7. fault tolerance through dynamic (or standby) redundancy the lowest-cost fault-tolerance technique...
Post on 19-Dec-2015
224 views
TRANSCRIPT

7. Fault Tolerance Through Dynamic (or Standby) Redundancy
The lowest-cost fault-tolerance technique in multiprocessors.
Steps performed:
When a fault is detected, a fault location or diagnosis procedure is triggered.
The faulty processor is then replaced by a spare processor or spare processing capability through reconfiguration.
Finally, error recovery is performed, whereby the spare processor, using typically checkpointed information, takes over the computations of the faulty processor from where it left off.

7. Fault Tolerance Through Dynamic or Standby Redundancy
In summary, Dynamic Redundancy is performed in 3 steps:
I. Fault detection and location
II. Reconfiguration of the system around the faulty processor
III. Error recovery

7. Fault Tolerance Through Dynamic or Standby Redundancy
Several approaches perform fault detectionfault detection in
multiprocessors:
Scheduled off-line testing for permanent faults
Duplication and comparison **
Diagnostics and coding techniques **
** Described next ...

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.1 Fault Detection Through Duplication and Comparison
– A)A) Each processor of the multiprocessor can be
duplicated, and the results compared before
communicating to the processor pairs.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.1 Fault Detection Through Duplication and Comparison
– B)B) Another approach is dividing the P processors of a
multiprocessor into P/2 pairs. The global memory which
consists of M memory modules can either be divided into M/2
pairs. Comparators can be kept inside each processor and
memory module, and results of both computations must
match for an operation to be executed. If an error is detected
by a processor pair, both processors of the pair are powered
off, and the computations are able to proceed on the P- 2
remaining processors, configured as (P-2)/2 pairs of
processors.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.1 Fault Detection Through Duplication and Comparison
– C)C) Alternatively, the comparison operation can also be
performed in software, by means of checkpoint
comparison techniques.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.1 Fault Detection Through Duplication and Comparison
– D)D) Finally, the duplication and comparison operation can be
performed by means of time redundancy. This is useful when one
cannot afford the redundancy of duplication for cost, weight, power,
and space constraints (e.g., embarked, battery-powered electronics).
In the presence of task dependencies (see example), one often finds
processors that are idle, since there are no ready tasks. In such
situations, one can map the original task graph on P/2 processors, get
better processor utilization, and use the remaining P/2 processors to
perform the duplicate computation of the task graph. Hence, in real
task graphs, one can observe less than 100% time overhead.
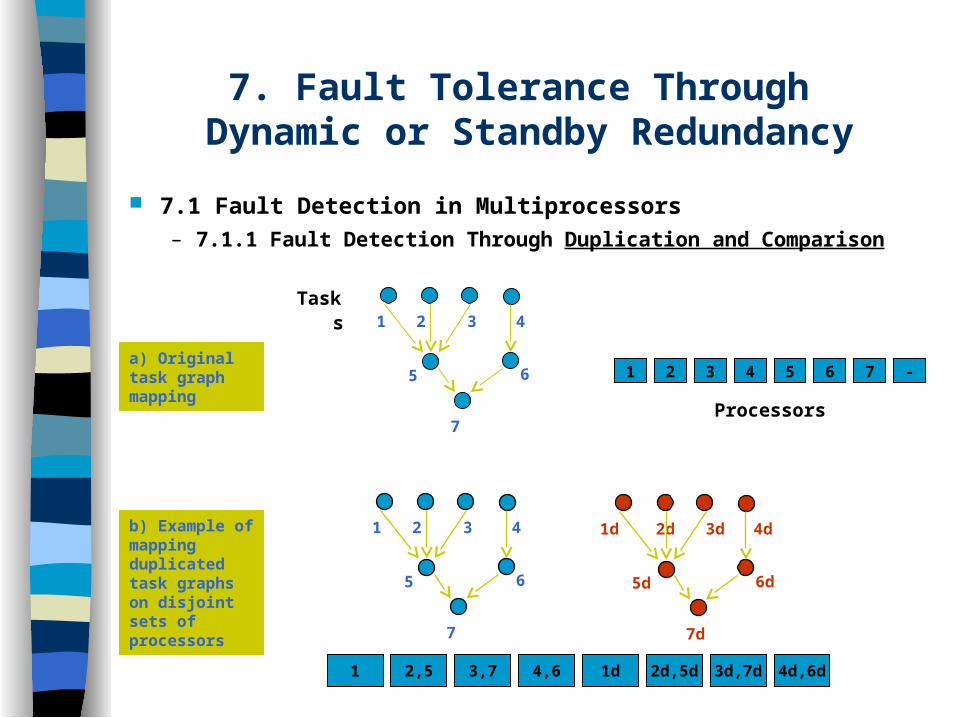
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.1 Fault Detection Through Duplication and Comparison
5
1 2 3 4
6
7
1 2 3 4 5 6 7 -a) Original task graph mapping
5
1 2 3 4
6
7
1 2,5 3,7 4,6 1d 2d,5d 3d,7d 4d,6d
b) Example of mapping duplicated task graphs on disjoint sets of processors
5d
2d 3d 4d
6d
7d
1d
Tasks
Processors

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.1 Fault Detection in Multiprocessors– 7.1.2 Fault Detection Using Diagnostics and Coding
Techniques
See “2.2 Information Redundancy”

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.2 Recovery Strategies for Multiprocessor Systems
Since most faults are transient or intermittent, s simple recovery procedure may be merely to reexcute the computation.
Recovery issues are more complex in distributed systems (communicating processes): one has to ensure that the correct execution of one process is not affected by the faulty execution of a communicating process.
Recovery techniques are different for distributed- and shared-memory multiprocessors: multiple processes can access memory and have different or erroneous copies of the same variables, creating an inconsistent state when the error is detected.
Therefore, some scheme must be devised that will be able to store enough error-free processor state information at a reliable place from where it can be retrieved and used to restart the program (rollback recovery) from a consistent state, in the event of a transient failure in one or more processors during program execution.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.2 Recovery Strategies for Multiprocessor Systems
The most popular scheme: CheckpointingCheckpointing !
It involves storing as much information about the processor state as necessary at discreet points (checkpoints, or rollback points) in the program to ensure that the
program can be rolled back to those points in the event of a node failure, and restarted from there, as though no fault had occurred.
Processor states: varies from one system to another. Generally it involves the register set of the processor, the program counter, the state of cache, and even memory as well, or at least those parts of it that have been altered by the processor since the last checkpoint.
This information is stored in reliable storage, that is, memory assumed not to fail. Such a memory could be a disk, or memory protected by using error-correcting codes, or duplicated memory and/or registers.

Rollback recovery using checkpoints is a very cost-effective method of providing fault tolerance
against transient and intermittent faults.
Various implementations and overhead issues are illustrated in the following.
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints
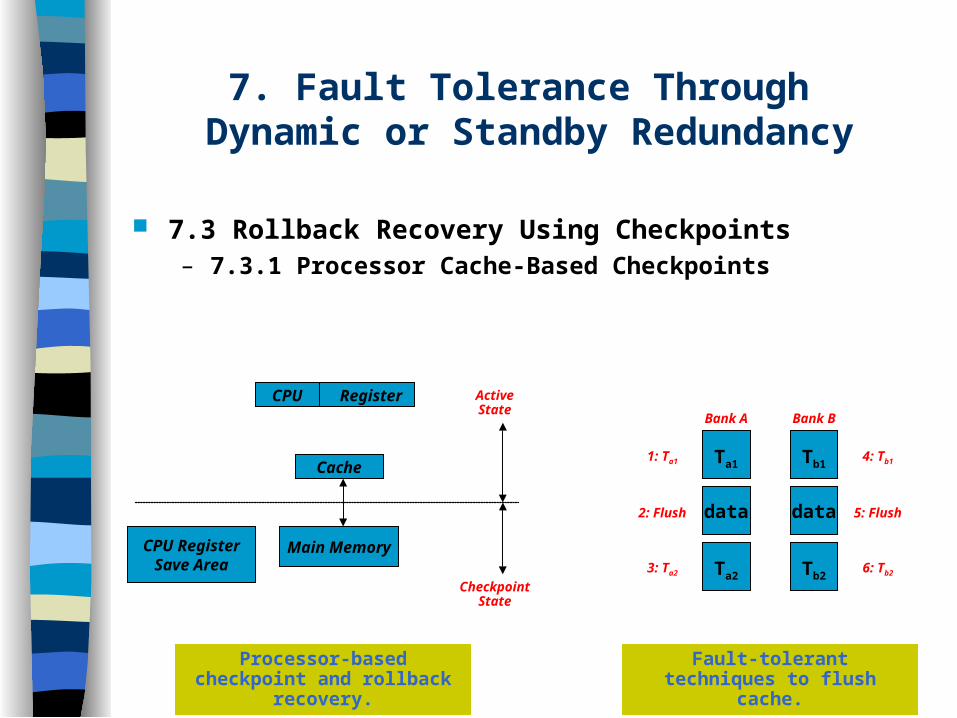
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints– 7.3.1 Processor Cache-Based Checkpoints
CPU Register
Cache
Main MemoryCPU RegisterSave Area
ActiveState
CheckpointState
Processor-based checkpoint and rollback recovery.
Fault-tolerant techniques to flush cache.
Ta1
data
Ta2
Bank A
1: Ta1
3: Ta2
2: Flush
Tb1
data
Tb2
Bank B
4: Tb1
6: Tb2
5: Flush

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints– 7.3.1 Processor Cache-Based Checkpoints
Condition Failure Action
Ta1 =Ta2 = Tb1 = Tb2 None None
Ta1 >Ta2 = Tb1 = Tb2 Flush A Copy Bank B to A
Ta1 =Ta2 > Tb1 = Tb2 Between Copy Bank A to B
Ta1 =Ta2 = Tb1 > Tb2 Flush B Copy Bank A to B
Failure Conditions.
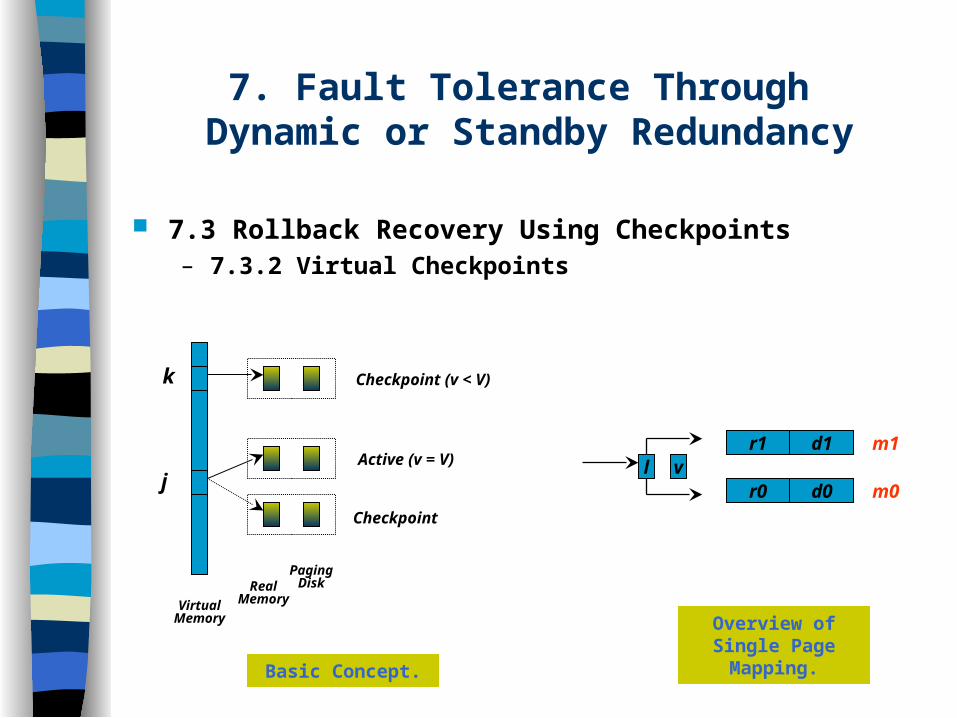
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints– 7.3.2 Virtual Checkpoints
k
j
Checkpoint (v < V)
Active (v = V)
Checkpoint
Virtual Memory
Real Memory
Paging Disk
Basic Concept.
Overview of Single Page Mapping.
r0
r1
d0
d1
m0
m1l v
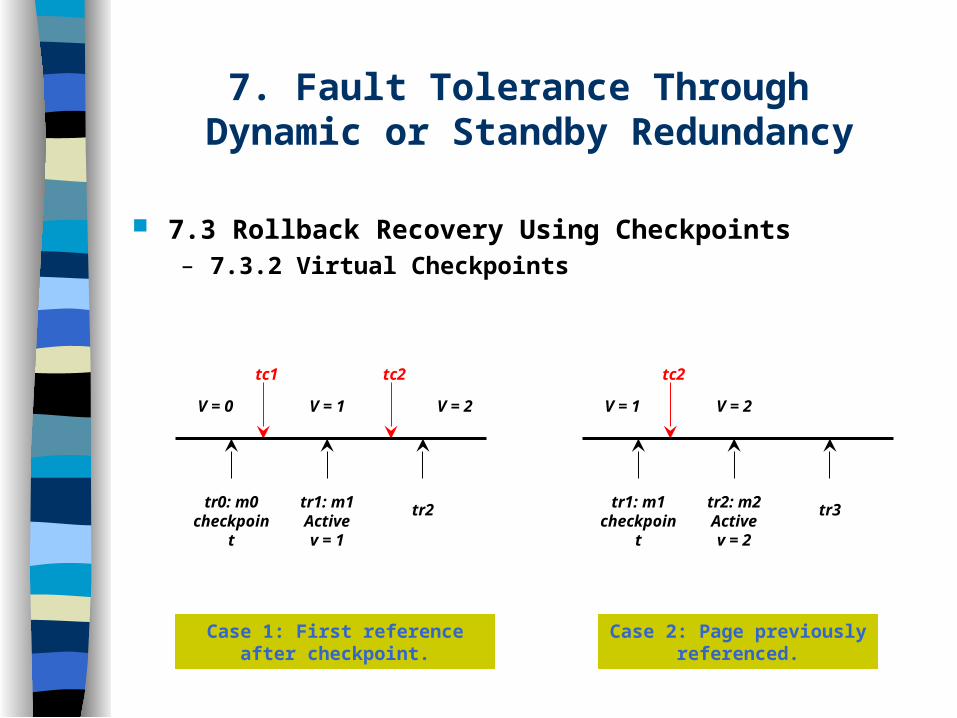
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints– 7.3.2 Virtual Checkpoints
Case 1: First reference after checkpoint.
Case 2: Page previously referenced.
tc1 tc2
V = 0 V = 1 V = 2
tr0: m0checkpoint
tr1: m1Activev = 1
tr2
tc2
V = 1 V = 2
tr1: m1checkpoint
tr2: m2Activev = 2
tr3
7. Fault Tolerance Through Dynamic or Standby Redundancy
7.3 Rollback Recovery Using Checkpoints– 7.3.2 Virtual Checkpoints
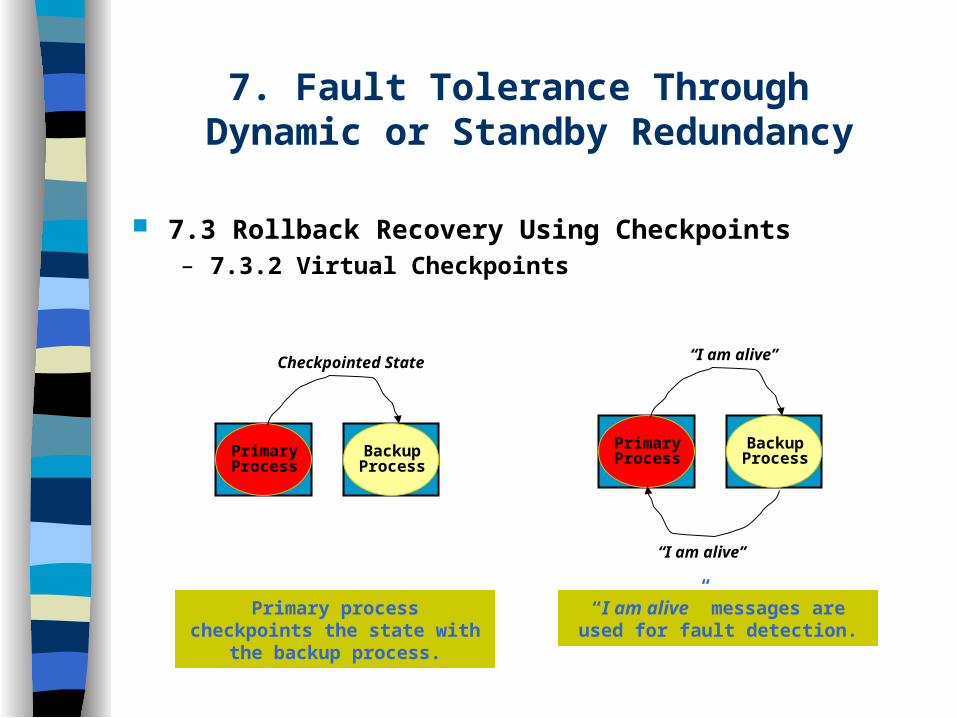
PriPrimary Process
Backup Process
Checkpointed State
PriPrimary Process
Backup Process
“I am alive”
“I am alive”
Primary process checkpoints the state with the backup process.
“I am alive” messages are used for fault detection.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating ......Multiprocessors– 7.4.1 Shared-Memory Multiprocessors
Bus lines.
Bus Line Set by Processor to Indicate ...
Shared sharing a block on the bus.
Establish Rollback Point
that a rollback point is being established.
Rollback that it is backing up to the prior rollback point.
: Checkpoint : Communication
7. Fault Tolerance Through Dynamic or Standby Redundancy
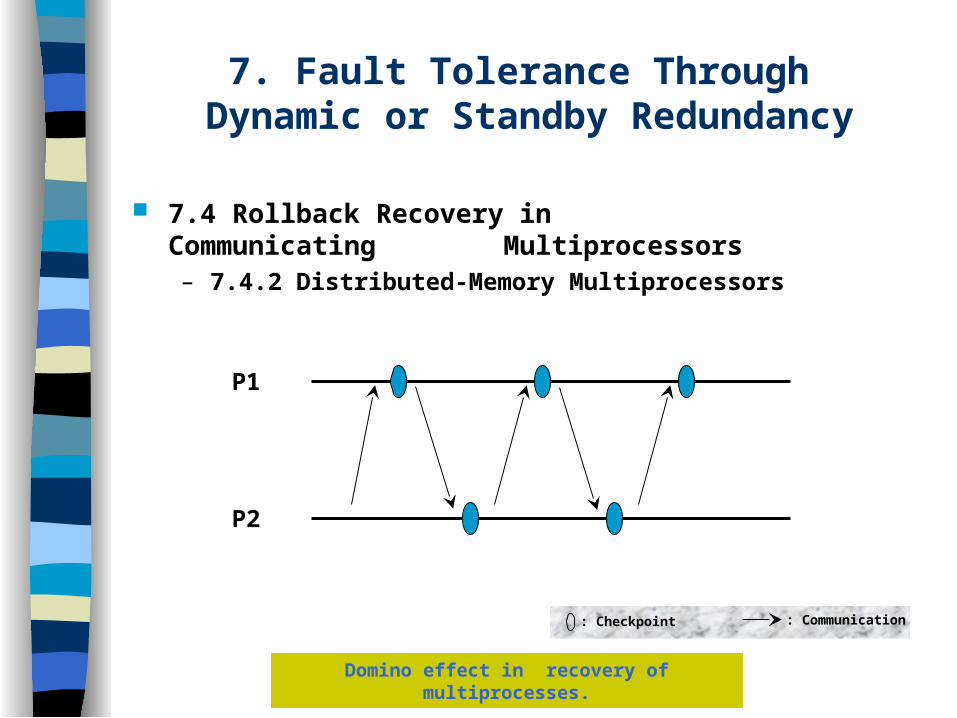
7.4 Rollback Recovery in Communicating ......Multiprocessors– 7.4.2 Distributed-Memory Multiprocessors
Domino effect in recovery of multiprocesses.
P1
P2

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating ......Multiprocessors– 7.4.2 Distributed-Memory Multiprocessors
Consistent and inconsistent recovery lines.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating Multiprocessors– 7.4.3 Recovery in Distributed Shared-Memory Systems
– Typically, distributed shared-memory (DSM) systems are loosely coupled, geographically distributed systems of processors, each processor with its own memory.
– Implemented by using Virtual Memory: programmers see a single shared memory, which in reality is made up of individual memories residing in different processors.
– Pages are used as the basic blocks of memory transfer. Each node keeps in its own local memory a subset of the total number of pages from the shared virtual memory.
– A page fault is generated whenever a node tries to access a nonresident page. A page request is then generated and sent to a distinguished owner node that has a copy of the page needed. Upon reception of the page request, the owner node transfers the new page to the requester, which then becomes the new owner.
– An owner-node keeps a page-table with information on the nodes which have read-only copies of pages that are owned by the owner-node.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating Multiprocessors– 7.4.3 Recovery in Distributed Shared-Memory Systems
– A local checkpoint for the mentioned system consists of (the important information that must be saved):
– a) the contents of locally owned pages that have been modified since the last checkpoint on the local node.
– b) the page-table entries for locally owned pages that have been modified since the last checkpoint.
– This is in addition to the state information of the local processor, which is also stored with each checkpoint in reliable storage.
– How the reliable storage is implemented depends upon the resources available, as well as on the level of reliability desired from the system.
– A process on a recovering processor is expected to retrieve any clean pages that it might need from previous checkpoints stored on disk, in addition to any dirty pages that were stored in the last checkpoint before failure.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating ......Multiprocessors– 7.4.4 Recovery in Database Systems
– Database systems employ atomic actions known as transactions to maintain consistency and integrity in the presence of concurrent activities.
– Since transactions are atomic activities, in the event a transaction is aborted, its actions have to be undone to restore consistency to the system.
– Because of the “all-or-nothing” property of atomic actions, an important amount of work might be abandoned needlessly when an internal error is encountered.

7. Fault Tolerance Through Dynamic or Standby Redundancy
7.4 Rollback Recovery in Communicating Multiprocessors
– 7.4.4 Recovery in Database Systems
– Shadowing is a typical implementation of recovery-oriented mechanism on database systems, which involves using a new disk page to write the modified version of a database page. When the transaction completes (or commits), the page to which it was writing becomes the permanent page, or it is discarded if the transaction aborts. Recovery is fast, since it only involves discarding the modified pages into which the transactions in the active list are writing.
– Thus, a scheme for distributed systems has been considered which uses pages as the invisible unit of memory that is stored as part of a checkpoint and used for recovery.