local search Stochastic local search: incomplete methods,
often work well in practice (esp. for intractable problems), but no guarantee
Need something that works in general

24
GLA as random walk Fix the update values, then GLA
behaves like a “drunken man”: Probability of moving in each
direction only depends on where you are
In general, does not “wander off”
Ranking value of *[+voi]
Ident(voi) Possible moves for GLA

25
Stationary distributions Suppose, we have a zillion GLA running
around independently, and look at their “collective answer” If they don’t wander off, than this answer
does’t change much after a while -- convergence to the stationary distribution
Equivalent to looking at many runs of just one program

26
The Bayesian approach to learning Stochastic OT grammars Key idea: simulating a distribution
with computer power What is a meaningful stationary
distribution? The posterior distribution p(G|D) --
peaks at grammars that explain the data well
How to construct a random walk that will eventually reach p(G|D)? Technique: Markov-chain Monte-Carlo

27
An example of Bayesian inference Guessing the heads-on probability
of a bent coin from the outcome of coin tosses
Prior Posteriorafter seeing1 head
Posteriorafter seeing10 heads
Posteriorafter seeing100 heads

28
Why Bayesian? Maximum-Likelihood difficult
Need to deal with product of integrals! Likelihood of d: “max {C1, C2} > C3”
No hope this can be done in a tractable way
Bayesian method gets around doing calculus all together

29
Data Augmentation Scheme for Stochastic OT Paradoxical aspect: “more is easier”
“Missing Data” (Y): the real values of constraints that generate the ranking d
G – grammar
Y – missing data
d: “max {C1, C2} > C3”
Idea: simulate P(G,Y|D) is easier than P(G|D)

30
Gibbs sampling for Stochastic OT p(G|Y,D)=p(G|Y) is easy: sampling
mean from normal posterior ~ Random number generation:
P(G|Y) ~ P(Y|G)P(G) p(Y|G,D) can also be done: fix each
d, then sample Y from G , so that d holds – use rejection sampling Another round of random generation
Gibbs sampler: iterate, and get p(G,Y|D) – works in general

31
Bayesian simulation: No need for integration! Once have samples (g,y) ~ p(G,Y|
D), g ~ p(G|D) is automatic
Use a few startingpoints to monitorconvergence
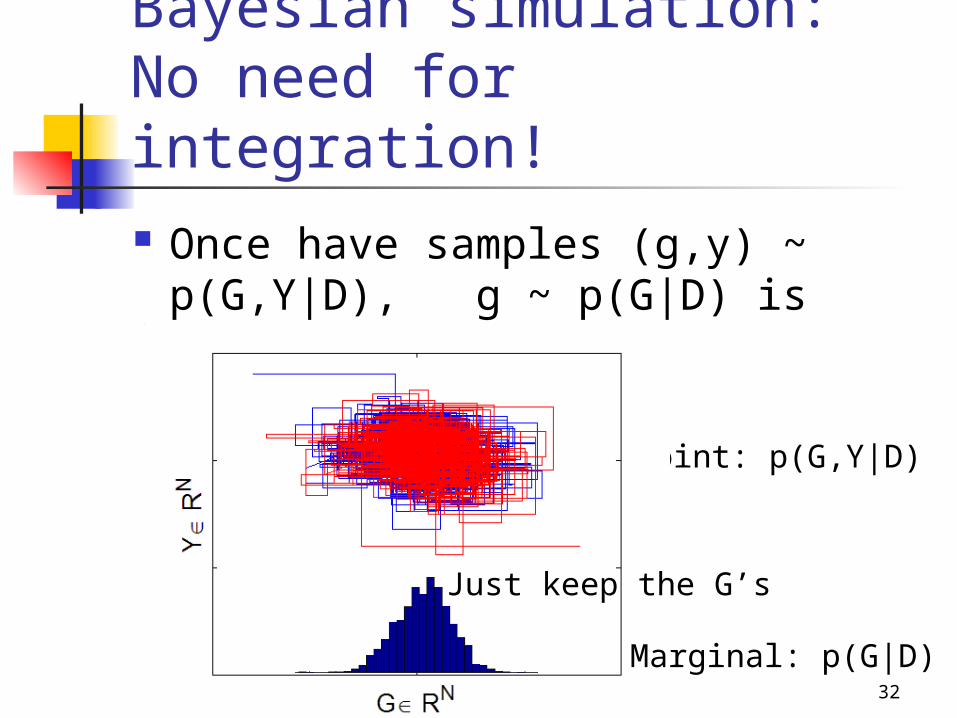
32
Bayesian simulation: No need for integration! Once have samples (g,y) ~ p(G,Y|
D), g ~ p(G|D) is automatic
Joint: p(G,Y|D)
Marginal: p(G|D)
Just keep the G’s

33
Result: Stringency Hierarchy Posterior marginal of the 3
constraints
grammar used for generation
*VoiceObs(coda)
Ident(voice)
*VoiceObs

34
Conditional sampling of parameters p(G|Y,D) Given Y, G is independent of D. So
p(G|Y,D) = p(G|Y) Sampling from p(G|Y) is just regular
Bayesian statistics: p(G|Y)~p(Y|G)p(G)
p(Y|G) is normal with mean \bar{y} and variance \sigma^2/m
p(G) is chosen to have infinite variance – an “uninformative” prior

35
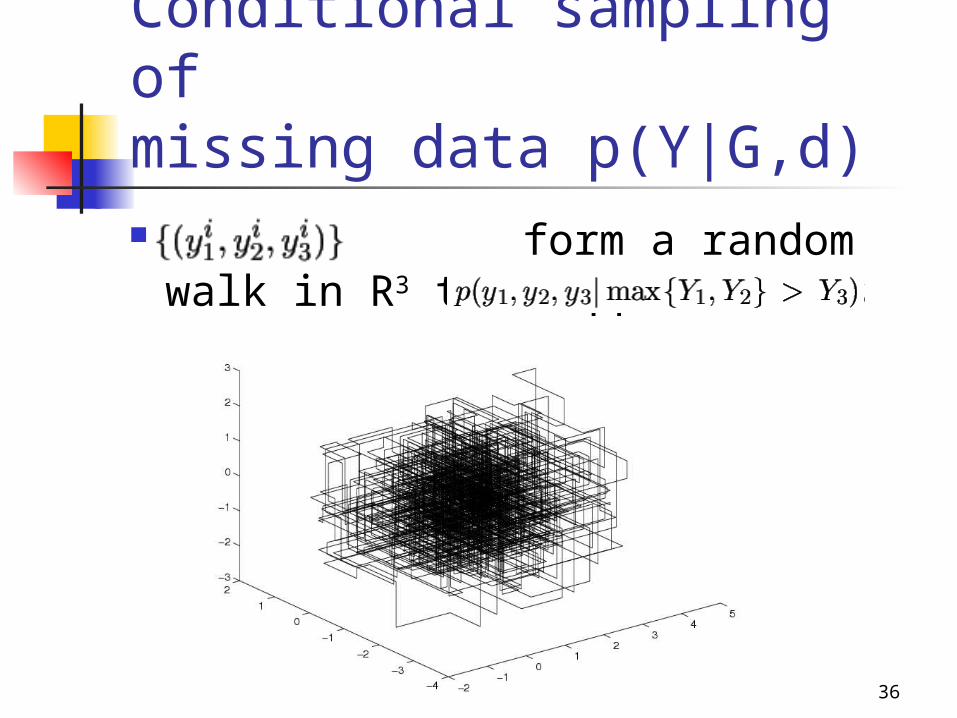
Conditional sampling ofmissing data p(Y|G,d) Idea: decompose Y into (Y_1, …, Y_N), and
sample one at a time Example: d = “max {C1, C2} > C3”
Easier than !
36
Conditional sampling ofmissing data p(Y|G,d) form a random walk in R3
that approximates

37
Sampling tails of Gaussians Direct sampling can be very slow
Need samples from tail
For efficiency: rejection sampling with exponential density envelope
Envelope Target
Shape of envelope optimized for minimal rejection rate

38
Ilokano-like grammar Is there a grammar that will generate p(.)?
Not obvious, since the interaction is not pair-wise. GLA always slightly off

39
Results from Gibbs sampler: Yes, and most likely unique

40
There may be many grammars: Finnish

41
Summary Two perspectives on the
randomized learning algorithm A Bayesian statistics simulation A general stochastic search scheme
Bayesian methods often provide approximate solutions to hard computational problems The solution is exact if allowed to run
forever