a survey of model comparison approaches and...
TRANSCRIPT

A Survey of Model Comparison Approaches and Applications
Matthew Stephan and James R. CordyQueen’s University, Kingston, Ontario, Canada
fstephan, [email protected]
Keywords: Model Comparison, Model-Driven Engineering, Model Versioning, Model Clone Detection.
Abstract: This survey paper presents the current state of model comparison as it applies to Model-Driven Engineering.We look specifically at how model matching is accomplished, the application of the approaches, and the typesof models that approaches are intended to work with. Our paper also indicates future trends and directions.We find that many of the latest model comparison techniques are geared towards facilitating arbitrary metamodels and use similarity-based matching. Thus far, model versioning is the most prevalent application ofmodel comparison. Recently, however, work on comparison for versioning has begun to stagnate, giving wayto other applications. Lastly, there is wide variance among the tools in the amount of user effort required toperform model comparison, as some require more effort to facilitate more generality and expressive power.
1 INTRODUCTION
Model-Driven Engineering (MDE) involves usinghigh-level software models as the main artifactswithin the development cycle. As MDE becomesmore prevalent in software engineering, the need foreffective approaches for finding the similarities anddifferences among high-level software models, ormodel comparison, becomes imperative. Since MDEinvolves models being considered first class artifactsby developers, it is clear model comparison is impor-tant as it assists model management and may helpfacilitate analysis of existing projects and MDE re-search. It not only provides merit as a stand-alonetask, but helps engineers with other MDE tasks suchas model composition and inferring and testing ofmodel transformations (Kolovos et al., 2006).
Despite model comparison’s importance in MDE,there are no definitive surveys on the state of the artin model comparison research. There are a few pa-pers that touch upon it, however, they look at onlya very small subset of the work in existence and ei-ther at those intended for only a specific model typeor application. In this survey paper, we present thecurrent state of model comparison research and dis-cuss the area’s future directions. The purpose in do-ing so is to investigate and describe the approaches toaccomplish model comparison, the various applica-tions that approaches are used for, and to categorizethe approaches by the types of models they are ableto compare. As such, this survey can be used by en-
gineers as a quick reference guide, organized by thetypes of models being compared: If they must workwith a specific model type or need a specific applica-tion to be accomplished via model comparison, theycan use this survey to determine if an approach is rightfor them or if they should build upon an existing one.
We begin with background information on modelcomparison in Section 2. Section 3 categorizes anddescribes the existing model comparison approachesby the type and subtype of models that they compare.Section 4 provides a summary of the survey resultsand future directions of the area. Section 5 identifiesother techniques and approaches related to the modelcomparison work discussed in this survey, as well asother surveys.
2 BACKGROUND
We begin by defining model comparison as it appliesin this survey. Much of the existing work can be splitinto two categories: those techniques aimed at modelversioning, and those aimed at model similarity anal-ysis, or “clone detection”, so we additionally definethose categories.
2.1 Model Comparison
This section discusses model comparison as a taskin MDE and refers specifically to the act of identi-fying similarities or differences between model ele-
265

ments. Aside from versioning and model clone de-tection, model comparison has merit in other areas ofMDE including being the foundation for model com-position, model transformation testing (Kolovos et al.,2006; Lin et al., 2004; Stephan and Cordy, 2013), andothers discussed in this survey.
Kolovos, Paige, and Polack (2006) define modelcomparison as an operation that classifies elementsinto four categories: (1) Elements that match andconform, (2) Elements that match and do not con-form, (3) Elements that do not match and are withinthe domain of comparison, and (4) Elements that donot match and are not within the domain of com-parison. Matching refers to elements that representthe same idea or artifact, while conformance is ad-ditional matching criteria. An example of non con-formance in an UML class diagram can be when aclass in both models has the same name but one isabstract. So while they likely represent the same ar-tifact, they do ’match enough’ or conform to one an-other (Kolovos et al., 2006). The specific definitionof conformance is dependent on the current compari-son context and goal. The domain of the comparisoncan be viewed as matching criteria. Non-matching el-ements that are outside the domain of comparison cancome from matching criteria that is either incompleteor intentionally ignoring them.
In the context of model versioning, model com-parison has been decomposed into three phases (Brunand Pierantonio, 2008): Calculation, Representation,and Visualization. However, there is nothing aboutthis decomposition that is specific to model version-ing. In the following paragraphs we elaborate on thesephases and provide examples of approaches.
Calculation. Calculation is the initial step of modelcomparison and is the act of identifying similaritiesand differences between different models. It can seenas the classification of elements into the four cate-gories presented earlier. Calculation techniques canwork with specific types of models, such as donewith UML-model comparison methods (Alanen andPorres, 2003; Girschick, 2006; Kelter et al., 2005;Ohst et al., 2003; Xing and Stroulia, 2005). How-ever, it is possible to have meta-model independentcomparisons, such as techniques for Domain Spe-cific Models (Lin et al., 2007) and other such ap-proaches (Rivera and Vallecillo, 2008; Selonen andKettunen, 2007; van den Brand et al., 2010). Kolovos,Di Ruscio, Pierantonio, and Paige (2009) break downcalculation methods into four different categoriesbased on how they match corresponding model ele-ments: 1]static identity-based matching, which usespersistent and unique identifiers; 2]signature-based
matching, which is based on an element’s uniquely-identifying signature that is calculated from a user-defined function; 3]similarity-based matching, whichuses the composition of the similarity of an element’sfeatures; and 4]custom language-specific matchingalgorithms, which uses matching algorithms designedto work with a particular modeling language. In theremainder of this survey we focus mainly on thisphase, as calculation is the most researched and isof the greatest interest to our industrial partners sinceit will help us with our goal of considering how todiscover common sub-patterns among models (Alalfiet al., 2012).
Representation. This phase deals with the underly-ing form that the differences and similarities detectedduring calculation will take. One approach to repre-sentation is the notion of edit scripts (Alanen and Por-res, 2003; Mens, 2002). Edit scripts are an operationalrepresentation of the changes necessary to make onemodel equivalent to another and can be comprisedof primitive operations such as add, edit, and delete.They tend to be associated with calculation meth-ods that use unique identifiers and may not be user-friendly due to their imperative nature. In contrast,model-based representation (Ohst et al., 2003) is amore declarative approach. It represents differencesby recognizing the elements and sub-elements thatare the same and those that differ. Most recently, anabstract-syntax-like representation (Brun and Pieran-tonio, 2008) has been proposed that represents thedifferences declaratively and enables further analysis.There are properties (Cicchetti et al., 2007; Van denBrand et al., 2010) for representation techniques thatseparate them from calculation approaches and makethem ideal for MDE environments. Cicchetti, Di Rus-cio, and Pierantonio (2008) provide a representationthat is ideal for managing conflicts in distributed en-vironments.
Visualization. Visualization involves displayingthe differences in a desirable form to the end user. Vi-sualization is considered somewhat secondary to cal-culation and representation and may be tied closely torepresentation. For example, model-based representa-tion can be visualized through colouring (Ohst et al.,2003). Newer visualization approaches try to sepa-rate visualization from representation (Van den Brandet al., 2010; Wenzel, 2008; Wenzel et al., 2009).There is also an approach (Schipper et al., 2009) to ex-tend visualization techniques for comparing text filesto work with models by including additional featuresunique to higher level representations, such as fold-ing, automatic layout, and navigation.
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
266

2.2 Model Versioning
The need for collaboration amongst teams in MDEprojects is equally significant as it is in traditionalsoftware projects. Traditional software projectsachieve this through Version Control Systems (VCS)such as CVS1 and Subversion2. Similarly, for MDE,it is imperative that modelers are able to work in-dependently but later be able to reintegrate updatedversions into the main project repository. TraditionalVCS approaches do not work well with models asthey are unable to handle model-specific problemslike the “dangling reference” problem and others (Alt-manninger et al., 2009).
Model versioning is broken into different phasesby different people (Alanen and Porres, 2003; Alt-manninger et al., 2008; Kelter et al., 2005). Gener-ally, it is seen to require some form of model com-parison or matching, that is, the identification of whatmodel elements correspond to what other model el-ements; detection and representation of differencesand conflicts; and model merging, that is, combiningchanges made to corresponding model elements whileaccounting for conflicts. For the purpose of this sur-vey, we focus mainly on the first phase, model com-parison. While the other phases are equally as im-portant, we are interested mostly in the way modelversioning approaches achieve model comparison.
2.3 Model Clone Detection
Another example of model comparison being used ina different and specific context is model clone detec-tion. In traditional software projects, a code clonerefers to collections of code that are similar to one an-other in some measure of similarity (Koschke, 2006).One common reason that code clones arise in theseprojects is the implementation of a similar conceptthroughout the system. The problem with code clonesis that a change in this one concept means that the sys-tem must be updated in multiple places. Research incode clones is very mature and there are many tech-niques and tools to deal with them (Roy et al., 2009).
The analogous problem of model clones refers togroups of model elements that are shown to be similarin some defined fashion (Deissenboeck et al., 2009).By comparison with code clone detection, research inmodel clone detection is quite limited (Deissenboecket al., 2010), with the majority of approaches thus fartailored for Simulink data-flow models.
1http://www.nongnu.org/cvs/2http://subversion.tigris.org
3 MODEL COMPARISONAPPROACHES ANDAPPLICATIONS
This section categorizes existing model comparisonmethods by the specific types of models they com-pare and discusses the applications of the compar-isons. Within each section, we further classify the ap-proaches by the sub type of model they are intendedfor. While some methods claim they can be extendedto work with other types of models, we still place eachone in only the category they have demonstrated theywork with and make note of the claimed extendability.
3.1 Methods for Multiple Model Types
This section looks at approaches that are able to dealwith more than one type of model, such as both struc-tural and behavioral models. Approaches like this canbe more general, but can not use information specificto the model type.
3.1.1 UML Models
UML is a meta model defined by the MOF and is themost prominent and well known example of a MOFinstance. This section looks at model comparison ap-proaches intended to compare more than one type ofUML model.
Alanen and Porres (2003; 2005) perform modelcomparison as a precursor to model versioning. Theirmodel matching is achieved through static identity-based matching as it relies on the UML’s univer-sally unique identifiers(UUID). Their work is focusedon identifying differences between matched models.They calculate and represent differences as directeddeltas, that is, operations that turn one model into theother and that can be reversed through a dual opera-tion. Their difference calculation is achieved throughthe three steps that results in a sequence of operations:1] Given a model V and V’, map matched model ele-ments through UUID comparison; 2] Add operationsto create the elements within V’ that do not exist inV and then add operations to delete the elements thatare in V that are not in V’; 3] For all the elements thatare in both V and V’, any changes that have occurredto the features within these elements from V to V’ areconverted to operations that ensure that feature order-ing is preserved.
Rational Software Architect. (RSA) is an IBMproduct intended to be a complete MDE developmentenvironment for software modeling. Early versionsof RSA, RSA 6 and earlier, allow for two ways ofperforming model comparison on UML models, both
A�Survey�of�Model�Comparison�Approaches�and�Applications
267

Figure 1: RSA “Compare with Local History” Window,adapted from (Letkeman, 2005).
of which are a form of model versioning: Compar-ing a model from its local history and comparing amodel with another model belonging to the same an-cestor (Letkeman, 2005). In both cases, model match-ing is done using UUIDs. The calculation for findingdifferences between matched elements is proprietary.
Figure 1 shows an example of the “compare withlocal history” RSA window. The bottom pane is splitbetween the two versions while the top right pane de-scribes the differences found between the two. Thewindow and process for comparing a model with an-other model within the same ancestry is very similar.In RSA version 7 and later a facility is provided by thetool to compare and merge two software models thatare not necessarily from the same ancestor (Letke-man, 2007). This is accomplished manually throughuser interaction, that is, there is no calculation takingplace other than the option to do a relatively simplestructural and UUID comparison. The user selects el-ements from the source that should be added to thetarget, maps matching elements from the source andtarget, and chooses the final names for these matchedelements.
Another example of a technique that comparesUML models and utilizes their UUIDs is proposed byOhst, Welle, and Kelter (2003). This technique trans-forms UML models to graphs and then traverses eachtree level with the purpose of searching for identicalUUIDs. The technique takes into account differencesamong the matched model elements, such as featuresand relationships.
Selonen and Kettunen (2007) present a techniquefor model matching that derives signature-match rulesbased on the abstract syntax of the meta model de-scribing the modeling language. Specifically, theysay that two models match if they belong to the samemeta class, have the same name and the same primarycontext, which includes the surrounding structure ofthe model comprised of neighbours and descendants.
They state that this technique can be extended to workwith any MOF-based modeling languages. Additionalrules can be added by extending the model with ap-propriate stereotypes that the technique can interpret.
Odyssey VCS (Oliveira et al., 2005) is a modelversioning tool intended to work with all types ofUML models in CASE environments. It does notperform model matching as all elements are linkedto a previous version, starting with a baseline ver-sion. Differences or conflicts are detected by process-ing XML Metadata Interchange (XMI) files and usingUML-specific knowledge to calculate what elementshave been added, modified, or deleted.
Storrle (2010) developed the MQlone tool to ex-periment with the idea of detecting UML modelclones. They convert XMI files from UML CASEmodels and turn them into Prolog 3. Once in Pro-log, they attempt to discover clones using static iden-tity matching combined with similarity metrics suchas size, containment relationships, and name similar-ity.
3.1.2 EMF Models
Eclipse Modeling Framework (EMF) models 4 areMOF meta-meta models that can define meta mod-els, such as UML. They are intended for use withinthe Eclipse development environment.
EMFCompare (Brun and Pierantonio, 2008) is anEclipse project. Rather than relying on EMF models’UUIDs, they use similarity based-matching to allowthe tool to be more generic and useful in a variety ofsituations. The matching calculation is based on vari-ous statistics and metrics that are combined to gener-ate a match score. This includes analyzing the name,content, type, and relations of the elements. They alsofilter out element data that comes from default val-ues. It should be noted that while EMFCompare isspecific to EMF models, the underlying calculationengine is meta-model independent, similar to the ap-proaches discussed in Section 3.1.3
TopCased (Farail et al., 2006) is a project provid-ing an MDE environment that uses EMF models andis intended specifically for safety critical applicationsand systems. It performs its matching and differenc-ing using static identity-based matching, similar toAlanen and Porres.
SmoVer (Reiter et al., 2007) is another modelversioning tool that can work with any EMF-basedmodel. In this approach they do both version-specificcomparisons like Odyssey VCS, termed syntactical,and semantic comparisons. Semantic comparisons
3www.swi-prolog.org4http://www.eclipse.org/emf/
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
268

are those that are carried out on semantic views. Se-mantic views, in this context, are the resulting modelsthat come from a user-defined model transformationthat SmoVer executes on the original models beingcompared in order to give the models meaning froma particular view of interest. These transformationsare specified in the Atlas Transformation Language(ATL) 5. Models are first compared syntactically, thentransformed, then compared once again. Matching isaccomplished through static-identity based matchingand differences are calculated by comparing structuralchanges. The authors note that the amount of work re-quired for creating the ATL transformations is not toolarge and that “the return on investment gained in bet-ter conflict detection clearly outweighs the initial ef-fort spent on specifying the semantic views.” The ex-amples they discuss required roughly 50 to 200 linesof ATL transformation language code.
Riveria and Vallecillo (2008) employ similarity-based matching in addition to checking persistentidentifiers for their tool, Maudeling. They useMaude (Clavel et al., 2002), a high-level language thatsupports rewriting-logic specification and program-ming, to facilitate the comparison of models fromvarying meta models specified in EMF. They providethis in the form of an Eclipse plugin called Maudel-ing. Using Maude, they specify a difference metamodel that represents differences as added, modified,or deleted elements. The process first begins by us-ing UUIDs. If there is no UUID match, they thenrely on a variant of similarity-based matching thatcalculates the similarity ratio by checking a varietyof structural features. Then, to calculate differences,they go through each element and categorize it basedon a number of scenarios and incorporate this infor-mation into its difference meta model. There is nouser work required as Maudeling has the ATL trans-formations within it that transforms the EMF modelsinto their corresponding Maude representations. Op-erations are executed in the Maude environment auto-matically, requiring no user interaction with Maude.
3.1.3 Metamodel-agnostic Approaches
This section discusses comparison approaches formodels that can conform to an arbitrary meta model,assuming it adheres to specific properties.
Examples of Metamodel-independent approachesthat use similarity-based matching strategies includethe Epsilon Comparison Language (Kolovos, 2009)and Domain-Specific Model DiffDSMDiff (Lin et al.,2007). DSMDiff is an extension of work done onUML model comparison techniques. DSMDiff uses
5http://eclipse.org/atl/
both similarity- and signature- based matching. Thesimilarity-based matching focuses on the similarityof edges among different model nodes. DSMD-iff evaluates differences between matched elementsand considers them directed deltas. While DSMDiffwas developed using DSMLs specified in the GenericModeling Environment (GME), the techniques canbe extended to work with any DSML creation tool.The creators of DSMDiff propose allowing user-interaction that will enable one to choose the map-pings (matches) from a list of applicable candidates.
Epsilon Comparison Language (ECL) was de-veloped after DSMDiff and SiDiff, which is dis-cussed later, and attempts to address the fact that itspredecessors do not allow for modellers to config-ure language-specific information that may assist inmatching model elements from different meta mod-els (Kolovos, 2009). This is accomplished in a im-perative yet high-level manner. ECL allows modelersto specify model comparison rule-based algorithmsto identify matched elements within different models.The trade off is that, while complex matching crite-ria can be expressed using ECL, it requires more timeand knowledge of ECL. Kolovos acknowledges thatmetamodel-independent approaches using similarity-based matching typically perform fairly well, butthere often are “corner cases” that ECL is well suitedto identify.
A plugin for meta-Case applications was devel-oped (Mehra et al., 2005) that performs model ver-sion comparison for models defined by a meta-Casetool. Meta-Case tools operate similarly to their CASEcounterparts except they are not constrained by a par-ticular schema or meta model. This plugin matchesall the elements by their unique identifiers and cal-culates the differences as directed deltas. Oda andSaeki (2005) describe a graph-based VCS that is quitesimilar in that it works with meta-Case models andmatches them using baselines and unique identifiers.Differences are calculated as directed deltas with re-spect to earlier versions.
Nguyen (2006) proposes a VCS that can detectboth structural and textual differences between ver-sions of a wide array of software artifacts. This ap-proach utilizes similarity-based matching by assign-ing all artifacts an identifier that encapsulates the ele-ment and representing them as nodes within a directedattributed graph, similar to model clone detection ap-proaches.
Van den Brand, Protic, and Verhoeff(2010) de-fine a set of requirements for difference represen-tations and argue that current meta-modeling tech-niques, such as MOF, are not able to satisfy them.They present their own meta-modeling technique and
A�Survey�of�Model�Comparison�Approaches�and�Applications
269

define differences with respect to it. They providea model comparison approach and prototype that al-lows user configuration of what combination of thefour model-matching strategies to employ. The au-thors provide examples where they extend the workdone previously for SiDiff, combining it with othermatching techniques, like using a UUID. This gener-ality comes at a cost of a large amount of configura-tion, work, and user-interaction.
There are methods that translate models into an-other language or notation that maintain the semanticsof the models to facilitate model comparison. Oneexample is the work done by Gheyi, Massoni,andBorba (2005) in which they propose an abstract equiv-alence notion for object models, in other words, away of representing objects that allows them to becompared. They use an alphabet, which is the set ofrelevant elements that will be compared, and views,which are mappings that express the different waysthat one element in one model can be interpretedby elements of a different model. Equivalence be-tween two models is defined as the case where, forevery interpretation or valid instance that satisfies onemodel, there exists an equivalent interpretation thatsatisfies an instance in the other model. They illus-trate their approach using Alloy models 6. Similarly,Maoz, Ringert, and Rumpe (2011b) present the no-tion of semantic diff operators, which represent therelevant semantics of each model, and diff witnesses,which are the semantic differences between two mod-els. Semantics are represented through the use ofmathematical formalisms. From these ideas, Maozet al. provide the tools cddiff and addiff for classdiagram differencing and activity class diagram dif-ferencing, respectively. Other examples of translat-ing models into another language include UML mod-els being translated into Promela/SPIN models (Chenand Cui, 2004; Latella et al., 1999; Lilius and Paltor,1999), although this work does not intend to performmodel comparison nor differencing explicitly.
The Query/View/Transform(QVT) standard pro-vides the outline for three model transformation lan-guages that can act on any arbitrary model or meta-model that conform to the MOF specification. One ofthese languages, QVT-Relations(QVT-R) allows for adeclarative specification of two-way (bi-directional)transformations and is more expressive than the otherQVT languages. This expressiveness allows for aform of model comparison through its checkonlymode, which is the mode where models are checkedfor consistency rather than making changes (Stevens,2009). In brief, game theory is applied to QVT-Rby using a verifier and refuter. The verifier confirms
6http://alloy.mit.edu
Figure 2: Normalised model graph of model clone example(Deissenboeck et al., 2009).
that the check will succeed and the refuter’s objec-tive is to disprove it. The semantics of QVT are ex-pressed in such a way that implies “the check returnstrue if and only if the verifier has a winning strategyfor the game”. This allows one to compare modelsassuming a transformation was expressed in this lan-guage that represented the differences or similaritiesbeing searched for. In this case, the transformationwill yield true if the pair/set of models are consistentaccording to the transformation.
3.2 Methods for Behavior/Data-flowModels
3.2.1 Simulink and Matlab Models
CloneDetective (Deissenboeck et al., 2009) is an ap-proach that uses ideas from graph theory and is appli-cable to any model that is represented as a data-flowgraph. Models are first flattened and unconnectedlines are removed. Subsequently, they are normalisedby taking all of the blocks and lines found within themodels and assigning them a label that consists ofessential information for comparison. The informa-tion described in the label changes according to thetype of clones being searched for by the tool. Fig-ure 2 displays the result of this step on a Simulinkmodel, including the labels that come from normal-isation, such as UnitDelay and RelOp:h. The greyportions within the graph represent a clone. This isaccomplished by CloneDetective in its second phase:clone pair extraction. This phase is the most similarto the model matching discussed thus far, however,rather than matching single elements, it is attemptingto match the largest common set of elements. It fallsinto the category of similarity-based matching as thefeatures of each element are extracted, represented asa label during normalisation, and compared.
Similarly, eScan and aScan algorithms attempt todetect exact-matched and approximate clones, respec-tively (Pham et al., 2009). Exact-matched clones aregroups of model elements having the same size andaggregated labels, which contain topology informa-tion and edge and node label information. Approx-imate clones are those that are not exactly matching
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
270

but fit some similarity criteria. aScan uses vector-based representations of graphs that account for a sub-set of structural features within the graph. The maindifference between these algorithms and CloneDetec-tive is that these algorithms group their clones firstand from smallest to largest. They claim that thishelps detect clones that CloneDetective can not. Thisis later refuted, however, by the authors of CloneDe-tective (Deissenboeck et al., 2010). aScan is ableto detect approximate clones while CloneDetective isnot. Much like CloneDetective, these algorithms uti-lize similarity-based matching.
Al-Batran, Schatz, and Hummel (2011) note thatexisting approaches deal with syntactic clones only,that is they can detect only syntactically and struc-tural similar copies. Using normalization techniquesthat utilize graph transformations, they extend theseapproaches to cover semantic clones that may havesimilar behavior but different structure. So, a clone inthis context is now defined as two (sub)sets of modelsthat have “equivalent unique normal forms” of mod-els. These unique normal forms are acquired by per-forming 40 semantic-preserving transformations onSimulink models. It was found that extending clonedetection in this way yields more clones than simplesyntactic comparison.
Most recently, Alalfi, Cordy, Dean, Stephan, andStevenson (2012) developed Simone, which detectsnear-miss clones in Simulink models. This is doneby modifying existing code-clone techniques to workwith the textual representations of the Simulink mod-els while still being model-sensitive. In comparisonto CloneDetective, they detect the same exact clonesand some additional near-miss ones.
3.2.2 Sequence Diagrams
Liu, Ma, Zhang, and Shao (Liu et al., 2007) discoverduplication in sequence diagrams. They convert se-quence diagrams into an array and represent that ar-ray as a suffix tree. This tree is traversed and dupli-cates are extracted by looking for the longest com-mon prefix, or elements that lead to the leaf node,of two suffixes. Duplicates are defined as a set ofsequence-diagram fragments that contain the same el-ements and have the same sequence-diagram specificrelationships. Figure 3 demonstrates an example ofa duplicate. In this case, the largest common pre-fix include the four elements highlighted within eachdiagram. The image is taken from their tool Dupli-cationDetector. Much like the model clone detec-tion approaches discussed, this technique employs avariation of similarity-based matching as it is com-paring a graph representation of a fragment‘s fea-tures/elements.
Figure 3: Duplicate sequence fragment (Liu et al., 2007).
3.2.3 Statechart Diagrams
Nejati et al. (2007) match state chart diagrams forthe purpose of model merging. They accomplishthis by using heuristics that include looking at ter-minological, structural, and semantic similarities be-tween models. The heuristics are split into 2 cat-egories: static heuristics that use attributes withoutsemantics, such as the names or features of ele-ments; and behavioural heuristics, which find pairsthat have similar dynamic behavior. Due to the useof heuristics, this approach requires a domain ex-pert look over the relations and add or remove re-lations, accordingly, to acquire the desired match-ing relation. This approach employs both similarity-based matching through static heuristics and custom-language specific matching through dynamic heuris-tics. After similarity is established between two statecharts, the merging operation calculates and repre-sents differences as variabilities, or guarded transi-tions, from one model to the other.
3.3 Methods for Structural Models
This section discusses approaches that are designedto work with models that represent the structure ofa system. They benefit from the domain knowledgegained by working with structural models only.
Early work on comparing and differencing soft-ware structural diagrams was done by Rho andWu (1998). They focus on comparing a current ver-sion of an artifact to its preceding ancestor.
3.3.1 UML Structural Models
UMLDiff (Xing and Stroulia, 2005) uses customlanguage-specific matching by using name-similarityand UML structure-similarity to identify matching el-ements. These metrics are combined and comparedagainst a user-defined threshold. It is intended to bea model versioning reasoner: It discovers changesmade from one version of a model to another.
A�Survey�of�Model�Comparison�Approaches�and�Applications
271

UMLDiff cld (Girschick, 2006) focuses on UMLclass diagram differencing. It uses a combinationof static identity-based and similarity-based match-ing within its evaluation function, which measuresthe quality of a match. Similarly, Mirador (Barrettet al., 2010) is a plugin created for the Fujaba (FromUml to Java and Back Again)7 tool suite that allowsfor user directed matching of elements. Specifically,users can select match candidates that are ranked ac-cording to a similarity measure that is a combinationof static identity-based and similarity-based match-ing, like UMLDiff cld .
Reddy et al. (2005) use signature-based match-ing in order to compare and compose two UML classmodels in order to assist with Aspect-oriented mod-eling (Elrad et al., 2002). Models are matched basedon their signatures, or property values associated withthe class. Each signature has a signature type, whichis the set of properties that a signature can take. UsingKerMeta8, a model querying language, the signaturesused for comparison are derived by the tool based onthe features it has within the meta model.
Berardi, Calvanese, and De Giacomo (2005)translate UML class diagrams into ALCQI, a “sim-ple” description logic representation. They show thatit is possible for one to reason about UML class di-agrams as ALCQI description logic representationsand provide an encoding from UML class diagramsto ALCQI. While the translation does not maintainthe entire semantics of the UML classes, it preservesenough of it to check for class equivalence. Becausethey use UML-specific semantics, we argue that theirsis a form of language-specific matching.
Maoz, Ringert, and Rumpe (2011a) extend workon semantic differencing and provide a transla-tion prototype, called CD2Alloy, that converts UMLclasses into Alloy. This Alloy code contains con-structs that determine the corresponding elements oftwo UML class diagrams and also allows for seman-tic comparisons, such as determining if one model isa refinement of another. It can be considered to bea custom-language specific comparison because of itsuse of UML semantics.
3.3.2 Metamodel-agnostic Approaches
Preliminary work on model comparison was doneby Chawathe, Rajaraman, Garcia-Molina, andWidom (1996) in which they devised a comparisonapproach intended for any structured document. Theyconvert the data representing the document structureinto a graph consisting of nodes that have identifiers
7http://www.fujaba.de/8http://www.kermeta.org
Figure 4: Example SiDiff comparison (Kelter et al., 2005).
derived from the corresponding elements they rep-resent. This approach, which is analogous to themodel clone detection techniques, uses similarity-based matching and describes differences in terms ofdirected deltas.
SiDiff (Kelter et al., 2005) is very similar toUMLDiff except SiDiff uses a simplified underlyingcomparison model in order to be able to handle anymodels stored in XMI format. Similarly to UMLDiff,it uses similarity-based metrics. In contrast to UMLD-iff, as shown by the up arrow in Figure 4, its calcula-tion begins bottom-up by comparing the sub elementsof a pair of model elements starting with their leaf el-ements. This is done with respect to the elements’similarity metrics. An example of a weighted sim-ilarity is having a class element consider the simi-larity of its class name weighted the highest. So, inthe case of the two Class elements being compared inFigure 4, all of the Classifier elements are comparedfirst. If a uniquely identifying element is matched,such as a class name, they are immediately identifiedas a match. This is followed by top-down propagationof this matching pair. This top-down approach allowsfor the algorithm to deduce differences by evaluatinga correspondence table that is the output of the match-ing phase.
Similarly to the translation of UML classdiagrams into ALCQI, D’Amato; Staab;andFanizzi (2008), propose a comparison measurefor description logics, such as those used in theSemantic Web 9. This is accomplished by using ex-isting ontology semantics. They describe a semanticsimilarity measure that is able use the semantics ofthe ontology that the concepts refer to.
3.4 Methods for Product LineArchitectures
Chen, Critchlow, Garg, Van der Westhuizen, and Vander Hoek (Chen et al., 2004) present work to do com-parisons of product line models for merging. The
9http://semanticweb.org/
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
272

assumption in this work is that the comparison isbeing done between two versions of the same arti-fact. Comparison is done recursively and is increas-ingly fine grained as the algorithm delves deeper intothe product-line hierarchy. This approach employssimilarity-based matching: lower elements in the hi-erarchy compare interfaces, optionality, and type; andhigher level elements compare the elements containedwithin them. Differences are represented as directeddeltas.
Rubin and Chechik (2012) devise a framework forcomparing individual products that allows for them tobe updated automatically to a product line conform-ing to those used in product-line engineering. Theyuse similarity-based matching, that is, products areviewed as model elements and a match is defined asthe case where a pair of model elements have featuresthat are similar enough to be above a defined weightedthreshold. The authors note that “(their) refactoringframework is applicable to a variety of model types,such as UML, EMF or Matlab/Simulink, and to differ-ent compare, match and merge operators”. The fore-seeable user work that would be required in using thisframework includes having a domain expert specifythe similarity weights and features of interest and alsodetermining the optimum similarity thresholds.
3.5 Methods for Process Models
Soto and Munch (2006) discuss the need for ascer-taining differences among software development pro-cess models and outline what such a difference sys-tem would require. They devise Delta-P (Soto, 2007),which can work with various UML process models.Delta-P converts process models into Resource De-scription Framework (RDF) 10 notation in order tohave them represented in a normalized triplebased no-tation. It then performs an identity-based compari-son and calculates differences. They employ static-identity based matching as they use unique identifiers.Differences are represented as directed deltas, whichcan be grouped together to form higher level deltas.
Similarly, Dijkman, Dumas, Van Dongen, Karik,and Mendling(Dijkman et al., 2011) discuss threesimilarity metrics that help compare stored processmodels: node matching similarity, which comparesthe labels and attributes attached to process model el-ements; structural similarity, which evaluates labelsand topology; and, behavioral similarity, which looksat labels in conjunction with causal relations from theprocess models.
10http://www.w3.org/RDF/
4 SUMMARY AND FUTUREDIRECTIONS
Table 1 summarizes the approaches discussed in thissurvey paper organized by the type and sub typeof model they can compare. As seen in the table,similarity-based matching is the most commonly em-ployed strategy. It is clear that one future direction ofwork in this area is the focus on tools that are able towork with models that conform to an arbitrary metamodel. This result is consistent with the recent trendin domain-specific modeling.
The majority of work in model comparison ap-pears to be geared towards model versioning, how-ever the most recent work is not. Much of the re-cent work is focusing on model transformation test-ing and model clone detection. Also, new extensionsof existing model comparison approaches are beingattempted such as the extension of model clone de-tection in order to detect common sub-structures orpatterns within models (Stephan et al., 2012). Thesepatterns can ideally be used by project engineers tofacilitate analysis and assist in the development of fu-ture MDE projects.
The last column showcases the relative amountof user work required to accomplish model compar-ison. This is based on our research performed for thissurvey and is purely qualitative. The justification foreach tool that has one * or more can be found in thetextual descriptions provided previously. ECL and theapproach presented by Van den Brand et al. requirethe most user work, however this is intentional to al-low for more power and generality. Many approachesrequire no user interaction as they operate under spe-cific conditions or are dynamic enough to understandthe context or meta models they are working with.
5 RELATED WORK
5.1 Other Comparison Approaches
There is an abundance of work in comparing softwareartifacts at the code level: However, there are manyarguments as to why these are not easily transferableto the modeling domain (Altmanninger et al., 2009).
There are approaches that serialize models totext, for example, XML document difference de-tection (Cobena et al., 2002), schema-based match-ing (Shvaiko and Euzenat, 2005), and tools likeXlinkit (Nentwich et al., 2003), which compares XMIrepresentations of models. These approaches focus ontoo low a level of abstraction in that they can not ac-
A�Survey�of�Model�Comparison�Approaches�and�Applications
273
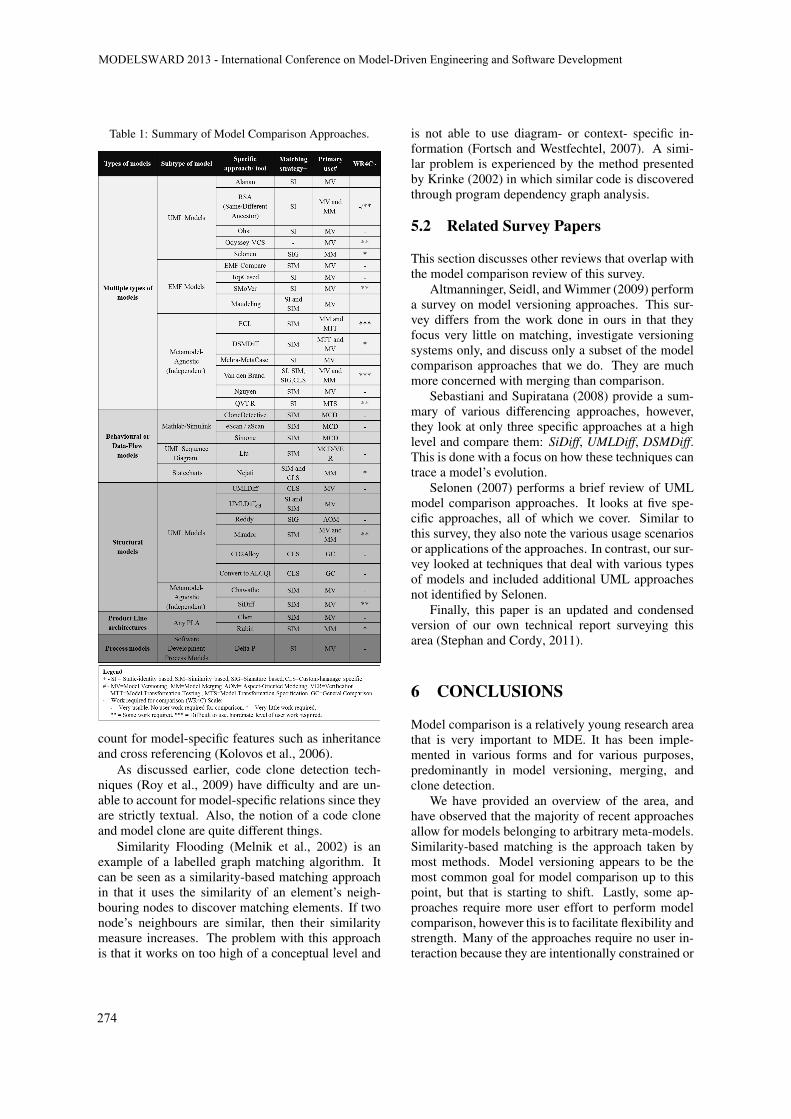
Table 1: Summary of Model Comparison Approaches.
count for model-specific features such as inheritanceand cross referencing (Kolovos et al., 2006).
As discussed earlier, code clone detection tech-niques (Roy et al., 2009) have difficulty and are un-able to account for model-specific relations since theyare strictly textual. Also, the notion of a code cloneand model clone are quite different things.
Similarity Flooding (Melnik et al., 2002) is anexample of a labelled graph matching algorithm. Itcan be seen as a similarity-based matching approachin that it uses the similarity of an element’s neigh-bouring nodes to discover matching elements. If twonode’s neighbours are similar, then their similaritymeasure increases. The problem with this approachis that it works on too high of a conceptual level and
is not able to use diagram- or context- specific in-formation (Fortsch and Westfechtel, 2007). A simi-lar problem is experienced by the method presentedby Krinke (2002) in which similar code is discoveredthrough program dependency graph analysis.
5.2 Related Survey Papers
This section discusses other reviews that overlap withthe model comparison review of this survey.
Altmanninger, Seidl, and Wimmer (2009) performa survey on model versioning approaches. This sur-vey differs from the work done in ours in that theyfocus very little on matching, investigate versioningsystems only, and discuss only a subset of the modelcomparison approaches that we do. They are muchmore concerned with merging than comparison.
Sebastiani and Supiratana (2008) provide a sum-mary of various differencing approaches, however,they look at only three specific approaches at a highlevel and compare them: SiDiff, UMLDiff, DSMDiff.This is done with a focus on how these techniques cantrace a model’s evolution.
Selonen (2007) performs a brief review of UMLmodel comparison approaches. It looks at five spe-cific approaches, all of which we cover. Similar tothis survey, they also note the various usage scenariosor applications of the approaches. In contrast, our sur-vey looked at techniques that deal with various typesof models and included additional UML approachesnot identified by Selonen.
Finally, this paper is an updated and condensedversion of our own technical report surveying thisarea (Stephan and Cordy, 2011).
6 CONCLUSIONS
Model comparison is a relatively young research areathat is very important to MDE. It has been imple-mented in various forms and for various purposes,predominantly in model versioning, merging, andclone detection.
We have provided an overview of the area, andhave observed that the majority of recent approachesallow for models belonging to arbitrary meta-models.Similarity-based matching is the approach taken bymost methods. Model versioning appears to be themost common goal for model comparison up to thispoint, but that is starting to shift. Lastly, some ap-proaches require more user effort to perform modelcomparison, however this is to facilitate flexibility andstrength. Many of the approaches require no user in-teraction because they are intentionally constrained or
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
274

are made to deal with multiple situations.There is still much room for maturity in model
comparison and it is an important area that must bein the minds of MDE supporters, as it has many ben-efits and is widely-applicable. It is our hope that thissurvey paper of model comparison acts as a refer-ence guide for both model-driven engineers and re-searchers.
REFERENCES
Al-Batran, B., Schatz, B., and Hummel, B. (2011). Seman-tic clone detection for model-based development of em-bedded systems. Model Driven Engineering Languagesand Systems, pages 258–272.
Alalfi, M. H., Cordy, J. R., Dean, T. R., Stephan, M., andStevenson, A. (2012). Models are code too: Near-missclone detection for simulink models. In ICSM, vol-ume 12.
Alanen, M. and Porres, I. (2003). Difference and union ofmodels. In UML, pages 2–17.
Alanen, M. and Porres, I. (2005). Version control of soft-ware models. Advances in UML and XML-Based Soft-ware Evolution, pages 47–70.
Altmanninger, K., Kappel, G., Kusel, A., Retschitzegger,W., Seidl, M., Schwinger, W., and Wimmer, M. (2008).AMOR-towards adaptable model versioning. In MCCM,volume 8, pages 4–50.
Altmanninger, K., Seidl, M., and Wimmer, M. (2009). Asurvey on model versioning approaches. InternationalJournal of Web Information Systems, 5(3):271–304.
Barrett, S., Butler, G., and Chalin, P. (2010). Mirador:a synthesis of model matching strategies. In IWMCP,pages 2–10.
Berardi, D., Calvanese, D., and De Giacomo, G. (2005).Reasoning on UML class diagrams. Artificial Intelli-gence, 168(1-2):70–118.
Brun, C. and Pierantonio, A. (2008). Model differences inthe Eclipse modelling framework. The European Journalfor the Informatics Professional, pages 29–34.
Chawathe, S., Rajaraman, A., Garcia-Molina, H., andWidom, J. (1996). Change detection in hierarchicallystructured information. In ICMD, pages 493–504.
Chen, J. and Cui, H. (2004). Translation from adapted UMLto promela for corba-based applications. Model Check-ing Software, pages 234–251.
Chen, P., Critchlow, M., Garg, A., Van der Westhuizen, C.,and van der Hoek, A. (2004). Differencing and mergingwithin an evolving product line architecture. PFE, pages269–281.
Cicchetti, A., Di Ruscio, D., and Pierantonio, A. (2007). Ametamodel independent approach to difference represen-tation. Technology, 6(9):165–185.
Cicchetti, A., Di Ruscio, D., and Pierantonio, A. (2008).Managing model conflicts in distributed development. InModels, pages 311–325.
Clavel, M., Duran, F., Eker, S., Lincoln, P., Marti-Oliet, N.,Meseguer, J., and Quesada, J. (2002). Maude: specifi-cation and programming in rewriting logic. TheoreticalComputer Science, 285(2):187–243.
Cobena, G., Abiteboul, S., and Marian, A. (2002). Detect-ing changes in XML documents. In ICDE, pages 41–52.
D’Amato, C., Staab, S., and Fanizzi, N. (2008). On theinfluence of description logics ontologies on conceptualsimilarity. Knowledge Engineering: Practice and Pat-terns, pages 48–63.
Deissenboeck, F., Hummel, B., Juergens, E., Pfaehler, M.,and Schaetz, B. (2010). Model clone detection in prac-tice. In IWSC, pages 57–64.
Deissenboeck, F., Hummel, B., Jurgens, E., Schatz, B.,Wagner, S., Girard, J., and Teuchert, S. (2009). Clonedetection in automotive model-based development. InICSE, pages 603–612.
Dijkman, R., Dumas, M., Van Dongen, B., Karik, R., andMendling, J. (2011). Similarity of business processmodels: Metrics and evaluation. Information Systems,36(2):498–516.
Elrad, T., Aldawud, O., and Bader, A. (2002). Aspect-oriented modeling: Bridging the gap between implemen-tation and design. In Generative Programming and Com-ponent Engineering, pages 189–201.
Farail, P., Gaufillet, P., Canals, A., Le Camus, C., Sciamma,D., Michel, P., Cregut, X., and Pantel, M. (2006). Thetopcased project: a toolkit in open source for criticalaeronautic systems design. ERTS, pages 1–8, electronic.
Fortsch, S. and Westfechtel, B. (2007). Differencing andmerging of software diagrams state of the art and chal-lenges. ICSDT, pages 1–66.
Gheyi, R., Massoni, T., and Borba, P. (2005). An abstractequivalence notion for object models. Electronic Notesin Theoretical Computer Science, 130:3–21.
Girschick, M. (2006). Difference detection and visualiza-tion in UML class diagrams. Technical University ofDarmstadt Technical Report TUD-CS-2006-5, pages 1–15.
Kelter, U., Wehren, J., and Niere, J. (2005). A generic dif-ference algorithm for UML models. Software Engineer-ing, 64:105–116.
Kolovos, D. (2009). Establishing correspondences be-tween models with the epsilon comparison language.In Model Driven Architecture-Foundations and Applica-tions, pages 146–157.
Kolovos, D., Di Ruscio, D., Pierantonio, A., and Paige,R. (2009). Different models for model matching: Ananalysis of approaches to support model differencing. InCVSM, pages 1–6.
Kolovos, D., Paige, R., and Polack, F. (2006). Model com-parison: a foundation for model composition and modeltransformation testing. In IWGIMM, pages 13–20.
Koschke, R. (2006). Survey of research on software clones.Duplication, Redundancy, and Similarity in Software,pages 1–24,electronic.
Krinke, J. (2002). Identifying similar code with programdependence graphs. In WCRE, pages 301–309.
A�Survey�of�Model�Comparison�Approaches�and�Applications
275

Latella, D., Majzik, I., and Massink, M. (1999). Automaticverification of a behavioural subset of UML statechartdiagrams using the SPIN model-checker. Formal Aspectsof Computing, 11(6):637–664.
Letkeman, K. (2005). Comparing and merging UML mod-els in IBM Rational Software Architect. IBM Rational -Technical Report (Online).
Letkeman, K. (2007). Comparing and merging UMLmodels in IBM Rational Software Architect: Part7. http://www.ibm.com/developerworks/rational/library/07/0410 letkeman/.
Lilius, J. and Paltor, I. (1999). Formalising UML state ma-chines for model checking. UML, pages 430–444.
Lin, Y., Gray, J., and Jouault, F. (2007). DSMDiff: a dif-ferentiation tool for domain-specific models. EuropeanJournal of Information Systems, 16(4):349–361.
Lin, Y., Zhang, J., and Gray, J. (2004). Model compari-son: A key challenge for transformation testing and ver-sion control in model driven software development. InOOPSLA Workshop on Best Practices for Model-DrivenSoftware Development, volume 108, pages 6, electronic.
Liu, H., Ma, Z., Zhang, L., and Shao, W. (2007). Detectingduplications in sequence diagrams based on suffix trees.In APSEC, pages 269–276.
Maoz, S., Ringert, J., and Rumpe, B. (2011a). Cd2alloy:Class diagrams analysis using alloy revisited. ModelDriven Engineering Languages and Systems, pages 592–607.
Maoz, S., Ringert, J., and Rumpe, B. (2011b). A mani-festo for semantic model differencing. In ICMSE, MOD-ELS’10, pages 194–203.
Mehra, A., Grundy, J., and Hosking, J. (2005). A genericapproach to supporting diagram differencing and merg-ing for collaborative design. In ASE, pages 204–213.
Melnik, S., Garcia-Molina, H., and Rahm, E. (2002). Simi-larity flooding: A versatile graph matching algorithm andits application to schema matching. In ICDE, pages 117–128.
Mens, T. (2002). A state-of-the-art survey on softwaremerging. TSE, 28(5):449–462.
Nejati, S., Sabetzadeh, M., Chechik, M., Easterbrook, S.,and Zave, P. (2007). Matching and merging of statechartsspecifications. In ICSE, pages 54–64.
Nentwich, C., Emmerich, W., Finkelstein, A., and Ellmer,E. (2003). Flexible consistency checking. TOSEM,12(1):28–63.
Nguyen, T. (2006). A novel structure-oriented differenceapproach for software artifacts. In CSAC, volume 1,pages 197–204.
Oda, T. and Saeki, M. (2005). Generative technique of ver-sion control systems for software diagrams. In ICSM,pages 515–524.
Ohst, D., Welle, M., and Kelter, U. (2003). Differences be-tween versions of UML diagrams. ACM SIGSOFT Soft-ware Engineering Notes, 28(5):227–236.
Oliveira, H., Murta, L., and Werner, C. (2005). Odyssey-vcs: a flexible version control system for UML modelelements. In SCM, pages 1–16.
Pham, N., Nguyen, H., Nguyen, T., Al-Kofahi, J., andNguyen, T. (2009). Complete and accurate clone detec-tion in graph-based models. In ICSE, pages 276–286.
Reddy, R., France, R., Ghosh, S., Fleurey, F., and Baudry,B. (2005). Model Composition - A Signature-Based Ap-proach.
Reiter, T., Altmanninger, K., Bergmayr, A., Schwinger,W., and Kotsis, G. (2007). Models in conflict-detectionof semantic conflicts in model-based development. InMDEIS, pages 29–40.
Rho, J. and Wu, C. (1998). An efficient version model ofsoftware diagrams. In APSEC, pages 236–243.
Rivera, J. and Vallecillo, A. (2008). Representing and op-erating with model differences. Objects, Components,Models and Patterns, pages 141–160.
Roy, C., Cordy, J., and Koschke, R. (2009). Comparison andevaluation of code clone detection techniques and tools:A qualitative approach. Science of Computer Program-ming, 74(7):470–495.
Rubin, J. and Chechik, M. (2012). Combining related prod-ucts into product lines. In 15th International Conferenceon Fundamental Approaches to Software Engineering.To Appear.
Schipper, A., Fuhrmann, H., and von Hanxleden, R. (2009).Visual comparison of graphical models. In ICECCS,pages 335–340.
Sebastiani, M. and Supiratana, P. (2008). Tracing thedifferences on an evolving software model. http://www.idt.mdh.se/kurser/ct3340/archives/ht08/papersRM08/28.pdf.
Selonen, P. (2007). A Review of UML Model ComparisonApproaches. In NW-MoDE, pages 37–51.
Selonen, P. and Kettunen, M. (2007). Metamodel-basedinference of inter-model correspondence. In ECSMR,pages 71–80.
Shvaiko, P. and Euzenat, J. (2005). A survey of schema-based matching approaches. Journal on Data SemanticsIV, pages 146–171.
Soto, M. (2007). Delta-p: Model comparison using seman-tic web standards. Softwaretechnik-Trends, 2:27–31.
Soto, M. and Munch, J. (2006). Process model differenceanalysis for supporting process evolution. Software Pro-cess Improvement, pages 123–134.
Stephan, M., Alafi, M., Stevenson, A., and Cordy, J. (2012).Towards qualitative comparison of simulink model clonedetection approaches. In IWSC, pages 84–85.
Stephan, M. and Cordy, J. R. (2011). A survey of methodsand applications of model comparison. Technical report,Queen’s University. TR. 2011-582 Rev. 2.
Stephan, M. and Cordy, J. R. (2013). Application of modelcomparison techniques to model transformation testing.In MODELSWARD. to appear.
Stevens, P. (2009). A simple game-theoretic approach tocheckonly qvt relations. Theory and Practice of ModelTransformations, pages 165–180.
Storrle, H. (2010). Towards clone detection in uml domainmodels. In ECSA, pages 285–293.
MODELSWARD�2013�-�International�Conference�on�Model-Driven�Engineering�and�Software�Development
276

van den Brand, M., Protic, Z., and Verhoeff, T. (2010).Fine-grained metamodel-assisted model comparison. InIWMCP, pages 11–20.
Van den Brand, M., Protic, Z., and Verhoeff, T. (2010).Generic tool for visualization of model differences. InIWMCP, pages 66–75.
Wenzel, S. (2008). Scalable visualization of model differ-ences. In CVSM, pages 41–46.
Wenzel, S., Koch, J., Kelter, U., and Kolb, A. (2009). Evo-lution analysis with animated and 3D-visualizations. InICSM, pages 475–478.
Xing, Z. and Stroulia, E. (2005). UMLDiff: an algorithmfor object-oriented design differencing. In ASE, pages54–65.
A�Survey�of�Model�Comparison�Approaches�and�Applications
277