a discriminative framework for modelling object classes abstract 1
TRANSCRIPT

A Discriminative Framework for Modelling Object Classes
Alex Holub and Pietro PeronaComputation and Neural SystemsCalifornia Institute of Technology
Pasadena, CA [email protected], [email protected]
Abstract
Here we explore a discriminative learning method on un-derlying generative models for the purpose of discriminat-ing between object categories. Visual recognition algo-rithms learn models from a set of training examples. Gen-erative models learn their representations by consideringdata from a single class. Generative models are popular incomputer vision for many reasons, including their ability toelegantly incorporate prior knowledge and to handle cor-respondences between object parts and detected features.However, generative models are often inferior to discrimi-native models during classification tasks. We study a dis-criminative approach to learning object categories whichmaintains the representational power of generative learn-ing, but trains the generative models in a discriminativemanner. The discriminatively trained models perform betterduring classification tasks as a result of selecting discrimi-native sets of features. We conclude by proposing a multi-class object recognition system which initially trains objectclasses in a generative manner, identifies subsets of similarclasses with high confusion, and finally trains models forthese subsets in a discriminative manner to realize gains inclassification performance.
1 Introduction
Humans can easily recognize and distinguish thousands ofvisual categories. The best computer algorithms achieveonly a fraction of human performance in terms of boththe number of classes recognized and the accuracy in dis-tinguishing between those classes. The impressive perfor-mance of the human system can be ascribed to both ourability to recognize the overall appearance of objects, and todetect subtle differences between very similar object classcategories, such as the difference between male and femalefaces or mopeds and motorcycles.
Algorithms for learning representations of object classcategories can be roughly grouped into two separate para-digms: Generative [1, 2, 3, 4, 5] and Discriminative [6, 7, 8,
9]. Generative object recognition algorithms create objectclass models using only the data of the class to be modelled.A significant benefit of generative models is their ability toelegantly handle missing data problems. In a local-featurebased object recognition context a particularly importantmissing data problem is the mapping of detected featuresto object parts. In addition, generative methods tend to al-low for elegant integration of prior knowledge [10]. Finally,generative techniques are well suited for modelling largenumbers of object categories, as they easily allow for theintroduction of new object classes. However, by not takingaccount the statistics of similar classes, these models canperform poorly when asked to classify similar object cate-gories. Discriminative object recognition techniques, on theother hand, utilize the data from multiple object classes tocreate classifiers. SVMs [11] and Boosting [6] are exam-ples of common discriminative techniques. Such methodstend to outperform their generative counterparts, but do not,in general, provide easy methods for handling missing dataand incorporating prior knowledge. Our goal is to createobject class models which take advantage of both the flexi-bility provided by generative methods and the classificationperformance increases provided by discriminative learning.
In this paper we use a principled probabilistic approachto extend the generative ‘Constellation Model’ [1, 2] frame-work for creating object class models to a discriminativesetting. We directly optimize the conditional distributionwhile maintaining an underlying generative model (this ap-proach is also known as maximizing the Conditional Likeli-hood or CL). Utilizing a generative framework in conjunc-tion with a discriminative optimization has been previouslyproposed by other authors [12, 13, 14]. These studies donot observe substantial gains in using CL over generativeapproaches on traditional learning systems data-sets suchas the UCI data-sets. One of the objectives of this study isto assess the performance of the discriminative method forlocal-feature based visual object recognition.
We conclude by proposing a general approach to objectrecognition which utilizes the relative merits of both thegenerative and discriminative learning paradigms. In this
1

Figure 1:Examples of generative Bicycle and Motorcycle mod-els. The circles indicate the positions of the best hypothesis. Thegenerative models tend to model the wheels, which are similar intheir relative positions and appearance for both classes.
system, models are initially trained in a generative fashion.Next, subsets of classes with high confusion are identified,which indicates similarity between classes. Each subset isthen trained in a discriminative manner. The result is a setof class representations that model the unique aspects of allthe classes.
This paper is organized as follows: First we will reviewthe Constellation Model. We will then outline our discrimi-native learning approach. Finally, we will show examples ofboth generative and discriminative models, highlight theirdifferences, and illustrate a system which utilizes both tech-niques.
2 Review of the Constellation Model
Our approach to object class modelling builds on earlierwork by Weber et al. [1] and more recently that of Ferguset. al. [2]. In this framework, an object is modelled by a‘constellation’ of several parts, with each model containinginformation on both the appearance and relative position ofeach part. In the following experiments we use a simplifiedversion of the constellation framework, which utilizes onlythree parts and does not include an explicit model for oc-clusion or relative scale. We use gaussian probability den-sities to represent the variations in appearance and shape ofthe three components. The parameters for our models arelearned by extracting interesting features from a set of train-ing images and using these features to maximize a modelrepresentation.
2.1 Feature Detection and Representation
Interesting locations, referred to asfeatures or interestpoints, must be identified within all images. We accomplish
Figure 2: Examples of discriminative Bicycle and Motorcyclemodels. The best hypotheses tend to model the body and frameof both the bicycle and motorcycle classes respectively. The loca-tions of the best hypotheses appear less consistent than in the MLmodels.
feature detection using either supervised or semi-supervisedlearning. For supervised learning, we manually select reg-istered regions of images for learning from labelled images.In semi-supervised learning, the feature detection processis accomplished using the Kadir and Brady [15] detector,however the algorithm maintains knowledge of the class la-bels for each image1.
For supervised learning, we manually register 9 featuresfor use by our learning algorithm: left eye, right eye, lefthairline, right hairline, center hairline, nose tip, left mouth,right mouth, and chin (see Figure 3). When features aremissing or occluded we choose the closest position in theimage as our feature. A constant scale was assumed for allfeatures across all images for the supervised experiments.
We automate the feature selection process by using a fea-ture detector in semi-supervised learning. The Kadir andBrady feature detector returns the positions, scales, and rel-ative saliency of interest points within an image. The detec-tor is well-tuned for detecting circular regions within im-ages, including eyes and wheels. The interest points withthe highest saliency are used as features for learning.
In order to construct an appearance representation for thesalient points, we extract11× 11 pixel patches centered onthe Kadir and Brady features. We scale the size of the patchextracted to correspond to the scale of detection and thensub-sample the patches to11× 11 matrices. We reduce thenumber of appearance parameters to be optimized by per-forming PCA on all patches from every image. We selectthe firstK principal components for our appearance mod-els, whereK is typically 10. We use a matrix,Ac
i , of size
1Note the departure from the terminology of [2] and [10] who considertheir algorithms ’unsupervised’. This distinction becomes particularly im-portant with the advent of purely unsupervised object learning algorithms,i.e. [16]
2

SUPERVISED KADIR + BRADY
Figure 3: (Left) Examples of features selected manually forSchwarzenegger. Nine total features are selected. (Center) Thesame image but with features found using the Kadir and Bradydetector. The 15 most salient features are shown.
F × K to represent the appearances of all features withinimagei of classc, whereF is the number of features used.F typically ranges from 25-30 for semi-supervised learning.
2.2 Shape Representation
We construct a shape model to represent the variations inposition for each model part. We record the positions of allinterest points within an imagei for classc in the variableXc
i . We attempt to find the optimal mean and variance ofgaussian densities for the shape model. The positions of allmodel parts are relative to the first part. By conditioning onthe first model component, the model becomes invariant totranslations.
2.3 Generative Model
Here we present a generative framework which obtainsmaximum likelihood estimates for parameter values of eachobject class. Our goal is to find a set of model parame-tersθc, wherec is a particular class of objects, which opti-mizes the appearance and relative positions of the patchesextracted from images in that class.θc represents both themeans and diagonal variance components. Consider a setof object classes ranging from1..C and indexed byc, andthe images belonging to each of these classes, ranging from1..Nc and indexed byi. We have extracted both appearance,Ac
i , and shape,Xci , information from each imageIc
i . We as-sume that the shape and appearance models are independentof one another and that the images are I.I.D. The log likeli-hood of the training images given a particular parameter setθ is:
∑
i∈c
log(p(Ici )) =
∑
i∈c
log(p(Aci |θc) · p(Xc
i |θc)) (1)
The maximum likelihood estimate will find the value ofθc
which optimizes the expression above. Given a particularimageIi
c, we obtain a set of interest points as describedabove. We must assign an interest point to a particular
model component. Since we do not a priori know whichinterest point belongs to which model component, we in-troduce a hypothesis variableh, which maps interest pointsto model parts. We order the interest points in ascendingorder of x-position. There areM model parts. This resultsin a total of
(FM
)unique combinations of interest points and
parts, where each hypothesish will assign a unique interestpoint to each model part.2 We marginalize over the hypoth-esis variable to obtain the following expression for the loglikelihood for a particular class:
=∑
i∈C
log(∑
h
p(Ici , h|θc)) (2)
=∑
i∈C
log(∑
h
p(Aci , h|θc) · p(Xc
i , h|θc)) (3)
This generative approach can lead to difficulties whenattempting to distinguish between similar object categories.Fig. 1 shows several images from two similar classes, Bi-cycles and Motorbikes, and the corresponding locations ofthe best hypothesis. The relative positions and appearanceof the parts seem similar between the two classes, leadingto confusion during classification tasks.
3 Discriminative Model
Here we consider a discriminative formulation for learn-ing object categories. Similar to the generative models de-scribed above, we assume that our models can be describedby a parameter vectorθc. However the discriminative ap-proach maximizes the conditional distribution,p(θc|Ii
c), ofall the classes given all the data. By maximizing the Condi-tional Likelihood (CL) expression, we are maximizing theprobability that each image (represented byIc
i ) belongs toits own label (c):
log(∏c
∏
i∈c
p(θc|Ici )) = (4)
∑c
∑
i∈c
{log(p(Ic
i |θc)) + log(p(c))− log(p(Ici ))
}
Next we expandp(Ici ) which corresponds to the proba-
bility of data-point from the current class belonging to anyof the classes. We index the ‘competing’ classes byg. Fur-thermore, we remove the prior probability of a class,p(c),as it is independent of the parameters we are optimizing,θc.We obtain:
2One of the significant limitations of the constellation model is thecomputational cost induced by the combinatorial explosion relating thenumber of interest points used and the number of model components.
3

∑c
∑
i∈C
{log(p(Ic
i |θc))︸ ︷︷ ︸ML
− log( ∑
g
p(Ici |θg)p(g)
)}(5)
The equation for maximizing CL consists of two terms.The first is the maximum likelihood term used in the gen-erative approach, from which we subtract the second term,the probability of a data-point belonging to any other class.Intuitively, data-points are being pulled towards their ownclass label while being pushed away from other competingclasses. Finally, we note that the relative strength of the MLand CL terms can be weighted using a termα, thereby al-lowing for a continuum between purely ML and purely CLmodels:
∑c
∑
i∈C
{log(p(Ic
i |θc))︸ ︷︷ ︸ML
−α · log(∑
g
p(Ici |θg)p(g)
)}(6)
Whereα = 0 is a an entirely ML approach andα = 1a pure CL approach. Varying the value ofα is useful forillustrating the relative merits of generative and discrimi-native techniques. All our object models used a completediscriminative model withα = 1 unless otherwise speci-fied.
Returning to the Motorcycle and Bicycle classes (Fig. 2),we notice that the model parts for CL models tend to repre-sent the body of the classes rather than the wheels. The fea-tures along the body intuitively seem to provide more dis-criminative power than the wheels for these object classes.
3.1 Model Testing
The performance of the discriminative models can be as-sessed by presenting a novel test image,Ic
i , and calculatingthe probability of this test image being generated by anygiven class:p(Ic
i |θ∗c ), whereθ∗c is an optimized CL model.Note that the term representing the competing classes in thediscriminative framework optimization,p(Ic
i ), is the samefor all classes. If the highest probability model correspondsto the class label for that image, the image is correctly clas-sified. For the generative models, we utilize a likelihoodratio between the class models, which is equivalent to find-ing the model with highest probability for a particular imageIci (see [2] for a full derivation of the generative approach).
3.2 Model Optimization
We wish to maximize the expressions for both the genera-tive and discriminative approaches derived above. We usethe Expectation Maximization [17] (EM) algorithm to op-timize the generative models. Learning is terminated after100 iterations. The conjugate gradient algorithm is used to
0 0.5 10
1
2
3
4
5
6
7
Alpha
Lo
g T
ime
(Min
ute
s)
Optimization Time
POLITICIANSCATSPOLITICIANS (EM)CATS (EM)
0 0.2 0.4 0.6 0.8 1
30
40
50
60
70
80
Alpha
Pe
rce
nt
Co
rre
ct
Performance vs. Alpha
POLIT TestPOLIT TrainCATS TestCATS Train
Figure 4: (Left) Optimization time as a function ofα. Both MLand CL models are trained using conjugate gradient. Atα = 0we have a purely generative approach, and forα = 1 a purely dis-criminative approach. The time scale is inlog10 minutes. The CLmodels take longer to optimize,6× longer for the Politicians data-set and10× longer for the Cats data-set. Results shown for both a9 interest points, 100 train images supervised ‘Politicians’ data-setand 20 interest points, 150 train images Cat Species data-set. Bothdata-sets contain 4 classes. Red and blue stars indicate the timetaken to optimize using the EM algorithm. (Right) Train and Testperformance as a function ofα for the Politicians data-set (blackcurves) and the Cat Species data-set (green curves). Increasingthe discriminative power increases the performance as well as theamount of over-fitting as measured in the difference between thetrain and test performance.
optimize the CL models. Conjugate gradient requires thederivative of the CL expression with respect to each para-meter of the model. The derivatives can be easily obtainedusing the following expression:
∂
∂θclog (p(θc|Ic
i )) =
∂
∂θclog p(Ic
i |θc)− ∂
∂θclog
∑g
p(Ici |θg)p(g) (7)
θc represents both the mean and variance for the parts of themodel. We also note that the parameters of a classθc ap-pear in the background term of all competing classes, andthese must be accounted for when taking the derivatives.Learning is terminated when either the gradient at a partic-ular iteration is below a threshold or the maximum numberof conjugate gradient iterations is reached. The maximumnumber of iterations is arbitrarily set to 100. We chooserandom initial starting conditions for all models to initializeboth the EM and conjugate gradient optimization routines.
By varying the value ofα we can explore how the com-putational cost changes as the model becomes more dis-criminative (see Fig. 4). Our experiments indicate a steepincrease in computational time when moving fromα = 0.9to α = 1 with a corresponding minimal increase in per-formance, indicating that it might be more computationallyfavorable to not use the fully discriminative learning model.
4

The term representing the competing classes in the CL ex-pression introduces many additional local minima to thosefound in ML. Large combinations of features and parts arecomputationally prohibitive using the current optimizationtechnique. We compare both the performance and optimiza-tion time between the conjugate gradient algorithm withα = 0 and the EM algorithm for the ML learned models.The EM algorithm is slightly faster but does not result in anoticeable change in performance.
4 Supervised Discrimination
Our initial experiments are conducted on a data-set con-sisting of 4 famous politicians. The Politicians data-set contains images of John Kerry, George Bush, ArnoldSchwarzenegger, and Bill Clinton. Each data-set containsabout 150 images of which typically 100-120 are used fortraining. The resolution is about200× 200. See the appen-dix for information on data collection.
Figure 5 illustrates a typical set of discriminative andgenerative models for the politicians data-set. There areseveral interesting things to note. (1) The models found byML and CL optimization differ as can be seen by the lo-cations for the best fitting hypotheses. (2) The CL appear-ance models seem to be less homogenous between classesthan their ML counterparts as indicated by the clustering ofpoints within the ML appearance models and the generaldispersion of points seen in the CL appearance models. (3)Features along the hairline are the highest probability hy-potheses for the CL models, while the ML models preferregions within the face. The increased performance exhib-ited by the CL models (see Figure 7) indicates that the ap-pearance and mutual positions of features along the hairlineis more discriminative.
5 Semi-Supervised Discrimination
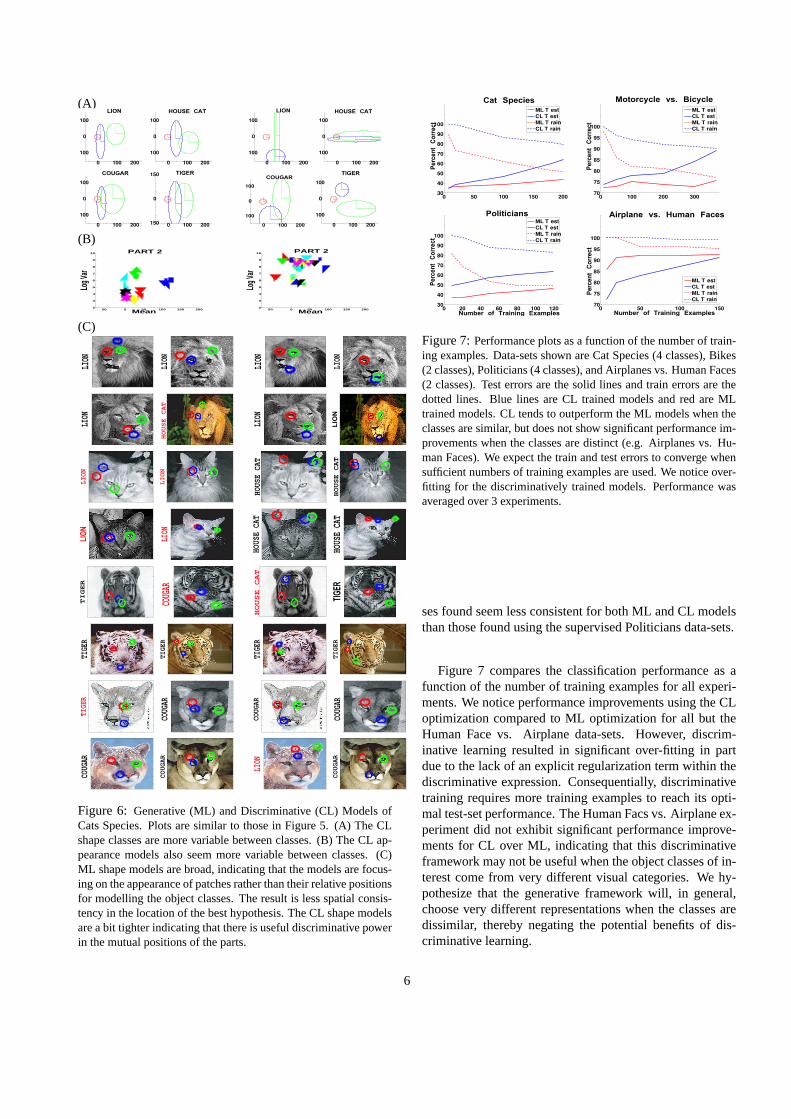
We performed experiments on two visually similar setsof classes using semi-supervised learning, Bikes (Motor-bikes, Bicycles) and Cat Species (House Cat, Tiger, Lion,Cougar), and one set of dissimilar classes, Human Facesand Airplanes. The Cat classes contained 240 images eachwith 200 being used for training, while the Bikes data-setshave about 450 images each with 370 used for training. Weused a maximum of 30 interest points per image. The Catsdata-set often contains very similar looking images, mak-ing the discrimination task particularly difficult. Figure 6compares ML and CL generated models for the Cats data-set. We make several observations: (1) Both the appearanceand shape models are more variable between classes for theCL optimized models than the corresponding shape and ap-pearance models of the ML models. (2) The best hypothe-
(A)
0 100 200−100
0
100CLINTON
0 100 200−100
0
100BUSH
0 100 200−100
0
100ARNE
0 100 200−100
0
100KERRY
0 100 200−100
0
100CLINTON
0 100 200−100
0
100BUSH
0 100 200−100
0
100ARNE
0 100 200−100
0
100KERRY
(B)
50 0 50 100 150 2002
3
4
5
6
7
8
9
10 PART 2
Log V
ar
Mean50 0 50 100 150 2002
3
4
5
6
7
8
9
10PART 2
Log V
ar
Mean
(C)
Figure 5: Generative (ML) and Discriminative (CL) PoliticianModels. Left column ML models, right column CL models. (A)Shape models for each class. The ovals represent the mean andvariance of the gaussian model for each part. Each unique colorcircle represents a different part. (B) Plots of the mean vs thenaturallog of the variance for the first 7 PCA components. OnlyPart 2 is shown, although it is representative of the other parts.Each unique shape represents a different class and each color adifferent PCA coefficient. ML models are more tightly bunchedbetween classes than the CL models. (C) The locations of thebest matching hypothesis in the same images for both ML andCL models. Predicted labels are to the left of each image, withincorrect predicted labels in red.
5
(A)
0 100 200�
� 100
0
100
0 100 200�
� 100
0
100
0 100 200�
� 100
0
100
0 100 200�
� 100
0
100
0 100 200�
� 100
0
100
0 100 200� 150
�
0
150
0 100 200�
� 100
0
100
0 100 200�
� 100
0
100
(B)
50 0 50 100 150 2002
3
4
5
6
7
8
9
10 PART 2
Log V
ar
Mean 50 0 50 100 150 2002
3
4
5
6
7
8
9
10 PART 2Lo
g Var
Mean
(C)
Figure 6: Generative (ML) and Discriminative (CL) Models ofCats Species. Plots are similar to those in Figure 5. (A) The CLshape classes are more variable between classes. (B) The CL ap-pearance models also seem more variable between classes. (C)ML shape models are broad, indicating that the models are focus-ing on the appearance of patches rather than their relative positionsfor modelling the object classes. The result is less spatial consis-tency in the location of the best hypothesis. The CL shape modelsare a bit tighter indicating that there is useful discriminative powerin the mutual positions of the parts.
0 50 100 150 20030
40
50
60
70
80
90
100
ML T est
CL T est
ML T rain
CL T rain
0 100 200 30070
75
80
85
90
95
100
ML T est
CL T est
ML T rain
CL T rain
0 20 40 60 80 100 12030
40
50
60
70
80
90
100
ML T est
CL T est
ML T rain
CL T rain
0 50 100 15070
75
80
85
90
95
100
ML T est
CL T est
ML T rain
CL T rain
Figure 7:Performance plots as a function of the number of train-ing examples. Data-sets shown are Cat Species (4 classes), Bikes(2 classes), Politicians (4 classes), and Airplanes vs. Human Faces(2 classes). Test errors are the solid lines and train errors are thedotted lines. Blue lines are CL trained models and red are MLtrained models. CL tends to outperform the ML models when theclasses are similar, but does not show significant performance im-provements when the classes are distinct (e.g. Airplanes vs. Hu-man Faces). We expect the train and test errors to converge whensufficient numbers of training examples are used. We notice over-fitting for the discriminatively trained models. Performance wasaveraged over 3 experiments.
ses found seem less consistent for both ML and CL modelsthan those found using the supervised Politicians data-sets.
Figure 7 compares the classification performance as afunction of the number of training examples for all experi-ments. We notice performance improvements using the CLoptimization compared to ML optimization for all but theHuman Face vs. Airplane data-sets. However, discrim-inative learning resulted in significant over-fitting in partdue to the lack of an explicit regularization term within thediscriminative expression. Consequentially, discriminativetraining requires more training examples to reach its opti-mal test-set performance. The Human Facs vs. Airplane ex-periment did not exhibit significant performance improve-ments for CL over ML, indicating that this discriminativeframework may not be useful when the object classes of in-terest come from very different visual categories. We hy-pothesize that the generative framework will, in general,choose very different representations when the classes aredissimilar, thereby negating the potential benefits of dis-criminative learning.
6

Figure 8: (Top) Initial confusion table for test sets on 6 classes.The x-axis indicates the true category of the image and the y-axisthe predicted category for the image. An(x, y) entry indicatesthe fraction of times classx was classified asy. The values alongthe main diagonal are the percent of the time an image from class‘x’ was correctly classified. The size of the green dots indicatesthe magnitude of confusion. Some subsets of classes have higherconfusion, namely Cat Species and Bikes. (Bottom) Confusion ta-ble after discriminative learning of the Cat Species cluster and theBike cluster. The performance on the Human Face class does notchange. Both discriminative and generative models were trainedusing the same subset of data. Confused classes were identifiedusing the Training set. Confusion tables shown indicate Test setperformance.
6 Generative/Discriminative System
The previous sections indicate that the CL learning frame-work can result in substantial performance gains when theclasses of interest are visually similar. But, these gainscome at the price of both increased computational resourcesand large numbers of training examples. This suggests anatural system for training large numbers of object cate-gories: (1) Initially train models in a generative fashion. (2)Identify areas of high confusion between classes. (3) Trainthese subsets of confused models with discriminative meth-ods, using high numbers of training examples if necessary.
We implemented such a system using a set of 6 classes:Cats Species (House Cat, Tiger, Cougar), Bikes (Motorcy-cles, Bicycles), and Human Faces. The confusion table cre-ated from the generative models appeals to our semantic no-tion of similarity, with the subsets Cat Species and Bikes ex-hibiting higher confusion among themselves than between
other classes for both the train set (not shown) as well as thetest set (shown in Figure 8). These 2 subsets of confusedclasses are good candidates for discriminative learning asidentified by the confusion matrices generated by the train-ing examples. Using the same training data used to createthe generative models, we train two sets of discriminativemodels, for both the Cat Species and Bikes. This resultsin 4 discriminatively trained Cat Species models and 2 dis-criminatively trained Bike models. We pool test examplesinto the superset categories Bikes, Cat Species, or HumanFaces according to the initial generatively trained models.This initial classification is followed by discriminative clas-sification when the test examples fall either into the groupof Bikes or Cat Species models.
Figure 8 illustrates the performance of first classifyingusing generative models followed by classification usingdiscriminative models. The performance increases by about10% for both the Cat Species and the Bike classes.
7 Conclusion
We have tested a discriminative learning paradigm on anunderlying generative model which maximizes the condi-tional distribution. We show how this discriminative set-ting can be used to improve object categorization perfor-mance. We suggest that this discriminative setting is par-ticulary useful when the object classes of interest are vi-sually similar. Furthermore we suggest that discriminativeclassifiers seem to create object models accentuating thedifferences between classes. We also highlight the trade-off between the discriminative and generative formulations,with the discriminative technique generally outperformingits generative counterpart but requiring both a larger numberof training images and greater computational resources. Weconcluded by proposing an object recognition system whichinitially trains models in a generative framework, then sep-arates the representations of similar classes using discrimi-native learning.
Appendix: Data Collection
The Motorcycle, Airplane, and Human Face data-sets are from the Caltech Image Data-Base located atwww.vision.caltech.edu. We collected images of all otherobject from the web using the Google, Yahoo, and Lycossearch engines. Images were sometimes cropped to em-phasize the category of interest and reduce the number ofnon-object features detected for semi-supervised learning.
7

Acknowledgements
C. Rasmussen for making the conjugate gradient code ’minimize’publicly available and L. Zelnik, R. Fergus, F.F. Li, and G. Hintonfor useful discussions.
References[1] M. Weber. Unsupervised Learning of Models for Object
Recognition, Ph.D thesis, Depeartment of Computational andNeural Systems, Caltech, Pasadena, CA, 2000.
[2] R. Fergus, P. Perona, A. Zisserman. Object Class Recognitionby Unsupervised Scale-Invariant Learning. InProc CVPR,June 2003.
[3] D. Lowe. Object Recognition from Local Scale-Invariant Fea-tures. InProc. ICCV, pp. 1150-1157, Sept. 1999.
[4] H. Schneiderman, T. Kanade. A statistical method for 3d ob-ject detection applied to faces and cars. InProc. CVPR, 2000.
[5] G. Dork, C. Schmid. Object class recognition using discrimi-native local features.IEEE PAMI (Submitted).
[6] P. Viola, M. Jones. Rapid object detection using a boosted cas-cade of simple features. InProc. CVPR, pp. 39-45, 2001.
[7] S. Kumar, M. Hebert. Discriminative Fields for ModelingSpatial Dependencies in Natural Images. InProc NIPS, 2003.
[8] A. Opelt, M. Fusseneger, A. Pinz, P. Auer. Generic ObjectRecognition with Boosting.IEEE, PAMI. submitted.
[9] A. Torralba, K.P. Murphy, W.T. Freeman. Sharing visual fea-tures for multiclass and multiview object detection. InProc.CVPR, pp. 762-769, 2004.
[10] L. Fei-Fei, R.Fergus, P. Perona. A Bayesian approach to un-supervised One-Shot learning of Object categories. InProc.ICCV, 2003.
[11] Vapnik, V. The Nature of Statistical Learning Theory.Springer, N.Y., 1995.
[12] T. Jebara.Discriminative, Generative and Imitative Learn-ing. PhD Thesis, Media Laboratory, MIT, December 2001.
[13] G. Bouchard. The Trade-off Between Generative and Dis-criminative Classifiers. Technical Note, INRIA.
[14] Y.D. Rubinstein, T. Hastie. Discriminative vs InformativeLearning. InAAAI, 1997.
[15] T. Kadir, M. Brady. Scale, saliency and image description. InIJCV 30(2), 1998.
[16] R. Fergus, P. Perona, A. Zisserman. A Visual Category Filterfor Google Images. InProc ECCV, 2004.
[17] A. Dempster, N. Laird, D. Rubin. Maximum Likelihoodfrom incomplete data via the em algorithm.JRSS B, 39:1-38,1976.
8