a self-managing wide-area data streaming...
TRANSCRIPT

Cluster ComputDOI 10.1007/s10586-007-0023-x
A self-managing wide-area data streaming service
Viraj Bhat · Manish Parashar · Hua Liu ·Nagarajan Kandasamy · Mohit Khandekar ·Scott Klasky · Sherif Abdelwahed
Received: 13 March 2007 / Accepted: 16 March 2007© Springer Science+Business Media, LLC 2007
Abstract Efficient and robust data streaming services are acritical requirement of emerging Grid applications, whichare based on seamless interactions and coupling betweengeographically distributed application components. Further-more the dynamism of Grid environments and applicationsrequires that these services be able to continually manageand optimize their operation based on system state and ap-plication requirements. This paper presents a design and im-
V. Bhat (�) · M. ParasharDepartment of Electrical and Computer Engineering, RutgersUniversity, 94 Brett Road, Piscataway, NJ 08854, USAe-mail: [email protected]
M. Parashare-mail: [email protected]
H. LiuXerox Innovation Group, 800 Phillips Rd, Mailstop 128-30E,Webster, NY 14580, USAe-mail: [email protected]
N. Kandasamy · M. KhandekarDepartment of Electrical and Computer Engineering, DrexelUniversity, 3141 Chestnut Street, Philadelphia, PA 19104, USA
N. Kandasamye-mail: [email protected]
M. Khandekare-mail: [email protected]
S. KlaskyOak Ridge National Laboratory, P.O. Box 2008, Oak Ridge,TN 37831, USAe-mail: [email protected]
S. AbdelwahedInstitute for Software Integrated Systems, 2015 Terrace Place,Nashville, TN 37235, USAe-mail: [email protected]
plementation of such a self-managing data-streaming ser-vice based on online control strategies. A Grid-based fu-sion workflow scenario is used to evaluate the service anddemonstrate its feasibility and performance.
Keywords Scientific data streaming · Autonomiccomputing · Grid computing · Model based online control
1 Introduction
Grid computing has established itself as the dominant para-digm for wide-area high-performance distributed comput-ing. As Grid technologies and testbeds mature, they areenabling a new generation of scientific and engineeringapplication formulations based on seamless interactionsand couplings between geographically distributed compu-tational, data, and information services. A key requirementof these applications is the support for high-throughput low-latency robust data streaming between the correspondingdistributed components. For example, a typical Grid-basedfusion simulation workflow consists of coupled simulationcodes running simultaneously on separate HPC resources atsupercomputing centers. Further, they must interact at run-time with services for interactive data monitoring, onlinedata analysis and visualization, data archiving, and collab-oration that also run simultaneously on remote sites. Thefusion codes generate large amounts of data, which mustbe streamed efficiently and effectively between these dis-tributed components. Moreover, the data-streaming servicesthemselves must have minimal impact on the execution ofthe simulations, satisfy stringent application/user space andtime constraints, and guarantee that no data is lost.
Satisfying the above requirements in large-scale, hetero-geneous and highly dynamic Grid environments with shared

Cluster Comput
computing and communication resources, and where the ap-plication behaviour and performance is highly variable, isa significant challenge. It typically involves multiple func-tional and performance-related parameters that must be dy-namically tuned to match the prevailing application require-ments and Grid operating conditions. As Grid applicationsgrow in scale and complexity, and with many of these ap-plications running in batch mode with limited or no directruntime access, maintaining desired QoS using current ap-proaches based on ad hoc manual tuning and heuristics is notjust tedious and error-prone, but infeasible. A practical datastreaming service must, therefore, be largely self-managing,i.e., it must dynamically detect and respond, quickly andcorrectly, to changes in application behaviour and state ofthe Grid.
This paper presents the design, implementation, and ex-perimental evaluation of such a self-managing data stream-ing service for wide-area Grid environments. The service isdeployed using an infrastructure for self-managing Grid ser-vices, including a programming system for specifying self-managing behaviour as well as models and mechanisms forenforcing this behaviour at runtime [22]. A key contributionof this paper is the combination of typical rule-based self-management approaches with more formal model-based on-line control strategies. While the former are relatively simpleand easy to implement, they require expert knowledge, arevery tightly coupled to specific applications, and their per-formance is difficult to analyse in terms of optimality, fea-sibility, and stability properties. Advanced control formula-tions offer a theoretical basis for self-managing adaptationsin distributed applications. Specifically, this paper com-bines model-based limited look-ahead controllers (LLC)with rule-based managers to dynamically achieve adaptivebehaviour in Grid applications under various operating con-ditions [8].
This paper also illustrates and evaluates the operation ofthe data streaming service using a Grid-based fusion sim-ulation workflow. This workflow consists of long-runningcoupled simulations, executing on remote supercomputingsites at NERSC (National Energy Research Scientific Com-puting Center) in California (CA) and ORNL (Oak RidgeNational Laboratory) in Tennessee (TN), and generatingseveral terabytes of data, which must be streamed over thenetwork for live analysis and visualization at PPPL (Prince-ton Plasma Physics Laboratory) in New Jersey (NJ) and forarchiving at ORNL (TN). The service aims to minimize theoverhead associated with data streaming on the simulation,adapt quickly to network conditions, and prevent any loss ofsimulation data.
The rest of this paper is organized as follows. Section 2describes the driving Grid-based fusion simulation projectand highlights its data streaming requirements and chal-lenges. Section 3 describes the models and mechanisms for
enabling self-managing Grid services and applications. Sec-tion 4 presents the design and implementation of the self-managing data streaming service. Section 5 presents theevaluation of rule driven autonomic services and the modelbased online control in conjunction with the rule driven au-tonomic services. Section 6 addresses the scalability of theservice and then proposes as well as evaluates hierarchicalcontrol strategies. Section 7 presents related work. Section 8concludes the paper.
2 Wide-area data streaming in the fusion simulationproject
The DoE SciDAC CPES fusion simulation project [18] isdeveloping a new integrated Grid-based predictive plasmaedge simulation capability to support next-generation burn-ing plasma experiments such as the International Thermonu-clear Experimental Reactor (ITER). Effective online man-agement and transfer of simulation data are critical to thisproject and the scientific discovery process. Figure 1 showsa typical workflow comprising of coupled simulation codesthe edge turbulence particle-in-cell (PIC) code (GTC) [20]and the microscopic MHD code (M3D) [12] running simul-taneously on thousands of processors at various supercom-puting centers. The data produced by these simulations mustbe streamed live to remote sites for online simulation mon-itoring and control, simulation coupling, data analysis andvisualization, online validation, and archiving.
2.1 Requirements for a wide-area data streaming service
The fundamental requirement of the wide area data stream-ing service is to efficiently and robustly stream data fromlive simulations to remote services while satisfying the fol-lowing constraints: (1) Enable high-throughput, low-latencydata transfer to support near real-time access to the data.(2) Minimize related overhead on the executing simulation.Since the simulation is long running and executes in batchfor days, the overhead due to data streaming on the sim-ulation should be less than 10% of the simulation execu-tion time. (3) Adapt to network conditions to maintain de-sired QoS. The network is a shared resource and the usagepatterns vary constantly. (4) Handle network failures whileeliminating data loss. Network failures can lead to bufferoverflows, and data has to be written to local disks to avoidloss. However, this increases overhead on the simulation andthe data is not available for real-time remote analysis and vi-sualization.

Cluster Comput
Fig. 1 Workflow for the fusionsimulation project
3 Model, mechanisms and infrastructure forself-management
The data streaming service described in this paper is con-structed using the Accord programming infrastructure [22],which provides the core models and mechanisms for realiz-ing self-managing Grid services. These include models andmechanisms for autonomic management using rules as wellas model-based online control. Its key components are de-scribed in the following sections.
3.1 The Accord autonomic services architecture
The Accord programming system defines conceptual, im-plementation and enforcement models for utilizing knowl-edge (in the form of rules and policies) to guide the execu-tion and adaptation of services. This is achieved by adaptingthe behaviours of individual services and their interactions(communication/coordination) to respond to changing appli-cation requirements/state and execution environments usingdynamically defined rules and policies.
The Accord self-managing service architecture extendsthe service-based Grid programming paradigm to relax as-sumptions of static (defined at the time of instantiation)application requirements and system or application behav-iours, and allows them to be dynamically specified. It alsoenables the behaviours of services and applications to besensitive to the dynamic state of the system and the chang-ing requirements of the application, and to adapt to thesechanges at runtime. This is achieved by extending Grid ser-vices to include the specifications of policies and mecha-nisms for self-management, and providing a decentralized
Fig. 2 An autonomic or self-managing service in Accord
runtime infrastructure for consistently and efficiently en-forcing these policies to enable self-managing functional,interaction, and composition behaviours based on current re-quirements, state and execution context.
3.1.1 Definition of autonomic services
An autonomic service (see Fig. 2) extends a Grid servicewith a control port for external monitoring and steering, anda service manager that monitors and controls the runtime be-haviours of the managed element/service. The control portconsists of sensors that enable the state of the service to bequeried, and actuators that enable the behaviours of the ser-vice to be modified. The control port and service port areused by the service manager to control the functions, perfor-mance, and interactions of the managed service. The controlport is described using WSDL (Web Service Definition Lan-guage) [14] and may be a part of the general service descrip-

Cluster Comput
Table 1 The control port forthe BMS
tion, or may be a separate document to control access to it.An example of the control port is shown in Table 1. Rulesare simple if-condition-then-action statements described us-ing XML and include service adaptation and service inter-action rules. An example of a rule is shown in Table 2.
3.1.2 The runtime infrastructure
The Accord runtime infrastructure (shown in Fig. 3) con-sists of a user/developer portal, peer service and applica-tion composition or coordination managers, the autonomicservices, and a decentralized rule enforcement engine. Thisinfrastructure enables adaptations of the behaviours of indi-vidual services as well as the interactions between services.
Behaviour Adaptation: Behaviour adaptation rules areused to adapt the behaviours of individual services and do
not change their functionalities (described by service portsas contracts) and as a result, these adaptations are transpar-ent to other services. This localized adaptation simplifies thespecification and execution of adaptation rules by restrictingthe conditions monitored and actions performed within theindividual services.
Behaviour adaptations include modification of serviceparameters and dynamic selection of algorithms and imple-mentations to optimize and tune service performance, meetQoS requirements, correct detected errors, avoid or recoverfrom failures, and/or to protect the service. Service man-agers execute these rules to adapt the functional behavioursof the managed services, and evaluate and tune their perfor-mance. These adaptations are realized by invoking appropri-ate control (sensors, actuators) and functional interfaces.

Cluster Comput
Table 2 The adaptation rule forBMS
Interaction Adaptation: An application compositionmanager decomposes incoming application workflows (de-fined by the user or a workflow engine) into interaction rulesfor individual services, and forwards these rules to corre-sponding service managers. Service managers execute theserules to establish interaction relationships among servicesby negotiating communication protocols and mechanismsand dynamically constructing coordination relationships ina distributed and decentralized manner.
Interaction rules are used to adapt service interactions,for example communication paradigms and/or coordinationrelationships. When local optimization of individual ser-
vices cannot satisfy the global objectives, interaction rulesare used to modify the application composition.
Rule Execution: Rule execution at the service managersconsists of three phases: condition inquiry, condition evalu-ation and conflict resolution, and batch action invocation.During condition inquiry, the service managers query thesensors used by the rules in parallel, assimilates their cur-rent values and fire corresponding triggers.
During the next phase, condition evaluations for all therules are performed in parallel. Rule conflicts are detectedduring this phase when the same actuator is invoked withdifferent values. These conflicts are resolved by relaxing

Cluster Comput
Fig. 3 Accord runtime infrastructure: Solid lines indicate interactionsamong services and dotted lines represent invocation of WS instancesproviding supporting services such as naming and discovery
the rule condition, using user-defined strategies, until theactuator-actuator conflict is resolved. If the conflicts arenot resolved, errors are reported to users. If interacting ser-vices try to use different communication/coordination par-adigms as a result of their independent adaptation behav-iours, the services negotiate with each other to resolve theconflict [21].
After rule conflict resolution, the actions are executed inparallel. Note that the rule execution model presented herefocuses on correct and efficient execution of rules, provid-ing mechanisms to detect and resolve conflicts at runtime.However, correctness of rules and conflict resolution strate-gies are the responsibilities of the users.
3.1.3 Autonomic service adaptation and composition
Dynamic and autonomic compositions are enabled in Ac-cord using a combination of interaction and adaptation rules.Composition consists of defining the organization of ser-vices and the interactions among them [21]. The service or-ganization describes a collection of services that are func-tionally compose-able, determined semantically (e.g., us-ing OWL (Ontology Workflow Language) [41]) or syntacti-cally using WSDL [14]. Interactions among services definethe coordination between services and the communicationparadigm used, e.g., message passing, RPC/RMI, or sharedspaces.
Once a workflow has been generated (e.g., using themechanism discussed in [5]), and the services have beendiscovered (using middleware services), the Accord com-position manager decomposes the workflow into interac-
tion rules. This decomposition process consists of map-ping workflow patterns [39] in the workflow into corre-sponding rule templates [21]. Accord provides templates forbasic communication paradigms such as notification, pub-lisher/subscriber, rendezvous, shared spaces and RPC/RMI,and control structures such as sequence, AND-split, XOR-split, OR-split, AND-join, XOR-join, and OR-join. Morecomplex interaction and coordination structures (e.g., loops)can be constructed from these basic patterns.
The interaction rules are then injected into correspondingservice managers, which execute the rules to establish com-munication and coordination relationships among involvedservices. Note that there is no centrally controlled orches-tration. While the interaction rules are defined by the com-position manager, the actual interactions are established byservice managers in a decentralized and parallel manner.
The communication paradigms and coordination rela-tionships between the interacting autonomic services can bedynamically changed according to current application stateand execution context by replacing or changing the relatedinteraction rules. As a result, a new service can be broughtinto an application, and interactions among services can bechanged at runtime, without taking the application offline.
The two adaptation approaches, adaptation within indi-vidual services and dynamic composition of services, canbe used separately or in combination to enable the auto-nomic self-configuring, self-optimizing and self-healing be-haviours of services and applications [21].
3.2 Model-based control within accord
Figure 4 shows the overall LLC (Limited Look-ahead Con-troller) framework [1, 17], where the management problemis posed as a sequential optimization under uncertainty. Rel-evant operating parameters of the Grid environment suchas data-generation patterns and network bandwidth are es-timated and used by a mathematical model to forecast fu-ture application behaviour over a prediction horizon N . Thecontroller optimizes the forecast behavior as per the speci-fied QoS requirements by selecting the best control inputsto apply to the system. At each time step k, the controllerfinds a feasible sequence u∗(i)|i ∈ [k + 1, k + N ] of inputs(or decisions) within the prediction horizon. Then, only thefirst move is applied to the system and the whole optimiza-tion procedure is repeated at time k+1 when the new systemstate is available.
The LLC approach allows for multiple QoS goals andoperating constraints to be represented in the optimizationproblem and solved for each control step. It can be usedas a management scheme for systems and applications thatexhibit non-linear behaviour where control or tuning inputsmust be chosen from a finite set.
As shown in Fig. 5, the element (service) managerswithin the Accord programming system are augmented with

Cluster Comput
Fig. 4 The LLC control structure
Fig. 5 A self managing element and interactions between the elementmanager and the corresponding controller
online controllers [8]. Each manager monitors the state ofits underlying elements and their execution context, collectsand reports runtime information, and enforces the adaptationactions decided by the controller. These managers thus aug-ment human-defined rules which may be error-prone and in-complete with mathematically sound models, optimizationtechniques, and runtime information. Specifically, the con-troller decides when and how to adapt the application behav-iour and the managers focus on enforcing these adaptationsin a consistent and efficient manner.
4 The self managing data streaming service
This section describes a self-managing data streaming ser-vices for the Grid-based fusion simulation workflow basedon the models and mechanisms presented in the previoussection. A specific driving simulation workflow is shown inFig. 6, and consists of a long running G.T.C. fusion simula-tion executing on a parallel supercomputer at NERSC (CA)and generating terabytes of data over its lifetime. This datamust be analysed and visualized in real time, while the sim-ulation is still running, at a remote site at PPPL (NJ), andalso archived either at PPPL (NJ) or ORNL (TN). The datastreaming service in Fig. 6 has four core services: (1) A Sim-ulation Service (SS) executing on an IBM SP machine atNERSC, and generating data at regular intervals; (2) A Data
Fig. 6 The self managing data streaming service
Analysis Service (DAS) executing on a computer cluster lo-cated at PPPL to analyse the data streamed from NERSC;(3) A Data Storage Service (DSS) to archive the streameddata using the Logistical Networking backbone [36], whichbuilds a Data Grid of storage services located at ORNL andPPPL; (4) An Autonomic Data Streaming Service (ADSS)that manages the data transfer from SS (at NERSC) to DAS(at PPPL) and DSS (at PPPL/ORNL).
The objectives of the self-managing ADSS are the fol-lowing. (1) Prevent any loss of simulation data: Since datacontinuously generated and the buffer sizes are limited, thelocal buffer at each data transfer node must be eventuallyemptied. Therefore, if the network link to the analysis clus-ter is congested, then data from the transfer nodes must bewritten to a local hard disk at NERSC itself. (2) Minimizeoverhead on the simulation: In addition to transferring thegenerated data, the transfer nodes must also perform usefulcomputations related to the simulation. Therefore, the ADSSmust minimize the computational and resource requirementsof the data transfer process on these nodes; (3) Maximize theutility of the transferred data: We would like to transfer asmuch of the generated data as possible to the remote clusterfor analysis and visualization. Storage on the local hard diskis an option only if the available network bandwidth is in-sufficient to accommodate the data generation rate and thereis a danger of losing simulation data.
4.1 Design of the ADSS controller
The ADSS controller is designed using the LLC conceptsdiscussed in Sect. 3.2. Figure 7 shows the system model forthe streaming service, where the key operating parametersfor a data transfer node ni at time step k are as follows:(1) State variable: The current average queue size at ni de-noted as qi(k); (2) Environment variables: λi(k) denotes thedata generation rate into the queue qi and B(k) the effectivebandwidth of the network link; (3) Control or decision vari-ables: Given the state and environment variables at time k,the controller decides μi(k) and ωi(k), the data-transfer rateover the network link and to the hard disk respectively. The

Cluster Comput
Fig. 7 The system model for the data streaming service
system dynamics at each node ni evolves as per the follow-ing equations:
q̂i (k + 1) = q̂i (k) + (λ̂i(k).(1 − μi(k) − ωi(k))).T
λi(k) = φ(λi(k − 1), k).
The queue size at time k + 1 is determined by the cur-rent queue size, the estimated data generation rate λi(k),and the data transfer rates, as decided by the controller, tothe network link and the local hard disk. The data genera-tion rate is estimated using a forecasting model φ, imple-mented here by an exponentially-weighted moving-average(EWMA) filter. The sampling duration for the controller isdenoted as T . Both 0 ≤ μi(k) ≤ 1 and 0 ≤ ωi(k) ≤ 1 arechosen by the controller from a finite set of appropriatelyquantized values. Note that in practice, the data transfer rateis a function of the effective network bandwidth B(k) at timek, the number of sending threads, and the size of each datablock transmitted from the queue. These parameters are de-cided by appropriate components within the data-streamingservice (discussed in Sect. 4.2). The LLC problem is nowformulated as a set-point specification where the controlleraims to maintain each node ni ’s queue qi around a desiredvalue q∗ while maximizing the utility of the transferred data,that is, by minimizing the amount of data transferred to thehard disk/local depots [35].
Minimize:
k+Np∑
j=k
n∑
i=1
αi(q∗ − qi(j))2 + βiωi(j)2
Subject to:n∑
i=1
μi(j) ≤ B(j) and qi(j) ≤ qmax ∀i.
Here, Np denotes the prediction horizon, qmax the max-imum queue size, and αi and βi denote user-specifiedweights in the cost function.
When control inputs must be chosen from a set of discretevalues, the LLC formulation, as posed above, will show anexponential increase in worst-case complexity with an in-creasing number of control options and longer predictionhorizons. Since the execution time available to the controlleris often limited by hard application bounds, it is necessary toconsider the possibility that we may have to deal with sub-optimal solutions. For adaptation purposes, however, it is notcritical to find the global optimum to ensure system stabil-ity; a feasible suboptimal solution will suffice. However, wewould still like to use the available time exploring the mostpromising solutions leading to optimality. Taking advantageof the fact that the operating environment does not changedrastically over a short period of time, we can obtain subop-timal solutions using local search methods, where given thecurrent values of μi(k) and ωi(k), the controller searches alimited neighborhood of these values for a feasible solutionfor the next step.
4.2 Implementation and deployment of ADSS
ADSS is a composite service comprising a Buffer ManagerService (BMS) managing the buffers allocated by the ADSS,and a Data Transfer Service (DTS) managing the transfer ofdata blocks from the buffers to remote services for analysisand visualization at PPPL, and archiving at PPPL or ORNL.The BMS supports two buffer management schemes. Uni-form buffering divides the data into blocks of fixed sizes,and is more suitable when the simulation can transfer all itsdata items to a remote storage. Aggregate buffering, on theother hand, aggregates blocks across multiple time steps fornetwork transfer, and is used when the network is congested.
A EWMA filter with a smoothing constant of 0.5 esti-mates the data generated by the simulation for the ADSScontroller. A single-step LLC strategy is used with a desiredbuffer size of q∗ = 0 on each node ni . The weights in themulti-objective cost function are set to αi = 1 and βi = 108,to penalize the controller very heavily for writing data to thehard disk. The decision variables μi and ωi are quantized inintervals of 0.1. The controller sampling time T is set to 80seconds in our implementation.
The ADSS Element Manager supplies the controller withinternal state of the ADSS and SS services, including theobserved buffer size on each node, ni the simulation-datageneration rate, and the network bandwidth. The effectivenetwork bandwidth of the link between NERSC and PPPLis measured using Iperf [32], which reports the TCP band-width available, delay jitter and datagram loss. The elementmanager also stores a set of rules, which are triggered basedon controller decisions.
Cluster Comput
The element manager triggers adaptations within theDTS/BMS service. For example, the controller decidesthe amount of data to be sent over the network or to lo-cal storage, and the element manager decides the corre-sponding buffer management scheme to be used within theBMS to achieve this. The element manager also adapts theDTS service to send data to local/low latency storage, e.g.,NERSC/ORNL, when the network is congested.
5 Evaluation of the self-managing data-streamingservice
This section presents an evaluation of the Accord-based self-managing data-streaming service. The first group of experi-ments evaluate the rule-based adaptations while the secondgroup evaluates a combination of rule-based and control-based adaptations. A comparison of the two strategies andthe overhead of the self managing data streaming serviceare also presented.
The setup for experiments presented in this section con-sisted of the GTC fusion simulation running on 32 to 256processors at NERSC, and streaming data for analysis toPPPL. A 155 Mbps (peak) ESNET connection betweenPPPL and NERSC was used. A single controller was used,and the controller and managers were implemented usingthreading. A maximum of four simulation processors wereused for data streaming.
5.1 Self-managing scenarios using rule based adaptations
Scenario 1: Self-optimizing behaviour of BMS
This scenario illustrates the self-optimizing behaviour of theBMS using rules. The service adaptation within BMS ser-vice is transparent to other services. BMS selects the appro-priate blocking technique, orders blocks in the buffer andoptimizes the size of the buffer(s) used to ensure low latencyhigh performance steaming and minimize the impact on theexecution of the simulation. The adaptations are based onthe current state of the simulation and more specifically thefollowing three runtime parameters. (1) The data generationrate, which is the amount of data generated per iteration di-vided by the time required for the iteration, and can varyfrom 1 to 400 Mbps depending on the domain decomposi-tion and the type of analysis to be performed. (2) The net-work connectivity and the network transfer rate. The latteris limited by the 100 Mbps link between NERC and PPPL.(3) The nature of data being generated in the simulation,e.g., parameters, 2D surface data or 3D volume data. BMSprovides three algorithms:
– Uniform Buffer Management: This algorithm divides thedata into blocks of fixed sizes, which are then transmit-ted by the DTS. This static algorithm is more suited for
the simulations generating data at a small or medium rate(50 Mbps). Using smaller block sizes have significant ad-vantages at the receiving end as less time is required fordecoding the data and processing it for analysis and visu-alization.
– Aggregate Buffer Management: This algorithm aggre-gates blocks across iterations and the DTS transmits theseaggregated blocks. This algorithm is suited for high datageneration rates, i.e., between 60–400 Mbps.
– Priority Buffer Management: This algorithms orders datablocks in the buffer based on the nature of the data.For example, 2D data blocks containing visualization orsimulation parameters are given higher priority as com-pared to 3D raw volume data. To enable adaptations,the BMS exports two sensors, “DataGenerationRate” and“DataType”, and one actuator, “BlockingAlgorithm” aspart of its control port shown in Table 1. This documentdescribes the name, type, message format and protocoldetails for each sensor/actuator. Further, the BMS self-optimization behaviour is governed by the rule shown inTable 2, which states that if the data generation rate isgreater than the peak network transfer rate (i.e., 100 Mps),the aggregate buffer management is used otherwise theuniform buffer management algorithm is used.
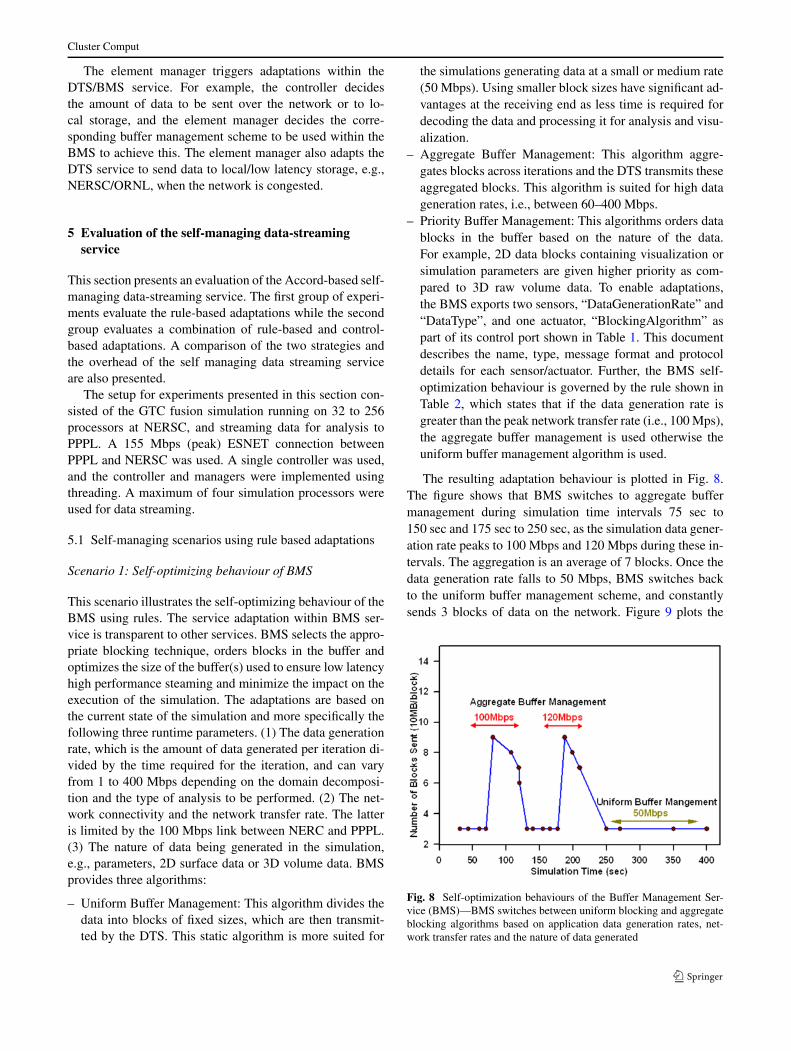
The resulting adaptation behaviour is plotted in Fig. 8.The figure shows that BMS switches to aggregate buffermanagement during simulation time intervals 75 sec to150 sec and 175 sec to 250 sec, as the simulation data gener-ation rate peaks to 100 Mbps and 120 Mbps during these in-tervals. The aggregation is an average of 7 blocks. Once thedata generation rate falls to 50 Mbps, BMS switches backto the uniform buffer management scheme, and constantlysends 3 blocks of data on the network. Figure 9 plots the
Fig. 8 Self-optimization behaviours of the Buffer Management Ser-vice (BMS)—BMS switches between uniform blocking and aggregateblocking algorithms based on application data generation rates, net-work transfer rates and the nature of data generated
Cluster Comput
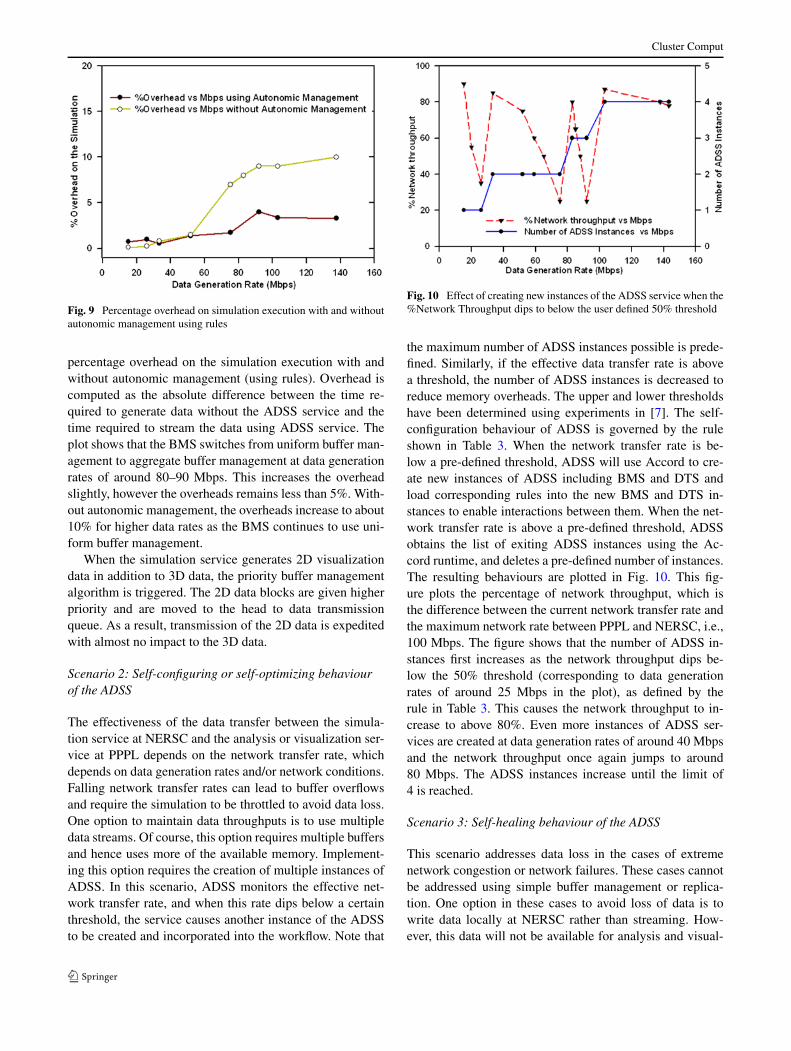
Fig. 9 Percentage overhead on simulation execution with and withoutautonomic management using rules
percentage overhead on the simulation execution with andwithout autonomic management (using rules). Overhead iscomputed as the absolute difference between the time re-quired to generate data without the ADSS service and thetime required to stream the data using ADSS service. Theplot shows that the BMS switches from uniform buffer man-agement to aggregate buffer management at data generationrates of around 80–90 Mbps. This increases the overheadslightly, however the overheads remains less than 5%. With-out autonomic management, the overheads increase to about10% for higher data rates as the BMS continues to use uni-form buffer management.
When the simulation service generates 2D visualizationdata in addition to 3D data, the priority buffer managementalgorithm is triggered. The 2D data blocks are given higherpriority and are moved to the head to data transmissionqueue. As a result, transmission of the 2D data is expeditedwith almost no impact to the 3D data.
Scenario 2: Self-configuring or self-optimizing behaviourof the ADSS
The effectiveness of the data transfer between the simula-tion service at NERSC and the analysis or visualization ser-vice at PPPL depends on the network transfer rate, whichdepends on data generation rates and/or network conditions.Falling network transfer rates can lead to buffer overflowsand require the simulation to be throttled to avoid data loss.One option to maintain data throughputs is to use multipledata streams. Of course, this option requires multiple buffersand hence uses more of the available memory. Implement-ing this option requires the creation of multiple instances ofADSS. In this scenario, ADSS monitors the effective net-work transfer rate, and when this rate dips below a certainthreshold, the service causes another instance of the ADSSto be created and incorporated into the workflow. Note that
Fig. 10 Effect of creating new instances of the ADSS service when the%Network Throughput dips to below the user defined 50% threshold
the maximum number of ADSS instances possible is prede-fined. Similarly, if the effective data transfer rate is abovea threshold, the number of ADSS instances is decreased toreduce memory overheads. The upper and lower thresholdshave been determined using experiments in [7]. The self-configuration behaviour of ADSS is governed by the ruleshown in Table 3. When the network transfer rate is be-low a pre-defined threshold, ADSS will use Accord to cre-ate new instances of ADSS including BMS and DTS andload corresponding rules into the new BMS and DTS in-stances to enable interactions between them. When the net-work transfer rate is above a pre-defined threshold, ADSSobtains the list of exiting ADSS instances using the Ac-cord runtime, and deletes a pre-defined number of instances.The resulting behaviours are plotted in Fig. 10. This fig-ure plots the percentage of network throughput, which isthe difference between the current network transfer rate andthe maximum network rate between PPPL and NERSC, i.e.,100 Mbps. The figure shows that the number of ADSS in-stances first increases as the network throughput dips be-low the 50% threshold (corresponding to data generationrates of around 25 Mbps in the plot), as defined by therule in Table 3. This causes the network throughput to in-crease to above 80%. Even more instances of ADSS ser-vices are created at data generation rates of around 40 Mbpsand the network throughput once again jumps to around80 Mbps. The ADSS instances increase until the limit of4 is reached.
Scenario 3: Self-healing behaviour of the ADSS
This scenario addresses data loss in the cases of extremenetwork congestion or network failures. These cases cannotbe addressed using simple buffer management or replica-tion. One option in these cases to avoid loss of data is towrite data locally at NERSC rather than streaming. How-ever, this data will not be available for analysis and visual-

Cluster Comput
Table 3 The self-configuringrule for the ADSS
ization until the simulation complete, which could be days.Writing data to the disk also causes significant overheads tothe simulation [7]. ADSS addresses these cases by temporar-ily or permanently switching the streaming of the data to theDSS at ORNL instead of PPPL. NERSC and ORNL are con-nected by a low latency [19] link which has a lower proba-bility of being saturated. The data can be later transmittedfrom ORNL to PPPL. Congestion is detected by observ-ing the buffer—when the buffer is filled to a capacity, theADSS switches subsequent streaming to ORNL, and whenthe buffer is no longer saturated, switches the steaming backto PPPL. If the service observes that buffer is being con-tinuously saturated, it infers that there is a network failureand permanently switches the streaming to ORNL. In thiscase, the blocks already in the PPPL buffer are transferred
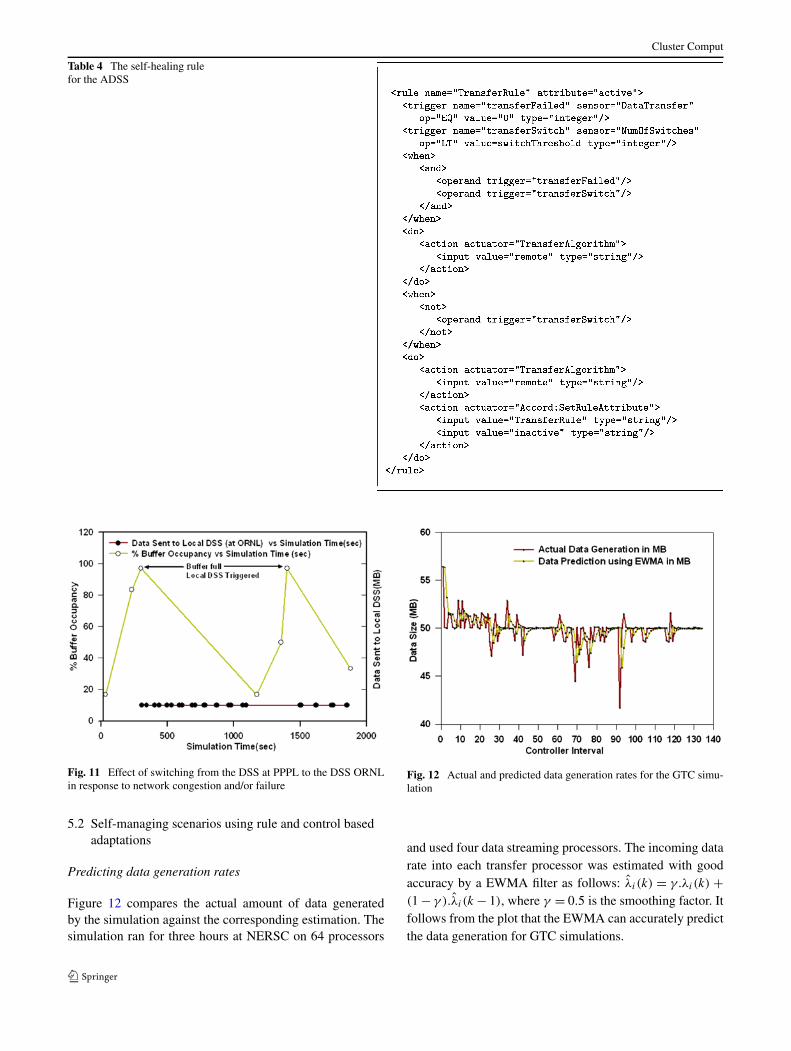
to the ORNL queue. Here ADSS communicates with DSS atPPPL or DSS at ORNL under different network conditions.This behaviour is defined by interaction rules in ADSS. Therule specifying this self-management behaviour is listed inTable 4. The resulting self-healing behaviour is plotted inFig. 11. The figure shows that as the ADSS buffer(s) get sat-urated, the data streaming switches to the DSS at ORNL,and when the buffer occupancy falls below 20% it switchesback to PPPL. Note that while the data blocks are writtento ORNL, data blocks already queued for transmission toPPPL continue to be streamed. The figure also shows that,at simulation time 1500 (X axis), the PPPL buffers onceagain get saturated and the streaming switches to ORNL. Ifthis persists, the steaming would be permanently switchedto ORNL.
Cluster Comput
Table 4 The self-healing rulefor the ADSS
Fig. 11 Effect of switching from the DSS at PPPL to the DSS ORNLin response to network congestion and/or failure
5.2 Self-managing scenarios using rule and control basedadaptations
Predicting data generation rates
Figure 12 compares the actual amount of data generatedby the simulation against the corresponding estimation. Thesimulation ran for three hours at NERSC on 64 processors
Fig. 12 Actual and predicted data generation rates for the GTC simu-lation
and used four data streaming processors. The incoming datarate into each transfer processor was estimated with goodaccuracy by a EWMA filter as follows: λ̂i (k) = γ.λi(k) +(1 − γ ).λ̂i(k − 1), where γ = 0.5 is the smoothing factor. Itfollows from the plot that the EWMA can accurately predictthe data generation for GTC simulations.
Cluster Comput
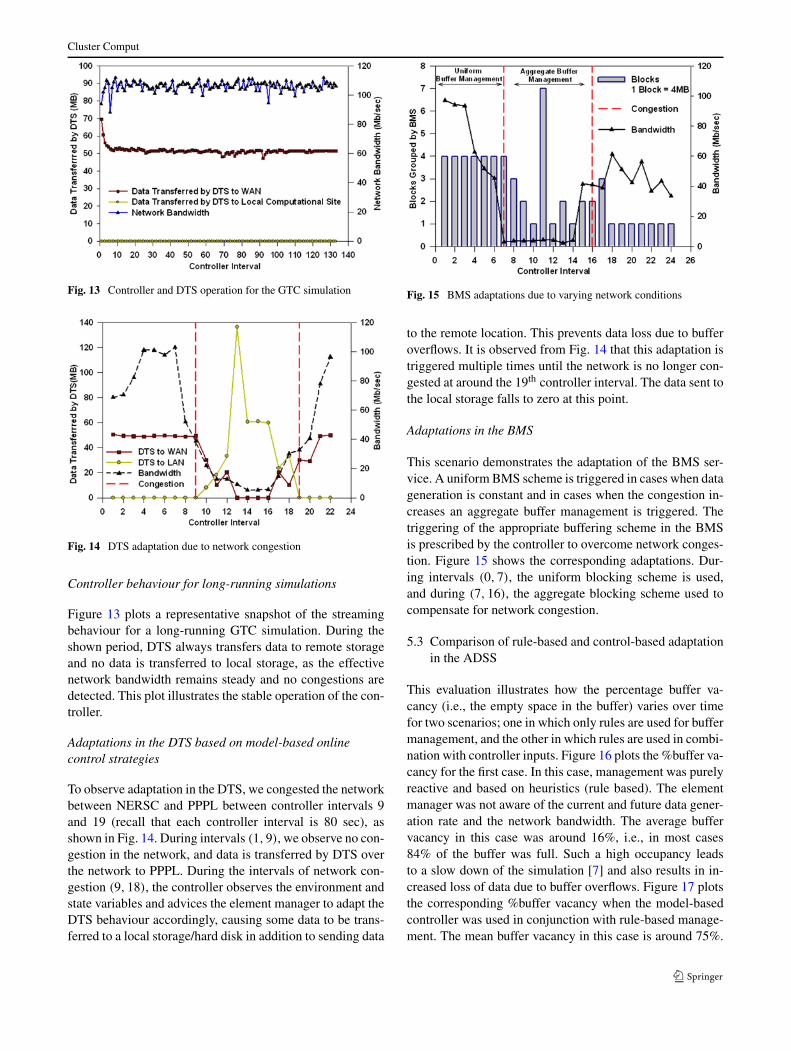
Fig. 13 Controller and DTS operation for the GTC simulation
Fig. 14 DTS adaptation due to network congestion
Controller behaviour for long-running simulations
Figure 13 plots a representative snapshot of the streamingbehaviour for a long-running GTC simulation. During theshown period, DTS always transfers data to remote storageand no data is transferred to local storage, as the effectivenetwork bandwidth remains steady and no congestions aredetected. This plot illustrates the stable operation of the con-troller.
Adaptations in the DTS based on model-based onlinecontrol strategies
To observe adaptation in the DTS, we congested the networkbetween NERSC and PPPL between controller intervals 9and 19 (recall that each controller interval is 80 sec), asshown in Fig. 14. During intervals (1,9), we observe no con-gestion in the network, and data is transferred by DTS overthe network to PPPL. During the intervals of network con-gestion (9,18), the controller observes the environment andstate variables and advices the element manager to adapt theDTS behaviour accordingly, causing some data to be trans-ferred to a local storage/hard disk in addition to sending data
Fig. 15 BMS adaptations due to varying network conditions
to the remote location. This prevents data loss due to bufferoverflows. It is observed from Fig. 14 that this adaptation istriggered multiple times until the network is no longer con-gested at around the 19th controller interval. The data sent tothe local storage falls to zero at this point.
Adaptations in the BMS
This scenario demonstrates the adaptation of the BMS ser-vice. A uniform BMS scheme is triggered in cases when datageneration is constant and in cases when the congestion in-creases an aggregate buffer management is triggered. Thetriggering of the appropriate buffering scheme in the BMSis prescribed by the controller to overcome network conges-tion. Figure 15 shows the corresponding adaptations. Dur-ing intervals (0,7), the uniform blocking scheme is used,and during (7,16), the aggregate blocking scheme used tocompensate for network congestion.
5.3 Comparison of rule-based and control-based adaptationin the ADSS
This evaluation illustrates how the percentage buffer va-cancy (i.e., the empty space in the buffer) varies over timefor two scenarios; one in which only rules are used for buffermanagement, and the other in which rules are used in combi-nation with controller inputs. Figure 16 plots the %buffer va-cancy for the first case. In this case, management was purelyreactive and based on heuristics (rule based). The elementmanager was not aware of the current and future data gener-ation rate and the network bandwidth. The average buffervacancy in this case was around 16%, i.e., in most cases84% of the buffer was full. Such a high occupancy leadsto a slow down of the simulation [7] and also results in in-creased loss of data due to buffer overflows. Figure 17 plotsthe corresponding %buffer vacancy when the model-basedcontroller was used in conjunction with rule-based manage-ment. The mean buffer vacancy in this case is around 75%.
Cluster Comput
Fig. 16 %Buffer Vacancy using heuristically based rules
Fig. 17 %Buffer Vacancy using control-based self-management
Higher buffer vacancy leads to reduced overheads and dataloss.
5.3.1 Overhead of the self-managing data streaming
Overheads on the simulation due the self-managing datastreaming service are primarily due to two factors. The firstare the activities of the controller during a controller inter-val. This includes the controller decision time, the cost ofadaptations triggered by rule executions and the operationof BMS and DTS. The second is the cost of the data stream-ing itself. These overheads are presented below.
Overheads due to controller activities: For a controllerinterval of 80 seconds, the average controller decision-timewas ≈2.1 sec (2.5%) at the start of the controller operation.This reduced to ≈0.12 sec (0.15%) as the simulation pro-gressed due to local search methods used. The network mea-surement cost was 18.8 sec (23.5%). The operating cost ofthe BMS and DTS was 0.2 sec (0.25%) and 18.8 sec (23.5%)respectively. Rule execution for triggering adaptations re-
quired less than 0.01 sec. The controller was idle for therest of the control interval. Note that the controller was im-plemented as a separate thread (using pthread [31]) and itsexecution overlapped with the simulation.
Overhead of data streaming: A key requirement of theself managing data streaming was that its overhead onthe simulation be less than 10% of the simulation execu-tion time. %Overhead of the data streaming is defined as:(T̂s − Ts)/Ts , where T̂s and Ts denote the simulation execu-tion time with and without data streaming respectively. The%Overhead of data streaming on the GTC simulation wasless than 9% for 16–64 processors and reduced to about 5%for 128–256 processors. The reduction was due to the factthat as the number of simulation processors increased, thedata generated per processors decreased.
6 Addressing scalability using hierarchical control
In a distributed application consisting of multiple interactingelements, a centralized scheme for enforcing self-managingbehaviours is not scalable—the number of control options tobe explored is simply too large. However, the dimensionalityof the overall optimization problem is drastically reduced,if it can be decomposed into simpler sub-problems, whereeach is solved independently. Higher-level control can beused to enable coordinated adaptations across these sub do-mains, as discussed below.
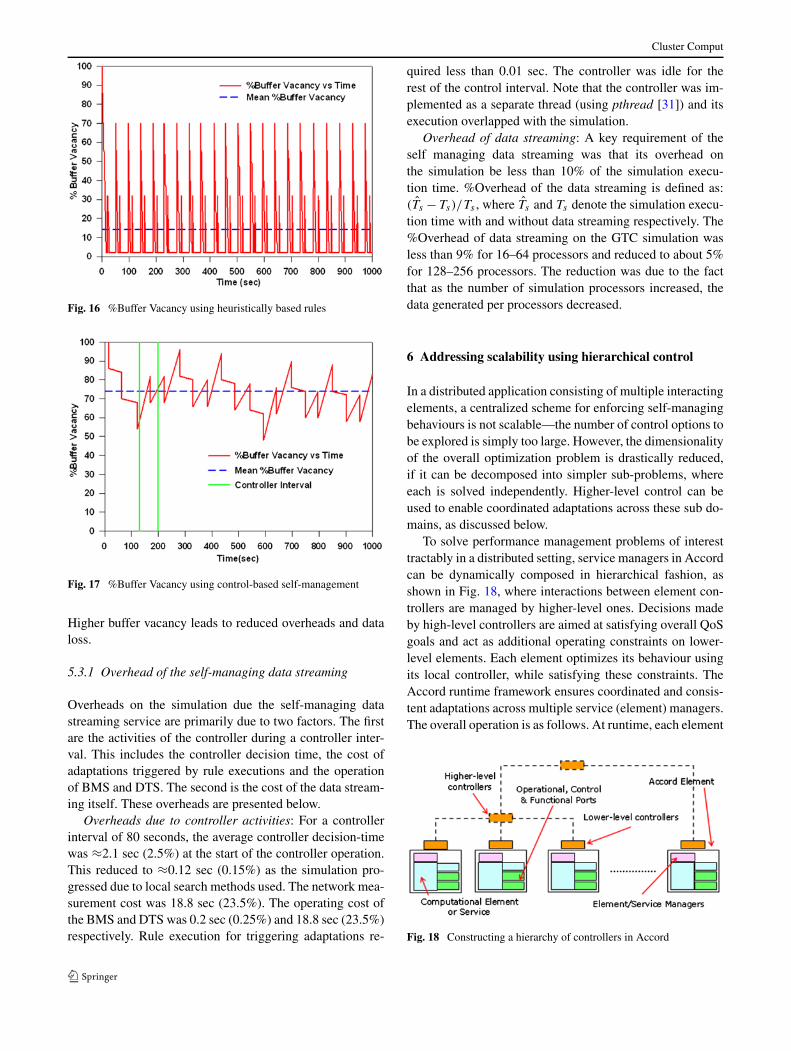
To solve performance management problems of interesttractably in a distributed setting, service managers in Accordcan be dynamically composed in hierarchical fashion, asshown in Fig. 18, where interactions between element con-trollers are managed by higher-level ones. Decisions madeby high-level controllers are aimed at satisfying overall QoSgoals and act as additional operating constraints on lower-level elements. Each element optimizes its behaviour usingits local controller, while satisfying these constraints. TheAccord runtime framework ensures coordinated and consis-tent adaptations across multiple service (element) managers.The overall operation is as follows. At runtime, each element
Fig. 18 Constructing a hierarchy of controllers in Accord

Cluster Comput
or service manager independently collects element and con-text state information using sensors exposed by the individ-ual elements and the environment. The managers then reportthis information to associated controllers, which then com-putes control actions and informs the service manager ofdesired adaptation behaviours. Service managers then exe-cute these adaptation behaviours using actuators exposed bythe environment and elements. If these local adaptations donot achieve the desired objectives, service managers collec-tively invoke higher-level controllers, which results in coor-dination among multiple interacting managers to change theelement state and their interactions. Composition managerscoordinate adaptations across service managers as describedabove.
6.1 Hierarchical controller design for data streaming
Recall that when control inputs must be chosen from a setof discrete values, the optimization problem described inSect. 4.1 will show an exponential increase in worst-casecomplexity with an increasing number of control optionsand longer prediction horizons. We can, however, substan-tially reduce the dimensionality of the optimization prob-lem via hierarchical control decomposition. Exhaustive andbounded search strategies are then used at different levels ofthe hierarchy to solve the corresponding optimization prob-lems with low run-time overhead. As an example of howto apply hierarchical control to the data streaming problem,consider the multi-level structure shown in Fig. 19. Here,we have a larger system compared to the one described in
Fig. 19 Hierarchical controller formulation for data streaming
Sect. 5.2—256 processors generate simulation data while 16data-transfer nodes (instead of 4) collect this data and streamit over the network link to PPPL. As before, the QoS goalsare to prevent any loss of simulation data and maximize theutility of the transferred data. First, the data-transfer nodesare logically partitioned, for the purposes of scalable con-trol, into four modules M1, M2, M3, and M4 where eachmodule Mi itself comprises four nodes. The data-generationor flow rate from the simulation cluster into each Mi at timek is denoted by Fi(k). This flow can be further split into sub-flows Fi1(k), Fi2(k), Fi3(k), and Fi4(k), incoming into eachnode within module Mi .
Figure 19 shows L1 and L0 controllers within a two levelhierarchy working together to achieve the desired QoS goalswith the following responsibilities. The L1 controller mustdecide the fraction of the available network bandwidth todistribute to the various modules. Therefore, given the in-coming flow-rates into the various modules, the effectivenetwork bandwidth B(k) and the current state of each mod-ule in terms of the average buffer size of the sending proces-sors, the L1 controller must decide the vector γi , i.e., thefraction of the network bandwidth γi .B(k) to allocate toeach Mi . The L0 controller within Mi solves the problem,originally formulated in Sect. 4.
It decides the following variables for each node nj in themodule: the fractions μij and ωij of the incoming flow rateFij (k) to send over the network link and to the local/nearbystorage, respectively. It is important to note that the L0 con-troller within a module operates under the dynamic con-straints imposed by the L1 controller, in terms of the band-width γi.B(k) that the L0 controller must distribute amongits sending processors.
The hierarchical structure in Fig. 19 reduces the di-mensionality of the original control problem substantially.Where a centralized solution must decide the variables μ
and ω for each of the 16 sending processors, in our method,the L1 controller only decides a single-dimensional variableγ for each of the four modules. Similarly, the L0 controllerdecides control variables only for those processors within itsmodule—far fewer compared to the total number of sendingprocessors in the system.
To realize the hierarchical structure in Fig. 19, each L1controller must know the approximate behavior of the com-ponents comprising the L0 level. For example, to solve thecombinatorial optimization problem of determining γi , thefraction of the available network bandwidth to allocate tothe modules, the L1 controller must be able to quickly ap-proximate the behavior of each module. More specifically,given the observed state of each Mi , and the estimated envi-ronment parameters in terms of the effective network band-width and flow rates, the L1 controller must obtain the costincurred by module Mi for various choices of γi . Note, how-ever, that Mi ’s behavior includes complex and non-linear
Cluster Comput
Fig. 20 GTC workload trace and effective network bandwidth be-tween NERSC and PPPL
interaction between its L0 controller and the correspondingsending processors, and the resulting dynamics cannot beeasily captured via explicit mathematical equations. A de-tailed model for each Mi will also increase the L1 con-troller’s overhead substantially, defeating our goal of scal-able hierarchical control.
We use simulation-based learning techniques [6] to gen-erate a look-up table that quickly approximates Mi ’s behav-ior. Here, Mi ’s behavior is learned by simulating the modulewith a large number of training inputs from the (quantized)domains of Fi , B , and γi . Once such an approximation isobtained off-line, it can be used by the L1 controller to gen-erate decisions fast enough for use in real time.
6.2 Simulation results for hierarchical data streaming
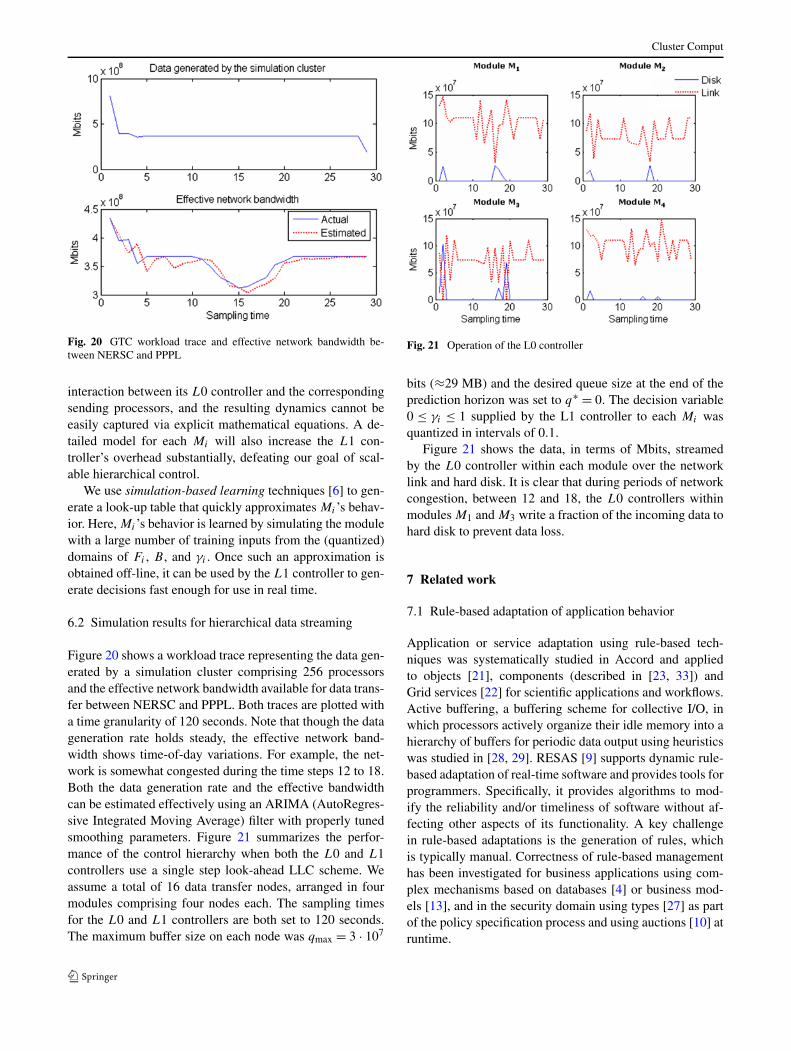
Figure 20 shows a workload trace representing the data gen-erated by a simulation cluster comprising 256 processorsand the effective network bandwidth available for data trans-fer between NERSC and PPPL. Both traces are plotted witha time granularity of 120 seconds. Note that though the datageneration rate holds steady, the effective network band-width shows time-of-day variations. For example, the net-work is somewhat congested during the time steps 12 to 18.Both the data generation rate and the effective bandwidthcan be estimated effectively using an ARIMA (AutoRegres-sive Integrated Moving Average) filter with properly tunedsmoothing parameters. Figure 21 summarizes the perfor-mance of the control hierarchy when both the L0 and L1controllers use a single step look-ahead LLC scheme. Weassume a total of 16 data transfer nodes, arranged in fourmodules comprising four nodes each. The sampling timesfor the L0 and L1 controllers are both set to 120 seconds.The maximum buffer size on each node was qmax = 3 · 107
Fig. 21 Operation of the L0 controller
bits (≈29 MB) and the desired queue size at the end of theprediction horizon was set to q∗ = 0. The decision variable0 ≤ γi ≤ 1 supplied by the L1 controller to each Mi wasquantized in intervals of 0.1.
Figure 21 shows the data, in terms of Mbits, streamedby the L0 controller within each module over the networklink and hard disk. It is clear that during periods of networkcongestion, between 12 and 18, the L0 controllers withinmodules M1 and M3 write a fraction of the incoming data tohard disk to prevent data loss.
7 Related work
7.1 Rule-based adaptation of application behavior
Application or service adaptation using rule-based tech-niques was systematically studied in Accord and appliedto objects [21], components (described in [23, 33]) andGrid services [22] for scientific applications and workflows.Active buffering, a buffering scheme for collective I/O, inwhich processors actively organize their idle memory into ahierarchy of buffers for periodic data output using heuristicswas studied in [28, 29]. RESAS [9] supports dynamic rule-based adaptation of real-time software and provides tools forprogrammers. Specifically, it provides algorithms to mod-ify the reliability and/or timeliness of software without af-fecting other aspects of its functionality. A key challengein rule-based adaptations is the generation of rules, whichis typically manual. Correctness of rule-based managementhas been investigated for business applications using com-plex mechanisms based on databases [4] or business mod-els [13], and in the security domain using types [27] as partof the policy specification process and using auctions [10] atruntime.

Cluster Comput
7.2 Control-based adaptation and performancemanagement
Recent research efforts [15, 16] have investigated usingfeedback (or reactive) control for resource and performancemanagement for single-processor computing applications.These techniques observe the current application state andtake corrective action to achieve specified QoS, and havebeen successfully applied to problems such as task schedul-ing [11, 25] bandwidth allocation and QoS adaptation inweb servers [3], load balancing in e-mail and file servers [15,24, 34] network flow control [30, 38] and processor powermanagement [26, 37]. Feedback control theory was simi-larly applied to data streams and log processing for con-trolling the queue length and for load balancing [42]. Clas-sical feedback control, however, has some inherent limita-tions. It usually assumes a linear and discrete-time modelfor system dynamics with an unconstrained state space, anda continuous input and output domain. The objective of theresearch presented in this paper is to address this limita-tion and manage the performance of distributed applicationsthat exhibit hybrid behaviors comprised of both discrete-event and time-based dynamics [2], and execute under ex-plicit operating constraints using the proposed LLC method.Predictive and change-point detection algorithms have beenproposed for managing application performance, primarilyto estimate key performance parameters such as achievedresponse time, throughput, etc., and predict correspondingthreshold violations [40].
8 Conclusion
The paper presented the design and implementation ofa self-managing data streaming service that enables effi-cient data transport to support emerging Grid-based scien-tific workflows. The presented design combines rule-basedheuristic adaptations with more formal model-based onlinecontrol strategies to provide a self-managing service frame-work that is robust and flexible, and can address the dy-namism in the application requirements and system state.A fusion simulation workflow was used to evaluate the data-streaming service and its self-managing behaviours. The re-sults demonstrate the ability of the service to meet Grid-based data-streaming requirements, as well as its efficiencyand performance. A hierarchical control architecture wasalso presented to address scalability issues for large sys-tems. Simulations were used to demonstrate the feasibilityand effectiveness of this scheme.
Acknowledgements The research presented in this paper is sup-ported in part by National Science Foundation via grants numbers ACI9984357, EIA 0103674, EIA 0120934, ANI 0335244, CNS 0305495,CNS 0426354, CNS 0613971, IIS 0430826, and by Department of En-ergy via the grant number DE-FG02-06ER54857.
References
1. Abdelwahed, S., Kandasamy, N., Neema, S.: A control-basedframework for self-managing distributed computing systems.In: Workshop on Self-Managed Systems (WOSS’04), NewportBeach, CA, USA, 2004
2. Abdelwahed, S., Kandasamy, N., Neema, S.: Online control forself-management in computing systems. In: 10th IEEE Real-Timeand Embedded Technology and Applications Symposium, LeRoyal Meridien, King Edward, Toronto, Canada, 2004, pp. 368–376
3. Abdelzaher, T.F., Shin, K.G., Bhatti, N.: Performance guaranteesfor web server end-systems: a control theoretic approach. IEEETrans. Parallel Distributed Syst. 13(1), 80–96 (2002)
4. Abrahams, A., Eyers, D., Bacon, J.: An asynchronous rule-basedapproach for business process automation using obligations. In:Third ACM SIGPLAN Workshop on Rule-Based Programming(RULE’02), Pittsburgh, PA, pp. 323–345. ACM, New York (2002)
5. Agarwal, M., Parashar, M.: Enabling autonomic compositions ingrid environments. In: Fourth International Workshop on GridComputing (Grid ’03), Phoenix, Arizona, USA, pp. 34–41. IEEEComputer Society, Los Alamitos (2003)
6. Bertsekas, D.P.: Dynamic Programming and Optimal Control,vol. 1, 3rd edn. Athena Scientific, Nashua (2005)
7. Bhat, V., Klasky, S., Atchley, S., Beck, M., McCune, D., Parashar,M.: High performance threaded data streaming for large scalesimulations. In: 5th IEEE/ACM International Workshop on GridComputing (Grid 2004), Pittsburgh, PA, USA, 2004, pp. 243–250
8. Bhat, V., Parashar, M., Liu, H., Khandekar, M., Kandasamy,N., Abdelwahed, S.: Enabling self-managing applications usingmodel-based online control strategies. In: 3rd IEEE InternationalConference on Autonomic Computing, Dublin, Ireland, 2006
9. Bihari, T.E., Schwan, K.: Dynamic adaptation of real-time soft-ware. ACM Trans. Comput. Syst. 9(2), 143–174 (1991)
10. Capra, L., Emmerich, W., Mascolo, C.: A micro-economic ap-proach to conflict resolution in mobile computing. In: Workshopon Self-healing Systems (SIGSOFT’02), Charleston, SC, USA,2002, pp. 31–40
11. Cervin, A., Eker, J., Bernhardsson, B., Arzen, K.: Feedback-feedforward scheduling of control tasks. Real-Time Syst. 23(1-2),25–53 (2002)
12. Chen, J.: M3D Home, http://w3.pppl.gov/%7ejchen, 200513. Cheng, J.J., Flaxer, D., Kapoor, S.: RuleBAM: a rule-based frame-
work for business activity management. In: IEEE InternationalConference on Services Computing(SCC’04), Shanghai, China,2004, pp. 262–270
14. Christensen, E., Curbera, F., Meredith, G., Weerawarana, S.: WebServices Description Language (WSDL) 1.1, http://www.w3.org/TR/wsdl, 15 March 2001
15. Hellerstein, J.L., Diao, Y., Parekh, S., Tilbury, D.M.: FeedbackControl of Computing Systems. Wiley-IEEE Press, Hoboken(2004)
16. Hellerstein, J.L., Diao, Y., Parekh, S.S.: Applying control theoryto computing systems. Technical report, December 7, 2004
17. Kandasamy, N., Abdelwahed, S., Hayes, J.P.: Self-optimization incomputer systems via online control: application to power man-agement. In: 1st IEEE International Conference on AutonomicComputing (ICAC’04), New York, NY, USA, 2004, pp. 54–61
18. Klasky, S., Beck, M., Bhat, V., Feibush, E., Ludäscher, B.,Parashar, M., Shoshani, A., Silver, D., Vouk, M.: Data manage-ment on the fusion computational pipeline. J. Phys. Conf. Ser.16(2005), 510–520 (2005)
19. Lawrence-Berkeley-National-Laboratory: The Energy SciencesNetwork (ESnet), http://www.es.net/ (2004)
20. Lin, Z., Hahm, T.S., Lee, W.W., Tang, W.M., White, R.B.: Turbu-lent transport reduction by zonal flows: massively parallel simula-tions. Science 281(5384), 1835–1837 (1998)

Cluster Comput
21. Liu, H.: Accord: a programming system for autonomic self-managing applications. PhD thesis, Rutgers University (2005)
22. Liu, H., Bhat, V., Parashar, M., Klasky, S.: An autonomic servicearchitecture for self-managing grid applications. In: 6th Interna-tional Workshop on Grid Computing (Grid 2005), Seattle, WA,USA, 2005, pp. 132–139
23. Liu, H., Parashar, M., Hariri, S.: A component-based program-ming framework for autonomic applications. In: 1st IEEE Inter-national Conference on Autonomic Computing (ICAC-04), NewYork, NY, USA, 2004, pp. 10–17
24. Lu, C., Alvarez, G.A., Wilkes, J.: Aqueduct: online data migrationwith performance guarantees. In: USENIX Conference on FileStorage Technologies (FAST’02), Monterey, CA, 2002, pp. 219–230
25. Lu, C., Stankovic, J.A., Son, S.H., Tao, G.: Feedback controlreal-time scheduling: framework, modeling, and algorithms. Real-Time Syst. 23(1-2), 85–126 (2002)
26. Lu, Z., Hein, J., Humphrey, M., Stan, M., Lach, J., Skadron, K.:Control-theoretic dynamic frequency and voltage scaling for mul-timedia workloads. In: International Conference on Compilers,Architectures, & Synthesis Embedded Systems (CASES), Greno-ble, France, pp. 156–163. ACM Press, New York (2002)
27. Lupu, E.C., Sloman, M.: Conflicts in policy-based distributedsystems management. IEEE Trans. Softw. Eng. 25(6), 852–869(1999)
28. Ma, X.: Hiding periodic I/O costs in parallel applications. PhDthesis, University of Illinois at Urbana-Champaign (2003)
29. Ma, X., Lee, J., Winslett, M.: High-level buffering for hiding pe-riodic output cost in scientific simulations. IEEE Trans. ParallelDistributed Syst. 17(3), 193–204 (2006)
30. Mascolo, S.: Classical control theory for congestion avoidance inhigh-speed Internet. In: 38th IEEE Conference on Decision andControl, Phoenix, Arizona, USA, 1999, vol. 3, pp. 2709–2714
31. Nichols, B., Buttlar, D., Farrell, J.P.: PThreads Programming. APOSIX Standard for Better Multiprocessing, 1st edn. O’Reilly, Se-bastopol (1996)
32. NLANR/DAST: Iperf 1.7.0: the TCP/UDP bandwidth measure-ment tool, http://dast.nlanr.net/Projects/Iperf/ (2005)
33. Parashar, M., Browne, J.C.: Conceptual and implementation mod-els for the grid. Proc. IEEE 93, 653–668 (2005)
34. Parekh, S., Gandhi, N., Hellerstein, J., Tilbury, D., Jayram, T., Bi-gus, J.: Using control theory to achieve service level objectivesin performance management. Real-Time Syst. 23(1-2), 127–141(2002)
35. Plank, J.S., Beck, M., Elwasif, W.R., Moore, T., Swany, M., Wol-ski, R.: The Internet backplane protocol: storage in the network.In: NetStore99: The Network Storage Symposium, Seattle, WA,USA, 1999
36. Plank, J.S., Beck, M.: The logistical computing stack—a designfor wide-area, scalable, uninterruptible computing. In: Depend-able Systems and Networks, Workshop on Scalable, Uninterrupt-ible Computing (DNS 2002), Bethesda, Maryland, USA, 2002
37. Sharma, V., Thomas, A., Abdelzaher, T., Skadron, K., Lu, Z.:Power-aware QoS management in web servers. In: Real-Time Sys-tems Symposium, Cancun, Mexico, 2003, pp. 63–72
38. Srikant, R.: Control of communication networks. In: T. Samad(ed.) Perspectives in Control Engineering: Technologies, Applica-tions, New Directions, pp. 462–488. Wiley-IEEE Press, New York(2000)
39. van-der Aalst, W.M.P., ter Hofstede, A.H.M., Kiepuszewski, B.,Barros, A.P.: Workflow patterns. Distributed Parallel Databases14(1), 5–51 (2003)
40. Vilalta, R., Apte, C., Hellerstein, J.L., Ma, S., Weiss, S.M.: Pre-dictive algorithms in the management of computer systems. IBMSyst. J. 41(3), 461–474 (2002)
41. W3C. OWL web ontology language overview, http://www.w3.org/TR/owl-features (2004)
42. Wu, X., Hellerstein, J.L.: Control theory in log processing sys-tems. In: Summer 2005 RADS (Reliable Adaptive DistributedSystems Laboratory) Retreat, 2005
Viraj Bhat is a Ph.D. candidate in the De-partment of Electrical and Computer Engi-neering. He has been a visiting researcher atPrinceton Plasma Physics Laboratory (PPPL) inPrinceton, New Jersey since 2004. His researchinterests include Autonomic and Grid com-puting. Viraj has been involved in severalresearch projects, including CORBACoG, Au-toMate/Accord and DISCOVER at CAIP (Rut-gers University) and development of systems
for distributed scientific data management using automated workflows.He has co-authored several technical papers in international journalsand conferences, and has also co-authored 2 book chapters. Viraj is theCyber Chair for the HiPC Conference (2005–2007) and a reviewer forseveral journals and conferences. He is a student member of the IEEEComputer Society. Prior to this he was a Software Engineer at SatyamComputer Services Ltd. in Bangalore with 2 years of industry experi-ence in information technology. Viraj received his B.E. degree (May1998) in Electrical Engineering from NIT/REC Bhopal India, and anM.S. degree (May 2003) in Computer Engineering from Rutgers Uni-versity.
Manish Parashar is Professor of Electrical andComputer Engineering at Rutgers University,where he also is director of the Applied Soft-ware Systems Laboratory. He received a BEdegree in Electronics and Telecommunicationsfrom Bombay University, India and MS andPh.D. degrees in Computer Engineering fromSyracuse University. He has received the Rut-gers Board of Trustees Award for Excellence inResearch (2004–2005), NSF CAREER Award
(1999) and the Enrico Fermi Scholarship from Argonne National Lab-oratory (1996). His research interests include autonomic computing,parallel & distributed computing (including peer-to-peer and Gridcomputing), scientific computing, and software engineering. Manishis a senior member of IEEE, member of the executive committee ofthe IEEE Computer Society Technical Committee on Parallel Process-ing (TCPP), part of the IEEE Computer Society Distinguished VisitorProgram (2004–2006), and a member of ACM. He is the co-founder ofthe IEEE International Conference on Autonomic Computing (ICAC),serves on the editorial boards of several journals, and on the steeringand program committees of several international workshops and con-ferences. For more information please visit http://www.caip.rutgers.edu/~parashar/.
Hua Liu is a research staff member of Xe-rox Innovation Group in Xerox Corporation.She received a BS degree in Computer Scienceand MS degree in Computer Engineering fromBeijing University of Posts&Telecoms (China)in 1998 and 2001, Ph.D. degree in ComputerEngineering from Rutgers University in 2005.She worked as Research Assistant at the Centerfor Advanced Information Processing (CAIP) inRutgers University from 2001 to 2005, Consul-
tant at Sandia National Lab in 2004 summer. She has over 10 publi-cations in international journals and conferences. Her current researchinterests include Autonomic Computing, High-Performance Comput-

Cluster Comput
ing, and Service-Oriented Software. Dr. Liu is a member of IEEE. Formore information, please visit http://www.caip.rutgers.edu/~marialiu
Nagarajan Kandasamy received his B.E. de-gree (1995) from Guindy Engineering College,Chennai, India, M.S. (1997) from the Univer-sity of Connecticut, and Ph.D. (2003) from theUniversity of Michigan, all in Computer Sci-ence and Engineering. He joined Drexel Univer-sity in September 2004 as an Assistant Profes-sor. He was a research assistant in the AdvancedComputer Architecture Lab. at the University ofMichigan from 1998–2003, and prior to joining
Drexel, was a research scientist at the Institute for Software IntegratedSystems, Vanderbilt University. His current areas of interest includeembedded systems, self-managing systems, reliable and fault-tolerantcomputing, distributed systems, computer architecture, and testing andverification of digital systems.
Mohit Khandekar completed his MS in Elec-trical Engineering from Drexel University in2006. His research interests include AutonomicComputing, Model Predictive Control and Dis-tributed Computing Systems. He is currentlyworking as a Software Engineer in VerizonCommunications, USA. Mohit can be contactedvia email at [email protected]
Scott Klasky is presently a senior research anddevelopment scientist in the Scientific Comput-ing Group within the National Center for Com-putational Sciences (NCCS) at ORNL. Prior tojoining ORNL, he was the head of visualizationand simulation data management at the Prince-ton Plasma Physics laboratory. Klasky’s tasks atORNL include working with many of the Fu-sion SciDAC projects (CEMM, SWIM, GPS,CPES), and developing end-to-end solutions for
these projects. Dr. Klasky received his BS in Physics from Drexel Uni-versity in 1989. He then received a Ph.D. in physics from the Univer-sity of Texas at Austin in 1994. The topic of Klasky’s thesis was in nu-merical methods to solve elliptical partial differential equations for nu-merical relativity. During his time as a student, Klasky also worked asa research assistant at the Center for High Performance Computing atTexas. His work there was in the visualization group, working on devel-oping visualization software for researchers at Texas. After receivinghis Ph.D., Klasky become a postdoctoral research associate at Texas,working on advanced computing techniques for the NSF funded grandchallenge, “The Binary Black Hole Grand Challenge”. Between 1996and 1999, Klasky became a senior research scientist at the NortheastParallel Architecture Center at Syracuse University. His research cen-tered around collaborative visualization and advance numerical meth-ods.
Sherif Abdelwahed received his Ph.D. degreein Electrical and Computer Engineering fromthe University of Toronto, Canada, in 2002. Hehas been with the Department of Electrical En-gineering and Computer Science at VanderbiltUniversity since 2001, as a Research AssistantProfessor. His research interests include mod-eling, verification, and control of distributedlarge-scale systems, and model-based diagno-sis of discrete-event and hybrid systems. He has
worked on several DARPA, NASA, and NSF funded projects devel-oping algorithms and tools for resource management, fault-adaptivecontrol, and model-based diagnosis of distributed real-time embeddedsystems. Dr. Abdelwahed has more than 60 publications and is a seniormember of the IEEE.