a machine learning approach to building domain specific search
TRANSCRIPT

Presented By:
Niharjyoti Sarangi
Roll:06/232
8th Semester, B.Tech, IT
VSSUT, Burla
A Machine Learning Approach to Building
Domain-Specific Search Engines

Machine Learningo Machine learning is a scientific discipline that is
concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases.
o A major focus of machine learning research is to automatically learn to recognize complex patterns and make intelligent decisions based on data.
o A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.

Vertical SearchoA vertical search engine, as distinct from a general
Web search engine, focuses on a specific segment of online content. The vertical content area may be based on topicality, media type, or genre of content.
o General Web search engines :- Attempt to index large portions of the World Wide Web using a Web crawler.
o Vertical search engines :- Typically use a focused crawler that attempts to index only Web pages that are relevant to a pre-defined topic or set of topics.

Domain-Specific SearchoDomain-specific search solutions focus on one area
of knowledge, creating customized search experiences, that because of the domain's limited corpus and clear relationships between concepts, provide extremely relevant results for searchers.
o Potential Benefits over general search engines:-
*Greater precision due to limited scope
*Leverage domain knowledge including taxonomies and ontologies
*Support specific unique user tasks

Anatomy of a Search Engine
1. Crawling the web
2. Indexing the web
3. Searching the indices
4. Major Data structuresi. Big Files
ii. Repositories
iii. Document Index
iv. Lexicon
v. Hit Lists
vi. Forward Index

Web CrawlingoA Web crawler is a computer program that browses
the World Wide Web in a methodical, automated manner or in an orderly fashion.
oOther terms for Web crawlers are ants, automatic indexers, bots, and worms or Web spider, Web robot, or—especially in the FOAF community—Web scutter.
oA Web crawler is one type of bot, or software agent. In general, it starts with a list of URLs to visit, called the seeds. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. URLs from the frontier are recursively visited according to a set of policies.

Web Crawling (contd.)

Information Extractionfoodscience.com-Job2
JobTitle: Ice Cream Guru
Employer: foodscience.com
JobCategory: Travel/Hospitality
JobFunction: Food Services
JobLocation: Upper Midwest
Contact Phone: 800-488-2611
DateExtracted: January 8, 2001
Source: www.foodscience.com/jobs_midwest.html
OtherCompanyJobs: foodscience.com-Job1

Information Extraction (contd.)
Filling slots in a database from sub-segments of text.As a task:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME TITLE ORGANIZATION
Filling slots in a database from sub-segments of text.As a task:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME TITLE ORGANIZATION

Information Extraction (contd.)
Filling slots in a database from sub-segments of text.As a task:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME TITLE ORGANIZATIONBill Gates CEO MicrosoftBill Veghte VP MicrosoftRichard Stallman founder Free Soft..
IE

Information Extraction (contd.) Information Extraction =
segmentation + classification + clustering + association
As a familyof techniques:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation

Information Extraction (contd.) Information Extraction =
segmentation + classification + association + clustering
As a familyof techniques:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation

Information Extraction (contd.) Information Extraction =
segmentation + classification + association + clustering
As a familyof techniques:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation

Information Extraction (contd.) Information Extraction =
segmentation + classification + association + clustering
As a familyof techniques:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation N
AME
TITLE ORGANIZATION
Bill Gates
CEO
Microsoft
Bill Veghte
VP
Microsoft
Richard Stallman
founder
Free Soft..
*
*
*
*

Context of Extraction
Create ontology
SegmentClassifyAssociateCluster
Load DB
Spider
Query,Search
Data mine
IE
Documentcollection
Database
Filter by relevance
Label training data
Train extraction models

IE Techniques
Any of these models can be used to capture words, formatting or both.
Lexicons
AlabamaAlaska…WisconsinWyoming
Sliding WindowClassify Pre-segmented
Candidates
Finite State Machines Context Free GrammarsBoundary Models
Abraham Lincoln was born in Kentucky.
member?
Abraham Lincoln was born in Kentucky.Abraham Lincoln was born in Kentucky.
Classifier
which class?
…and beyond
Abraham Lincoln was born in Kentucky.
Classifier
which class?
Try alternatewindow sizes:
Classifier
which class?
BEGIN END BEGIN END
Abraham Lincoln was born in Kentucky.
Most likely state sequence?
Abraham Lincoln was born in Kentucky.
NNP V P NPVNNP
NP
PP
VP
VP
S
Mos
t lik
ely
pars
e?

Sliding Window GRAND CHALLENGES FOR MACHINE LEARNING
Jaime Carbonell School of Computer Science Carnegie Mellon University
3:30 pm 7500 Wean Hall
Machine learning has evolved from obscurity in the 1970s into a vibrant and popular discipline in artificial intelligence during the 1980s and 1990s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e.g. analogy, explanation-based learning), learning theory (e.g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on.
CMU UseNet Seminar Announcement
E.g.Looking forseminarlocation

Sliding Window GRAND CHALLENGES FOR MACHINE LEARNING
Jaime Carbonell School of Computer Science Carnegie Mellon University
3:30 pm 7500 Wean Hall
Machine learning has evolved from obscurity in the 1970s into a vibrant and popular discipline in artificial intelligence during the 1980s and 1990s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e.g. analogy, explanation-based learning), learning theory (e.g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on.
CMU UseNet Seminar Announcement
E.g.Looking forseminarlocation

Sliding Window GRAND CHALLENGES FOR MACHINE LEARNING
Jaime Carbonell School of Computer Science Carnegie Mellon University
3:30 pm 7500 Wean Hall
Machine learning has evolved from obscurity in the 1970s into a vibrant and popular discipline in artificial intelligence during the 1980s and 1990s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e.g. analogy, explanation-based learning), learning theory (e.g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on.
CMU UseNet Seminar Announcement
E.g.Looking forseminarlocation

Sliding Window GRAND CHALLENGES FOR MACHINE LEARNING
Jaime Carbonell School of Computer Science Carnegie Mellon University
3:30 pm 7500 Wean Hall
Machine learning has evolved from obscurity in the 1970s into a vibrant and popular discipline in artificial intelligence during the 1980s and 1990s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e.g. analogy, explanation-based learning), learning theory (e.g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on.
CMU UseNet Seminar Announcement
E.g.Looking forseminarlocation

Naïve Bayes Model
00 : pm Place : Wean Hall Rm 5409 Speaker : Sebastian Thrunw t-m w t-1 w t w t+n w t+n+1 w t+n+m
prefix contents suffix
mnt
nti,i-t-ni
nt
tii
t
mti,i-ti wPwPwPnPtP
1suffixcontents
1
prefixlengthstart )|()|()|()|()|)(bin(
P(“Wean Hall Rm 5409” = LOCATION) =
Prior probabilityof start position
Prior probabilityof length
Probabilityprefix words
Probabilitycontents words
Probabilitysuffix words
Try all start positions and reasonable lengths
If P(“Wean Hall Rm 5409” = LOCATION) is above some threshold, extract it.
Estimate these probabilities by (smoothed) counts from labeled training data.
…

Hidden Markov Model
St -1
St
Ot
St+1
Ot +1
Ot -1
...
...
Finite state model Graphical model
Parameters: for all states S={s1,s2,…} Start state probabilities: P(st ) Transition probabilities: P(st|st-1 ) Observation (emission) probabilities: P(ot|st )Training: Maximize probability of training observations (w/ prior)
||
11 )|()|(),(
o
ttttt soPssPosP
HMMs are the standard sequence modeling tool in genomics, music, speech, NLP, …
...transitions
observations
o1 o2 o3 o4 o5 o6 o7 o8
Generates:
State sequenceObservation sequence
Usually a multinomial over atomic, fixed alphabet
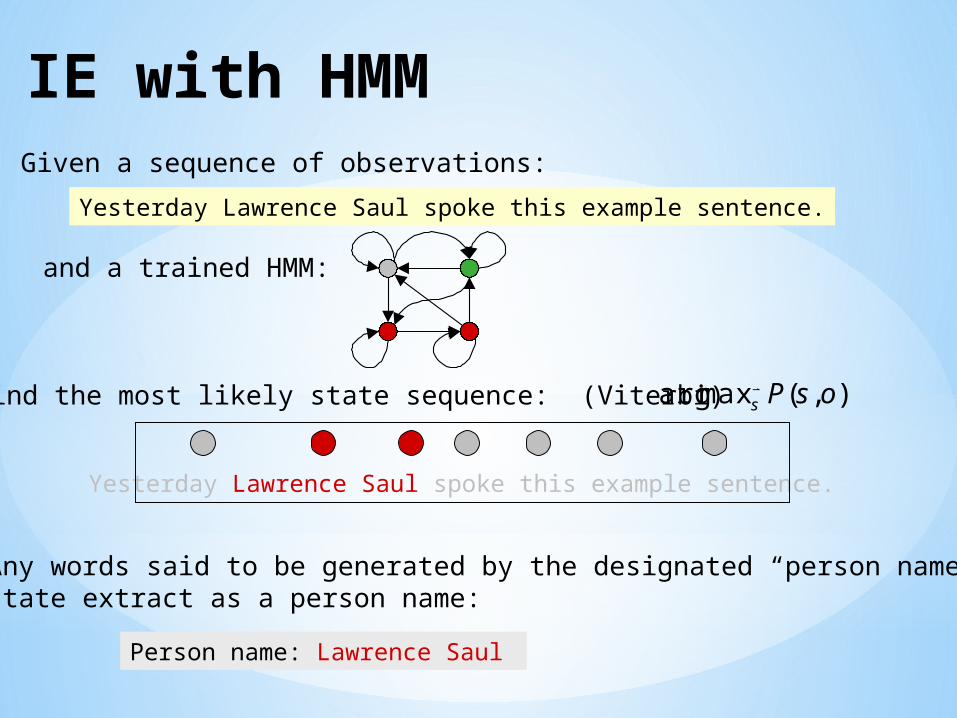
IE with HMM
Yesterday Lawrence Saul spoke this example sentence.
Yesterday Lawrence Saul spoke this example sentence.
Person name: Lawrence Saul
Given a sequence of observations:
and a trained HMM:
Find the most likely state sequence: (Viterbi)
Any words said to be generated by the designated “person name”state extract as a person name:
),(maxarg osPs

Limitations of HMM
HMM/CRF models have a linear structure.Web documents have a hierarchical structure.

Tree Based Models*Extracting from one web site
*Use site-specific formatting information: e.g., “the JobTitle is a bold-faced paragraph in column 2”
*For large well-structured sites, like parsing a formal language
*Extracting from many web sites:
*Need general solutions to entity extraction, grouping into records, etc.
*Primarily use content information
*Must deal with a wide range of ways that users present data.
*Analogous to parsing natural language
*Problems are complementary:*Site-dependent learning can collect training data for a site-
independent learner

Stalker: Hierarchical decomposition of two
web sites

Wrapster
*Common representations for web pages include:
*a rendered image
*a DOM tree (tree of HTML markup & text)
*gives some of the power of hierarchical decomposition
*a sequence of tokens
*a bag of words, a sequence of characters, a node in a directed graph, . . .
*Questions:
*How can we engineer a system to generalize quickly?
*How can we explore representational choices easily?
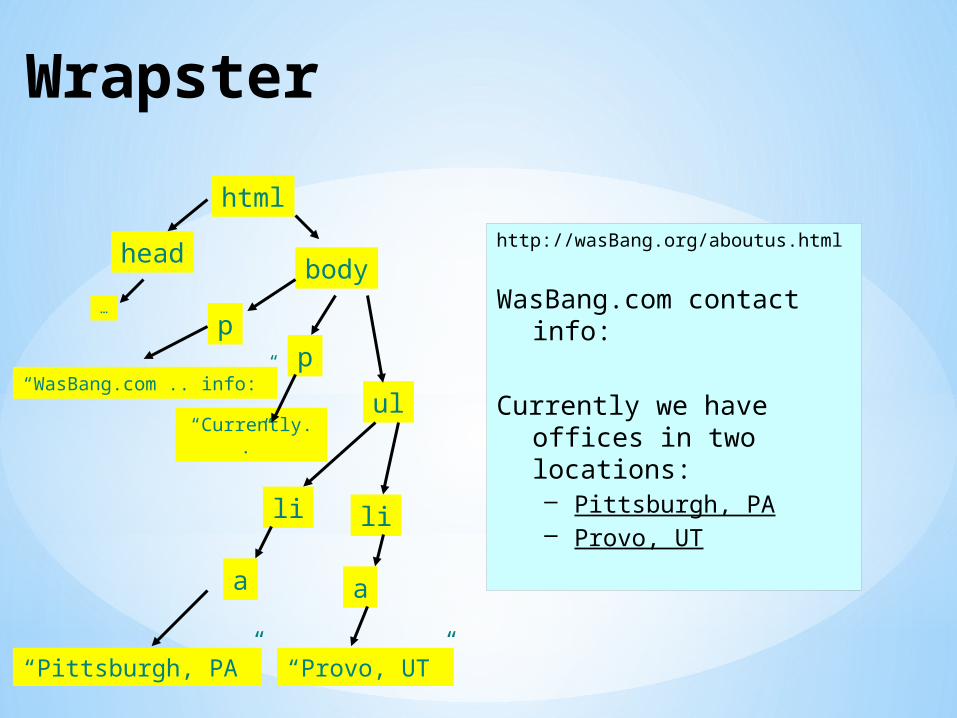
Wrapster
http://wasBang.org/aboutus.html
WasBang.com contact info:
Currently we have offices in two locations:– Pittsburgh, PA– Provo, UT
html
headbody
pp
ul
li li
a a
“Pittsburgh, PA” “Provo, UT”
“WasBang.com .. info:”
“Currently..”
…

Wrapster Builders • Compose `tagpaths’ and `brackets’
– E.g., “extract strings between ‘(‘ and ‘)’ inside a list item inside an unordered list”
• Compose `tagpaths’ and language-based extractors– E.g., “extract city names inside the first paragraph”
• Extract items based on position inside a rendered table, or properties of the rendered text– E.g., “extract items inside any column headed by
text containing the words ‘Job’ and ‘Title’”– E.g. “extract items in boldfaced italics”

Table Based Builders
How to represent “links to pages about singers”?Builders can be based on a geometric view of a page.
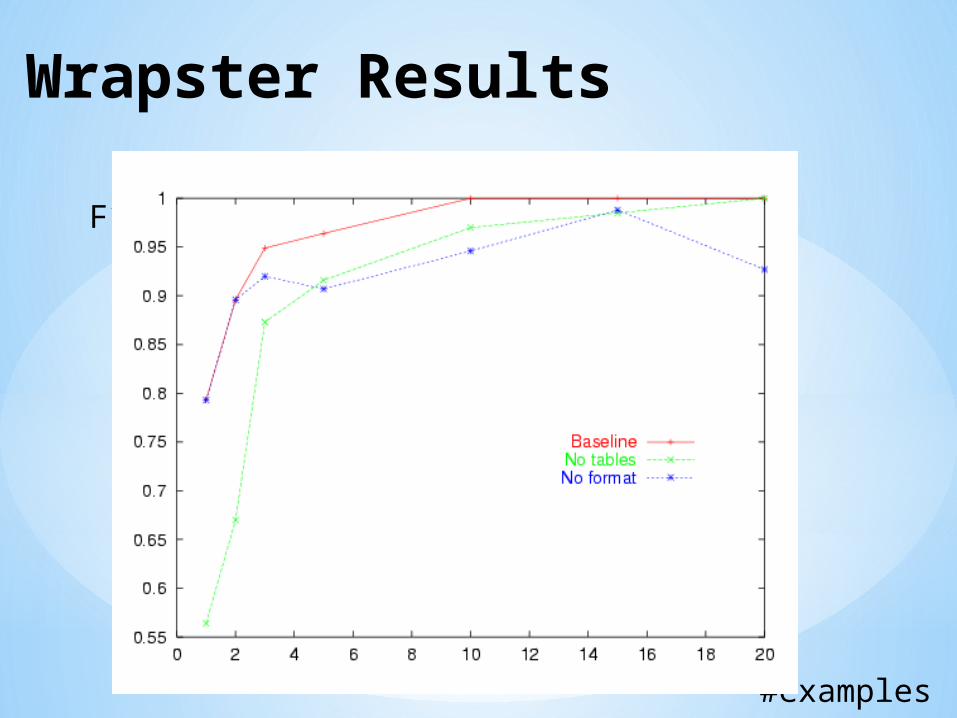
Wrapster Results
F1
#examples

References* [Bikel et al 1997] Bikel, D.; Miller, S.; Schwartz, R.; and Weischedel, R. Nymble: a
high-performance learning name-finder. In Proceedings of ANLP’97, p194-201.
* [Califf & Mooney 1999], Califf, M.E.; Mooney, R.: Relational Learning of Pattern-Match Rules for Information Extraction, in Proceedings of the Sixteenth National Conference on Artificial Intelligence (AAAI-99).
* [Cohen, Hurst, Jensen, 2002] Cohen, W.; Hurst, M.; Jensen, L.: A flexible learning system for wrapping tables and lists in HTML documents. Proceedings of The Eleventh International World Wide Web Conference (WWW-2002)
* [Cohen, Kautz, McAllester 2000] Cohen, W; Kautz, H.; McAllester, D.: Hardening soft information sources. Proceedings of the Sixth International Conference on Knowledge Discovery and Data Mining (KDD-2000).
* [Cohen, 1998] Cohen, W.: Integration of Heterogeneous Databases Without Common Domains Using Queries Based on Textual Similarity, in Proceedings of ACM SIGMOD-98.
* [Cohen, 2000a] Cohen, W.: Data Integration using Similarity Joins and a Word-based Information Representation Language, ACM Transactions on Information Systems, 18(3).
* [Cohen, 2000b] Cohen, W. Automatically Extracting Features for Concept Learning from the Web, Machine Learning: Proceedings of the Seventeeth International Conference (ML-2000).

*THANK YOU
Niharjyoti Sarangi
VSSUT, Burla