[email protected] - arxiv
TRANSCRIPT

Specular- and Diffuse-reflection-based Face Liveness Detection forMobile Devices
Akinori F. Ebihara Kazuyuki Sakurai Hitoshi ImaokaNEC Biometrics Research Laboratories, Japan
Abstract
In light of the rising demand for biometric-authentication sys-tems, preventing face spoofing attacks is a critical issue forthe safe deployment of face recognition systems. Here, wepropose an efficient liveness detection algorithm that requiresminimal hardware and only a small database, making it suit-able for resource-constrained devices such as mobile phones.Utilizing one monocular visible light camera, the proposedalgorithm takes two facial photos, one taken with a flash, theother without a flash. The proposed SpecDiff descriptor isconstructed by leveraging two types of reflection: (i) specularreflections from the iris region that have a specific intensitydistribution depending on liveness, and (ii) diffuse reflec-tions from the entire face region that represents the 3D struc-ture of a subject’s face. Classifiers trained with SpecDiffdescriptor outperforms other flash-based liveness detectionalgorithms on both an in-house database and on publiclyavailable NUAA and Replay-Attack databases. Moreover,the proposed algorithm achieves comparable accuracy to thatof an end-to-end, deep neural network classifier, while beingapproximately ten-times faster execution speed.
1 Introduction
A biometric authentication system has an advantage overa traditional password-based authentication system: it usesintrinsic features such as a face or fingerprint, so the userdoes not have to remember anything to be authenticated.Among the various biometric authentication systems, face-recognition-based ones take advantage of the huge variety offacial features across individuals, and thus have the potentialto offer convenience and high security. Face authentication,however, has a major drawback common to other forms ofbiometric authentication: a nonzero probability of false re-jection and false acceptance. While false rejection is lessproblematic, because a genuine user can usually make asecond attempt to be authorized, false acceptance entails ahigher security risk. When a false acceptance occurs, thesystem may actually be under an attack by a malicious im-poster attempting to break into it. Acquiring facial images
Real Fake
(a) (b) (c)
Real Fake
Figure 1: Construction of the proposed SpecDiff descriptor.(a) Two photos, one taken with a flash (top), the other withouta flash (bottom), are shot within ≈ 200 milliseconds. (b)Face and eye regions are extracted from the two photos andresized, and the Speculum Descriptor (Dspec ∈ R3200 foreach eye) and the Diffusion Descriptor (Ddiff ∈ R10000) arecalculated from these regions. Two example results obtainedwith real (left) and fake (right) faces are shown. Note thatthe actual region used to calculate DSpec is 40 × 40 pixelssquare region inside the iris centered on the pupil. (c) Thetwo descriptors are vectorized and concatenated to build theSpecDiff descriptor, which is then classified by standardclassifiers such as a support vector machine (SVM, [1]) or aneural network.
via social networks is now easier than ever, allowing attack-ers to execute a variety of attacks using printed photos orrecorded video. The demand for technologies for detectingface spoofing (i.e., face liveness detection) is thus rising in aneffort to ensure the security of sites deploying face recogni-tion systems. Face recognition systems are being used at, forexample, airports and office entrances and as login systemsof edge devices. Each site has its own hardware availability;i.e., it may have access to a server that can perform com-putationally expensive calculations, or it may be equippedwith infrared imaging devices. On the other hand, it mayonly have access to a low-performance CPU. It is thus nat-ural that the suitable face liveness detection algorithm willdiffer according to the hardware availability. The advent
1
arX
iv:1
907.
1240
0v1
[cs
.CV
] 2
9 Ju
l 201
9
0 2000 4000 6000 8000 10000
− 0.20
− 0.10
0.00
0.10
Dimension
Desc
rip
tor
mag
nit
ud
e (
A.U
.)
0 500 1000 1500 2000 2500 3000
− 0.2
0.0
0.2
0.4
Average
Average
Desc
rip
tor
mag
nit
ud
e (
A.U
.)(a)
(b)
RealFake
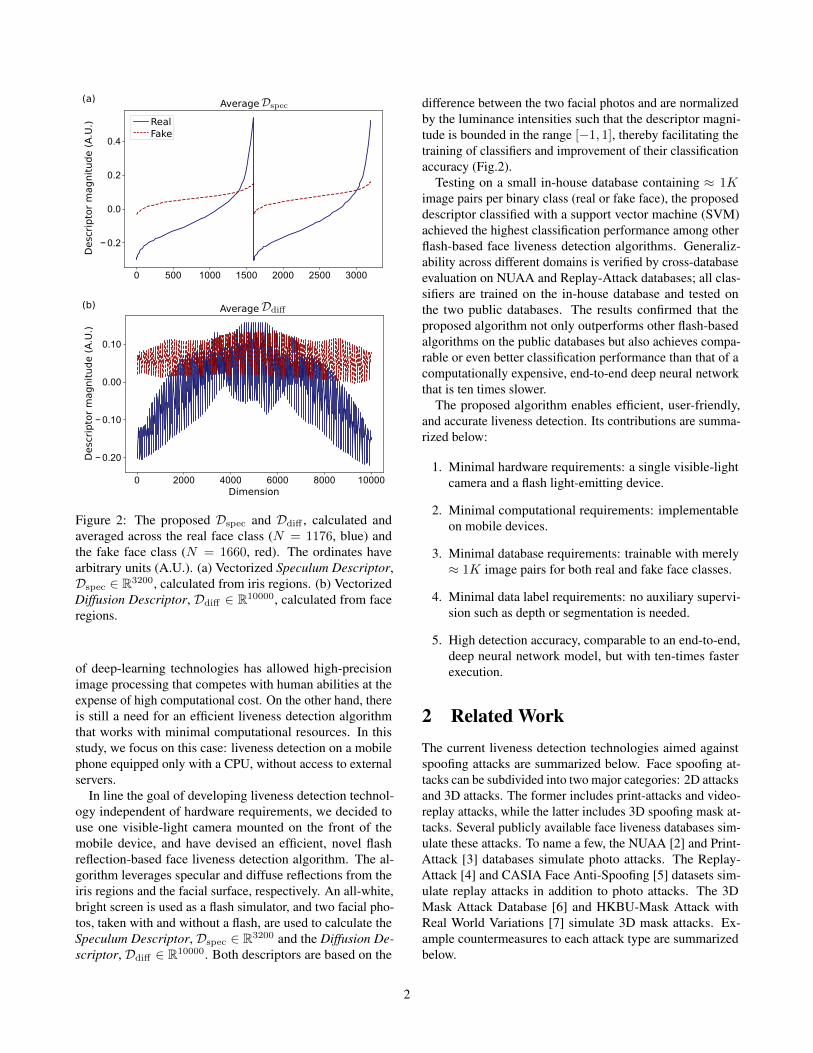
Figure 2: The proposed Dspec and Ddiff , calculated andaveraged across the real face class (N = 1176, blue) andthe fake face class (N = 1660, red). The ordinates havearbitrary units (A.U.). (a) Vectorized Speculum Descriptor,Dspec ∈ R3200, calculated from iris regions. (b) VectorizedDiffusion Descriptor, Ddiff ∈ R10000, calculated from faceregions.
of deep-learning technologies has allowed high-precisionimage processing that competes with human abilities at theexpense of high computational cost. On the other hand, thereis still a need for an efficient liveness detection algorithmthat works with minimal computational resources. In thisstudy, we focus on this case: liveness detection on a mobilephone equipped only with a CPU, without access to externalservers.
In line the goal of developing liveness detection technol-ogy independent of hardware requirements, we decided touse one visible-light camera mounted on the front of themobile device, and have devised an efficient, novel flashreflection-based face liveness detection algorithm. The al-gorithm leverages specular and diffuse reflections from theiris regions and the facial surface, respectively. An all-white,bright screen is used as a flash simulator, and two facial pho-tos, taken with and without a flash, are used to calculate theSpeculum Descriptor, Dspec ∈ R3200 and the Diffusion De-scriptor, Ddiff ∈ R10000. Both descriptors are based on the
difference between the two facial photos and are normalizedby the luminance intensities such that the descriptor magni-tude is bounded in the range [−1, 1], thereby facilitating thetraining of classifiers and improvement of their classificationaccuracy (Fig.2).
Testing on a small in-house database containing ≈ 1Kimage pairs per binary class (real or fake face), the proposeddescriptor classified with a support vector machine (SVM)achieved the highest classification performance among otherflash-based face liveness detection algorithms. Generaliz-ability across different domains is verified by cross-databaseevaluation on NUAA and Replay-Attack databases; all clas-sifiers are trained on the in-house database and tested onthe two public databases. The results confirmed that theproposed algorithm not only outperforms other flash-basedalgorithms on the public databases but also achieves compa-rable or even better classification performance than that of acomputationally expensive, end-to-end deep neural networkthat is ten times slower.
The proposed algorithm enables efficient, user-friendly,and accurate liveness detection. Its contributions are summa-rized below:
1. Minimal hardware requirements: a single visible-lightcamera and a flash light-emitting device.
2. Minimal computational requirements: implementableon mobile devices.
3. Minimal database requirements: trainable with merely≈ 1K image pairs for both real and fake face classes.
4. Minimal data label requirements: no auxiliary supervi-sion such as depth or segmentation is needed.
5. High detection accuracy, comparable to an end-to-end,deep neural network model, but with ten-times fasterexecution.
2 Related WorkThe current liveness detection technologies aimed againstspoofing attacks are summarized below. Face spoofing at-tacks can be subdivided into two major categories: 2D attacksand 3D attacks. The former includes print-attacks and video-replay attacks, while the latter includes 3D spoofing mask at-tacks. Several publicly available face liveness databases sim-ulate these attacks. To name a few, the NUAA [2] and Print-Attack [3] databases simulate photo attacks. The Replay-Attack [4] and CASIA Face Anti-Spoofing [5] datasets sim-ulate replay attacks in addition to photo attacks. The 3DMask Attack Database [6] and HKBU-Mask Attack withReal World Variations [7] simulate 3D mask attacks. Ex-ample countermeasures to each attack type are summarizedbelow.
2

2.1 Countermeasures to 2D attacksBecause of the reflectance of printed media and the use ofphoto compression, printed photos have surface textures orpatterns that differ from those of a real human face, and thesetextures can be used to detect print attacks. Replay attacksare conducted by playing video on displays such as monitorsor screens, which also have surface properties different fromthose of a real face. Here, local binary pattern (LBP, [4,8,9]),Gaussian filtering [10, 11], and their variants can be used todetect 2D attacks.
Infrared imaging can be used to counter replay attacks,because the display emits light only at visible wavelengths(i.e., a face does not appear in an infrared picture taken ofa display whereas it appears in an image of an actual per-son [12]). Another replay-attack-specific surface property ismoiré pattern [13].
A prominent feature of these 2D attacks is the flat, 2Dstructure of the spoofing media. Here, stereo vision [14],depth measurement from defocusing [15], and flash-based3D measurements [16–19] are effective countermeasures thatdetect flatness as a surrogate of 2D spoofing attacks. In thispaper, we focus on using flash-based liveness detection tocounter 2D attacks.
Some algorithms, including ours, construct descriptorsfrom pictures taken with or without a flash. The followingfour are mono-colored-flash-based algorithms: (i) LBP_FI(LBP on the flash image), in which the LBP of a picturetaken with a flash is used as a descriptor [16]; (ii) SD_FIC(the standard deviation of face intensity change), in whichthe standard deviation of the difference between photos ofthe same subject taken with and without a flash is used as adescriptor [16]; (iii) Face flashing, in which the descriptor ismade from the relative reflectance between two different pix-els in one photo taken with a flash, i.e., the reflectance of eachfacial pixel divided by that of a reflectance pixel (hereafterabbreviated as RelativeReflectance [17]); (iv) implicit 3Dfeatures, where pixel-wise differences in pictures taken withand without a flash are calculated and divided by the pixelintensity of the picture without the flash on a pixel-by-pixelbasis [18]. We compare these algorithms with ours in Resultsection.
2.2 Countermeasures to 3D mask attacksThe recent 3D reconstruction and printing technologies havegiven malicious users the ability to produce realistic spoofingmasks [20]. One example countermeasure against such a 3Dattack is multispectral imaging. Steiner et al. [21] have re-ported the effectiveness of short-wave infrared (SWIR) imag-ing for detecting masks. Another approach is remote pho-toplethysmography (rPPG), which calculates pulse rhythmsfrom periodic changes in face color [22].
In this paper, however, we do not consider 3D attacks be-cause they are less likely due to the high cost of producing
3D masks. Our work focuses on preventing photo attacksand replay attacks.
2.3 End-to-end deep neural networksThe advent of deep learning has allowed researchers to con-struct an end-to-end classifier without having to design anexplicit descriptor. Research on face liveness is no excep-tion; that is, deep neural network-based countermeasureshave been found for not only photo attacks but also replayand 3D mask attacks [23–25]. The Experiment section com-pares our algorithm’s performance with that of a deep neuralnetwork-based, end-to-end classifier.
3 Proposed algorithmWe propose a liveness detection algorithm that uses both spec-ular and diffuse reflection of flash light. The iris regions andthe facial surface are used to compute the Speculum Descrip-tor, Dspec, and the Diffusion Descriptor, Ddiff , respectively.The two descriptors are vectorized and concatenated to buildthe SpecDiff descriptor, which can be classified as a realor fake face by using a standard classifier such as SVM or aneural network.
The procedure is as follows. During and after the flashillumination, two RGB, three-channel photos are taken: P (f)
with a flash, and P (b) under background light. Since not allfront cameras of smartphones are equipped with a flash LED,all display pixels are simultaneously excited with the highestluminance intensity to simulate light from a flash. The flashduration is approximately 200 ms.
Before Dspec and Ddiff are calculated, the following com-mon preprocessing functions are applied to both P (f) andP (b):
• Function FaceDetection: detect face location(Faceloc) from each image.
• Function FeatExtraction: extract locations of facialfeature points (Faceloc) from each face.
• Function FaceCrop: crop the region of interest.
• Function GaussF ilter: apply Gaussian filter to in-crease position invariance.
• Function Resize: resize the region of interest.
For face detection and facial feature extraction, the LBP-AdaBoost algorithm [26] and the supervised descent method[27] are used in combination. The parameters used for crop-ping, Gaussian filtration, and resizing differ according towhether Dspec or Ddiff is being calculated.
The positions of the faces detected in the two photos, P (f)
and P (b), may potentially be different. However, becausethe flash duration is short and Gaussian filtration is applied,
3

cropping the faces with two different binding boxes does notcause a major problem with face alignment.
3.1 Dspec: specular-reflection-based descrip-tor
Real Fake
Attackw/
Attackw/
ROI
len
len/3
(a) (b) (c)
Figure 3: Specular reflections from iris regions. (a) Regionof interest (ROI). A square ROI whose edge is one-thirdof the horizontal eye length (“len” in the panel) is used tocrop the iris region. (b) Real iris pictures taken with (i(f))or without (i(b)) a flash. (c) Fake iris pictures taken with(i(f)) or without (i(b)) a flash. Top row: a print attack witha picture taken without a flash (P (b)). Bottom row: a printattack with a picture taken with a flash (P (f)).
Unlike a printed photo or image shown on a display, thehuman iris shows specular reflection (due to its curved, glassbeads-like structure) when light is flashed in front of it. Thus,if P (f) is from a real face, a white spot reflecting the flashappears, whereas in the case of a real P (b), a white spotdoes not appear (Fig.3b). On the other hand, if P (f) andP (b) are from a fake face, a white spot appears in neitherof them, but if a flashed face is used as the spoof face, itappears in both of them (Fig.3c). To utilize this differenceas Dspec, the iris regions are extracted from the cropped faceaccording to Faceloc. The iris regions are defined as twosquare boxes centered on each eye, having an edge lengththat is one-third of the horizontal length of the eye (Fig.3a).A Gaussian kernel with a two-pixel standard deviation isapplied to each of the regions and then they are resized to40 × 40 pixels. Hereafter, the extracted and resized irisregions from both eyes are denoted as i(f) ∈ R40×40×2 andi(b) ∈ R40×40×2. Pixel intensities at the vertical locationh, horizontal location w, and eye position s are denoted asi(f)h,w,s and i(b)
h,w,s. An intermediate descriptor S is calculated
by pixel-wise subtraction of i(b)h,w,s from i
(f)h,w,s, which is then
normalized by the sum of the luminance magnitudes, i(f)h,w,s +
i(b)h,w,s, as follows:
Sh,w,s =
0 if i(f)h,w,s = i
(b)h,w,s = 0
i(f)h,w,s − i
(b)h,w,s
i(f)h,w,s + i
(b)h,w,s
otherwise.(1)
Because i(f)h,w,s and i(b)h,w,s are greater than or equal to zero,
Sh,w,s ∈ [−1, 1].
One potential weakness ofDspec is its sensitivity to changein the position of the reflected-light spot. Depending on therelative position of the subject’s face and direction of theflash, the position of the white-reflection spot inside theiris region changes. Although Gaussian filtering increasespositional invariance, the variance of the spot position ismuch larger than the Gaussian-kernel width. Thus, to furtherincrease positional invariance, the elements of the vectorizeddescriptor that are originated from each eye are sorted inascending order to obtain Dspec ∈ R3200 as follows:
S = vectorize(S)Dspec = sort(S)
(2)
The steps for calculating Dspec are summarized in the algo-rithm 1.
Algorithm 1 Calculation of Dspec.
Input: P (f), P (b)
Output: Dspec
1: Faceloc = FaceDetection(P (f), P (b))
2: Faceloc = FeatExtraction(P (f), P (b), Faceloc)
3: [i(f), i(b)] = IrisCrop(P (f), P (b), Faceloc)
4: [i(f), i(b)] = GaussF ilter(i(f), i(b), σ = 2pixels)
5: [i(f), i(b)] = Resize(i(f), i(b), [40, 40])
6: for h,w, s in i(f/b) do7: if (ifh,w,s == ibh,w,s == 0) then8: Sh,w,s = 09: else
10: Sh,w,s =i(f)h,w,s − i
(b)h,w,s
i(f)h,w,s + i
(b)h,w,s
11: end if12: end for13: S = vectorize(S)14: Dspec = sort(S)
15: return Dspec
3.2 Ddiff: diffuse-reflection-based descriptorAlthough it has been confirmed thatDspec by itself can detectspoofing attacks, it has several pitfalls. Firstly, if a realsubject is wearing glasses, the lens surface reflects the flash.The false-negative rate is increased when glasses-originatedspecular light contaminates the iris-originated specular light.Secondly, if a photo printed on a glossy paper is bent and usedfor an attack, there is a slight chance that the flash will reflectat the iris region of the printed photo, leading to increasedfalse-negative rate. To compensate for this risk, we proposeanother liveness descriptor based on facial diffuse reflection,
4

called the Diffusion Descriptor or Ddiff . Ddiff represents thesurface structure of a face: real faces have the 3D structures,whereas fake faces have 2D flat surfaces. An intermediatedescriptor S is calculated from the pixel intensities in theface region (in a similar manner to equation 1) as follows:
Sh,w =
0 if I(f)
h,w = I(b)h,w = 0
I(f)h,w − I
(b)h,w
I(f)h,w + I
(b)h,w
otherwise(3)
where I(f) ∈ R100×100 and I(b) ∈ R100×100 are faceregions in photos P (f) and P (b), cropped with rectanglescircumscribing all Faceloc, filtered with a Gaussian kernelwith a five-pixel standard deviation, and resized to 100× 100
pixels. Here, Sh,w ∈ [−1, 1] because I(f)h,w and I
(b)h,w are
greater than or equal to zero. Unlike the case of Dspec, theintermediate descriptor S is vectorized without sorting topreserve the spatial integrity of the face region:
Ddiff = vectorize(S). (4)
In light of the Lambertian model, we can understand whydoes Ddiff represent the 3D structure of a face. Moreover,the Lambertian model explains an additional advantage ofDdiff : color invariance (also see [18]). This can be seen asfollows: assuming that the entire face is a Lambertian surface(i.e., a uniform diffuser), the surface-luminance intensitydepends on the radiant intensity per unit area in the directionof observation. Thus, the pixel intensity Ih,w at the verticalposition h and horizontal position w can be described as:
Ih,w = LKh,w cos θh,w (5)
where L, Kh,w, and θh,w denote the light-source intensity,surface reflectance coefficient, and angle of incidence, re-spectively. As equation 5 indicates, the luminance intensityIh,w depends on the 3D structure of the facial surface thatdetermines θh,w. Additionally, Ih,w depends on the surfacereflectance Kh,w. This means that differences in color of thesurface (e.g., light skin vs. dark skin) affect the observedluminance intensity even under the same light intensity, L.The design of equation 3 solves color-dependency problemby canceling out the surface reflectance Kh,w. Under theassumption of a Lambertian surface, the terms I(f)
h,w and I(b)h,w
are expressed as:
I(f)h,w = L(f)Kh,w cos θh,w + L(f)Kh,w
I(b)h,w = L(b)Kh,w
(6)
where L(f) and L(b) are the intensities of the flash lightand background light (ambient light), respectively. Sinceambient light coming from all directions is integrated, thebackground-light term does not depend on the incident angle
of the light. Substituting I(f)h,w and I(b)
h,w into equation 3 yieldsthe intermediate descriptor S:
Sh,w =
0 if I(f)
h,w = I(b)h,w = 0
L(f) cos θh,w
L(f) cos θh,w + 2L(b)otherwise.
(7)
Equation 7 depends on θ and represents the 3D structure ofthe facial surface. Yet equation 7 is independent of the sur-face reflectance K, thereby avoiding the skin-color problem.Thus, although Lambertian reflections from the facial sur-face can be modeled as a function of the surface reflectanceand surface 3D structure, equation 3 cancels K in order toconfer color invariance as an additional advantage to Ddiff .Algorithm 2 lists the steps for calculating Ddiff .
Algorithm 2 Calculation of Ddiff .
Input: P (f), P (b)
Output: Ddiff
1: Faceloc = FaceDetection(P (f), P (b))
2: Faceloc = FeatExtraction(P (f), P (b), Faceloc)
3: [I(f), I(b)] = FaceCrop(P (f), P (b), Faceloc)
4: [I(f), I(b)] = GaussF ilter(I(f), I(b), σ = 5pixels)
5: [I(f), I(b)] = Resize(I(f), I(b), [100, 100])
6: for h,w in I(f/b) do7: if (I(f)
h,w == I(b)h,w == 0) then
8: Sh,w = 09: else
10: Sh,w =I
(f)h,w − I
(b)h,w
I(f)h,w + I
(b)h,w
11: end if12: end for13: Ddiff = vectorize(S)
14: return Ddiff
3.3 SpecDiff descriptorThe two descriptors are concatenated into the SpecDiffdescriptor:
SpecDiff = concatenate(Dspec,Ddiff) (8)
The SpecDiff descriptor attains higher classification accu-racy compared to either Dspec or Ddiff alone. As both Dspec
and Ddiff are normalized in the range [−1, 1], SpecDiffalso has a bounded descriptor magnitude that helps modeltraining and classification. The experiments described below,however, tested not only SpecDiff ; the ablation studiestested Dspec and Ddiff by themselves.
5

6ch. image
7x7 conv, 64, /2
3x3 conv, 128
3x3 conv, 128
global ave. pool
FC 2
3ch. imagew/o flash
3ch. imagew/ flash
descriptor calculation
SVM (linear or RBF)
3ch. imagew/o flash
3ch. imagew/ flash
descriptor calculation
FC 200
FC 100
FC 50
FC 2
(b) (c)(a) All flash-baseddescriptors
only End-to-end(ResNet4)
Figure 4: Classifiers. (a) SVM classifier applied to the calculated descriptors, Dspec, Ddiff , and SpecDiff . (b) FC layersinterleaved with nonlinear operations (ReLU), classifying the same descriptors as in (a). (c) ResNet4, an end-to-end classifiertaking I ′(f) and I ′(b) as a six-channel tensor.
4 Experiments
4.1 Models
The classification performances of the proposed descrip-tors are evaluated using mainly SVM, either with a lin-ear or radial basis function (RBF) kernel (Fig.4a). Dspec,Ddiff , and SpecDiff are compared with four previouslyreported descriptors: SD_FIC (R, [16]), LBP_FI (R10000,[16]), RelativeReflectance (R10000, [17]), and Implicit3D(R10000, [18]).
For SpecDiff , a neural network consisting of four fully-connected (FC) layers is also tested as a classifier (Fig.4b).The first three FC layers have 200, 100, and 50 hidden units,respectively, interleaved with a rectified linear unit (ReLU).The SpecDiff descriptor is resized to R2500 before beingused as an input to the first layer.
ResNet4 based on ResNet-version 2 [28] is constructed asan end-to-end deep neural network (Fig.4c). ResNet4 takesas input a six-channel image that is constructed with twothree-channel images I ′(f) and I ′(b) concatenated along thechannel axis. I ′(f) and I ′(b) are facial images of 244× 244pixels, with and without a flash. The initial convolution isfollowed by one residual connection skipping the next twoconvolutions. After global average pooling, the FC layersclassify the data into one of the two alternative classes.
All the analyses are conducted with customized scriptsrunning on either MATLAB R2016b with an Intel® CoreTM
i7-4790 [email protected], or on python-TensorFlow1.4 withan NVIDIA GeForce GTX1080 or RTX2080 graphics card.SVM training is executed using the libsvm package [29].
4.2 Databases
As of early 2019, there is no publicly available facial-imagedatabase of images taken with and without a flash. There-fore, we collected 1176 and 1660 photos of real and fakefaces of 20 subjects, respectively. The photographing con-
ditions in the real and fake categories are varied as follows:two lighting conditions (bright office area and dark corridorarea), and three facial-accessory conditions (glasses, a sur-gical mask, or nothing). To make the fake photos, the realfaces are printed on papers or projected on displays in orderto simulate photo- or display- attacks (≈ 15% of the entiredataset is composed of display attacks). Leave-one-ID-outcross-validation is conducted using this in-house database,and the average equal error rate (EER) is calculated as anevaluation measure. The device used for the data collectionis an iPhone7 (A1779). The display-attack devices are aniPad Pro (A1584) and ASUS ZenFone Go (ZB551KL).
To test the generalizability of the proposed method, a cross-database validation is conducted using two public databases,NUAA and Replay-Attack, which consist of 15 IDs / 12614pictures and 50 IDs / 600 videos, respectively, simulatingphoto and display attacks. Due to the inaccessibility of thereal subjects in the databases, only the false acceptance rate(FAR) is evaluated. The models are initially trained usingall of the data in the in-house database, and then tested onNUAA and Replay-Attack databases.
To test vulnerability to the two attack types, the SpecDiffdescriptor with the RBF-kernel SVM is tested separatelyagainst photo and replay attacks by using both the in-housedatabase and the Replay-Attack database. Leave-one-ID-out-cross-validation was performed on the in-house database. Tocompare accuracies by using FAR, we fix the false rejectionrate (FRR) to 0.1 % and evaluated FAR. On the Replay-Attack database, FAR is calculated.
In each training epoch, 10 % of the available non-test datais randomly selected as validation data, on which hyperpa-rameter optimization is conducted.
4.3 Speed test on actual mobile devices
To compare the execution speeds of our proposed algorithmand ResNet4, a deep-neural-network classifier, a custom-made iOS application for liveness detection is built on Xcode
6

10.2.1 / MacBook Pro, written in Swift, C, and C]. ForGaussian filtration, an OpenCV [30] built-in function is used.The app is then installed on an iPhone7 (A1779), iPhoneXR (A2106), and iPad Pro (A1876) for the speed evaluation.Execution speed is measured during the preprocessing stepand the descriptor calculation/classification step.
5 Results
5.1 Classification performanceA leave-one-ID-out cross-validation is conducted on the in-house database to calculate the average EER. The results aresummarized in Table1, with the best model is highlightedin bold. The average Dspec and Ddiff calculated using thein-house database are shown in Fig.2a and b, respectively.The results of the cross-database test, conducted with theNUAA and the Replay-Attack databases, are summarized inTable 2. Among all the descriptors-classifiers combination,the proposed SpecDiff descriptor with RBF kernel-SVMachieves the highest classification accuracy on average, onboth the in-house database and on the two public databases.Moreover, its accuracy is comparable or even better thanResNet4, the end-to-end deep-neural-network classifier. Theresults of the evaluation by attack type are summarized inTable 3. Although the display attack slightly increases FARon the in-house database, the cross-database evaluation on theReplay-Attack database resulted in a low FAR on both photoand display attacks, confirming that the proposed approachis robust against changes in attack types.
5.2 Execution speed on mobile devicesThe results of the speed evaluation of the proposed algorithmand deep neural network classifier on the iPhone7, iPhoneXR and iPad Pro are summarized in Fig.5. On all devices,the proposed algorithm is approximately ten-times faster interms of the descriptor calculation/classification time thanResNet4.
6 DiscussionLiveness detection based on the SpecDiff descriptorachieves the highest classification performance among theflash-based algorithms tested. Moreover, its performance iscomparable to that of more complex end-to-end deep-neural-network, ResNet4. The RBF kernel-based SVM classifierhas approximately 6.6 million floating operations (FLOPs),while ResNet4 has 7 giga-FLOPs (which is larger than theoriginal ResNets due to the large input size, large channelsize, and lack of an initial pooling layer). Accordingly, theproposed SpecDiff descriptor classified with RBF kernel-SVM is approximately ten times faster than the deep neural
Table 1: Leave-one-ID-out cross-validation results obtainedwith the in-house database. The best result is highlighted inbold.
Descriptor Classifier EER (%)
SD_FIC [16] SVMlinear 34.19RBF 33.93
LBP_FI [16] SVM linear 3.07RBF 4.46
RelativeReflectance [17] SVM linear 25.75RBF 10.45
Implicit3D [18] SVMlinear 5.15RBF 1.93
Dspec [PROPOSED] SVMlinear 2.33RBF 2.63
Ddiff [PROPOSED] SVM linear 2.59RBF 1.48
SpecDiff [PROPOSED]SVM linear 1.47
RBF 0.713 FC layers 0.91
ResNet4 0.90
network. Additionally, the model requires only a single cam-era and a single-colored flash light without an additionalimaging device (e.g., IR camera) or auxiliary supervision(e.g., depth information). Thus, the proposed model’s highcomputational efficiency and minimal requirements will en-able it to have a wide range of application.
The proposed Dspec is simple, yet it achieves competitiveclassification accuracy. One drawback is, however, that itsaccuracy is affected by the presence of eyewear. For exam-ple, sunglasses occluding the eye region make the livenessdetection impossible. Even with transparent glasses, specularreflection on the lenses can potentially interfere with the de-scriptor. Because of this drawback, it is recommended to useDdiff simultaneously with Dspec. The combined SpecDiffdescriptor achieved top-tier classification performance in allthe evaluation schemes, indicating its robustness.
Both Ddiff and Dspec are based on the difference betweentwo photos, one taken with, the other without a flash, normal-ized by the pixel intensities of the two photos. Because ofthe normalization, the descriptors are bounded in the range[−1, 1], and the classification accuracy is better than those ofunnormalized descriptors.
Both our original database and the Replay-Attack databasecontain display attacks, by which a photo or a video is playedon an electronic display such as a smartphone or a tablet. The-oretically speaking, displays violate the assumption regardingDdiff : equation 3 applies to a Lambertian surface, whereasdisplays not only diffuse light but also emit light by them-selves, interfering with Ddiff . Despite the violation of thisassumption, the classification performance of the proposed
7

Table 2: Cross-database validation results. The best result is highlighted in bold.
NUAA Replay AttackDescriptor Classifier FAR (%) FAR (%)
SD_FIC [16] SVMlinear 16.15 39.28RBF 27.71 32.81
LBP_FI [16] SVM linear 5.67 0.39RBF 1.96 0.37
RelativeReflectance [17] SVM linear 22.87 27.42RBF 10.67 5.19
Implicit3D [18] SVMlinear 0.63 6.46RBF 0.92 1.96
Dspec [PROPOSED] SVMlinear 1.07 5.19RBF 1.47 1.57
Ddiff [PROPOSED] SVM linear 0.92 9.01RBF 1.07 3.33
SpecDiff [PROPOSED]SVM linear 0.07 3.07
RBF 0.00 0.203 FC layers 0.36 0.10
ResNet4 0.23 0.29
Table 3: Evaluation on spoofing subcategories by usingSpecDiff descriptor with SVM-RBF kernel classifier.
In-house database Replay-AttackFAR@FRR=0.1 (%) FAR(%)
photo display photo display0.88 2.66 0.34 0. 00
model on display attacks is comparable to its performance onphoto attacks. This might have been because the subtractionin the numerator of equation 3 cancels out the display-emittedlight. Although the emitted light increases the denominator,it decreases the overall descriptor magnitude (i.e., it “flattens”the descriptor) leading to correct classification of a face as aspoofing class rather than a real-face class.
When implementing an algorithm for practical use, it isgenerally difficult to choose one best algorithm, becauseeach algorithm has different hardware requirements. A deep-neural-network model or high-resolution infrared-camera-based liveness detection are powerful algorithms, but theyrequire computationally expensive processing units or spe-cialized imaging devices. On the other hand, our proposed al-gorithm, with the SpecDiff descriptor classified with RBFkernel-SVM, is efficient yet effective, having minimal hard-ware and database requirements suitable for mobile devices,web cameras, and edge devices.
Feature calculation / classificationCommon preprocessings
iPhone7
iPhoneXR
iPad Pro
×SVM-RBF [PROPOSED]
×SVM-RBF [PROPOSED]
×SVM-RBF [PROPOSED]
0 50 100 150 200 250 300 350 400
ResNet4
ResNet4
ResNet4
Computing time (ms)
Figure 5: Summary of execution speeds. The proposedSpecDiff descriptor classified with the SVM-RBF kernel iscompared with ResNet4. The preprocessing step is commonto both classifiers. Execution speeds on iPhone7, iPhone XR,and iPad Pro are measured.
7 ConclusionBy using specular and diffusion reflection from a subject’sface, the proposed algorithm based on the SpecDiff descrip-tor achieved the best liveness detection accuracy among otherflash-based algorithms at execution speed approximately ten-times faster than that of a deep neural network. The algo-rithm requires only one visible-light camera and a flash light.A small database containing ≈ 1K image pairs per classwith binary labels is sufficient to train a classifier using theSpecDiff descriptor, enabling the easy and wide applica-
8

tion of the liveness detection algorithm. Experiments con-ducted on the algorithm operating on actual devices confirmsthat it has a practical level of performance on mobile deviceswithout the need for computationally expensive processingunits.
AcknowledgementsWe would like to thank Koichi Takahashi, Kazuo Sato, Yoshi-toki Ideta, and Taiki Miyagawa for the insightful discussionsand supports of the project.
References[1] V. Vapnik and A. Lerner. Pattern recognition using generalized
portrait method. Automation and Remote Control, 24:774–780,1963.
[2] Xiaoyang Tan, Yi Li, Jun Liu, and Lin Jiang. Face livenessdetection from a single image with sparse low rank bilineardiscriminative model. In Kostas Daniilidis, Petros Maragos,and Nikos Paragios, editors, Computer Vision – ECCV 2010,pages 504–517, Berlin, Heidelberg, 2010. Springer BerlinHeidelberg.
[3] A. Anjos and S. Marcel. Counter-measures to photo attacksin face recognition: A public database and a baseline. In 2011International Joint Conference on Biometrics (IJCB), pages1–7, Oct 2011.
[4] I. Chingovska, A. Anjos, and S. Marcel. On the effectivenessof local binary patterns in face anti-spoofing. In 2012 BIOSIG- Proceedings of the International Conference of BiometricsSpecial Interest Group (BIOSIG), pages 1–7, Sep. 2012.
[5] Z. Zhang, J. Yan, S. Liu, Z. Lei, D. Yi, and S. Z. Li. A faceantispoofing database with diverse attacks. In 2012 5th IAPRInternational Conference on Biometrics (ICB), pages 26–31,March 2012.
[6] N. Erdogmus and S. Marcel. Spoofing in 2d face recogni-tion with 3d masks and anti-spoofing with kinect. In 2013IEEE Sixth International Conference on Biometrics: Theory,Applications and Systems (BTAS), pages 1–6, Sep. 2013.
[7] S. Liu, B. Yang, P. C. Yuen, and G. Zhao. A 3d mask faceanti-spoofing database with real world variations. In 2016IEEE Conference on Computer Vision and Pattern RecognitionWorkshops (CVPRW), pages 1551–1557, June 2016.
[8] Tiago de Freitas Pereira, André Anjos, José Mario De Martino,and Sébastien Marcel. Lbp - top based countermeasure againstface spoofing attacks. In Jong-Il Park and Junmo Kim, editors,Computer Vision - ACCV 2012 Workshops, pages 121–132,Berlin, Heidelberg, 2013. Springer Berlin Heidelberg.
[9] J. Maatta, A. Hadid, and M. Pietikainen. Face spoofing detec-tion from single images using texture and local shape analysis.IET Biometrics, 1(1):3–10, March 2012.
[10] K. Kollreider, H. Fronthaler, and J. Bigun. Verifying livenessby multiple experts in face biometrics. In 2008 IEEE Com-puter Society Conference on Computer Vision and PatternRecognition Workshops, pages 1–6, June 2008.
[11] B. Peixoto, C. Michelassi, and A. Rocha. Face liveness de-tection under bad illumination conditions. In 2011 18th IEEEInternational Conference on Image Processing, pages 3557–3560, Sep. 2011.
[12] Lingxue Song and Changsong Liu. Face Liveness DetectionBased on Joint Analysis of RGB and Near-Infrared Image ofFaces. Electronic Imaging, 2018(10):373–1–373–6, January2018.
[13] D. C. Garcia and R. L. de Queiroz. Face-spoofing 2d-detectionbased on moiré-pattern analysis. IEEE Transactions on Infor-mation Forensics and Security, 10(4):778–786, April 2015.
[14] Avinash Kumar Singh, Piyush Joshi, and G.C. Nandi. Faceliveness detection through face structure analysis. Interna-tional Journal of Applied Pattern Recognition, 1(4):338, 2014.
[15] S. Kim, S. Yu, K. Kim, Y. Ban, and S. Lee. Face livenessdetection using variable focusing. In 2013 International Con-ference on Biometrics (ICB), pages 1–6, June 2013.
[16] P. P. K. Chan, W. Liu, D. Chen, D. S. Yeung, F. Zhang,X. Wang, and C. Hsu. Face liveness detection using a flashagainst 2d spoofing attack. IEEE Transactions on InformationForensics and Security, 13(2):521–534, Feb 2018.
[17] Di Tang, Zhe Zhou, Yinqian Zhang, and Kehuan Zhang. Faceflashing: a secure liveness detection protocol based on lightreflections. arXiv, abs/1801.01949, 2018.
[18] J. Matias Di Martino, Qiang Qiu, Trishul Nagenalli, andGuillermo Sapiro. Liveness detection using implicit 3d fea-tures. arXiv, abs/1804.06702, 2018.
[19] Yao Liu, Ying Tai, Ji-Lin Li, Shouhong Ding, Chengjie Wang,Feiyue Huang, Dongyang Li, Wenshuai Qi, and Rongrong Ji.Aurora guard: Real-time face anti-spoofing via light reflection.arXiv, abs/1902.10311, 2019.
[20] Si-Qi Liu, Pong C. Yuen, Xiaobai Li, and Guoying Zhao.Recent Progress on Face Presentation Attack Detection of3d Mask Attacks. In Sébastien Marcel, Mark S. Nixon,Julian Fierrez, and Nicholas Evans, editors, Handbook of Bio-metric Anti-Spoofing, pages 229–246. Springer InternationalPublishing, Cham, 2019.
[21] H. Steiner, A. Kolb, and N. Jung. Reliable face anti-spoofingusing multispectral swir imaging. In 2016 International Con-ference on Biometrics (ICB), pages 1–8, June 2016.
[22] Siqi Liu, Pong C. Yuen, Shengping Zhang, and Guoying Zhao.3d mask face anti-spoofing with remote photoplethysmogra-phy. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling,editors, Computer Vision – ECCV 2016, pages 85–100, Cham,2016. Springer International Publishing.
[23] Jianwei Yang, Zhen Lei, and Stan Z. Li. Learn convolutionalneural network for face anti-spoofing. arXiv, abs/1408.5601,2014.
[24] D. Menotti, G. Chiachia, A. Pinto, W. R. Schwartz, H. Pedrini,A. X. Falcão, and A. Rocha. Deep representations for iris,face, and fingerprint spoofing detection. IEEE Transactionson Information Forensics and Security, 10(4):864–879, April2015.
[25] Chaitanya Nagpal and Shiv Ram Dubey. A performance eval-uation of convolutional neural networks for face anti spoofing.arXiv, abs/1805.04176, 2018.
9

[26] P. Viola and M. Jones. Rapid object detection using a boostedcascade of simple features. In Proceedings of the 2001 IEEEComputer Society Conference on Computer Vision and PatternRecognition. CVPR 2001, volume 1, pages I–I, Dec 2001.
[27] X. Xiong and F. De la Torre. Supervised descent method andits applications to face alignment. In 2013 IEEE Conferenceon Computer Vision and Pattern Recognition, pages 532–539,June 2013.
[28] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Identity mappings in deep residual networks. In ComputerVision - ECCV 2016 - 14th European Conference, Amsterdam,The Netherlands, October 11-14, 2016, Proceedings, Part IV,pages 630–645, 2016.
[29] Chih-Chung Chang and Chih-Jen Lin. LIBSVM: A libraryfor support vector machines. ACM Transactions on Intel-ligent Systems and Technology, 2:27:1–27:27, 2011. Soft-ware available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[30] G. Bradski. The OpenCV Library. Dr. Dobb’s Journal ofSoftware Tools, 2000.
10