3d multi object gan
TRANSCRIPT

3D Multi Object GANFully Convolutional Refined Auto-Encoding Generative Adversarial
Networks for 3D Multi Object Scenes
8/31/2017
Real/Fake
Encoder Generator
FullyConvolution
x
NormalDistribution
z Generator
Discriminatorz enc
reshape
CodeDiscriminatorReal/Fake
Refiner
Refiner
xgen
x rec

Agenda
• Introduction
• Dataset
• Network Architecture
• Loss Functions
• Experiments
• Evaluations
• Suggestions of Future Work
Source Code:https://github.com/yunishi3/3D-FCR-alphaGAN

Introduction3D multi object generative models should be an extremely important tasks
for AR/VR and graphics fields.- Synthesize a variety of novel 3D multi objects- Recognize the objects including shapes, objects and layouts
Only single objects are generated so farSimple 3D-GANs[1]
Simple 3D-VAE[2]
Multi Object Scenes

Dataset
• SUNCG dataset
Extracted only voxel models from SUNCG dataset
-Voxel size: 80 x 48 x 80 (Downsized from 240x144x240)-12 Objects
[empty, ceiling, floor, wall, window, chair, bed, sofa, table, tvs, furn, objs]-Amount: around 185000-Got rid of trimming by camera angles-Chose the scenes that have over 10000 amount of voxels.-No label
From Princeton [3]

Challenges, Difficulties
Sparse, so much varieties
empty ceiling floor wall window chair bed sofa table tv furnitureobjects
92.466 0.945 1.103 1.963 0.337 0.070 0.368 0.378 0.107 0.009 1.406 0.846
Average occupancy ratio of each objects in dataset [%]
[%] Average occupancy ratioDining room
Bedroom
Garage
Living room

Network ArchitectureFully Convolutional Refined Auto-Encoding Generative Adversarial Networks
-Similar architecture with 3DGAN[1]-Encoder, discriminator are almost mirrored from generator-Latent space is fully convolutional layer (5x3x5x16)
-Fully convolution enables Zenc to represent more features-Last activation of generator is softmax -> Divide 12 classes-Code discriminator is fully connected (2 hidden layers)[4]-Refiner is similar architecture of simGAN[5]
-Multi class activationfor multi object scenes
-Fully Convolution
Novel Contribution
Real/Fake
Encoder Generator
Fully Convolution
Normal Distribution
z Generator
Discriminatorz enc
reshape
CodeDiscriminatorReal/Fake
Refiner
Refiner
xgen
x rec
x

Network Architecture
Inspired by [1]
z
5x3x5x512 10x6x10x256 20x12x20x128 40x24x40x64 80x48x80x12
Each Network
-3D deconv (Stride:2)-Batch Norm-LRelu(Discriminator)
Relu(Encoder, Generator)
Last Activation
-Softmax
5x3x5x16
Reshape& FCbatchnormrelu
5x3x5stride 2batchnormrelu
Generator Network
5x3x5stride 2batchnormrelu
5x3x5stride 2batchnormrelu
5x3x5stride 2softmax
[Wu et al. 2016, MIT]

Network Architecture
Inspired by [5]
Each Network
-3D deconv (Stride:1)-Relu(Encoder, Generator)-ResNet Block loops 4 times(different weights)
Last Activation
-Softmax
Refiner Network
Unlabeled Real Images
Syn
the
tic
Simulated images
Refin
ed
Figure 5. Exampleoutput of SimGAN for theUnityEyes gazeestimation dataset [40]. (Left) real images from MPIIGaze [43]. Our
refiner network doesnot useany label information from MPIIGaze dataset at training time. (Right) refinement resultson UnityEye.
The skin texture and the iris region in the refined synthetic images are qualitatively significantly more similar to the real images
than to the synthetic images. More examples are included in the supplementary material.
Conv
f@nxn
Conv
f@nxn+
Input feature maps
Output feature maps
ReLU
ReLU
ResNet Block
Conv
f@nxn
Conv
f@nxn
+
ReLU
ReLU
Input
FeaturesOutput
Features
Figure6. A ResNet block with two n⇥n convolutional layers,
each with f feature maps.
At each iteration of discriminator training, we compute
the discriminator loss function by sampling b/ 2 images
from the current refiner network, and sampling an addi-
tional b/ 2 images from the buffer to update parameters
φ. We keep the size of the buffer, B , fixed. After each
training iteration, we randomly replace b/ 2 samples in
thebuffer with thenewly generated refined images. This
procedure is illustrated in Figure 4.
3. Exper iments
We evaluate our method for appearance-based gaze
estimation in thewild on theMPIIGaze dataset [40, 43],
and hand poseestimation on theNYU hand posedataset
of depth images [35]. Weuse fully convolutional refiner
network with ResNet blocks (Figure6) for all our exper-
iments.
3.1. Appearance-based Gaze Estimation
Gaze estimation is a key ingredient for many human
computer interaction (HCI) tasks. However, estimat-
ing the gaze direction from an eye image is challeng-
ing, especially when the image is of low quality, e.g.
from alaptop or amobilephonecamera–annotating the
eye images with a gaze direction vector is challenging
even for humans. Therefore, to generate large amounts
of annotated data, several recent approaches [40, 43]
train their models on large amounts of synthetic data.
Here, we show that training with the refined synthetic
imagesgenerated by SimGAN significantly outperforms
the state-of-the-art for this task.
The gaze estimation dataset consists of 1.2M syn-
thetic images from eye gaze synthesizer UnityEyes [40]
and 214K real images from the MPIIGaze dataset [43]
– samples shown in Figure 5. MPIIGaze is a very chal-
lenging eye gaze estimation dataset captured under ex-
treme illumination conditions. For UnityEyes we use a
single generic rendering environment to generate train-
ing data without any dataset-specific targeting.
QualitativeResults: Figure5 showsexamplesof syn-
thetic, real and refined images from theeyegazedataset.
Asshown, weobserveasignificant qualitative improve-
ment of the synthetic images: SimGAN successfully
captures the skin texture, sensor noise and the appear-
ance of the iris region in the real images. Note that our
method preserves the annotation information (gaze di-
rection) while improving the realism.
‘Visual Tur ing Test’ : To quantitatively evaluate the
visual quality of the refined images, we designed a sim-
ple user study where subjects were asked to classify
images as real or refined synthetic. Each subject was
shown a random selection of 50 real images and 50 re-
fined images in a random order, and was asked to label
the images as either real or refined. The subjects were
constantly shown 20 examples of real and refined im-
ages while performing the task. The subjects found it
very hard to tell the difference between the real images
and the refined images. In our aggregate analysis, 10
subjects chose the correct label 517 times out of 1000
trials (p = 0.148), which is not significantly better than
chance. Table 1 shows the confusion matrix. In con-
trast, when testing on original synthetic images vs real
images, we showed 10 real and 10 synthetic images per
subject, and the subjects chose correctly 162 times out
of 200 trials (p 10− 8), which is significantly better
than chance.
Quantitative Results: We train a simple convolu-
tional neural network (CNN) similar to [43] to predict
theeyegazedirection (encoded by a3-dimensional vec-
tor for x, y, z) with l2 loss. We train on UnityEyes and
test on MPIIGaze. Figure 7 and Table 2 compare the
performance of a gaze estimation CNN trained on syn-
thetic data to that of another CNN trained on refined
80x48x80x1280x48x80x32 80x48x80x32
80x48x80x12
ResNet Block x4
3x3x3relu
3x3x3relu
3x3x3
Relu

Loss / Training
Encoder
Distribution GAN Loss
Reconstruction Loss
Discriminator discriminates real and fake scenes accuratelyGenerator fools discriminator
ℒ𝑟𝑒𝑐 =
𝑛
𝑐𝑙𝑎𝑠𝑠
𝑤𝑛 −𝛾𝑥𝑙𝑜𝑔 𝑥𝑟𝑒𝑐 − 1 − 𝛾 1 − 𝑥 𝑙𝑜𝑔 1 − 𝑥𝑟𝑒𝑐
Reconstruction accuracy would be highw is occupancy normalized weights with every batch
GAN Loss
ℒ𝐺𝐴𝑁 𝐷 = −log 𝐷 𝑥 − log 1 − 𝐷 𝑥𝑟𝑒𝑐 − log 1 − 𝐷 𝑥𝑔𝑒𝑛
ℒ𝐺𝐴𝑁 𝐺 = − log 𝐷 𝑥𝑟𝑒𝑐 − log 𝐷 𝑥𝑔𝑒𝑛
min𝐸ℒ = ℒ𝑐𝐺𝐴𝑁 𝐸 + 𝜆ℒ𝑟𝑒𝑐
TrainingLoss
Generator with refiner
min𝐺ℒ = 𝜆ℒ𝑟𝑒𝑐 + ℒ𝐺𝐴𝑁 𝐺
Discriminator
min𝐷ℒ = ℒ𝐺𝐴𝑁 𝐷
Learning rate: 0.0001Batch size: 20(Base), 8(Refiner)Iteration: 100000
(75000:Base, 25000:Refiner)
ℒ𝑐𝐺𝐴𝑁 𝐷 = −log 𝐷𝑐𝑜𝑑𝑒 𝑧 − log 1 − 𝐷𝑐𝑜𝑑𝑒 𝑧𝑒𝑛𝑐ℒ𝑐𝐺𝐴𝑁 𝐸 = − log 𝐷𝑐𝑜𝑑𝑒 𝑧𝑒𝑛𝑐
Code discriminator discriminates real and fake distribution accuratelyEncoder fools code discriminator
Code Discriminator
min𝐶ℒ = ℒ𝑐𝐺𝐴𝑁 𝐷
Refiner is trained after 75000 iterations
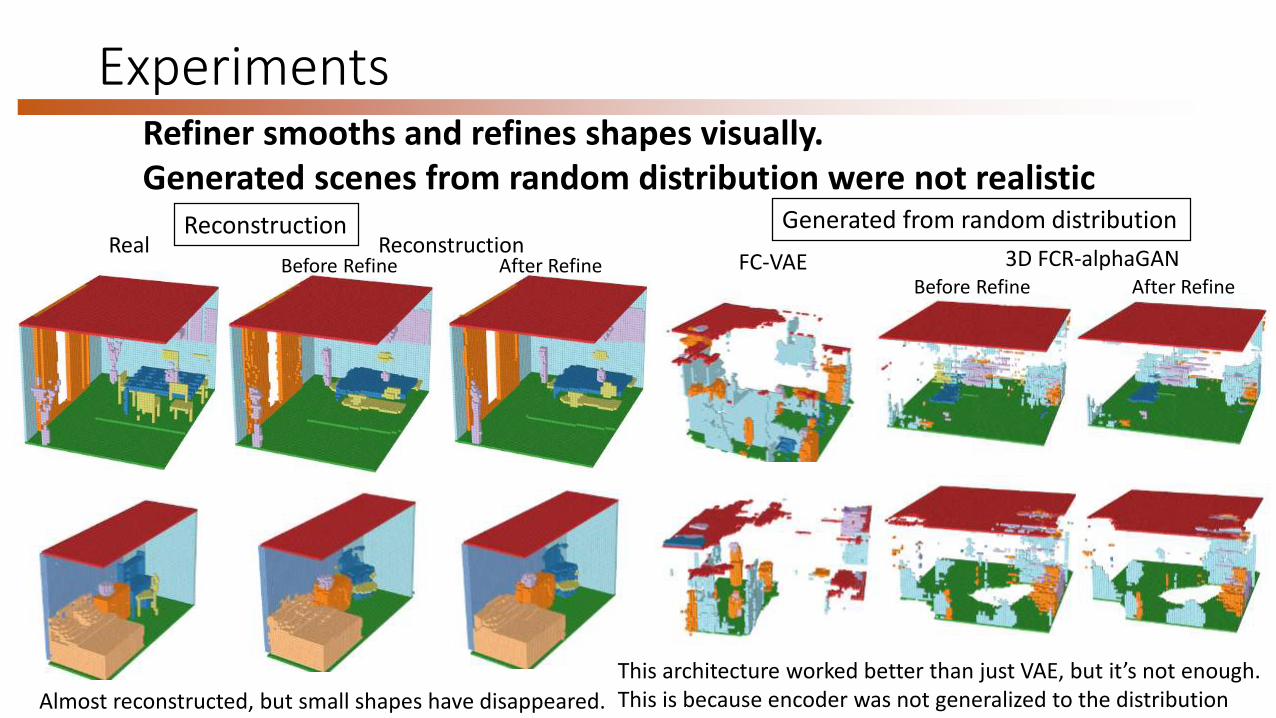
ExperimentsRefiner smooths and refines shapes visually.Generated scenes from random distribution were not realistic
Generated from random distribution
FC-VAE 3D FCR-alphaGAN
ReconstructionReal Reconstruction
Almost reconstructed, but small shapes have disappeared.
Before Refine After Refine
This architecture worked better than just VAE, but it’s not enough.This is because encoder was not generalized to the distribution
Before Refine After Refine

Result
Numerical evaluation of reconstruction by IoU
Intersection-over Union(IoU) [6]
Reconstruction accuracy got high due to the fully convolution and alphaGAN
IoU for every class
IoU for all
Same number of latent space dimension
Same number of latent space dimension

Evaluations
Interpolation
Smooth transition between scenes are built

Evaluations
Latent Space EvaluationThe 2D represented mapping by SVD of 200 encoded samplesColor:1D embedding by SVD of centroid coordinates of each scene
Fully convolution Standard VAE
Fully Convolution enables the latent space to be related to spatial context
This follows 1d embedding of centroid coordinates from lower right to upper left. This does not.

Evaluations
Latent space evaluation by added noiseThe effects of individual spatial dimensions composed of 5x3x5 as the latent space.Red means the level of changes given by normal distribution noises of one dimension.
・2,0,4 dimension changes objects in right back area.
・4,0,1 dimension changes objects in left front area.
・1,0,0 dimension changes objects in left back area.
・4,0,4 dimension changes objects in right front area.
Fully Convolution enables the latent space to be related to spatial context

Suggestions of Future Work
・Revise the datasetThis dataset is extremely sparse and has plenty of varieties. Floors and small objects are allocated to huge varieties of
positions, also some of the small parts like legs of chairs broke up in the dataset because of the downsizing. That makes predicting latent space too hard. Therefore, it is an important work to revise the dataset like limiting the varieties or adjusting the positions of objects.
・Redefine the latent spaceIn this work, I defined the latent space with one space which includes all information like shapes and positions of each
object. Therefore, some small objects disappeared in the generated models, and a lot of non-realistic objects were generated. In order to solve that, it is an important work to redefine the latent space like isolating it to each object and layout. However, increasing the varieties of objects and taking account into multiple objects are required in that case.

References
[1]Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum; Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling; arXiv:1610.07584v1
[2]Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston; Generative and Discriminative Voxel Modeling with Convolutional Neural Networks; arXiv:1608.04236v2
[3]Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser; Semantic Scene Completion from a Single Depth Image; arXiv:1611.08974v1
[4]Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, Shakir Mohamed; Variational Approaches for Auto-Encoding Generative Adversarial Networks; arXiv:1706.04987v1
[5]Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb; Learning from Simulated and Unsupervised Images through Adversarial Training; arXiv:1612.07828v1
[6]Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, Silvio Savarese; 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction; arXiv:1604.00449v1