a comparative study of some concurrency control … · algorithms for cluster-based communication...
TRANSCRIPT

www.elsevier.com/locate/compeleceng
Computers and Electrical Engineering 30 (2004) 615–636
A comparative study of some concurrency controlalgorithms for cluster-based communication networks
Constant Wette 1, Samuel Pierre *, Jean Conan
Department of Computer Engineering, Ecole Polytechnique de Montreal, C.P. 6079, succ. Centre-ville,
Montreal, Que., Canada H3C 3A7
Received 12 March 2003; accepted 20 August 2004
Abstract
This paper presents a comparative study of some concurrency control algorithms for distributed data-
bases of computer clusters which emphasize high availability and high performance requirements. For this
purpose, we have analyzed some concurrency control algorithms which are used in commercial DBMSs,
such as the pessimistic locking algorithm as it verifies transaction conflicts early in their execution phase,
and the optimistic algorithm which investigates the presence of conflicts after the execution phase. Anew algorithm is proposed and implemented by a simulation program. The three algorithms were tested
using different configurations. Simulation results showed that the locking algorithm performed better than
the optimistic method in presence of conflicts between transactions, while the optimistic algorithm provided
better results in the absence of conflicts. Furthermore, in a distributed database with a certain probability of
conflicts, the locking algorithm can be used to guarantee strong consistency and an acceptable level of per-
formance. However, if this probability is negligible, the system performance can be improved by using the
optimistic algorithm. The proposed algorithm offers improved performance in numerous cases. As a result,
it can be used in a distributed database to guarantee a satisfactory level of performance in the presence ofconflicts.
� 2005 Elsevier Ltd. All rights reserved.
0045-7906/$ - see front matter � 2005 Elsevier Ltd. All rights reserved.
doi:10.1016/j.compeleceng.2004.08.003
* Corresponding author. Tel.: +1 514 34 047 11; fax: +1 514 34 032 40.
E-mail addresses: [email protected] (C. Wette), [email protected] (S. Pierre).1 Ericsson Canada Inc., 8400 Decarie Blvd., Town of Mount Royal, Que., Canada H4P 2N2.

616 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
Keywords: Concurrency control algorithm; Consistency preservation; Performance evaluation; Distributed databases;
Cluster computing
1. Introduction
Over the last two decades, research in distributed systems and computer networks has broughtabout numerous changes in the design of database systems. Data distribution and replication con-cepts have introduced new constraints in the design of algorithms for distributed database man-agement systems (DDBMS) compared to their equivalent for centralized DBMS. Thus, it becamenecessary to design high performance distributed algorithms to solve consistency problems in dis-tributed databases [1–4]. In a distributed database system, the purpose of a concurrency controlalgorithm is to produce both a local and a global schedule of concurrent transactions in order topreserve database consistency [5–10].
There are basically three types of concurrency control algorithms: locking, timestamp and opti-mistic algorithms [4,11]. In a distributed database, objects are shared between applications whichare running either on the local site or on remote sites. However, the algorithm must satisfy theconsistency constraint. When the degree of concurrency increases, some transactions are eitherdelayed, as in the case of the locking algorithm, or aborted, as in the case of the optimistic algo-rithm. This situation increases the average response time and leads to performance deterioration.To ensure an acceptable level of performance, designers of concurrency control algorithms recom-mend a trade-off that can be achieved by relaxing some constraints pertaining to consistency.
This paper presents a comparative study of various concurrency control algorithms for com-puter clusters and emphasizes the specific applications required to achieve both a high level ofavailability and a high level of performance. In this context, a new concurrency control algorithmis proposed and its performance is evaluated and compared to some existing algorithms, morespecifically the one used in Ericsson TelORB system [12–15]. The circumstances that can compro-mise database consistency, as well as some proposed solutions [16–18] are analyzed. Section 2 pre-sents an analysis of some concurrency control approaches and algorithms. Section 3 describes theproposed algorithm and its performance analysis, while Section 4 compares the simulation results.
2. Background and related work
Acronym Meaning
ACID Atomicity–consistency–isolation–durabilityDB DatabaseDBMS Database management systemDBN TelORB�s DBMSDDB Distributed databaseDDBMS Distributed database management systemDM Data manager

Acronym Meaning
GSM Global system for mobile communicationHLR Home location registerOCC Optimistic concurrency controlODMG Object database management groupSC SchedulerSS7 Signaling system 7TelORB Ericsson�s distributed operating systemTM Transaction managerVLR Visitor location register2PL Two-phase locking
C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 617
2.1. Basic concepts
A database is a collection of recorded data, deprived of expensive or useless redundancies,which can be used by several applications. In a database, data and applications act independently.A database management system (DBMS) is a type of software which can be used to create data-bases and to add, query or modify data stored in secondary memories. At any given moment, thestate of the database is determined by the value of its objects which coherently represent some realobjects. This state is modified by each execution of a transaction.
A transaction is a reliable program consists of a sequence of read-and-write operations on thedatabase. Its execution maps the modifications of the database from one state to another. Theconsistent state of a database is defined by a set of rules known as integrity constraints. Transac-tion consistency and reliability are a consequence of the four following fundamental properties(ACID):
• Atomicity: the system must complete all transaction updates or none;• Consistency: if a transaction failure occurs, the initial consistent state must be restored;• Isolation: in order to avoid interference, results of transaction updates should not be visible toother transactions before their commitment;
• Durability: once a transaction occurs, the system must guarantee that its results are permanentand cannot be erased from the database.
All of these properties must be guaranteed by both the centralized and distributed databasemanagement systems. Moreover, two types of control are required to process transactions in aDBMS: concurrency control and robustness.
The main components of a DDBMS are presented in Fig. 1. Each line represents a node, whichincludes: a transaction manager (TM), a scheduler (SC), a data manager (DM) and a data storagecomponent (DB). The communication network is connected by the links used to join differentnode components. A scheduler is an algorithm used to synchronize transaction operations inorder to avoid inconsistencies.
A distributed database (DDB) is composed of a set of databases stored in several distinct nodeswhich are connected through a communication network. Applications consider them as a single

Fig. 1. DDBMS architecture.
618 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
database. A distributed transaction is a transaction which operates on data located in more thanone node. A distributed transaction is divided (by the transaction manager of the originatingnode) into a number of subtransactions, which will be executed by many nodes. According tothe convention, data distribution and replication performed by the DBMS must be transparentto the applications. For example, the database can be modeled as a set of logical entities, so thatan entity may have one or more physical copies (replicas). Applications have a logical view of thedata. While it has access, the DBMS is responsible for the translation of a read operation on alogical data entity into a read operation on only one physical copy, and for the translation ofa write operation on a logical data entity into a write operation on all physical copies.
Databases are usually distributed over various locations in order to minimize the risk of failuresand to speed up local access [19]. For performance, reliability, and availability reasons, data rep-lication is performed by storing more than one copy of a piece of data in different nodes [20]. Inorder to guarantee data consistency, replica updates must be synchronized. However, this require-ment increases the average response time of the system.
A distributed database is managed by a DDBMS whose components are spread over variouslocations, as illustrated in Fig. 1. Let us analyze the communication scenario between the compo-nents of a DBMS during the execution of a transaction when data is being replicated. The TMrecords a transaction submitted by an application with an identifier, TrId. Then, for each opera-tion, the TM then contacts the scheduler that controls access to the data requested. For a readoperation, the SC contacts only one of the nodes where a replica is stored; for a write operation,each node containing a replica is contacted. SCs must synchronize various data access, and pro-duce a global and serializable schedule that preserves the consistent state of the distributed DBafter the commitment of all transactions in progress. To satisfy this requirement, a SC sends someoperations directly to the DM if it does not find any conflicts, and delays or rejects certain oper-ations if there is a risk of conflict. For a read operation, the DM provides access to the databaseand returns the value of the data. For a write operation the DM modifies the value and returns anacknowledgment to the SC that will, in turn, relay the result of the operation to the program thatsubmitted the transaction via the TM.
As mentioned above, scheduling mechanisms can be grouped into three main classes: locking,timestamp and optimistic method. Locking and timestamp algorithms solve transaction conflictsearly in their execution phase, according to the syntactic information provided. Although this prin-

C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 619
ciple guarantees database consistency after the commitment of transactions, the average responsetime may become significant factor. The optimistic method assumes that conflict between transac-tions are not common occurrences and it allows simultaneous access to the same data until the val-idation phase. Unlike the two other methods which are known as pessimistic, solving conflicts afterexecution takes the semantic information into account and reinitiates conflicting transactions.
2.2. Overview of existing scheduling algorithms
The analysis of some selected algorithms reveals that the optimistic method offers improvedperformance over locking when transaction conflicts are rare [7,11,18,21,22]. However, in theoptimistic approach, too many transactions can be restarted due to frequent conflicts, a situationwhich may cause severe performance deterioration. This explains why the locking algorithm is stillpreferred for commercial DBMS.
For both methods, designers will try to minimize the number of messages sent between nodes oroptimize the processing capacity and use of memory. A scheduling method is more efficient if itcan satisfy different application requirements and adapt itself to some hardware or runtime envi-ronment limitations. Here are some common applications requirements: minimum response time,high availability of data, real-time constraints, high throughput, guarantee of data consistency. Acluster system may not necessarily make use of high capacity hardware (processor or memory)however, it must be scalable. To meet the ever-increasing number of user requirements, it is thusnecessary to explore the three basic scheduling methods and design a new mechanism which canbest satisfy them.
In spite of the fact that two-phase locking (2PL) is considered a pessimistic approach, commercialDBMS are still using this method to synchronize database access. Several optimistic concurrencycontrol algorithms have been proposed for centralized DBs and distributed DBs. A critical analysisof both classes of algorithms—pessimistic and optimistic—is presented in [11].
Database systems are essential for new applications running through communication networks;their need for more complex transactions and higher throughput lead to increased concurrencyand, hence, a higher probability of conflict (denoted by M), which manifests itself by an increaseddelay in obtaining a required lock in the case of locking or an increased frequency of restarts in thecase of the optimistic method. As demonstrated by Thomasian [23], as M increases, there may bea sudden reduction in the number of active transactions caused by transaction blocking, whicheventually leads to severe performance deterioration.
For some applications, it becomes difficult to satisfy both the consistency constraints and theperformance requirements. Thus, the best solution for concurrency control will no longer be nei-ther the 2PL nor the optimistic method. Some authors, like Thomasian [23] or Graham and Shriv-astava [22], have proposed hybrid algorithms where transactions are synchronized eitherpessimistically or optimistically if certain conditions are met.
For database systems where both the preservation of consistency and high performance arerequired, hybrid algorithms seem to offer the best compromise. For a DBMS used in bankingapplications where the preservation of consistency prevails over fast response time, the two-phaselocking algorithm could be the most appropriate model [18], while the optimistic method could bemore advantageous for a DBMS used in some real-time applications, provided few conflicts occurbetween transactions [20].

620 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
2.3. Three selected algorithms
Thomasian [11,23] designed a hybrid concurrency control algorithm for a distributed DB thatemphasizes performance. This algorithm can be used for high performance transaction process-ing. The protocol exhibits the following characteristics:
1. Transactions are executed optimistically, ignoring locks held by other transactions on theobject.
2. Before global validation is performed, the validating transactions request appropriate locksfor all items accessed. Locks are only held during the commit phase (if validation is success-ful) so that lock conflicts are far less likely to occur than with standard locking.
3. If validation fails, all previously acquired locks are retained by the transaction while it is beingexecuted once again. This guarantees that the second execution phase will be successful if nonew objects are referenced. Thus, both frequent restarts and starvation, can be prevented.
4. Deadlocks resulting from lock requests are prevented by using a static locking paradigm, i.e.,preclaiming locks for objects accessed by a transaction in its first phase and processing theserequests in the same order in all nodes.
5. Lock requests produce no additional messages.6. The protocol is fully distributed.
Fig. 2 describes the execution of a transaction (T) at its primary node, according to Thom-asian�s Algorithm [11]. In this figure, OCC1 protocol states that an operation is first executedaccording to an optimistic protocol, ignoring locks held by other transactions on the object untilthe beginning of the validation phase; OCC2 protocol states that the second execution of an oper-ation follows optimistic protocol, preclaiming locks at the beginning of the reading phase. Allobjects accessed or modified by T are denoted as its read set RS(T) and write set WS(T), respectively.
Graham and Shrivastava [22] proposed a flexible technique to implement more than one type ofconcurrency control algorithms in the same system using object-oriented properties. With thismethod, a base class is defined with basic concurrency control facilities that are required and thenspecific concurrency control algorithms are derived from the base class by inheritance.
The concurrency control protocol implemented in TelORB [12,13,15] considers two additionalfeatures ignored in Thomasian�s Algorithm: real-time constraints and data replication. Two-phaselocking is the basic algorithm used in TelORB, with a little degree of optimism in the sense thatsome consistency constraints are released for some types of read operations. Each object in thedatabase exists in at least two replicas. To modify an object, a transaction locks one replica, atthe most, at the beginning of the reading phase. Write locks for the other replicas are obtainedat the beginning of the validation phase. If this phase fails, then, the transaction is aborted.
3. Proposed concurrency control algorithm
This section describes the new concurrency control algorithm that we propose for distributeddatabases. After a brief description of our cluster system, we present the new algorithm and ana-lyze its performance.

{read phase of first execution, OCC1 is the default policy } for each object O to be accessed do
if O belongs to local partition thenif (OCC2 and (X-lock set or X-lock request is waiting for O)) then
queue A-lock request into WL;wait until conflicting X-locks are released;
else perform object access;if OCC2 then append A-lock;
else record O with current version number in RS(T);if write access then also add O to WS(T); {perform modification on private copy of O} end if;
else perform remote object access;{wait at remote system when conflicts with X-locks arise}
end if;
{commit phase 1} broadcast validation request to remote systems involved during T's read phase; local lock acquisition and validation of T;receive validation results from remote systems;
{commit phase 2 } if (all validations successful) then write commit record;
broadcast COMMIT to all participating systems;else {re-execution}
restart and re-execute transaction;if (no new objects referenced) then write commit record;
broadcast COMMIT to all participating systems;else
perform two-phase commit with validation;end if;
end if;
Fig. 2. Execution of a transaction T according to Thomasian�s Algorithm [11].
C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 621
3.1. Specifications of the computer clusters considered
As shown in Fig. 3, the cluster system considered in this study meets the followingspecifications:
• the database is distributed and replicated over a number of processors P1,P2, . . . ,Pn;• the distributed database is located in the processors� memory;• the nodes of the distributed database are linked by a reliable network;• the system can be built with commodity processors (300–600 MHz) providing the best cost/performance ratio;
• the system is scalable in terms of capacity: operators can increase system capacity simply byplugging in new processors.
The front-end node of the cluster receives traffic from the public telephone network through anSS7 interface. The transaction�s arrival rate is limited to a maximum of 4000 transactions/s by thebandwidth of the SS7 interface. Two types of distributed databases are used in a mobile network:the home location register (HLR) and the visitor location register (VLR) [25]. The HLR is the

Processor 1
Processes
Primary copy
Processes
Processor 2
Processes
Processor n ReplicaData Data Data
ETHERNET
SS7 Link
Front end Processor
Fig. 3. Representation of a typical computer cluster.
622 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
main database of permanent subscriber information. Maintained by the subscriber�s home carrier(or the network operator where the user initiates the call), the HLR contains pertinent user infor-mation, including addresses, account statuses, and preferences. The HLR interacts with theMobile Switching Center (MSC), a switch used to control and process calls. The VLR, maintainstemporary user information (such as current location) to manage requests from subscribers whoare out of the area covered by their home system.
When a user initiates a call, the switching equipment determines whether or not the call comesfrom within the device�s home area. If the user is out of this home area, the VLR sends out theinformation request required to process the call. An MSC queries the HLR identified by the callfor information, which it is relayed to the appropriate MSC, which is then relayed to the VLR.The VLR returns routing information to the MSC, thereby allowing it to find the station fromwhence the call originated and connect the mobile device. To establish the call, one process readsthe location information of the called user. Another process updates the location information ifthe mobile user moves from one cell to another. In order to respect concurrency, the network mustnot reject any call.
Traffic databases contain data used by applications that manage network resources, and theycan be subject to frequent updates.
Sometimes, data and applications are collocated on the same processor in order to minimize theprocessing delay. Data replication is used to achieve fault-tolerance and high availability. Read orwrite operations are usually performed to establish communication or update a subscriber�s data.In order to provide satisfactory quality of service, the system response time must not exceed a pre-defined value. When Jyhi-Kong et al. [24] analyzed and estimated SS7 signalling traffic perfor-mance on GSM databases (HLRs and VLRs) in Taiwan, they realized that the percentage ofupdated operations were meaningless compared to the percentage of reading operations. Giventhat result, we assume that the probability of conflicts between transactions in GSM databasesappears to be negligible. This assumption is only valid for areas or cities where the density of usersis lower or equal to that of Taiwan. The percentage of update operations may increase in an areacontaining smaller cells.
With Thomasian�s proposal, a hybrid algorithm is implemented and reused by each node of thedistributed database. However, the update frequency in the traffic database is usually differentfrom the update frequency in users� location database. Furthermore, new databases could be cre-ated for some types of applications with different update frequencies. In this paper, we consider a

C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 623
hybrid algorithm (scheduler) where a node can implement either the locking or the optimistic con-currency control algorithm. Moreover, we assume that this algorithm can improve performance ifthe database is partitioned. The first partition, made up of nodes that implement the optimisticalgorithm, will be used to store data with less updates. The second partition, made up of nodesthat implement the two-phase locking algorithm, will be used to store data with high update fre-quencies. A similar approach was adopted by Graham and Shrivastava [22].
3.2. The proposed algorithm
Using a class diagram proposed by Graham and Shrivastava [22], we designed a hybrid algo-rithm that integrates two high performance concurrency control mechanisms: the pessimistic Tel-ORB Algorithm, which is implemented in database partitions where transaction conflicts arelikely to happen, and the optimistic Thomasian�s Algorithm which is implemented in databasepartitions where transaction conflicts rarely occur.
The TelORB Algorithm performs write operations with a certain degree of optimism as onlyone replica is locked by a transaction until the beginning of the write phase, where all locksare needed. With Thomasian�s Algorithm, the execution of a transaction follows an optimisticprotocol and when a conflict is detected, the re-execution follows the locking protocol. Grahamand Shrivastava [22] proposed some basic class definitions to integrate several locking algorithmswith different lock levels. Unlike the previous approaches, our proposed algorithm uses both thelocking and optimistic methods in an exclusive mode. The execution of a transaction follows onlyone protocol, as shown in Fig. 4.
To evaluate performance, the response time of the proposed algorithm is calculated and com-pared with TelORB and Thomasian�s Algorithms. Let us consider:
k arrival rate of transactions in the system,N0 total number of transactions,Nc number of conflicting transactions,c proportion of conflicting transactions following 2PL;
N c ¼ cN 0 ð1Þ
Fig. 4. DDBMS architecture with the proposed algorithm.

x proportion of conflicting transactions following an optimistic approach;
624 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
N c ¼ xN 0 ð2Þ
te average processing time of a transaction operation.In the locking algorithm, conflicts between transactions are checked by analyzing their syntacticinformation. This preventive approach may consider some conflicts that will not actually occur.The optimistic approach solves conflicts after execution once sufficient information is available.Thus, fewer transactions will be subjected to conflicts in the optimistic approach, thus, alwaysobtaining x < c.
In the case of the locking algorithm, a conflicting transaction joins the queue. Let us consider tqto be the average time delay waiting in queue.
According to Little�s Formula,
N c ¼ ktq ð3Þ
Thus, the average response time per transaction is represented by:tORB ¼ ðN 0 � N cÞ � te þ N c � ðtq þ teÞ=N 0 ð4Þ
Eqs. (1), (3) and (4) yieldtORB ¼ te � cte þ cN c=k þ cte ¼ cN c=k þ te
tORB ¼ c2 � N 0=k þ teð5Þ
In the case of Thomasian�s Algorithm, a transaction is executed before checking for conflicts. Ifa conflict is detected, the transaction is re-executed according the locking protocol. Thus, the aver-age response time is:
tTh ¼ ðN 0 � N cÞ � te þ N c � te þ N cðtq þ teÞ=N 0 ð6Þ
Eqs. (2), (3) and (6) yieldtTh ¼ xN c=k þ te þ xte
tTh ¼ x2 � N 0=k þ te þ xteð7Þ
In the case of the proposed algorithm, one portion of the transactions (aN0) is executed in data-base partitions within the locking algorithm, and the other portion (bN0) is executed in databasepartitions within the optimistic algorithm.
We also obtain,
a þ b ¼ 1 ð8Þ
From (5) and (7), the average response time per transaction can be expressed as:tPR ¼ ðaN 0Þ � ½c2 � ðaN 0Þ=k þ te� þ ðbN 0Þ � ½x2 � ðbN 0Þ=k þ te þ xte�=ðN 0Þ¼ a � ½c2 � ðaN 0Þ=k þ te� þ b � ½x2 � ðbN 0Þ=k þ te þ xte� ð9Þ
When there are minimal conflicts, c ! 0, and x ! 0, since x < c:
tTh ¼ tORB ¼ te

C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 625
and (8) and (9) yield
tPR ¼ a � te þ b � te ¼ ða þ bÞ � te ¼ te
When there is a sufficient number of conflicts, c ! 1. By adding this to (5),
tORB ¼ N 0=k þ te ð10Þ
and we distinguish between two cases in the evaluation of tTh and tPR. After the execution,• if there are fewer conflicts than expected, then x ! 0 and Eq. (9) becomes
tPR ¼ tTh ¼ te ð11Þ
This case corresponds to a scenario where the majority of transactions are executed in nodeswithin the optimistic Thomasian�s Algorithm.• if there is a greater quantity of conflicts than expected, then x ! 1 and Eq. (9) becomes
tPR ¼ tORB ¼ N 0=k þ te while tTh ¼ te þ tORB ð12Þ
This case corresponds to a scenario where most transactions are executed in nodes with the Tel-ORB Algorithm.From these theoretical results, we can predict that the proposed algorithm will provide betterperformance results for a greater number of use cases compared to the other two algorithms.
From (10) and (11), when there are fewer conflicts, tPR = tTh < tORB.From (10) and (12), when there is a greater number of conflicts, tPR = tORB < tTh.The following section will present some simulations carried out using the three algorithms to
validate these theoretical results.
4. Simulation results
To compare the performance of concurrency control algorithms, we modeled a distributeddatabase, which is presented in Fig. 5. The source generates transactions in the system at a givenfrequency; the transaction manager ensures the coordination of the execution of a transactionwhich involves the local node and, possibly, some distant nodes; the scheduler implements theconcurrency control algorithms to be evaluated, and, finally, the monitor displays statistics asso-ciated with response time, service rate, and restart percentage. For each component of theDDBMS, a corresponding class is created in our simulation program. In those classes, the attri-butes characterize the state of the component, while the methods characterize its behaviour.
4.1. Simulation environment
We conducted our simulations on a PC equipped with a 600 MHz Pentium processor,128 Mbytes of RAM, and a 6 Gbyte SCSI disk. As for the software, we used a Borland C++v.5.02 programming environment and the CSIM18 simulation tool. CSIM18 can be used to sim-ulate execution models of processes and discrete events [26]. It is a library of classes, functions,

Fig. 5. The DDB model.
626 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
procedures and heading files that can be integrated into a programming environment such as C orC++ to implement and simulate complex applications. CSIM18 is often used to model a variety ofsystems: information systems, computer networks, communication systems, microprocessor sys-tems, etc.
The simulated distributed database system consists of a set of nodes. Each node includes a DM,a TM and an SC. Some transactions enter into the system at anytime, while other transactions areleaving.
Our simulator contains three independent binary modules, which implement the new algorithmproposed, the locking algorithm and Thomasian�s Algorithm, respectively. The simulator can beconfigured to run many test cases with different traffic characteristics by setting the followingparameters:
Parameter Definition
Svtmp Service timeIatmp Inter-arrival timeNb_nodes Number of nodesNb_obj Number of objects per nodeNb_replica Number of replica per objectTransaction size Number of operations per transactionR_prob Percentage of read operationsW_prob Percentage of write operations
The simulator output can be measured by different metrics: the throughput (i.e., number of out-going transactions per second), the response time, the cost of communication between nodes, andthe rate of restarted transactions.
Given the number of variables, too many test scenarios can be constructed simply by varyingthe value of any of the configuration parameters and measuring the variation of an output para-

C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 627
meter. As stated in Section 3.1, we assume that the system is reliable and scalable in terms ofcapacity and this is particularly the case for the TelORB system. Thus, throughout the experi-ments only the case of an eight-node network has been considered. To determine the algorithmthat offers the best performance under strong consistency and high availability constraints, thefollowing test scenarios were configured and investigated: in-memory DDBMS, disk-basedDDBMS, DDBMS with data replication and real-time DDBMS.
Similar to previous experiments of this type [2,11,16], the number of incoming transactionsvaries from 100 to 10,000 arrivals per second and the throughput will be measured when apply-ing the locking algorithm, the Thomasian�s Algorithm and the new algorithm proposed,respectively.
4.2. Simulation of an in-memory DDBMS
In this simulation, we distinguish a first scenario where some conflicts occur between transac-tions and a second scenario where conflicts are rare. We assume that there is no data replication,nor real-time constraints. The number of arrivals per second (NAPS) varies from 100 to 10,000and the parameters are configured with the following values:
Svtmp for a read operation = 1.0 sSvtmp for a write operation = 1.5 sIatmp = 1.0 sNb_nodes = 8Nb_obj = 100Transaction size = 2 operations
4.2.1. Transactions with conflicts scenario
R_prob = 5/6W_prob = 1/6
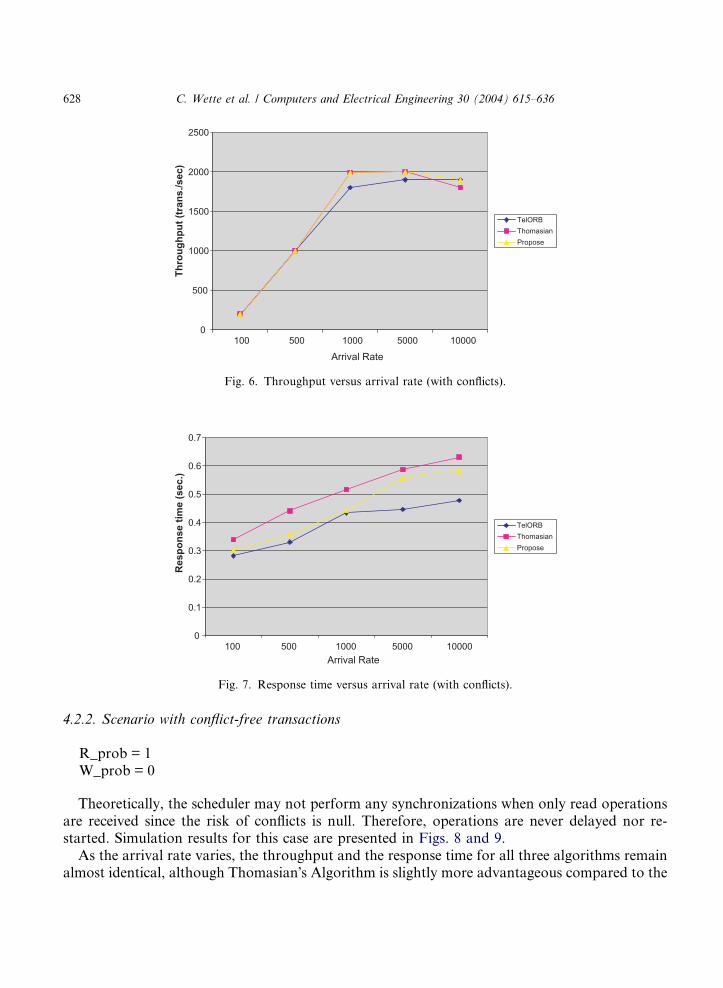
The purpose of having a 1/6 proportion of write operations is to produce some conflicts in thedatabase. Simulation results are shown in Figs. 6 and 7. In the case of Thomasian�s Algorithm, asthe arrival rate varies, we observe that the throughput curve increases dramatically before stabi-lizing (compared to the curve representing the TelORB Algorithm). Finally, the throughput asso-ciated with Thomasian�s Algorithm decreases at a faster rate for high transactions arrival rate.The locking algorithm provides the best response time. As for the algorithm proposed, thethroughput curve resembles the curve associated with the locking algorithm for low arrival ratesand that is similar to the curve associated with Thomasian�s Algorithm for high arrival rates. Thissituation results from the fact that the new algorithm switches from the optimistic method whichit employs when the probability of conflicts is low, to the locking algorithm which it uses when theprobability of conflicts is high.
Given these results, we conclude that the best consistency/performance trade-off can be reachedby using a locking algorithm in the case of database applications with a high probability of con-flicts between transactions.
0
500
1000
1500
2000
2500
100 500 1000 5000 10000
Arrival Rate
Thro
ughp
ut (t
rans
./sec
)
TelORBThomasianPropose
Fig. 6. Throughput versus arrival rate (with conflicts).
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
100 500 1000 5000 10000Arrival Rate
Res
pons
e tim
e (s
ec.)
TelORBThomasianPropose
628 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
4.2.2. Scenario with conflict-free transactions
R_prob = 1W_prob = 0
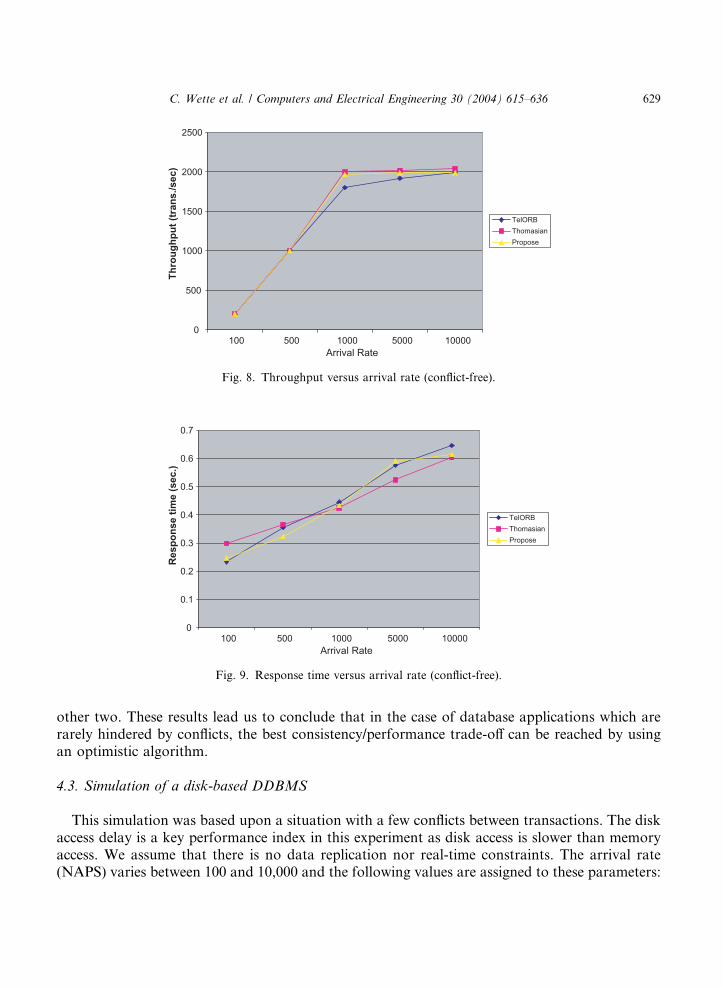
Theoretically, the scheduler may not perform any synchronizations when only read operationsare received since the risk of conflicts is null. Therefore, operations are never delayed nor re-started. Simulation results for this case are presented in Figs. 8 and 9.
As the arrival rate varies, the throughput and the response time for all three algorithms remainalmost identical, although Thomasian�s Algorithm is slightly more advantageous compared to the
Fig. 7. Response time versus arrival rate (with conflicts).
0
500
1000
1500
2000
2500
100 500 1000 5000 10000Arrival Rate
Thro
ughp
ut (t
rans
./sec
)
TelORBThomasianPropose
Fig. 8. Throughput versus arrival rate (conflict-free).
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
100 500 1000 5000 10000Arrival Rate
Res
pons
e tim
e (s
ec.)
TelORBThomasianPropose
Fig. 9. Response time versus arrival rate (conflict-free).
C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 629
other two. These results lead us to conclude that in the case of database applications which arerarely hindered by conflicts, the best consistency/performance trade-off can be reached by usingan optimistic algorithm.
4.3. Simulation of a disk-based DDBMS
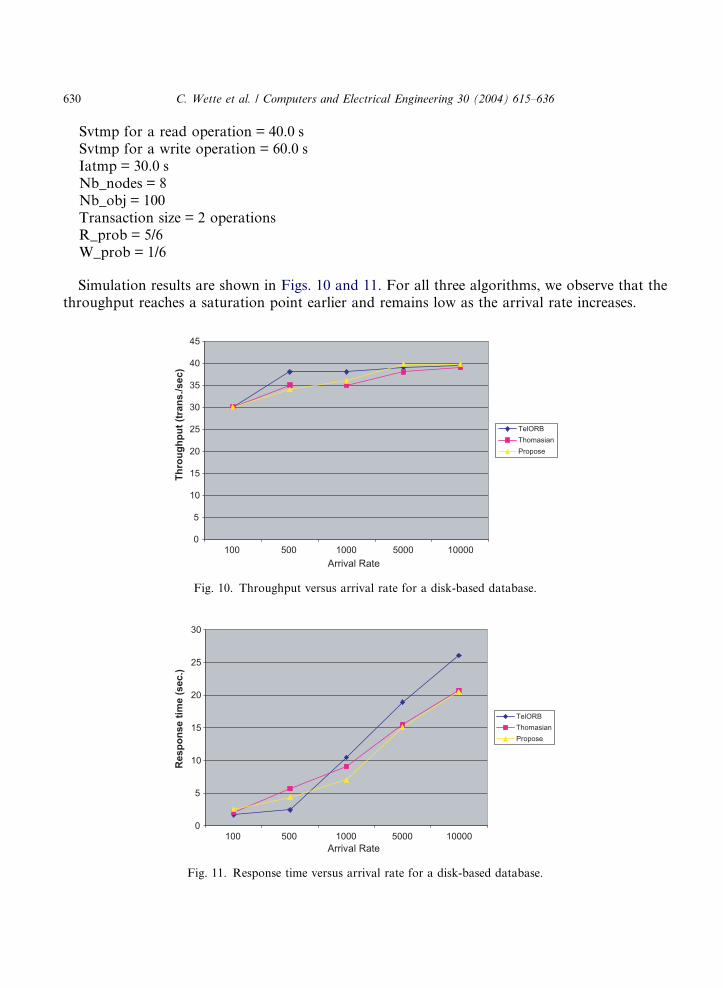
This simulation was based upon a situation with a few conflicts between transactions. The diskaccess delay is a key performance index in this experiment as disk access is slower than memoryaccess. We assume that there is no data replication nor real-time constraints. The arrival rate(NAPS) varies between 100 and 10,000 and the following values are assigned to these parameters:
630 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
Svtmp for a read operation = 40.0 sSvtmp for a write operation = 60.0 sIatmp = 30.0 sNb_nodes = 8Nb_obj = 100Transaction size = 2 operationsR_prob = 5/6W_prob = 1/6
Simulation results are shown in Figs. 10 and 11. For all three algorithms, we observe that thethroughput reaches a saturation point earlier and remains low as the arrival rate increases.
0
5
10
15
20
25
30
35
40
45
100 500 1000 5000 10000Arrival Rate
Thro
ughp
ut (t
rans
./sec
)
TelORBThomasianPropose
Fig. 10. Throughput versus arrival rate for a disk-based database.
0
5
10
15
20
25
30
100 500 1000 5000 10000Arrival Rate
Res
pons
e tim
e (s
ec.)
TelORBThomasianPropose
Fig. 11. Response time versus arrival rate for a disk-based database.
C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 631
The response time increases more quickly compared to the results obtained during the in-memory database experiment. The performance of the locking algorithm is worse when comparedto the performance of the other two algorithms. These results lead us to conclude that, for a disk-based distributed database, the system performance can be improved by using either the optimis-tic algorithm or the algorithm that we propose.
4.4. Simulation of a replicated DDBMS
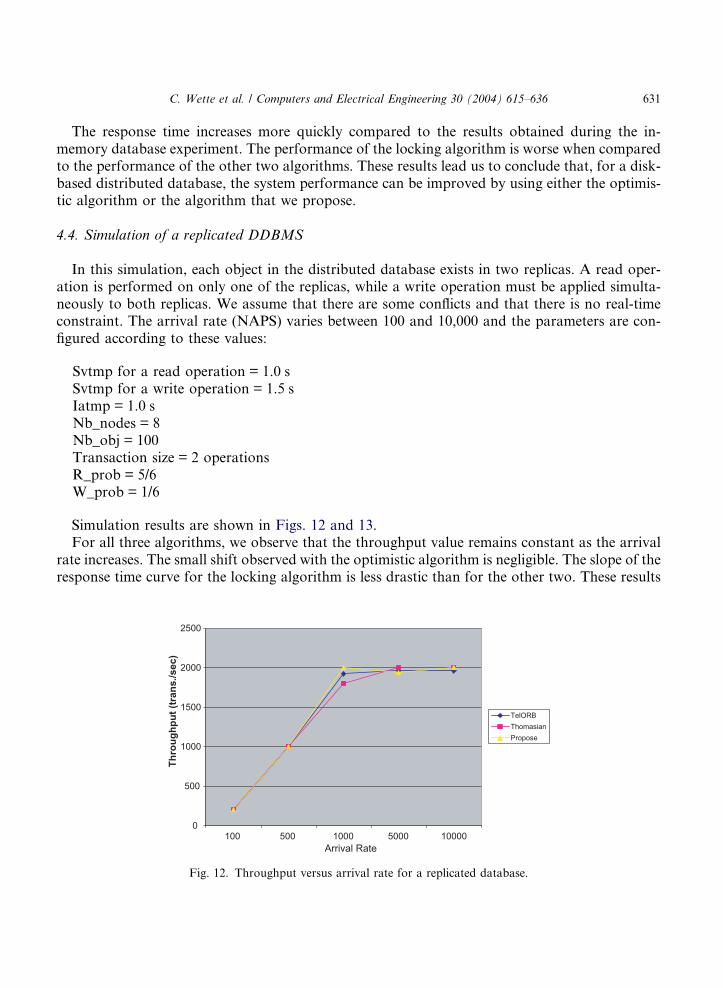
In this simulation, each object in the distributed database exists in two replicas. A read oper-ation is performed on only one of the replicas, while a write operation must be applied simulta-neously to both replicas. We assume that there are some conflicts and that there is no real-timeconstraint. The arrival rate (NAPS) varies between 100 and 10,000 and the parameters are con-figured according to these values:
Svtmp for a read operation = 1.0 sSvtmp for a write operation = 1.5 sIatmp = 1.0 sNb_nodes = 8Nb_obj = 100Transaction size = 2 operationsR_prob = 5/6W_prob = 1/6
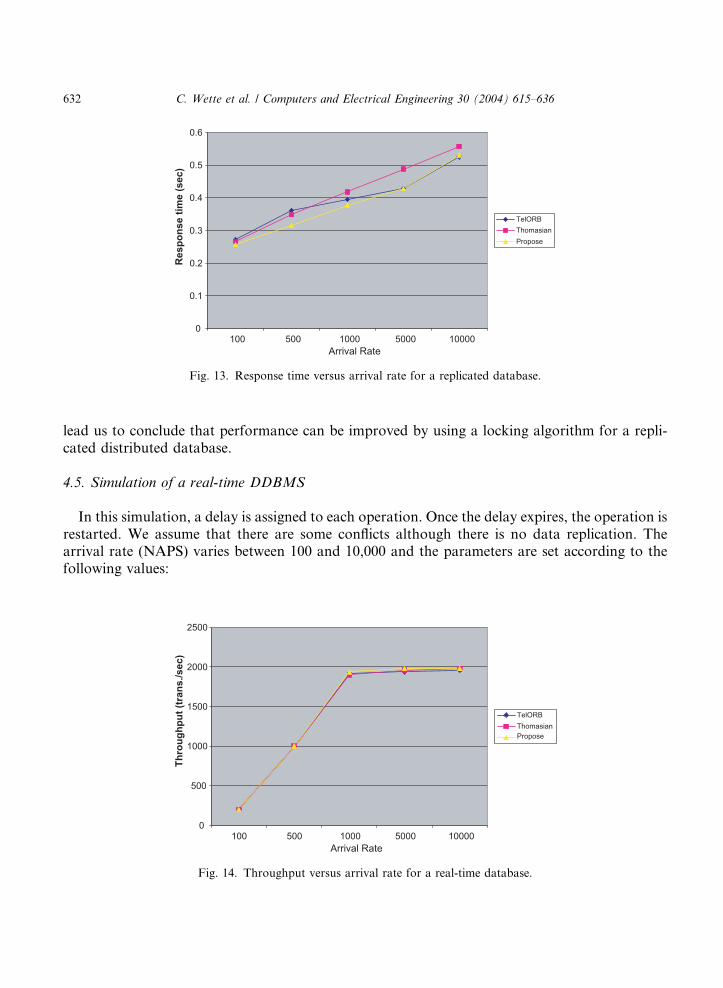
Simulation results are shown in Figs. 12 and 13.For all three algorithms, we observe that the throughput value remains constant as the arrival
rate increases. The small shift observed with the optimistic algorithm is negligible. The slope of theresponse time curve for the locking algorithm is less drastic than for the other two. These results
0
500
1000
1500
2000
2500
100 500 1000 5000 10000Arrival Rate
Thro
ughp
ut (t
rans
./sec
)
TelORBThomasianPropose
Fig. 12. Throughput versus arrival rate for a replicated database.
0
0.1
0.2
0.3
0.4
0.5
0.6
100 500 1000 5000 10000Arrival Rate
Res
pons
e tim
e (s
ec)
TelORBThomasianPropose
Fig. 13. Response time versus arrival rate for a replicated database.
632 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
lead us to conclude that performance can be improved by using a locking algorithm for a repli-cated distributed database.
4.5. Simulation of a real-time DDBMS
In this simulation, a delay is assigned to each operation. Once the delay expires, the operation isrestarted. We assume that there are some conflicts although there is no data replication. Thearrival rate (NAPS) varies between 100 and 10,000 and the parameters are set according to thefollowing values:
0
500
1000
1500
2000
2500
100 500 1000 5000 10000Arrival Rate
Thro
ughp
ut (t
rans
./sec
)
TelORBThomasianPropose
Fig. 14. Throughput versus arrival rate for a real-time database.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
100 500 1000 5000 10000Arrival Rate
Res
pons
e tim
e (s
ec.)
TelORBThomasianPropose
Fig. 15. Response time versus arrival rate for a real-time database.
C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 633
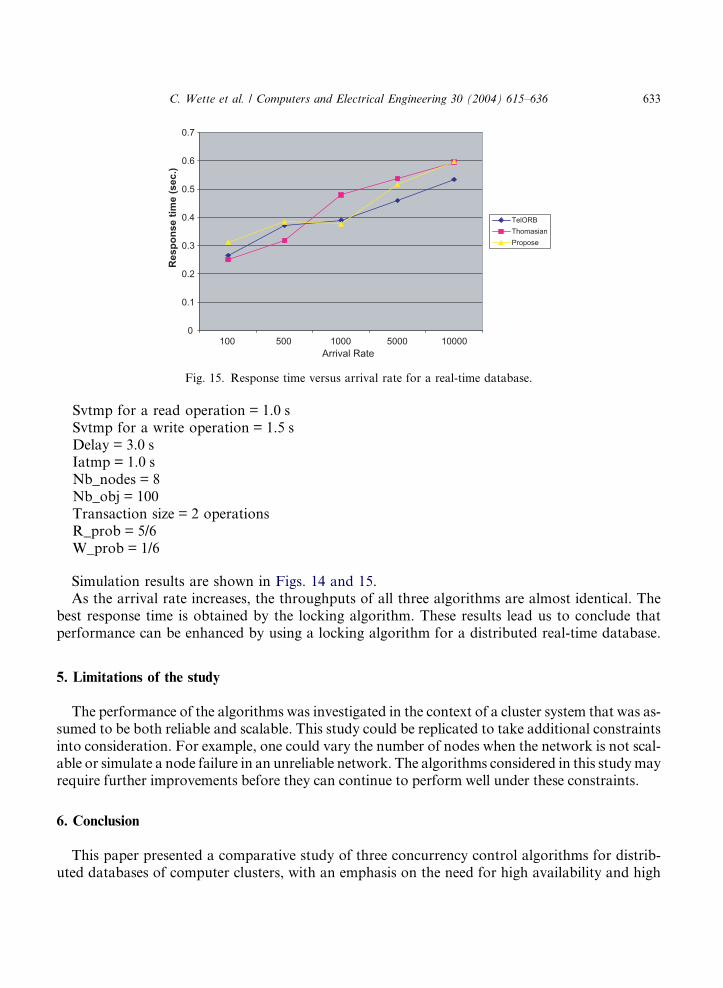
Svtmp for a read operation = 1.0 sSvtmp for a write operation = 1.5 sDelay = 3.0 sIatmp = 1.0 sNb_nodes = 8Nb_obj = 100Transaction size = 2 operationsR_prob = 5/6W_prob = 1/6
Simulation results are shown in Figs. 14 and 15.As the arrival rate increases, the throughputs of all three algorithms are almost identical. The
best response time is obtained by the locking algorithm. These results lead us to conclude thatperformance can be enhanced by using a locking algorithm for a distributed real-time database.
5. Limitations of the study
The performance of the algorithms was investigated in the context of a cluster system that was as-sumed to be both reliable and scalable. This study could be replicated to take additional constraintsinto consideration. For example, one could vary the number of nodes when the network is not scal-able or simulate a node failure in an unreliable network. The algorithms considered in this studymayrequire further improvements before they can continue to perform well under these constraints.
6. Conclusion
This paper presented a comparative study of three concurrency control algorithms for distrib-uted databases of computer clusters, with an emphasis on the need for high availability and high

634 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
performance and the different types of concurrency control algorithms which are implemented incommercial DBMSs, especially the algorithm used in Ericsson�s TelORB system were presentedand analyzed. It appears that DBMSs usually prefer the locking, pessimistic algorithm, althoughone must take into consideration that optimistic algorithms have yet to be implemented in realsystems as they remain at the prototype stage.
The new algorithm proposed was implemented in a simulation program. Its features were out-lined and its performance was measured and compared to those of a locking and an optimistic algo-rithm. All three algorithms were tested under four different configurations: in-memory DDBMS,disk-based DDBMS, DDBMS with replication, real-time DDBMS. During these experiments,the arrival rate of transactions was modified to measure the throughput and average response time.
Simulation results showed that the locking algorithm provides the best performance if conflictsoccur between transactions, while the optimistic algorithm provides better results in conflict-free sit-uations. It was also noted that, in a distributed database with the probability of conflicts occurring,the locking algorithm can be used to guarantee strong consistency and acceptable performance. Theoptimistic algorithm can be used to improve system performance when the probability of conflict isnegligible. The optimistic Thomasian�s Algorithm avoids successive restarts by switching to a pes-simistic approach if the transaction must be restarted. The hybrid algorithm proposed can be usedto achieve the best performance level in a partitioned distributed database. As a result, it can be usedto improve the performance of telecommunication database systems.
References
[1] Agrawal D, El Abbadi A, Jeffers R. Using delayed commitment in locking protocols for real-time databases. ACM
SIGMOD 1992(June):104–13.
[2] Bhargava B. Concurrency control in database systems. IEEE Trans Knowledge Data Eng 1999;11(1):3–16.
[3] Franaszek PA, Robinson JT, Thomasian A. Concurrency control for high contention environments. ACM Trans
Database Syst 1992;17(2):304–45.
[4] Ozsu MT, Valduriez P. Principles of distributed database systems. 2nd ed. New Jersey: Prentice Hall; 1999.
[5] Franaszek PA, Haritsa JR, Robinson JT, Thomasian A. Distributed concurrency control with limited waith depth.
In: Proceedings of 12th international conference on distributed computing systems, Yokohama, Japan, June 1992.
p. 160–7.
[6] Hong D, Johnson T, Chakravarthy S. Real-time transaction scheduling: a cost conscious approach. ACM
SIGMOD 1993(May):197–206.
[7] Huang J, Stankovic JA, Ramamritham K, Towsley D. Experimental evaluation of real-time optimistic concurrency
control schemes. In: Proceedings of the 17th international conference on very large databases, Barcelona,
September 1991. p. 35–46.
[8] Pitoura E, Bhargava B. Maintaining consistency of data in mobile distributed environments. In: Proceedings of
15th IEEE international conference on distributed computing systems, May 1995. p. 404–13.
[9] Wong MH, Agrawal D. Tolerating bounded inconsistency for increasing concurrency in database systems. In:
Proceedings of 11th ACM symposium on principles of database systems (PODS), 1992. p. 236–45.
[10] Zhang A, Elmagarmid A. A theory of global concurrency control in multidatabase systems. VLDB J
1993;2(3):331–59.
[11] Thomasian A. Distributed optimistic concurrency control methods for high-performance transaction processing.
IEEE Trans Knowledge Data Eng 1998;10(1):173–89.
[12] Hennert L, Larruy A. TelORB—The distributed communications operating system. Ericsson Rev 1999:(03).
[13] TelORB/DBN, DPI Exercise—Database, 1996.
[14] TelORB/DBN, DPI Programmer�s Guide—Database, 1996.

C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636 635
[15] TelORB/DBN, DPI Concepts Manuel—Database, 1996.
[16] Bhargava A, Bhargava B. Measurements and quality of service issues in electronic commerce software. In:
Proceedings of the 1999 IEEE symposium on application-specific systems and software engineering & technology,
1999.
[17] Buyya R. High performance cluster computing, vol. 1, Architectures and systems. New Jersey: Prentice Hall; 1999.
[18] Chiu A, Kao B, Lam K-Y. Comparing two-phase locking and optimistic concurrency control protocols in
multiprocessor real-time databases. In: IEEE Proceedings of the 1997 joint workshop on parallel and distributed
real-time systems (WPDRTS/OORTS�97), 1997. p. 141–8.[19] Krishnamurthi G, Chessa S, Somani AK. Fast recovery from database/link failures in mobile networks. Comp
Commun 2000:561–74.
[20] Ulusoy O. Processing of real-time transactions in a replicated database systems. J Distrib Parallel Databases
1994;2(4):405–36.
[21] Cingiser LD, Wolfe VF. Object-based semantic real-time concurrency control with bounded imprecision. IEEE
Trans Knowledge Data Eng 1997;9(1):135–47.
[22] Graham DP, Shrivastava SK. Implementing concurrency control in reliable distributed object-oriented systems. In:
Proceedings of the second european conference on object-oriented programming, ECOOP88, Oslo, August 1988. p.
1–17.
[23] Thomasian A. On the number of remote sites accessed in distributed transaction processing. IEEE Trans Parallel
Distrib Process 1993;4(1):99–103.
[24] Jyhi-Kong W, Yang W-P, Sun L-F. Traffic impacts of international roaming on mobile and personal
communications with distributed data management. ACM/Baltzer Mobile Networks Appl 1998;2(4):345–56.
[25] Available from http://www.whatis.com.
[26] Schwetman H. Object-oriented simulation modeling with C++/CSIM17. In: Alexopoulos C, Kang K, Lilegdon W,
Goldsman D, editors. Proceedings of the 1990 winter simulation conference, Washington, DC, 1990. p. 529–33.
Constant Wette received a master�s degree in Electrical Engineering from Ecole Nationale
Superieure Polytechnique de Yaounde, Cameroon in 1996 and a master�s degree in Computer
Engineering from Ecole Polytechnique de Montreal, Canada in 2001.
Currently a System Designer at Ericsson Research Center, in Montreal, he is working on IP
Multimedia Subsystem and Service Engineering in Third Generation Mobile Networks. His
research has focused on Distributed Database Management Systems for Mobile Networks.
Previously, he also worked on distribution, fault-tolerance and scalability in multiprocessor
operating systems. He is a member of IEEE.
Samuel Pierre received the B.Eng. degree in Civil Engineering in 1981 from Ecole Polytechnique
de Montreal, Quebec, the B.Sc. and M.Sc. degrees in Mathematics and Computer Science in 1984
and 1985, respectively, from the UQAM, Montreal, the M.Sc. degree in Economics in 1987 from
the Universite de Montreal, and the Ph.D. degree in Electrical Engineering in 1991 from Ecole
Polytechnique de Montreal. Dr. Pierre is currently a Professor of Computer Engineering at Ecole
Polytechnique de Montreal where he is Director of the Mobile Computing and Networking
Research Laboratory (LARIM) and NSERC/Ericsson Industrial Research Chair in Next-gen-
eration Mobile Networking Systems. He is the author of four books, co-author of two books and
seven book chapters, as well as over 250 other technical publications including journal and
proceedings papers.
He received the Best Paper Award of the Ninth International Workshop in Expert Systems and their Applica-
tions (France, 1989), a Distinguished Paper Award from OPNETWORK�2003 (Washington, USA). One of these
co-authored books, Telecommunications et Transmission de donnees (Eyrolles, 1992), received special mention from

636 C. Wette et al. / Computers and Electrical Engineering 30 (2004) 615–636
Telecoms Magazine (France, 1994). His research interests include wireline and wireless networks, mobile computing,
performance evaluation, artificial intelligence, and electronic learning. He is a Fellow of Engineering Institute of
Canada, senior member of IEEE, a member of ACM and IEEE Communications Society. He is an Associate Editor of
IEEE Communications Letters and IEEE Canadian Review, a Regional Editor of Journal of Computer Science, and he
serves on the editorial board of Telematics and Informatics published by Elsevier Science.
Jean Conan received the degrees in radio electronics and nuclear engineering from the Institut
Polytechnique de Grenoble, Grenoble, France, in 1964 and 1965, respectively, the M.S.Eng.
degree from the University of Michigan, Ann Arbor, in 1971 and the Ph.D. degree from McGill
University, Montreal, P.Q., Canada, in 1981. He is currently a Full Professor of Electrical
Engineering at Ecole Polytechnique de Montreal. His current research interests include infor-
mation theory, with emphasis on channel coding and MIMO wireless systems, as well as problems
pertaining to the analysis and design of wireless communication networks.