1 outline for today objective –physical page placement matters power-aware memory superpages...
TRANSCRIPT

1
Outline for Today
• Objective– Physical Page Placement matters
• Power-aware memory• Superpages
• Announcements– Deadline extended (wrong kernel was our
fault)

Memory System Power Consumption
• Laptop: memory is small percentage of total power budget
• Handheld: low power processor, memory is more important
Memory
Other
Memory
Other
Laptop Power Budget9 Watt Processor
Handheld Power Budget1 Watt Processor
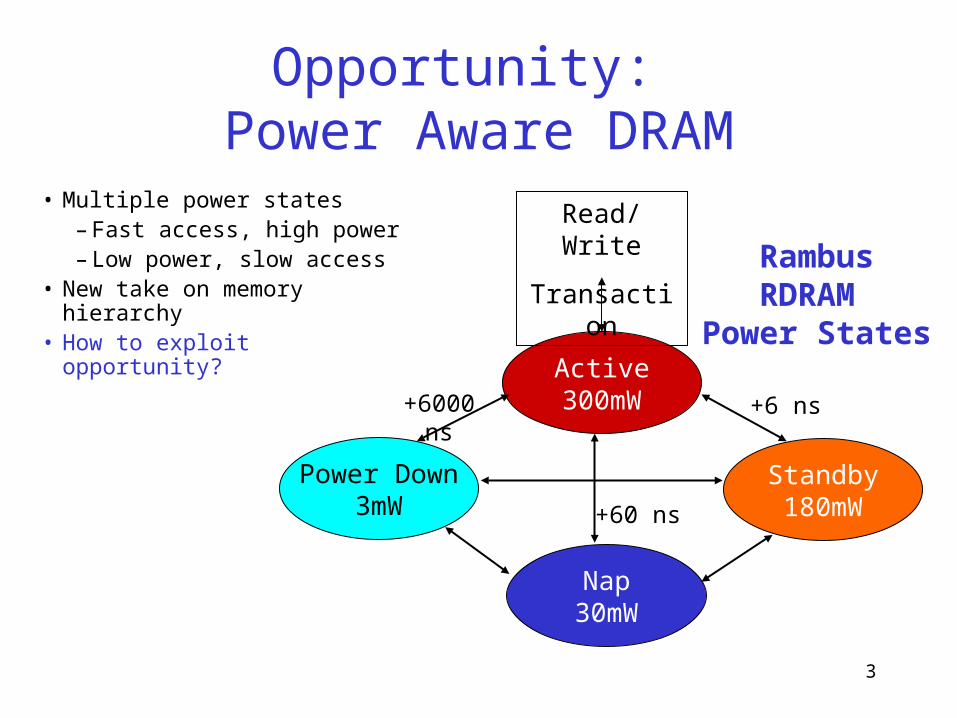
3
Opportunity: Power Aware DRAM
• Multiple power states– Fast access, high power– Low power, slow access
• New take on memory hierarchy
• How to exploit opportunity?
Standby180mW
Active300mW
Power Down3mW
Nap30mW
Read/Write
Transaction
+6 ns+6000 ns
+60 ns
RambusRDRAM
Power States

4
RDRAM as a Memory Hierarchy
• Each chip can be independently put into appropriate power mode
• Number of chips at each “level” of the hierarchy can vary dynamically.
Active Nap
Policy choices– initial page placement in an
“appropriate” chip– dynamic movement of page
from one chip to another– transitioning of power state of
chip containing page
Active

5
CPU/$
Chip 0
Chip 1
Chip 3
RAMBUS RDRAM Main Memory Design
Chip 2
Part of Cache Block
• Single RDRAM chip provides high bandwidth per access– Novel signaling scheme transfers multiple bits on one wire– Many internal banks: many requests to one chip
• Energy implication: Activate only one chip to perform access at same high bandwidth as conventional design
Power DownStandbyActive

6
CPU/$
Chip 0
Chip 1
Chip 3
Conventional Main Memory Design
Chip 2
Part of Cache Block
• Multiple DRAM chips provide high bandwidth per access– Wide bus to processor– Few internal banks
• Energy implication: Must activate all those chips to perform access at high bandwidth
Active Active Active Active

8
Exploiting the Opportunity
Interaction between power state model and access locality
• How to manage the power state transitions?– Memory controller policies– Quantify benefits of power states
• What role does software have?– Energy impact of allocation of data/text to
memory.

9
CPU/$
OS Page Mapping
Allocation
Chip 0
Chip 1
Chip n-1
Power Down
StandbyActive
ctrl ctrl ctrl
Hardware control
Software control
• Properties of PA-DRAM allow us to access and control each chip individually
• 2 dimensions to affect energy policy: HW controller / OS
• Energy strategy:
– Cluster accesses to already powered up chips
– Interaction between power state transitions and data locality
Power-Aware DRAM Main Memory Design

10
Power State Transitioning
time
requestscompletionof last request in run
gap
phigh
plowph->l pl->h
phighth->l tl->h
tbenefit
(th->l + tl->h + tbenefit ) * phigh > th->l * ph->l + tl->h * pl->h + tbenefit * plow
Ideal case:Assume we wantno added latency
constant

12
Power State Transitioning
time
requestscompletionof last request in run
gap
phigh
plowph->l
phighth->l tl->h
On demand case-adds latency oftransition back uppl->h

13
Power State Transitioning
time
requestscompletionof last request in run
gap
phigh
plowph->l pl->h
phighth->l tl->h
Threshold based-delays transition down
threshold

14
Page Allocation Polices
Virtual to Physical Page Mapping• Random Allocation – baseline policy
– Pages spread across chips
• Sequential First-Touch Allocation– Consolidate pages into minimal number of chips– One shot
• Frequency-based Allocation– First-touch not always best– Allow (limited) movement after first-touch

15
Power-Aware Virtual Memory Based On Context Switches
Huang, Pillai, Shin, “Design and Implementation of Power-Aware Virtual Memory”, USENIX 03.
• Power state transitions under SW control (not HW controller)• Treated explicitly as memory hierarchy: a process’s active set of nodes
is kept in higher power state• Size of active node set is kept small by grouping process’s pages in
nodes together – “energy footprint” – Page mapping - viewed as NUMA layer for implementation
– Active set of pages, i, put on preferred nodes, i
• At context switch time, hide latency of transitioning– Transition the union of active sets of the next-to-run and likely next-after-
that processes to standby (pre-charging) from nap– Overlap transitions with other context switch overhead

16
CPU/$
OS Page Mapping
Allocation
Chip 0
Chip 1
Chip n-1
NapStandbyActive
ctrl ctrl ctrl
Software control
• Properties of PA-DRAM allow us to access and control each chip individually
• 2 dimensions to affect energy policy: HW controller / OS
• Energy strategy:
– Cluster accesses to preferred memory nodes per process
– OS triggered power state transitions on context switch
Power-Aware DRAM Main Memory Design

17
Rambus RDRAM
Standby225mW
Active313mW
Power Down7mW
Nap11mW
Read/Write
Transaction
+3 ns
+22510 ns
+20 ns
RambusRDRAM
Power States
+20 ns
+225 ns

18
RDRAM Active Components
Refresh Clock Rowdecoder
Coldecoder
Active X X X X
Standby X X X
Nap X X
Pwrdn X

19
Determining Active Nodes• A node is active iff at least one page from the node is mapped into process i’s
address space.• Table maintained whenever page is mapped in or unmapped in kernel.• Alternatives
rejected due to overhead:– Extra page faults– Page table scans
• Overhead is onlyone incr/decrper mapping/unmapping op
count n0 n1 … n15
p0108 2 17
…
pn193 240 4322

20
Implementation Details
Problem: DLLs and files shared by multiple processes (buffer cache) become scattered all over memory with a straightforward assignment of incoming pages to process’s active nodes – large energy footprints afterall.

21
Implementation DetailsSolutions:• DLL Aggregation
– Special case DLLs by allocating Sequential first-touch in low-numbered nodes
• Migration– Kernal thread – kmigrated – running in background
when system is idle (waking up every 3s)– Scans pages used by each process, migrating if
conditions met• Private page not on
• Shared page outside i

22

23
Evaluation Methodology• Linux implementation• Measurements/counts taken of events and
energy results calculated (not measured)• Metric – energy used by memory (only).• Workloads – 3 mixes: light (editting, browsing,
MP3), poweruser (light + kernel compile), multimedia (playing mpeg movie)
• Platform – 16 nodes, 512MB of RDRAM• Not considered: DMA and kernel maintenance
threads

24
Results
• Base – standby when not accessing
• On/Off –nap when system idle
• PAVM

25
Results
• PAVM• PAVMr1 - DLL
aggregation• PAVMr2 –
both DLL aggregation & migration

26
Results

27
Conclusions
• Multiprogramming environment.
• Basic PAVM: save 34-89% energy of 16 node RDRAM
• With optimizations: additional 20-50%
• Works with other kinds of power-aware memory devices

Discussion: What about page replacement
policies? Should (or how could) they
be power-aware?

29
Related Work
• Lebeck et al, ASPLOS 2000 – dynamic hardware controller policies and page placement
• Fan et al– ISPLED 2001– PACS 2002
• Delaluz et al, DAC 2002

30
Dual-state HW Power State Policies
• All chips in one base state• Individual chip Active
while pending requests• Return to base power
state if no pending access
access
No pending access
Standby/Nap/Powerdown
Active
access
Time
Base
Active
Access

31
Quad-state HW Policies
• Downgrade state if no access for threshold time
• Independent transitions based on access pattern to each chip
• Competitive Analysis– rent-to-buy
– Active to nap 100’s of ns
– Nap to PDN 10,000 ns
no access for Ts-n
no access for Ta-s
no access for Tn-p
accessaccess
accessaccess
Active STBY
NapPDN
Time
PDN
ActiveSTBYNap
Access

33
Page Allocation Polices
Virtual to Physical Page Mapping• Random Allocation – baseline policy
– Pages spread across chips
• Sequential First-Touch Allocation– Consolidate pages into minimal number of chips– One shot
• Frequency-based Allocation– First-touch not always best– Allow (limited) movement after first-touch

48
Summary of Results (Energy*Delay product, RDRAM,
ASPLOS00)
Quad-stateHardware
Dual-stateHardware
RandomAllocation
SequentialAllocation
Nap is best dual-state policy60%-85%
Additional10% to 30% over Nap
Improvement not obvious,Could be equal to dual-state
Best Approach:6% to 55% over dual-nap-seq,80% to 99% over all active.
2 statemodel
4 statemodel

50
OS Support for Superpages
Juan Navarro, Sitaram Iyer, Peter Druschel, Alan CoxOSDI 2002
• Increasing cost in TLB miss overhead– growing working sets– TLB size does not grow at same pace
• Processors now provide superpages– one TLB entry can map a large region
• OSs have been slow to harness them– no transparent superpage support for apps
• Proposed: a practical and transparent solution to support superpages

51
Translation look-aside buffer• TLB caches virtual-to-physical address
translations
• TLB coverage – amount of memory mapped by TLB– amount of memory that can be accessed
without TLB misses

52
TLB coverage trend
0.001%
0.01%
0.1%
1.0%
10.0%
1985 1990 1995 2000
TLB coverage as percentage of main memory
Factor of 1000 decrease in
15 years
TLB miss overhead:
5% 5-10%
30%

53
How to increase TLB coverage
• Typical TLB coverage 1 MB
• Use superpages!– large and small pages
• Increase TLB coverage– no increase in TLB size– no internal fragmentation
If only large pages:larger working sets, more I/O.

54
What are these superpages anyway?
• Memory pages of larger sizes– supported by most modern CPUs
• Otherwise, same as normal pages– power of 2 size– use only one TLB entry– contiguous– aligned (physically and virtually)– uniform protection attributes– one reference bit, one dirty bit

55
A superpage TLB
base page entry (size=1)
superpage entry (size=4)
physical memory
virtual memory
virtualaddress
TLB
physicaladdress
Alpha: 8,64,512KB; 4MB
Itanium:4,8,16,64,256KB; 1,4,16,64,256MB

The superpage problem

57
Issue 1: superpage allocation
virtual memory
physical memory
superpage boundaries
B
B
A
A
C
C
D
D A B C D
How / when / what size to allocate?How / when / what size to allocate?

58
Issue 2: promotion• Promotion: create a superpage out of a
set of smaller pages– mark page table entry of each base page
• When to promote?
Create small superpage?May waste overhead.
Wait for app to touch pages? May lose opportunity to increase
TLB coverage.
Forcibly populate pages?May cause internal fragmentation.

59
Issue 3: demotion
• when page attributes of base pages of a superpage become non-uniform
• during partial pageouts
Demotion: convert a superpage into smaller pages

60
Issue 4: fragmentation
• Memory becomes fragmented due to– use of multiple page sizes– persistence of file cache pages– scattered wired (non-pageable) pages
• Contiguity: contended resource• OS must
– use contiguity restoration techniques– trade off impact of contiguity restoration against
superpage benefits

Design

62
Key observationOnce an application touches the first page
of a memory object then it is likely that it will quickly touch every page of that object
• Example: array initialization
• Opportunistic policies– superpages as large and as soon as possible– as long as no penalty if wrong decision

63
Superpage allocation
virtual memory
physical memory
superpage boundaries
B
Preemptible reservations
B
reserved frames
D
D
A
A
C
C
How much do we reserve? Goal: good TLB coverage,
without internal fragmentation.

64
Allocation: reservation size
Opportunistic policy
• Go for biggest size that is no larger than the memory object (e.g., file)
• If size not available, try preemption before resigning to a smaller size– preempted reservation had its chance

65
Allocation: managing reservations
largest unused (and aligned) chunk
best candidate for preemption at front: reservation whose most recently populated
frame was populated the least recently
1
2
4

66
Incremental promotionsPromotion policy: opportunistic
2
4
4+2
8

67
Speculative demotions
• One reference bit per superpage– How do we detect portions of a superpage
not referenced anymore?
• On memory pressure, demote superpages when resetting ref bit
• Re-promote (incrementally) as pages are referenced

68
Demotions: dirty superpages• One dirty bit per superpage
– what’s dirty and what’s not?– page out entire superpage
• Demote on first write to clean superpage
write
Re-promote (incrementally) as other pages are dirtied

69
Fragmentation control• Low contiguity: modified page daemon
– restore contiguity• move clean, inactive pages to the free list
– minimize impact • prefer pages that contribute the most to
contiguity• keep contents for as long as possible
(even when part of a reservation: if reactivated, break reservation)
• Cluster wired pages

Experimentalevaluation

71
Experimental setup
• FreeBSD 4.3
• Alpha 21264, 500 MHz, 512 MB RAM
• 8 KB, 64 KB, 512 KB, 4 MB pages
• 128-entry DTLB, 128-entry ITLB
• Unmodified applications

72
Best-case benefits• TLB miss reduction usually above 95%• SPEC CPU2000 integer
– 11.2% improvement (0 to 38%)
• SPEC CPU2000 floating point– 11.0% improvement (-1.5% to 83%)
• Other benchmarks– FFT (2003 matrix): 55%– 1000x1000 matrix transpose: 655%
• 30%+ in 8 out of 35 benchmarks

74
Why multiple superpage sizes
Improvements with only one superpage size vs. all sizes
64KB 512KB 4MB All
FFT 1% 0% 55% 55%
galgel 28% 28% 1% 29%
mcf 24% 31% 22% 68%

76
Conclusions
• Superpages: 30%+ improvement– transparently realized; low overhead
• Contiguity restoration is necessary– sustains benefits; low impact
• Multiple page sizes are important– scales to very large superpages