a design/study of a self-aware codelet runtime systempfotouhi/docs/toward_a_self-aware... · a...
TRANSCRIPT

A Design/Study of a Self-Aware Codelet Runtime System
Professor Guang R. GaoMentors:
Dr. Stephane Zuckerman, Aaron Landwehr, Joshua Suetterlein
Spring 2014
Laura Rozo
Chuanzhen Wu
Pouya Fotouhi
1

Agenda• Motivation
• Backgroundo Control Theory
o Codelet
o Self-aware System for Exascale Architectures
• Problem Formulation
• Solution
• Related work
• Conclusion
• References2

Motivation
• To meet constrains defined by user:o Time, energy, reliability, etc.
• Increasing demand for higher performance and more complex functionality in exascale systems:o Increasing number of cores implies:
• Increasing energy consumption.
• More source of failures.
o Shrinking device size: more sensitive to environmental issues
• To tackle these challenges, systems need to have the ability to:o Act proactively and adapt themself based on current conditions.
o Apply the corresponding schemes that optimize desired goals (i.e. performance, reliability, energy consumption).
3
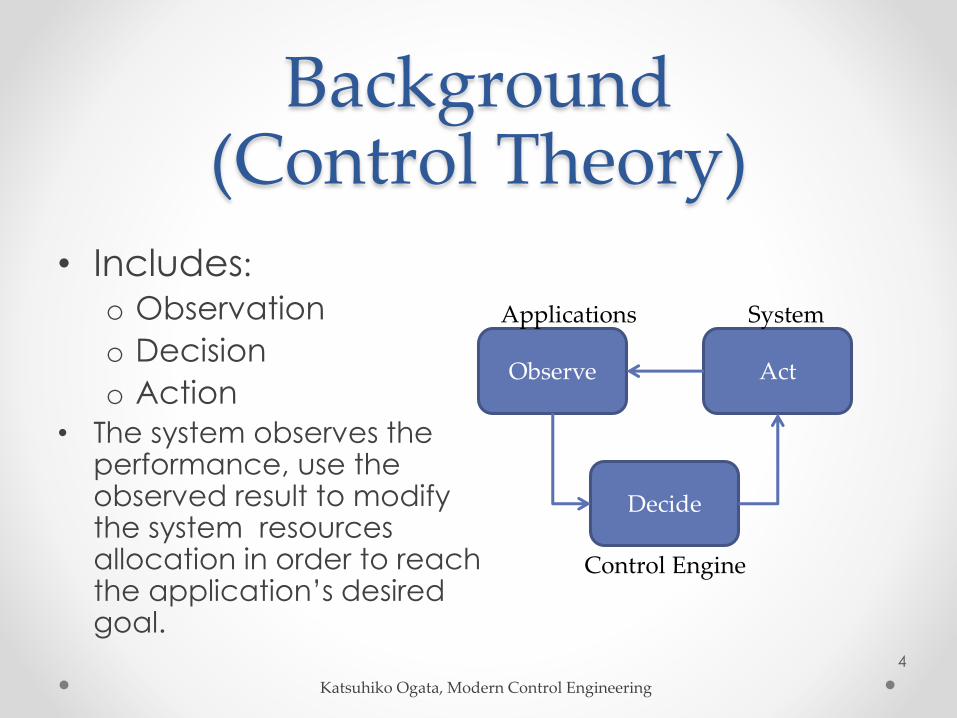
Background(Control Theory)
• Includes:
o Observation
o Decision
o Action
• The system observes the performance, use the observed result to modify the system resources allocation in order to reach the application’s desired goal.
4
Observe
Decide
Act
Applications System
Control Engine
Katsuhiko Ogata, Modern Control Engineering

• Aaron et al. has proposed a self-aware
system:o based on extreme scale architectures.
o With one level of parallelism.
• Clusters contains blocks, including:o XEs (eXecution Engines).
o CEs (Control Engines).
o PMU (Performance Monitoring Unit).
o Memory and Net.
• According to results from PMU, system will
adapt for optimization. 5
Aaron Landwehr et al, ROME 2013, 2013.
Background(Self-aware system for Exascale Architectures)
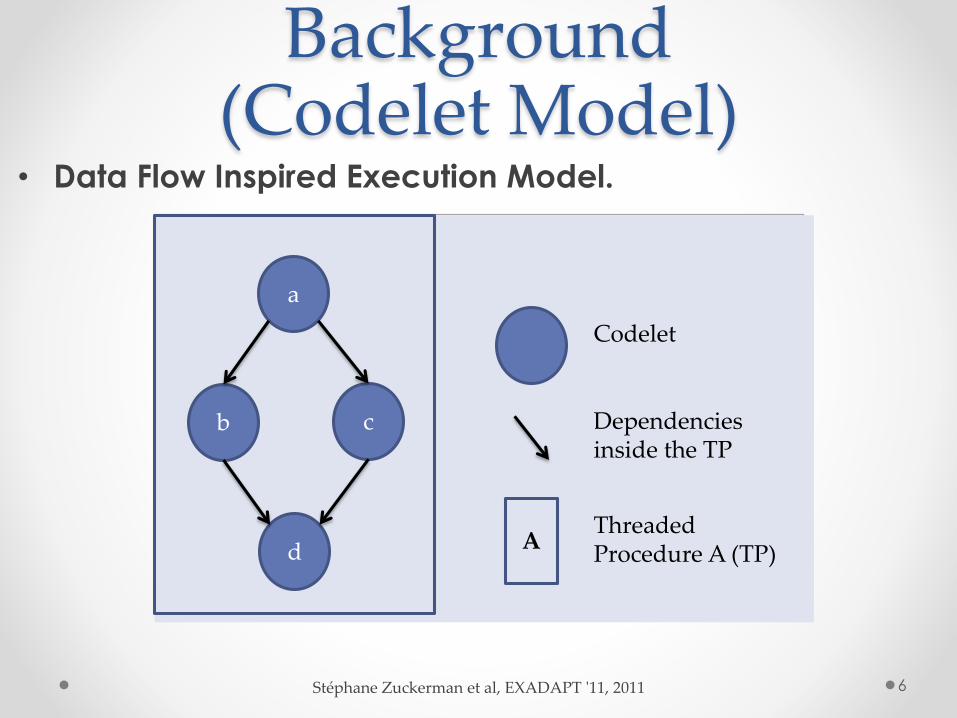
Background(Codelet Model)
• Data Flow Inspired Execution Model.
6Stéphane Zuckerman et al, EXADAPT '11, 2011
Program
Tree of Threaded ProceduresPool of Threaded Procedures
A
B
D
C
E
F
a
b c
d A
Codelet
Dependencies inside the TP
Threaded Procedure A (TP)
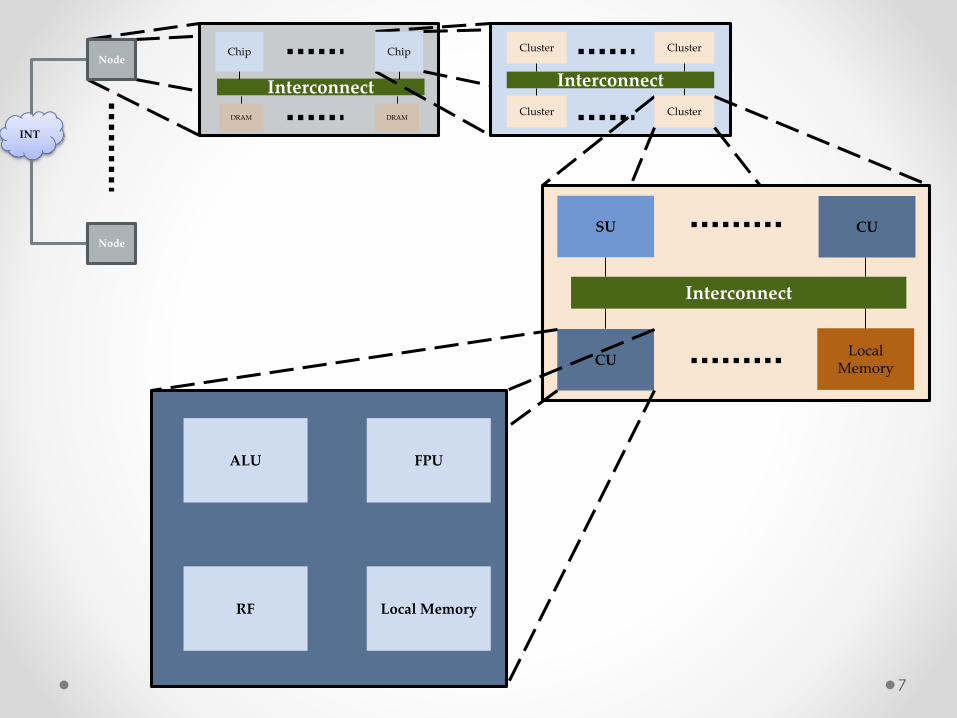
7
INT
Node
NodeChip
Interconnect
DRAMDRAM
Chip Cluster
Interconnect
Cluster
Cluster
SU
Interconnect
Cluster
CULocal
Memory
FPU
Local Memory
ALU
RF
CU

Problem Formulation
• Combine self aware cycle and codelet model and analyze the interaction between:o Performance
o Energy Consumption
o Resiliency
• Optimize “Resource Management” and “Scheduling Policies”, considering the trade-off between:o Maximizing performance.
o Minimizing energy consumption.
o Enhancing reliability.
8
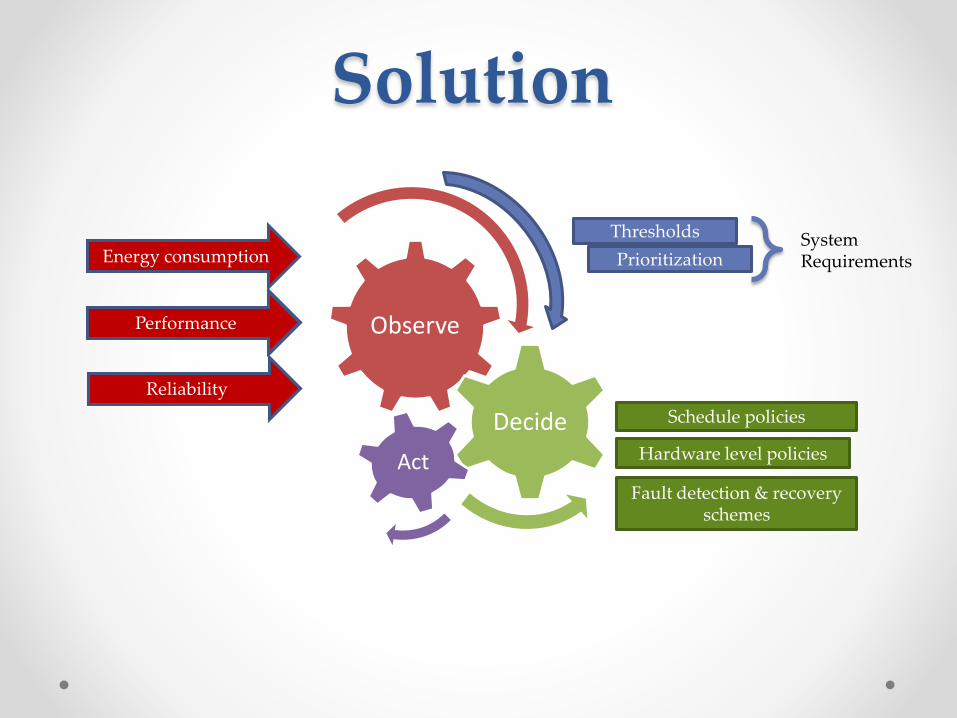
Solution
Observe
Decide
Act
Energy consmption
Reliability
Thresholds
PrioritizationSystem Requirements
Fault detection & recovery schemes
Schedule policies
Hardware level policies
Performance
Energy consumption
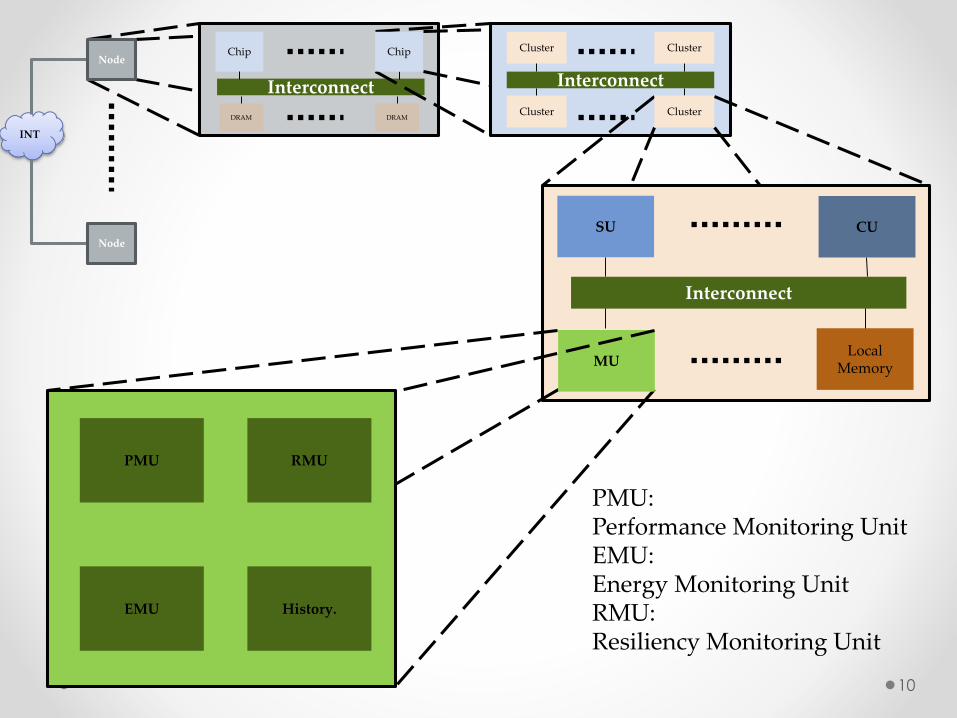
10
INT
Node
NodeChip
Interconnect
DRAMDRAM
Chip Cluster
Interconnect
Cluster
Cluster
SU
Interconnect
Cluster
Local Memory
RMU
History.
PMU
EMU
CU
MU
PMU:Performance Monitoring UnitEMU:Energy Monitoring UnitRMU:Resiliency Monitoring Unit

Codelet’s Meta-data
• In order to minimize
computations at runtime,
some useful information can
be computed offline for
each of the codelets.o Criticality for performance
optimization.
o Vulnerability for resiliency.
o Time constrains based on system
requirements.
11
ADDITIONAL CODELET
PROPERTIES
Criticality
Vulnerability
Deadline
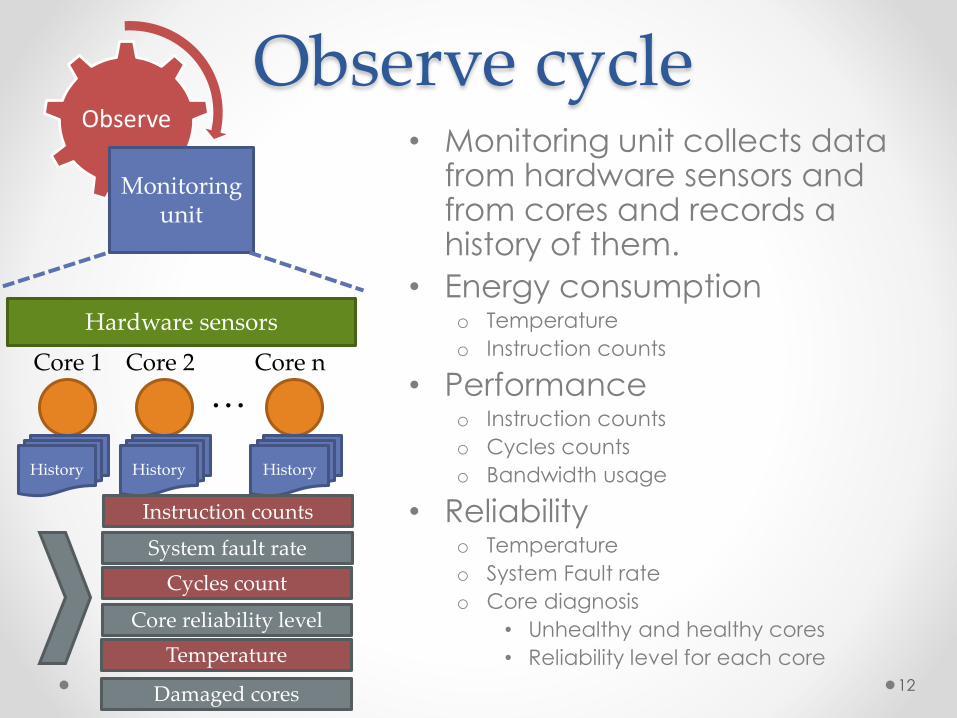
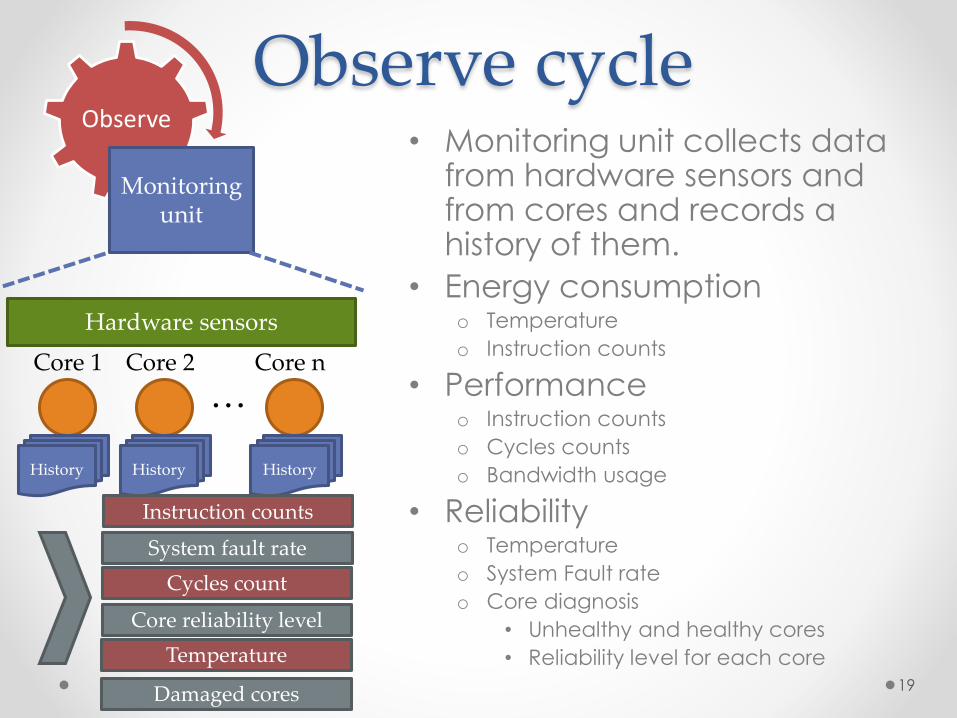
Observe cycle• Monitoring unit collects data
from hardware sensors and from cores and records a history of them.
• Energy consumptiono Temperature
o Instruction counts
• Performanceo Instruction counts
o Cycles counts
o Bandwidth usage
• Reliabilityo Temperature
o System Fault rate
o Core diagnosis
• Unhealthy and healthy cores
• Reliability level for each core
12
Observe
Monitoring unit
…
History History History
Core 1 Core 2 Core n
System fault rate
Cycles count
Hardware sensors
Core reliability level
Temperature
Instruction counts
Damaged cores
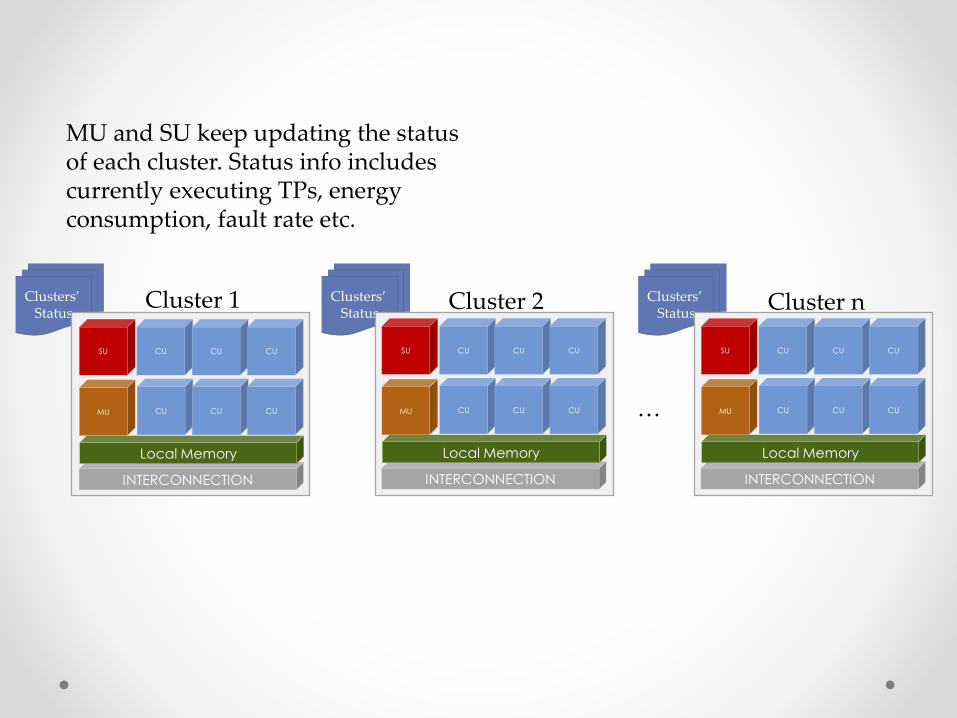
Clusters’ Status
Clusters’ Status
Clusters’ Status
CU
INTERCONNECTION
CU
Cluster n
MU and SU keep updating the statusof each cluster. Status info includes currently executing TPs, energy consumption, fault rate etc.
Local Memory
SU
MU
CU
CU CU CU
Cluster 2
CU
INTERCONNECTION
CU
Local Memory
SU
MU
CU
CU CU CU
CU
INTERCONNECTION
CU
Local Memory
SU
MU
CU
CU CU CU…
Cluster 1
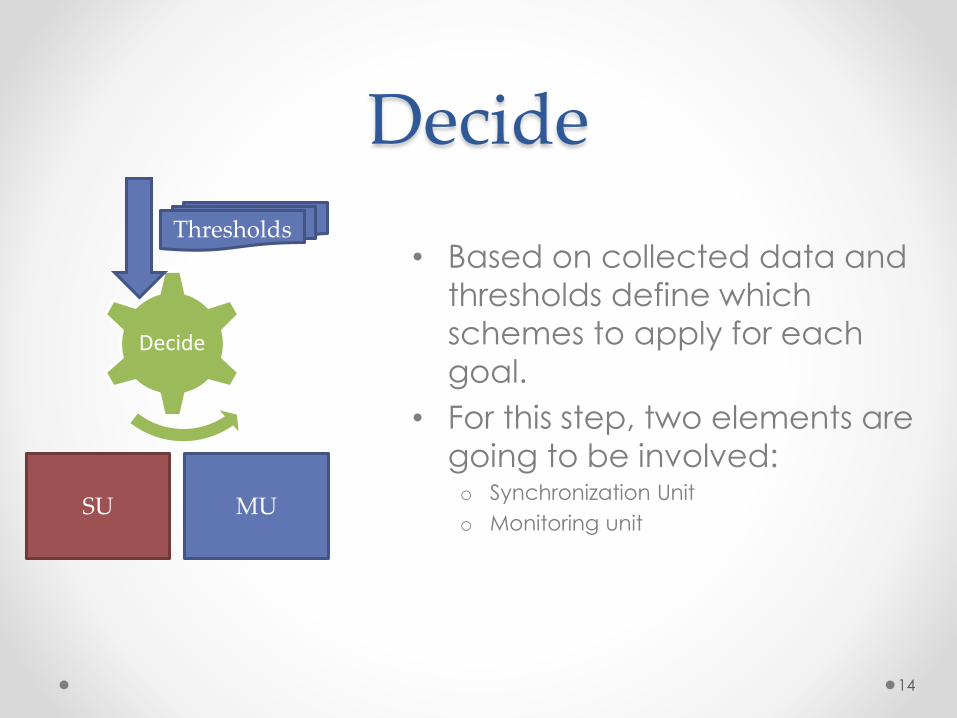
Decide• Decide
14
Decide
MUSU
Thresholds
• Based on collected data and
thresholds define which
schemes to apply for each
goal.
• For this step, two elements are
going to be involved:o Synchronization Unit
o Monitoring unit

Decide• Decide
15
• Energy consumptiono Energy budgets for each cluster are
defined: Initialization
o Based on number of unhealthy
cores energy budgets should be
updated
o Based on current energy
consumption of the whole cluster,
decide the appropriate energy
optimization schemes
• Clock gate
• Power gate
• Dynamic Voltage and
Frequency Scaling (DVFS)
Decide• Decide
16
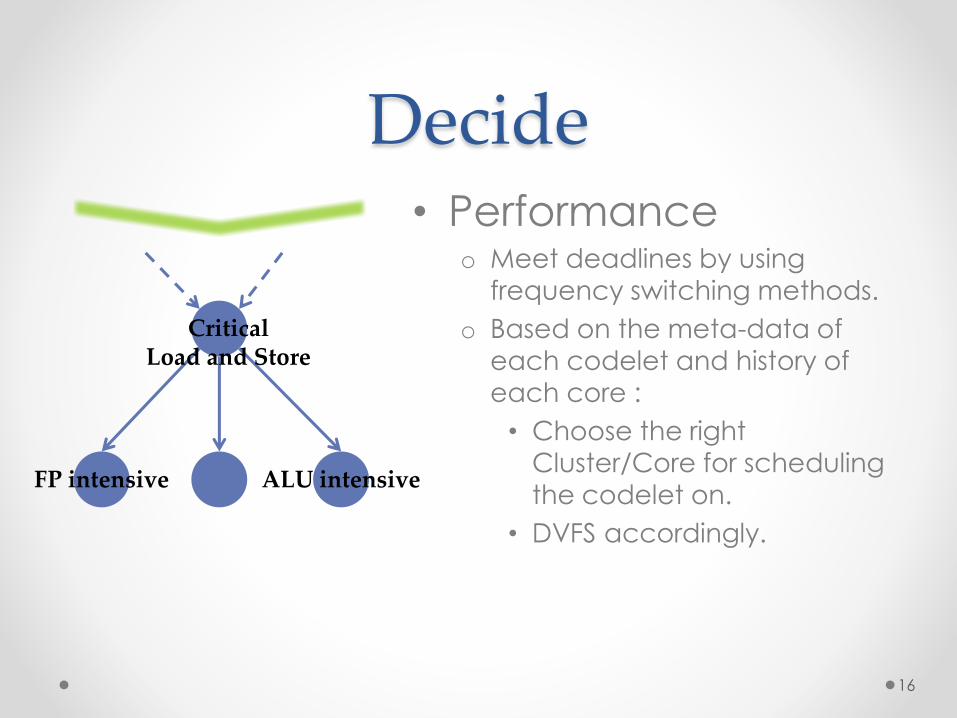
• Performanceo Meet deadlines by using
frequency switching methods.
o Based on the meta-data of
each codelet and history of each core :
• Choose the right
Cluster/Core for scheduling
the codelet on.
• DVFS accordingly.
CriticalLoad and Store
FP intensive ALU intensive
Decide• Decide
17
SU
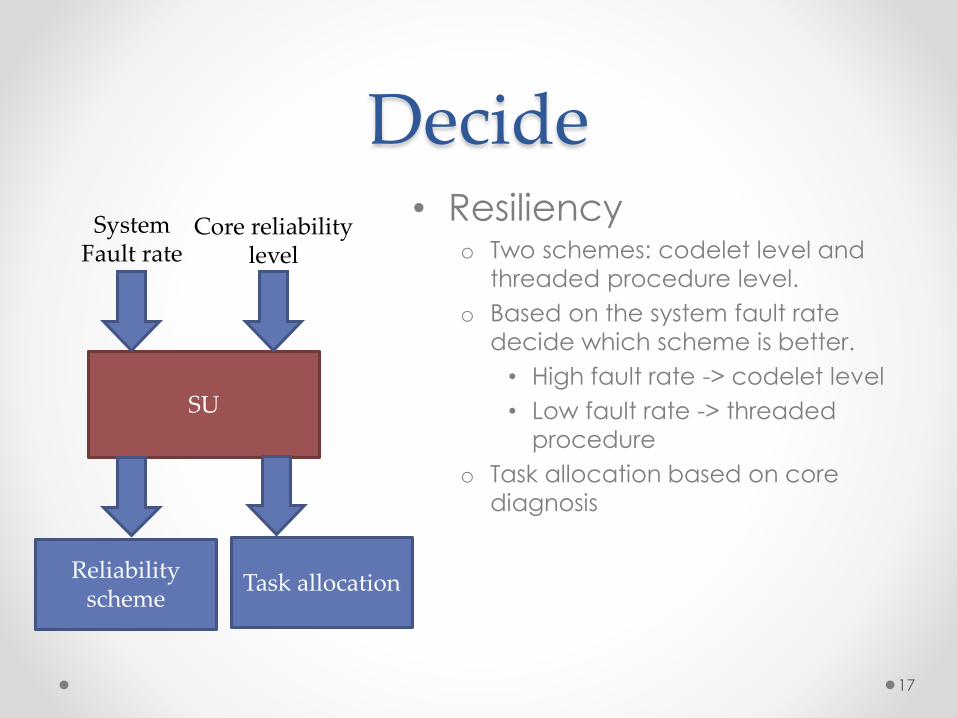
• Resiliencyo Two schemes: codelet level and
threaded procedure level.
o Based on the system fault rate
decide which scheme is better.
• High fault rate -> codelet level
• Low fault rate -> threaded
procedure
o Task allocation based on core
diagnosis
System Fault rate
Core reliability level
Reliability scheme
Task allocation
Act• Decide
18
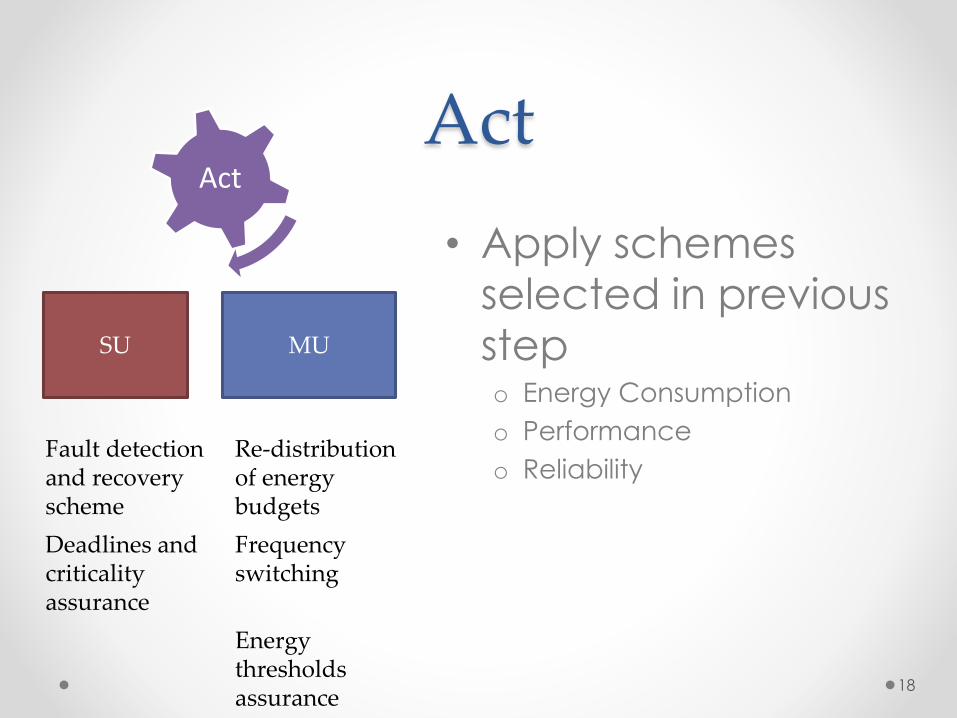
• Apply schemes
selected in previous
stepo Energy Consumption
o Performance
o Reliability
Act
MUSU
Fault detection and recovery scheme
Re-distributionof energy budgets
Deadlines andcriticality assurance
Frequency switching
Energy thresholdsassurance
Observe cycle• Monitoring unit collects data
from hardware sensors and from cores and records a history of them.
• Energy consumptiono Temperature
o Instruction counts
• Performanceo Instruction counts
o Cycles counts
o Bandwidth usage
• Reliabilityo Temperature
o System Fault rate
o Core diagnosis
• Unhealthy and healthy cores
• Reliability level for each core
19
Observe
Monitoring unit
…
History History History
Core 1 Core 2 Core n
System fault rate
Cycles count
Hardware sensors
Core reliability level
Temperature
Instruction counts
Damaged cores
CU
INTERCONNECTION
CU
Local Memory
SU
MU
CU
CU CU CU
Pool of Threaded procedures
SU
B
D E
C
F
App’sThresholds
Clusters’ Status
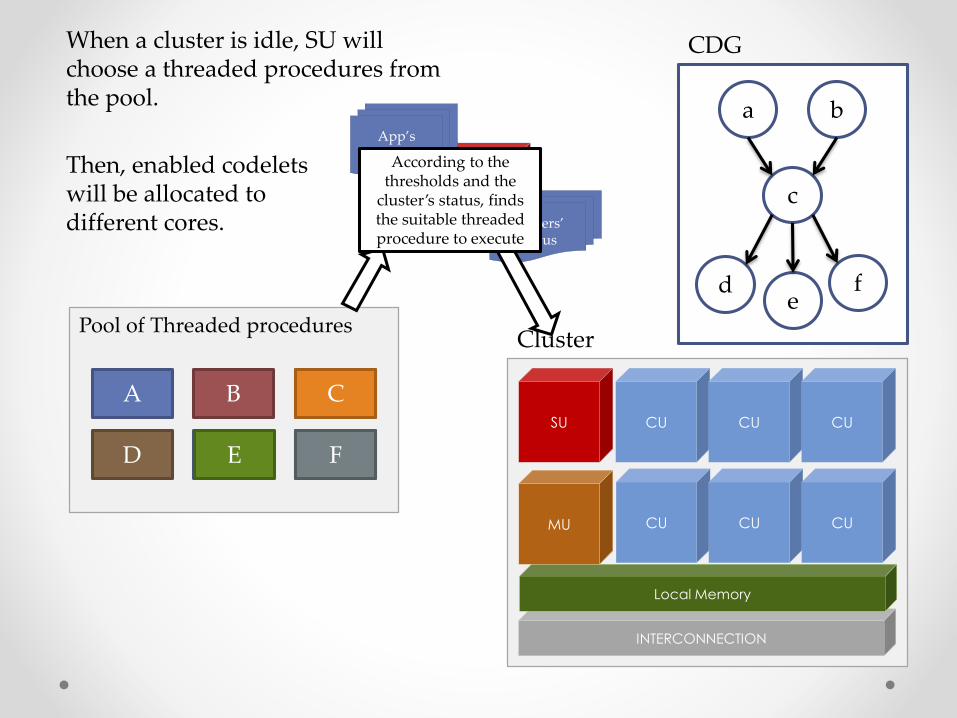
When a cluster is idle, SU will choose a threaded procedures from the pool.
A
According to the thresholds and the
cluster’s status, finds the suitable threaded procedure to execute
Cluster
E
C
F
a b
c
fe
d
CDG
Then, enabled codelets will be allocated to different cores.
21
CU
INTERCONNECTION
CU
Cluster
Local Memory
SU
MU
CU
CU CU CU
a b
c
fe
d
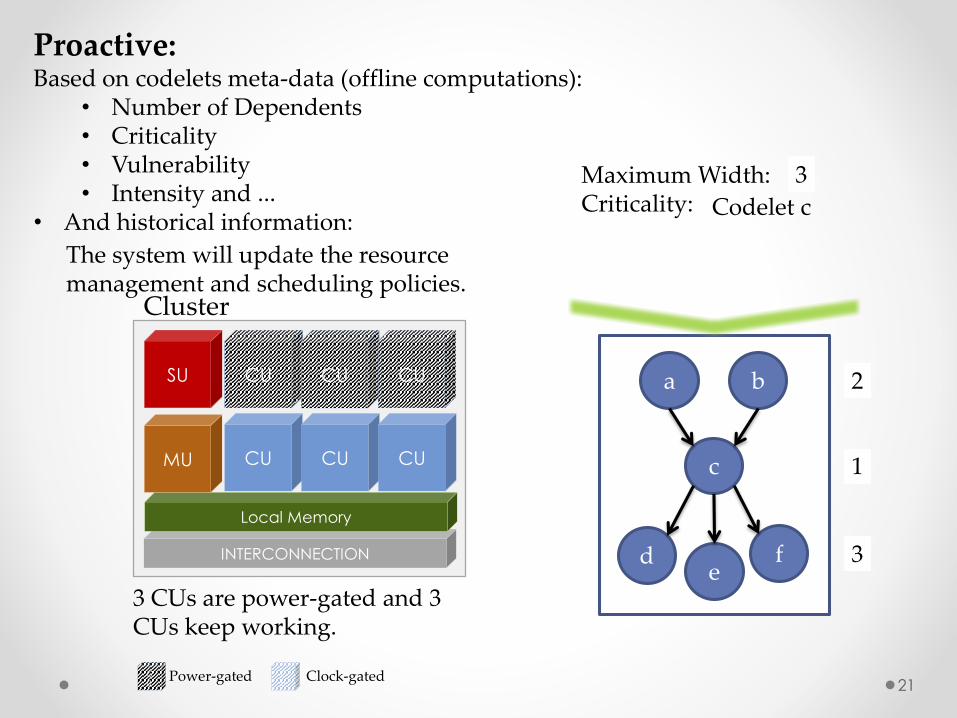
Maximum Width: Criticality:
2
Codelet c
3
Based on the information from Codelet Graph, SU predicts the resource needed and MU makes adjustment accordingly.
CU CU CU
3 CUs are power-gated and 3 CUs keep working.
Proactive:Based on codelets meta-data (offline computations):
• Number of Dependents• Criticality• Vulnerability• Intensity and ...
• And historical information:
3
1
2
C
U
C
UPower-gated Clock-gated
The system will update the resource management and scheduling policies.
22
CU
INTERCONNECTION
CU
Cluster
Local Memory
SU
MU
CU
CU
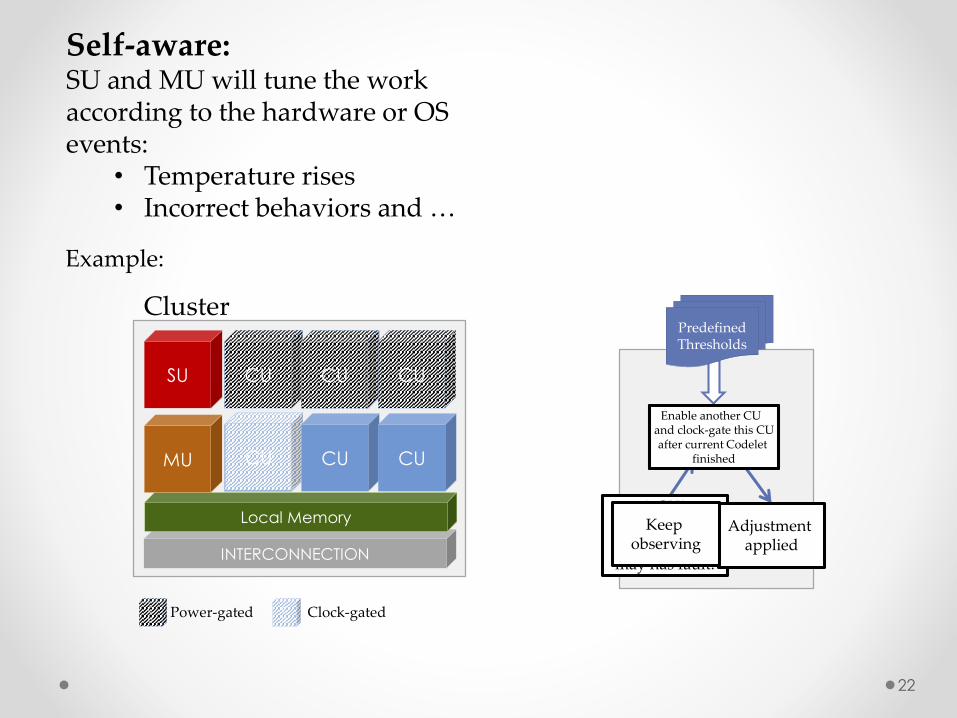
Self-aware:SU and MU will tune the work according to the hardware or OS events:
• Temperature rises• Incorrect behaviors and …
CU CU CU
OBSERVE
DECIDE
ACT
Deciding what to do accordingly
A CU’s temperature is
increasing, may has fault.
PredefinedThresholds
Enable another CUand clock-gate this CUafter current Codelet
finished
Adjustment applied
CU CU CU
Example:
Keep observing
C
U
C
UPower-gated Clock-gated

Related work(SEEC)
• Uses ODA loop to meet performance
and energy consumption goals.o Heartbeat, A method of observing performance.
• Uses Machine Learning techniques.
• Cons:o One prioritization for optimization.
o Not designed for extreme scale machines.
23
Henry Hoffmann et al, MIT-CSAIL-TR-2011-046, 2011Martina Maggio et al, FeBID 2011
Conclusion
24
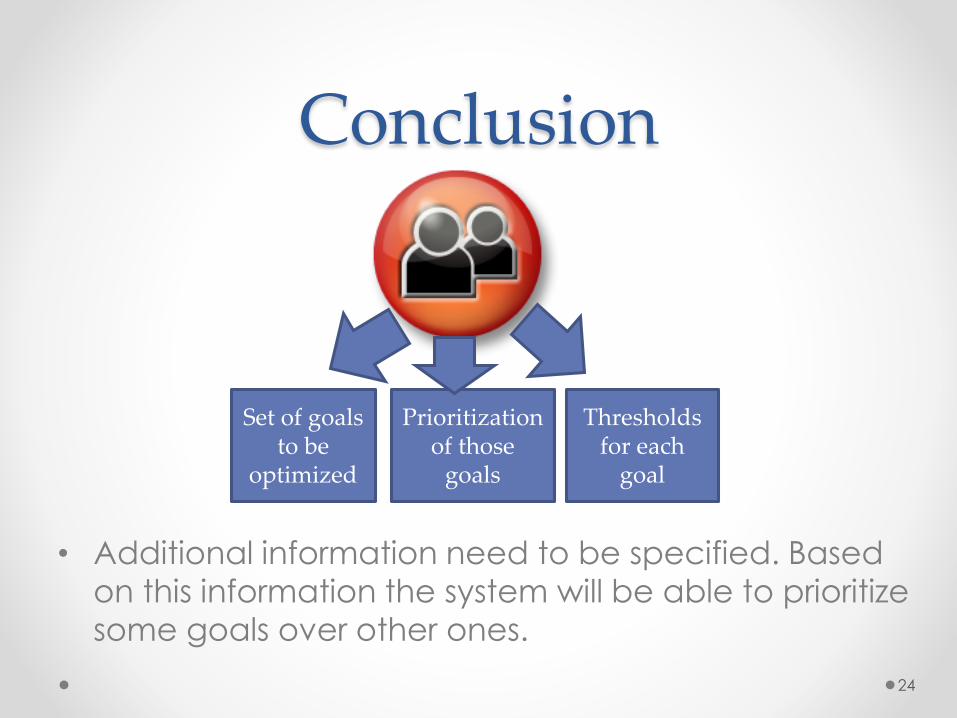
• Additional information need to be specified. Based
on this information the system will be able to prioritize
some goals over other ones.
Set of goals to be
optimized
Prioritization of those
goals
Thresholds for each
goal

Thank you!
25

References• Shekhar Borkar , Thousand Core Chips—A Technology Perspective, Proceedings of the 44th Annual
Design Automation Conference, San Diego, California, DAC '07, 2007
• Henry Hoffmann, Martina Maggio, Marco D. Santambrogio, Alberto Leva, and Anant Agarwal, SEEC: A General and Extensible Framework for Self-Aware Computing, MIT CSAIL Technical Report, MIT-CSAIL-TR-2011-046, November 2011.
• Henry Hoffmann, Jim Holt, George Kurian, Eric Lau, Martina Maggio, Jason E. Miller, Sabrina M. Neuman, Mahmut Sinangil, Yildiz Sinangil, Anant Agarwal, Anantha P. Chandrakasan, Srinivas Devadas, Self-aware Computing in the Angstrom Processor, Proceedings of the 49th Design Automation Conference (DAC), June 2012.
• Tom St. John, Benoit Meister, Andres Marquez, Joseph B. Manzano, Guang R. Gao, and Xiaoming Li, ASAFESSS: A Scheduler-driven Adaptive Framework for Extreme Scale Software Stacks, In Proceedings of the 4th International Workshop on Adaptive Self-Tuning Computing Systems (ADAPT'14), Vienna, Austria. January 20-22, 2014.
• Aaron Landwehr, Stephane Zuckerman, and Guang R. Gao, Toward a Self-aware System for Exascale Architectures, the 1st Workshop on Runtime and Operating Systems for the Many-core Era (ROME 2013), Aachen, Germany. August 26th, 2013.
• Martina Maggio, Henry Hoffmann, Anant Agarwal, and Alberto Leva, Control-theoretical CPU allocation: Design and Implementation with Feedback Control, The 6th International Workshop on Feedback Control Implementation and Design in Computing Systems and Networks (FeBID 2011).
• Stéphane Zuckerman, Joshua Suetterlein, Rob Knauerhase and Guang R. Gao, Using a “Codelet” Program Execution Model for Exascale Machines, the 1st International Workshop on Adaptive Self-Tuning Computing Systems for the Exaflop Era.
26
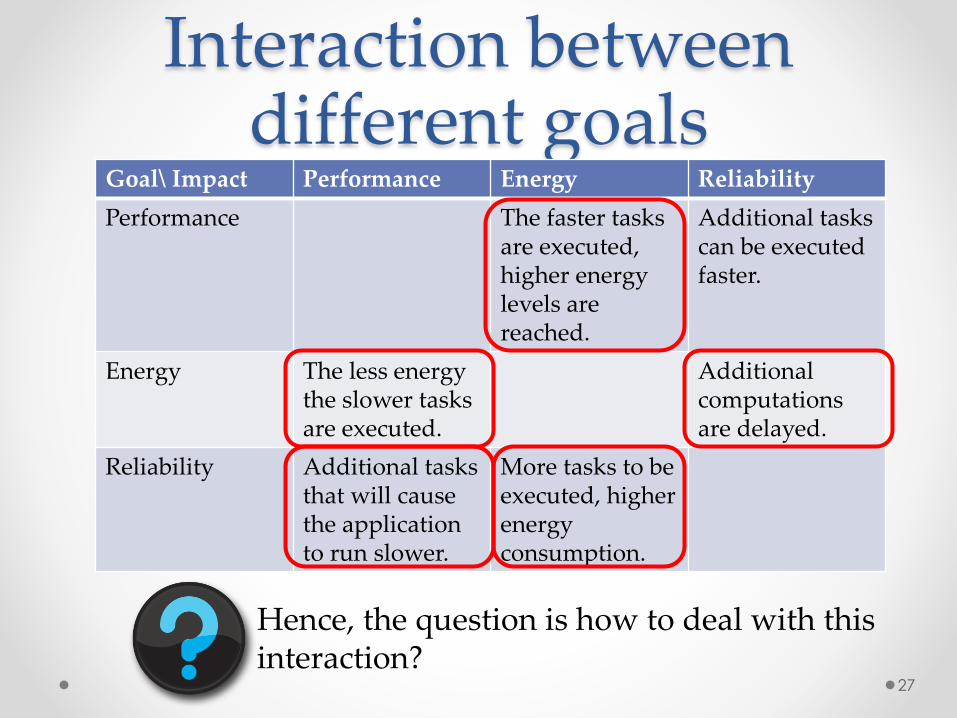
Interaction between different goals
27
Goal\ Impact Performance Energy Reliability
Performance The faster tasks are executed,higher energy levels are reached.
Additional taskscan be executed faster.
Energy The less energy the slower tasks are executed.
Additional computations are delayed.
Reliability Additional tasks that will cause the application to run slower.
More tasks to be executed, higher energy consumption.
Hence, the question is how to deal with this interaction?