a methodology and tool suite for evaluating the accuracy of interoperating nlp engines
TRANSCRIPT

A Methodology and Tool Suite for Evaluating the Accuracy of Interoperating Statistical Natural Language Processing Engines
Uma Murthy Virginia Tech
John Pitrelli, Ganesh Ramaswamy, Martin Franz, and Burn Lewis IBM T.J. Watson Research Center
Interspeech 22-26 September 2008 Brisbane, Australia

2
Outline
• Motivation • Context • Issues • Evaluation methodology • Example evaluation modules • Future directions

3
Motivation
• Combining Natural Language Processing (NLP) engines for information processing in complex tasks
• Evaluation of accuracy of output of individual NLP engines exists – sliding window, BLEU score, word-error rate, etc.
• No work on evaluation methods for large combinations, or aggregates, of NLP engines – Foreign language videos transcription
translation story segmentation topic clustering

4
Project Goal
To develop a methodology and tool suite for evaluating the accuracy (of output) of
interoperating statistical natural language processing engines
in the context of IOD
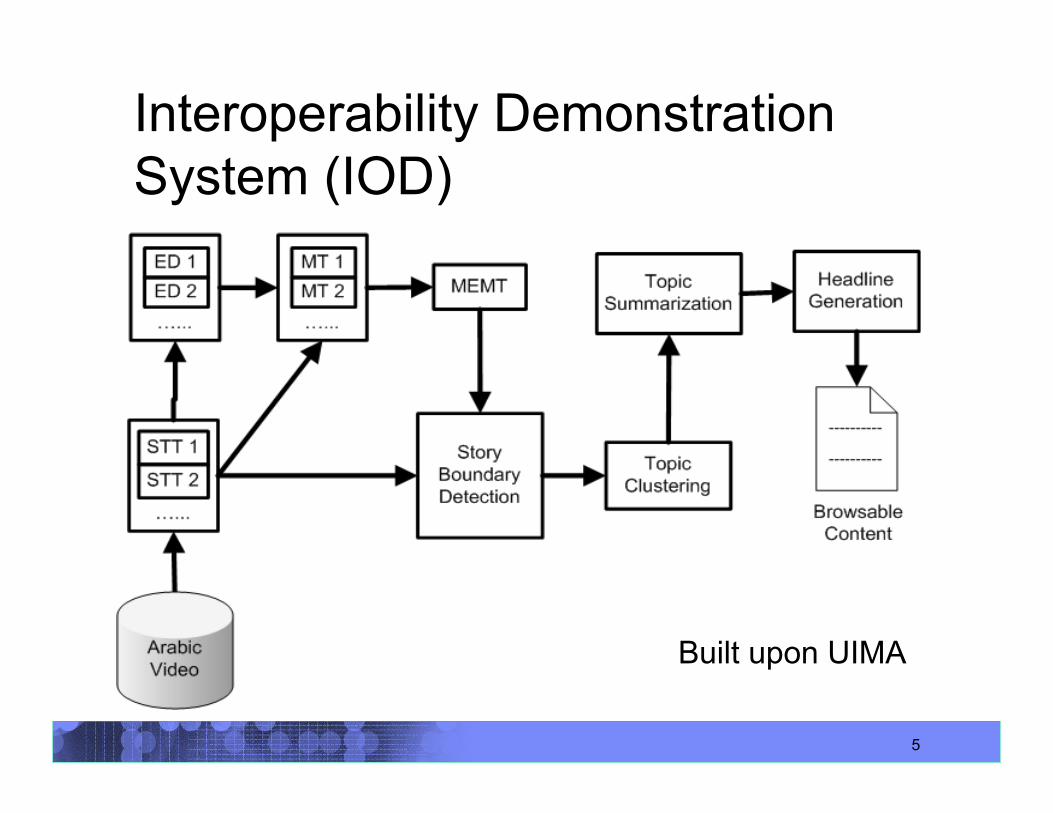
5
Interoperability Demonstration System (IOD)
Built upon UIMA

6
Issues
1. How is the accuracy of one engine or a set of engines evaluated, in the context of being present in an aggregate?
2. What is the measure of accuracy of an aggregate and how can it be computed?
3. How can the mechanics of this evaluation methodology be validated and tested?

7
“Evaluation Space”
• Core of the evaluation methodology • Various options of comparison of
evaluation space of ground truth options based on human-generated and machine-generated outputs at every stage in the pipeline

8

9
1. Comparison between M-M-M… and H-H-H…evaluates the accuracy of the entire aggregate
2. Emerging pattern
3. Comparison of adjacent evaluations determines how much one engine (TC) degrades accuracy of the aggregate
4. Do not consider H-M sequences
5. Comparing two engines of the same function
6. Assembling ground truths is the most expensive task

10
Evaluation Modules
• Uses evaluation space as a template to automatically evaluate the performance of an aggregate
• Development – Explore methods that are used to evaluate the last
engine in the aggregate – If required, modify these methods, considering
• Preceding engines and, their input and output • Different ground truth formats
• Testing: – Focus on validating the mechanics of evaluation and
not the engines in question

11
Example Evaluation Modules • STTSBD
– Sliding-window scheme – Automatically generated comparable
ROC curves • Validated module with six 30-minute Arabic
news shows
• STTMT – BLEU metric – Automatically generated BLEU scores
• Validated module with two Arabic-English MT engines on 38 minutes of audio

12
Future Directions
• Develop more evaluation modules and validate them – Test with actual ground truths – Test with more data-sets – Test on different engines (of the same
kind) • Methodology
– Identify points of error – How much does an engine impact the
performance of the aggregate?

13
Summary
• Presented a methodology for automatic evaluation of accuracy of aggregates of interoperating statistical NLP engines – Evaluation space and evaluation modules
• Developed and validated evaluation modules for two aggregates
• Miles to go! – Small portion of a vast research area

14
Thank You
? ?

15
Back-up Slides

16
Evaluation Module Implementation • Each module was implemented as a
UIMA CAS consumer • Ground truth and other evaluation
parameters were input as CAS Consumer parameters

17
Measuring the performance of story boundary detection
TDT-style sliding window approach: partial credit for slightly misplaced segment boundaries
true system
Source: Franz, et al. “Breaking Translation Symmetry”
• True and system agree within the window t correct. • No system boundary in a window containing a true boundary t Miss • System boundary in a window containing no true boundary t False Alarm
• Window length: 15 seconds

18
STTSBD Test Constraints
• Ground truth availability: word-position-based story boundaries on ASR transcripts – Transcripts were already segmented into
sentences • For the pipeline (STTSBD) output, we
needed to compare time-based story boundaries on Arabic speech