9.2 pipelining suppose we want to perform the combined multiply and add operations with a stream of...
TRANSCRIPT

9.2 Pipelining
Suppose we want to perform the combined multiply and add operations with a stream of numbers:
Ai * Bi + Ci for i =1,2,3,…,7

9.2 Pipelining
The suboperations performed in each segment of the pipeline are as follows:
R1 Ai, R2 Bi
R3 R1 * R2 R4 Ci
R5 R3 + R4



Pipeline Performance
n:instructions k: stages in
pipeline : clockcycle Tk: total time
))1(( nkTk
)1(1
nk
nk
T
TSpeedup
k
n is equivalent to number of loads in the laundry examplek is the stages (washing, drying and folding.Clock cycle is the slowest task time
n
k

Pipelining: Laundry Example
Small laundry has one washer, one dryer and one operator, it takes 90 minutes to finish one load:
Washer takes 30 minutes Dryer takes 40 minutes “operator folding” takes
20 minutes
A B C D

Sequential Laundry
This operator scheduled his loads to be delivered to the laundry every 90 minutes which is the time required to finish one load. In other words he will not start a new task unless he is already done with the previous task
The process is sequential. Sequential laundry takes 6 hours for 4 loads
A
B
C
D
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Midnight
Task
Order
Time
90 min
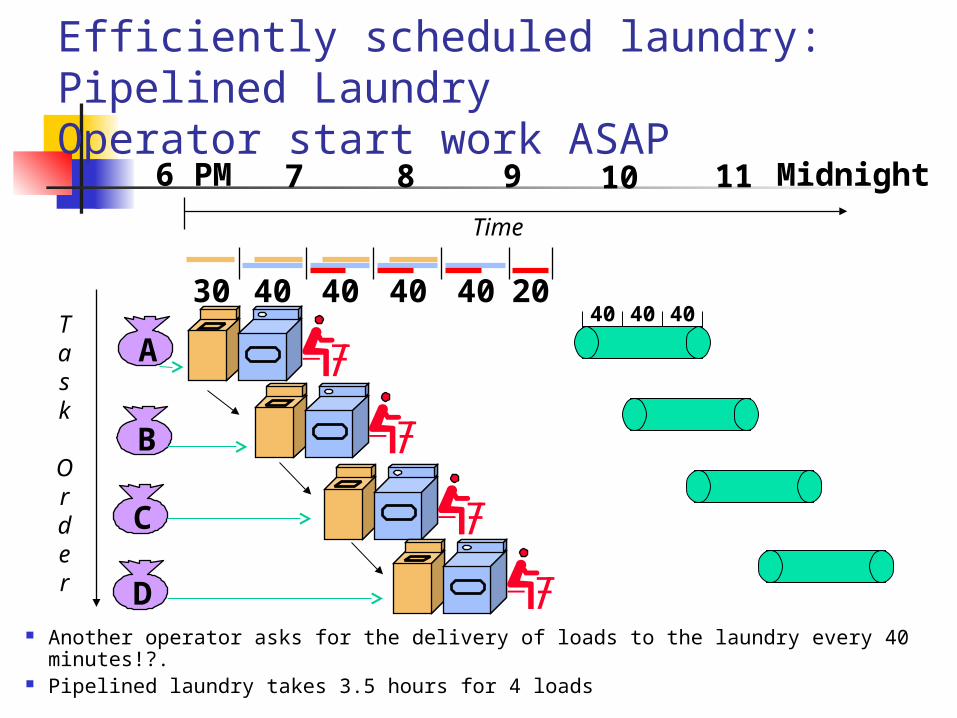
Efficiently scheduled laundry: Pipelined LaundryOperator start work ASAP
Another operator asks for the delivery of loads to the laundry every 40 minutes!?. Pipelined laundry takes 3.5 hours for 4 loads
A
B
C
D
6 PM 7 8 9 10 11 Midnight
Task
Order
Time
30 40 40 40 40 2040 40 40

Pipelining Facts Multiple tasks
operating simultaneously
Pipelining doesn’t help latency of single task, it helps throughput of entire workload
Pipeline rate limited by slowest pipeline stage
Potential speedup = Number of pipe stages
Unbalanced lengths of pipe stages reduces speedup
Time to “fill” pipeline and time to “drain” it reduces speedup
A
B
C
D
6 PM 7 8 9
Task
Order
Time
30 40 40 40 40 20
The washer waits for the dryer for 10
minutes

Some definitions
Pipeline: is an implementation technique where multiple instructions are overlapped in execution.
Pipeline stage: The computer pipeline is to divided instruction processing into stages. Each stage completes a part of an instruction and loads a new part in parallel. The stages are connected one to the next to form a pipe - instructions enter at one end, progress through the stages, and exit at the other end.

Throughput of the instruction pipeline is determined by how often an instruction exits the pipeline. Pipelining does not decrease the time for individual instruction execution. Instead, it increases instruction throughput.
Machine cycle . The time required to move an instruction one step further in the pipeline. The length of the machine cycle is determined by the time required for the slowest pipe stage.
Some definitions

Instruction pipeline versus sequential processing
sequential processing
Instruction pipeline
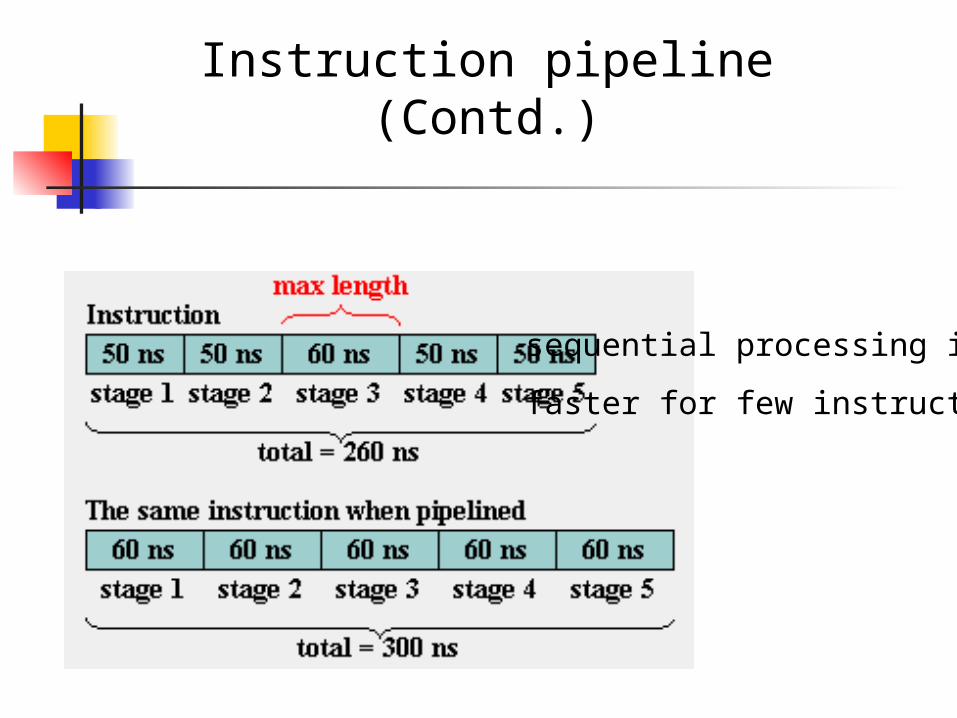
Instruction pipeline (Contd.)
sequential processing is
faster for few instructions

Two Stage Instruction Pipeline

Difficulties...
If a complicated memory access occurs in stage 1, stage 2 will be delayed and the rest of the pipe is stalled.
If there is a branch, if.. and jump, then some of the instructions that have already entered the pipeline should not be processed.
We need to deal with these difficulties to keep the pipeline moving

5-Stage Pipelining
Fetch Instruction
(FI)
FetchOperand
(FO)
Decode Instruction
(DI)
WriteOperand
(WO)
Execution Instruction
(EI)
S3 S4S1 S2 S5
1 2 3 4 98765S1
S2
S5
S3
S4
1 2 3 4 8765
1 2 3 4 765
1 2 3 4 65
1 2 3 4 5
Time

Five Stage Instruction Pipeline
Fetch instruction Decode
instruction Fetch operands Execute
instructions Write result

6-Stage Pipelining
InstructionFetch
Decode ExecutionFetch
Operand
S3 S4S1 S2 S5
1 2 3 4 98765S1
S2
S5
S3
S4
1 2 3 4 8765
1 2 3 4 765
1 2 3 4 65
1 2 3 4 5
Time
6
Writeoperand
Calculate operand
S6

Six Stage Instruction Pipeline
Fetch instruction Decode instruction Calculate operands(Find effective address)
Fetch operands Execute
instructions Write result

Flow chart for four segment pipeline

Two major difficulties
Branch Difficulties Data Dependency


Prefetch target instruction
Prefetch the target instruction in addition to the instruction following th branch
If the branch condition is successful, the pipeline continues from the branch target instruction

Branch target buffer (BTB)
BTB is an associative memory Each entry in the BTB consists of
the address of a previously executed branch instruction and the target instruction for the branch

Branch Prediction
A pipeline with branch prediction uses some additional logic to guess the outcome of a conditional branch instruction before it is executed

Delayed Branch
In this procedure, the compiler detects the branch instruction and rearrange the machine language code sequence by inserting useful instructions that keep the pipeline operating without interrupts
An example of delay branch is presented in the next section