17.01.18_論文紹介_discrimination- and privacy-aware patterns
TRANSCRIPT

Discrimination- and privacy-aware patternsSara Hajian, Josep Domingo-Ferrer, Anna Monreale, Dino Pedreschi and Fosca GiannottiData Mining and Knowledge Discovery 29 (6), 1733-1782, 2015
紹介者:Motoyuki Oki
2017.01.18

2017.01.18 2
00. 概要
• 様々な計測技術により容易に利⽤できる⼤量のヒューマンデータが収集され、そのためデータマイニングの技術は社会的に勢いを増している
• ゆえに私たちは前例のない機会やリスクに直⾯している:⼈間の活動のより深い理解や私たちの社会の働き⽅が抽出されたプロフィールやパターンによりプライバシー侵害や不公平な差別を引き起こす
• 個々の⼈の⼈⼝データから抽出されるパターンの集合がクレジットの否決のような決定をするために、継続的な利⽤のため公表される場合を考える
• 最初にパターンの集合が個⼈についてのセンシティブな情報を明らかにするかもしれない、第⼆にそのようなパターンに基づく決定ルールが不公平な差別を引き起こすかもしれない
• データマイニングではプライバシーや差別に独⽴して取り組んでいる⼿法がこれまで提案されているが、私たちはプライバシーと差別リスクが⼀緒に取り組まれるべきであると述べ、頻出パターンマイニングの結果を公開するための⽅法論を説明する
• 私たちは2つの可能性のあるプライバシ保護(k匿名性と差分プライバシ)の組み合わせで頻出パターンの公平な公開を達成するために、パターンの集合のサニタイゼーション⼿法、⽂献で利⽤される差別的な指標を説明する
• 私たちのk匿名性に基づくサニタイゼーション⼿法は、リーズナブルにパターンを歪ませながら、プライバシーと差別保護の両⽅を達成する
• それらは差分プライバシに基づくサニタイゼーション⼿法より良い保護とデータの質のトレードオフを⼿に⼊れる
• 最後に、私たちの提案法の効果は実験により評価される

2017.01.18 3
00. ⽬次
• 01. Introduction• 02. Related work• 03. Background• 04. Problem Statement• 05. Discrimination aware frequent patterns• 06. Simultaneous discrimination-privacy awareness
in frequent patterns discovery• 07. Experimental Analysis• 08. On the trade-off between protection and data
utility• 09. Conclusion and future research

2017.01.18 4
1 Introduction
• データマイニングの重要性が増し、⼤量のデータから隠れた知識を取り出す分析プロセスになっている
• 特に、⼈間や社会の複雑な現象を理解し知識を抽出する新しい機会が増えいている。プライバシーや無差別のような基本的な⼈権の崩壊リスクとともに。
• プライバシーとは、⼈のセンシティブな情報を機密なものとして維持する個⼈の権利を⾔う
• 差別とは、カテゴリ・グループ・少数派への帰属に基づく⼈々の不公平や不平等な扱いを⾔う
• データの保護だけでなく、⺠族・肌の⾊・宗教・国籍・性別・結婚歴・年齢・姙娠で保護されるべきグループに対して、クレジット・保険・⼈事・賃⾦・公共サービスへのアクセスへの差別を禁じる必要がある
• プライバシー保護や差別保護をしながら、マイニングの利点を保持することがたくさんのサービスやアプリケーションに広く社会的に受け⼊れられるだろう

2017.01.18 5
1 Introduction
• プライバシ保護の問題は1970年代から研究され始めた– データ匿名化、ランダムノイズ、⼀般化、抑圧、マイクロアグ
リゲーション• それぞれのアプローチによりデータが匿名化され、再識別の可能性
やレコードリンケージの実験を⾏うことで、どの程度匿名化が達成されたかを測る
• 1990年代後半に、k匿名化[Sweeney2002]について述べられ始めた– 攻撃者により、k個以内にレコードを識別できないモデル– 匿名化すべき属性を事前に決め、⼀般化や抑圧、マイクロアグ
リゲーションなどで匿名化する• 差分プライバシ[Dwork2006]がより最近の匿名化モデル。公開さ
れる結果に個⼈の存在有無の影響が無視してもよいとみなせるものを求める– 最初にラプラスノイズの付与に基づくものが提案されている

2017.01.18 6
1 Introduction
• 反差別の問題はデータマイニングの観点では最近考えられ始めた[Pedreschi2008]
• マイニングを使って差別の測定や発⾒を⽬指した⼿法が提案されている
• バイアスのあるデータから抽出される判別モデルに基づいて⾃動で決定されるマイニング結果⾃体が差別の元にならないようにするための研究もされている
• DPDM(Discrimination prevention in data mining)は差別を含むデータで訓練されたとしても差別のある決定を引き起こさないようなモデルを抽出する

2017.01.18 7
1 Introduction
• これまで、PPDMとDPDMは独⽴で研究されてきた• この論⽂では、⼀緒に取り組むべきであることを述べる• パーソナルデータから抽出されたパターン集合が「クレ
ジットを否認する or 許可するか」のような決定プロセスで利⽤するために公開することを考える
(例)銀⾏のデータから決定ルールが抽出される

2017.01.18 8
1 Introduction
• プライバシの脅威のみに対する保護– k匿名性により候補者のプライバシーを保護するために少なくと
もk以上異なるクレジット応募者で使われるルールのみが公開される。
– これはk以上⼥性の応募者がクレジットを否認されていたら、「Sex = female -> Credit = no」が抽出される。これは⼥性に対する差別につながる
• 差別の脅威のみに対する保護– ⼥性の応募者への差別を保護するために差別的なルールがサニ
タイジングされる。– しかしながら以下の2つのルールが抽出されるとする。カッコの
数は⽀持する対象の数。• r1:「Job = veterinarian ∧ salary>15000 -> credit = yes」(41)• r2:「Job = veterinarian -> credit = yes」(40)
– 「Job = veterinarian ∧ salary < 15000 -> credit = yes」(1) とわかり潜在的なプライバシ崩壊につながる

2017.01.18 9
1 Introduction
• シンプルな例からプライバシーと無差別の両⽅を保護することが必要とされることを⽰した
• 私たちはこの論⽂でPPDMのあとに、DPDM適⽤することが望ましいプライバシー保護をすることを保証しないことを⽰す
• ゆえに私たちは、2つの保護を⼀緒に可能にする全体的な⼿法を必要とする
• 最初に私たちはパーソナルデータからのパターン抽出における⾃然なシナリオを述べる
• 次にパターン公開における差別とプライバシの問題を述べる
• 次に、差別保護のための新しいパターンサニタイゼーション⼿法を提案する

2017.01.18 10
1 Introduction
• 次に、α保護k匿名化パターン、差分プライバシとα保護の両⽅を保証するアルゴリズムを提案する
• この論⽂で述べるトピックの要約を図1に述べる

2017.01.18 11
1 Introduction
• 2章で関連研究について述べる• 3章でこの論⽂で使われる背景となる考えや⼿法を述べ
る• 4章でこの論⽂で取り組む主要な問題を述べる• 5章で差別をなくすパターン集合を作るアルゴリズムを
述べる• 6章でプライバシと反差別の問題を同時に解決する⽅法
を述べる• 7章で提案法の評価を⾏う• 8章で保護とデータの有⽤性とのトレードオフを議論す
る• 9章で結論と今後の研究について述べる

2017.01.18 12
2.1 Privacy
• 最近15年で、データやモデルの質とプライバシーのトレードオフをコントロールしながら、個⼈のプライバシーを保護するモデルが広く提案されてきた
• k-anonymity(k匿名性, Sweeney[2002])• l-diversity(l多様性, Machanavajihala et al.[2007])
– グループ内では少なくともl種類のsensitive なデータ値が存在する
• t-closeness(t近似性, Li et al.[2007])– グループ内の多様性の極端な偏りをなくす⼿法。全属性データ
との分布とsensitive属性データの分布との距離が t 以下であることを保証する
• Differential privacy(差分プライバシー, Dwork[2006])– 真のDと異なるDʼにおいて、クエリ結果の誤差の上限を確率的
に保証する関連技術• crowd-blending(Gehrke[2012])
– データ内の個⼈i が別のk⼈のうちの1⼈jとブレンドする(?)

2017.01.18 13
2.2 Anti-discrimination
• 差別はそのグループが他より”Less favorably” として扱われる• 過去の研究では、主に差別を発⾒する/評価する研究が多く、差別
を保護することが扱われる• 差別を評価する指標 [Pedreschi et al.2009]• 他の属性により説明される差別を発⾒するための指標 [Kamiran et
al. 2013]• 保護すべきグループと全体でPositiveなクラスへの分類率は同⼀で
あるべきという公平な分類法の提案[Zemel et al 2013]• 差別発⾒の先に知識ベースの決定⽀援システムが差別発⾒するのを
防ぐことがさらに困難なタスクになる– 偏った学習により⼥性への差別を⾃動で発⾒するなど
• 差別保護アプローチは、Preprocessing, in-processing, post-processing ⼿法に分類される

2017.01.18 14
2.3 – 2.5 Pre-processing / In-processing / Post-processing methods
• Pre-processing– マイニングされたモデルが不公平な決定をしないようにデータ
に含まれる差別的な偏⾒を削除し、データを変形するアプローチ
• In-processing– 不公平な決定を含まないモデルができないようにデータマイニ
ングアルゴリズムを修正するアプローチ• Post-processing
– データセットやデータマイニングアルゴリズムを修正するのではなく、抽出されたマイニング結果を後処理するアプローチ
• 本研究のアプローチは、抽出された頻出パターンをサニタイジングするアプローチ– 反差別保護を保証するためにパターンのサポートを変形する– 最終的に、プライバシーと反差別の両⽅を保護する

2017.01.18 15
3-1. Basic definition
: a set of items: item. The form is “attribute = value”
: a collection of one or more items
: database
: recordPD(potentially discriminatory) items
:PD itemset or protected-by-law (or protected for short) groups
PND itemset : Xが である itemset

2017.01.18 16
3-1. Basic definition
Identifiers : attributes that uniquely identify individuals in the database (例:パスポート番号)
Quasi-identifier(QI) : 個⼈を特定するために外部情報と組み合わせれる極⼩集合 (例:性別、郵便番号、誕⽣⽇)
Sensitive attribute:センシティブ情報(例:病気や給料)
PD attribute:PD Items(例:⺠族、性別)QI and/or Sensitive attributes とオーバーラップし得る

2017.01.18 17
3-1. Basic definition
Decision(class) attributes : モデルの結果を表す値を取る属性(例:Yes or No)
Support:データベースDでXを含むレコードの数
σ-Frequent patterns : な頻出パターンのコレクション
この論⽂では、Aprioriを使って頻出パターンを求める
Classification Rule:
Confidence:

2017.01.18 18
3.2 Privacy-aware frequent patterns
• この節ではプライバシーを保護するパターンを抽出する2つのアプローチを紹介する

2017.01.18 19
3.2.1 k-Anonymous frequent patterns [Atzori+ 2008]
• k-anonymous frequent patterns を紹介• それぞれのパターンpが であるな
ら、パターンの集合はk-anonymous• non-k-anonymousパターンが搾取されてしまう可能性
のある攻撃を紹介
p1 : Job = v ∧ Class = yes , supp(p1)=41p2 : Job = v ∧ Salary > 15000 ∧ Class = yes , supp(p2)=40⇒ Job = v ∧ ¬(Salary > 15000) ∧ Class = yes , supp(p1) - supp(p2)=1
p1, p2からk = 8 を満たさないパターンが抽出されてしまう

2017.01.18 20
3.2.1 k-Anonymous frequent patterns [Atzori+ 2008]
• Inference Chanel を導⼊– non-k-anonymousが推測される可能性のあるパター
ンの集合
I = {b}, J = {b,d,e} supp_{D}(C{^J}_I) = supp(b) – supp(b,d) – supp(b,e) + supp(b,d,e)が k未満なら、non-k-anonymous が推測され得る

2017.01.18 21
3.2.1 k-Anonymous frequent patterns [Atzori+ 2008]
• k-Anonymous pattern set が定義される
• F(D,σ) からk-Anonymous pattern setを⽣成する⽅法– Inference channel を発⾒する– I のsupport を を満たすために、kだけ増
加させる– I のすべての部分集合のsupportもkだけ増加させる

2017.01.18 22
3.2.2 Differentially private frequent patterns
• [Li et al.2012]はPrvBasisアルゴリズムを提案した– 差分プライバシを満たすTop K 頻出パターンを⽣成
する• 差分プライバシは以下を保証する
– 個⼈のレコードが存在するかどうかにかかわらず個⼈について攻撃者が何も知ることがない
– たとえどのレコードが増減していようとも分析のアウトプットがほぼ同じである
Range(A):アルゴリズムAが取りうる出⼒S:任意の出⼒の部分集合

2017.01.18 23
3.2.2 Differentially private frequent patterns
• 直列合成定理– εをプライバシーバジェットと呼ぶ– 複数のステップでεの⼀部を使い、合計がεを超えな
ければ、複数のステップでどのように配分してもε-差分プライバシーは保証される

2017.01.18 24
3.2.2 Differentially private frequent patterns
• ε-差分プライバシーを満たすためのアルゴリズムがいくつかあり、ここでは2つ紹介する。
1.ラプラスメカニズムデータDに関数Fで計算する際に、ラプラス分布のランダムノイズを付与する。敏感度Sをノイズの⼤きさとして利⽤して、ラプラスメカニズムを定義する
:1つのレコードのみ異なるデータのペア

2017.01.18 25
3.2.2 Differentially private frequent patterns
2.指数メカニズム任意の関数Fでアルゴリズム が に⽐例する確率でアウトプット t を選択するなら、ε-差分プライバシを満⾜する⇒アウトプットが離散であるものに対するメカニズム
:Utility function。メカニズムの出⼒値の望ましさ。⼊⼒データDに対する出⼒Rがどれだけ正確かを⽰す
:utility function の敏感度
参考メカニズムMはε差分プライバシを満たす(例)q(D,r1) – q(D,r2) = 1 なら r1はr2よりy倍返される

2017.01.18 26
3.2.2 Differentially private frequent patterns
• ε-差分プライバシ頻出パターンセットの定義
アルゴリズムAがε差分プライバシを満⾜するなら
• σ-basis set : を新たに定義する• それぞれのBi はアイテムの集合で、Biのどの部分集合も
σより⼤きいサポートを持つ⇒ 頻出パターンセットを⽣成するための基本となる集合

2017.01.18 27
3.2.2 Differentially private frequent patterns
⇒ 得られたパターンセットは、差分プライバシにより(1)いくつかのパターンのサポートが異なる(2)F(D,σ)になかったパターンや⽭盾したパターンが⽣成される
(1) Top K頻出パターンに関わるユニークアイテムの数λを決める(指数メカニズム)
(2) データベースDのすべてのアイテムの集合Iから頻出アイテムFをλ個決める(指数メカニズム)
(3) Fのアイテムの頻出ペアの集合Pを決める(指数メカニズム)(4) FとPでσ-basis set B をつくる(5) 最後に候補集合C(B)にサポートノイズを付与し、その集合から
Top K頻出パターンを選択する(ラプラスノイズ)
PrivBasisのアルゴリズムは以下のステップで⾏われる
(1)(2)(3)(5)でεi を分配して設定する(直列合成定理より、全体でε差分プライバシを満⾜する)

2017.01.18 28
3.3 Discrimination protected frequent patterns[Pedreschi+ 2008,2009]
• Classification rule の PD rule を紹介
• Protected Group :• Negative Decision :
PD rule の例:PND rule の例:
• PDパターンの定義
(1)PがNegativeなクラスCを含む(2)PがDIbにあるアイテムを含む

2017.01.18 29
• PD rule がどの程度差別的かを測る指標(Aと¬Aで測る指標) 1より⼤きいと潜在的な差別を⽰す
3.3 Discrimination protected frequent patterns[Pedreschi+ 2008,2009]
• Aがバイナリ値じゃないときのために拡張
• Aとその他すべてで測る指標(1より⼤きいと潜在的な差別を⽰す)

2017.01.18 30
3.3 Discrimination protected frequent patterns[Pedreschi+ 2008,2009]
• 差分指標、[-1,1]を取る。0より⼤きいと潜在的な差別を⽰す
• Chance measure。1より⼩さいと潜在的な差別を⽰す

2017.01.18 31
• 紹介した指標にもとづいてruleが差別的かどうかが考えられる
3.3 Discrimination protected frequent patterns[Pedreschi+ 2008,2009]
Example. 3f = slift, alpha=1.25, Dib = {Sex=female}|sex = woman ∧ job = veterinarian|=34|sex = woman ∧ job = veterinarian ∧ credit = no| =20|sex = man ∧ job = veterinarian|=47|sex = man ∧ job = veterinarian ∧ credit = no| = 19このとき、r1 : sex = woman ∧ job = veterinarian -> Credit = no は PD rule (slift(r) = (20/34) / (19/47) = 1.45なので)
f(r)がαより⼩さいならα保護、じゃなければα差別

2017.01.18 32
3.3 Discrimination protected frequent patterns[Pedreschi+ 2008,2009]
• パターンがα-差別的かどうかを判定し、α-差別的なパターンがなければα-保護な集合になる

2017.01.18 33
4. Problem Statement
• 本論⽂の研究は、同時にプライバシとanti-discriminationを保護する頻出パターンの集合を⽣成するアプローチを提案すること
• Two-step アプローチ– 1. プライバシ保護– 2. 差別的なパターンを排除
• プライバシ保護では、3.2.1(k匿名性) / 3.2.2(差分プライバシ) の⽅法を⽤いる
• 5章で、α保護パターンを⽣成するアプローチを提案• 6章で、プライバシ保護とα保護の相互作⽤が分析される

2017.01.18 34
5.1 Achieving a α-protective pattern set
• F(D, σ)のα差別パターンを発⾒する (Alg. 1)
4⾏⽬:DIb と クラスCを含むパターンの集合を抽出する8-10⾏⽬:差別の程度を測り、それがα保護を満たすかどうかチェック。満たさなければ α差別的なパターン集合 に追加

2017.01.18 35
5.1.1 Anti-discrimination pattern sanitization for slift and its variants
• f = slift のときを考える
⇔
• 不等式を満たすには、{A,B}のパターンのsupportを増やすこと
⇔
• cliftも同様に変形可能(13)

2017.01.18 36
5.1.2 Anti-discrimination pattern sanitization for elift and its variants
• f = elift のときを考える
⇔
• 不等式を満たすには、slift同様にするとうまくいかない。なぜなら{A,B}のパターンとその部分集合を増やすと分⺟と分⼦で増減するため。そのため代わりに{B,C}を増やす
⇔

2017.01.18 37
• Proof– それぞれのα差別パターンをα保護したときに、元のα保護パタ
ーンがα差別にならないことを証明すれば良い– 2つのPDパターンp1: p2:
– Special Case の場合• p1をα保護にすると、fに応じて と を増やす。
これは、p2のα保護の程度を減らさない• p2をα保護にすると、p1とオーバーラッピングがないため、p1には影響し
ない– その他の場合:互いにsupportの増加は影響しない
5.1.3 Discrimination analysis
• 提案法では、新たな差別パターンが⽣成されないことを保証する

2017.01.18 38
5.1.3 Discrimination analysis
• α差別パターンからα保護パターンを⽣成する(Alg. 2)
すべての差別パターン集合DDについて
⊿f を計算する
⊿f をプラスする集合を取り出す

2017.01.18 39
5.2 Extension of the discrimination protection to closed frequent pattern
• Closed frequent pattern[Pasquier et al. 99]にα保護⼿法を適⽤することを考える
Supportが同じで、Xより⼤きいYがない
• Alg.1 では、8⾏⽬の計算に影響する
• パターン{A, B, C}, f = slift を考えると、{A,B,C}, {A,B}, {¬A, B, C}, {¬A, B}のsupportを考える必要がある。

2017.01.18 40
5.2 Extension of the discrimination protection to closed frequent pattern
• 2つのケース:(a) 上記のアイテムセットすべてがclosed pattern (b) それらの⼀部はclosedじゃない
(a)はすべての情報が にある。(b)は{A,B}がClosed patternじゃないとすると、可能性のある上位集合{X1,…,Xn}でsupp(A,B)=max_i(supp(Xi))を計算
理由:{A, B} が no closed patternのとき、⊿slfitで{A,B}のsupportを増加させたとき、supp(A,B) = supp(Y) の関係をなくし、{A,B} が closed になる
• eliftのときも同じようなことがおこる• つまり、私達のサニタイゼーションはGhost Patternを⽣成しない
が、ghost closed patternを⽣成する可能性はある
• 強調することは、Closed patternsを含むサニタイゼーションは Ghost closed patterns を⽣成し得る

2017.01.18 41
5.3 Achieving a d-explainable α-protective pattern set
• 別の法的な概念として、 ではない属性で部分的に説明される差別がある– 例:⼥性へのクレジットが否決されるのは⼤部分が
低い給料or返⾦遅れによって説明される– これは合法的に許容される理由である
:差別における合法的に許容されるPNDアイテムセット
DIbとDIeを与えられたとき、DIbとDIe間の相関が⾼く、DIeとクラスCの相関が⾼いなら、差別は説明される

2017.01.18 42
• α差別パターンが説明できるかできないかを決定するために、d-instanceを使う[Pedreschi et al., 2009]
5.3 Achieving a d-explainable α-protective pattern set
• dが⼤きい値のとき、条件1はクラスと法的に根拠のある(Legally-grouded)グループ間の⾼い相関を⽰す
• 条件2は法的に根拠のあるグループとProtectedグループ間に⾼い相関があることを⽰す

2017.01.18 43
• Definition 15よりd説明可能(不可能)な頻出パターンを定義する
5.3 Achieving a d-explainable α-protective pattern set
• Definition 16よりd説明可能α保護な頻出パターンセットを定義する
「”d説明不可能なパターンpのうちα差別パターン“ではないパターンのセットF(D, σ)」のこと

2017.01.18 44
• α差別なパターンを発⾒し、それらのうちd説明不可能なパターンを⾒つける(Alg. 3)
5.3 Achieving a d-explainable α-protective pattern set
Alg. 1でα差別なパターンを⾒つける
α差別なパターンのうち説明不能なパターン

2017.01.18 45
• Alg. 3で⼿に⼊れたα差別でd説明不能なパターンをα保護にする際のサニタイゼーションのインパクトを調べる
5.3 Achieving a d-explainable α-protective pattern set
頻出パターンセットF(D,σ)をAlg.2によりd説明可能α保護にすることは、新たなd説明不能パターンを⽣成しない(f = elift の場合)
頻出パターンセットF(D,σ)をAlg.2によりd説明可能α保護にすることは、新たなd説明不能パターンを⽣成するかもしれない(f = slift の場合)

2017.01.18 46
• 定理3により、Alg.2はすべてのfに関してd説明可能α保護にできない。そのため、Alg.4を提案する
5.3 Achieving a d-explainable α-protective pattern set
eliftの場合
sliftの場合⼀旦Alg2 で ⊿f だけsupport を増やす
新たにd説明不能なパターンができたらそれをDbadへ加える

2017.01.18 47
6 Simultaneous discrimination-privacy awareness infrequent pattern discovery
• 本章では、頻出パターンにおいて同時に反差別とプライバシ保護を達成する⽅法を⽰す
• 最初にk匿名化とα保護を⼿に⼊れるためのアプローチを述べる
• 次に、説明不能差別とプライバシ保護を⼿に⼊れるためのアプローチを述べる
• 最後に、差分プライバシとα保護を⼿に⼊れるためのアプローチを述べる

2017.01.18 48
6.1 Achieving an α-protective and k-anonymous pattern set
• 差別保護とプライバシ保護を達成するパターン集合を定義する
• このパターン集合を⼿に⼊れるために、2つの問題を考える– (1)k匿名化パターンをα保護パターンにするときのイ
ンパクト– (2)α保護パターンをk匿名化パターンにするときのイ
ンパクト• (1)に関して2つのシナリオを提⽰する

2017.01.18 49
Scenario 1
6.1 Achieving an α-protective and k-anonymous pattern set
パターンp1は1.25差別(slfitの値が2.58 = )パターンpsとp2のインファレンスチャネルは45 – 42=3よって、プライバシ保護が実⾏される⇒結果、psのサポートは53になるしたがって、新しいsliftの値は2.19( )このシナリオでは、k匿名化は差別も下げることになる

2017.01.18 50
Scenario 2
6.1 Achieving an α-protective and k-anonymous pattern set
パターンp1は1.25差別じゃない(slfitの値が1.14 = )パターンpsとp2のインファレンスチャネルは58 – 56=2よって、プライバシ保護が実⾏される⇒結果、psのサポートは66になるしたがって、新しいsliftの値は1.3( )このシナリオでは、k匿名化が差別の程度を上げてしまう

2017.01.18 51
• 2つのシナリオからk匿名化はα保護を強く or 弱くする• そのため、k匿名化パターンにおいて、α差別を発⾒する
ことが必要となる• (2)の問題で述べたことについて、F(D,σ)がk匿名化パタ
ーンセットなら、5.1節で述べたα保護サニタイゼーション⼿法はF(D,σ)をnon-k匿名化にしないことを証明するためには、私たち新しいInference channel を⽣成しないことを証明する必要がある⇒ 定理4:α保護にすることは新しいInference channelを⽣成しない
6.1 Achieving an α-protective and k-anonymous pattern set

2017.01.18 52
• α保護k匿名化パターンを得るためにAlg. 5を提案する
6.1 Achieving an α-protective and k-anonymous pattern set
Alg. 1でα差別なパターンを⾒つける
k匿名化パターンセットを作る
Alg. 2でα差別パターンをα保護にする
*
* 定理1より、インパクトの⼤きいパターンを最初にα保護にし、パターンを歪めるのを最⼩化するためにソートする

2017.01.18 53
6.2 Achieving d-explainable α-protective and k-anonymous pattern set
• 説明不能差別とプライバシ保護を達成するパターン集合を定義する
• このパターン集合を⼿に⼊れるために、2つの問題を考える– (1)d説明可能/不能パターンをk匿名化パターンにするとき
のインパクト– (2) k匿名化パターンをd説明可能α保護にするときのイン
パクト• (1)に関して2つのシナリオを提⽰する

2017.01.18 54
6.2 Achieving d-explainable α-protective and k-anonymous pattern set
Scenario 3
パターンp1は1.25差別だが、0.9説明可能( > , > 0.9)
パターンpnsとp2のインファレンスチャネルは64–59=5よって、プライバシ保護が実⾏される⇒結果、pnsのサポートは72になるしたがって、新しいd説明可能指標の値は0.513 ( )このシナリオでは、k匿名化が、p1をd説明不能にしてしまう

2017.01.18 55
Scenario 4
パターンp1は1.25差別で、0.9説明不能( < , > 0.9)
パターンpsとp2のインファレンスチャネルは30–29=1よって、プライバシ保護が実⾏され、psのサポートは32になるしたがって、新しいd説明可能指標を計算すると、満たすことがわかるこのシナリオでは、k匿名化が、p1をd説明可能にする
6.2 Achieving d-explainable α-protective and k-anonymous pattern set

2017.01.18 56
• k匿名化はF(D,σ)をd説明可能α保護の程度を⼤きくor⼩さくし得る
• そのため、最初にk匿名化パターンを⼿に⼊れ、その後でd説明不能パターンを探し、保護することを考え、Alg.6を提案する。Alg.6は定理4より、新たなinference channelを⽣成しない
Alg. 3でd説明不能α差別なパターンを探索
Alg. 4でd説明可能α保護なパターンに変換
6.2 Achieving d-explainable α-protective and k-anonymous pattern set

2017.01.18 57
• α保護とε差分プライバシをみたす頻出パターンセットを⽣成することを⽬指す
6.3 Discrimination protected and differentially private frequent patterns
• このパターン集合を⼿に⼊れるために、α保護頻出パターンセットをε差分プライバシにするときのインパクトを調べる
⇒ ε差分プライバシにすることは、α保護の程度を⼤きくor ⼩さくする

2017.01.18 58
• K匿名化のときと同様に、最初にε差分プライバシパターンを⼿に⼊れたあと、差別アプローチを実⾏する(Alg.7)
6.3 Discrimination protected and differentially private frequent patterns
アイテムセットIからTop K頻出パターンと差分プライバシが⼊ったデータ
Alg. 1でα差別なパターンを⾒つける
Alg. 2でα差別パターンをα保護にする
⇒ Step 4からは後処理で、Dにアクセスしない。Step 6で⊿f 分だけSuporrtにノイズを付与する処理も差分プライバシの事後処理なので影響しない

2017.01.18 59
7. Experimental analysis
• 提案した⼿法の実験的な結果を⽰す• 表記
– FP:アプリオリによってDから抽出されたパターン– FPʼ : FPのk匿名化パターン– FPʼʼ:FPのα保護k匿名化パターン(by Alg.5)– FP*:FPのα保護パターン(by Alg.2)– TP:FPʼ or FPʼʼ or FP* を指す

2017.01.18 60
7. Experimental analysis
• UCIからデータセットとしてAdultとGerman Creditの2つを利⽤する
• Adult– 48,842のレコード、14の属性(クラスを除く)
• Train : 32561, Test : 16281– クラスはある⼈の年収が50k$より⼤きいかどうか– DIb : {Sex=female(33%), Age=young(29%)}
• Young : Ageが30歳以下• German Credit
– 1,000のレコード、20の属性(クラスを除く)– クラスは⼈のGood or Bad– DIb : {Age=old(11%), Foreign worker=yes(96%)}
• Old : Ageが50歳以上

2017.01.18 61
7.1 Utility measures
• プライバシー保護と反差別を達成するために引き起こされる情報損失を評価する– Support altered : 元のFPのうち、TPによりSupport
が変わってしまったパターン割合
– Pattern distortion error : 元のFPのsupportからTPによりsupportが変化した程度
– Misses Cost:元のFPからTPにより無くなったパターンの割合
– Ghost Cost:TPにより新たに出現してしまったパターンの割合

2017.01.18 62
7.1 Utility measures
• CMAR(Li et al.2001)で分類精度も評価する1. データをTrain(D_train) と Test(D_test)に分ける2. D_trainからFPを抽出する3. FPからTPを⾏い、クラス分類のためのパターンTPs:
{X, C} を抽出4. D_testのそれぞれのレコードでマッチするパターンを
TPsから取り出す5. すべてのパターンが同じクラスなら、そのクラスを割
り当てる。異なるなら、以下を計算する⇒そのパターンのカイ⼆乗値の上界を計算している(?)

2017.01.18 63
7.1 Utility measures
それぞれのパターンで、重み付きカイ⼆乗値を計算し、⼤きいクラスに割り当てる[Greenwood et al. 1996]
6. それぞれのレコードで予想されたクラスを使い、どの程度実際のクラスと正しいかを評価する
• FPʼ(FPのk匿名化)の差別の程度を測るため、以下の指標で評価する– DPD : FPでα差別だったパターンでFPʼでα保護にな
った割合– NDD:FPでα保護だったパターンがFPʼでα差別にな
った割合

2017.01.18 64
7.2 Pattern distortion
• 7.2.1でk匿名化頻出パターンの結果• 7.2.2でα保護頻出パターンの結果• 7.2.3でα保護k匿名化頻出パターンの結果• 7.2.4で別の指標で、α保護頻出パターン、α保護k匿名
化頻出パターンの結果• 7.2.5でd説明可能α保護頻出パターン、d説明可能α保護
頻出k匿名化パターンの結果• 7.2.6でε差分プライバシ保護、 α保護ε差分プライバシ
保護の結果をそれぞれ説明する

2017.01.18 65
7.2.1 k-anonymous frequent patterns
• X軸:support σ, Y軸:各指標の値(⼩さい⽅が良い)• GermanデータのほうがPDEが⼤きい• これはinference channelの数に違いがあるため
– Adult : 500, German : 2164
39.48%

2017.01.18 66
7.2.2 α-protective frequent patterns
• f=slift• αとσを⼩さくするとスコアが⼤きくなる
– α差別パターンの数が増加するため• Fig3と4を⽐較すると、Fig3のほうが⾼い
– プライバシ保護のほうがより歪みを発⽣させる– Inference channelのほうがα差別パターンより数が多いため

2017.01.18 67
7.2.3 α-protective k-anonymous frequent patterns
• Inference channelの数はkが⼤きいほど増えるので、α差別パターンの数もαが⼩さいほど増える
• Fig3, Fig5, Fig6を⽐較すると、k匿名化パターンとほとんど差がないことがわかる(e.g. 39.48% / 42.1%)– プライバシの脅威のみに対して保護し、それにわず
かに歪みを⼊れることで、プライバシと差別の両⽅保護できると結論付けれる
42.1%

2017.01.18 68
7.2.4 Alternative discrimination measures
• f = elift で同様の実験をする• f = sliftと同様に、αとσを⼩さくするとスコアが⼤きく
なる。kを増やすとスコアが⼤きくなる• f=sliftの結果と⽐較すると、若⼲異なる
– 理由1:α差別パターンの数が異なるため– 理由2:元のパターンのsupportに加える値⊿の違い
2017.01.18 69
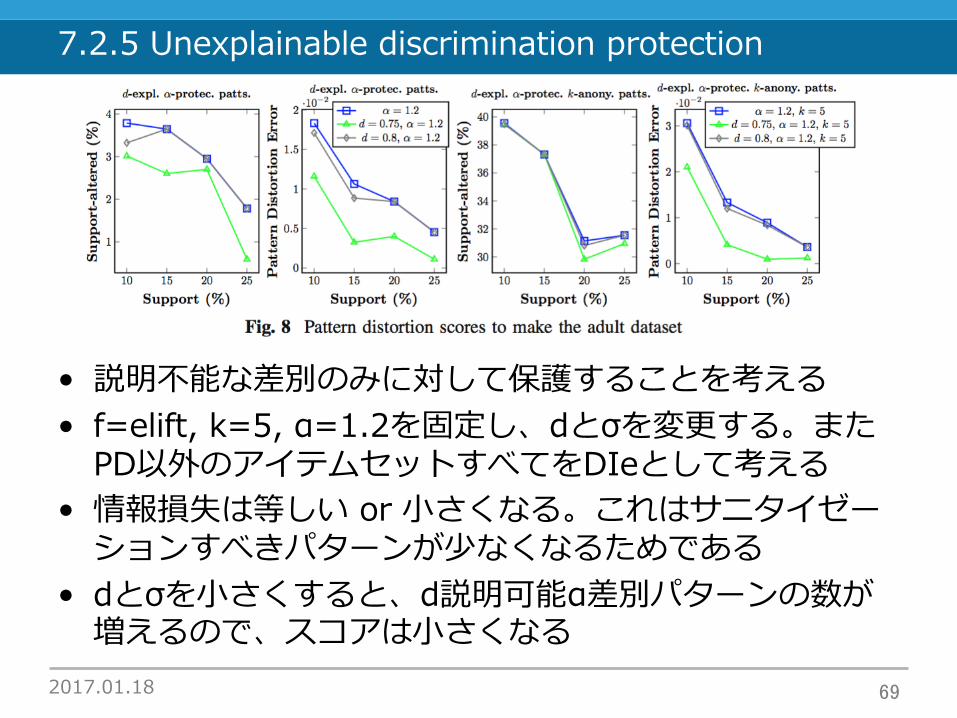
7.2.5 Unexplainable discrimination protection
• 説明不能な差別のみに対して保護することを考える• f=elift, k=5, α=1.2を固定し、dとσを変更する。また
PD以外のアイテムセットすべてをDIeとして考える• 情報損失は等しい or ⼩さくなる。これはサニタイゼー
ションすべきパターンが少なくなるためである• dとσを⼩さくすると、d説明可能α差別パターンの数が
増えるので、スコアは⼩さくなる

2017.01.18 70
7.2.6 Differentially private frequent patterns
• ε差分プライバシによる保護の性能を評価する(Fig.9)– KはSupportの閾値σを使う
• 差分プライバシはすべてのパターンのSupportを変化させ、偽のパターンも⽣成される– Ghost Ruleが⽣成される = GC > 0– εが⼩さいほど、ノイズが⼤きくなるので、スコアは増加する– k匿名化と⽐べて歪みが⼤きい
• α保護ε差分プライバシでの性能を評価する(Fig.10)– ε差分プライバシのみと結果に差はあまりない(?)– α保護k匿名化と⽐べると⼤きな差がある(ε差分プライバシのせい)

2017.01.18 71
7.3 Preservation of the classification task
• FP,FPʼ,FPʼʼ,FP*による分類器の精度を評価する• f=slift, σ=10%• FPと他の⽅法で統計的に⼗分な差はなかった• kが⼤きくαが⼩さいほど精度は⼩さくなった• Germanデータのほうが精度の低下が⼤きい
– 前節の実験より、Germanのほうが歪みが⼤きいため

2017.01.18 72
7.4 Degree of discrimination
• k匿名化パターンにより差別の発⽣有無を確認する– DPD(α保護になった割合)/NDD(α差別になった割合)指標で確認
• kが増加するとDPD/NDDが増加– AdultではNDD -> よりα差別になる– GermanではDPDが増加 -> よりα保護になる
Adult
german

2017.01.18 73
7.4 Degree of discrimination
• d説明可能なパターンの集合がどれだけ含まれているか確認する
• dを⼤きくすると、⽐率は低下する• FPをk匿名化にすると、その⽐率は増減する(6.2節の
とおり、k匿名化にすることはd説明可能α保護の程度を強める or 弱めるため)

2017.01.18 74
7.5 Execution time
• 提案されたアルゴリズムの計算時間は|D|と|FP|の⼤きさで線形に増加する
• 頻出パターンの数はレコードの数に応じて指数増加する• アルゴリズム5と7で、プライバシ保護をする部分の計算
時間は、minimum supportで1分〜10分かかる• α差別パターンの発⾒とサニタイゼーションに2分かかる• PDの分割表をあらかじめ計算しておくとパフォーマン
スは改善する• 最終的にアルゴリズム5と7は12分以内で完了する• オフラインプロセスとしてはリーズナブルなパフォーマ
ンス

2017.01.18 75
8 On the trade-off between protection and data utility
• 差別とプライバシ保護を同時に達成する⽅法を⽰したが、いくつかの情報損失がある
• しかし、7章の実験からかなり⼿頃に達成でき、損失のほとんどはk匿名性を達成するためのもので差別保護による追加の損失は⼩さい
• サニタイゼーションは偽の頻出パターンや真の頻出パターンを消さないため、いつもMCとGCは0であり、この性質は好ましい
• 7.3節の実験で⽰したとおりプライバシと無差別を保証し分類精度も⼩さなロスに抑えた
• 差分プライバシのアプローチはプライバシの点だけでは、最悪ケースのプライバシを保護するが、情報損失が⼤きく、データの品質が低下させることを⽰した

2017.01.18 76
9 Conclusion and future research
• 頻出パターンにおける差別とプライバシ保護の問題を調査した
• 公開されたパターンにおけるサニタイゼーションメソッドを提案した
• それぞれの差別指標に関して差別のないパターンを⽣成するアルゴリズムを提案した
• また説明できない差別に対してのみを保護するアプローチを提案した
• k匿名化と差分プライバシと同時に組み合わせるアプローチを提案した
• 実験により、提案法の情報損失の度合いや、分類精度を評価した

2017.01.18 77
9 Conclusion and future research
• それぞれの関係を表10にまとめた

2017.01.18 78
9 Conclusion and future research
• データマイニングにおいて差別とプライバシの両⽅を扱う保護の問題に深く取り組んだ最初の研究である
• 今後の研究では、– データ品質の問題かどうかを検証するために異なる
プライバシアプローチとの統合をすること– 反差別とプライバシ保護を統合するフレームワーク
の設計– 間接差別を扱うこと– 差別とプライバシ保護のデータ公開– 実世界データでの検証

2017.01.18 79
Appendix : Theorem 2 の証明
• d説明不能なパターンをα保護にするサニタイゼーション⼿法が、d説明可能なパターンをd説明不能にしないことを証明すればよい
• PDパターンp1, p2を考える• 以下の関係が考えられる
• すべての場合でd説明不能なパターンp1をsupp(B,C), supp(B)を増加させて、α保護にする
• これはアイテムのオーバーラップがないため、d説明可能なp2をd説明不能にしない
• 同様に、d説明不能なp2をα保護にしてもd説明可能なp1をd説明不能にしない

2017.01.18 80
Appendix : Theorem 3 の証明
• d説明不能なパターンをα保護にするサニタイゼーション⼿法が、d説明可能なパターンをd説明不能にすることを証明すればよい
• PDパターンp1, p2を考える• 以下の関係が考えられる
• すべての特別な場合(p2 ⊂ p1)でd説明不能なパターンp1をsupp(A,B) を増加させて、α保護にする
• これはアイテムのオーバーラップがあり定義15の条件2のconf(Aʼ,Bʼ->D)に影響し、d説明可能なp2をd説明不能にし得る
• その他はオーバーラップがないため影響しない

2017.01.18 81
Appendix : Theorem 4 の証明
• α差別パターン についてf=sliftなら、f=eliftなら、 でα保護にする
• Inference channelは2つの異なるケースに現れる– (a)psとそのsuperset– (b)psとその部分集合
(a)においてF(D,σ)がk匿名化なので、psのsupportを増加させると も増加するのでk以上が保たれる(b)においてF(D,σ)がk匿名化なので、psのsupportを増加させると(2)式のそれぞれの項が増加するので、 もk以上が保たれる

2017.01.18 82
Appendix : Theorem 5 の証明
• ε差分プライバシのF(D,σ)を とする• は元のF(D,σ)にないパターン(GP) / F(D,σ)からな
くなったパターン(MP)を含むかもしれない• さらにF(D,σ)と の両⽅にあるパターンで、 は
サポートにノイズが⼊っている• 以下の異なる状態が考えられる(1)F(D,σ)にあったα差別パターンがFPdで無くなった⇒ α保護の程度を強くする(2)F(D,σ)になかったが、FPdでα差別パターンができた⇒α保護の程度を低くする(3)F(D,σ)とFPdにもあるパターンだと、FPdでサポートのノイズが⼊るため、F(D,σ)をα保護にするかどうかわからない