a quadratic programming problem arising from vector precoding
TRANSCRIPT

Journal of Physics Conference Series
OPEN ACCESS
A quadratic programming problem arising fromvector precoding in wireless communicationsTo cite this article R R Muumlller et al 2008 J Phys Conf Ser 95 012006
View the article online for updates and enhancements
You may also likeOrthogonal Array Testing for TransmitPrecoding based Codebooks in SpaceShift Keying SystemsMohammed Al-Ansi Syed Alwee AljunidEssam Sourour et al
-
Research on Massive MIMO KeyTechnology in 5GJiarui Wu
-
Analysis of Linear Precoding Techniquesfor Massive MIMO-OFDM Systems undervarious scenariosD Subitha and R Vani
-
This content was downloaded from IP address 11649888 on 14112021 at 0823
A quadratic programming problem arising from
vector precoding in wireless communications
Ralf R Muller1 Dongning Guo2 and Aris L Moustakas3
1 Department of Electronics amp Telecommunications Norwegian University of Science andTechnology Trondheim Norway2 Department of Electrical Engineering amp Computer Science Northwestern UniversityEvanston IL USA3 Physics Department National amp Kapodistrian University of Athens Athens Greece
E-mail ralfietntnuno dGuonorthwesternedu arislmphysuoagr
Abstract A quadratic programming problem is studied in the limit of asymptotically largekernel matrices by means of the replica method It is found that inverse Wishart kernelsaremdashwithin the validity range of the replica symmetric solutionmdashasymptotically invariant toCartesian relaxations In the context of vector precoding for wireless communication systemswith dual antenna arrays so-called MIMO systems this implies that adding more transmitantennas cannot reduce the minimum required transmit energy per bit significantly By contrasta new convex relaxation is proposed and shown to be a practical and useful method
1 IntroductionNon-convex quadratic programming problems arise in many applications in wirelesscommunications One of them is vector precoding for wireless multiple-input multiple-output(MIMO) systems [1 2] Wireless MIMO technology promises to increase data rate overconventional wireless communications without need for more physical radio spectrum by meansof multiple antenna elements at both the transmitter side and the receiver side [3 4] As adesign choice there can be need for major signal processing at the receiver side the transmitterside or both of them Here we are concerned with systems where sophisticated signal processingis required solely at the transmitter side This is advantageous for transmitting data to low-costor battery-driven devices such as cell-phones and personal digital assistants (PDAs)
It is an unavoidable feature of wireless MIMO systems that signals sent from different antennaelements of the transmit array are received with severe crosstalk at the respective antennaelements of the receive array In order to compensate for the crosstalk one can use linearjoint transmitter processing also known as linear vector precoding as suggested in [5 6]This comes however at the expense of the need for an increased transmit power in orderto maintain the distance properties of the received signal constellation A more sophisticatedmethod for transmitter processing is nonlinear vector precoding which is simply referred to asvector precoding in this work It is based on the concept of Tomlinson-Harashima precoding[7 8] which was originally proposed to combat intersymbol interference It was proposed for usein the context of MIMO systems in [1 2] For a general survey on vector precoding the readeris referred to [9]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
ccopy 2008 IOP Publishing Ltd 1
In this work we are mainly concerned with the performance analysis of vector precoding inthe limit where the number of antennas goes to infinity This problem was addressed in [10]employing the replica method which was originally invented for the analysis of spin glasses instatistical physics [11 12] and has become increasingly powerful to address problems in wirelesscommunications and coding theory [13]
The remainder of the paper consists of five sections Section 2 shows that inverse Wishartkernels are asymptotically invariant to Cartesian relaxations Section 3 introduces vectorprecoding and discusses the implications of section 2 Section 4 proposes a new convex relaxationof the signal set to reduce the complexity of vector precoding and compares its performance tothe benchmarks found in [10] Section 5 concludes the paper
2 An invariance property of the inverse Wishart kernelConsider the following quadratic programming problem
E(ρ) =1K
minxisinX
xdaggerJx (1)
withX = X1 timesX2 times middot middot middot times XK timesR (2)
Xk sube C k = 1 2 and R sube CdρKe In the limit K rarr infin the problem is well-defined forany ρ ge 0 and any random matrix J isin CdK+ρKetimesdK+ρKe which provides enough randomness tomake the quadratic programming problem self-averaging
We call the problem E(ρ) for any ρ gt 0 a Cartesian relaxation of the problem E(0) sincethe constraint set is relaxed by a Cartesian product between the original constraint set and therelaxation set R Since relaxations cannot hurt we have
dE(ρ)dρ
le 0 (3)
In vector precoding for wireless communication systems the kernel takes the form of an inverseWishart matrix That is let H isin CKtimesKα α le 1 be composed of independent identicallydistributed zero-mean complex Gaussian entries we have
J = (HHdagger)minus1 (4)
Intuitively one would expect (3) to hold with strict inequality in most non-trivial cases Thuswhen studying such relaxations by means of replica symmetric analysis it came as a surpriseto the authors to discover that for an inverse Wishart matrix (3) holds with equality ie the(rather generous) relaxation of the constraint set does not reduce the objective function
We will devote the remainder of this section to manifest this invariance property of the inverseWishart kernel within the limitations of the replica-symmetric ansatz We are aware of thefact that quadratic programming problems as they can be formulated as ground state energyproblems are vulnerable to replica-symmetry breaking Nevertheless the replica-symmetricansatz still provides strict inequality in (3) for eg the standard Wishart kernel and presumablymost other random matrices If after all it will turn out that the discovered invariance is nota feature of the inverse Wishart kernel but the replica symmetric solution of the quadraticprogramming problem we hope that our discovery can still be helpful for a better insight intoreplica symmetry and its limitations
We start from a result we recently showed in context of vector precoding for wireless multi-antenna communication systems [10]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
2
Proposition 1 Let the following assumption hold
(i) The random matrix J is bi-unitarily invariant ie it can be de-composed into J = ODOdagger
such that the matrices D and O are diagonal and Haar distributed respectively Moreoveras K rarr infin the asymptotic eigenvalue distribution of J converges to a non-randomdistribution function which can be uniquely characterized by its R-transform R(w)1
(ii) The quadratic programming problem (1) is self-averaging(iii) The parameters q and b are solutions to the following pair of coupled fixed-point equations
q = limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (5)
b = limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(6)
with Dz = exp(minusz22)(2π)dz being the complex Gaussian measure
Then if 0 lt b ltinfin the replica symmetric ansatz yields
E(0)rarr qpart
partbbR(minusb) (7)
as K rarrinfin
In order to fit (1) into the framework of Proposition 1 we first let R = CdρKe without lossof generality Thus we find
E(ρ)rarr (1 + ρ) qpart
partbbR(minusb) (8)
with
q =1
1 + ρ
ρ qRprime(minusb)R2(minusb)
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(9)
b =1
1 + ρ
ρ
R(minusb)+ limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(10)
For the inverse Wishart matrix we find from [10]
R(minusb) =αminus 1 +
radic(1minus α)2 + 4αb
2αb(11)
Rprime(minusb) =
(αminus 1 +
radic(1minus α)2 + 4αb
)2
4αb2radic
(1minus α)2 + 4αb(12)
with α = (1 + ρ)α and α being a free parameter of the Wishart distribution It also turns outhelpful to recognize that
R2(minusb)Rprime(minusb)
=
radic(1minus α)2 + 4αb
α(13)
1 The R-transform of a measure micro(X) is given as R(w) = Gminus1(minusw)minuswminus1 where Gminus1(middot) is the functional inverse(inverse with respect to composition) of G(middot) and G(w) =
R(X minus w)minus1dmicro(X) [14 15]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
3
and it is convenient to replace the parameter b by the substitution
p =radic
(1minus α)2 + 4αb (14)
Thus we get
q =1
(1 + ρ)
ρ qαp
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(15)
b =1
(1 + ρ)R(minusb)
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
](16)
E(ρ) = (1 + ρ)q
p (17)
Plugging (11) into (16) and re-arranging terms we find
p = 1minus α+2α
1 + ρ
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
] (18)
Thus we find from (17)
E(ρ) =ρE(ρ)α+ lim
Krarrinfin1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+ 2αρ+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz(19)
and after some trivial algebra
E(ρ) =limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz (20)
Clearly E(ρ) does not depend on ρ and the proof is complete
3 Vector precodingFollowing [10] vector precoding is conveniently introduced in a general way as follows
Vector precoding aims to minimize the transmitted power that is associated with thetransmission of a certain data vector s isin SK of length K For that purpose the original symbolalphabet S is relaxed into the alphabet B The data representation in the relaxed alphabet isredundant That means that several symbols in the relaxed alphabet represent the same dataDue to the redundant representation we can now choose that representation of our data whichrequires the least power for transmission This way of saving transmit power is what we callvector precoding
That means for any s isin S there is a set Bs sub B such that all elements of Bs represent the datas Take quaternary phase-shift keying (QPSK) as an example ie S = 00 01 10 11 Let j =radicminus1 Without vector precoding it is most common (Gray mapping) to choose B00 = +1 + jB01 = +1minus j B10 = minus1 + j and B11 = minus1minus j For QPSK modulation vector precoding
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
4
Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

A quadratic programming problem arising from
vector precoding in wireless communications
Ralf R Muller1 Dongning Guo2 and Aris L Moustakas3
1 Department of Electronics amp Telecommunications Norwegian University of Science andTechnology Trondheim Norway2 Department of Electrical Engineering amp Computer Science Northwestern UniversityEvanston IL USA3 Physics Department National amp Kapodistrian University of Athens Athens Greece
E-mail ralfietntnuno dGuonorthwesternedu arislmphysuoagr
Abstract A quadratic programming problem is studied in the limit of asymptotically largekernel matrices by means of the replica method It is found that inverse Wishart kernelsaremdashwithin the validity range of the replica symmetric solutionmdashasymptotically invariant toCartesian relaxations In the context of vector precoding for wireless communication systemswith dual antenna arrays so-called MIMO systems this implies that adding more transmitantennas cannot reduce the minimum required transmit energy per bit significantly By contrasta new convex relaxation is proposed and shown to be a practical and useful method
1 IntroductionNon-convex quadratic programming problems arise in many applications in wirelesscommunications One of them is vector precoding for wireless multiple-input multiple-output(MIMO) systems [1 2] Wireless MIMO technology promises to increase data rate overconventional wireless communications without need for more physical radio spectrum by meansof multiple antenna elements at both the transmitter side and the receiver side [3 4] As adesign choice there can be need for major signal processing at the receiver side the transmitterside or both of them Here we are concerned with systems where sophisticated signal processingis required solely at the transmitter side This is advantageous for transmitting data to low-costor battery-driven devices such as cell-phones and personal digital assistants (PDAs)
It is an unavoidable feature of wireless MIMO systems that signals sent from different antennaelements of the transmit array are received with severe crosstalk at the respective antennaelements of the receive array In order to compensate for the crosstalk one can use linearjoint transmitter processing also known as linear vector precoding as suggested in [5 6]This comes however at the expense of the need for an increased transmit power in orderto maintain the distance properties of the received signal constellation A more sophisticatedmethod for transmitter processing is nonlinear vector precoding which is simply referred to asvector precoding in this work It is based on the concept of Tomlinson-Harashima precoding[7 8] which was originally proposed to combat intersymbol interference It was proposed for usein the context of MIMO systems in [1 2] For a general survey on vector precoding the readeris referred to [9]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
ccopy 2008 IOP Publishing Ltd 1
In this work we are mainly concerned with the performance analysis of vector precoding inthe limit where the number of antennas goes to infinity This problem was addressed in [10]employing the replica method which was originally invented for the analysis of spin glasses instatistical physics [11 12] and has become increasingly powerful to address problems in wirelesscommunications and coding theory [13]
The remainder of the paper consists of five sections Section 2 shows that inverse Wishartkernels are asymptotically invariant to Cartesian relaxations Section 3 introduces vectorprecoding and discusses the implications of section 2 Section 4 proposes a new convex relaxationof the signal set to reduce the complexity of vector precoding and compares its performance tothe benchmarks found in [10] Section 5 concludes the paper
2 An invariance property of the inverse Wishart kernelConsider the following quadratic programming problem
E(ρ) =1K
minxisinX
xdaggerJx (1)
withX = X1 timesX2 times middot middot middot times XK timesR (2)
Xk sube C k = 1 2 and R sube CdρKe In the limit K rarr infin the problem is well-defined forany ρ ge 0 and any random matrix J isin CdK+ρKetimesdK+ρKe which provides enough randomness tomake the quadratic programming problem self-averaging
We call the problem E(ρ) for any ρ gt 0 a Cartesian relaxation of the problem E(0) sincethe constraint set is relaxed by a Cartesian product between the original constraint set and therelaxation set R Since relaxations cannot hurt we have
dE(ρ)dρ
le 0 (3)
In vector precoding for wireless communication systems the kernel takes the form of an inverseWishart matrix That is let H isin CKtimesKα α le 1 be composed of independent identicallydistributed zero-mean complex Gaussian entries we have
J = (HHdagger)minus1 (4)
Intuitively one would expect (3) to hold with strict inequality in most non-trivial cases Thuswhen studying such relaxations by means of replica symmetric analysis it came as a surpriseto the authors to discover that for an inverse Wishart matrix (3) holds with equality ie the(rather generous) relaxation of the constraint set does not reduce the objective function
We will devote the remainder of this section to manifest this invariance property of the inverseWishart kernel within the limitations of the replica-symmetric ansatz We are aware of thefact that quadratic programming problems as they can be formulated as ground state energyproblems are vulnerable to replica-symmetry breaking Nevertheless the replica-symmetricansatz still provides strict inequality in (3) for eg the standard Wishart kernel and presumablymost other random matrices If after all it will turn out that the discovered invariance is nota feature of the inverse Wishart kernel but the replica symmetric solution of the quadraticprogramming problem we hope that our discovery can still be helpful for a better insight intoreplica symmetry and its limitations
We start from a result we recently showed in context of vector precoding for wireless multi-antenna communication systems [10]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
2
Proposition 1 Let the following assumption hold
(i) The random matrix J is bi-unitarily invariant ie it can be de-composed into J = ODOdagger
such that the matrices D and O are diagonal and Haar distributed respectively Moreoveras K rarr infin the asymptotic eigenvalue distribution of J converges to a non-randomdistribution function which can be uniquely characterized by its R-transform R(w)1
(ii) The quadratic programming problem (1) is self-averaging(iii) The parameters q and b are solutions to the following pair of coupled fixed-point equations
q = limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (5)
b = limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(6)
with Dz = exp(minusz22)(2π)dz being the complex Gaussian measure
Then if 0 lt b ltinfin the replica symmetric ansatz yields
E(0)rarr qpart
partbbR(minusb) (7)
as K rarrinfin
In order to fit (1) into the framework of Proposition 1 we first let R = CdρKe without lossof generality Thus we find
E(ρ)rarr (1 + ρ) qpart
partbbR(minusb) (8)
with
q =1
1 + ρ
ρ qRprime(minusb)R2(minusb)
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(9)
b =1
1 + ρ
ρ
R(minusb)+ limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(10)
For the inverse Wishart matrix we find from [10]
R(minusb) =αminus 1 +
radic(1minus α)2 + 4αb
2αb(11)
Rprime(minusb) =
(αminus 1 +
radic(1minus α)2 + 4αb
)2
4αb2radic
(1minus α)2 + 4αb(12)
with α = (1 + ρ)α and α being a free parameter of the Wishart distribution It also turns outhelpful to recognize that
R2(minusb)Rprime(minusb)
=
radic(1minus α)2 + 4αb
α(13)
1 The R-transform of a measure micro(X) is given as R(w) = Gminus1(minusw)minuswminus1 where Gminus1(middot) is the functional inverse(inverse with respect to composition) of G(middot) and G(w) =
R(X minus w)minus1dmicro(X) [14 15]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
3
and it is convenient to replace the parameter b by the substitution
p =radic
(1minus α)2 + 4αb (14)
Thus we get
q =1
(1 + ρ)
ρ qαp
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(15)
b =1
(1 + ρ)R(minusb)
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
](16)
E(ρ) = (1 + ρ)q
p (17)
Plugging (11) into (16) and re-arranging terms we find
p = 1minus α+2α
1 + ρ
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
] (18)
Thus we find from (17)
E(ρ) =ρE(ρ)α+ lim
Krarrinfin1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+ 2αρ+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz(19)
and after some trivial algebra
E(ρ) =limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz (20)
Clearly E(ρ) does not depend on ρ and the proof is complete
3 Vector precodingFollowing [10] vector precoding is conveniently introduced in a general way as follows
Vector precoding aims to minimize the transmitted power that is associated with thetransmission of a certain data vector s isin SK of length K For that purpose the original symbolalphabet S is relaxed into the alphabet B The data representation in the relaxed alphabet isredundant That means that several symbols in the relaxed alphabet represent the same dataDue to the redundant representation we can now choose that representation of our data whichrequires the least power for transmission This way of saving transmit power is what we callvector precoding
That means for any s isin S there is a set Bs sub B such that all elements of Bs represent the datas Take quaternary phase-shift keying (QPSK) as an example ie S = 00 01 10 11 Let j =radicminus1 Without vector precoding it is most common (Gray mapping) to choose B00 = +1 + jB01 = +1minus j B10 = minus1 + j and B11 = minus1minus j For QPSK modulation vector precoding
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
4
Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

In this work we are mainly concerned with the performance analysis of vector precoding inthe limit where the number of antennas goes to infinity This problem was addressed in [10]employing the replica method which was originally invented for the analysis of spin glasses instatistical physics [11 12] and has become increasingly powerful to address problems in wirelesscommunications and coding theory [13]
The remainder of the paper consists of five sections Section 2 shows that inverse Wishartkernels are asymptotically invariant to Cartesian relaxations Section 3 introduces vectorprecoding and discusses the implications of section 2 Section 4 proposes a new convex relaxationof the signal set to reduce the complexity of vector precoding and compares its performance tothe benchmarks found in [10] Section 5 concludes the paper
2 An invariance property of the inverse Wishart kernelConsider the following quadratic programming problem
E(ρ) =1K
minxisinX
xdaggerJx (1)
withX = X1 timesX2 times middot middot middot times XK timesR (2)
Xk sube C k = 1 2 and R sube CdρKe In the limit K rarr infin the problem is well-defined forany ρ ge 0 and any random matrix J isin CdK+ρKetimesdK+ρKe which provides enough randomness tomake the quadratic programming problem self-averaging
We call the problem E(ρ) for any ρ gt 0 a Cartesian relaxation of the problem E(0) sincethe constraint set is relaxed by a Cartesian product between the original constraint set and therelaxation set R Since relaxations cannot hurt we have
dE(ρ)dρ
le 0 (3)
In vector precoding for wireless communication systems the kernel takes the form of an inverseWishart matrix That is let H isin CKtimesKα α le 1 be composed of independent identicallydistributed zero-mean complex Gaussian entries we have
J = (HHdagger)minus1 (4)
Intuitively one would expect (3) to hold with strict inequality in most non-trivial cases Thuswhen studying such relaxations by means of replica symmetric analysis it came as a surpriseto the authors to discover that for an inverse Wishart matrix (3) holds with equality ie the(rather generous) relaxation of the constraint set does not reduce the objective function
We will devote the remainder of this section to manifest this invariance property of the inverseWishart kernel within the limitations of the replica-symmetric ansatz We are aware of thefact that quadratic programming problems as they can be formulated as ground state energyproblems are vulnerable to replica-symmetry breaking Nevertheless the replica-symmetricansatz still provides strict inequality in (3) for eg the standard Wishart kernel and presumablymost other random matrices If after all it will turn out that the discovered invariance is nota feature of the inverse Wishart kernel but the replica symmetric solution of the quadraticprogramming problem we hope that our discovery can still be helpful for a better insight intoreplica symmetry and its limitations
We start from a result we recently showed in context of vector precoding for wireless multi-antenna communication systems [10]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
2
Proposition 1 Let the following assumption hold
(i) The random matrix J is bi-unitarily invariant ie it can be de-composed into J = ODOdagger
such that the matrices D and O are diagonal and Haar distributed respectively Moreoveras K rarr infin the asymptotic eigenvalue distribution of J converges to a non-randomdistribution function which can be uniquely characterized by its R-transform R(w)1
(ii) The quadratic programming problem (1) is self-averaging(iii) The parameters q and b are solutions to the following pair of coupled fixed-point equations
q = limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (5)
b = limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(6)
with Dz = exp(minusz22)(2π)dz being the complex Gaussian measure
Then if 0 lt b ltinfin the replica symmetric ansatz yields
E(0)rarr qpart
partbbR(minusb) (7)
as K rarrinfin
In order to fit (1) into the framework of Proposition 1 we first let R = CdρKe without lossof generality Thus we find
E(ρ)rarr (1 + ρ) qpart
partbbR(minusb) (8)
with
q =1
1 + ρ
ρ qRprime(minusb)R2(minusb)
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(9)
b =1
1 + ρ
ρ
R(minusb)+ limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(10)
For the inverse Wishart matrix we find from [10]
R(minusb) =αminus 1 +
radic(1minus α)2 + 4αb
2αb(11)
Rprime(minusb) =
(αminus 1 +
radic(1minus α)2 + 4αb
)2
4αb2radic
(1minus α)2 + 4αb(12)
with α = (1 + ρ)α and α being a free parameter of the Wishart distribution It also turns outhelpful to recognize that
R2(minusb)Rprime(minusb)
=
radic(1minus α)2 + 4αb
α(13)
1 The R-transform of a measure micro(X) is given as R(w) = Gminus1(minusw)minuswminus1 where Gminus1(middot) is the functional inverse(inverse with respect to composition) of G(middot) and G(w) =
R(X minus w)minus1dmicro(X) [14 15]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
3
and it is convenient to replace the parameter b by the substitution
p =radic
(1minus α)2 + 4αb (14)
Thus we get
q =1
(1 + ρ)
ρ qαp
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(15)
b =1
(1 + ρ)R(minusb)
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
](16)
E(ρ) = (1 + ρ)q
p (17)
Plugging (11) into (16) and re-arranging terms we find
p = 1minus α+2α
1 + ρ
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
] (18)
Thus we find from (17)
E(ρ) =ρE(ρ)α+ lim
Krarrinfin1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+ 2αρ+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz(19)
and after some trivial algebra
E(ρ) =limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz (20)
Clearly E(ρ) does not depend on ρ and the proof is complete
3 Vector precodingFollowing [10] vector precoding is conveniently introduced in a general way as follows
Vector precoding aims to minimize the transmitted power that is associated with thetransmission of a certain data vector s isin SK of length K For that purpose the original symbolalphabet S is relaxed into the alphabet B The data representation in the relaxed alphabet isredundant That means that several symbols in the relaxed alphabet represent the same dataDue to the redundant representation we can now choose that representation of our data whichrequires the least power for transmission This way of saving transmit power is what we callvector precoding
That means for any s isin S there is a set Bs sub B such that all elements of Bs represent the datas Take quaternary phase-shift keying (QPSK) as an example ie S = 00 01 10 11 Let j =radicminus1 Without vector precoding it is most common (Gray mapping) to choose B00 = +1 + jB01 = +1minus j B10 = minus1 + j and B11 = minus1minus j For QPSK modulation vector precoding
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
4
Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

Proposition 1 Let the following assumption hold
(i) The random matrix J is bi-unitarily invariant ie it can be de-composed into J = ODOdagger
such that the matrices D and O are diagonal and Haar distributed respectively Moreoveras K rarr infin the asymptotic eigenvalue distribution of J converges to a non-randomdistribution function which can be uniquely characterized by its R-transform R(w)1
(ii) The quadratic programming problem (1) is self-averaging(iii) The parameters q and b are solutions to the following pair of coupled fixed-point equations
q = limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (5)
b = limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(6)
with Dz = exp(minusz22)(2π)dz being the complex Gaussian measure
Then if 0 lt b ltinfin the replica symmetric ansatz yields
E(0)rarr qpart
partbbR(minusb) (7)
as K rarrinfin
In order to fit (1) into the framework of Proposition 1 we first let R = CdρKe without lossof generality Thus we find
E(ρ)rarr (1 + ρ) qpart
partbbR(minusb) (8)
with
q =1
1 + ρ
ρ qRprime(minusb)R2(minusb)
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(9)
b =1
1 + ρ
ρ
R(minusb)+ limKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(10)
For the inverse Wishart matrix we find from [10]
R(minusb) =αminus 1 +
radic(1minus α)2 + 4αb
2αb(11)
Rprime(minusb) =
(αminus 1 +
radic(1minus α)2 + 4αb
)2
4αb2radic
(1minus α)2 + 4αb(12)
with α = (1 + ρ)α and α being a free parameter of the Wishart distribution It also turns outhelpful to recognize that
R2(minusb)Rprime(minusb)
=
radic(1minus α)2 + 4αb
α(13)
1 The R-transform of a measure micro(X) is given as R(w) = Gminus1(minusw)minuswminus1 where Gminus1(middot) is the functional inverse(inverse with respect to composition) of G(middot) and G(w) =
R(X minus w)minus1dmicro(X) [14 15]
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
3
and it is convenient to replace the parameter b by the substitution
p =radic
(1minus α)2 + 4αb (14)
Thus we get
q =1
(1 + ρ)
ρ qαp
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(15)
b =1
(1 + ρ)R(minusb)
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
](16)
E(ρ) = (1 + ρ)q
p (17)
Plugging (11) into (16) and re-arranging terms we find
p = 1minus α+2α
1 + ρ
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
] (18)
Thus we find from (17)
E(ρ) =ρE(ρ)α+ lim
Krarrinfin1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+ 2αρ+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz(19)
and after some trivial algebra
E(ρ) =limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz (20)
Clearly E(ρ) does not depend on ρ and the proof is complete
3 Vector precodingFollowing [10] vector precoding is conveniently introduced in a general way as follows
Vector precoding aims to minimize the transmitted power that is associated with thetransmission of a certain data vector s isin SK of length K For that purpose the original symbolalphabet S is relaxed into the alphabet B The data representation in the relaxed alphabet isredundant That means that several symbols in the relaxed alphabet represent the same dataDue to the redundant representation we can now choose that representation of our data whichrequires the least power for transmission This way of saving transmit power is what we callvector precoding
That means for any s isin S there is a set Bs sub B such that all elements of Bs represent the datas Take quaternary phase-shift keying (QPSK) as an example ie S = 00 01 10 11 Let j =radicminus1 Without vector precoding it is most common (Gray mapping) to choose B00 = +1 + jB01 = +1minus j B10 = minus1 + j and B11 = minus1minus j For QPSK modulation vector precoding
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
4
Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

and it is convenient to replace the parameter b by the substitution
p =radic
(1minus α)2 + 4αb (14)
Thus we get
q =1
(1 + ρ)
ρ qαp
+ limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣∣argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣∣∣∣∣∣2
Dz
(15)
b =1
(1 + ρ)R(minusb)
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
](16)
E(ρ) = (1 + ρ)q
p (17)
Plugging (11) into (16) and re-arranging terms we find
p = 1minus α+2α
1 + ρ
[ρ+
radicp
2qαlimKrarrinfin
1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣∣zradicqα
2pminus x
∣∣∣∣∣ zlowast
Dz
] (18)
Thus we find from (17)
E(ρ) =ρE(ρ)α+ lim
Krarrinfin1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+ 2αρ+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz(19)
and after some trivial algebra
E(ρ) =limKrarrinfin
1K
Ksumk=1
int ∣∣∣∣argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣∣∣∣∣2 Dz
1minus α+radic
2αE(ρ) lim
Krarrinfin1K
Ksumk=1
intlt
argminxisinXk
∣∣∣∣zradicE(ρ)α2 minus x
∣∣∣∣ zlowastDz (20)
Clearly E(ρ) does not depend on ρ and the proof is complete
3 Vector precodingFollowing [10] vector precoding is conveniently introduced in a general way as follows
Vector precoding aims to minimize the transmitted power that is associated with thetransmission of a certain data vector s isin SK of length K For that purpose the original symbolalphabet S is relaxed into the alphabet B The data representation in the relaxed alphabet isredundant That means that several symbols in the relaxed alphabet represent the same dataDue to the redundant representation we can now choose that representation of our data whichrequires the least power for transmission This way of saving transmit power is what we callvector precoding
That means for any s isin S there is a set Bs sub B such that all elements of Bs represent the datas Take quaternary phase-shift keying (QPSK) as an example ie S = 00 01 10 11 Let j =radicminus1 Without vector precoding it is most common (Gray mapping) to choose B00 = +1 + jB01 = +1minus j B10 = minus1 + j and B11 = minus1minus j For QPSK modulation vector precoding
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
4
Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

Figure 1 Four equally spaced integer lattices representing the four QPSK states 00 01 10and 11 respectively
is the idea to have B00 sup +1 + j B01 sup +1 minus j B10 sup minus1 + j and B11 sup minus1 minus j ieto allow for supersets of the quaternary constellation A popular choice for those supersetsis due to Tomlinson Harashima and Miyakawa [7 8] where B00 = (4Z + 1) times (4jZ + j)B01 = (4Z + 1) times (4jZ minus j) B10 = (4Z minus 1) times (4jZ + j) and B11 = (4Z minus 1) times (4jZ minus j) aredisjoint subsets of the odd integer lattice points (see also figure 1)
In order to avoid ambiguities we should have
Bi cap Bj = empty foralli 6= j (21)
In addition one would like to design the sets Bi such that the distance properties of the receivedsignals are preserved This is for instance easily achieved by letting the sets Bi to be distinctsub-lattices of B as in figure 1 However the choice of non-convex sets Bi in general leads toNP-hardness of the vector precoding problem Therefore it is advantageous to use convex setsBi even if that increases the transmitted energy per symbol for sake of feasibility
Let s = [s1 sK ]T denote the information to be encoded Let t = Tx be the Kα times 1vector being sent where α denotes the ratio between data streams to transmit antennas and theK times 1 vector x be the redundant representation of the data Then the precoding problem canbe written as the minimization of the following quadratic form
minxisinX||Tx||2 = min
xisinXxdaggerJx (22)
over the discrete setX = Bs1 times Bs2 times middot middot middot times BsK (23)
with J = T daggerT Consider a vector-valued communication system Let the received vector be given as
r = Ht + n (24)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
5
where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

where n is additive noise Let the components of the transmitted and received vectors be signalssent and received at different antenna elements respectively
We want to ensure that the received signal is (up to additive noise) identical to the datavector This design criteria leads us to choose the precoding matrix
T = Hdagger(HHdagger
)minus1 (25)
This means that we invert the channel and get r = x + n if the matrix inverse exists Thisallows to keep the signal processing at the receiver at a minimum This is advantageous if thereceiver shall be a low-cost or battery-powered device
To model the statistics of the entries of H is a non-trivial task and a topic of ongoing researchsee eg [16] and references therein For sake of convenience we choose in this first order approachthat the entries of the channel matrix H are independent and identically distributed complexGaussian random variables with zero mean and variance αK Thus the kernel matrix J is aninverse Wishart matrix
For inverse Wishart matrices the invariance property found in section 2 applies But whatdoes it mean in context of vector precoding A Cartesian relaxation in a MIMO system withvector precoding would be to add a couple of receive antennas precisely speaking ρK of themto the K receive antennas already in use and design dummy data-streams for those receiveantennas The dummy data does not bear any useful information but intends to reduce theradiated power at the transmit antennas The invariance property for inverse Wishart matricesmeans in this context that regardless of how many additional receive antennas we provide andregardless how we design the dummy data the radiated power at the transmitter will not decay
The situation does not become better for Cartesian relaxations if we are willing to compromiseon the data rate That is we do not add receive antennas but reduce the total data rate inorder to free some of the existing receive antennas for the dummy data In such a case we wouldreduce the radiated power at the transmit antennas However we could achieve the same powersaving by simply shutting down those receive antennas that are meant to receive the dummydata
4 A new convex relaxationWe aim to perform vector precoding at feasible complexity Lattice precoding performs verywell [10] but is NP-hard We have seen in section 2 that Cartesian relaxations do not helpIn order to allow for polynomial complexity we should allow for convex sets Since we shouldnot reduce the minimum distance between the signal constellation it seems intuitive to try thefollowing convex relaxation
S = 00 01 10 11 (26)B00 = z isin C ltz le minus1 and =z le minus1 (27)B01 = z isin C ltz le minus1 and =z ge +1 (28)B10 = z isin C ltz ge +1 and =z le minus1 (29)B11 = z isin C ltz ge +1 and =z ge +1 (30)
These signal sets are depicted in figure 2 All these signal sets are convex The kernel matrixJ is positive-semidefinite Therefore the corresponding quadratic programming problems canbe solved in polynomial time Furthermore the mapping is independent of each other in bothquadrature components
From Proposition 1 and (14) we get
q =int ∣∣∣∣∣argmin
xisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣∣∣∣∣∣2
Dz (31)
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
6
Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9

Figure 2 Complex convex relaxation representing the four quaternary states 00 01 10 and11 respectively
=
radic2π
+infinintminusinfin
1 z ltradic
2pqα
z2 qα2p z gt
radic2pqα
exp(minusz22)dz (32)
= 2minus 2Q(radic
2pqα
)+qα
pQ(radic
2pqα
)+radicqα
πpexp
(minus p
qα
)(33)
b =intlt
argminxisinB11
∣∣∣∣∣zradicqRprime(minusb)2R2(minusb)
minus x
∣∣∣∣∣ zlowast
Dzradic2qRprime(minusb)
(34)
p = 1minus α+ 2αradic
p
2qα
radic2π
+infinintminusinfin
z z ltradic
2pqα
z2radic
qα2p z gt
radic2pqα
exp(minusz22)dz (35)
= 1minus α+ 2αQ(radic
2pqα
) (36)
with Q(x) =intinfinx exp(minusx22)dx
radic2π Finally we can use (36) to simplify (33)
q = 2 +2minus 2pα
minus q
p(1minus α) + 2
radicqα
πpexp
(minus p
qα
) (37)
The solutions to these fixed point equations are shown in figure 3 For unit load the energyper symbol is found to be approximately 3 times higher than with lattice precoding This isthe price to be paid for precoding with polynomial complexity In comparison to sole channelinversion the proposed convex relaxation allows to increase the load by about 30 without needfor more transmitted energy This means that the transmitter can achieve the same performancewith at least 30 fewer transmit antennas
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
7
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9
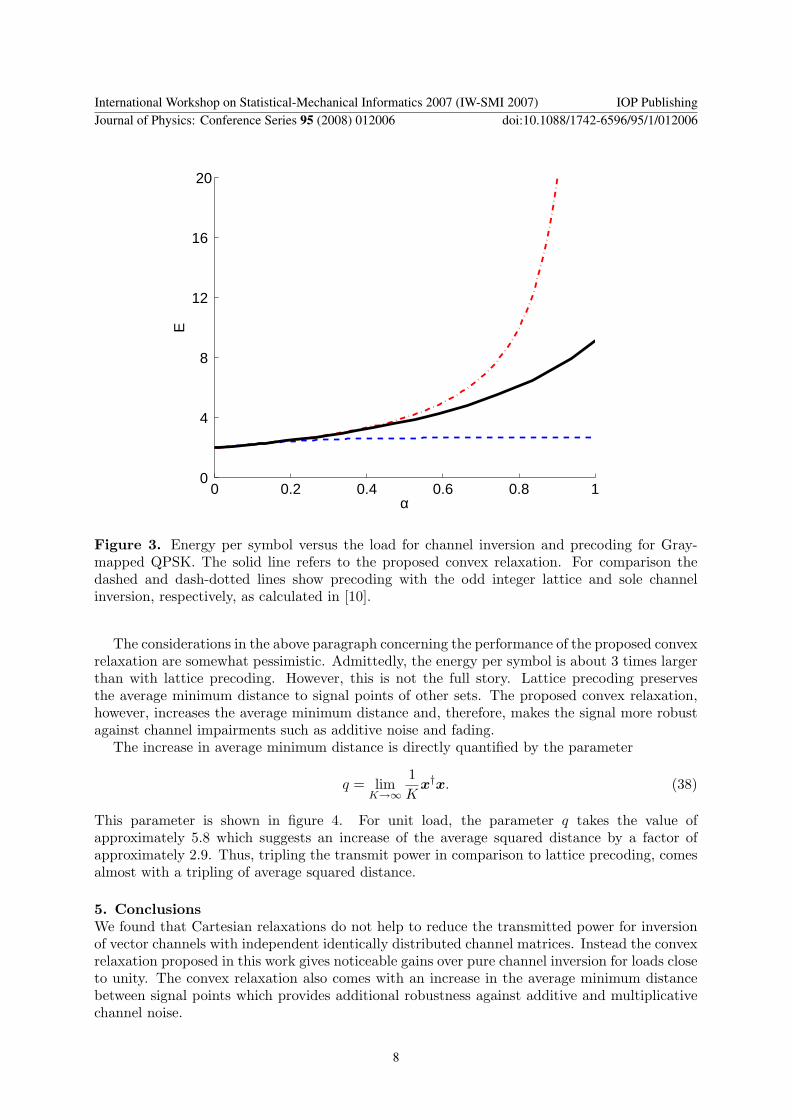
0 02 04 06 08 10
4
8
12
16
20
α
E
Figure 3 Energy per symbol versus the load for channel inversion and precoding for Gray-mapped QPSK The solid line refers to the proposed convex relaxation For comparison thedashed and dash-dotted lines show precoding with the odd integer lattice and sole channelinversion respectively as calculated in [10]
The considerations in the above paragraph concerning the performance of the proposed convexrelaxation are somewhat pessimistic Admittedly the energy per symbol is about 3 times largerthan with lattice precoding However this is not the full story Lattice precoding preservesthe average minimum distance to signal points of other sets The proposed convex relaxationhowever increases the average minimum distance and therefore makes the signal more robustagainst channel impairments such as additive noise and fading
The increase in average minimum distance is directly quantified by the parameter
q = limKrarrinfin
1K
xdaggerx (38)
This parameter is shown in figure 4 For unit load the parameter q takes the value ofapproximately 58 which suggests an increase of the average squared distance by a factor ofapproximately 29 Thus tripling the transmit power in comparison to lattice precoding comesalmost with a tripling of average squared distance
5 ConclusionsWe found that Cartesian relaxations do not help to reduce the transmitted power for inversionof vector channels with independent identically distributed channel matrices Instead the convexrelaxation proposed in this work gives noticeable gains over pure channel inversion for loads closeto unity The convex relaxation also comes with an increase in the average minimum distancebetween signal points which provides additional robustness against additive and multiplicativechannel noise
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
8
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9
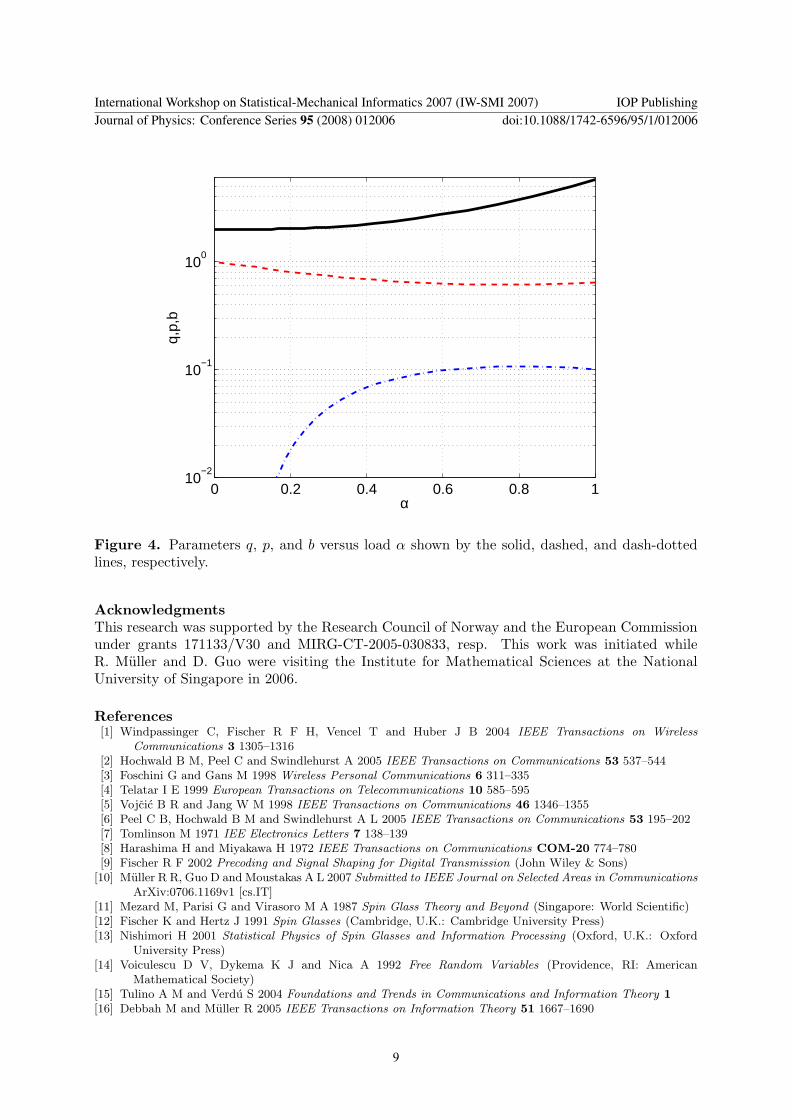
0 02 04 06 08 110
minus2
10minus1
100
α
qp
b
Figure 4 Parameters q p and b versus load α shown by the solid dashed and dash-dottedlines respectively
AcknowledgmentsThis research was supported by the Research Council of Norway and the European Commissionunder grants 171133V30 and MIRG-CT-2005-030833 resp This work was initiated whileR Muller and D Guo were visiting the Institute for Mathematical Sciences at the NationalUniversity of Singapore in 2006
References[1] Windpassinger C Fischer R F H Vencel T and Huber J B 2004 IEEE Transactions on Wireless
Communications 3 1305ndash1316[2] Hochwald B M Peel C and Swindlehurst A 2005 IEEE Transactions on Communications 53 537ndash544[3] Foschini G and Gans M 1998 Wireless Personal Communications 6 311ndash335[4] Telatar I E 1999 European Transactions on Telecommunications 10 585ndash595[5] Vojcic B R and Jang W M 1998 IEEE Transactions on Communications 46 1346ndash1355[6] Peel C B Hochwald B M and Swindlehurst A L 2005 IEEE Transactions on Communications 53 195ndash202[7] Tomlinson M 1971 IEE Electronics Letters 7 138ndash139[8] Harashima H and Miyakawa H 1972 IEEE Transactions on Communications COM-20 774ndash780[9] Fischer R F 2002 Precoding and Signal Shaping for Digital Transmission (John Wiley amp Sons)
[10] Muller R R Guo D and Moustakas A L 2007 Submitted to IEEE Journal on Selected Areas in CommunicationsArXiv07061169v1 [csIT]
[11] Mezard M Parisi G and Virasoro M A 1987 Spin Glass Theory and Beyond (Singapore World Scientific)[12] Fischer K and Hertz J 1991 Spin Glasses (Cambridge UK Cambridge University Press)[13] Nishimori H 2001 Statistical Physics of Spin Glasses and Information Processing (Oxford UK Oxford
University Press)[14] Voiculescu D V Dykema K J and Nica A 1992 Free Random Variables (Providence RI American
Mathematical Society)[15] Tulino A M and Verdu S 2004 Foundations and Trends in Communications and Information Theory 1[16] Debbah M and Muller R 2005 IEEE Transactions on Information Theory 51 1667ndash1690
International Workshop on Statistical-Mechanical Informatics 2007 (IW-SMI 2007) IOP PublishingJournal of Physics Conference Series 95 (2008) 012006 doi1010881742-6596951012006
9