a spark framework for < $100, < 1 hour, accurate personalized dna analysis at scale
TRANSCRIPT

A Spark Framework for < $100, < 1 Hour, Accurate Personalized DNA Analysis at Scale
Zaid Al-Ars Delft University of Technology The Netherlands
DELFT UNIVERSITY OF TECHNOLOGY
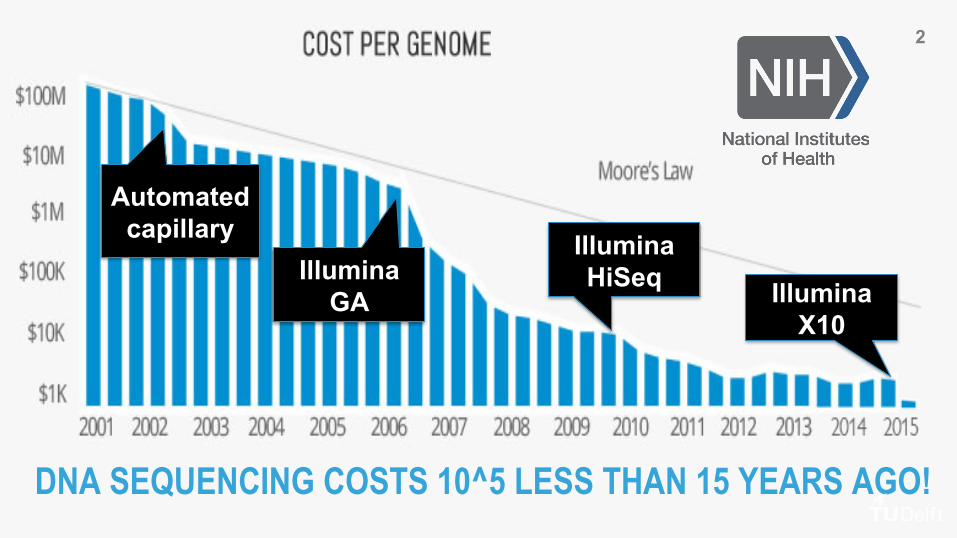
DNA SEQUENCING COSTS 10^5 LESS THAN 15 YEARS AGO!
Automated capillary
Illumina GA
Illumina HiSeq Illumina
X10
2

HUGE DATA SETS REQUIRE INTENSE COMPUTING CAPACITY
3
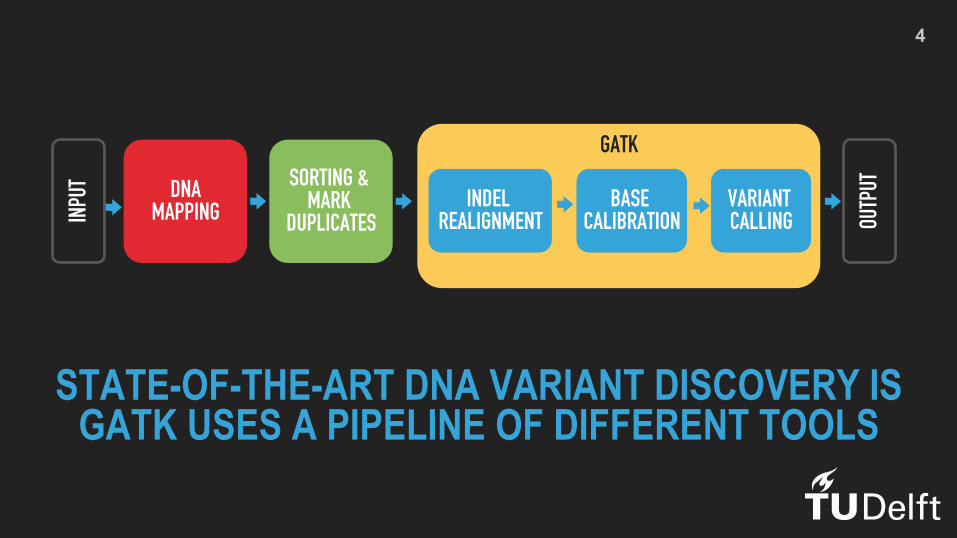
STATE-OF-THE-ART DNA VARIANT DISCOVERY IS GATK USES A PIPELINE OF DIFFERENT TOOLS
DNA MAPPING
SORTING & MARK
DUPLICATES
GATK
OUTP
UT
4
INDEL REALIGNMENT
BASE CALIBRATION
VARIANT CALLING IN
PUT

EXISTING PIPELINES DON’T EFFICIENTLY USE COMPUTERS
5

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
IDEA ▸ We use input data segmentation to group data of the same chromosome for
parallelization.
▸ Data of the same chromosome can further be divided to create more segments.
6

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
COMPARISON OF BIG DATA TECHNIQUES GATK Queue o Slow scheduling o Hard to setup o Disk intensive o Poorly documented
Halvade o Disk intensive o Limited memory use o Static load balancing
Our Tool ü In-memory compute ü Dynamic load balancing ü Effective use of disk ü Easy to setup
7
Lack of genomics verification of the outputs
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
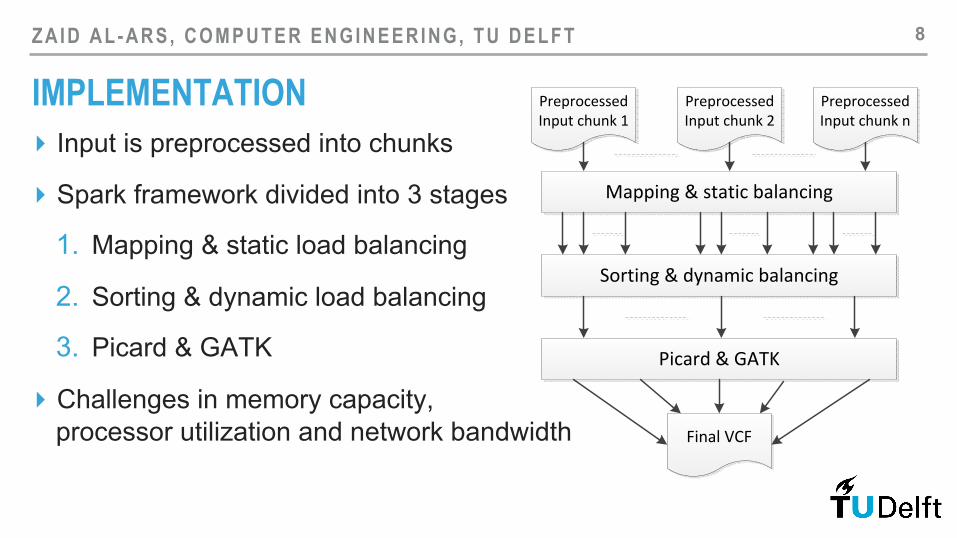
IMPLEMENTATION ▸ Input is preprocessed into chunks
▸ Spark framework divided into 3 stages
1. Mapping & static load balancing
2. Sorting & dynamic load balancing
3. Picard & GATK
▸ Challenges in memory capacity, processor utilization and network bandwidth
8
Preprocessed Input chunk 1
Preprocessed Input chunk 2
Mapping & static balancing
Sorting & dynamic balancing
Picard & GATK
Final VCF
Preprocessed Input chunk n
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
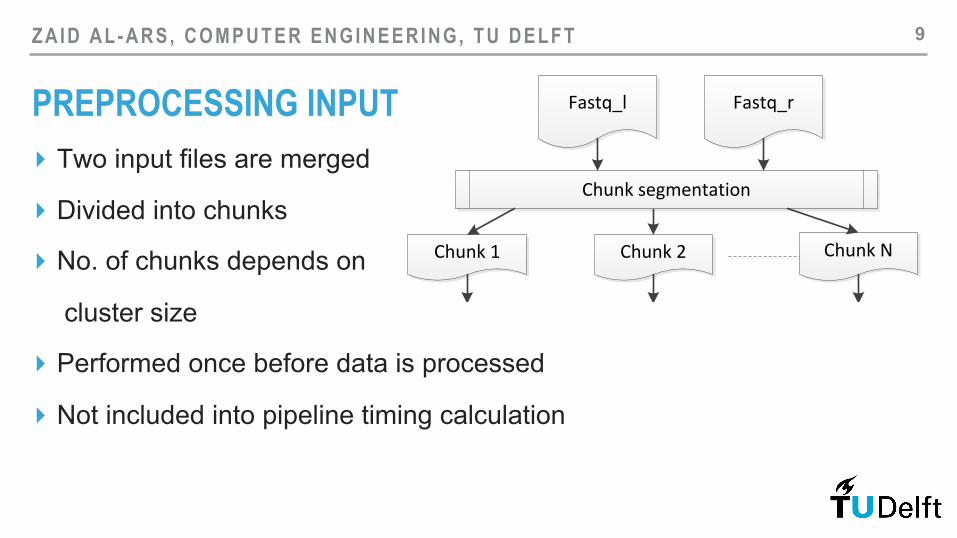
PREPROCESSING INPUT ▸ Two input files are merged
▸ Divided into chunks
▸ No. of chunks depends on
cluster size
▸ Performed once before data is processed
▸ Not included into pipeline timing calculation
Fastq_l Fastq_r
Chunk 1 Chunk 2 Chunk N
Chr 1a Chr 1b Chr 2a Chr Y
VCF 1a VCF 1b VCF Y
Final VCF
BWA-MEM BWA-MEM BWA-MEM
Chunk segmentation
Picard and
GATK
Picard and
GATK
Picard and
GATK
Sam1_1b
Sam1_1a Sam1_2
Sam1_y Sam2_1b
Sam2_1a Sam2_2
Sam2_y
Load balancer
Chr 2b
SamN_1b
SamN_1a SamN_2
SamN_y
VCF 2a
Picard and
GATK
VCF 2b
Picard and
GATK
Preprocessing
Fastq_l Fastq_r
Mapping & static balancing
Sorting & dynamic balancing
Picard & GATK
Final VCF
9

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
1. MAPPING & STATIC LOAD BALANCING ▸ Chunks mapped w/ BWA => easily scalable to all cores
▸ Output divided into chromosomal regions
▸ Reduces memory needs
for dynamic
load balancing
Fastq_l Fastq_r
Chunk 1 Chunk 2 Chunk N
Chr 1a Chr 1b Chr 2a Chr Y
VCF 1a VCF 1b VCF Y
Final VCF
BWA-MEM BWA-MEM BWA-MEM
Chunk segmentation
Picard and
GATK
Picard and
GATK
Picard and
GATK
Sam1_1b
Sam1_1a Sam1_2
Sam1_y Sam2_1b
Sam2_1a Sam2_2
Sam2_y
Load balancer
Chr 2b
SamN_1b
SamN_1a SamN_2
SamN_y
VCF 2a
Picard and
GATK
VCF 2b
Picard and
GATK
Preprocessing
Fastq_l Fastq_r
Mapping & static balancing
Sorting & dynamic balancing
Picard & GATK
Final VCF
10
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
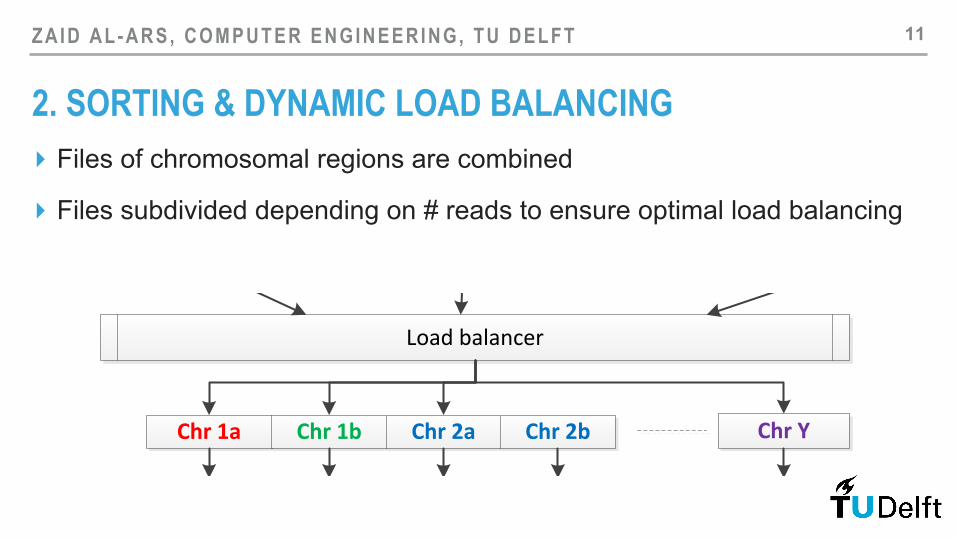
2. SORTING & DYNAMIC LOAD BALANCING ▸ Files of chromosomal regions are combined
▸ Files subdivided depending on # reads to ensure optimal load balancing
Fastq_l Fastq_r
Chunk 1 Chunk 2 Chunk N
Chr 1a Chr 1b Chr 2a Chr Y
VCF 1a VCF 1b VCF Y
Final VCF
BWA-MEM BWA-MEM BWA-MEM
Chunk segmentation
Picard and
GATK
Picard and
GATK
Picard and
GATK
Sam1_1b
Sam1_1a Sam1_2
Sam1_y Sam2_1b
Sam2_1a Sam2_2
Sam2_y
Load balancer
Chr 2b
SamN_1b
SamN_1a SamN_2
SamN_y
VCF 2a
Picard and
GATK
VCF 2b
Picard and
GATK
Preprocessing
Fastq_l Fastq_r
Mapping & static balancing
Sorting & dynamic balancing
Picard & GATK
Final VCF
11
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
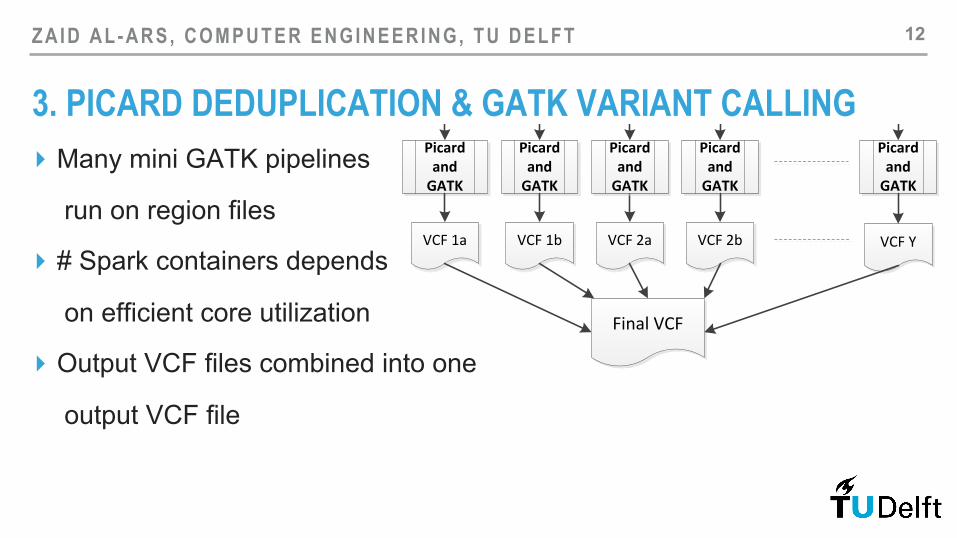
3. PICARD DEDUPLICATION & GATK VARIANT CALLING ▸ Many mini GATK pipelines
run on region files
▸ # Spark containers depends
on efficient core utilization
▸ Output VCF files combined into one
output VCF file
Fastq_l Fastq_r
Chunk 1 Chunk 2 Chunk N
Chr 1a Chr 1b Chr 2a Chr Y
VCF 1a VCF 1b VCF Y
Final VCF
BWA-MEM BWA-MEM BWA-MEM
Chunk segmentation
Picard and
GATK
Picard and
GATK
Picard and
GATK
Sam1_1b
Sam1_1a Sam1_2
Sam1_y Sam2_1b
Sam2_1a Sam2_2
Sam2_y
Load balancer
Chr 2b
SamN_1b
SamN_1a SamN_2
SamN_y
VCF 2a
Picard and
GATK
VCF 2b
Picard and
GATK
Preprocessing
Fastq_l Fastq_r
Mapping & static balancing
Sorting & dynamic balancing
Picard & GATK
Final VCF
12

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
POWER8 Cluster § 20 POWER8 S822LC nodes, bare metal § 2x SCM 10-core, SMT8; 160 HW threads per node § 512 GB of RAM per node § Mellanox Infiniband EDR ConnectX-4 adapters (100Gb/s) § IBM General Parallel File System (GPFS)
EXPERIMENT SETUP
Data Used: § Raw reads: G15512.HCC1954 (whole human genome, 400GB uncompressed) § Reference: human_g1k_v37
13
§ Red Hat EL 7.2 § Spark 1.5.1, openJDK 1.8 § IBM LSF for resource management § Configured as 1 master + 19 slaves

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
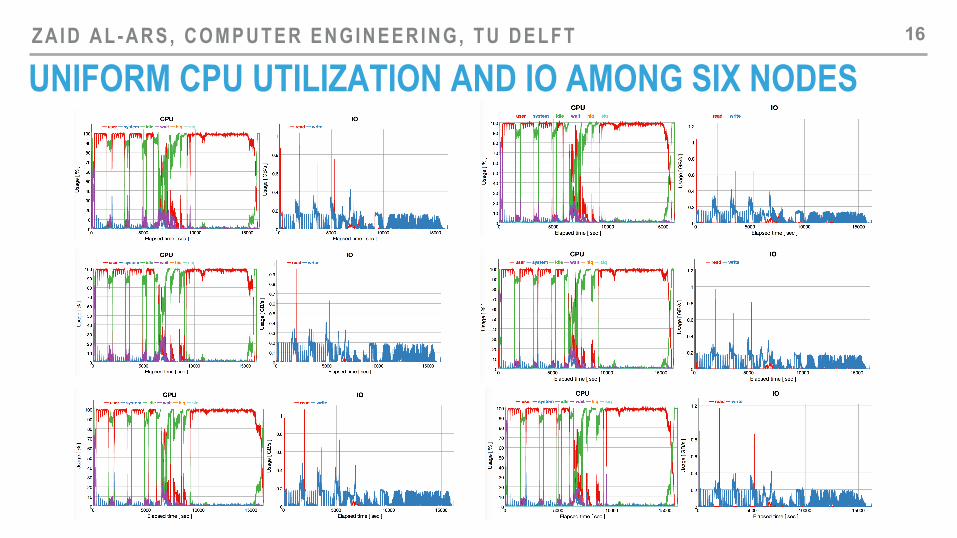
CPU UTILIZATION ON SMALLER CLUSTER Stage 1: Mapping
Stage 2: sorting &
load balance Stage 3:
Picard and GATK
14
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
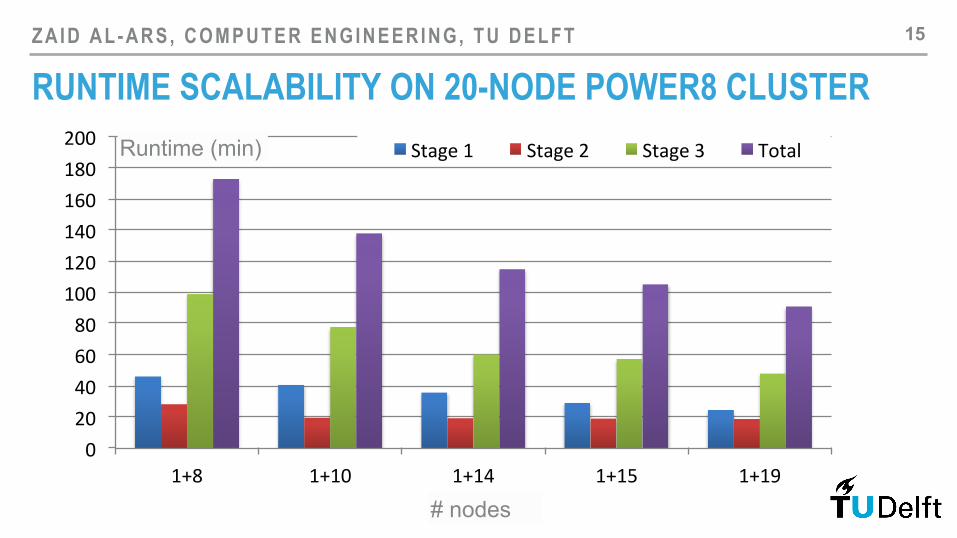
RUNTIME SCALABILITY ON 20-NODE POWER8 CLUSTER 15
0"20"40"60"80"100"120"140"160"180"200"
1+8" 1+10" 1+14" 1+15" 1+19"
Stage"1" Stage"2" Stage"3" Total"
# nodes
Runtime (min)
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
UNIFORM CPU UTILIZATION AND IO AMONG SIX NODES 16

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
SCALABILITY ANALYSIS FOR LARGER CLUSTERS
10
20
30
40
50
60
70
80
90
100
1000 1500 2000 2500 3000 3500 4000 4500 5000 5500 6000
Part1 Part4 Part1 extrapolated Part4 extrapolated
Stage1 + Stage3 ~ 42 min Total runtime ~ 60 min
Estimated cost ~ 1 node-day
# HW threads
Runtime (min)
17
‣ 90 min runtime on 20-node cluster
‣ Stage 1 & 3 are scalable
‣ Runtime scales down to 1 hour for 35 node cluster
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
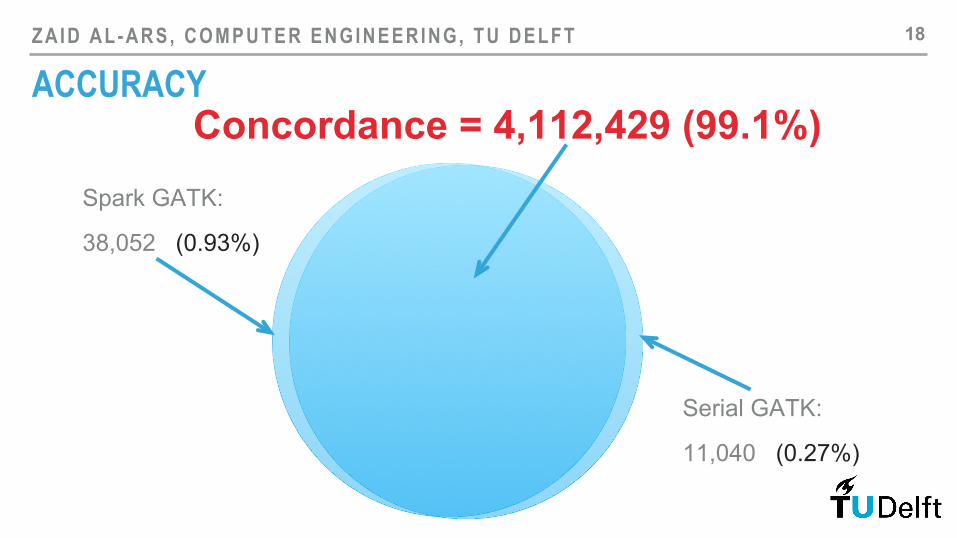
ACCURACY
Concordance = 4,112,429 (99.1%)
Serial GATK:
11,040 (0.27%)
Spark GATK:
38,052 (0.93%)
18
ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
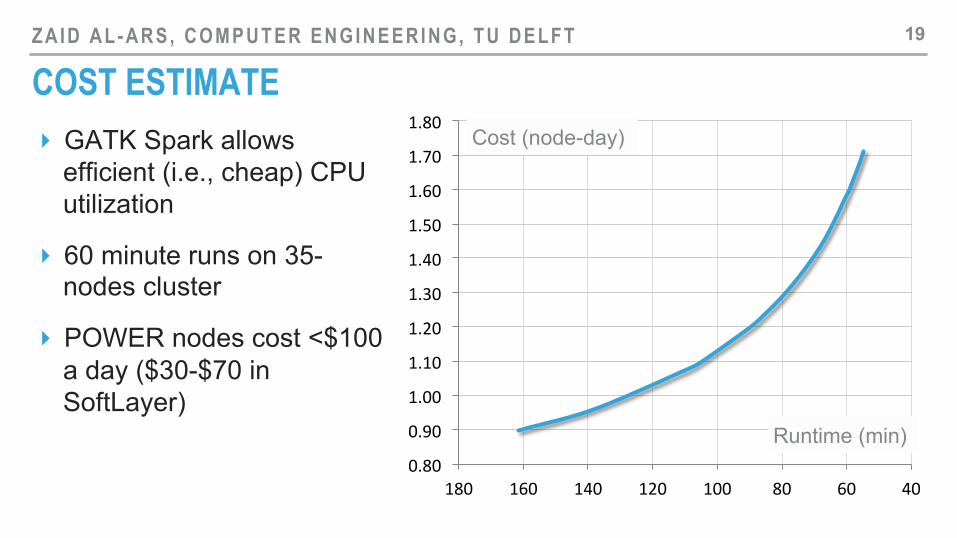
COST ESTIMATE 19
0.80
0.90
1.00
1.10
1.20
1.30
1.40
1.50
1.60
1.70
1.80
40 60 80 100 120 140 160 180
Runtime (min)
Cost (node-day) ‣ GATK Spark allows efficient (i.e., cheap) CPU utilization
‣ 60 minute runs on 35-nodes cluster
‣ POWER nodes cost <$100 a day ($30-$70 in SoftLayer)

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
CONCLUSIONS ▸ GATK pipeline runs on Apache Spark framework
▸ Solution shows good scalability without sacrificing accuracy
▸ 400GB WGS data scales to under 1 hour for 35 nodes
▸ Price point is below $100 for POWER8 cluster
▸ Future work
▸ We are accelerating our solution further using FPGAs through the IBM POWER8’s CAPI interface
▸ Examples: compression & math-heavy kernels like pairHMM
20

ZAID AL-ARS, COMPUTER ENGINEERING, TU DELFT
ACKNOWLEDGEMENTS
▸ Hamid Mushtaq (TUDelft)
▸ Carlos Costa (IBM)
▸ Neil Graham (IBM)
▸ Peter Hofstee (IBM)
▸ Raj Krishnamurthy (IBM)
21
▸ Frank Liu (IBM)
▸ Gang Liu (IBM)
▸ Rei Odaira (IBM)
▸ Indrajit Poddar (IBM)

THANK YOU. Zaid Al-Ars [email protected] Delft University of Technology The Netherlands http://ce.ewi.tudelft.nl/zaid