a survey on ant colony clustering papers
TRANSCRIPT

A survey on
Ant Clustering papers
Zahra Sadeghi

A Survey on using Ant-Based
techniques for clustering
M Aranha, Claus de Castro,
2006

INTRODUCTION


• The high number of individuals and the decen-tralized approach to task coordination means that
▫ ant colonies show high degrees of parallelism, self-organization and fault tolerance.
▫ All of which are desired characteristics in modern computer systems.

• The work on ant-based techniques is considered to have started by the Ant Colony Optimization my Dorigo et. al., [6].
• In this work, a group of ant- agents is used to solve the TSP problem.
• While each ant walks on the graph, it leaves a pheromone signal through the path it used.
• Shorter paths will leave stronger signals. • The next ants, when deciding which path to take, tend to
choose paths with stronger signals with a higher probability, so as shorter paths are found, more ants try to explore these paths, by a positive reinforcement cycle.

• One important characteristic of the ant-inspired technologies is shown on the work on network routing by Ant Colony Optimization, ANT NET [4].

stigmergy
• The root of this adaptation is the stigmergicnature of the ant-system.
• Stigmergy is a central idea of all ant-based algorithms.
• Here, it happens, as described before, by the leaving of “pheromone" trails.

• The pheromone value of the path that composes the optimal solution is higher than that of the non- optimal solutions after the end of the algorithm.
• If there is any change in the topology, like a route that fails or a new route, the system can use the existing values of the pheromone trails to adapt to the changes while online.

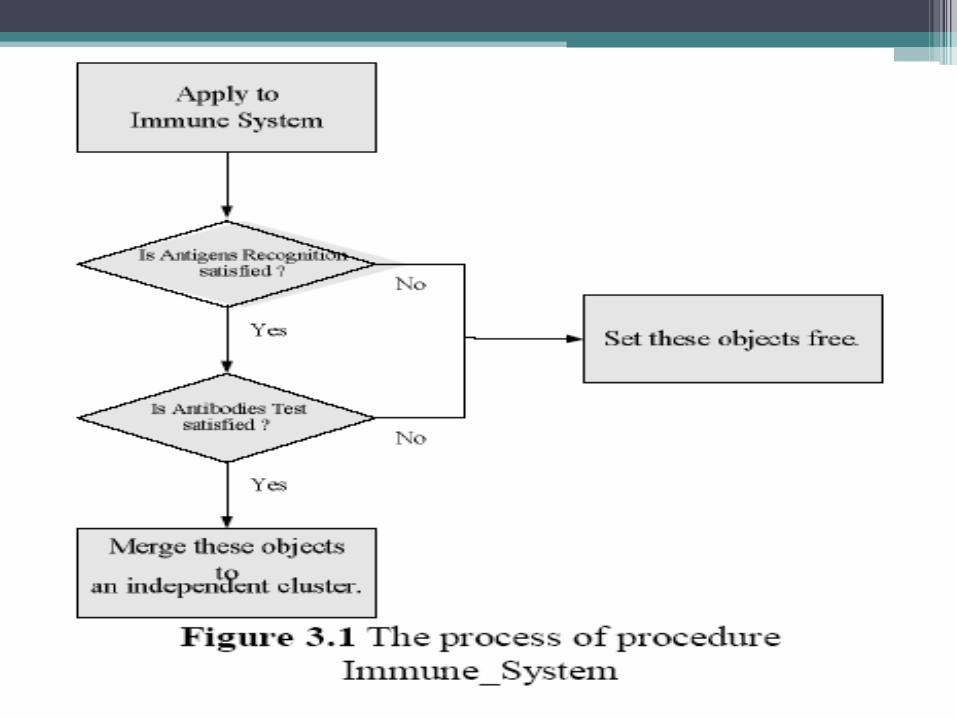
• we will call this bi-dimensional grid the workspace, and the n-dimensional space the feature space.

• The first step in a \canonical" ant-clustering system is to distribute the data (objects) randomly into the workspace.
• Each object is projected onto one grid of the workspace

• Then a number na of ants is put on random positions of the workspace.
• It is defined that only one ant and only one object can be put into one grid of the work space.
• Each ant is also able to carry one data object with itself.

• At each time step, each ant will, if loaded, try to unload its object onto its current position or, if unloaded, try to pick an object in the same grid as itself.
• The probability of picking or dropping an object is based on the disparity (or distance in feature space) between that object and other objects in its neighborhood.
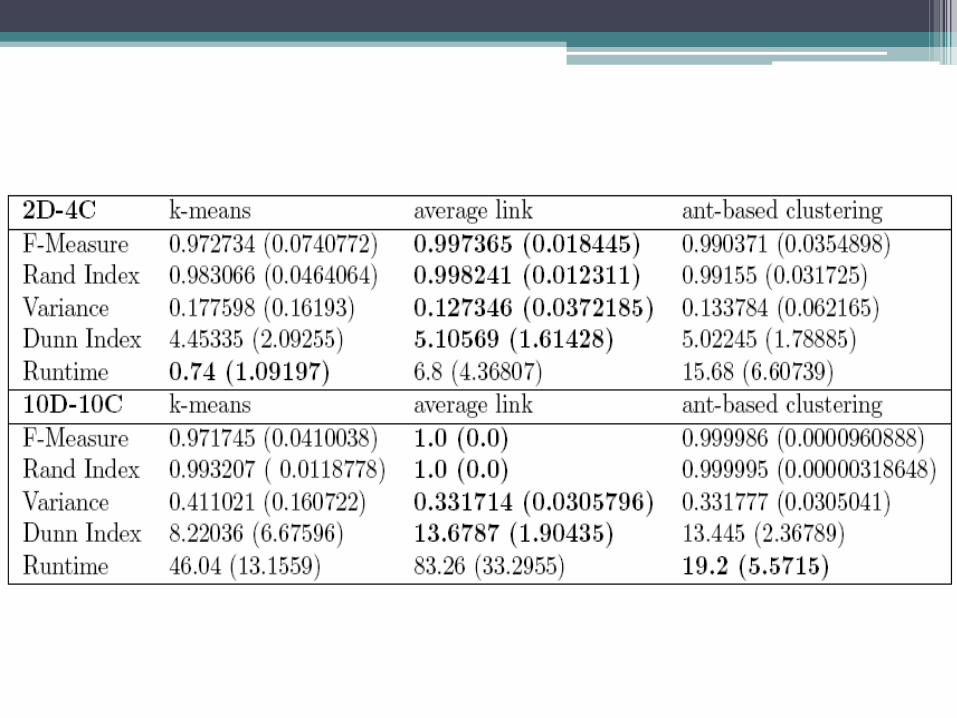

• Ant-based clustering usually came first or in a close second (as shown in the data selected for this work).
• When observing the run-time, it was observed that for low dimensionality data, ant-based clustering would be slightly slower than the other techniques, but its runtime scales linearly, so that it becomes the fastest algorithm for high-dimensionality data.

• ant-based clustering techniques are an appropriate alternative to traditional clustering algorithms.
• it has the ability of automatically discovering the number of clusters.
• Also, it linearly scales against the dimensionality of data.
• It automatically generates a representation of the formed clusters that can be intuitively understood by humans.

Towards Improving Clustering Ants:
An Adaptive Ant Clustering Algorithm
André L. Vizine, Leandro N. de Castro, Eduardo R. Hruschka, Ricardo R. Gudwin2005

• Among the many bio-inspired techniques, ant-based clustering algorithms have received special attention from the community over the past few years for two main reasons.
• First, they are particularly suitable to perform exploratory data analysis and,
• second, they still require much investigation to improve performance, stability, convergence, and other key features that would make such algorithms mature tools for diverse applications.

Cooling Schedule for kp
• a cooling schedule for the parameter that drives the picking probability kp is employed.
• The adopted scheme is simple: after one cycle (10,000 ant steps) has passed, the value of the parameter kp starts being geometrically decreased, at each cycle, until it reaches a minimal allowed value, kpmin, which corresponds to the stopping criterion for the algorithm.

• In the current implementation, kp is cooled based on a geometric scheme presented in Eq. (4).

Progressive Vision
• The definition of a fixed value for s^2 may sometimes cause inappropriate behaviors, because a fixed perceptual area does not allow distinguishing between clusters of different sizes.
• A small area of vision implies a small perception of the cluster at a global level.
• Thus, small clusters and large clusters are all the same in this sense, for the agent only perceives a limited area of the environment.

Progressive Vision
• On the other hand, a large vision field may be inefficient in the initial iterations, when the data elements are scattered at random on the grid, because analyzing a broad area may imply in analyzing a large number of small clusters simultaneously.

Progressive Vision

‘How can an ant agent detect the size of a cluster
so as to control the size of its vision field?’
• There is a relationship between the size of a cluster and its density dependent function: the average value of f(i) increases as the clustering proceeds, and this happens because larger clusters tend to be formed.
• When f(i) achieves a value greater than a pre-specified threshold θ, the parameter s2 is incremented by ns units until it reaches its maximum value.

Pheromone Heuristics
• Sherafat et al. (2004a,b) introduced a pheromone function, Phe( φmax, φmin,P, φ(i)), given by Eq. (6), that influences the probability of picking up and dropping off objects from and on the grid.
• The proposed pheromone function varies linearly with the pheromone level at each grid position, φ(i), and depends on a number of userdefinedparameters, such as
the φmax and φmin values of pheromone perceived by the agent, and
the maximal influence of pheromone allowed, P.

Pheromone Heuristics
• To accommodate the addition of pheromone on the grid, some variations on the picking and dropping probability functions of SACA were proposed in (Sherafat et al.,2004a,b), as described in Eqs. (7) and (8), respectively:

Pheromone Heuristics
• where φmax represents the current largest amount of pheromone perceived by this agent;
• φmin corresponds to the current smallest amount of pheromone perceived by this agent;
• P is the maximum influence of the pheromone in changing the probability of picking and dropping data elements;
• and φ(i) is the quantity of pheromone in the current position i.

• the probability that an ant picks up an item from the grid is inversely proportional to the amount of pheromone at that position and also to the density of objects around i.

• The rate at which pheromone evaporates is preset
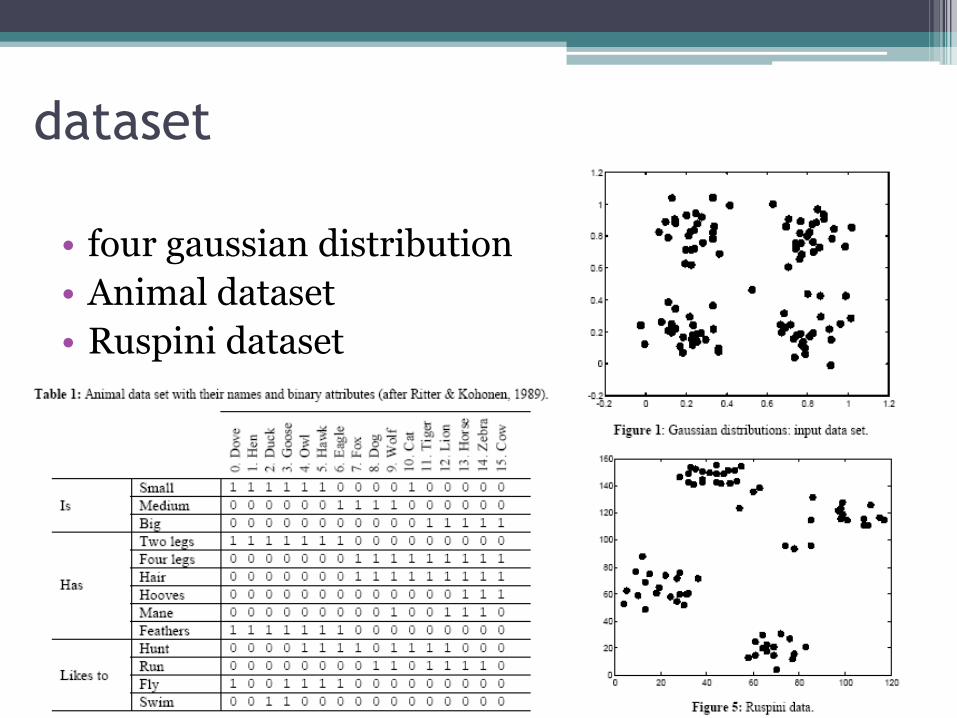
dataset
• four gaussian distribution
• Animal dataset
• Ruspini dataset

The effect of using evolutionary
algorithms on Ant Clustering
Techniques
Claus Aranha1 and Hitoshi Iba

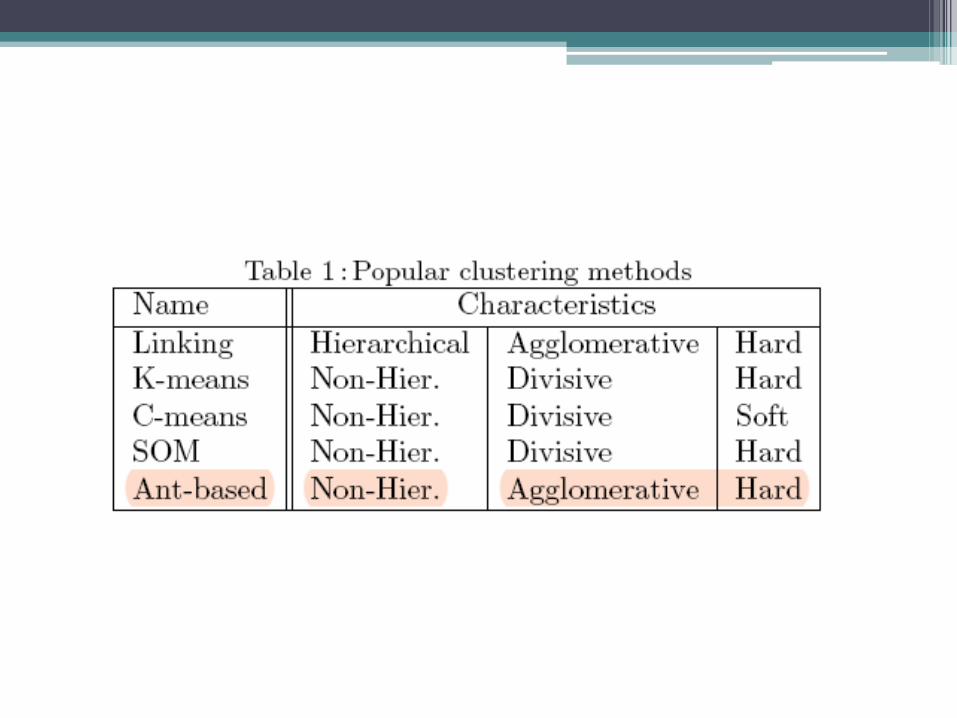
• Ant-based clustering algorithms can be considered non-hierarchical, hard, agglomerative clustering methods. ▫ Non-hierarchical means that there is no parent-
child relationship between the objects or the clusters formed by the technique.
▫ Hard means that each object is assigned to only one cluster.
▫ Agglomerative means that the clusters are formed bottom-up - in other words, isolated objects are progressively put together to form bigger clusters.

• Ramos et al. [15]. applied ant-based clustering to the classification of stone images.
• In their works, they noticed that the normal LF algorithm would generate a large quantity of small clusters, and that many actions were wasted when the ants moved through empty space.
• To address this concerns they used pheromones to guide the ant movement.

• Handl et al. [9] changed the ants’ movement policy so that the ants, after dropping an object, would “teleport” to the next isolated object, and pick it automatically.
• In this way, an ant would never give a step while not carrying an object, which did not add anything to the clustering effort.
• They also added limited local memory to each ant, which would give them “hints” to the best place to drop the carried object.

• Hartmann [11] proposes the use of Neural Networks to replace the pick and drop functions.

neighborhood disparity function
• xs is an object within the neighborhood radius of i,
• Md is the maximum distance between any two objects,
• and St is the total number of objects in the neighborhood of I
• The neighborhood of an object is given by all the objects within Manhattan distance sight of the object

crowdedness factor, c(i)

Use of Genetic Algorithms
• it is commented that the sensitivity of the many parameters in ant-clustering is a topic worthy of study
• To improve the ant clustering algorithm, we’ll try to optimize its parameters (presented in table 1) by using Genetic algorithms.

each individual
• each individual is represented by the set of configuration parameters in table 1.
• For each generation, we run the program once with each set of parameters, and take the fitness from each run.

Elite selection
• We use the Elite selection strategy for GA, where, for each generation, the best elite size individuals are directly copied into the next generation, and the remaining individuals of the population are deleted and replaced by crossover between this elite.

• For the crossover operator, we randomly choose two parents from the elite, and create a new individual by choosing one parameter value from each parent (equal probability for both parents).
• After that we run the mutation operator (with a probability equal to the mutation parameter for each individual).
• The mutation operator can either change the value of one parameter by 10%, or generate a new random value for that parameter.

• The key in a successful application of GA to a problem is an appropriate choice of the fitness function.
• One of the strong points of ant clustering is the ability to auto-detect the number of clusters.

To extract the clusters
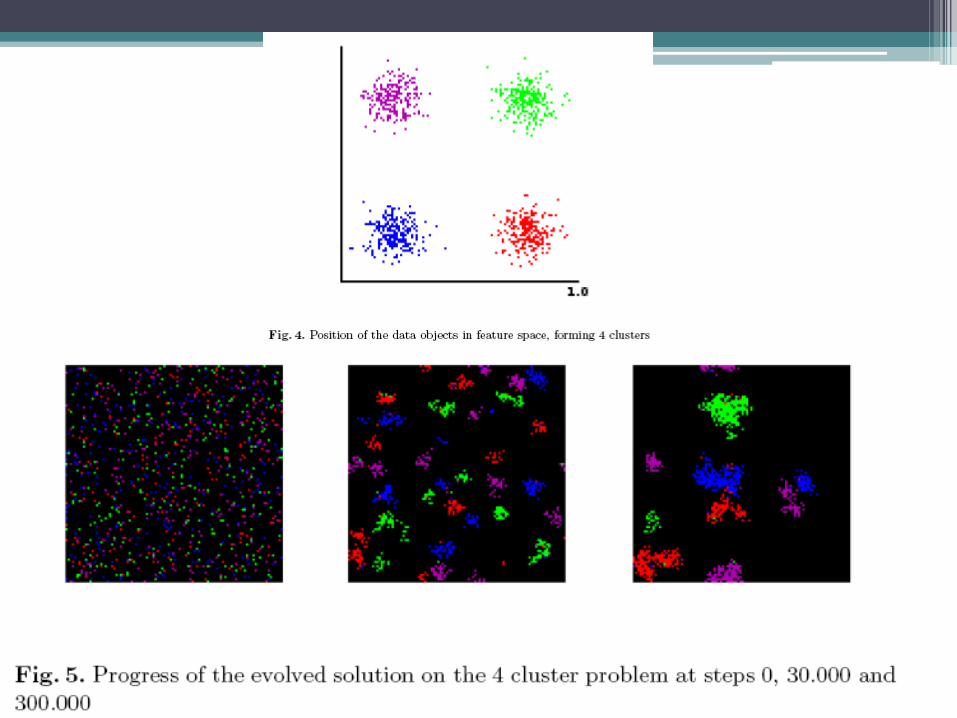
• To extract the clusters from the workspace, we define a cluster as a group of objects within 2 units of Manhattan distance from any member of the group.
• In this way, in figure 2, we can see 2 such different clusters.

• However, the number of clusters alone does not tell us how good the clustering is, so we must also account for the quality of the clusters.
• We Average Local Linkage, to measure the quality of one cluster.

Local Linkage
• First, we take the neighborhood disparity function f(i) to determine the local Linkage of one object.
• From this value, we calculate the ALL for the cluster as:
• Where Csize is the number of objects in the cluster, and each is an object belonging to the cluster.

fitness of one individual
• To calculate the fitness of one individual, then, we identify the clusters by using the definition in figure 2,
• and then averaging ALL(C) for all clusters where Csize > 1.

• There is, however, one extra thing that must be taken care with when calculating the fitness of ant clustering algorithms.
• As reported in [18], LF does not reach an stable configuration - since the pick and drop probabilities are not deterministic, the ants may pick some pieces from established clusters, lowering the fitness, just to put them back a few turns later.
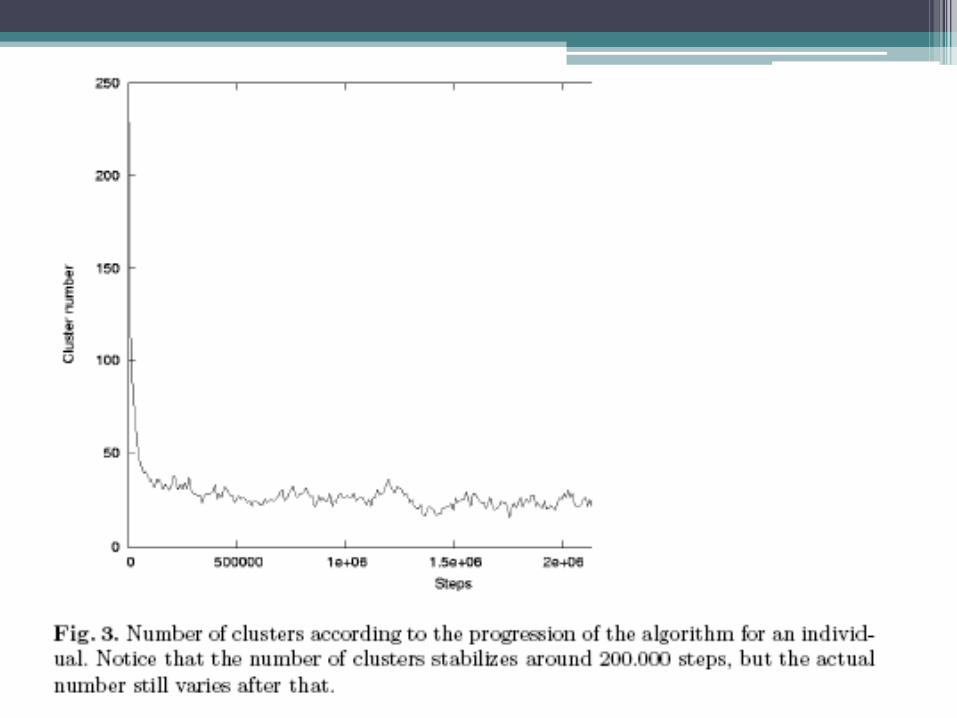

• Therefore, if we just pick any one time step, and measure the fitness at that moment, we can get a lucky high or low unstable state
• In order to avoid that, after a given turn t, we start measuring the fitness for the next fit turns, and take the average fitness of this period as the individual’s fitness.

Experiments
• Running the experiment, we found out that in fact the evolved solutions could generate a smaller number of clusters with the passing of the generations

Effects of Inter-agent
Communication in Ant-Based
Clustering Algorithms: A case
Study on Communication Policies
in Swarm Systems
Marco A. Montes de Oca, Leonardo Garrido, and Jos´e L. AguirreSpringer-Verlag Berlin Heidelberg 2005

• In natural settings, stigmergy [6] plays a key role as it provides the means for indirect communication among insects through the environment.
• we need to consider the question of whether agents should/could communicate in other ways to achieve organization or better solutions to problems.
• we need to study the effects of letting agents use different communication policies.

pheromone
• In ACO, we can see stigmergy in action whenever an artificial ant deposits a pheromone trail on a problem solution space.
• If an artificial ant come across a pheromone trail, it is attracted to it, very much like termites are attracted by clusters of soil pellets.
• By means of this indirect communication channel, ants share knowledge and the pheromone trail is a “blue print” to build a good solution to the problem at hand.

• The similarity measure used in all the experiments was the cosine metric
• S is the steepness of the response curve and D serves as a displacement factor.
• S was fixed to 5 because it provides a similarity value close to 0 when the cosine measure is minimum,
• when the cosine measure gives a value of −1, and D to 1 because this allows us to better distinguish vectors with separation angles between 0 and π/2.

• All algorithms were tested 30 times with every database for 1,000,000 simulation cycles.
• We tried with populations of 10 and 30 agents within an environment of 100 × 100 locations in all the experiments.

Direct Information Exchange
• direct information exchange occurs only when two or more agents meet at a location on the grid.
• Hence, the probability of an encounter between two agents moving randomly raises as the number of agents is increased

Indirect Information Exchange
• agents lay packets which contain information about data distribution on the environment for others to pick and use.
• Direct communication among agents in ant-based clustering has two disadvantages:
• (i) even when the number of exchanges increases, we cannot expect many of them to happen since the number of agents must be kept small (for performance reasons),
• and (ii) many exchanges do not have any effect since agents walk in a randomly fashion, i.e., two agents coincide many times, over and over again, before they follow different trajectories.

• So the idea is that if we let agents lay information on their environment, it could be possible to increase dramatically the number of exchanges without even increasing the number of agents.
• Two information laying policies were studied: ▫ a periodic laying policy and
With the periodic laying policy, an agent drops information packets every given number of simulation cycles.
▫ an adaptive laying policy. With the adaptive laying policy, an agent drops
information after it has modified the environment and a given number of simulation cycles have passed.

AN ANT COLONY CLUSTERING
ALGORITHM
BAO-JIANG ZHAO2007

• The algorithm considers R agents, namely artificial ants, to build solutions.
• An agent starts with an empty solution string S of length N where each element of string corresponds to one of the test samples.
• The value assigned to an element of solution string S represents the cluster number to which the test sample is assigned in S.

• To construct a solution, the agent uses the pheromone trail information to allocate each element of string S to an appropriate cluster label.
• At the start of the algorithm, the pheromone matrix, τ is initialized to a value τ0.
• The trail value, τij at location (i, j) represents the pheromone concentration of sample iassociated to the cluster j.

• For the problem of separating N samples into K clusters the pheromone matrix is of size.
• The pheromone trail matrix evolves as we iterate.• At any iteration level, each one of the agents will develop
such trial solutions using the process of pheromone-mediated communication with a view to obtain a near-optimal partition of the given N test samples into K groups satisfying the defined objective.
• After generating a population of R trial solutions, crossover operator is performed to further improve fitness of these solutions.
• The pheromone matrix is then updated depending on the quality of solutions produced by the agents.
• the above steps are repeated for certain number of iterations.

• the agent select cluster number for each element of string S by the following way:
is a parameter which determines the relative influence of the heuristic information. J is a random variable selected according to the probability distribution given by
• probability for element i belongs to cluster j:


Cluster Analysis Based on
Artificial Immune System and
Ant Algorithm
Chui-Yu Chiu and Chia-Hao Lin
IEEE 2007

Immunity-based Ant Clustering
Algorithm(IACA)
• immune system utilizes problem-specific heuristic to conduct local search and fine-tuning in the solution space.
• using artificial immune system to fine-tune the objects between two different clusters is the most important characteristic of IACA