a class of asynchronous parallel multisplitting blockwise relaxation methods
TRANSCRIPT

A class of asynchronous parallel multisplittingblockwise relaxation methods 1
Zhong-Zhi Bai 2
State Key Laboratory of Scienti®c/Engineering Computing, Institute of Computational Mathematics and
Scienti®c Engineering Computing, Chinese Academy of Sciences, P.O. Box 2719, Beijing 100080, People's
Republic of China
Received 22 April 1997; received in revised form 9 December 1998
Abstract
By the principle of using su�ciently the delayed information and based on the technique of
successively accelerated overrelaxation (AOR), we set up a class of asynchronous multisplit-
ting blockwise relaxation methods for solving the large sparse blocked system of linear
equations, which comes from the discretizations of many di�erential equations. These new
methods are e�cient blockwise variants of the asynchronous parallel matrix multisplitting
relaxed iterations discussed by Bai et al. (Parallel Computing 21 (1995) 565±582), and they are
very smart for implementations on the MIMD multiprocessor systems. Under reasonable
restrictions on the relaxation parameters as well as the multiple splittings, we establish the
convergence theories of this class of new methods when the coe�cient matrices of the blocked
systems of linear equations are block H-matrices of di�erent types. A lot of numerical ex-
periments show that our new methods are applicable and e�cient, and have better numerical
behaviours than their pointwise alternatives investigated by Bai et al. Ó 1999 Elsevier Science
B.V. All rights reserved.
Keywords: Blocked system of linear equations; Block matrix multisplitting; Blockwise relaxation;
Asynchronous parallel method; Convergence theory; Block H-matrix
1. Introduction
The matrix multisplitting methodology was originally invented by O'Leary andWhite (see Ref. [16]) in 1985 for solving parallely the large sparse systems of linear
Parallel Computing 25 (1999) 681±701
www.elsevier.com/locate/parco
1 Project 19601036 supported by the National Natural Science Foundation of China.2 Tel.: +86 10 626 30992; fax: +86 10 625 42285; email: [email protected]
0167-8191/99/$ ± see front matter Ó 1999 Elsevier Science B.V. All rights reserved.
PII: S 0 1 6 7 - 8 1 9 1 ( 9 9 ) 0 0 0 1 5 - 0

equations on the multiprocessor systems. Then, many authors have further improvedand extended the method models, and deeply investigated the corresponding con-vergence theories from various angles. For example, Neumann and Plemmons [15]developed some more re®ned convergence results for one of the cases considered inRef. [16], Elsner [11] established the comparison theorems about the asymptoticconvergence rate of this case, Frommer and Mayer [13] discussed the successiveoverrelaxation (SOR) method in the sense of multisplitting, White [24,25] studied theconvergence properties of the above matrix multisplitting methods for the symmetricpositive de®nite matrix class, as well as matrix multisplitting methods as precondi-tioners, respectively, and Bai [4] extended these matrix multisplitting methods to thesystem of nonlinear equations. For details one can refer to [2,3,6±16], [22±25] andreferences therein.
Since the ®nite element or the ®nite di�erence discretizations of many partialdi�erential equations usually result in the large sparse systems of linear equations ofregularly blocked structures, recently, [1,5] further generalized the matrix multi-splitting concept of O'Leary and White [16] to a blocked form and proposed a classof parallel matrix multisplitting blockwise relaxation methods. This class of meth-ods, besides enjoying all the advantages of the existing pointwise parallel matrixmultisplitting methods discussed in Refs. [16,22], possesses better convergenceproperties and robuster numerical behaviours. Therefore, it is very smart to imple-ment on the SIMD multiprocessor systems, or in other words, in the synchronousparallel computational environments. Under reasonable constraints on both therelaxation parameters and the multiple splittings, the convergence and the conver-gence rate of this class of methods were investigated in detail in Refs. [1,5] when thecoe�cient matrices of the blocked systems of linear equations are block H -matricesand block M-matrices, respectively.
To suit the requirements of the MIMD multiprocessor systems, this paper willemphatically discuss e�cient asynchronous variants of the parallel matrix multi-splitting blockwise relaxation methods in Refs. [1,5]. In light of the principle ofusing su�ciently the delayed information and with the utilization of the techniqueof successively accelerated overrelaxation (AOR), we set up a class of asynchronousparallel blockwise relaxation methods for solving the blocked system of linearequations in the sense of block matrix multisplitting (BMM). Because thesemethods simultaneously take into account the special structures of the linear sys-tems of equations and the concrete characteristics of the high-speed multiprocessorsystems, they have a lot of good properties such as simple and convenient opera-tions, ¯exible and freed communications and so on. Moreover, besides using newinformation as soon as available, these methods increase the e�cient numericalcomputations and decrease the unnecessary data communications. Therefore, theycan greatly execute the parallel computing e�ciency of the MIMD-systems. Since atleast two arbitrary parameters are involved in this class of novel methods, thesuitable adjustments of these parameters can not only considerably improve theconvergence properties of the new methods, but also generate a series of applicableand e�cient asynchronous multisplitting blockwise relaxation methods, e.g., theasynchronous multisplitting blockwise Jacobi method, the asynchronous
682 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

multisplitting blockwise Gauss-Seidel method and the asynchronous multisplittingblockwise SOR method, etc.
Under reasonable restrictions on the relaxation parameters and the multiplesplittings, we establish the convergence theory of this class of asynchronous multi-splitting blockwise relaxation methods when the coe�cient matrices of the blockedsystems of linear equations are block H -matrices of di�erent types. Lastly, a lot ofnumerical experiments show that these new methods are applicable and e�cient, andthey have better convergence behaviours than their pointwise alternatives.
2. Establishments of the methods
First of all, we recall the mathematical descriptions of the blocked system of linearequations and the BMM introduced in Ref. [1].
Let N�6 n� and ni�6 n��i � 1; 2; . . . ;N� be given positive integers satisfyingPNi�1 ni � n, and denote
Vn�n1; . . . ; nN� � x 2 Rn j xn
� �xT1 ; . . . ; xT
N �T; xi 2 Rni
o;
Ln�n1; . . . ; nN � � A 2 Rn�n j A� � �Aij�N�N ;Aij 2 Rni�nj:
When the context is clear we will simply use Ln for Ln�n1; . . . ; nN � and Vn forVn�n1; . . . ; nN�. Then, the blocked system of linear equations to be solved can beexpressed as the form
Ax � b; A 2 Ln nonsingular; x; b 2 Vn; �2:1�where A 2 Ln and b 2 Vn are general known coe�cient matrix and right-hand vector,respectively, and x is the unknown vector. The partition of the linear system (2.1)may correspond to a partition of the underlying grid, or of the domain of the dif-ferential equation being studied, or it may originate from a partitioning algorithm ofthe sparse matrix A, as done, e.g., in Ref. [17].
Given a positive integer a�a6N�, we separate the number set f1; 2; . . . ;Ng into anonempty subsets Jk�k � 1; 2; . . . ; a� such that
Jk � f1; 2; . . . ;Ng and[ak�1
Jk � f1; 2; . . . ;Ng:
Note that there may be overlappings among the subsets J1; J2; . . . ; Ja. Correspondingto this separation, we introduce matrices
D � Diag�A11; . . . ;ANN � 2 Ln;
Lk � �L�k�ij � 2 Ln; L
�k�ij �
L�k�ij for i; j 2 Jk and i > j;
0 otherwise;
(
Uk � �U�k�ij � 2 Ln; U�k�ij �
U �k�ij for i 6� j;
0 otherwise;
(
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 683

Ek � Diag�E�k�11 ; . . . ;E�k�NN � 2 Ln; E�k�ii � E�k�ii for i 2 Jk;
0 otherwise;
�i; j � 1; 2; . . . ;N ; k � 1; 2; . . . ; a:
Here, L�k�ij and U �k�ij are ni � nj sub-matrices, and E�k�ii are ni � ni sub-matrices. Ob-viously, D is a blocked diagonal matrix, Lk�k � 1; 2; . . . ; a� are blocked strictly lowertriangular matrices, Uk�k � 1; 2; . . . ; a� are blocked zero-diagonal matrices, andEk�k � 1; 2; . . . ; a� are blocked diagonal matrices. If they satisfy1. D is nonsingular;2. A � Dÿ Lk ÿ Uk; k � 1; 2; . . . ; a;3.Pa
k�1 Ek � I ,then we call the collection of triples �Dÿ Lk;Uk;Ek��k � 1; 2; . . . ; a� a BMM of theblocked matrix A 2 Ln. Here, I denotes the identity matrix of order n� n.
Note that di�erently from the (pointwise) matrix multisplitting (PMM) in theliterature, e.g., [2,3,6±9,11±13,15,16,22±25], the BMM allows that the weightingmatrices Ek�k � 1; 2; . . . ; a� are blocked diagonal matrices, and may have nonposi-tive elements. This property can be utilized to design new methods so that their it-eration matrices have smaller condition numbers. However, when N � n andni � 1�i � 1; 2; . . . ;N�, the BMM naturally reduces to the PMM.
Assume that the referred multiprocessor system is constructed by a processors. Todescribe the new asynchronous multisplitting blockwise relaxation methods, we needto introduce the following notations:
(1) for k 2 f1; 2; . . . ; ag and p 2 N0 :� f0; 1; 2; . . .g, Jk�p� is used to denote a subset(may be empty set ;) of the set Jk, and J �k� � Jk�p�f gp2N0
;(2) for i 2 f1; 2; . . . ;Ng and p 2 N0, Ni�p� :� k j i 2 Jk�p�; k � 1; 2; . . . ; af g;(3) for k 2 f1; 2; . . . ; ag, fs�k�i �p�gp2N0
�i � 1; 2; . . . ;N� are used to denote N in®nite
nonnegative integer sequences, and S�k� � fs�k�1 �p�; s�k�2 �p�; . . . ; s�k�N �p�gp2N0;
J �k� and S�k��k � 1; 2; . . . ; a� have the following properties:(a) for k 2 f1; 2; . . . ; ag and i 2 f1; 2; . . . ;Ng, the set fp 2 N0 j i 2 Jk�p�g is in®nite;(b) for p 2 N0, [a
k�1Jk�p� 6� ;;(c) for k 2 f1; 2; . . . ; ag, i 2 f1; 2; . . . ;Ng and p 2 N0, s�k�i �p�6 p;(d) for k 2 f1; 2; . . . ; ag and i 2 f1; 2; . . . ;Ng, limp!1 s�k�i �p� � 1.Now, based on the above prerequisites, we can establish the following asyn-
chronous multisplitting blockwise AOR method for solving the blocked system oflinear equations (2.1).
Method I. Let x0 2 Vn be an initial vector and assume that we have got the ap-proximate solutions x0; x1; . . . ; xp of the blocked system of linear equations (2.1).Then the �p � 1�th approximate solution
xp�1 � �xp�11 �T; �xp�1
2 �T; . . . ; �xp�1N �T
� �T
2 Vn
can be got in an element by element manner from
xp�1i �
Xa
k�1
E�k�ii xp;ki ; i � 1; 2; . . . ;N ; �2:2�
684 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

where for each k 2 f1; 2; . . . ; ag; xp;ki is successively determined either by
xp;ki � Aÿ1
ii cXj<i
j2Jk�p�
L�k�ij xp;kj
8>><>>: � �xÿ c�Xj<i
j2Jk
L�k�ij xs�k�j �p�j
� cXj<i
j2JknJk�p�
L�k�ij xs�k�j �p�j � x
Xj 6�i
U �k�ij xs�k�j �p�j � xbi
9>>=>>;� �1ÿ x�xs�k�i �p�i �2:3�
if i 2 Jk�p�, or by
xp;ki � xp
i �2:4�if i 62 Jk�p�, while c 2 �0;1� and x 2 �0;1� are the relaxation and accelerationfactors, respectively.
The description of Method I evidently shows that when we implement thismethod on an MIMD multiprocessor system, each processor can update any subsetof the components of the global approximation, in which the subscripts of thecomponents belong to some corresponding subset Jk, k 2 f1; 2; . . . ; ag, or retrive anysubset of the components of the global approximation residing in the host processor,at any time. This therefore avoids loss of time and e�ciency in processor utilization,and makes the multiprocessor system attain its maximum e�ciency. Moreover,compared with the asynchronous parallel multisplitting pointwise relaxation meth-ods discussed in Ref. [6] as well as in Refs. [8,9,12,13,15,16,22±25], Method I is muchrich in block matrix and vector operations. This then not only considerably improvesthe convergence conditions and properties of this method, but also increases thee�cient numerical computations and decreases the unnecessary information ex-changes. Therefore, it can possibly result in better computing results.
Noticing that two arbitrary parameters c and x are included in Method I, we canreasonably adjust these parameters so that this method possesses better convergencebehaviour. Moreover, suitable choices of these two parameters can result in a seriesof applicable and e�cient asynchronous multisplitting blockwise relaxation meth-ods, e.g., the asynchronous multisplitting blockwise Jacobi method (c � 0;x � 1),the asynchronous multisplitting blockwise Gauss±Seidel method (c � 1, x � 1), andthe asynchronous multisplitting blockwise SOR method (c � x > 0).
On the other hand, Method I also covers a lot of important cases of existing andnovel matrix multisplitting relaxation methods. For example, when N � n,ni � 1�i � 1; 2; . . . ;N�, it naturally becomes the asynchronous matrix multisplittingAOR method discussed in Ref. [6] for solving the (pointed) system of linear equa-tions, which, in particular, covers the synchronous parallel multisplitting relaxationmethods presented in Refs. [8,13,22], cf., also [2,3,11,12,15,16,24,25]; when
Jk�p� � Jk � f1; 2; . . . ;Ng; s�k�i �p� � p;
8i 2 f1; 2; . . . ;Ng; 8k 2 f1; 2; . . . ; ag; 8p 2 N0;
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 685

it turns to the synchronous matrix multisplitting blockwise AOR method studied inRef. [1] for solving the blocked system of linear equations (2.1), cf., also [5]; andwhen
Jk�p� � Jk; s�k�i �p� � sk�p� 2 N0 �sk�p� a positive integer sequence�;8i 2 f1; 2; . . . ;Ng; 8k 2 f1; 2; . . . ; ag; 8p 2 N0;
it presents a novel asynchronous multisplitting blockwise AOR method for solvingthe blocked system of linear equations (2.1), which is just a blocked variant of theasynchronous matrix multisplitting AOR method investigated in Ref. [23], which, inparticular, includes the parallel chaotic iteration method models proposed in Ref.[9,10].
The above illustrations show why Method I has rather generality and attractivecomputational properties.
If we supplement xp;kj � x
s�k�j �p�j for all j 2 Jk n Jk�p�, k 2 f1; 2; . . . ; ag, p 2 N0, and
de®ne the projection operator Pi : Vn ! Rni�i � 1; 2; . . . ;N� by
Pi�x� � xi; 8x � �xT1 ; x
T2 ; . . . ; xT
N �T 2 Vn; �2:5�then Method I can be equivalently expressed as the concise form
xp�1i �
Xk2Ni�p�
E�k�ii Pi�yp;k� �X
k 62Ni�p�E�k�ii xp
i ; i � 1; 2; . . . ;N ; �2:6�
where
yp;k � �Dÿ cLk�ÿ1 �1� ÿ x�D� �xÿ c�Lk � xUk�xs�k��p� � �Dÿ cLk�ÿ1�xb�;�2:7�
and
xs�k��p� � xs�k�
1�p�
1
� �T
; xs�k�
2�p�
2
� �T
; . . . ; xs�k�N �p�N
� �T !T
: �2:8�
Furthermore, if Method I is relaxed by another parameter b 2 �0;1�, we can extendit to be the following extrapolated one:
Method II. Let x0 2 Vn be an initial vector and assume that we have got the ap-proximate solutions x0; x1; . . . ; xp of the blocked system of linear equations (2.1).Then the �p � 1�th approximate solution
xp�1 � �xp�11 �T; �xp�1
2 �T; . . . ; �xp�1N �T
� �T
2 Vn
can be got in an element by element manner from
xp�1i �
Xa
k�1
E�k�ii xp;ki ; i � 1; 2; . . . ;N �2:9�
686 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

with
xp;ki � bxp;k
i � �1ÿ b�xs�k�i �p�i for i 2 Jk�p�;
xpi for i 62 Jk�p�;
(k � 1; 2; . . . ; a; �2:10�
where for each k 2 f1; 2; . . . ; ag, xp;ki is successively determined either by Eq. (2.3) for
i 2 Jk�p� or by Eq. (2.4) for i 62 Jk�p�, while c 2 �0;1� is the relaxation factor andx; b 2 �0;1� are the acceleration factors.
Evidently, besides having all the advantages of Method I, Method II is more¯exible and extensive than Method I since it involves three arbitrary parameters,which can be chosen arbitrarily in practical implementations. Note that when b � 1,Method II naturally reduces to Method I.
Analogously, suitable combinations of Eqs. (2.9) and (2.10) as well as Eqs. (2.3)and (2.4) give the following uni®ed form of Method II:
xp�1i �
Xk2Ni�p�
E�k�ii Pi�yp;k� �X
k 62Ni�p�E�k�ii xp
i ; i � 1; 2; . . . ;N �2:11�
with
yp;k � byp;k � �1ÿ b�xs�k��p�; k 2 Ni�p�; i � 1; 2; . . . ;N ; �2:12�where yp;k and xs�k��p� are de®ned by Eqs. (2.7) and (2.8), respectively, while theprojection operators Pi : Vn ! Rni�i � 1; 2; . . . ;N� are de®ned by Eq. (2.5).
3. Preliminaries
The partial orderings <, 6 and the absolute values j � j in Rm and Rm�m�m �n;N ; ni�i � 1; 2; . . . ;N�� are de®ned according to the elements. For a matrixG � �gij� 2 Rm�m, we call it an M-matrix if gij6 0�i 6� j; i; j � 1�1�m�, Gÿ1 exists andGÿ1 P 0. Here, for simplicity, we denote i � 1; 2; . . . ;m by i � 1�1�m, and this no-tation will be used in the sequel. Let DG � Diag�g11; . . . ; gmm� and BG � DG ÿ G.Then G is an M-matrix if and only if DG is positive diagonal and q�JG� < 1, whereq��� denotes the spectral radius of a matrix and JG � Dÿ1
G BG. We refer to [20,21] forfurther details.
De®ne two matrix sets
Ln;I�n1; . . . ; nN� � fM � �Mij� 2 Ln j Mii 2 Rni�ni nonsingular; i � 1�1�Ng;
Ldn;I�n1; . . . ; nN� � fM � Diag�M11; . . . ;MNN � j Mii 2 Rni�ni nonsingular;
i � 1�1�Ng:Again, we do not write the parameters �n1; . . . ; nN � when they are clear from thecontext. In the following, we will review the concepts of the block H -matrices and
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 687

several related conclusions. To simplify the statements we denote by k � k anyconsistent matrix norm satisfying kIk � 1.
De®nition 3.1 (see Ref. [1,18,19]). Let M 2 Ln;I . Then its type-I and type-II blockcomparison matrices hMi � �hMiij� 2 RN�N and hhMii � �hhMiiij� 2 RN�N arerespectively de®ned by
hMiij � kMÿ1ij kÿ1
for i � j;ÿkMijk for i 6� j;
�i; j � 1; 2; . . . ;N
and
hhMiiij �1 for i � j;ÿkMÿ1
ii Mijk for i 6� j;
�i; j � 1; 2; . . . ;N :
For two matrices L 2 Ln and M 2 Ln;I , if we write
D�L� � Diag�L11; . . . ; LNN �; B�L� � D�L� ÿ L;
J�M� � D�M�ÿ1B�M�; l1�M� � q�JhMi�; l2�M� � q�I ÿ hhMii�;then from [1] we know that
hI ÿ J�M�i � hhI ÿ J�M�ii � hhMii; l2�M�6 l1�M�:
De®nition 3.2 (see Ref. [1]). Let M 2 Ln;I . If there exist P ;Q 2 Ldn;I such that hPMQi is
an M-matrix, then M is called a type-I block H -matrix, simply denoted as H �I�B �P ;Q�-matrix, according to the nonsingular blocked diagonal matrices P and Q. If thereexist P ;Q 2 Ld
n;I such that hhPMQii is an M-matrix, then M is called a type-II blockH -matrix, simply denoted as H �II�
B �P ;Q�-matrix, according to the nonsingularblocked diagonal matrices P and Q. Evidently, an H �I�B �P ;Q�-matrix is certainly anH �II�
B �P ;Q�-matrix, but conversely, it is not true.
De®nition 3.3 (see Ref. [1]). Let M 2 Ln. We call �M � � �kMijk� 2 RN�N the blockabsolute value of the blocked matrix M . The block absolute value �x� 2 RN of ablocked vector x 2 Vn is de®ned in an analogous way.
These kinds of block absolute values have the following important properties.
Lemma 3.1 (see Ref. [1]). Let L;M 2 Ln; x; y 2 Vn and c 2 R1. Then1. j�L� ÿ �M �j6 �L�M �6 �L� ��M � �j�x� ÿ �y�j6 �x� y�6 �x� � �y��;2. �LM �6 �L��M � ��Mx�6 �M ��x��;3. �cM �6 jcj�M � ��cx�6 jcj�x��;4. q�M�6 q�jM j�6 q��M �� (here, k � k is either k � k1 or k � k1).
Lemma 3.2 (see Ref. [1]). Let M 2 Ln;I be an H �I�B �P ;Q�-matrix. Then1. M is nonsingular;2. ��PMQ�ÿ1�6 hPMQiÿ1
;3. l1�PMQ� < 1.
688 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

Lemma 3.3 (see Ref. [1]). Let M 2 Ln;I be an H �II�B �P ;Q�-matrix. Then
1. M is nonsingular;2. ��PMQ�ÿ1�6 hhPMQiiÿ1�D�PMQ�ÿ1�;3. l2�PMQ� < 1.
De®nition 3.4 (see Ref. [1]). Let M � �Mij� 2 Ln;I and write
X�I�B �M� � fF � �Fij� 2 Ln;I j kF ÿ1ii k � kMÿ1
ii k; kFijk � kMijk; i 6� j; i; j � 1�1�Ng;
X�II�B �M� � fF � �Fij� 2 Ln;I j kF ÿ1
ii Fijk � kMÿ1ii Mijk; i; j � 1�1�Ng:
Then X�I�B �M� and X�II�B �M� are called the type-I and the type-II equimodular matrix
sets associated with the matrix M 2 Ln;I .
We recall from [13,22] that for a matrix A 2 Rm�m, its PMM means a collection oftriples �DÿLk;Uk;Ek��k � 1; 2; . . . ; a� for which D � Diag�A�, Lk 2 Rm�m�k �1; 2; . . . ; a� are strictly lower triangular matrices, Uk 2 Rm�m�k � 1; 2; . . . ; a� are zero-diagonal matrices and Ek 2 Rm�m�k � 1; 2; . . . ; a� are nonnegative diagonal matricessuch that
(a) D is nonsingular;(b) A � DÿLk ÿUk, k � 1; 2; . . . ; a;(c)Pa
k�1 Ek � I (the m� m identity matrix).Denote ej the jth unit vector in Rm for j � 1; 2; . . . ;m, and let Nj�p�, s�k�j �p��j �1�1�m; p 2 N0� be de®ned as in section two for k � 1; 2; . . . ; a. To establish theconvergence theories of Methods I and II, we state the following crucial conclusion,which is a simpli®ed variant of Theorem 1 in Ref. [6].
Lemma 3.4 (see Ref. [6]). Let A 2 RN�N be an M-matrix and �DÿLk;Uk;Ek��k � 1; 2; . . . ; a� be its multisplitting with B � DÿA, and Lk P 0 and Uk P 0,k � 1; 2; . . . ; a. For any starting vector �0 2 RN , de®ne the sequence f�pgp2N0
recursivelyby
�p�1 � ��p�11 ; �p�1
2 ; . . . ; �p�1N �T; �s�k��p� � �
s�k�1�p�
1 ; �s�k�
2�p�
2 ; . . . ; �s�k�N �p�N
� �T
;
�p�1j �
Xk2Nj�p�
eTj Ek�Dÿ rLk�ÿ1 j1� ÿ wjD� �wÿ r�Lk � wUk��s�k��p�
�X
k 62Nj�p�eT
j Ek�p;
j � 1; 2; . . . ;N ; k � 1; 2; . . . ; a; p � 0; 1; 2; . . . ;
where r;w 2 �0;1� are arbitrary parameters. Then the sequence f�pgp2N0converges to
zero if r and w satisfy 06 r6w and 0 < w < 2=�1� q�Dÿ1B��.
In the subsequent discussions, the norm k � k is taken to be either k � k1 or k � k1.
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 689

4. Convergence theories
Assume x� 2 Vn is the unique solution of the blocked system of linear equations(2.1) and fxpgp2N0
is an approximate sequence of x�. De®ne the error sequencefepgp2N0
by ep � xp ÿ x� �8p 2 N0� and denote
es�k��p� � es�k�
1�p�
1
� �T
; es�k�
2�p�
2
� �T
; . . . ; es�k�N �p�N
� �T !T
;
k � 1; 2; . . . ; a; p � 0; 1; 2; . . . :
Then, from Eqs. (2.5)±(2.8) and Eqs. (2.11) and (2.12) the error sequences fepgp2N0
corresponding to the iterative sequences fxpgp2N0generated by Methods I and II can
be respectively expressed as
ep�1i �
Xk2Ni�p�
E�k�ii Pi Lk�c;x�es�k��p�� �
�X
k 62Ni�p�E�k�ii ep
i ; i � 1; 2; . . . ;N ; �4:1�
ep�1i �
Xk2Ni�p�
E�k�ii Pi Lk�c;x;b�es�k��p�� �
�X
k 62Ni�p�E�k�ii ep
i ; i � 1; 2; . . . ;N ; �4:2�
where
Lk�c;x� � �Dÿ cLk�ÿ1 �1� ÿ x�D� �xÿ c�Lk � xUk�;Lk�c;x; b� � bLk�c;x� � �1ÿ b�I ;
k � 1; 2; . . . ; a:
�4:3�
Evidently, to prove the convergence of Methods I and II, we only need to prove thatthe sequences fepgp2N0
de®ned by Eqs. (4.1) and (4.2), respectively, converge to zero.
Theorem 4.1. Let A 2 Ln;I be an H �I�B �P ;Q�-matrix, H 2 X�I�B �PAQ� and �Dÿ Lk;U k;Ek��k � 1; 2; . . . ; a� be a BMM of the blocked matrix H with
Pak�1�Ek�6 I and
hHi � hDi ÿ �Lk� ÿ �U k� � DhHi ÿ BhHi; k � 1; 2; . . . ; a: �4:4�Then, for any starting vector x0 2 Vn,
(i) the sequence fxpgp2N0generated by Method I for solving the blocked system of
linear equations
Hx � b; H 2 X�I�B �PAQ�; x; b 2 Vn �4:5�converges to its unique solution x� 2 Vn provided the relaxation parameters c and xsatisfy
06 c6x; 0 < x <2
1� l1�PAQ� ; �4:6�(ii) the sequence fxpgp2N0
generated by Method II for solving the blocked system oflinear equations (4.5) converges to its unique solution x� 2 Vn provided the relaxationparameters c and x satisfy Eq. (4.6), and b satis®es
690 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

0 < b <2
1� g�x�1 �PAQ�; g�x�1 �PAQ� � j1ÿ xj � xl1�PAQ�: �4:7�
Proof. Simply denote
~Lk � Dÿ1
Lk; ~U k � Dÿ1
Uk; k � 1; 2; . . . ; a: �4:8�Then we have
Lk�c;x� � �I ÿ c~Lk�ÿ1 �1�ÿ x�I � �xÿ c�~Lk � x ~U k
�; k � 1; 2; . . . ; a �4:9�
from Eq. (4.3). Clearly, �I ÿ c~Lk��k � 1; 2; . . . ; a� are H �I�B �I ; I�-matrix. In light ofLemma 3.2(2), it holds that
��I ÿ c~Lk�ÿ1�6 hI ÿ c~Lkiÿ1 � �I ÿ c�~Lk��ÿ1; k � 1; 2; . . . ; a:
Therefore, applying Lemma 3.1(1)±(3) we get
�Lk�c;x��6 ��I ÿ c~Lk�ÿ1� j1�ÿ xjI � �xÿ c��~Lk� � x� ~U k�
�6 �I ÿ c�~Lk��ÿ1 j1
�ÿ xjI � �xÿ c��~Lk� � x� ~U k�
��4:10�
for k � 1; 2; . . . ; a, from Eq. (4.9).On the other hand, by Lemma 3.2(2) and Eq. (4.8) we see that
�~Lk�6Dÿ1hHi�Lk�; � ~U k�6Dÿ1
hHi�Uk�; k � 1; 2; . . . ; a; �4:11�and thereafter, it holds that
�I ÿ c�~Lk��ÿ1 �Xp2N0
�c�~Lk��p6Xp2N0
�cDÿ1hHi�Lk��p
� �I ÿ cDÿ1hHi�Lk��ÿ1 � �DhHi ÿ c�Lk��ÿ1DhHi
for k � 1; 2; . . . ; a. Substituting these inequalities and Eq. (4.11) into Eq. (4.10), weobtain
�Lk�c;x��6 �DhHi ÿ c�Lk��ÿ1DhHi j1�ÿ xjI � �xÿ c�Dÿ1
hHi�Lk� � xDÿ1hHi�U k�
�� �DhHi ÿ c�Lk��ÿ1 j1ÿ ÿ xjDhHi � �xÿ c��Lk� � x�Uk�
� �4:12�for k � 1; 2; . . . ; a.
Write
Lk�c;x� � �DhHi ÿ c�Lk��ÿ1 j1ÿ ÿ xjDhHi � �xÿ c��Lk� � x�U k��;
k � 1; 2; . . . ; a: �4:13�Then Eq. (4.12) is equivalent to
�Lk�c;x��6Lk�c;x�; k � 1; 2; . . . ; a: �4:14�Now, to prove (i) we take the block absolute values on both sides of Eq. (4.1).
This then gives
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 691

�ep�1i �6
Xk2Ni�p�
�E�k�ii � Pi Lk�c;x�es�k��p�� �h i
�X
k 62Ni�p��E�k�ii ��ep
i �
6X
k2Ni�p��E�k�ii �eT
i �Lk�c;x�� es�k��p�h i
�X
k 62Ni�p��E�k�ii ��ep
i �
6X
k2Ni�p��E�k�ii �eT
i Lk�c;x� es�k��p�h i
�X
k 62Ni�p��E�k�ii ��ep
i � �4:15�
for i � 1; 2; . . . ;N , by our making use of Eq. (4.14).Denote
D � DhHi; B � BhHi; Lk � �Lk�; Uk � �U k�;E�k�i � �E�k�ii �; E�k� � Diag�E�k�1 ;E
�k�2 ; . . . ;E
�k�N �;
~epi � �ep
i �; ~ep � �~ep1;~e
p2; . . . ;~ep
N �T;~es�k��p� � �~es�k�
1�p�
1 ;~es�k�
2�p�
2 ; . . . ;~es�k�N �p�N �T;
i � 1; 2; . . . ;N ; k � 1; 2; . . . ; a; p � 0; 1; 2; . . .
Then Eqs. (4.13) and (4.15) can be equivalently represented as
Lk�c;x� � �Dÿ cLk�ÿ1 j1� ÿ xjD� �xÿ c�Lk � xUk�; k � 1; 2; . . . ; a;
~ep�1i 6
Xk2Ni�p�
E�k�i eT
i Lk�c;x�~es�k��p� �X
k 62Ni�p�E�k�i ~ep
i ; i � 1; 2; . . . ;N :
Again, de®ne A�x� � ��1ÿ j1ÿ xj�=x�DÿB. Then A�x� 2 RN�N is evidentlyan M-matrix under the restriction (4.6). Moreover, �DÿLk;Uk;Ek��k � 1; 2; . . . ; a�forms a PMM of the matrix A�x�, and it holds that Lk P 0 and Uk P 0,k � 1; 2; . . . ; a. In accordance with Lemma 3.4, the sequence f�pgp2N0
determinedrecursively by �0 � ~e0 and
�p�1i �
Xk2Ni�p�
E�k�i eT
i Lk�c;x��s�k��p� �X
k 62Ni�p�E�k�i �p
i ;
i � 1; 2; . . . ;N ; p � 0; 1; 2; . . .
converges to zero.In addition, we can inductively verify that the sequence f�pgp2N0
majorizes thesequence f~epgp2N0
, i.e., ~ep 6 �p�8p 2 N0�. In fact, the case of p � 0 is trivial. If we
assume ~ep6 �p for some p 2 N0, then it holds that ~es�k�j �p�j 6 �s�k�j �p�
j
�j � 1�1�N ; k � 1; 2; . . . ; a�, and hence, we have
~ep�1i 6
Xk2Ni�p�
E�k�i eT
i Lk�c;x�~es�k��p� �X
k 62Ni�p�E�k�i ~ep
i
6X
k2Ni�p�E�k�i eT
i Lk�c;x��s�k��p� �X
k 62Ni�p�E�k�i �p
i � �p�1i
for i � 1; 2; . . . ;N . This completes the induction process. Therefore, f~epgp2N0, or in
other words, f�ep�gp2N0converges to zero, which immediately gives ep ! 0�p !1�,
or xp ! x��p!1�.
692 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

We now turn to (ii). Noticing from Eq. (4.3) that for k � 1; 2; . . . ; a, it holdsthat
Lk�c;x; b� � �Dÿ cLk�ÿ1 �1� ÿ xb�D� �xbÿ c�Lk � xbUk�� �Dÿ cLk�ÿ1 �1� ÿ r�D� �rÿ c�Lk � rUk� � Lk�c; r�;
with r � xb, we can conclude from (i) and Eq. (4.2) that the error sequence fepgp2N0,
de®ned by Eq. (4.2), corresponding to Method II converges to zero providedj1ÿ rj � rl1�PAQ� < 1.
Considering g�x�1 �PAQ� < 1 when c and x are within the region (4.6), we easilyknow that Eq. (4.7) is equivalent to j1ÿ bj � bg�x�1 �PAQ� < 1. However, we have
j1ÿ rj � rl1�PAQ� � j1ÿ rj ÿ jbÿ rj � bg�x�1 �PAQ�6 j1ÿ bj � bg�x�1 �PAQ� < 1:
Therefore, the conditions of Theorem 4.1 guarantee the validity of its conclusion (ii).
Theorem 4.2. Let A 2 Ln;I be an H �II�B �P ;Q�-matrix, H 2 X�II�
B �PAQ� and �Dÿ Lk;U k;Ek��k � 1; 2; . . . ; a� be a BMM of the blocked matrix H with
Pak�1�Ek�6 I and
hhHii � I ÿ �Dÿ1Lk� ÿ �Dÿ1
U k� � I ÿ BhhHii; k � 1; 2; . . . ; a:
Then, for any starting vector x0 2 Vn,(i) the sequence fxpgp2N0
generated by Method I for solving the blocked system oflinear equations
Hx � b; H 2 X�II�B �PAQ�; x; b 2 Vn �4:16�
converges to its unique solution x� 2 Vn provided the relaxation parameters c and xsatisfy
06 c6x; 0 < x <2
1� l2�PAQ� ; �4:17�(ii) the sequence fxpgp2N0
generated by Method II for solving the blocked system oflinear equations (4.16) converges to its unique solution x� 2 Vn provided the relaxationparameters c and x satisfy Eq. (4.17), and b satis®es
0 < b <2
1� g�x�2 �PAQ�; g�x�2 �PAQ� � j1ÿ xj � xl2�PAQ�:
Proof. Under the conditions of the theorem, we easily know that H 2 Ln;I is anH �II�
B �I ; I�-matrix and hhHii � hhPAQii. Hence, in light of Lemma 3.3(3) and fromJhhHii � BhhHii, it holds that
l2�H� � q�JhhHii� � q�BhhHii� � q�BhhPAQii�� q�JhhPAQii� � l2�PAQ� < 1:
The remainder of the proof is much analogous to that of Theorem 4.1, so it isomitted here.
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 693

We comment that Theorems 4.1 and 4.2 apply to matrix A which may not have anonsingular D�A�, or such that it does not belong to H �I�B �I ; I� or H �II�
B �I ; I� but suchthat there exist nonsingular block diagonal matrices P and Q, such that PAQ hasthese properties.
5. Numerical example
We consider the blocked system of linear equations
Ax � b; A 2 Ln; b 2 Vn; �5:1�with n1 � n2 � � � � � nN � N and n � N 2, where
A �
B ÿ I
ÿI B ÿ I
. .. . .
. . ..
ÿ I B ÿ I
ÿ I B
0BBBBBB@
1CCCCCCA 2 Rn�n;
B �
4 ÿ 1
ÿ1 4 ÿ 1
. .. . .
. . ..
ÿ 1 4 ÿ 1
ÿ 1 4
0BBBBBB@
1CCCCCCA 2 RN�N ;
�5:2�
and b 2 Rn is chosen such that the solution of this blocked system of linear equationshas all components equal to one. This blocked system of linear equations is yieldedby discretizing some Dirichlet problem de®ned on the square domain �0; 1� � �0; 1�through using the ®nite di�erence method at N 2 equidistant nodes of a quadraticgrid.
Take a � 2 and two positive integers m1 and m2 satisfying 16m26m16N . Then,corresponding to the number sets J1 � f1; 2; . . . ;m1g and J2 � fm2;m2 � 1; . . . ;Ng,we determine a BMM �Dÿ Lk;Uk;Ek��k � 1; 2� of the blocked matrix A 2 Ln inaccordance with the following way:
D � Diag�B; . . . ;B� 2 Ln;
L1 � �L�1�ij � 2 Ln; L
�1�ij �
I for j � iÿ 1 and 26 i6m1;
0 otherwise;
(
U1 � �U�1�ij � 2 Ln; U�1�ij �
I for j � iÿ 1 and m1 � 16 i6N ;
I for j � i� 1 and 16 i6N ÿ 1;
0 otherwise;
8><>:L2 � �L�2�
ij � 2 Ln; L�2�ij �
I for j � iÿ 1 and m26 i6N ;
0 otherwise;
(
694 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

U2 � �U�2�ij � 2 Ln; U�2�ij �
I for j � iÿ 1 and 26 i6m2 ÿ 1;
I for j � i� 1 and 16 i6N ÿ 1;
0 otherwise;
8>><>>:Ek � Diag�E�k�11 ; . . . ;E�k�NN � 2 Ln; k � 1; 2;
E�1�ii �I for 16 i < m2;
12I for m26 i6m1;
0 for m1 < i6N ;
8>><>>: E�2�ii �0 for 16 i < m2;
12I for m26 i6m1;
I for m1 < i6N :
8>><>>:In particular, we select the positive integer pair �m1;m2� to be
�a� m1 � Int2N3
� �; m2 � Int
N3
� �; and
�b� m1 � Int4N5
� �; m2 � Int
N5
� �;
respectively, then we can get two kinds of concrete cases of the weighting ma-trices E1 and E2, here, Int��� denotes the integer part of the corresponding realnumber.
We sequentially imitate our new methods on the SGI INDY workstation by theasynchronous multisplitting blockwise Jacobi method, the asynchronous multi-splitting blockwise Gauss-Seidel method, the asynchronous multisplitting blockwiseSOR method and the asynchronous multisplitting blockwise AOR method ac-cording to di�erent N (hence n), or a ®xed N (then n) but di�erent relaxation pa-rameters c and x. In all our computations, we start with an initial vector having allcomponents equal to 0:5 and terminated once the current iterations xp satisfykAxp ÿ bk16 10ÿ4. We list the corresponding iteration numbers in Tables 1±6 to
Table 1
Asynchronous multisplitting blockwise Jacobi method
N 10 15 20 30 40 50 100 150 200 250
(a) 327 636 1109 2325 4107 6288 24 348 53 863 95 586
148 939
Table 2
Asynchronous multisplitting blockwise Gauss±Seidel method
N 10 15 20 30 40 50 100 150 200 250
(a) 176 336 576 1194 2094 3194 12 270 27 073 47 983 74 696
(b) 154 312 528 1127 1952 3003 11 652 25 953 45 912 71 520
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 695

show the feasibility and e�ciency of our new methods. For clearness, a star `*' isused to show the optimal number of iteration steps for a case in a numerical table.From these tables it is easy to see that suitable selections of the weighting matricesand reasonable matches of the relaxation parameters can usually produce bettercomputing e�ects.
For comparisons, we also consider the blocked system of linear equations (5.1)and (5.2) in the point sense. Likewise, we take a � 2 and two positive integers m1
and m2 such that 16 m26 m16 n. Then, corresponding to the number setsJ 1 � f1; 2; . . . ; m1g and J 2 � fm2; m2 � 1; . . . ; ng, we determine a PMM�Dÿ Lk; U k; Ek��k � 1; 2� of the pointed matrix A 2 Rn�n in accordance with thefollowing way:
Table 4
Asynchronous multisplitting blockwise AOR method �N � 100�c 1.90 1.95 2.00
x 2.00 1.60 1.65 1.70 1.75 1.80 1.85 1.90 2.0 1.90
(a) 5260 606 591 577 564 555 549� 552 4960 3504
(b) 2923 555 540 525 513 504 499� 509 4037 3555
Table 6
Asynchronous multisplitting blockwise AOR method �N � 15�c 1.75 1.7 1.65 1.6
x 1.7 1.5 [1.55, 1.6] 1.65 1.5 1.55 1.6 1.65 1.65
(a) 89 75 76 77 75 72 70� 72 81
(b) 84 77 72 65 63� 63� 67 68
Table 3
Asynchronous multisplitting blockwise SOR method �N � 100�x 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
(a) 10 059 8216 6657 5316 4155 3135 2235 1431 702� 1(b) 9546 7788 6300 5025 3918 2949 2091 1323 612� 1
Table 5
Asynchronous multisplitting blockwise SOR method �N � 15�x 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
(a) 276 228 185 147 114 84� 84� 121 211 1120
(b) 257 210 169 135 102 67� 77 109 178 446
696 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

D � diag�4; 4; . . . ; 4� 2 Rn�n;
L1 � �L�1�ij � 2 Rn�n; L
�1�ij �
1 for j � iÿ 1; i � kN � s;
and 06 k6 Int�m1=N� ÿ 1; 26 s6N ;
1 for j � iÿ 1; i � Int�m1=N� � N � s;
and 26 s6mod�m1;N�;1 for j � iÿ N ;N � 16 i6 m1;
0 otherwise;
8>>>>>>>>>><>>>>>>>>>>:
U 1 � �U�1�ij � 2 Rn�n; U�1�ij �
1 for j � i� 1; i � kN � s;
and 06 k6N ÿ 1; 16 s6N ÿ 1;
1 for j � i� N ; 16 i6 nÿ N ;
1 for j � iÿ 1; i � kN � s;
Int�m1=N�6 k6N ÿ 1;
and maxf2;mod�m1;N� � 1g6 s6N ;
1 for j � iÿ N ; m1 � 16 i6 n;
0 otherwise;
8>>>>>>>>>>>>>>><>>>>>>>>>>>>>>>:
L2 � �L�2�ij � 2 Rn�n; L
�2�ij �
1 for j � iÿ 1; i � kN � s;
and Int�m2=N� � 16 k6N ÿ 1;
26 s6N ;
1 for j � iÿ 1; i � Int�m2=N� � N � s;
and mod�m2;N� � 16 s6N ;
1 for j � iÿ N ; m2 � N 6 i6 n;
0 otherwise;
8>>>>>>>>>>>><>>>>>>>>>>>>:
U 2 � �U�2�ij � 2 Rn�n; U�2�ij �
1 for j � i� 1; i � kN � s;
and 06 k6N ÿ 1; 16 s6N ÿ 1;
1 for j � i� N ; 16 i6 nÿ N ;
1 for j � iÿ 1; i � kN � s;
and 06 k6 Int��m2 ÿ 1�=N� ÿ 1;
26 s6N ;
1 for j � iÿ 1; i � kN � s;
k � Int��m2 ÿ 1�=N�;and 26 s6mod�m2 ÿ 1;N�;
1 for j � iÿ N ;N � 16 i6 m2 ÿ 1;
0 otherwise;
8>>>>>>>>>>>>>>>>>>>>>>><>>>>>>>>>>>>>>>>>>>>>>>:
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 697

Ek � diag�e�k�1 ; e�k�2 ; . . . ; e�k�n � 2 Rn�n; k � 1; 2;
e�1�i �1 for 16 i < m2;
0:5 for m26 i6 m1;
0 for m1 < i6 n;
8>>><>>>: e�2�i �0 for 16 i < m2;
0:5 for m26 i6 m1;
1 for m1 < i6 n:
8>>><>>>:In particular, if we select the positive integer pair �m1; m2� to be
�a� m1 � Int2N3
� �� N ; m2 � Int
N3
� �� N ; and
�b� m1 � Int4N5
� �� N ; m2 � Int
N5
� �� N ;
respectively, then we can get two kinds of concrete cases of the weighting matrices E1
and E2. Clearly, the PMMs de®ned here are just the same as the BMMs de®nedabove, respectively. Their di�erence is just in the expressions; the former is describedin the pointed manner, while the later is in the blocked manner.
Using the same starting vector and the same stopping criterion as above, wesequentially imitate the asynchronous multisplitting (pointwise) Jacobi method,the asynchronous multisplitting (pointwise) Gauss±Seidel method, the asynchro-nous multisplitting (pointwise) SOR method and the asynchronous multisplitting(pointwise) AOR method described in Ref. [6] also on the SGI INDY worksta-tion according to di�erent n (hence N ), or a ®xed n (then N ) but di�erent re-laxation parameters c and x (here, we use c instead of r there). Thecorresponding iteration numbers are listed in Tables 7±10. Comparing the com-puting results in Table 1 with Table 7, Table 2 with Table 8, Table 5 with Table 9and Table 6 with Table 10, we easily see that the asynchronous multisplittingblockwise relaxation methods discussed in this paper substantially have betternumerical behaviours than their point alternatives studied in Ref. [6]. That is tosay, for the divergence cases of the asynchronous multisplitting pointwise relax-ation methods, the corresponding asynchronous multisplitting blockwise relax-ation methods give convergence, while for the convergence cases of theasynchronous multisplitting pointwise relaxation methods, the correspondingasynchronous multisplitting blockwise relaxation methods require considerably
Table 7
Asynchronous multisplitting Jacobi method
N 5 10 15 20 30 40 50 100 150 200
(a) 186 618 1 1 1 1 1 1 1 1(b) 169 561 1 1 1 1 1 1 1 1
698 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701
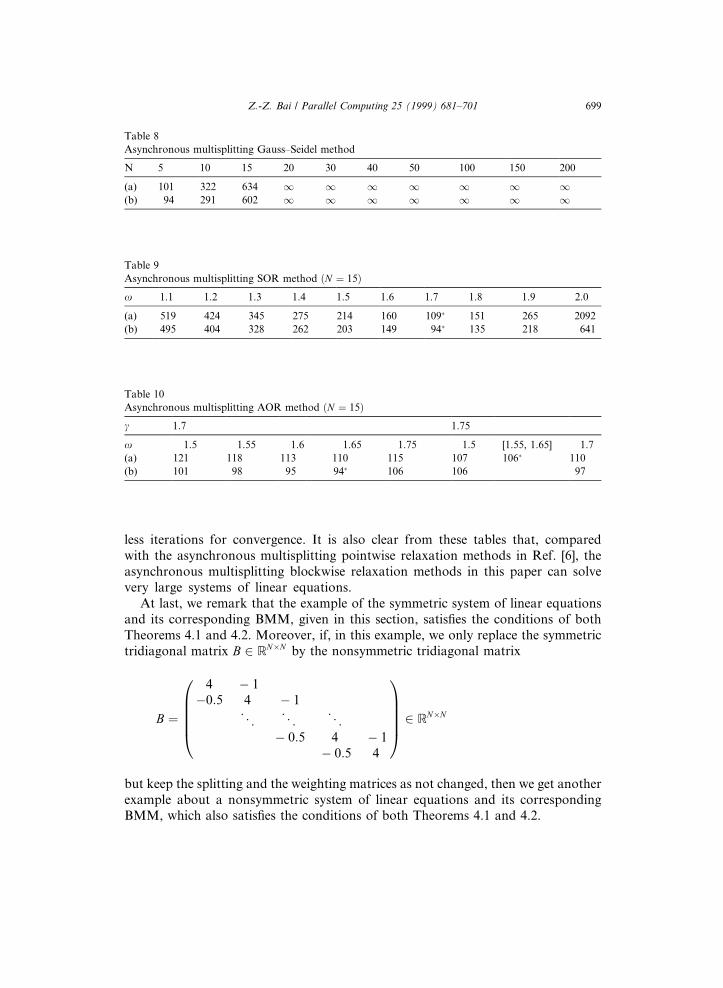
less iterations for convergence. It is also clear from these tables that, comparedwith the asynchronous multisplitting pointwise relaxation methods in Ref. [6], theasynchronous multisplitting blockwise relaxation methods in this paper can solvevery large systems of linear equations.
At last, we remark that the example of the symmetric system of linear equationsand its corresponding BMM, given in this section, satis®es the conditions of bothTheorems 4.1 and 4.2. Moreover, if, in this example, we only replace the symmetrictridiagonal matrix B 2 RN�N by the nonsymmetric tridiagonal matrix
B �
4 ÿ 1ÿ0:5 4 ÿ 1
. .. . .
. . ..
ÿ 0:5 4 ÿ 1ÿ 0:5 4
0BBBB@1CCCCA 2 RN�N
but keep the splitting and the weighting matrices as not changed, then we get anotherexample about a nonsymmetric system of linear equations and its correspondingBMM, which also satis®es the conditions of both Theorems 4.1 and 4.2.
Table 10
Asynchronous multisplitting AOR method �N � 15�c 1.7 1.75
x 1.5 1.55 1.6 1.65 1.75 1.5 [1.55, 1.65] 1.7
(a) 121 118 113 110 115 107 106� 110
(b) 101 98 95 94� 106 106 97
Table 9
Asynchronous multisplitting SOR method �N � 15�x 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
(a) 519 424 345 275 214 160 109� 151 265 2092
(b) 495 404 328 262 203 149 94� 135 218 641
Table 8
Asynchronous multisplitting Gauss±Seidel method
N 5 10 15 20 30 40 50 100 150 200
(a) 101 322 634 1 1 1 1 1 1 1(b) 94 291 602 1 1 1 1 1 1 1
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 699

Acknowledgements
The author is very much indebted to the referees for a lot of valuable commentsand constructive suggestions on the original manuscript of this paper. He also thanksheartily Professors G.R. Joubert and M. Shimasaki for their help.
References
[1] Z.Z. Bai, Parallel matrix multisplitting block relaxation iteration methods, Math. Numer. Sinica 17
(1995) 238±252.
[2] Z.Z. Bai, On the convergence of the generalized matrix multisplitting relaxed methods, Comm.
Numer. Meth. Engrg. 11 (1995) 363±371.
[3] Z.Z. Bai, Comparisons of the convergence and divergence rates of the parallel matrix multisplitting
iteration methods, Chinese J. Engrg. Math. 11 (1994) 99±102.
[4] Z.Z. Bai, Asynchronous multisplitting AOR method for a system of nonlinear algebraic equations,
Int. J. Computer Math. 55 (1995) 223±233.
[5] Z.Z. Bai, D.R. Wang, On the convergence of the matrix multisplitting block relaxation methods, in:
Proceedings of the National Forth Parallel Algorithm Conference, Aeronautical Industry Press,
Beijing, 1993.
[6] Z.Z. Bai, D.R. Wang, D.J. Evans, Models of asynchronous parallel matrix multisplitting relaxed
iterations, Parallel Comput. 21 (1995) 565±582.
[7] Z.Z. Bai, D.R. Wang, D.J. Evans, On the convergence of asynchronous nested matrix multisplitting
methods for linear systems, to appear in J. Comp. Math.
[8] Z.Z. Bai, J.C. Sun, D.R. Wang, A uni®ed framework for the construction of various matrix
multisplitting iterative methods for large sparse system of linear equations, Comput. Math. Appl. 32
(12) (1996) 51±76.
[9] R. Bru, L. Elsner, M. Neumann, Models of parallel chaotic iteration methods, Linear Algebra Appl.
103 (1988) 175±192.
[10] D. Chazan, W.L. Miranker, Chaotic relaxation, Linear Algebra Appl. 2 (1969) 199±222.
[11] L. Elsner, Comparisons of weak regular splittings and multisplitting methods, Numer. Math. 56
(1989) 283±289.
[12] D.J. Evans, D.R. Wang, Z.Z. Bai, Matrix multi-splitting multi-parameter relaxation methods, Int. J.
Computer Math. 43 (1992) 173±188.
[13] A. Frommer, G. Mayer, Convergence of relaxed parallel multisplitting methods, Linear Algebra
Appl. 119 (1989) 141±152.
[14] I. Marek, D.B. Szyld, Comparison theorems for weak splittings of bounded operators, Numer. Math.
58 (1990) 387±397.
[15] M. Neumann, R.J. Plemmons, Convergence of parallel multisplitting iterative methods for
M-matrices, Linear Algebra Appl. 88 (1987) 559±573.
[16] D.P. O'Leary, R.E. White, Multi-splittings of matrices and parallel solutions of linear systems, SIAM
J. Alg. Disc. Meth. 6 (1985) 630±640.
[17] J. O'Neil, D.B. Szyld, A block ordering method for sparse matrices, SIAM J. Sci. Stat. Comput. 11
(1990) 811±823.
[18] F. Robert, M. Charnay, F. Musy, It�erations chaotiques s�erie-parall�ele pour des �equations non-
lin�eaires de point ®xe, Aplikace Matematiky 20 (1975) 1±38.
[19] F. Robert, Blocs-H-Matrices et Convergence des M�ethodes It�eratives Classiques par Blocs, Linear
Algebra Appl. 2 (1969) 223±265.
[20] R.S. Varga, Matrix Iterative Analysis, Prentice-Hall, Englewood Cli�s, NJ, 1962.
[21] R.S. Varga, On recurring theorems on diagonal dominance, Linear Algebra Appl. 13 (1976) 1±9.
[22] D.R. Wang, On the convergence of the parallel multisplitting AOR algorithm, Linear Algebra Appl.
154±156 (1991) 473±486.
700 Z.-Z. Bai / Parallel Computing 25 (1999) 681±701

[23] D.R. Wang, Z.Z. Bai, D.J. Evans, A class of asynchronous parallel matrix multisplitting relaxation
methods, Parallel Algorithms Appl. 2 (1994) 173±192.
[24] R.E. White, Multisplitting of a symmetric positive de®nite matrix, SIAM J. Matrix Anal. Appl. 11
(1990) 69±82.
[25] R.E. White, Multisplitting with di�erent weighting schemes, SIAM J. Matrix Anal. Appl. 10 (1989)
481±493.
Z.-Z. Bai / Parallel Computing 25 (1999) 681±701 701