2 association rules
TRANSCRIPT

Frequent item set and Association rules
Viet-Trung Tran
1

Credits • Jure Leskovec, Anand Rajaraman, Jeff Ullman
Stanford University
2

Supermarket shelf management
• Goal: Identify items that are bought together by sufficiently many customers
• Approach: Process sales data to find dependencies among items
• A classic rule: – if someone buy diaper and milk, he/she will buy
beer
3

The market-basket model • A large set of items • A large set of baskets • Each basket is a small
subset of items • Want to discover
association rules – People who buy {a,b,c} tend
to buy {x,y,z}
4

Generalization
• Many-to-many mapping between two kinds of things – But asks about connections among "items", not
baskets – Items and baskets are abstract
• products/shopping • words/documents • drugs/patients
5

Application • Products = items , sets of products = baskets • Amazon people who buy X also buy Y • Real market baskets: chain stores keep TB of data
about what customers buy together – Tell how typical customers navigate stores – Run sale on diaper and milk but raise the price of beer
6

Application [2] • Documents = items; sentences = baskets
– Items that appear together too often could represent plagairism
• Patients = items; drugs & side-effect = baskets – detect combinations of drugs that result in side-effect
7

Application [3]
• Finding community in graphs (e.g., Twitter)
8

Frequent itemsets • Simplest question: find set of
items that appear together "frequently" in baskets
• Support for itemset I – Number of baskets containing all
items in I • Given a support threadshold s
– Set of items that appear in at least s baskets are called frequent itemsets
9

Example
10

Association rules
• If-then rules about the contents of baskets • {i1,i2,...,ik} -> j means: "if a basket contains
all of i then it is likely to contain j" • Confidence of this association rule is the
probability of j given I = {i1, i2,...,ik}
11

Observation
• Not all high confidence rules are interesting – The rule X -> milk is high confidence but it is just
milk is purchased very often • Interest of an association rule I -> j
– Different between its confidence and the fraction of baskets that contain J
– Interest on those with high positive or negative
12

Example
13

Finding association rules
• Goal: finding all association rules with support >= s and confidence >= c
• Hard part: finding the frequent itemsets – If {i1,i2,...,ik} -> j has high support and
confidence, then bot {i1,i2,...ik} and {i1,i2,...,ik,j} will be frequent
14

Itemsets: computation models
• Hardest problems often be finding frequent pairs – Probability of being frequent drops
exponentially with size, number of sets grow more slowly with size
• First concentrate on pairs, and then extend to large datasets
15

Naive algorithm
• Read file once, counting in main memory • For each basket of n items, generate n(n-1)/2
pairs by two nested loop • Failed if (#items)^2 exceeds memory
– 100K (Walmark) , 10B web pages,
16

A-priori algorithm [1] • A two-pass approach limits the need
for memory • Key idea: monotonicity
– if a set of items I appears at least s times, so does every subset J of I
• Contrapositive for pairs – If items i does not appear in s baskets,
then no pair including i can appear in s baskets
17

A-priori algorithm [2]
• Pass 1: Read baskets and count in main memory the occurrences of each individual item
• Items that appear >= s time are the frequent items
• Pass 2: Read baskets again and count those pairs where both elements are frequent
18

Main-Memory: Picture of A-Priori
19
Item counts
Pass 1 Pass 2
Frequent items
Mai
n m
emor
y Counts of pairs of
frequent items (candidate
pairs)
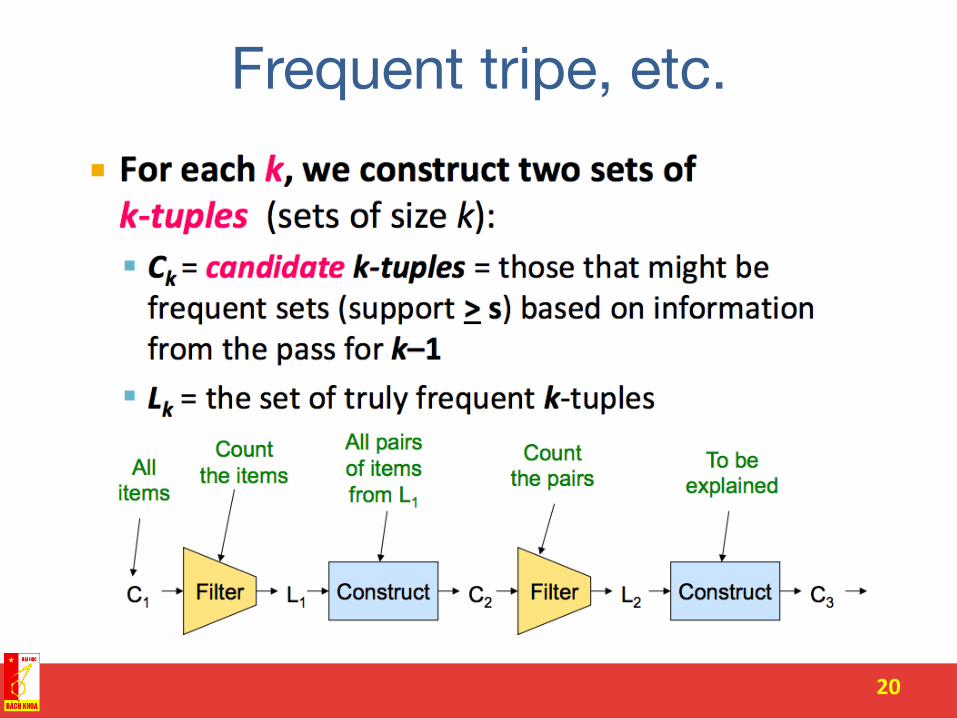
Frequent tripe, etc.
20

PCY (Park-Chen-Yu) Algorithm • Observation:
In pass 1 of A-Priori, most memory is idle – We store only individual item counts – Can we use the idle memory to reduce
memory required in pass 2? • Pass 1 of PCY: In addition to item counts, maintain a hash
table with as many buckets as fit in memory – Keep a count for each bucket into which
pairs of items are hashed • For each bucket just keep the count, not the actual
pairs that hash to the bucket!
21
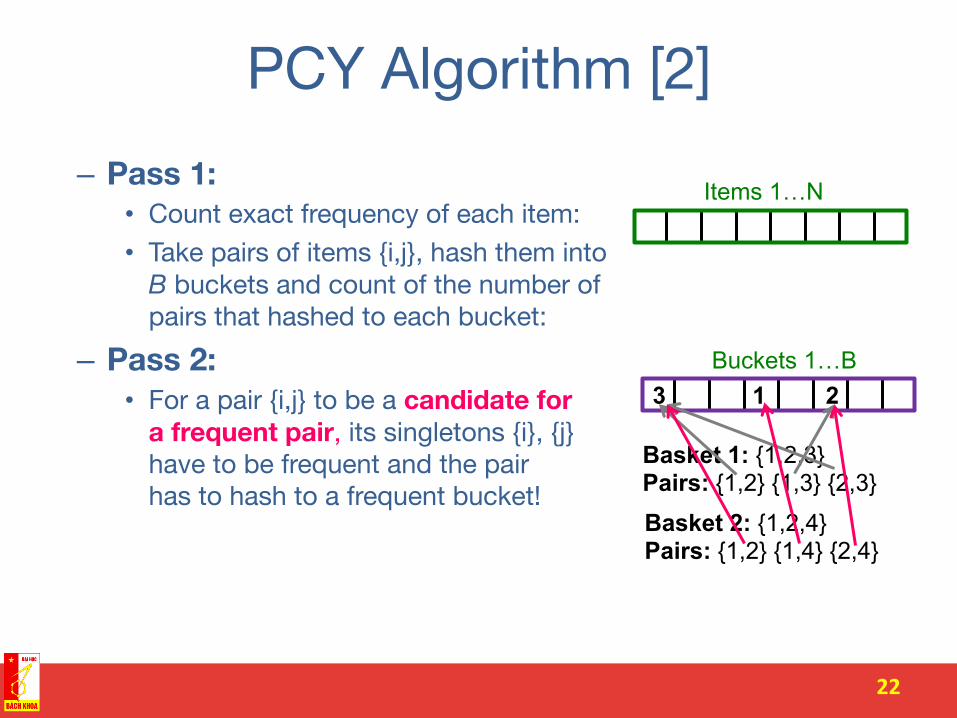
PCY Algorithm [2] – Pass 1:
• Count exact frequency of each item: • Take pairs of items {i,j}, hash them into B buckets and count of the number of pairs that hashed to each bucket:
– Pass 2: • For a pair {i,j} to be a candidate for
a frequent pair, its singletons {i}, {j} have to be frequent and the pair has to hash to a frequent bucket!
22
Items 1…N
Basket 1: {1,2,3} Pairs: {1,2} {1,3} {2,3}
Basket 2: {1,2,4} Pairs: {1,2} {1,4} {2,4}
Buckets 1…B 3 1 2

Frequent Itemsets in < 2 Passes

Frequent Itemsets in < 2 Passes • A-Priori, PCY, etc., take k passes to find frequent
itemsets of size k • Can we use fewer passes? • Use 2 or fewer passes for all sizes,
but may miss some frequent itemsets – Random sampling – SON (Savasere, Omiecinski, and Navathe) – Toivonen
24

Random Sampling [1] • Take a random sample of the market baskets
• Run a-priori or one of its improvementsin main memory – So we don’t pay for disk I/O each
time we increase the size of itemsets – Reduce support threshold
proportionally to match the sample size
25
Copy of sample baskets
Space for counts
Mai
n m
emor
y

26
SON Algorithm [1] • Repeatedly read small subsets of the baskets into
main memory and run an in-memory algorithm to find all frequent itemsets – Note: we are not sampling, but processing the entire file
in memory-sized chunks • An itemset becomes a candidate if it is found to be
frequent in any one or more subsets of the baskets.

27
SON Algorithm [2] • On a second pass, count all the candidate
itemsets and determine which are frequent in the entire set
• Key “monotonicity” idea: an itemset cannot be frequent in the entire set of baskets unless it is frequent in at least one subset.

SON – Distributed Version • SON lends itself to distributed data mining • Baskets distributed among many nodes
– Compute frequent itemsets at each node – Distribute candidates to all nodes – Accumulate the counts of all candidates
28

SON: Map/Reduce • Phase 1: Find candidate itemsets
– Map? – Reduce?
• Phase 2: Find true frequent itemsets – Map? – Reduce?
29