a unified architecture for accelerating distributed dnn
TRANSCRIPT

A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters
Yimin Jiang∗†, Yibo Zhu†, Chang Lan‡, Bairen Yi†, Yong Cui∗, Chuanxiong Guo†
*Tsinghua University, †ByteDance, ‡Google

Deep Neural Network (DNN)
ResNet-50 (26M params)
BERT-Large(387M params)
DNNModels
DNNTraining
DNN model Device Computation time (FP + BP)
Estimated #iters. to converge
Estimated training time
ResNet-50 1x Tesla V100
32ms + 64ms(batch size 32) 3.6M 96 hours
BERT-Large 1x Tesla V100
339ms + 508ms (batch size 35) 8M 78.4 days
GPT-3 (175B params)
2Need distributed training to scale out!

Data-parallel DNN Training
3
X Y
GPU-1
Wa Wb Wc
Forward Propagation (FP)
Back Propagation (BP)
X Y
GPU-2
Wa Wb Wc
Input: X1
Input: X2
𝑌! = 𝑓(𝑋!)
𝑌" = 𝑓(𝑋")
∇𝑊! =𝜕𝐿𝑜𝑠𝑠(𝑌!, .𝑌!)
𝜕𝑊X Y
GPU-1
Wa’ Wb’ Wc’
GPU-2
X Y
Wa’ Wb’ Wc’
𝑊# = 𝑊 − 𝑓(∇𝑊)
Next Iteration
∇𝑊" =𝜕𝐿𝑜𝑠𝑠(𝑌", .𝑌")
𝜕𝑊
Communication∇𝑊 = ∇𝑊! + ∇𝑊"
Update Parameter
This work covers these two stages

All-reduce and PS• Architectures based on data parallelism: All-reduce and PS
GPU Worker
CPU Server
CPU Server
GPU Worker
GPU Worker
GPU Worker
GPU Worker
GPU Worker
All-reduce Parameter Server (PS)
Gradie
nts
Gradien
ts Parameters
• All workers are homogeneous • Use collective communication
to exchange the gradients
• Heterogeneous bipartite graph• GPU workers + CPU servers• Push gradients + pull parameters
4

Existing Solutions Are InsufficientVGG-16 performance with 32 GPUs. ByteScheduler is from [SOSP’19].
0
2000
4000
6000
PS PS +ByteScheduler
All-reduce All-reduce +ByteScheduler
Optimal
Imag
es /
sec
-76%-52%
-34%-28%
What are the problems of existing solutions?5

P1: Sub-optimal Inter-machine Communication
6
GPU Machines
CPU Machines
Heterogeneous ClustersIf use all-reduce à cannot leverage CPU machines
If use PS à may create traffic hotspot when CPU not enough
0
20
40
60
80
100
0 1 2 3 4 5 6 7 8
Good
put (
Gbps
)
The number of CPU machines
Application goodput (8 GPU machines)
Optimal
All-reduce
PS
Existing solutions fail to address the characteristics of heterogeneous clusters
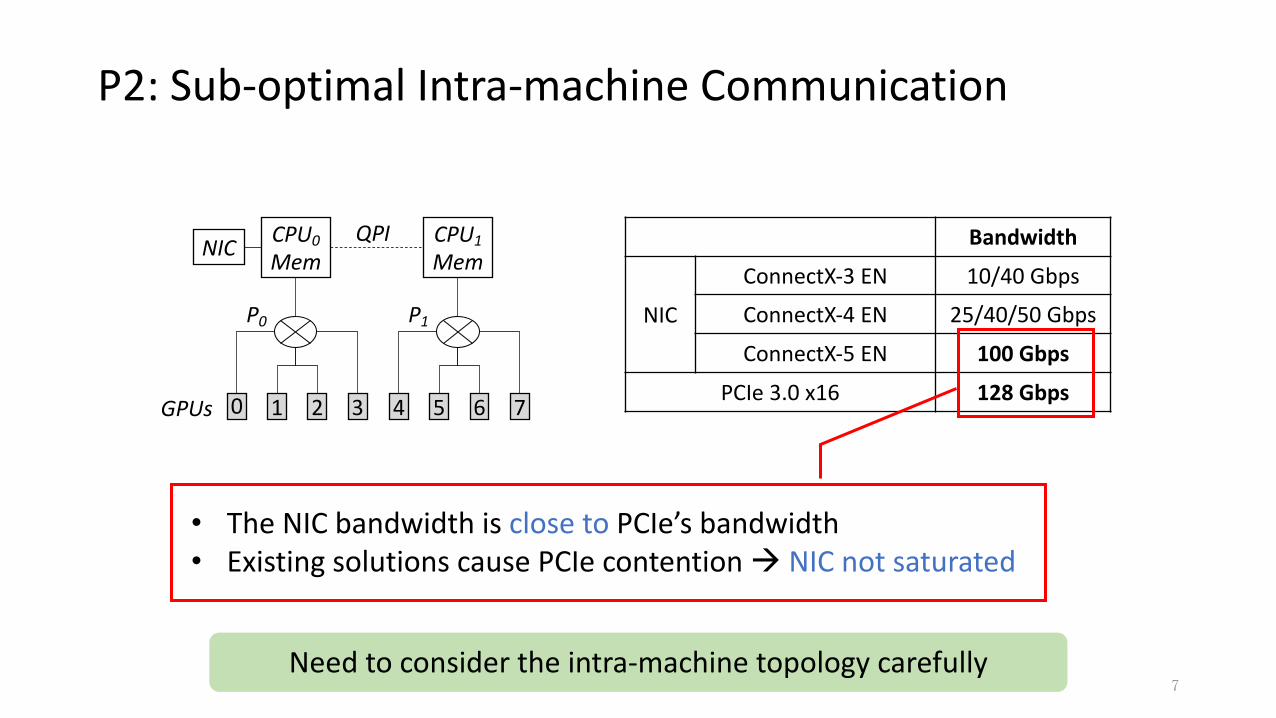
P2: Sub-optimal Intra-machine Communication
7
0
CPU0MemNIC
P0
1 2 3
QPI CPU1Mem
4
P1
5 6 7
• The NIC bandwidth is close to PCIe’s bandwidth• Existing solutions cause PCIe contention à NIC not saturated
Bandwidth
NIC
ConnectX-3 EN 10/40 Gbps
ConnectX-4 EN 25/40/50 Gbps
ConnectX-5 EN 100 Gbps
PCIe 3.0 x16 128 GbpsGPUs
Need to consider the intra-machine topology carefully

P3: The CPU Bottleneck
GPU Worker CPU
Server
How to address the CPU bottleneck?
0
20
40
60
80
100
Thro
ughp
ut (G
bps)
RMSProp on CPU
CPU
CPU-MKL
Network
8
GPU Worker
∇𝑊!
∇𝑊"
∇𝑊 = ∇𝑊! + ∇𝑊"
𝑓: Optimizer function 𝑊# = 𝑊 − 𝑓(𝛻𝑊)
0
5
10
15
20
# Estimated Memory Access
Max. Capacityon DDR4-2666
RMSProp
Adam
100Gbps
e.g., 6-channel DDR4-2666 memory (1024Gbps) (Max. # memory access: 1024/100≈10)
CPU cannot match network rate
Exceed the limit

Problem 1 Sub-optimal inter-machine
communication
Problem 2 Sub-optimal intra-machine
communication
Problem 3 The CPU bottleneck
Our solution: BytePS
An optimal inter-machine communication strategy that is
generic and unifies all-reduce and PS
Intra-machine optimization that accelerates communication inside
GPU machines with diverse topology
Summation Service that aggregates gradients on CPUs and moves
parameter update to GPUs9

Outline
1. Background and Motivation
2. Design and Implementation
3. Evaluation
10

Opportunity and Design Goal
11
• Opportunity: There are spare CPUs and bandwidth in heterogeneous clusters
• Design goal: leverage any spare resources
3 months trace from ByteDance Clusters
GPU Machines
CPU Machines
Heterogeneous Clusters
Avg CPU utilization: 20~35%
20~45% run non-dist jobs (BW unused)

1. Inter-machine Communication
12
GPU Machine
CPU Machine
GPU Machine
GPU Machine
CPU Machine
GPU Machine
CPU Machine
GPU Machine
GPU Machine
CPU Machine
GPU Machine
CPU Machine
GPU Machine
GPU Machine
CPU Machine
PS only uses links between GPU-CPU All-reduce only uses links between GPUs
B B
2𝐵3
2𝐵3
2𝐵3
Bandwidth not saturated
CPU Bandwidth not utilized at allBest strategy: combine together
How to partition the link workload?

Best Partition Strategy
This strategy unifies PS and all-reduce, and is optimal with any # of CPU machines
0
2
4
6
8
0 1 2 3 4 5 6 7 8
Tim
e
k (the number of CPU machines)
Comm. Time (n = 8)
PS
All-reduce
Optimal
13
𝑥 =2𝑘 𝑛 − 1
𝑛" + 𝑘𝑛 − 2𝑘𝑦 =
𝑛(𝑛 − 𝑘)𝑛" + 𝑘𝑛 − 2𝑘
Optimal partition strategy:
GPU Machine
CPU Machine
GPU Machine
GPU Machine
CPU Machine
𝒙: % traffic between GPU-CPU 𝒚: % traffic between GPU-GPU
n: # of GPU machines k: # of CPU machines 𝑘 = 0: equal to all-reduce 𝑘 = 𝑛: equal to PS
0<𝑘<𝑛: better than all-reduce and PS

2. Intra-machine Communication
0CPU0MemNIC
P0
1 2 3
QPI CPU1Mem
4
P1
5 6 7
0CPU0MemNIC
P0
1 2 3
QPI CPU1Mem
4
P1
5 6 7
Existing solutions (e.g., MPI, NCCL)Bottleneck link: M*2(8-1)/8 = 7M/4 traffic
> 300Gbps
~80Gbps
~105Gbps
Bottleneck
7M/4~80Gbps
Our solution: CPU-assisted AggregationBottleneck link: M/4*4 = M traffic
Sum on CPU
M
• CPU-assisted aggregation outperforms MPI/NCCL by 24% in theory• Principle: avoid direct copy between GPUs under different PCIe switches
14
Reduce-scatter
Copy
(M: model size on each GPU)

More Details in the Paper
• Solution for NVLink-based machines
• Design principles for different topology
• Optimality analysis
• Discussion about GPU Direct RDMA
15

3. Address the CPU Bottleneck
16
0
50
100
Thro
ughp
ut (G
bps)
RMSProp on CPU
CPU
CPU-MKL
Network
GPU Worker CPU
ServerGPU
Worker 𝑓: Optimizer function 𝑊# = 𝑊 − 𝑓(𝛻𝑊)
Gradient Summation
Parameter Update
+
0
100
200
300
Thro
ughp
ut (G
bps)
Summation
CPU is good at summation
FP16
FP32
Network bandwidth
Heavy for CPUCPU-friendly
CPU Summation is faster than network

Summation Service
fp
bp
update
sum
GPU
Optimizer
CPU
Parameter Server Summation Service
17
fp
bp
update
sum
GPU
CPU
Summation Service can address the CPU bottleneck efficiently

GPUComputation
GPUComputation
GPUComputation
System Architecture
GPUComputation Summation
Service
CommunicationService
GPU Machine0 …
SummationService
CPU Machine0
GPUComputation
GPUComputation
GPUComputation
GPUComputationSummation
Service
CommunicationService
GPU Machinen-1
SummationService
CPU Machinek-1
…
Intra-machine optimization
Address the CPU bottleneck
Optimal Inter-machine strategy
18

Usage and DeploymentBytePS supports TensorFlow, PyTorch and MXNet
Easy to use: compatible to most widely used APIs• Horovod-alike APIs • Native APIs for PyTorch and TensorFlow
BytePS Core
BytePS has been deployed in ByteDance for CV/NLP tasks19

Outline
1. Background and Motivation
2. Design and Implementation
3. Evaluation
20

Evaluation Setup
Item ContentCV models ResNet-50 (TF), VGG-16 (MXNet), UGATIT-GAN (PyTorch)
NLP models Transformer (TF), BERT-Large (MXNet), GPT-2 (PyTorch)Hardware Each machine with 8x V100 GPUs (32GB) and a 100GbE NIC Network RoCEv2, full-bisection bandwidthBaseline Horovod, PyTorch DDP, Native-PS of TF and MXNet
• All experiments are performed on production clusters• All chosen models are representative of production workloads
21

Inter-machine Communication
[Traffic microbenchmark] on 8x 1-GPU machines with different # CPU machines
[End-to-end] on 8x 8-GPU machines with different # CPU machines. Models: GPT-2 and UGATIT-GAN
22
BytePS achieves near-optimal communication performance
Better
With more CPU machines, BytePS achieves higher E2E performance

Intra-machine Optimization
[PCIe-only] 8x 8-GPUs [NVLink-based] 8x 8-GPUs
23
For PCIe-only topology, up to 20% gain
1
1.1
1.2
1.3
GPT-2 UGATIT-GAN
Spee
dup
wrt
. Al
l-red
uce
Baseline BytePS
1
1.1
1.2
1.3
GPT-2 UGATIT-GAN
Spee
dup
wrt
. Al
l-red
uce
Baseline BytePS
For NVLink-based topology, up to 18% gain
+10%
+20%+18%
+8%

End-to-end Scalability (up to 256 GPUs)TensorFlow ResNet-50 MXNet VGG-16 PyTorch UGATIT-GAN
PyTorch GPT-2TensorFlow Transformer MXNet BERT-Large
CV Models
NLP Models
BytePS outperforms All-reduce and PS by up to 84% and 245%, respectively
24

Breakdown of Performance Gains
0
1000
2000
3000Im
ages
/ se
c
Native-PS+Inter-machine+Intra-machine+Summation Service
25
VGG-16 (batch size / GPU = 32), 4x 8-GPUs machines, 2x CPU machines
+ Inter-machine: +66%
+ Intra-machine: +22%+ Summation Service: +18%

Related Work• Communication Acceleration • Gradient compression: 1-bit, top-k, Adacomp [AAAI’18]• Scheduling: ByteScheduler [SOSP’19], P3/TicTac [SysML’19]• Pipelined parallelism: PipeDream [SOSP’19]• Hierarchical all-reduce: BlueConnect [SysML’19]
• New hardware or architecture for DNN training• New AI chips: TPU, Habana• In-network all-reduce: Infiniband switch ASIC (SHArP)• In-network PS: P4 switch [HotNets’17] • Rack-scale dedicated servers: PHub [SoCC’18]
26
Complementary to BytePS
à BytePS design is generic and not GPU-specific
Require special re-design of hardware or architecture
à Still does not leverage heterogeneous resources
à BytePS can benefit its data-parallel stage

ConclusionBytePS: A unified system for distributed DNN training acceleration- Optimal inter-machine communication- Topology-aware intra-machine optimizations- Address the CPU bottleneck with Summation Service
Deployed in ByteDance for CV and NLP training tasks
Open-sourced at https://github.com/bytedance/byteps- Support TensorFlow, PyTorch, MXNet
27
