6 sampling and sampling distributions - york university · 6 sampling and sampling distributions...
TRANSCRIPT

6 Sampling and Sampling Distributions
In order to make inferences about random phenomena, we observe the outcomes of a sequence of trials. In other words, we collect sample data in order to learn more about characteristics of the distributions of random variables. From the particular results obtained in a sample we reach general but uncertain conclusions about the unknown, underlying probability distributions.
As we have seen in several examples, the basic logic of inference depends on comparison between data observed in a sample and the results one would predict given various possible forms of the underlying distribution. In Example 3-2, for instance, the relative frequency distribution for the length in games of the 66 World Series played through 1969 was compared with probability distributions based on assumptions of evenly and unevenly matched teams. In Example 2-3, it was seen that 46 of the 86 Red Sox wins in 1968 were played at home. According to our estimation, if playing at home is not advantageous, as many as 46 of 86 wins would be expected to occur at home about one time in four; thus, the evidence is not strong that playing at home is advantageous. In Example 5-7, the relative frequencies were quite different from those expected if successive stock price changes were independent. Therefore Niederhoffer and Osborne concluded (inferred) that successive price changes are not independent.
In each case, a number (or set of numbers) was calculated from the observations in the sample. Such numbers are known as the values of sample statistics. Sample statistics are random variables; they are functions of sample observations which themselves are simply the observed
110

::;ampllng ana :sampling Distributions 111
values of random variables. Sample statistics take different values in different samples; they have a probability distribution. If, for instance, the ticker tape record for September 1970 were used to find ajoint frequency distribution for price changes, the values for the relative frequencies would be different from those obtained using data for October 1964. Similarly, the 1970 Red Sox record represents a different sample than the 1968 record. In 1970 the Red Sox won 87 games, 52 of which were played at home. The relative frequency N(WH)/N(W) 52/87= 0.598 for the 1970 season; it was 46/86 = 0.535 in 1968.
The probability distribution of a sample statistic is known as a sam· pling distribution. In order to make sensible inferences from an observed sample statistic, one should know what values the statistic could have taken and the corresponding probabilities; that is, one should know the sampling distribution of the statistic. Since the sample statistic depends on the sample observations, it appears that the distribution of the sample statistic depends on the joint probability distribution of the sample observations.
Suppose a sample is drawn consisting of n observations on a random variable. Each observation has the same probability distribution. Call
, the observations X! , X 2, ••• , X n' Now, a sample statistic is calculated from . these n observations. The probability distribution of the sample statistic depends on the joint probability distribution of X! , X 2, ••• , X n' If X! , X 2,
•.. , Xn are independent, and if each Xi has the same (marginal) probability distribution p(x;), then p(X!, X2, •.• , Xn) = P(XI) P(X2) ... P(Xn).
We say that XI' X 2 , ••• , Xn constitute a Simple random sample. We shall assume in most of what follows that the sampling procedure is simple
l\,ranlClolm sampling. Thus, for a given or assumed fonn of the marginal disp(x;), we can find by multiplication the joint probability distri
bution of the sample, and from that the relevant sampling distributions. Notice that not every collection of data can be regarded as a simple
sample and that the underlying distribution may vary, depending the method of sampling. For example, the distribution of possible
of the average income of a sample of 100 families living side by side a randomly chosen street in New York City is likely to be quite different
the distribution of average income of 100 families each drawn at from the whole of New York City.
example: the binomial distribution
The concepts of sampling and sampling distributions will be explored this section by means of an important and useful example. Suppose a
experiment is repeated n times. On each independent trial it is

-.j.,
\
112 Probability and Statistical Inference
observed whether or not some particular event occurs. The number of times the event occurs in n trials is a random variable. Because on each trial there are only two possible outcomes (either the event occurs or it does not) and because the probability distribution can be found by expanding a binomial expression,) this random variable is known as a binomial random variable.
To be more concrete, suppose a possibly unfair coin is tossed three times. On each toss there are only two possible outcomes - either a head occurs or it does not. If a head does not occur, then the outcome is a taiL On each toss the probability of a head is p and, therefore, the probability of a tail is 1 p. The possible outcomes in three tosses and the corresponding probabilities are shown in the first two columns of Table 6-1.
We define four random variables-R, XI' X 2 , and Xa-on the basis of this coin-tossing experiment. R is the number of heads obtained in the three tosses. R is a binomial variable. XI' X 2 , and Xa are also binomial, having the simplest possible form: Xi is the number of heads obtained on the ith toss.
TABLE 6-1 Outcomes of Coin-Tossing Experiment and Their Probabilities
Outcome Probability R Xl X2 X3
HHH p3 3 1 HHT p2(1 - p) 2 1 0 HTH p2(1 - p) 2 0 1 HTT p(1-p)2 0 0 THH p2(1 -p) 2 0 THT p(1_p)2 0 1 0 TTH p(1-p)2 0 0 1 TIT (1-p)3 0 0 0 0
Now, let us find the probability distribution of R. There are four possible values-O, 1, 2, and 3. The value of R is 3 only if HHH occurs, so P(R 3) = p3. R is 2 for three possible outcomes, so P(R 2) = P(HHT) + P(HTH) + P(THH) = p2(l- p) + p2(l- p) + p2(l p) = 3p2(1- p).
Notice that all outcomes that have two heads have the same probability, therefore P(R = 2) may be found by counting the number of outcomes for which R 2 and multiplying this number by the common probability for
I The appropriate binomial expression is (p + q) • where p is the probability the event occurs on a single trial and q(= 1 - p) is the probability it doas not occur. For n = 3, (p + q)3 = p3 + 3p2q + 3pq2 + q3.

Sampling and Sampling Distributions 113
each such outcome. Similarly, P(R = 1) = 3p(1 - p)2, and P(R = 0) = (1- p)3.
p2 + 2p(l- p) + (1- p)2] = p[p + (1- p»)2 = p.

There is a general formula for the binomial distribution; it is
(r 0,1,2, ... , n).
The symbol (;) means
n! 1'2"'(n-l)n rl(n-r)! (1·2'" r)(l· 2 .. · (n r-l)(n-r»'
(Note: 01 = 1.) And, since p = R/n, P(p = rln) peR r). Of course, this formula is itself tedious to use if n is large; when n = 100, there are 101

~a"II.111I1Y I:1llU ~alllJ.llllly UISlIlUUlIUIIS I.! I
probabilities to calculate in order to find the sampling distribution of R or p.
The mean and variance of a probability distribution are sometimes used to describe the distribution. They can be found easily for the sampling distributions of Rand p: Recall that R is equal to ~~ Xi where Xl> X 2 , ••• , Xn are independently and identically distributed. Each Xi has mean p and variance p(l- p). The mean of R is therefore
E(R) = E(X 1 + X 2 + ... + Xn)
E(X 1 ) + E(X2 ) + ... + E(X,,)
p + P + ... + p
np.
Since the X/s are independent, the variance of their sum is the sum of their variances.
var (R) = var (~~ Xi) = var (Xd + var (X 2 ) + ... + var (X,,)
=p(1-p)+p(l p)+"'+p(l-p)
np(l p).
Now, we can find the mean and variance of p from the mean and variance of R: Since p = R/n,
And
E(P> = E(R/n) = 1 E(R) n
1 - (np) =p. n
var (p) = var (R/n) 1 1
---;; var (R) = 2 [np(l- p)] n n
p(l-p)/n.
Whatever the sample size and value of p, the sampling distribution of p is centered at p-the mean of p is always p. The variance is not always the same, however; it is inversely proportional to the sample size. As the sample size increases, the distribution of p remains centered at p but becomes more and more concentrated near p.

O:>i:UIIIJIII1Y allu o:>afT1IJIlIlY U15lnOUllOnS 1""
Distribution of a sample mean
One of the most frequently used sample statistics is the sample mean. Suppose XI> X2 , ••• , Xn constitute a simple random sample; the X/s are independent random variables, each having the same probability distribution. Suppose the mean of Xi is ~ and the variance of Xi is (J"2. The sample mean, i, is (X 1+ X2 + ... + Xn)/n. X is a random variable; it has a probability distribution.
The mean of X is ~, the same as the mean of each Xi:
1 = - [~ + ~ + ... + ~]
n
1 = - (n~)
n
=~.

124 Probability and Statistical Inference
Since the X;'s are independent, the variance of X is
= (;;)2 var (Xl + X2 + . : . + X,,)
1 2 ' •
• = (;;-) [var (Xl) + var (X 2 ) + ... + var (X n )]
=(~r [
n
2 0- + 2 0-
The sampling distribution of X is centered at 11-, the mean of X, and has variance equal to 0-2/n, where c.-2 is the variance of the distribution from which individual observations come and n is the number of observations in the sample. As the sample size increases, the variance of X shrinks so that the distribution of X becomes more and more concentrated near 11-.
Since the variance of X can be made as small as one likes by making n large, the probability limit of X is 11-. Thus, by taking a large enough sample, one can make the probability that X is more than an arbitrarily small distance c from II--P( IX - 11-1 '"" c) -as small as one wishes. This is known as the weak law of large numbers.
In the preceding section we showed that the probability limit of p is p. This is a special case of the weak law of large numbers because p = B/n = (Xl + Xz + ... + Xn)fn is a special example of a sample mean. The binomial variable Xi has mean p and variance p(1- p).
We know the mean and variance of X in relation to the mean and variance of X, the distribution from which individual observations come. Using Tchebycheff's inequality, we can reach some general conclusions about the probability of X being close to 11-. But these are rather loose estimates of the actual probabilities. To be more exact we need to know better the form or shape of the sampling distribution of X. To find the exact sampling distribution of X from the distribution of X is likely to be difficult, but for large. samples there is a very useful approximation.
Central limit theorem. If X has a probability distribution with mean 11- and variance 0-2, then the sample mean X, based on a random sample of

Sampling and Sampling Distributions 125
size n, has an approximately normal distribution with mean ~ and variance (T2/n. The approximation becomes increasingly good as n increases.
This says that no matter what the original distribution of X (so long as it has finite mean and variance) the distribution of X from a large sample can be approximated by a symmetrical curve known as a normal distribution. This is a theorem of great importance in statistics. It clearly makes the normal distribution an important distribution to know. We cannot understand the theorem or proceed further without knowing what is meant by a,normal distribution.
Normal distribution
The normal distribution is a continuous, symmetrical, bell-shaped probability distribution. If a random variable X has a normal probability distribution, then X is said to be a normal variable or to be normally distributed.
A normal probability density function is depicted in Figure 6-5. The mean of this normal distribution is 8; the distribution is centered at the value 8. The variance for the distribution is 4.
It is instructive to examine the rather complicated mathematical representation of a normal Curve. If X is a normal random variable with mean ~ and variance (T2, then the probability density function of X is
1 1("-"')' p(x) =--e 2 <T •
v'21T (T
p(x)
o 4 12 14
Figure 6-5. Normal probability distribution, p. = 8, (T2 4.

126 Probability and Statistical Inference
For example, the fonnula for the nonnal distribution pictured above is
1 (' 8)' p(x) = 1 e-"2 -2- ,
v'2; (2)
since IL = Band u= V4 = 2. From the fonnula one can see that p(x) is greatest when the exponent of e is equal to zero,2 If x B, the exponent is
Oandthusp(B) ~()eo ~()=0.1995.Ifxisl0,theexponentof 2'7T 2 2'7T 2
e is - ~(IO; 8) 2 = ~,so p(lO) = ~(2) e-j 0.1995(0.6065) = 0.1210.
But notice that if x 6 (2 below the mean rather than 2 above the mean), 1 1
the exponent of e is again-2, so p(6) = v'27T(2) e-j=0.121O p(lO). Ifx
is 4 above or below the mean (x 12 or 4), then the exponent of e is ~2.
So p(4) p(12) ~(2) e-2 (0.1995)(0.1353) 0.0270. The probability
density function is symmetrical around the mean and, as x gets farther from the mean, the value of p(x) decreases, approaching zero.
Returning to the general formula, it can be seen that the probability density function depends on only two parameters, IL and u. If we know the mean and standard deviation of a nonnal random variable, we know its entire probability distribution. If two nonnal random variables have the same standard deviation but different means, their probability densities differ in location but not in dispersion, as shown in Figure 6-6. If two nonnal variables have the same mean but different standard devia~ tions, then they differ in height at the mean and in dispersion. See Figure 6-7.
Since p(x) is a probability density function, it is required that the area under the function be equal to one. This may help you see why the height of the nonnal probability density at IL decreases when dispersion increases.
Finding probabilities from normal distribution. Suppose X is a normal random variable with mean ILx and variance ul. For short, this is sometimes denoted X - N (ILx, ux2
). What is the probability that the event (a ~ X ~ b) occurs? That is, what is the probability that X takes a value greater than or equal to a but less than or equal to b?
The probability Pea ~ X ~ b) is equal to the area under the probabil-
2 e is the base of the natura! system of logarithms. The value of e is approximately 2.72.

Sampling and Sampling Distributions 127
p(x)
Figure &-6. Normal probability density functions. showing different means. same standard deviation.
p(x)
x
Figure 6-7. Normal probability density functions, showing same mean, different standard deviations «(1'1 = 2(1'.).
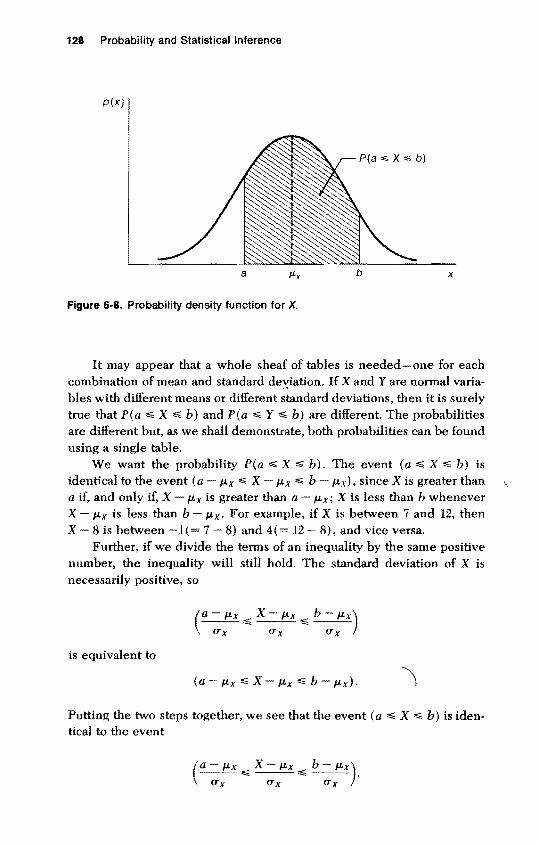
ity density function between a and b, as shown in Figure 6-8.3 Given the complicated form of the normal density function, it would seem that finding such an area would be a difficult task. But tables have been made which give areas under normal density curves, and we shall use such a table.
b b 1 _~(,--".)2 3This is an integral. P(a '" X '" b) = f. p(x) dx = f. : =- e 2 ". dx.
• • v21rfJ'z
128 Probability and Statistical Inference
p(x)
Figure 6·8. Probability density function for X.
It may appear that a whole sheaf of tables is needed-one for each combination of mean and standard dexiation. If X and Yare normal variables with different means or different standard deviations, then it is surely true that pea ,,;; X ,,;; b) and pea ,,;; Y ,,;; b) are different. The probabilities are different but, as we shall demonstrate, both probabilities can be found using a single table.
We want the probability pea ,,;; X ,,;; b). The event (a,,;; X,,;; b) is identical to the event (a /-Lx";; X /-Lx";; b /-Lx), since X is greater than a if, and only if, X /-Lx is greater than a - /-Lx; X is less than b whenever X /-Lx is less than b - /-Lx. For example, if X is between 7 and 12, then X 8 is between -1 7 - 8) and 4(= 12 - 8), and vice versa.
Further, if we divide the terms of an inequality by the same positive number, the inequality will still hold. The standard deviation of X is necessarily positive, so
is equivalent to
Putting the two steps together, we see that the event (a ,,;; X,,;; b) is identical to the event

Therefore,
Sampling and Sampling Distributions 129
(a - J.Lx X - J.Lx b - J.Lx) P(a ~ X ~ b) =P ---~ ---~ --- .
o-x o-x o-x
If, for example, a = 7, b = 12, J.Lx = 8, and o-x = 2, we see that
(7- 8 X - 8 12 - 8) P(7 ~ X ~ 12) = P -- ~ --~- ~ --
2 2 2
(X - 8 ) = P -1/2 ~ -2 - ~ 2 .
X - a - J.Lx b J.Lx Now, if we let Z = a~ = ---, and b~ = ---, we see that
o-x o-x o-x P(a ~ X ~ b) and P(a~ ~ Z ~ bO) are the same. Can we find P(aO ~ Z ~ bO)?
What do we know about the random variable Z? To get Z, we have subtracted a constant, /.Lx, from X and then divided (X - /.Lx) by another constant, O-x. X has a normal distribution. If we subtract J.Lx from X we simply shift the location of the random variable- it still is normal. Dividing a normal random variable iry 0-x will change the dispersion but not the form
of the distribution, so Z = X - is normally distributed. o-x
If we find the mean and variance of Z we can determine its entire probability density function. The mean and variance of Z can be found from the mean and variance of X:
1 1 = - (E(X) - J.Lx] = - [J.Lx - J.Lx]
o-x o-x
=0.
o-l = E(Z - J.LZ)2 = E(Z2) = E [( ~ ::xrJ 1
= - E( (X - J.LX)2] o-l
1 = - (o-J)
o-l
=1.
130 Probability and Statistical Inference
Thus Z is a nonnal random variable with mean 0 and variance I; Z - N(O, I). Z is said to have a standard nonnal distribution. We have changed a question involving X - N(lLx, ul) into an equivalent one involving Z. By similar steps the probability that any nonnal random variable falls in a given interval can be shown to equal the probability that a standard nonnal variable falls in a corresponding interval.
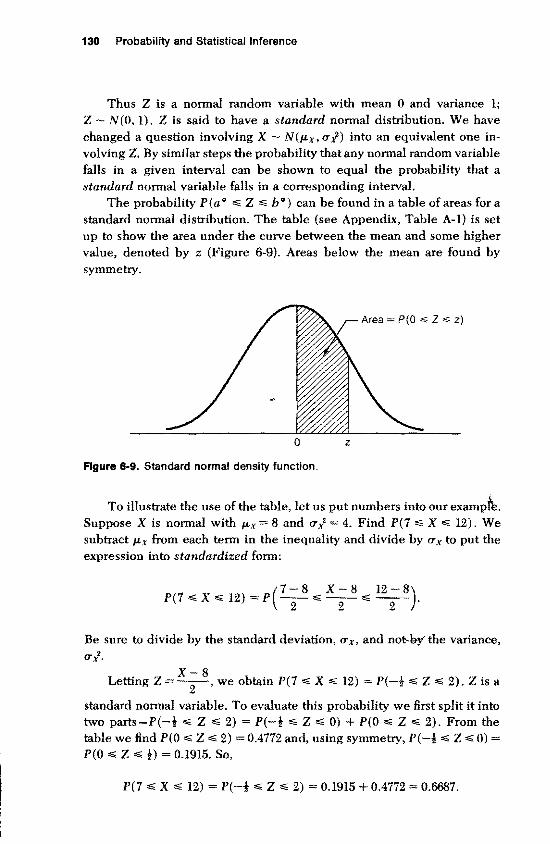
The probability P(aO "'" Z "'" bO) can be found in a table of areas for a standard nonnal distribution. The table (see Appendix, Table A-I) is set up to show the area under the curve between the mean and some higher value, denoted by z (Figure 6-9). Areas below the mean are found by symmetry.
P(O ~ Z ~ z)
o z
Figure 6-9. Standard normal density function.
To illustrate the use of the table, let us put numbers into our exampIe. Suppose X is nonnal with ILx = 8 and ul 4. Find P(7 "'" X "'" 12). We subtract ILx from each tenn in the inequality and divide by Ux to put the expression into standardized fonn:
(7- 8 X - 8 12 - 8)
P(7"",X"",I2)=P -2-""'-2-""'-2-'
Be sure to divide by the standard deviation, ux, and no~ the variance, ul.
Letting Z = X ; 8, we obtain P(7 "'" X "'" 12) = P(-t "'" Z "'" 2). Z is a
standard nonnal variable. To evaluate this probability we first split it into two parts-P(-t "'" Z "'" 2) = P(-t "'" Z "'" 0) + P(O "'" Z "'" 2). From the table we find P(O "'" Z "'" 2) = 0.4772 and, using symmetry, P(-t "'" Z "'" 0) = P(O "'" Z "'" t) = 0.1915. So,
P(7 "'" X "'" 12) = P(-t "'" Z "'" 2) = 0.1915 + 0.4772 = 0.6687.

Sampling and Sampling Distributions 131
Notice that in putting the expression into standardized form you find the number of standard deviations that a and b are from the mean of X:
aft
In the example, a was 7 and b was 12; a was one unit from JLx (7 - 8), but since a standard deviation is 2, a is only 1/2 a standard deviation length from JLx. a<> -1-. Similarly, b is 4 units or 2 standard deviation lengths
12- 8 from JLx; so b<> = -2- = 2.
It may be helpful in dealing with normal variables to remember a few probabilities. The area under any normal distribution from one standard deviation below to one standard deviation above the mean is 0.6826. Stated differently, P(JLx - Ux .:; X .:; JLx + ux) = P(-l .:; Z .:; 1) = 0.6826. The area under a normal probability density within 2 standard deviations of the mean is 0.9544; P(JLx 2ux':; X .:; JLx + 2ux) = P(-2 .:; Z .:; 2) 0.9544. And almost all the area is within three standard deviations of the mean; P(-3 .:; Z .:; 3) = 0.9974 . ..
Sums of normal variables. We saw earlier that adding (or subtracting) a constant to a random variable would change the mean of the variable but not its form. If X is normal, then X plus a constant is also normal. Also, if we multiply a normal variable, X, by a constant, c, its mean and variance change but the new variable, eX, will still be a normal variable. \
What if we add two or more normal variables? It can be shown that their sum will always be a) normal variable (even if they are not independent).
Suppose X 1> X., ... , X" are independent, normal random variables each with mean JL and variance u 2
• T!!!n their sum (XI + X. + ... + X,} is also a normal variable. To find the sample mean, we divide (X I + X. + ,.. i + X .. , by n. This will not change the form of the distribution, so X = (XI + X2 + ... + X .. )/n is normally distributed if each of the X/s in the sample is normal. Earlier we established that E (X) = JL and var (X) =
2
~ so long as each Xi in the sample has mean JL and variance u 2• Here we n 2
see that if each X, - N (JL, ( 2), then X - N (JL' : ).
Central limit theorem: an illustration
The central limit theorem tells us that for large n the distribution of X is approximately normal no matter what distributipn the individual

132 Probabifity and Statistical Inference
X/s have. If the X/s have mean IL and variance (J"2, then in large samples
X is approximately N(IL' :2). (Recall that if the X/s are normal, then X
is normal in any size sample.) To say that X is approximately N(IL' :2) means that for any a and b, P(a ~ X ~ b) is approximately equal to the
2
area under the normal probability density with mean IL and variance ~. n
This can happen only if a histogram of the sampling distribution of X looks very similar to a normal distribution.
The following experiment may illustrate how the distribution of a sample mean becomes approximately normal even though the individual observations do not come from a normal distribution. A table of random digits was used in the experiment. The table may be regarded as a long sequence of independent observations on a mndom variable X with probability distribution given by P(X = x) = 1/10, if x = 0, 1, 2, ... , 9 and P(X = x) = 0 for all other x's. The distribution of X is shown as a histogram in Figure 6-10. The mean of X is IL = 4.5 and the variance of X is (J"2 = 8.25.
Two empirical frequency distributions were obtained by repeated sampling from the table of random digits. Their histogmms (Figures 6-11 and 6-12) were drawn so as to have equal areas.
The first distribution (Figure 6-11) is based on a sample of 100 observations Xl' X 2 , ••• , X IOO ' It approximates the probability distribution of X. The sample mean is 4.45 and the sample variance is 8.351.
Figure 6-12 shows relative frequencies ,,(or sample means based on samples of size 25. The histogram is based. on 100 observations on
pix)
0.10
o 2 3 4 6 789 x
FIgure 6-10. Probability distribution of X shown as a histogram.

Sampling and Sampling Distributions 133
r----r---
t--- t--- I---
o 2 3 4 5 6 7 8 9 x
Figure 8-11. Histogram of X .
..
J
\
o 2 3 4 5 6 7 8 9 x
Figure 8-12. Histogram of X.

134 Probability and Statistical Inference
- ::Ef!1 Xi th fi b - If' X =~. To get erst 0 servation, Xl> a samp eo 25 X S-Xl' X 2 ,
... , X2S -was taken, and the mean of these 25 observations was Xl' Another sample of 25 X's was taken and their sample mean was X2 • This continued until X 100 was found. Then these 100 X· s were grouped and the histogram drawn. The histogram is a sampling approximation to the probability distribution of X when n 25.
Since J.L = 4.5 and (1"2 = 8.25, we know that for samples of size 25, (1"2 8.25
Wi = 4.5 and CTx2 = 25 = 25 0.33. Based on the sample X I, X2 , • •• ,X 100
we found a sample mean of 4.5416 and sample variance sx2 0.2875. Comparing the two histograms, one can readily see that the distribu
tion of sample means is much more concentrated than the original uniform distribution. More important, it is clear that the distribution of sample means has taken on a peaked, roughly symmetrical shape even though the sample size is only 25.
Another illustration of how the distribution of a sample mean tends to normality is provided by the probability distribution of p, which is tabulated in Table 6-4 and shown graphically for p = 1/2 and p = 2/3 in Figure 6-4. Recall that p is a special example of a sample mean. Even for n = 12, the distribution of p has started to look normal. ..
Normal approximation to the binomial distribution
Since p is a special example of a sample mean, the central limil.\ theorem tells us that p is approximately normal in large samples. And, if the sample proportion p is approximately normal, it appears that the binomial variable R should be also since p is simply a constant (lIn) times R. R can be well approximated by a normal distribution. In a sample of size n, E(R) = np and (1"R
2 np(l pl. If n is large, R = N[np, np(1 p)].
For example, suppose 86 independent tosses of a fair coin are made. R is the number of heads. The mean of R is 86(1) = 43, and the variance of R is 86m m = 21.5. What is the probability that 46 or more heads are obtained?
From the formula given on page 120 it can be seen that P(R = r) =
(8r6) (~)~ Therefore, from the binomial distribution,

Sampling and Sampling Distributions 135
peR ;;;. 46) peR = 46) + peR = 47) + ... + peR = 86)
(!:)(~r + (!~)(~r + ... + G:)(~r
= ar r~6 (8r6).
This is not a formula one would want to calculate by hand; however, with the help of a computer it has been evaluated: peR ;;;. 46) = 0.2950.
A reasonably accurate estimate of the probability may be obtained using a normal approximation to R, however. Assume R - N(43, 21.5). Note that if CTR2 21.5, the standard deviation CTR = 4.637. Now
(R 43 46-43)
peR ;;;. 46) P 4.637 ;;;. 4.637
= P(Z ;;;. 0.65)
0.2578.
A.u.impr:(,wement ott this estimate can be made if one recalls that R is >
a discrete variable bein a roximated by a continuous variable. Since can take only integer values, it would seem reasonable to approximate
P(R = r) by the area under the normal curve from r 0.5 to r + 0.5. Then the probability that R is 46 or more would be approximated by the area under the normal curve beginning at 45.5. With this adju\tment, we calculate
P(R;;;. 46) p(z;;;. 45~~~743) = P(Z;;;. 0.54) 0.2946.
This probability is the one we decided was needed to give a basis for inference in Example 2-3 (pages 20-21). By a sampling procedure, we estimated the probability to be 0.27.
Earlier in this chapter we asked how large a sample was needed to insure that the sample proportion f; would differ from p by as much as 0.02 only 5 percent of the time. In other words, what must n be so that P(If; - pi ;;;. 0.02) ~ 0.05? Using Tchebycheff's inequality, it was shown that a sample of 12,500 would suffice (see page 123).
We have seen that for large samples the distribution of p is approxi-
mately normal; p - N[p, p(l: p) l Let us use the normal approximation

136 Probability and Statistical Inference
to get a closer estimate of the sample size n needed to satisfy the requirement P(lp pi;;. 0.02) ~ 0.05. The problem is to find n large enough to insure that the distribution of p is so concentrated around p that only 5 percent of the area under the probability density function lies outside a band of width 0.04 centered at p. In Figure 6-13, when the sample size is n z, only 5 percent of the area under the probability density function of p is more than 0.02 away from p. For smaller samples (nl is less than nz),
the variance of p is larger and a larger area is more than 0.02 from p.
We have seen that for any normal distribution 95.44 percent of the area under the curve is within 2 standard deviations of the mean; therefore, the probability of observing a value that is more than 2 standard deviations from the mean is 0.0456. The distribution of p is approximately normal. So if we can make the standard deviation of p small enough so that
/P(ln- p), 2uj) = 0.02, we will achieve the desired precision. Since up 'J we can make Up as small as we like by increasing n. To find how large an
n is required, set 2~P(1:: p) = 0.02, and solve for n. Dividing by 2 and
squaring gives p(l p) 0.0001, and n-- 10,000p(l p). We do not n
know the value of p but, as was seen before, p(l
1/4. Thus a sample of size n = 10,OOOU-) = 2,500 P(p - pi ;;. 0.02) ~ 0.05.
probability density
p) cannot exceed will assure that
shaded area 0.05
p 0.02 ~ P L P +0.02
2a"
Figure 6-13. Probability density function, sample size n2.

Sampling and Sampling Distributions 137
Suppose a sample of 12,500 had been taken, as Tchebycheff's inequality suggested might be required. How probable would it be that the sample proportion p differs from p by as much as 0.02? If n 12,500, then p would be normal with mean p and variance p(1-p)/12,500. Sincep(l-p)";; 1/4, we can be sure that the variance of p is at most 1/50,000, and the standard deviation U'f> is at most 0.0045. Therefore,
PClp - pi ;;;. 0.02) ( I p - p I 0.02) P -- ;;;. -- = P(IZI ;;;. 4.44) 0.0045 0.0045 '
where Z is the standard normal variable. Most tables do not go this high. If you can find one that does, you will see that the probability is only 0.000009, less than 1 chance in 100,000. In a sample as large as 12,500, PClp pi;;;. 0.01) would he only 0.0264.
Sampling from finite populations
We defined a random sample to be a sequence of independent, identically distributed random v~ables. This definition fits comfortably with the notion of an easily repeated experiment with random outcomes, such as coin tossing. But often a sample is thought of as a selected subgroup of a larger population, such as a group of voters asked opinions in a poll, or a few television sets monitored to determined program preferences during a day's TV output. Indeed, sampling is often discussed in terms of , learning about populations. How do we reconcile these notions? '
Suppose a political candidate wants to know before the election what proportion of voters in his district favor him. He knows that there are a large number of voters, say N, some of whom favor him and the rest of whom do not. For simplicity, we shall ignore the possibility that those who do not now favor him may be divided into several categories, such as "favor the opponent," "undecided," etc. If all N voters could be polled, a proportion p would favor the candidate. For example, if there were 100,000 voters and 55,000 favor him, then p 0.55.
It would be prohibitively expensive to interview all the voters. Suppose the candidate has a sample taken in such a way as to insure that each voter is equally likely to be chosen. Let X, be 1 if the first voter chosen favors the candidate and 0 if he does not. What is P(X1 1)? It is p-there are N voters of whom Np favor the candidate. Each voter has equal proba-
bility of being chosen (namely, !) and for Np of the N voters XII, so
P(X 1 = 1) = NP(~) = p. And, of course, P(X, = 0) 1 p. Each person

138 Probability and Statistical Inference
is also equally likely to be the second one drawn, so X2 = 1 with probability p and 0 otherwise, etc.
If n voters are chosen, then XI' X 2 , ••• , Xn will be n identically distributed binomial variables. It would be natural to use the sample proportion p = L~ Xdn as an estimate of the population proportion p. If the X/s are independent, then XI' X2 , ••• , Xn is a simple random sample, and we know that the sample proportion p is approximately normal with mean p and variance p(1- p)/n. The notion of sampling for opinion from a fixed population seems to lead to a random sample.
The situation we have described fits the problem of Example 1-1. There it was asserted that if n = 2,500 and p = 0.50, the probability of getting a sample proportion as large as 0.53 was less than 1/100. Let us check that. We want to find P (p ;a. 0.53) when p - N(O.50, 0.0001).4
P(p ;a. 0.53) =p(P - 0.50 ;a. 0.53 - 0.50) P(Z;a. 3) = 0.0013. 0.01 0.01
The probability is little more than 1 in 1,000.
Sampling without replacement. It would s;em that any imagined difference has been resolved. But there does remain one problem. It was assumed that the X/s were independent. Is that a reasonable assumption?
The answer depends on how the sampling was done. If, for example, names were drawn from a hat (a big one) and then replaced before the next draw, it would be reasonable to assume that each of the drawings from the same distribution was independent. But this would make it possible for the same name to be drawn twice. To avoid this possibility the sampling might be done without replacing the names that had been drawn. If this is done, successive X;' s are not independent.
Suppose Xt = 1 and the voter's name is not replaced in the hat before the second name is drawn; when the second name is drawn, there are Np - 1 possibilities for X2 = 1 out of N - 1 names in the hat. Therefore,
P(X2 = I!X t = 1) = ;; -11 '" p. The drawings are identically distributed
but not independent.s They are "almost independent," however, if N is
large because;; 11 is almost the same as p when N is large.
• p(1 p)ln 0.5(0.5)/2500 = 0.0001. And up = VO.0001 = 0.01.
• One may be tempted to think that the (marginal) distributions of X, and X. are not the same. But this is not so. The probability PIX. 1) = P although the conditional probability PIX. = 1IX,) is not p. It may be useful to reread Example 2-1 to see this.

Sampling and Sampling Distributions 139
Since the drawings made without replacement are not independent, some alteration of the analysis is necessary. Fortunately, the corrections are easy to make. The sample proportion found without replacement still has mean p, so it is still a reasonable estimator of p. The variance of p is no longer p( 1 - p )/n, however. When sampling is done without replace-
N-n ment, the variance of p is reduced by the factor N _ l' where N is the
number in the population and n is the number in the sample. That is,
.2= (N- n)(p(l- p») CTp N -1 n •
We shall not attempt here to prove the validity of this adjustment, although its reasonableness can be seen from the following: If N is very
N-n large, then -- will be nearly equal to 1, so almost no adjustment is
N-l made. Since the effect of removing a few members from a very large population is hardly noticeable, almost no adjustment should be expected. Only when the sample is an appreciable part of the total population should the adjustment be important. An9, if n = N, notice that CTf/ O. This is surely as it should be; when the whole population is included in the sample canvassed, the sample proportion p cannot be other than the population proportion p.
To continue the previous example, suppose there were 200,000 voters in the candidate's district. With a sample of 2,500, the correction factor is 197,500 199,999 0.9875. So, the variance is CT/ (0.9875) (0.0001), and CTp =
0.00994 instead of 0.01. Reestimating the probability, one finds
A ( P 0.50 0.53 - 0.50) P(p ~ 0.53) P 0.00994 ~ 0.00994 = P(~ ~ 3.02) = 0.0012.
The correction is clearly of little importance in a sample as large as 2,500.
Example 8-1. In Example 1-2 it was stated that the sample mean height for a group of 50 Amherst seniors was found to be 5 feet 10 inches-or, 70 inches. Suppose the distribution of heights among the 300 Amherst seniors is known to have a standard deviation of 3 inches. If the mean height /L in the population is 69 inches, what is the probability that a group of 50 students would average 70 inches? What is P(X ~ 70), if E(X) = /L = 69, CTx = 3, and X = l:Xi/50?

140 Probability and Statistical Inference
We need to know the distribution of X. Since X = 'EXl/n and we assume that each Xi has mean 69, E(X) = /-Lx = 69 also. If the X;'s are independent, then ux2 = ux2/n, or Ux = 3/V50 = 0.424, and X will be approximately normal according to the central limit theorem.
So,
P(X- ~ 70) = p(X - 69 ~ 70 - 69) P(Z 2 36) 00091 0.424 0.424 ~. =. .
If the average height of all 300 Amherst seniors is as little as 69 inches, we have obtained a very unlikely sample result. Almost surely we should conclude that the true average height is more than 69 inches.
Still, something is amiss. A group of 50 students was chosen and then measured; apparently sampling was done without replacement. The same corrections used before are required here. The mean of X is .still the same
as the population mean, but ux2 (~ =- ~) (u:2
). This time the correction
factor may make a difference, for the sample is 1/6 of the population:
ux2 (~: _ ~)(:O) = ~ (~) 0.15, and Ux = 0.387. So,
- (X 69 70 - 69) P(X ~ 70) = P 0.387 ~ 0.387 .c= P(Z ~ 2.58) = 0.0049.
We said in Example 1-2 that any conclusion reached from the data would involve considerable uncertainty. But maybe not. If our assumptions are correct and the sample was randomly drawn, there is little doubt about the conclusion.