1 scalable formal dynamic verification of mpi programs through distributed causality tracking...
Post on 19-Dec-2015
225 views
TRANSCRIPT

1
Scalable Formal Dynamic Verification of MPI Programs through Distributed Causality Tracking
Dissertation Defense
Anh Vo
Committee: Prof. Ganesh Gopalakrishnan (co-advisor), Prof. Robert M. Kirby (co-advisor),
Dr. Bronis R. de Supinski (LLNL), Prof. Mary Hall and Prof. Matthew Might

2
Our computational ambitions are endless!• Terascale
• Petascale (where we are now)
• Exascale
• Zettascale• Correctness is important
Jaguar, Courtesy ORNL
Protein Folding, Courtesy Wikipedia
Computation Astrophysics, Courtesy LBL

3Yet we are falling behind when it comes to correctness
• Concurrent software debugging is hard• It gets harder as the degree of parallelism in applications
increases– Node level: Message Passing Interface (MPI)– Core level: Threads, OpenMPI, CUDA
• Hybrid programming will be the future– MPI + Threads – MPI + OpenMP– MPI + CUDA
• Yet tools are lagging behind!– Many tools cannot operate at scale
MPI AppsMPI Correctness Tools

4
We focus on dynamic verification for MPI
• Lack of systematic verification tools for MPI
• We need to build verification tools for MPI first– Realistic MPI programs run at large scale– Downscaling might mask bugs
• MPI tools can be expanded to support hybrid programs

5
We choose MPI because of its ubiquity
• Born 1994 when the world had 600 internet sites, 700 nm lithography, 68 MHz CPUs
• Still the dominant API for HPC– Most widely supported and understood– High performance, flexible, portable

6
Thesis statement
Scalable, modular and usable dynamic verification of realistic MPI programs is feasible
and novel.

7
Contributions• Need scalable distributed algorithms to discover alternate
schedules– Using only local states and observed matches– Matches-before ( is necessary
• DAMPI– Distributed Analyzer for MPI programs– Implements distributed causality tracking using matches-before
• ISP (previous work)– Dynamic verifier for MPI– Implements a scheduler which exerts control to enforce matches-before
• Publications: PACT 2011 (in submission), SC 2010, FM 2010, EuroPVM 2010, PPoPP 2009, EuroPVM 2009

8
Agenda
• Motivation and Contributions• Background• MPI ordering based on Matches-Before• The centralized approach: ISP• The distributed approach: DAMPI• Conclusions

9
• Example: Deterministic operations are permuted
MPI_Barrier MPI_Barrier … MPI_Barrier
P1 P2 … Pn
Exploring all n! permutations is wasteful
Traditional testing is wasteful….

10
10
P0---
MPI_Send(to P1…);
MPI_Send(to P1, data=22);
P1---
MPI_Recv(from P0…);
MPI_Recv(from P2…);
MPI_Recv(*, x);
if (x==22) then ERROR else MPI_Recv(*, x);
P2---
MPI_Send(to P1…);
MPI_Send(to P1, data=33);
Unlucky (bug missed)
Testing can also be inconclusive; without non-determinism coverage, we can miss bugs

11
11
P0---
MPI_Send(to P1…);
MPI_Send(to P1, data=22);
P1---
MPI_Recv(from P0…);
MPI_Recv(from P2…);
MPI_Recv(*, x);
if (x==22) then ERROR else MPI_Recv(*, x);
P2---
MPI_Send(to P1…);
MPI_Send(to P1, data=33);
Lucky (bug caught!)
Testing can also be inconclusive; without non-determinism coverage, we can miss bugs

12
12
P0---
MPI_Send(to P1…);
MPI_Send(to P1, data=22);
P1---
MPI_Recv(from P0…);
MPI_Recv(from P2…);
MPI_Recv(*, x);
if (x==22) then ERROR else MPI_Recv(*, x);
P2---
MPI_Send(to P1…);
MPI_Send(to P1, data=33);
Verification: test all possible scenarios
• Find all possible matches for the receive– Ability to track causality is a prerequisite
• Replay the program and force the other matches

13
Dynamic verification of MPI
• Dynamic verification combines strength of formal methods and testing– Avoids generating false alarms– Finds bugs with respect to actual binaries
• Builds on the familiar approach of “testing”
• Guarantee coverage over nondeterminism

14
Overview of Message Passing Interface (MPI)
• An API specification for communication protocols between processes
• Allows developers to write high performance and portable parallel code
• Rich in features– Synchronous: easy to use and understand– Asynchronous: high performance– Nondeterministic constructs: reduce code
complexity

15
MPI operations
MPI_Send(void* buffer, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm)send(P,T)send(P)
MPI_Recv(void* buffer, int count, MPI_Datatype type, int src, int tag, MPI_Comm comm, MPI_Status status)
send(P,T)- send a message with tag T to process P
recv(P,T)- recv a message with tag T from process Precv(*,T)- recv a message with tag T from any processrecv(*,*)- recv a message with any tag from any processMPI_Isend(void* buffer, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request h)isend(P,T,h) – nonblocking send, communication handle h
irecv(P,T,h) – nonblocking recv, communication handle hirecv(*,T,h)irecv(*,*,h)
MPI_Irecv(void* buffer, int count, MPI_Datatype type, int src, int tag, int comm, MPI_Request h)
MPI_Wait(MPI_Request h, MPI_Status status)wait(h) – wait for the completion of h
barrier – synchronizationMPI_Barrier(MPI_Comm comm)

16
Nonovertaking rule facilitates message matching
• Sender sends two messages:– Both can match to a receive operation– First message will match before second message
• Receiver posts two receives:– Both can match with an incoming message– First receive will match before second receive
P0
P1
send(1) send(1)
recv(0) recv(0)
P0
P1
send(1) send(1)
recv(*) recv(0)
P0
P1
send(1) send(1)
irecv(*) recv(0)

17
Happens-before is the basis of causality tracking
• e1 happens-before () e2 iff:– e1 occurs before e2 in the same process
– e1 is the sending of a message m and e2 receives it
– e1 e3 and e3 e2
a
b c
d
e
f
a eb cd f
a bc de f
a ca da fb db fc f

18
Tracking causality with Lamport clocks• Each process keeps a clock (an integer)• Increase the clock when it has an event• Attach the clock to outgoing messages (piggyback)• Upon receiving piggybacked clock, update the clock to the value
greater or equal to its clock, but higher than the piggybacked clock
1a
2b 3c
4d
2e
5f
If e1 e2 then the clock of e1 is less than the clock of e2
What about e and d? The converse does not hold!

19
Tracking causality with vector clocks• Each process keeps a vector of clocks (VC)• Increase its clock component when it has an event• Attach the VC to outgoing messages (piggyback)• Upon receiving piggybacked VC clock, update each component to the
maximum between the current VC and the piggybacked VC
1,0,0a
1,1,0b 1,2,0c
1,2,1d
2,0,0e
2,2,2f
What about e and d? They are concurrent!
e1 e2 iff VC of e1 is less than VC e2

20
Agenda
• Motivation and Contributions• Background• Matches-Before for MPI• The centralized approach: ISP• The distributed approach: DAMPI• Conclusions

21
The necessity for matches-before
• The notion of happening does not mean much• Local ordering does not always hold– For example, P0: send(1); send(2);
• The notion of completion also does not work
P0---send (1)send (1)
P1---irecv (*,h)recv (*)wait(h)
The irecv(*) happens before the recv(*) but completes after it

22
Possible states of an MPI call
• All possible states of an MPI call– Issued– Matched– Completed– Returned
• It’s always possible to know exactly which state the call is in– Except for the Matched state, which has a matching
window
P1
isend(0,h1)barriersend(0)wait(h1)
P2
irecv(0,h2)barrierrecv(0)wait(h2)

23
Definition of matches-before• recv, barrier, and wait match before all the calls following it• sends and receives have matches-before order according to the
non-overtaking rule• Nonblocking calls match before their waits• Matches-before is irreflexive, asymmetric and transitive
isend(0,h1) send(0)barrier wait(h1)
irecv(0,h2) recv(0)barrier wait(h2)

24
The role of match-sets• When a send and a receive match, they form a match-set• When barriers match, they form a match-set• Members of a match-set do not have • e M iff e (the send call or some barrier call) of M• M e iff (the receive call or some barrier call) of M e
send
recv e2
e1barrier
barrier
barrier
e3

25
Agenda
• Motivation and Contributions• Background• Matches-Before for MPI• The centralized approach: ISP• The distributed approach: DAMPI• Conclusions
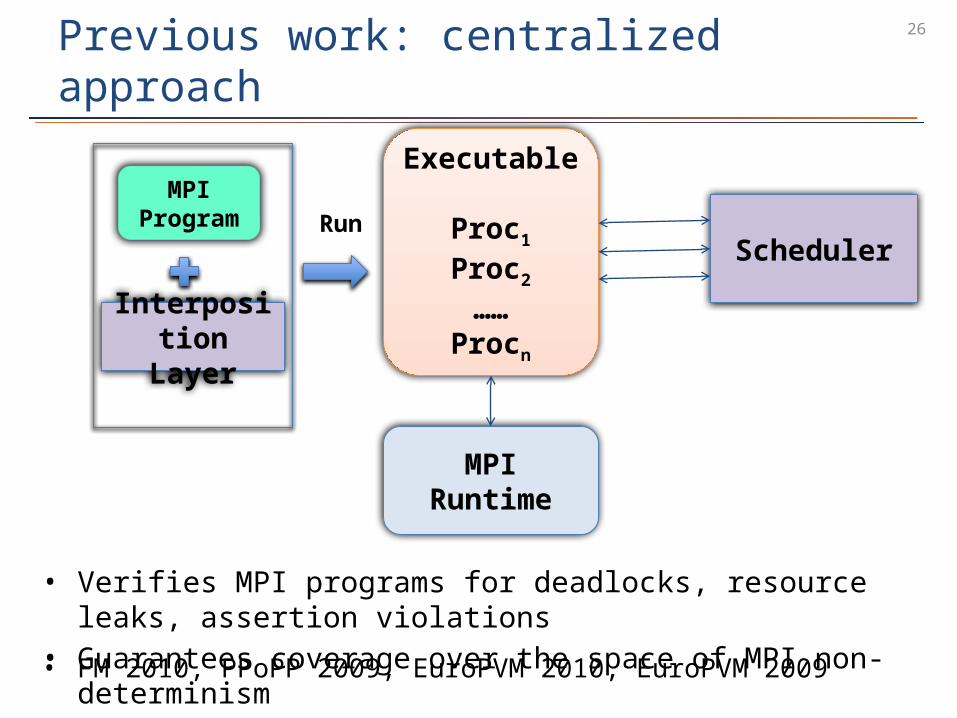
26
Executable
Proc1
Proc2
……Procn
SchedulerRun
MPI Runtime
Previous work: centralized approach
MPI Program
Interposition Layer
• Verifies MPI programs for deadlocks, resource leaks, assertion violations• Guarantees coverage over the space of MPI non-determinism• FM 2010, PPoPP 2009, EuroPVM 2010, EuroPVM 2009

27
Drawbacks of ISP
• Scales only up to 32-64 processes
• Large programs (of 1000s of processes) often exhibit bugs that are not triggered at low ends– Index out of bounds– Buffer overflows– MPI implementation bugs
• Need a truly In-Situ verification method for codes deployed on large-scale clusters!– Verify an MPI program as deployed on a cluster

28
Agenda
• Motivation and Contributions• Background• Matches-Before for MPI• The centralized approach: ISP• The distributed approach: DAMPI• Conclusions

29
DAMPI
• Distributed Analyzer of MPI Programs• Dynamic verification focusing on coverage over
the space of MPI non-determinism• Verification occurs on the actual deployed code• DAMPI’s features:– Detect and enforce alternative outcomes– Scalable– User-configurable coverage

30
DAMPI Framework
Executable
Proc1
Proc2
……Procn
Alternate Matches
MPI runtime
MPI Program
DAMPI - PnMPI modules
Schedule Generator
EpochDecisions
Rerun
DAMPI – Distributed Analyzer for MPI

31
Main idea in DAMPI: Distributed Causality Tracking• Perform an initial run of the MPI program
• Track causalities (discover which alternative non-deterministic matches could have occurred)
• Two alternatives:– Use of Vector Clocks (thorough, but non-scalable)– Use Lamport Clocks (our choice)
• Omissions possible – but only in unrealistic situations
• Scalable!

32DAMPI uses Lamport clocks to maintainMatches-Before
• Use Lamport clock to track Matches-Before– Each process keeps a logical clock– Attach clock to each outgoing message– Increases it after a nondeterministic receive has matched
• Mb allows us to infer when irecv’s match
– Compare incoming clock to detect potential matches
barrier[0]
irecv(*)[0]
recv(*)[1]
send(1)[0]
send(1)[0]
P0
P1
P2
barrier[0]
barrier[0]
wait[2]
Excuse me, why is the second
send RED?
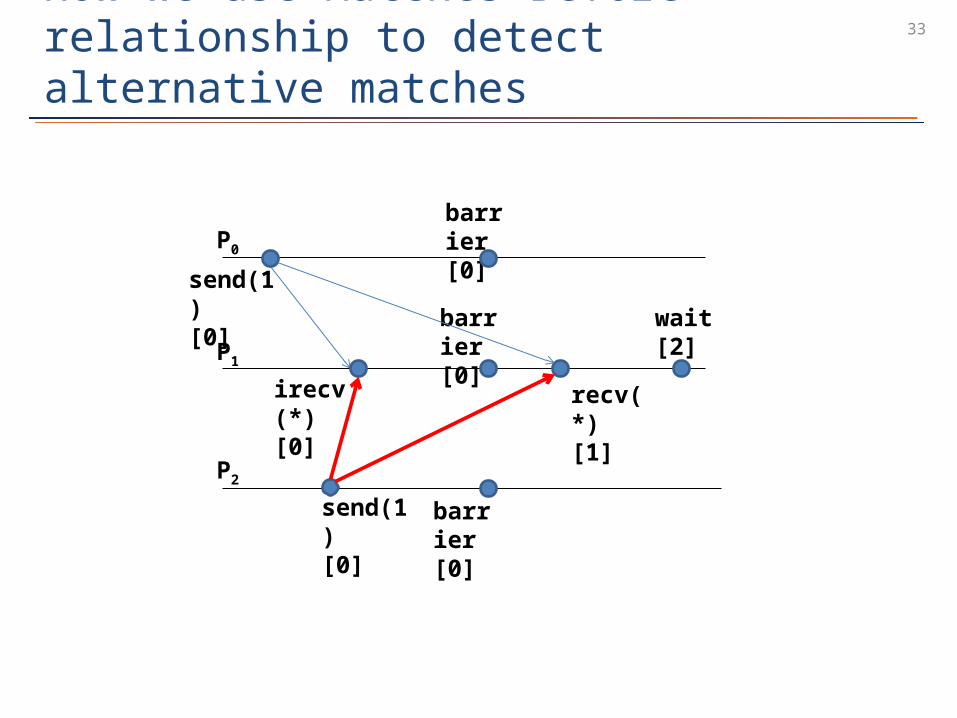
33How we use Matches-Before relationship to detect alternative matches
barrier[0]
irecv(*)[0]
recv(*)[1]
send(1)[0]
send(1)[0]
P0
P1
P2
barrier[0]
barrier[0]
wait[2]
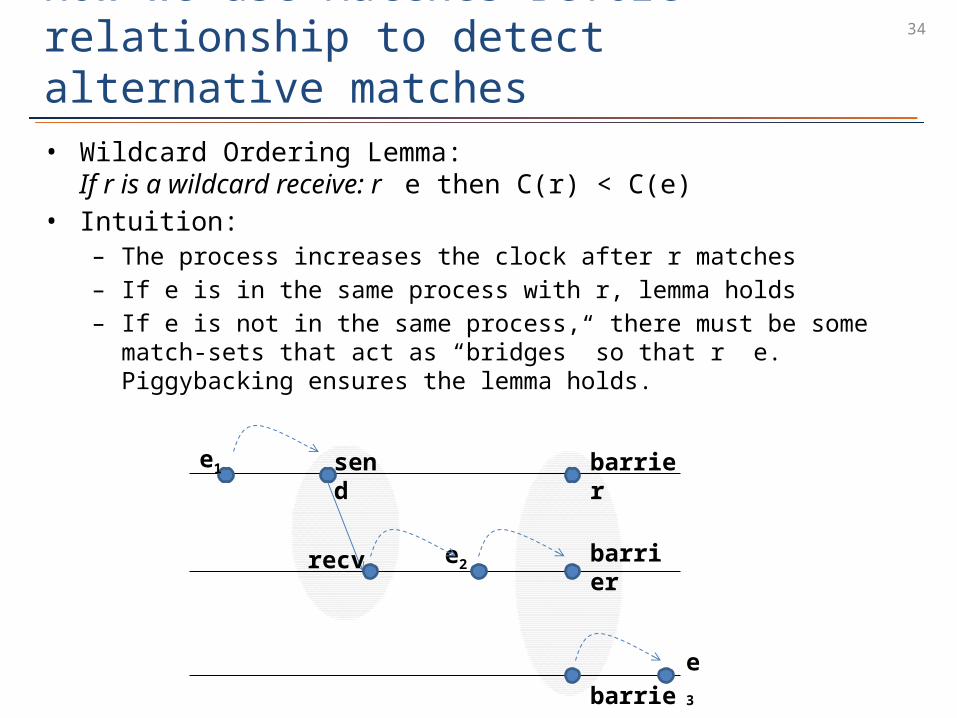
34How we use Matches-Before relationship to detect alternative matches• Wildcard Ordering Lemma:
If r is a wildcard receive: r e then C(r) < C(e)• Intuition:
– The process increases the clock after r matches– If e is in the same process with r, lemma holds– If e is not in the same process, there must be some match-sets that act as
“bridges” so that r e. Piggybacking ensures the lemma holds.
send
recv e2
e1 barrier
barrier
barriere3

35How we use Matches-Before relationship to detect alternative matches
barrier[0]
R = irecv(*)[0]
R’= recv(*)[1]
S = send(1)[0]
send(1)[0]
P0
P1
P2
barrier[0]
barrier[0]
wait[2]
• If S R then S R’ , which violates the match-set property– Thus, we have S R
• Wildcard ordering lemma gives : R S• Thus, S and R are concurrent

36
Limitations of Lamport Clock
R1(*)
0
0
0
0
1
pb(3)
S(P2)P0
P1
P2
P3
R2(*)
2
S(P2)
R3(*)
3
S(P2)
pb(0)
pb(0)
pb(0)
R(*)
1
S(P3)
pb(0)
This send is a potential
match
S(P3)
Our protocol guarantees that impossible matches will not be forced (there could be deadlocks otherwise)

37
Lamport Clocks vs Vector Clocks
• DAMPI provides two protocols– Lamport clocks: sound and scalable– Vector clocks: sound and complete
• We evaluate the scalability and accuracy– Scalability: bandwidth, latency, overhead– Accuracy: omissions
• The Lamport Clocks protocol does not have any omissions in practice– MPI applications have well structured communication
patterns

38
Experiments setup
• Atlas cluster in LLNL– 1152 nodes, 8 cores per node– 16GB of memory per node– MVAPICH-2
• All experiments run at 8 tasks per node• Results averaged out over five runs
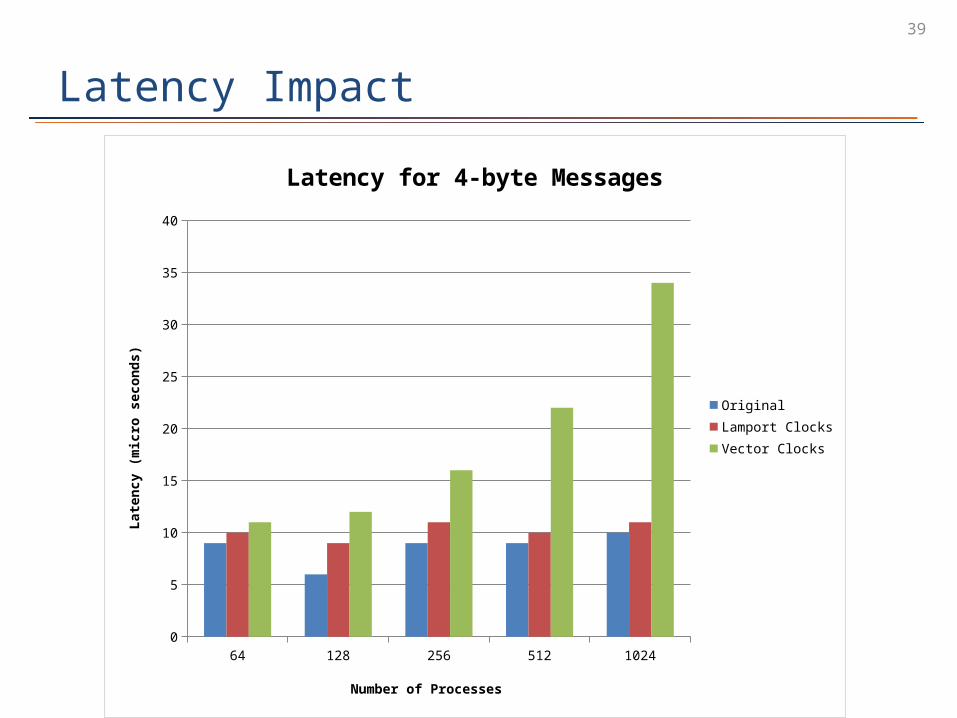
39
Latency Impact
64 128 256 512 10240
5
10
15
20
25
30
35
40
Latency for 4-byte Messages
OriginalLamport ClocksVector Clocks
Number of Processes
Late
ncy
(micr
o se
cond
s)

40
Bandwidth Impact
64 128 256 512 10240
5000
10000
15000
20000
25000
Original
Lamport Clocks
Vector Clocks
Number of Processes
Mes
sage
Size

41
Application overhead – ParMETIS
64 128 256 512 10240
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
ParMETIS-3.1.1
OriginalLamport ClocksVector Clocks
Number of Processes
Slow
dow
n

42
Application overhead – AMG 2006
64 128 256 512 10240
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
AMG2006
OriginalLamport ClocksVector Clocks
Number of Processes
Slow
dow
n

43
Application overhead – SMG2000
64 128 256 512 10240
0.2
0.4
0.6
0.8
1
1.2
1.4
SMG2000
OriginalLamport ClocksVector Clocks
Number of Processes
Slow
dow
n

44
DAMPI’s Implementation Detail: using PnMPI
Executable
Proc1
Proc2
……Procn
Alternate Matches
MPI runtime
MPI Program
DAMPI - PnMPI
modules
Schedule Generator
EpochDecisions
Status module
Request module
Communicator module
Type module
Deadlock module
DAMPI - PnMPI modules
Core Module
Optional Error Checking Module
Piggyback module
DAMPI driver

45
Piggyback implementation details
• MPI does not provide a built-in mechanism to attach piggyback data to messages
• Most common piggyback mechanisms– Attach piggyback to the buffer: • easy to use but expensive
– Send piggyback as a separate message: • low overhead but has issues with wildcard receives
– Using user-defined datatype to transmit piggyback• low overhead, difficult to piggyback on collectives

46
DAMPI uses a mixed piggyback scheme
• Datatype piggyback for point-to-point• Separate message piggyback for collectives
Piggyback Message Data
pb_buf stores piggyback
int MPI_Send(buf,count,user_type,…){ Create new datatype D from pb_buf and buf return PMPI_Send(MPI_BOTTOM,1,D,…);}
int MPI_Recv(buf,count,user_type,…) { Create new datatype D from pb_buf and buf return PMPI_Recv(MPI_BOTTOM,1,D,…);}
Wrapper – Piggyback Layer
Datatype D
Piggyback Message Data
Sending/Receiving(MPI_BOTTOM,1,D) instead of (buffer,count,user_type)
Datatype D

47
Experiments
• Comparison with ISP:– 64-node cluster of Intel Xeon X5550 (8 cores per
node, 2.67 GHZ), 24GB RAM per node– All experiments were run with 8 tasks per node
• Measuring overhead of DAMPI:– 800-node cluster of AMD Opteron (16 cores per
node, 2.3GHZ), 32GB RAM per node– All experiments were run with 16 tasks per node

48
DAMPI maintains very good scalability vs ISP
4 8 16 320
100
200
300
400
500
600
700
800
900
ParMETIS-3.1 (no wildcard)
ISPDAMPI
Number of tasks
Tim
e in
seco
nds

49
DAMPI is also faster at processing interleavings
250 500 750 10000
1000
2000
3000
4000
5000
6000
7000
8000
Matrix Multiplication with Wildcard Receives
ISPDAMPI
Number of Interleavings
Tim
e in
sec
onds
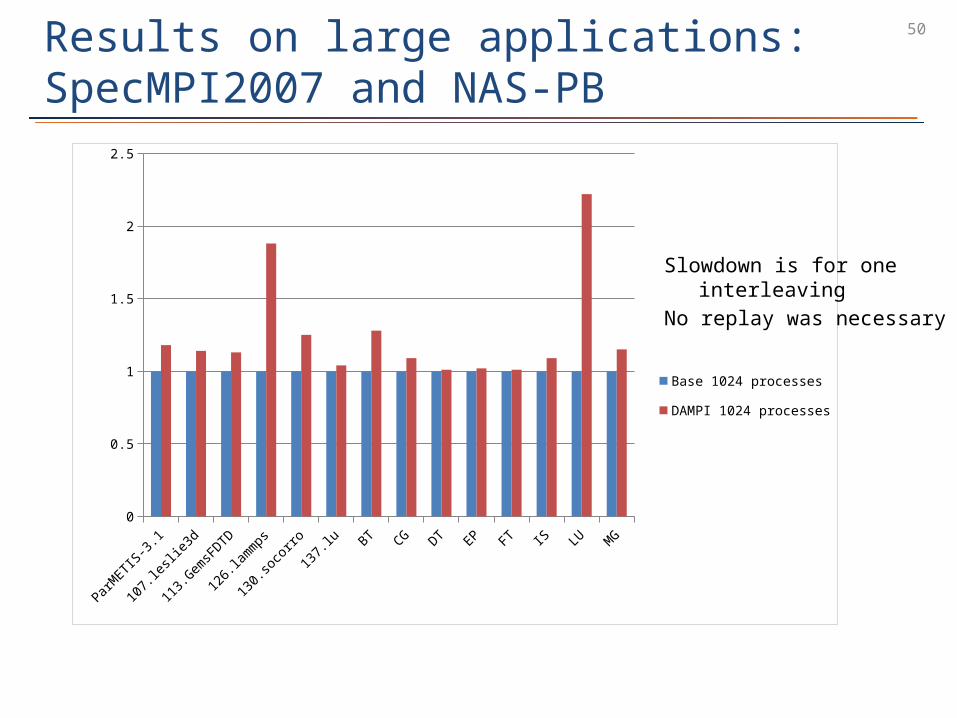
50Results on large applications: SpecMPI2007 and NAS-PB
ParMET
IS-3.1
107.leslie
3d
113.GemsFD
TD
126.lammps
130.soco
rro137.lu BT CG DT EP FT IS LU MG
0
0.5
1
1.5
2
2.5
Base 1024 processes
DAMPI 1024 processes
Slowdown is for one interleaving No replay was necessary

51
Heuristics for Overcoming Search Explosion
• Full coverage leads to state explosion– Given limited time, full coverage biases towards the
beginning of the state space
• DAMPI offers two ways to limit search space:– Ignore uninteresting regions• Users annotate programs with MPI_Pcontrol
– Bounded mixing: limits impact of non-det. choice• bound = infinity: full search

52
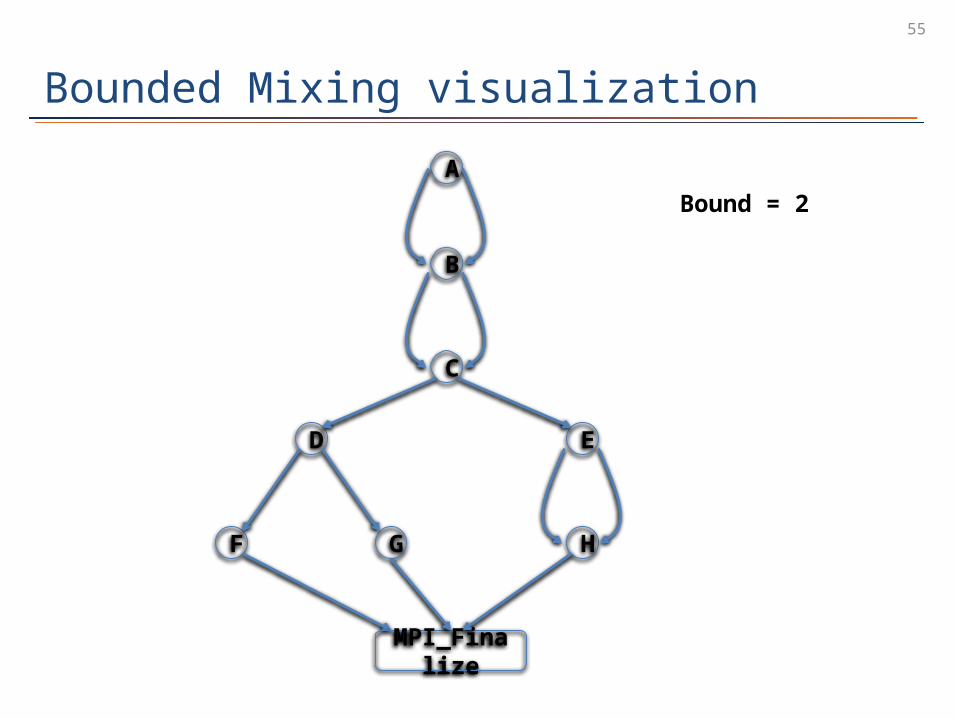
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 1

53
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 1

54
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 1Total interleavings: 8
55
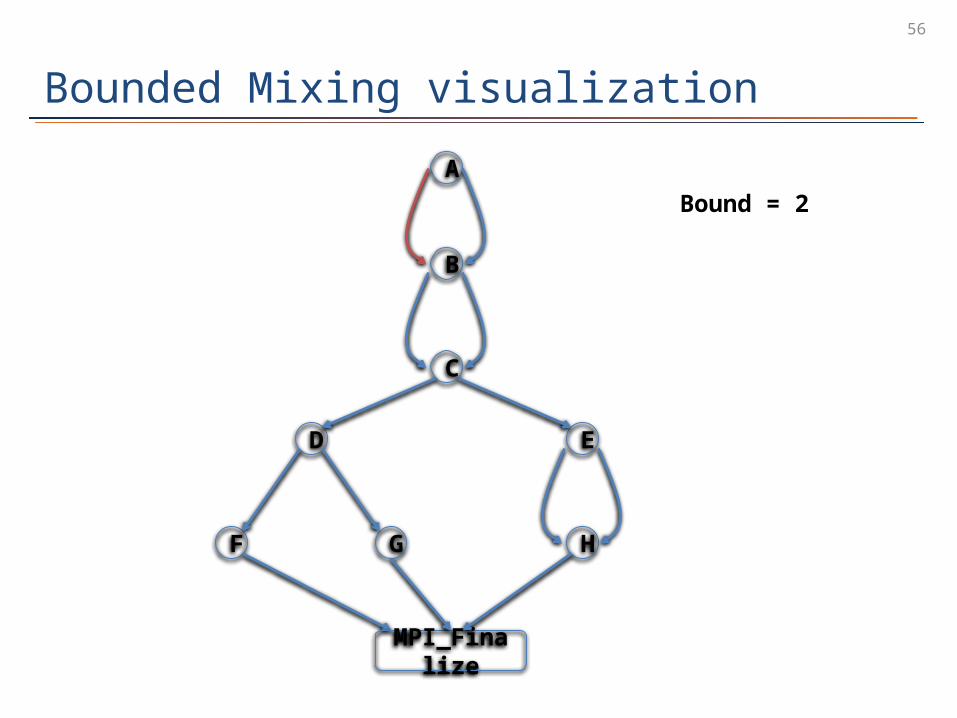
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 2
56
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 2

57
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 2

58
Bounded Mixing visualization
A
B
C
D E
F G H
MPI_Finalize
Bound = 2Total interleavings: 10
Bound >= 3Total interleavings: 16

59
Applying Bounded Mixing on ADLB

60
How well did we do?
• DAMPI achieves scalable verification– Coverage over the space of nondeterminism– Works on realistic MPI programs at large scale
• Further correctness checking capabilities can be added as modules to DAMPI

61
• Questions?

62
Concluding Remarks
• Scalable dynamic verification for MPI is feasible– Combines strength of testing and formal methods– Guarantees coverage over nondeterminism
• Matches-before ordering for MPI provides the basis for tracking causality in MPI
• DAMPI is the first MPI verifier that can scale beyond hundreds of processes

63
Moore Law still holds
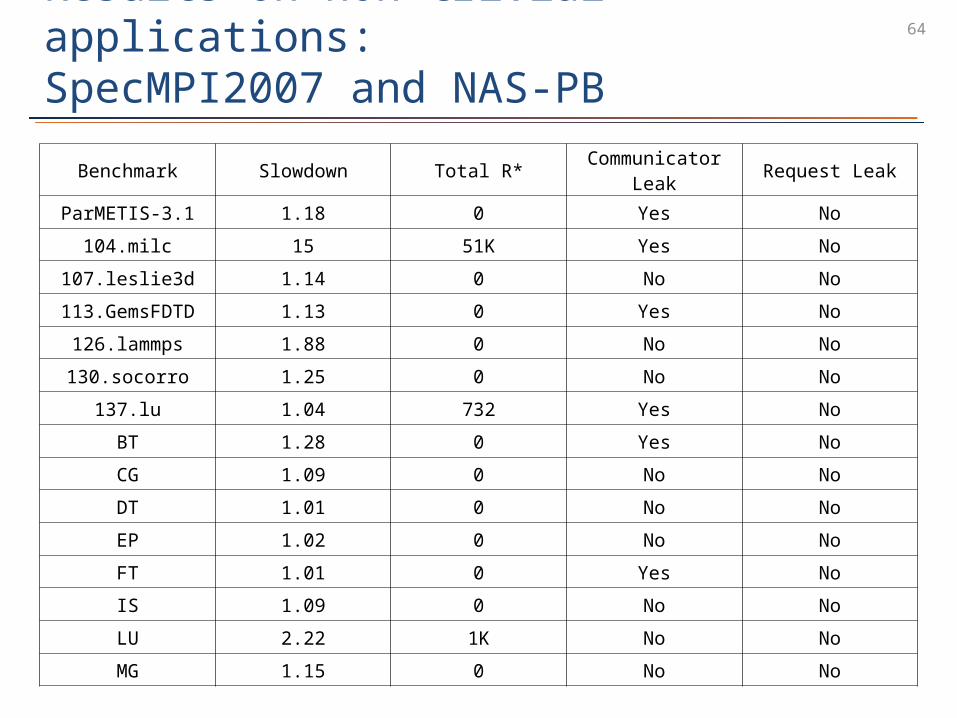
64Results on non-trivial applications:SpecMPI2007 and NAS-PB
Benchmark Slowdown Total R*Communicator
LeakRequest Leak
ParMETIS-3.1 1.18 0 Yes No
104.milc 15 51K Yes No
107.leslie3d 1.14 0 No No
113.GemsFDTD 1.13 0 Yes No
126.lammps 1.88 0 No No
130.socorro 1.25 0 No No
137.lu 1.04 732 Yes No
BT 1.28 0 Yes No
CG 1.09 0 No No
DT 1.01 0 No No
EP 1.02 0 No No
FT 1.01 0 Yes No
IS 1.09 0 No No
LU 2.22 1K No No
MG 1.15 0 No No

65
P0 P1 P2
Barrier
Isend(1, req)
Wait(req)
Scheduler
Irecv(*, req)
Barrier
Recv(2)
Wait(req)
Isend(1, req)
Wait(req)
Barrier
Isend(1)
sendNext Barrier
MPI Runtime
How ISP Works: Delayed Execution

66
P0 P1 P2
Barrier
Isend(1, req)
Wait(req)
Scheduler
Irecv(*, req)
Barrier
Recv(2)
Wait(req)
Isend(1, req)
Wait(req)
Barrier
Isend(1)
sendNextBarrier
Irecv(*)Barrier
MPI Runtime
Delayed Execution
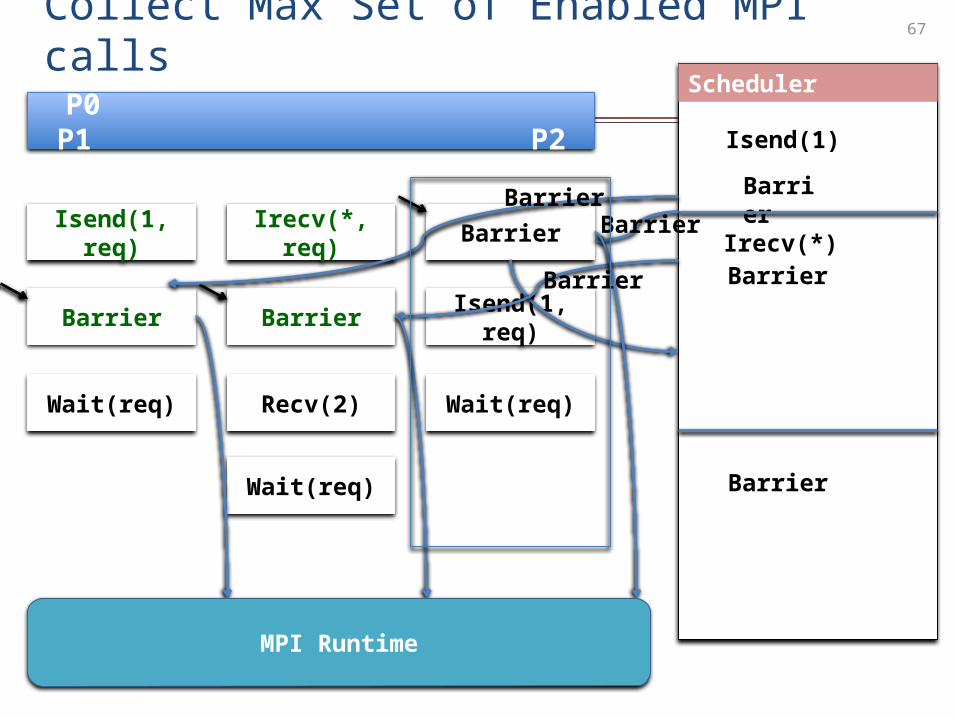
67
P0 P1 P2
Barrier
Isend(1, req)
Wait(req)
Scheduler
Irecv(*, req)
Barrier
Recv(2)
Wait(req)
Isend(1, req)
Wait(req)
Barrier
Isend(1)
Barrier
Irecv(*)Barrier
Barrier
Barrier
Barrier
Barrier
MPI Runtime
Collect Max Set of Enabled MPI calls

68
P0 P1 P2
Barrier
Isend(1, req)
Wait(req)
MPI Runtime
Scheduler
Irecv(*, req)
Barrier
Recv(2)
Wait(req)
Isend(1, req)
Wait(req)
Barrier
Isend(1)
Barrier
Irecv(*)
Barrier
Barrier
Wait (req)
Recv(2)
Isend(1)
SendNext
Wait (req)
Irecv(2)Isend
Wait
No Match
Deadlock!
Build Happens-Before Edges