abap4 sap r3 in 21 tagen ebook
TRANSCRIPT


InhaltsverzeichnisEinführung
Auf einen Blick
Tag 1 Die Entwicklungsumgebung
KapitelzieleWas ist R/3®? Wie sieht R/3® aus? Die Basis Client-ServerR/3-SystemarchitekturArchitektur des Applikationsservers Open SQL von SAP ZusammenfassungFragen & Antworten Workshop
Tag 2 Ihr erstes ABAP/4®-Programm
KapitelzieleBevor es weitergeht Die Entwicklungsumgebung ProgrammtypenReportbestandteileIhr erstes Programm Der Quelltexteditor HilfeIhre Entwicklungsobjekte wiederfinden Das R/3-Data Dictionary Die ABAP/4-Syntax

ZusammenfassungFragen & Antworten Workshop
Tag 3 Das Data Dictionary®, Teil 1
KapitelzieleR/3-Release-StändeTiefer im R/3-Data Dictionary stöbern Die verschiedenen Tabellentypen in R/3 TabellenkomponentenNamenskonventionen für Tabellen und ihre Komponenten Anlegen einer transparenten Tabelle und ihrer Komponenten TabellenmodifizierungArbeiten mit Daten Zugriff auf die Datenbrowser-Funktionalität aus DDIC heraus ZusammenfassungFragen & Antworten Workshop
Tag 4 Das Data Dictionary®, Teil 2
KapitelzieleFremdschlüsselBesondere Tabellenfelder Strukturen im Data Dictionary ZusammenfassungFragen & Antworten Workshop
Tag 5 Das Data Dictionary®, Teil 3
KapitelzieleTabellenindizesTechnische Einstellungen ZusammenfassungFragen & Antworten Workshop

Tag 6 Das Data Dictionary®, Teil 4
KapitelzieleAutomatische Tabellenhistorie und Änderungsbelege Zusammenfassung der Technischen Einstellungen Überarbeitete und aktive Versionen Das Datenbank-Utility benutzen ZusammenfassungFragen & Antworten Workshop
Tag 7 Datendefinitionen in ABAP/4®, Teil 1
KapitelzieleProgrammpuffer und der Rollbereich ABAP/4-SyntaxelementeDatenobjekte definieren ZusammenfassungFragen & Antworten Workshop
Rückblick
Auf einen Blick
Tag 8 Datendefinition in ABAP/4®, Teil 2
KapitelzieleDefinition der Konstanten Definition von Feldleisten Definition von Typen Strukturierte Typen ZusammenfassungFragen & Antworten Workshop
Tag 9 Zuweisungen, Konvertierungen und Berechnungen
Kapitelziele

Bevor Sie weiterlesen Arbeiten mit Systemvariablen Systemvariablen suchen ZuweisungsanweisungenDynamische Zuweisungen ZusammenfassungFragen & Antworten Workshop
Tag 10 Allgemeine Kontrollanweisungen
KapitelzieleDie if-Anweisung Die case-Anweisung Die Anweisung do Der Anweisung while Die Anweisung continue Die Anweisung check Vergleich der Anweisungen exit, continue und check Einfache Positions- und Längenspezifikationen für die Anweisung write ZusammenfassungFragen & Antworten Workshop
Tag 11 Interne Tabellen
KapitelzieleGrundlagen interner Tabellen ZusammenfassungFragen & Antworten Workshop
Tag 12 Interne Tabellen, Teil 1
KapitelzieleDen Inhalt interner Tabellen testen und modifizieren Informationen über eine interne Tabelle erhalten Daten von einer internen Tabelle in eine andere kopieren Die editor-call-Anweisung

Zeilen in eine interne Tabelle einfügen Zeilen einer internen Tabelle modifizieren Den Inhalt einer internen Tabelle löschen Das Anlegen von Top-Ten-Listen mit Hilfe von append sorted by Eine interne Tabelle mit collect füllen ZusammenfassungFrage & Antwort Workshop
Tag 13 Interne Tabellen, Teil 2
KapitelzieleEine interne Tabelle mit Daten aus einer Datenbanktabelle füllen Der Gebrauch von lfa1-, lfb1-, lfc1- und lfc3-Beispieltabellen GruppenwechselZusammenfassungFragen & Antworten Workshop
Tag 14 Die write-Anweisung
KapitelzieleStandardlängen und Formatierungen Ergänzungen zur write-Anweisung Das Arbeiten mit Unter(Sub)feldern ZusammenfassungFragen & Antworten Workshop
Rückblick
Auf einen Blick
Tag 15 Formatierungstechniken, Teil 1
KapitelzieleGrafische Formatierung mit Hilfe der write-Anweisung Berichtsformatierung und Druckausgabe Zusammenfassung

Fragen & Antworten Workshop
Tag 16 Formatierungstechniken, Teil 2
KapitelzieleAnweisungen für die Ausgabeaufbereitung Die Anweisung skip Die Syntax der Anweisung skip ZusammenfassungFragen & Antworten Workshop
Tag 17 Modularisierung: Ereignisse und Unterprogramme
KapitelzieleModularisierungseinheiten in ABAP/4 EreignisseUnterprogrammeZusammenfassungFragen & Antworten Workshop
Tag 18 Modularisierung: Übergabe von Parametern an Unterprogramme
KapitelzieleParameterübergabeExterne Unterprogramme definieren und aufrufen ZusammenfassungFragen & Antworten WorkshopKontrollfragenÜbung 1
Tag 19 Modularisierung: Funktionsbausteine, Teil 1
KapitelzieleVerwendung der include-Anweisung

FunktionsbausteineFunktionsgruppenAufruf von Funktionsbausteinen Anlegen eines Funktionsbausteins ZusammenfassungFragen & Antworten Workshop
Tag 20 Modularisierung: Funktionsbausteine, Teil 2
KapitelzieleGlobale Daten für Funktionsbausteine definieren Eine interne Tabelle an einen Funktionsbaustein übergeben Unterprogramme in einer Funktionsgruppe definieren Einen Funktionsbaustein freigeben Einen Funktionsbaustein testen Existierende Funktionsbausteine finden Die Komponenten Ihrer Funktionsgruppe untersuchen Fehler in Funktionsbausteinen finden und beheben Den Rückgabewert von sy-subrc setzen Die call function-Anweisung automatisch einfügen ZusammenfassungFragen & Antworten Workshop
Tag 21 Selektionsbilder
KapitelzieleEreignisgesteuerte Programmierung Datenprüfungen mit Fremdschlüsseln Datenprüfungen mit Matchcodes Selektionsbilder formatieren selection-screen-Anweisungen benutzen Selektionsbild Parameter Selektionsbild checkbox Selektionsbild select-options Selektionsbild Auswahlknöpfe (Optionen) Beispielprogramm für ein Selektionsbild Die Meldungsanweisung benutzen

ZusammenfassungFragen & Antworten Workshop
Rückblick
Anhang A Namenskonventionen
Programm-NamenskonventionenKundennamensräume
Anhang B Antworten zu den Kontrollfragen und Übungen
Kapitel 1 Kapitel 2 Kapitel 3 Kapitel 4 Kapitel 5 Kapitel 6 Kapitel 7 Kapitel 8 Kapitel 9 Kapitel 10 Kapitel 11 Kapitel 12 Kapitel 13 Kapitel 14 Kapitel 15 Kapitel 16 Kapitel 17 Kapitel 18 Kapitel 19 Kapitel 20 Kapitel 21

Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

EinführungNachdem ich ABAP/4®-Zertifizierungskurse mit Hunderten von Anfängern und erfahrenen Entwicklern bei der SAPAG und anderen Instituten durchgeführt habe, bin ich mir der Probleme und Fragen bewußt, die beim Erlernen dieser mächtigen Sprache auftauchen können. Ich hoffe, daß ich Ihnen dieselben Lernerfahrungen übermitteln kann, indem ich die besten Techniken, mit denen ich in Berührung kam, mit in dieses Buch einbaue. Es bietet eine Fülle von detaillierten Diagrammen, Bildschirmfotos, Beispielprogrammen, ScreenCams und Schritt-für-Schritt-Prozeduren. Alle Beispielprogramme befinden sich auch auf der CD-ROM. Die Hilfsmittel, die ich all meinen Klassen zukommen lasse, sind auch auf der CD-ROM, einschließlich einiger neuer, die ich speziell für dieses Buch geschrieben habe.
ABAP/4® ist trotz seiner simplen Oberfläche im Unterbau eine sehr komplexe Programmiersprache. Deshalb ist ein Anfänger oft vom Verhalten der Sprache verwirrt. Versteht man aber erst, wie es unter der Oberfläche funktioniert, ist man auch in der Lage, sie zu beherrschen. Wenn man die Wies und Warums versteht, wird man schnell Verständnis für dieses interessante Gebiet bekommen.
Dieses Buch wird Sie Schritt für Schritt in die ABAP/4®-Sprache und ihre Umgebung einführen. Nach jedem Kapitel werden Sie die Übungen einsetzen, die das Erlernte vertiefen sollen. Für alle Aufgaben finden Sie die Lösungen auch auf der CD-ROM.
Sowohl erfahrene Programmierer als auch Anfänger können sehr schnell herausfinden, daß das Schreiben eines ABAP/4®-Programms mehr bedeutet, als irgendein Programm zu schreiben. Häufig muß man Entwicklungsobjekte anlegen, um es zu unterstützen. Wie man diese Objekte anlegt, wird detailliert in durchdachten Schritten erklärt. Jeder Schritt enthält den Titel der Maske, auf die Sie stoßen, sowie die zu erwartende Antwort für jedes Kommando. Alle Prozeduren sind begleitet von ScreenCams, die genau aufzeigen, wie was funktioniert. So können Sie nicht nur vom Zusehen etwas lernen, Sie können ebenso vor- und rückwärtsspulen.
Die Beherrschung der ABAP/4®-Programmiersprache ist, wie gesagt, nicht einfach. Ich habe aber versucht, die wichtigsten Informationen, die man hierfür benötigt, in 21 Abschnitte zu packen. Mit diesem Wissen, das Ihnen dies Buch vermittelt, werden Sie in der Lage sein, komplexe ABAP/4®-Arbeiten zu erledigen.
Wenn Sie Probleme beim Durcharbeiten dieses Materials haben, zögern Sie nicht, mich im Internet

unter http://www.abap4.net zu besuchen. Dort werde ich dann versuchen, die am häufigsten gestellten Fragen sowie Probleme, auf die Sie beim Durcharbeiten stoßen, zu beantworten. Wenn Sie glauben, einen Fehler gefunden zu haben, können Sie mir dort davon berichten.
Ich hoffe, daß Sie dieses Buch mit der gleichen Freude benutzen werden, die ich beim Schreiben hatte.
Viel Spaß - und hier ist Ihr »ABAP/4® in 21 Tagen«.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Auf einen Blick Tag 1 Die Entwicklungsumgebung 17
Tag 2 Ihr erstes ABAP/4®-Programm 55
Tag 3 Das Data Dictionary®, Teil 1 111
Tag 4 Das Data Dictionary®, Teil 2 157
Tag 5 Das Data Dictionary®, Teil 3 195
Tag 6 Das Data Dictionary®, Teil 4 223
Tag 7 Datendefinitionen in ABAP/4®, Teil 1 243
In der ersten Woche lernen Sie etwas über die Umgebung von R/3®, einschließlich der Basis, des Anmeldemandantens, der ABAP/4-Development Workbench® und des Data Dictionary®. Innerhalb des Dictionary werden Sie transparente Tabellen unter Verwendung von Datenelementen und Domänen anlegen, Fremdschlüssel hinzufügen, um Eingaben zu überprüfen, sowie sekundäre Indizes oder Puffer anlegen, um Datenzugriffe zu beschleunigen. Sie werden auch lernen, die (F1)- und die (F4)-Hilfe für den Benutzer einzurichten. Sie beginnen mit dem Schreiben einfacher ABAP/4®- Programme und lernen den ABAP/4®-Editor kennen.
■ Am ersten Tag, »Die Entwicklungsumgebung«, wird erklärt, was das R/3®-System ist und wie es für den Benutzer aussieht. Sie erfahren etwas über die Systemarchitektur, unter der ABAP/4®-Programme laufen.
■ Am zweiten Tag, »Ihr erstes ABAP/4®-Programm«, lernen Sie, wie Sie einfache ABAP/4®-Programme anlegen und modifizieren. Sie werden sowohl eine Tabelle und ihren Inhalt mit Hilfe des Data Dictionary® anzeigen als auch Ihren Programmen Kommentare und Dokumentation hinzufügen.
■ Tag drei, »Das Data Dictionary®, Teil 1«, beschreibt den Unterschied zwischen transparenten, Pool- und Clustertabellen. Und Sie lernen, wie man Domänen, Datenelemente und transparente Tabellen im Data Dictionary® anlegt.
■ Am vierten Tag, »Das Data Dictionary®, Teil 2« legen Sie Fremdschlüssel und Texttabellen an und benutzen diese. Sie beschreiben den Unterschied zwischen einer Struktur und einer Tabelle und legen im R/3-Data Dictionary® Strukturen an.

■ Während des fünften Tages, »Das Data Dictionary®, Teil 3«, legen Sie Sekundärindizes an und verwenden sie entsprechend. Außerdem richten Sie sowohl die technischen Attribute für transparente Tabellen als auch die Pufferung für Tabellen ein.
■ Am sechsten Tag, »Das Data Dictionary®, Teil 4«, verwenden Sie die Datenbankhilfsmittel, um Konsistenzchecks zu machen, Sie zeigen datenbankspezifische Tabelleninformationen an, und Sie löschen Tabellen in der Datenbank und stellen sie wieder her.
■ Nach dem siebten Tag, »Datendefinitionen in ABAP/4®, Teil 1«, verstehen Sie die Elemente der ABAP/4®-Syntax, können das Konzept von Datenobjekten und ihre Auswahl beschreiben, verwenden Literale und wissen, wie man die unterschiedlichen Datentypen kodiert bzw. definiert und verwenden Konstanten.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 1
Die Entwicklungsumgebung
Kapitelziele
Wenn Sie dieses Kapitel bearbeitet haben, sollten Sie folgende Fragen beantworten können:
■ Was ist ein R/3®-System? ■ Was ist eine R/3®-Instanz? ■ Was versteht man unter der Basis? ■ Welche Betriebssysteme werden von R/3® unterstützt? ■ Wie sehen mögliche R/3®-Konfigurationen aus? ■ Wie kann eine R/3®-Server-Architektur aussehen? ■ Was ist ein Anmeldemandant?
Was ist R/3®?
R/3 ist ein integriertes Paket von Anwendungen für die Datenverarbeitung, vor allem in Großunternehmen. Es wurde von der Firma SAP AG entwickelt. (SAP ist ein Akronym für »Systeme, Anwendungen und Produkte in der Datenverarbeitung«.)
Abbildung 1.1: Anwendungsmodule sind alle in ABAP/4 geschrieben, das von den ausführbaren Programmen der Basis interpretiert wird, welche wiederum auf dem Operationssystem laufen.
R/3 benutzt eine sogenannte Laufzeitumgebung, um Anwendungsprogramme auszuführen, die in der SAP-eigenen Programmiersprache ABAP/4® geschrieben sind. Diese Anwendungsprogramme sind für die Datenverarbeitung in großen Konzernen entwickelt worden. R/3 und sein Vorgänger R/2® werden bevorzugt in der Industrie angewendet.
Die von Ihnen erstellten ABAP/4-Programme werden unter R/3 laufen (logisch dargestellt in Abb.1.1).
Sinn und Zweck von R/3
R/3 besteht aus sogenannten Modulen, die diverse Geschäftsanwendungen wie z.B. Finanzbuchhaltung repräsentieren. Folgende Anwendungen werden standardmäßig ausgeliefert:
■ PP (Produktionsplanung) ■ MM (Materialwirtschaft) ■ SD (Vertrieb) ■ FI (Finanzbuchhaltung) ■ CO (Controlling) ■ AM (Vermögensmanagement) ■ PS (Projektsystem) ■ WF (Workflow) ■ IS (Branchenlösungen) ■ HR (Personalwirtschaft) ■ PM (Instandhaltung) ■ QM (Qualitätsmanagement)
Diese Anwendungen heißen Funktions- oder Anwendungsbereiche, oder manchmal auch funktionelle Module von R/3. Alle diese Begriffe sind miteinander sinnverwandt.
Normalerweise stellen Geschäftsleute ein Paket von DV Anwendungen zusammen, indem sie individuelle Produkte begutachten und diese dann bei verschiedenen

Softwareanbietern kaufen. In solchen Fällen benötigt man Schnittstellen zwischen den einzelnen Komponenten. Zum Beispiel wird die Materialverwaltung Verbindungen zum Verkauf, zur Distribution und zum Finanzwesen brauchen, und das Workflow-System wird Zugriffe auf das HR-System benötigen. Hierdurch wird sehr viel Zeit und Geld für Implementierung und Wartung verschwendet.
R/3 enthält die Kerngeschäfts-Anwendungen, die in großen Unternehmen benötigt werden. Diese Anwendungen koexistieren in einer homogenen Umgebung. Sie wurden mit Hilfe einer Datenbank und einer sehr großen Anzahl von Datenbanktabellen entwickelt. Gegenwärtige Produktionsdatenbanken schwanken zwischen 12 Gigabyte und 3 Terabyte. In der Version 3.0F wurden ungefähr 8000 Datenbanktabellen mit dem standardmäßigen R/3 Produkt ausgeliefert.
Warum müssen Sie das wissen?
Für Sie als ABAP/4-Programmierer ist es wichtig, die Anwendungen zu verstehen, da sie alle ausschließlich in ABAP/4 geschrieben sind.
Nehmen Sie zum Beispiel an, Sie kennen ABAP/4 und werden gebeten, einen Finanzbericht zu schreiben, der im Steuerjahr Soll und Haben für jeden Verkäufer eines Unternehmens zusammenfassen soll. Sie mögen in ABAP/4 programmieren können, aber würden Sie wissen, wie man es anfängt, eine solche Aufgabe zu lösen?
Oder Ihre Aufgabe besteht vielleicht in einer Neuentwicklung in ABAP/4. Sie werden aufgefordert, ein System zu entwerfen, das potentiellen Käufern Aktiennotierungen zur Verfügung stellt. Wenn Sie die Finanz-, Verkaufs- und Distributionssysteme nicht kennen, werden Sie nicht wissen, ob Sie etwas entwickeln, das vielleicht schon in R/3 existiert. Ebensowenig können Sie wissen, ob es R/3-Tabellen gibt, die schon Daten enthalten, welche ähnlich oder identisch sind mit denen, die Sie speichern wollen. Ein Entwickler, der die Einstellung hat »Ich erstelle meine eigenen Tabellen und führe meine eigenen Datenkopien«, wird bald feststellen, daß seine Daten überflüssig sind und mit dem Rest der Datenbank synchronisiert werden müssen. Er hat eine Anwendung erstellt, welche die hochentwickelte Form der R/3-Umgebung nicht nutzt.
Ich erwähne dies nur, weil viele Entwickler, die selbständige Berater werden wollen, denken, daß es ausreicht, ABAP/4 zu lernen, um im R/3-System zu programmieren. Es ist sicherlich ein wichtiger Anfang, aber eben nur ein Anfang. Die Bedeutung, in einem Funktionsbereich zu üben, kann von jemandem, der ein fähiger ABAP/4-Berater werden will, leicht übersehen werden oder ihm unbekannt sein. Offensichtlich kann und wird man viel während der Arbeit lernen. Ich hoffe, ich kann veranschaulichen, daß das Erlernen von ABAP/4 nur der Anfang einer langen Reise durch SAP sein wird. Wenn Sie als selbständiger Berater erfolgreich sein möchten, werden Sie Funktionsbereichswissen erwerben müssen.
Über die Funktionsebenen können Sie in der R/3-Online-Referenz (Menüpfad Hilfe- >R/3-Bibliothek) nachlesen. Diese enthält Tutorien und Dokumentation für alle Funktionsebenen. Wenn Sie Zugriff haben zu einem System mit IDES-Daten (International Demo and Education System), können Sie sich auch durch die R/3-Bibliotheksübungen durcharbeiten. Was das Angebot an Trainingskursen betrifft, so wenden Sie sich an SAP (http://www.sap.de).
Wie sieht R/3® aus?
Bei einer Windows-Umgebung melden Sie sich normalerweise zu R/3 an, indem Sie einen Menüpfad vom Startmenü wählen oder durch einen Doppelklick auf eine R/3- Ikone (Abb. 1.2).
Abbildung 1.2: Die R/3-Ikone auf dem Desktop
Das R/3-System wird Sie nach einem Benutzernamen und einem Kennwort fragen. Die Anmeldemaske erscheint wie in Abb. 1.3. Füllen Sie diese beiden Felder aus, und drücken Sie die Entertaste.

Abbildung 1.3: Die R/3-Einwählmaske fragt Sie nach dem Paßwort
Es folgt eine Copyrightmaske, nach deren Bestätigung durch die Entertaste das R/3- Hauptmenü angezeigt wird (s. Abb. 1.4).
Abbildung 1.4: Das R/3-Hauptmenü
Die konzeptionellen R/3-Anwendungsgebiete
Vom Hauptmenü aus können Sie drei konzeptionelle Gebiete im R/3-System ausrufen:
■ die Anwendungsebene ■ die SAP Basis ■ die Entwicklungsumgebung
In der Anwendungsebene initiieren Sie Transaktionen (Systembefehle in R/3) für die Funktionsbereiche innerhalb von R/3. Um darauf zuzugreifen, wählen Sie aus dem R/3-Hauptmenü: Logistik, Buchhaltung, Personalwirtschaft oder Datensysteme.
In der SAP Basis können Sie Transaktionen aufrufen, in denen sich das R/3-System selbst überwacht. Um auf die Basis zuzugreifen, wählen Sie den Menüpfad Werkzeug ->Administration aus dem Hauptmenü. Sie werden hier verschiedene Werkzeuge zu Performance, Tuning und Datenbankverwaltung finden.
In der Entwicklungsumgebung werden ABAP/4-Programme entwickelt und geprüft. Als ABAP/4-Programmierer werden Sie die meiste Zeit innerhalb dieser Umgebung verbringen. Um auf die Entwicklungsumgebung zuzugreifen, wählen Sie den Menüpfad Werkzeuge->ABAP/4-Workbench. Allerdings wird Ihr Programm-Code höchstwahrscheinlich Anwenderdaten lesen oder aktualisieren und somit Teil der Anwendungsebene werden. Mit diesem Wissen im Hinterkopf lassen Sie uns zuerst einen Blick auf ein Anwendungsgebiet werfen.
Für unser Beispiel stellen Sie sich vor, Sie wären Angestellter in der Abteilung Kreditoren. Ein Lieferant ruft an, um mitzuteilen, daß sich seine Adresse geändert hat. Sie legen ein Lesezeichen in den Zeitschriftenartikel, den Sie gerade lasen (»Probleme kreativer Buchhaltung aus Sicht eines Kriminologen«) und schicken sich an, seine Adresse im R/3-
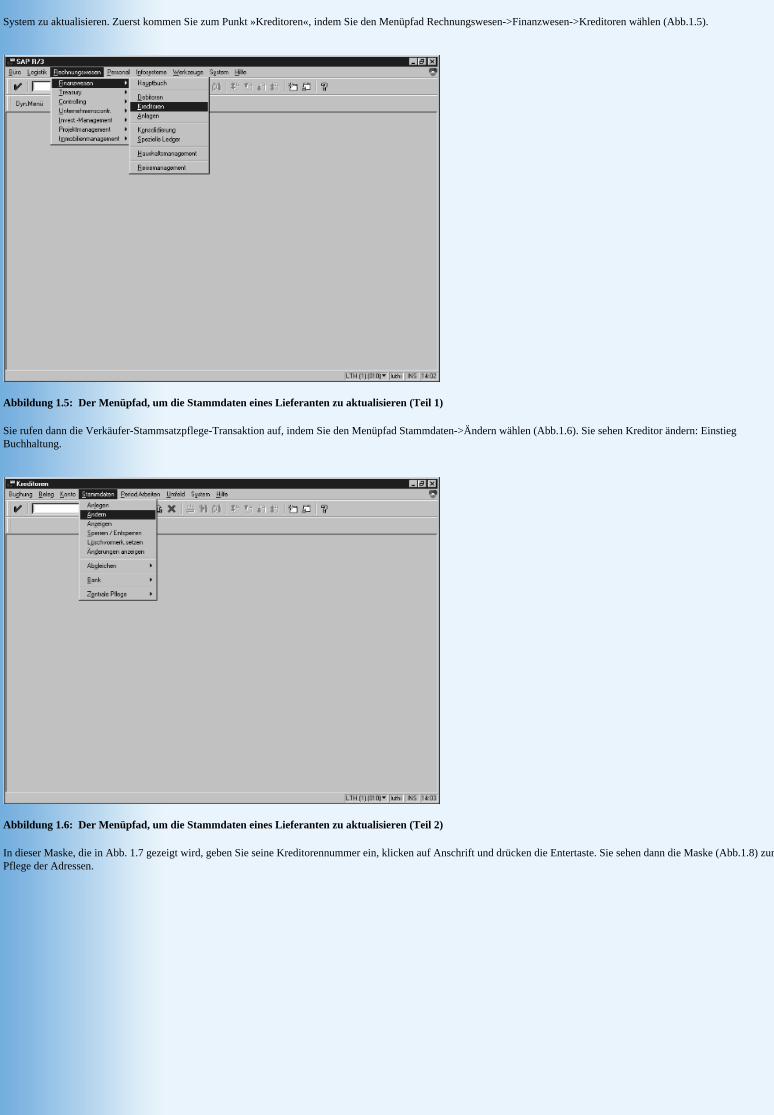
System zu aktualisieren. Zuerst kommen Sie zum Punkt »Kreditoren«, indem Sie den Menüpfad Rechnungswesen->Finanzwesen->Kreditoren wählen (Abb.1.5).
Abbildung 1.5: Der Menüpfad, um die Stammdaten eines Lieferanten zu aktualisieren (Teil 1)
Sie rufen dann die Verkäufer-Stammsatzpflege-Transaktion auf, indem Sie den Menüpfad Stammdaten->Ändern wählen (Abb.1.6). Sie sehen Kreditor ändern: Einstieg Buchhaltung.
Abbildung 1.6: Der Menüpfad, um die Stammdaten eines Lieferanten zu aktualisieren (Teil 2)
In dieser Maske, die in Abb. 1.7 gezeigt wird, geben Sie seine Kreditorennummer ein, klicken auf Anschrift und drücken die Entertaste. Sie sehen dann die Maske (Abb.1.8) zur Pflege der Adressen.
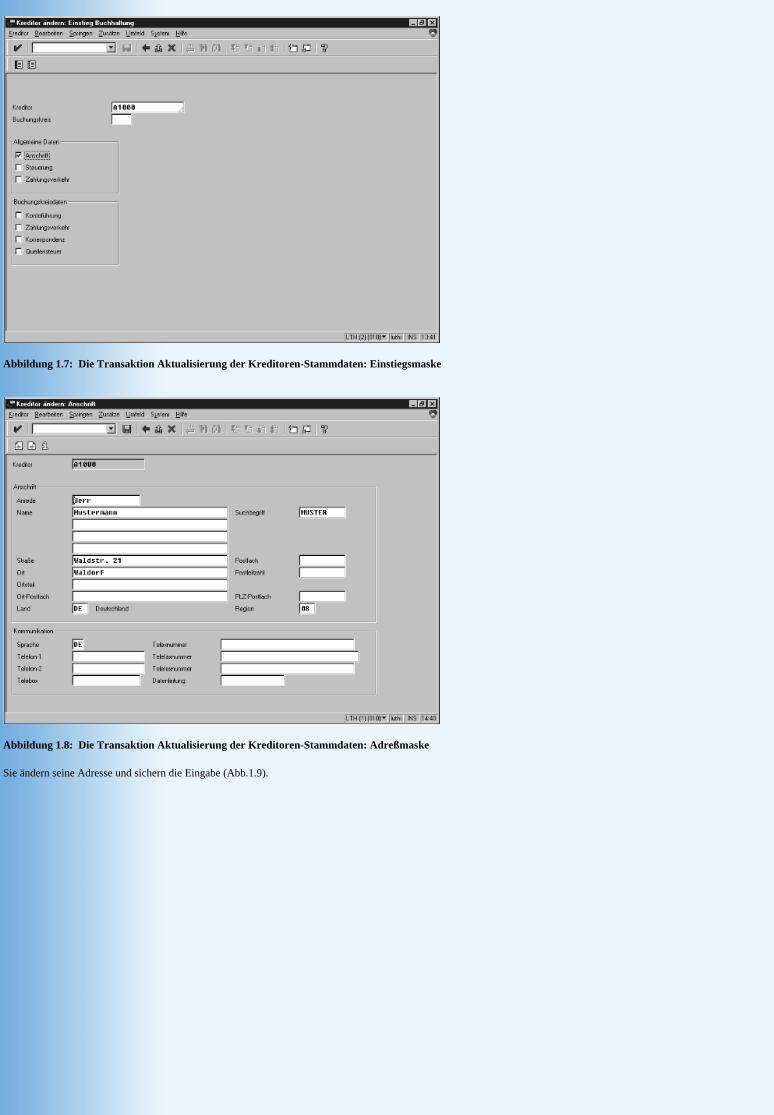
Abbildung 1.7: Die Transaktion Aktualisierung der Kreditoren-Stammdaten: Einstiegsmaske
Abbildung 1.8: Die Transaktion Aktualisierung der Kreditoren-Stammdaten: Adreßmaske
Sie ändern seine Adresse und sichern die Eingabe (Abb.1.9).

Abbildung 1.9: Sicherung der Änderungen in der Lieferantenadresse
Beim Sichern geht das System zurück zu Einstieg Buchhaltung. Das System zeigt auch eine Erfolgsmeldung innerhalb der Statusleiste an, die sich am unteren Rand des Bildschirms befindet (Abb.1.10).
Abbildung 1.10: Die Einstiegsmaske gibt die Bestätigung, daß die Adressenänderung vollzogen wurde
Diese Transaktion ist repräsentativ für viele Transaktionen im R/3-System. Die meisten Stammdatentransaktionen sehen ähnlich aus.
Die R/3-Anwenderschnittstelle
Abb.1.11 zeigt wieder das Hauptmenü; die wichtigsten Bildschirmbereiche sind gekennzeichnet.
Jede R/3-Maske enthält die folgenden Elemente:
■ Titelleiste: Zeigt den Namen der gegenwärtigen Maske. ■ Menüleiste: Die Inhalte der Menüleiste verändern sich mit jeder Maske. Wenn Sie innerhalb der Menüs blättern, können Sie alle Funktionen entdecken, die auf der
gegenwärtigen Maske möglich sind. Die System- und Hilfsmenüs sind auf jeder Maske präsent, und die Menüpunkte, die sie enthalten, verändern sich nie. ■ Befehlsfeld: Hier werden die Ausführungsbefehle eingegeben (Transaktionscodes). Sie können sich zum Beispiel durch Eingabe von /nex in diesem Feld und Drükken
der Entertaste abmelden. Der Abschnitt »Benutzung des Befehlsfelds« beschreibt dieses Feld ausführlicher. ■ Symbolleiste: Enthält das Befehlsfeld und eine Reihe von Symbolen. Sie werden sich in der Erscheinungsform, der Position oder der Funktion nie verändern, und sie
werden in jeder Maske präsent sein. Einige können ausgegraut sein, wenn ihre Funktion zur Zeit nicht verfügbar ist. ■ Drucktastenleiste: Verändert sich mit jeder Maske. Zeigt Schaltflächen, die Ihnen den schnellen Zugang zu den Menüpunkten für diese Maske ermöglichen.

Abbildung 1.11: Wichtige Elemente auf der R/3-Maske
Wenn Sie den Mauspfeil auf irgendeine Schaltfläche positionieren und einige Sekunden warten, zeigt R/3 Ihnen die Verwendbarkeit dieser Schaltfläche. In R/3 heißt dieser Service Quick Info. Er enthält eine Kurzbeschreibung dieser Schaltfläche und die zugehörige Funktionstaste.
■ Schnittstellenmenü: Ermöglicht Ihnen, die Merkmale der Anwenderschnittstelle an spezielle Bedürfnisse anzupassen, auf den Windows Zwischenspeicher (Clipboard) zuzugreifen und Grafiken zu erzeugen. Der folgende Abschnitt wird mehr Merkmale des Schnittstellenmenüs in der Tiefe abdecken.
■ Arbeitsbereich: Dies ist der große Bereich in der Mitte des Bildschirms, der die Berichtsdaten oder die Maske eines Dialogprogramms anzeigt. ■ Statusleiste: Zeigt Nachrichten, den Systemnamen, die Anzahl der Modi, die Mandantennummer, den Einfüge-/ Überschreibmodusindikator und die aktuelle Zeit an.
Sie können die meisten Bildschirmelemente an- und abschalten. Wenn Ihr Bildschirm nicht so aussieht wie in diesem Kapitel beschrieben, beachten Sie bitte die Anweisungen im nächsten Abschnitt.
Arbeiten mit dem Schnittstellenmenü
Die Ikone mit den drei farbigen Kreisen in der oberen rechten Ecke des R/3-Fensters heißt Schnittstellenmenü. Damit können Sie Benutzereinstellungen wie Bildschirmfarben, Schriftgrößen und das Cursorverhalten an spezielle Bedürfnisse anpassen. Dafür klicken Sie einmal die Ikone an (Abb.1.12). Ein Menü wird geöffnet; klicken Sie auf Optionen (Anmerkung: die hier geschilderten Einstellungen basieren auf dem SAPGUI V4.0B. Bei älteren Sapguis können die beschriebenen Bilder anders aussehen).
Abbildung 1.12: Das Schnittstellenmenü mit dem ausgewählten Menüpunkt Optionen
Klicken Sie die Karteikarte General an und ändern Sie Ihre Einstellungen so, wie in Abb.1.13 gezeigt. So stellen Sie sicher, daß Ihre Anwenderschnittstelle so aussieht wie in diesem Buch beschrieben.

Abbildung 1.13: Die Optionen der Schnittstelle General
Aktivieren Sie alle Werkzeugleisten (markieren Sie diese) und stellen Sie Quick Info auf »Quick« ein. Markieren Sie die erste und letzte Nachrichten Check Box wie gezeigt und klicken Sie auf Übernehmen.
Sie müssen auf Übernehmen oder OK drücken, bevor Sie den nächsten Tab aufrufen. Wenn Sie dies nicht tun, werden Ihre Änderungen nicht wirksam.
Klicken Sie auf Colors In Lists, und markieren Sie die Lines In Lists wie in Abb.1.14 gezeigt. Klicken Sie auf OK, um zurückzukehren.
Abbildung 1.14: Markierung der Checkbox Colors In Lists
Die Lines In Lists Option schaltet die Anzeige vertikaler und horizontaler Linien in Ihrem Ausgabebericht an oder aus. Sie sollten dies prüfen, um die Wirkung der Zeilengrafik-Anweisungen zu sehen, die Sie später in diesem Buch programmieren werden.
Zeigen Sie sich alle Einstellungen der Funktionsschlüssel an, indem Sie irgendwo in der Maske auf die rechte Maustaste klicken. Dies gilt für alle Masken. Die Funktionsschlüssel 1 bis 12 sind in der oberen Tastenreihe auf Ihrer Tastatur hinterlegt. Die Funktionsschlüssel 13 bis 24 erhalten Sie über die selbe Tastenreihe, wenn Sie gleichzeitig (Umsch) drücken. So erhält man z.B. F13 über (Umsch)+(F1). Für die Funktionsschlüssel 24 bis 36 verwenden Sie (Strg) anstatt (Umsch). Für 37 bis 48 nehmen Sie (Alt). Für alle Schlüssel über 48 halten Sie die (Strg) Taste gedrückt und tippen Sie die gewünschte Ziffer ein. Für F50 z.B. halten Sie (Strg) gedrückt und tippen die 5 und die 0 ein.
Benutzung des Befehlsfelds
In der Symbolleiste gibt es ein Eingabebereich, der Befehlsfeld heißt. Sie können hier Systembefehle eingeben. Um eine Liste dieser Befehle zu erhalten, bewegen Sie den Cursor in das Befehlsfeld und drücken Sie (F1).

Dieses Feld wird meistens benutzt, um eine neue Transaktion zu starten.
Im Moment genügt es, eine Transaktion als Programm zu verstehen. Die beiden sind einander recht ähnlich. Wenn Sie eine Transaktion starten, starten Sie ein Programm.
Anstatt dafür einen Menüpfad zu wählen, können Sie Ihren Transaktionscode in das Befehlsfeld eingeben. Ein Transaktionscode ist ein drei- oder vier-stelliger Zeichencode, verknüpft mit einer Transaktion. Sie können ihn benutzen, um die Transaktion zu starten, ohne einen Menüpfad zu verwenden. Jede Transaktion hat einen Transaktionscode (auch tcode genannt).
Um den Transaktionscode für eine Transaktion zu finden, müssen Sie die Transaktion aufrufen und dann den Menüpfad System->Status wählen. Die System-Statusmaske wird gezeigt. Der Transaktionscode erscheint im Transaktionsfeld.
Wählen Sie zum Beispiel aus dem R/3-Hauptmenü den Menüpfad Rechnungswesen ->Finanzwesen->Kreditoren. Sie sehen die Kreditorenmaske. Nun wählen Sie den Menüpfad Stammdaten->Anzeigen. Sie werden die Anzeige Kreditor anzeigen: Einstieg Buchhaltung sehen. Wählen Sie den Menüpfad System->Status. Nun sehen Sie die System-Statusmaske. Im Transaktionsfeld steht der Transaktionscode für diese Maske: FK03.
Da Sie nun den Transaktionscode haben, können Sie diese Transaktion von jeder Maske aus starten, wenn Sie sich im Befehlsfeld /n befinden und dann den Transaktionscode eingeben.
Kehren Sie zum Beispiel zum Hauptmenü zurück (klicken Sie zweimal auf den grünen Pfeil). Im Befehlsfeld geben Sie /nfk03 ein und drücken die Entertaste. Sie werden sofort die Anzeige Kreditor anzeigen: Einstieg Buchhaltung sehen.
Sie finden in jeder Maske den Transaktionscode für die aktuelle Transaktion. Wählen Sie dafür den Menüpfad System->Status.
Die Basis
Die Basis ist für R/3 wie ein Betriebssystem. Sie bildet die Schnittstelle zwischen dem ABAP/4-Code und dem Betriebssystem des Computers.
Der Vorgänger von R/3 ist R/2®. R/2 basiert auf Großrechenanlagen. SAP hat R/2 in die Client-Server-Umgebung portiert. Für diese Prozedur entwickelte SAP die Basisumgebung. Diese ermöglicht es, mit Hilfe des existierenden ABAP/4-Codes auch auf anderen Plattformen zu laufen.
Schauen Sie sich noch einmal Abb.1.1 an: Sie sehen die R/3-Basis zwischen ABAP/4 und dem Betriebssystem liegen. Ein ABAP/4-Programm kann nicht direkt auf einem Betriebssystem laufen. Es benötigt ein Programmpaket (genannt Basis), um seine Ein- und Ausgaben zu steuern, zu interpretieren und zu puffern.
Die Basis arbeitet in gewisser Hinsicht wie die Windows-Umgebung. Windows bietet eine Umgebung, in der Windows-Programme laufen können, während es aktiv ist. Ohne Windows können Programme, die für die Windows-Umgebung geschrieben werden, nicht laufen.
Die Basis ist für ABAP/4-Programme das, was Windows für Windows-Programme ist. Die Basis stellt die Laufzeitumgebung für ABAP/4-Programme zur Verfügung. Ohne die Basis können ABAP/4-Programme nicht laufen. Wenn der Operator R/3 startet, können Sie sich vorstellen, er starte die Basis. Die Basis besteht aus einer Reihe von R/3-Systemprogrammen, die sich Ihnen mit einer Schnittstelle präsentieren. Der Benutzer kann ABAP/4-Programme starten, indem er diese Schnittstelle benutzt.
Von der Befehlsprompt-Ebene des Betriebssystems startet ein Programm die Basis-Installation. Wie bei den meisten Installationen wird eine Inhaltsverzeichnisstruktur geschaffen und dort hinein eine Gruppe von ausführbaren Programmen kopiert. Alle diese ausführbaren Programme als Einheit zusammengefaßt, ergeben die Basis.
Um das R/3-System in Betrieb zu setzen, gibt der Operator einen Befehl zum Starten des SAP-Systems ein, der die ausführbaren Programme der Basis startet. Während diese laufen, akzeptieren sie Anfragen des Benutzers, um ABAP/4-Programme auszuführen.
ABAP/4-Programme laufen innerhalb der geschützten Basisumgebung; sie sind keine ausführbaren Programme, die auf dem Betriebssystem laufen. Stattdessen lesen die Basisprogramme den ABAP/4-Code und übersetzen ihn in Betriebssystemanweisungen.
ABAP/4-Programme greifen nicht direkt auf Betriebssystemfunktionen zu. Sie benutzen stattdessen Basisfunktionen, um die Dateiein- und ausgabe auszuführen und Daten anzuzeigen. Durch diese Isolation vom Betriebssystem können ABAP/4-Programme ohne Modifikation in jedes System portiert werden, das R/3 unterstützt. Diese Abstraktion ist direkt in die ABAP/4-Sprache eingebaut und für den Programmierer völlig transparent.
Die Basis macht ABAP/4-Programme portierbar. Die Betriebssysteme, auf denen R/3 laufen kann, sind in Tabelle 1.1 aufgezeigt.
Tabelle 1.1: Von R/3 unterstützte Betriebssysteme und Datenbanken

Betriebssysteme Unterstützte Hardware Unterstützte Front-ends Unterstützte Datenbanken
AIX SINIX IBM SNI SUN Win 3.1/95/NT/98 DB2 für AIX
SOLARIS HP-UX Digital HP OSF/Motif Informix-Online
Digital-UNIX Bull OS/2
Macintosh
Oracle
ADABAS D
Windows NT AT&T Compaq
Bull/Zenith
HP (Intel) SNI
IBM (Intel)
Digital (Intel)
Data-General
Win 3.1/95/NT/98
OSF/Motif
OS/2
Macintosh
Oracle
SQL Server
ADABAS D
OS/400 AS/400 Win95/98/OS/2 DB2/400
Linux PC Alle (incl. Linux) Oracle
Informix
Wenn Sie zum Beispiel ein ABAP/4-Programm auf Digital Unix mit einer Informix- Datenbank und einem OSF/Motif-Frontend schreiben, sollte dieses Programm ohne Modifikationen auf einer Windows-NT-Maschine mit einer Oracle-Datenbank und einem Windows-95-Frontend laufen, ebenso wie auf einer AS/400 mit einer DB2-Datenbank und OS/2 als Frontend.
SAP stellt auch ein Paket von Werkzeugen zur Verfügung, um das Basissystem zu verwalten. Diese Werkzeuge führen Aufgaben wie Systemleistungsüberwachung,Konfiguration und Systemwartung aus. Um auf die Basis-Verwaltungs-Werkzeuge vom Hauptmenü aus zuzugreifen, wählen Sie Werkzeug->Administration.
Hier sind einige Beispiele von Basis-Verwaltungs-Werkzeugen:
■ Um eine Liste der Server zu sehen, die zur Zeit in Ihrem R/3-System laufen, wählen Sie den Menüpfad Werkzeug->Administration, Monitor->Systemüberwachung->Server.
■ Um das aktuelle Systemlog anzusehen, wählen Sie Werkzeuge->Administration ->Monitor->Systemlog. ■ Um Systemleistungsstatistiken zu erhalten, tragen Sie die Transaktion ST03 in das Befehlsfeld ein, wählen This Application Server, Last Minute Load und analysieren
die letzten 15 Minuten. Drücken Sie auf den Dialogknopf am unteren Rand des Bildschirm und sehen Sie sich die durchschnittliche Antwortzeit der letzten 15 Minuten (Av.Response Time) an.
Die Basis wurde für eine Client-Server-Konfiguration entwickelt.
Client-Server
Client-Server: zwei Programme, die miteinander kommunizieren (Abb.1.15).
Abbildung 1.15: Die Grundlage von Client-Server
Wir sehen hier Programm 1, das Programm 2 nach irgendeiner Auskunft fragt. Programm 1 ist der Client, und Programm 2 ist der Server. Programm 2 bedient (engl. to serve) Programm 1 mit der gewünschten Auskunft. Dies ist anders als bei einem Hauptprogramm, das ein Unterprogramm aufruft und dann zurückkehrt.
Ein Programm, das ein Unterprogramm aufruft, überträgt die Kontrolle an das Unterprogramm und kann keine Prozesse ausführen, bis das Unterprogramm die Kontrolle zurückgibt.
Bei Client-Server sind die Client- und Server-Programme unabhängige Prozesse. Wenn der Client dem Server eine Anfrage übermittelt, kann er noch andere Arbeiten ausführen, während er auf die Antwort wartet.
Abb.1.16 zeigt die drei standardmäßigen Client-Server-Konfigurationen. R/3 kann so konfiguriert werden, daß es in jeder dieser Konfigurationen laufen kann.
Wenn die Client- und Serverprogramme auf einem Rechner laufen, bezeichnet man die Konfiguration als einstufig (eine Stufe ist die Grenze zwischen zwei Rechnern). Wenn sie auf verschiedenen Rechnern laufen, handelt es sich um eine zweistufige Client-Server-Architektur.

Abbildung 1.16: Ein-, zwei und dreistufige Client-Server-Konfigurationen
Ein Programm kann sowohl als Client als auch als Server fungieren, wenn es sowohl Informationen anfordert als auch auf Anfragen antwortet. Wenn Sie drei Programme haben, die miteinander kommunizieren, wie es in Abb.1.16 gezeigt wird, nennt man dies eine dreistufige Client-Server-Konfiguration.
Die Client-Server-Konfiguration ermöglicht dem R/3-System, seine Auslastung auf mehrere Rechner zu verteilen. Dies ermöglicht dem Kunden, die Leistung des Systems zu vergrößern, indem er einfach einen weiteren Rechner zu einer bestehenden Konfiguration hinzufügt, anstatt einen einzelnen Rechner zu ersetzen, der die gesamte Rechnerlast trägt, so wie es in der Großrechnerwelt praktiziert wird.
R/3-Systemarchitektur
Die R/3-Architektur basiert auf einem dreistufigen Client-Server-Modell. Abb.1.17 zeigt die R/3-Systemarchitektur.

Abbildung 1.17: Die R/3-Systemarchitektur
Präsentationsserver
Der Präsentationsserver ist eigentlich ein Programm, das allgemein als Sapgui.exe bezeichnet wird. Es ist üblicherweise auf der Workstation eines Benutzers installiert. Um es zu starten, klickt der Benutzer eine Ikone auf dem Desktop an oder wählt einen Menüpfad. Beim Start zeigt der Präsentationsserver die R/3-Menüs in einem Fenster. Dieses Fenster wird üblicherweise SAPGUI oder Anwenderschnittstelle genannt (oder einfach Schnittstelle oder Frontend). Die Schnittstelle akzeptiert die Eingabe vom Benutzer in Form von Tastendruck, Mausklicks und Funktionstasten und sendet diese Aufforderungen an den Applikationsserver zur Bearbeitung. Der Applikationsserver sendet die Ergebnisse zurück zum SAPGUI, das dann die Ausgabe für die Anzeige an den Benutzer formatiert.
Applikationsserver
Ein Applikationsserver stellt eine Gruppe ausführbarer Programme dar, die die ABAP/4-Programme interpretieren und die Ein- und Ausgabe für sie verwalten. Wenn ein Applikationsserver gestartet wird, starten alle diese ausführbaren Programme gleichzeitig. Wenn ein Applikationsserver gestoppt wird, hören alle gleichzeitig auf. Die Anzahl von Prozessen, die starten, wenn Sie den Applikationsserver aufrufen, ist in einer einzelnen Konfigurationsdatei definiert, die als Applikationsserverprofil bezeichnet wird. Jeder Applikationsserver hat ein Profil, das seine Merkmale bestimmt, wenn er startet und während er läuft. Zum Beispiel spezifiziert ein Applikationsserverprofil:
■ die Anzahl von Prozessen und ihre Typen ■ den Speicherplatz, den jeder Prozeß benötigen könnte ■ die Zeitdauer, die ein Benutzer inaktiv ist, bevor er automatisch abgemeldet wird
Der Applikationsserver ist dazu da, ABAP/4-Programme zu interpretieren; diese laufen nur hier und nicht auf dem Präsentationsserver. Ein ABAP/4-Programm kann ein ausführbares Programm auf dem Präsentationsserver starten, aber ein ABAP/4-Programm selbst kann dort nichts ausführen.
Wenn Ihr ABAP/4-Programm Informationen aus der Datenbank abfragt, wird der Applikationsserver die Anforderung formatieren und sie an den Datenbankserver senden.
Datenbankserver
Der Datenbankserver besteht aus einer Gruppe ausführbarer Programme, die Datenbankanfragen vom Applikationsserver akzeptiert. Diese Anfragen werden zum RDBMS (relationales Datenbankmanagementsystem) weitergeleitet. Das RDBMS sendet die Daten zurück an den Datenbankserver, der dann die Information zurück an den Applikationsserver leitet. Der Applikationsserver leitet diese Auskunft dann zu Ihrem ABAP/4-Programm weiter.
Üblicherweise hat der Datenbankserver einen getrennten Rechner; das RDBMS kann auch auf diesem Rechner laufen oder auf seinem eigenen Rechner installiert werden.
Server-Konfigurationen
Während der Installation können die Server auf vier Arten konfiguriert werden (Abb.1.18).

Abbildung 1.18: Mögliche R/3-Systemkonfigurationen
In einer dreistufigen Client-Server-Konfiguration laufen Präsentations-, Applikations- und Datenbankserver auf getrennten Maschinen. Dies ist die gebräuchlichste Konfiguration für große Systeme und in einer Produktionsumgebung.
Auf kleineren Systemen, die häufig als Entwicklungssysteme genutzt werden, sind die Applikations- und Datenbankserver auf einem Rechner, und die Präsentationsserver laufen getrennt.
In der zweistufigen Client-Server-Konfiguration laufen die Präsentations- und Applika- tionsserver auf einem Rechner, und der Datenbankserver läuft getrennt davon. Diese Konfiguration wird in Verbindung mit anderen Applikationsservern für einen Batchserver genutzt, wenn die Hintergrundverarbeitung (Batch) von den Online-Servern getrennt ist. Ein SAPGUI ist darauf installiert, um lokal die Kontrolle zu ermöglichen.
Wenn alle Server auf einer einzelnen Maschine laufen, spricht man von einer Zentralkonfiguration. Dies ist äußerst selten, weil es ein selbständiges R/3-System bei nur einem einzigen Benutzer beschreibt.
Definition eines R/3-Systems
Die einfachste Definition eines R/3-Systems ist »eine Datenbank«. In einem R/3-System gibt es nur eine Datenbank. Um die Definition zu erweitern: R/3 steht für alle Bestandteile, die mit dieser einen Datenbank verbunden sind. Ein R/3-System besteht aus einem Datenbankserver, der auf eine einzelne Datenbank zugreift, einem oder mehreren Applikationsservern und einem oder mehreren Präsentationsservern. Es steht für alle Bestandteile, die mit einer Datenbank verbunden sind. Wenn Sie eine Datenbank haben, haben Sie ein System. Wenn Sie ein System haben, haben Sie eine Datenbank. Während einer Einführung ist üblicherweise ein System (oder eine Datenbank) zuständig für die Entwicklung, eines oder mehrere zum Testen und eines für die Produktion.
Der Begriff »R/3-Systemlandschaft« zeigt innerhalb einer SAP-Installation eine Beschreibung der Anzahl von Systemen und wofür sie vorgesehen sind: Entwicklung, Test oder Produktion.
Definition einer R/3-Instanz
Wenn Sie den Begriff Instanz hören, wird in den meisten Fällen der Applikationsserver gemeint sein. Der Ausdruck Instanz ist ein Synonym für Applikationsserver.
Der Begriff »Zentrale Instanz« bezieht sich auf den Datenbankserver. Wenn sich ein Applikationsserver und ein Datenbankserver auf der gleichen Maschine befinden, bezieht sich der Begriff »Zentrale Instanz« auf den Rechner, auf dem sich beide befinden.
In den allermeisten Fällen ist mit einer Instanz ein Server gemeint. Darunter versteht man auch eine Anzahl von R/3-Prozessen, die das R/3-System bedienen.
Architektur des Applikationsservers
Die Bestandteile eines Applikationsservers sind in Abb. 1.19 abgebildet. Er besteht aus einem Dispatcher und vielen Arbeitsprozessen (Work Process/WP).
Alle Anfragen, die von Präsentationsservern kommen, werden zuerst zum Dispatcher geleitet. Der Dispatcher schreibt sie in die Dispatcher Queue. Er verwaltet die Anfragen aus der Queue nach dem Prinzip »Wer zuerst kommt, mahlt zuerst«. Jede Anfrage wird dem ersten freien Arbeitsprozeß zugewiesen. Ein Arbeitsprozeß behandelt jeweils eine Anfrage zur Zeit.

Abbildung 1.19: Architektur eines Applikationsservers
Um jede Benutzeranfrage auszuführen, muß ein Arbeitsprozeß zwei gesonderte Speicherfelder ansprechen: den Benutzerkontext und den Programmrollbereich. Der Benutzerkontext ist ein Speicherfeld, das Informationen über den Benutzer enthält, und der Rollbereich ist ein Speicherfeld mit Informationen über die Programmdurchführung.
Benutzerkontext
Ein Benutzerkontext ist ein Speicher, der die Charakteristika eines Benutzers enthält, der auf dem R/3-System angemeldet ist. Er enthält Informationen über den Benutzer, die von R/3 benötigt werden, wie:
■ die gegenwärtigen Einstellungen des Benutzers ■ die Benutzerberechtigungen ■ die Namen der Programme, die der Benutzer zur Zeit laufen läßt
Wenn sich ein Benutzer anmeldet, wird ein Benutzerkontext für diese Anmeldung angelegt. Bei der Abmeldung werden die Speicherbereiche mit dem Benutzerkontext wieder gelöscht. Der Benutzerkontext wird während der Verarbeitung benutzt; seine Bedeutung wird in den folgenden Abschnitten beschrieben.
Rollbereich
Ein Rollbereich ist ein Speicherbereich, auf den von einem Arbeitsprozeß einer Instanz während der Programmausführung zugegriffen wird. Er enthält Informationen, die von R/3 über die Durchführung des Programms benötigt werden, wie:
■ die Werte der Variablen ■ die dynamischen Speicherbelegungen ■ der gegenwärtige Programmzeiger
Bei jedem Programmstart wird ein Rollbereich für die Programminstanz kreiert. Wenn zwei Benutzer gleichzeitig das gleiche Programm laufen lassen, existieren zwei Rollbereiche - für jeden Benutzer einer. Der Rollbereich wird frei, wenn das Programm endet.
Wenn Sie mit einem Basisberater sprechen, werden Sie feststellen, daß der Terminus »Rollbereich« für alle Rollbereiche eines Benutzers gebraucht wird oder sogar für alle Rollbereiche auf einem Applikationsserver. Normalerweise können Sie aus dem Zusammenhang erkennen, was gerade gemeint ist.
Sowohl der Rollbereich als auch der Benutzerkontext spielen in der Dialogschritt-Verarbeitung eine wichtige Rolle.
Dialogschritt
Jeder Bildschirmwechsel ist ein Dialogschritt (Abb. 1.20).

Abbildung 1.20: Der Wechsel von der Einstiegs- zur Adressenmaske kann als Dialogschritt angesehen werden
Ein Dialogschritt ist für Basisberater die Maßeinheit für Systemantwortzeit.
Ein Dialogschritt ist die Bearbeitung, die benötigt wird, um von einer Maske zur nächsten zu kommen. Er umfaßt alle Bearbeitungen, die vorkommen, nachdem der Benutzer eine Anfrage startet, bis zur Bearbeitung, die benötigt wird, um die nächste Maske aufzubauen. Wenn zum Beispiel der Benutzer die Eingabe-Taste auf dem Kreditor Ändern: Einstieg Buchhaltung anklickt, initiiert er einen Dialogschritt, und die Sanduhr erscheint, wobei sie eine weitere Eingabe verhindert. Das Programm sapmf02k empfängt die Information und zeigt sie auf der Maske Kreditor Ändern an; die Adreßmaske und die Sanduhr verschwinden. Dies markiert das Ende des Dialogschritts, und der Benutzer kann jetzt eine andere Anfrage starten.
Es gibt vier Wege, einen Dialogschritt aus dem SAPGUI zu initiieren:
■ Drücken der Eingabe-Taste ■ Drücken einer Funktionstaste ■ Anklicken einer Schaltfläche ■ Auswählen eines Menüpunkts
Es ist wichtig für einen ABAP/4-Programmierer, über Dialogschritte Bescheid zu wissen.
Roll-In/Roll-Out-Bearbeitung
Ein ABAP/4-Programm benutzt nur einen Arbeitsprozeß für einen Dialogschritt. Am Anfang eines Dialogschrittes werden der Rollbereich und der Benutzerkontext in einen Arbeitsprozeß eingelagert (Roll In). Am Ende des Dialogschritts werden sie wieder ausgelagert (Roll Out), siehe Abb. 1.21.
Abbildung 1.21: Roll-In/Roll-Out-Bearbeitung
Während der Roll-In Phase werden die Zeiger (Pointer) auf den Rollbereich und den Benutzerkontext dem Arbeitsprozeß zugewiesen. Dies ermöglicht dem Arbeitsprozeß, auf die Daten in diesen Bereichen zuzugreifen und so die Bearbeitung für diesen Benutzer und dieses Programm auszuführen. Die Bearbeitung wird so lange fortgesetzt, bis das Programm dem Benutzer ein Ende der Bearbeitung signalisiert. Danach werden beide Bereiche ausgelagert (Roll Out). Der Roll-Out erklärt die Zeiger für ungültig und löst diese Bereiche vom Arbeitsprozeß los. Dieser Arbeitsprozeß ist jetzt frei und kann andere Nachfragen ausführen. Das Programm belegt jetzt nur Speicherplatz und verbraucht keine CPU-Zeiten. Der Benutzer sieht das Ergebnis auf dem Bildschirm und kann sofort eine neue Anfrage starten.
Sobald die nächste Anfrage vom Benutzer gestartet wird, weist sie der Dispatcher dem ersten freien Arbeitsprozeß zu. Dies kann entweder der gleiche oder ein anderer Arbeitsprozeß sein. Der Benutzerkontext und der Rollbereich für dieses Programm werden wieder dem Arbeitsprozeß zugeführt, wobei die Verarbeitung an dem Punkt weitermacht, an dem das vorherige Programm aufgehört hat. Die Verarbeitung geht so lange weiter, bis die nächste Maske gezeigt wird oder das Programm aufhört. Wenn eine andere Maske gezeigt wird, werden die Bereiche wieder ausgelagert. Wenn das Programm aufhört, ist der Rollbereich frei geworden. Der Benutzerkontext bleibt so lange zugewiesen, bis sich der Benutzer abmeldet.

In einem System, in dem viele Benutzer mit vielen Programmen arbeiten, sind nur einige dieser Programme in Arbeitsprozessen gleichzeitig aktiv. Wenn sie keinen Arbeitsprozeß besetzt halten, werden sie in den Speicherbereich ausgelagert. Dies entlastet die CPU und ermöglicht dem R/3-System hohen Transaktionsdurchsatz.
ABAP/4-Programme können viele gebräuchliche Windows-Ereignisse nicht abfangen. Die Ereignisse, die viele Nachrichten erzeugen, wie Tastendruck, Ansichtsänderungen und Mausbewegungen, werden ABAP/4-Programmen nicht übermittelt. Daraus resultiert, daß es keine Möglichkeit gibt, einige Funktionen auszuführen, die man in anderen Windows-Programmen findet. Sie können zum Beispiel in ABAP/4 nicht den Inhalt eines Felds prüfen, wenn der Benutzer die (ÿ__)-Taste drückt. Stattdessen müssen Sie warten, bis der Benutzer einen Dialogschritt initiiert.
Wie die Daten zum Präsentationsserver gelangen
Die Nachrichten, die zwischen Präsentationsserver und Applikationsserver ausgetauscht werden, liegen in einem SAP-eigenen Format vor. Das SAPGUI akzeptiert die Bildschirminformation, die vom Applikationsserver gesendet wird und formatiert sie für das Betriebssystem, auf dem es läuft. Dies ermöglicht dem Endbenutzer, von verschiedenen Hardware-Plattformen aus Verbindung zu einem einzelnen Applikationsserver aufzunehmen. Zum Beispiel können ein OS/2-PC und ein Windows-PC gleichzeitig mit dem gleichen Applikationsserver verbunden sein.
Die Bestandteile eines Arbeitsprozesses
Jeder Arbeitsprozeß hat vier Bestandteile (siehe Abb. 1.22).
Abbildung 1.22: Die Komponenten eines Arbeitsprozesses
Diese vier Komponenten sind:
■ ein Task Handler (engl. to handle=behandeln) ■ ein ABAP/4-Interpreter ■ ein Screen-Interpreter ■ eine Datenbankschnittstelle
Alle Anfragen werden durch den Task Handler gefiltert und vom entsprechenden Teil des Arbeitsprozesses bearbeitet.
Die Interpreter interpretieren den ABAP/4-Code. Beachten Sie, daß es zwei Interpreter gibt: den ABAP/4-Interpreter und den Screen-Interpreter. Es gibt zwei Dialekte von ABAP/4: Einer ist die ABAP/4-Datenverarbeitungs-Sprache und der andere eine sehr spezielle Masken-Bearbeitungssprache. Jeder wird von seinem eigenen Interpreter bearbeitet.
Die Datenbankschnittstelle hat die Aufgabe, mit der Datenbank zu kommunizieren.
Arbeitsprozesse des SAP-Systems
Es gibt sieben Arten von Arbeitsprozessen. Jede behandelt eine bestimmte Art der Anfrage. Die Art der Prozesse und der Anfragen, die sie behandeln, werden in Tabelle 1.2 gezeigt.
Tabelle 1.2: Arten von Arbeitsprozessen und Anfragen
Arbeitsprozeß (WP)-Typ Anfragetyp
D (Dialog) Dialoganforderungen
V (Verbucher) Anfrage, Daten in der Datenbank zu aktualisieren
B (Background) Hintergrundjobs
S (Spool) Druckausgaben
E (Enqueue) Logische Sperranforderungen
M (Message) Lenkt Nachrichten zwischen Applikationsservern innerhalb eines R/3 Systems um
G (Gateway) Schleust Nachrichten in das R/3-System und aus dem R/3-System
Anmeldemandanten
Der Anmeldemandant bezieht sich auf die Nummer, die der Benutzer im Mandantenfeld auf der Anmeldemaske eingibt (siehe Abb. 1.23).

Abbildung 1.23: Der Benutzer gibt den Anmeldemandanten in das Feld Mandant auf der Anmeldemaske ein.
Diese Nummer korrespondiert mit Einträgen innerhalb einer mandantenabhängigen Tabelle in der Datenbank.
Mandantenabhängige und mandantenunabhängige Tabellen
Es gibt zwei Arten von Tabellen in einer R/3-Datenbank: mandantenabhängige und mandantenunabhängige. Eine Tabelle ist mandantenabhängig, wenn das erste Feld vom Typ CLNT ist. Die Länge wird immer 3 sein, und per Konvention wird dieses Feld immer mandt genannt. Wenn das erste Feld nicht Typ CLNT ist, ist die Tabelle mandantenunabhängig. Beispiele einer mandantenabhängigen und einer mandantenunabhängigen Tabelle zeigen Abb. 1.24 und Abb. 1.25.
Abbildung 1.24: Diese Tabelle ist mandantenabhängig, weil das erste Feld vom Typ CLNT ist.

Abbildung 1.25: Diese Tabelle ist mandantenunabhängig, weil das erste Feld nicht vom Typ CLNT ist.
Abb.1.26 zeigt, wie dieses Feld den Benutzer beeinflußt.
In Abb. 1.26 meldet sich der Benutzer in Mandant 800 an und aktiviert das folgende Beispielprogramm. Dieses Programm selektiert Zeilen (rows) aus Tabelle lfa1 und schreibt lfa1-lifnr aus. Nachdem dieses Programm gelaufen ist, wurden nur zwei Zeilen ausgewählt: nämlich diejenige, in der das Feld mandt gleich 800 ist. Dies geschieht automatisch, weil das erste Feld in der Tabelle vom Typ CLNT ist. Es gibt fünf Zeilen in der Tabelle, aber das Programm schreibt nur die Zeilen aus, in denen das Feld mandt gleich 800 ist. Wenn der Benutzer im gleichen Programm den Mandanten 700 ausgewählt hätte, wären 3 Zeilen gefunden und geschrieben worden. Im Falle des Mandanten 900 wäre nur eine Zeile gefunden worden.
Abbildung 1.26: Der Effekt von Mandantenabhängigkeit
Das Mandantenanmeldeverfahren teilt die Zeilen innerhalb einer mandantenabhängigen Tabelle in charakteristische Gruppen ein. Um auf eine andere Datengruppe zuzugreifen, wählt sich der Benutzer ein, indem er eine andere Mandantennummer eingibt.
Die Anwenderstammdaten (einschließlich der R/3-Benutzer-IDs) sind mandantenabhängig. Daher muß der Sicherheitsadministrator für Sie eine neue Benutzer-ID innerhalb dieses Mandanten erstellen, um auf diesen Zugriff zu haben.
Um innerhalb einer einzelnen Tabelle verschiedene unabhängige Daten anzulegen und darauf zuzugreifen, benutzen Entwickler und Tester das Mandantenanmeldeverfahren.
Nehmen wir einmal an, wir hätten zwei Programmierer, die an einer Verbesserung des Abrechnungssystems arbeiten. Jim modifiziert die Updatetransaktion, und Jane kreiert einen neuen Bericht (report), der Jims Modifikationen benutzt, ohne daß sie vorher miteinander kommuniziert hätten.
Jane richtet Daten für ihren Probelauf ein und führt ihren Bericht aus. Jim arbeitet am nächsten Arbeitsplatz, aber wegen seines unkommunikativen Verhaltens ist ihm nicht bewußt, daß seine Transaktion die gleichen Tabellen benutzt wie der Report von Jane. Er führt seine Transaktion aus und aktualisiert die Daten. Jim bekommt, was er wollte, aber Jane modifiziert ihren Code und läßt wieder ihr Programm laufen. Ihre Ausgabe unterscheidet sich vom letzten Lauf, doch viele der Unterschiede resultieren nicht aus ihren Änderungen, sondern aus den Änderungen von Jim. Was wir hier haben, ist ein Abstimmungsfehler.
Wären die Tabellen, die von Jims und Janes Programmen benutzt werden, mandantenabhängig, könnte sich jeder in verschiedenen Mandanten anmelden, ihre voneinander unabhängigen Daten einrichten und ihre Programme testen, ohne jemals miteinander geredet zu haben. Sie könnten ihre gesamten Tests bequem am Arbeitsplatz und unabhängig

vom Mitarbeiter ausführen.
Um ihre Tabellen mandantenabhängig zu machen, benötigen sie nur mandt als das erste Feld, und das R/3-System wird sich um den Rest kümmern. Wenn Datensätze der Tabelle hinzugefügt werden, trägt das System den gegenwärtigen Anmeldemandanten automatisch in das Feld mandt ein, wenn der Datensatz an die Datenbank gesendet wird. Die Open SQL select-Anweisungen liefern nur Zeilen, wo die Mandantennummer in der Tabelle gleich der gegenwärtigen Anmeldemandantennummer ist. Die Open SQL Datenbank-Anweisungen insert, update, modify und delete beinhalten automatische Mandantenpflege.
Wenn alle betroffenen Tabellen mandantenabhängig sind, kann es mehr als eine Gruppe von Testern geben, die gleichzeitig in einem Testsystem arbeiten. Zwei Gruppen von Prüfern können gleichzeitig die divergente Funktionalität in gleichen Programmen zur gleichen Zeit austesten, wenn sie sich in verschiedenen Mandanten anmelden. Die Updates, die von einer Gruppe gemacht werden, werden die Daten der anderen Gruppe nicht ändern.
Ein Testmandant könnte auch auf dem Testsystem existieren. Die Studenten könnten sich in einem Mandanten anmelden, und die Tester in einem anderen. Beide würden mit den gleichen Programmen arbeiten, aber die Programme würden auf unabhängige Daten zugreifen.
Die gebräuchliche R/3-Installation hat drei Systeme: Entwicklung, Test und Produktion. Jedes System hat Voreinstellungen für drei Mandanten: 000, 001 und 066. Es ist üblich, drei bis sechs Mandanten in den Entwicklungs- und Testsystemen zu haben, aber Sie werden selten mehr als einen Mandanten in der Produktion finden.
Open SQL von SAP
Der ABAP/4-Code ist zwischen Datenbanken portierbar. Um auf die Datenbank in einem ABAP/4-Programm zuzugreifen, werden Sie mit SAPs Open SQL programmieren. Open SQL ist eine Untermenge und Variation von ANSI-SQL. Der ABAP/4-Interpreter reicht alle Open SQL-Anweisungen an die Datenbankschnittstelle als Teil des Arbeitsprozesses weiter (Abb. 1.27). Dort werden sie in das SQL (Native SQL) des installierten RDBMS verwandelt. Wenn Sie eine Oracle-Datenbank laufen ließen, würde Ihr ABAP/4 Open SQL zum Beispiel von der Datenbankschnittstelle in Oracle- SQL-Anweisungen umgewandelt werden.
Abbildung 1.27: Die Komponenten der Datenbankschnittstelle im Arbeitsprozeß
Wenn Sie Open SQL benutzen, werden Ihre SQL-Anweisungen zur Datenbankschnittstelle übertragen. Es gibt drei Vorteile, Open SQL zu benutzen. Alle diese Vorteile sind mit Hilfe der Datenbankschnittstelle realisiert.
Portierbarkeit
Der erste Vorteil besteht darin, daß Ihre SQL-Anweisungen zwischen Datenbanken portierbar sind. Sollte Ihre Firma zum Beispiel von einer Oracle- zu einer Informix-Datenbank wechseln wollen, könnte Ihr ABAP/4-Code ohne Modifikation in der neuen Datenbank laufen.
Puffern von Daten auf dem Applikationsserver
Zweitens puffert die Datenbankschnittstelle die Information aus der Datenbank auf dem Applikationsserver. Wenn Daten aus der Datenbank gelesen werden, können sie in Puffern auf dem Applikationsserver gespeichert werden. Wenn eine Anfrage gemacht wird, um auf die gleichen Datensätze zuzugreifen, würden sie schon auf dem Applikationsserver bereitliegen, und die Anfrage wird aus dem Puffer bearbeitet, ohne auf die Datenbank zugreifen zu müssen. Dieses Pufferungsverfahren reduziert die Last auf dem Datenbankserver und auf der Netzwerkverbindung zwischen Datenbank und Applikationsserver und kann die Datenbankzugriffszeiten mit Faktor 10 bis 100 beschleunigen.
Automatische Mandantenpflege

Der dritte Vorteil, Open SQL zu benutzen, ist eine automatische Mandantenpflege. Mit Open SQL wird das Mandantenfeld automatisch von der Datenbankschnittstelle besetzt. Dies gibt Ihren Entwicklern und Prüfern viele Vorteile, wie die Fähigkeit, vielfache gleichzeitige Tests und Übungen auf einer einzelnen Datenbank durchzuführen, ohne sich gegenseitig zu stören.
Zusammenfassung
■ R/3 unterstützt zahlreiche Hardwareplattformen, Betriebssysteme und Datenbanken. ■ Zusätzlich liefert ABAP/4 Open SQL, um Native SQL benutzen zu können. Open SQL macht Ihren Code portierbar, schneller und stellt eine automatische
Mandantenpflege zur Verfügung. ■ Der Anmeldemandant ermöglicht vielen unabhängigen Datengruppen, in der gleichen Tabelle gespeichert zu werden. Die Daten, auf die Sie zugreifen, sind abhängig von
der Mandantennummer, die Sie beim Einwählen eingeben.
Fragen & Antworten
Frage:Kann ich einen bestehenden Mandanten auf einen neuen Mandanten kopieren?
Antwort:Der Basisberater wird dies für Sie tun, wobei er Mandanten-Kopierfunktionen benutzt. Jedes Entwicklungssystem hat mindestens einen Referenzmandanten und einen Arbeitsmandanten. Ihre »guten« Daten werden im Referenzmandanten geführt. Er wird kopiert, um den Arbeitsmandanten zu kreieren. Wenn Sie den Arbeitsmandanten zerstören, kann der Basisberater ihn in seinen ursprünglichen Zustand zurücksetzen, indem er wieder den Referenzmandanten kopiert.
Frage:Kann ich ein Programm schreiben, das Daten von einem Mandanten liest, in dem ich nicht angemeldet bin?
Antwort:Ja. Sie können die Schlüsselwörter Client Specified jedem Open SQL Statement hinzufügen. Um Daten in Mandant 900 zu lesen, könnten Sie zum Beispiel programmieren:
select * from tbl client specified where mandt = '900'.
Es muß Ihnen allerdings klar sein, daß Sie dies nur tun sollten, wenn Sie ein System- und kein Anwendungsprogramm schreiben. Die Programme sollten immer mandantenunabhängig sein. Wenn Sie Daten zwischen zwei Produktionsmandanten übertragen müssen, sollten Sie den Datentransfer mit Hilfe von ALE realisieren.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, die Ihnen helfen sollen, Ihr Verständnis für die versprochene Thematik zu vertiefen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie das Gelernte anwenden. Antworten auf die Prüfungsaufgaben und die Übungen können Sie im Anhang B (»Antworten zu den Kontrollfragen und Übungen«) finden.
Kontrollfragen
1. Wählen Sie den Menüpfad Werkzeug->Administration, Monitor->Systemüberwachung->Benutzerübersicht. Wie lautet der Transaktionscode für diese Transaktion?
2. Wie lautet der Transaktionscode für das R/3-Hauptmenü? (Das Hauptmenü ist das erste Menü, das nach der Anmeldung angezeigt wird.)
3. Wie lautet der Transaktionscode für den Menüpfad Werkzeug->Development- Workbench?
4. Wie viele Datenbanken existieren, wenn es drei R/3-Systeme in Ihrer gegenwärtigen Systemlandschaft gibt?
5. Wie viele Instanzen hat ein R/3-System mit zwei Applikationsservern?
6. Was ist Open SQL?
7. Welche Vorteile bietet Open SQL gegenüber Native SQL?
8. Welcher Teil des Arbeitsprozesses wird benutzt, um Open SQL zu realisieren?
9. Wann wird ein Rollbereich allokiert, wann wird er deallokiert, und was enthält er?
10. Wann wird ein Benutzerkontext allokiert, wann wird er deallokiert, und was enthält er?
11. Wann und warum kommt der Roll-Out vor?
Übung 1
Sind die Tabellen in Abb. 1.28 bis 1.31 mandantenabhängig oder mandantenunabhängig?


Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 2
Ihr erstes ABAP/4®-Programm
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes können:
■ einfache ABAP/4®-Programme anlegen und modifizieren ■ Standardfunktionen im ABAP/4-Editor verwenden ■ (F1)- und R/3®-Bibliotheks-Hilfefunktionen benutzen ■ Ihre Programme mit Hilfe des Object Browser® und des Editor finden ■ eine Tabelle und ihren Inhalt anzeigen, indem Sie das Datenwörterbuch (Data Dictionary ®, auch DDIC genannt)
benutzen■ die Anweisungen tables und select benutzen ■ Anweisungen mit Hilfe des Kettenoperators verketten ■ Ihren Programmen Kommentare und Dokumentationen hinzufügen
Bevor es weitergeht
■ Sie sollten mit einer Programmiersprache wie C, COBOL oder Visual Basic vertraut sein. Um den vollen Nutzen aus diesem und den folgenden Kapiteln zu ziehen, sollten Sie auch zwei oder mehrere Jahre Entwicklungserfahrung haben.
■ Falls noch nicht geschehen, sollten Sie Ihr Schnittstellenmenü so einstellen, wie in Kapitel Tag 1, Abschnitt »Arbeiten mit dem Schnittstellenmenü« empfohlen.
■ Führen Sie das Installationsverfahren für die ScreenCams auf der CD-ROM aus. Das Installationsverfahren und weitere Informationen sind in der readme.txt-Datei beschrieben, die im Hauptverzeichnis der CD-ROM liegt.
Viele Vorgehensweisen in diesem Buch sind in ScreenCams demonstriert. ScreenCams sind mit Filmen vergleichbar; sie zeigen eine Reihe von Masken, einschließlich Tastendruck und Mausbewegungen mit einem erklärenden Text. Sie finden die ScreenCams auf der CD-ROM in diesem Buch.
Die Entwicklungsumgebung
Ein Entwicklungsobjekt ist alles, was von einem Entwickler angelegt wird. Programme, Masken, Tabellen, Views, Strukturen, Datenmodelle, Nachrichten und Includes sind Beispiele für Entwicklungsobjekte.
Das R/3®-System enthält Werkzeuge, um Entwicklungsobjekte anzulegen und zu testen. Diese Werkzeuge befinden sich in der R/3-Development Workbench®. Um auf irgendein Entwicklungswerkzeug zuzugreifen, gehen Sie zur ABAP/4 Workbench®.

Die Workbench enthält die folgenden Werkzeuge, die Ihnen helfen, Entwicklungsobjekte zu schaffen:
■ den ABAP/4-Programm-Editor, in dem Sie den ABAP/4-Quelltext und andere Programmbestandteile anlegen und modifizieren können
■ das Data Dictionary, in dem Sie Tabellen, Strukturen und Views anlegen können ■ den Datenmodellierer, in dem Sie die Beziehungen zwischen Tabellen dokumentieren können ■ die Funktionsbibliothek, in der Sie globale ABAP/4-Funktionsmodule anlegen können ■ die Screen- und Menu-Painter, in denen Sie eine Anwenderschnittstelle für Ihre Programme programmieren können
Folgende Prüf- und Suchwerkzeuge sind vorhanden:
■ der ABAP/4-Debugger ■ das SQL-Trace Tool, um SQL-Anweisungen zu beschleunigen ■ der Laufzeitanalysator, um die Ausführung Ihres Programms zu optimieren ■ ein Verwendungsnachweis für die Wirkungsanalyse ■ ein computergestütztes Prüfwerkzeug für Rückgangsprüfungen ■ ein Repository-Suchwerkzeug für das Auffinden von Entwicklungsobjekten ■ der Workbench Organizer, um Änderungen an den Objekten aufzuzeichnen und sie in die Produktionsumgebung zu
befördern
Alle Entwicklungsobjekte sind portierbar, d.h., sie können von einem R/3-System zu einem anderen kopiert werden. Dies geschieht in der Regel, um Ihre Entwicklungsobjekte vom Entwicklungssystem zum Produktionssystem zu übertragen. Wenn sich die Quell- und Zielsysteme auf verschiedenen Betriebssystemen befinden oder verschiedene Datenbanksysteme benutzen, werden Ihre Entwicklungsobjekte ohne jegliche Modifizierung im Istzustand laufen. Dies gilt für alle Betriebssysteme, die von R/3 unterstützt werden. (Eine Liste unterstützter Hardware und Betriebssysteme finden Sie in Tabelle 1.1.)
Programmtypen
Es gibt zwei Haupttypen von ABAP/4-Programmen:
■ Reports (Berichte) ■ Dialogprogramme
Reports definieren
Der Zweck eines Reports ist, Daten aus der Datenbank zu lesen und sie auszuschreiben. Er besteht aus nur zwei Masken (siehe Abb. 2.1).
Die erste Maske ist die Auswahlmaske. Sie enthält Eingabefelder, die dem Benutzer erlauben, Auswahlkriterien für einen Report einzugeben. Zum Beispiel könnte der Report eine Liste von Verkäufen für einen vorgegebenen Datenbereich erzeugen. In diesem Fall würden die Datenbereichseingabefelder auf der Auswahlmaske des Reports erscheinen.
Die zweite Maske ist die Ausgabemaske. Sie enthält die Liste. Die Liste ist die Ausgabe vom Report und hat normalerweise keine Eingabefelder. In unserem Beispiel würde sie eine Liste der Verkäufe enthalten, die innerhalb des bestimmten Datenbereichs vorkamen.
Die Auswahlmaske ist optional. Nicht alle Reports haben eine solche. Alle Reports erzeugen allerdings eine Liste.
In diesem Buch werden Sie lernen, wie man Reportprogramme anlegt.

Abbildung 2.1: Die Auswahl- und die Ausgabemaske
Dialogprogramme definieren
Dialogprogramme sind flexibler als Reports und deshalb auf der Programmebene komplexer. Sie können mehrere Masken enthalten, und die Maskenfolge kann sich dynamisch während der Laufzeit ändern. Auf jeder Maske stehen Ihnen Eingabefelder, Ausgabefelder, Drucktasten und mehrere Möglichkeiten zum Blättern zur Verfügung.
Reportbestandteile
ABAP/4-Reports bestehen aus fünf Komponenten (siehe Abb. 2.2):
■ Quelltext■ Attribute■ Textelemente■ Dokumentation■ Varianten
Abbildung 2.2: Die Komponenten eines ABAP/4-Programms
Nur die Quelltext- und Programmattributkomponenten sind erforderlich. Die anderen Bestandteile sind optional.
Alle Entwicklungsobjekte und ihre Bestandteile sind in der R/3-Datenbank gespeichert. Zum Beispiel wird der Quelltext für einen Bericht in Datenbanktabelle dd010s gelagert.
Das Laufzeitobjekt
ABAP/4-Programme werden interpretiert und nicht kompiliert. Wenn Sie das erste Mal ein Programm ausführen, erzeugt das System automatisch ein Laufzeitobjekt. Das Laufzeitobjekt ist eine vorkompilierte Form des Quelltexts. Allerdings ist es kein ausführbares Programm, das Sie auf der Betriebssystemebene laufen lassen können. Es erfordert stattdessen eine

Interpretation vom R/3-System. Das Laufzeitobjekt wird auch die generierte Form des Programms genannt.
Wenn Sie den Quelltext ändern, wird das Laufzeitobjekt automatisch beim nächsten Programmaufruf regeneriert.
Programmnamenskonventionen
Die Firma, für die bzw. bei der Sie arbeiten, ist Kunde von SAP. Programme, die Sie in Ihrer Firma schreiben, heißen deswegen Kundenprogramme.
Kundenentwicklungsobjekte folgen Namenskonventionen, die von SAP vordefiniert werden. Diese Konventionen folgen dem sogenannten Kundennamensbereich. Der Kundennamensbereich ist zwischen 2 und 8 Zeichen lang und muß mit dem Buchstaben y oder z anfangen (ab Version 4.0x 40 Zeichen). SAP behält sich für ihre eigenen Programme die Buchstaben a bis x vor.
Nehmen Sie sich jetzt einen Moment Zeit, um ein persönliches Kennzeichen für Ihre Programme zu wählen, das drei Zeichen lang sein muß. Innerhalb dieses Buchs werde ich mich auf dieses Kennzeichen beziehen. Es muß mit einem y oder z beginnen. Sie könnten z.B. den Buchstaben z benutzen, gefolgt von Ihren beiden Initialen. Die Notation zeigt an, wo Sie Ihr Kennzeichen benutzen sollten. Wenn Sie zkg wählen und die Aufforderung »Geben Sie einen Programmnamen ***abc ein« sehen, müssen Sie zkgabc eingeben. Ich empfehle Ihnen, beim Durcharbeiten dieses Buches für alle Entwicklungsobjekte, die Sie anlegen, immer Ihr persönliches Kennzeichen zu benutzen. Wenn Sie sich daran halten, werden Ihre Objekte später leichter zu erkennen und zu finden sein.
Die Programmnamenskonventionen, die für dieses Buch angenommen werden, sind wie folgt:
■ Beispielprogramme der Kapitel folgen der Konvention ztxccnn, wobei cc die Kapitelnummer und nn eine sequentielle Nummer von 01 bis 99 ist.
■ Programmnamen, die in Übungen benutzt werden, folgen der Konvention ztyccnn , wobei cc die Kapitelnummer und nn eine sequentielle Nummer ist. Der Programmname für die Lösung lautet ztzccnn.
■ Dienstprogramme, die auf der CD-ROM zur Verfügung gestellt werden, folgen der Namenskonvention y-xxxxxx,wobei xxxxxx der Name des Hilfsmittels ist.
Das Aufbauprogramm, das Entwicklungsobjekte anlegt und sie für die Übungen mit Daten lädt, wird y-setup genannt. Es kann jederzeit im Bedarfsfall wieder aufgerufen werden, um die Übungsdaten wieder in ihren ursprünglichen Zustand zu bringen. Um alle Entwicklungsobjekte und Daten, die vom Setup-Programm angelegt wurden, zu entfernen, lassen Sie das Programm y-uninst laufen. In der readme.txt-Datei auf Ihrer CD-ROM finden Sie weitergehende Informationen.
Ihr erstes Programm
Es folgt jetzt eine Beschreibung, wie ein Programm geschrieben wird.
Wenn Sie sich im R/3 anmelden, um Ihr erstes ABAP/4-Programm zu schreiben, sehen Sie zuerst das SAP-Hauptmenü. Von dort gehen Sie zur Entwicklungsworkbench und dann zum Editor. Sie geben einen Programmnamen ein und legen das Programm an. Die erste Maske, die Sie sehen, ist die Programmattributmaske. Sie geben dort die Programmattribute ein und sichern. Sie gehen dann zum Quelltexteditor. Im Quelltexteditor geben Sie den Quelltext ein, sichern und führen das Programm aus.
Starten Sie jetzt das ScreenCam »How to Create Your First Program«.
Mit diesem Verfahren schreiben Sie Ihr erstes Programm. Hilfe zu normalen Problemen finden Sie in der darauffolgenden Problemliste.
1. Wählen Sie den Menüpfad Werkzeug->ABAP/4-Workbench aus dem R/3-Hauptmenü. Eine Maske mit dem Titel

ABAP/4-Workbench wird angezeigt.
2. Klicken Sie die ABAP/4-Editor-Schaltfläche auf der Symbolleiste an. Die Maske ABAP/4-Editor:Einstieg erscheint.
3. Geben Sie den Programmnamen ***0201 im Programmfeld ein.
4. Klicken Sie die Schaltfläche Anlegen an. Die Maske ABAP/4:Programmattribute »Programmname« wird angezeigt. Die Felder, die Fragezeichen enthalten, müssen ausgefüllt werden.
5. Tippen Sie Mein erstes ABAP/4-Programm in das Titelfeld. Per Voreinstellung wird der Inhalt dieses Feldes am Anfang der Liste erscheinen.
6. Eine 1 in das Typenfeld eingeben. Die 1 zeigt an, daß es sich um einen Report handelt.
7. Ein Sternzeichen (*) in das Anwendungsfeld eingeben. Der Wert im Anwendungsgebiet zeigt an, zu welchem Anwendungsbereich dieses Programm gehört. Die vollständige Liste von Werten kann erhalten werden, indem Sie den Cursor auf dieses Feld positionieren und dann den Pfeil unten rechts von ihm anklicken. Wenn dieses Programm z.B. zum Inventory Management gehört, würden Sie ein L in das Anwendungsgebiet eingeben. Da dies ein einfaches Prüfprogramm ist, habe ich ein Sternzeichen benutzt, um zu zeigen, daß dieses Programm nicht zu einem speziellen Anwendungsbereich gehört.
8. Kennzeichnen Sie die »Editorsperre«. Damit stellen Sie sicher, daß niemand außer Ihnen das Programm verändern kann. Sie sollten dies allerdings nicht benutzen, um Entwicklungsprogramme zu sperren. Es würde andere Programmierer daran hindern, die Programme später instandzuhalten.
9. Um die Programmattribute zu sichern, klicken Sie auf das Sicherungssymbol auf der Symbolleiste. Die Maske Objektkatalogeintrag anlegen wird angezeigt.
10. Klicken Sie Lokales Objekt an. Die Programmattributmaske wird wieder angezeigt. In der Statusleiste am unteren Rand des Bildschirms erscheint die Nachricht »Attribute gesichert«. (Anmerkung: die Nachricht, die Sie sehen, enthält auch den Programmnamen, da sich aber dieser Name für jeden Benutzer verändert, wird er in diesem Buch nicht erwähnt.)
11. Drücken Sie die Quelltextschaltfläche auf der Drucktastenleiste. Die Maske ABAP: Editor Editieren Programm wird angezeigt.
12. Den Menüpfad Einstellungen->Editor-Modus wählen. Die Editor Einstellungsmaske wird angezeigt.
13. Wählen Sie die Option PC-Modus mit Zeilennummerierung.
14. Wählen Sie Kleinschreibung aus.
15. Klicken Sie auf den grünen Haken. Sie haben jetzt Ihre Editoreinstellungen gesichert. (Editoreinstellungen müssen nur einmal gesetzt werden.)
16. Schauen Sie auf Zeile 1. Wenn sie nicht die Anweisung Report ***0201. enthält, tippen Sie diese jetzt ein, wie in Listing 2.1 gezeigt.
17. Auf Zeile 2 schreiben Sie write 'Hallo SAP Welt'. Benutzen Sie Apostrophe, und setzen Sie einen Punkt an das Zeilenende.
18. Sichern Sie das Programm.
19. Um Ihr Programm auszuführen, wählen Sie den Menüpfad Programm->Ausführen. Eine Maske mit dem Titel »Mein erstes ABAP/4-Programm« wird angezeigt und darunter die Worte Hallo SAP Welt. Dies ist die Ausgabe des Reports,

auch als Liste bezeichnet.
Listing 2.1: Ihr erstes-ABAP/4-Programm
1 report ztx0201.2 write `Hallo SAP Welt´.
Der Text in Listing 2.1 erzeugt diese Ausgabe:
Hallo SAP Welt
Herzlichen Glückwunsch, Sie haben gerade Ihr erstes ABAP/4-Programm geschrieben! Um zum Editor zurückzukehren, drücken Sie auf den grünen Pfeil auf der Symbolleiste (oder die (F3)-Taste).
Problem Lösung
Wenn Sie die Schaltfläche Anlegen drükken, bekommen Sie eine Dialogbox angezeigt, die sagt: Syntax für den Objektnamen nicht möglich
Sie haben den falschen Programmnamen eingegeben. Ihre Programmnamen müssen mit y oder z anfangen. Drücken Sie den Annullierknopf (das rote X), um abzubrechen, und geben Sie einen neuen Programmnamen ein.
Wenn Sie die Schaltfläche Anlegen drükken, bekommen Sie eine Dialogbox angezeigt, die einen Schlüssel verlangt.
Sie haben den falschen Programmnamen eingegeben. Ihre Programmnamen müssen mit y oder z anfangen. Drücken Sie den Annullierknopf (das rote X), um zurückzukehren und einen neuen Programmnamen einzugeben.
Sie werden nach einer Auftragsnummer für eine Änderung gefragt.
In der Maske Objektkatalogeintrag anlegen lassen Sie das Feld Entwicklungsklasse leer und klicken stattdessen Lokales Objekt an.
Der Quelltexteditor
In diesem Abschnitt werden Sie lernen, wie man sich die Möglichkeiten des ABAP/4- Editor nutzbar macht, indem man zwei Masken benutzt:
■ ABAP/4-Editor: Einstieg ■ ABAP/4-Editor: Editieren Programm
Die Maske Editor: Einstieg
Die Maske ABAP/4-Editor: Einstieg wird in Abb. 2.3 gezeigt. Sie können von dort aus alle Programmbestandteile anzeigen oder ändern. Um den Quelltext zu ändern, kennzeichnen Sie Quelltext und drücken auf Ändern. Oder wählen Sie Attribute und drücken auf Anzeigen, um die Attribute anzuzeigen.

Abbildung 2.3: Aus der Maske ABAP/4-Editor: Einstieg können Sie Programmkomponenten anzeigen oder ändern.
Die Schaltfläche Ändern führt Sie in den Änderungsmodus, der es Ihnen ermöglicht, die ausgewählte Komponente zu ändern.
Beachten Sie in Abbildung 2.3, daß die Gruppenbox Objektkomponenten, Optionsfelder und auch die Schaltflächen Anzeigen und Ändern enthält. In einer Gruppenbox, die sowohl Options- als auch Drucktastenfelder enthält, bestimmen die Optionsfelder die Komponente, die von den Drucktastenfeldern verwaltet wird. Die Wirksamkeit der Optionsfelder ist auf die Gruppenbox beschränkt; sie haben keine Auswirkungen auf Drucktastenfelder außerhalb der Gruppenbox.
Die Funktionalität des Quelltexteditors
Vom ABAP/4-Editor: Einstieg wählen Sie Quelltext. Die ABAP/4-Editor: Programm- editiermaske wird angezeigt (Abb. 2.4).

Abbildung 2.4: Benutzen Sie die Maske ABAP/4-Editor: Programme editieren, um die Funktionalität der Komponenten zu verändern.
Manche Entwickler empfinden die R/3-Anwenderschnittstelle als zu komplex und daher schwer zu erlernen. Ich schlage vor, Sie wählen einen methodischen Weg, der es Ihnen ermöglicht, sich jeder neuen Maske anzunähern. Immer, wenn Sie auf eine neue Maske stoßen, gehen Sie langsam an die Menüteile und Schaltflächen heran. Beginnen Sie links oben in der Maske, und arbeiten Sie sich bis nach rechts unten vor. Halten Sie den Cursor lange genug über jeder Fläche, um sie und die begleitenden Erklärungen zu lesen. Wenn Sie sich für jede neue Maske ein paar Minuten Zeit nehmen, werden Sie bald mit allen verfügbaren Funktionen vertraut sein.
Die Symbolleiste
Starten Sie jetzt das ScreenCam »Exploring the Standard Toolbar«.
Die Symbole der Symbolleiste werden in Abb. 2.5 dargestellt.

Abbildung 2.5: Dies sind die Schaltflächen auf der Symbolleiste im ABAP/4-Editor.
Die Symbole der Symbolleiste (s. Abb. 2.3) von links nach rechts:
■ Enter: Die Schaltfläche Enter hat die gleiche Wirkung wie die Entertaste. Sie enthält gleichzeitig die Zeile Teilen Funktion. Um eine Programmzeile zu teilen, positionieren Sie den Cursor an die Stelle, wo die Zeile geteilt werden soll, und drükken Sie (Enter).
■ Befehlsfeld: Hier werden Transaktionstexte und verschiedene andere Befehle eingegeben. ■ Zurück und Exit: Beide bringen Sie zur Maske ABAP/4-Editor: Einstieg. Wenn Sie nicht gesicherte Änderungen
haben, werden Sie zum Sichern aufgefordert. ■ Annullieren (Cancel): Bringt Sie in den ABAP/4-Editor: Einstieg zurück, ohne Ihre Änderungen zu sichern. Wenn
Ihre Änderungen nicht gesichert sind, werden Sie dazu aufgefordert. ■ Drucken: Druckt den Quelltext Ihres Programms. Beim Ausführen wird die Druckparametermaske angezeigt. Um
Ihre Ausgabe zu erhalten, prüfen Sie, ob Sofort Ausgeben aktiviert ist. ■ Suchen: Unterstützt die Funktionalität Suchen und Ersetzen. Beim Ausführen wird die Suchen/Ersetzen-Maske
gezeigt. Eine detailliertere Erklärung folgt weiter unten. ■ Weiter Suchen: Dies ist eine praktische Abkürzung, um die Zeichenkette zu finden, die als nächste vorkommt. ■ Erste Seite, vorherige Seite, nächste Seite und letzte Seite: Dies ermöglicht es Ihnen, im Quelltext auf und ab zu
blättern.■ Hilfe: Sie zeigt eine Dialogbox, von der Sie neben anderen Hilfethemen Hilfe zum Editor- und zur ABAP/4-Syntax
erhalten können. Positionieren Sie den Cursor auf ein ABAP/4-Schlüsselwort oder eine Leerzeile, bevor Sie die Hilfeschaltfläche drücken. Der Abschnitt »Hilfe« später in diesem Kapitel enthält mehr Informationen.
Erlaubt Nicht erlaubt
Sichern Sie Ihr Programm, bevor Sie einen /n-Befehl eingeben. Sie verlieren sonst Ihre Änderungen.
Schließen Sie niemals das Editorfenster mit dem X in der rechten oberen Fensterecke. Sie verlieren ungesicherte Änderungen.
Suchen und Ersetzen
Starten Sie jetzt das ScreenCam »Using Find and Replace«.
Drücken Sie auf die Schaltfläche Suchen auf der Symbolleiste, und das System wird die Suchen/Ersetzen-Maske anzeigen (Abb. 2.6). Geben Sie die Zeichenkette, die Sie finden wollen, in das Suchfeld ein.

Es gibt mehrere Möglichkeiten, auf dieser Maske den Suchprozeß zu kontrollieren:
■ Als Zeichenkette wird Ihr Suchtext überall im Programm gefunden. ■ Als Wort wird er nur gefunden, wenn er von Leerzeichen oder Interpunktion auf jeder Seite innerhalb des
Quelltextes umgeben ist. ■ Es läßt sich auch nach Groß- und Kleinbuchstaben suchen.
Das Feld Suchen hat einige ungewöhnliche Qualitäten:
■ Um nach einer Zeichenkette zu suchen, die eingeschlossene Leerzeichen enthält, tippen Sie einfach die Zeichenkette zusammen mit den Leerzeichen in das Feld Finden. Die Zeichenkette nicht mit Hochkommata einschließen, da diese sonst ein Teil der Suchkette werden.
■ Um eine Jokersuche durchzuführen, müssen Sie die Zeichen + und * benutzen. Das + prüft jedes einzelne Zeichen, während * eine beliebige Zeichenkette überprüft. Allerdings kann * nur als Stellvertreter an den Anfang oder das Ende einer Zeichenkette gesetzt werden; innerhalb der Zeichenkette wird es nicht als Stellvertreter erkannt. Zum Beispiel wird die engl. Suchkette wo+d word oder wood finden; die Zeichenkette j++n wird john oder joanfinden aber nicht jan. *an wird ian oder joan finden und sogar an. Da * innerhalb einer Suchkette nicht als Stellvertreter funktioniert, muß man, um die Zeichenfolge select * from zu finden, den Text genauso eingeben, nämlich select * from. Wenn eine Zeichenkette ein * am Anfang oder am Ende hat, erzeugt das die gleichen Ergebnisse wie die Suche ohne *; * als Joker ist deswegen nicht besonders hilfreich.
■ - . , : ; sind Sonderzeichen. Wenn Ihre Zeichenkette mit einem dieser Zeichen anfängt, müssen Sie sie mit Trennzeichen einschließen. Sie können als Trennzeichen irgendeines dieser Zeichen wählen, solange es nicht innerhalb Ihrer Suchkette erscheint. Zum Beispiel fängt :hh mit einem Sonderzeichen an. Um diese Zeichenkette zu finden, geben Sie -:hh- oder .:hh. oder ,:hh, oder ;:hh;. ein.
■ Das Zeichen # ist auch ein Sonderzeichen. Um in einer Zeichenfolge an beliebiger Stelle das # zu finden, muß man ## für jedes # ersetzen, das in der Zeichenkette enthalten ist. Um die Zeichenkette a#b zu finden, muß man z.B. die Suchkette a##b benutzen.
Abbildung 2.6: Dies ist die Maske Suchen/Ersetzen. Hier können Sie Zeichenketten suchen und ändern bzw. ersetzen.
Starten Sie jetzt das ScreenCam »Setting the Scope of a Search or Replace Function«.
Um den Bereich für Suchen oder Ersetzen abzugrenzen, folgen Sie den nächsten Schritten:

1. Auf der Suchen/Ersetzen-Maske geben Sie die Zeichenkette im Suchfeld ein, die Sie finden wollen.
2. Wählen Sie im Suchbereich die Option Im Aktuellen Quelltext aus.
3. Mit der Option Ab Cursor starten Sie die Suche von der gegenwärtigen Cursorposition aus. Alternativ können Sie in bestimmten Zeilenabschnitten suchen.
4. Schaltfläche Weiter drücken. Der Cursor wird links von der ersten Vergleichszeichenkette positioniert.
5. Drücken Sie Weiter Suchen, um die nächste Vergleichszeichenkette zu lokalisieren.
Starten Sie jetzt das ScreenCam »How to Find All Occurrences of a String«.
Um alle Vorkommen einer Zeichenkette zu finden:
1. Auf der Suchen/Ersetzen-Maske geben Sie die Zeichenkette im Suchfeld ein, die Sie finden wollen.
2. Wählen Sie die Option Globale Suche im Programm.
3. Wählen Sie Weiter. Ein Überblick der globalen Suche wird angezeigt.
4. Doppelklicken Sie auf eine Zeile, um den Zusammenhang mit dem Quelltext zu sehen.
5. Zurück drücken, um in der Programmmaske zur globalen Suche zurückzuspringen.
6. Noch einmal Zurück drücken, um zum Quelltexteditor zurückzuspringen.
Starten Sie jetzt das ScreenCam »How to Search and Replace in the Source Text«.
Suchen und Ersetzen im Quelltext:
1. Auf der Suchen/Ersetzen-Maske geben Sie die Zeichenkette im Suchfeld ein, die Sie finden wollen.
2. Kennzeichnen Sie Ersetzen durch und geben Sie eine Ersatzzeichenkette ein.
3. Drücken Sie auf Weiter. Die ABAP/4-Programmeditiermaske wird angezeigt. Der Cursor ist links von der nächsten Vergleichszeichenkette positioniert.
4. Zum Ersetzen auf die Schaltfläche Ersetzen drücken. Die Zeichenkette an der Cursorposition wird ersetzt, und der Cursor wird an der nächsten Vergleichszeichenkette positioniert.
5. Um ohne zu ersetzen an die nächste Position zu gelangen, drücken Sie die Schaltfläche Nächster Treffer. Der Cursor wird an der nächsten Vergleichszeichenkette positioniert.
6. Um alles von der gegenwärtigen Cursorposition bis zum Ende des Quelltextes zu ersetzen, drücken Sie auf die Schaltfläche Ohne Bestätigung.
Starten Sie jetzt das ScreenCam »How to Search and Replace Via a Summary Screen«.
Globales Suchen und Ersetzen:
1. Auf der Suchen/Ersetzen-Maske geben Sie die Zeichenkette im Suchfeld ein, die Sie finden wollen.

2. Kennzeichnen Sie Ersetzen durch und geben Sie eine Ersatzzeichenkette ein.
3. Wählen Sie die Option Globale Suche im Programm.
4. Die Schaltfläche Weiter drücken. Die globale Ersetzungsprogramm-Maske wird angezeigt und der Cursor auf der ersten Vergleichszeichenkette positioniert. Alle Zeilen, die Vergleichszeichenketten enthalten, werden angezeigt, und die Vergleichszeichenketten werden hervorgehoben.
5. Um die Zeichenkette an der Cursorposition zu ersetzen, drücken Sie die Schaltfläche Ersetzen. Die Zeichenkette an der Cursorposition wird ersetzt, und der Cursor wird an der nächsten Vergleichszeichenkette positioniert.
6. Um ohne zu ersetzen an die nächste Position zu gelangen, drücken Sie die Schaltfläche Nächster Treffer. Der Cursor wird an der nächsten Vergleichszeichenkette positioniert.
7. Um alles von der gegenwärtigen Cursorposition bis zum Ende des Quelltextes zu ersetzen, drücken Sie auf die Schaltfläche Ohne Bestätigung.
Wenn Sie irgendeine Zeichenkette ersetzen, müssen Sie Ihre Änderungen sichern, bevor Sie zum Quelltexteditor zurückkehren. Drücken Sie deshalb erst auf Sichern und dann auf Zurück. Wenn Sie Ihre Änderungen annullieren wollen, wählen Sie bei der Frage »Vor Beenden des Editors sichern?« Nein.
Die Drucktastenleiste
Starten Sie jetzt das ScreenCam »Exploring the Application Toolbar of the ABAP/4 Editor«.
Bevor Sie weitermachen, maximieren Sie Ihr Fenster (wenn nicht schon geschehen), weil Sie u.U. sonst die Schaltflächen ganz rechts auf der Drucktastenleiste nicht sehen können.
Die Schaltflächen der Drucktastenleiste sehen Sie in Abb. 2.7.

Abbildung 2.7: Die Schaltflächen der Drucktastenleiste
Es folgt eine Beschreibung der Symbole, wie sie auf dem Bildschirm erscheinen:
■ Anzeigen<->Ändern: Ändert die Maske vom Anzeige- in den Änderungsmodus. Drücken Sie wieder auf die Schaltfläche, um zurück in den Anzeigemodus zu gelangen.
■ Prüfen: Überprüft die Syntax des gegenwärtigen Programms. ■ Verwendungsnachweis: Wenn Sie diese Schaltfläche drücken, während Ihr Cursor auf einer Variablen steht, werden
alle Programmzeilen angezeigt, die sie benutzen. ■ Stapel: Zeigt die Inhalte des gegenwärtigen Navigierungsstapels an. ■ Ausschneiden: Schneidet die Zeile aus, auf welcher der Cursor steht, und stellt den Inhalt in den Zwischenspeicher. ■ In den Puffer kopieren: Kopiert die Inhalte der Zeile, auf welcher der Cursor steht, in den Zwischenspeicher. ■ Aus dem Puffer einfügen (Einsetzen Puffer): Fügt die Inhalte des Zwischenspeichers über der momentanen
Cursorposition in eine neue Zeile ein. ■ Zeile einfügen: Fügt eine Leerzeile über der gegenwärtigen Cursorposition ein. ■ Markieren: Wählt eine Einzelzeile oder einen Block von Zeilen aus, um sie an andere Textstellen zu bringen,
auszuschneiden und wieder einzufügen. Stellen Sie dazu den Cursor auf die letzte Zeile des Blocks und drücken Sie wieder auf Markieren. Die Zeilen, die der Block enthält, werden rot. Sie können jetzt den Textblock ausschneiden, kopieren oder verdoppeln, genauso, wie Sie es für eine Einzelzeile täten. Um die ausgewählten Zeilen zu deselektieren, wählen Sie den Menüpfad Bearbeiten->Entmarkieren.
■ Widerrufen: Macht Ihre letzte Änderung rückgängig. Es ist nur eine Ebene »Zurück« möglich. ■ ABAP/4-Hilfe: Liefert Hilfe über den Editor und über ABAP/4 im allgemeinen. ■ Muster: Ermöglicht Ihnen, eine automatisch erzeugte ABAP/4-Anweisung einzufügen. Um z.B. eine write-
Anweisung einzufügen, die den Inhalt einer Variablen v1 anzeigt, drücken Sie die Musterschaltfläche, dann kennzeichnen Sie write und drücken auf Weiter. Tippen Sie den Variablennamen in »Feld« ein und drücken Sie auf Übernehmen. Eine write- Anweisung wird an der gegenwärtigen Cursorposition eingefügt.
■ Verketten: Verbindet zwei Zeilen. Positionieren Sie den Cursor am Ende einer Zeile und drücken Sie auf die Schaltfläche Verketten, um sie mit der nächsten Zeile zu verknüpfen. Um eine Zeile zu teilen, positionieren Sie den Cursor an der Stelle, wo die Teilung vorgenommen werden soll, und drücken Sie die Eingabetaste.
■ Doppeln: Dupliziert eine Einzelzeile oder einen ganzen Textblock, sofern einer ausgewählt wird (s.a. Schaltflächen
Auswählen).■ Zeile verschieben: Verschiebt Zeilen von links nach rechts. Um eine Zeile zu verschieben, stellen Sie den Cursor an
die Zielposition und drücken auf die Schaltfläche Schieben. Um einen ganzen Textblock des Quellcodes zu verschieben, kennzeichnen Sie den Block und setzen Sie den Cursor auf die Anfangszeile des Blocks an die Stelle, an die der Block verschoben werden soll, und drücken dann auf die Schaltfläche Schieben. Um den Block nach links zu bewegen, stellen Sie den Cursor links an den Anfang der Zeile und drücken auf die Schaltfläche Schieben.
■ Zeile merken: Setzt ein Merkzeichen auf eine Zeile. Sie können über den Menüpfad Springen->Merker alle markierten Zeilen anzeigen.
Um eine Zeile an die oberste Stelle im Editorfenster zu stellen, doppelklicken Sie zwischen zwei Wörtern oder am Ende der Zeile. Doppelklicken Sie aber nicht auf ein Wort; das funktioniert nicht. Alternativ hierzu plazieren Sie den Cursor an das Ende der Zeile, und drücken Sie (F2).
Ausschneiden und Einfügen
In den meisten Windows-Anwendungen gibt es eine Zwischenablage (Clipboard) für Ausschneide- und Einfüge-Operationen. R/3 besitzt fünf Zwischenablagen, die in Tabelle 2.1 beschrieben werden.
Tabelle 2.1: Ausschneide- und Einfüge-Puffer
Bezeichnung VerwendungWie man in den Puffer kopiert
Wie man aus dem Puffer einfügt
Der Puffer Ausschneiden und Einfügen in ein Programm
Die Ausschneide- oder Einfüge-Schaltfläche im Editor benutzen
Auf die Schaltfläche Einfügen drücken
Die Ablagen X, Y und Z Ausschneiden und Einfügen zwischen zwei Programmen
Menüpfad: Block/Ablage->Kopieren in X-Ablage
Menüpfad: Block/Ablage->Einsetzen X-Ablage
Der Zwischenspeicher (Clipboard)
Ausschneiden und Einfügen zwischen:
■ - zwei R/3-Sitzungen ■ - R/3 und anderen
Windows Anwendungen (z.B. Notizblock)
Menüpfad: Block/Ablage-> Kopieren in Clipboard
Menüpfad: Block/Ablage--> Einsetzen Clipboard. Den Text aus dem Zwischenspeicher in das Programm an der aktuellen Cursorposition einfügen. Oder mit (Strg)+(V) über die existierenden Zeilen kopieren. Es gehen Zeichen verloren, wenn der Platz nicht ausreicht.
■ - Kopieren des Codes von der (F1)- Hilfe zum Editor
■ - Kopieren von mehr als einer Codezeile
■ - Einmal klicken ■ - (Strg)+(Y) ■ - Ziehen und
markieren■ - (Strg)+(C)

Die erste Reihe der Tabelle 2.2 ist die programmspezifische Zwischenablage, die einfach Puffer heißt. Sie ermöglicht es Ihnen, innerhalb eines Programms zu kopieren. Um sie zu benutzen, setzen Sie den Cursor auf eine Zeile oder kennzeichnen einen Block und drücken auf Ausschneiden, Kopieren, oder auf Einfügen aus dem Puffer. Der Inhalt der Zwischenablage geht verloren, wenn Sie den Editor verlassen.
Die Zwischenablagen X, Y, und Z werden benutzt, um von einem Programm in ein anderes zu kopieren. Um auf sie zuzugreifen, müssen Sie das Block/Ablage-Menü benutzen. Obwohl drei getrennte Zwischenablagen vorhanden sind, werden sie alle auf die gleiche Art genutzt. Ihr Inhalt bleibt erhalten, wenn Sie den Editor verlassen, aber sie gehen verloren, wenn Sie sich abmelden.
Die Zwischenablage ist identisch mit der Windows-Zwischenablage. Benutzen Sie sie, um mit Ausschneiden und Einfügen auf andere Windows-Anwendungen zuzugreifen, wie z.B. MS Word oder Notepad. Sie wird auch benutzt, um Text von der (F1)-Hilfemaske zu kopieren (s.a. den folgenden Abschnitt »Hilfe«).
Zusätzlich zu den Schaltflächen auf der Drucktastenleiste und den Menüs können Sie standardmäßige Windows-Funktionen benutzen, um Ausschneide- und Einfüge-Operationen durchzuführen. Um ein Wort oder eine Zeile hervorzuheben, ziehen Sie den Cursor darüber, oder drücken Sie die Umschalttaste, und betätigen Sie die linken oder rechten Pfeiltasten (mit dieser Methode können Sie nur eine Zeile zur Zeit hervorheben). Um mehrere Zeilen hervorzuheben, klicken Sie einmal mit der Maus auf die Bildschirmmaske und drücken dann (Strg)+(Y). Der Zeiger wird verändert. Ziehen Sie den Zeiger über den Abschnitt, den Sie kopieren wollen. Drücken Sie (Strg)+(C), um den hervorgehobenen Text in die Zwischenablage zu kopieren oder (Strg)+(X), um ihn auszuschneiden. Mit (Strg)+(V)kann der Text wieder aus der Zwischenablage geholt werden.
Weitere nützliche Editorfunktionen
Tabelle 2.2 enthält einen Überblick über am häufigsten benutzte Editorfunktionen. Auf alle Funktionen wird vom ABAP/4-Editor: Programm Editieren zugegriffen, wenn nicht anders erwähnt.
Tabelle 2.2: Andere nützliche Programm- und Editor-Funktionen
Um ... ,
(Das Ziel)
muß man ...
(Der Weg)
Hilfe für den Editor zu bekommen den Menüpfad Hilfe->Erweiterte Hilfe wählen.
Hilfe für irgendein ABAP/4-Schlüsselwort zu erhalten den Cursor auf ein Schlüsselwort innerhalb des Codes positionieren und (F1) drücken.
das Programm zu sichern (F11) drücken.
das Programm auszuführen (F8) drücken.
Funktionstasten anzuzeigen an beliebiger Stelle des Bildschirmbereichs mit der rechten Maustaste klicken.
den Cursor zum Befehlsfeld zu führen (Strg)+(ÿ) drücken.
irgendeine Zeile an den Anfang zu stellen auf das weiße Feld (Zeilenende) doppelklicken oder den Cursor auf das weiße Feld plazieren und (F2) drücken.
eine Zeile einzufügen den Cursor an den Anfang oder das Ende einer Zeile plazieren und (Enter) drücken.
eine Zeile zu löschen den Cursor auf diese Zeile stellen und Ausschneiden drücken.

einen Textblock zu markieren den Cursor auf die erste Zeile stellen und (F9) drükken (Auswählen). Dann den Cursor auf die Schlußzeile des Blocks setzen und wieder (F9) drücken.
einen Zeilenblock zu löschen den Block auswählen und Ausschneiden drücken.
eine Zeile oder einen Block zu wiederholen die Schalfläche Duplizieren drücken.
eine Zeile zu teilen den Cursor an der Trennstelle positionieren und die (Enter)-Taste drücken.
zwei Zeilen zu verbinden den Cursor an das Zeilenende stellen und Verketten drücken.
Zeilen innerhalb des laufenden Programms zu kopieren einen Block markieren. Die Schaltfläche Kopieren in Zwischenspeicher wählen. Dann den Cursor auf dem Punkt plazieren, wo der Block eingefügt werden soll, und Einfügen aus Zwischenspeicher wählen.
Zeilen in ein anderes Programm zu kopieren einen Block markieren, den Menüpfad Block/Ablage->Kopieren in X-Ablage wählen. Ein neues Programm öffnen und den Menüpfad Block/Ablage->Einsetzen X-Ablage wählen. (In gleicher Weise können Sie auch die Y- und Z-Ablage verwenden.)
aus dem oder in das Windows-Clipboard zu kopieren einen Block markieren. Den Menüpfad Block/Ablage->Kopieren in Clipboard wählen, dann den Menüpfad Block/Ablage->Einsetzen Clipboard.
einen Zeilenblock zu kommentieren einen Block markieren und den Menüpfad Block/Ablage->Kommentar einfügen wählen.
einen Zeilenblock auszukommentieren einen Block markieren und den Menüpfad Block/Ablage->Kommentar wählen.
das Programm zu drucken auf Drucken klicken.
die Programmausgabe zu drucken sich die Ausgabe ansehen und den Menüpfad System ->Liste->Drucken wählen.
zu suchen und weiterzusuchen die Schaltflächen Suchen und Weiter Suchen wählen.
Programmzeilen nach links/rechts zu verschieben den Cursor auf die Zeile, die verschoben werden soll, positionieren. Dann auf die Schaltfläche Zeile Verschieben drücken ((F6)). Um einen Block zu verschieben, positionieren Sie den Cursor auf der Anfangszeile und drücken dann auf die Schaltfläche Zeile Verschieben.
die letzte Änderung rückgängig zu machen die Schaltfläche Widerrufen drücken. Man kann nur eine Stufe zurück.
automatisch den Quelltext zu formatieren den Menüpfad Programm->Pretty-Printer wählen.
ein Programm auf dem PC zu speichern den Menüpfad Hilfsmittel->Download wählen.
ein Programm vom PC zu holen den Menüpfad Hilfsmittel->Upload wählen.
eine temporäre Kopie Ihres Programms zu sichern den Menüpfad Programm->Zwischenspeicher wählen. Die aktuelle temporäre Kopie wird beim Sichern des Programms gelöscht.
eine temporäre Version eines Programms wiederzugewinnen
den Menüpfad Programm->Zwischensp. holen wählen. Sie können die gesicherten Kopien so oft Sie wollen wiederholen, bis Sie das Programm gesichert haben.
direkt in den Editor zu springen an beliebiger Stelle /nse38 im Befehlsfeld eingeben und (Enter) drücken.

ein Programm zu kopieren vom ABAP/4-Editor: Einstieg den Menüpfad Programm->Kopieren wählen.
ein Programm umzubenennen vom ABAP/4-Editor: Einstieg den Menüpfad Programm->Umbenennen wählen.
ein Programm zu löschen vom ABAP/4-Editor: Einstieg den Menüpfad Programm->Löschen wählen.
Ihre Änderungen unter einem neuen Programmnamen zu speichern
während des Editierens den Menüpfad Programm->Sichern als wählen.
zwei Programme gleichzeitig anzuzeigen von beliebiger Stelle aus einen neuen Modus öffnen. Benutzen Sie den Menüpfad System->Erzeugen Modus. In dem neuen Modus gehen Sie in den ABAP/4-Editor unter Angabe des zweiten Namens und drücken auf Anzeigen oder Ändern.
zwei Programme zu vergleichen vom ABAP/4-Editor: Einstieg den Menüpfad Hilfsmittel->Splitscreen-Editor wählen. Geben Sie zwei Programmnamen ein und drücken Sie auf Anzeigen. Um den ersten Unterschied anzuzeigen, drücken Sie auf Nächste Differenz. Um beide Programme an der nächsten identischen Zeile auszurichten, betätigen Sie die Schaltfläche Angleichen.
zwei Programme auf verschiedenen Systemen zu vergleichen
vom ABAP/4-Editor: Einstieg den Menüpfad Hilfsmittel->Splitscreen-Editor wählen. Drücken Sie auf Vergl. über Systeme. Geben Sie zwei Programmnamen und eine Systemnummer ein und drücken auf Anzeigen.
eine Version von einem Programm zu sichern innerhalb des Editors Programm-> Generieren wählen. Das gegenwärtige Programm wird in der Versionsdatenbank gespeichert.
eine Programmversion wiederzugewinnen im Editor Hilfsmittel-> Versionsverwaltung wählen. Die Maske Versionen des Objekts ...vom Typ REPS wird angezeigt. Deselektieren Sie die aktive Version und kennzeichnen Sie die Version, die Sie wieder herstellen wollen. Drücken Sie auf Zurückholen und dann auf Zurück. Drücken Sie jetzt auf die Schaltfläche Ja, und die gegenwärtige Version wird die 1. Generation werden, während eine Kopie der ausgewählten Version die gegenwärtige Version wird.
Programmversionen zu vergleichen Hilfsmittel->Versionverwaltung wählen. Die Maske Versionen des Objekts ...vom Typ REPS wird angezeigt. Kennzeichnen Sie die Version, die Sie vergleichen wollen und drücken auf die Schaltflächen Vergleichen (oder benutzen Sie den Menüpfad Versionen->Vergleichen). Die Vergleichsprogramme: Blättern Sie nach unten, um die Unterschiede anzusehen.
Ihr Programm zu drucken Programm->Drucken wählen. Wählen Sie einen Drucker aus und kennzeichnen Sie Sofort Ausgeben.
Hilfe
Starten Sie jetzt das ScreenCam »Getting Help«.
So erhalten Sie einen vollständigen Tutorenkurs zum Editor:
1. Rufen Sie den ABAP/4-Editor auf.

2. Über den Menüpfad Hilfe->Erweiterte Hilfe wird die SAP R/3-Hilfemaske angezeigt.
3. Durch einen Klick auf den Text ABAP/4-Editor wird die Hilfe zur ABAP/4-Entwicklungsworkbench angezeigt.
4. Klicken Sie auf irgendeinen unterstrichenen Text, um Hilfe zu diesem Thema zu erhalten.
Es gibt zwei grundlegende Arten von Hilfe im Editor, die (F1)-Hilfe und die R/3-Bibliothekshilfe. (F1)-Hilfe wird auch als ABAP/4-Schlüsselwortdokumentation bezeichnet.
Die (F1)-Hilfe beschreibt die Syntax von ABAP/4-Schlüsselworten und führt Beispiele ihrer Verwendung auf. Sie ist textbasierend und in Tabellen innerhalb der R/3-Datenbank abgelegt.
Die R/3-Bibliothekshilfe ist weitreichender und enthält Übersichten von Entwicklungsobjekten und Prozeduren, um Entwicklungsobjekte anzulegen. Sie basiert auf Windows und befindet sich außerhalb der R/3-Datenbank, üblicherweise auf einer CD- ROM.
F1-Hilfe
Die (F1)-Hilfe ist praktisch, um die Syntax nachzuschlagen, und enthält oft nützliche Programmierbeispiele.
So rufen Sie die (F1)-Hilfe auf:
1. Gehen Sie zum ABAP/4-Editor.
2. Plazieren Sie den Cursor auf das ABAP/4-Schlüsselwort, für welches Sie Hilfe brauchen.
3. Drücken Sie (F1). Die Hypertext-Maske wird angezeigt.
Innerhalb der (F1)-Hilfe sind hervorgehobene Worte Hypertext-Verbindungen. Wenn Sie diese gekennzeichneten Texte anklicken, erhalten Sie weitergehende Informationen.
Mit dem Hilfsmittel Find/t auf der CD-ROM finden Sie weitere Beispiele.
Innerhalb der Hilfe finden Sie oft Programmierbeispiele. Um sie auszuschneiden und in Ihr Programm einzufügen, drücken Sie (Strg)+(Y) und markieren dann einen Block, indem Sie den Cursor von der oberen linken zur unteren rechten Ecke ziehen. Drücken Sie jetzt (Strg)+(C), und kehren Sie zum ABAP/4-Editor zurück. Fügen Sie den Block über Block/Ablage->Einsetzen Clipboard ein. Oder benutzen Sie (Strg)+(V).
R/3-Bibliotheks-Hilfe
Die R/3-Bibliothekshilfe ist in Windows-Hilfsdateien gespeichert. Um sie aufzurufen, gehen Sie folgendermaßen vor:
1. Der Menüpfad Hilfe->R/3-Bibliothek kann aus jeder Maske heraus gewählt werden. Die R/3-Online-Hilfe wird angezeigt.
2. Klicken Sie die Text-Basis-Bestandteile für Hilfe zu ABAP/4 an. Der Basisbildschirm wird angezeigt.

3. Klicken Sie auf den Text ABAP/4-Entwicklungsworkbench. Die Maske ABAP/4- Entwicklungsworkbench wird angezeigt.
4. Sie können von hier aus detaillierte Hilfe zu fast jedem Aspekt über das Programmieren in ABAP/4 bekommen. Klicken Sie einfach auf das Thema, für das Sie Hilfe benötigen.
Zusätzlich können Sie durch die folgende Prozedur Hilfe aus dem ABAP/4-Editor erhalten:
1. Gehen Sie in den ABAP/4-Editor.
2. Wählen Sie den Menüpfad Hilfsmittel->Schlüsselwortdoku wählen. Strukturanzeige: Die ABAP/4-4GL Programmiersprache von SAP wird angezeigt.
3. Drücken Sie auf die Schaltfläche Suchen. Die entsprechende Maske wird angezeigt.
4. Geben Sie den gesuchten Text in das Suchfeld ein.
5. Drücken Sie Weiter. Die Anfangszeile des gesuchten Textes ist hervorgehoben.
6. Doppelklicken Sie auf diese erste Zeile, um weitere Informationen zu erhalten, oder drücken Sie Weitersuchen auf der Symbolleiste, um das nächste Auftreten zu lokalisieren.
Auch innerhalb des Editors kann man Hilfe erhalten, während der Quelltext editiert wird. Wählen Sie den Menüpfad Hilfsmittel->Hilfe zu. Sie können hier die folgenden Arten von Hilfe bekommen:
■ Editorhilfe■ ABAP/4-Übersicht■ ABAP/4-Schlüsselwort■ Neues zu ABAP/4 ■ Funktionsbaustein■ Tabellenstrukturen■ Logische Datenbanken ■ Berechtigungsobjekte■ Infotypen
Ihre Entwicklungsobjekte wiederfinden
Starten Sie jetzt das ScreenCam »Finding Your Development Objects«.
Gehen Sie folgendermaßen vor, um alle Entwicklungsobjekte anzuzeigen, die Sie im R/3-System angelegt haben:
1. Starten Sie den Object Browser von der ABAP/4-Entwicklungsworkbench.
2. Lokale Priv. Objekte auswählen.
3. Anzeigen auswählen. Der Repository Browser: Entwicklungsklasse $TMP wird angezeigt. Sie sehen hier eine Liste von Entwicklungsobjektkategorien. Links von jeder Kategorie ist ein Pluszeichen.
4. Klicken Sie einmal das Pluszeichen an, um den Knoten aufzublättern.
5. Doppelklicken Sie auf einen Objektnamen, um ihn anzuzeigen. Wenn das Objekt, das Sie zweimal angeklickt haben, ein Programm ist, wird eine Baumstruktur des Programms und seiner Bestandteile angezeigt.

6. Um den Programmquelltext anzuzeigen, doppelklicken Sie auf den Namen des Programms am Oberteil der Baumstruktur. Es erscheint die Maske ABAP/4-Editor: Programm Anzeigen.
Sie sind jetzt im Anzeigemodus des ausgewählten Objekts. Nun können Sie die Schaltfläche Anzeigen <-> Ändern drücken, um in den Editiermodus zu gelangen.
Diese Methode funktioniert nur bei Objekten, die als lokale Objekte gesichert wurden. Sie werden hier nur angezeigt, wenn Sie die Schaltfläche Lokales Objekt auf der Maske Objektkatalogeintrag gedrückt haben, als Sie das Objekt anlegten.
Wenn Sie ein Programm suchen und die ersten Buchstaben seines Namens kennen, können Sie es vom ABAP/4-Editor aus folgendermaßen finden:
1. Rufen Sie den ABAP/4-Editor auf.
2. Geben Sie die ersten Buchstaben Ihres Programmnamens im Programmfeld ein, gefolgt von einem Sternzeichen. Um z.B. alle Programme anzuzeigen, die mit ztx anfangen, geben Sie einfach ztx* ein.
3. Klicken Sie auf den Pfeil nach unten rechts von dem Programmfeld. Die Programm-Maske wird angezeigt. Eine Liste von Vergleichsprogrammnamen erscheint auf dieser Maske. Rechts von den Programmnamen ist die Kurzbeschreibung der Programme.
4. Doppelklicken Sie auf den Programmnamen, den Sie editieren wollen. Der Programmname wird im Feld Programm angezeigt.
Das R/3-Data Dictionary
Das R/3-Data Dictionary (Datenwörterbuch, kurz DDIC genannt) ist ein Hilfsmittel, um Datenobjekte zu definieren. Indem Sie das Data Dictionary benutzen, können Sie Objekte wie Tabellen, Strukturen und Views anlegen und speichern. Um das Datenwörterbuch aufzurufen, müssen Sie folgende Schritte ausführen:
1. Rufen Sie die ABAP/4-Workbench auf.
2. Drücken Sie auf die ABAP/4-Dictionary-Schaltfläche auf der Symbolleiste. Das Data Dictionary erscheint (siehe Abb. 2.8).

Abbildung 2.8: Die Dictionary-Einstiegsmaske
Das Data Dictionary liegt innerhalb des R/3-Systems. Sie können es sich so vorstellen, als ob es über einer Datenbank wie Oracle oder Informix sitzt und das Generieren und Senden von SQL-Anweisungen steuert. Sie könnten z.B. eine Tabellendefinition im Data Dictionary anlegen. Wenn Sie die Tabellendefinition aktivieren, werden SQL- Anweisungen generiert und an das RDBMS gesandt, was zur Folge hat, daß sie die eigentliche Tabelle in der Datenbank anlegt. Wenn Sie die Tabelle verändern wollen, müssen Sie die Tabellendefinition in dem Data Dictionary modifizieren. Wenn Sie die Tabelle wieder aktivieren, entstehen zusätzliche SQL-Anweisungen, was zur Folge hat, daß das RDBMS die Tabelle modifiziert.
Erlaubt Nicht erlaubt
Benutzen Sie das Data Dictionary, um alle Datenbankobjekte anzulegen und zu modifizieren.
Modifizieren Sie keine Tabelle oder andere Objekte auf der RDBMS-Ebene. Die Data Dictionary-Definitionen können sich nicht selbst aktualisieren und werden nicht synchron mit der Datenbank sein. Dies kann zu Anwendungsfehlern und zu einem Verlust der Datenintegrität führen.
Tabellen und Strukturen
In R/3 ist eine Tabelle eine Sammlung von Zeilen. Jede Zeile enthält Felder, auch Spalten genannt. Innerhalb einer Tabelle, hat jede Zeile die gleiche Anzahl von Spalten wie die anderen Zeilen der Tabelle.
Eine Tabelle behält die eingegebenen Daten. Mit anderen Worten, wenn Sie Daten in eine Tabelle einfügen, bleiben sie dort, nachdem Ihr Programm endet. Sie werden dort solange bleiben, bis sie von Ihrem Programm oder einem anderen Programm geändert oder gelöscht werden. Der Name einer Tabelle ist innerhalb des ganzen R/3- Systems eindeutig.
Wenn Sie sich eine Tabelle in dem Data Dictionary ansehen, sehen Sie sich die Beschreibung einer Tabelle in der zugrunde

liegenden Datenbank an. Sie sehen die Datenbanktabelle nicht direkt. Abb. 2.9 zeigt, wie eine Tabellendefinition im R/3-Data Dictionary erscheint.
Abbildung 2.9: Die DDIC-Definition der Tabelle lfa1
In R/3 bedeutet eine Struktur die Beschreibung einer Gruppe von Feldern. Sie beschreibt die Feldnamen, ihre Folge und ihre Datentypen und Längen. Jede Struktur hat einen Namen, der innerhalb des ganzen R/3-Systems eindeutig ist. Eine Struktur kann nicht namensgleich mit einer Tabelle sein.
Ein Strukturname kann auf zwei Arten benutzt werden:
■ In einem Programm kann ein Strukturname benutzt werden, um Speicherplatz für eine Gruppe von Feldern zu allokieren.
■ In einer Tabelle kann ein Strukturname benutzt werden, um eine Gruppe Felder zu beschreiben.
Eine Struktur ist streng genommen etwas, das nur innerhalb des R/3-Datenwörterbuchs existiert. Wenn Sie das Wort »Struktur« sehen, sollten Sie sofort an »Data Dictionary-Strukturen« denken. Allerdings benutzt die SAP-Dokumentation zeitweilig das Wort »Struktur«, um sich innerhalb eines Programms auf eine Gruppe von Variablen zu beziehen. Die Struktur emara in Abb. 2.10 ist ein Beispiel dafür, wie eine Struktur im Data Dictionary erscheint.

Abbildung 2.10: Die DDIC-Definition der Struktur emara
In R/3 sind sowohl Tabellen als auch Strukturen im Data Dictionary definiert. Sie werden jedoch bemerken, daß es sehr geringe Unterschiede zwischen ihnen gibt. Das kommt daher, daß eine Tabelle in R/3 die Beschreibung einer aktuellen Datenbanktabelle ist. Es ist die Struktur der Tabelle in der Datenbank. Sowohl Tabellen als auch Strukturen innerhalb des Data Dictionarys definieren eine Anordnung - eine Serie von Feldern. Der Hauptunterschied zwischen den beiden ist, daß eine Tabelle eine zugrunde liegende Datenbanktabelle hat, die sich damit assoziiert. Eine Struktur tut das nicht.
Die R/3-Dokumentation erscheint manchmal verwirrend, da SAP diese zwei Begriffe auswechselbar benutzt.
Eine Tabelle oder Strukturdefinition anzeigen
So zeigen Sie eine Tabellen- oder Strukturdefinition im Data Dictionary an:
1. Gehen Sie zum Data Dictionary.
2. Tragen Sie den Tabellen- oder Strukturnamen in das Objektnamensfeld ein.
3. Kennzeichnen Sie die Tabelle oder die Struktur.
4. Klicken Sie auf Anzeigen. Die Maske Dictionary: Tabelle/Struktur: Felder Anzeigen erscheint wie in Abb. 2.9 und 2.10.
Was Sie in Abbildung 2.9 sehen, ist die Struktur von Tabelle lfa1 im R/3-Data Dictionary, nicht die eigentliche Datenbanktabelle. In R/3 kann einzig die Struktur einer Tabelle definiert werden, zusammen mit einigen Merkmalen wie den Primärschlüsselfeldern.
Daten in der Tabelle anzeigen

R/3 bietet auch ein Hilfsmittel, um Ihnen das Anzeigen von Daten zu ermöglichen, die innerhalb einer Tabelle existieren, und zwar folgendermaßen:
1. Öffnen Sie Dictionary: Tabelle/Struktur: Felder Anzeigen.
2. Wählen Sie den Menüpfad Hilfsmittel->Tabelleninhalt. Die Maske Data Browser: Tabelle: Auswahl wird angezeigt.
3. Um alle Zeilen in der Tabelle anzuzeigen, drücken Sie auf die Schaltfläche Ausführen, ohne irgendwelche Suchkriterien einzugeben. Die Maske Data Browser: Tabelle: Selektion wird angezeigt (s. Abb. 2.11).
Die Anzahl von Sätzen, die angezeigt werden, ist abhängig vom Wert der maximalen Treffer.
Löschen Sie nicht die Feldinhalte der maximalen Trefferzahl, um alle Datensätze anzuzeigen, außer Sie beabsichtigen, die ganze Liste zu überprüfen. Für große Tabellen kann dies viel CPU-Zeit auf den beiden Datenbank- und Anwendungsservern verbrauchen, den Netzverkehr bedeutend erhöhen und das System verlangsamen. Wenn solch ein großer Report benötigt würde, liefe er normalerweise im Hintergrund. Es sollten vorzugsweise Selektionswerte im Data Browser eingegeben werden. Dies wird ausführlich in einem späteren Kapitel beschrieben.

Abbildung 2.11: Data Browser:Tabelle:Selektionsbild
Angezeigte Felder
Sie können kontrollieren, welche Felder Sie über den Data Browser anzeigen wollen.
1. Gehen Sie zum Data Browser: Tabelle: Selektionsbild (oder Transaktionscode SE11).
2. Wählen Sie den Menüpfad Einstellungen->Felder für Selektion. Die Auswahlmaske wird angezeigt.
3. Markieren Sie die Felder, die Sie für die Data Browser: Tabelle: Auswahlmaske nutzen wollen. Was nicht erscheinen soll, müssen Sie deselektieren.
4. Drücken Sie die Schaltfläche Ausführen. Die Data Browser: Tabelle: Selektionsbildmaske wird angezeigt und enthält die Felder, die Sie ausgewählt haben.
Die ABAP/4-Syntax
Bevor Sie fortfahren, sollten Sie jetzt die Übung Setup Utility von der beiliegenden CD-ROM laufen lassen. Hier werden die Tabellen und Daten angelegt, die für die Übungen in diesem Buch benötigt werden. In der readme.txt-Datei im Hauptverzeichnis der CD-ROM finden Sie weitere Instruktionen.
Die select-Anweisung
Die select-Anweisung erhält Datensätze aus der Datenbank.
Syntax für die select-Anweisung
Der folgende Programm-Code zeigt die vereinfachte Syntax für die select-Anweisung:
select * from t1 [into wa] [where f1 op v1 and/or f2 op v2 ...][order by f1].(other abap/4 statements)endselect.
Erläuterungen:
■ * zeigt an, daß alle Felder in der Tabelle gelesen werden sollten. ■ t1 ist der Name einer Tabelle, die vorher über eine tables-Anweisung definiert wird. ■ wa ist der Name des Arbeitsbereichs, der zur Struktur der Tabelle paßt. ■ f1 ist der Name eines Feldes in Tabelle t1.■ op ist eine der folgenden logischen Operationen: = <> > >= < <=. ■ v1 ist ein Literal oder eine Variable. ■ and/or ist entweder das Wort and oder das Wort or.
Schreiben Sie ein neues Programm, und nennen Sie es ***0202. Benutzen Sie den Code, wie in Listing 2.2 gezeigt.
Listing 2.2: Ihr zweites Programm
1 report ztx0202.

2 tables ztxlfa1.3 select * from ztxlfa1 into ztxlfa1 order by lifnr.4 write / ztxlfa1-lifnr.5 endselect.
Der Code in Listing 2.2 sollte diese Ausgabe erzeugen:
10001010102010301040105010601070108010902000V1V10V11V12V2V3V4V5V6V7V8V9
Lfa1 ist die Kreditorenhaupttabelle in R/3. Ztxlfa1 wurde von der CD-ROM-Setup- Routine kreiert und ist lfa1 ähnlich, wird aber für die Übungen in diesem Buch benutzt. Das Feld lifnr ist das Kreditorennummernfeld.
Dieses Programm liest alle Datensätze aus der Tabelle ztxlfa1 und schreibt die Inhalte des Feldes lifnr (die Kreditorennummer) in aufsteigender Ordnung aus.
■ In Zeile 1 wird die report-Anweisung als Anfangszeile eines Reports verlangt. ■ In Zeile 2 macht die tables-Anweisung zwei Dinge: Sie allokiert zum einen den Speicherbereich (Arbeitsbereich
genannt) namens ztxlfa1. Der Arbeitsbereich hat die gleiche Anlage wie die DDIC-Definition von Tabelle ztxlfa1. Zum anderen ermöglicht sie dem Programm den Zugriff auf die Datenbanktabelle ztxlfa1.
■ In Zeile 3 macht die select-Anweisung eine Schleife. Das endselect in Zeile 5 markiert das Ende der Schleife. Die Codezeilen zwischen select und endselect werden jeweils einmal ausgeführt, und zwar für jede Zeile, die aus der Datenbank kommt.
■ In Zeile 4 wird die write-Anweisung einmal für jede Zeile ausgeführt, die von der Tabelle gelesen wird. Der / (Slash) nach write fängt eine neue Zeile an.
Beachten Sie in Ihrem Programm, daß Sie zwei Dinge namens ztxlfa1 haben: einen Arbeitsbereich und eine Tabelle. Beide haben den gleichen Namen - ztxlfa1. Die Position des Namens ztxlfa1 innerhalb einer Anweisung entscheidet, worauf Sie sich beziehen. In Zeile 3 bezieht sich das erste Vorkommen von ztxlfa1 auf die

Datenbanktabelle, das zweite auf den Arbeitsbereich.
Starten Sie jetzt das ScreenCam »AVI Select Statement Processing«.
Die Verarbeitung läuft folgendermaßen ab (Abb. 2.12):
1. Das Betätigen der (F8)-Taste ( um das Programm auszuführen ), bewirkt eine Anfrage vom SAPGUI an den Dispatcher auf dem Applikationsserver, das Programm ztx0202 auszuführen.
2. Die Anfrage wird zum ersten verfügbaren Work-Prozeß gesandt.
3. Der Benutzerkontext wird in den Work-Prozeß eingelesen (gerollt).
4. Das Programm wird aus der Datenbank zurückgeholt.
5. Der Work-Prozeß allokiert einen Rollbereich, um die Variablen des Programms, den gegenwärtigen Programmzeiger und die persönliche Memorybelegungen zu halten.
6. Das Programm wird vom Work-Prozeß auf dem Applikationsserver ausgeführt und beginnt auf Zeile 3 zu laufen. (Zeilen 1 und 2 sind Deklarationen, keine ausführbaren Codes.)
7. Zeile 3 bewirkt, daß eine Zeile aus der Datenbanktabelle ztxlfa1 gelesen und in den Arbeitsbereich ztxlfa1 gesetzt wird.
8. Beim ersten Mal wird Zeile 4 ausgeführt, eine virtuelle Seite wird für die Liste allokiert.
9. Zeile 4 bewirkt, daß das Feld lifnr vom Arbeitsbereich ztxlfa1 an die virtuelle Seite geschrieben wird.
10. Von Zeile 5 geht eine Schleife zurück zu Zeile 3.
11. Die nächste Reihe wird von Tabelle ztxlfa1 gelesen und in den Arbeitsbereich ztxlfa1 gestellt, wobei die vorherige Reihe überschrieben wird.
12. Das Feld lifnr wird in die nächste Zeile der virtuellen Seite geschrieben.
13. Die Schritte 9 bis 11 werden für alle Reihen in Tabelle ztxlfa1 wiederholt.
14. Die Schleife endet automatisch, wenn die letzte Zeilen von ztxlfa1 gelesen ist.
15. Das Programm endet, aber der Rollbereich (welcher die virtuelle Seite enthält) bleibt allokiert.
16. Der Work-Prozeß bestimmt die Zeilenanzahl, die die Maske des Benutzers anzeigen kann, und sendet so viele Zeilen von der virtuellen Seite als erste Seite der Liste an den Präsentationsserver.
17. Der Benutzerkontext und der Rollbereich werden aus dem Work-Prozeß gerollt.
Wenn der Benutzer dann Bild Abwärts (Blättern) drückt, geht der Prozeß folgendermaßen weiter (Abb. 2.13):
1. Indem Bild Abwärts gedrückt wird, startet eine Anfrage von dem SAPGUI an den Dispatcher auf dem Applikationsserver, um die nächste Seite von ztx0202 zu bekommen.
2. Die Anfrage wird an den ersten verfügbaren Work-Prozeß gesandt.

3. Der Benutzerkontext und der Rollbereich für ztx0202 werden in den Work-Prozeß gerollt.
4. Der Work-Prozeß sendet dem Präsentationsserver die nächste Seite.
5. Der Rollbereich und der Benutzerkontext werden aus dem Work-Prozeß gerollt.
Abbildung 2.12: So arbeitet die select-Anweisung.
Abbildung 2.13: Dies passiert, wenn der Benutzer Abwärts Rollen drückt.

Wenn der Benutzer dann Zurück drückt, geht der Prozeß folgendermaßen weiter:
1. Indem Zurück gedrückt wird, startet eine Anfrage von dem SAPGUI an den Dispatcher auf dem Applikationsserver, um Programm ztx0202 zu beenden.
2. Die Anfrage wird an den ersten verfügbaren Work-Prozeß gesandt.
3. Der Benutzerkontext und der Rollbereich für ztx0202 werden in den Work-Prozeß gerollt.
4. Das System macht den Rollbereich für das Programm frei.
5. Der Benutzerkontext wird ausgerollt.
Um ein neues R/3-Fenster (Modus genannt) zu öffnen, wählen Sie von jeder Maske aus den Menüpfad System->Erzeugen Modus. Sie können maximal sechs Modi öffnen. Wenn Sie mehr als sechs öffnen wollen, wählen Sie sich einfach ein zweites Mal ein.
Tabellenarbeitsbereiche
Auf Reihe 3 in Listing 2.2 sind die Worte into ztxlfa1 optional. Wenn Sie sie fortlassen, wird der Arbeitsbereich mit dem gleichen Namen wie dem der Tabelle benutzt. Mit anderen Worten: Die gegenwärtige Reihe wandert automatisch in den ztxlfa1- Arbeitsbereich. Aus diesem Grund wird er Vorgabetabellenarbeitsbereich genannt. Der Arbeitsbereich ztxlfa1 ist in diesem Fall der Vorgabearbeitsbereich der Tabelle ztxlfa1. Der Code in Listing 2.2 kann daher so vereinfacht werden, wie das in Listing 2.3 gezeigt wird.
Listing 2.3: Ihr zweites Programm vereinfacht
1 report ztx0203.2 tables ztxlfa1.3 select * from ztxlfa1 order by lifnr.4 write / ztxlfa1-lifnr.5 endselect.
Im Vergleich mit Listing 2.2 hat sich nur die Zeile 3 verändert. Dieses Programm arbeitet genau so wie das bisherige und erzeugt die gleiche Ausgabe. Solange kein into auf der select-Anweisung spezifiziert wird, benutzt das System den Vorgabetabellenarbeitsbereich ztxlfa1.
Um ein Programm zu kopieren, wählen Sie den Menüpfad Programm->Kopieren. Während Sie ein Programm editieren, können Sie alternativ den Menüpfad Programm->Sichern als wählen.
Benutzung eines expliziten Arbeitsbereichs
Die tables-Anweisung legt immer einen Vorgabetabellenarbeitsbereich an, so daß Sie normalerweise Ihren eigenen

nicht definieren müssen. In einigen Fällen kann es allerdings passieren, daß Sie zusätzliche Tabellenarbeitsbereiche definieren wollen. Wenn Sie die Originalfassung von einer Reihe behalten und auch eine modifizierte Version haben wollten, bräuchten Sie zum Beispiel zwei Arbeitsbereiche.
Sie können zusätzliche Tabellenarbeitsbereiche definieren, indem Sie die data-Anweisung benutzen.
Vereinfachte Syntax für die data-Anweisung
Unten sehen Sie die vereinfachte Syntax für die data-Anweisung.
data wa like t1.
wobei gilt:
■ wa ist der Name von einem Tabellenarbeitsbereich, den Sie definieren wollen. ■ t1 ist der Name einer Tabelle, nach der Sie Ihren Arbeitsbereich strukturieren wollen.
Listing 2.4 zeigt, wie man mit Hilfe der data-Anweisung einen neuen Arbeitsbereich anlegt.
Listing 2.4: Ihr eigener Tabellenarbeitsbereich
1 report ztx0204.2 tables ztxlfa1.3 data wa like ztxlfa1.4 select * from ztxlfa1 into wa order by lifnr.5 write / wa-lifnr.6 endselect.
Der Code in Listing 2.4 sollte die gleiche Ausgabe erzeugen wie die bisherigen zwei Listings (vergleiche die Ausgabe von Listing 2.3). Bitte beachten Sie, daß es in diesem Beispiel nicht notwendig ist, einen neuen Arbeitsbereich zu definieren - es soll hier nur der Begriff veranschaulicht werden.
■ Zeile 3 definiert einen neuen Arbeitsbereich, genannt wa, mit der Struktur von ztxlfa1 aus dem Data Dictionary.
■ Zeile 4 liest eine Zeile zur Zeit aus der Tabelle ztxlfa1 in den Arbeitsbereich wa anstatt in den Vorgabetabellenarbeitsbereich.
■ Zeile 5 schreibt die Reihe von wa statt von ztxlfa1 aus.
Wenn Sie einen Arbeitsbereich explizit mit der select-Anweisung benennen (wie into wa auf Zeile 5), wird dieser »expliziter Arbeitsbereich« genannt.
Die where-Klausel
Um die Anzahl von Zeilen zu beschränken, die aus der Datenbank gelesen werden, kann der select-Anweisung eine where-Klausel hinzugefügt werden. Um Kreditoren zu erhalten, deren Nummern kleiner sind als 2000, können Sie z.B. den Code in Listing 2.5 benutzen.
Listing 2.5: Eingrenzung der ausgewählten Kreditoren
1 report ztx0205.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr < '0000002000' order by Lifnr.4 write / ztxlfa1-lifnr.

5 endselect.
Der Code in Listing 2.5 sollte diese Ausgabe erzeugen:
1000101010201030104010501060107010801090
Dieses Programm liest alle Sätze von der Tabelle ztxlfa1, in denen die Kreditorennummer kleiner als 2000 ist, und schreibt den Inhalt des Feldes lifnr aus. In der Datenbank ist lifnr ein Zeichenfeld mit numerischen Werten, rechtsbündig und links mit Nullen aufgefüllt. Der Wert, der mit lifnr zu vergleichen ist, sollte deswegen das gleiche Format und den gleichen Datentyp haben, um Datenumsetzung zu umgehen und sicherzustellen, daß die geplanten Ergebnisse erzielt werden.
Beachten Sie, daß Sie die Zeichenkette mit Anführungszeichen (wie `0000002000´ auf Zeile 3) versehen müssen, um ein Zeichenliteral in ABAP/4 zu programmieren.
Arbeiten mit Systemvariablen
Das R/3-System macht Systemvariable innerhalb Ihres Programms verfügbar. Sie müssen sie nicht definieren, um auf sie zuzugreifen, sie sind immer verfügbar und werden automatisch vom System auf den neuesten Stand gebracht, wenn sich die Umgebung Ihres Programms ändert. Alle Systemvariablen beginnen mit dem Präfix sy-. Zum Beispiel ist das gegenwärtige Systemdatum in dem Systemfeld sy-datum, und die gegenwärtige Zeit in der sy-uzeit verfügbar. Sie heißen kurz Sy -Felder.
Alle Systemvariablen sind im Data Dictionary unter der Struktur syst definiert. Definieren Sie syst nicht in Ihren Programmen; seine Felder sind innerhalb jedes Programms automatisch verfügbar.
Systemvariable können entweder mit dem Präfix Sy- oder syst- programmiert werden. sy-datum kann z.B. auch als syst-datum programmiert werden; sie sind funktionell gleichwertig. Sy- ist die bevorzugte Form, obwohl Sie gelegentlich noch syst- in älteren Programmen finden. syst ist die einzige Struktur, die eine Dualität von Präfixen hat. Für alle anderen müssen Sie den vollen Strukturnamen als Präfix benutzen.
Zwei Systemvariable sind sehr nützlich, wenn Sie die select-Anweisung programmieren:
■ sy-subrc■ sy-dbcnt
sy-subrc
Um herauszufinden, ob die endselect-Anweisung überhaupt Zeilen zurückliefert, testen Sie den Wert der

Systemvariablen sy-subrc nach der endselect-Anweisung. Wenn Zeilen gefunden werden, wird der Wert von sy-subrc 0 sein. Wenn keine Zeilen gefunden wurden, wird der Wert 4 sein (siehe Listing 2.6.)
Listing 2.6: Mit Hilfe von sy-subrc entscheiden, ob Zeilen selektiert wurden
1 report ztx0206.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr > 'Z'.4 write / ztxlfa1-lifnr.5 endselect.6 if sy-subrc <> 0.7 write / 'No records found'.8 endif.
Der Code in Listing 2.6 erzeugt diese Ausgabe:
No records found
Die select-Anweisung auf Zeile 3 ist beschränkt durch eine where-Klausel. In diesem Fall passen keine Zeilen zu den Kriterien der where-Klausel, so daß hinter dem endselect der Wert von sy-subrc auf 4 gesetzt wird.
Viele Schlüsselworte weisen dem sy-subrc Werte zu, einige Schlüsselworte überhaupt nicht. Wenn ein Schlüsselwort sy-subrc setzt, werden die Werte, die es enthalten kann, in der (F1)-Hilfe für dieses Schlüsselwort dokumentiert.
Wenn Sie select programmieren und den Wert von sy-subrc prüfen wollen, muß Ihr Test hinter endselectkommen. Warum? Die Antwort liegt in der Tatsache begründet, daß der Code zwischen select und endselect nur einmal für jede Zeile ausgeführt wird, die von der Datenbank zurückgeliefert wird.
Wenn Nullreihen aus der Datenbank zurückgeliefert werden, wird der Code zwischen select und endselect niemals ausgeführt. Deswegen müssen Sie den Test für sy- subrc hinter endselect programmieren.
sy-subrc ist nicht automatisch auf Null initialisiert, wenn Ihr Programm startet. Darum müssen Sie sich jedoch nicht kümmern, weil Sie es nicht prüfen sollten, bevor eine Anweisung ausgeführt wird, die die Initialisierung vornimmt.
sy-dbcnt
Um die Anzahl von Zeilen zu bestimmen, die von einer select-Anweisung zurückgeliefert werden, testen Sie den Wert von sy-dbcnt hinter endselect. Sie können es auch als einen Schleifenzähler benutzen; es enthält zwischen selectund endselect einen Zähler der laufenden Iteration. Für die erste Reihe ist sy-dbcnt 1, für die zweite 2 und so weiter. Nach endselect wird es seinen Wert behalten und so die Anzahl der selektierten Zeilen enthalten. Um zum Beispiel sequentielle Zahlen neben jeden Kreditor zu drucken und am Ende des Reports die Gesamtanzahl der selektierten Zeilen, benutzen Sie den Code in Listing 2.7.

Listing 2.7: Benutzung von sy-dbcnt, um die Anzahl der von der select-Anweisung zurückgelieferten Zeilen zu zählen
1 report ztx0207.2 tables ztxlfa1.3 select * from ztxlfa1 order by lifnr.4 write / sy-dbcnt.5 write ztxlfa1-lifnr.6 endselect.7 write / sy-dbcnt.8 write 'records found'.
Der Code in Listing 2.7 erzeugt diese Ausgabe:
1 10002 10103 10204 10305 10406 10507 10608 10709 108010 109011 200012 V113 V1014 V1115 V1216 V217 V318 V419 V520 V621 V722 V823 V923 records found
■ Zeile 4 schreibt den Wert von sy-dbcnt für jede Zeile, die von der select Anweisung zurückgeliefert wird. Der Slash (/) fängt eine neue Zeile an, d.h., jeder sy- dbcnt beginnt auf einer neuen Zeile.
■ Zeile 5 schreibt den Wert von ztxlfa1-lifnr auf die selbe Zeile wie sy-dbcnt.
Die syst-Struktur anzeigen
Es gibt zwei Möglichkeiten, die Bestandteile der Struktur von syst anzuzeigen:
■ Vom ABAP/4-Editor: Doppelklicken Sie auf den Namen irgendeines sy Feldes innerhalb Ihres Codes. ■ Gehen Sie im Data Dictionary auf syst. Wählen Sie die Option Struktur, und drücken Sie auf Anzeigen.
Um Felder innerhalb der Struktur zu finden, drücken Sie die Schaltfläche Finden auf der Symbolleiste und tragen Sie den Feldnamen ein, den Sie finden wollen.
Wenn Sie den Namen des Feldes, das Sie suchen, nicht wissen, können Sie es auch über die Beschreibung finden.

Starten Sie jetzt das ScreenCam »How to Search Through Filed Descriptions«.
Um Feldbeschreibungen zu durchsuchen, gehen Sie wie folgt vor:
1. Beginnen Sie beim Data Dictionary: Tabelle/Struktur: Felder anzeigen.
2. Den Menüpfad Tabelle->Drucken wählen. Eine Dialogbox erscheint; Sie werden gefragt, welche Bestandteile Sie drucken möchten.
3. Haken Sie alle Checkboxen an, und drücken Sie auf die Schaltfläche Weiter. Eine Dialogbox erscheint; Sie werden nach den Druckparametern gefragt.
4. Drücken Sie auf die Schaltfläche Druckvorschau. Die Dialogbox schließt sich, und eine Liste mit einem kleinen Zeichensatz erscheint.
5. Wählen Sie den Menüpfad Springen-> Liste anzeigen. Die Liste verändert sich in ein größeres Ausgabestandardformat.
6. Tippen Sie %sc in das Befehlsfeld und drücken die Eingabetaste. Die Dialogbox Finden erscheint.
7. Tippen Sie den Text ein, den Sie finden wollen, und drücken Sie die Eingabetaste. Eine Trefferliste wird angezeigt, und jeder Treffer wird hervorgehoben.
8. Klicken Sie einmal auf ein hervorgehobenes Wort, um sofort zu dieser Zeile in der Liste zu springen. Wenn Sie ein anderes Vorkommen des Texts finden wollen, gehen Sie wieder zu Punkt 6 in dieser Beschreibung.
Der Kettenoperator
Der Doppelpunkt (:) heißt Kettenoperator. Benutzen Sie ihn, um Codezeilen zu kombinieren, die mit dem gleichen Wort oder der gleichen Wortfolge beginnen. Stellen Sie den allgemeinen Teil an den Anfang der Anweisung, gefolgt von einem Doppelpunkt. Um zwei Tabellen zu definieren, könnten Sie zum Beispiel programmieren:
tables ztxlfa1.tables ztxlfb1.
Oder Sie könnten den Kettenoperator benutzen:
tables: ztxlfa1, ztxlfb1.
Die zwei vorhergehenden Codesegmente sind funktionell identisch, und während der Laufzeit ist kein Unterschied in der Performance. Während der Codegenerierung wird das zweite Codesegment in zwei Anweisungen erweitert, so daß die zwei Programme vom funktionellen Standpunkt aus identisch sind.
Kettenoperatoren sollten benutzt werden, um die Lesbarkeit Ihres Programms zu verbessern. Die Verwendung des Kettenoperators ist in Listing 2.8 veranschaulicht.
Listing 2.8: Benutzung des Kettenoperators zur Vermeidung von Redundanz in der write-Anweisung
1 report ztx0208.2 tables ztxlfa1.3 select * from ztxlfa1 order by lifnr.4 write: / sy-dbcnt, ztxlfa1-lifnr.5 endselect.

6 write : / sy-dbcnt, 'records found'.
Der Programm-Code in Listing 2.8 erzeugt die gleiche Ausgabe wie das vorherige Programm (siehe die Ausgabe von Listing 2.7).
■ Zeile 4 verbindet die Zeilen 4 und 5 von Listing 2.7 mit Hilfe des Kettenoperators in eine Einzelzeile. ■ Zeile 6 verbindet die Zeilen 7 und 8 von Listing 2.7 in eine Einzelzeile, wobei diese den Kettenoperator benutzt.
Die select single-Anweisung
Die select single-Anweisung holt einen Satz aus der Datenbank. Wenn Sie den ganzen Primärschlüssel des Satzes wissen, den Sie auslesen wollen, ist select single viel schneller und effizienter als select/endselect.
Syntax für die select single-Anweisung
Hier sehen Sie die vereinfachte Syntax für die select single-Anweisung.
select * from t1-[into wa] [where f1 op v1 and/or f2-op v2 ...].
mit folgenden Bedeutungen:
■ * zeigt an, daß alle Felder in der Tabelle gelesen werden sollten. ■ t1 ist der Name einer Tabelle, die vorher über eine tables-Anweisung definiert wird. ■ wa ist der Name des Arbeitsbereichs, der zur Struktur der Tabelle paßt. ■ f1 ist der Name eines Felds in Tabelle t1.■ op ist eine der folgenden logischen Operatoren: = <> > >= < <=.■ v1 ist ein Literal oder eine Variable. ■ and/or ist entweder das Wort and oder das Wort or.
Dabei gelten die folgenden Punkte:
■ select single bildet keine Schleife, da es nur eine Zeile zurückliefert. Programmieren Sie deswegen keine endselect-Anweisung. Sie werden sonst einen Syntaxfehler bekommen.
■ Um sicherzustellen, daß nur eine einzige Zeile zurückgeliefert wird, sollten Sie alle Primärschlüsselfelder in der where-Klausel spezifizieren. Wenn Sie dies unterlassen, wird Ihr Programm zwar laufen, aber Sie erhalten eine Warnung. (Um die Warnungen anzuzeigen, wählen Sie den Menüpfad Programm->Prüfen->Warnungen anzeigen.)
Listing 2.9 illustriert die select single-Anweisung. Legen Sie übungshalber ein neues Programm an, und programmieren Sie, wie in Listing 2.9 gezeigt.
Listing 2.9: Die Anweisung select single
1 report ztx0209.2 tables ztxlfa1.3 select single * from ztxlfa1 where lifnr = 'V1'.4 if sy-subrc = 0.5 write: / ztxlfa1-lifnr, ztxlfa1-name1.6 else.7 write 'record not found'.8 endif.
Der Code in Listing 2.9 erzeugt diese Ausgabe:
V1 Quantity First Ltd.

Zeile 3 findet den Kreditor V1 in Tabelle ztxlfa1. Weil nur eine Zeile zurückgeliefert wird, werden order by und endselect nicht gebraucht.
Kommentarzeilen und formale Dokumentation
Es gibt zwei Möglichkeiten, Kommentare in Ihren Code zu schreiben:
■ Ein * (Sternzeichen) in Spalte 1 zeigt, daß die ganze Zeile ein Kommentar ist. Im Editor wird sie als Kommentarzeile rot angezeigt.
■ Ein " (Anführungszeichen) an beliebiger Stelle auf der Zeile zeigt an, daß der Rest der Zeile ein Kommentar ist. Der Kommentar wird nicht, wie ein Vollzeilenkommentar, rot angezeigt.
Zum Beispiel:
* This is a commenttables ztxlfa1. " This is also a comment
Es gibt kein Kommentar-Ende-Zeichen, d.h., wenn Sie einen Kommentar anfangen, wird der Rest der Zeile auch nur Kommentar sein. Keine andere Programmierung kann auf dieser Zeile folgen. Der Kommentar endet am Ende der gegenwärtigen Zeile.
Neben den Kommentaren können Sie Ihren Programm-Code formal mit der Dokumentationskomponente des Programms beschreiben. Dafür gehen Sie in den Editor, wählen die Option Dokumentation aus und gehen auf Ändern. Schreiben Sie Ihre Dokumentation, und sichern Sie sie.
Zusammenfassung
■ ABAP/4-Programme werden aus Komponenten zusammengesetzt. Die Komponenten sind Attribute, Quellcode, Varianten, Textelemente und Dokumentation. Ein Programm muß mindestens Attribute und Quellcode enthalten.
■ ABAP/4-Reports müssen mit den report-Anweisungen beginnen. ■ Die tables-Anweisung allokiert einen Vorgabetabellenarbeitsbereich und gibt dem Programm Zugriff auf die
Datenbanktabelle mit dem gleichen Namen. ■ Die select-Anweisung liest Zeilen aus einer Datenbanktabelle. Benutzen Sie select single, um eine Zeile
auszulesen. Benutzen Sie select/endselect, um mehrere Zeilen zu erhalten. ■ select/endselect bilden eine Schleife. Der Code in der Schleife wird einmal für jede Tabellenreihe
ausgeführt, die der where-Klausel genügt. Die Schleife endet automatisch, wenn alle Zeilen bearbeitet worden sind. Wenn Sie keine into-Klausel spezifizieren, wird jede Zeile in den Vorgabetabellenarbeitsbereich gestellt und die vorherige Zeile überschrieben. sy-subrc wird auf 0 gesetzt, wenn alle Zeilen und auf 4, wenn keine Zeile selektiert wurden. sy-dbcnt wird jedes Mal durch die Schleife um 1 hochgezählt. Nach endselect enthält sie die Anzahl der wiedergewonnen Zeilen.
■ Der Kettenoperator ist ein Doppelpunkt (:). Er wird benutzt, um die Redundanz zu verringern, wenn zwei oder mehr Anweisungen mit dem gleichen Wort oder der gleichen Wortfolge beginnen.
Fragen & Antworten
Frage:Was passiert mit meinen Änderungen, wenn ich beim Editieren eines Programms die Verbindung zu R/3 verliere, wenn ich z.B. nach einem PC-Absturz neu booten muß? Werde ich meine Änderungen verlieren?
Antwort:Wenn Sie sich innerhalb von 5 oder 10 Minuten wieder anmelden, können Sie in Ihren Modus zurückkehren (reconnect).

Wenn Sie sich wieder anmelden, geben Sie Ihre Benutzerkennung und das Paßwort ein, drücken aber nicht (Enter) auf der Anmeldemaske, sonder wählen stattdessen den Menüpfad Benutzer->Copy-Modus. Sie werden mit Ihrem bisherigen Modus wieder verbunden, und alles ist wiederhergestellt wie zuvor, als Sie die Verbindung verloren hatten.
Frage:Gibt es ein AutoSave im Editor wie in MS Word?
Antwort:Nein. Aber wenn Sie sichern wollen, drücken Sie (F11).
Frage:Manchmal, wenn ich ein Programm editiere, erhalte ich eine Dialogbox mit folgendem Text: »Das Programm wurde temporär gepuffert (möglicherweise wegen eines Systemfehlers). Wählen Sie eine der folgenden Möglichkeiten.« Warum sehe ich die Box, und was sollte ich tun?
Antwort:Das heißt, daß es zwei Kopien Ihres Programms im System gibt: das »wirkliche« und ein temporäres. Das temporäre wird angelegt, wenn Sie Ihr Programm ausführen, ohne es vorher gesichert zu haben. Normalerweise wird es gelöscht, wenn Sie zum Editor zurückkehren und Ihre Änderungen sichern, aber wenn Sie den Editor fehlerbedingt verlassen, bleibt es erhalten. Sie könnten z.B. Ihr Programm modifizieren und es dann sofort ohne Sicherung ausführen. Wenn Ihr Programm einen Abbruch verursacht, müssen Sie die Schaltfläche Exit drücken, und Sie werden zur Workbench zurückspringen. Ihr Editormodus wäre aufgelöst. Es gibt jetzt zwei Versionen Ihres Programms in der Datenbank: die geänderte Version (das, was Sie gerade ausführen) und das Original. Die geänderte Version wird unter einem temporären Namen gespeichert, bestehend aus einem ! und den letzten sieben Stellen Ihres Programmnamens. Wenn Sie jetzt zum Editor zurückkehren und versuchen, Ihr Programm wieder zu editieren, wird das System die Anwesenheit von beiden Versionen in der Datenbank entdecken und eine Dialogbox anzeigen, die Sie fragt, welche Version Sie editieren wollen, die gespeicherte oder die temporäre. Drücken Sie einfach auf die Schaltfläche Weiter, um die temporäre Kopie (das, was Sie ausführten) anzuzeigen.
Frage:Wenn ich ein ganzes Programm kopiere, hat die report-Anweisung noch den alten Reportnamen. Aber wenn ich es laufen lasse, läuft es ohne den Fehler. Sollte es mir keine Fehlermeldung geben?
Antwort:Der Programmname auf der report-Anweisung wird verlangt, aber er muß nicht zum eigentlichen Programmnamen passen. Er ist nur für Dokumentationzwecke bestimmt.
Frage:Jedesmal, wenn ich mich von R/3 abmelde, bekomme ich die Nachricht »Ungesicherte Daten können verlorengehen« - sogar, wenn ich alles gesichert habe. Warum?
Antwort:Trotz der Formulierung bedeutet diese Nachricht nicht, daß es nicht gesicherte Daten gibt, die verloren gehen werden. Es bedeutet »Wenn Sie Ihre Daten nicht gesichert haben, gehen sie verloren«. Das Beste, was Sie tun können, ist, die Meldung zu ignorieren, so wie jeder das tut.
Frage:Kann ich select-Anweisungen ineinander verschachteln?
Antwort:Ja, das können Sie. Sie sollten es aber nicht tun, weil es extrem unwirksam sein kann. Eine bessere Alternative ist es, view's zu benutzen.
Workshop

Die folgenden Übungen werden Ihnen Praxis im Umgang mit dem Editor vermitteln und helfen, einfache Programme mit Hilfe der Anweisungen write, tables und select zu schreiben. Die Antworten finden Sie in Anhang B (»Antworten zu Aufgaben und Übungen«).
Kontrollfragen
1. Welche zwei Dinge bewirkt die tables-Anweisung?
2. Worauf bezieht sich der Begriff Vorgabetabellenarbeitsbereich?
3. Was passiert mit den Zeilen, wenn in der select-Anweisung eine into-Klausel fehlt?
4. Wenn eine write-Anweisung keinen Slash (/) enthält, wird dann die Ausgabe in die gleiche Zeile geschrieben wie die vorherige write-Anweisung oder in eine neue Zeile?
5. Wie heißt die Systemvariable, welche anzeigt, ob Zeilen von der select-Anweisung gefunden wurden?
6. Wie heißt die Systemvariable, welche anzeigt, wie viele Zeilen von der select-Anweisung gefunden wurden?
7. Wie oft wird Zeile 4 ausgeführt, wenn es 30 Zeilen in Tabelle ztxlfa1 gibt (siehe Listing 2.6)?
8. Wie oft wird Zeile 4 ausgeführt, wenn Tabelle ztxlfa1 leer ist (siehe Listing 2.6)?
Editor Übungen
In der folgenden Übung werden Sie ein Programm kopieren, Fehler im Code beseitigen, neuen Code hinzufügen, es ausführen, drucken, importieren, exportieren, eine Version anlegen und Versionen vergleichen. Falls notwendig, sehen Sie in Tabelle 2.3 nach.
1. Kopieren Sie Programm zty0200a auf Programm ***0200a. Um zu kopieren, benutzen Sie die Schaltfläche Kopieren auf der Drucktastenleiste vom ABAP/4-Editor.
report zty0200a.select * from ztxlfa1.write / ztxlfa1-lifnr.endselect.endselect. " intentional duplicate line
report zty0200b.if sy-subrc <> 0.write: / 'no records found'.endif.
2. Editieren Sie Programm ***0200a. Korrigieren Sie den Reportnamen auf der report -Anweisung.
3. Fügen Sie eine neue Zeile nach Zeile 1 ein. Tippen Sie die entsprechende tables- Anweisung auf diese Zeile.
4. Rufen Sie die Hilfe für die tables-Anweisung auf. (Setzen Sie den Cursor auf die tables-Anweisung, und drücken Sie (F1).)
5. Gehen Sie von der Hilfe zurück zu Ihrem Programm. (Drücken Sie die Schaltfläche Zurück auf der Drucktastenleiste.)
6. Zeigen Sie die Funktionstastenzuweisungen an. (An beliebiger Stelle den Bildschirmbereich des Fensters mit der rechten

Maustaste anklicken.)
7. Bringen Sie Zeile 3 an den oberen Rand des Bildschirms. (Doppelklick auf ein Leerzeichen auf Zeile 3, nicht auf ein Wort.)
8. Löschen Sie Zeile 6. (Setzen Sie den Cursor auf Zeile 6, und drücken Sie auf die Schaltfläche Ausschneiden auf der Drucktastenleiste.)
9. Öffnen Sie einen neuen Modus und zeigen Programm zty0200b an. (Wählen Sie den Menüpfad System->Erzeugen Modus. Ein neues SAP-R/3-Fenster wird angezeigt. Wählen Sie den Menüpfad Werkzeuge->ABAP/4-Workbench. Sie kommen in die ABAP/4-Entwicklungsworkbench. Die ABAP/4-Editor-Schaltfläche auf der Drucktastenleiste drücken. Geben Sie im Feld Programmname zty0200b ein, und drücken Sie auf Anzeigen.)
10. Markieren Sie die Zeilen 2 bis 4 mit der Schaltfläche Auswahl. (Setzen Sie den Cursor auf Zeile 2. Drücken Sie auf die Schaltfläche Auswahl auf der Drucktastenleiste. Zeile 2 wird blau. Setzen Sie den Cursor auf Zeile 4. Drücken Sie wieder auf die Schaltfläche Auswählen. Zeilen 2 bis 4 werden blau markiert.)
11. Kopieren Sie den markierten Block in die Zwischenablage. (Wählen Sie den Menüpfad Block/Ablage, und kopieren Sie den Block in die Zwischenablage.)
12. Gehen Sie zurück zu dem Fenster, in dem Programm ***0200a angezeigt wird.
13. Fügen Sie die Zeilen aus der Zwischenablage hinter Zeile 5 ein. (Setzen Sie den Cursor auf Zeile 6. Wählen Sie den Menüpfad Block/Ablage: In die Zwischenablage einfügen.)
14. Markieren Sie den Block von Zeile 6 bis 8. (Setzen Sie den Cursor auf Zeile 6. Drücken Sie die Schaltfläche Auswahl auf der Drucktastenleiste. Setzen Sie den Cursor auf Zeile 8. Drücken Sie nochmals auf die Schaltfläche Auswahl.)
15. Bewegen Sie den Block vier Schritte nach links, indem Sie die if-Anweisung auf die select-Anweisung ausrichten. (Setzen Sie den Cursor auf Zeile 6 in Kolonne 1. Drücken Sie die Schaltfläche Zeilen Verschieben auf der Drucktastenleiste.)
16. Wählen Sie den Menüpfad Programm->Sichern als, und sichern Sie Ihr modifiziertes Programm unter ***0200b.
17. Rufen Sie Programm ***0200b auf, wobei Sie den Menüpfad Programm->Anderes Programm benutzen.
18. Korrigieren Sie den Programmnamen in der report-Anweisung. (Ändern Sie ***0200a auf Zeile 1 in ***0200b.)
19. Wählen Sie die Zeilen 3 bis 5. (Setzen Sie den Cursor auf Zeile 3. Drücken Sie die Schaltfläche Auswahl auf der Drucktastenleiste. Setzen Sie den Cursor auf Zeile 5. Drücken Sie abermals auf die Schaltfläche Auswahl.)
20. Kopieren Sie den ausgewählten Block in die programminterne Zwischenablage. (Drücken Sie auf die Schaltfläche Kopieren in Zwischenablage auf der Drucktastenleiste.)
21. Fügen Sie den gerade kopierten Block an das Ende Ihres Programms ein. (Setzen Sie den Cursor auf Zeile 9, und drücken Sie die Schaltfläche Einfügen auf der Drucktastenleiste.)
22. Fügen Sie denselben Block nochmals am Ende Ihres Programms ein. (Setzen Sie den Cursor auf Zeile 12, und drücken Sie die Schaltfläche Einfügen auf der Drucktastenleiste.)
23. Machen Sie die letzte Einfügung rückgängig. (Drücken Sie auf die Schaltflächen Rückgängig auf der Drucktastenleiste.)
24. Tippen Sie den folgenden Code in die Zeilen 12 bis 14. Beginnen Sie jede Zeile in Kolonne 1.

if sy-dbcnt > 0.write: / sy-dbcnt, 'records found'.endif.
25. Fixieren Sie die Einrückung automatisch, indem Sie den Menüpfad Programm- >Pretty-Printer wählen.
26. Sichern Sie Ihr Programm. (Drücken Sie auf die Schaltfläche Sichern.)
27. Gehen Sie zurück zum ABAP/4-Editor: Einstieg, und dokumentieren Sie Ihr Programm. (Drücken Sie auf die Schaltfläche Zurück auf der Symbolleiste. Wählen Sie die Option Dokumentation. Drücken Sie Ändern.)
28. Sichern Sie Ihre Dokumentation, und gehen Sie zurück, um den Quellcode zu editieren. (Drücken Sie die Schaltfläche Sichern, dann Zurück. Wählen Sie die Option Quellcode. Tippen Sie ***0200b in das Programmfeld. Drücken Sie auf Ändern.)
29. Zeigen Sie durch einen Doppelklick auf ein Sy-Feld die Bestandteile der SYST Struktur an. (Doppelklicken Sie auf das Wort sy-subrc in Zeile 6. Die SYST Struktur wird angezeigt.)
30. Kehren Sie zum Editieren Ihres Programms zurück. (Drücken Sie auf die Schaltfläche Zurück.)
31. Finden Sie das erste Auftauchen des String ztxlfa1 in Ihrem Programm. (Drükken Sie auf die Schaltflächen Finden. Die Suchen/Ersetzen-Maske wird angezeigt. Tippen Sie ztxlfa1 in das Feld Finden. Wählen Sie die Option From Line. Drükken Sie auf die Schaltfläche Weiter.)
32. Wiederholen Sie Finden für jedes Auftauchen, bis Sie alle Strings gefunden haben. (Drücken Sie so oft auf das Feld Weiter Suchen, bis die Nachricht »String write nicht gefunden« in der Statusleiste am unteren Rand des Fensters angezeigt wird.)
33. Fügen Sie den Tabellennamen ztxlfa1 der tables-Anweisung hinzu. (Verändern Sie die tables-Anweisung wie folgt: tables: ztxlfa1, ztxlfb1.)
34. Ersetzen Sie den String ztxlfa1 in den Zeilen 10 und 11 durch den String ztxlfb1 mit Hilfe der Funktion Suchen/Ersetzen. (Setzen Sie den Cursor auf Zeile 10. Drücken Sie die Schaltfläche Auswahl. Setzen Sie Ihren Cursor auf Zeile 11. Drücken Sie Auswahl. Die Zeilen 10 und 11 sind jetzt als ein Block rot markiert. Drücken Sie auf die Schaltfläche Finden. Die Suchen/Ersetzen-Maske wird angezeigt. Tippen Sie ztxlfa1 in das Feld Finden. Haken Sie Ersetze Durch an. Tippen Sie ztxlfb1 in das Feld Ersetze Durch. Drücken Sie auf die Schaltfläche Weiter. Die ABAP/4-Editor: Einstiegsmaske wird angezeigt. Drücken Sie auf die Schaltfläche Ohne Bestätigung. Jeder String innerhalb des markierten Blocks wurde ersetzt.)
35. Benutzen Sie eine Funktionstaste, um Ihr Programm zu sichern, und eine andere, um es auszuführen. (Drücken Sie (F11) und (F8).)
36. Sichern Sie die Listenausgabe in einer Datei auf Ihrer Festplatte mit dem Menüpfad Liste ->Sichern Datei. Benutzen Sie ein unkonvertiertes Format.
37. Zeigen Sie Ihre importierte Ausgabe unter Verwendung von Notepad an.
38. Kehren Sie zum Editieren Ihres Codes zurück. (Die Schaltfläche Zurück drücken.)
39. Importieren Sie Ihr Programm in die Datei c:\temp\020***0b.txt. (Wählen Sie den Menüpfad Hilfsmittel->Download. Die Übertragung auf eine lokale Dateimaske wird angezeigt. Tippen Sie C:\temp\***0200b.txt in das Feld Dateiname. Die Schaltfläche OK drücken. Die Nachricht »277 bytes transferred« erscheint in der Statusleiste am unteren Rand des Fensters.)

40. Editieren Sie Ihr importiertes Programm unter Verwendung von Notepad. Fügen Sie einen ganzzeiligen Kommentar mit Ihrem Namen hinter der report-Anweisung hinzu. (Fügen Sie eine neue Zeile hinter der report-Anweisung hinzu: *Angelegt von IHR_NAME.)
41. Tippen Sie die folgende Bemerkung hinter die erste select-Anweisung: »read all records from table ztxlfa1«.
42. Sichern Sie Ihr modifiziertes Programm in Notepad auf Diskette.
43. Exportieren Sie es, indem Sie das Programm ***0200b ersetzen. (Wechseln Sie zur Maske ABAP/4-Editor: Programm ***0200b editieren. Wählen Sie den Menüpfad Utilities->Upload. Der Import einer lokalen Dateimaske wird angezeigt. Tippen Sie in das Dateinamensfeld C:\temp\02***00b.txt. Drücken Sie die Schaltfläche OK.)
44. Sichern Sie das exportierte Programm. (Drücken Sie auf Sichern.)
45. Drucken Sie Ihr Programm aus. (Drücken Sie die Schaltfläche Drucken auf der Symbolleiste. Die Druckparametermaske wird angezeigt. Stellen Sie sicher, daß die Checkbox Sofort ausgeben ausgewählt ist. Wählen Sie Drucken. Ihre Ausgabe wird an den Drucker gesandt, und Sie kehren zum ABAP/4-Editor zurück.)
46. Lassen Sie Ihr Programm laufen und die Ausgabe drucken. (Wählen Sie den Menüpfad Programm->Ausführen. Die Listenausgabe wird angezeigt. Wählen Sie Drucken auf der Symbolleiste. Die Aufdruck-Masken-Listen-Maske wird angezeigt. Stellen Sie sicher, daß die Checkbox Sofortdruck angehakt ist. Drücken Sie auf die Schaltfläche Drucken. Sie kehren zu der Listenausgabe zurück.)
47. Kehren Sie zum Editierprogramm ***0200b zurück, und sichern Sie eine Version in der Datenbank Versionen. (Drücken Sie auf die Schaltfläche Zurück, um zur Maske ABAP/4-Editor: Programm editieren zu kommen. Wählen Sie den Menüpfad Programm->Version generieren.)
48. Ersetzen Sie den String ztxlfb1 durch ztxlfc3. (Drücken Sie auf die Schaltfläche Finden. Die Suchen/Ersetzen-Maske wird angezeigt. Tippen Sie ztxlfb1 in das Feld Finden. Kennzeichnen Sie Ersetzen durch. Tippen Sie ztxlfc3in das Feld Ersetze durch. Kennzeichnen Sie jetzt die übrigen Merkmale, die Sie benutzen wollen. Drücken Sie auf Keine Bestätigung. Alle Zeichenketten werden ersetzt. Drücken Sie Sichern und dann Zurück.
49. Sichern Sie Ihre Änderungen. (Die Schaltfläche Sichern betätigen.)
50. Kehren Sie zurück zur Editoreinstiegsmaske und vergleichen die beiden Versionen. (Wählen Sie Zurück. Die Maske ABAP/4-Editor: Einstieg wird angezeigt. Wählen Sie den Menüpfad Hilfsmittel->Versionsverwaltung. Die Maske Versionen des Objekts ***0200b vom Typ-REPS wird angezeigt. Haken Sie die Checkbox Version 00001 an. Drücken Sie auf die Schaltfläche Vergleichen auf der Symbolleiste. Die Maske Vergleichsprogramme: Alle wird angezeigt. Blättern Sie abwärts, um die Unterschiede anzusehen.)
51. Holen Sie die Originalfassung zurück. (Drücken Sie die Schaltfläche Zurück. Die Maske Versionen des Objekts ***0200b vom Typ-REPS wird angezeigt. Entfernen Sie den Haken von der Checkbox Akt.. Drücken Sie auf die Schaltfläche Zurückholen auf der Drucktastenleiste (das System stellt keine Antwort zur Verfügung). Wählen Sie Zurück. Die Maske Versionen Wiederherstellen wird angezeigt. Drükken Sie auf Ja. Die Maske Versionen des Objekts ***0200bvom Typ-REPS werden angezeigt. Drücken Sie auf Zurück. Die Maske ABAP/4-Editor: Einstieg wird angezeigt.)
52. Editieren Sie Ihr Programm und markieren die letzten drei Zeilen als einen Block. (Drücken Sie auf Ändern. Die Maske ABAP/4-Editor: Programm editieren wird angezeigt. Setzen Sie den Cursor auf Zeile 13. Drücken Sie die Schaltfläche Auswahl. Zeile 13 wird rot. Setzen Sie den Cursor auf Zeile 15. Drücken Sie Auswahl. Der Block wird rot markiert.)
53. Kommentieren Sie den Block, indem Sie den Menüpfad Block/Ablage->Kommentar * Einfügen benutzen.
54. Markieren Sie die letzten drei Zeilen als einen Block (siehe Schritt 51).

55. Entfernen Sie den Kommentar mit dem Menüpfad Block/Ablage->Kommentar * Entfernen.
Programmierübungen
1. Schreiben Sie ein Programm, das alle Zeilen aus der Tabelle ztxlfb1 liest, wobei der Firmencode größer/gleich 3000 ist. In jeder Ausgabezeile sollten zuerst ein Firmencode und danach eine Kreditorennummer stehen. Die Ausgabe sollte zuerst nach dem Firmencode in steigender Ordnung sortiert werden, dann durch die Kreditorennummer in absteigender Ordnung (Verwenden Sie die (F1)-Hilfe, um die richtige Syntax zu finden). Nennen Sie Ihr Programm ***e0201.Nachfolgend ein Beispiel, wie Ihre Ausgabe aussehen sollte.
1000 V91000 V81000 V62000 V9
2. Kopieren Sie das Programm zty0202 nach ***e0202 (das Listing erscheint unten). Es erzeugt keine Ausgabe. Finden Sie den Fehler, und korrigieren Sie ihn. Wenn Sie dies getan haben, sollte die richtige Ausgabe no records found sein.
1 report zty0202.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr like 'W%'.4 if sy-subrc <> 0.5 write / 'no records found'.6 endif.7 write / ztxlfa1-lifnr.8 endselect.
3. Kopieren Sie das Programm zty0203 nach ***e0203 (das Listing erscheint unten). Es enthält einen Syntaxfehler und einen Programmfehler. Korrigieren Sie beide. Dann sollten Kreditorennummern von Tabelle ztxlfa1 angezeigt werden, die größer als 1050 sind.
1 report zty0203.2 tables ztxlfa13 select * from ztxlfa1 where lifnr > '1050'.4 write / ztxlfa1-lifnr.5 endselect.
4. Kopieren Sie das Programm zty0204 nach ***e0204 (das Listing erscheint unten). Die Ausgabe ist falsch. Entdecken Sie den Fehler, und korrigieren Sie das Programm.
1 report zty0204.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr > '0000001050'.4 write / ztxlfa1-lifnr.5 endselect.6 if sy-dbcnt <> 0.7 write / 'no records found'.8 endif.
5. Kopieren Sie das Programm zty0205 nach ***e0205 (das Listing erscheint unten). Die Ausgabe ist falsch. Entdecken Sie den Fehler, und korrigieren Sie das Programm.
1 report zty0205.

2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr > '0000001050'.4 endselect.5 write / ztxlfa1-lifnr.6 if sy-subrc <> 0.7 write / 'no records found'.8 endif.
6. Kopieren Sie das Programm zty0206 nach ***e0206 (das Listing erscheint unten). Vereinfachen Sie das Programm durch Weglassen unnötiger Befehle und Worte.
1 report zty0206.2 tables: ztxlfa1, ztxlfb1, ztxlfc3.3 data wa like ztxlfb1.4 select * from ztxlfa1 into ztxlfa1.5 write / ztxlfa1-lifnr.6 write ztxlfa1-name1.7 endselect.8 if sy-subrc <> 0 or sy-dbcnt = 0.9 write / 'no records found in ztxlfa1'.10 endif.11 uline.12 select * from ztxlfb1 into wa.13 write / wa-lifnr.14 write wa-bukrs.
15 endselect.16 if sy-subrc <> 0.17 write / 'no records found'.18 endif.
7. Kopieren Sie das Programm zty0207 nach ***e0207 (das Listing erscheint unten). Es enthält sowohl einen Syntax- als auch einen Programmierfehler. Entdecken Sie die Fehler, und korrigieren Sie das Programm. Die Ausgabe sollte einen einzelnen Satz (Kreditor 1000) anzeigen, wobei sie die rationellste Programmierkonstruktion benutzt.
1 report zty0207.2 tables ztxlfa1.3 select single * from ztxlfa1 where lifnr > '0000001000'.4 write / ztxlfa1-lifnr.5 endselect.6 if sy-subrc <> 0.7 write / 'no records found'.8 endif.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 3
Das Data Dictionary ®, Teil 1
Kapitelziele
Wenn Sie sich dieses Kapitel erarbeitet haben, sollten Sie folgendes können:
■ die Unterschiede zwischen transparenten, Pool- und Clustertabellen beschreiben ■ Domänen, Datenelemente und transparente Tabellen im Data Dictionary einrichten ■ (F1)-Hilfe für die Tabellenfelder und Hypertexte innerhalb der (F1)-Hilfe einrichten ■ die vier von SAP bereitgestellten Datenbrowser benutzen, um Daten in Tabellen anzusehen und zu
modifizieren
R/3-Release-Stände
Heutzutage sind viele Versionen von R/3 - auch Release-Stände genannt - in Anwendung. Seit seiner Einführung hat SAP die verschiedensten Versionen (z.B. 2.2x, 3.0.x, 3.1.x, 4.0x) herausgebracht. Sie können den Release-Stand Ihres Systems feststellen, indem Sie den Menüpfad System->Status benutzen.
Dieses Buch wurde auf einem 3.0f-System erstellt und mit 4.0b überarbeitet. Ihr System kann auf einem anderen Systemstand sein. Obwohl die meisten Unterschiede bei den Themen, die hier behandelt werden, gering sein sollten, können einige Unterschiede zu Verwirrung führen oder die Information in diesem Buch als falsch erscheinen lassen. Es können sich z.B. Menüpfade zwischen Release-Ständen ändern. Aber wenn die Funktionalität Ihres Systems sich von dem zu unterscheiden scheint, was hier beschrieben wird, können Sie auf die R/3-Release-Informationen zurückgreifen, die online verfügbar sind, um zu entscheiden, ob der Unterschied dem Release zuzuordnen ist. Gehen Sie folgendermaßen vor, um auf die Release-Information zuzugreifen:
Starten Sie jetzt das ScreenCam »How to Display R/3 Release Notes«.
Um die Release-Information anzuzeigen:
1. Gehen Sie zum Hauptmenü und wählen Sie den Menüpfad Werkzeuge->Suchen ->Informationssystem->Release-Infos.
2. Die Release-Informationsmaske wird angezeigt.

3. Wenn Sie Informationen zum Release 3.0x suchen, klicken Sie auf das Pluszeichen (+), um den Knoten aufzublättern. Änderungen zu ABAP werden unter dem Basisknoten angezeigt, unter dem Unterknoten ABAP/4-Development Workbench.
Tiefer im R/3-Data Dictionary stöbern
Bitte nehmen Sie sich jetzt ein paar Minuten Zeit, und lesen Sie noch einmal den Abschnitt »Einführung des R/3-Data Dictionary« im Kapitel Tag 2.
Data Dictionary-Objekte werden in den meisten ABAP/4-Programmen benutzt. Die Verklammerungsnatur von ABAP/4-Programmen und DDIC-Objekten macht gründliches Wissen des R/3-Data Dictionary zu einer wesentlichen Grundlage der Programmierfähigkeit. Mit diesem Kapitel beginnen Sie zu lernen, wie man DDIC-Objekte wie Tabellen, Datenelemente und Domänen einrichtet.
Viele Entwicklungsobjekte, die in diesem Buch als Beispiel verwendet werden (wie Tabellen, Domänen und Datenelemente), basieren auf aktuellen Entwicklungsobjekten im R/3-System. Die Beispielobjekte haben die selben Namen wie die aktuellen R/3- Objekte, allerdings mit dem Präfix ztx. Lfa1 ist zum Beispiel eine reale Tabelle in R/ 3, und die Beispielstabelle in diesem Buch ist ztxlfa1.
Die verschiedenen Tabellentypen in R/3
In R/3 gibt es drei verschiedene Tabellentypen: transparente Tabellen, Pool- und Clustertabellen. Sie sehen sie in Abb. 3.1.

Transparente Tabellen
Eine transparente Tabelle im Wörterbuch hat eine Eins-zu-eins-Beziehung zu einer Tabelle in der Datenbank. Ihre Struktur im R/3-Data Dictionary entspricht einer einzelnen Datenbanktabelle. Für jede Definition einer transparenten Tabelle im Wörterbuch gibt es eine entsprechende Tabelle in der Datenbank. Die Datenbanktabelle hat den gleichen Namen, die gleiche Feldanzahl, und die Felder haben den gleichen Namen wie die R/3-Tabellendefinition. Wenn Sie sich die Definition einer transparenten Tabelle in R/3 ansehen, könnten Sie glauben, Sie sähen die Datenbanktabelle selbst.
Transparente Tabellen sind weitaus gebräuchlicher als Pool- oder Clustertabellen. Sie werden für Anwendungsdaten benutzt. Anwendungsdaten sind Stammdaten oder Bewegungsdaten, die von einer Anwendung benutzt werden. Ein Beispiel für Stammdaten ist die Kreditorentabelle (genannt: Kreditorenstammdaten) oder die Kundentabelle (genannt: Kundenstammdaten). Ein Beispiel für Bewegungsdaten: die Bestellungen von Kunden oder bei Kreditoren.
Transparente Tabellen sind wahrscheinlich der einzige Tabellentyp, den Sie jemals anlegen werden. Pool- und Clustertabellen werden üblicherweise nicht für Anwendungsdaten, sondern für Systemdaten benutzt, wie Systemkonfigurationsinformationen oder historische und statistische Daten.
Sowohl Pool- als auch Clustertabellen haben mehr als eine Beziehung mit Datenbanktabellen. Beide können in R/3 als mehrere Tabellen erscheinen, aber in der Datenbank werden sie als einzelne Tabelle gespeichert. Die Datenbanktabelle hat einen anderen Namen, eine andere Feldanzahl und andere Feldnamen als die R/3-Tabelle. Der Unterschied zwischen den beiden Arten liegt in den Merkmalen ihrer Daten und wird in den folgenden Abschnitten erklärt.
Tabellenpools und Pooltabellen

Eine Pooltabelle in R/3 hat eine n-zu-1-Beziehung mit einer Tabelle in der Datenbank (s. Abb. 3.1 und 3.2). Für eine Tabelle in der Datenbank gibt es viele Tabellen im R/3- Data Dictionary. Die Tabelle in der Datenbank hat einen anderen Namen als die Tabelle im DDIC, eine andere Feldanzahl, und die Felder haben auch andere Namen. Pooltabellen sind ein proprietäres SAP-Konstrukt.
Wenn Sie sich eine Pooltabelle in R/3 ansehen, sehen Sie die Beschreibung einer Tabelle. In der Datenbank wird sie allerdings mit anderen Pooltabellen zusammen in einer einzelnen Tabelle gespeichert, Tabellenpool genannt. Ein Tabellenpool ist eine Datenbanktabelle mit einer besonderen Struktur, in der die Daten vieler R/3-Tabellen gespeichert werden können. Er kann nur Pooltabellen enthalten.
R/3 verwendet Tabellenpools, um eine Vielzahl (Zehntausende) sehr kleiner Tabellen (mit jeweils ungefähr 10 bis 100 Zeilen) zusammenzuhalten. Tabellenpools reduzieren die Menge an Datenbankressourcen, die benötigt werden, wenn viele kleine Tabellen gleichzeitig geöffnet sein müssen. SAP benutzt sie für Systemdaten. Sie sollten einen Tabellenpool einrichten, wenn Sie Hunderte kleiner Tabellen einrichten müssen, von denen jede einzelne nur wenige Zeilen lang ist. Um diese kleinen Tabellen als Pooltabellen zu implementieren, legen Sie zuerst die Definition eines Tabellenpools in R/3 an. Daraufhin wird jede einzelne Tabelle (der Tabellenpool) in der Datenbank eingerichtet. Sie können dann Pooltabellen innerhalb von R/3 definieren und alle Ihrem Tabellenpool zuweisen (s. Abb. 3.2).
Pooltabellen werden von SAP primär für Kundendaten benutzt.
Wenn eine Firma ein großes System installiert, wird das System auf die eine oder andere Art speziellen Bedürfnissen angepaßt, um den firmenspezifischen Anforderungen gerecht zu werden. Solche Anpassungen (Customizing) werden in R/3 mit Customizing- Tabellen gemacht. Customizing-Tabellen enthalten Codes, Feldwerte, Zahlenbereiche und Parameter, die sich so verändern, wie sich die R/3-Anwendungen verhalten.

Abbildung 3.1: Pooltabellen haben eine n-zu-1-Beziehung mit Tabellenpools.
Einige Beispiele von Daten, die in Customizing-Tabellen enthalten sind, sind Länderkennzahlen, Postleitzahlen, Abrechnungsnummern, Wechselkurse, Abschreibungsmethoden und Preiskonditionen. Selbst Maskendurchflüsse, Feldwerte und individuelle Feldattribute sind manchmal tabellengesteuert durch Settings in Customizing-Tabellen.
Während der Einführungsphase des Systems werden die Daten in den Customizing- Tabellen von einem Funktionsanalytiker eingesetzt. Er oder sie wird Erfahrungen bezüglich des Geschäftsbereichs, der implementiert wird, und eine weitreichende Ausbildung in der Konfiguration eines R/3-Systems haben.
Tabellencluster und Clustertabellen
Eine Clustertabelle ist einer Pooltabelle ähnlich. Auch sie hat eine n-zu-1-Beziehung mit einer Tabelle in der Datenbank. Viele Clustertabellen sind in einer einzelnen Tabelle in der Datenbank gespeichert, die Tabellencluster heißt.
Ein Tabellencluster ähnelt einem Tabellenpool Er enthält viele Tabellen, die alle Clustertabellen sind.
Wie Pooltabellen sind auch Clustertabellen ein proprietäres SAP-Konstrukt. Sie werden benutzt, um einige sehr große Tabellen (ungefähr 2 bis 10) zusammenzufassen, die einen Teil ihres Primärschlüssels gemeinsam haben und auf deren Daten simultan zugegriffen wird. Die Daten sind logisch gespeichert, wie in Abbildung 3.3 gezeigt

wird.
Tabellencluster enthalten weniger Tabellen als Tabellenpools, und der Primärschlüssel jeder Tabelle beginnt, im Gegensatz zu Tabellenpools, innerhalb des Tabellenclusters mit dem gleichen Feld oder den gleichen Feldern. Zeilen der Clustertabellen werden im Tabellencluster auf der Basis des gemeinsamen Primärschlüssels zu einer einzelnen Zeile kombiniert. Wenn eine Zeile von irgendeiner Tabelle im Cluster gelesen wird, werden auch alle zugehörigen Zeilen in allen Clustertabellen gefunden, aber es wird nur ein einziger I/O benötigt.
Ein Cluster ist in dem Fall von Vorteil, wo auf Daten simultan von vielen Tabellen zugegriffen wird, und diese Tabellen mindestens eines ihrer Primärschlüsselfelder gemeinsam haben. Clustertabellen reduzieren die Anzahl von Datenbanklesezugriffen und verbessern dadurch die Leistung.
Abbildung 3.2: Tabellencluster enthalten Daten verschiedener Tabellen, basierend auf dem Primärschlüsselfeld, welches sie gemeinsam haben.
Wie z.B. in Abbildung 3.4 gezeigt wird, sind die ersten vier Primärschlüsselfelder in cdhdr und cdposidentisch. Sie werden für den Tabellencluster zum Primärschlüssel mit dem Zusatz eines standardmäßigen Systemfelds pageno, um sicherzustellen, daß jede Zeile eindeutig ist.

Abbildung 3.3: Den Tabellen cdhdr und cdpos sind die ersten vier Primärschlüsselfelder gemeinsam, die immer zusammen aufgerufen werden, so daß sie beide gemeinsam im Tabellencluster cdcls gespeichert sind.
Oder nehmen wir zum Beispiel einmal an, daß die Daten von Orderheader- und Order-Itemtabellen immer gleichzeitig benötigt werden und beide einen Primärschlüssel haben, der mit der Ordernummer beginnt. Sowohl der Header als auch die Items können in einer einzelnen Clustertabelle gespeichert werden, weil das erste Primärschlüsselfeld gleich ist. Wenn eine Header Zeile gelesen wird, die als Cluster implementiert wurde, werden auch alle Items Zeilen gelesen, weil sie alle in einer einzelnen Zeile im Tabellencluster gespeichert sind. Wenn ein einzelnes Item gelesen wird, werden auch der Header und alle anderen Items gelesen, weil sie in einer einzelnen Zeile gespeichert sind.

Beschränkungen von Pool- und Clustertabellen
Pool- und Clustertabellen werden üblicherweise nur von SAP und nicht von Kunden benutzt, wahrscheinlich wegen des proprietären Formats der Tabellen innerhalb der Datenbank und wegen der technischen Beschränkungen innerhalb des Gebrauchs mit ABAP/4-Programmen. Für Pool- oder Clustertabellen gilt:
■ Sekundärindizes können nicht eingerichtet werden. ■ Die ABAP/4-Konstrukte select distinct und group by können nicht benutzt werden. ■ Sie können kein Native SQL verwenden. ■ Sie können Feldnamen nach der Klausel order by nicht spezifizieren, order by primary key ist
die einzig zugelassene Variante.
Die Verwendung von Pool- und Clustertabellen kann Ihre Firma davor bewahren, Reporthilfsmittel in vollem Umfang von dritter Seite benutzen zu müssen, wenn sie Datenbanktabellen direkt lesen, weil Pool- und Clustertabellen ein proprietäres SAP-Format haben. Wenn Ihre Firma solche Hilfsmittel von Dritten benutzen möchte, sollten Sie vielleicht nach Alternativen suchen, bevor Sie Pool- und Clustertabellen anlegen.
Wegen dieser Beschränkungen der Pool- und Clustertabellen und wegen ihres begrenzten Nutzens konzentriert sich dieses Buch auf Anlage und Anwendung von transparenten Tabellen. Die Anlage von Pool- und Clustertabellen wird nicht behandelt.
Tabellenkomponenten
Sie wissen jetzt, was transparente Tabellen sind, und Sie kennen den Unterschied zwischen transparenten, Pool- und Clustertabellen. Jetzt lernen Sie die Komponenten kennen, die benötigt werden, um Tabellen anzulegen.
Eine Tabelle besteht aus Feldern. Um ein Feld anzulegen, benötigen Sie ein Datenelement. Das Datenelement enthält die Feldkennungen und Online-Dokumentation (auch (F1)-Hilfe genannt) für das Feld. Es ist ausschließlich beschreibend; es enthält semantische Merkmale für das Feld, auch bekannt unter »business context«. Die Kennsätze, die Sie innerhalb eines Datenelements zur Verfügung stellen, werden auf der Maske neben einem Eingabefeld angezeigt. Das Datenfeld enthält auch eine Dokumentation, die angezeigt wird, wenn der Anwender durch Drücken der (F1)-Taste nach Hilfe für dieses Feld fragt.
Die Definition eines Datenelements erfordert eine Domäne (s. Abb. 3.5). Die Domäne enthält die technischen Merkmale eines Felds wie Feldlänge und Datentyp.

Abbildung 3.4: Tabellen bestehen aus Feldern, die ihrerseits aus Datenelementen bestehen, welche wiederum aus Domänen bestehen.
Domänen und Datenelemente sind wiederverwendbar. Eine Domäne kann in mehr als einem Datenelement verwendet werden und ein Datenelement in mehr als einem Feld und einer Tabelle.
Stellen Sie sich z.B. vor, Sie müßten eine Kundeninformationstabelle namens zcust erstellen, die Büro-, Fax- und Privatrufnummern enthalten soll (s. Abb. 3.6).
Abbildung 3.5: Ein Beispiel, in dem Tabellen, Datenelemente und Domänen verwendet werden.
Um ein Feld anzulegen, beginnen Sie normalerweise damit, eine Domäne zu erstellen. Sie könnten in diesem Fall eine generische Rufnummerndomäne anlegen, sie zphone nennen und ihr den Datentyp CHAR mit einer Länge von 12 geben. Sie könnten die meisten Rufnummern mit dieser generischen Rufnummerndomäne speichern und auch bestimmte Rufnummernarten wie »Fax« oder »Privat« definieren.
Um nach der Anlage der Domäne die ausschließlich technische Beschreibung eines Feldes zu halten, können Sie ein Datenelement anlegen, um die beschreibenden Attribute des Felds zu halten. In das Datenelement müssen Sie den Namen einer Domäne eintragen, um ihm die technischen Merkmale zu geben.
Dann geben Sie die Kennsätze und die Dokumentation (F1)-Hilfe ein, um die Daten zu beschreiben, die Sie

speichern wollen. In diesem Beispiel würden Sie wahrscheinlich drei Datenelemente anlegen, je eines für die Privat-, Büro- und Faxnummer. In jedes Datenelement würden Sie Feldkennungen eintragen, welche die Art der Telefonnummern beschreiben, die Sie damit speichern wollen, und die (F1)-Hilfe für den Endbenutzer.
Nach den Datenelementen können Sie jetzt die Tabelle anlegen. Sie könnten drei Telefonnummernfelder in der Tabelle einrichten (Privat, Büro, Fax) und jedem Feld das entsprechende Datenelement zuweisen. Ein Datenelement ist jedem Feld zugewiesen. Dies gibt dem Feld beschreibende Information vom Datenelement und technische Information von der Domäne, die sich darauf bezieht. Wenn das Feld in einer Maske benutzt wird, erhält es einen Kennsatz und (F1)-Hilfe-Dokumentation vom Datenelement und sowohl seine Länge als auch den Datentyp von der Domäne innerhalb des Datenelements.
Ein anderes Beispiel: Sie müssen den Namen einer Person in drei verschiedenen Tabellen speichern: als Kunden, als Kreditoren und als Angestellten. In der Kundentabelle wollen Sie einen Kundennamen speichern, in der Kreditorentabelle den Kreditornamen und den Angestelltennamen in der Angestelltentabelle. Weil es eine gute Idee ist, allen Personennamensfeldern den gleichen Datentyp und die gleiche Länge zu geben, können Sie eine einzelne generische Personennamensdomäne einrichten, zum Beispiel zpersname. Dann können Sie ein Datenelement für jeden Geschäftsgebrauch vom Namen einer Person einrichten: für den Kundennamen, den Kreditornamen und den Angestelltennamen. Innerhalb jeden Datenelements beziehen Sie sich immer auf Ihre zpersname-Domäne, um allen die gleichen Merkmale zu geben. Sie können dann diese Datenelemente benutzen, um Felder innerhalb jeder Tabelle einzurichten.
Technische Merkmale von Feldern pflegen
Wenn Sie die Länge des Feldes ändern müssen, nachdem Sie die Tabelle angelegt haben, brauchen Sie diese nur in der Domäne ändern. Wenn die Domäne in mehr als einer Tabelle benutzt wird, wird die Änderung automatisch in allen Feldern wirksam, die diese Domäne benutzen.
Wenn zum Beispiel der Geschäftsanalytiker verlangt, daß Sie die Länge Ihres Personennamensfelds von 12 auf 15 abändern, verändern Sie einfach die Länge in der zpersname-Domäne. Wenn Sie Ihre Änderung aktivieren, werden sich die Längen von allen Namensfeldern, die auf dieser Domäne basieren (Kunden-, Kreditoren-, Angestelltentabelle), ebenfalls verändern.
Wann werden Domänen und Datenelemente angelegt oder wiederverwendet?
In jedem R/3-System existieren bereits mehr als 13.000 Domänen, die von SAP angelegt wurden. Wenn Sie ein neues Feld anlegen, müssen Sie sich entscheiden, ob Sie eine neue Domäne anlegen oder eine bereits existierende verwenden. Um diese Entscheidung zu treffen, legen Sie fest, ob der Datentyp oder die Feldlänge von einem bestehenden SAP-Feld abhängig sein soll. Wenn Ihr Feld unabhängig sein soll, richten Sie eine neue Domäne ein. Wenn Ihr Feld abhängig sein soll, verwenden Sie eine bestehende SAP-Domäne. Entsprechend sollten Sie Datenelemente wiederverwenden, so sich Ihre Feldkennungen und Ihre Dokumentation dann verändern sollen, wenn sich diese auch bei SAP verändern.
Nehmen wir an, Sie wollen zum Beispiel eine neue Tabelle anlegen, die zusätzliche Kreditorinformationen enthalten soll. Wenn Sie die Tabelle anlegen, müssen Sie die Kreditoren in Ihrer Tabelle mit denen in der SAP-Tabelle verbinden.
Legen Sie einen Primärschlüssel in Ihrer Tabelle an, der die Kreditorennummer enthält. Benutzen Sie das bestehende Datenelement, um Ihr Feld einzurichten. Beide Tabellen werden jetzt in das SAP-

Kreditorennummernfeld eingegeben, wobei die gleichen Datenelemente und Domänen benutzt werden. Wenn sich bei SAP der Datentyp oder die Länge eines Feldes verändert, werden sich Ihre automatisch mit verändern.
Namenskonventionen für Tabellen und ihre Komponenten
Tabellen, Datenelemente und Domänen, die am Kundenstandort angelegt werden, müssen den SAP-Namenskonventionen für Kundenobjekte folgen. Diese werden in Tabelle 3.1 gezeigt.
Tabelle 3.1: Namenskonventionen für Tabellen, Felder, Datenelemente und Domänen, eingerichtet vom Kunden
Objekttyp Max. Namenslänge (bis Version 4.0x) Erlaubtes erstes Zeichen
Tabelle 10 y, z
Datenelement 10 y, z
Domäne 10 y, z
Feld 10 Jedes Zeichen
Alle Namen sind bis zur Version 4.0 maximal 10 Zeichen lang.
Die Namen aller Tabellen, Domänen und Datenelemente, die Sie anlegen, müssen mit y oder z beginnen. Sie können kein anderes Zeichen für den Anfang benutzen; alle anderen sind belegt von SAP. Das R/3-System erzwingt diese Konvention; Sie erhalten eine Fehlermeldung, wenn Sie versuchen, ein Objekt mit einem Namen anzulegen, der diesen Konventionen nicht entspricht.
Feldnamen können mit jedem Zeichen anfangen. Gewisse Worte sind allerdings vorbesetzt und können nicht als Feldnamen belegt werden. Die DDIC-Tabelle trese enthält die vollständige Auflistung der reservierten Worte. Der Inhalt von trese kann angezeigt werden, indem man die Prozedur von Tag 2 im Abschnitt »Daten in der Tabelle anzeigen« ausführt.
Anlegen einer transparenten Tabelle und ihrer Komponenten
In den folgenden Abschnitten werden Sie Domänen, Datenelemente und schließlich Ihre erste transparente Tabelle anlegen - es wird eine kleine Version der von SAP gelieferten Kreditorenstammtabelle lfa1 sein.
Für den Zweck dieses Buches stellen Sie sich bitte vor, daß das R/3-System bisher noch keine Kreditorenstammdaten gespeichert hat. Stellen Sie sich auch vor, die Tabelle lfa1 würde noch

nicht existieren, auch nicht ihre Datenelemente oder Domänen. Deshalb werden wir sie in diesen Übungen anlegen.
Um Kreditorenstamminformationen zu speichern, müssen Sie die Tabelle ***lfa1 anlegen. Sie enthält Felder für eine Kreditornummer, einen Namen, eine Postleitzahl und eine Länderkennzahl. Die Feldnamen und technischen Merkmale, die Sie verwenden werden, sind in Tabelle 3.2 aufgeführt. Ein x in der Spalte PK zeigt Felder, die den Primärschlüssel bilden. (Die Installationsprozedur hat eine Tabelle namens ztxlfa1 in Ihrem R/3-System angelegt. Sie ist der ***lfa1-Tabelle sehr ähnlich. Verwenden Sie diese als Referenz, während Sie dieses Kapitel lesen.)
Tabelle 3.2: Felder und ihre Merkmale für Tabelle ***lfa1
Feldname PK DE Name DM Name Datentyp Länge
mandt x mandt
lifnr x ***lifnr ***lifnr CHAR 10
name1 ***name1 ***name CHAR 35
regio ***regio ***regio CHAR 3
land1 ***land1 ***land1 CHAR 3
Diese Feldnamen und ihre technischen Merkmale basieren auf den aktuellen Feldern der Tabelle ***lfa1.
Ändern Sie nicht die oben verwendeten Namen. Die Übungen später in diesem Buch beziehen sich auf diese Feldnamen. Wenn Sie nicht die genauen Namen verwenden, werden die nachfolgenden Übungen nicht funktionieren.
Da diese Tabelle Anwendungsdaten enthält, sollte sie mandantenabhängig sein. Das erste Feld muß daher mandt sein (Gehen Sie zurück zu Kapitel 1, wenn Sie sich noch einmal über mandantenabhängige Tabellen informieren möchten).
Anlegen von Tabellen
Es gibt zwei Möglichkeiten, Tabellen anzulegen:
■ von unten nach oben (Methode 1) ■ von oben nach unten (Methode 2)
Wenn man von unten nach oben anfängt, legt man zuerst die Domänen an, dann die Datenelemente und dann die Tabelle.

Im umgekehrten Fall wird zuerst die Tabelle angelegt, dann die Datenelemente und dann die Domänen.
Die erste Methode ist für den Anfänger intuitiver, wird aber auch schnell hinderlich. Die zweite Methode ist viel leichter zu benutzen, wenn man sich etwas mit dem Anlegen von Tabellen vertraut gemacht hat. Aus diesen Gründen werde ich beide Verfahren erläutern. Auf den folgenden Seiten werden Sie zuerst etwas über ein Objekt ,wie z.B. eine Domäne, lernen, und dann werden Sie eines anlegen. Die Objekte, die Sie einrichten werden, sind beschrieben in Tabelle 3.2.
Denken Sie daran, immer Ihr persönliches Kennzeichen (***) als die ersten drei Zeichen eines Objektnamens zu verwenden, wenn Sie irgendein Objekt in diesem Buch anlegen. (Die Zeichen *** repräsentieren Ihr persönliches Kennzeichen und wurden in Kapitel 2 »Programmnamenskonventionen« vorgestellt)
Benutzen Sie nicht ztx als erste drei Zeichen, denn dann wird es sehr schwierig werden, zu bestimmen, welches Ihre Objekte sind.
Aktivierung von DDIC-Objekten
Bevor Sie sich etwas gründlicher mit DDIC-Objekte befassen, sollten Sie etwas über Objektaktivierung wissen. Die Aktivierung bezieht sich auf alle Dictionary-Objekte.
Nachdem Sie ein Data Dictionary-Objekt angelegt haben, müssen Sie es aktivieren. Ein Objekt zu aktivieren ist einfach: Sie müssen nur auf die Schaltfläche Aktivieren drücken. Damit ändern Sie den Status des Objekts auf Aktiv.
Ein Objekt muß aktiv sein, bevor es benutzt werden kann. Sollten Sie versuchen, ein inaktives Datenelement zu benutzen, wenn Sie ein Feld einrichten, werden Sie zum Beispiel eine Meldung bekommen, die sagt, daß das Datenelement nicht existiert oder nicht aktiv ist. Ihre Reaktion würde sein, das Datenelement zu aktivieren.
Wenn Sie ein Objekt wechseln, müssen Sie es für die Änderungen nochmals aktivieren, damit diese wirksam werden. Wenn Sie die Änderungen sichern, aber nicht aktivieren, »wissen« die Objekte nichts von den Änderungen.
Domänen
Bevor ich eine Domäne einrichte, beschreibe ich die Maske, die Sie zum Anlegen benutzen.
In Abbildung 3.7 sehen Sie die Maske, die Sie benutzen werden, um eine Domäne einzurichten: Dictionary: Domäne Pflegen. Auf dieser Maske geben Sie eine Kurzbeschreibung, den Datentyp, die Zahl der Stellen und optional eine Ausgabelänge ein. Diese Punkte sind in den folgenden Abschnitten erklärt.
Abbildung 3.6: Domäne Pflegen wird zum Anlegen einer Domäne verwendet.
Kurzbeschreibung
Das Textfeld enthält eine Beschreibung der Domäne. Der Endbenutzer sieht sie nie; sie wird nur Entwicklern angezeigt. Sie sehen sie, wenn Sie eine Liste von Domänen aufrufen oder wenn Sie eine Domäne suchen.
In diesem Feld werden Sie die Art von Daten beschreiben, die für die Domäne vorgesehen sind. Zum Beispiel würde die Beschreibung einer wiederverwendbaren Rufnummerndomäne »generische Rufnummer« oder »allgemeine Rufnummer« sein.
Es ist überflüssig, das Wort »Domäne« an das Ende einer Kurzbeschreibung zu setzen. Zum Beispiel sollte die Bezeichnung »Generische Telefonnummerndomäne« vermieden werden; schreiben Sie einfach »Generische Telefonnummer«.
Das Datentypfeld
Das Datentypfeld gibt die Darstellung an, die intern von der Datenbank benutzt wird, um den Wert für dieses Feld zu speichern. Für einige Datentypen bestimmt es die Eingabeformatprüfung und das Ausgabeformat des

Feldes. Felder vom Datentyp DATS (Datum) und TIMS (Zeit) sind zum Beispiel automatisch mit Trennzeichen formatiert, wenn man eine Liste ausdruckt oder sie auf dem Bildschirm anzeigt. Sie müssen im Datums- oder Zeitformat eingegeben werden, oder eine Fehlermeldung wird dem Anwender angezeigt.
Die üblicherweise am meisten benutzten Datentypen sind in Tabelle 3.3 aufgelistet.
Tabelle 3.3: Gebräuchliche Datentypen
Typ Beschreibung
CHAR Zeichenketten (maximal 255 Zeichen)
DEC Dezimalwerte (maximal 31 Stellen)
DATS Datenfeld
TIMS Zeitfeld
INT1, INT2, INT4 Integer-Werte
NUMC Feld mit ausschließlich numerischen Zeichen
Sie sollten immer die Entertaste drücken, wenn Sie das Datentypenfeld ausgefüllt haben. Durch Betätigen der Entertaste wird die Maske verändert, basierend auf dem Datentyp, den Sie bestimmt haben. Wenn der Datentyp numerisch ist, erscheint eine Zeichencheckbox. Für Felder mit Dezimalstellen wird ein Feld Dezimalstellen angezeigt, für Zeichenfelder sehen Sie die Checkbox Kleinbuchstaben auf der Maske.
Zahl der Stellen, Dezimalstellen und Kleinbuchstaben
Das Ausgabelängenfeld zeigt die Anzahl von Bytes an, die benötigt werden, um das Feld in einer Liste oder einer Maske auszugeben, einschließlich Kommata, Dezimalpunkt, Vorzeichen und allen anderen Formatierungszeichen. Bei der Ausgabe sind Datum und Zeitfelder zum Beispiel durch Trennzeichen automatisch formatiert. Ein Datum wird intern als acht Zeichen gespeichert (immer JJJJMMTT), aber die Ausgabelänge in der Domäne sollte mit 10 angegeben werden, damit zwei Trennelemente eingefügt werden können. Wenn das Ausgabelängenfeld leer bleibt, werden die Werte automatisch vom System beim Drücken der Entertaste errechnet.
Für dezimale Felder können Sie die Anzahl von Dezimalstellen im Dezimalstellenfeld angeben.
Zeichenfelder werden üblicherweise in Großbuchstaben umgewandelt, bevor sie in der Datenbank gespeichert werden. Diese Konvertierung kann durch die Häkchenmarkierung im Feld Kleinbuchstaben verhindert werden.
Die meisten Entwickler haben keine Probleme, die interne Darstellung von Zeichen oder Ganzzahlfeldern zu verstehen. Der Standort des Dezimalpunkts in dezimalen Feldern ist allerdings oft verwirrend, so daß er hier erklärt wird.

Für Felder vom Typ DEC ist der Dezimalpunkt nicht in der Datenbank gespeichert. Nur der numerische Teil ist gespeichert, nicht der dezimale. Bei der Ausgabe wird die Position der Dezimalzahl von dem Wert bestimmt, den Sie im Dezimalstellenfeld der Domäne anlegen.
Um das Feld richtig anzuzeigen, müssen Sie eine Ausgabelänge angeben, die ein Byte für den Dezimalpunkt und ein Byte für jedes 1000-er Trennelement umfaßt, die angezeigt werden können. Wenn Sie das Feld allerdings leer lassen, wird das System die Ausgabelänge für Sie bestimmen.
Eine Domäne anlegen
In diesem Abschnitt lernen Sie, nach Methode 1 eine Domäne einzurichten.
Starten Sie jetzt das ScreenCam »How to Create a Domain«.
Führen Sie diese Prozedur zweimal aus, um die Domänen ***lifnr und ***name1 anzulegen. Hilfe zu den üblichen Problemen finden Sie im Störungssucher. Wenn Sie mit irgendwelchen Schritten ein Problem haben, vergessen Sie nicht, im Störungssucher nachzusehen.
1. Starten Sie im Wörterbuch.
2. Geben Sie den Domänennamen im Objektnamensfeld ein.
3. Wählen Sie die Option Domäne.
4. Legen Sie die Domäne an.
5. Geben Sie eine Kurzbeschreibung ein.
6. Füllen Sie das Datentypenfeld aus. Positionieren Sie den Cursor in das Feld, und drücken Sie auf den Pfeil nach unten, um eine Auflistung von erlaubten Datentypen anzuzeigen. Wählen Sie einen aus, oder geben Sie ihn ein.
7. Geben Sie die Feldlänge ein.
8. Aktivieren Sie die Domäne (sie wird gleichzeitig gesichert). Die Maske Objektkata- logeintrag anlegen erscheint.
9. Drücken Sie die Schaltfläche Lokales Objekt. Sie kommen in die Ausgangsmaske zurück.
10. Durch Drücken der Schaltfläche Zurück kommen Sie an den Anfang dieses Vorgangs.
Problem Mögliche Symptome Lösung

Ich kann keine Domäne anlegen.
Wenn Sie auf Anlegen drücken, passiert nichts.
Schauen Sie auf die Statusleiste unten auf Ihrem Bildschirm, und drücken Sie nochmals auf Anlegen. Es ist möglich, daß Sie dort jetzt eine Mitteilung sehen.
Wenn Sie auf Anlegen drücken, sehen Sie die Nachricht »Das System erlaubt keine Änderungen an SAP-Objekten«.
Ändern Sie den Domänennamen so, daß er mit y oder z beginnt.
Wenn Sie auf Anlegen drücken, sehen Sie die Mitteilung »Geben Sie den Zugangsschlüssel ein«.
Ändern Sie den Domänennamen so, daß er mit y oder z beginnt.
Wenn Sie auf Anlegen drücken, sehen Sie die Mitteilung »Sie haben keine Berechtigung«.
Erbitten Sie die Autorisierung von Ihrem Sicherheitsadministrator.
Wenn Sie auf Anlegen drücken, sehen Sie die Mitteilung »ist bereits vorhanden«.
Ihr gewählter Name existiert schon im Data Dictionary. Wählen Sie einen anderen Domänennamen.
Ich erhalte eine Nachricht
»W: Die errechnete Ausgabelänge ist kleiner als die angegebene«.
Leeren Sie das Feld Zahl der Stellen, und drücken Sie erst (Enter) und dann Aktivieren.
«E: Wertetabelle existiert nicht«. Leeren Sie das Feld Wertetabelle, und drücken Sie erst (Enter) und dann Aktivieren.
SAP-Dokumentation über Domänen erhalten
Es gibt viele Stellen, SAP-Dokumentation über die Merkmale von Domänen zu erhalten.
Wenn Sie sich die Dokumentation ansehen wollen, die alle Datentypen und ihre Anwendungsmöglichkeiten beschreibt, gehen Sie auf das Datentypenfeld und drücken (F1). Sie sehen eine Dialogbox mit markierten Feldern. Klicken Sie auf diese Felder für mehr Details.
Sie können auch die R/3-Bibliothek-Hilfe in Anspruch nehmen für zusätzliche Dokumentationen über Datentypen und andere Eigenschaften der Domäne. Um diese Dokumentation anzusehen, wählen Sie aus jeder Maske den Menüpfad Hilfe->R/3-Bibliothek. Sie kommen in das Hauptmenü der R/3-Bibliothek.
Für noch mehr Dokumentation über die Datentypen in der Domäne wählen Sie den Menüpfad Hilfe->Erweiterte Hilfe innerhalb der Domäne und klicken dann den Bereich an, für den Sie Hilfe brauchen.
Um eine Dokumentation zu erhalten, welche die Abbildung von Domänendatentypen zu den ABAP/4-Datentypen beschreibt, zeigen Sie die (F1)-Hilfe für die »Tabellen«- Schlüsselwörter an. (Um das innerhalb des ABAP/4-Editors zu machen, gehen Sie auf den Begriff tables und drücken (F1)).
Datenelemente
Vor dem Anlegen eines Datenelementes wird die Maske beschrieben, die Sie benutzen, um es einzurichten.
Abbildung 3.8 zeigt die Maske, die benutzt wird, um ein Datenelement einzurichten. Sie geben hier die Kurzbeschreibung, den Domänennamen, die Kennsätze und eine Kopfzeile ein, die in den folgenden Abschnitten

erklärt werden. Eine Dokumentation kann auch eingerichtet werden, nachdem das Datenelement gesichert geworden ist.
Abbildung 3.7: Die Maske Dictionary: Datenelement Ändern
Kurzbeschreibung
Das Textfeld beschreibt einen Geschäftszusammenhang für eine Domäne. Eine »Kundenrufnummer« ist zum Beispiel ein spezifischer Geschäftszusammenhang für eine »generische Rufnummerndomäne«, so daß sie eine entsprechende Beschreibung für ein Datenelement sein würde. Der Endbenutzer sieht diese Beschreibung, wenn er die (F1)-Hilfe aufruft für ein Feld, das angelegt wurde, um dieses Datenelement zu benutzen.
Feldbezeichner und Überschrift
Am unteren Rand der Maske, die in Abbildung 3.8 gezeigt wird, sind vier Textfelder. Die ersten drei sind Feldkennungen. Wenn irgendein Feld auf einer Maske erscheint (wie z.B. ein Eingabefeld auf einer Eingabemaske), wird eines der kurzen, mittleren oder langen Felder links davon als Feldkennung erscheinen. Der Programmierer wählt eine dieser Feldbezeichnungen, wenn er eine Maske anlegt. Die Inhalte der Überschrift erscheinen als Spaltenüberschriften am Anfang von Auflistungen.
Wenn die Felder, die Sie mit diesem Datenelement anlegen, nicht auf allen Masken erscheinen, deaktivieren Sie Feldbezeichner pflegen. Sie werden die Feldkennung und die Überschriften nicht mehr sehen. Sie müssen zweimal (Enter) eingeben, damit die Felder verschwinden, wenn sie Werte enthalten.

Datenelementedokumentation
Nachdem Sie das Datenelement gesichert haben, erscheint die Dokumentationsschaltfläche auf der Drucktastenleiste, so daß Sie freie Texte speichern können. Der Anwender sieht diesen Text, wenn er die (F1)-Hilfe aufruft. Anders ausgedrückt: wenn ein Tabellenfeld, das dieses Datenelement benutzt, auf einer Maske erscheint, kann der Anwender seinen Cursor in dieses Feld bewegen und (F1) drücken, um die Dokumentation anzuzeigen, die Sie hier eingegeben haben.
Wenn Sie die Dokumentationsmaske sehen, wird die Anfangszeile die Zeichen &DEFINITION& enthalten.Dies ist eine Überschrift; ändern Sie diese Zeile niemals. Beginnen Sie die Eingabe Ihrer Dokumentation auf Zeile 2.
Die Dokumentation der Datenelemente ist für den Programmierer oft sehr nützlich. Indem er die (F1)-Hilfe liest, kann er die geschäftliche Verwendbarkeit der Daten bestimmen. Deshalb sollten Sie die (F1)-Hilfe für den Benutzer immer über die Schaltfläche Dokumentation anlegen.
Anlegen eines Datenelements
In diesem Abschnitt lernen Sie die Methode 2 kennen, ein Datenelement anzulegen.
Starten Sie jetzt das ScreenCam »How to Create a Data Element«.
Führen Sie diesen Vorgang zweimal aus, um die Datenelemente ***lifnr und ***name1 anzulegen. Hilfe finden Sie in der Tabelle im Anschluß. Bei auftauchenden Problemen sehen Sie unbedingt hier nach.
1. Starten Sie mit dem Dictionary (Transaktion SE11 oder über den Menüpfad)
2. Geben Sie den Namen des Datenelements in das Feld Objektname ein.
3. Wählen Sie die Option Datenelemente.
4. Drücken Sie die Schaltfläche Anlegen. Die Maske Dictionary:Datenelement Ändern erscheint.
5. Geben Sie die Kurzbeschreibung für das Datenelement ein.
6. Geben Sie einen Domänennamen ein, und drücken Sie (Enter). Wenn die Domäne existiert und aktiv ist, werden ihr Datentyp und die Länge erscheinen. Wenn Sie nach dem Betätigen der Entertaste keinen Datentyp und keine Datenlänge sehen, überprüfen Sie den Namen des Datenelements. Wenn der Name korrekt ist, überprüfen Sie durch Öffnen eines neuen Modus, ob es aktiv ist (benutzen Sie den Pfad System->Erzeugen Modus), und lassen Sie es sich im Data Dictionary anzeigen.
7. Geben Sie die Feldnamen in die Feldbezeichner kurz, mittel, lang und die Überschrift ein. Der Wert im Kurzfeld darf höchstens 10 Zeichen haben, der mittlere 15, und der lange ist auf 20 Zeichen begrenzt. Der Wert

in der Überschrift sollte höchstens so lang sein wie die Ausgabelänge in der Domäne.
8. Drücken Sie Sichern auf der Symbolleiste. Die Maske Objektkatalogeintrag anlegen erscheint.
9. Drücken Sie die Schaltfläche Lokales Objekt. Das Statusfeld enthält die Werte Neu und gesichert, und die Mitteilung »gesichert ohne Prüfung« erscheint unten im Fenster der Statusleiste. Unter anderen erscheint die Schaltfläche Dokumentation auf der Drucktastenleiste.
10. Drücken Sie die Schalfläche Dokumentation. Sie gelangen in die Dokumentationserfassungsmaske. Hier können Sie eine Endbenutzerdokumentation eingeben. Diese Dokumentation erscheint, wenn der Benutzer die (F1)-Hilfe für Felder aufruft, die angelegt wurden, diese Datenelemente zu benutzen. Die erste Zeile enthält die Zeichen &DEFINITION&. Dies ist eine Überschrift; ändern Sie diese niemals. Beginnen Sie mit der Eingabe Ihrer Dokumentation in Zeile 2. Drücken Sie die Entertaste zu Beginn eines jeden Absatzes.
11. Drücken Sie Sichern und Aktivieren. Die Mitteilung »Das Dokument wurde im Status aktiv gesichert« erscheint in der Statusleiste.
12. Drücken Sie Zurück - Sie kehren zur Maske Dictionary: Datenelement ändern zurück.
13. Drücken Sie auf Aktivieren. Der Wert im Statusfeld ändert sich zu Akt. , und die Mitteilung »Wurde erfolgreich aktiviert« erscheint in der Statusleiste.
14. Drücken Sie auf Zurück. Sie kehren zum Anfang des Vorgangs zurück.
Problem Mögliche Symptome Lösung
Ich kann kein Datenelement anlegen
Wenn Sie die Schaltfläche Anlegen drücken, passiert nichts.
Schauen Sie auf die Statusleiste unten im Fenster, und drücken Sie nochmals auf Anlegen. Sehr wahrscheinlich sehen Sie hier eine Mitteilung.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »Das System erlaubt keine Änderungen an SAP-Objekten«.
Ändern Sie den Namen des Datenelements, beginnend mit y oder z.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »Geben Sie den Zugangsschlüssel ein«.
Ändern Sie den Namen des Datenelements, beginnend mit y oder z.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »...keine Berechtigung...«.
Erbitten Sie die Autorisierung von Ihrem Sicherheitsadministrator.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »ist bereits vorhanden«.
Ihr gewählter Name existiert schon im Data Dictionary. Wählen Sie einen anderen Domänennamen.
Ich kann das Datenelement nicht aktivieren
Sie sehen die Mitteilung »Es existiert keine aktive Domäne mit diesem Namen«.
Gehen Sie zur Maske Dictionary: Datenelement ändern und doppelklicken Sie auf den Domänennamen.

Der Domänenname, den Sie in der vorherigen Maske eingegeben haben, existiert nicht oder ist nicht aktiv.
Sie sehen entweder eine Dialogbox oder die Maske Dictionary: Domäne anzeigen.
Wenn Sie eine Dialogbox mit dem Namen Domäne Anlegen sehen, existiert die Domäne nicht. Überprüfen Sie den Namen. Haben Sie den falschen Namen eingegeben? Es könnte eine gute Idee sein, eine neue Session zu öffnen und alle Objekte anzeigen zu lassen, die Sie bisher mit dem Object-Browser angelegt haben (Schauen Sie in Tag 2 in das Kapitel »Ihre Entwicklungsobjekte wiederfinden«).
Wenn Sie nach einem Doppelklick die Maske Dictionary: Datenelement anzeigen sehen, schauen Sie auf die Statusleiste auf dieser Maske. Ist der Status Neu? In diesem Fall muß die Domäne aktiviert werden. Drükken Sie auf Aktivieren und dann auf Zurück, um zum Datenelement zurückzukehren, und versuchen Sie noch einmal, es zu aktivieren.
Ich erhalte die Nachricht: »Bitte Feldbezeichner pflegen«. Fügen Sie die Kurz-, Mittel- und Langfelder ein, und aktivieren Sie dann.
»W Länge wurde auf die tatsächliche Länge heraufgesetzt«.
Die von Ihnen eingegebene Überschrift war länger als die Feldlänge. Dies ist kein großes Problem. Drücken Sie einfach auf (Enter),und aktivieren Sie erneut.
Ich komme nicht in die Feldkennungen hinein.
Die Eingabefelder fehlen auf der Maske.
Haken Sie die Feldbezeichner pflegen an, und drücken Sie (Enter).
Transparente Tabellen
In Abbildung 3.9 sehen Sie die Maske, die benutzt wird, um transparente Tabellen anzulegen. Hier spezifizieren Sie die Kurzbeschreibung, die Auslieferungsklasse, Feldnamen, ein Datenelement für jedes Feld, und selektieren das Primärschlüsselfeld. In den folgenden Abschnitten werden die einzelnen Punkte detaillierter erläutert.

Abbildung 3.8: In die Maske Dictionary :Tabelle/Struktur: Felder Ändern können Kurzbeschreibungen, Attribute und Feldnamen eingegeben werden.
Kurzbeschreibung
Das Textfeld wird für die gleichen Zwecke benutzt wie die Kurzbeschreibung von Domänen. Der Endbenutzer wird diese Beschreibungen nicht sehen, aber der Entwickler sieht sie, wenn er eine Tabellenliste aufruft.
Feld Auslieferungsklasse (AusliefKlasse)
Der Wert im Feld Auslieferungsklasse identifiziert den »Besitzer« der Daten in dieser Tabelle. Der Besitzer ist verantwortlich für die Pflege des Tabelleninhalts. In Kundentabellen geben Sie hier immer ein A ein, um anzuzeigen, daß die Tabelle Anwendungsdaten enthält, die nur dem Kunden gehören. Andere Werte, die in das Feld eingetragen werden, sind nur nützlich für SAP und zeigen an, daß die Daten entweder SAP gehören oder aber sowohl SAP als auch dem Kunden.
Um eine komplette Liste der zulässigen Werte und ihrer Bedeutung zu erhalten, positionieren Sie den Cursor auf das Feld Auslieferungsklasse, und drücken Sie (F1).

Feld Tabellenpflege erlaubt (Tab.pflege erlaubt)
Indem Sie die Tab.pflege erlaubt anhaken, kann der Menüpfad Hilfsmittel->Einträge erfassen benutzt werden. Wenn Sie die Tabelle aktiviert und diesen Menüpfad gewählt haben, erscheint die Maske Tabelle einfügen und ermöglicht Ihnen, Daten in Ihre Tabelle einzutragen. Dies ist sinnvoll zum Testen und zur manuellen Eingabe von geringen Datenmengen. Wenn Tab.pflege erlaubt nicht angehakt ist, erscheint der Menüpfad ausgegraut.
Feldnamenspalte
In der unteren Hälfte des Bildschirms können Sie Feldnamen eingeben. Die Primärschlüsselfelder müssen in dieser Liste zuerst auftauchen und durch ein Häkchen in der Schlüsselspalte markiert werden. Rechts von jedem Feldnamen muß ein Datenelementsname eingegeben werden. Wenn Sie alle Felder ausgefüllt haben, drücken Sie die Schaltfläche Neue Felder auf der Symbolleiste, um weitere Felder hinzuzufügen.
Anlegen einer transparenten Tabelle unter Benutzung bereits existierender Domänen und Datenelemente
In diesem Abschnitt lernen Sie, wie man mit Hilfe der ersten Methode (von unten nach oben) eine transparente Tabelle anlegt.
Starten Sie jetzt das ScreenCam »How to Create a Transparent Table Using Preexisting Domains and Date Elements«.
Führen Sie diesen Vorgang aus, um die Tabelle ***lifnr anzulegen. Wir werden die Tabelle anlegen, aber nur die ersten drei Felder mandt, ***lifnr und ***name1 aufnehmen. Später werden wir die übrigen Felder mit Hilfe der zweiten Methode (von oben nach unten) hinzufügen.
Hilfe finden Sie in der Tabelle im Anschluß. Wenn Sie mit irgendeinem der Schritte Probleme haben, schauen Sie dort nach.
1. Starten Sie mit der Maske Dictionary: Einstieg.
2. Geben Sie den Tabellennamen ***lifnr in das Feld Objektname ein
3. Wählen Sie die Option Tabellen.
4. Drücken Sie die Schaltfläche Anlegen. Es erscheint die Maske Dictionary: Tabelle/Struktur: Felder ändern.
5. Geben Sie die Kurzbeschreibung für die Tabelle ein.
6. Geben Sie ein A in das Auslieferungsklassefeld ein.
7. Machen Sie ein Häkchen Tab.pflege Erlaubt.
8. Tragen Sie den Namen des ersten Feldes der Tabelle in die Feldnamenspalte ein.
9. Haken Sie Key an, wenn es Teil des Primärschlüssels ist.
10. Tragen Sie den Namen eines Datenelements in die Spalte Datenelement ein.

11. Drücken Sie die Entertaste.
12. Sehen Sie auf die Statusleiste. Wenn Sie die Mitteilung »Datenelement ist nicht aktiv« sehen, existiert das Datenelement entweder noch nicht, oder es ist nicht aktiviert. Folgende Gründe können vorliegen:
■ Es wurde gar nicht angelegt. ■ Ihnen unterlief ein Rechtschreibfehler, als Sie das Datenelement anlegten. ■ Der Name des Datenelements wird auf der gegenwärtigen Maske falsch geschrieben. ■ Das Datenelement existiert, und es ist richtig geschrieben, aber es ist nicht aktiv.
Überprüfen Sie den Namen. Wenn die Schreibweise korrekt ist, führen Sie einen Doppelklick aus. Wenn ein Datenelement mit diesem Namen nicht existiert, sehen Sie jetzt eine Dialogbox Datenelement anlegen. Wenn das Datenelement existiert, wird es jetzt angezeigt.- Wenn Sie sich jetzt das Datenelement ansehen, achten Sie auf den Wert im Statusfeld. Das Statusfeld muß Akt. enthalten. Wenn das Datenelement aktiviert ist, drücken Sie auf Zurück, um zur Ausgangsmaske zurückzukehren.
13. Wiederholen Sie Schritt 8 bis 12 für die verbleibenden Felder in der Tabelle (***lifnr und ***name1).
14. Drücken Sie auf Sichern. Sie sehen die Maske Objektkatalogeintrag anlegen.
15. Drücken Sie auf die Schaltfläche Lokales Objekt. Sie kehren zurück zu der Maske Dictionary:Tabelle/Struktur:Felder ändern.
16. Wählen Sie Technische Einstellungen - die Maske ABAP/4 Dictionary:Technische Einstellungen pflegen wird angezeigt.
17. Geben Sie APPL0 im Feld Datenart ein (mit einer Null, nicht dem Buchstaben O).
18. Tragen Sie 0 (Null) in das Feld Größenkategorie ein.
19. Sichern Sie.
20. Drücken Sie Zurück - Sie kommen wieder zu der Ausgangsmaske zurück.
21. Wählen Sie Aktivieren. War die Aktivierung erfolgreich, erscheint jetzt die Meldung »wurde erfolgreich aktiviert« in der Statusleiste; das Statusfeld enthält den Wert Akt.
22. Mit Zurück kommen Sie wieder zum Anfang.
Problem Mögliche Symptome Lösung
Ich kann keine Tabelle anlegen.
Wenn Sie die Schaltfläche Anlegen drücken, passiert nichts.
Schauen Sie auf die Statusleiste unten im Fenster, und drücken Sie nochmals auf Anlegen. Sehr wahrscheinlich sehen Sie hier eine Nachricht.

Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »Geben Sie den Zugangsschlüssel ein«.
Ändern Sie den Namen der Tabelle, beginnend mit y oder z.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »Das System erlaubt keine Änderungen an SAP Objekten«.
Ändern Sie den Namen der Tabelle, beginnend mit y oder z.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »Geben Sie den Zugangsschlüssel ein«. Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »... keine Berechtigung ...«.
Erbitten Sie die Autorisierung von Ihrem Sicherheitsadministrator.
Wenn Sie Anlegen drücken, sehen Sie die Mitteilung »ist bereits vorhanden«.
Ihr gewählter Name existiert schon im Data Dictionary. Wählen Sie einen anderen Domänennamen.
Ich kann die Tabelle nicht aktivieren.
Sie sehen die Mitteilung »Datenelement oder Domäne ist nicht aktiv oder existiert nicht«.
Gehen Sie eine Maske zurück zur Maske Dictionary: Tabelle/Struktur: Felder Ändern und doppelklicken Sie auf den Namen des Datenelements. Sie sehen entweder eine Dialogbox oder direkt das Datenelement.
Wenn Sie eine Dialogbox mit dem Namen Datenelement Anlegen sehen, existiert das Datenelement nicht. Überprüfen Sie den Namen. Haben Sie den falschen Namen eingegeben? Es könnte eine gute Idee sein, eine neue Session zu öffnen und alle Objekte anzeigen zu lassen, die Sie bisher mit dem Objectbrowser angelegt haben (Schauen Sie in Tag 2 in das Kapitel »Ihre Entwicklungsobjekte wiederfinden«).
Wenn Sie das Datenelement anzeigen können, schauen Sie auf die Statusleiste. Ist der Status Neu? Falls nicht, muß das Datenelement aktiviert werden. Drükken Sie auf Aktivieren und dann auf Zurück, um zur Tabelle zurückzukehren.
Ich sehe die Maske Dictionary: Technische Einstellungen Pflegen.
Die technischen Attribute wurden entweder nicht eingegeben oder nicht gesichert. Geben Sie diese jetzt ein, drücken Sie Sichern und dann Zurück.
Mitteilungen in roter Schrift werden angezeigt.
»E-Feld (Datenelement oder Domäne ist nicht aktiv oder existiert nicht).«
Siehe oben (Kann Tabelle nicht aktivieren)

»E-Anfang in Tabelle TAORA fehlt.«
Schauen Sie weiter unten nach einer (roten) Nachricht über Datenklasse oder Grössenkategorie.
»E-Fehler in der Codegeneration für Tabellenanlage in DB.«
dito
»E-Tabelle (Anweisungen konnten nicht generiert werden).«
dito
»E-Feld Größenkategorie (Wert nicht erlaubt).«
Sie haben einen ungültigen Wert eingegeben in das Feld Größenkategorie. Drücken Sie Zurück, dann Technische Einstellungen, und ändern Sie die Größenkategorie auf 0 (Null).
»E-Feld Datenklasse (Wert nicht erlaubt).«
Sie haben einen ungültigen Wert eingegeben in das Feld Datenklasse. Drücken Sie Zurück, dann Technische Einstellungen, und ändern Sie die Datenklasse auf APPL0 (mit Null am Ende).
»E-Schlüssel ist bereits definiert; Feld kann nicht im Schlüssel sein.«
Die Primärschlüsselfelder sind nicht benachbart. Wählen Sie Zurück und versichern Sie sich, daß Ihre Primärschlüsselfelder alle am Anfang der Tabelle stehen ohne dazwischenliegende Nichtschlüsselfelder (Alle Haken in der Schlüsselspalte müssen zusammen am Anfang der Tabelle stehen).
Die Dialogbox mit dem Namen Tabelle Anpassen zeigt an Table must be adjusted in the database.
Die Tabelle muß konvertiert werden.
Sie haben die Tabelle gewechselt, und jetzt muß eine Tabellenkonvertierung vorgenommen werden, um die Aktivierung abzuschließen. Wählen Sie einen Prozessortyp von Online und drücken Sie die Schaltfläche Anpassen.
Am unteren Bildschirmrand erscheint die Nachricht »Initialwert nicht erlaubt als Feldname«
oder: Ich kann nicht hochrollen.
oder: Ich sehe die eingegebenen Felder nicht.
Sie haben versucht, ein Feld zu entfernen, indem Sie es leerten. Sie dürfen nicht so vorgehen. Sie müssen die Felder mit der Schaltfläche Ausschneiden löschen. Drükken Sie Ausschneiden, bis Sie die Nachricht »Selektierte Eingaben wurden in das Clipboard kopiert« am unteren Bildschirmrand in der Statusleiste sehen.
Ich kann eine Nachricht nicht übergehen.
Eine Nachricht mit dem Zeichen »W:« erscheint in der Statusleiste, und Sie kommen nicht weiter.
Drücken Sie die Entertaste als Antwort auf die Nachricht.
Anlegen einer transparenten Tabelle ohne Benutzung bereits existierender Domänen und

Datenelementen
In diesem Abschnitt lernen Sie, mit Hilfe der Methode 2 einer Tabelle Felder hinzuzufügen. Sie werden die verbleibenden Felder (***regio und ***land1) Ihrer Tabelle ***lfa1 hinzufügen.
Mit Methode 2 können Sie Felder einer Tabelle hinzufügen, bevor Sie die Datenelemente und Domänen anlegen. Sie legen die Datenelemente und Domänen einfach während Ihres normalen Fortschreitens an.
Um so zu verfahren, geben Sie einfach den Namen eines Datenelements oder einer Domäne ein, und führen Sie darauf einen Doppelklick aus. Sie legen dann die Domäne oder das Datenelement an, aktivieren Sie beide und drücken dann die Schaltfläche Zurück, um zum Ausgangspunkt zurückzukehren.
Nun folgt der Vorgang, einer transparenten Tabelle Felder hinzuzufügen, ohne vorher Domänen oder Datenelemente anzulegen.
Starten Sie jetzt das ScreenCam »How to Create a Transparent Table Without Preexisting Domains and Data Elements«.
1. Sie beginnen wieder mit der Maske Dictionary: Einstieg.
2. Geben Sie den Tabellennamen ***lfa1 in das Feld Objektname ein.
3. Wählen Sie die Option Tabellen.
4. Drücken Sie Ändern.
5. Drücken Sie die Schaltfläche Neue Felder. Sie sehen leere Zeilen am unteren Rand des Bildschirms, und die existierenden Tabellenfelder werden aufwärts gerollt.
6. Tragen Sie den Namen des Feldes, welches Sie hinzufügen möchten, in die Spalte Feldname ein.
7. Haken Sie Key an, wenn es einen Teil des Primärschlüssels bildet (Die Felder ***regio und ***land1 tun dies nicht, aber dieser Abschnitt ist allgemeingültig für jede Situation).
8. Geben Sie den Namen des assoziierten Datenelements in die Spalte Datenelement ein.
9. Drücken Sie (Enter).
10. Sehen Sie zur Statuszeile. Sie sehen die Nachricht »Datenelement ist nicht mehr aktiv«, weil das Datenelement nicht existiert.
11. Doppelklicken Sie auf den Namen des Datenelements. Die Dialogbox zum Anlegen von Datenelementen wird angezeigt. Im Feld Datenelement steht der Name des Datenelements, welches angelegt werden soll. Dies ist natürlich das Datenelement, das Sie anlegen wollen, also ändern Sie es hier nicht, wenn es nicht falsch geschrieben sein sollte.
12. Drücken Sie auf Weiter. Die Maske Dictionary: Datenelement Ändern erscheint.
13. Geben Sie die Kurzbeschreibung für das Datenelement ein.

14. Geben Sie einen Domänennamen ein.
15. Machen Sie einen Doppelklick auf den Namen der Domäne, um sie anzulegen. Die Dialogbox Domäne Anlegen erscheint. Im Feld steht der Name der Domäne, die angelegt werden soll. Dies ist die Domäne, die Sie anlegen wollen, also ändern Sie diese hier nicht, es sei denn, sie ist falsch geschrieben.
16. Drücken Sie auf Weiter. Die Maske Dictionary: Domäne Pflegen erscheint.
17. Geben Sie in die Felder Kurzbeschreibung, Datentyp und Feldlänge ein.
18. Drücken Sie auf Aktivieren.
19. Drücken Sie die Schaltfläche Lokale Objekte. Sie kehren zur Maske zurück. Der Wert im Statusfeld ändert sich in Akt., und die Nachricht »wurde erfolgreich aktiviert« erscheint in der Statuszeile.
20. Drücken Sie auf Zurück, um zur Maske Dictionary: Datenelement Ändern zurückzukehren.
21. Geben Sie die noch verbleibenden Felder für das Datenelement ein (schauen Sie auf Schritt 7 im Abschnitt »Anlegen eines Datenelements«).
22. Drücken Sie auf Aktivieren. Sie sehen die Maske Objektkatalogeintrag.
23. Drücken Sie nun Lokales Objekt. Sie kehren zur Maske zurück. Der Wert im Statusfeld ändert sich auf Akt., und die Nachricht »wurde aktiviert« erscheint auf der Statusleiste.
24. Drücken Sie Zurück. Sie kommen zur Maske Dictionary: Tabelle/Struktur: Felder Ändern. In der Statusleiste sollten keine Mitteilungen stehen.
25. Wiederholen Sie Schritt 5 bis 23 für jedes neue Datenelement, welches Sie anlegen möchten.
26. Wenn Sie alle Domänen und Datenelemente angelegt haben, drücken Sie auf Aktivieren. War die Aktivierung erfolgreich, erscheint nun die Nachricht »wurde erfolgreich aktiviert« auf der Statusleiste, und das Statusfeld enthält den Wert Akt.
27. Drücken Sie Zurück, um an Ihren Ausgangspunkt zu gelangen.
Tabellenmodifizierung
Wenn Sie eine Tabelle angelegt haben, können Sie folgendes mit ihr machen:
■ sie kopieren ■ sie löschen ■ Felder hinzufügen ■ Felder löschen ■ Felder ändern
Der folgende Abschnitt beschreibt, wie Sie diese Funktionen anwenden.

Eine Tabelle kopieren
Wenn eine Tabelle im DDIC aktiv ist, können Sie diese kopieren. Sie könnten dies zum Beispiel wollen, wenn eine bereits existierende Tabelle sehr ähnlich derjenigen ist, die Sie anlegen möchten. Oder vielleicht wollen Sie mit einigen Wörterbuchfunktionen ein wenig herumexperimentieren, möchten aber eine bereits existierende nicht modifizieren.
So kopieren Sie eine Tabelle:
1. Starten Sie in der Maske Dictionary: Einstieg.
2. Wählen Sie die Option Tabellen.
3. Drücken Sie Kopieren.
4. Geben Sie die Namen der Start- und Zieltabellen ein.
5. Drücken Sie Aktivieren. Sie kehren zum Ausgangspunkt zurück und sehen die Mitteilung ++ auf der Statusleiste.
Diese Prozedur kopiert lediglich die Tabellenstruktur, nicht ihre Daten. Um die Daten zu kopieren, müssen Sie selbst ein kleines ABAP/4-Programm schreiben.
Tabellen können nicht umbenannt werden. Um einen Tabellennamen zu ändern, müssen Sie die Tabelle in eine andere kopieren, die den gewünschten Namen hat, und dann die Originaltabelle löschen. Wenn Sie dies getan haben, kopieren Sie unbedingt sowohl die Struktur als auch die Daten.
Eine Tabelle löschen
Sie können existierende DDIC-Tabellen löschen. Dies ist z.B. dann sinnvoll, wenn eine existierende Tabelle nicht mehr benötigt wird, oder für eine Tabelle, die Sie lediglich angelegt haben, um Ihnen unbekannte Wörterbuchfunktionen auszuprobieren.
Um eine Tabelle zu löschen, gehen Sie folgendermaßen vor:
1. Starten Sie mit der Maske Dictionary: Einstieg.
2. Geben Sie den Tabellennamen in das Feld Objektname ein.
3. Wählen Sie die Option Tabellen.

4. Drücken Sie Löschen. Sie werden zur Bestätigung aufgefordert.
5. Prüfen Sie noch einmal den Tabellennamen, und drücken Sie Ja, wenn Sie fortfahren möchten.
Felder hinzufügen
Es gibt zwei Möglichkeiten, existierenden Tabellen Felder hinzuzufügen:
■ einfügen■ anhängen
Wenn Sie ein Feld einfügen, können Sie dies auch vor ein bereits existierendes Feld positionieren.
Wenn Sie ein Feld anhängen, können Sie dies am Ende der Tabelle machen, zumindest am Ende von allen existierenden Feldern.
Ein Feld einfügen
Um ein neues Feld vor einem existierenden Feld einzufügen, führen Sie folgenden Vorgang aus:
1. Der Start erfolgt wieder von der Dictionary: Einstieg-Maske aus.
2. Geben Sie den Tabellennamen im Objektname-Feld ein.
3. Wählen Sie die Option Tabellen.
4. Drücken Sie Ändern.
5. Positionieren Sie den Cursor auf einem Feld.
6. Drücken Sie die Schaltfläche Einfügen. Über der Cursorposition erscheint eine neue Zeile.
7. Legen Sie Ihr neues Feld in der Zeile an, die Sie gerade eingefügt haben.
Ein Feld anhängen
Um ein Feld an das Ende einer Tabelle anzuhängen, gehen Sie so vor:
1. Dictionary: Einstieg-Maske.
2. Geben Sie den Tabellennamen in das Feld Objektname ein.
3. Wählen Sie Tabellen.
4. Drücken Sie Ändern.
5. Drücken Sie auf Neue Felder. Auf der unteren Bildschirmhälfte rollt das existierende Feld nach oben, so daß Sie ein zusätzliches Feld anhängen können.

6. Legen Sie Ihre neuen Felder in den Zeilen an, die Sie gerade eingefügt haben.
Felder löschen
Sie können existierende Felder aus einer Tabelle löschen, weil das Feld z.B. nicht mehr benötigt wird oder es nur probeweise angelegt war.
Um ein Feld aus einer Tabelle zu löschen, gehen Sie folgendermaßen vor:
1. Zuerst wieder unsere bekannte Maske Dictionary: Einstieg.
2. Geben Sie den Tabellennamen ein.
3. Wählen Sie den Punkt Tabellen.
4. Drücken Sie Ändern.
5. Plazieren Sie den Cursor in das Feld, welches Sie löschen wollen.
6. Drücken Sie die Schaltfläche Ausschneiden auf der Drucktastenleiste, oder wählen Sie den Menüpfad Bearbeiten: Ausschneiden.
7. Aktivieren Sie die Tabelle. Die Maske Tabelle Anpassen erscheint. Drücken Sie Anpassen, um die Tabelle in der Datenbank zu konvertieren.
Um ein Feld aus einer Tabelle zu löschen, leeren Sie keinesfalls den Feldnamen. Positionieren Sie statt dessen den Cursor auf den Feldnamen und drücken Sie Ausschneiden. Wenn Sie den Namen nur leeren, erhalten Sie in der Statusleiste am unteren Bildschirmrand die Nachricht »Initialwert als Feldname nicht erlaubt«; Sie können nicht weiterarbeiten, bis Sie die Zeile löschen, die Sie geleert haben.
Ändern des Datentyps oder der Länge eines Feldes
Sie können sowohl den Datentyp als auch die Länge eines existierenden Feldes in der Tabelle verändern. Dies wird z.B. notwendig, wenn die Feldlänge erweitert werden muß, um größere Werte aufnehmen zu können, oder wenn die Gültigkeit für die Felder sich ändert und der Datentyp nicht mehr geeignet ist für die neuen Daten, die eingegeben werden sollen.
Vollziehen Sie die untenstehenden Schritte nach:
1. Sie starten wieder in der Maske Dictionary: Einstieg.

2. Geben Sie den Tabellennamen ein.
3. Wählen Sie Tabellen.
4. Drücken Sie auf Anzeigen.
5. Doppelklicken Sie auf das Datenelement, das dem Feld entspricht, welches Sie ändern möchten. Das Datenelement wird angezeigt.
6. Machen Sie nun einen Doppelklick auf den Domänennamen im Datenelement. Die Domäne wird jetzt angezeigt.
7. Drücken Sie die Schaltfläche Anzeigen<->Ändern. Sie können jetzt die Attribute der Domäne verändern.
8. Leeren Sie das Feld Ausgabelänge.
9. Ändern Sie den Datentyp und/oder die Länge.
10. Drücken Sie Aktivieren. Eine Maske erscheint mit einer Liste aller Tabellen und Strukturen, die diese Domäne verwenden und daher betroffen sind. Drücken Sie auf Weiter, um fortzufahren.
Änderungen in der Domäne wirken sich auf alle Felder aus, welche die Domäne verwenden.
Arbeiten mit Daten
Wenn Sie es bisher noch nicht getan haben, legen Sie Ihre Tabelle jetzt an und aktivieren Sie diese, bevor Sie weitermachen.
In R/3 gibt es von SAP mitgelieferte Hilfsmittel, Datenbrowser genannt, mit denen Sie Daten innerhalb von Tabellen manipulieren können. Obwohl der Name Browser impliziert, daß Sie die Daten nur lesen werden, können Datenbrowser sowohl zum Lesen als auch zur Aktualisierung verwendet werden.
Sie können die Datenbrowser-Hilfsmittel verwenden, um Tabellendaten folgendermaßen darzustellen oder zu modifizieren:
■ Zeilen suchen und anzeigen, die spezifizierten Kriterien entsprechen ■ neue Zeilen hinzufügen ■ existierende Zeilen modifizieren ■ Zeilen löschen
Zugriff auf die Datenbrowser-Funktionalität aus DDIC heraus

Wie schon erwähnt, ist eine Funktion des Datenbrowsers, neue Zeilen in eine Tabelle einzufügen. Ein schneller und einfacher Weg, auf diese Funktionalität zuzugreifen, ist aus der Maske Dictionary: Tabelle/Struktur (entweder im Anzeige- oder Änderungsmodus). Wählen Sie den Menüpfad Hilfsmittel->Einträge erfassen. Dieser Menüpfad ist eine Abkürzung - er ruft den Datenbrowser auf, umgeht dabei die Einstiegsmaske und führt Sie direkt zu der Maske, von der aus Sie neue Zeilen in eine Tabelle einfügen können.
Wenn dieser Menüpfad nicht möglich ist, haken Sie Tab.pflege Erlaubt an, und reaktivieren Sie Ihre Tabelle.
Durch die Wahl dieses Menüpfades werden automatisch die folgenden Aufgaben ausgeführt:
■ Für Ihre Tabelle wird speziell ein ABAP/4-Updateprogramm generiert, das einen Datenbrowser aufrufen kann. (Dieses ABAP/4-Programm wird nur beim ersten Mal generiert, wenn Sie auf diesen Menüpfad für eine vorgegebene Tabelle zugreifen. Sie greifen jedesmal darauf zu, wenn eine Änderung in der Tabelle vorgenommen wurde.)
■ Der Datenbrowser wird aufgerufen, der seinerseits das neu generierte ABAP/4- Programm aufruft. ■ Eine Maske wird angezeigt, von der aus Sie direkt Zeilen in der Tabelle anlegen können.
Starten Sie jetzt das ScreenCam »How to Add Data to a Table«.
Führen Sie diese Prozedur aus, um Ihrer Tabelle Daten hinzuzufügen. In der nachfolgenden Tabelle finden Sie Hilfe für einige eventuell auftretende Probleme.
1. Starten Sie in der Maske Dictionary: Einstieg.
2. Geben Sie Ihren Tabellennamen in das Objektnamensfeld ein.
3. Drücken Sie auf Anzeigen.
4. Wählen Sie den Menüpfad Hilfsmittel->Einträge erfassen. Achten Sie auf die Statusleiste, wenn Sie diesen Menüpfad wählen; möglicherweise sehen Sie die Nachricht »Compiling«. Diese Meldung zeigt an, daß das System das Update-Programm generiert. Die Maske Tabelle Einfügen wird angezeigt. Auf dieser Maske ist ein Eingabefeld für jedes Feld in Ihrer Tabelle. Links vom Eingabefeld steht der Feldname. Die Primärschlüsselfelder erscheinen zuerst, gefolgt von einer leeren Zeile, und dann die übrigen Felder der Tabelle. Um das Programm zu sehen, welches generiert wurde, wählen Sie Hilfsmittel: Einträge Erfassen und dann den Menüpfad System->Status. Der Programmname erscheint im Programmfeld.
Wenn Sie den Cursor auf irgendein Feld bewegen und die (F1)-Taste drücken, erscheint die Maske Hilfe:Tabelle Einfügen. Auf dieser Maske sehen Sie die Dokumentation, die Sie in das Datenelement eingegeben haben. Um zur Maske Tabelle Einfügen zurückzukehren, drücken Sie entweder auf Weiter oder auf Abbrechen.
5. Füllen Sie die Felder mit den Daten, die Sie in Ihre Tabelle einfügen wollen.

6. Drücken Sie Sichern. Sie sehen die Mitteilung »Datensatz erfolgreich angelegt« in der Statusleiste.
7. Wiederholen Sie die Schritte 5 und 6 für jede Zeile, welche Sie einfügen möchten.
8. Drücken Sie Zurück, um zur Ausgangsmaske (Punkt 1) zu kommen.
9. Wählen Sie den Menüpfad Hilfsmittel->Tabelleninhalt, um die Zeilen anzuzeigen, die Sie gerade angelegt haben. Die Maske Data Browser: Tabelle: Selektionsbild erscheint.
10. Um alle Zeilen der Tabelle anzuzeigen, drücken Sie auf Ausführen, ohne irgendwelche Suchkriterien einzugeben. Die Maske Data Browser: Tabelle wird geöffnet, und die von Ihnen eingegebenen neuen Zeilen werden in einer Liste gezeigt.
Problem Mögliche Symptome Lösung
Ich kann keine Daten hinzufügen.
Der Menüpunkt Einträge Erfassen ist ausgegraut, und es passiert nichts, wenn Sie darauf klicken.
Die Checkbox Tab.pflege Erlaubt wurde nicht geprüft. Gehen Sie zur Maske Dictionary: Tabelle Suchen (um dorthin zu gelangen, zeigen Sie die Tabelle an, und klicken Sie auf die Schaltfläche Anzeigen<->Ändern, bis die Felder modifizierbar sind). Machen Sie ein Häkchen in die Tab.pflege Erlaubt-Checkbox, und drücken Sie Aktivieren.
Wenn Sie auf Sichern drükken, sehen Sie die Nachricht »Ein Datensatz mit dem spezifischen Schlüssel existiert bereits« unten im Fenster.
Die Tabelle enthält bereits einen Datensatz mit dem selben Primärschlüssel wie derjenige, den Sie sichern wollen. Die Primärschlüsselfelder erscheinen zuerst auf dem Bildschirm. Unter dem letzten Feld im Primärschlüssel ist ein Leerzeichen. Ändern Sie einen Wert in einem der Felder darüber, und versuchen Sie erneut, Ihren Datensatz zu sichern.
Allgemeine Datenbrowser-Hilfsmittel
Die Funktionalität, auf die Sie im vorangegangenen Abschnitt zugegriffen haben, ist nur eine Funktion eines einzelnen Datenbrowsers. Im R/3-System gibt es vier allgemeine Hilfsmittel für den Datenbrowser: SE16, SE17, SM30 und SM31. In einer gewissen Weise ähneln sie sich, und doch bieten sie unterschiedliche Arten von Funktionalität.
SE16 verwenden
SE16 ist das am meisten verwendete universelle Hilfsprogramm für den Datenbrowser. Hiermit können Sie Tabellen nach bestimmten Zeilen durchsuchen und diese anzeigen, aktualisieren, löschen, kopieren, neue Zeilen einfügen und vieles mehr. SE16 kann auf zwei Weisen verwendet werden:
■ Von der Maske Dictionary: Tabelle/Struktur aus, mit dem Menüpfad Hilfsmittel ->Tabelleninhalt. ■ Geben Sie /nse16 in das Transaktionsfeld ein.
Starten Sie jetzt das ScreenCam »How to Display Table Data Using the Data Browser«.

1. Geben Sie /nse16 in das Transaktionsfeld ein.
2. Drücken Sie (Enter); die Maske Data Browser:Einstieg erscheint.
3. Geben Sie Ihren Tabellennamen in das Feld Tabellenname ein.
4. Drücken Sie auf die Schaltfläche Tabelleninhalt auf der Drucktastenleiste. Falls die Tabelle mehr als 40 Felder enthält, sehen Sie eine Auswahlmaske. In diesem Fall machen Sie ein Häkchen neben die Felder, für die Sie Suchkriterien eingeben wollen, und drücken Sie auf Ausführen. Die angehakten Felder sehen Sie auf der nächsten Maske. Diese Maske wird einfach Auswahlmaske genannt. Hier können Sie Suchkriterien eingeben, um bestimmte Tabellenzeilen zu finden. Um alle Zeilen anzuzeigen, geben Sie einfach kein Suchkriterium ein. Wenn mehr als 500 Zeilen zu Ihren Suchkriterien passen und Sie alle anzeigen wollen, löschen Sie den Wert im Feld Maximale Trefferzahl.
5. Drücken Sie auf Ausführen. Sie sehen jetzt die Maske Data Browser: Tabelle Selektionsbild. Alle Zeilen, die zu Ihren Suchkriterien passen, werden angezeigt bis zur Maximalanzahl, die im Feld Maximale Trefferzahl spezifiziert wurde.
Problem Lösung
Wenn Sie die Schaltfläche Ausführen drücken, passiert nichts.
■ Sie haben absichtlich oder versehentlich in das Feld der Auswahlmaske geschrieben, und dies trifft auf keine Zeile zu. Löschen Sie alle Feldinhalte in der Auswahlmaske und drücken Sie nochmals auf Ausführen.
■ Die Tabelle enthält keine Daten. ■ Haben Sie Sichern nach jedem Datensatz gedrückt? ■ Haben Sie Daten in die Tabelle eingegeben?
In der Ausgabeliste stehen weniger Datensätze als Sie in die Tabelle eingegeben haben.
■ Haben Sie nach jedem Datensatz Sichern gedrückt? ■ Haben Sie jedem Datensatz einen eigenen Primärschlüssel
zugewiesen?■ Sie haben absichtlich oder versehentlich etwas in ein Feld der
Auswahlmaske getippt, und nicht alle Datensätze passen zu diesem Suchkriterium. Kehren Sie zur Auswahlmaske zurück, löschen Sie alle Eingabefelder, und drücken Sie erneut auf Ausführen.
Der Menüpfad Hilfsmittel->Tabelleninhalt generiert genauso ein Programm wie Hilfsmittel->Einträge Erfassen, und er wird regeneriert, wenn Sie die Tabellenstruktur verändern. Um das Programm anzuzeigen, das er generiert, wählen Sie den Menüpfad System->Status von der Auswahlmaske.

Starten Sie jetzt das ScreenCam »Data Browser Functionality«.
Auf der Datenbrowsermaske können Sie folgendes machen:
■ auf - und abrollen ■ nach links und rechts schieben ■ auf eine Zeile doppelklicken, um gleichzeitig mehrere Felder zu sehen ■ eine neue Zeile anlegen mit dem Menüpfad Tabelleneintrag->Anlegen mit Vorlage ■ eine existierende Zeile ändern durch Anhaken und den Menüpfad Tabelleneintrag->Ändern ■ mehrere Zeilen ändern durch Anhaken, Wahl des Menüpfads Tabelleneintrag- >Ändern und Drücken der
Schaltflächen Nächster Eintrag und Vorheriger Eintrag ■ eine existierende Zeile kopieren durch Anhaken und den Menüpfad Tabelleneintrag->Anlegen mit
Vorlage■ mehrere Zeilen kopieren durch Anhaken, Menüpfad Tabelleneintrag->Ändern und Drücken von
Vorheriger Eintrag und Nächster Eintrag auf der Drucktastenleiste ■ Löschen einer oder mehrerer Zeilen durch Anhaken, in Menüpfad Tabelleneintrag->Anlegen mit Vorlage
und Drücken von Löschen für jede Zeile, die Sie löschen wollen ■ Auswählen und ausschließen aller Zeilen durch Drücken der entsprechenden Schaltflächen ■ Drucken der Liste durch Betätigen der Schaltfläche Drucken auf der Symbolleiste ■ Sortieren der Liste durch Plazieren Ihres Cursors auf die zu sortierende Spalte und Drücken von
Sort.Aufsteigend oder Sort.Absteigend auf der Drucktastenleiste ■ Auffinden einer Zeichenkette durch Drücken von Suchen. Geben Sie die Zeichenkette ein, drücken Sie
auf Suchen, und klicken Sie dann auf einen hervorgehobenen Bereich, um die Zeile sichtbar zu machen. ■ Herunterladen der Liste in eine Datei auf Ihrer Festplatte mit Hilfe des Menüpfades Bearbeiten-
>Download. Sie können wählen zwischen ASCII, Spreadsheet oder Rich Text Format. ■ Auswählen der Felder, die Sie sehen möchten, mit dem Menüpfad Einstellungen ->Feldauswahl ■ Setzen verschiedener anderer Parameter unter Verwendung des Menüpfades Einstellungen-
>Benutzerparameter. Hier sehen Sie die Ausgabebreite, die maximale Anzahl der Zeilen, die angezeigt werden können. Sie können Konvertierungsausgänge freigeben oder die aktuelle Anzahl der Zeilen anzeigen, welche die Suchkriterien erfüllen. Sie können auch die Spaltenüberschriften ändern, um die Kennungen von Datenelementen zu benutzen statt der Feldnamen von Tabellen.
SM31 und SM30 einsetzen
SM31 und SM30 können auch verwendet werden, um Tabellendaten anzuzeigen und zu aktualisieren. SM31 ist eine ältere Version von SM30 und hat weniger Funktionen. Das Eingabefeld auf der ersten Maske von SM30 ist lang genug, um jeden Tabellennamen aufzunehmen; bei SM31 ist es nur 5 Zeichen lang. Bevor Sie eines von beiden benutzen können, muß ein spezielles Programm, ein Standard-Pflegedialog, für die Tabelle generiert werden, die Sie anzeigen möchten.
Ein Standard-Pflegedialog ist ein ABAP/4-Programm, welches Sie generieren. Wenn Sie SM31 oder SM30 aufrufen, wird der Datenbrowser automatisch das generierte Programm finden und aufrufen. Es bietet eine komplexere Schnittstelle und mehr Funktionalität als SE16. Für weitere Informationen über Wartungsdialoge und den Vorgang, sie anzulegen, rufen Sie die R/3-Bibliothekshilfe auf.

Um Informationen über Wartungsdialoge in der R/3 Bibliothek zu erhalten, wählen Sie den Menüpfad Hilfe->R/3 Bibliothek. Von dort aus klicken Sie auf die folgenden Komponenten: Basis Komponenten->ABAP/4 Development Workbench->Erweiterte Anwendungsfunktionsbibliothek->Erweiterte Tabellenpflege.
Vergleich zwischen SE17 und SE16
SE17 ist SE16 sehr ähnlich, da es auch benutzt werden kann, um bestimmte Zeilen innerhalb einer Tabelle aufzufinden. Allerdings kann SE17 nicht für Aktualisierungen benutzt werden. Mit SE16 können Sie komplexe Suchkriterien für maximal 40 Felder angeben; mit SE17 können Sie einfache Suchkriterien für jede Anzahl Felder bestimmen. SE16 ermöglicht zur gleichen Zeit nur die Ausgabe, die von einer einzelnen Spalte sortiert wurde; SE17 wiederumermöglicht Ihnen, jegliche Sortierfolge über mehrere Spalten zu spezifizieren. SE16 kann - im Gegensatz zu SE17 - nicht mit einer Tabelle arbeiten, die einen standardmäßigen Wartungsdialog hat.
Alle Datenbrowser im Überblick
In speziellen Fällen, in denen Sie nur anzeigen wollen und mehrere bestimmte Suchkriterien benötigen, benutzen Sie SE17. Aber für die meisten, tagtäglichen Belange zum Anzeigen und Aktualisieren benötigen Sie SE16. Wiederum können Sie aber SE16 nicht verwenden, wenn die Tabelle einen standardmäßigen Wartungsdialog hat. In diesem Fall benutzen Sie SM31.
Der einfachste Weg, Ihnen zu erklären, wann Sie SE16 und wann SM31 benutzen sollten: Probieren Sie es einfach aus. Wenn's der eine nicht tut, tut's wahrscheinlich der andere. Und wenn nichts mehr geht: Probieren Sie es mit SM30.
Anzeige von Daten mit Hilfe Ihrer eigenen ABAP/4-Programme
Anstatt einen Datenbrowser zu verwenden, ist es einfacher, ein kleines ABAP/4-Programm zu schreiben, um die Daten Ihrer Tabelle anzuzeigen. Versuchen Sie, eines anzulegen. Konstruieren Sie das Programm so, daß es eine passende Meldung schreibt, wenn die Tabelle keine Zeilen enthält.
Ein Lösungsbeispiel sehen Sie in Listing 3.1. Versuchen Sie aber, Ihr eigenes Programm zu schreiben, bevor Sie auf die Lösung schauen.
Listing 3.1: Einfaches Programm zum Anzeigen der Daten in der Tabelle ztxlfa1
1 report ztx0301.2 tables ztxlfa1.3 select * from ztxlfa1.4 write: / ztxlfa1-lifnr,5 ztxlfa1-name1,6 ztxlfa1-regio,7 ztxlfa1-land1.8 endselect.9 if sy-subrc <> 0.10 write 'Table is empty.'.11 endif.
Nutzung der (F1)-Hilfe

Die (F1)-Hilfe ist die Dokumentation, die vom Benutzer für ein Feld gesehen wird. Um die Hilfe aufzurufen, positioniert der Benutzer seinen Cursor auf das Feld und drückt (F1). Die Dokumentation wird in einer Dialogbox angezeigt. Gehen Sie wie folgt vor, um die (F1)-Hilfe zu modifizieren, die Sie früher für das Feld lifnr angelegt haben:
Starten Sie jetzt das ScreenCam »How to Create or Modify F1 Help«.
Die (F1)-Hilfe einem Feld hinzufügen
1. Starten Sie in der Dictionary: Einstiegsmaske.
2. Lokalisieren Sie das Feld, für welches Sie die Hilfe hinzufügen möchten, und doppelklicken Sie auf den Namen des entsprechenden Datenelements.
3. Drücken Sie auf Anzeigen<->Ändern. Die Maske schaltet um auf den Modus Ändern/Anzeigen.
4. Drücken Sie die Schaltfläche Dokumentation auf der Drucktastenleiste. Die Dokumentationsmaske erscheint.
5. Geben Sie den Text ein, den der Benutzer später erhalten soll, wenn er die Hilfe aufruft. Die erste Zeile enthält den Zeichensatz &DEFINITION&. Dies ist eine Überschrift; ändern Sie niemals diese Zeile. Beginnen Sie mit Ihrer Eingabe in Zeile zwei. Drücken Sie jedesmal (Enter), wenn Sie einen neuen Paragraphen anfangen.
6. Sichern Sie Ihre Änderungen. Sie erhalten die Nachricht »Dokument wurde im aktiven Status gesichert« auf der Statusleiste.
7. Drücken Sie auf Zurück auf der Symbolleiste. Sie kommen zur Maske Dictionary: Datenelement Ändern.
8. Drücken Sie nochmals auf Zurück, um zum Ausgangspunkt zurückzukehren.
(F1)-Hilfe testen
1. Starten Sie mit der Maske Dictionary: Tabelle/Struktur (entweder im Modus Ändern oder Anzeigen).
2. Wählen Sie den Menüpfad Hilfsmittel->Einträge Erfassen.
3. Positionieren Sie den Cursor auf das Feld mit dem modifizierten Hilfetext.
4. Drücken Sie (F1). Das System zeigt Ihnen Ihre modifizierte Dokumentation.
Hypertexte der (F1)-Hilfe hinzufügen
Hypertexte ermöglichen Ihnen, in der (F1)-Hilfe auf ein hervorgehobenes Wort oder eine hervorgehobene Phrase zu klicken und hierfür zusätzliche Hilfe anzufordern. Um Hypertexte hinzuzufügen, legen Sie zuerst ein Dokument an, für welches Sie Hypertexte einfügen möchten, und dann fügen Sie einen Verweis auf dieses Dokument in Ihren Hilfetext ein. Dokumentennamen müssen mit einem y oder z beginnen. Sie können Hypertexte auch in Ihr neues Dokument aufnehmen und von dort mit einem anderen Dokument verbinden.
Starten Sie jetzt das ScreenCam »How to Create a Hypertext Link in F1 Help«.

1. Starten Sie im R/3-Hauptmenü und wählen Sie den Menüpfad Werkzeuge ->ABAP Workbench. Die Maske ABAP/4 Development Workbench wird angezeigt.
2. Über den Menüpfad Hilfsmittel->Dokumentation kommen Sie zur Maske Dokumentenpflege: Einstieg.
3. Drücken Sie auf den Pfeil nach unten auf dem Feld Dokumentenklasse. Eine Liste von Dokumentenklassen erscheint.
4. Doppelklicken Sie auf Allg.Text. Das Feld Dokumentenklasse enthält jetzt den Wert Allg.Text. (Das Feld Dokumentationstyp sollte bereits den Wert Original Benutzer enthalten. Falls nicht, klicken Sie auf den Pfeil nach unten am Ende des Feldes und ändern Sie es entsprechend.)
5. Geben Sie in das Feld Allg.Text den Namen des Dokuments ein, welches Sie anlegen möchten. Der Name muß mit y oder z beginnen. Merken Sie sich diesen Namen.
6. Drücken Sie auf Aktivieren. Sie sehen die Maske Allg.Text Ändern: Sprache DE.
7. Geben Sie hier Ihre Dokumentation ein. Drücken Sie (Enter) am Ende eines jeden Paragraphen.
8. Drücken Sie Aktivieren. Die Maske Objektkatalogeintrag erscheint.
9. Drücken Sie auf Lokales Objekt. Sie kehren zur Maske Allg.Text Ändern: Sprache DE zurück, und die Mitteilung »Das Dokument wurde im Status aktiv gesichert« erscheint auf der Statusleiste.
10. Drücken Sie Zurück. Sie befinden sich wieder im Bild Dokumentenpflege: Einstieg.
11. Drücken Sie nochmals auf Zurück, um auf die Maske ABAP/4-Development Workbench zu kommen.
12. Gehen Sie ins Data Dictionary und lassen Sie Ihr Datenelement anzeigen.
13. Drücken Sie auf Anzeigen<->Ändern, und Ihre Maske wechselt in den Modus Ändern.
14. Drücken Sie auf Dokumentation für die Maske Datenelement Ändern: Sprache DE.
15. Gehen Sie mit dem Cursor an die Stelle, an der Sie den Hyperlink einfügen wollen.
16. Wählen Sie den Menüpfad Einbinden->Verweis, um zur Maske Link Erstellen zu gelangen.
17. Betätigen Sie den Pfeil nach unten am Ende des Feldes Ausgewählter Verweis. Die Titelmaske erscheint; beachten Sie, daß sie eine Liste von Dokumentenklassen enthält.
18. Doppelklicken Sie auf Allg.Text. Das Feld Ausgewählter Verweis enthält nun den Wert Allg.Text, und ein Feld namens Allg.Text wird oben auf der Maske angezeigt.
19. Tippen Sie in das Feld Allg.Text den Namen der Dokumentation, die Sie in Schritt 6 angelegt haben.
20. Geben Sie den Hyperlink-Text in das Feld Bezeichn. im Dokument ein. Dies ist der Text, der markiert wird und auf den der Benutzer klicken kann, um mehr Hilfe zu erhalten.

21. Drücken Sie Weiter. Sie kommen zur Maske Datenelement Ändern: Sprache DE, und ein Link erscheint auf der Cursorposition.
22. Drücken Sie Aktivieren.
23. Sie können Ihren neuen Hyperlink sofort ausprobieren mit dem Menüpfad Dokument->Bildschirmausgabe. Die Maske Dokumentation Anzeigen wird angezeigt, Sie sehen Ihren Hilfetext, und Ihr Hyperlink sollte markiert sein.
24. Klicken Sie auf den Hyperlink. Auf der Maske Hypertext Anzeigen sollte nun Ihr Dokument erscheinen.
25. Drücken Sie dreimal auf Zurück, um zur Maske Dictionary: Tabelle/Struktur zu kommen.
26. Um Ihren Hyperlink zu testen, rufen Sie Ihre Tabelle auf, und wählen Sie den Menüpfad Hilfsmittel->Einträge erfassen.
27. Positionieren Sie den Cursor in dem Feld, für welches Sie die (F1)-Hilfe angelegt haben.
28. Drücken Sie (F1) - Ihr Hilfetext mit dem Hyperlink sollte angezeigt werden.
29. Klicken Sie auf den Hyperlink. Jetzt sollten Sie Ihr neues Dokument sehen.
Problem Lösung
Ich kann den Allg.Text nicht in der Liste der Dokumentenklassen finden.
Blättern Sie aufwärts.
Ich sehe die Mitteilung »Übersetzungsrelevante Änderung«. Drücken Sie auf die Schaltfläche Aktivieren auf der Drucktastenleiste, nicht auf Sichern auf der Symbolleiste.
Ich sehe die Nachricht »Datenelement wird nicht in einer ABAP/4-Struktur verwendet«.
Ändern Sie die Dokumentenklasse zu Allg.Text.
Ich drücke die Schaltfläche Dokumentation, aber es passiert rein gar nichts.
Heißt die Maske Dictionary: Datenelement anzeigen? Wenn ja, sind Sie im Modus Anzeigen, Sie sollten aber in Ändern sein. Drücken Sie auf Anzeigen/Ändern, und versuchen Sie es nochmals.
Zusammenfassung
■ Das Data Dictionary ist ein Werkzeug, welches von ABAP/4-Programmen benutzt wird, um Tabellen anzulegen und zu warten. Es gibt drei Arten von Tabellen: transparente, Pool- und Clustertabellen. Transparente Tabellen sind am gebräuchlichsten und enthalten Anwendungsdaten. Pool- und Clustertabellen werden von SAP hauptsächlich für Systemdaten verwendet.
■ Um eine Tabelle anzulegen, brauchen Sie erst einmal Domänen und Datenelemente. Domänen stellen die technischen Charakteristika eines Feldes zur Verfügung, Datenelemente die Feldkennungen und die (F1)-Hilfe. Beide sind wiederverwendbar.

■ Dictionary-Objekte müssen aktiv sein, bevor man sie verwendet. Wenn Sie ein Dictionary-Objekt verändern, müssen Sie das Objekt reaktivieren, bevor die Änderung wirksam wird.
■ Mit Datenbrowsern können Sie Tabellendaten anzeigen und modifizieren. SE16 ist der gebräuchlichste Datenbrowser. Die anderen Browser sind SE17, SM30 und SM31, die verschiedene Möglichkeiten bieten.
■ In einem Datenelement können Sie (F1)-Hilfe anlegen, indem Sie auf die Schaltfläche Dokumentation drücken. Innerhalb dieser (F1)-Hilfe können Sie Hypertexte zu anderen (F1)-Hilfedokumenten anlegen.
Fragen & Antworten
Frage:Was passiert, wenn ich die Länge eines Feldes kleiner mache, indem ich die Domäne ändere, dieses Feld aber von einer Tabelle benutzt wird, die schon Daten enthält, welche die gesamte Feldlänge ausfüllen?
Antwort:Wenn Sie die Domäne aktivieren, wird das System versuchen, die Tabellen zu aktivieren, die domänenabhängig sind. Die Aktivierung der Tabellen, die Daten verlieren würden, wird nicht funktionieren, und Sie erhalten eine Liste mit diesen Tabellen. Wenn Sie diese Tabellen dann öffnen, wird das System automatisch die enthaltenen Daten konvertieren und die Daten in der Spalte, die sich auf die Domäne bezieht, kürzen.
Frage:Wie findet man heraus, welche Tabellen betroffen sein werden, bevor man die Domäne verändert?
Antwort:Machen Sie einen Verwendungsnachweis in der Domäne. Dafür lassen Sie die Domäne anzeigen, drücken die Schaltfläche Verwendungsnachweis, wählen Andere Objekte und drücken auf Weiter. Eine Baumstruktur wird angezeigt. Doppelklicken Sie auf die Zeile namens Tabelle. Die Liste mit den Tabellennamen erscheint. Doppelklicken Sie auf irgendeine Zeile, um die Tabelle anzuzeigen.
Frage:Ist es möglich, ein Tabellenfeld anzulegen, ohne ein Datenelement oder eine Domäne zu benutzen? Es scheint ziemlich aufwendig zu sein, diese für jedes Feld anlegen zu müssen.
Antwort:Ja, das ist möglich. Zeigen Sie die Tabelle im Modus Ändern an, und wählen Sie den Menüpfad Bearbeiten->Direkte Typeingabe. Dann können Sie die Feldlänge und den Datentyp direkt eingeben. Diese Methode ist nicht empfehlenswert für Felder, die auf der Maske zu sehen sind; sie ist nur geeignet für Felder, die niemals zu sehen sein werden und die niemals Fremdschlüssel-Beziehungen zu anderen Tabellen haben werden (der Ausdruck »foreign key« wird im nächsten Kapitel erklärt). SAP verwendet diese Methode, um Tabellen anzulegen, die Systeminformationen enthalten wie z.B. Datenbank Cursor IDs. Sie könnten so in einer Tabelle verfahren, die seltene Daten im Transit in ein oder aus einem R/3-System beinhaltet. Es gibt zwei Nachteile bei dieser Methode. Der eine: Es werden keine Datenelemente benutzt, also existieren auch keine Feldkennungen und keine (F1)-Hilfe. Der zweite: Es werden keine Domänen verwendet, also können auch keine Fremdschlüssel angelegt werden.
Workshop
Durch die nachfolgenden Übungen erhalten Sie Praxis darin, Objekte im Data Dictionary anzulegen und diese in einfachen Programmen mit den Anweisungen tables, select und write zu verwenden. Die Lösungen

finden Sie im Anhang.
Kontrollfragen
1. Was ist der Zweck einer Domäne?
2. Was enthält das Datenelement?
3. Worauf bezieht sich der Terminus Anwendungsdaten ?
4. Ist der Dezimalpunkt für Felder vom Typ DEC mit dem Wert im Feld gespeichert?
5. Was sind die Transaktionscodes der vier Datenbrowser? Welcher ist der gebräuchlichste, und welcher kann nicht dazu benutzt werden, Daten zu aktualisieren ?
6. Was ist der Unterschied zwischen einer transparenten Tabelle und einer Pool- oder Clustertabelle?
Übung 1
Fügen Sie die in Tabelle 3.4 gezeigten Felder Ihrer Tabelle ***lfa1 hinzu. Keines dieser Felder hat ein x in der Schlüsselspalte, weil sie nicht Teil des Primärschlüssels sind. Der Zweck dieser Felder ist es, einen zweiten Namen für den Kreditor zu enthalten, Tag und Uhrzeit, wann diese Zeile angelegt wurde, und die ID des Benutzers, der diesen Datensatz angelegt hat. Legen Sie ein neues Datenelement für alle Felder an. Verwenden Sie die Domäne vom Feld name1 auch für das Feld name2. Für die übrigen Felder benutzen Sie die existierenden R/3-Domänennamen, die Sie weiter unten sehen. Dokumentieren Sie diese Felder mit der Schaltfläche Dokumentation im Datenelement. Nachdem Sie Ihre Änderungen aktiviert haben, verwenden Sie einen Datenbrowser, um die existierenden Zeilen in Ihrer Tabelle zu aktualisieren und Daten in die neuen Felder einzugeben. Während Sie die Zeilen aktualisieren, testen Sie Ihre (F1)-Hilfe.
Tabelle 3.4: Neue Felder und ihre Charakteristika für Tabelle ztxlfa1
Feldname DE Name DM Name
name2 ***name2 ***name
erdat ***erdat datum
ertim ***ertim time
ername ***ername usnam
Übung 2
Legen Sie eine transparente Tabelle ***kna1 an, die Kundenstammdaten enthalten soll, wie in Tabelle 3.5 gezeigt. Verwenden Sie einen Datenbrowser, um der Tabelle Daten hinzuzufügen. Legen Sie ein neues Programm ***e0302 an, welches die Daten dieser Tabelle liest und in die Liste schreibt.

Tabelle 3.5: Felder und ihre Merkmale für Tabelle ***kna1
Beschreibung
Feldname PK DE Name DM Name Typ Länge
Mandant
mandt x mandt
Kundennummer
kunnr x ***kunnr ***kunnr CHAR 10
Kundenname
name1 ***kname1 ***name CHAR 35
Stadt
cityc ***cityc ***cityc CHAR 4
Region
regio ***regio ***regio CHAR 3
Land
land1 ***land1 ***land1 CHAR 3
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 4
Das Data Dictionary ®, Teil 2
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, können Sie:
■ einen Fremdschlüssel einrichten ■ die Wertetabelle einer Domäne benutzen ■ eine Texttabelle anlegen und benutzen ■ den Unterschied beschreiben zwischen einer Struktur und einer Tabelle und Strukturen im R/3-
Data Dictionary einrichten ■ Tabellen und Strukturen anlegen, die Währungs- und Mengenfelder enthalten ■ Strukturen innerhalb anderer Strukturen oder Tabellen verschachteln
Fremdschlüssel
Ein Fremdschlüssel ist ein Feld in einer Tabelle, das über eine Fremdschlüsselbeziehung mit einer anderen Tabelle verbunden ist. Der Zweck dieser Fremdschlüsselbeziehung ist es, Daten gegen eine zulässige Wertmenge in einer anderen Tabelle zu überprüfen. Die Tabelle, die den Fremdschlüssel enthält, heißt Fremdschlüsseltabelle. Die Tabelle, welche die zulässige Wertmenge beinhaltet, wird Prüftabelle genannt (s. Abb. 4.1). Das Feld, das überprüft und über das die Fremdschlüsselbeziehung eingerichtet wird, ist dann der Fremdschlüssel.

Abbildung 4.1: Die Fremdschlüsseltabelle und die Prüftabelle
Zum Beispiel enthält die ***lfa1-Tabelle Landeskennzahlen im Feld land1. Sie können eine zweite Tabelle (zum Beispiel ***t005) einrichten und diese mit einer Auflistung der zulässigen Landeskennzahlen füllen. Wenn Sie dann einen Fremdschlüssel einrichten (wie in Abb. 4.1 gezeigt), wird der eingegebene Wert automatisch gegen die zulässigen Werte in der Prüftabelle überprüft. Mit diesem Fremdschlüssel kann der Anwender keine ungültigen Landeskennzahlen in die Tabelle ***lfa1 einfügen.
Der Fremdschlüssel bekommt seinen Namen von der Tatsache, daß er immer gegen das Feld des Primärschlüsssels einer anderen Tabelle überprüft werden muß.
Auslösung der Fremdschlüsselüberprüfung
Die Fremdschlüsselüberprüfung wird von der R/3-Benutzerschnittstelle ausgeführt. Wenn Sie einen Wert in ein Feld eingeben und die Entertaste drücken, formuliert dieses im Hintergrund eine select-Anweisung und übermittelt selbige an die Datenbank, um das Fremdschlüsselfeld zu überprüfen. Wenn kein Eintrag in der Prüftabelle gefunden wird, bekommt der Anwender eine Standardmeldung angezeigt, daß der eingebene Wert ungültig ist. Existiert der eingegebene Wert in der Prüftabelle, werden die Feldinhalte an das der Eingabemaske zugrunde liegende ABAP/4-Programm übergeben. Der Fremdschlüssel wird also schon überprüft, bevor das Programm die Werte aufnimmt. Zusätzlich zur Entertaste wird die Überprüfung des Fremdschlüssels auch vorgenommen, wenn eine Funktionstaste, eine Drucktaste oder ein Menüpunkt angesprochen werden.
Die Überprüfung des Fremdschlüssels wird nur durch die Benutzerschnittstelle vorgenommen. Fremdschlüssel existieren nicht in der Datenbank und werden somit bei Datenbankupdates nicht überprüft. Ein falsch programmiertes ABAP/4-Programm kann deswegen die Konsistenz verletzen; es kann ungültige Werte in Datenbanktabellen einfügen. Aus diesem Grund benutzen ABAP/4-

Programme, welche die Datenbank mit von außen kommenden Daten aktualisieren sollen, in der Regel die Anwenderschnittstelle, um die Daten zu überprüfen.
Für weitere Informationen über die Verwendung der Benutzerschnittstelle zur Datenüberprüfung schlagen Sie in der R/3-Bibliothekshilfe unter BDC (Batch Data Communication) Programmen nach. Um sich diese Dokumentation anzusehen, wählen Sie (egal aus welcher Maske) den Menüpfad Hilfe->R/3-Bibliothek. Sie erhalten das Hauptmenü der R/3-Bibliothek. Klicken Sie jetzt auf folgende Tabs: Basis->ABAP/4- Workbench->Basisprogrammierschnittstellen->Daten mit Batch-Input übernehmen.
Technische Voraussetzungen zum Anlegen eines Fremdschlüssels
Um einen Fremdschlüssel einzurichten:
■ muß die Überprüfung gegen ein Feld innerhalb des Primärschlüssels der Prüftabelle vorgenommen werden
■ müssen die Domänen des Fremdschlüsselfelds und des Prüftabellenfelds übereinstimmen
Die zweite Voraussetzung stellt sicher, daß die Felder, die hierbei verglichen werden, jeweils vom gleichen Typ sind und die gleiche Länge haben (s. Abb. 4.2).
In Abbildung 4.2 verwenden beide Felder dieselben Datenelemente und dieselbe Domäne. Beachten Sie, daß die Verwendung derselben Datenelemente nicht verlangt wird, lediglich die Domäne muß dieselbe sein.
Weil sich diese Felder eine allgemeine Domäne teilen, ist die Vergleichsintegrität zwischen diesen beiden Feldern garantiert, da ihre Datentypen und Längen immer zusammenpassen werden.

Abbildung 4.2: Dies ist ein Diagramm des Fremdschlüsselfeldes, des Prüftabellenfeldes und der allgemeinen Domäne, die sie sich teilen.
Anlegen des Fremdschüssels
Nun ist es an der Zeit, einen einfachen Fremdschlüssel anzulegen. Dieses Beispiel soll Sie mit der dafür vorgesehenen Oberfläche vertraut machen. Alle Felder dieser Masken werden später ausführlich in diesem Kapitel erläutert. Im folgenden wird aufgezeigt, wie die Prüftabelle ztxt005 eingerichtet und anschließend der Fremdschlüssel über das Feld ztxlfa1-land1 angelegt wird. Nachdem Sie sich dieses Verfahren angeschaut haben, werden Sie aufgefordert, Ihre eigene ***t005-Tabelle und die dazugehörige Fremdschlüsselbeziehung von ***lfa1-land1 zu erstellen.
Bevor Sie einen Fremdschlüssel einrichten, muß zuerst eine Prüftabelle vorhanden sein. Obwohl schon eine Ländertabelle in R/3 vorhanden ist, werden Sie als praktische Übung Ihre eigene erstellen. Die Prüftabelle wird ***t005 genannt. Die in ihr enthaltenen Felder und Datenelemente sind in der Tabelle 4.1 aufgeführt. (Ein X in der PK-Spalte zeigt die Felder auf, die den Primärschlüssel bilden.)
Tabelle 4.1: Die Felder der Tabelle ***t005 und ihre
Eigenschaften
Feldname PK DE-Name

mandt x mandt
land1 x ***land1
Verfahren zum Anlegen einer Prüftabelle
Im folgenden wird das Einrichten der Prüftabelle ***t005 aufgezeigt. Falls Sie Probleme dabei haben, benutzen Sie den Störungssucher für das Anlegen von transparenten Tabellen (vorhandene Domänen und Datenelemente) im Kapitel von Tag 3.
Starten Sie jetzt das ScreenCam »How to Create Check Table ***t005«.
Um Ihre Prüftabelle einzurichten:
1. Gehen Sie in die Einstiegsmaske des Data Dictionary.
2. Geben Sie den Tabellennamen im Feld Objektname ein.
3. Markieren Sie die Auswahl für Tabellen.
4. Drücken Sie auf die Schaltfläche Anlegen.
5. Geben Sie eine Kurzbeschreibung ein. Als Auslieferungsklasse wird A festgelegt. Kreuzen Sie Tabellenpflege erlaubt an.
6. Tippen Sie die Feld- und die Datenelementnamen ein.
7. Kreuzen Sie bei beiden Feldern das Feld für den Primärschlüssel an.
8. Drücken Sie die Sichern-Taste auf der Symbolleiste. Die Maske Objektkatalogeintrag erscheint.
9. Drücken Sie die Schaltfläche Lokales Objekt. Danach wird zum Dictionary zurückgesprungen: Tabelle/Struktur: Felder ändern.
10. Drücken Sie auf die Schaltfläche Technische Einstellungen auf der Drucktastenleiste. Das ABAP/4-Dictionary: das Änderungsbild Technische Einstellungen pflegen wird angezeigt.
11. Geben Sie APPL0 im Feld Datenart ein (APPL0 mit einer Null, nicht APPLO mit dem Buchstaben O).
12. Geben Sie 0 (Null) im Feld Größenkategorie ein.
13. Drücken Sie die Sichern-Taste.
14. Drücken Sie die Zurück-Taste. Danach wird ins Dictionary zurückgesprungen: Tabelle/Struktur:

Änderungsbild.
15. Aktivieren Sie die Tabelle durch Drücken der entsprechenden Schaltfläche. Nach der Meldung Tabelle wurde aktiviert ändert sich der Status auf aktiv.
Wählen Sie danach den Menüpfad Hilfsmittel->Einträge erfassen aus, um Daten in Ihre neu eingerichtete Prüftabelle einzugeben. Geben Sie ins Feld land1 die Werte US, CA, DE, IT, JP und AUein.
Verfahren zum Anlegen des Fremdschlüssels
Starten Sie nun das ScreenCam »How to Create a Foreign Key«.
Um einen Fremdschlüssel einzurichten:
1. Gehen Sie ins Data Dictionary: Einstiegsbild.
2. Tippen Sie den Namen der Tabelle ein, die den Fremdschlüssel enthalten soll (***lfa1).
3. Markieren Sie die Auswahl Tabelle.
4. Drücken Sie nun auf die Schaltfläche Ändern. Dictionary: Tabelle/Struktur: Felder ändern wird angezeigt.
5. Positionieren Sie den Cursor auf das Feld, das als Fremdschlüssel vorgesehen ist (land1).
6. Drücken Sie auf die Schaltfläche Fremdschlüssel (oder benutzen Sie den Menüpfad Springen->Fremdschlüssel). Danach befinden Sie sich in der Änderungsmaske für Fremdschlüssel (s. Abb. 4.3).
7. Tippen Sie nun den Namen des Fremdschlüssels in die Kurzbeschreibung ein, zum Beispiel Gültige Landeskennzahlen.
8. Geben Sie dann den Namen der Prüftabelle (***t005) im entsprechenden Feld ein, oder klicken Sie auf den Pfeil nach unten und wählen die Tabelle in der Eingabehilfe aus.
9. Das Fremdschlüssel-Popup erscheint mit der Meldung, daß die Prüftabelle eingerichtet oder geändert wurde. Bestätigen Sie den Systemvorschlag mit Ja.
10. Nach dem Rücksprung zum Änderungsbild, werden die Felder der Prüftabelle inklusive der Fremdschlüsselfelder angezeigt. (Die Felder der Prüftabelle sind ***t005-mandt und ***t005-land1. Die Fremdschlüsselfelder sind ***lfa1-mandt und ***lfa1-land1).
11. Drücken Sie auf Übernehmen. Danach springen Sie automatisch zum Dictionary zurück: Tabelle/Strukturen: Im Änderungsbild erscheint die Meldung, daß der Fremdschlüssel übertragen wurde. Die Statusfelder stehen auf überarbeitet und nicht gesichert.

12. Drücken Sie auf die Schaltfläche Aktivieren auf der Drucktastenleiste. Die Meldung »wurde aktiviert« erscheint in der Statusleiste. Der Status steht jetzt auf aktiv und gesichert.
Sie haben eine Fremdschlüsselbeziehung zwischen den Tabellen ***lfa1 und ***t005eingerichtet. Das Feld ***lfa1-land1 ist der Fremdschlüssel und ***t005 ist die Prüftabelle. Die Benutzerschnittstelle überprüft den Inhalt des Felds ***lfa1- land1 gegen die Werte des Felds land1 in der Tabelle ***t005.
Abbildung 4.3: Die Maske Fremdschlüssel Anlegen zeigt die Prüftabellenfelder und die zugehörigen Fremdschlüsselfelder.
Prüfen der Fremdschüsselbeziehung
Das folgende Verfahren wird im nächsten Abschnitt ausführlich beschrieben. Um Ihren Fremdschlüssel zu prüfen,
1. gehen Sie ins Einstiegsbild des Dictionary: Tabelle/Struktur (Anzeige- oder Änderungsbild)
2. wählen Sie den Menüpunkt Hilfsmittel->Einträge erfassen

3. geben Sie die Bezeichnung des Fremdschlüssels ein (Gültige Landeskennzahlen)
4. drücken Sie die Entertaste. Wenn der Wert nicht in der Tabelle gefunden wird, existiert der Eintrag nicht, und die Meldung »bitte Eingabe überprüfen« erscheint.
Das Prüftabellenfeld
Nachdem Sie den Fremdschlüssel eingerichtet haben, erscheint der Name der Prüftabelle in der entsprechenden Spalte im Dictionary.
Schauen Sie sich jetzt Ihre Tabelle an. Sie sehen den Namen Ihrer Prüftabelle in der dafür vorgesehenen Spalte.
Automatische Festlegung von Fremdschlüsseln
Als Sie den Fremdschlüssel eingerichtet haben, mußten Sie Felder, die an der Fremdschlüsselbeziehung teilnehmen, nicht spezifizieren. Diese wurden durch das System automatisch ausgewählt. Dieser Abschnitt erklärt, wie das System diese Feldnamen bestimmt.
Beim Anlegen eines Fremdschlüssels haben Sie Ihren Cursor auf dem Fremdschlüsselfeld positioniert und die dazugehörige Schaltfläche gedrückt. Danach hat Ihnen das System Feldpaare vorgeschlagen, für die Sie eine Fremdschlüsselbeziehung aufbauen können. In jedem Paar steht jeweils ein Feld aus der Fremdschlüsseltabelle und ein Feld aus der Prüftabelle. Die Anzahl der Paare ist gleich der Anzahl der Primärschlüsselfelder in der Prüftabelle. Alle Primärschlüsselfelder der Prüftabelle müssen in die Fremdschlüsselbeziehung eingebunden werden.
Das System sucht nach Primärschlüsselfeldern, welche die gleiche Domäne haben wie die Fremdschlüsselfelder und stellt daraus mögliche Paare zusammen.
Wenn es mehrere Primärschlüsselfelder in der Prüftabelle gibt, wird versucht einen Eintrag für jedes der übrigen Felder zu finden. Das System versucht für jedes Feld der Fremdschlüsseltabelle ein Feld in der Prüftabelle zu finden, das die gleiche Domäne besitzt. Falls dies nicht gelingt, wird versucht, ein Feld zu finden, das den gleichen Datentyp und die gleiche Länge hat. Wenn das System mehr als ein darin übereinstimmendes Feld findet, wird ein beliebiges Feld ausgewählt und die Warnung ausgegeben, daß die Zuweisung nicht eindeutig ist. Dieser Prozeß wird so oft wiederholt, bis alle Primärschlüsselfelder der Prüftabelle den korrespondierenden Feldern in der Fremdschlüsseltabelle zugewiesen sind.
Zuordnung des Fremdschlüssels zur Eingabehilfe bzw. F4-Hilfe
Zusätzlich zur (F1)-Hilfe können Sie dem Anwender auch die sogenannte (F4)-Hilfe zur Verfügung stellen. Die (F4)-Hilfe ist eine Auflistung der zulässigen Werte, die der Anwender in ein Feld eingeben kann. Um die (F4)-Hilfe zu erhalten, positioniert der Anwender den Cursor in ein Eingabefeld und drückt die (F4)-Taste oder klickt den nach unten zeigenden Pfeil an. (F4)-Hilfe wird auch als

Eingabehilfe bezeichnet. Beide Bezeichnungen werden synonym von SAP benutzt.
Für einen angelegten Fremdschlüssel wird die (F4)-Hilfe automatisch unterstützt.
Starten Sie nun das ScreenCam »Using a Foreign Key to Provide F4 Help«.
Wenn Sie den Cursor in ein Fremdschlüsselfeld der Eingabemaske stellen, wird am rechten Rand des Eingabefeldes ein nach unten zeigender Pfeil erscheinen. Dies ist das Zeichen der (F4)-Hilfe. Wenn Sie nun auf den Pfeil nach unten klicken oder die (F4)-Taste drücken, wird eine Auflistung der möglichen bzw. zulässigen Eingaben angezeigt. Diese Auflistung zeigt den Inhalt der Prüftabelle, wobei alle Schlüsselfelder der Prüftabelle mit Ausnahme des Felds mandt angezeigt werden.
Wenden Sie folgendes Verfahren an, um die auf ***lfa1-land1 eingerichtete Fremdschlüsselbeziehung zu testen. Wenn Ihr Fremdschlüssel nicht funktioniert, vergleichen Sie Ihre Tabelle mit ztxlfa1, um den Fehler zu beheben.
1. Starten Sie von einer beliebigen Maske aus.
2. Geben Sie /nse16 im Befehlsfeld ein.
3. Drücken Sie die Entertaste. Der Data-Browser: Die Einstiegsmaske wird angezeigt.
4. Tippen Sie ***lfa1 als Tabellennamen ein.
5. Drücken Sie auf die Schaltfläche Einträge erfassen auf der Drucktastenleiste (oder wählen Sie den Menüpfad Tabelle->Springen->Einträge erfassen). Die Maske Tabelle einfügen wird angezeigt.
6. Tippen Sie irgendeinen Wert im Feld Kreditorennummern ein, zum Beispiel MY- V1.
7. Positionieren Sie den Cursor auf dem Feld Landeskennzahlen (land1). Obwohl ein Pfeil nach unten am Ende des Felds erscheint, klicken Sie ihn noch nicht an.
8. Geben Sie den Wert XX im Feld Landeskennzahlen ein.
9. Drücken Sie die Sichern-Taste auf der Symbolleiste. Es erscheint die Meldung »Eintrag XX nicht vorhanden (Bitte Eingabe überprüfen)«. Ihr Cursor ist am Anfang des Felds positioniert, das den falschen Wert enthält. Der Pfeil nach unten erscheint am Ende des Felds.
10. Klicken Sie auf den Pfeil nach unten, oder drücken Sie die (F4)-Taste. Es erscheint ein Popup, das die Schlüsselfelder der Prüftabelle ***t005 enthält.
11. Doppelklicken Sie auf den Eintrag US. Das Popup verschwindet, und der Wert US wird in das Feld Länderkennzahlen gestellt.
12. Drücken Sie abschließend auf die Sichern-Taste auf der Symbolleiste. Die Meldung »Datensatz

erfolgreich weggeschrieben« erscheint auf der Statusleiste.
Die Fremdschlüsselbeziehung ermöglicht dem Anwender, Bildschirmeingaben auf ihre Gültigkeit hin zu überprüfen. Ist ein Feld ein Fremdschlüsselfeld, wird der Wert gegen die Prüftabelle geprüft. Wenn der Wert nicht in der Prüftabelle existiert, wird eine Standardfehlermeldung ausgegeben.
Fremdschlüssel und Batch-Programme
Batch-Programme, die sequentielle Dateien oder andere Datenquellen einlesen und direkt die Datenbank aktualisieren, müssen die Daten im Gegensatz zur Bildschirmeingabe selbst überprüfen. Diese Programme sollten in einer der folgenden drei Weisen programmiert werden:
■ Die Daten sollten über die Benutzerschnittstelle durch Aufruf der Transaktion, welche die Eingabemaske enthält, übergeben werden. Dies geschieht komplett im Hintergrund. Die Daten werden automatisch den Eingabefeldern zugewiesen, für die dann die Überprüfung des Fremdschlüssels vorgenommen wird. Dieses Verfahren wird BDC (Batch Data Communications) genannt und wurde schon im Abschnitt »Exkurs in den Fremdschlüssel« erwähnt. BDC ist das Standardverfahren, um Daten in das R/3-System zu importieren.
■ Sie können selbst select-Anweisungen enthalten, welche die Fremdschlüsselprüfungen ausführen. Dieses Verfahren ist weniger zuverlässig, weil die Programme aktualisiert werden müssen, wenn neue Fremdschlüssel hinzugefügt oder existierende verändert worden sind.
■ Die Daten können über besondere Funktionsmodule übergeben werden, die sowohl die Fremdschlüsselprüfung als auch das Datenbankupdate ausführen. Diese Module (genannt BAPIs, oder Business APIs) werden von SAP angelegt und im R3-System zur Verfügung gestellt.
Zusammengesetzter Fremdschlüssel
Ein zusammengesetzter Fremdschlüssel besteht aus zwei oder mehreren Feldern. Eine Überprüfung wird vorgenommen, in dem zum Beispiel zwei Felder der Fremdschlüsseltabelle mit zwei Feldern der Prüftabelle verglichen werden. Die Kombination der Werte muß in der Prüftabelle existieren, bevor sie in die Fremdschlüsseltabelle eingefügt werden kann. Allerdings reicht ein Eingabefeld aus, die Prüfung des zusammengesetzten Fremdschlüssels auszulösen.
Wenn Sie einen zusammengesetzten Fremdschlüssel einrichten, heißt das Feld, auf dem Sie den eigentlichen Fremdschlüssel definieren, Prüffeld. Nur ein beschriebener Wert (ungleich Space) im Prüffeld löst die Überprüfung gegen die Prüftabelle aus. Ein Wert innerhalb eines anderen Felds des zusammengesetzten Fremdschlüssels führt nicht zur Überprüfung. Das Feld regio in der Tabelle ztxlfa1 z.B. sollte nur gültige Länder und Regionskennzahlen enthalten. Die Kombination von land1 und regio muß also zulässig sein. Deswegen muß diese Kombination in der Prüftabelle (ztxt005s) vorhanden sein. Nachdem diese Prüftabelle angelegt ist, wird ein zusammengesetzter Fremdschlüssel in ztxlfa1 benötigt, um die Zulässigkeit der Kombination von regio und land1festzulegen. Zusätzlich soll ztxt005s-land1 noch gegen ztxt005-land1 geprüft werden (s. Abb. 4.4).

Abbildung 4.4: Ein zusammengesetzter Fremdschlüssel bestätigt die Kombination von Region und Land gegen die Prüftabelle.
Ein zusammengesetzter Fremdschlüssel wird im Prinzip genauso angelegt wie ein Fremdschlüssel, der ein einzelnes Feld enthält. Sie fangen an, indem Sie den Cursor auf ein Feld, in diesem Fall ztxlfa1-regio, positionieren und dann auf die Schaltfläche Fremdschlüssel drücken. Weil der Cursor auf regio steht, wird dieses Feld das Prüffeld des zusammengesetzten Fremdschlüssels. Obwohl der Fremdschlüssel aus mehreren Feldern besteht, wird nur dieses Feld die Überprüfung gegen die Datenbank anstoßen. Wenn das Feld beschrieben ist und der Anwender die Entertaste drückt, wird eine Überprüfung gegen die Prüftabelle vorgenommen, die alle Felder des Fremdschlüssels vergleicht. Wenn das Überprüfungsfeld leer ist, findet keine Überprüfung statt, auch wenn die anderen Felder Werte enthalten.
Was den einfachen Fremdschlüssel betrifft, so müssen die Domänennamen des Prüffeldes und die zugehörigen Felder in der Prüftabelle übereinstimmen. Wenn jedoch der Fremdschlüssel angelegt wurde, müssen die restlichen Domänennamen in dem zusammengesetzten Fremdschlüssel nicht passen; der Fremdschlüssel kann angelegt werden, wenn ihre Datentypen und Längen übereinstimmen. Wird zu einem späteren Zeitpunkt der Datentyp oder die Länge in einer dieser Domänen geändert, passen die Felder nicht mehr zusammen, somit wird das Ergebnis der Fremdschlüsselprüfung unvorhersehbar. Aus diesem Grund ist es äußerst ratsam, daß alle Domänennamen eines zusammengesetzten Fremdschlüssels übereinstimmen, obwohl R/3 dies nicht ausdrücklich verlangt.
Als Faustregel gilt: Wenn ein Datentyp oder die Länge eines Feldes, außer derjenigen

des Prüffeldes, in einem zusammengesetzten Fremdschlüssel geändert werden, müssen Sie checken, ob der Fremdschlüssel und die Prüftabellenfelder die gleiche Domäne benutzen. Wenn dies nicht der Fall ist, müssen sie auf den gleichen Stand gebracht werden, da es sonst zu unvorhergesehenen Tätigkeiten des Fremdschlüssels kommen kann.
Wenn Sie eine Fremdschlüsselbeziehung zu einer Prüftabelle einrichten, die mehr als ein Feld im Primärschlüssel enthält, müssen alle Primärschlüsselfelder der Prüftabelle in den Fremdschlüssel einbezogen werden. Diese Felder müssen nicht alle überprüft werden (siehe Abschnitt »generische Fremdschlüssel«). Trotzdem müssen sie alle im Fremdschlüssel vorhanden sein.
Da die meisten Prüftabellen das Feld mandt enthalten, ist dieses in fast allen Fällen Teil des Fremdschlüssels (s. Abb.4.5 und 4.6).
Mit der Aufnahme dieses Felds in die Prüftabelle können unabhängige Wertemengen für jeden Anmeldemandanten definiert werden. Diese Möglichkeit ist oft erwünscht, um Daten zwischen den einzelnen Mandanten zu unterscheiden bzw. sicherzustellen, daß sie völlig unabhängig voneinander sind.
Die (F4)-Hilfe ist nur für das Prüffeld eines zusammengesetzten Fremdschlüssels verfügbar. Beim Aufruf der (F4)-Hilfe werden alle Primärschlüsselfelder der Prüftabelle angezeigt. Die Spalte, die das Prüffeld enthält, wird in der Liste hervorgehoben. Die Spaltenbreiten und Titel werden aus den Beschreibungen der Datenelemente ermittelt.
Abbildung 4.5: Ein zusammengesetzter Fremschlüssel bezieht das mandt-Feld mit ein.

Abbildung 4.6: Die Definition des Fremdschlüssels aus Abb. 4.5
Kardinalität
Die Kardinalität der Fremdschlüsselbeziehung beschreibt, wie viele Einträge in der Fremdschlüsseltabelle für jeden Wert der Prüftabelle vorhanden sein dürfen. Sie wird im Änderungsbild für Fremdschlüssel angegeben (Abb. 4.3). Die Kardinalität wird mit X:Y bezeichnet, wobei sich X auf die Prüftabelle und Y auf die Fremdschlüsseltabelle bezieht. X kann dabei die Werte 1 oder C annehmen, Y die Werte 1 , C, N oder CN.
Die Werte für X bedeuten:
■ 1: Wenn das Anwendungsprogramm eine Zeile aus der Prüftabelle löscht, wird es auch die entsprechenden Zeilen in der Fremdschlüsseltabelle löschen. Wenn zum Beispiel das Programm den Wert US aus der Prüftabelle löscht, werden alle Zeilen aus der Fremdschlüsseltabelle gelöscht, in denen das Feld land1 = US enthält. Für jeden unterschiedlichen Wert in der Fremdschlüsseltabelle, gibt es genau einen Wert in der Prüftabelle.
■ C: Das Löschen von Einträgen in der Prüftabelle ist erlaubt, ohne daß die entsprechenden Zeilen aus der Fremdschlüsseltabelle gelöscht werden. Das heißt, es können Werte in der Fremdschlüsseltabelle vorhanden sein, ohne daß die entsprechenden Werte in der Prüftabelle existieren.
Die Werte für Y bedeuten:

■ 1: Es gibt genau eine Zeile in der Fremdschlüsseltabelle für jede Zeile in der Prüftabelle. ■ C: Es gibt maximal eine Zeile in der Fremdschlüsseltabelle für jede Zeile in der Prüftabelle. ■ N: Es gibt mindestens eine Zeile in der Fremdschlüsseltabelle für jede Zeile in der Prüftabelle. ■ CN: Es können eine, keine oder mehrere Zeilen in der Fremdschlüsseltabelle für jede Zeile in
der Prüftabelle vorhanden sein.
Die Angabe der Kardinalität wird vom R/3-System nicht erzwungen. Die Festlegung ist optional. Die Kardinalität wird auch vom System nicht überprüft, wenn es darum geht, Datenbankupdates durch ein ABAP/4-Programm vorzunehmen. Die Kardinalität wird vor allem beim Einrichten von zusammengesetzten Objekten im DDIC benutzt.
Ein zusammengesetztes Objekt ist ein DDIC-Objekt, das aus mehr als einer Tabelle besteht. Ein Beispiel für ein solches Objekt ist ein View.
Wenn Sie einen Fremdschlüssel einrichten, sollten Sie die Kardinalität angeben, da Sie sonst die Tabelle nicht in ein zusammengesetztes Objekt aufnehmen können.
Der Typ des Fremdschlüsselfelds
Der Typ des Fremdschlüsselfelds wird auf der gleichen Maske wie die Kardinalität angegeben (auf Abb. 4.3 beziehen). Er kann folgende Werte einnehmen:
■ Schlüsselfelder/-kandidaten■ keine Schlüsselfelder/-kandidaten ■ Schlüsselfelder einer Texttabelle
Schlüsselfelder
Für den Fall, daß das Fremdschlüsselfeld ein Primärschlüsselfeld der Fremdschlüsseltabelle ist, müssen an dieser Stelle Schlüsselfelder/-kandidaten ausgewählt werden. Ist dies nicht der Fall, werden keine Schlüsselfelder/-kandidaten ausgewählt. Nehmen wir zum Beispiel an, daß die Tabelle t1 aus den Feldern f1 bis f10 und den Primärschlüsselfelder f1, f2 und f3 besteht. Wenn Sie einen Fremdschlüssel auf Feld f3 definieren wollen, müßten Sie Schlüsselfelder/-kandidaten anklicken, da f3 Teil des Primärschlüssels ist. Wenn der Fremdschlüssel auf Feld f5 definiert werden soll, müßten Sie dagegen Keine Schlüsselfelder/-kandidaten angeben, weil f5 kein Primärschlüsselfeld ist.
Schlüsselkandidaten
Ein Schlüsselkandidat ist ein Feld, das allein oder in Verbindung mit einem anderen Feld, das nicht Teil des Primärschlüssels ist, Einträge in der Tabelle eindeutig identifizieren kann. Wenn es außerhalb des Primärschlüssels die Möglichkeit gibt, alle Einträge eindeutig zu bestimmen, muß ein Schlüsselkandidat vorhanden sein. Dieser kann dann alternativ als Schlüssel benutzt werden.
Zum Beispiel hat ztxlfa1 nur ein einziges Primärschlüsselfeld. Wenn wir nun annehmen, daß die

Kombination von erdat und ertim (Erstellungsdatum und Zeit) für jede Zeile ebenfalls eindeutig ist, dann sind diese Felder Schlüsselkandidaten. Auch wenn nur eines dieser beiden Felder im Fremdschlüssel vorkommen würde, wäre der Fremdschlüsseltyp Schlüsselfelder/-kandidaten.
Wenn Sie einen Fremdschlüssel für die oben gezeigte Konstellation einrichten, sollten Sie Schlüsselfelder/-kandidaten wählen. Ansonsten wählen Sie keine Schlüsselfelder/- kandidaten.
Schlüsselfelder einer Texttabelle
Das R/3-System unterstützt viele Sprachen und ermöglicht dem Anwender, sich in der Sprache seiner Wahl anzumelden. Dafür werden Beschreibungen im R/3 in besonderen sprachabhängigen Tabellen gespeichert, die als Texttabellen bezeichnet werden.
Anwender können Ihre eigene Anmeldesprache einrichten. Das wird im Benutzerprofil über den Menüpfad System->Benutzervorgaben->Eigene Daten vorgenommen. Änderungen werden erst bei der nächsten Anmeldung wirksam.
Eine Texttabelle ist eine sprachenspezifische Prüftabelle. Der Primärschlüssel der Texttabelle ist der gleiche wie der der eigentlichen Prüftabelle (ohne Texte) mit dem zusätzlichen Schlüsselfeld spras(Sprache).
Die Tabelle ztxt005 enthält z.B. die Landeskennzahlen. Die Namen der Länder sind dagegen in einer gesonderten Tabelle gespeichert, der ztxt005t (s. Abb. 4.7), die für jede unterstützte Sprache jeweils einen Eintrag enthält. Die Tabelle ztxt005t ist somit die Texttabelle der Länderkennzahlen.

Abbildung 4.7: Die Texttabelle für ztxt005 ist ztxt005t. Sie besteht aus den Feldern mandt, spras, land1, landx und natio.
Der Primärschlüssel einer Texttabelle besteht aus dem Feld mandt, dem Feld spras und einem oder mehreren Prüffeldern. Dahinter folgt das Textfeld (ggf. mehrere).
Eine Fremdschlüsselbeziehung ist auf ztxt005t-land1 zur Prüftabelle ztxt005 definiert. Der Typ des Fremdschlüsselfelds sollte Schlüsselfeld einer Texttabelle sein.
Zuordnung von Texttabellen zur F4-Hilfe
Der Typ Schlüsselfeld einer Texttabelle eines Fremdschlüsselfeldes zeigt dem R/3-System an, daß diese Tabelle eine Texttabelle ist. Wenn Sie diesen Typ wählen, werden die Textfelder der (F4)-Hilfe in der Anmeldesprache des Anwenders angezeigt. Dieser Schlüsseltyp hat deswegen zwei besondere Eigenschaften:
■ Beim Aufrufen der (F4)-Hilfe werden die Einträge der Texttabelle angezeigt, als wären sie Teil der Prüftabelle.
■ Nur die Einträge der Texttabelle, die den gleichen Sprachenschlüssel wie den der gegenwärtigen Anmeldesprache haben, erscheinen in der (F4)-Hilfe-Liste.

Zum Beispiel enthält die Texttabelle ztxt005t eine Fremdschlüsselbeziehung von ztxt005t-land1 zur Prüftabelle ztxt005, wobei der Typ Schlüsselfeld einer Texttabelle ist. Wenn Sie die (F4)-Hilfe auf ztxt005-land1 aufrufen, sehen Sie die Primärschlüsselspalten der Prüftabelle ztxt005 und zusätzlich den Inhalt der ersten Spalte, die dem Primärschlüssel von ztxt005t folgt. Nur die Zeilen für die gegenwärtige Anmeldesprache (spras = sy-langu) werden angezeigt.
Die Inhalte der Tabellen ztxt005 und ztxt005t werden in den Tabellen 4.2 und 4.3 gezeigt.
Tabelle4.2:
Inhaltder
Tabelleztx005
Land1
US
CA
DE
IT
JP
AQ
CC
Tabelle 4.3: Inhalt der Tabelle ztxt005t
spras Land1 landx
E CA Canada
D CA Kanada
E DE Germany
D DE Deutschland
E US United States
D US USA

E IT Italy
D IT Italien
E JP Japan
D JP Japan
E AQ Antarctica
D AQ Antarktis
E CC Coconut Islands
D CC Kokosinseln
Starten Sie nun das ScreenCam »Text Table Demonstration: The Effect of the Logon Language«.
1. Transaktion SE16 (/nse16 im Befehlsfeld eingeben und die Eingabetaste drücken).
2. Geben Sie den Tabellennamen ztxlfa1 im Tabellennamensfeld ein.
3. Drücken Sie Schaltfläche Einträge erfassen auf der Drucktastenleiste.
4. Positionieren Sie den Cursor auf das Feld Landeskennzahlen (land1).
5. Drücken Sie die (F4)-Taste, oder klicken Sie auf den Pfeil nach unten am Ende des Feldes. Es erscheint ein Popup, das sowohl die Spalten der Tabelle ztxt005 als auch die der Tabelle ztxt005t anzeigt. Beachten Sie, daß neben dem Feld land1 der Tabelle ztxt005 die deutschsprachigen Beschreibungen aus der Tabelle ztxt005t erscheinen.
6. Melden Sie sich ein weiteres Mal an (Sie müssen sich dazu nicht abmelden). Diesmal tragen Sie Efür englisch in das Sprachfeld der R/3-Anmeldemaske ein.
7. Wiederholen Sie die Schritte 1 bis 5 in dieser Session.
8. Beachten Sie in dieser Zeit die englischen Beschreibungen der Tabelle ztxt005t.
Einrichten einer Texttabelle mit dem dazugehörigen Fremdschlüssel
Im folgenden werden Sie nun Ihre eigene Texttabelle einrichten. Die ztxt005t soll hierbei als Vorlage dienen. Diese Texttabelle wird ***t005t genannt. Die benutzten Felder, Datenelemente und Domänen werden in der Tabelle 4.4 aufgezeigt. Das Datenelement ***landx muß hierfür noch eingerichtet werden. Als Domäne verwenden Sie dafür die bereits bestehende text15.
Tabelle 4.4: Felder und deren Eigenschaften für Tabelle ***t005t

Feldnamen PK DE-Name DM-Name
mandt x mandt
spras x spras
Land1 x ***land1
landx ***landx Text15
Nachdem Sie die Tabelle ***t005t aktiviert haben, geben Sie Daten mit Hilfe der SE16 ein. Benutzen Sie diejenigen Daten, die schon in Tabelle 4.3 gezeigt wurden.
Danach muß ein Fremdschlüssel auf das Feld ***t005t-land1 eingerichtet werden. Das Verfahren ist das gleiche wie bei den vorherigen Übungen. Die ***t005 wird dabei als Prüftabelle benutzt. In der Maske Fremdschlüssel anlegen geben Sie als Feldtyp Schlüsselfeld einer Texttabelle an.
Nachdem Sie den Fremdschlüssel eingerichtet haben, testen Sie ihn wie schon gezeigt für das Feld ***lfa1-land1. Nach erneuter Anmeldung mit dem Sprachschlüssel E (englisch) sehen Sie nun beim Wiederholen des Tests die englischsprachigen Texte.
Generische und konstante Fremdschlüssel
Wenn Sie einen Fremdschlüssel anlegen, müssen, wie gesagt, alle Primärschlüsselfelder der Prüftabelle in der Fremdschlüsselbeziehung eingebunden werden. Es kann aber Fälle geben, bei denen die Überprüfung gegen alle Felder unerwünscht ist. Oder es soll nur gegen einen konstanten Wert überprüft werden. Für diese Fälle läßt sich ein generischer bzw. ein konstanter Fremdschlüssel definieren.
Generischer Fremdschlüssel
Bei einem generischen Fremdschlüssel wird ein Schlüsselfeld der Prüftabellen als generisch gekennzeichnet, was bedeutet, daß dieses Feld an der Überprüfung nicht teilnimmt.
Zum Beispiel ist die Tabelle mara innerhalb der Materialwirtschaft eine zentrale Tabelle. Sie enthält die Auflistung derjenigen Materialien, die für die Fertigung benutzt werden, inklusive der Materialeigenschaften.
Das Setup-Programm zu diesem Buch richtet eine ähnliche Tabelle mit Namen ztxmara ein. Die Felder von ztxmara sind in der Abbildung 4.8 enthalten.

Abbildung 4.8: Tabelle ztxmara ist ähnlich der R/3-Tabelle Materialstamm mara.
Das Feld ztxmara-stoff enthält die Nummer des Gefahrenstoffs. Eine Ziffer in diesem Feld zeigt an, daß das Material eine besondere Handhabung erfordert und gibt Auskunft über die Art der Handhabung. Diese Nummern sind in der Tabelle ztxmgef definiert, die in Abbildung 4.9 gezeigt wird. In unserem Beispiel wird angenommen, daß ztxmgef den Eintrag mit stoff gleich 1 enthält. Dieser Eintrag zeigt an, daß die Handhabung dieses Stoffes Handschuhe erfordert.
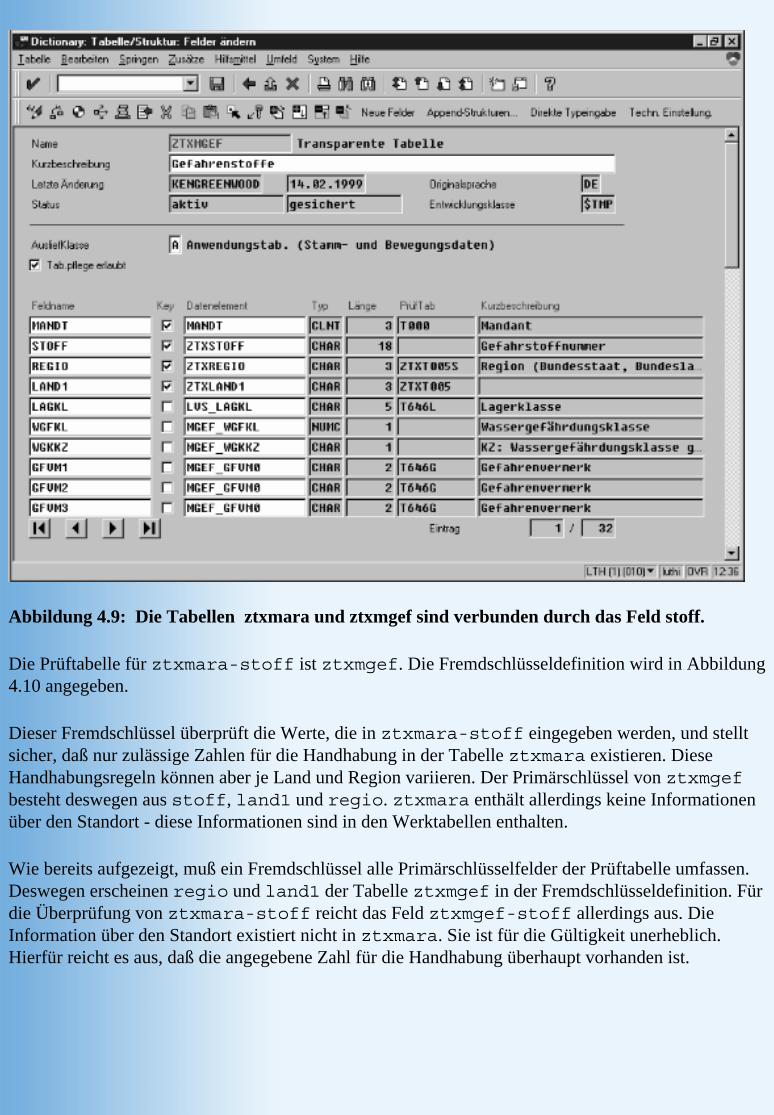
Abbildung 4.9: Die Tabellen ztxmara und ztxmgef sind verbunden durch das Feld stoff.
Die Prüftabelle für ztxmara-stoff ist ztxmgef. Die Fremdschlüsseldefinition wird in Abbildung 4.10 angegeben.
Dieser Fremdschlüssel überprüft die Werte, die in ztxmara-stoff eingegeben werden, und stellt sicher, daß nur zulässige Zahlen für die Handhabung in der Tabelle ztxmara existieren. Diese Handhabungsregeln können aber je Land und Region variieren. Der Primärschlüssel von ztxmgefbesteht deswegen aus stoff, land1 und regio. ztxmara enthält allerdings keine Informationen über den Standort - diese Informationen sind in den Werktabellen enthalten.
Wie bereits aufgezeigt, muß ein Fremdschlüssel alle Primärschlüsselfelder der Prüftabelle umfassen. Deswegen erscheinen regio und land1 der Tabelle ztxmgef in der Fremdschlüsseldefinition. Für die Überprüfung von ztxmara-stoff reicht das Feld ztxmgef-stoff allerdings aus. Die Information über den Standort existiert nicht in ztxmara. Sie ist für die Gültigkeit unerheblich. Hierfür reicht es aus, daß die angegebene Zahl für die Handhabung überhaupt vorhanden ist.

Abbildung 4.10: Ein Häkchen in der Checkbox Generic bewirkt, daß ein Feld während der Fremdschlüsselprüfung ignoriert wird.
In dieser Fremdschlüsselbeziehung werden regio und land1 im Primärschlüssel von ztxmgefignoriert. Um dies zu erreichen, werden die entsprechenden Felder im Fremdschlüssel als generisch definiert. Kreuzen Sie dazu die entsprechende Checkbox in Maske Fremdschlüssel anlegen an.
Durch den Fremdschlüssel wird so nur die Kombination von mandt und stoff geprüft. Die Felder regio und land1 werden dabei ignoriert.
Konstanter Fremdschlüssel
Der konstante Fremdschlüssel ist ein zusammengesetzter Fremdschlüssel, bei dem eines der Felder der Prüftabelle einen konstanten Wert beinhaltet. Dieser konstante Wert wird beim Einrichten in der Maske Fremdschlüssel anlegen eingegeben (s. Abbildung 4.11).
Angenommen, Sie müßten zum Beispiel eine Kreditorentabelle ztxlfa1us anlegen, die nur amerikanische Kreditoren enthalten soll und aus Kompatibilitätsgründen genauso wie ztxlfa1aufgebaut sein muß. Die Landeskennzahl in dieser Tabelle würde immer US sein. Hierfür können Sie einen konstanten Fremdschlüssel einrichten, um die Werte in Tabelle ztxlfa1 auf US einzugrenzen (s. Abb. 4.11).

Abbildung 4.11: Das Landesfeld als konstanter Fremdschlüssel
Angepaßte Fremdschlüssel
Die Felder eines zusammengesetzten Fremdschlüssels müssen nicht aus einer einzigen Tabelle stammen. Einen solchen Fremdschlüssel nennt man dann einen angepaßten Fremdschlüssel. Angenommen, die Landeskennzahl eines Kreditors wird nicht in ztxlfa1 gespeichert, sondern in ztxlfa1cc. Wenn Sie nun einen Fremdschlüssel auf dem Feld Region einrichten, würden Sie das Feld land1der Prüftabelle ändern in ztxlfa1cc-land1 (s. Abb. 4.12). Für das Feld regio wird nun geprüft werden, ob die Kombination von mandt und regio in ztxt005s existiert und ob land1 in ztxt005cc vorhanden ist.

Abbildung 4.12: Ein Beispiel für einen angepaßten Fremdschlüssel
Definition einer Wertetabelle
Beim Pflegen einer Domäne kann eine Wertetabelle angegeben werden. Diese Tabelle bewirkt folgendes:
■ Sie wird automatisch als Prüftabelle vorgeschlagen, wenn, bezogen auf diese Domäne, ein Fremdschlüssel eingerichtet werden soll.
■ Sie stellt die Einträge für die (F4)-Hilfe zur Verfügung, ohne daß dabei die Gültigkeit geprüft wird.
Immer, wenn Sie einen Fremdschlüssel anlegen, geht das System in das Feld Wertetabelle. Findet es einen Tabellennamen, schlägt es diesen für die Prüftabelle vor.
Auf dieses Konzept wird im folgenden Abschnitt ausführlich eingegangen.
Die Wertetabelle
Zum besseren Verständnis des Zwecks von Wertetabellen soll ein komplexeres Beispiel im Bereich des Datenbankdesigns und der Entwicklung dargestellt werden.

Bevor Tabellen im DDIC eingerichtet werden können, müssen in der Regel bestimmte Voraussetzungen im Bereich des Datenbankdesigns geschaffen sein. Dieses Design beschreibt die Tabellen, die angelegt werden sollen, ihre Beziehungen und die Art von Daten, die sie enthalten sollen. Bestimmte Tabellen werden als Prüftabellen deklariert, um Daten innerhalb anderer Tabellen zu prüfen. Die Prüftabelle für die Landeskennzahlen kann z.B. überall dort eingesetzt werden, wo Landeskennzahlen abgespeichert werden. Wenn Sie mehrere Tabellen innerhalb des R/3 einrichten, werden Sie in der Regel zuerst die Prüftabellen anlegen.
Es können mehrere Fremdschlüsselbeziehungen eingerichtet werden, die andere Tabellen mit einer einzigen Prüftabelle verketten. Das Wertetabellenfeld in der Domäne soll diese Aufgabe vereinfachen.
Der Begriff der Wertetabelle innerhalb der Domäne ist an dieser Stelle ein etwas verwirrender Ausdruck. Eigentlich ist sie der Vorschlagswert für die Prüftabelle. Im weiteren wird diese Tabelle auch als »Default-Prüftabelle« bezeichnet.
Um das Beispiel zu vereinfachen, wird unsere Prüftabelle nur ein Primärschlüsselfeld enthalten (Abb. 4.13). Das Verfahren für das Anlegen der Prüftabelle werde ich noch einmal beschreiben, um dieses Konzept zu veranschaulichen.
Abbildung 4.13: Das Feld Wertetabelle in der Domäne enthält den Namen einer Prüftabelle.
Bevor eine Prüftabelle eingerichtet wird, muß zunächst eine Domäne vorhanden sein. Diese muß ggf. erst einmal angelegt werden. Danach werden erst das Datenelement und dann die Tabelle eingerichtet und aktiviert. Im Anschluß wird beim nachträglichen Pflegen der Domäne (des Primärschlüsselfelds) der Name der angelegten Prüftabelle im Feld Wertetabelle (Default-Prüftabelle) eingegeben.
Für unser Beispiel wird nun die Tabelle ztxlfa1 angelegt. Hierfür wird das Feld land1eingerichtet, wobei ztxland1 als Datenelement benutzt wird. Beide Felder greifen somit die gleiche Domäne zu.
Danach richten Sie den Fremdschlüssel ein, um land1 überprüfen zu können. Dafür wird der Cursor

auf das Feld ztxlfa1-land1 gesetzt und auf die Schaltfläche Fremdschlüssel gedrückt. Dabei sieht das System in der Domäne nach, ob eine Wertetabelle (Default-Prüftabelle) vorhanden ist. Falls die Tabelle dort existiert, schlägt das System diese automatisch als Prüftabelle vor. In unserem Fall wird das System ztxt005 finden und als Prüftabelle vorsehen. Abschließend bestätigen und sichern Sie den Fremdschlüssel.
In diesem Beispiel hat uns im Prinzip das System den Fremdschlüssel automatisch eingerichtet, weil wir im Vorfeld den Namen der Prüftabelle im Feld Wertetabelle eingegeben haben. Mit drei Mausklicken haben wir einen Fremdschlüssel eingerichtet! Dies ist in erster Linie der Grund für die Existenz des Werttabellenfeldes. Es erleichtert im wesentlichen die Einrichtung des Fremdschlüssels.
Zusammenfassend gesagt, wird die Wertetabelle durch das System für zwei Aufgaben benutzt:
■ Die Wertetabelle wird beim Einrichten eines Fremdschlüssels automatisch als Prüftabelle vorgeschlagen.
■ Die Wertetabelle stellt die (F4)-Liste zur Verfügung, ohne dabei die Gültigkeit zu überprüfen.
Wertetabelle als Vorschlagswert für die Prüftabelle
In diesem Abschnitt werden Sie einer Domäne eine Wertetabelle zuordnen und die damit verbundene Auswirkung auf die Einrichtung eines Fremdschlüssels beobachten.
Pflegen Sie nun die Domäne ***land1, und tragen Sie ***t005 in das Wertetabellenfeld ein. Danach aktivieren Sie die Domäne.
Löschen Sie jetzt den Fremdschlüssel auf dem Feld ***lfa1-land1. Richten Sie ihn nochmals ein, um die Wirkung des Wertetabellenfeldes beim Bearbeiten des Fremdschlüssels erkennen zu können. Benutzen Sie dazu das unten stehende Verfahren.
1. Fangen Sie in der Einstiegsmaske des Dictionary an.
2. Tippen Sie den Namen der Tabelle in das Feld Objektname ein (***lfa1).
3. Wählen Sie die Option Tabellen aus.
4. Drücken Sie auf die Schaltfläche Ändern.
5. Positionieren Sie den Cursor auf dem Fremdschlüsselfeld (land1).
6. Drücken Sie auf die Schaltfläche Fremdschlüssel auf der Drucktastenleiste (oder gehen Sie über den Menüpfad). Das Änderungsbild für den Fremdschlüssel wird angezeigt.
7. Drücken Sie am unteren Ende des Fensters auf die Schaltfläche Löschen (Abfalleimer).
8. Es wird zum Dictionary zurückgesprungen: Tabelle/Struktur: Änderungsbild für die Felder. Die

Meldung, daß der Fremdschlüssel gelöscht wurde, erscheint in der Statusleiste.
9. Während der Cursor noch auf dem Fremdschlüsselfeld (land1) steht, drücken Sie nochmals auf die Fremdschlüsselschaltfläche. Die Maske Fremdschlüssel anlegen wird angezeigt. Das System meldet, daß kein Fremdschlüssel existiert und will den Vorschlag mit der Wertetabelle als Überprüfungstabelle generieren. Sie sehen diese Meldung, weil das System im Wertetabellenfeld der Domäne einen Eintrag gefunden hat.
10. Drücken Sie nun auf Ja. Die Maske Fremdschlüssel anlegen wird angezeigt, und das Prüftabellenfeld enthält nun die Wertetabelle der Domäne. Die Prüftabellen- und Fremdschlüsselfelder sind jetzt gefüllt.
11. Drücken Sie nun auf die Schaltfläche Kopieren. Sie Springen zum Dictionary zurück: Tabelle/Struktur: Änderungsbild. Die Meldung Fremdschlüssel wurde übertragen erscheint in der Statusleiste. Die Statusfelder zeigen an, daß die Tabelle überarbeitet und nicht gesichertist.
12. Drücken Sie die Schaltfläche Aktivieren. Die Meldung wurde gesichert erscheint in der Statusleiste. Die Statusfelder zeigen aktiv und gesichert an.
Mit dem Wertetabellenfeld in der Domäne können Sie Fremdschlüssel schnell und zuverlässig einrichten.
Die Prüftabellenspalte
Die Prüftabellenspalte im Dictionary: Tabelle/Struktur erfüllt hierbei zwei Aufgaben:
■ Wenn ein Feld Fremdschlüssel ist, enthält diese Spalte den Namen der Prüftabelle. ■ Ein Stern (*) in dieser Spalte bedeutet, daß zwar keine Prüftabelle für das Feld definiert ist, eine
Wertetabelle in der Domäne aber existiert.
Zum zweiten Punkt gibt es jedoch eine Ausnahme. Wenn Sie sich die Wertetabelle der Domäne selbst anschauen, wird der Stern nicht angezeigt.
Die Wertetabelle als Liste möglicher Eingabewerte
Bei einem Feld, das eine Wertetabelle enthält, aber kein Fremdschlüssel ist, wird bei Eingabe eines Wertes auf der Bildschirmmaske keine Prüfung auf Gültigkeit vorgenommen.
Für diesen Fall wird auch kein Pfeil nach unten am Ende des Felds angezeigt, wie es für ein Fremdschlüsselfeld üblich ist. Trotzdem wird, wenn Sie den Cursor in das Feld stellen und (F4) drücken, die (F4)-Hilfe mit der Auflistung der Wertetabelle angezeigt. In diesem Fall ist es für den Anwender nicht ersichtlich, daß die (F4)-Funktionalität verfügbar ist.
Diese Funktionalität bietet sich an, wenn dem Anwender zwar eine Liste von Vorschlagswerten zur

Verfügung gestellt werden soll, er aber andererseits auch die Möglichkeit haben soll, andere Werte einzugeben.
Besondere Tabellenfelder
Zwei Arten von Tabellenfeldern benötigen eine besondere Behandlung:
■ Währungsfelder■ Mengenfelder
Währungsfelder
Nehmen wir an, daß Sie zur Bank gehen und nach 1000 fragen. Der Kassierer würde wahrscheinlich fragen: »1000 was?«. Sie könnten »1000 Mark« antworten. Oder Sie könnten genauer sein und nach »1000 DM« fragen. Geldbeträge im R/3 sind in zwei Feldern gespeichert: in einem, das den eigentlichen numerischen Betrag (1000) enthält, und in einem für die Währung (DEM). Das Betragsfeld heißt hierbei Währungsfeld und das andere Feld Währungsschlüsselfeld.
Was viele Leute als »Währung« bezeichnen, ist genaugenommen ein Währungscode (z.B. USD für US Dollar oder DEM für Deutsche Mark etc.). Die SAP benutzt das Wort »Schlüssel« als Synonym für »Code«, somit heißt das Feld, das den Währungsschlüssel beinhaltet, der »Währungsschlüssel«. Das trifft auf die meisten Codefelder in R/3 zu; der Ländercode wird Länderschlüssel genannt, der Regionalcode ist der Regionalschlüssel und so weiter.
Währungsfelder müssen zwei Anforderungen erfüllen:
■ Der Datentyp der Domäne muß CURR sein. ■ Sie müssen mit einem Feld vom Typ CUKY verbunden sein, das die Währung enthält, wie zum
Beispiel US-$ (US-Dollar), CAD (kanadische Dollar), ITL (italienische Lira) und so weiter.
Der Währungsschlüssel ist dabei das Referenzfeld, welches ein Feld der gleichen oder einer anderen Tabelle ist.
Nehmen wir zum Beispiel an, daß Sie eine Tabelle einrichten wollen, die Zahlungen zu Kreditoren enthalten soll. Hierzu brauchen Sie ein Betragsfeld (wrbtr) und ein Währungsschlüsselfeld (üblicherweise waers), um diese Zahlungen komplett anzeigen zu lassen. Die beiden Felder werden miteinander verknüpft, indem Sie in der Tabelle auf das Währungsfeld doppelklicken und dann die Tabelle und das Feld des Währungsschlüssel als Verweis angeben (s. Abb. 4.14).
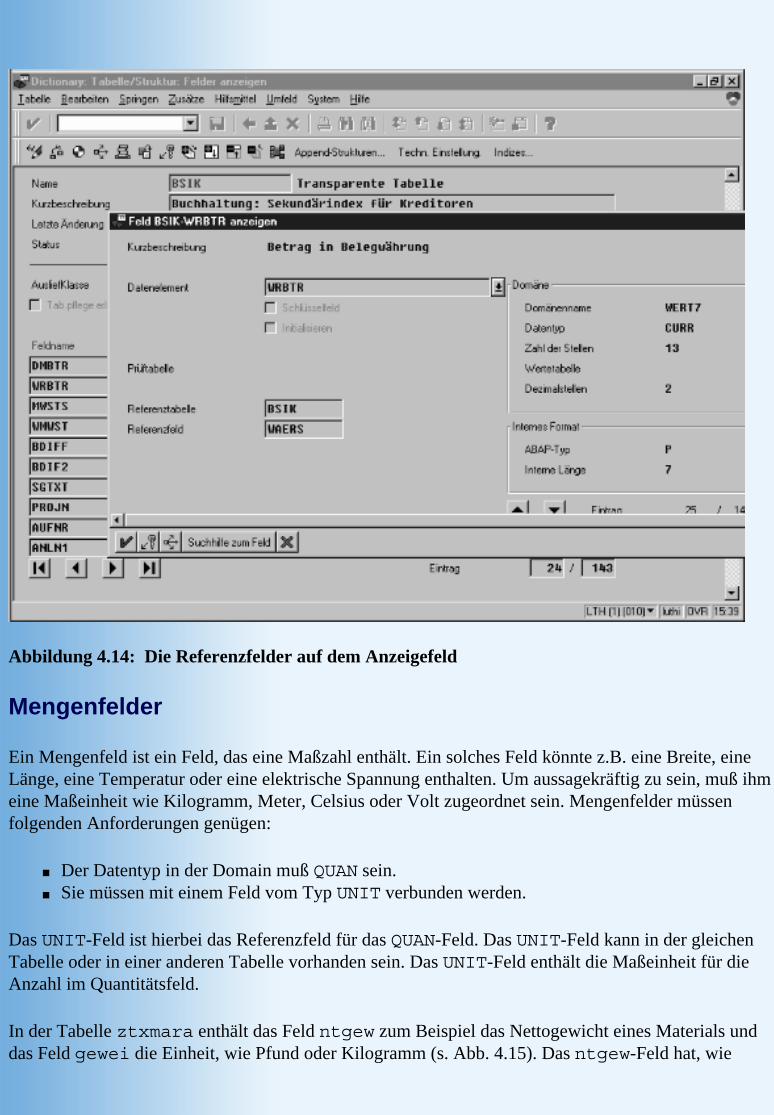
Abbildung 4.14: Die Referenzfelder auf dem Anzeigefeld
Mengenfelder
Ein Mengenfeld ist ein Feld, das eine Maßzahl enthält. Ein solches Feld könnte z.B. eine Breite, eine Länge, eine Temperatur oder eine elektrische Spannung enthalten. Um aussagekräftig zu sein, muß ihm eine Maßeinheit wie Kilogramm, Meter, Celsius oder Volt zugeordnet sein. Mengenfelder müssen folgenden Anforderungen genügen:
■ Der Datentyp in der Domain muß QUAN sein. ■ Sie müssen mit einem Feld vom Typ UNIT verbunden werden.
Das UNIT-Feld ist hierbei das Referenzfeld für das QUAN-Feld. Das UNIT-Feld kann in der gleichen Tabelle oder in einer anderen Tabelle vorhanden sein. Das UNIT-Feld enthält die Maßeinheit für die Anzahl im Quantitätsfeld.
In der Tabelle ztxmara enthält das Feld ntgew zum Beispiel das Nettogewicht eines Materials und das Feld gewei die Einheit, wie Pfund oder Kilogramm (s. Abb. 4.15). Das ntgew-Feld hat, wie

verlangt, den Datentyp QUAN. Der Datentyp von gewei ist UNIT. Wenn Sie ntgew doppelklicken, wird Ihnen die Referenztabelle ztxmara und das Referenzfeld gewei angezeigt (s. Abb. 4.16).
Abbildung 4.15: Dies ist die Struktur der Tabelle ztxmara mit den Feldern ntgew und gewei.

Abbildung 4.16: Dies sind die Feldattribute des Feldes ntgew. Beachten Sie, daß die beiden Felder Referenztabelle und Referenzfeld die Verbindung zum Feld UNIT anbieten.
Strukturen im Data Dictionary
Zusätzlich zu Tabellen können Strukturen (auch Feldleisten) genannt im Data Dictionary definiert werden. Eine Struktur ist eine Reihe von Feldern, die unter einem gemeinsamen Namen gruppiert werden. Strukturen sind Tabellen ähnlich. Wie eine Tabelle können sie innerhalb eines Programms über die Anweisung tables benutzt werden, um einen Arbeitsbereich zu definieren.
Die Unterschiede zwischen einer Struktur und einer Tabelle sind folgende:
■ Eine Struktur ist keiner Datenbanktabelle zugeordnet. ■ Eine Struktur hat keinen Schlüssel. ■ Eine Struktur hat keine technischen Attribute.
Bei Strukturen gelten die gleichen Namenskonventionen wie bei transparenten Tabellen. Innerhalb eines Programms darf es keine Namensgleichheit zwischen einer Tabelle und einer Struktur geben.
Eine Struktur wird im DDIC eingerichtet, wenn sie als Arbeitsbereich (Work Area) in mehreren Programmen definiert werden soll. Wenn Sie zum Beispiel über ein ABAP/4-Programm Datensätze in eine sequentielle Datei abspeichern und durch ein anderes einlesen wollen, muß in beiden Programmen der Aufbau dieser Datensätze bekannt sein. In diesem Fall bietet es sich an, eine Struktur im DDIC einzurichten, die das Datensatzlayout festlegt und diese dann über die tables-Anweisung in beide Programme einbindet. Dies würde einen identischen Arbeitsbereich in beiden Programmen anlegen.
Das Verfahren beim Anlegen einer Struktur ist im Prinzip das gleiche wie bei einer transparenten Tabelle (sehen Sie sich hierzu die Prozedur zum Einrichten einer transparenten Tabelle an). Die einzigen Unterschiede sind folgende:

■ Es wird die Strukturoption statt der Tabellenoption ausgewählt. ■ Die Felder Auslieferungsklasse und Tabellenpflege Erlaubt erscheinen nicht. ■ Strukturen haben keinen Primärschlüssel. ■ Es werden keine technischen Eigenschaften angegeben, die die Kategorie oder
Zwischenspeicherung wie eine Datenklasse messen.
Include-Strukturen
Eine Struktur kann ihrerseits eine andere Struktur enthalten, d.h., Strukturen können miteinander verschachtelt werden. Dies geschieht, um den Wartungsaufwand zu reduzieren, indem man Felder innerhalb einer Struktur gruppiert und diese dann in eine andere Struktur oder in eine Tabelle einbindet.
Zum Beispiel besteht die Adresse einer Person aus Feldern wie Straße, Wohnort, Region, Land und Postleitzahl. Die Adresse wird in der Regel in mehreren Tabellen geführt. Innerhalb der Kreditorentabelle könnte die Adresse des Kreditors geführt werden. Das gleiche gilt für die Kundentabelle und die Tabelle, in der die Adressen der Mitarbeiter stehen. Sind nun die Adreßfelder in einer Struktur zusammengefaßt, kann diese Struktur in die entsprechenden Tabellen aufgenommen werden. Beim Aktivieren der Tabelle werden die Felder der Struktur hinzugefügt und existieren in der Datenbanktabelle, als wären sie hier definiert worden. Hier stehen dann die Felder mit den gleichen Namen wie in der Struktur. Um eine Struktur in eine Tabelle (oder innerhalb einer anderen Struktur) aufzunehmen, wird .INCLUDE in der Feldnamenspalte und der Strukturname in der Datenelementspalte eingegeben.
In Abbildung 4.17 enthält die Tabelle ztxempl (Angestelltentabelle) die Struktur ztxaddr (s. Abb. 4.18), welche die Adreßfelder stras (Straße), ort01 (Wohnort), regio und land1 umfaßt. Die Tabelle ztxempl enthält deswegen die Felder: ztxempl- stras, ztxempl-ort01, ztxempl-regio, und ztxempl-land1.

Abbildung 4.17: Die Tabelle ztxempl enthält .INCLUDE, damit die Felder von ztxaddr mit aufgenommen werden können.
Um sich die include-Struktur komplett von der Tabellendefinition aus anzusehen, wählen Sie den Menüpfad Zusätze->Unterstrukturen->Alle Unterstrukturen (Ustr) auflösen. Alle Felder, die unter der Struktur zusammengefaßt sind, erscheinen danach unter .INCLUDE wie in Abbildung 4.19 gezeigt.
Die Kette von Strukturen, die eingerichtet wird, wenn man eine Struktur innerhalb einer anderen aufnimmt, nennt man auch include chain. Die maximale Schachtelungstiefe beträgt neun, und nur eine Tabelle kann in einer include chain erfaßt werden. Mit anderen Worten: Sie können keine Tabelle innerhalb einer Tabelle aufnehmen.

Abbildung 4.18: Die Struktur von ztxaddr enthält die Adreßfelder, die in Tabelle ztxempl aufgenommen werden.

Abbildung 4.19: Die Tabelle ztxempl benutzt die .INCLU-XXX-Form der include-Anweisung, so daß ztxaddr zweimal aufgenommen werden kann, ohne Namensfelder zu duplizieren.
Mehrfaches Einbinden der gleichen Struktur
Wenn Sie die gleiche Struktur mehrfach innerhalb einer Tabelle verwenden, müssen Sie statt .INCLUDE .INCLU-XXX benutzen. XXX steht hier für drei beliebige Zeichen. Diese drei Zeichen werden an jeden Feldnamen angehängt, um diese voneinander unterscheiden zu können.
Nehmen wir beispielsweise an, daß Sie zwei Adressen in ztxempl speichern müssen: eine Rechnungsanschrift und eine Versandadresse. Wie in Abbildung 4.20 gezeigt, umfaßt ztxempl2zweimal die Struktur ztxaddr. Die erste Include-Struktur .INCLU-01 bewirkt, daß »01« an jeden der Feldnamen der Struktur angehängt wird. Die zweite, .INCLU-02, hängt »02« an jeden Feldnamen. Das Ergebnis (in Abb. 4.21) sieht man, wenn man den Menüpfad Zusätze->Unterstrukturen->alle Unterstrukturen auflösen auswählt.

Abbildung 4.20: Die Tabelle ztxempl2 benutzt die .INCLU-XXX-Form der include-Anweisung, so daß ztxaddr zweimal aufgenommen werden kann, ohne Namensfelder zu duplizieren

Abbildung 4.21: ??????
Zusammenfassung
■ Fremdschlüssel sorgen bei Bildschirmeingaben für die Konsistenz der Daten durch Überprüfung der Gültigkeit und liefern der (F4)-Hilfe Listen der zulässigen Werte.
■ Die Wertetabelle dient als Vorschlagswert für die Prüftabelle und stellt die (F4)- Hilfe zur Verfügung.
■ Texttabellen stellen Beschreibungen in verschiedenen Sprachen dem R/3 und besonders der (F4)-Hilfe zur Verfügung.
■ Innerhalb einer Tabelle muß jedes Währungsfeld einem Währungsschlüsselfeld zugeordnet werden und jedes Quantitätsfeld wiederum einem Feld, das die Maßeinheiten enthält.
■ Tabellen und Strukturen sind sehr ähnlich. Der Hauptunterschied ist, daß eine Tabelle im Gegensatz zur Struktur eine zugrunde liegende Datenbanktabelle besitzt.
■ Sie können Strukturen benutzen, um identische Arbeitsbereiche in mehreren Programmen zu definieren. Sie können eine Struktur in andere Strukturen und Tabellen einbinden.
Fragen & Antworten

Frage:Kann ein ABAP/4-Programm Fremdschlüsselbeziehungen ignorieren und Einträge einfügen, welche die Datenkonsistenz verletzen?
Antwort:Ja. Die Daten kommen aber in der Regel mit Hilfe der Anwenderschnittstelle ins System. Die Anwenderschnittstelle überprüft die Daten, bevor diese in die Datenbank einfügt werden, so daß der Fremdschlüssel im Vorfeld schon überprüft wird. Wenn Sie Daten von externen Systemen importieren, sollten Sie das Batch-Input-Verfahren (BDC) benutzen, um die Tabellen zu aktualisieren. Die Datenkonsistenz wird dadurch erreicht, daß eine Benutzersitzung simuliert wird und die Daten mittels der Schnittstelle ins System gelangen. Wenn Sie die Datenbank aktualisieren, ohne die Daten durch die Anwenderschnittstelle überprüfen zu lassen, dann muß Ihr ABAP/4-Programm so geschrieben sein, daß die Konsistenz nicht verletzt wird.
Frage:Wenn ich die Konsistenz meiner Datenbank garantieren will, kann ich das auf der Datenbankebene tun? Welche Auswirkungen hätte diese Maßnahme auf das R/3?
Antwort:Aktualisieren Sie das RDBMS nie direkt. Sie sollten nur das R/3-DDIC benutzen, um die Definitionen innerhalb der Datenbank zu ändern. Wenn Sie die Datenbank von Hand aktualisieren, werden die Datenbankdefinitionen und die R/3-DDIC-Definitionen inkonsistent, und das Ergebnis wird unvorhersehbar.
Frage:Wenn ich eine Zeile aus einer Prüftabelle lösche, werden dann auch automatisch die entsprechenden Einträge in der Fremdschlüsseltabelle gelöscht?
Antwort:Nein. Diese Funktion ist in R/3 so nicht verfügbar. Dieses Merkmal wird normalerweise als »Cascade on delete« bezeichnet.
Frage:Der Fremdschlüsseltyp Schlüsselfelder einer Texttabelle zwingt das System zu unterschiedlichem Verhalten. Verbirgt sich hinter den anderen Fremdschlüsselfeldtypen irgendeine Funktionalität?
Antwort:Nein. Nur die Schlüsselfelder einer Texttabelle haben Systemfunktionalität, die anderen dienen meistens der Dokumentation.
Frage:Können Strukturen Fremdschlüsseldefinitionen haben?
Antwort:Ja. Das kommt häufig vor, da eine Tabelle, die eine Struktur beinhaltet, von dieser

Fremdschlüsseldefinitionen vererbt bekommt. Man kann diese Art der Vererbung ausschalten, indem man die Struktur bei Bedarf einbindet.
Workshop
Die folgenden Übungen sollen Ihnen Praxis beim Anlegen von Fremdschlüsseln, Strukturen und Feldern vermitteln.
Kontrollfragen
1. Was müssen das Fremdschlüsselfeld und das Prüftabellenfeld beim Einrichten des Fremdschlüssels gemeinsam haben?
2. Wie lautet die Syntax zum Einbinden der Struktur zs1 in die Tabelle zt1?
3. Welchen Zweck erfüllt eine Texttabelle?
4. Nehmen wir an, daß eine Prüftabelle zc existiert, deren Primärschlüssel aus den Feldern mandt, f1und f2 besteht. Welche Primärschlüsselfelder müßte die Texttabelle für zc enthalten?
5. Wenn Sie ein Währungsfeld einrichten, welchen Typ muß dann das Feld haben, auf das es sich bezieht?
Übung 1
Legen Sie die Prüftabelle ***t005 für die Landeskennzahlen an. Sie wird benutzt, um alle Landeskennzahlen zu überprüfen, die in Ihre Tabellen eingegeben werden. Der Aufbau erscheint in Tabelle 4.5.
Tabelle 4.5: Felder und ihre Eigenschaften für die Tabelle
***t005
BeschreibungFeldname
PK DE-Name
Mandant
mandt x mandt
Landeskennzahl
mandt x ***land1

Nachdem Sie diese Tabelle aktiviert haben, gehen Sie in die Domäne ***land1. Geben Sie ***t005 im Feld Wertetabelle ein, und aktivieren Sie die Domäne. Benutzen Sie SE16, um Ihrer Tabelle Landeskennzahlen hinzuzufügen.
Übung 2
Legen Sie die Prüftabelle ***t005s an. Sie wird benutzt, um alle Regionskennzahlen zu überprüfen, die in Ihre Tabellen eingegeben werden. Ihr Aufbau steht in Tabelle 4.6.
Tabelle 4.6: Felder und ihre Eigenschaften für die Tabelle ***t005s
BeschreibungFeldname
PK DE-Name Prüftabelle
Mandant
mandt x mandt
Landeskennzahl
land1 x ***land1 ***t005
Region
regio x ***regio
Nachdem Sie diese Tabelle aktiviert haben, gehen Sie in die Domäne ***regio, und geben Sie ***t005s im Wertetabellenfeld ein, dann aktivieren Sie dieses. Benutzen Sie SE16, um Ihrer Tabelle Regionskennzahlen hinzuzufügen. Testen Sie Ihren Fremdschlüssel auf land1, indem Sie eine ungültige Landeskennzahl eingeben.
Übung 3
Fügen Sie Ihrer Tabelle ***lfa1 einen entsprechenden Fremdschlüssel für die Felder land1 undregio hinzu. Benutzen Sie SE16, um die bestehenden Zeilen innerhalb von ***lfa1 zuaktualisieren und die zulässigen Landes- und Regionskennzahlen einzugeben.
Übung 4
Richten Sie eine Prüftabelle für das Feld cityc der Tabelle ***kna1 ein, die Sie am dritten Tag angelegt haben. Nennen Sie die Prüftabelle ***t005g. Sie sollte eine Auflistung der zulässigen Wohnorte enthalten. Der Aufbau ist in Tabelle 4.7 aufgeführt.
Tabelle 4.7: Felder und ihre Eigenschaften für die Tabelle ***t005g

BeschreibungFeldname
PK DE-Name DM-Name Typ Länge Prüftabelle
Mandant
mandt x mandt
Landeskennzahl
land1 x ***land1 ***t005
Region
regio X ***regio ***t005s
Stadt
cityc x ***cityc ***cityc CHAR 4
Vergessen Sie nicht, die Fremdschlüsselbeziehungen auf den Feldern land1 und regio einzurichten.
Übung 5
Gehen Sie in die Domäne Cityc, tragen Sie ***t005g im Wertetabellenfeld ein, und aktivieren Sie die Domäne. Benutzen Sie SE16, um Schlüssel für die Wohnorte in Tabelle ***t005g hinzuzufügen. Testen Sie den Fremdschlüssel, indem Sie versuchen, ungültige Landes- und Regionskennzahlen einzugeben. Dann richten Sie den Fremdschlüssel auf dem Feld Cityc in der Tabelle ***kna1 ein und benutzen SE16, um Kunden in ***kna1 einzufügen. Prüfen Sie die Fremdschlüsselbeziehung, indem Sie versuchen, ungültige Wohnorte einzugeben. Legen Sie eine Texttabelle für ***t005g an und nennen Sie diese ***t005h. Der Aufbau ist in Tabelle 4.8 dargestellt.
Tabelle 4.8: Felder und ihre Merkmale für Tabelle ***t005h
BeschreibungFeldname
PK DE-Name DM-Name Typ Länge Prüftabelle
Mandant
mandt x mandt
Sprachschlüssel
spras x spras t002
Landeskennzahl
land1 x ***land1 ***t005
Region

regio x ***regio ***t005s
Stadt
cityc x ***cityc ***t005g
bezei ***bezei20 text20 CHAR 20
Der Fremdschlüssel auf dem Feld Cityc sollte dem Typ Schlüsselfeld einer Texttabelle entsprechen. Benutzen Sie SE16, um Beschreibungen für jeden Ort einzurichten. Legen Sie diese Beschreibungen in zwei Sprachen an: E (englisch) und D (deutsch). Testen Sie die Texttabelle durch Anlegen eines neuen Eintrags in Tabelle ***kna1 und Bedienen der (F4)-Taste. Die Beschreibungen sollten nun in ihrer gegenwärtigen Anmeldungssprache in der (F4)-Liste erscheinen. Melden Sie sich danach in englisch an, um die englischen Beschreibungen zu sehen.
Übung 6
Richten Sie die Struktur ***tel ein. Der Aufbau steht in Tabelle 4.9.
Tabelle 4.9: Felder und ihre Eigenschaften für die Struktur
***tel
BeschreibungFeldname
DE-Name
Erste Rufnummer
telf1 telf1
Zweite Rufnummer
telf2 telf2
Faxnummer
telfx telfx
Telexnummer
telx1 telx1
Binden Sie diese Struktur am Ende der Tabellen ***kna1 und ***lfa1 ein. Benutzen Sie SE16, um einige Ihrer bestehenden Datensätze zu aktualisieren und Rufnummern hinzuzufügen.
Übung 7
Fügen Sie der Tabelle ***kna1 zwei Felder hinzu. Der Aufbau wird in Tabelle 4.10 gezeigt.

Tabelle 4.10: Zusätzliche Felder und ihre Eigenschaften für die Tabelle ***kna1
BeschreibungFeldname
DE-Name DM-Name Typ Länge Dezimalstellen Prüftabelle
Kreditgrenze
creditl ***creditl ***creditl CURR l2 2
Währungsschlüssel
waers waers tcurc
Das Feld creditl enthält die Kreditgrenze des Kunden, das Feld waers das Währungsfeld für diese Kreditgrenze. Vergessen Sie nicht, die Fremdschlüsselbeziehung hinzuzufügen, um die Tabelle tcurczu überprüfen. Legen Sie eine (F1)-Hilfe für das Feld creditl an, indem Sie auf die Schaltfläche Dokumentation im Datenelement drücken.
Nach dem Einrichten dieser beiden Felder doppelklicken Sie auf credit. Geben Sie im Feld Referenztabellen ***kna1 und im Feld Referenztypen creditl ein. Dann aktivieren Sie die Tabelle. Benutzen Sie SE16, um die Kundendatensätze zu aktualisieren und jedem eine Kreditgrenze hinzuzufügen. Sehen Sie sich die (F1)-Hilfe an, die Sie eingerichtet haben.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 5
Das Data Dictionary ®, Teil 3
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes können:
■ Sekundärindizes anlegen und benutzen ■ die technischen Attribute für transparente Tabellen einrichten ■ Pufferung für Tabellen einrichten
Tabellenindizes
Ein Index ist ein sehr wirksamer Mechanismus, um Zeilen innerhalb einer Tabelle schnell zu finden. Er wird benötigt, weil Daten in einer Tabelle in der Reihenfolge gespeichert werden, in der sie hinzugefügt wurden (die Reihenfolge der Ankunft).
Stellen Sie sich vor, Sie würden alle Seiten aus diesem Buch herausreißen, sie in die Luft werfen und durcheinander bringen. Danach legen Sie sie ohne Rücksicht auf die Reihenfolge zu einem Stapel zusammen. Was würden Sie machen, um jetzt eine einzelne Seite innerhalb dieses Stapels zu suchen?
Einige Leute würden einfach den Stapel durchblättern, in der Hoffnung, die richtige Seite zu finden. Ich bin sicher, daß die meisten es bald aufgeben würden, die Seiten eine nach der anderen umzudrehen. Diese Arbeit würde offensichtlich leichter sein, wenn alle Seiten sortiert wären. Bei geordneten Seiten könnten Sie irgendwo starten und wüßten, in welche Richtung Sie die Seiten wenden, so daß Sie die gesuchte Seite schnell finden würden.
Nehmen Sie an, daß Sie die Seiten geordnet zurückgelegt haben. Indem Sie das neu geordnete Buch nehmen, fangen Sie vielleicht an, die Seite zu suchen, die die Transaktion SE16 beschreibt. Wo schauen Sie nach, wenn Sie die Seitenzahl nicht wissen? Sie sehen in das Register (Index). Das Register enthält die wichtigsten Wörter, die in alphabetischer Reihenfolge sortiert sind. Sie lokalisieren SE16 schnell im Register und erhalten eine Seitenzahl. Nun durchsuchen Sie das Buch,

um diese Seite zu finden.
Um ein Register anzulegen, dupliziert der Verlag wichtige Informationen und sortiert sie. Danach stellt er sie an das Ende des Buches. Wenn Sie es sich dann ansehen, sehen Sie sich die ursprüngliche Information an? Nein, natürlich nicht. Sie sehen eine Kopie der ursprünglichen Information. Das Buch nimmt ein wenig mehr Platz wegen des Registers ein und wird ein bißchen teurer wegen der längeren Bearbeitung, aber niemand beklagt sich, weil weniger Zeit zum Suchen gebraucht wird.
Eine Tabelle in der Datenbank ist ähnlich wie ein Buch. Eine sequentielle Zahl wird jeder Zeile zugeordnet, wenn sie einer Tabelle hinzugefügt wird, ähnlich einer Seitenzahl. Die wichtigen Spalten werden dann zu einem Register zusammengefaßt und sortiert - wie im Register am Ende eines Buches. Um alle Daten zu finden, durchsucht das System zuerst das Register, um die Zeilennummer zu eruieren und ermittelt dann schnell die Zeile.
Jede R/3®-Tabelle hat einen primären Index, der auf dem primären Schlüssel der Tabelle aufbaut. Dieser Index wird gebraucht, weil die Daten in der Tabelle nach der Reihenfolge gespeichert sind, in der sie hinzugefügt werden. Wenn eine Zeile hinzugefügt ist, wird die Schlüsselinformation sortiert und zum Index kopiert, zusammen mit einem Zeiger auf die ursprüngliche Zeile. Abbildung 5.1 zeigt ein Beispiel mit Tabelle ztxlfal. Die Daten aus dem lifnr-Feld in ztxlfal werden zum Index kopiert, alphabetisch sortiert und zusammen mit der Zeilenanzahl der ursprünglichen Zeile gespeichert. (Das mandt-Feld ist ausgelassen geworden, um das Beispiel zu vereinfachen.)
Die Zeilennummer wird intern von der Datenbank vergeben; Sie sehen sie niemals im Data Dictionary. Sie wird vom Index benutzt, um auf die Originalzeile zu verweisen, aus der die Daten kommen.
Abbildung 5.1: Ein Tabellenindex ist die Kopie von einer oder mehreren Spalten, die in

verschiedenen Reihenfolgen mit Hinweisen auf die Originalzeilen sortiert sind .
Wenn die Anweisung select * from ztxlfal where lifnr = '0000001050'ausgeführt wird, erkennt das System, das es lifnr schon sortiert im Index hat und benutzt es automatisch. Es findet 1050 im Index und erhält Zeilennummer 2. EsDann sucht es in der Tabelle nach Zeilennummer 2.
Nehmen Sie jetzt an, die Anweisung select * from ztxlfa where land1 = 'US' wirdausgeführt. Der Index ist nach lifnr sortiert, nicht nach land1. Die land1-Spalte steht nicht in einer besonderen Reihenfolge in der Tabelle. Das System wird vom Anfang der Tabelle bis z deren Ende alle Zeilen nach land1 = 'US' durchsuchen. Die Tabelle in Abbildung 5.1 ist sehr klein, aber ihre Erstellung kann in einer größeren Tabelle ein sehr zeitaufwendiger Prozeß sein.
Kehren wir zurück zum Buchbeispiel. Ein Buch hat manchmal mehr als einen Index. So könnte ein medizinisches Buch über den Gebrauch von Kräutern das übliche Register haben, zusätzlich eines nur für Pflanzennamen und ein drittes ausschließlich über medizinische Wirkungen. Um diese Register anzulegen, muß die Information sortiert und drei mal am Buchende dupliziert werden. Damit vergrößert sich die Seitenzahl des Buches. Es gibt somit verschiedene Möglichkeiten, eine Seitenzahl zu finden, z.B. mit Hilfe des üblicherweise benutzten Registers oder eines der drei zusätzlichen Register.
Der Aufbau des allgemein benutzten Registers ähnelt dem primären Index einer Tabelle. Die zusätzlichen Register entsprechen den Sekundärindizes. Um eine where-Klausel auf einem nichtprimären Schlüsselfeld zu unterstützen, kann ein sekundärer Index definiert werden. Eine Tabelle kann mehrere Sekundärindizes haben.
Abbildung 5.2 zeigt einen sekundären Index auf ztxlfal-land1.
Ein Index verkürzt die Zugriffszeiten enorm. In einer Tabelle, die eine Million Zeilen enthält, kann ein select- Kommando auf eine Spalte mit gleichen Werten, die nicht mit einem Index versehen ist, ca. 500.000 Sätze lesen, um den richtigen Satz zu finden. Im schlimmsten Fall würden 1 Million Vergleiche gemacht werden.

Abbildung 5.2: Ein Sekundärindex ermöglicht Ihnen eine schnelle Suche auch in anderen als Primärschlüsselspalten.
Wenn Sie einen Index hinzufügen, kann das System einen binären Suchvorgangsalgorithmus benutzen, um den Datensatz zu finden, nachdem es durchschnittlich 10 Datensätze vergleicht, im schlechtesten Fall 20 Datensätze! Das ist 50.000mal schneller. Aus diesem Grund sollten Sie sicherstellen, daß Felder in einer where-Klausel immer von einem Index unterstützt werden. Dies kann durch bestehende Indizes geschehen, mit deren Hilfe Sie dann ihre Logik organisieren, oder indem Sie sekundäre Indizes anlegen.
Indizes anzeigen
Jedes Register in R/3 hat ein einmaliges, ein bis drei Zeichen langes Kennzeichen oder Kennung. Der primäre Index hat immer eine Kennung von 0 (Null). Ein sekundärer Index kann jede andere Zahl oder ein Alphazeichen sein.
Starten Sie jetzt das ScreenCam »How to Display Secondary Indexes«.
Um bestehende Sekundärindizes einer Datenbanktabelle anzuzeigen, folgen Sie dieser Prozedur:
1. Lassen Sie sich die Tabelle anzeigen.
2. Drücken Sie die Schaltfläche Indizes auf der Drucktastenleiste. Wenn Sie diese Schaltfläche nicht sehen, könnte Ihr Fenster zu schmal sein. Verbreitern Sie es, oder wählen Sie den Menüpfad Springen->Indizes.
3. Wenn Sekundärindizes existieren, wird eine Auflistung von ihnen in einer Dialogbox angezeigt werden. Wenn keine existieren, wird eine entsprechende Meldung angezeigt.
4. Um einen Sekundärindex anzuzeigen, klicken Sie zweimal darauf (Abb. 5.3).
Der Zustand des Index wird im Statusfeld angezeigt. Ob der Index in der Datenbank existiert, wird von einer Meldung, die unter dem Statusfeld erscheint, angezeigt. Im DB-Index-Namensfeld steht der Name des Index, wie er in der Datenbank abgelegt ist. Der Indexname in der Datenbank ist von dem Tabellennamen abgeleitet, gefolgt von Unterstrichen und der Indexkennung. Im unteren Teil des Fensters befinden sich die Felder, die die Indizes umfassen. Die Index-Sortierreihenfolge ist die gleiche wie die Feldreihenfolge.

Abbildung 5.3: Der Sekundärindex Z in der Tabelle ztxlfa1 wird von der Feldern mandt und land1 erstellt.
Die vorherige Prozedur zeigt nur Sekundärindizes an. Der Index auf den primären Schlüssel (Index 0) erscheint nicht in dieser Auflistung.
Starten Sie jetzt das ScreenCam »How to Display all Indexes«.
Um alle Indizes einschließlich des primären Indexes anzuzeigen, folgen Sie diesen Schritten:
1. Lassen Sie sich die Tabelle anzeigen.
2. Den Menüpfad Hilfsmittel->Datenbank-Utility wählen. Das ABAP/4-Dictionary: Utility für Datenbanktabellen wird angezeigt.
3. Den Menüpfad Zusätze->Datenbankobjekt->Anzeigen wählen. Eine Auflistung von allen Feldern in der Tabelle wird angezeigt. Darunter ist eine Auflistung von allen Indizes mit ihren Feldern, einschließlich des Index 0.

Überlegungen, wann ein Index angelegt wird
Ein Index kann aus mehr als einem Feld bestehen. Um beispielsweise einen sekundären Index vom land1 und regio aufzubauen, hilft die Anweisung select * from ztxlfa1 where land1 = 'US' and regio = 'MA' schnell Vergleichszeilen zu finden. Wenn mehrere Indizes existieren (ein primärer und ein oder mehrere sekundäre Indizes), benutzt das Relationale Datenbankmanagementsystem (RDBMS) einen Optimierer, um den effizientesten auszuwählen. Um einen Index zu wählen, sieht sich der Optimierer die Feldnamen in der where-Klausel an und sucht dann einen Index, der die gleichen Feldnamen in der gleichen Reihenfolge hat, die die where-Klauselspezifiziert. Um sicherzustellen, daß das System den Index wählt, den Sie möchten, spezifizieren Sie die Felder in der gleichen Reihenfolge, wie sie im Index erscheinen.
Indizes und mandt
Wenn eine Tabelle mit dem mandt Feld anfängt, sollten so auch ihre Indizes anfangen. Wenn eine Tabelle mit mandt anfängt und der Index nicht, wird der Optimierer den Index vermutlich nicht benutzen.
Vergegenwärtigen Sie sich die automatische Mandantenpflege von OPEN SQL. Wenn die Anweisung select * from ztxlfa1 where land1 = `US´ ausgeführt wird, lautet die wirkliche SQL-Anweisung select * from ztxlfa1 where mandt = sy-mandt and land1 = 'US'. Sy-mandt enthält den aktuellen Anmeldemandanten. Wenn Sie Zeilen aus einer Tabelle mit OPEN SQL selektieren, fügt das System sy-mandt automatisch der where-Klausel zu, die also nur die Zeilen aussucht, die zum gegenwärtigen Anmeldemandanten gehören.
Wenn Sie einen Index auf einer Tabelle anlegen, die mandt enthält, sollten Sie deshalb mandt auch mit im Index aufnehmen. Es sollte als erstes in den Index kommen, weil es im generierten SQL-Code immer zuerst erscheint.
Für den Rest dieser Darstellung nehmen Sie bitte an, daß mandt in allen Indizes vorhanden ist.
Programmierung einer select-Anweisung, um einen bestehenden Index zu benutzen
Wenn Sie select * from ztxlfa1 where regio = 'MA' programmieren, muß ein Index mit mandt und regio vorhanden sein, damit der Optimierer ihn benutzen kann.
Wenn Sie select * from ztxlfa1 where land1 = 'US' and regio = 'MA'programmieren, muß ein Index vorhanden sein, der mandt,land1 und regio enthält. Der ideale Index würde sie auch in dieser Reihenfolge beinhalten. Wenn es keine Indizes mit dieser Reihenfolge gibt, aber einen Index, der mit mandt und land1 anfängt, würde der Optimierer ihn benutzen, um die ersten zwei Felder der where-Klausel zu vergleichen, dann einen Indexbereich zu durchsuchen und schließlich eine Übereinstimmung zu regio zu finden. Das Durchsuchen eines Index-Bereiches stellt eine sequentielle Suche durch einen Teil eines Index dar.

Selektive Indizes und die Wirksamkeit von Indizes
Wenn die where-Klausel mehr Felder als der Index enthält, benutzt das System den Index, um den Suchvorgang zu verkürzen. Es liest dann Datensätze von der Tabelle und prüft, ob Übereinstimmungen zu finden sind.
Wenn z.B. ein Index aus den Feldern F1 und F2 zusammengesetzt ist und Sie F1 = 1, F2 = 2 und F3 = 3 programmieren, wird das System nur die Indizes zur Lokalisierung von Datensätzen benutzen, in denen F1 = 1 und F2 = 2 ist. Es wird nur diejenigen Sätze aus der Tabelle auslesen, um herauszufinden, welche Sätze F3 = 3 haben. Somit ist der Index nur teilweise effektiv. Er wäre effektiver, wenn er alle Felder enthielte: F1, F2 und F3.
Ist der Index mit F3 effektiver? Es hängt davon ab, auf welche Weise die Daten in der Tabelle verteilt sind. Wenn die Kombination aus F1 und F2 sehr spezifisch ist (oder selektiv) und aus nur wenigen passenden Zeilen resultiert, ist der Index schon sehr effektiv. Wenn F3 in diesem Fall zum Index hinzukommt, dürfte das wegen des Pflegeaufwandes beim Modifizieren der Tabelle nicht lohnend sein. Wenn die Kombination aus F1 und F2 aus einer Vielzahl von Zeilen resultiert, die aus der Tabelle selektiert wurden, ist der Index nicht sehr selektiv, und das Hinzufügen von F3 würde wahrscheinlich die Leistungsfähigkeit des Systems erhöhen und Resourcenverbrauch reduzieren.
Wenn Sie Indizes anlegen oder modifizieren, versuchen Sie, kein Feld zu benutzen, das schon in einem Index vorhanden ist. Wenn ein präexistierendes Programm läuft, besteht die Möglichkeit, daß der Optimierer den neuen Index wählt, mit der Folge, daß das Programm wahrscheinlich langsamer laufen wird.
Richtlinien, um einen Index anzulegen
Diese Richtlinien gelten als Faustregel, der Sie folgen sollten, wenn Sie einen Index anlegen:
■ Versuchen Sie, keine unnötigen Indizes hinzuzufügen. Fragen Sie sich »Kann ich so programmieren, um einen bestehenden Index zu benutzen?«
■ Vermeiden Sie sich überschneidende Indizes; mit anderen Worten, vermeiden Sie gleiche Felder in mehreren Indizes.
■ Versuchen Sie, Indizes selektiv zu machen, aber nehmen Sie keine Felder, die die Selektivität minimal erhöhen.
Einen sekundären Index anlegen
Starten Sie jetzt das ScreenCam »How to Create a Secondary Index«.
Um einen sekundären Index anzulegen, gehen Sie wie folgt vor:
1. Lassen Sie sich die Tabelle anzeigen. Sie sollten beim Dictionary anfangen: Tabellen/Strukturen: Anzeigen.

2. Wählen Sie den Menüpfad Springen->Indizes oder drücken Sie auf Indizes.
3. Wenn schon Sekundärindizes existieren, wird eine Auflistung von ihnen in einer Dialogbox für Tabelle xxxxx angezeigt. Drücken Sie auf die Schaltfläche Anlegen, um einen Index anzulegen.
4. Wenn keine Sekundärindizes existieren, sehen Sie keine Auflistung. Statt dessen erscheint die Dialogbox Index Anlegen.
5. Tragen Sie eine Indexnummer in die Indexkennung ein. Kundenindizes sollten mit Y oder Z anfangen, obwohl dies das System nicht erzwingt.
6. Drücken Sie auf Weiter. Das ABAP/4-Dictionary: Index Tabelle xxx pflegen wird angezeigt.
7. Tippen Sie eine Beschreibung des Indexes im Textfeld ein.
8. In dem Feld Feldname geben Sie die Felder ein, aus denen der Index bestehen soll, und zwar in der Reihenfolge, in der sie sortiert werden.
9. Wenn alle Werte in diesen Feldern zusammengenommen eindeutig sein müssen, markieren Sie Unique-Index.
10. Sichern Sie. Die Werte in den Statusfeldern sind nun NEW und SAVED. Direkt darunter erscheint die Meldung existiert nicht in der Datenbank. Ebenso erscheint die Nachricht in der Statuszeile: Index xxx von Tabelle xxxxx wurde gesichert .
11. Drücken Sie Aktivieren. Das System generiert nun SQL-Anweisungen und sendet sie an das RDBMS, die die Indizes in der Datenbank anlegt. Bei Erfolg erscheint die Meldung aktiv und gesichert und darunter die Meldung Existiert in der Datenbank. Das DB-Index-Namensfeld wird den Namen des Index in der Datenbank enthalten. In der Statusleiste wird die Meldung erfolgreich aktiviert angezeigt.
12. Kehren Sie nun zum Dictionary zurück.
Sie haben gelernt, wie man einen sekundären Index anlegt. Indizes verbessern die Leistungsfähigkeit der select-Anweisungen.
Wenn Sie die Checkbox Unique Index anhaken, wird die Einzigartigkeit der Feldkombinationen im Index garantiert; dies wird von der Datenbank unterstützt. Die Anweisung insert oder modify wird scheitern, wenn die Wertkombination in den

Indexfeldern schon in der Tabelle präsent ist.
Einen sekundären Index löschen
Starten Sie jetzt das ScreenCam »How to Delete a Secondary Index«.
So gehen Sie vor, um einen Sekundären Index zu löschen:
1. Lassen Sie sich die Tabelle im Dictionary anzeigen.
2. Gehen Sie zu Springen->Indizes oder drücken Sie auf Indizes auf der Drucktastenleiste. Wenn Sie die Dialogbox zum Anlegen von Indizes sehen, existieren keine Sekundärindizes für die Tabelle, so daß Sie keinen löschen können. Wenn Sekundärindizes bereits existieren, wird eine Auflistung von ihnen in einer Dialogbox angezeigt, die Indizes zur Tabelle xxxxx genannt wird.
3. Klicken Sie zweimal auf den Index, den Sie löschen wollen. Das Bild Anzeigen Index erscheint.
4. Drücken Sie auf die Schaltfläche Ändern<->Anzeigen auf der Drucktastenleiste. Sie kommen in den Änderungsmodus.
5. Den Menüpfad Index->Löschen wählen. Eine Dialogbox erscheint, die Sie auffordert, die Löschanfrage zu bestätigen.
6. Bestätigen Sie, um zu löschen. Es erscheint die Meldung Index xxxxx gelöscht.
Die Bestätigung in Schritt 6 hat zur Folge, daß der Index aus der Datenbank gelöscht wird. Wenn Sie zum Dictionary: Tab./Struk. zurückkommen, brauchen Sie die Tabelle nicht zu sichern. Beachten Sie auch, daß Sie den Vorgang nicht rückgängig machen können, wenn Sie auf die Schaltfläche Beenden drücken.
Bestimmen Sie, welcher Index benutzt wird
Wenn eine select-Anweisung ausgeführt wird, versucht der Optimierer, den günstigsten Weg der Indizierung zu wählen, um schnell an Daten zu kommen. Wie kann man erfahren, welcher Index aktuell in Benutzung ist, wenn es mehrere Indizes einer Tabelle gibt, oder ob er überhaupt benutzt wird?
Um das zu erfahren, gibt es das SQL-Trace-Werkzeug.

Es kann nur jeweils eine Person zur Zeit das SQL-Trace-Werkzeug benutzen. Vergessen Sie nicht, den Trace nach Benutzungsende wieder auszuschalten. SQL Tracing verringert die Leistung des Systems.
Starten Sie jetzt das ScreenCam »How to Use SQL Trace to Determine the Index Used«.
Um zu bestimmen, welcher Index für eine select-Anweisung benutzt wird, gehen Sie bitte so vor:
1. Schreiben Sie ein kleines ABAP/4-Programm, das nur die select-Anweisung enthält. Bevor Sie weitermachen, prüfen Sie, ob das Programm auch funktioniert.
2. Öffnen Sie das Programm im Editor nur, um es auszuführen.
3. Eröffnen Sie einen neuen Modus (System->Erzeugen Modus).
4. Rufen Sie die Transaktion ST05 im Transaktionsfeld auf (Syntax:/nst05) oder gehen Sie über den Menüpfad System->Hilfsmittel->SQL-Trace.
5. Zeigt das SQL-Trace Status Bild die Meldung Trace SQL is switched off an, gehen Sie zu Punkt 7.
6. Dieser Schritt beinhaltet die Meldung Trace SQL is switched on, gefolgt von der Benutzerkennung mit Datum und Uhrzeit desjenigen, der den Trace angeschaltet hat. Um weiterzumachen, muß der Trace erst ausgeschaltet werden. Wurde der Trace erst vor kurzem gestartet, so ist es möglich, daß er arbeitet. Setzen Sie sich mit der Person in Verbindung, die den Trace angeschaltet hat. Sollte der Trace schon seit geraumer Zeit laufen, so ist vermutlich vergessen worden, ihn auszuschalten. Sie können ihn beruhigt abstellen. Ausgeschaltet wird der Trace, indem die Schaltfläche Trace Off angeklickt wird. In der Statusleiste erscheint nun die Meldung Trace SQL is switched off.
7. Drücken Sie jetzt wieder auf die Schaltfläche Trace On. Im Trace Request User Dialog erscheint Ihr Benutzername. Wenn nicht, müßten Sie ihn jetzt eintragen.
8. Bestätigen Sie mit OK. In der Statuszeile erscheint die Meldung Trace SQL is switched on.
9. Kehren Sie jetzt in den Programmeditiermodus zurück.
10. Drücken Sie (F8), um Ihr Programm zu starten.
11. Wenn Ihr Programm die Bearbeitung beendet hat, kehren Sie in das Trace Fenster zurück.
12. Beenden Sie den Trace (Trace off). Im Statusfeld erscheint die Meldung Trace SQL is switched off.

13. Drücken Sie jetzt auf die Schaltfläche List Trace. Es erscheint ein neues Bild mit Daten.
14. Drücken Sie auf OK. Nach einer Weile sehen Sie die Anzeige Trace SQL: List Database Requests.
15. Geben Sie %sc in das Transaktionsfeld ein, und bestätigen Sie mit Enter. Ein neues Dialogbild wird gezeigt.
16. Geben Sie nun den Namen der Tabelle ein, die sie analysieren wollen (das ist der Tabellenname aus Ihrer select-Anweisung).
17. Drücken sie Find. Sie bekommen eine Ergebnisliste angezeigt, der Tabellenname ist hervorgehoben.
18. Klicken Sie auf den ersten hervorgehobenen Tabellennamen. Sie kommen zum SQL-Trace: List Database Requests Bild zurück. Ihr Cursor ist auf der ersten Zeile positioniert, die den Tabellennamen beinhaltet. Rechts davon, in der Operationsspalte, sollten die Worte PREPARE, OPEN oder REOPENstehen.
19. Drücken Sie jetzt auf Explain SQL auf der Drucktastenleiste.
20. Blättern Sie nun im Ergebnisbild. Der verwendete Index wird in Blau angezeigt.
Sie haben jetzt gelernt, einen SQL-Trace auszuführen. Dies wird Ihnen helfen, zu erkennen, welcher Index benutzt wird.
Technische Einstellungen
Um die technischen Einstellungen einer Tabelle zu sehen, lassen Sie sich die Tabelle anzeigen. Drücken Sie dann auf die Schaltfläche Technische Einstellungen auf der Drucktastenleiste (sollte die Schaltfläche nicht zu sehen sein, ist Ihr Fenster vermutlich nicht groß genug. Vergrößern Sie das Fenster, oder benutzen Sie den Menüpfad Springen->Technische Einstellungen). Die Einstellungen ändern Sie, indem Sie auf Ändern<->Anzeigen drücken. Das Bild Technische Einstellungen Pflegen erscheint wie in Abbildung 5.4.

Abbildung 5.4: In der Maske ABAP/4-Dictionary:Technische Einstellungen Pflegen können Sie die Datenart, die Größenkategorie und Pufferungsoptionen anlegen.
Datenarten
Die Datenart bestimmt, welche Tabelle welchem Tablespace zugeordnet ist. (Die Bezeichnung »Tablespace« gilt nur für Oracle-Datenbanken. Für Informix ersetzen Sie die Bezeichnung mit »DB Space«). Ein Tablespace ist eine physikalische Datei auf einer Datenplatte und wird zum Speichern von Tabellen benutzt. Jede Tabelle ist einem Tablespace zugeordnet. Tabellen mit ähnlichen Eigenschaften sind gewöhnlich in einem Tablespace gruppiert, d.h. Tablespaces sind administrative Einheiten, die vom Datenbankadministrator zum Verwalten der Datenbank benutzt werden. So werden z.B. Tabellen, die sehr schnell anwachsen, in einem Tablespace auf der Datenplatte gruppiert, der sehr viel Speicherplatz besitzt.
Jede Datenart ist mit einem Tablespace assoziiert. Wenn Sie eine Tabelle aktivieren, wird die Tabelle in dem Tablespace angelegt, der mit der entsprechenden Datenart assoziiert ist. Wenn Sie die Datenart wechseln, während die Tabelle aktiv ist, passiert nichts; die Tabelle wird nicht in einen anderen Tablespace gelegt.

Die wichtigsten Datenarten sind:
■ APPL0 oder Stammdaten. Wenn Sie APPL0 (Stammdaten) wählen, deuten Sie damit an, daß Sie erwarten, daß die Tabelle nicht oft aktualisiert wird und langsam wächst. Sie werden in einen Tablespace mit ähnlichen Tabellen gelegt. Kreditoren- und Kundentabellen sind Beispiele für Stammdaten.
■ APPL1 oder Bewegungsdaten. Wählen Sie APPL1 (Bewegungsdaten), deuten Sie damit an, daß Sie erwarten, daß die Tabelle oft aktualisiert wird und schnell wächst. Kundenbestellungen sind ein Beispiel für Bewegungsdaten.
■ APPL2 oder Customizing Daten. Wenn Sie APPL2 (Customizing Daten) wählen, deuten Sie damit an, daß die Tabelleninhalte vor der Implementierung bestimmt werden und sich danach nicht mehr oft verändern. Prüftabellen und ihre assoziierten Texttabellen, wie z.B. ztx005und ztx005t, sind gute Beispiele für Tabellen, die die Datenart APPL2 haben sollten.
Zusätzlich zu diesen Kategorien kann es auch USER-Klassen geben. Diese werden von Ihrem DBA (Datenbankadministrator) angelegt, der Sie zur angemessenen Zeit anleiten wird, diese auch zu benutzen.
Weitere Datenarten können angezeigt werden, indem man auf den Pfeil nach unten am Ende des Datenartfeldes drückt und die Systemdatenarten auswählt. Diese Klassen sollten nur von SAP benutzt werden; sie sind für R/3-Systemtabellen gedacht, die z.B. Data Dictionary-Informationen und den Quellcode enthalten.
Größenkategorien
Mit dem Größenkategoriefeld bestimmen Sie die maximale Anzahl an Sätzen, die Sie in dieser Tabelle erwarten. Sie stellen hier sowohl die Größe der Initial- und Next Extent-Werte ein, als auch die maximale Anzahl an Extents, die für diese Tabelle erlaubt sind. Ein Extent ist eine bestimmte Menge an allokiertem Speicherplatz für eine Tabelle. Der Initial Extent ist der Speicherplatz, der allokiert wird, wenn die Tabelle angelegt wird. Wenn eine Tabelle diesen Speicherplatz verbraucht hat, wird ein neuer Extent allokiert, was dazu führt, daß der Speicherplatz der Tabelle vergrößert wird.
Die Größenkategorien gehen immer von 0 bis 4. Die Zahl der zu erwartenden Datensätze in jeder Größenkategorie wird sich aber abhängig von der Länge der Sätze für jede Tabelle ändern. Wählen Sie eine angemessene Größenkategorie aus, basierend auf der maximalen Anzahl der zu erwartenden Sätze für die Tabelle.

Seien Sie beim Anlegen von Größenkategorien großzügig. Für R/3 gilt: Nehmen Sie besser einen höheren Wert als einen zu niedrigen. Wenn die gewählte Größenkategorie zu klein ist und die Tabelle stärker anwächst als die Initialallokierung, wird die Datenbank einen neuen Extent anlegen. Sekundäre Extents reduzieren die Leistungsfähigkeit des Systems und erfordern eine Tablespace-Reorganisation. Reorganisationen können bei großen Datenbanken äußerst schwierig werden, insbesondere wenn vom System eine hohe Verfügbarkeit verlangt wird. Es ist wesentlich einfacher, Größenkategorien zu verkleinern als eine zu kleine zu vergrößern.
Anzeigen der Extents einer Tabelle
Mit der folgenden Prozedur können Sie sich die Anzahl von Extents einer Tabelle anzeigen lassen.
Starten Sie jetzt das ScreenCam »How to Display the Number of Extents Used by a Table«.
So wird die Anzahl von Extents angezeigt:
1. Geben Sie den Transaktionscode DB02 ein (Geben Sie /ndb02 im Transaktionsfeld ein). Es erscheint das Bild: Database Performance tables and indices.
2. Gehen Sie auf Detailed Analysis. Die Dialogmaske Storage management: tables and indices erscheint.
3. Geben Sie jetzt den Namen der Tabelle ein und bestätigen Sie. Es erscheint das Bild Tables and Indices: Analysis. Der Tabellenname taucht in der Liste auf.
4. Doppelklicken Sie auf den Tabellennamen. Sie sehen jetzt das Bild Tables and Indices: Indices of table ...
5. Wählen Sie Extents.
6. Bestätigen Sie. Die Maske Tables and Indices:extents of ... erscheint. Sie enthält eine Liste der Extents, ihre Tablespace Namen, Block Size, etc. Für jeden Extent gibt es eine Zeile.
Sie haben jetzt gelernt, die Anzahl von Extents einer Tabelle zu erkennen. Damit erhalten Sie Aufschluß darüber, ob eine Tabelle reorganisiert werden muß oder nicht.
Puffern einer Tabelle
Wie schon im ersten Kapitel erwähnt, können Daten im RAM-Bereich des Applikationsservers

gespeichert werden. Dieser Mechanismus kann per Tabelle kontrolliert werden und wird über die technischen Einstellungen jeder einzelnen Tabelle spezifiziert (s. Abb. 5.4).
Wann immer eine Open SQL-Anweisung versucht, einen Datensatz zu lesen, wird zuerst immer der Puffer überprüft, um zu sehen, ob die Tabelle im Puffer liegt. Wenn nicht, wird die Tabelle aus der Datenbank gelesen. Zeigen die Attribute der Tabelle an, daß die Daten gepuffert werden sollen, wird der Datensatz im RAM-Bereich des Applikationsservers in Datenpuffern gespeichert. Wird der Datensatz später noch einmal gebraucht, wird er aus dem Puffer gelesen statt aus der Datenbank. Diesen Prozeß soll Abbildung 5.5 veranschaulichen.
Abbildung 5.5: Daten können im RAM auf dem Applikationsserver gepuffert werden.
Wenn Sie Daten puffern, erhöhen Sie den Datendurchsatz in zwei wichtigen Schritten:
■ Die Programme, die gepufferte Daten benutzen, laufen schneller, da sie nicht aus der Datenbank geholt werden. Somit werden Wartezeiten bzw. Verzögerungen auf dem Netzwerk und der Datenbank reduziert.
■ Andere Programme, die Zugriffe auf die Datenbank benötigen, laufen schneller, weil weniger Last auf der Datenbank liegt und weniger Netzverkehr herrscht.
Das Puffern einer Tabelle bedeutet für eine select-Anweisung 10- bis 100mal schnellere Laufzeiten. So erscheint es erst einmal sinnvoll, jede Tabelle im System zu puffern. Da jedoch die Puffer im RAM-Bereich liegen, wird der Pufferplatz durch die Größe des RAMs begrenzt. Da es aber viel mehr Daten als RAM-Speicherplatz gibt, müssen Tabellen vernünftig gepuffert werden, um Überläufe zu verhindern.. Wenn ein Puffer überläuft, wird er auf eine Festplatte ausgelagert (»geswapt«), was dazu führt, daß der Zugriffsvorteil durch Pufferung aufgehoben wird.

Tabellen, die numerische Datentypen im Primärschlüssel enthalten, können nicht gepuffert werden. Es handelt sich hierbei um die Datentypen CURR, DEC, FLTP, INT1, INT2, INT4, PREC und QUAN im Data Dictionary.
Mit Hilfe der Transaktion ST02 können Sie sich die Puffer und die dazugehörigen Statistiken anschauen. Im Tune Summary-Bild heißen die Daten Puffer Generic Key und Single Record. Ein Doppelklick auf jede Zeile zeigt eine detaillierte Analyse. Von hier aus können die Objekte im Puffer angezeigt werden, indem man Buffered Objects auf der Drucktastenleiste drückt.
Der Basisberater ist verantwortlich für das Beobachten der Puffer und muß verhindern, daß Pufferengpässe das System verlangsamen. Bevor Sie mit dem Puffern von Tabellen beginnen, sollten Sie mit dem Basisberater gesprochen haben.
Puffer-Synchronisation
Wenn Sie zwei Applikationsserver benutzen, kann der gleiche Datensatz auf beiden gepuffert werden. Das wäre kein Problem, solange die Sätze nicht aktualisiert werden. Wird ein Datensatz aktualisiert, muß das dem anderen Applikationsserver gemeldet werden. Dieses wird von einem Prozeß initialisiert, der Puffersynchronisation. Diese Synchronisation wird in ein- bis vierminütigen Intervallen vollzogen, abhängig von der Konfiguration Ihres Systems.
Im Beispiel in Abbildung 5.6 ist ein Anwender auf Applikationsserver 1 und ein weiterer Anwender auf Applikationsserver 2 angemeldet. Anwender 1 liest einen Datensatz auf Applikationsserver 1. Der Datensatz ist jetzt im Puffer des Applikationsservers 1.

Abbildung 5.6: Schritt A: Benutzer 1 liest Datensatz 1 und bewirkt, daß er in Applikationsserver 1 gepuffert wird.
In Abbildung 5.7 liest Anwender 2 den gleichen Datensatz. Der Datensatz ist jetzt im Puffer des Applikationsservers 2. Auf beiden Applikationsservern ist jetzt der gleiche Datensatz im Puffer.
Abbildung 5.7: Schritt B: Benutzer 2 liest ebenfalls Datensatz 1 und bewirkt, daß er in Applikationsserver 2 gepuffert wird.
In Abbildung 5.8 aktualisiert Anwender 1 den Satz. Die Aktualisierung wird sowohl in der Datenbank
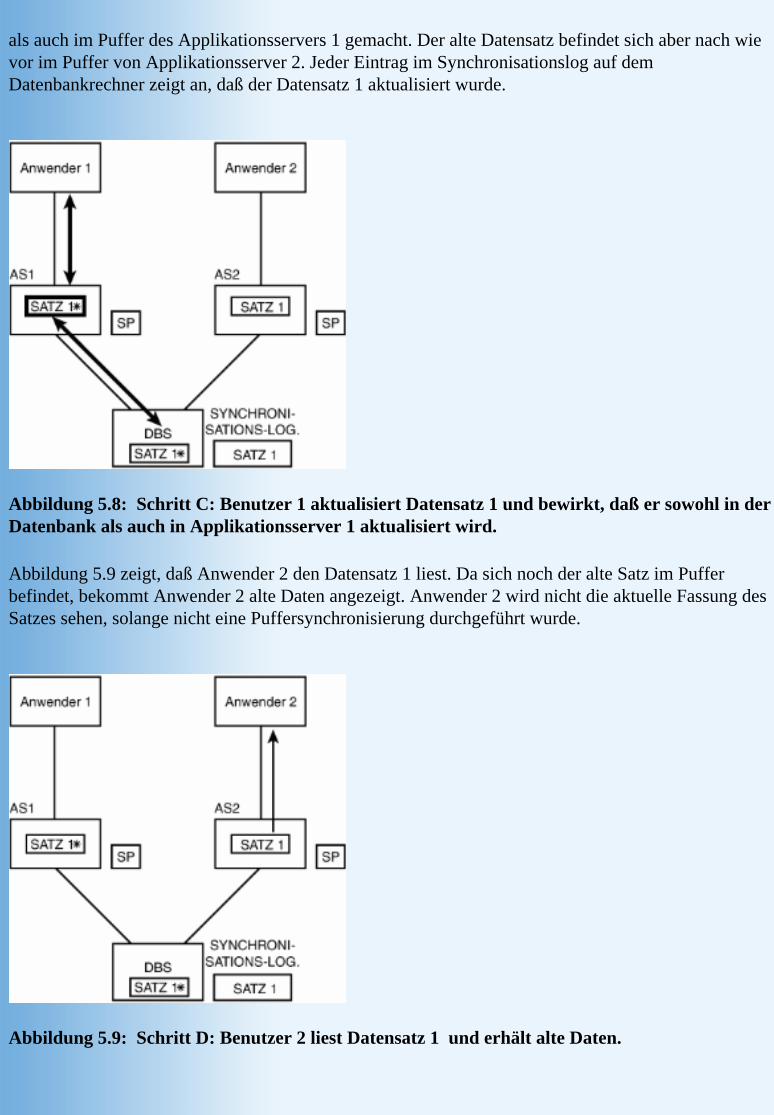
als auch im Puffer des Applikationsservers 1 gemacht. Der alte Datensatz befindet sich aber nach wie vor im Puffer von Applikationsserver 2. Jeder Eintrag im Synchronisationslog auf dem Datenbankrechner zeigt an, daß der Datensatz 1 aktualisiert wurde.
Abbildung 5.8: Schritt C: Benutzer 1 aktualisiert Datensatz 1 und bewirkt, daß er sowohl in der Datenbank als auch in Applikationsserver 1 aktualisiert wird.
Abbildung 5.9 zeigt, daß Anwender 2 den Datensatz 1 liest. Da sich noch der alte Satz im Puffer befindet, bekommt Anwender 2 alte Daten angezeigt. Anwender 2 wird nicht die aktuelle Fassung des Satzes sehen, solange nicht eine Puffersynchronisierung durchgeführt wurde.
Abbildung 5.9: Schritt D: Benutzer 2 liest Datensatz 1 und erhält alte Daten.
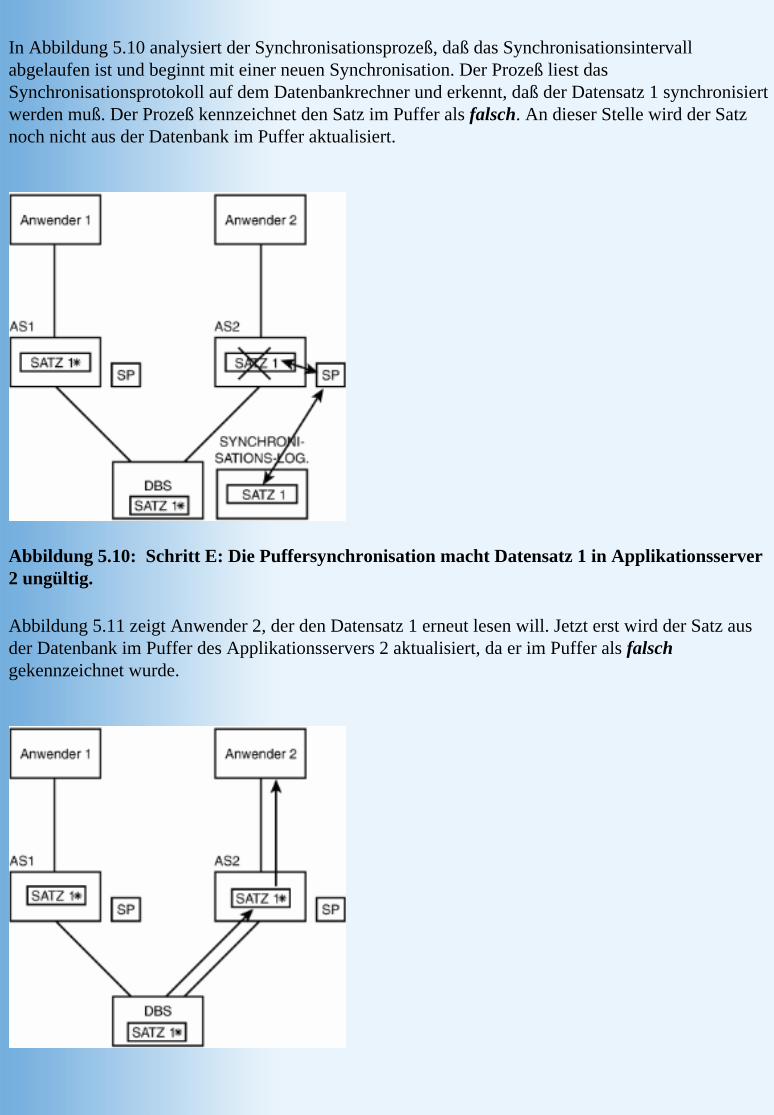
In Abbildung 5.10 analysiert der Synchronisationsprozeß, daß das Synchronisationsintervall abgelaufen ist und beginnt mit einer neuen Synchronisation. Der Prozeß liest das Synchronisationsprotokoll auf dem Datenbankrechner und erkennt, daß der Datensatz 1 synchronisiert werden muß. Der Prozeß kennzeichnet den Satz im Puffer als falsch. An dieser Stelle wird der Satz noch nicht aus der Datenbank im Puffer aktualisiert.
Abbildung 5.10: Schritt E: Die Puffersynchronisation macht Datensatz 1 in Applikationsserver 2 ungültig.
Abbildung 5.11 zeigt Anwender 2, der den Datensatz 1 erneut lesen will. Jetzt erst wird der Satz aus der Datenbank im Puffer des Applikationsservers 2 aktualisiert, da er im Puffer als falschgekennzeichnet wurde.

Abbildung 5.11: Schritt F: Benutzer 2 versucht erneut, Datensatz 1 zu lesen, aber dieser ist im Puffer als falsch markiert. Er wird aus der Datenbank heraus erneuert.
Wie Sie in den Abbildungen 5.6 bis 5.11 gesehen haben, wird die Puffersynchronisation mit Hilfe eines Synchronisationsprozesses auf jedem Applikationsserver und auf einem Synchronisationsprotokoll durchgeführt. In einem bestimmten Intervall prüft jeder Synchronisationsprozeß das Synchronisationsprotokoll, um zu erkennen, ob irgendwelche gepufferten Daten aktualisiert wurden. Wenn ja, werden sie im Puffer als falsch gekennzeichnet. Beim nächsten Zugriff auf diese Daten werden sie aus der Datenbank erneuert.
Der Basisberater bestimmt die Länge des Puffersynchronisationsintervalls mit Hilfe des Parameters rdisp/bufreftime.
Für diese Anzeige benutzen Sie Transaktion RZ10 wie folgt:
■ Geben Sie im Transaktionsfeld RZ10 ein (/nrz10).■ Wählen Sie den Menüpfad Springen->Profilwerte->Eines Servers. ■ Doppelklicken Sie auf einen Applikationsserver. Es erscheint eine Liste mit aktuellen
Parametern des ausgewählten Applikationsservers. ■ Geben Sie %sc im Transaktionsfeld ein. Es erscheint die Suchmaske. ■ Geben Sie jetzt rdisp/buf im Suchfeld ein. Die Pufferparameter werden hervorgehoben
angezeigt.■ Klicken Sie auf rdisp/bufreftime.■ Die Aktualisierungszeit (in Sekunden) wird angezeigt.
Aktualisierung der gepufferten Tabellen
Wenn Sie eine Transaktion programmieren, die gepufferte Tabellen aktualisiert, sollten Sie immer sicher sein, daß Sie sich auf der Datenbank befinden und aktuelle Informationen erhalten, bevor Sie dem Anwender erlauben, den Datensatz zu ändern. Das folgende Beispiel soll dies verdeutlichen. Im folgenden Paragraphen wird der Vollständigkeit halber eine Satzsperre angenommen.
Nehmen Sie an, Satz 1 enthält die Felder F1 und F2. Anwender 2 liest als erster den Satz, mit der Folge, daß der Satz im Puffer gespeichert wird (s. Abb. 5.12).

Abbildung 5.12: Schritt A: Benutzer 2 liest Datensatz 1 und bewirkt, daß er auf dem Applikationsserver 2 gepuffert wird.
Anwender 1, der nun den Datensatz aktualisieren will, sperrt und liest ihn (s. Abb. 5.13).
Anwender 1 ändert F1, schreibt ihn auf die Datenbank zurück (s. Abb. 5.14) und entsperrt ihn.
Zu diesem Zeitpunkt hat der Puffer auf Applikationsserver 1 immer noch die Originalkopie von Satz 1 mit dem Originalinhalt von F1. Wenn Anwender 2 Satz 1 sperrt und liest (aus dem Puffer), dann F2ändert (s. Abb. 5.15) und den Satz auf die Datenbank zurückschreibt (sichert), wären die Änderungen von Anwender 1 verloren (s. Abb. 5.16).

Abbildung 5.13: Schritt B: Benutzer 1 sperrt und liest Satz 1 und bewirkt, daß er auf dem Applikationsserver 1 gepuffert wird.
Abbildung 5.14: Schritt C: Benutzer 1 aktualisiert Satz 1 und bewirkt, daß dieser in der Datenbank und im Puffer des Applikationsservers aktualisiert wird. Die Sperre wird zurückgenommen.
Benutzen Sie bypassing buffer in der select-Anweisung, wann immer Sie die aktuellste Information haben wollen (z.B.: select * from ztxlfa1 bypassing buffer). Sie

umgehen somit den Puffer, und die Daten werden direkt aus der Datenbank gelesen. Sie sollten beim reading for update immer so verfahren, d.h. einen Satz lesen, der aktualisiert und auf die Datenbank zurückgeschrieben werden soll.
Abbildung 5.15: Schritt D: Anwender 2 liest den alten Datensatz und sperrt ihn.
Abbildung 5.16: Schritt E: Anwender 2 sichert den Datensatz 1 in der Datenbank und überschreibt damit die Änderung von Anwender 1.
Beispielsweise in Schritt D: Wenn Anwender 2 mit bypassing buffer den Datensatz liest, wird immer die aktuellste Version des Satzes gelesen, und die Änderungen von Anwender 1 gehen nicht verloren.

Bypassing buffer zum Aktualisieren ist am ausgewogensten, wenn man zwischen Sicherheit und Geschwindigkeit entscheiden muß. Wenn Sie jedoch sicher sind, daß alle Aktualisierungen von einem einzigen Applikationsserver gemacht werden, müssen Sie nicht bypassing buffer programmieren. Aktualisierungen am Puffer vorbei verzögern den Aktualisierungsprozeß, weil ein Datenbankzugriff erfolgt. Wenn Sie schnelle Aktualisierungen brauchen und sich sicher sind, daß es nur einen Applikationsserver gibt, sollten Sie diese Alternative benutzen. Reden Sie mit Ihrem Basisberater darüber.
Auflistung der Methoden für das Puffern mit Aktualisierungen
Sie können sich für eine von drei Varianten des Pufferns von Tabellen entscheiden, die aktualisiert werden können. In der Reihenfolge vom besten zum schlechtesten Durchsatz:
■ Puffern Sie die Tabelle, und benutzen Sie nicht bypassing buffer. Vergewissern Sie sich, daß nur ein Applikationsserver für Datenbankaktualisierungen aktiv ist.
■ Puffern Sie die Tabelle, und benutzen Sie bypassing buffer.■ Puffern Sie die Tabelle nicht.
Wenn eine Tabelle oft aktualisiert wird, benutzen Sie bypassing buffer nicht. Jede Aktualisierung veranlaßt eine Erneuerung der Puffer auf allen Applikationsservern bei der nächsten Synchronisation. In diesem Fall würde das Puffern den ganzen Netzverkehr erhöhen, statt ihn zu verringern.
Puffertechniken
Die untere Hälfte des Bildes Technische Einstellungen (s. Abb. 5.4) enthält die Möglichkeiten der Einstellungen. Wenn Sie eine Tabelle anlegen, haben Sie die gesamte Kontrolle darüber. Um eine SAP-eigene Tabelle zu ändern, benötigen Sie einen Zugangsschlüssel seitens SAP.
Sie können die Pufferung direkt beim Anlegen einstellen oder auch später.
Mit den folgenden Einstellungen schalten Sie die Pufferung ein oder aus:
■ Pufferung nicht erlaubt ■ Pufferung erlaubt, aber ausgeschaltet ■ Pufferung eingeschaltet
Wählen Sie Pufferung nicht erlaubt, wenn die Tabelle nie gepuffert werden soll, was in den

folgenden Fällen passieren kann:
■ Anwender müssen immer die aktuellen Werte beim Lesen und Schreiben von Datensätzen erhalten, wie z.B. bei der Real Time-Verarbeitung oder bei Börsennotierungen.
■ Datensätze werden jedesmal beim Lesen mit aktualisiert, so daß ein Puffern unwirksam werden würde (s.u.).
Wählen Sie deshalb Pufferung erlaubt, aber ausgeschaltet oder Pufferung erlaubt, wenn die Anwender Verzögerungen von 1 bis 4 Minuten tolerieren. Vergessen Sie nicht, daß diese Verzögerungen nicht existieren, wenn Sie bypassing buffer programmieren, um immer auf dem neuesten Stand zu sein.
Pufferung nicht erlaubt bei SAP-Tabellen heißt, daß Sie die Pufferung für diese Tabellen ausgeschaltet lassen sollten. Wenn Sie die Pufferung einschalten, kann es zu Datenverlusten/Inkonsistenzen und unvorhersehbaren Operationen der R/3-Anwendungen kommen.
Puffertypen
Wie Sie auf der Maske der Technischen Einstellungen in Abbildung 5.4 sehen, sind drei Arten der Pufferung möglich:
■ Volle Pufferung ■ Generische Pufferung ■ Einzelsatz-Pufferung
Sie wählen aus, welche Art der Pufferung Sie möchten. Es ist nur eine Möglichkeit erlaubt. Wenn Sie mehr als eine Art auswählen wollen, bekommen Sie eine Fehleranzeige.
Es gibt zwei Arten von Datenpuffern auf jedem Applikationsserver. Mit der Pufferart bestimmen Sie, welche benutzt wird. Beim Applikationsserver sind es:
■ der generische Satzpuffer ■ der Einzelsatzpuffer
Der generische Satzpuffer wird TABL (Kurzform für Tabelle) genannt. Der Einzelsatzpuffer heißt TABLP (»P« steht für engl. »partial«).
Volle Pufferung

Um volles Puffern zu aktivieren, kennzeichnen Sie Vollständig Gepuffert. Wenn ein Versuch gemacht wird, Daten aus einer voll gepufferten Tabelle zu lesen, sieht das System im TABL Puffer nach. Wenn dort nichts gefunden wird, werden alle Zeilen aus der Datenbank in die TABL geladen (s. Abb. 5.17). Das passiert jedesmal, wenn eine select -Anweisung ausgeführt wird, unabhängig davon, wie viele Sätze mit der where- Klausel übereinstimmen. Auch wenn keine Sätze übereinstimmen, werden alle in den Puffer geladen, wenn die Tabelle nicht schon gepuffert ist oder bei der Puffersynchronisierung ungültig gemacht wurde.
Abbildung 5.17: Alle Zeilen einer vollständig gepufferten Tabelle werden in TABL geladen.
Das Laden von TABL kommt nicht bei select single-Anweisungen vor, sondern nur bei select/endselect. Wenn die Tabelle voll gepuffert ist und eine select single-Anweisung ausgeführt wird, werden keine Sätze in TABL geladen. Ist die Tabelle bereits in TABLgeladen worden, wird die select single-Anweisung daraus lesen.
Während der Puffersynchronisation wird die gesamte Tabelle ungültig, wenn sich auch nur ein Datensatz geändert hat. Beim nächsten Lesezugriff wird die gesamte Tabelle wieder eingelesen.
Volle Pufferung eignet sich für kleine Tabellen, die sich selten ändern. Prüftabellen und ihre Texttabellen, wie z.B. ztx005, ztx005t, ztx005s und ztxt005u, sollten voll gepuffert sein. Sie werden mit gültigen Initialwerten und Beschreibungen aufgesetzt und selten modifiziert.
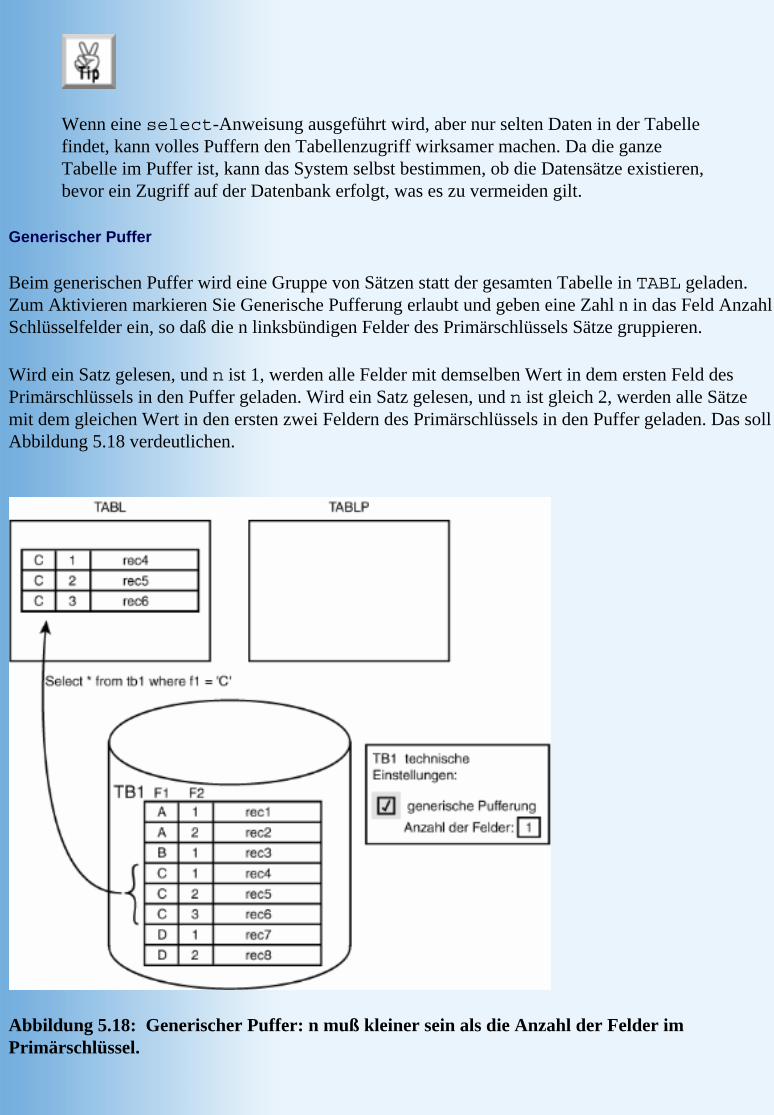
Wenn eine select-Anweisung ausgeführt wird, aber nur selten Daten in der Tabelle findet, kann volles Puffern den Tabellenzugriff wirksamer machen. Da die ganze Tabelle im Puffer ist, kann das System selbst bestimmen, ob die Datensätze existieren, bevor ein Zugriff auf der Datenbank erfolgt, was es zu vermeiden gilt.
Generischer Puffer
Beim generischen Puffer wird eine Gruppe von Sätzen statt der gesamten Tabelle in TABL geladen. Zum Aktivieren markieren Sie Generische Pufferung erlaubt und geben eine Zahl n in das Feld Anzahl Schlüsselfelder ein, so daß die n linksbündigen Felder des Primärschlüssels Sätze gruppieren.
Wird ein Satz gelesen, und n ist 1, werden alle Felder mit demselben Wert in dem ersten Feld des Primärschlüssels in den Puffer geladen. Wird ein Satz gelesen, und n ist gleich 2, werden alle Sätze mit dem gleichen Wert in den ersten zwei Feldern des Primärschlüssels in den Puffer geladen. Das soll Abbildung 5.18 verdeutlichen.
Abbildung 5.18: Generischer Puffer: n muß kleiner sein als die Anzahl der Felder im Primärschlüssel.

Ein anderes Beispiel: Nehmen Sie an, Sie wählen Generische Pufferung für Tabelle ztxlfa1 und setzen eine 1 in das Feld Anzahl Schlüsselfelder ein. Da das erste Feld mandt ist, werden alle Sätze eines Mandanten zur gleichen Zeit in die Tabelle geladen.
Wenn Sie volle Pufferung für eine mandantenabhängige Tabelle wählen (mit mandt in der ersten Spalte), wird das System automatisch die Tabelle allgemein mit n gleich 1 puffern. Das heißt, wenn eine Tabelle gelesen wird, werden nur Sätze mit der gleichen Mandantennummer in den Puffer geladen. Man kann das anhand der technischen Einstellungen nicht erkennen; sie sind einfach so eingestellt.
Generische Pufferung paßt auf alle Tabellen, in denen in der Regel auf Sätze in Gruppen zugegriffen wird. Wenn auf einen Satz einer Gruppe zugegriffen wird, treten gewöhnlich mehrere Zugriffe auf Sätze der gleichen Gruppe auf. Meldet sich z.B. ein Anwender in Englisch an, so ist es sehr wahrscheinlich, daß nur englische Beschreibungen von diesem und anderen Anwendern auf diesem Applikationsserver benutzt werden. Texttabellen, in denen Beschreibungen gespeichert sind, haben immer mandt und spras (den Sprachencode) in den ersten beiden Feldern. Deshalb ist generische Pufferung mit n gleich 2 am sinnvollsten.
Jede Satzgruppe im Puffer hat einen administrativen Überhang. Versuchen Sie, eine möglichst große Anzahl von Sätzen pro Gruppe anzulegen. Eine voll gepufferte Tabelle ist effizienter, wenn bei generischer Pufferung viele Sätze in vielen kleinen Gruppen zusammengefaßt sind.
Ist während der Puffersynchronisation eine Tabelle generisch gepuffert und ein Datensatz im Puffer ungültig, werden alle Sätze dieser Gruppe ungültig. Beim nächsten Lesezugriff auf diese Gruppe wird die gesamte Gruppe neu eingelesen.
Einzelsätze gepuffert
Das Markieren von Einzelsätze gepuffert aktiviert die Einzelsatzpufferung. Bei dieser Art der Pufferung liest select single einen Satz in den Einzelsatzpuffer TABLP, wie in Abbildung 5.19 gezeigt. Diese Pufferart puffert Sätze nur, wenn eine select single- Anweisung ausgeführt wird. Weder liest noch lädt select/endselect TABLP.

Abbildung 5.19: select single lädt einen Datensatz nach dem anderen in den TABLP Puffer, wenn Einzelsätze puffern aktiviert ist.
Wenn z. . Tabelle ztxlfa1 eine Einzelsatzpufferung hat, wird die Anweisung select * from ztxlfa1 where lifnr = 'V1' den TABLP Puffer dazu veranlassen, nach Satz V1 zu suchen. Wird er hier gefunden, wird die Kopie benutzt. Wird er nicht gefunden, wird er aus der Datenbank in Tabelle TABLP geladen.
Wird ein Satz nicht gefunden, wird ein Eintrag im Einzelsatzpuffer gemacht. Der Eintrag zeigt an, daß der Satz nicht in der Datenbank existiert. Sollte der Satz ein nächstes Mal gelesen werden, kann der Puffer dazu benutzt werden, die Anfrage zu lösen, und es ist kein Datenbankzugriff nötig.
Nehmen Sie z.B. an, Kreditor X1 existiert nicht in der Datenbank. Beim Ausführen von select single * from ztxlfa1 where lifnr = 'X1' würde ein Eintrag im Einzelsatzpuffer angelegt, der anzeigt, daß der Satz X1 nicht in der Datenbank existiert. Beim nächsten Zugriff auf X1erkennt das System anhand des Puffers, daß er nicht existiert und braucht somit nicht auf die Datenbank zuzugreifen.
Einzelsatzpufferung ist für sehr große Tabellen mit einer geringen Anzahl an oft gelesenen Sätzen angemessen. Damit die Einzelsatzpufferung funktioniert, muß der Satz mit select single-Anweisungen gelesen werden.
Zusammenfassung von Puffer-Arten

Es gibt zwei Arten von Puffern: TABL (den generischen Satzpuffer) und TABLP (den Einzelsatzpuffer). Dafür gibt es auch zwei Varianten der select-Anweisung: select und selectsingle. Die select-Anweisung lädt Tabelle TABL, und die select single-Anweisung lädt TABLP.
Beim Lesen benutzt select nur TABL; es ignoriert TABLP. Select single liest beide Puffer. Dieses Verhalten sehen Sie zusammengefaßt in Abbildung 5.20. Denken Sie daran, daß ein Satz nur in einem Puffer zur selben Zeit existieren kann, da eine Tabelle nur über eine Pufferart verfügt.
Abbildung 5.20: Wie die select-Anweisung mit den Puffern arbeitet
Um den Inhalt von TABL und TABLP zu löschen, können Sie im Transaktionsfeld /$tab eingeben. Diese Methode kann man benutzen, nachdem der Puffer ausgeschaltet worden ist, um vor dem Testen von Programmlaufzeiten die Pufferinhalte zu löschen.
Puffer-Auslagerung
Ist TABLP voll, und ein neuer Satz muß geladen werden, wird der älteste Satz (der Satz, der am längsten in der Tabelle steht, ohne daß auf ihn zugegriffen wurde) gelöscht, um Platz für den neuen zu machen.
Alte Sätze werden in TABL nicht aufgegeben, wenn neue dazu kommen. Statt dessen wird die gesamte Tabelle periodisch aus dem Puffer entladen. Die Zeitspanne zwischen den Entladungen und welche Tabellen entladen werden, wird durch einen sogenannten Caching Algorithmus von R/3 bestimmt. Dieser komplexe Algorithmus basiert auf dem Verbrauch von Speicherplatz einer Tabelle im Puffer im Gegensatz zur Anzahl von Lesezugriffen auf diese Tabelle in der vorhergehenden Periode, der Menge an Freiplatz, der im Puffer zur Verfügung steht, und der aktuellen Zugriffsqualität des Puffers.
Die Entscheidung, ob gepuffert werden soll

Das Ziel der Pufferung ist die Reduktion von Datenbankzugriffen und Netzverkehr von der Datenbank zum Applikationsserver. Der folgende Abschnitt listet Szenarios mit gepufferten Tabellen auf, die nicht aktualisiert werden, einhergehend mit Pufferung und Indizierung.
Gepufferte Tabellen, die nicht aktualisiert werden
Wird auf eine Tabelle häufig zugegriffen, ohne daß diese häufig aktualisiert wurde, sollte sie gepuffert werden. Sie sollten mit Ihrem Basisadministrator sprechen, ob genügend Platz im Puffer ist, um Ihre Tabelle mit aufzunehmen. Wenn dies nicht der Fall ist und auf Ihre Tabelle oft zugegriffen wird, sollte es möglich sein, mehr RAM für die Allokierung von Puffern zur Verfügung zu stellen. Alternativ kann man die Tabellen aus dem Puffer nehmen, auf die nicht so häufig zugegriffen wird wie auf Ihre Tabelle.
Pufferung und Indizes
Sätze in einem Puffer haben ihren eigenen Primärindex, der im RAM-Bereich gebildet wird. Werden Sätze benötigt, wird der Index benutzt, um sie im Puffer zu lokalisieren, und zwar auf die gleiche Art, wie der Primärindex in der Datenbank benutzt wird, um Sätze in einer Tabelle zu lokalisieren. Es werden jedoch keine Sekundärindizes im Puffer angelegt, genauso wenig wie die Sekundärindizes aus der Datenbank dazu benutzt werden, auf gepufferte Daten zuzugreifen. Sie sollten deshalb beim Programmieren einer select...where-Anweisung in eine gepufferte Tabelle auf die Primärschlüsselfelder in der where-Klausel zurückgreifen. Beginnen Sie mit dem ersten Feld des Primärschlüssels und benutzen Sie davon so viele wie möglich. Wenn das erste Feld des Primärschlüssels in der where-Klausel fehlt (wenn man mandt nicht mitzählt), wird ein voller Suchlauf in der gepufferten Tabelle durchgeführt. Ein Beispiel: wenn Tabelle ztxlfa1 voll gepuffert ist, wird die Anweisung select * from ztxlfa1 where lifnr = 'V1' vom Primärindex des Puffers unterstützt. Select * from ztxlfa1 where land1 = 'CA' wird dagegen zu einem gesamten Durchlesen der gepufferten Tabelle führen.
Da man nicht in der Lage ist, Sekundärindizes zu benutzen, auch wenn große Tabellen voll gepuffert werden, die Sekundärindizes haben, führt das zu einem Nebeneffekt. Eine so gepufferte Tabelle wird select-Anweisungen auf dem Primärindex beschleunigen, wird aber select auf Sekundärindizes verlangsamen. Eine select-Anweisung auf einer großen Tabelle (Größenkategorie 1 oder größer), die gänzlich mit Sekundärindizes auf der Datenbank versehen ist, kann im Puffer langsamer laufen, da hier Sekundärindizes nicht unterstützt werden. Um wievieles langsamer, hängt von der Anzahl der Datensätze in der Tabelle ab.
Um dieses Problem zu kompensieren, vermeiden Sie den Puffer und benutzen sie Sekundärindizes, indem Sie bypassing buffer Ihrer select-Anweisung hinzufügen, damit ein Sekundärindex benutzt werden kann.
Tabelle TSTC z.B. enthält über 12000 Zeilen. Ihre Größenkategorie ist 1. Sie ist voll gepuffert und hat einen Sekundärindex auf dem Feld pgmna. Messungen haben gezeigt, daß die Anweisung select * from tstc bypassing buffer where pgmna = 'ZTXTEST' im Durchschnitt 18mal schneller läuft als select * from tstc where pgmna = 'ZTXTEST', obwohl die Tabelle

voll gepuffert ist. Das erste select-Kommando wurde in der Datenbank aufgelöst durch die Benutzung des Sekundärindex auf pgmna; die zweite select-Anweisung führte eine komplette Durchsuchung der Tabelle im Puffer aus (full table scan).
Seien Sie äußerst vorsichtig, wenn Sie bypassing buffer auf eine gepufferte Tabelle durchführen, die auch aktualisiert wird. Wenn Sie es in einer select-Anweisung benutzen, sollten Sie es in allen anderen select-Anweisungen für diese und alle weiteren zu dieser in Beziehung stehenden Tabellen in einer einzigen Transaktion tun. Wenn nicht, werden Sie gepufferte und ungepufferte Daten mischen.
Zusammenfassung Pufferung
Die folgenden Punkte sollten Sie sich über Pufferung und Indizierung merken:
■ Das Puffern von Tabellen beschleunigt Ihre Programme. Wenn die Pufferung allerdings gedankenlos benutzt wird, kann sie den gegenteiligen Effekt haben.
■ Die Puffer sitzen im RAM-Bereich der Applikationsserver; somit ist der Platz an Pufferkapazität limitiert. Eine Tabelle, auif die nicht oft zugegriffen wird, sollte nicht gepuffert werden, um Pufferplatz zu sparen und einen Überlauf zu verhindern.
■ Tabellen, die klein sind (Größenkategorie 0), auf die oft zugegriffen wird und die selten aktualisiert werden, sollten voll gepuffert werden.
■ Tabellen, die eine Größenkategorie größer als 0 haben und oft mit select single im Zugriff sind, sollten Einzelsatzpufferung benutzen.
■ In einer Tabelle, in der Sätze aus einer Gruppe zusammen im Zugriff sind, sollte man generische Pufferung benutzen. Ein partieller Primärschlüssel muß die Gruppe identifizieren.
■ Tabellen, die oft aktualisiert werden, sollten nicht gepuffert werden, wenn Sie mehrere Applikationsserver im Einsatz haben. Wenn Sie puffern, wird das die Netzlast erhöhen, weil die Daten jedesmal in den Puffer des Applikationsservers zurückgeladen werden, wenn sich etwas ändert.
■ Wenn eine Tabelle gepuffert ist, benutzen Sie bypassing buffer um die jüngsten Daten zu fassen zu kriegen, bevor Sie aktualisieren.
■ Benutzen Sie, wenn möglich, die Felder des Primärindex in einer where-Klausel auf gepufferte Tabellen. Wenn das nicht möglich und die Tabelle recht umfangreich ist (Größenkategorie größer als 0), fügen Sie bypassing buffer hinzu und benutzen Sie Felder, die vom Sekundärindex in der Datenbank unterstützt werden.
Zusammenfassung
■ Ein Index ist eine Kopie von spezifischen Spalten einer Tabelle, sortiert in aufsteigender Folge.

■ Indizes beschleunigen select-Anweisungen. Eine select-Anweisung sollte immer von Indizes unterstützt werden.
■ Es können auch Sekundärindizes auf einer Tabelle angelegt werden. Legen Sie welche an, wenn Sie die Felder eines existierenden Index in Ihrer where-Klausel nicht benutzen können.
■ Die Felder in Ihrer where-Klausel sollten in Ihrem Programm in der gleichen Reihenfolge aufgelistet werden, wie sie im Index erscheinen.
■ Mit Hilfe der Transaktion ST05 können Sie sich anzeigen lassen, ob ein - und wenn ja, welcher - Index von einer select-Anweisung benutzt wird.
■ Über die technischen Einstellungen einer Tabelle haben Sie Kontrolle über Datenart, Größenkategorie und Pufferart sowie darüber, ob die Protokollierung eingeschaltet ist.
■ Die Datenart bestimmt, in welchem Tablespace die Tabelle angelegt werden soll. Die gebräuchlichsten Arten sind APPL0 (Stammdaten) und APPL1 (Bewegungsdaten).
■ Die Größenkategorie bestimmt die Größe der Initial- und Next-Extents sowie deren höchstens erlaubte Anzahl einer Tabelle. Sie sollten so gewählt werden, daß der Initial-Extent groß genug ist, um die gesamte Tabelle zu beinhalten. Sekundär- Extents verringern die Systemleistung und machen eine Reorganisation notwendig.
■ Pufferung beschleunigt den Datenzugriff durch Speicherung der am meisten benutzten Daten im RAM-Bereich des Applikationsservers. Da der RAM-Speicher begrenzt ist, sollten Tabellen vernünftig gepuffert werden.
Erlaubt Nicht erlaubt
Plazieren Sie die Felder in der where-Klausel in der gleichen Reihenfolge wie sie im Index erscheinen.
Programmieren Sie keine select-Anweisung ohne einen Index.
Seien Sie großzügig, wenn Sie eine Größenkategorie anlegen.
Wählen Sie keine Größenkategorie, die eine Tabelle dazu zwingt, Sekundär-Extents anzulegen.
Benutzen Sie bypassing buffer, wenn Sie einen Satz zum Aktualisieren aus einer gepufferten Tabelle lesen.
Fragen & Antworten
Frage:Ich bekomme einige von den Masken, die Sie erwähnen, nicht angezeigt. Ich erhalte die Fehlermeldung: Keine Berechtigung für Transaktion xxxx. Wie kann ich weitermachen?
Antwort:Fragen Sie Ihren Berechtigungsadministrator.
Frage:Wenn ich mir mit Hilfe von ST02 die Puffer ansehe, werden viele andere Puffer angezeigt. Wofür sind die alle?

Antwort:Es gibt nur zwei Datenpuffer innerhalb der großen Zahl von Puffern auf dem Applikationsserver. Die sogenannten nametabs (Tabellen, Laufzeit, Objekte) sind alle gepuffert, genauso wie die Programme, Menüs und Werkzeugleisten (auch als CUA-n oder GUI-Status bekannt), Masken und Kalender. Alle diese Puffer sind hier aufgelistet.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, die Ihnen helfen sollen, Ihr Verständnis für die besprochene Thematik zu vertiefen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie das Gelernte anwenden. Antworten auf die Prüfungsaufgaben und die Übungen können Sie im Anhang B (»Antworten zu Kontrollfragen und Übungen«) finden.
Kontrollfragen
1. Kann ich irgendwo den genauen Index spezifizieren, den ich einer select-Anweisung mitgeben will?
2. Kann ich Sekundärindizes auf SAP-Tabellen anlegen und sie puffern?
3. Kann ich feststellen, ob mein Programm mit gepufferten Tabellen schneller läuft als mit ungepufferten?
Übung 1
Welche Datenart haben die Tabellen MARA, LFA1 und KNA1? Und welche Größenkategorie gilt für MARA, LFA1 und KNA1?
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 6
Das Data Dictionary ®, Teil 4
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes beherrschen:
■ aktive und überarbeitete Versionen von DDIC-Objekten anzeigen und vergleichen ■ das Datenbank-Utility benutzen, um Konsistenzprüfungen durchzuführen, datenbankabhängige
Tabelleninformation anzuzeigen, Tabellen in der Datenbank zu löschen und wieder anzulegen.
Automatische Tabellenhistorie und Änderungsbelege
Änderungen an Daten in Tabellen können automatisch aufgezeichnet werden. Solch ein automatisches Protokollieren von Änderungen nennt man automatische Tabellenhistorie. Um das Aufzeichnen einzuschalten, markieren Sie mit einem Klick das Feld: automatische Tabellenprotokollierung im Fenster: Technische Einstellungen (siehe Abb. 5.4). Falls es nicht bereits geschehen ist, muß der Basisberater auch im Systemprofilparameter rec/client die Mandantennummer(n) angeben, für die die Protokollierung durchgeführt werden soll.
Um die rec/client-Einstellungen in Ihrem System anzuzeigen, folgen Sie den Anweisungen im Abschnitt »Puffer Synchronisation« von Tag 5.
Änderungsbelege
Für jedes Einfügen, Ändern oder Löschen in einer Tabelle, für das die automatische Tabellenhistorie eingeschaltet ist, wird ein Satz in der Tabelle dbtabprt erzeugt. Jeder einzelne Satz heißt

Änderungsbeleg. Jeder Änderungsbeleg enthält das Datum und die Zeit der Änderung, den Namen des Benutzers, der die Änderung durchführte, den Transaktionscode und den Programmnamen, die zum Ändern benutzt wurden, und den Typ der durchgeführten Änderung. Der Änderungstyp ist INS, wenn der Satz eingefügt wurde, UPD, wenn der Satz geändert wurde oder DEL, wenn der Satz gelöscht wurde.
Mit der Transaktion SCU3 oder OY18 (siehe Abb. 6.1) können Sie die Änderungsbelege anzeigen und mit den aktuellen Werten in der Tabelle vergleichen. Es gibt keinen Unterschied zwischen diesen beiden Transaktionscodes; sie starten beide dasselbe Programm.
Abbildung 6.1: Die Transaktion Tabellenhistorie zeigt veränderte Dokumente von Tabellen an, wenn automatische Tabellenhistorie ermöglicht ist.
Vom Fenster: Tabellenhistorie -Auswählen Funktion, können Sie folgende Funktionen durchführen:
■ Um die Änderungsbelege des aktuellen Tages anzuzeigen, wählen Sie den Auswahlknopf: Änderungsbelege Tagesauswertung und drücken die Schaltfläche Liste. Eine Liste mit allen Änderungen des aktuellen Tages wird angezeigt.
■ Um über das Datum oder den Tabellennamen nach Änderungsbelegen zu suchen, wählen Sie den Auswahlknopf: Änderungsbelege: Selektiv, und drücken Sie die Schaltfläche Liste. Das Fenster: Auswertung der Tabellen Protokoll Datenbank wird angezeigt. Tippen Sie Ihre Suchkriterien ein, und drücken Sie die Schaltfläche Ausführen. Eine Liste von Änderungsbelegen für die

angegebenen Kriterien wird angezeigt. Oben auf der Liste steht eine Zusammenfassung von Informationen über die Liste, dann ein Abschnitt Bemerkungen und dann die Analyse. Für jede Tabelle werden zuerst die Felder angezeigt (siehe Abb. 6.2), und dann folgen die zugehörigen Änderungsbelege (siehe Abb. 6.3).
Abbildung 6.2: Die Felder der Tabelle HRP1007 erscheinen vor den Änderungsbelegen und zeigen die Feldnamen, den Primärschlüsselindikator, den Datentyp und die Länge sowie den Spaltennamen und ihre Beschreibung an.

Abbildung 6.3: Die Änderungsbelege von Tabelle HRP1007 erscheinen nach der Feldliste. Der Primärschlüssel jedes Datensatzes erscheint zuerst (in türkis), gefolgt von den Daten (in weiß).
■ Um die Anzahl der Änderungsbelege zu einem gegebenen Datum oder einer Tabelle anzuzeigen, drücken Sie die Schaltfläche Anz. Änderungsbelege (Auswahl).
■ Um eine Liste der Tabelle anzuzeigen, für die die automatische Historie eingeschaltet ist, wählen Sie den Auswahlknopf: Tabellen mit Historienverwaltung, und drücken Sie die Schaltfläche List. Diese Liste zeigt alle Tabellen, deren Feld: Änderungen protokollieren markiert ist.
■ Um die Gesamtanzahl Änderungsbelege in der Tabelle dbtabprt anzuzeigen, drücken Sie die Schaltfläche: Beleganzahl gesamt in der Drucktastenleiste.
■ Um Feldwerte in Änderungsbelegen mit den aktuellen Feldwerten einer Tabelle zu vergleichen, wählen Sie den Auswahlknopf: Historie<->Aktuell und drücken die Schaltfläche Vergleichen. Das Fenster: Tabellenhistorie wird angezeigt. Geben Sie Suchkriterien für die Änderungsbelege ein, und drücken Sie die Schaltfläche Vergleichen. Das Fenster: Tabellenhistorie - Vergleich mit aktuellem Stand wird angezeigt. Der Primärschlüssel jedes Satzes erscheint links, und die Unterschiede erscheinen rechts (siehe Abb. 6.4).

Abbildung 6.4: Hier werden die Daten in dbtabprt mit den aktuellen Inhalten jedes Datensatzes verglichen.
Der Primärschlüssel erscheint in türkis auf der linken Hälfte des Fensters. Die rechte Hälfte des Fensters ist aufgeteilt in die aktuellen Werte und die Historienwerte. Graue Linien zeigen an, daß ein Unterschied existiert. Um die Bedeutung der Zeichen in der Spalte ganz links anzuzeigen, positionieren Sie den Cursor darauf, und drücken Sie (F1). Dieser Report zeigt, daß in der Tabelle EKPA vier Sätze existieren, aber keine Historiensätze dazu.
Wann Sie die automatische Tabellenhistorie benutzen sollten
Die automatische Tabellenhistorie sollte für Tabellen benutzt werden, die kritische Informationen enthalten und bei denen jede Änderung lückenlos verfolgt werden muß, unabhängig vom benutzten Änderungsprogramm. Unglücklicherweise wird das Ändern der Tabelle verlangsamt, da in die dbtabprt ein Satz für jeden geänderten Satz geschrieben wird. In den meisten Fällen, in denen eine Tabellenhistorie gebraucht wird, stellen die Änderungsbeleg-Objekte eine schnellere und effizientere Alternative dar und sollten daher statt dessen benutzt werden. Mehr Information über Änderungsbelegobjekte erhalten Sie in der R/3-Bibiliothek (Menüpfad Hilfe->R/3-Bibliothek, Basis, ABAP/4 Workbench, Erweiterte Anwendungsfunktionsbibliothek Anwendungen, Änderungsbelege).

Wenn der Primärschlüssel Ihrer Tabelle größer ist als 86 Bytes oder der Rest der Zeile länger als 500 Bytes, können Sie die automatische Tabellenhistorie nicht verwenden. Sie erhalten eine Fehlermeldung, wenn Sie versuchen, die Tabelle zu aktivieren, und Änderungen werden nicht angenommen. Der Grund für die Beschränkungen liegt in der Tabelle dbtabprt. Das Feld vkey enthält den Schlüssel des Datensatzes, der geändert wurde, und ist 86 Bytes lang. Das Feld vdata enthält den Rest des Datensatzes und ist 500 Bytes lang.
Zusammenfassung der Technischen Einstellungen
Die Technischen Einstellungen für Pufferung, Tabellenerweiterungen und automatisches Aufzeichnen geänderter Information:
■ Die Datenklasse bestimmt den Tablespace, in welchem die Tabelle angelegt wird. Der Datenbankadministrator benutzt Tablespaces, um die Datenbank zu organisieren und zu warten. Wenn man den richtigen Tablespace wählt, macht dies die Datenbankadministration leichter, erhöht den Systemdurchsatz und verbessert bis zu einem gewissen Grad sogar die Systemverfügbarkeit, da die Datenbank normalerweise für Reorganisationen offline geschaltet wird.
■ Die Größenkategorie bestimmt die Größe des initial extents und next extents, ebenso die Anzahl möglicher next extents. Wird die Nummer zu klein gewählt, verursacht dies das Hinzufügen eines oder mehrerer zusätzlicher extents. Eine Tabelle, die sich über mehrere extents erstreckt, verlangsamt den Systemdurchsatz, erhöht die Datenbankwartung und verringert die Systemverfügbarkeit, weil die Datenbank für Reorganisationen offline geschaltet wird.
■ Pufferung erhöht den Systemdurchsatz, indem die Daten lokal auf dem Applikationsserver zwischengespeichert werden. Wenn dies sauber funktioniert, sind weniger Datenbankzugriffe nötig, weil die meistgelesenen Daten im Hauptspeicher auf dem Applikationsserver abgelegt sind. Gute Kandidaten für eine Pufferung sind Tabellen, die selten geändert und oft gelesen werden.
■ Wird die automatische Protokollierungsfunktion einer Tabelle aktiviert, bewirkt das, daß bei jedem Ändern der Tabelle ein Änderungsbeleg erzeugt wird. Diese Funktion verlangsamt Tabellenänderungen, und wird daher nur für Tabellen mit kritischen Daten benutzt. Für nichtkritische Tabellen sollten Änderungsbelegobjekte benutzt werden.
Überarbeitete und aktive Versionen
Es können zwei Versionen einer Tabelle (oder einem anderen DDIC-Objekt) existieren: Die überarbeitete Version und die aktive Version. Wenn Sie eine Tabelle ändern und die Schaltfläche: Sichern bestätigen bedienen, ohne Aktivieren zu drücken, haben Sie eine überarbeitete Version der Tabelle mit Ihren Änderungen erzeugt. Die aktive Version existiert ebenfalls noch; es ist die letzte Version, die aktiviert wurde. ABAP/4- Programme nutzen nur aktive Versionen. Das Vorhandensein überarbeiteter Versionen beeinflußt sie nicht.

Es gibt die überarbeitete Version, damit Sie eine Änderung vorbereiten können, bevor sie gebraucht wird, und diese dann aktivieren, wenn sie benötigt wird. Sie ermöglicht Ihnen auch, viele Objekte zu ändern und dann alle gleichzeitig zu aktivieren. Wenn Sie sie aktivieren, werden die aktuellen aktiven Versionen gelöscht, und Ihre überarbeiteten Versionen werden aktiv und ersetzen diese.
Abbildung 6.5: Wenn eine Tabelle angezeigt wird, die eine überarbeitete Version hat, können Sie diese sehen.
Die überarbeitete Version wird, falls vorhanden, sichtbar , wenn Sie eine Tabelle anzeigen (das Statusfeld wird überarbeitet enthalten). Die Drucktastenleiste besitzt eine Schaltfläche Aktive Version (siehe Abb. 6.5). Wenn Sie sie drücken, wird die aktive Version angezeigt, und die Schaltfläche auf der Symbolleiste wird sich in Überarbeitete Version ändern, so daß Sie sie erneut drücken und zur vorigen Anzeige zurückkehren können.
Starten Sie nun das ScreenCam »How to Compare Revised and Active Versions«.
Vergleichen von überarbeiteten und aktiven Versionen:
1. Auf dem Fenster: Dictionary: Tabelle/Struktur: Anzeigen Feld, wählen Sie den Menüpfad Hilfsmittel->Versionsverwaltung. Das Fenster Objektversionen wird angezeigt. Die erste Zeile enthält das Word mod.. Dies ist die überarbeitete Version. Die nächste Zeile enthält akt.. Dieses ist die aktive Version.

2. Um die beiden Versionen zu vergleichen, markieren Sie beide durch Einfachklick, und drücken Sie die Schaltfläche Vergleichen. Das Fenster Versionsvergleich für Tabellen wird angezeigt. Die geänderten Zeilen werden am rechten Rand markiert. <- nur aktiv bedeutet, daß die Zeile nur in der aktiven Version existiert. <- nur modifiziert bedeutet, daß die Zeile nur in der überarbeiteten Version existiert.
3. Um eine Zusammenfassung der Änderungen zu sehen, drücken Sie die Schaltfläche Delta Anzeige auf der Drucktastenleiste. Die Liste wird angepaßt und enthält nur noch die Unterschiede zwischen den zwei Versionen.
Zusätzliche Versionen
Neben den aktiven und überarbeiteten Versionen können Sie auch temporäre Versionen erzeugen. Dazu wählen Sie den Menüpfad Tabelle->Version ziehen. Die Meldung: Temporäre Version vom aktiven Objekt gezogen erscheint am unteren Fensterrand. Diese temporäre Version bleibt erhalten, bis die Tabelle in das Produktionssystem transportiert wird. Um die neue Version anzusehen, wählen Sie den Menüpfad Hilfsmittel->Versionsverwaltung. Die Version mit der höchsten Nummer ist diejenige, die Sie gerade erstellt haben.
Löschen einer überarbeiteten Version
Um eine überarbeitete Version zu löschen ohne sie zu aktivieren, müssen Sie zuerst eine temporäre Version aus der aktiven Version erzeugen und sie dann zurückladen, wie es im folgenden Verfahren gezeigt wird.
Starten Sie nun das ScreenCam »How to Discard a Revised Version«.
Um eine überarbeitete Version zu löschen und die aktive Version wiederherzustellen, gehen Sie so vor:
1. Auf dem Fenster:Dictionary: Tabelle/Struktur: Feld ändern wählen Sie den Menüpfad Tabelle->Version ziehen. Ein Dialogfenster erscheint mit der Meldung: Version vom >>aktiven<< Objekt gezogen.
2. Drücken Sie die Schaltfläche Weiter. Sie kehren zurück zum Fenster: Dictionary: Tabelle/Struktur: Feld ändern, und die Meldung: Temporäre Version vom aktiven Objekt gezogen. wird am unteren Fensterrand angezeigt.
3. Wählen Sie den Menüpfad Hilfsmittel->Versionsverwaltung. Das Fenster: Versionen des Objektes wird angezeigt. Neben dem Wort aktiv wird die Markierung angeklickt sein.
4. Entfernen Sie die Markierung neben dem Wort aktiv.
5. Klicken Sie die Markierung unterhalb der Zeile: Version(en) in der Versionsdatenbank, neben der Zeile mit der höchsten Versionsnummer an.

6. Drücken Sie die Schaltfläche Zurückholen in der Drucktastenleiste. Ein Dialogfenster erscheint mit der Meldung: Version nnnnn wird nun zur überarbeiteten (nicht aktiven) Version. Weiter?.
7. Drücken Sie die Schaltfläche Ja. Sie kehren zurück zum Fenster Versionen der Objekte, und die Meldung: Überarbeitete Version muß noch aktiviert werden! erscheint am unteren Fensterrand. Neben dem Wort aktiv wird die Markierung angeklickt sein. Die überarbeitete Version ist nun dieselbe wie die der Schaltfläche Aktive Version.
8. Um zu bestätigen, daß die überarbeitete Version mit der aktiven übereinstimmt, klicken Sie die Markierung neben dem Word mod. an. Sowohl die aktiv- als auch die mod.- Zeile sollten nun markiert sein.
9. Drücken Sie die Schaltfläche Vergleichen auf der Drucktastenleiste. Das Fenster: Versionsvergleich für Tabellen wird angezeigt.
10. Drücken Sie die Schaltfläche: Delta Anzeige auf der Drucktastenleiste. Die Liste sollte eine Zeile mit dem Inhalt: Allgemeine Eigenschaften: unverändert und eine andere Zeile mit dem Inhalt: Felder: unverändert enthalten. Sie haben nun bestätigt, daß die aktive und die überarbeitete Version übereinstimmen.
11. Drücken Sie die Schaltfläche Zurück auf der Symbolleiste. Sie kehren zurück zum Fenster: Versionen der Objekte.
12. Drücken Sie die Schaltfläche Zurück auf der Symbolleiste. Sie kehren zurück zum Fenster: Dictionary: Tabelle/Struktur: Felder ändern.
13. Drücken Sie die Schaltfläche Aktivieren auf der Drucktastenleiste. Das Statusfeld enthält aktiv, und die Meldung xxxxx wurde aktiviert erscheint am unteren Fensterrand.
Alle DDIC-Objekte, wie Domänen und Datenelemente, haben überarbeitete und aktive Versionen. Sie können alle in gleicher Weise angezeigt und verglichen werden. Objekte können nur aktive Versionen benutzen. Wenn Sie zum Beispiel eine Domäne ändern und eine überarbeitete Version erzeugen, benutzen Datenelemente weiterhin die aktive Version, bis Sie die Domäne aktivieren.
Das Datenbank-Utility benutzen
Innerhalb des DDIC liegt ein Werkzeug namens Datenbank-Utility. Damit können Sie Tabellen auf Datenbankebene prüfen und ändern.
Starten Sie nun das ScreenCam »How to Access the Database Utility«.
Um zum Datenbank-Utility zu gelangen:
1. Beginnen Sie mit dem Dictionary: Einstiegsbild.

2. Geben Sie einen Tabellennamen im Feld Objektname ein.
3. Drücken Sie die Schaltfläche Anzeigen.
4. Wählen Sie den Menüpfad Hilfsmittel->Datenbank-Utility. Das Fenster ABAP/4 Dictionary: Utility für Datenbanktabellen wird angezeigt, wie in Abb.6.6 gezeigt.
Abbildung 6.6: Mit ABAP/4-Dictionary:Utility für Datenbanktabellen können Sie direkt mit der Datenbank kommunizieren, um Tabellen anzuzeigen oder zu verändern.
Von hier aus können Sie:
■ die Konsistenz der R/3-DDIC-Definitionen gegen die Datenbank prüfen ■ das Aktivierungsprotokoll ansehen, um die tatsächlichen SQL-Anweisungen zu sehen, die an die
Datenbank übergeben wurden ■ Datenbankspeicherparameter anzeigen und ändern ■ eine Tabelle in der Datenbank löschen oder leeren, indem Sie sie in der Datenbank löschen und
wieder anlegen
Konsistenzprüfungen

Die Definition einer transparenten Tabelle gibt es an zwei Stellen: im R/3-Data Dictionary und in der Datenbank. Um die Konsistenz zwischen diesen beiden zu prüfen, wählen Sie im Datenbank-Utility den Menüpfad Zusätze->Datenbankobjekt->Prüfen. Die aktive Version der Tabelle wird mit der Datenbanktabelle verglichen. Das Fenster Tabelle xxxxx: Datenbankobjekt prüfen wird angezeigt, und eine Meldung oben in der Liste zeigt an, ob das Datenbankobjekt konsistent ist (siehe Abb. 6.7).
Abbildung 6.7: Eine Konsistenzprüfung gegen die Datenbank bestätigt, daß die R/3-DDIC-Definition der Tabelle ztxlfa1 und die Datenbankdefinition identisch sind.
Inkonsistenzen können auftreten, wenn:
■ die Tabellendefinition auf Datenbankebene geändert wurde. Das kann passieren, wenn jemand die Datenbankdefinition manuell, oder ein ABAP/4-Programm sie mit Native SQL ändert;
■ die Datenbank korrupt wird.
Sie werden eine Konsistenzprüfung durchführen, wenn Sie beim Testen eines Programms einen ungewöhnlichen SQL-Fehler bekommen, oder falsche Ergebnisse aus einem Programm, das richtig arbeiten sollte, dies aber unerklärlicherweise nicht tut. Falls Sie eine Inkonsistenz finden, deutet dies daraufhin, daß die Ursache des Problems außerhalb Ihres Programms liegen könnte.

Eine R/3-Tabelle ist in mancher Hinsicht wie ein herkömmliches Programm. Es gibt sie in zwei Formen: die »Quelle«, die Sie anzeigen lassen und ändern können, und die übersetzte Form, die zur Laufzeit benutzt wird, Laufzeitobjekt genannt. Das Laufzeitobjekt wird erzeugt, wenn Sie die Tabelle aktivieren; es ist auch als nametab bekannt.
Wenn eine Konsistenzprüfung durchgeführt wird, wird die nametab gegen die Datenbank verglichen.
Abbildung 6.8: Die nametab ist das Laufzeitobjekt für eine Tabelle. Sie enthält alle technischen Charakteristika einer Tabelle, wie z.B. Feldnamen, Datentypen und Längen.
Sie können die nametab aus dem Datenbank-Utility heraus anzeigen, indem Sie den Menüpfad wählen Zusätze->Laufzeitobjekt->Anzeigen. Das Fenster Object xxxxx: Anzeige des aktiven Laufzeitobjekts, wird angezeigt (siehe Abb. 6.8). Am oberen Rand sind der Zeitstempel der nametab und die Kopfinformation. Sie enthält den Tabellentyp (T für transparent), die Tabellenform in der Datenbank (wieder steht T für transparent), die Anzahl Felder in der Tabelle, die Länge des Satzes in Byte, die Anzahl Schlüsselfelder, die Länge der Schlüsselfelder in Bytes, Pufferungsinformation und weiteres mehr. (Für detaillierte Informationen über die Kopffelder und ihre Werte lassen Sie sich die Struktur XD30Lanzeigen). Unter dem Kopf ist eine Liste der Felder, ihrer Position in der Tabelle, des Datentyps, der Länge, Anzahl, Dezimalstellen, des Abstands vom Beginn des Satzes, der externe Länge, der Referenztabelle, der Prüftabelle und mehr. Die technischen Eigenschaften der Tabelle werden vollständig durch die nametab beschrieben.

Rolle der nametab in ABAP/4-Programmen
Wie Sie am 2. Tag gelernt haben, müssen Sie eine tables-Anweisung programmieren, wenn Sie ein ABAP/4-Programm schreiben, das Daten aus einer Tabelle liest. Die tables-Anweisung gibt dem Programm die Struktur der Tabelle bekannt. Wenn Sie jedoch das Laufzeitobjekt für das Programm erzeugen, wird die Tabellendefinition nicht darin eingebettet. Statt dessen wird, wenn das Programmlaufzeitobjekt ausgeführt wird, die nametab aufgerufen, um die Tabellenstruktur zur Laufzeit zu bestimmen. Dies ermöglicht Ihnen, eine Tabelle (oder Struktur) zu ändern, ohne die von Ihnen benutzten ABAP/4-Programme übersetzen zu müssen. Sie bestimmen dynamisch die Tabellencharakteristika zur Laufzeit, indem Sie die nametab aufrufen.
Obwohl Sie nicht alle Programme jedesmal neu übersetzen müssen, wenn eine Tabelle geändert wurde, erfordern bestimmte Änderungen (solche wie ein Feld umbenennen oder löschen), daß Sie Ihr ABAP/4-Programm ändern. In diesem Fall müssen Sie alle Programme finden, die sie benutzen.
Starten Sie nun das ScreenCam »How to Perform a Where-Used List on a Table«.
Um alle Programme zu finden, die eine gegebene Tabelle benutzen, gehen Sie wie folgt vor:
1. Beginnen Sie mit dem Dictionary: Eingangsbild.
2. Geben Sie den Tabellennamen in das Feld: Objektname ein.
3. Drücken Sie die Schaltfläche: Verwendungsnachweis auf der Drucktastenleiste. Ein Dialogfenster: Verwendungsnachweis erscheint.
4. Wählen Sie Programme.
5. Drücken Sie die Schaltfläche Weiter. Das Fenster Tabelle xxxxx in Programmen wird angezeigt. Eine Liste aller Programme, die die Tabelle benutzen, erscheint.
6. Doppelklicken Sie auf einen Programmnamen, um alle Programmzeilen anzuzeigen, in welchen die Tabelle benutzt wird.
7. Doppelklicken Sie auf eine Zeile, um das Programm beginnend mit dieser Zeile anzuzeigen.
Die Konsistenz der nametab prüfen
Die nametab bezieht ihre Merkmale von den Datenelementen und Domänen, die die Tabelle bilden. Es ist möglich, daß die Definition der nametab nicht mit den Datenelementen und Domänen übereinstimmt. Wenn Sie zum Beispiel eine Änderung an einer Domäne aktivieren, müssen auch die Tabellen, die sie enthalten, aktiviert werden, um diese Änderung zu übernehmen. Dies geschieht automatisch; trotzdem kann eine Reaktivierung fehlschlagen, z.B. wegen einer Einschränkung der Datenbank oder weil die Tabelle Daten enthält und erst konvertiert werden muß. Diese Situation kann gecheckt werden, indem man eine Konsistenzprüfung auf dem Laufzeitobjekt durchführt.

Um die Konsistenz zwischen der nametab und den Data Dictionary-Objekten zu prüfen, wählen Sie im Datenbank-Utility den Menüpfad Zusätze->Laufzeitobjekt->Prüfen. Das Laufzeitobjekt wird mit den DDIC-Quellobjekten verglichen. Das Fenster Objekt xxxxx: Prüfen aktives Laufzeitobjekt, wird angezeigt, und eine Meldung am oberen Listenrand zeigt, ob das Datenbankobjekt konsistent ist. Abbildung 6.9 und 6.10 zeigen ein Beispiel einer Inkonsistenz in der nametab für Tabelle ztxlfal.
Wenn eine Domäne geändert wird, und die Tabellenaktivierung geht schief, kann es eine Inkonsistenz zwischen der nametab und der Domäne geben.
Im Fall von Abbildung 6.10 deckt die Prüfung auf, daß der Datentyp von Feld lifnr char 10 in der nametab ist und int4 in der Domäne.
ABAP/4-Programme benutzen nur die nametab. Daher »wissen« sie nichts von Inkonsistenzen und werden deshalb im Entwicklungssystem nicht von ihnen beeinflußt. Transportiert man DDIC-Objekte, bevor Inkonsistenzen bereinigt sind, kann das Probleme während des Imports in Qualitätssicherungs- oder Produktionssystemen verursachen oder sogar bewirken, daß ABAP/4-Programme in diesen Umgebungen falsche Ergebnisse erzeugen. Der Grund dafür ist, daß die Änderungen die ABAP/4- Programme nicht beeinflußt haben und deshalb noch nicht getestet worden sind.
Abbildung 6.9: Hier findet die Konsistenzprüfung den Fehler, daß Satzlänge, Schlüssellänge und

Tabellenausrichtung inkonsistent sind.
Abbildung 6.10: Beim Herunterblättern findet man die Felder der nametab und den Grund der Inkonsistenz.
Das Aktivierungsprotokoll anzeigen
Aus dem Datenbank-Utility heraus können Sie sich das Aktivierungsprotokoll anzeigen lassen, indem Sie die Schaltfläche Objektprotokoll auf der Drucktastenleiste drükken. Dieses Protokoll wird nur bereitgestellt, wenn die Aktivierung SQL-Anweisungen erzeugt (In manchen Fällen kann eine Tabellenänderung aktiviert werden, ohne die Datenbank zu betreffen, z.B. eine Änderung am Kurztext). Das Protokoll enthält die Reihenfolge der durchgeführten Schritte und alle SQL-Anweisungen, die während der letzten Aktivierung zur Datenbank gesandt wurden (siehe Abb. 6.11 und 6.12).

Abbildung 6.11: Das Aktivierungsprotokoll zeigt die Sequenz der Schritte während der Aktivierung und das generierte SQL. Dieses Protokoll zeigt, daß während der Aktivierung die Tabelle in die Datenbank gesetzt und neu angelegt wurde.

Abbildung 6.12: Dies ist der Rest des Aktivierungsprotokolls aus Abbildung 6.11.
Um erläuternde Detailinformation zu einer Meldung im Protokoll anzuzeigen, positionieren Sie den Cursor auf die Meldung und drücken die (F1)-Taste.
Speicherparameter anzeigen und ändern
Wird die Schaltfläche Speicherparameter im Datenbank-Utility gedrückt (siehe Abb. 6.1), wird das Fenster DB Utility: Transparente Tabellen - Datenbank Parameter angezeigt. Abbildung 6.13 zeigt, wie dieses Fenster aussieht, wenn eine Oracle-Datenbank installiert ist. Dieses Fenster dient hauptsächlich dem Datenbankadministrator (DBA), um Speicherparameter aus R/3 heraus zu ändern, nachdem eine Tabelle aktiviert wurde. Der Vollständigkeit halber wird es hier vorgestellt.

Abbildung 6.13: Datenbankspezifische Parameter werden im Fenster DB Utility: Transparente Tabellen - Datenbank Parameter gezeigt. Diese Maske zeigt, daß sich Speicherparameter für die Tabelle ztxlfa1 nach der Aktivierung verändert haben, weil die Zeilen DBS und CMP nicht passen.
Hier wird eine datenbankspezifische Information über die Tabellenspeicherparameter angezeigt. Die Src-Spalte zeigt die Quelle der Werte an. DBS bedeutet, daß diese Werte die aktuellen Werte in der Datenbank sind. CMP bedeutet, daß diese Werte aus der Größenkategorie und Datenklasse berechnet wurden. Die USR-Zeile ermöglicht Ihnen, Werte für NextE, MaxE, Pf und Pu einzugeben und sie unmittelbar anzuwenden, indem Sie die Schaltfläche Parameter NextE, MaxE, Pf beziehungsweise Pu sofort anwendendrücken. Meistens werden die DBS und CMP-Zeilen gleich sein, außer wenn die Speicherparameter für die Datenbanktabellen manuell geändert wurden, nachdem die Tabelle aktiviert worden ist.
Die InitExt- und NextExt-Spalten enthalten die Größen (in Blöcken) der initial und next extents. Die MinE- und MaxE-Spalten enthalten die Minimal- und Maximalanzahl erlaubter extents. Als nächstes kommt der Tablespace-Name, gefolgt von den FG- und Fr-Spalten, welche die Anzahl der freelist-Gruppen und l der freelists in einer Gruppe enthalten (diese zwei Spalten werden nur benutzt, wenn Oracle im parallel processing mode betrieben wird). Die Pf- und Pu-Spalten enthalten die Prozentangabe des Freiplatzes und des benutzten Platzes in den Datenblöcken. Wenn Sie mehr zu einer Spalte wissen möchten, stellen Sie den Mauszeiger auf die Spalte und drücken Sie (F1).
Obwohl die einzigen Parameter, die geändert werden können, NextE, MaxE, Pf und Pu sind, müssen Sie die Zeile vollständig ausfüllen, bevor Sie die Schaltfläche Anwenden drücken. Um zum Beispiel die

Größe des next extent auf 64 zu ändern und die Maximalzahl von extents auf 4 zu setzen, wählen Sie zuerst den Auswahlknopf USR. Dann geben Sie 64 in der NextExt-Spalte ein, geben 4 in die MaxE-Spalte ein, kopieren den Rest der Werte aus der DBS-Zeile und drücken dann die Schaltfläche Anwenden.
Ihre Änderungen werden sofort in der Datenbank wirksam, wenn Sie die Schaltfläche Anwenden drücken. Um die Ergebnisse anzusehen, drücken Sie die Schaltfläche Zurück, um zum Fenster ABAP/4-Dictionary Utility für Datenbanktabellen zurückzukehren, und drücken die Schaltfläche Speicherparameter auf der Drucktastenleiste. Die Zeile mit DBS in der Src-Spalte wird die neuen Werte enthalten.
Tabellen in der Datenbank löschen und neu anlegen
Der schnellste Weg, die Daten einer Tabelle zu löschen, ist, diese zu löschen und dann neu anzulegen. Um eine Tabelle zu löschen, drücken Sie im Datenbank-Utility die Schaltfläche Datenbanktabelle löschen. Ein Dialogfenster wird angezeigt werden, um Ihre Anforderung zu bestätigen. Die Tabelle und ihr Inhalt werden aus der Datenbank gelöscht. Um sie wieder anzulegen, drücken Sie die Schaltfläche Datenbanktabelle anlegen. Die Tabelle wird wieder angelegt, indem die aktive Version der Tabelle benutzt wird. Sie können das Datenbank-Utility hierfür einsetzen, anstatt ein ABAP/4-Programm zu schreiben, das alle Zeilen löscht.
Das Löschen einer Tabelle bewirkt, daß alle Daten unwiederbringlich verlorengehen. Machen Sie unbedingt eine Datensicherung der Tabelle, bevor Sie sie löschen. Denken Sie daran: wenn Sie die Tabelle manuell kopieren, müssen Sie sowohl die Tabellendefinition als auch die Daten kopieren.
Wenn die Tabelle mehr als einen extent besitzt, ist Löschen und Neuanlage einer Tabelle ein schneller und einfacher Weg, um sie zu reorganisieren. Sie müssen die Daten zeitweilig auf einer anderen Tabelle sichern, bevor Sie löschen und dann später zurückkopieren.
Zusammenfassung
■ Änderungen an kritischen Daten können automatisch in Änderungsbelegen protokolliert werden. Für nichtkritische Daten sollten statt dessen Änderungsbelegobjekte benutzt werden.
■ Eine überarbeitete Version einer Tabelle wird angelegt, wenn Sie ändern ohne zu aktivieren. Nur die aktive Version eines Objektes kann benutzt werden.
■ Mittels des Datenbank-Utility können Sie die nametab untersuchen und ihre Konsistenz zum Data

Dictionary und zur Datenbank vergleichen. ■ Das Datenbank-Utility ermöglicht Ihnen ebenso, das Aktivierungsprotokoll einer Tabelle und der
Speicherparameter anzusehen sowie eine Tabelle in der Datenbank zu löschen und wieder anzulegen.
Fragen & Antworten
Frage:Wo würde ein DBA die Speicherparameter einer aktivierten Tabelle vom SAP R/3-System aus ändern?
Antwort:Rufen Sie das Datenbank-Utility auf, und drücken Sie die Schaltfläche Speicherparameter.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, um Ihnen zu helfen, Ihr Verständnis für die Materie zu vertiefen, und der Übungsabschnitt unterstützt Sie mit Erfahrungen, das Erlernte umzusetzen. Antworten auf die Prüfungsaufgaben und die Übungen können Sie im Anhang B (»Antworten zu Kontrollfragen und Übungen«) finden.
Kontrollfrage
1. Ist es möglich, daß die Definition von Tabelle, Datenelementen und Domänen nicht zusammenpassen?
Übung 1
1. Was ist der schnellste Weg, die Daten aus einer Tabelle zu löschen?
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 1
Tag 7
Datendefinitionen in ABAP/4®, Teil 1
Kapitelziele
Am Ende dieses Kapitels können Sie:
■ den Rollbereich und dessen Inhalt erklären ■ die Syntax der Datenelemente von ABAP/4 verstehen ■ die Konzepte der Datenobjekte und deren Auswahl beschreiben ■ Literale benutzen und verstehen, wie jeder Typ im Programmcode verwendet wird ■ Konstanten definieren und benutzen ■ die data-Anweisung anwenden, um Variablen und Feldleisten zu definieren ■ die Datentypen von ABAP/4 verstehen und sowohl alphanumerische als auch numerische
Datentypen identifizieren ■ die ABAP/4 Definition der allgemeinen DDIC Datentypen verstehen
Bitte lesen Sie sich jetzt noch einmal den Abschnitt »ABAP/4-Syntax« des Tags 2 durch, bevor Sie fortfahren.
Programmpuffer und der Rollbereich
Programme werden auf dem Applikationsserver in einem Programmpuffer zwischengespeichert. Wenn ein Benutzer ein Programm aufruft, wird in diesem Programmpuffer nach dem jeweiligen Programm gesucht. Wird dieses Programm dort gefunden, und wurde es in der Datenbank nicht verändert, wird diese zwischengespeicherte Kopie benutzt. Wenn es nicht gefunden wird oder die Datenbank einen neueren Stand hat, wird das Programm neu geladen.
Nicht für jeden Benutzer, der ein Programm aufruft, wird eine separate Kopie im Speicher abgelegt. Statt dessen rufen alle Benutzer dieselbe Kopie des Programms auf. Der Unterschied ist eine separate Speicherzuweisung, der sogenannte Rollbereich (oder Roll Area). Ein Rollbereich wird jeder Programmausführung eines Benutzers zugewiesen. Das System nutzt den Rollbereich, um dort alle

Informationen über die laufende Programmausführung und die Speicherallokationen abzulegen. Informationen wie Variablen und deren Werte, der aktuelle Programmzeiger und die Listenausgabe werden in dem Rollbereich gehalten. Ein Beispiel: Der Benutzer führt ein Programm aus, und der Rollbereich wird zugewiesen. Wenn derselbe Benutzer, ohne zu warten, daß das Programm beendet ist, zu einem anderen Modus wechselt und dasselbe Programm noch einmal startet, wird ein anderer Rollbereich für diese zweite Programmausführung zugewiesen. Der Benutzer hat dann zwei Rollbereiche, einen für jede Programmausführung. Wenn der Benutzer ein anderes Programm aufgerufen hätte, dann hätte er genauso zwei Rollbereiche, einen für jedes Programm.
ABAP/4-Syntaxelemente
Jedes ABAP/4-Programm besteht aus einer oder mehreren Anweisungen. Jede Anweisung beinhaltet ein oder mehrere Wörter, die durch wenigstens ein Leerzeichen getrennt werden. Das erste Wort einer Anweisung ist ein Schlüsselwort. Eine Anweisung kann ein oder mehrere Zusätze beinhalten und endet immer mit einem Punkt.
In Listing 7.1 heißen die Schlüsselwörter select, write und endselect. Zwei Zusätze erscheinen in der select-Anweisung: where und order by. Was in anderen Programmiersprachen normalerweise eine »Klausel« genannt wird, wird in ABAP/4 »Zusatz« genannt: das ist ein Wort oder eine Gruppe von Wörtern nach dem Schlüsselwort, die das Verhalten der Anweisung verändern.
Listing 7.1: Beispiel einer grundlegenden ABAP/4-Syntax
1 select * from ztxlfa1 where lifnr > '0000001050' order by lifnr.2 write: \ ztxlfa1-lifnr, ztxlfa1-name1, ztxlfa1-land1.3 endselect.
Eine Anweisung kann in jeder Spalte beginnen und jede Anzahl von Zeilen umfassen. Um eine Anweisung in einer anderen Zeile fortzusetzen, wird die Anweisung zwischen zwei Wörtern getrennt. Ein Fortsetzungszeichen wird dabei nicht benötigt. Beispiel: Das Listing 7.1 kann auch anders formatiert werden, wie Listing 7.2 zeigt.
Listing 7.2: Dieser Code ist derselbe wie in Listing 7.1. Er wurde nur anders formatiert.
1 select * from ztxlfa12 where lifnr > '0000001050'3 order by lifnr.4 write: \ ztxlfa1-lifnr,5 ztxlfa1-name1,6 ztxlfa1-land1. endselect.
ABAP/4 ist nicht case sensitive, d.h. ABAP/4 unterscheidet nicht zwischen Groß- und Kleinschreibung.

Datenobjekte definieren
Datenobjekte sind Speicherbereiche, die benutzt werden, um Daten zu halten, während das Programm ausgeführt wird. Es gibt zwei Typen von Datenobjekten: veränderbare und nicht veränderbare. Die nicht veränderbaren Datentypen sind Literale und Konstanten. Die veränderbaren Datenobjekte sind Variablen, Feldleisten und interne Tabellen. Eine Feldleiste ist das ABAP/4-Äquivalent einer Struktur. Eine interne Tabelle ist das Äquivalent eines Array.
Wenn ein Programm startet, wird die Speicherbelegung für jedes Datenobjekt in dem Rollbereich abgelegt. Während ein Programm abläuft, kann der Inhalt des nicht veränderbaren Datenobjektes gelesen werden, oder die Daten der veränderbaren Objekte können geschrieben und gelesen werden. Wenn das Programm endet, löscht das System den Speicher für alle Datenobjekte und, deren Inhalte gehen verloren.
Datenobjekte haben drei Stufen der Auswahl: lokal, global und extern. Die Auswahl eines Datenobjektes zeigt an, von wo aus in dem Programm auf diese Datenobjekte zugegriffen werden kann.
Lokal auswählbare Datenobjekte sind nur in dem Unterprogramm zugänglich, in dem sie definiert sind. Auf global auswählbare Objekte kann von überall aus dem Programm zugegriffen werden. Extern auswählbare Objekte können auch von anderen Programmen genutzt werden. Die Abbildung 7.1 zeigt diese drei Ebenen des Zugriffs.
In Abbildung 7.1 sind die lokalen Datenobjekte des Unterprogramms 1A nur innerhalb dieses Unterprogramms auswählbar. Eine Anweisung, die außerhalb dieses Unterprogramms liegt, kann nicht auf das Datenobjekt zugreifen. Gleichfalls können die lokalen Datenobjekte der Unterprogramme 1B und 2A nur innerhalb dieses Programms genutzt werden.
Jede Anweisung in Programm 1 kann auf die globalen Datenobjekte in Programm 1 zugreifen, unabhängig davon, wo die Anweisung steht. Ebenso kann jede Anweisung in Programm 2 auf die globalen Datenobjekte des Programms 2 zugreifen.

Abbildung 7.1: Die Auswählbarkeit von Datenobjekten bestimmt ihre Zugänglichkeit. Wenn die Objekte lokal auswählbar sind, kann auf sie nur innerhalb des Unterprogramms zugegriffen werden. Wenn sie global auswählbar sind, sind sie innerhalb des Programms zugänglich. Sind sie extern auswählbar, können auch andere Programme auf diese Datenobjekte zugreifen.
Die externen Datenobjekte können von jeder Anweisung in Programm 1 oder Programm 2 genutzt werden. Tatsächlich hängt die Zugänglichkeit der externen Datenobjekte vom Typ des genutzten externen Speichers und der Beziehung zwischen den zwei Programmen ab. Die Details dieses Punktes sind in den Abschnitten SPA/GPA- Speicher und ABAP/4-Speicher beschrieben.
Definition von Literalen
Ein Literal ist ein nicht veränderbares Datenobjekt. Literale können überall in einem Programm auftauchen und sind allein durch ihre Eingaben definiert. Es gibt vier Typen von Literalen: Zeichenketten, numerische, Gleitpunktzahl und hexadezimale.
Zeichenkettenliterale
Zeichenkettenliterale sind case-sensitive Zeichenketten beliebiger Länge, umschlossen von einfachen Anführungsstrichen. 'JACK' ist z.B. ein Zeichenkettenliteral aus Großbuchstaben. 'Caesar the cat' ist ein Zeichenkettenliteral mit einer Mischung aus Groß- und Kleinbuchstaben. Das erste

Programm nutzte ein Zeichenkettenliteral namens 'Hello SAP World'.
Weil ein Zeichenkettenliteral in Anführungsstrichen steht, ist es nicht möglich, ein einfaches Anführungszeichen alleine als Wert dieses Literals zu benutzen. Um ein einfaches Anführungszeichen darzustellen, müssen zwei aufeinanderfolgende Anführungszeichen benutzt werden. Beispiel: Die Anweisung write 'Caesar''s tail'. gibt genau Caesar's tail aus. Die Anweisung write 'Caesar's tail' würde einen Syntaxfehler erzeugen, da die Zeichenkette ein einfaches Anführungszeichen enthält. Die Anweisung write ''''. schreibt ein einfaches Anführungszeichen in die Ausgabeseite, da zwei aufeinanderfolgende Anführungszeichen innerhalb von Anführungszeichen ein einfaches Anführungszeichen ergeben. Also: nur die Anweisung write:'''', 'Hello Caesar', ''''. gibt ' Hello Caesar ' aus.
Im folgenden sind Beispiele ungültiger Zeichenkettenliterale dargestellt und die korrekte Art, sie zu programmieren. "Samantha" ist nicht korrekt, es müssen einfache statt doppelte Anführungszeichen benutzt werden. 'Samantha' wäre korrekt. In 'Never ending fehlt das abschließende Anführungszeichen, korrekt wäre 'Never ending'. 'Don't bite' sollte von zwei aufeinanderfolgenden einfachen Anführungszeichen eingeschlossen sein, korrekt wäre 'Don''tbite'.
Wenn ein Literal in einem Vergleich benutzt wird, gilt als Faustregel: immerGroßbuchstaben verwenden. Vergleiche mit Zeichenkettenliteralen sind immer casesensitive , so daß es notwendig ist, stets auf die korrekte Groß- und Kleinschreibung zu achten, um die beabsichtigten Ergebnisse zu erhalten. Wenn die Schreibweise nicht gleich ist, läuft ein Programm für gewöhnlich weiter, aber die Ausgabe wird nicht korrekt sein, oder es wird überhaupt keine Ausgabe geben. In 99,99 Prozent der Fälle werden die Werte der Zeichenkettenliterale in Großbuchstaben verglichen. Deshalb sollten Zeichenkettenliterale immer in Großbuchstaben geschrieben werden, es sei denn, sie werden für andere Zwecke genutzt. Beispiel: select single * from ztxlfa1 where lifnr = 'v1' findet keinen Datensatz, aber selectsingle * from ztxlfa1 where lifnr = 'V1' findet Datensätze. Haben Sie die Kleinschreibung von v bemerkt?
Numerische Literale
Numerische Literale sind hart programmierte numerische Werte mit einem optionalen Vorzeichen. Sie sind normalerweise nicht von Anführungszeichen umgeben. Wenn allerdings ein numerisches Literal eine Dezimalzahl beinhaltet, dann muß es von einfachen Anführungszeichen umgeben werden. Wenn eine Dezimalzahl ohne Anführungszeichen dargestellt wird, ergibt es den Syntaxfehler Anweisung x ist nicht definiert. Bitte überprüfen Sie Ihre Eingabe.Tabelle 7.1 zeigt die richtige und falsche Weise, numerische Literale zu programmieren.

Beispiel: 256 ist ein numerisches Literal, genauso wie -99. '10.5' ist ein numerisches Literal mit einem Dezimalpunkt, so daß es von Anführungszeichen umgeben sein muß. Ein Literal kann als Vorgabewert für eine Variable dienen oder dazu benutzt werden, einen Wert für eine Anweisung zur Verfügung zu stellen. Beispiele von ungültigen Literalen sind: 99- (nachfolgendes negatives Vorzeichen), "Confirm" (umgeben von doppelten Anführungszeichen) und 2.2 (trotz Dezimalpunkt nicht in einfachen Anführungszeichen).
Gleitkommaliterale
Gleitkommaliterale werden in einfachen Anführungszeichen spezifiziert '<Mantisse>E<Exponent>' . Die Mantisse kann mit einem Vorzeichen und ohne Dezimalpunkte angegeben werden, der Exponent kann mit oder ohne Vorzeichen sowie mit oder ohne führende Nullen benutzt werden. Beispiel: '9.99E9', '-10E-32' und '+1E09' sind gültige Gleitkommaliterale.
Hexadezimale Literale
Ein Hexadezimalliteral wird in einfachen Anführungszeichen wie ein Zeichenkettenliteral spezifiziert. Die erlaubten Werte sind 0-9 und A-F. Es muß eine gerade Anzahl von Zeichen in der Kette sein, und alle Zeichen müssen groß geschrieben werden.
Wenn ein Hexadezimalliteral mit klein geschriebenen Zeichen benutzt wird, wird keine Fehlermeldung oder Warnung ausgegeben. Wenn das Programm läuft, ist das Literal jedoch falsch.
Beispiele von gültigen hexadezimalen Literalen sind '00', 'A2E5' und 'F1F0FF'. Beispiele von ungültigen Literalen sind 'a2e5' (enthält kleingeschriebene Zeichen), '0' (enthält eine ungerade Anzahl von Zeichen), "FF" (eingeschlossen von doppelten Anführungszeichen) und x'00' (sollte kein führendes x haben).
Hexadezimale Werte werden in ABAP/4 kaum benutzt, weil sie häufig maschinenabhängig sind. Der Gebrauch eines hexadezimalen Wertes, der Maschinenabhängigkeit erzeugt, sollte vermieden werden.

Tabelle 7.1 gibt einen Überblick über richtig und falsch programmierte numerische und hexadezimale Literale.
Tabelle 7.1: Richtig und falsch programmierte Literale
Richtig Falsch Erläuterung
-99 99- Ein nachfolgendes Vorzeichen ist nicht erlaubt, es sei denn, es steht innerhalb der Anführungszeichen.
'-12' Numerische Zahlen zwischen Anführungszeichen können ein führendes oder nachfolgendes '12-' Vorzeichen haben.
'12.3' 12.3 Numerische Zahlen mit einem Dezimalpunkt müssen in einfachen Anführungszeichen geschrieben werden.
'Hi' "Hi" Doppelte Anführungszeichen sind nicht erlaubt.
'Can''t' 'Can't' Zwei aufeinanderfolgende einfache Anführungszeichen in der Zeichenkette ergeben in der Ausgabe ein einfaches Anführungszeichen.
'Hi' 'Hi Das Nachfolgende Anführungszeichen fehlt.
'7E1' 7E1 Gleitkommazahlen müssen von Anführungszeichen umschlossen sein.
'7w1' Kleinschreibung ist in Gleitkommaliteralen nicht erlaubt.
'0A00' '0a00' Kleinschreibung in hexadezimalen Literalen ergibt nicht korrekte Ergebnisse.
'0A00' 'A00' Eine ungerade Zahl von hexadezimalen Stellen ergibt nicht korrekte Resultate.
'0A00' X'0A00' Ein vorangestelltes oder nachfolgendes Zeichen ist für hexadezimale Literale nicht erlaubt.
Definition von Variablen
Zwei Anweisungen werden gewöhnlich benutzt, um Variablen in ABAP/4-Programmen zu definieren:
dataparameters
Definition von Variablen mit der data-Anweisung
Variablen können mit der data-Anweisung für das Programm definiert werden. Variablen, die mit der data-Anweisung definiert werden, werden einem Datentyp zugewiesen und können Vorgabewerte haben.

Syntax der data-Anweisung
Nun folgt die Syntax, um Variablen mit der data-Anweisung zu definieren:
data v1[(l)] [type t] [decimals d] [value 'xxx'].
oder
data v1 like v2 [value 'xxx'].
wobei gilt:
■ v1 ist der Variablenname. ■ v2 ist der Name der Variablen, die vorher im Programm definiert wurde, oder der Name eines
Feldes, das zu einer Tabelle oder Struktur im Data Dictionary gehört. ■ (l) ist die interne Längenangabe. ■ t ist der Datentyp. ■ d ist die Anzahl der Dezimalstellen (wird nur mit Typ p benutzt). ■ 'xxx' ist ein Literal, das den Vorgabewert liefert.
Listing 7.3 zeigt ein Beispiel mit Variablen, die mit der data-Anweisung definiert sind.
Listing 7.3: Beispiele mit Variablen, die mit der data-Anweisung definiert sind
1 data f1(2) type c.2 data f2 like f1.3 data max_value type i value 100.4 data cur_date type d value '19980211'.
Variablennamen können von 1 bis 30 Zeichen lang sein. Sie können jedes Zeichen bis auf ( ) + . , : beinhalten und müssen wenigstens ein alphanumerisches Zeichen haben.
SAP empfiehlt, daß Variablennamen immer mit einem Buchstaben beginnen und keinen Bindestrich enthalten sollten. Der Bindestrich hat eine besondere Bedeutung (siehe Feldleisten weiter unten). Statt eines Bindestrichs sollte ein Unterstrich (_) verwendet werden.
Benutzen Sie nicht USING oder CHANGING als Variablennamen. Obwohl sie syntaktisch korrekt sind, kann es zu Problemen kommen, wenn sie an Unterprogramme weitergegeben werden.

Die folgenden Punkte sind weiterhin bei der data-Anweisung zu beachten:
■ Die Standardlänge hängt von dem Datentyp ab. (Standardlängen sind in Tabelle 7.2 aufgelistet) ■ Der Standarddatentyp ist c (Zeichen). ■ Der vorgegebene Initialwert ist 0, außer für Datentyp c, für den der vorgegebene Wert das
Leerzeichen ist. ■ Der Wertzusatz akzeptiert lediglich ein Literal oder eine Konstante (siehe unten); Sie können
eine Variable nicht benutzen, um einen Vorgabewert zu liefern. ■ Bei Benutzung des Zusatzes like erhält die zu definierende Variable ihre Länge und den
Datentyp von der Referenzvariablen. Sie kann nicht in einer Anweisung mit like spezifiziert werden.
■ Bei Benutzung des Zusatzes like wird der Wert nicht von der Referenzvariablen erhalten. Sie können den Wertzusatz nutzen, um der Variablen einen Vorgabewert zu geben. Wenn Sie das nicht tun, wird der Variablen der vorgegebene Initialwert 0 zugewiesen (oder Leerzeichen für den Datentyp Zeichen).
Die data-Anweisung kann überall im Programm verwendet werden. Die Definition der Variablen muß vor den Anweisungen erfolgen, die diese Variable benutzen. Wenn Sie die data-Anweisungnach dem ausführbaren Programmcode plazieren, dann können die Anweisungen darüber nicht auf die von der data-Anweisung definierte Variable zugreifen. Ein Beispiel finden Sie im Listing 7.4.
Listing 7.4: Beispiel einer Variablen, auf die zugegriffen wird, bevor sie definiert ist
1 report ztx0704.2 data f1(2) value 'Hi'.3 write: f1, f2.4 data f2(5) value 'there'.
Die Variable F2 ist in Zeile 4 definiert, und die write-Anweisung in Zeile 3 versucht, auf diese Variable zuzugreifen. Dies wird einen Syntaxfehler hervorrufen. Die data- Anweisung in Zeile 4 muß vor Zeile 3 stehen.
Es ist guter Programmierstil, alle data-Definitionen am Beginn eines Programms vor die erste ausführbare Anweisung zu setzen.
ABAP/4-Datentypen
Es gibt zwei Hauptkategorien von Daten in ABA/4: Zeichen und numerische Daten. Variablen erhalten eine spezielle Behandlung vom ABAP/4-Prozessor, basierend auf ihrer Kategorie, die weiter

geht als die übliche Behandlung in anderen Programmiersprachen. Deswegen ist es besonders wichtig für Sie, zwischen Zeichen und numerischen Daten zu unterscheiden.
Datentypzeichen
Die Datentypzeichen sind in Tabelle 7.2 aufgeführt. Beachten Sie, daß sie auch den Typ n umfassen. Die internen Längen werden in Bytes angegeben. Ein Strich symbolisiert in der Spalte Maximale Länge die Datentypen mit fester Länge.
Die Spalte vorgegebener Initialwert zeigt den Vorgabewert der Variablen, wenn kein Wert mit Hilfe der Wertzuweisung angegeben wird.
Tabelle 7.2: Liste der Datentypzeichen
Datentyp Beschreibung InterneStandardlänge
MaximaleinterneLänge
GültigeWerte
VorgegebenerInitialwert
c Zeichen 1 65535 JedesZeichen
Leerzeichen
n Numerischer Text 1 65535 0-9 0
d Datum 8 (fest) - 0-9 00000000
t Zeit 6 (fest) - 0-9 000000
x Hexadezimal 1 65535 JedesZeichen
Interne Darstellung von Variablen
Numerische Textvariablen werden numerische Zeichenvariablen genannt. Sie enthalten positive ganze Zahlen ohne Vorzeichen. Jede Zahl wird durch ein Byte dargestellt und intern als Zeichen gespeichert. Nur Zeichen 0-9 können abgelegt werden.
Benutzen Sie numerischen Text, um eindeutige Nummern darzustellen, die zur Identifikation dienen, wie Dokumentennummern, Kontonummern oder Sortierzahlen. Auch für Variablen, die einen numerischen Teil aus einem Datentyp Zeichen extrahieren, können numerische Textvariablen dienen. Wenn Sie zum Beispiel einen Monat mit zwei Zeichen aus einem Datumsfeld extrahieren wollen, dann sollten Sie den Datentyp n benutzen.
Datum und Zeit sind Datentypen mit fester Länge. Sie brauchen keine Länge bei der data-Anweisung für diesen Datentyp anzugeben. Werte für Datum und Zeit werden intern immer als YYYYMMDD (JJJJMMTT) bzw. HHMMSS (SSMMSS) gespeichert. Das aktuelle Datum ist über sy-datum und die aktuelle Zeit über sy-uzeit abzurufen.

Die Werte von sy-datum und sy-uzeit werden zu Beginn der Programmausführung gesetzt und ändern sich nicht bis zum Ende des Programms. Wenn Sie bei einem länger laufenden Programm das aktuelle Datum bzw. die aktuelle Zeit benötigen, benutzen Sie die Anweisung get time. Diese Anweisung aktualisiert die Werte von sy-datum und sy-uzeit.
Die absoluten Zeitwerte mit einer Genauigkeit von Millisekunden werden nicht in R/3 benutzt. Relative Zeitwerte sind allerdings im Millisekundenbereich verfügbar. Um diese zu erhalten, muß die Anweisung get run time benutzt werden und der Datentyp i. Schauen Sie in das Kapitel »Laufzeitanalyse« für tiefergehende Details.
Numerische Datentypen
Die numerischen Datentypen werden in Tabelle 7.3 gezeigt. Ein Strich in der Spalte Maximallänge zeigt an, daß die Länge nicht verändert werden kann. Ein Stern zeigt an, daß die Attribute maschinenabhängig sind.
Tabelle 7.3: Numerische Datentypen
Datentyp Beschreibung InterneStandardlänge
MaximaleLänge
MaximaleDezimalstellen
GültigeWerte
VorgegebenerInitialwert
i Ganze Zahl 4(fest) - 0 -231 bis +231
0
p GepackteDezimalzahl
8 16 14 0-9 0
f Gleitkomma 8 8 15* -1E-307bis1E308
0.0
Alle Variablen in Tabelle 7.3 haben ein Vorzeichen. In Gleitkommavariablen hat der Exponent ebenfalls ein Vorzeichen.
Ganze Zahlen werden benutzt, wenn einfache Berechnungen gemacht werden sollen oder kein Dezimalpunkt benötigt wird. Variablen wie Zähler, Index, Positionen oder Offsets sind gute Beispiele.

Eine dezimale Variable speichert (L*2)-1 Stellen, wobei L die Länge der Variablen in Bytes ist. Dezimale Werte speichern zwei Stellen pro Byte außer dem Byte am Ende, welches eine Stelle und das Vorzeichen speichert. Der Dezimalpunkt selbst wird nicht gespeichert, es ist ein Attribut der Definition. Beispiel: data f1(4) type p definiert eine Variable f1, die vier Byte lang ist und sieben Stellen (plus Vorzeichen) aufnehmen kann (siehe Abb. 7.2.). data f2(3) type p decimals 2 definiert eine Variable f2, die drei Byte lang ist und 5 Stellen (plus Vorzeichen) speichern kann. Die Definition data f3 type p definiert eine Variable f3 mit der Möglichkeit 15 Stellen zu speichern, da die Standardlänge für Datentyp p 8 ist.
Abbildung 7.2: Gepackte Dezimalwerte werden mit zwei Stellen pro Byte gespeichert. Das Byte am Ende ist eine Ausnahme; es speichert eine Stelle und das Vorzeichen. Der Dezimalpunkt wird nicht gespeichert und verbraucht so auch keinen Speicher. Er ist Teil der Definition.
Gleitkommazahlen sind immer nur annäherungsweise genau. Sie können für Berechnungen mit sehr großen Werten oder vielen Dezimalstellen benutzt werden. Die Genauigkeit bis zu 15 Dezimalstellen ist möglich, hängt aber von der jeweiligen Hardware ab.
Seien Sie vorsichtig, wenn Sie die Initialwerte mit der data-Anweisung und dem Wertzusatz definieren. Diese Werte werden nicht daraufhin überprüft, ob sie mit dem Datentyp kompatibel sind. Mit dem Wertzusatz können Sie absichtlich oder unabsichtlich ungültige Werte für Ganzzahlen-, Datums- und Zeitvariablen, numerische Texte, gepackte Dezimalvariablen oder Gleitkommavariablen zuweisen. Die Ergebnisse dieser Zuweisung sind maschinenabhängig und undefiniert.
Zuweisung von DDIC-Datentypen zu ABAP/4-Datentypen
Datentypen im Data Dictionary werden aus ABAP/4-Datentypen gebildet. Tabelle 7.4 zeigt die allgemeinen Data Dictionary-Datentypen und ihre korrespondierenden ABAP/4-Datendefinitionen. List die Länge, die in der Domäne spezifiziert wird. Für eine vollständige Liste rufen Sie bitte die (F1)-Hilfe für die tables-Anweisung auf.

Tabelle 7.4: Data Dictionary-Datentypen und ihre korrespondierenden ABAP/4-Datentypen
DDIC-Datentypen Beschreibung ABAP/4-Datendefinition
char Zeichen (Character) c(L)
clnt Mandant (Client) c(3)
dats Datum (Date) d
tims Zeit (Time) t
cuky Währungsschlüssel (Currency key) c(5)
curr Währung (Currency) p((L+2)/2)
dec Dezimalzahl (Decimal) p((L+2)/2)
fltp Gleitkommazahl (Floating-point) f
int1 Ganze Zahl 1 Byte (1-byte integer) (none)
int2 Ganze Zahl 2 Byte (2-byte integer) (none)
int4 Ganze Zahl 4 Byte (4-byte integer) i
lang Sprache (Language) c(1)
numc Numerischer Text (Numeric text) n(L)
prec Genauigkeit (Precision) x(2)
quan Menge (Quantity) p((L+2)/2)
unit Einheit (Units) c(L)
Definition von Variablen mit der parameters-Anweisung
Ein Parameter ist eine spezielle Variable, die mit der parameters-Anweisung definiert wird. parameters ist ähnlich der data-Anweisung, aber wenn Sie das Programm ausführen, wird das System die Parameter als Eingabefeld auf dem Selektionsbild anzeigen, bevor das Programm endgültig ausgeführt wird. Der Benutzer kann Werte eingeben oder verändern und dann die Ausführen-Taste drücken, um die Programmausführung zu starten. Sie können sowohl parameters als auch data im selben Programm benutzen. Die Konventionen für parameters-Namen sind dieselben wie für die Variablen. Ausnahmen:
■ Die maximale Länge ist 8 Zeichen statt 30 Zeichen. ■ In dem Zusatz für Literale und Konstanten können Sie auch eine Variable nutzen, um einen
Wert als Vorgabe zu liefern.
Syntax für die parameters-Anweisung

Der folgende Programmcode ist die Syntax, um eine Variable mit der parameters-Anweisung zu definieren.
parameters p1[(l)] [type t] [decimals d] ...
oder
data p1 like v1 ...... [default 'xxx'] [obligatory] [lower case] [as checkbox] [radiobutton group g]
wobei gilt:
■ p1 ist der Parametername. ■ V1 ist der Name der vorher definierten Variablen oder des vorher definierten Parameters bzw.
der Name eines Feldes, das zu einer Tabelle oder Struktur im Data Dictionary gehört. ■ l ist die interne Längenangabe. ■ t ist der Datentyp. ■ d ist die Zahl der Dezimalstellen (wird nur mit Typ p benutzt). ■ 'xxx' ist ein Literal oder eine vorher definierte Variable, das den Vorgabewert liefert.
Listing 7.5 zeigt ein Beispiel von Parametern, die mit der parameters-Anweisung definiert sind.
Listing 7.5: Beispiele von Parametern, definiert mit der parameters-Anweisung
1 parameters p1(2) type c.2 parameters p2 like p1.3 parameters max_value type i default 100.4 parameters cur_date type d default '19980211' obligatory.5 parameters cur_date like sy-datum default sy-datum obligatory.
Es gibt zwei Variationen der parameters-Anweisung: parameter und parameters. In der Anwendung gibt es keinen Unterschied zwischen beiden, sie sind komplett austauschbar. Allerdings werden Sie für die parameter-Anweisung in der (F1)-Hilfe nichts finden. Aus diesem Grund empfehle ich Ihnen die parameters-Anweisung.
Ein Beispielprogramm mit der parameters-Anweisung zeigt Listing 7.6; das erzeugte Eingabebild ist in Abbildung 7.3 dargestellt. Bitte führen Sie den Report jetzt aus.

Listing 7.6: Beispiel eines Programms, das Eingabeparameter durch die parameters-Anweisung akzeptiert
1 report ztx0706.2 parameters: p1(15) type c,3 p2 like p1 obligatory lower case,4 p3 like sy-datum default sy-datum,5 cb1 as checkbox,6 cb2 as checkbox,7 rb1 radiobutton group g1 default 'X',8 rb2 radiobutton group g1,9 rb3 radiobutton group g1.10 write: / 'You entered:',11 / ' p1 =', p1,12 / ' p2 =', p2,13 / ' p3 =', p3,14 / ' cb1=', cb1,15 / ' cb2=', cb2,16 / ' rb1=', rb1,17 / ' rb2=', rb2,18 / ' rb3=', rb3.
Die Zusätze für die parameters-Anweisung sind in Tabelle 7.5 beschrieben
Tabelle 7.5: Zusätze zu den parameters-Anweisungen und deren Nutzung
Zusatz Benutzung
type Gleich der data-Anweisung
decimals Gleich der data-Anweisung
like Gleich der data-Anweisung
default Gleich der Wertzusatz in der data-Anweisung
obligatory Der Benutzer muß einen Wert in dieses Feld eintragen, bevor das Programm ausgeführt wird
lower case Verhindert, daß Werte in Großbuchstaben übersetzt werden
as checkbox Zeigt das Eingabefeld wie ein Ankreuzfeld.
radiobutton group g Zeigt das Eingabefeld wie einen Auswahlknopf zugehörig zur Gruppe g.
.

Abbildung 7.3: Wenn Sie den Report ztx0706 ausführen, erscheinen die Parameter zuerst in dem Selektionsbild. Obligatorische Parameter werden mit einem Fragezeichen versehen. Um das Programm weiter auszuführen, muß der Benutzer die Taste Ausführen in der Drucktastenleiste drükken.
Die folgenden Punkte sind auch für die parameters-Anweisung zu beachten:
■ In einem Selektionsbild werden obligatorische Felder mit einem Fragezeichen gekennzeichnet. Das zeigt, daß der Benutzer dieser Felder erst ausfüllen muß, bevor er weitermachen kann.
■ Der vorgegebene Datentyp ist c (Zeichen). ■ Der Vorgabewert ist 0, außer bei dem Datentyp c, wo das Leerzeichen der Vorgabewert ist. ■ Der Wertzusatz akzeptiert ein Literal, eine sy-Variable oder eine vorher im Programm
definierte Variable. ■ Wenn der Zusatz like genutzt wird, dann erhält der definierte Parameter seine Länge und den
Datentyp von der Referenzvariablen. Sie können sie nicht in derselben Anweisung spezifizieren.
■ Wenn der Zusatz like genutzt wird, wird der Wert nicht von der Referenzvariablen übertragen. Sie können den Wertzusatz nutzen, um dem Parameter einen Vorgabewert zuzuweisen. Wenn Sie das nicht tun, ist der vorgegebene Initialwert 0 zugewiesen (oder

Leerzeichen für den Datentyp Zeichen). ■ Wie die data-Anweisung kann die parameters-Anweisung überall im Programm stehen;
allerdings muß die Definition vor dem ersten Zugriff der Anweisungen auf diese Variable erfolgen.
■ Parameter erscheinen in dem Selektionsbild in derselben Reihenfolge, in der sie im Programm definiert sind.
■ Alle parameters-Anweisungen, egal wo sie im Programm definiert sind, werden durch den ABAP/4-Interpreter gesammelt und auf dem Selektionsbild angezeigt. Auch wenn die parameters-Anweisung in der Mitte des Programms steht, werden die Parameter auf dem Selektionsbild angezeigt, bevor das Programm weiter ausgeführt wird.
■ Die Parameter werden im SAP-Standardformat angezeigt. Um ihren Aufbau zu verändern, z.B. um das Eingabefeld nach links oder die Beschriftung nach rechts zu verschieben, benutzen Sie die selection-screen-Anweisung, die am Tag 21 beschrieben wird.
Benutzung des Zusatzes Kleinbuchstaben (lower case)
Alle Werte, die in die Parameter eingegeben werden, werden standardmäßig in Großbuchstaben umgewandelt. Um diese Umwandlung zu unterbinden, verwenden Sie bitte den Zusatz lower case.Dieser Zusatz ist nur für Zeichenfelder anwendbar.
Benutzung des Zusatzes Ankreuzfeld (as checkbox)
Ein Ankreuzfeld hat nur zwei Zustände: angekreuzt oder leer. Es wird gebraucht, um dem Benutzer eine Auswahl an/aus oder wahr/falsch zu geben. Es können mehrere Ankreuzfelder auf einem Bild benutzt werden. Wenn Sie mehrere Ankreuzfelder auf einem Bild haben, so sind diese völlig unabhängig voneinander.
Um einen Parameter als Ankreuzfeld anzuzeigen, muß der Zusatz as checkbox benutzt werden. Sie können für diesen Zusatz keinen Datentyp und keine Länge angeben, standardmäßig wird der Datentyp c und die Länge 1 für diesen Zusatz vorgesehen. Der Parameter wird ein X enthalten, wenn das Feld angekreuzt ist und ein Leerzeichen, wenn das Ankreuzfeld leer ist. Wenn das Ankreuzfeld initial angekreuzt sein soll, dann benutzen Sie bitte als Vorgabewert ein X. Rufen Sie das Programm ztx506 auf, um ein Ankreuzfeld zu sehen.
Das Leerzeichen und das X sind die einzigen gültigen Werte. Keine anderen Werte sind für das Ankreuzfeld gültig.
Benutzung des Zusatzes Auswahlknopf (radiobutton group g)
Wie bei einem Ankreuzfeld hat der Auswahlknopf auch nur zwei Zustände: ausgewählt oder nicht ausgewählt. Anders als Ankreuzfelder werden Auswahlknöpfe niemals alleine, sondern nur in Gruppen benutzt. Sie können mehrere Auswahlknöpfe in einer Gruppe zusammenfassen, aber nur ein Auswahlknopf ist ausgewählt. Sie werden verwendet, um dem Benutzer eine Liste mit Alternativen zu präsentieren, in der lediglich eine Auswahl getroffen wird.
Um einen Parameter als Auswahlknopf anzuzeigen, benutzen Sie bitte den Zusatz radiobutton

group g. Sie können für diesen Zusatz keinen Datentyp und keine Länge angeben, standardmäßig wird der Datentyp c und die Länge 1 für diesen Zusatz vorgesehen. g ist ein beliebiger Gruppenname von vier Zeichen Länge. Sie können mehr als eine Gruppe in einem Programm verwenden. Der Parameter wird ein X enthalten, wenn das Feld angekreuzt ist und ein Leerzeichen, wenn der Auswahlknopf leer ist. Wenn der Auswahlknopf initial angekreuzt sein soll, dann benutzen Sie bitte als Vorgabewert ein X. Es gibt keine anderen gültigen Werte für den Auswahlknopf. Probieren Sie es aus, indem Sie das Programm ztx006 laufen lassen.
Parameter-Beschriftung der Eingabefelder
Auf einem Selektionsbild gibt es links von jedem Eingabefeld eine Beschriftung. Standardmäßig entspricht diese Beschriftung dem Namen des Parameters. Sie können diese Beschriftung allerdings auch anders bezeichnen. Für Parameter wie Data Dictionary-Felder erhalten Sie die Beschriftung automatisch aus den Datenelementen.
Änderung der Beschriftung für Parameter
Starten Sie jetzt das ScreenCam »How to Change Input Field Labels«.
1. Um eine Beschriftung für Eingabefeld zu ändern, gehen Sie wie folgt vor:
2. Starten Sie im ABAP/4-Editor.
3. Wählen Sie den Menüpfad Springen->Textelemente->Selektionstext. Das ABAP/ 4-Textelementebild wird angezeigt. Im Programmfeld steht Ihr aktueller Programmname.
4. Drücken Sie die Schaltfläche Ändern. Jetzt können Sie manuell die Beschriftungen in der Textspalte ändern.
5. Ändern Sie die Feldbeschriftungen in der Textspalte.
6. Für einen Parameter, der wie ein DDIC Feld definiert ist, können Sie die Beschriftungen aus dem Datenelement erhalten. Um eine Beschriftung für ein Datenelement zu erhalten, positionieren Sie den Cursor in dem Feld und wählen den Menüpfad Hilfsmittel->DD-Texte übernehmen. Die Beschriftung mittlerer Länge des Datenelementes erscheint als geschütztes Textfeld und der Datentyp des Feldes wechselt und enthält die Zeichen DDIC. Am unteren Rand des Fensters erscheint die Meldung AlleSelektionstexte aus Dictionary übernommen.
7. Um den Schutz eines einzelnen Feldes aufzuheben, positionieren Sie den Cursor auf dem Feld und wählen aus dem Menüpfad Hilfsmittel->Kein DD-Text. Das Textfeld wird ungeschützt und die Zeichen DDIC werden vom Feld entfernt. Am unteren Rand des Fensters erscheint die Meldung Textzu xxx wird nicht mehr aus dem Dictionary übernommen.
8. Um die Feldbeschriftungen für alle Parameter zu erhalten, die wie ein DDIC Feld definiert ist, wählen Sie den Menüpfad Hilfsmittel->DD Texte übernehmen. Feldbezeichungen für alle DDIC

Felder werden geholt und sind geschützt. Alle existierenden Werte in der Textspalte werden überschrieben. Am unteren Rand des Fensters erscheint die Meldung Alle Selektionstexte aus Dictionary übernommen.
9. Bedienen Sie die Drucktaste Sichern in der Drucktastenleiste. Am unteren Rand des Fensters erscheint die Meldung Textelemente für Programm xxxxx in Sprache D übernommen.
10. Drücken Sie zweimal die Drucktaste Zurück in der Drucktastenleiste, um zu dem Programm zurückzukehren.
Wenn Sie die Beschriftung für einige, aber nicht für alle DDIC-Felder überschreiben wollen, dann geben Sie die Beschriftungen in den Textspalten ein und wählen dann den Menüpfad Hilfsmittel->DD-Texte ergänzen. Alle leeren Textfelder werden aus dem Data Dictionary gefüllt und die eingegebenen Werte bleiben erhalten.
Wenn die Beschriftung sich im DDIC ändert, wird die Beschriftung auf den jeweiligen Bildern nichtautomatisch geändert. Um die Beschriftung dort zu ändern, müssen Sie zu den ABAP/4-Textelementen gehen und dort entweder den Menüpfad Hilfsmittel- >DD-Text übernehmen oder Hilfsmittel->DD-Texte übernehmen wählen.
Der Wertzusatz der Anweisung parameters wird nicht auf Kompatibilität mit dem Datentyp geprüft.
Ein Vorgabewert für ein Ankreuzfeld oder Auswahlknopf, der nicht Leerzeichen oder Xist, ist ungültig. Obwohl eine cursory evaluation (Cursor Auswertung) die Probleme aufzeigen kann, kann intensives Testen mit dem Programm unvorhersehbares Verhalten hervorrufen.
Auswirkung der Parameter Definitionen: type gegen like
Benutzen Sie immer den Zusatz like, um einen Parameter zu definieren. Wenn Sie diesen Zusatz benutzen, erhält dieser Parameter die folgenden Eigenschaften des Data Dictionary:
■ Die (F1)-Hilfe wird von der Drucktaste Dokumentation des Datenelements genutzt. ■ Die (F4)-Hilfe wird benutzt, wenn der Parameter dem der Prüftabelle gleicht. ■ Eine Beschriftung des Feldes wird vom Datenelement übertragen.
Zu den eben genannten Vorteilen kommt noch folgendes hinzu:

■ Eine Feldbeschriftung, die aus dem Data Dictionary kommt, garantiert die Verträglichkeit mit anderen Feldbeschriftungen aus anderen Programmen für das gleiche Feld (vorausgesetzt sie erhalten ihre Definition auch aus dem DDIC). Das beseitigt das Problem, zwei Felder mit unterschiedlichen Beschriftungen zu erhalten, die dieselben Daten aufweisen.
■ Änderungen des Datentyps oder der Länge im DDIC werden automatisch in Ihrem Programm berücksichtigt.
Bei Berücksichtigung dieser Vorteile sollten Sie immer den Zusatz like benutzen, um Parameter zu definieren. Das gilt auch für Ankreuzfelder oder Auswahlknöpfe. Wenn notwendig, sollten Sie eine Struktur im DDIC anlegen, die like benutzt. Dann können Sie zumindest auf die (F1)-Hilfe zurückgreifen. Beachten Sie, daß die (F1)-Hilfe auch für Ankreuzfelder oder Auswahlknöpfe verfügbar ist.
Auswirkung der Prüftabelle auf einen Parameter
Wenn Sie einen Parameter mit like st-f1 definieren, und st-f1 hat eine Prüftabelle, dann erscheint der nach unten gerichtete Auswahlpfeil. Sie können auf diesen Auswahlpfeil drücken und erhalten ein Liste mit gültigen Werten für das Feld. Allerdings werden die eingegebenen Werte nicht gegen die Prüftabelle geprüft. Eine Prüfung wird nur für die Dialogbilder vorgenommen, wie Sie es beispielsweise für die Transaktion SE16 gesehen haben. Der Benutzer kann jeden beliebigen Wert in das Eingabefeld eingeben, und dieser wird an das Programm übergeben, sobald die Drucktaste Ausführen gedrückt wird.
Sie können eigene Prüfungen für Selektionsbilder anlegen. Sie werden detailliert am Tag 21 im Abschnitt »Selektionsbilder« behandelt.
Zusammenfassung
■ Programme werden auf dem Applikationsserver in einem Programmpuffer gehalten. Es gibt nur eine Programmkopie, so daß ein Rollbereich für jede Programmausführung notwendig ist. Der Rollbereich enthält die Werte der Variablen und den aktuellen Programmzeiger.
■ Ein ABAP/4-Programm besteht aus Anweisungen, die mit einem Schlüsselwort beginnen und mit einem Punkt enden. Anweisungen können in jeder Spalte beginnen und sich über mehrere Zeilen erstrecken.
■ Ein Datenobjekt ist ein Speicherplatz, der Daten zur Laufzeit eines Programms enthält. Literale und Konstanten sind nicht veränderbare Datenobjekte. Die veränderbaren Datenobjekte sind Variablen, Feldleisten und interne Tabellen. Datenobjekte werden im Rollbereich eines Programms gehalten und gelöscht, wenn das Programm endet.
■ Datenobjekte haben drei Ebenen der Auswahl: lokal, global und extern. Die Auswahl der

Datenobjekte steuert, von wo aus auf die Datenobjekte zugegriffen wird. ■ Literale sind Daten, die im Programm hart programmiert sind. Konstanten können Literale
ersetzen; hierdurch wird ein Programm einfacher zu warten. ■ Bei Datentypen werden zwei Gruppen unterschieden: Zeichen und numerische Typen. Die
Datentypzeichen sind c, n, d, t und x; die numerischen Datentypen sind i, p und f.■ Variablen werden mit den data- und parameters-Anweisungen definiert. Der Unterschied
ist, daß für Parameter bei der Programmausführung ein Eingabefeld auf dem Selektionsbild angezeigt wird. Der Benutzer kann dann Werte eingeben bzw. die Vorgabewerte ändern.
■ Werte, die in ein Parameter-Eingabefeld eingegeben werden, werden standardmäßig in Großbuchstaben umgesetzt. Um das zu verhindern, benutzen Sie bitte den Zusatz lowercase.
■ Sie können die Parameter Eingabefelder über den Menüpfad Springen -> Textelemente ändern.
Erlaubt Nicht erlaubt
Benutzen Sie den Unterstrich, um Ihre Variablen einfacher lesbar zu machen.
Benutzen Sie keinen Bindestrich in Variablennamen. Ein Bindestrich grenzt die Komponenten einer Feldleiste ab.
Fragen & Antworten
Frage:Warum muß man zwischen Anführungszeichen in Großbuchstaben programmieren? Woher soll ich wissen, ob ich in Kleinbuchstaben programmieren muß?
Antwort:In den meisten Fällen konvertiert das Programm automatisch die Daten in Großbuchstaben, bevor die Daten in die Datenbank geschrieben werden. Die Konvertierung wird durch die Domäne durchgeführt. Sie können feststellen, welche Daten konvertiert werden, wenn Sie sich die Domäne anschauen. Wenn der Datentyp des Feldes CHAR ist, und wenn das Ankreuzfeld Lower Case angekreuzt ist, dann können die Felder Klein- und Großbuchstaben enthalten.
Frage:Kann ich Parameter definieren, die mehrere Werte akzeptieren?
Antwort:Ja, die Anweisung select-options ermöglicht es dem Benutzer, verschiedenste Werte und komplexe Kriterien einzugeben.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, die Ihnen helfen sollen, Ihr Verständnis für die besprochene Thematik zu vertiefen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie

das Gelernte anwenden. Antworten auf die Prüfungsaufgaben und die Übungen können Sie im Anhang B (»Antworten zu Kontrollfragen und Übungen«) finden.
Kontrollfragen
Welche Literale sind falsch? (Es kann mehr als einen Fehler geben, und einige haben keine Fehler.) Schreiben Sie die richtigen Definitionen auf.
1. Zeichenkettenliteral: "Don't bite."
2. Gleitkommazahl: '+2.2F03.3'
3. Numerisches Literal: -99
4. Hexadezimales Literal: x'0000f'
5. Numerisches Literal: 9.9-
6. Gleitkommazahl: '1.1E308'
7. Hexadezimales Literal: 'HA'
8. Zeichenkettenliteral: ''''
9. Zeichenkettenliteral: '''"'''
Was ist an diesen Datendefinitionen falsch? (Es kann mehrere Fehler geben, und einige Beispiele haben keine Fehler.) Schreiben Sie die richtigen Definitionen auf.
1. data first-name(5) type c.
2. data f1 type character.
3. data 1a(5) type i.
4. data per-cent type p value 55.5.
5. data f1(2) type p decimals 2 value '12.3'.
Übung 1
Schreiben Sie ein Programm, das Parameter für die Abbildung 7.4 benutzt.

Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

RückblickIn der vergangenen Woche haben Sie die folgenden Bereiche und Aufgaben bearbeitet :
■ die R/3-Umgebung einschließlich der Basis, der Anmeldemandanten, der ABAP/4-Entwicklungsumgebung und des Data Dictionary kennengelernt
■ einfache ABAP/4-Programme geschrieben und sich mit dem ABAP/4-Editor vertraut gemacht ■ transparente Tabellen, Datenelemente und Domänen angelegt ■ Fremdschlüssel angelegt, um den Anwender mit der (F4)-Hilfe zu unterstützen ■ Datenelemente dokumentiert, um (F1)-Hilfe anzubieten ■ Sekundärindizes und Puffer angelegt, um den Datenzugriff zu beschleunigen
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Auf einen Blick Tag 8 Datendefinition in ABAP/4®, Teil 2 271
Tag 9 Zuweisungen, Konvertierungen und Berechnungen 291
Tag 10 Allgemeine Kontrollanweisungen 327
Tag 11 Interne Tabellen 363
Tag 12 Interne Tabellen, Teil 1 403
Tag 13 Interne Tabellen, Teil 2 441
Tag 14 Die write-Anweisung 481
In Woche 2 legen Sie feste und variable Datenobjekte an, wobei Sie sowohl vordefinierte als auch benutzerdefinierte Datentypen verwenden. Sie lernen die Regeln der ABAP/4-Syntax und die Anweisungen zur Kontrolle des Programmflusses und zur Zuweisung sowie die Umsetzungsregeln kennen. Außerdem definieren Sie interne Tabellen, füllen Sie mit impliziten und expliziten Arbeitsbereichen, führen Gruppenwechsel aus und optimieren die select-Anweisungen, um direkt und effizient interne Tabellen zu füllen. Schließlich verwenden Sie die Formatoptionen der write-Anweisung, erleben den Effekt von Datentypen in der Ausgabe, erarbeiten conversion exits und entdecken ihre Präsenz in Domänen.
■ Am 8. Tag verwenden Sie die tables-Anweisung, um Feldleisten zu definieren, verstehen die types-Anweisung und verwenden sie, um Ihre eigenen Datentypen zu definieren.
■ Der 9. Tag lehrt Sie, allgemeine Systemvariablen zu benutzen und sie anzuzeigen oder zu finden, Datenumsetzungen vorherzusagen und mit zugehörigen Anweisungen auszuführen sowie mathematische Ausdrücke zu codieren.
■ Am 10. Tag lernen Sie, die allgemeinen Kontrollanweisungen if, case, do und while zu codieren, Programmsequenzen mit exit, continue und check zu kontrollieren und einfache Positions- und Längenspezifikationen in der write-Anweisung zu codieren.
■ Der 11. Tag macht Sie mit der Definition einer internen Tabelle mit oder ohne Überschrift, vertraut. Sie füllen eine interne Tabelle mit append durch eine Überschrift oder einen expliziten Arbeitsbereich, sortieren eine interne Tabelle und verwenden den as text-Zusatz.
■ Am 12. Tag lernen Sie, den Tabellenrumpfoperator zu erkennen und zu verwenden, um nach

der Existenz von Daten in internen Tabellen zu suchen und die Inhalte zweier interner Tabellen auf Gleichheit hin zu überprüfen.
■ Der 13. Tag zeigt Ihnen, wie man eine interne Tabelle aus einer Datenbanktabelle füllt, indem man die erfolgreichsten Konstrukte verwendet; Sie führen Gruppenwechsel in internen Tabellen mit at und on change of aus.
■ Schließlich verstehen Sie nach dem 14. Tag den Effekt von Datentypen in der Ausgabe, verwenden die Formatoptionen der write-Anweisung, benutzen conversion exits und entdecken ihre Präsenz in Domänen.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 8
Datendefinition in ABAP/4®, Teil 2
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes können:
■ die tables-Anweisung benutzen, um Feldleisten zu definieren und den Unterschied zwischen Feldleisten verstehen, die mit der data-Anweisung definiert wurden, und solchen, die mit der tables-Anweisung definiert wurden
■ die Anweisung types verstehen und sie benutzen, um Ihre eigenen Datentypen zu definieren
Definition der Konstanten
Eine Konstante ist mit einer Variablen beinahe identisch. Der Unterschied ist, daß sich ihr Wert nicht ändern kann. Um eine Konstante zu definieren, benutzen Sie die Anweisung constants.
Benutzen Sie eine Konstante dann, wenn Sie das gleiche Literal mehrere Male in einem Programm aufnehmen müssen. Sie können eine Konstante mit dem gleichen Wert wie das Literal definieren und die Konstante im Rumpf des Programms an Stelle des Literals benutzen. Wenn Sie den Wert des Literals später ändern müssen, ändern Sie einfach den Wert der Konstanten, was zur Folge hat, daß ihr Wert aktualisiert wird, wo immer er im Programm benutzt wird.
ABAP/4 hat eine vordefinierte Konstante: SPACE. Es ist eine Konstante, die den Wert von einem Leerzeichen hat. Sie können sie anstelle des Literals '' benutzen.
Syntax für die Anweisung constants
Der folgende Code demonstriert die Syntax zur Definition einer Konstanten. Er ist der Anweisung data ähnlich; der Zusatz value wird allerdings gebraucht. Ansonsten folgen die Konstanten den gleichen Regeln wie Variablen, welche mit Hilfe der data- Anweisung definiert wurden. In Listing 8.1 finden Sie Beispiele von Konstanten-Definitionen.

constants c1[(l)] [type t] [decimals d] value 'xxx'.
oder
constants c1 like cv value 'xxx'.
wobei gilt:
■ c1 ist der Name der Konstanten. ■ cv ist der Name einer vorher definierten Konstanten oder Variablen oder der Name eines
Felds, das im Data Dictionary zu einer Tabelle oder Struktur gehört. ■ (l) ist die interne Längenangabe. ■ t ist der Datentyp. ■ d ist die Anzahl der Dezimalstellen (wird nur mit Typ p benutzt). ■ 'xxx' ist ein Literal, das den Wert der Konstanten liefert.
Listing 8.1: Definitionen von Konstanten
1 constants c1(2) type c value 'AA'.2 constants c2 like c1 value 'BB'.3 constants error_threshold type i value 5.4 constants amalgamation_date like sy-datum value '19970305'.
Konstanten können in einem Typenpool definiert werden. In diesem Fall können sie von mehreren Programmen genutzt werden. Für weitere Informationen lesen Sie den Abschnitt »Pooltypen« am Ende dieses Kapitels.
Definition von Feldleisten
Eine Feldleiste ist eine Art Variable und einer Struktur im DDIC gleichwertig, aber innerhalb eines ABAP/4-Programms definiert. Eine Feldleiste ist wie eine Struktur eine Reihe gruppierter Felder unter einem gebräuchlichen Namen. Der Hauptunterschied liegt in der Definition. Der Terminus Struktur in R/3 bezieht sich nur auf ein Data Dictionary-Objekt, welches eine Sammlung von Feldern enthält. Der Terminus Feldleiste bezieht sich auf eine Sammlung von Feldern, die in einem ABAP/4-Programm definiert werden.
Zwei Anweisungen werden üblicherweise benutzt, um Feldleisten in einem ABAP/4- Programm zu definieren:

■ data■ tables
Verwendung der data-Anweisung zur Definition einer Feldleiste
Eine Feldleiste, die mit der data-Anweisung definiert ist, ist ein modifizierbares Datenobjekt. Es kann eine globale oder lokale Sichtbarkeit haben.
Syntax zur Definition einer Feldleiste unter Verwendung der data-Anweisung
Im folgenden wird die Syntax gezeigt, mit der eine Feldleiste mit Hilfe der data-Anweisungdefiniert wird.
data: begin of fs1,f1[(l)] [type t] [decimals d] [value 'xxx'],f2[(l)] [type t] [decimals d] [value 'xxx'],...end of fs1.
oder
data begin of fs1.data f1[(l)] [type t] [decimals d] [value 'xxx'].data f2[(l)] [type t] [decimals d] [value 'xxx']....[include structure st1.]data end of fs1.
oder
data fs1 like fs2.
wobei gilt:
■ fs1 ist der Name der Feldleiste. ■ f1 und f2 sind die Felder (auch Komponenten genannt) der Feldleiste. ■ fs2 ist der Name einer vorher definierten Feldleiste oder der Name einer Tabelle oder
Struktur im Data Dictionary. ■ (l) ist die interne Längenangabe. ■ t ist der Datentyp. ■ d ist die Anzahl der Dezimalstellen (wird nur mit Typ p benutzt). ■ 'xxx' ist ein Literal, das den Wert der Konstanten liefert.

■ st1 ist der Name einer Struktur oder Tabelle im Data Dictionary.
Feldleisten folgen den gleichen Regeln wie Variablen, die definitionsgemäß die data- Anweisung benutzen. Um sich auf eine Einzelkomponente zu beziehen, muß ihr Name mit dem der Feldleiste beginnen, gefolgt von einem Bindestrich (-). Um zum Beispiel die Komponente number der Feldleiste cust_info zu schreiben, würden Sie die Anweisung write cust_info-numberbenutzen.
Die Anweisung include ist nicht Teil der Anweisung data; sie ist eine gesonderte Anweisung. Sie kann deswegen nicht mit der data-Anweisung verkettet werden. Die Anweisung davor muß mit einem Punkt verbunden werden.
Beispiele von Programmen, die Feldleisten definieren und benutzen, werden in den Listings 8.2 bis 8.6 gezeigt.
Listing 8.2: Ein einfaches Beispiel einer Feldleiste, die definitionsgemäß die Anwendung databenutzt
1 report ztx0802.2 data: begin of totals_1,3 region(7) value 'unknown',4 debits(15) type p,5 count type i,6 end of totals_1,7 totals_2 like totals_1.89 totals_1-debits = 100.10 totals_1-count = 10.11 totals_2-debits = 200.1213 write: / totals_1-region, totals_1-debits, totals_1-count,14 / totals_2-region, totals_2-debits, totals_2-count.
In Zeile 2 fängt die Definition der Feldleiste totals_1 an. Sie enthält drei Felder, von denen das erste mit dem Wert 'unknown' initialisiert ist. In Zeile 7 wird die Feldleiste totals_2 genau wie totals_1 definiert. Der Wert von totals_1-region wird nicht für totals_2-regionübernommen. In den Zeilen 9 bis 11 werden die Werte den Komponenten der Feldleisten zugewiesen, und in den Zeilen 13 und 14 werden die Werte von allen Komponenten ausgeschrieben.
Listing 8.3: Eine Feldleiste kann eine andere beinhalten.
1 report ztx0803.2 data: begin of names,3 name1 like ztxkna1-name1,4 name2 like ztxkna1-name2,

5 end of names.6 data: begin of cust_info,7 number(10) type n,8 nm like names, "like a field string9 end of cust_info.1011 cust_info-number = 15.12 cust_info-nm-name1 = 'Jack'.13 cust_info-nm-name2 = 'Gordon'.1415 write: / cust_info-number,16 cust_info-nm-name1,17 cust_info-nm-name2.
In Zeile 2 fängt die Definition der Feldleiste names an. Sie enthält zwei Felder, die wie Felder von Tabelle ztxkna1 im Data Dictionary definiert sind. Sie enthalten keine Anfangswerte. In Zeile 8 wird die Komponente cust_info-name wie die Feldleiste names definiert. Bei der Verwendung in den Zeilen 12 und 13 wird nm dem Komponentennamen hinzugefügt.
Listing 8.4: Eine Feldleiste kann genauso definiert werden wie eine DDIC-Tabelle oder -Struktur.
1 report ztx0804.2 data: my_lfa1 like ztxlfa1, "like a table in the DDIC3 my_addr like ztxaddr. "like a structure in the DDIC45 my_lfa1-name1 = 'Andrea Miller'.6 my_lfa1-telf1 = '1-243-2746'.7 my_addr-land1 = 'CA'.89 write: / my_lfa1-name1,10 my_lfa1-name2,11 my_addr-land1.
In Zeile 2 ist my_lfa1 genauso definiert wie die DDIC-Tabelle ztxlfa1, und my_addr wird wie die DDIC-Struktur ztxaddr definiert.
Um sich die DDIC-Definition der Tabelle ztxlfa1 anzuschauen, doppelklicken Sie auf den Namen in Ihrem Quellcode.

Listing 8.5: DDIC-Tabellen und -Strukturen können auch in eine Feldleiste eingebunden werden.
1 report ztx0805.2 data begin of fs1.3 include structure ztxlfa1.4 data: extra_field(3) type c,5 end of fs1.67 fs1-lifnr = 12.8 fs1-extra_field = 'xyz'.910 write: / fs1-lifnr,11 fs1-extra_field.
In Zeile 2 fängt die Definition der Feldleiste fs1 an. Die Anweisung endet mit einem Punkt, weil include structure nicht Teil der Anweisung data ist und deshalb gesondert aufgepaßt werden muß. In Zeile 3 ist die Struktur von Tabelle ztxlfa1 in die Feldleiste eingebunden. In Zeile 4 ist ein anderes Feld in der Feldleiste nach den Feldern von Tabelle ztxlfa1 eingeschlossen. Mehrere Felder könnten eingebunden werden, ebenso mehrere Strukturen oder jede Kombination davon.
Listing 8.6: Wenn Sie like statt include benutzen, erhalten Sie ein anderes Ergebnis. Den Namen der eingebundenen Felder ist der Name einer Zwischenkomponente vorangestellt.
1 report ztx0806.2 data: begin of fs1,3 mylfa1 like ztxlfa1,4 extra_field(3) type c,5 end of fs1.67 fs1-mylfa1-lifnr = 12.8 fs1-extra_field = 'xyz'.910 write: / fs1-mylfa1-lifnr,11 fs1-extra_field.
In Zeile 2 fängt die Definition der Feldleiste lfa1_with_extra_field an. Die Anweisung endet mit einem Punkt, weil include structure nicht Teil der Anweisung data ist sondern hiervon unabhängig. In Zeile 3 ist die Struktur von Tabelle ztxlfa1 in die Feldleiste eingeschlossen. In Zeile 4 ist ein anderes Feld in der Feldleiste nach den Feldern von Tabelle ztxlfa1 eingeschlossen. Mehrere Felder könnten eingebunden werden, ebenso mehrere Strukturen oder jede Kombination davon.
Verwendung einer Feldleiste als Variable vom Typ char

Sie können nicht nur die Einzelkomponenten einer Feldleiste, sondern auch alle Komponenten auf einmal adressieren, als seien sie einzelne Variablen vom Typ char.
Listing 8.7 veranschaulicht dieses Konzept.
Listing 8.7: Ein Beispiel zur Verwendung einer Feldleiste sowohl als multiple Variable als auch als einzelne Variable vom Typ char.
1 report ztx0807.2 data: begin of fs1,3 c1 value 'A',4 c2 value 'B',5 c3 value 'C',6 end of fs1.78 write: / fs1-c1, fs1-c2, fs1-c3,9 / fs1.1011 fs1 = 'XYZ'.1213 write: / fs1-c1, fs1-c2, fs1-c3,14 / fs1.
Der Code in Listing 8.7 sollte diese Ausgabe erzeugen:
A B CABCX Y ZXYZ
Die Zeilen 2 bis 6 definieren die Feldleiste fs1. Sie hat drei Komponenten, jede mit einem Standardwert. In Zeile 8 ist jede Komponente individuell ausgeschrieben. In Zeile 9 ist die Feldleiste ausgeschrieben, als sei sie eine einzelne Variable. Folglich zeigt die Ausgabe die Inhalte von fs1 so, als sei es eine einzelne, als char 3 definierte Variable. In Zeile 11 wird der Wert 'XYZ' der Feldleiste zugewiesen, und sie wird wieder als char-Variable behandelt. Die resultierende Ausgabe zeigt, daß die Einzelglieder die Änderung »reflektieren«, weil sie auf die gleiche Speicherung zugreifen.
Eine Feldleiste kann einer anderen zugewiesen werden, wenn beide die gleiche Struktur haben, wie es in Listing 8.8 gezeigt wird.
Listing 8.8: Ein Beispiel einer Zuweisung zweier Feldleisten.
1 report ztx0808.2 data: begin of fs1,

3 c1 value 'A',4 c2 value 'B',5 c3 value 'C',6 end of fs1,7 fs2 like fs1.89 fs2 = fs1.10 write: / fs2-c1, fs2-c2, fs2-c3.
Der Code in Listing 8.8 sollte diese Ausgabe erzeugen:
A B C
Die Zeilen 2 bis 6 definieren die Feldleiste fs1. Zeile 7 definiert die Feldleiste fs2 genau wie fs1.In Zeile 9 erhält fs2 die gleiche Zuweisung wie fs1, genauso, als wäre sie eine einzelne Variable vom Typ char. In Zeile 10 sind die Komponenten von fs2 ausgeschrieben.
Eine Feldleiste, die numerische Daten enthält, braucht spezielle Überlegungen während der Zuweisung. Diese werden am neunten Tag im Abschnitt »Zuweisungen« behandelt.
Verwendung der tables-Anweisung zur Definition einer Feldleiste
Eine Feldleiste, die definitionsgemäß die Anweisung tables verwendet, ist ein modifizierbares Datenobjekt. Solche Feldleisten folgen den gleichen Regeln wie die Feldleisten, die definitionsgemäß die Anweisung data benutzen. Ein Beispiel für ein Programm, welches eine tables-Feldleistebenutzt, finden Sie in Listing 8.9.
Syntax zur Definition einer Feldleiste, welche die Anweisung tables benutzt.
tables fs1.
wobei gilt:
■ fs1 ist der Name der Feldleiste. Eine Tabelle oder Struktur gleichen Namens muß im Data Dictionary existieren.
Listing 8.9: Einfaches Beispiel einer Feldleiste, die definitionsgemäß die Anweisung tables verwendet.

1 report ztx0809.2 tables ztxlfa1.34 ztxlfa1-name1 = 'Bugsy'.5 ztxlfa1-land1 = 'US'.67 write: / ztxlfa1-name1, ztxlfa1-land1.
Zeile 2 definiert die Feldleiste ztxlfa1. Ihre Definition ist genau wie die der Data Dictionary-Tabelle gleichen Namens. In den Zeilen 4 und 5 werden zwei ihrer Komponenten Werte zugeordnet, die in Zeile 7 ausgeschrieben werden.
Definition einer Feldleiste unter Verwendung von tables in Interaktion mit select
Die Anweisung tables bewirkt mehr, als einfach nur eine Feldleiste zu definieren. Sie führt zwei Dinge aus:
■ Sie definiert eine Feldleiste. ■ Sie ermöglicht dem Programm den Zugriff auf eine Datenbanktabelle gleichen Namens, wenn
eine solche existiert.
Ihr erstes Beispiel für eine select-Anweisung steht in Listing 8.10. Sie können es jetzt aus einer neuen Perspektive analysieren.
Listing 8.10: Ihr zweites Programm in überarbeiteter Fassung
1 report ztx0810.2 tables ztxlfa1.3 select * from ztxlfa1 into z lfa1 order by lifnr.4 write / z lfa1-lifnr.5 endselect.
Zeile 2 definiert die Feldleiste ztxlfa1. Ihre Definition lautet genauso wie die der Data Dictionary-Tabelle gleichen Namens. Es gibt auch eine Datenbanktabelle mit dem gleichen Namen, so daß das Programm Zugriff auf diese Tabelle hat, was bedeutet, daß sie jetzt in einer select-Anweisungbenutzt werden kann. Jedes Mal, wenn Zeile 3 ausgeführt wird, wird ein Datensatz von der Datenbanktabelle ztxlfa1 in die Feldleiste ztxlfa1 eingelesen. Für jeden Datensatz wird der Wert der Komponente ztxlfa1- lifnr ausgeschrieben (Zeile 4).
Sichtbarkeit einer Feldleiste, die definitionsgemäß tables verwendet

Eine Zeichenkette, die definitionsgemäß tables benutzt, hat immer sowohl globale als auch externe Sichtbarkeit, unabhängig davon, wo sie im Programm definiert ist. Dies bedeutet: Wenn Sie eine tables-Anweisung in einem Unterprogramm plazieren, ist die Definition global, und Sie können in diesem Programm an beliebiger Stelle keine andere Definition für die gleiche Feldleiste haben.
Die Feldleiste ist auch extern sichtbar. Das heißt: Wenn in einem aufrufenden und aufgerufenen Programm die gleiche tables-Anweisung erscheint, werden diese Feldleisten den gleichen Speicher gemeinsam nutzen. Dieses Konzept ist in Abbildung 8.1 veranschaulicht. Wenn das aufgerufene Programm ausgeführt wird, »sieht« es den Wert in ztxlfa1 vom ersten Programm. Wenn es ztxlfa1 ändert, »sieht« das aufrufende Programm die Änderungen in dem Moment, in dem es die Kontrolle wiedererlangt.
Abbildung 8.1: Identische tables-Definitionen in einem aufrufenden und aufgerufenen Programm bewirken die gemeinsame Nutzung des Speichers für diese Feldleisten.
Definition von Typen
Sie können Ihre eigenen Datentypen definieren, indem Sie die Anweisung types auf der Basis von bestehenden Datentypen benutzen.
Syntax für die types-Anweisung
Es folgt die Syntax zur Typendefinition unter Verwendung der Anweisung types.
types t1[(l)] [Type t] [decimals d].
oder
types t1 like v1.

wobei gilt:
■ t1 ist der Typenname. ■ v1 ist der Name einer Variablen, die vorher im Programm definiert wird oder der Name eines
Felds, das zu einer Tabelle oder Struktur im Data Dictionary gehört. ■ (l) ist die interne Längenangabe. ■ t ist der Datentyp. ■ d ist die Anzahl von Dezimalstellen (nur benutzen mit Typ p).
Listings 8.11 und 8.12 zeigen Beispiele von Programmen, die ihre eigenen Datentypen definieren und benutzen.
Listing 8.11: Einfaches Beispiel eines benutzerdefinierten Datentyps char2
1 report ztx0811.2 types char2(2) type c.3 data: v1 type char2 value 'AB',4 v2 type char2 value 'CD'.56 write: v1, v2.
Der Code in Listing 8.11 erzeugt diese Ausgabe:
AB CD
Zeile 2 definiert einen Datentyp, der char2 genannt wird. Es ist ein char-Feld mit zwei Byte. In den Zeilen 3 und 4 werden die Variablen v1 und v2 als char-Felder mit zwei Byte definiert, wobei der Datentyp char2 benutzt wird. Diesen werden Standardwerte zugeteilt, und in Zeile 6 werden sie ausgeschrieben.
Listing 8.12: Typenbenutzung kann Ihren Code klarer und leichter lesbar machen.
1 report ztx0812.2 types: dollars(16) type p decimals 2,3 lira(16) type p decimals 0. "italian lira have no decimals45 data: begin of american_sums,6 petty_cash type dollars,7 pay_outs type dollars,8 lump_sums type dollars,9 end of american_sums,10 begin of italian_sums,11 petty_cash type lira,12 pay_outs type lira,13 lump_sums type lira,

14 end of italian_sums.1516 american_sums-pay_outs = '9500.03'. "need quotes when literal contains a decimal17 italian_sums-lump_sums = 5141.1819 write: / american_sums-pay_outs,20 / italian_sums-lump_sums.
Der Code in Listing 8.12 erzeugt diese Ausgabe:
9,500.005,141
Zeile 2 definiert einen Datentyp namens dollars als 16-Byte-Dezimalzahlfeld mit zwei Dezimalstellen. Zeile 3 definiert einen ähnlichen Datentyp mit 0 Dezimalstellen namens lira. In den Zeilen 5 bis 14 werden zwei Feldleisten definiert, welche die neuen Datentypen benutzen. Je einer Komponente wird in den Zeilen 16 und 17 ein Wert zugewiesen, und in den Zeilen 19 und 20 werden sie ausgeschrieben.
Stellen Sie sich einen benutzerdefinierten Typ als eine Variable vor, aber als eine, die Sie nicht benutzen können, um Daten zu speichern. Sie kann nur eingesetzt werden, um andere Variablen anzulegen. Die gleichen Regeln beziehen sich auf Typen wie auf Variablen und Feldleisten. Typennamen sind, genau wie Variablennamen, 1 bis 30 Zeichen lang, aber anders als bei Variablen können ihre Namen nicht die Zeichen - < > enthalten.
Strukturierte Typen
Ein benutzerdefinierter Typ kann auf der Definition einer Feldleiste basieren. Dies wird als »strukturierter Typ« bezeichnet. Listing 8.13 zeigt, wie Sie ein Programm verkürzen können, indem Sie einen strukturierten Typ einsetzen.
Listing 8.13: Die Verwendung von strukturierten Typen kann die Redundanz verringern und macht die Unterstützung einfacher.
1 report ztx0813.2 types: begin of address,3 street(25),4 city(20),5 region(7),6 country(15),7 postal_code(9),8 end of address.9

10 data: customer_addr type address,11 vendor_addr type address,12 employee_addr type address,13 shipto_addr type address.1415 customer_addr-street = '101 Memory Lane'.16 employee_addr-country = 'Transylvania'.1718 write: / customer_addr-street,19 employee_addr-country.
Die Zeilen 2 bis 8 definieren einen Datentyp namens address, der fünf Felder enthält. In den Zeilen 10 bis 13 werden vier Feldleisten definiert, welche den neuen Typ verwenden. Ohne den neuen Typ hätten diese Definitionen zusätzlich 24 Code-Zeilen benötigt. Die Unterstützung wird auch leichter gemacht: Wenn eine Definitionsänderung der Adreßfeldleisten notwendig wird, muß nur die Definition des Typs geändert werden.
Typgruppen
Die Anweisung types kann in einer Typgruppe gespeichert werden. Die Typgruppe (auch Typenpool genannt) ist ein Data Dictionary-Objekt, welches nur existiert, um eine oder mehrere types- oder constants-Anweisungen zu enthalten. Wenn Sie die Anweisung type-pools in Ihrem Programm benutzen, greifen Sie auf Typen oder Konstanten einer Typgruppe zu und benutzen diese in Ihrem Programm. Mehrere Programme können eine Typgruppe gemeinsam nutzen, was Ihnen die Möglichkeit gibt, zentrale Definitionen anzulegen. Abbildung 8.2 veranschaulicht dieses Konzept. Listing 8.14 enthält ein Beispiel einer Typgruppe, und Listing 8.15 stellt ein Beispiel eines Programms dar, welches daraus types und constants verwendet.
Abbildung 8.2: Eine Typgruppe ist ein Behälter für types- und constants-Anweisungen. Sie kann von verschiedenen Programmen benutzt werden.
Listing 8.14: Eine Beispielanweisung type-pool mit Typen und Konstanten

1 type-pool ztx1.2 types: ztx1_dollars(16) type p decimals 2,3 ztx1_lira(16) type p decimals 0.4 constants: ztx1_warning_threshold type i value 5000,5 ztx1_amalgamation_date like sy-datum value '19970305'.
Zeile 1 zeigt den Anfang der Typgruppe an und gibt ihm einen Namen. Die Zeilen 2 bis 5 definieren types und constants, die in jedem Programm benutzt werden können.
Listing 8.15: Die Verwendung von Typgruppen reduziert die Codeverdoppelung zur einfacheren Unterstützung.
1 report ztx0815.2 type-pools ztx1.3 data: begin of american_sums,4 petty_cash type ztx1_dollars,5 pay_outs type ztx1_dollars,6 lump_sums type ztx1_dollars,7 end of american_sums.89 american_sums-pay_outs = '9500.03'.1011 if american_sums-pay_outs > ztx1_warning_threshold.12 write: / 'Warning', american_sums-pay_outs,13 'exceeds threshold', ztx1_warning_threshold.14 endif.
Zeile 2 bringt die Definitionen von Typgruppe ztx1 in das Programm. Die Zeilen 3 bis 7 definieren eine Feldleiste unter Verwendung des Typs ztx1_dollars aus der Typgruppe. Zeile 9 weist pay_outs einen Wert zu, und diese werden mit der Konstanten ztx1_warning_thresholdaus der Typgruppe von Zeile 11 verglichen.
Wenn die Typgruppe schon eingebracht wurde, werden die nachfolgenden Versuche, sie aufzunehmen, ignoriert, und sie verursachen keinen Fehler.
Typgruppennamen können 1 bis 5 Zeichen lang sein und müssen mit einem y oder z anfangen. Typen und Konstanten, die in einem Programm eingeschlossen sind, das die Anweisung type-poolsbenutzt, haben immer eine globale Sichtbarkeit.
Eine Typgruppe anlegen
Um eine Typgruppe im Data Dictionary anzulegen, benutzen Sie die folgende Prozedur.

Starten Sie jetzt das ScreenCam »How to Create a Type Group«.
1. Beginnen Sie in der Dictionary: Einstiegsmaske (Menüpfad Werkzeuge->ABAP/4-Workbench, Entwicklung->Dictionary).
2. Geben Sie den Namen Ihrer Typgruppe in das Objektnamensfeld ein.
3. Markieren Sie die Option Typgruppen.
4. Drücken Sie auf Anlegen. Sie sehen die Maske Typgruppe xxxx: Text Anlegen.
5. Geben Sie eine Beschreibung Ihrer Typgruppe in das entsprechende Feld ein.
6. Sichern Sie. Die Maske Objektkatalogeintrag ändern wird angezeigt.
7. Wählen Sie Lokales Objekt. Auf der Maske ABAP/4-Editor sehen Sie in der Anfangszeile die Anweisung type-pool t., wobei t der Name Ihrer Typgruppe ist. Wenn dieser nicht erscheint, sollten Sie ihn jetzt eingeben.
8. Tippen Sie in die nachfolgenden Zeilen constants- und types-Anweisungen. Alle Namen müssen mit t_ anfangen.
9. Sichern Sie wieder. Am unteren Rand des Fensters sehen Sie die Nachricht Typgruppe wurde gesichert.
10. Mit der Taste Zurück kommen Sie wieder an den Anfang.
Um eine Typgruppe zu löschen, führen Sie die Schritte 1 bis 3 aus und drücken dann auf Löschen.
Zusammenfassung
■ Feldleisten sind wie Strukturen, die innerhalb Ihres Programms definiert sind. Sie können sie definieren, wobei Sie entweder data oder tables benutzen. Feldleisten, die definitionsgemäß tables verwenden, haben sowohl globale als auch externe Sichtbarkeit.
■ Sie können Ihre eigenen Datentypen definieren, sogar strukturierte Typen, indem Sie die Anweisung types benutzen. Benutzerdefinierte Typen reduzieren die Redundanz und machen eine Wartung leichter.
■ Sie können eine Typgruppe im Data Dictionary definieren, um Ihre benutzerdefinierten Typen und Konstanten wiederverwendbar zu machen.
Erlaubt Nicht erlaubt

Benutzen Sie einen Unterstrich, um Ihre Variablennamen lesbarer zu machen.
Benutzen Sie niemals einen Bindestrich in einem Variablennamen; ein Bindestrich begrenzt die Komponenten einer Feldleiste.
Fragen & Antworten
Frage:Frage: Warum muß ich Feldleisten anlegen? Warum kann ich nicht einfach simple Variablen benutzen?
Antwort:Antwort: Feldleisten helfen Ihnen, Ihre Variablen in Gruppen zu organisieren. Wenn Sie Hunderte von Variablen in einem Programm haben, werden die Beziehungen zwischen den Variablen klarer, wenn sie in Feldleisten organisiert sind. Die Verwendung von Feldleisten, um Felder zu gruppieren, ermöglicht Ihnen auch Operationen mit einer Gruppe von Variablen, als seien diese eine einzelne Variable. Wenn Sie also zum Beispiel 100 Variablen bewegen müssen, können Sie normalerweise eine einzige Anweisung codieren, um die Bewegung von einer Feldleiste zu einer anderen auszuführen, anstatt 100 Zuweisungsanweisungen für individuelle Variable zu codieren. Eine einzelne Feldleiste zu bewegen ist auch effizienter als 100 Bewegungsanweisungen, so daß Ihr Programm schneller läuft. Sie werden in den nächsten Kapiteln sehen, daß viele Anweisungen eine Feldleiste als einen Operanden benutzen können. Wenn Sie Feldleisten benutzen, können Sie diese ausnutzen und sich viel Zeit für Codierung und Debugging sparen.
Frage:Frage: Warum würde ich meinen eigenen strukturierten Typ statt einer DDIC- Struktur benutzen? Kann ich Feldleisten nicht mit beiden anlegen?
Antwort:Antwort: Doch, das können Sie. Die Funktionalität von DDIC-Strukturen überwiegt bei weitem diejenige, welche von strukturierten Typen zur Verfügung gestellt wird, weil sie Kennsätze, F1 und F4-Hilfe zur Verfügung stellen können. Allerdings kann types benutzt werden, um verschachtelte strukturierte Typen zu definieren, die interne Tabellen enthalten. DDIC-Strukturen können dies nicht. Dies wird am Tag 12 im Abschnitt der internen Tabellen vorgeführt werden.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten zu zeigen, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen sollen Ihnen helfen, Ihr Verständnis für die behandelten Themen zu erhärten, und im Übungsabschnitt können Sie Erfahrungen sammeln, indem Sie anwenden, was Sie gelernt haben. Alle Antworten finden Sie in Anhang B.
Kontrollfragen

1. Wie heißt die eine vordefinierte Konstante, die in einem ABAP/4-Programm benutzt werden kann. Was ist ihr Äquivalent unter Zuhilfenahme eines Literals?
2. Welche Arten von Typenanweisung können benutzt werden, und welcher Typ kann im Data Dictionary definiert werden?
Übung 1
Welchen anderen Weg gibt es, die unten genannte Variable mit Hilfe der »type« Anweisung zu deklarieren?
data: begin of usd_amount,hotel type p decimals 2,rent_car type p decimals 2,plane type p decimals 2,food type p decimals 2,end of usd_amount,begin of amex_pt,hotel type p decimals 2,rent_car type p decimals 0,plane type p decimals 0,food type p decimals 0,end of amex_pt.
Übung 2
Welche Ausgabe bewirkt dieses Programm?
report ztx0816.
data: begin of fld_stg1,var1 value '1',var2 value '3',var3 value '5',var4 value '7',var5 value '9',var6 value '4',var7 value '8',var8 value '6',end of fld_stg1,fld_stg2 like fld_stg1.
fld_stg2 = fld_stg1.write: / fld_stg2-var1, fld_stg1-var2, fld_stg2-var6, fld_stg1-var3.write: / fld_stg1-var5, fld_stg2-var7, fld_stg2-var4, fld_stg1-var8.

Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 9
Zuweisungen, Konvertierungen und Berechnungen
Kapitelziele
Wenn Sie das Kapitel durchgearbeitet haben, können Sie
■ allgemeine Systemvariablen benutzen sowie beliebige Systemvariablen finden und anzeigen ■ die clear-Anweisung benutzen und ihre Wirkung auf Variablen und Feldleisten verstehen ■ Zuweisungen mittels move- und move corresponding-Anweisungen durchführen ■ Datenkonvertierungen bestimmen und mit Zuweisungsanweisungen durchführen ■ mathematische Ausdrücke codieren
Bevor Sie weiterlesen
Programme in diesem und in den folgenden Kapiteln benutzen Ein- und Ausgabeformate, die in den Benutzervorgabewerten gesetzt werden und für jeden Benutzer verschieden sein können. Bevor Sie weiterlesen, empfiehlt es sich, Ihre Benutzervorgabewerte so anzugleichen, daß sie mit denen dieses Buches übereinstimmen.
1. Bitte setzen Sie jetzt Ihre Benutzervorgabewerte wie folgt:
2. Wenn Sie gerade im R/3-System angemeldet sind, sichern Sie nun Ihre Arbeit.
3. Wählen Sie den Menüpfad System->Benutzervorgaben->Eigene Daten. Das Bild Pflege eigener Benutzervorgaben wird angezeigt.
4. In der Feldgruppe Festwerte wählen Sie JJJJ/MM/TT.
5. In der Feldgruppe Dezimaldarstellung wählen Sie den Punkt.

6. Drücken Sie die Schaltfläche Sichern auf der Anwendungsleiste. Am Fuß des Fensters erscheint die Meldung Werte für Benutzer xxxxx gesichert. Änderungen an Ihrem Benutzerprofil werden erst bei Neuanmeldung wirksam.
7. Melden Sie sich ab.
Ihre neuen Benutzereinstellungen werden beim nächsten Anmelden wirksam.
Arbeiten mit Systemvariablen
Es gibt 176 Systemvariablen, die in jedem ABAP/4-Programm verfügbar sind. Sie brauchen sie nicht zu definieren; sie sind automatisch definiert und immer verfügbar.
Um eine Liste der Systemvariablen anzuzeigen, zeigen sie die DDIC-Struktur syst an. Sie können sie über das Dictionary :Eingangsbild oder durch Doppelklick auf den Namen einer Systemvariablen in Ihrem Programm anzeigen. Abbildung 9.1 zeigt die erste Seite von syst.
Sie sehen in Abbildung 9.1, daß in der ersten Spalte die Feldnamen und rechts die Beschreibungen erscheinen. Um die vollständige Beschreibung anzusehen, blättern Sie nach rechts, indem Sie auf die Schaltfläche Spalte Rechts; Nächste... unten am Fenster klicken.
Um ein Feld mit mit Hilfe seines Namens zu finden, drücken Sie die Schaltfläche Suchen auf der Symbolleiste. Das Fenster Feld Suchen wird angezeigt und Sie nach dem Namen des Feldes fragen, das Sie suchen möchten.
Der Alias für syst ist sy (»sü« ausgesprochen). In Ihrem Programm können Sie beide Namen verwenden. Zum Beispiel können Sie entweder sy-datum oder syst-datum programmieren; dies ist gleichbedeutend. Die meisten Programmierer benutzen sy. Tabelle 9.1 enthält eine kurze Liste häufig benutzter Systemvariablen. Im weiteren Verlauf dieses Buches werden zusätzliche Variablen eingeführt.

Abbildung 9.1: Dies ist die Struktur syst. Sie enthält die Definitionen für alle Systemvariablen. Die Schaltfläche Spalte Rechts; Nächste ... blättert rechts eine Spalte nach der anderen auf und bewirkt, daß die gesamte Länge der Kurzbeschreibung sichtbar wird.
Tabelle 9.1: Häufig benutzte Systemvariablen
Name Beschreibung
sy-datum Aktuelles Datum
sy-uzeit Aktuelle Zeit
sy-uname Aktuelle Benutzer-ID
sy-subrc Letzter Rückgabewert
sy-mandt Anmeldemandant
sy-pagno Aktuelle Ausgabeseitennummer

sy-colno Aktuelle Ausgabespaltennummer
sy-linno Aktuelle Ausgabenlistennummer
sy-vline Senkrechte Linie
sy-uline Waagerechte Linie
sy-repid Aktueller Reportname
sy-cprog Hauptprogrammname
sy-tcode Aktueller Transaktionscode
sy-dbcnt Aktueller Wiederholungszähler innerhalb eines select. Enthält nach dem endselect die Zeilenzahl, die der where-Klausel entsprichtn.
Listing 9.1 zeigt ein Beispielprogramm, das Systemvariablen benutzt.
Listing 9.1: Grundlegende Systemvariablen benutzen
1 report ztx0901.2 tables ztxlfa1.3 parameters `land1 like ztxlfa1-land1 obligatory default 'US'.4 write: / 'Current date:', sy-datum,5 / 'Current time:', sy-uzeit,6 / 'Current user:', sy-uname,7 / 'Vendors having country code', `land1,8 /.9 select * from ztxlfa110 where land1 = `land111 order by lifnr.12 write: / sy-dbcnt, ztxlfa1-lifnr.13 endselect.14 write: / sy-dbcnt, 'records found'.15 if sy-subrc <> 0.16 write: / 'No vendors exist for country', `land1.17 endif.
Der Code im Listing 9.1 erzeugt diese Ausgabe:
Current date: 1998/02/22Current time: 14:38:24Current user: KENGREENWOODVendors having country code US
1 10402 10803 1090

4 20005 V16 V27 V38 V49 V510 V710 records found
■ Zeile 2 definiert eine Feldleiste xtxlfal analog der gleichnamigen Tabelle. ■ Zeile 3 definiert einen Eingabeparameter `land1.■ In den Zeilen 4 bis 6 werden die Langtexte current date, time und user id der Systemvariablen sy-datum, sy-uzeit und sy-uname ausgegeben.
■ Zeile 7 gibt den Länderschlüssel aus, der in dem Eingabeparameter `land1 auf dem Selektionsbild eingegeben wird.
■ Zeile 8 gibt eine Leerzeile aus. ■ Zeile 9 liest Sätze aus der Tabelle ztxlfal und überträgt sie einzeln in die Feldleiste ztxlfal.
■ Zeile 10 beschränkt die Selektion von Sätzen auf diejenigen mit dem gleichen Länderschlüssel, der auf dem Selektionsbild eingegeben wurde.
■ Zeile 11 veranlaßt, daß die Sätze aufsteigend nach lifnr (Lieferantennumer) sortiert werden. ■ Zeile 12 gibt den aktuellen Wiederholungszähler der Systemvariablen sy-dbcnt und die
Lieferantennummer aus jedem Datensatz aus. ■ Zeile 13 markiert das Ende der select/endselect-Schleife.■ Zeile 14 gibt die Gesamtanzahl der Wiederholungen der select-Schleife mit der
Systemvariablen sy-dbcnt aus. Diese stimmt mit der Anzahl der Sätze überein, die der where-Klausel entsprechen.
■ In Zeile 15 wird der Rückgabewert des select in der Systemvariablen sy-subrc geprüft. Falls er Null ist, wurden Sätze gefunden. Falls er nicht Null ist, wurden keine Sätze gefunden, und es wird eine Meldung in Zeile 16 ausgegeben.
Systemvariablen suchen
Angenommen, Sie wollen ein Programm schreiben, welches mit einem eingegebenen Länderschlüssel die Länderbeschreibung aus Tabelle ztxt005t in der aktuellen Anmeldesprache ausgibt. Sie erinnern sich, ztxt005t ist eine Texttabelle, welche die Länderschlüsselbeschreibungen in mehreren Sprachen enthält. Die Primärschlüssel sind mandt, spras (Sprache) und land1. Eine Beispiellösung zeigt Listing 9.2, es fehlt aber eine entscheidende Information in Zeile 5: der Wert der aktuellen Anmeldesprache.
In Listing 9.2 fehlt eine Variable an der Stelle des Fragezeichens. Wenn Sie mit ABAP/4 arbeiten, werden Sie oft mit der Herausforderung konfrontiert, Variablen zu finden, welche die von Ihnen benötigte Information enthalten.

Listing 9.2: Ein Beispielprogramm mit einer fehlenden Variablen
1 report ztx0902.2 tables ztxt005t.3 parameters `land1 like ztxlfa1-land1 obligatory default 'US'.4 select single * from ztxt005t5 where spras = ? "current logon language6 and land1 = `land1.7 if sy-subrc = 0.8 write: 'Description:', ztxt005t-landx.9 else.10 write: 'No description exists for', `land1.11 endif.
■ Zeile 2 definiert eine Feldleiste ztxt005t analog der gleichnamigen Tabelle. ■ Zeile 3 definiert einen Eingabeparameter land1..■ Zeile 4 bis 6 liest einen Satz aus Tabelle ztxt005t in die Feldleiste ztxt005t, mit der
aktuellen Anmeldesprache aus einer noch unbekannten Quelle und mit dem Länderschlüssel aus Parameter land1. Es gibt kein endselect, da dies eine single select-Anweisungist. Sie liefert nur einen einzigen Satz, es wird keine Schleife erzeugt.
■ Zeile 7 prüft den Rückgabewert des select und gibt die Beschreibung in Zeile 8 aus, falls ein Satz gefunden wurde. Falls kein Satz gefunden wurde, gibt Zeile 10 eine entsprechende Meldung aus.
Die aktuelle Anmeldesprache erhält man aus einer Systemvariablen. Unglücklicherweise braucht man für die Schaltfläche Suchen auf der Drucktastenleiste deren Namen. Sie kennen den Namen des Feldes nicht, also ist die Schaltfläche Suchen von geringem Nutzen. Statt dessen benutzen Sie das folgende Verfahren, um die Beschreibungen der Struktur syst zu durchsuchen.
Diese Prozedur ist sehr bequem, weil sie zur Suche von Beschreibungen jeglicher Struktur oder Tabelle verwendet werden kann.
Starten Sie nun das ScreenCam »How to Search the Descriptions of a Structure or Table«.
Durchsuchen der Beschreibungen einer Struktur oder Tabelle:
1. Beginnen Sie mit dem Fenster Dictionary: Tabelle/Struktur: Felder Anzeigen.
2. Die Maske Druckparameter wird angezeigt.

3. Wenn das Feld Ausgabegerät leer ist, positionieren Sie Ihren Mauszeiger dorthin, drücken den Abwärtspfeil und wählen irgendein Ausgabegerät. (Es spielt keine Rolle, welches Gerät Sie wählen; es wird nicht benutzt werden.)
4. Erzeugen Sie einen neuen Spool-Auftrag.
5. Wählen Sie den Menüpfad Werkzeuge->CCMS->Spool->Output management oder die Transaktion SP01. Geben Sie Ihre Spool-Auftragsnummer ein. Aus der Maske Spool: Aufträge kennzeichnen Sie den Auftrag und lassen ihn sich über den Menüpfad Spool-Auftrag->Anzeige ausgeben.
6. Tippen Sie %sc in das Feld OK-Code in der Symbolleiste ein.
7. Drücken Sie die Entertaste. Das Fenster Suchen wird angezeigt.
8. Im Feld Suchen Nach geben Sie eine Zeichenfolge ein, nach der gesucht werden soll. Wenn Sie nach der aktuellen Anmeldesprache suchen, könnten Sie Sprache eingeben. Wildcard-Zeichen sind nicht erlaubt.
9. Drücken Sie die Schaltfläche Suchen. Ein zweites Suchen-Fenster erscheint und zeigt die Zeilen, welche den Text enthalten, den Sie eingegeben haben. Treffer sind hell dargestellt.
10. Um einen Treffer auszuwählen, klicken Sie einmal auf ein hell dargestelltes Wort. Sie kehren zurück zum Fenster Druckvorschau für xxxx; die Liste blättert nach unten bis zur Zeile, die Sie ausgewählt haben, und der Mauszeiger wird auf diese Zeile positioniert.
11. Um erneut zu suchen, drücken Sie den Abwärts-Pfeil am Ende des OK-Code-Feldes in der Symbolleiste. Ein Kästchen klappt auf, das die zuletzt eingegebenen Kommandos enthält.
12. Blättern Sie, falls nötig, zu dem %sc Kommando und klicken Sie darauf. %sc erscheint im OK-Code.
13. Drücken Sie die Entertaste. Das Fenster Suchen wird erneut angezeigt.
14. Drücken Sie die Schaltfläche Suchen. Die Suche wird ab der aktuellen Zeile gestartet. Das zweite Suchen-Fenster wird wieder angezeigt und die Treffer dargestellt.
15. Klicken Sie einmal auf ein hell dargestelltes Wort, um es anzuzeigen.
Man kann die Druckvorschau auch als Textdatei für spätere Verwendungen auf seiner

Festplatte speichern. Das geschieht über den Menüpfad System->Liste->Sichern->Lokale Datei. Wählen Sie in der nächsten Maske unkonvertiert und geben dann den Dateinamen mit Pfadangabe ein. Zum Beispiel: c:\temp\syst.txt. Damit legen Sie die Datei auf Ihrer Festplatte ab. Dort können Sie sie nun mit einem beliebigen Editor bearbeiten.
Indem Sie dem vorangegangenen Verfahren folgten, haben Sie herausgefunden, daß die aktuelle Anmeldesprache in sy-langu gespeichert ist. Das vervollständigte Programm erscheint in Listing 9.3.
Listing 9.3: Listing 9.2 ergänzt durch die fehlende sy-Variable in Zeile 5.
1 report ztx0903.2 tables ztxt005t.3 parameters `land1 like ztxlfa1-land1 obligatory default 'US'.4 select single * from ztxt005t5 where spras = sy-langu "current logon language6 and land1 = `land1.7 if sy-subrc = 0.8 write: 'Description:', ztxt005t-landx.9 else.10 write: 'No description exists for', `land1.11 endif.
Der Code in Listing 9.3 erzeugt diese Ausgabe:
Description: United States
Zeile 5 begrenzt den select, um nur die Sätze aus ztxt005t zu liefern, die den gleichen Sprachenschlüssel wie die aktuelle Anmeldesprache haben. Da mandt automatisch jedem wherevorangestellt wird, ist der Primärschlüssel jetzt voll qualifiziert, und ein einzelner Satz wird geliefert. Beachten Sie, daß der Primärindex diesen select unterstützt, so wurden die Felder der where-Klausel in derselben Reihenfolge spezifiziert, wie sie im Primärindex erscheinen.
Zuweisungsanweisungen
Eine Zuweisungsanweisung weist einer Variablen oder Feldleiste einen Wert zu. Drei Zuweisungsanweisungen werden häufig benutzt:
■ clear■ move■ move-corresponding

Anwenden der clear-Anweisung
Die clear-Anweisung setzt den Wert einer Variablen oder Feldleiste auf Nullen. Wenn der Datentyp c ist, wird der Wert statt dessen auf Leerzeichen gesetzt. Leerzeichen und Nullen heißen Standard-Anfangswerte (Defaultwerte). Man sagt oft, daß clear den Variablen die Standard-Anfangswerte zuweist.
Syntax der clear-Anweisung
Dies ist ist die Syntax der clear-Anweisung:
clear v1 [with v2 | with 'A' | with NULL]
wobei gilt:
■ v1 und v2 sind Variablen oder Feldleistennamen. ■ 'A' ist ein Literal beliebiger Länge.
Es gelten folgende Punkte:
■ Wenn v1 eine Variable vom Typ c ohne Zusätze ist, wird sie mit Leerzeichen gefüllt. Wenn v1 von einem anderen Datentyp ist, wird sie mit Nullen gefüllt. Wenn v1 eine Feldleiste ist, werden ihre einzelnen Komponenten mit Leerzeichen oder Nullen gefüllt, je nach dem individuellen Datentyp.
■ Wird v2 auf v1 addiert, wird das erste Byte von v2 benutzt, um die gesamte Länge von v1 zu füllen. Wenn v1 eine Feldleiste ist, wird sie wie eine Variable vom Typ c behandelt.
■ Wird 'A' auf v1 addiert, wird die gesamte Länge von v1 mit dem ersten Byte des Literals 'A' gefüllt.
■ Wird Null auf v1 addiert, wird die gesamte Länge von v1 mit hexadezimalen Nullen gefüllt.
Listing 9.4 zeigt ein Beispielprogramm, welches Variablen und Feldleisten initialisiert.
Listing 9.4: Variablen werden durch die clear-Anweisung auf Leerzeichen oder Nullen gesetzt.
1 report ztx0904.2 tables ztxlfa1.3 data: f1(2) type c value 'AB',4 f2 type i value 12345,5 f3 type p value 12345,6 f4 type f value '1E1',7 f5(3) type n value '789',8 f6 type d value '19980101',9 f7 type t value '1201',10 f8 type x value 'AA',

11 begin of s1,12 f1(3) type c value 'XYZ',13 f2 type i value 123456,14 end of s1.15 ztxlfa1-lifnr = 'XXX'.16 ztxlfa1-land1 = 'CA'.17 write: / 'f1=''' no-gap, f1 no-gap, '''',18 / 'f2=''' no-gap, f2 no-gap, '''',19 / 'f3=''' no-gap, f3 no-gap, '''',20 / 'f4=''' no-gap, f4 no-gap, '''',21 / 'f5=''' no-gap, f5 no-gap, '''',22 / 'f6=''' no-gap, f6 no-gap, '''',23 / 'f7=''' no-gap, f7 no-gap, '''',24 / 'f8=''' no-gap, f8 no-gap, '''',25 / 's1-f1=''' no-gap, s1-f1 no-gap, '''',26 / 's1-f2=''' no-gap, s1-f2 no-gap, '''',27 / 'ztxlfa1-lifnr=''' no-gap, ztxlfa1-lifnr no-gap, '''',28 / 'ztxlfa1-land1=''' no-gap, ztxlfa1-land1 no-gap, ''''.29 clear: f1, f2, f3, f4, f5, f6, f7, f8, s1, ztxlfa1.30 write: / 'f1=''' no-gap, f1 no-gap, '''',31 / 'f2=''' no-gap, f2 no-gap, '''',32 / 'f3=''' no-gap, f3 no-gap, '''',33 / 'f4=''' no-gap, f4 no-gap, '''',34 / 'f5=''' no-gap, f5 no-gap, '''',35 / 'f6=''' no-gap, f6 no-gap, '''',36 / 'f7=''' no-gap, f7 no-gap, '''',37 / 'f8=''' no-gap, f8 no-gap, '''',38 / 's1-f1=''' no-gap, s1-f1 no-gap, '''',39 / 's1-f2=''' no-gap, s1-f2 no-gap, '''',40 / 'ztxlfa1-lifnr=''' no-gap, ztxlfa1-lifnr no-gap, '''',41 / 'ztxlfa1-land1=''' no-gap, ztxlfa1-land1 no-gap, ''''.
Der Code in Listing 9.4 erzeugt diese Ausgabe:
f1='AB'f2=' 12,345 'f3=' 12,345 'f4=' 1.000000000000000E+01'f5='789'f6='19980101'f7='120100'f8='AA's1-f1='XYZ's1-f2=' 123,456 'ztxlfa1-lifnr='XXX 'ztxlfa1-land1='CA '

f1=' 'f2=' 0 'f3=' 0 'f4=' 0.000000000000000E+00'f5='000'f6='00000000'f7='000000'f8='00's1-f1=' 's1-f2=' 0 'ztxlfa1-lifnr=' 'ztxlfa1-land1=' '
■ Zeile 2 definiert die Feldleiste ztxlfal.■ Zeile 4 bis 10 definieren Variablen jeden Typs und weist ihnen Anfangswerte zu. ■ Eine weitere Feldleiste s1 wird in Zeile 11 mit Anfangswerten für jede Komponente definiert. ■ In den Zeilen 15 und 16 erhalten zwei dieser Komponenten Werte zugewiesen. ■ Alle Variablen und Komponenten der Feldleisten werden durch die clear-Anwei- sung in
Zeile 29 auf Nullen und Leerzeichen gesetzt. Man kann auch sagen, daß alle Variablen und Komponenten auf Standard-Anfangswerte gesetzt werden.
■ Die write-Anweisung, die in Zeile 30 beginnt, gibt die initialisierten Variablen und Komponenten aus, eingeschlossen in Einfachhochkommata und ohne Zwischenräume zwischen den Hochkommata und den eingeschlossenen Werten.
Listing 9.5 zeigt ein Beispielprogramm, das Variablen und Komponenten von Feldleisten mit anderen Werten als Leerzeichen oder Nullen füllt.
Listing 9.5: Variablen, die mit anderen Werten als Leerzeichen oder Nullen gefüllt sind und den with-Zusatz der clear-Anweisung verwenden
1 report ztx0905.2 tables ztxlfa1.3 data: f1(2) type c value 'AB',4 f2(2) type c,5 f3 type i value 12345,6 begin of s1,7 f1(3) type c value 'XYZ',8 f2 type i value 123456,9 end of s1.10 write: / 'f1=''' no-gap, f1 no-gap, '''',11 / 'f2=''' no-gap, f2 no-gap, '''',12 / 'f3=''' no-gap, f3 no-gap, '''',13 / 's1-f1=''' no-gap, s1-f1 no-gap, '''',14 / 's1-f2=''' no-gap, s1-f2 no-gap, '''',15 / 'ztxlfa1-lifnr=''' no-gap, ztxlfa1-lifnr no-gap, '''',16 / 'ztxlfa1-land1=''' no-gap, ztxlfa1-land1 no-gap, '''',

17 /.18 clear: f1 with 'X',19 f2 with f1,20 f3 with 3,21 s1 with 'X',22 ztxlfa1 with 0.23 write: / 'f1=''' no-gap, f1 no-gap, '''',24 / 'f2=''' no-gap, f2 no-gap, '''',25 / 'f3=''' no-gap, f3 no-gap, '''',26 / 's1-f1=''' no-gap, s1-f1 no-gap, '''',27 / 's1-f2=''' no-gap, s1-f2 no-gap, '''',28 / 'ztxlfa1-lifnr=''' no-gap, ztxlfa1-lifnr no-gap, '''',29 / 'ztxlfa1-land1=''' no-gap, ztxlfa1-land1 no-gap, ''''.
Der Code in Listing 9.5 erzeugt diese Ausgabe:
f1='AB'f2=' 'f3=' 12,345 's1-f1='XYZ's1-f2=' 123,456 'ztxlfa1-lifnr=' 'ztxlfa1-land1=' '
f1='XX'f2='XX'f3='50,529,027 's1-f1='XXX's1-f2='1482184792 'ztxlfa1-lifnr='##########'ztxlfa1-land1='###'
■ Zeile 18 füllt f1 mit dem Buchstaben X.■ Zeile 19 füllt f2 mit dem ersten Byte von f1, ebenfalls ein X.■ Zeile 20 füllt f3 mit dem ersten Byte des Literals 3. Ein bis zu neun Ziffern langes
numerisches Literal wird als Vier-Byte-Ganzzahl gespeichert (siehe auch das folgende Kapitel »Data Conversion«). f3 wird mit dem ersten Byte dieser Vier-Byte- Ganzzahl gefüllt, im wesentlichen werden f3 sinnlose Werte zugewiesen.
■ Zeile 21 behandelt s1 als eine Typ c-Variable und füllt sie mit X. Komponente f1 ist vom Typ c, also erhält sie gültige Werte. Komponente f2 ist vom Typ I und erhält so ungültige Werte.
■ Die Feldleiste ztxlfal wird mit dem ersten Byte der Vier-Byte-Ganzzahl mit Wert 0 gefüllt, und wird mit sinnlosen Werten gefüllt. Solche Werte werden in diesem Fall als Nummernzeichen (#) ausgegeben.

Die move-Anweisung benutzen
Um einen Wert von einem Feld zu einem anderen zu übertragen, benutzen Sie die move-Anweisung.Der vollständige Inhalt oder ein Teil davon kann übertragen werden. Anstelle von move können Sie den Zuweisungsoperator = benutzen, wie es unten gezeigt wird. Beide werden als move-Anweisungbezeichnet.
Die Syntax der move-Anweisung
Es folgt die Syntax der move-Anweisung. Operatoren und Operanden müssen durch Leerzeichen getrennt werden. Mehrfachzuweisungen werden von rechts nach links durchgeführt.
move v1 to v2.
oder
v2 = v1.
oder
v2 = v1 = vm = vn....
oder
move v1[+N(L)] to v2[+N(L)].
oder
v2[+N(L)] = v1[+N(L)].
wobei gilt:
■ V1 ist die sendende Variable oder Feldleiste. ■ V2 ist die empfangende Variable oder Feldleiste. ■ N ist ein Offset vom Anfang der Variablen oder Feldleiste. ■ L ist die Anzahl zu übertragender Byte.
Tabelle 9.2 zeigt zwei Beispiele für den richtigem und den falschem Weg, Zuweisungen zu programmieren. Falsches Programmieren führt zu Syntaxfehlern.
Tabelle 9.2: Richtiges und falsches Programmieren von
Zuweisungen

Richtig Falsch
f1 = f2. f1=f2.
f1 = f2 = f3. f1=f2=f3.
Datenkonvertierungen
Wenn zwei Variablen verschiedene Datentypen oder Längen haben, werden die Daten beim Übertragen konvertiert. Dies heißt: automatische Anpassung. Wenn die Längen der sendenden und empfangenden Variablen nicht übereinstimmen, wird eine automatische Längenanpassung durchgeführt. Wenn die Datentypen nicht übereinstimmen, wird eine automatische Typenkonvertierung durchgeführt.
Wenn die Datentypen des sendenden und empfangenden Feldes gleich sind, aber die Längen unterschiedlich sind, wird eine Längenanpassung durchgeführt, wie in Tabelle 9.3 gezeigt. In dieser Tabelle ist das sendende Feld das Feld »From«.
Tabelle 9.3: Die Wirkung der Längenanpassung hängt vom Datentyp ab.
TypWenn in ein längeres Feld übertragen wird, ist der Wert »From«:
Wenn in ein kürzeres Feld übertragen wird, wird der Wert »From«:
c Rechts aufgefüllt mit Leerzeichen Rechts abgeschnitten
x Rechts aufgefüllt mit Nullen Rechts abgeschnitten
n Links aufgefüllt mit Nullen Links abgeschnitten
p Links aufgefüllt mit Nullen übertragen, wenn der numerische Wert in das 'to' Feld paßt.
Wenn der numerische Wert zu groß für das empfangende Feld ist, gibt es einen Programmabbruch.
Die verbleibenden Datentypen (f, i, d und t) haben alle eine feste Länge, so daß sendende und empfangende Felder immer dieselbe Länge haben, vorausgesetzt, sie sind vom selben Datentyp.
Regeln für Typanpassungen gibt es in Tabelle 9.4. Die Konvertierungsregeln für den Typ i sind dieselben wie für den Typ p. Eingeschlossen sind Konvertierungen mit ungewöhnlichem Verhalten. Beachten Sie die Punkte:

■ die spezielle Komprimierung, die von Typ c nach n durchgeführt wird ■ die Möglichkeit, ungültige Werte den Typen d und t zuzuweisen ■ die unsaubere Behandlung ungültiger Zeichen während der Konvertierung von Typ c nach x■ das unerwartete Benutzen des reservierten Vorzeichenbyte in p nach c Konvertierungen ■ das Benutzen von *, um Überläufe in p nach c Konvertierungen anzuzeigen ■ Ein vollständig leeres c-Feld wird in ein p-Feld mit Wert Null konvertiert.
Ein vollständiges Listing der Konvertierungsregeln finden Sie in der ABAP/4-Schlüsselwortdokumentation für die move-Anweisung. Das Verfahren, diese anzuzeigen, folgt im nächsten Abschnitt.
Tabelle 9.4: Regeln für Typenanpassungen
»Von«-Typ »Nach«-Typ Konvertierungsregeln
c p Das sendende Feld kann nur Zahlen, einen einzigen Dezimalpunkt und ein optionales Vorzeichen enthalten. Das Vorzeichen kann führend oder nachgestellt sein. Leerzeichen können auf jeder Seite des Wertes vorkommen. Sie werden rechtsbündig eingestellt und auf der linken Seite mit Nullen aufgefüllt. Ein vollständig leeres Sendefeld wird auf Null konvertiert.
c d Das sendende Feld sollte ausschließlich ein gültiges Datum der Form JJJJMMTT enthalten. Ist dies nicht der Fall, gibt es keinen Fehler, statt dessen wird dem Empfangsfeld ein ungültiger Wert zugewiesen. Benutzt man diesen Wert, sind die Resultate nicht definiert.
c t Das sendende Feld sollte ausschließlich eine gültige Uhrzeit im Format HHMMSS enthalten. Ist dies nicht der Fall, gibt es keinen Fehler, statt dessen wird dem Empfangsfeld ein ungültiger Wert zugewiesen. Benutzt man diesen Wert, sind die Resultate nicht definiert.
c n Das sendende Feld wird von links nach rechts durchsucht, und nur die Ziffern 0-9 werden (rechtsbündig) in das Empfangsfeld übertragen und auf der linken Seite mit Nullen aufgefüllt. Alle anderen Zeichen werden schlicht ignoriert.
c x Gültige Werte für das Sendefeld sind 0-9 und Großbuchstaben A-F. Der Wert wird linksbündig eingestellt und auf der rechten Seite mit Nullen aufgefüllt oder auf der rechten Seite abgeschnitten. Alle Zeichen nach dem ersten ungültigen Wert im Sendefeld werden ignoriert.

p c Der Wert wird rechtsbündig im Empfangsfeld eingestellt, wobei das äußerste rechte Byte für das nachgestellte Vorzeichen reserviert wird. Das Vorzeichen wird nur angezeigt, wenn die Zahl negativ ist; positive Zahlen werden daher rechtsbündig mit einem nachgestellten Leerzeichen eingestellt. Falls Sie versuchen, einen positiven Wert mit ebenso vielen Ziffern wie das Empfangsfeld lang ist, zu übertragen, wird das System die gesamte Länge des Empfangsfeldes für den Wert benutzen, ohne das äußerste rechte Byte für das Vorzeichen zu reservieren. Betrachtet man das bisher Gesagte, so ist festzuhalten, daß, wenn der Wert im Sendefeld nicht ins Empfangsfeld paßt, die Zahl links abgeschnitten wird. Wenn abgeschnitten wurde, zeigt das System dies an, indem das äußerste linke Byte durch einen Stern (*) ersetzt wird. Wenn der Wert ins Empfangsfeld paßt, werden führende Nullen unterdrückt. Wenn das Sendefeld gleich Null ist, erhält das Empfangsfeld eine einzige Null.
p d Die Zahl wird als Anzahl der Tage seit 01.01.0001 interpretiert, zu einem Datum konvertiert und intern im Format JJJJMMTT abgespeichert.
p t Die Zahl wird als Anzahl der Sekunden seit Mitternacht interpretiert, zu 24 Stunden Uhrzeit konvertiert und intern im Format HHMMSS abgespeichert.
d p Das Datum wird zu einer Zahl konvertiert, welche die Anzahl der Tage seit 01.01.0001 repräsentiert.
t p Die Zeit wird zu einer Zahl konvertiert, welche die Anzahl der Sekunden seit Mitternacht repräsentiert.
Listing 9.6 enthält ein Demonstrationsprogramm, welches Beispiele für Datenkonvertierungen durchführt.
Listing 9.6: Beispiele für Datenkonvertierungen
1 report ztx0906.2 constants >(3) value '==>'. "defines a constant named '>'3 data: fc(10) type c value '-A1B2C3.4',4 fn(10) type n,5 fp type p,6 fd type d,7 ft type t,8 fx(4) type x,9 fc1(5) type c value '-1234',10 fc2(5) type c value '1234-',11 fp1 type p value 123456789,12 fp2 type p value '123456789-',

13 fp3 type p value 1234567899,14 fp4 type p value 12345678901,15 fp5 type p value 12345,16 fp6 type p value 0.1718 fn = fc. write: / fc, >, fn, 'non-numeric chars are ignored'.19 fd = 'ABCDE'. write: / fd, 'date and time fields are invalid'.20 ft = 'ABCDE'. write: / ft, ' when you load them with junk'.21 fp = sy-datum. write: / sy-datum, >, fp, 'd->p: days since 0001/01/01'.22 fp = sy-uzeit. write: / sy-uzeit, >, fp, 'd->t: secs since midnight'.23 fx = 'A4 B4'. write: / 'A4 B4', >, fx, 'ignore all after invalid char'.24 fp = fc1. write: / fc1, >, fp, 'allows leading sign'.25 fp = fc2. write: / fc2, >, fp, 'also allows trailing sign'.26 fc = fp1. write: / fp1, >, fc, 'rightmost byte reserved for sign'.27 fc = fp2. write: / fp2, >, fc, 'only negative numbers use it, but'.28 fc = fp3. write: / fp3, >, fc, '+ve nums that need it use it too'.29 fc = fp4. write: / fp4, >, fc, 'overflow indicated by leading *'.30 fc = fp5. write: / fp5, >, fc, 'leading zeros are suppressed'.31 fc = fp6. write: / fp6, >, fc, 'zero in = zero out'.32 fp = ' '. write: / ' ', >, fp, 'blanks in = zero out'.
Das Programm in Listing 9.6 erzeugt folgende Ausgabe:
-A1B2C3.4 ==> 0000001234 non-numeric chars are ignoredE ABCD date and time fields are invalidABCDE0 when you load them with junk1998/02/22 ==> 729,443 d->p: days since 0001/01/0114:57:05 ==> 53,825 d->t: secs since midnightA4 B4 ==> A4000000 ignore all after invalid char-1234 ==> 1,234- allows leading sign1234- ==> 1,234- also allows trailing sign123,456,789 ==> 123456789 rightmost byte reserved for sign123,456,789- ==> 123456789- only negative numbers use it, but1,234,567,899 ==> 1234567899 +ve nums that need it use it too12,345,678,901 ==> *345678901 overflow indicated by leading *12,345 ==> 12345 leading zeros are suppressed0 ==> 0 zero in = zero out==> 0 blanks in = zero out
Starten Sie jetzt den ScreenCam »How to Display the Conversion Rules in the ABAP/ 4 Keyword

Documentation«.
Um die Konvertierungsregeln in der ABAP/4-Schlüsselwortdokumentation anzuzeigen gehen Sie wie folgt vor:
1. Beginnen Sie mit dem ABAP/4-Editor: Eingangsbildschirm.
2. Wählen Sie den Menüpfad Hilfsmittel->ABAP/4-Schlüsselwort Dok. Das Fenster Anzeigestruktur: ABAP/4 SAP's 4GL Programmiersprache wird angezeigt.
3. Wählen Sie die Schaltfläche: Suchen auf der Anwendungssymbolleiste. Die Dialogbox Suchen in den Kapiteltiteln wird angezeigt.
4. Im Feld Suchen geben Sie move ein.
5. In der Feldgruppe Art der Suche wählen Sie den Auswahlknopf: Aus Struktur starten.
6. Drücken Sie die Schaltfläche Weiter. Die Dialogbox verschwindet, und die move- Zeile wird hell dargestellt.
7. Doppelklicken Sie auf die hell unterlegte Zeile. Das Fenster Anzeigen Hypertext wird angezeigt.
8. Drücken Sie zweimal die Taste Bild abwärts. Der Anfang der Konvertierungstabellen wird angezeigt.
Teilfelder
Teile von Feldern, die durch Offset und/oder Länge angesprochen werden, heißen Teilfelder.
Syntax eines Teilfeldes
v1[+o][(L)] = v2[+o][(L)].
Es gilt:
■ v1 und v2 sind Variablen oder Feldleistennamen. ■ o ist ein Offset vom Anfang des Feldes. ■ L ist eine Länge in Byte.
Beachten Sie außerdem folgende Punkte:
■ Ein Teilfeld kann sowohl für das Sende- als auch für das Empfangsfeld oder für beide spezifiziert werden.
■ Entweder das Offset oder die Länge ist optional. Es können auch beide angegeben werden.

■ Wenn das Offset nicht angegeben ist, beginnt das Teilfeld am Feldanfang. ■ Wenn die Länge nicht angeben ist, reicht das Teilfeld bis zum Ende des Feldes. ■ Es können keine Leerzeichen innerhalb der Teilfeldspezifikation angegeben werden. ■ Dem Offset, falls angegeben, wird immer ein Pluszeichen (+) vorangestellt. ■ Die Länge, falls angegeben, wird immer in Klammern eingeschlossen.
Listing 9.7 zeigt ein Beispielprogramm, das Zuweisungen durchführt und Teilfelder benutzt.
Listing 9.7: Teile eines mit einer Teilfeldzuweisung übertragenen Feldes
1 report ztx0907.2 data: f1(7),3 f2(7).4 f1 = 'BOY'. "same as: move 'BOY' to f1.5 f2 = 'BIG'. "same as: move 'BIG' to f2.6 f1+0(1) = 'T'. "f1 now contains 'TOY '.7 write / f1.8 f1(1) = 'J'. "same as: f1+0(1) = 'J'.9 write / f1. "f1 now contains 'JOY '.10 f1(1) = f2. "same as: f1(1) = f2(1).11 write / f1. "f1 now contains 'BOY '.12 f1+4 = f1. "same as: f1+4(3) = f1(3).13 write / f1. "f1 now contains 'BOY BOY'.14 f1(3) = f2(3). "same as: f1+0(3) = f2+0(3).15 write / f1. "f1 now contains 'BIG BOY'.
Das Programm in Listing 9.7 erzeugt diese Ausgabe:
TOYJOYBOYBOY BOYBIG BOY
■ In Zeile 6 wird ein Offset von 0 und eine Länge von 1 benutzt, um ein Teilfeld zu spezifizieren, das nur aus dem ersten Byte von f1 besteht. Wird der Buchstabe 'T'übertragen, wird also nur das erste Byte von f1 gefüllt.
■ In Zeile 8 wird das Offset von 0 weggelassen. 0 ist der Defaultwert, also ist das Teilfeld dasselbe wie in Zeile 6.
■ In Zeile 10 wird dasselbe Teilfeld benutzt, aber diesmal wird von f2 her übertragen. Nur das erste Byte wird von f2 übertragen, da das empfangende Teilfeld nur ein einziges Byte lang ist.
■ In Zeile 12 spezifiziert ein Offset von 4, daß das Teilfeld in f1 mit dem fünften Byte beginnt und bis zum Ende von f1 reicht, es ist also drei Bytes lang. Das Sendefeld ist f1, was bewirkt, daß die ersten drei Bytes von f1 in die Positionen 4 bis 6 verdoppelt werden.
■ In Zeile 14 ersetzen die ersten drei Bytes von f2 die ersten drei Bytes von f1.

move mit Feldleisten benutzen
Mit move wird ein Feldleistenname, der ohne einen Komponentennamen spezifiziert ist, wie eine Variable vom Typ c behandelt. Bild 9.2 und Listing 9.8 illustrieren diesen Sachverhalt.
Abbildung 9.2: Die Verwendung von move in einer Feldleiste ohne einen Komponentennamen bewirkt, daß dieses wie eine Variable vom Typ c behandelt wird.
Listing 9.8: Die move-Anweisung behandelt einen Feldleistennamen ohne Komponentennamen wie eine Variable vom Typ c.
1 report ztx0908.2 data: f1(4) value 'ABCD',3 begin of s1,4 c1(1),5 c2(2),6 c3(1),7 end of s1.8 s1 = f1. "s1 is treated as a char 4 variable9 write: / s1, "writes ABCD10 / s1-c1, s1-c2, s1-c3. "writes A BC D
Das Programm in Listing 9.8 erzeugt diese Ausgabe:
ABCDA BC D

■ Zeile 2 definiert f1 als vier-Byte-Variable vom Typ c.■ Die Zeilen 3 bis 7 definieren s1 als eine Feldleiste mit drei Komponenten: f1, f2 und f3. Die
Gesamtlänge von s1 berechnet sich durch die Addition der Längen ihrer Komponenten: 1+2+1=4.
■ Zeile 8 überträgt die Werte von f1 nach s1 Byte für Byte, als ob beide Variablen vom Typ cwären.
■ Zeile 9 gibt s1 als eine Vierzeichen-Variable aus. ■ Zeile 10 gibt die Inhalte der Komponenten von s1 aus.
Übertragen von Feldleisten mit numerischen Feldern
Wenn das Sendefeld der Kategorie Zeichen (Typen c, n, d, t, oder x) angehört, und das Ziel eine Feldleiste mit einem numerischen Feld ist (Typen i, p, oder f), wird keine Datenkonvertierung durchgeführt. Die Übertragung erfolgt so, als ob beide reine Zeichenfelder wären. Die Umkehrung stimmt ebenfalls. Es werden keine Konvertierungen durchgeführt, wenn ein numerisches Feld in eine Feldleiste mit einem Zeichenfeld übertragen wird. In beiden Fällen sind die Ergebnisse ungültig und nicht definiert.
Listing 9.9 zeigt ein Beispielprogramm, welches eine ungültige Konvertierung eines numerischen Feldes in ein Zeichenfeld durchführt.
Listing 9.9: Ein numerisches Feld in ein Zeichenfeld zu übertragen, ist ungültig.
1 report ztx0909.2 data: fc(5) type c,3 begin of s,4 fi type i,5 end of s.67 fc = '1234'.8 s = fc. "c<-c, no conversion performed9 write s-fi. "writes junk1011 s-fi = 1234. "assign a valid value12 fc = s. "c<-c, no conversion performed13 write / fc. "writes junk1415 s-fi = 1234. "assign a valid value16 fc = s-fi. "c<-i conversion performed17 write / fc. "writes 1234
Auf meinem Computer produziert das Programm in Listing 9.9 die folgende Ausgabe. Ihre Ergebnisse mögen wegen der ungültigen Zuweisungen für die ersten beiden Zeilen der Ausgabe variieren.

875770,417Ò###1234
■ In Zeile 2 wird f1 als Ganzzahl mit dem Wert 1234 definiert. ■ In den Zeilen 3 bis 5 wird s1 als Einzelkomponente c1 vom Typ c in Länge l2 definiert. ■ In Zeile 6 wird f1 nach s1 übertragen. Es wird keine Konvertierung durchgeführt, da s1 eine
Feldleiste ist, also wie Typ c behandelt wird. ■ In Zeile 7 wird s1-c1 ausgegeben und die Ergebnisse sind sinnlos. ■ In Zeile 8 wird s1-c1 eine gültige Zeichenkette '1234' zugewiesen. ■ In Zeile 9 wird s1 nach f1 übertragen. Es wird keine Konvertierung durchgeführt. ■ Zeile 10 gibt f1 aus, und wieder sind die Ergebnisse sinnlos. ■ In Zeile 11 wird f1 ein gültiger Wert von 1234 zugewiesen. ■ In Zeile 12 wird f1 nach s1-c1 zugewiesen. Da die Zuweisung in die Komponente erfolgt
und nicht zur Feldleiste, wird eine Konvertierung durchgeführt, und Zeile 13 gibt einen gültigen Wert aus.
Sie sollten niemals eine Variable vom Typ c in eine Feldleiste oder aus einer Feldleiste heraus bewegen, die einen numerischen Typ beinhaltet. Die Ergebnisse sind abhängig vom Computer und daher nicht definiert.
Übertragen mit Zeichendatentypen von einer Feldleiste in eine andere
Sie können die move-Anweisung für zwei Feldleisten benutzen, wenn beide Leisten nur Komponenten mit Zeichendatentypen (c, n, d, t, und x) enthalten. Listing 9.10 illustriert dieses Konzept.
Listing 9.10: Die Verwendung der move-Anweisung mit zwei Feldleisten, ausschließlich aus Zeichendatentypen bestehend
1 report ztx0910.2 data: begin of s1,3 d1 type d value '19980217', "8 Byte4 n1(4) type n value '1234', "4 Byte5 c1 value 'A', "1 byte6 c2 value 'B', "1 byte7 end of s1,8 begin of s2,9 y1(4) type n, "4 Byte

10 m1(2) type c, "2 Byte11 d1(2) type n, "2 Byte12 n1(2) type c, "2 Byte13 c1(4) type c, "4 Byte14 end of s2.15 s2 = s1.16 write: / s1,17 / s2,18 / s1-d1, s1-n1, s1-c1, s1-c2,19 / s2-y1, s2-m1, s2-d1, s2-n1, s2-c1.
Das Programm in Listing 9.10 erzeugt diese Ausgabe:
199802171234AB199802171234AB19980217 1234 A B1998 02 17 12 34AB
■ Zeile 2 bis 14 definieren zwei Feldleisten, die ausschließlich aus Zeichentypfeldern bestehen. Jede Feldleiste ist insgesamt 14 Bytes lang.
■ In Zeile 15 wird s1 nach s2 übertragen, wobei jede Feldleiste behandelt wird, als wäre sie ein einziges 14 Bytes langes Typ c-Feld.
■ In den Zeilen 16 und 17 werden beide als Zeichenfelder ausgegeben. ■ In den Zeilen 18 und 19 werden die Komponenten jeder Feldleiste ausgegeben. S1-d1 wurde
über s2-y1, m1 und d1 verteilt. Die ersten beiden Bytes von s1-n1 wanderten in s2-n1.Die restlichen Bytes von s1 gingen nach s2-c1.
Übertragen einer Feldleiste in eine andere mit numerischen Datentypen
Die meisten Betriebssysteme erfordern, daß die Maschinenadresse von numerischen Feldern bestimmten Regeln genügt. Es kann zum Beispiel erforderlich sein, daß die Adresse einer Vier-Byte-Ganzzahl durch zwei teilbar ist. Diese Regel wird oft bezeichnet als »eine Vier-Byte-Ganzzahl muß auf eine gradzahlige Byte-Grenze ausgerichtet sein«. Folglich wird die Regel, der eine Adresse genügen muß, als Ausrichtung bezeichnet.
Um Ausrichtungsanforderungen zu erfüllen, fügt ein typischer Compiler s vor einem Feld, welches eine Ausrichtung erfordert, Füllbytes ein. Wenn zum Beispiel Ihre Vier- Byte-Ganzzahl am Offset 0003 vom Anfang des Programmes beginnt, ist ein Füllbytes nötig, um sie auf eine Zwei-Byte-Grenze auszurichten. Der Compiler wird ein unbenutztes Byte auf Offset 0003 setzen, so daß die Ganzzahl am Offset 0004 beginnt, und sie so sauber ausrichten. Füllbytes sind für den Programmierer unsichtbar, aber ihre Wirkung kann man manchmal sehen.
Wenn Sie eine Feldleiste mit einer Mischung aus Zeichen und numerischen Feldern anlegen, werden manchmal vom System Füllbytes eingefügt, um numerische Felder auszurichten. Wenn Sie versuchen, eine move-Anweisung zu benutzen, um die Inhalte solch einer Feldleiste in eine andere zu

übertragen, können diese Füllbytes unerwartete Ergebnisse verursachen.
Daher können Sie move nur verwenden, wenn einer der folgenden Punkte zutrifft:
Beide Feldleisten bestehen ausschließlich aus Zeichenfeldern (Typen c, n, d, t, und x).
Die Datentypen, Längen und Positionen aller Komponenten in beiden Feldleisten stimmen exakt überein (die Namen der Komponenten brauchen nicht übereinzustimmen).
Wenn sowohl die Sendefelder als auch die Empfangsfelder ausschließlich aus Zeichenfeldern zusammengesetzt sind, gibt es keine Füllbytes und das Ergebnis der move-Anweisung ist vorhersagbar. Falls es eine Mischung aus Zeichen- und numerischen Feldern gibt, können Füllbytes existieren und das Ergebnis der move-Anweisung kann unerwartet sein. Ein Beispiel wird in Listing 9.11 gezeigt.
Listing 9.11: Füllbytes können unerwartete Ergebnisse verursachen, wenn Daten zwischen Feldleisten übertragen werden.
1 report ztx0911.2 data: begin of s1,3 c1 value 'A', "one byte
4 c2 type i value 1234, "four Byte, usually needs padding5 c3 value 'B', "one byte6 end of s1,
7 begin of s2,8 c1, "one byte9 c2(4), "four Byte, no padding10 c3, "one byte11 end of s2,12 begin of s3, "s3 matches s1 exactly:13 x1, "- data types the same14 x2 type i, "- number of fields the same15 x3, "- fields in the same order16 end of s3. "(names don't have to match)17 s2 = s1.18 write: / s2-c1, s2-c2, s2-c3.19 s3 = s1.20 write: / s3-x1, s3-x2, s3-x3.
Auf meiner Maschine produziert das Programm in Listing 9.11 die folgende Ausgabe. In Ihrem System können die Ergebnisse für Felder mit ungültigen Zuweisungen variieren.

A ###Ò #A 1,234 B
S1-c1 ist nur ein Byte lang, so daß c2 ein ungerades Offset vom Anfang der Feldleiste hat und auf den meisten Systemen ein Auffüllen erfordert, wodurch s1 länger als s2 wird. Wenn s1 nach s2zugewiesen wird, liegt c3 außerhalb von s2 und einiges von s1-c2 fällt in s2-c3. Andererseits stimmt s3 exakt mit s1 überein, so daß die Übertragung in Zeile 14 perfekt funktioniert.
Dieses Beispiel zeigt, daß Sie die Wirkung von numerischen Feldern innerhalb einer Struktur nicht ignorieren können. Die Tatsache, daß jedes Empfangsfeld dieselbe Anzahl Byte wie jedes Sendefeld hat, genügt nicht, um zu garantieren, daß die Komponenten aufeinanderpassen.
Die Ausrichtungsregeln hängen vom Betriebssystem ab, so variieren die Anzahl und Position der Füllbytes. Die Ergebnisse einer move-Anweisung auf einem Betriebssystem können auf einem anderen verschieden sein. Um sicherzustellen, daß Ihre Programme übertragbar sind, verlassen Sie sich niemals auf Füllbytes und verwenden Sie sie nicht während Übertragungen. Jede Feldleiste muß ausschließlich aus Zeichendatentypen bestehen, oder alle Komponenten müssen exakt übereinstimmen (mit Ausnahme des Namens).
Die move-corresponding-Anweisung
Um eine Übertragung von einer Feldleiste zu einer anderen durchzuführen, in der die Datentypen und/oder Längen nicht übereinstimmen, benutzen Sie die move-corresponding -Anweisung.Sie erzeugt individuelle move-Anweisungen für Komponenten mit übereinstimmenden Namen. Komponenten in der Empfangsfeldleiste, die keine korrespondierenden Namen in der Sendefeldleiste haben, werden nicht verändert. Listing 9.12 zeigt dies.
Syntax für die move-corresponding-Anweisung
Das folgende Listing ist die Syntax für die move-corresponding-Anweisung. Operatoren und Operanden müssen durch Leerzeichen getrennt werden. Mehrfachzuweisungen erfolgen von rechts nach links.
move-corresponding v1 to v2.
wobei:
■ v1 die sendende Variable oder Feldleiste ist. ■ v2 die empfangende Variable oder Feldleiste ist.
Listing 9.12: Die move-corresponding-Anweisung erzeugt individuelle move-Anweisungen und führt so Datenkonvertierungen durch.
1 report ztx0912.

2 data: begin of s1,3 c1 type p decimals 2 value '1234.56',4 c2(3) value 'ABC',5 c3(4) value '1234',6 end of s1,7 begin of s2,8 c1(8),9 x2(3) value 'XYZ',10 c3 type i,11 end of s2.12 write: / 's1 :', s1-c1, s1-c2, s1-c3.13 write: / 's2 before move-corresponding:', s2-c1, s2-x2, s2-c3.14 move-corresponding s1 to s2. "same as coding the following two statements15 * move s1-c1 to s2-c1. "performs conversion16 * move s1-c3 to s2-c3. "performs conversion17 write: / 's2 after move-corresponding:', s2-c1, s2-x2, s2-c3.
Das Programm in Listing 9.12 erzeugt diese Ausgabe:
s1 : 1,234.56 ABC 1234s2 before move-corresponding: XYZ 0s2 after move-corresponding: 1234.56 XYZ 1,234
Zeile 14 erzeugt zwei move-Anweisungen; zur Verdeutlichung sind sie als Kommentar in Zeile 15 und 16 dargestellt. Normalerweise können Sie diese move-Anweisungen nicht sehen; das System erzeugt und führt sie automatisch im Hintergrund aus. Eine move-Anweisung wird für jede Komponente der Empfangsfeldleiste erzeugt, die denselben Namen wie eine Komponente im Sendefeld hat. In diesem Fall haben c1 und c3 dieselben Namen, es werden also zwei move-Anweisungen erzeugt. Datenkonvertierungen werden genauso durchgeführt, als ob Sie diese Anweisungen selbst programmiert hätten. Die Inhalte von c2 sind unverändert, wenn die move-corresponding-Anweisung beendet ist.
Berechnungen
Sie können Berechnungen mit den folgenden Anweisungen durchführen:
■ compute■ add oder add-corresponding■ subtract oder subtract-corresponding■ multiply oder multiply-corresponding■ divide oder divide-corresponding
Die compute-Anweisung benutzen

Compute ist die am häufigsten benutzte Anweisung, um Berechnungen durchzuführen.
Syntax der compute-Anweisung
Das Folgende ist die Syntax der compute-Anweisung. Operatoren und Operanden müssen durch Leerzeichen getrennt werden. Es ist mehr als ein Operator pro Anweisung erlaubt.
compute v3 = v1 op v2 [op vn ...].
oder
v3 = v2 op v2 [op vn ...].
wobei:
v3 die Empfangsvariable für das Ergebnis der Berechnung ist.
v1, v2 und vn die Operanden sind.
op ein mathematischer Operator ist.
Tabelle 9.5 enthält eine Liste der gültigen Operatoren.
Tabelle 9.5: Gültige Operatoren für die compute-Anweisung
Operator Operation
+ Addition
- Subtraktion
* Multiplikation
/ Division
** Exponentiation
DIV Ganzzahldivision
MOD Rest der Ganzzahldivision
Es gibt auch eingebaute Funktionen. Eine Liste erhalten Sie über die F1-Hilfe des Schlüsselwortes compute.

Die Operatorenreihenfolge ist wie folgt:
■ Zunächst werden eingebaute Funktionen ausgewertet, ■ dann Exponenten, ■ dann *,/,DIV, und MOD in der Reihenfolge ihres Vorkommens im Ausdruck, ■ dann + und - in der Reihenfolge ihres Vorkommens im Ausdruck.
Division durch Null ergibt einen Kurzdump, außer beide Operanden sind Null. In diesem Fall ist das Ergebnis Null. Werte werden, falls nötig, während der Berechnung konvertiert. Die Regeln für die Datenkonvertierung und die Reihenfolge der Datentypenpriorität (weiter unten bei der if-Anweisungbeschrieben) bestimmen, wie die Konvertierung durchgeführt wird.
Mathematische Ausdrücke können eine beliebige Anzahl Klammern enthalten. Vor und nach jeder Klammer muß mindestens ein Leerzeichen stehen. Es gibt jedoch eine Ausnahme zu dieser Regel. Es darf kein Leerzeichen nach einem eingebauten Funktionsnamen stehen; die öffnende Klammer muß unmittelbar danach folgen. Tabelle 9.6 zeigt die richtigen und falschen Wege, mathematische Ausdrücke zu programmieren.
Tabelle 9.6: Richtige und falsche Wege, mathematische Anweisungen zu programmieren
Richtig Falsch
f1 = f2 + f3. f1 = f2+f3.
f1 = ( f2 + f3 ) * f4. f1 = (f2 + f3) * f4.
f1 = sqrt( f2 ). f1 = sqrt ( f2 ).
f1 = sqrt(f2).
Der Auswahlknopf Festpunktarithmetik in den Programmattributen steuert, auf welche Weise die Dezimalberechnungen durchgeführt werden, und sollte immer aktiv sein. Wenn er es ist, werden Zwischenergebnisse auf 31 Dezimalstellen genau berechnet und bei der Zuweisung an die Ergebnisvariable aufgerundet. Ist dem nicht so, haben die Zwischenergebnisse keine Dezimalstellen, womit die Dezimalgenauigkeit dahin ist. Wenn zum Beispiel Festpunktarithmetik nicht ausgewählt ist, ergibt die Berechnung 1/*3 das Ergebnis Null, da das Zwischenergebnis 0.333333 auf Null gerundet wird, bevor es mit 3 multipliziert wird. Wenn es ausgewählt ist, ist das Ergebnis 1.
Die add- und add-corresponding-Anweisungen
Benutzen Sie die add-Anweisung, um eine Zahl zu einer anderen zu addieren. Feldleisten mit gleichnamigen Komponenten können mit add-corresponding addiert werden.

Syntax für die add-Anweisung
Nun folgt die Syntax für die add-Anweisung. Datenkonvertierungen werden, falls nötig, durchgeführt, ebenso wie bei der compute-Anweisung.
add v1 to v2.
wobei:
■ v2 die Variable ist, auf die addiert wird. ■ v1 die Variable ist, die aufaddiert wird.
Die Syntax für die subtract-, multiply- und divide-Anweisungen ist ähnlich.
Syntax für die add-corresponding-Anweisung
Untenstehend ist die Syntax für die add-corresponding-Anweisung.
add-corresponding s1 to s2.
wobei:
s2 die Feldleiste ist, auf die addiert wird.
s1 die Feldleiste ist, die aufaddiert wird.
Eine add-Anweisung wird für jedes Paar gleichnamiger Komponenten in s1 und s2 erzeugt. Datenkonvertierungen werden in der gleichen Weise durchgeführt, wie für die add-Anweisung.Subtract-corresponding, multiply-corresponding und divide-corresponding funktionieren in entsprechender Weise.
Beispiele bietet Listing 9.13.
Listing 9.13: Die add-, subtract-, multiply-, divide- und corresponding-Anweisungen.
1 report ztx0913.2 data: f1 type i value 2,3 f2 type i value 3,4 begin of s1,5 c1 type i value 10,6 c2 type i value 20,7 c3 type i value 30,8 end of s1,

9 begin of s2,10 c1 type i value 100,11 x2 type i value 200,12 c3 type i value 300,13 end of s2.14 add f1 to f2. write / f2. "f1 is unchanged15 subtract f1 from f2. write / f2.16 multiply f2 by f1. write / f2.17 divide f2 by f1. write / f2.18 add-corresponding s1 to s2. write: / s2-c1, s2-x2, s2-c3.19 subtract-corresponding s1 from s2. write: / s2-c1, s2-x2, s2-c3.20 multiply-corresponding s2 by s1. write: / s2-c1, s2-x2, s2-c3.21 divide-corresponding s2 by s1. write: / s2-c1, s2-x2, s2-c3.
Das Programm in Listing 9.13 erzeugt diese Ausgabe:
5363110 200 330100 200 3001,000 200 9,000100 200 300
Datumsberechnungen
Eine Datumsvariable (Type d) kann innerhalb mathematischer Ausdrücke benutzt werden. Weist man das Ergebnis einer Datumsberechnung einer gepackten Variablen zu, ergibt das die Differenz in Tagen. Ein Beispiel bietet Listing 9.14.
Listing 9.14: Datumsberechnungen mittels der Datumsvariablen in einem Ausdruck
1 report ztx0914.2 type-pools ztx1. "contains ztx1_amalgamation_date3 data: d1 like sy-datum,4 d2 like d1,5 num_days type p.6 d1 = d2 = sy-datum.78 subtract 1 from d1. write / d1. "yesterday's date9 d2+6 = '01'. write / d2. "first day of current month10 subtract 1 from d2. write / d2. "last day of previous month11

12 num_days = sy-datum - ztx1_amalgamation_date.13 write / num_days. "number of days since amalgamation
Am 22. Februar 1999 erzeugt das Programm in Listing 9.14 diese Ausgabe:
1999/02/211999/02/011999/01/31354
■ In Zeile 2 bewirkt die type-pools-Anweisung, daß die Konstante ztxl_amalgamation_date in das Programm eingeschlossen wird.
■ In Zeile 6 wird das aktuelle Datum d1 und d2 zugewiesen. ■ In Zeile 8 wird das gestrige Datum berechnet, indem 1 vom aktuellen Datum abgezogen wird. ■ In Zeile 9 wird das Teilfeld d2 am Offset 6 mit Länge 2 (die Länge stammt vom Sendefeld)
auf '01' gesetzt. Da Datumswerte immer im internen Format JJJJMMTT gespeichert werden, wird der Tageswert des Datums in d2 auf '01' gesetzt. Das Ergebnis ist, daß d2 ein Datum gleich dem ersten Tag des aktuellen Monats enthält.
■ In Zeile 10 wird 1 von d2 abgezogen, das ergibt das Datum des letzten Tag des Vormonats. ■ In Zeile 12 wird die Differenz in Tagen zwischen dem aktuellen Datum und dem
Amalgamationsdatum berechnet. Das Ergebnis wird dem gepackten Feld num_dayszugewiesen und in Zeile 13 ausgegeben.
Dynamische Zuweisungen
Ein Feldsymbol ist ein Zeiger, den Sie dynamisch einem Feld zuweisen können. Nach der Zuweisung können Sie das Feldsymbol irgendwo in Ihrem Programm anstelle des tatsächlichen Feldnamens benutzen. Benutzen Sie die field-symbol-Anweisung, um ein Feldsymbol zu definieren, und benutzen Sie assign, um diesem ein Feld zuzuweisen. Der Feldsymbolname muß mit spitzen Klammern beginnen und enden. Listing 9.15 enthält ein einfaches Beispiel.
Listing 9.15: Ein Feldsymbol ist eine Referenz zu einem anderen Feld.
1 report ztx0915.2 data f1(3) value 'ABC'.3 field-symbols <f>.4 assign f1 to <f>. "<f> can now be used in place of f1
5 write <f>. "writes the contents of f16 <f> = 'XYZ'. "assigns a new value to f17 write / f1.
Das Programm in Listing 9.15 erzeugt diese Ausgabe:

ABCXYZ
■ Zeile 3 definiert ein Feldsymbol mit Namen <f>.■ Zeile 4 weist das Feld f1 dem Feldsymbol <f> zu. <f> zeigt nun auf die Hauptspeicherstelle
der Variablen f1 und kann anstelle von f1 irgendwo im Programm benutzt werden. ■ Zeile 5 gibt <f> aus und bewirkt, daß der Inhalt von f1 ausgegeben wird. ■ Zeile 6 ändert den Inhalt von <f>, ändert aber tatsächlich f1.■ Zeile 7 gibt den geänderten Inhalt von f1 aus.
Sie können Feldsymbole benutzen, um sehr flexible Programme zu erzeugen. Angenommen zum Beispiel, Sie wollen ein Programm schreiben, das einen Tabellennamen als Eingabeparameter einliest und den Inhalt anzeigt: Sie können die Feldnamen in der write-Anweisung nicht fest programmieren, weil die Namen in jeder Tabelle verschieden sind. Sie können statt dessen ein Feldsymbol in der write-Anweisung benutzen, um auf das Feld einer Tabelle Bezug zu nehmen.
Zusammenfassung
■ Systemvariablen sind in der Struktur syst gespeichert. Sie können die Beschreibungen der Felder und ihrer Datenelemente durchsuchen, um Ihr gesuchtes Feld zu finden. Dieses Verfahren kann benutzt werden, um alle Felder irgendeiner Tabelle zu durchsuchen.
■ Die Zuweisungsanweisungen sind clear, move und move-corresponding.■ Clear weist Standard-Anfangswerte einer Variablen oder Feldleiste zu. Sie können sie auch
benutzen, um ein Feld mit beliebigen Zeichen oder Nullen zu füllen. ■ Die move-Anweisung kann auch als = geschrieben werden. Mehrfachzuweisungen in einer
einzigen Zeile sind möglich, beispielsweise v1 = v2 = v3. Konvertierungen werden automatisch durchgeführt. Ein Feldleistenname ohne Komponentennamen wird wie eine Variable vom Typ c behandelt.
■ Um Daten zwischen Feldleisten zu übertragen, welche exakt in Komponentenanzahl, Datentyp und Länge jeder Komponente übereinstimmen, benutzen Sie move. Um Daten zwischen Feldleisten mit (wenigstens einer) gleichnamigen Komponenten, aber unterschiedlichen Datentypen oder Längen zu bewegen, benutzen Sie move-corresponding.
■ Um die einzelnen Bytes eines Feldwertes anzusprechen, benutzen Sie ein Teilfeld. Ein Teilfeld kann sowohl als Sende- als auch als Empfangsfeld oder als beides verwendet werden.
■ Sie können Berechnungen durchführen, indem Sie compute, add, subtract, multiply, divide, add-corresponding, subtract-corresponding, multiply-corresponding und divide-corresponding eingeben.
Erlaubt Nicht erlaubt
Um Konversionen zu vermeiden, benutzen Sie Felder des gleichen Datentyps.
Bewegen Sie keine ungültigen Werte in Felder.

Verwenden Sie move-corresponding, um Felder von einer zu einer anderen Feldleiste zu bewegen, wenn die Komponenten den gleichen Namen haben, aber die Datentypen und Längen nicht zueinander passen.
Verwenden Sie die clear-Anweisung, um Default-Initiale einer Variablen oder Feldleiste zuzuweisen.
Fragen & Antworten
Frage:Ich kann zwar die clear-Anweisung benutzen, um einen Wert auf Leerzeichen oder Nullen zu setzen, aber gibt es auch eine Anweisung, die eine Variable auf den Wert zurücksetzen kann, den ich mit dem value-Zusatz der data-Anweisung angegeben habe?
Antwort:Nein, die gibt es leider nicht.
Frage:Kann ich die move-Anweisung mit Feldleisten unterschiedlicher Länge benutzen?
Antwort:Ja, können Sie. Sie werden beide als Variablen vom Typ c behandelt. Der Sendewert wird entsprechend abgeschnitten oder am Ende mit Leerzeichen aufgefüllt, bevor er der Empfangsfeldleiste zugewiesen wird.
Frage:Warum muß ich über Füllbytes Bescheid wissen? Kümmert sich nicht das System darum, wenn ich nur alle Regeln befolge?
Antwort:Technisch gesehen, ja. Wenn Sie allerdings mehrere Programme erstellen, werden Sie gelegentlich unvermeidlich eine Feldleiste falsch mit move zuweisen. Wenn Sie Füllbytes verstehen und wissen, wie sie Ihre Ausgabe beeinflussen, sind Sie hoffentlich in der Lage, die Ursache Ihres Problems zu erkennen, und müssen nicht auf »Tricks« zurückgreifen, um Ihr Programm zum Laufen zu bringen.
Frage:Es scheint seltsam, daß ich Variablen ungültige Werte zuweisen kann. Was passiert, wenn ich solch eine Variable mit ungültigem Wert weiter benutze?
Antwort:Es kann alles passieren. Ich würde kein Programm schreiben, das sich bewußt auf ungültige Variablen verläßt. Versuchen Sie zum Beispiel nicht, einen speziellen Datumswert zu benutzen, der nur aus x besteht, um etwas Besonderes wie ein fehlendes Datum anzuzeigen. Das Verhalten Ihres

Programms wird unvorhersehbar, wenn Sie die erlaubten Grenzen der Sprache überschreiten.
Frage:Die Syntaxmeldungen zeigen oft nicht an, was wirklich falsch ist in meinem Programm. Liegt das an mir, oder arbeitet der Syntaxprüfer manchmal nicht richtig?
Antwort:Anwort: Sagen wir einfach: An Ihnen liegt es nicht. Meine ewige Lieblingsmeldung ist xxxx wirderwartet. Es bedeutet in Wirklichkeit »xxxx wird nicht erwartet«. Wenn Sie also diese Meldung sehen, ergänzen Sie das Wort nicht, und sie wird richtig.
Workshop
Der Workshop bietet Ihnen zwei Varianten, das, was Sie in diesem Kapitel gelernt haben, zu vertiefen. Der Abschnitt mit den Kontrollfragen hilft Ihnen, Ihr Verständnis des behandelten Stoffes zu festigen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie das Gelernte anwenden. Sie finden die Antworten im Anhang B (»Antworten zu Kontrollfragen und Übungen«).
Kontrollfragen
1. Nennen Sie mehrere Möglichkeiten, den Wert von einer Variablen zu einer anderen zu übertragen!
2. Was muß Operanden und Operatoren trennen, damit die Berechnung funktioniert?
Übung 1
Benutzen Sie das Verfahren »Wie man die Beschreibungen einer Struktur oder Tabelle sucht«, um folgendes zu finden:
1. den Namen des Zahlungsblockfeldes in der Tabelle lfal
2. den Namen des Gruppenschlüsselfeldes in der Tabelle kna1
3. den Namen des Systemfeldes, das die Position einer Zeichenkette enthält
4. den Namen des Systemfeldes, das die Meldungsnummer enthält
5. den Namen des Materialgruppenfeldes in der Tabelle mara
Zwei Dinge sind falsch im Programm in Listing 9.16. Welche sind dies?
Listing 9.16: Dieses Programm zeigt den Gebrauch einiger wichtiger Systemvariablen.

report zty0916.tables ztxlfa1.parameters land1 like ztxlfa1-land1 obligatory default 'US'.select * from ztxt005twhere land1 = land1and spras = sy-langu.write: / 'Description:', ztxt005t-landx.endselect.if sy-subrc <> 0.write: / 'No descriptions exist for country', land1.endif.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 10
Allgemeine Kontrollanweisungen
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes können:
■ die allgemeinen Kontrollanweisungen if, case, do und while codieren ■ Programmsequenzen unter Verwendung von exit, continue und check kontrollieren ■ einfache Positions- und Längenspezifikationen in der write-Anweisung codieren
Die if-Anweisung
Die if-Anweisung in ABAP/4 hat Vergleichsoperatoren für Gleichheit und Ungleichheit und spezielle Vergleichsoperatoren für Zeichenketten und Bitmasken.
Bitvergleiche sind nicht sehr häufig in ABAP/4 und werden hier deshalb nicht behandelt. Gleichwohl werden sie in der ABAP/4-Schlüsselwörterdokumentation unter der Überschrift »Vergleichsoperatoren für Bitmasken« erwähnt.
Syntax für die if-Anweisung
Es folgt die Syntax für die if-Anweisung.
if [not] exp [ and [not] exp ] [ or [not] exp ].---

[elseif exp.---][else.---]endif.
wobei gilt:
■ exp ist ein logischer Ausdruck, der als ein wahrer oder nicht wahrer Zustand ausgewertet wird. ■ --- stellt jegliche Anzahl von Code-Zeilen dar. Sogar Nullzeilen sind erlaubt.
Folgende Punkte gelten:
■ Jedes if braucht ein entsprechendes endif.■ else und elseif sind optional. ■ Klammern können benutzt werden. Alle Klammern müssen durch eine Leerstelle getrennt
werden. Richtig ist zum Beispiel if ( f1 = f2 ) or ( f1 = f3 ), während if (f1 = f2) or (f1 = f3) falsch ist.
■ Mit Hilfe von is initial können Variable mit Leerzeichen oder Nullen verglichen werden. Zum Beispiel ist if f1 is initial richtig, wenn f1 Typ c und leer ist. Wenn f1irgendein anderer Datentyp ist, ist die Anweisung wahr, wenn f1 Nullen enthält.
■ Um die Negation zu erfüllen, muß not dem logischen Ausdruck vorausgehen. Richtig ist zum Beispiel if not f1 is initial, falsch dagegen if f1 is not initial .
■ Variablen können mit Nullen verglichen werden mit dem Zusatz null. Zum Beispiel: if f1 is null.
Die logischen Operatoren für Operanden jeden Typs sind in Tabelle 10.1 aufgelistet.
Tabelle 10.1: Gebräuchliche Vergleiche und ihre alternativen Formen
Vergleich Alternative Formen Wahr, wenn
v1 = v2 EQ v1 gleich v2
v1 <> v2 NE, >< v1 ungleich v2
v1> v2 GT v1 ist größer als v2
v1 <v2 LT v1 ist kleiner als v2
v1 >= v2 GE, => v1 ist größer oder gleich v2
v1 <= v2 LE, =< v1 ist kleiner oder gleich v2
v1 between v2and v3
v1 liegt zwischen v2 und v3(einschließlich)

not v1 between v2 and v3
v1 liegt außerhalb des Bereiches von v2 und v3 (einschließlich)
In Tabelle 10.1 können v1 und v2 Variablen, Literale oder Feldleisten sein. Im Fall von Variablen oder Literalen wird die automatische Konvertierung ausgeführt, wenn der Datentyp oder die Länge nicht übereinstimmen. Feldleisten werden wie Variablen vom Typ c behandelt.
Der Vergleich zweier Werte, die nicht die gleichen Datentypen haben, mündet in einer internen automatischen Typenanpassung von einem oder beiden Werten. Ein Typ wird den Vorrang haben und diktieren, welche Art von Konvertierung ausgeführt wird. Die Reihenfolge dieses Vorrangs ist:
■ Wenn ein Feld Typ f ist, wird das andere in Typ f konvertiert.■ Wenn ein Feld Typ p ist, wird das andere in Typ p konvertiert. ■ Wenn ein Feld Typ i ist, wird das andere in Typ i konvertiert. ■ Wenn ein Feld Typ d ist, wird das andere in Typ d konvertiert. Die Typen c und n werden
allerdings nicht konvertiert. Sie werden direkt verglichen. ■ Wenn ein Feld Typ t ist, wird das andere in Typ t konvertiert. Die Typen c und n werden
allerdings nicht konvertiert. Sie werden direkt verglichen. ■ Wenn ein Feld Typ n ist, werden beide in Typ p konvertiert (in diesem Fall kann das andere
Feld nur Typ c oder x sein). ■ An diesem Punkt ist ein Feld Typ c und das andere Typ x. x wird zu p konvertiert.
Konvertierungen folgen den gleichen Konventionen wie die, die von der move-Anweisung ausgeführt werden. Typkonvertierungen werden detailliert beschrieben in der ABAP/4-Schlüsselwörterdokumentation »Relational Operators for All Data Types.«
Datenkonvertierungen von Literalen während Vergleichsoperationen
Literale sind intern mit Datentypen gespeichert, wie sie in Tabelle 10.2 gezeigt werden.
Tabelle 10.2: Datentypen von Literalen
Beschreibung Datentyp
Zahlen mit 1 bis 9 Ziffern i
Zahlen mit 10 oder mehr Ziffern p
Alle anderen c
Typkonvertierungen für Literale folgen der gleichen Reihenfolge von Vorrängen, und es gelten die gleichen Konvertierungsregeln.

Listing 10.1: Ein Beispiel für die Verwendung von if im Programm
1 report ztx1001.2 data: begin of s1,3 x value 'X',4 y value 'Y',5 z value 'Z',6 end of s1,7 begin of s2,8 x value 'X',9 z value 'Z',10 end of s2.1112 if s1-x = s2-x.13 write: / s1-x, '=', s2-x.14 else.15 write: / s1-x, '<>', s2-x.16 endif.1718 if s1-x between s2-x and s2-z.19 write: / s1-X, 'is between', s2-x, 'and', s2-z.20 else.21 write: / s1-X, 'is not between', s2-x, 'and', s2-z.22 endif.2324 if s1 = s2. "comparing field strings byte by byte25 write: / 's1 = s2'.26 else.27 write: / 's1 <> s2'.28 endif.2930 if 0 = ' '. "Watch out for this one31 write: / '0 = '' '''.32 else.33 write: / '0 <> '' '''.34 endif.
Listing 10.1 zeigt ein Beispielprogramm mit den gebräuchlichen Vergleichsoperatoren und einer Konvertierung.
Der Code in Listing 10.1 erzeugt diese Ausgabe:
X = XX is between X and Zs1 <> s20 = ' '

■ Auf Zeile 12 wird s1-x mit s2-x verglichen. Beide sind vom Typ c und haben die Länge 1. Es erfolgt keine Konvertierung, und die Variablen sind gleich.
■ Zeile 18 ist ähnlich, benutzt aber den between-Operator. Der Wert X liegt zwischen X und Z,und daher ergibt der Test wahr.
■ Zeile 24 vergleicht die Feldleisten s1 und s2, als ob sie Variablen vom Typ c wären. Der Wert von s1 ist deswegen XYZ, der Wert von s2 ist XZ. Sie sind ungleich.
■ Auf Zeile 30 wird das Literal 0 mit einem Leerfeld verglichen. Die Null ist intern als Typ igespeichert, das andere als Typ c. Wegen der Reihenfolge der Vorränge wird Typ c in Typ ikonvertiert. Die Konvertierung eines Leerzeichens in eine ganze Zahl bewirkt einen Nullwert, und der Vergleich erweist sich als unerwartet wahr.
Konvertierungen anzeigen
Wenn Sie eine Programmanalyse ausführen, können Sie entscheiden, wo Konvertierungen innerhalb eines Programms vorkommen. Um eine Programmanalyse auszuführen, verwenden Sie die folgende Prozedur.
1. Starten Sie das ScreenCam »How to Perform a Program Analysis«.
2. Starten Sie den Report RSANAL00.
3. Es erscheint die Maske ABAP/4-Programmanalyse.
4. Drücken Sie auf Konvertierungen.
5. Klicken Sie zweimal auf irgendeine Zeile, um sie sich innerhalb des Programms anzusehen.
elseif verwenden
Sie benutzen elseif, um verschachtelte ifs zu vermeiden. Verschachtelte ifs können schwierig zu lesen und zu pflegen sein. (Siehe Listing 10.2).
Listing 10.2: Die Verwendung von elseif ist klarer als die von verschachtelten ifs.
1 report ztx1002.2 parameters: f1 default 'A',3 f2 default 'B',4 f3 default 'C'.56 if f1 = f2. write: / f1, '=', f2.7 elseif f1 = f3. write: / f1, '=', f3.8 elseif f2 = f3. write: / f2, '=', f3.9 else. write: / 'all fields are different'.10 endif.

1112 *lines 5-9 do the same as lines 14-261314 if f1 = f2.15 write: / f1, '=', f2.16 else.17 if f1 = f3.18 write: / f1, '=', f3.19 else.20 if f2 = f3.21 write: / f2, '=', f3.22 else.23 write: / 'all fields are different'.24 endif.25 endif.26 endif.
Der Code in Listing 10.2 erzeugt diese Ausgabe:
all fields are differentall fields are different
■ Wenn f1 = f2, ist Zeile 6 richtig. ■ Wenn f1 = f3, ist Zeile 7 richtig. ■ Wenn f2 = f3, ist Zeile 8 richtig. ■ Wenn nichts davon wahr ist, ist Zeile 9 richtig. ■ Die Zeilen 14 bis 26 führen das gleiche wie die Zeilen 6 bis 10 aus. Sie wurden mitaufgeführt,
so daß Sie die beiden Verfahren nebeneinander sehen können.
Verwendung von Zeichenkettenoperatoren
Besondere Operatoren für Zeichenketten sind in Tabelle 10.3 aufgeführt.
Tabelle 10.3: Besondere Operatoren für Zeichenketten
Operator Bedeutet Wahr, wenn
Case Sensitiv?
(Unterscheidung von Groß- und Kleinbuchstaben)
NachgestellteLeerzeichenignoriert?
v1 CO v2 Enthält nur v1 besteht nur aus Zeichen von v2
Ja Nein

v1 CN v2 not v1 CO v2 v1 enthält Zeichen, die nicht in v2 vorkommen
Ja Nein
v1 CA v2 Enthält irgendein v1 enthält mindestens ein Zeichen aus v2
Ja Nein
v1 NA v2 not v1 CA v2 v1 enthält nicht ein einziges Zeichen aus v2
Ja Nein
v1 CS v2 Enthält eine Zeichenkette
v1 enthält die Zeichenkette v2
Nein Ja
v1 NS v2 not v1 CS v2 v1 enthält nicht die Zeichenkette v2
Nein Ja
v1 CP v2 Enthält ein Muster
v1 enthält die Muster in v2
Nein Ja
v1 NP v2 not v1 CP v2 v1 enthält nicht die Muster in v2
Nein Ja
Diese Operatoren können in jedem Vergleich benutzt werden. Die CS-, NS-, CP- und NP-Operatorenignorieren nachgestellte Leerzeichen und berücksichtigen keine Groß- /Kleinschreibung.
Obwohl Sie Variable, Konstanten oder Literale mit Vergleichsoperatoren für Zeichenketten benutzen können, verwendet Listing 10.3 wegen der Übersichtlichkeit nur Literale. Ebenfalls wegen der Übersichtlichkeit steht hier jede if-Anweisung in einer eigenen Zeile.
Listing 10.3: Ein Beispielprogramm für Übungen mit CO, CN, CA und NA
1 report ztx1003.2 * operator: co3 write / '''AABB'' co ''AB'''.4 if 'AABB' co 'AB'. write 'True'. else. write 'False'. endif.5 write / '''ABCD'' co ''ABC'''.6 if 'ABCD' co 'ABC'. write 'True'. else. write 'False'. endif.78 * operator: cn9 write / '''AABB'' cn ''AB'''.10 if 'AABB' cn 'AB'. write 'True'. else. write 'False'. endif.11 write / '''ABCD'' cn ''ABC'''.12 if 'ABCD' cn 'ABC'. write 'True'. else. write 'False'. endif.1314 * operator: ca15 write / '''AXCZ'' ca ''AB'''.

16 if 'AXCZ' ca 'AB'. write 'True'. else. write 'False'. endif.17 write / '''ABCD'' ca ''XYZ'''.18 if 'ABCD' ca 'XYZ'. write 'True'. else. write 'False'. endif.1920 * operator: na21 write / '''AXCZ'' na ''ABC'''.22 if 'AXCZ' na 'ABC'. write 'True'. else. write 'False'. endif.23 write / '''ABCD'' na ''XYZ'''.24 if 'ABCD' na 'XYZ'. write 'True'. else. write 'False'. endif.
Der Code in Listing 10.3 erzeugt diese Ausgabe:
'AABB' co 'AB' True'ABCD' co 'ABC' False'AABB' cn 'AB' False'ABCD' cn 'ABC' True'AXCZ' ca 'AB' True'ABCD' ca 'XYZ' False'AXCZ' na 'ABC' False'ABCD' na 'XYZ' True
■ co ist der contains only-Operator. Zeile 4 ist wahr, weil 'AABB' nur Zeichen von 'AB'enthält.
■ Zeile 6 ist nicht wahr, weil 'ABCD' ein D enthält, das nicht in 'ABC' ist. ■ Die Zeilen 10 und 12 sind die Gegenstücke zu den Zeilen 4 und 6, weil cn das gleiche ist wie not v1 co v2. Die Ergebnisse werden deswegen umgekehrt. Zeile 10 ist nicht wahr, und Zeile 12 ist wahr.
■ ca ist der contains any-Operator, und Zeile 16 ist wahr, wenn 'AXCZ' alle Zeichen von 'AB'enthält. Es ist wahr, weil es A enthält.
■ Zeile 18 ist nicht wahr, weil 'ABCD' keine Zeichen von 'XYZ' enthält. ■ na ist gleich not v1 ca v2. Daher sind die Zeilen 22 und 24 die logische Negation der
Zeilen 16 und 18.
In Bezug auf Tabelle 10.3 führen die CP (contains pattern)- und NP (no pattern)-Operatoren einen Zeichenkettensuchvorgang aus, der einen Mustervergleich mit bestimmten Zeichen erlaubt. Der Ausdruck v1 CP v2 ist wahr, wenn v1 eine Zeichenkette enthält, die dem Muster in v2 entspricht. Der Ausdruck v1 NP v2 ist wahr, wenn v1 keine Zeichenkette enthält, die zum Muster in v2 paßt. Er ist gleichwertig zu not v1 cp v2. Die Zeichen, die für den Mustervergleich in v2 erlaubt sind, werden in Tabelle 10.4 aufgeführt.
Tabelle 10.4: CP- und NP-Operatoren
Zeichen Verwendung

* Zu jeder Zeichensequenz passend
+ Zu jedem einzelnen Zeichen passend
# Wörtlich das nächste Zeichen interpretierend
# ist das »Fluchtzeichen« (escape character). Das nächste ihm folgende Zeichen wird genau interpretiert. Sollte eine spezielle Bedeutung existieren, geht diese verloren. Sie können # auch dazu benutzen um nach Groß-/Kleinschreibung zu suchen, oder nach den Zeichen *, +, oder #. Tabelle 10.5 zeigt Beispiele dafür, wie Sie diese Zeichen benutzen könnten. Der escape character wird benötigt, wenn Sie nach Groß-/Kleinschreibung suchen wollen, wobei Sie CS, NS, CP oder NP benutzen. Sie brauchen ihn auch, wenn Sie einen Mustersuchvorgang (CP oder NP) für eine Zeichenkette ausführen wollen, die *, + oder # enthält.
Tabelle 10.5: Verwendung von Zeichen
Anweisung Wahr, wenn
v1 CP 'A+C' v1 enthält »a« an der ersten Position und »c« an der dritten. Jedes Zeichen kann groß oder klein geschrieben sein. Jedes Zeichen kann an der zweiten Position erscheinen.
v1 CP '*Ab*' Die Zeichenkette »ab« kommt innerhalb v1 an beliebiger Stelle vor. Jedes Zeichen kann groß oder klein geschrieben sein.
v1 CP '*#A#b*' v1 enthält ein großes A, gefolgt von einem klein geschriebenen b.
v1 CP '*##*' v1 enthält ein #.
Der Gebrauch dieser Operatoren setzt immer die Systemvariable sy-fdpos ein. Wenn das Ergebnis des Vergleichs wahr ist, enthält sy-fdpos den auf Null basierenden Offset des ersten passenden oder nicht passenden Zeichens. Ansonsten enthält sy-fdpos die Länge von v1. Der Wert, der sy-fdpos durch jeden Operator zugewiesen wird, ist in Tabelle 10.6 beschrieben.
In dieser Tabelle bedeutet »1st char(v1)« das »Offset des ersten Zeichens der Zeichenkette bzw. des Musters von v1«. Wenn Sie also »1st char(v1) in v2« sehen, lesen Sie es als »das basierende Nulloffset des ersten Zeichens von v1, das auch in v2 enthalten ist«. Length (v1) bedeutet »die Länge von v1«. Achten Sie darauf, daß die erste Spalte ABAP/4-Anweisungen enthält.
Tabelle 10.6: Wert, der sy-fdpos durch den jeweiligen Operator zugewiesen wird
Vergleich if TRUE sy-fdpos = if FALSE sy-fdpos =
v1 CO v2 length (v1) 1stchar (v1) not in v2

v1 CN v2 1stchar (v1) in v2 length (v1)
v1 CA v2 1stchar (v1) in v2 length (v1)
v1 NA v2 length (v1) 1stchar (v1) in v2
v1 CS v2 1stchar (v2) in v1 length (v1)
v1 NS v2 length (v1) 1stchar (v1) in v2
v1 CP v2 1stchar (v2) in v1 length (v1)
Listing 10.4 ist Listing 10.3 ähnlich, es sind aber Zeilen hinzugefügt worden, um nach jedem Vergleich den Wert von sy-fdpos anzuzeigen.
Listing 10.4: sy-fdpos wird benutzt, um das Offset der ersten passenden oder nicht passenden Zeichen zu sehen.
1 report ztx1004.2 * operator: co3 write / '''AABB'' co ''AB'''.4 if 'AABB' co 'AB'. write 'True'. else. write 'False'. endif.5 write: 'sy-fdpos=', sy-fdpos.6 write / '''ABCD'' co ''ABC'''.7 if 'ABCD' co 'ABC'. write 'True'. else. write 'False'. endif.8 write: 'sy-fdpos=', sy-fdpos.910 * operator: cn1 write / '''AABB'' cn ''AB'''.12 if 'AABB' cn 'AB'. write 'True'. else. write 'False'. endif.13 write: 'sy-fdpos=', sy-fdpos.14 write / '''ABCD'' cn ''ABC'''.15 if 'ABCD' cn 'ABC'. write 'True'. else. write 'False'. endif.16 write: 'sy-fdpos=', sy-fdpos.1718 * operator: ca19 write / '''AXCZ'' ca ''AB'''.20 if 'AXCZ' ca 'AB'. write 'True'. else. write 'False'. endif.21 write: 'sy-fdpos=', sy-fdpos.2223 write / '''ABCD'' ca ''XYZ'''.24 if 'ABCD' ca 'XYZ'. write 'True'. else. write 'False'. endif.25 write: 'sy-fdpos=', sy-fdpos.262728 * operator: na29 write / '''AXCZ'' na ''ABC'''.30 if 'AXCZ' na 'ABC'. write 'True'. else. write 'False'. endif.31 write: 'sy-fdpos=', sy-fdpos.

3233 write / '''ABCD'' na ''XYZ'''.34 if 'ABCD' na 'XYZ'. write 'True'. else. write 'False'. endif.35 write: 'sy-fdpos=', sy-fdpos.
Der Code in Listing 10.4 erzeugt diese Ausgabe:
'AABB' co 'AB' True sy-fdpos= 4'ABCD' co 'ABC' False sy-fdpos= 3'AABB' cn 'AB' False sy-fdpos= 4'ABCD' cn 'ABC' True sy-fdpos= 3'AXCZ' ca 'AB' True sy-fdpos= 0'ABCD' ca 'XYZ' False sy-fdpos= 4'AXCZ' na 'ABC' False sy-fdpos= 0'ABCD' na 'XYZ' True sy-fdpos= 4
■ Zeile 4, ein co-Vergleich, ist wahr. Sy-fdpos enthält deswegen 4, die Länge des ersten Operanden.
■ Zeile 7, auch ein co-Vergleich, ist nicht wahr, weil v1 Werte enthält, die nicht in v2 sind. Sy-fdpos enthält 3, das nullbasierende Offset des ersten Zeichens in v1, das nicht in v2vorkommt.
■ Obwohl die Zeilen 12 und 15 die logischen Gegenteile der Zeilen 4 und 7 sind, ändern sich die Werte von sy-fdpos nicht.
■ Zeile 20, ein ca-Vergleich, ist wahr, weil v1 ein Zeichen von v2 enthält. Sy-fdpos enthält 0: das nullbasierende Offset des ersten Zeichens in v1, das auch in v2 ist.
■ Auf Zeile 24 enthält v1 kein Zeichen aus v2, sy-fdpos enthält deswegen 4: die Länge von v1.
■ Zeile 30 ist die logische Negation eines ca-Tests. 'AXCZ' enthält einen Wert von 'ABC',daher ist der ca-Test wahr. Die Negierung dieses Ergebnises würde falsch erzeugen. Sy-fdpos ist in das nullbasierende Offset des ersten Zeichens von 'AXCZ' gesetzt, das auch in 'ABC' ist.
■ Zeile 34 ist ebenfalls eine logische Negation eines ca-Tests. 'ABCD' enthält keinen Wert von 'XYZ', daher wäre ein ca-Test nicht wahr. Die Negierung dieses Ergebnises würde wahr erzeugen. Sy-fdpos ist auf die Länge von 'ABCD' eingestellt.
Die case-Anweisung
Die case-Anweisung führt eine Reihe von Vergleichen aus.
Syntax für die case-Anweisung
Das Folgende ist die Syntax für die case-Anweisung.
case v1.

when v2 [ or vn ... ].---when v3 [ or vn ... ].---[ when others.--- ]endcase.
wobei gilt:
■ v1 oder v2 können eine Variable, ein Literal, eine Konstante oder eine Feldleiste sein. ■ --- stellt jegliche Anzahl von Code-Zeilen dar. Sogar Nullzeilen sind erlaubt.
Die folgenden Punkte gelten:
■ Nur Anweisungen, die dem ersten passenden when folgen, werden ausgeführt. ■ when others paßt, wenn keines des vorhergehenden whens übereinstimmt. ■ Wenn when others nicht codiert ist und kein when paßt, macht die Verarbeitung weiter mit
der ersten Anweisung, endcase folgt. ■ Ausdrücke sind nicht erlaubt. ■ Feldleisten werden als Typ c behandelt.
Case ist if/elseif sehr ähnlich. Der einzige Unterschied ist, daß Sie komplexe Ausdrücke auf jedem if/elseif angeben können. Mit case können Sie nur einen Einzelwert angeben, der verglichen werden soll, und Werte werden immer auf Gleichheit geprüft. Ein Beispiel wird in Listing 10.5 gezeigt.
Listing 10.5: Die case-Anweisung führt eine Serie von Vergleichen durch.
1 report ztx1005.2 parameters f1 type i default 2.34 case f1.5 when 1. write / 'f1 = 1'.6 when 2. write / 'f1 = 2'.7 when 3. write / 'f1 = 3'.8 when others. write / 'f1 is not 1, 2, or 3'.9 endcase.1011 * The following code is equivalent to the above case statement12 if f1 = 1. write / 'f1 = 1'.13 elseif f1 = 2. write / 'f1 = 2'.14 elseif f1 = 3. write / 'f1 = 3'.15 else. write / 'f1 is not 1, 2, or 3'.16 endif.

Der Code in Listing 10.5 erzeugt diese Ausgabe:
f1 = 2f1 = 2
■ Zeile 2 definiert f1 als einzelnen Zeichenparameter, der den Standardwert 2 hat. ■ Auf Zeile 4 fängt die case-Anweisung an, und f1 wird nacheinander mit 1, 2 und 3
verglichen.■ Zeile 6 stimmt überein und führt die write-Anweisung aus, die ihr sofort folgt. Die
verbleibenden when-Anweisungen werden ignoriert. ■ Die nächste Zeile, die ausgeführt wird, ist Zeile 12.
Die Anweisung exit
Die exit-Anweisung verhindert Weiterverarbeitungen.
Syntax für die Anweisung exit
Dies ist die Syntax für die exit-Anweisung.
exit
Listing 10.6: zeigt ein Beispielprogramm unter Verwendung von exit
Listing 10.6: Mit exit wird die Programmverarbeitung unterbrochen.
1 report ztx1006.2 write: / 'Hi'.3 exit.4 write: / 'There'.
Der Code in Listing 10.6 erzeugt diese Ausgabe:
Hi
Exit verhindert Weiterverarbeitungen, das heißt, exit auf Zeile 3 hält Zeile 4 davon ab, ausgeführt zu werden.
Exit kann in vielen Situationen benutzt werden. Es kann unterschiedliche Wirkungen haben, die davon abhängen, wo es im Code erscheint. Es verhindert allerdings immer die Weiterverarbeitung. Innerhalb von Schleifenstrukturen verläßt es die Schleifenbearbeitung, die von solchen Anweisungen wie loop, select, do und while gestartet werden. Innerhalb von Unterprogrammen verläßt es die Unterprogramme, die von FORM gestartet werden. Seine Wirkungen in anderen Situationen werden dort erklärt, wo sie entstehen.

Die Anweisung do
Die do-Anweisung ist ein grundlegender Schleifenmechanismus.
Syntax für die Anweisung do
Das Folgende ist die Syntax für die Anweisung do.
do [ v1 times ] [ varying f1 from s-c1 next s-c2 [ varying f2 from s2-c1 next s2- c2 ... ] ].---[exit.]---enddo.
wobei gilt:
■ v1 ist eine Variable, ein Literal, oder eine Konstante. ■ s ist eine Feldleiste mit den Komponenten c1 und c2.■ f1 ist eine Variable. Die Komponenten von s müssen in den Datentyp und die Datenlänge von f1 konvertiert werden können.
■ ... stellt jegliche Anzahl vollständiger varying-Klauseln dar. ■ --- stellt jegliche Anzahl von Code-Zeilen dar.
Die folgenden Punkte gelten:
■ do-Schleifen können unbegrenzt verschachtelt werden. ■ exit verhindert weitere Schleifenverarbeitung und steigt sofort aus der laufenden Schleife aus.
Es beendet das Programm nicht, wenn es sich im Inneren einer do- Schleife befindet. Die Verarbeitung macht weiter an der nächsten ausführbaren Anweisung nach enddo.
■ Sie können durch die Codierung von do eine unendliche Schleife ohne weitere Zusätze anlegen. In dieser Situation benutzen Sie exit innerhalb der Schleife, um die Schleifenverarbeitung zu beenden.
■ Die Veränderung des Wertes von v1 innerhalb der Schleife wirkt sich auf die Schleifenverarbeitung nicht aus.
Innerhalb der Schleife enthält sy-index die laufende Iterationsnummer. Zum Beispiel wird beim ersten Schleifendurchlauf sy-index den Wert 1 haben, beim zweiten Mal den Wert 2, und so weiter. Nach enddo hat sy-index den Wert, den es hatte, vor der Schleifenverarbeitung. Mit verschachtelten do-Schleifen enthält sy-index die Iterationsanzahl der Schleife, in der es benutzt wird (siehe Listing 10.7).
Listing 10.7: Sy-index enthält die laufende Iterationsnummer.

1 report ztx1007.2 sy-index = 99.3 write: / 'before loop, sy-index =', sy-index, / ''.4 do 5 times.5 write sy-index.6 enddo.7 write: / 'after loop, sy-index =', sy-index, / ''.89 do 4 times.10 write: / 'outer loop, sy-index =', sy-index.11 do 3 times.12 write: / ' inner loop, sy-index =', sy-index.13 enddo.14 enddo.1516 write: / ''. "new line17 do 10 times.18 write sy-index.19 if sy-index = 3.20 exit.21 endif.22 enddo.
Der Code in Listing 10.7 erzeugt diese Ausgabe:
before loop, sy-index = 991 2 3 4 5after loop, sy-index = 99outer loop, sy-index = 1inner loop, sy-index = 1inner loop, sy-index = 2inner loop, sy-index = 3outer loop, sy-index = 2inner loop, sy-index = 1inner loop, sy-index = 2inner loop, sy-index = 3outer loop, sy-index = 3inner loop, sy-index = 1inner loop, sy-index = 2inner loop, sy-index = 3outer loop, sy-index = 4inner loop, sy-index = 1inner loop, sy-index = 2inner loop, sy-index = 31 2 3

Manchmal muß man in einem Programm »die Zeit totschlagen«. Das sollte man nicht mit einer Leerschleife tun, da hiermit unnötig CPU-Zeit verbraucht wird. Statt dessen kann man den Funktionsbaustein rzl_sleep benutzen.
Änderungen am Wert von sy-index beeinflussen die Schleifenkontrolle nicht. Wenn Sie zum Beispiel do 10 times codieren und während der allerersten Schleife den Wert von sy-index auf 11 ändern, würde dieser Wert bewahrt bleiben, bis die enddo-Anweisung ausgeführt wird. An diesem Punkt wird der Wert auf 1 zurückgesetzt, dann auf 2 erhöht, und die Schleife wird mit der Bearbeitung fortfahren, als ob Sie sie überhaupt nicht geändert hätten.
Eine Endlosschleife beenden
Es gibt Situationen, in denen sich das Programm, mit dem Sie arbeiten, in einer Endlosschleife befindet. Listing 10.8 zeigt solch ein Programm.
Listing 10.8: Eine Endlosschleife kann frustrieren, wenn man nicht weiß, wie man wieder herauskommt.
1 report ztx1008.2 do.3 write sy-index.4 if sy-index = 0.5 exit.6 endif.7 enddo.
Wenn Sie dieses Programm laufen lassen, wird es in einer Endlosschleife laufen, und dieser Modus wird getaktet. Die Beendigung der SAPGUI-Aufgabe oder erneutes Booten wird das Programm nicht unterbrechen, weil es in einem Arbeitsprozeß auf dem Applikationsserver läuft und nicht auf Ihrem PC. Wenn Sie neu booten und dann nochmals einloggen, werden Sie feststellen, daß Sie dieses Programm nicht einmal editieren können (wenn Sie im Editor waren, als Sie den Rechner neu gestartet haben). Ihr Anmeldemodus ist immer noch »dort draußen« auf dem Applikationsserver und hat Ihren Quelltext immer noch gesperrt. Nach ungefähr fünf oder zehn Minuten ist Ihr Anmeldemodus abgelaufen, und Sie können Ihren Quellcode noch einmal editieren. Das Programm könnte in dem Arbeitsprozeß allerdings nach wie vor laufen, was das ganze System verlangsamen würde. Schließlich wird Ihr Programm die maximale Menge von CPU verbrauchen, die in Ihrer Konfiguration erlaubt ist, und der Arbeitsprozeß wird sich selbst wieder starten.
Um eine Endlosschleife zu beenden, müssen Sie mindestens zwei Modi laufen haben, die mit dem Menüpfad System->Erzeugen-Modus angelegt wurden. Sie müssen sie in Gang setzen, bevor Sie Ihr

Programm laufen lassen. Wenn Sie in einer Endlosschleife sind und keinen anderen Modus laufen haben, ist es zu spät. Modi, die durch nochmaliges Einloggen angelegt wurden, funktionieren nicht.
Starten Sie jetzt das ScreenCam »How to Terminate an Endless Loop«.
Eine Endlosschleife beenden:
1. Wenn Sie sich das erste Mal anmelden, wählen Sie den Menüpfad System->Erzeugen-Modus.
2. Minimieren Sie Ihren neuen Modus und lassen Sie ihn im Hintergrund, bis Sie ihn brauchen. Sie können jetzt Programme testen.
3. Jetzt lassen Sie ein Programm laufen, das eine Endlosschleife enthält, wie ztx1008. Sie sehen eine Sanduhr, wenn Ihr Zeiger über dem Fenster ist. Beachten Sie Ihre Modusnummer in der Statusleiste am unteren Rand des Fensters.
4. Halten Sie die (Alt)-Taste gedrückt und betätigen Sie mehrmals (ÿ), bis der Fokus auf der R/3-Ikone bleibt, die Ihren anderen Modus darstellt.
5. Lassen Sie die (ÿ)-Taste los.
6. Tippen Sie /o in das Befehlsfeld auf der Symbolleiste.
7. Die (Enter)-Taste drücken. Die Dialogbox Modusliste erscheint. Sie enthält eine Auflistung Ihrer Modi. Links von jedem sehen Sie die zugehörige Modusnummer.
8. Suchen Sie die Nummer des Schleifenmodus, und klicken Sie einmal diese Zeile an.
9. Drücken Sie auf die Schaltfläche Modus löschen.
Der varying-Zusatz
Verwenden Sie den Zusatz varying, um von einer Feldleiste Komponenten in Folge zu erhalten. next baut eine Distanz (in Byte) zwischen zwei Komponenten durch Iteration auf. Die Annahmekomponente begründet die Anzahl von Byte, um von jeder Komponente zu lesen. Dies erklärt sich am besten durch ein Beispiel, wie es in Listing 10.9 gezeigt wird.
Listing 10.9: Der varying-Zusatz wiederholt die Komponenten einer Feldleiste in Folge.
1 report ztx1009.2 data: f1,3 begin of s,4 c1 value 'A',5 c2 value 'B',

6 c3 value 'C',7 c4 value 'D',8 c5 value 'E',9 c6 value 'F',10 end of s.1112 write / ''.13 do 6 times varying f1 from s-c1 next s-c2.14 write f1.15 enddo.1617 write / ''.18 do 3 times varying f1 from s-c1 next s-c3.19 write f1.20 enddo.
Der Code in Listing 10.9 erzeugt diese Ausgabe:
A B C D E FA C E
In Zeile 13 baut next per Iteration eine gleiche Distanz auf wie zwischen c1 und c2. Die Länge von f1 bestimmt die Anzahl der Byte, die von jeder Komponente gelesen wird. Dann beginnt do bei s-c1 und weist seinen Wert f1 zu. In aufeinanderfolgenden Schleifendurchläufen wird die vorher etablierte Distanz der Adresse der laufenden Komponente zugezählt. Dies bewirkt aufeinanderfolgende Werte, die von s an f1 zugewiesen werden.
Alle Komponenten von s, auf die von do zugegriffen wird, müssen durch exakt dieselbe Anzahl von Byte getrennt werden. Datenkonvertierung durch Zuordnung zu f1 wird nicht ausgeführt.
Einige Tabellen in R/3 sind nicht völlig genormt. Anstatt viele Datensätze zu haben, könnte ein einzelner Satz eine Serie von Feldern enthalten, die nacheinander wiederholt werden. Sie können varying benutzen, um diese Werte in Folge wiederzufinden.
Zum Beispiel enthält Tabelle lfc1 Kreditorenstammdaten. Die Felder umNNs, umNNh und umNNuenthalten alle Soll- und Habenposten eines Monats und die Verkäufe in diesem Zeitraum. Diese Gruppe von Feldern wird 16mal für jeden Satz in dieser Tabelle wiederholt (NN ist eine sequenzielle Nummer von 01 bis 16). Tabelle knc1 enthält eine ähnliche Sequenz von Feldern. In einem anderen Beispiel enthält Tabelle mvke, innerhalb von include envke, 10 Felder für Produktattribute: prat1 bis prata. Sie stehen nebeneinander, gleich weit voneinander entfernt, und somit kann mit varying auf sie zugegriffen werden.
Ein komplexeres Beispiel für den Gebrauch von varying zeigt Listing 10.10.
Listing 10.10: Der varying-Zusatz kann mehr als einmal in der do-Anweisung auftauchen.

1 report ztx1010.2 data: f1 type i,3 f2 type i,4 tot1 type i,5 tot2 type i,6 begin of s,7 c1 type i value 1,8 c2 type i value 2,9 c3 type i value 3,10 c4 type i value 4,11 c5 type i value 5,12 c6 type i value 6,13 end of s.1415 do 3 times varying f1 from s-c1 next s-c316 varying f2 from s-c2 next s-c4.17 write: / f1, f2.18 add: f1 TO tot1,19 f2 to tot2.20 enddo.21 write: / '---------- -----------',22 / tot1, tot2.
Der Code in Listing 10.10 erzeugt diese Ausgabe:
1 23 45 6---------- -----------9 12
F1 ist jeder anderen Komponente von s zugewiesen, die mit s-c1 beginnt, und f2 jeder anderen Komponente, die mit s-c2 beginnt.
Modifizierung von Werten innerhalb von do ... varying/enddo
Sie können den Wert von f1 oder s mit der Schleife do ... varying/enddo modifizieren. Wenn die enddo-Anweisung ausgeführt wird, wird der gegenwärtige Wert von f1 zurückkopiert zu der Komponente, aus der er stammte, egal ob er verändert wurde oder nicht. In Listing 10.11 veranschaulicht der Report ztx1011 diese Funktionalität.
Listing 10.11: Der gegenwärtige Wert von f1 wird zurückgeschrieben zu der sendenden Komponente, wenn enddo ausgeführt wird.
1 report ztx1011.

2 data: f1 type i,3 begin of s,4 c1 type i value 1,5 c2 type i value 2,6 c3 type i value 3,7 c4 type i value 4,8 c5 type i value 5,9 c6 type i value 6,10 end of s.11 field-symbols <f>.1213 write / ''.14 do 6 times varying f1 from s-c1 next s-c2.15 if sy-index = 6.16 s-c6 = 99.17 else.18 f1 = f1 * 2.19 endif.20 assign component sy-index of structure s to <f>. "<f> now points to21 write <f>. "a component of s22 enddo.2324 write / ''.25 do 6 times varying f1 from s-c1 next s-c2.26 write f1.27 enddo.
Der Code in Listing 10.11 erzeugt diese Ausgabe:
1 2 3 4 5 992 4 6 8 10 6
Die folgenden Punkte gelten:
■ Auf Zeile 14 werden die Werte einzeln von den Komponenten der Feldleiste s in f1 gelesen. ■ Zeile 18 modifiziert den Wert jedes f1, indem sie ihn mit 2 multipliziert. Der letzte Wert von f1 wird nicht verändert. Statt dessen wird der sendenden Komponente der Wert 99zugewiesen.
■ Zeile 20 weist dem Feldsymbol <f> eine Komponente von s zu. Bei der ersten Schleife wird die Komponente 1 (c1) <f> zugewiesen. Bei der zweiten wird Komponente 2 (c2)zugewiesen, und so weiter. Zeile 21 schreibt die Inhalte der Komponente aus, die ihren Wert zu f1 gesendet hat. In der Ausgabeliste können Sie die Inhalte von jeder Komponente von ssehen, bevor enddo ausgeführt wurde.
■ Wenn die enddo-Anweisung auf Zeile 22 ausgeführt wird, ersetzen die Inhalte von f1 die Inhalte der Sendekomponente.

■ Wenn man mit varying wieder durch die Schleife geht (Zeilen 25 bis 27), erscheint der neue Inhalt von s. Dies zeigt, daß der Wert von f1 innerhalb der Schleife immer die Inhalte der Sendekomponente überschreibt.
Eine exit-Anweisung innerhalb der Schleife wird die modifizierten Inhalte von f1 nicht davon abhalten, zum Sendefeld zurückgeschrieben zu werden. Die einzige Möglichkeit, die Schleife zu verlassen, ohne daß die Inhalte von f1 das Sendefeld überschreiben, ist, eine stop-Anweisung oder eine error message-Anweisung innerhalb der Schleife auszuführen (beide Anweisungen werden in späteren Kapiteln erklärt).
Der Anweisung while
Die while-Anweisung ist ein Schleifenmechanismus, ähnlich der Anweisung do Syntax für die Anweisung while
Es folgt die Syntax für die while-Anweisung.
while exp [ vary f1 from s-c1 next s-c2 [ vary f2 from s2-c1 next s2-c2 ...]---[ exit. ]---endwhile.
wobei gilt:
■ exp ist ein logischer Ausdruck. ■ s ist eine Feldleiste mit den Komponenten c1 und c2.■ f1 ist eine Variable. Die Komponenten von s müssen in den Datentyp und die Datenlänge von f1 konvertiert werden können.
■ ... stellt jegliche Anzahl von kompletten vary-Klauseln dar. ■ --- stellt jegliche Anzahl von Code-Zeilen dar.
Die folgenden Punkte gelten:
■ while-Schleifen können unendlich oft verschachtelt und auch innerhalb jeglicher anderen Art von Schleifen verschachtelt werden.
■ exit verhindert eine weitere Schleifenverarbeitung und steigt sofort aus der laufenden Schleife aus. Die Verarbeitung macht an der nächsten ablauffähigen Anweisung nach endwhileweiter.
■ Innerhalb der Schleife enthält das sy-index die gegenwärtige Iterationsnummer. Nach endwhile enthält sy-index den Wert, den es hatte, bevor es in die Schleife eintrat. Mit verschachtelten while-Schleifen enthält sy-index die Iterationsnummer der Schleife, in der es benutzt wird.
■ endwhile kopiert immer den Wert von f1 in die Sendekomponente zurück.

■ In einer while-Anweisung mit einem logischen Ausdruck und einer varying-Addition wird der logische Ausdruck zuerst ausgewertet.
while ist do sehr ähnlich. Es wird hier benutzt, um eine gleiche Anzahl von Strichen auf jede Seite einer Zeichenkette zu setzen.
Listing 10.12: Ein Beispiel für die Verwendung einer while-Anweisung
1 report ztx1012.2 data: l, "leading characters3 t, "trailing characters4 done. "done flag5 parameters p(25) default ' Vendor Number'.6 while done = ' ' "the expression is evaluated first7 vary l from p+0 next p+1 "then vary assignments are performed8 vary t from p+24 next p+23.9 if l = ' ' and t = ' '.10 l = t = '-'.11 else.12 done = 'X'.13 endif.14 endwhile.15 write: / p.
Der Code in Listing 10.12 erzeugt diese Ausgabe:
----Vendor Number ----
■ Die Zeilen 2 und 3 definieren zwei einzelne Zeichenvariable l und t. Zeile 3 definiert eine Flagge, um anzuzeigen, wenn die Verarbeitung beendet ist.
■ Zeile 5 definiert p als Zeichen mit einem Standardwert 25.■ Auf Zeile 6 wird der Ausdruck der while-Anweisung zuerst ausgewertet. Beim ersten
Schleifendurchlauf wird sie als wahr erkannt. Die Zuweisungen auf den Zeilen 7 und 8 werden dann ausgeführt. Zeile 7 weist das erste Zeichen von p zu l zu, und Zeile 8 weist t das letzte Zeichen zu.
■ Wenn l und t beide unbeschrieben sind, weist Zeile 10 beiden einen Strich zu. Wenn nicht, weist Zeile 12 der done-Flagge ein 'X' zu.
■ Auf Zeile 14 kopiert endwhile die Werte von l und t zurück zu p. Die while- Schleife wiederholt diese Prozedur von Zeile 6 an so lange, bis die done-Flagge unbeschrieben ist.
Die Anweisung continue
Die continue-Anweisung ist innerhalb einer Schleife codiert. Sie verhält sich wie goto , indem sie sofort die Kontrolle an die abschließende Anweisung der Schleife abgibt und einen neuen Schleifendurchgang beginnt. Tatsächlich bewirkt sie, daß die Anweisungen darunter innerhalb der

Schleife ignoriert werden und ein neuer Schleifendurchgang beginnt. Die Wirkung der continue-Anweisung ist in Abbildung 10.1 gezeigt.
Abbildung 10.1: Die Anweisung continue springt an das Ende der Schleife und ignoriert alle Anweisungen für den momentanen Schleifendurchgang.
Der Code in Abbildung 10.1 erzeugt diese Ausgabe:
1 2 9 10
Syntax für die Anweisung continue
Es folgt die Syntax für die Anweisung continue. Sie kann innerhalb von do, while, select oder loop benutzt werden. (Die loop-Anweisung wird im nächsten Kapitel behandelt.)
[do/while/select/loop]---continue.---[enddo/endwhile/endselect/endloop]
wobei gilt:
■ --- stellt jegliche Anzahl von Code-Zeilen dar.
Die folgenden Punkte gelten:
■ continue kann nur innerhalb einer Schleife verwendet werden. ■ continue hat keine Zusätze.
Listing 10.13 ist wie eine goto-Anweisung. Es verursacht einen Sprung zum Ende der Schleife. Dieses Programm entfernt überflüssige Doppelpunkt- und Rückstrichzeichen von einer Eingabezeichenkette.
Listing 10.13: Ein Beispiel für die Verwendung einer continue-Anweisung

1 report ztx1013.2 parameters p(20) default 'c::\\\xxx\\yyy'.3 data: c, "current character4 n. "next character56 do 19 times varying c from p+0 next p+17 varying n from p+1 next p+2.8 if c na ':\'.9 continue.10 endif.11 if c = n.12 write: / 'duplicate', c, 'found', 'at position', sy-index.13 endif.14 enddo.
Der Code in Listing 10.13 erzeugt diese Ausgabe:
duplicate : found at position 2duplicate \ found at position 4duplicate \ found at position 5duplicate \ found at position 10
■ Zeile 2 definiert einen 20 Zeichen langen Eingabeparameter p und weist ihm einen Standardwert zu.
■ Zeile 6 startet eine Schleife. Beim ersten Schleifendurchgang wird das erste Zeichen von p czugewiesen und das nachfolgende Zeichen n.
■ Zeile 8 ist wahr, wenn c ein anderes Zeichen als : oder / enthält. ■ Zeile 9 springt direkt zu Zeile 14, was zur Folge hat, daß sich die Schleife wiederholt, wobei sie
das nächste Zeichen benutzt. ■ Wenn Zeile 8 nicht wahr ist, wird Zeile 11 ausgeführt und ist wahr, wenn das nächste Zeichen
das gleiche wie das gegenwärtige Zeichen ist. ■ enddo kopiert die Werte von c und n zurück in p, und die Schleife wiederholt alles 19mal.
Die Anweisung check
Die check-Anweisung wird innerhalb einer Schleife codiert. Sie kann sich genauso verhalten wie continue, indem sie die Kontrolle sofort zur abschließenden Anweisung der Schleife abgibt und alle Anweisungen dazwischen umgeht. Anders als continue akzeptiert sie einen logischen Ausdruck. Wenn der Ausdruck wahr ist, führt er nichts aus. Wenn er nicht wahr ist, springt er zum Ende der Schleife. Die Wirkung der check- Anweisung ist in Abbildung 10.2 gezeigt.

Abbildung 10.2: Die Anweisung check ist eine konditionale continue-Anweisung. Sie springt an das Schleifenende, wenn der logische Ausdruck falsch ist.
Der Code in Abbildung 10.2 erzeugt die gleiche Ausgabe wie der in Abbildung 10.1:
1 2 9 10
Syntax für die Anweisung check
Jetzt folgt die Syntax für die check-Anweisung. Sie kann innerhalb von do, while, select oder loop benutzt werden. (Die loop-Anweisung wird im nächsten Kapitel behandelt.)
[do/while/select/loop]---check exp.---[enddo/endwhile/endselect/endloop]
wobei gilt:
■ exp ist ein logischer Ausdruck. ■ --- stellt jegliche Anzahl von Code-Zeilen dar.
In Listing 10.14 verhält sich check wie eine continue-Anweisung, wenn der logische Ausdruck nicht wahr ist. Wenn er wahr ist, führt es nichts aus.
Listing 10.14: Listing 10.3 wurde neu programmiert, um die check-Anweisung anstelle von continue zu benutzen.
1 report ztx1014.2 parameters p(20) default 'c::\\\xxx\\yyy'.3 data: c, "current character4 n. "next character56 do 19 times varying c from p+0 next p+17 varying n from p+1 next p+2.8 check c ca ':\'.

9 if c = n.10 write: / 'duplicate', c, 'found', 'at position', sy-index.11 endif.12 enddo.
Der Code in Listing 10.14 erzeugt diese Ausgabe:
duplicate : found at position 2duplicate \ found at position 4duplicate \ found at position 5duplicate \ found at position 10
Die Zeilen 8 bis 10 in Listing 10.13 wurden in Listing 10.14 durch Zeile 8 ersetzt. Das Programm arbeitet auf genau die gleiche Weise.
Die Verwendung von check oder continue innerhalb einer select-Schleife kann sehr unergiebig sein. Sie sollten nach Möglichkeit die where-Klausel so modifizieren, daß sie weniger Datensätze auswählt.
Vergleich der Anweisungen exit, continue und check
In Tabelle 10.7 werden die Anweisungen exit, continue und check miteinander verglichen.
Tabelle 10.7: Vergleich von exit, continue und check
Anweisung Wirkung
exit Verläßt die momentane Schleife
continue Bedingungsloser Sprung an das Schleifenende
check exp Springt an das Schleifenende, wenn exp falsch ist
Einfache Positions- und Längenspezifikationen für die Anweisung write

Die write-Anweisung erlaubt die Spezifikation einer Ausgabeposition und Länge.
Obwohl die write-Anweisung viele komplexe Spezifikationen erlaubt, werden hier elementare Positions- und Längenspezifikationen dargestellt, um Ihnen zu ermöglichen, die grundlegenden Reports in diesem und in den folgenden Kapiteln anzulegen. Ein detaillierter Umgang der write-Anweisung erscheint später in Kapitel 14.
Syntax für die einfache Positions- und Längenspezifikationen in der write-Anweisung
Die Syntax für einfache Positions- und Längenspezifikationen über die write-Anweisung lautet folgendermaßen:
write [/][P][(L)] v1.
wobei gilt:
■ v1 ist eine Variable, ein Literal oder eine Konstante. ■ P ist eine Zahl, die eine Position auf der gegenwärtigen Ausgabenreihe anzeigt. ■ L ist eine Zahl, die die Anzahl von Byte anzeigt, die in der Auflistung verteilt werden, um v1
auszugeben.
Die folgenden Punkte gelten:
■ / fängt eine neue Zeile an. ■ /, P und L müssen ohne alle dazwischenliegenden Leerzeichen codiert werden.
Tabelle 10.8 zeigt die richtigen und falschen Wege, Position und Längenspezifikationen über die write-Anweisung zu codieren.
Tabelle 10.8: Richtige und falsche Wege, Positions- und Längenspezifikationen über die write-Anweisung zu
codieren
Richtig Falsch
write /10(2) 'Hi'. write / 10(2) 'Hi'.
write / 10 (2) 'Hi'.
write /10 (2) 'Hi'.

write /10( 2) 'Hi'.
write /10( 2 ) 'Hi'.
write (2) 'Hi'. write ( 2 ) 'Hi'.
write 'Hi'(2).
write 10 'Hi'. write 10'Hi'.
write 'Hi' 10.
Wenn Sie zwischen / und der Positions- oder Längenspezifikation ein Leerzeichen gelassen haben, kann der Syntaxtester dies für Sie automatisch korrigieren. Korrigieren Sie, wenn Sie dazu aufgefordert werden.
Listing 10.15 veranschaulicht den Gebrauch der einfachen Positions- und Längenspezifikationen über die write-Anweisung. Es zeigt auch einige der Fallen. Zeile 4 gibt ein Lineal aus, so daß Sie die Anzahl der Spalten auf der Ausgabe sehen können.
Listing 10.15: Die Verwendung einfacher Positions- und Längenspezifikationen in der write-Anweisung
1 report ztx1015.2 data: f1 type p value 123,3 f2 type p value -123.4 write: / '....+....1....+....2....+....3....+....4',5 /1 'Hi', 4 'There',6 /1 'Hi', 3 'There',7 /1 'Hi', 2 'There',8 /1 'Hi', 1 'There',9 /2 'Hi', 'There',10 /2(1) 'Hi', 'There',11 /2(3) 'Hi', 'There',12 /2 'Hi', 10(3) 'There',13 / f1, f2,14 / f1, 4 f2,15 /(3) f1,16 /(2) f1.
Der Code in Listing 10.15 erzeugt diese Ausgabe:
....+....1....+....2....+....3....+....4

Hi ThereHiThereHthereThereHi ThereH ThereHi ThereHi The123 123-123-123*3
■ Zeile 4 schreibt ein Zeilenlineal aus, so daß Sie deutlich die Spalten in der Ausgabeliste sehen können.
■ Zeile 5 schreibt Hi, das bei Position 1 anfängt und There, das bei Position 4 anfängt. ■ Zeile 6 schreibt Hi, das bei Position 1 anfängt und There, das bei Position 3 anfängt. ■ Zeile 7 schreibt Hi, das bei Position 1 anfängt und There, das bei Position 2 anfängt. There
überschreibt die letzte Position von Hi.■ Zeile 8 schreibt Hi, das bei Position 1 anfängt und There, das auch bei Position 1 anfängt. There überschreibt Hi vollständig, und Sie können nicht sagen, ob Hi überhaupt in die Liste geschrieben wurde.
■ Zeile 9 schreibt Hi an Position 2 und There danach. Write läßt ein Leerzeichen zwischen den Werten, wenn Sie keine Ausgabeposition angeben.
■ Zeile 10 schreibt Hi, das für eine Länge von 1 bei Position 2 anfängt. Dies schreibt nur das erste Zeichen aus: H.
■ Zeile 11 schreibt Hi, das für eine Länge von 3 bei Position 2 anfängt. ■ Zeile 12 schreibt Hi, das an Position 2 beginnt, und There bei Position 10 für eine Länge von
3, wodurch The in der Liste erscheint. ■ Zeile 13 schreibt die gepackten dezimalen Felder f1 und f2 nacheinander. ■ Zeile 14 schreibt auch f1 und f2. f2 wird diesmal bei Position 4 beginnend geschrieben. Die
Vorlaufleerzeichen, die bei Position 4 anfangen, überschreiben den Wert von f1, was zur Folge hat, daß nur f2 in der Ausgabe erscheint.
■ Zeile 15 schreibt f1 und verteilt nur 3 Byte für den Wert in der Ausgabeliste. f1 erscheint in der Liste bei Position 1; es füllt das ganze Ausgabefeld.
■ Zeile 16 schreibt f1 und verteilt nur 2 Byte für den Wert in der Ausgabeliste. Der Wert von f1kann nicht in 3 Byte angezeigt werden, so daß ein Sternzeichen (*) in der ersten Spalte erscheint, um den Überlauf anzuzeigen.
Zusammenfassung
■ Die Vergleichsanweisungen sind if und case.■ case stellt eine ähnliche Möglichkeit wie if/elseif zur Verfügung, vergleicht aber nur
zwei Werte, und nur auf ihre Gleichheit hin. ■ Konvertierungen kommen vor, wenn unterschiedliche Datentypen verglichen werden. Das

Programmanalyse-Werkzeug legt Konvertierungen genau fest, wo immer sie vorkommen. ■ Besondere Operatoren sind für Zeichenkettenvergleiche verfügbar. Benutzen Sie CP und NP,
um Zeichenketten mit Mustern zu vergleichen. sy-index wird nach jedem Vergleich eingestellt.
■ Die Schleifenanweisungen sind do und while.■ sy-index enthält immer den Zähler für den laufenden Schleifendurchgang. Nach Beendigung
der Schleife wird der Wert auf den Wert zurückgestellt, den er hatte, als die Schleife anfing. Obwohl Sie sy-index ändern können, wird sein Wert mit dem nächsten Schleifendurchgang wieder in Ausgangsposition gebracht.
■ Benutzen Sie varying, um einer Variablen den nächsten Wert einer Serie zuzuweisen. Wenn Sie diese Variable modifizieren, kopiert enddo oder endwhile den modifizierten Wert wieder dorthin zurück, woher er stammte.
■ Benutzen Sie einen anderen Modus und den /o Befehl, um eine Endlosschleife zu beenden. ■ Benutzen Sie die Anweisungen exit, continue und check, um die Schleifenverarbeitung
zu modifizieren. ■ exit beendet die Schleifenverarbeitung und macht mit der Ausführung bei der ersten
Anweisung nach der Schleife weiter. ■ continue springt sofort zum Ende der Schleife. ■ check exp springt zum Ende der Schleife, wenn exp nicht wahr ist. Wenn exp wahr ist,
führt check nichts aus. ■ Über die write-Anweisung können Position und Länge sofort vor dem Ausgangswert
spezifiziert werden. Es sollten keine dazwischenliegenden Leerzeichen zwischen jeder Spezifikation erscheinen.
Erlaubt Nicht erlaubt
Öffnen Sie immer zwei Modi, wenn Sie sich einwählen. So können Sie immer eine Endlosschleife beenden.
Benutzen Sie niemals check oder continue in einer select-Schleife, um Datensätze herauszufiltern; benutzen Sie statt dessen die where-Klausel.
Benutzen Sie varying, um eine Serie gleichweit voneinanderentfernter Felder einer Feldleiste zu lesen.
Lesen Sie niemals mit der varying-Addition hinter dem Ende einer Variablen oder Feldleiste. Das kann zu Schutzverletzungen und unvorhergesehenem Verhalten führen.
Fragen & Antworten
Frage:Warum werden Bitoperationen nicht oft in ABAP/4 benutzt? Was wird statt dessen benutzt?
Antwort:Der Gebrauch einer Bitoperation ist betriebssystemabhängig. Dies reduziert Portabilität, so daß sie nur benutzt werden, wenn unbedingt notwendig. Eine einzelne Zeichenvariable benutzt statt dessen einen einzelnen ein/aus-Wert. Meistens stellt »X« »eingeschaltet« dar, und ein Leerfeld bedeutet

»aus«.
Frage:Warum werden X und Leerfeld benutzt, um die binären Werte von ein und aus darzustellen, und nicht 1/0, T/F oder Y/N, wie es in der Industrie üblich ist?
Antwort:Diese Konvention ist für die Kompatibilität mit zeichenorientierten Anwenderschnittstellen. Ausgeschrieben zeigt X eine gegenwärtige Selektion an, und das Leerfeld bedeutet nicht gegenwärtig.
Frage:Sie empfehlen, mehrere Modi anzumelden, wann immer ich mich anmelde. Ist dies keine Ressourcenverschwendung? Wenn jeder das täte, würde dies nicht den Applikationsserver verlangsamen?
Antwort:Die kostbarsten Ressourcen sind CPU. Es ist wahr, daß eine kleine Menge von zusätzlichem Speicher auf dem Applikationsserver gebraucht wird, um jeden neuen Modus zu versorgen. Keine CPU wird allerdings vom stillstehenden Modus benutzt, sie verlangsamt den Server also nicht. Wenn Sie ein Programm schreiben, das in eine Schleife kommt, wird es eine enorme Menge von Ressourcen, primär CPU, verschwenden und den Server ohne Zweifel verlangsamen, während es läuft. Wenn Sie unfähig sind, es zu stoppen, werden Sie unfähig sein, die Ressourcenverschwendung zu verhindern. Ungeprüft wird das Programm laufen, womöglich für fünf oder zehn Minuten, bis es seine Zuteilung von CPU überschreitet und beendet wird. Das nächste Mal, wenn Sie es laufen lassen, könnte es das gleiche nochmals machen. Kurz gesagt: Wenn Sie eine weitere Sitzung öffnen, wählen Sie das kleinere von zwei Übeln.
Frage:Wie beeinflussen Füllbytes den Gebrauch von varying? Muß ich irgend etwas beachten, wenn ich mich von und zu Feldleisten bewege?
Antwort:Der einfachste Weg, um sicherzustellen, daß varying arbeitet, ist, sich zu überzeugen, daß sich die genaue Sequenz von Feldern wiederholt. Wenn die gleiche Sequenz von Feldern wiederholt wird, wird die gleiche Anzahl von Byte sie immer abtrennen. Solange Sie dieser Konvention folgen, gibt es keinen Grund, über Füllbytes nachzudenken.
Frage:Kann ich eine Variable benutzen, um die Position bzw. die Länge einer write-Anweisunganzuzeigen?
Antwort:Ja. Die write-Anweisung wird ausführlich in Tag 14 behandelt, und verschiedene Spezifikationen werden dort gezeigt.

Workshop
Im Workshop können Sie auf zwei Weisen feststellen, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen helfen Ihnen, Ihr Verständnis für den Stoff zu vertiefen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie das Erlernte anwenden. Antworten auf die Kontrollfragen und Übungen finden Sie in Anhang B.
Kontrollfragen
1. Ändern Sie die if-Anweisungen in case-Anweisungen ab.
write 'The number is five.'.endif.if v1 eq 10.write 'The number is ten.'.endif.if v1 <> 5 and v1 <> 10.write 'The number is not five or ten.'.endif.
2. Welche Zeichenketten-Vergleichsoperatoren benutzen die drei Zeichen *, + und #?
3. Welche drei Programmsteuerungsanweisungen werden in diesem Kapitel besprochen? Welche Unterschiede bestehen zwischen ihnen?
Übung 1
Schreiben Sie ein Programm, das die Ausgabe in der Abbildung erzeugt.

Abbildung 10.3: 10fig03.pcx
Codieren Sie die Zahlen nicht hart als Zeichenkette. Berechnen Sie die Zahlen, und schreiben Sie diese einzeln aus.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 11
Interne Tabellen
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sind Sie in der Lage:
■ interne Tabellen mit oder ohne Kopfzeile mit der data- oder include structure-Anweisung zu definieren.
■ eine interne Tabelle mit der Kopfzeile oder einem expliziten Arbeitsbereich zu füllen. ■ Loop at und loop at...where zu benutzen, um den Inhalt einer internen Tabelle zu
lesen und sy-tabix, um den aktuellen Zeilenindex zu bestimmen. ■ einzelne Zeilen einer internen Tabelle mit Hilfe von read table inklusive der möglichen
Variationen zu lokalisieren. ■ interne Tabellen zu sortieren und den Zusatz text zu benutzen.
Grundlagen interner Tabellen
Eine interne Tabelle ist eine temporäre Tabelle, die im RAM auf dem Applikationsserver gespeichert wird. Sie wird während der Programmausführung angelegt und gefüllt und gelöscht, wenn das Programm endet. Wie die Tabelle einer Datenbank besteht eine interne Tabelle aus einer oder mehreren Zeilen identischer Struktur. Anders als die Tabelle einer Datenbank kann die interne Tabelle keine Daten nach Beendigung des Programms speichern. Die interne Tabelle ist als temporärer Speicher für die Bearbeitung von Daten oder als privater temporärer Puffer zu nutzen.
Definition einer internen Tabelle
Eine interne Tabelle besteht aus einem Rumpf und einer optionalen Kopfzeile (siehe Abb. 11.1).

Der Rumpf besteht aus den Zeilen der internen Tabelle. Alle Zeilen haben die gleiche Struktur. Der Ausdruck »interne Tabelle« bezieht sich nur auf den Rumpf der internen Tabelle.
Die Kopfzeile ist eine Feldleiste mit der gleichen Struktur wie sie die Zeilen des Rumpfs haben, allerdings besteht dieser nur aus einer Zeile. Sie ist ein Puffer, um den Datensatz zu speichern, der zu der internen Tabelle hinzugefügt wird oder von der internen Tabelle gelesen wird.
Abbildung 11.1 zeigt die Definition einer internen Tabelle mit dem Namen it.
In diesem Buch wird eine Namenskonvention für interne Tabellen gebraucht. Für einfache Programme mit einer internen Tabelle, wird der Name der internen Tabelle gewöhnlich it sein (für interne Tabelle). Wenn mehrere interne Tabellen existieren, beginnt der Name gewöhnlich immer mit it.
Abbildung 11.1: Die Definition einer internen Tabelle mit dem Namen it wird zu Beginn dieser Abbildung gezeigt. Die Kopfzeile und der Rumpf werden ebenso gezeigt.
Um den Rumpf einer internen Tabelle zu definieren, benutzen Sie occurs n bei der Definition der Feldleiste außer bei tables. Mit occurs wird der Rumpf der internen Tabelle erzeugt. Der Speicherplatz eines Rumpfs wird nicht zugeordnet, bis die erste Zeile hinzugefügt wird. Ohne occurs haben Sie lediglich eine Feldleiste definiert.
Um eine interne Tabelle mit einer Kopfzeile zu erzeugen, müssen Sie entweder begin of oder with header line in der Definition hinzufügen. Eine Kopfzeile wird automatisch erzeugt, wenn begin of in der Definition erscheint. Wenn Sie like anstatt begin of benutzen, wird die interne

Tabelle keine Kopfzeile haben, es sei denn, sie fügen with header line hinter der occurs-Klausel mit ein. Dieses wird in den Zeilen 2 bis 10 des Listings 11.1 gezeigt.
Eine interne Tabelle ohne Kopfzeile benutzen Sie in der Regel nur im Fall von verschachtelten internen Tabellen. Eine verschachtelte interne Tabelle kann keine Kopfzeile haben.
Listing 11.1: Grundlegende Schritte, eine interne Tabelle mit oder ohne Kopfzeile zu definieren
1 report ztx1101.2 data: begin of it1 occurs 10, "has a header line3 f1,4 f2,5 f3,6 end of it1.78 data it2 like ztxlfa1 occurs 100. "doesn't have a header line910 data it3 like ztxlfa1 occurs 100 with header line. "it does now
Der Programm-Code in Listing 11.1 erzeugt keine Ausgabe.
■ Zeile 2 beginnt mit der Definition einer internen Tabelle mit dem Namen it1. Es ist eine interne Tabelle wegen der occurs-Klausel. Sie hat drei Komponenten: f1, f2 und f3. Jede vom Typ c mit der Länge 1. Diese interne Tabelle hat eine Kopfzeile, da die Definition die Schlüsselwörter begin of enthält.
■ Zeile 8 definiert die interne Tabelle it2. Sie hat die gleichen Komponenten wie die DDIC-Struktur ztxlfa1. Sie hat keine Kopfzeile, da sie weder mit begin of noch mit withheader line definiert ist.
■ Die Definition von it3 in Zeile 10 ist fast die gleiche wie die Definition für it2 in Zeile 8. Der einzige Unterschied ist der Zusatz with header line. Das bedeutet natürlich, daß it3 eine Kopfzeile hat.
Eliminierung der Hauptursache von Irrtümern im Zusammenhang mit internen Tabellen
Abbildung 11.1 zeigt eine typische Definition einer internen Tabelle. Es werden zwei Dinge definiert: der Rumpf einer internen Tabelle und eine Kopfzeile. Verwirrung kann entstehen, weil sowohl der Rumpf als auch die Kopfzeile den Namen it haben. Wenn Sie it in Ihrem Programm-Code verwenden, bestimmen Sie, ob Sie sich auf den Rumpf oder die Kopfzeile beziehen.
Wenn Sie it in einem Zuweisungsausdruck verwenden, dann bezieht es sich immer auf die Kopfzeile. Zum Beispiel bezieht sich it-f1 = 'A' auf eine Komponente f1 der Kopfzeile mit dem Namen it. In f3 = it-f1 bezieht sich it auch auf die Kopfzeile.
Beispiele von Definitionen interner Tabellen

Um interne Tabellen mit und ohne Kopfzeilen zu definieren, benutzen Sie bitte die Konventionen, die in Listing 11.2 empfohlen werden.
Listing 11.2: Diese Definitionen erzeugen interne Tabellen mit oder ohne Kopfzeile.
1 report ztx1102.2 data: begin of it1 occurs 10, "has a header line3 f1,4 f2,5 f3,6 end of it1.78 data it2 like ztxlfa1 occurs 100. "doesn't have a header line910 data it3 like ztxlfa1 occurs 100 with header line. "it does now1112 data it4 like it3 occurs 100. "doesn't have a header line1314 data begin of it5 occurs 100. "has a header line15 include structure ztxlfa1.16 data end of it5.1718 data begin of it6 occurs 100. "this is why you might use19 include structure ztxlfa1. "the include statement20 data: delflag,21 rowtotal,22 end of it6.2324 data: begin of it7 occurs 100, "don't do it this way25 s like ztxlfa1, "component names will be26 end of it7. "prefixed with it7-s-2728 data it8 like sy-index occurs 1029 with header line.3031 data: begin of it9 occurs 10,32 f1 like sy-index,33 end of it9.
Der Programm-Code in Listing 11.2 erzeugt keine Ausgabe.
■ Die Zeilen 2 bis 10 sind dieselben wie in Listing 11.1; sie wurden zur Wiederholung eingefügt. ■ In Zeile 12 wird it4 mit der Feldleiste it3 definiert und nicht mit der internen Tabelle it3.
Um eine interne Tabelle zu erzeugen, wird der Zusatz occurs benötigt; diese Definition hat

keine Kopfzeile, weil kein begin of oder with header line aufgeführt ist. ■ Die Zeilen 14 bis 16 zeigen einen alten Weg, interne Tabellen zu definieren. it5 ist die gleiche
wie die in Zeile 10 definierte it3. Der Zusatz like wurde erst in Release 3.0 eingeführt; frühere Programme nutzen Definitionen wie die in Zeile 14 bis 16. Include structurewird normalerweise nicht gebraucht. Eine Ausnahme wird in der folgenden Definition von it6gezeigt. (Jetzt können Sie noch einmal die include structure-Anweisung aus dem Kapitel des 5. Tages »Das Data Dictionary, Teil 3« wiederholen.)
■ Das könnte der einzige Grund sein, warum Sie die include-Anweisung benutzen (nach Release 3.0). Sie ermöglicht Ihnen, Feldleisten mit allen Komponenten einer DDIC-Struktur und einigen weiteren Feldern zu erzeugen. Die Definition von it6 beinhaltet die Komponenten von ztxlfa1 und zwei zusätzliche Felder delflag und rowtotal. Diese interne Tabelle hat eine Kopfzeile, weil sie die Definition begin of enthält.
■ Zeile 24 bis 26 zeigt eine falsche Weise, like zu benutzen. Die Komponenten dieser internen Tabelle beginnen alle mit it7-s, z.B. it7-s-lifnr und it7-s-land1. Dies ist zwar möglich, aber wahrscheinlich wollen Sie diese Definition nicht, weil sie eine unnötige Stufe in den Namen der Komponenten erzeugt.
■ Wenn Sie eine interne Tabelle mit nur einer Komponente definieren, können Sie entweder den Programm-Code in Zeile 28 oder Zeile 31 benutzen.
Daten einer internen Tabelle mit der append-Anweisung hinzufügen
Um eine einer internen Tabelle einzelne Zeile hinzuzufügen, können Sie die append- Anweisung benutzen. Die append-Anweisung kopiert eine einzelne Zeile aus jedem Arbeitsbereich und fügt sie in den Rumpf am Ende der schon bestehenden Zeilen ein. Der Arbeitsbereich kann entweder die Kopfzeile oder jede beliebige Feldleiste mit derselben Struktur wie die Zeile in dem Rumpf sein.
Syntax der append-Anweisung
Das Folgende ist die Syntax der append-Anweisung.
append [wa to] [initial line to] it.
wobei:
■ wa der Name des Arbeitsbereichs ist. ■ it der Name der vorher definierten internen Tabelle ist.
Folgende Punkte sind zu beachten:
■ wa muß dieselbe Struktur wie die Zeilen des Rumpfs haben. ■ wa kann die Kopfzeile oder jede andere Feldleiste mit derselben Struktur wie die Zeile des
Rumpfs sein. ■ Wenn Sie einen Arbeitsbereich spezifizieren, benutzt das System standardmäßig die Kopfzeile.
Die Kopfzeile ist somit der vorgegebene Arbeitsbereich.

■ Nach der append-Anweisung wird sy-tabix auf die relative Zeilennummer entsprechend der eingefügten Zeile gesetzt. Zum Beispiel wird nach dem Einfügen der ersten Zeile sy-tabix auf 1 gesetzt. Nach dem Einfügen der zweiten Zeile wird sy-tabix auf 2 gesetzt und so weiter.
Die Anweisung append it to it fügt eine Kopfzeile mit dem Namen it in den Rumpf it ein.Die Anweisung append it fügt ebenfalls eine Kopfzeile mit dem Namen it in den Rumpf it ein,da der vorgegebene Arbeitsbereich die Kopfzeile ist. Üblicherweise wird append it verwendet.
Ein Arbeitsbereich, der ausdrücklich in der Anweisung append genannt wird, wird auch expliziter Arbeitsbereich genannt. Eine Feldleiste mit derselben Struktur wie die Zeile einer internen Tabelle kann wie ein expliziter Arbeitsbereich benutzt werden. Wenn ein Arbeitsbereich nicht genannt wird, dann wird ein impliziter Arbeitsbereich (die Kopfzeile) benutzt.
Die Anweisung append initial line to it fügt eine Zeile mit initialen Werten (Leerzeichen und Nullen) in die interne Tabelle ein. Wenn Sie die Anweisungen clear it und append it hintereinander ausführen, erhalten Sie das gleiche Ergebnis.
Listing 11.3: zeigt ein Beispielprogramm, das drei Zeilen in eine interne Tabelle einfügt.
1 report ztx1103.2 data: begin of it occurs 3,3 f1(1),4 f2(2),5 end of it.6 it-f1 = 'A'.7 it-f2 = 'XX'.8 append it to it. "appends header line IT to body IT9 write: / 'sy-tabix =', sy-tabix.10 it-f1 = 'B'.11 it-f2 = 'YY'.12 append it. "same as line 813 write: / 'sy-tabix =', sy-tabix.14 it-f1 = 'C'.15 append it. "the internal table now contains three rows.16 write: / 'sy-tabix =', sy-tabix.
Der Programm-Code in Listing 11.3 erzeugt folgende Ausgabe:
sy-tabix = 1sy-tabix = 2sy-tabix = 3
■ Zeile 2 definiert eine interne Tabelle it mit der Kopfzeile it. Beide haben zwei Komponenten: f1 und f2.

■ Die Zeilen 6 bis 7 weisen den Feldern der Kopfzeile f1 und f2 Inhalte zu (siehe auch Abb. 11.2). Hier bezieht sich it auf die Kopfzeile.
Abbildung 11.2: Hier werden Zuweisungen verwendet, also bezieht sich it auf die Kopfzeile.
■ In Zeile 8 wird der Inhalt der Kopfzeile it in den Rumpf mit dem Namen it kopiert (siehe auch Abb. 11.3).
Abbildung 11.3: Append it to it kopiert den Inhalt der Kopfzeile it in den Rumpf it.
■ In den Zeilen 10 und 11 wird den Komponenten der Kopfzeile neuer Inhalt zugewiesen, der den alten Inhalt überschreibt (siehe auch Abb. 11.4).

Abbildung 11.4: Diese Zuweisungen überschreiben den existierenden Inhalt der Kopfzeile it.
■ In Zeile 12 wird der neue Inhalt der Kopfzeile dem Rumpf hinzugefügt (siehe auch Abb. 11.5). Diese Anweisung ist der in Zeile 8 funktional gleich. Weil der Arbeitsbereich nicht genannt wird, wird der vorgegebene Arbeitsbereich - die Kopfzeile - benutzt.
Abbildung 11.5: Der vorgegebene Arbeitsbereich ist die Kopfzeile. Damit wird it implizit dem Rumpf hinzugefügt.
■ In Zeile 14 wird der Wert von it-f1 geändert und in it-f2 unverändert gelassen (siehe auch Abb. 11.6).

Abbildung 11.6: Der Wert der Komponente it-f1 der Kopfzeile wird überschrieben. Der Wert in it-f2 wird nicht geändert.
■ In Zeile 15 wird eine dritte Zeile aus der Kopfzeile it in den Rumpf it hinzugefügt (siehe auch Abb. 11.7).
Abbildung 11.7: Hier wird der Inhalt des impliziten Arbeitsbereiches dem Rumpf hinzugefügt.
Den Zusatz occurs benutzen
occurs begrenzt nicht die Anzahl der Zeilen, die einer internen Tabelle hinzugefügt werden können. Wenn Sie zum Beispiel occurs 10 verwenden, können Sie mehr als 10 Zeilen einer internen Tabelle hinzufügen. Die Anzahl der Zeilen, die Sie einer internen Tabelle hinzufügen können, ist theoretisch nur durch die Menge des virtuellen Speichers auf dem Applikationsserver begrenzt.

In der Praxis wird Ihr Basisberater die maximale Menge an Speicher für eine interne Tabelle begrenzen. Wenn Sie diese Menge überschreiten, wird Ihr Programm dem Arbeitsprozeß Speicher abziehen und er wird nicht länger in der Lage sein, Ihr Programm auszulagern. Damit ist der Arbeitsprozeß für andere Programme nicht mehr verfügbar, und zwar so lange, bis Ihr Programm vollständig ausgeführt ist. Um dieses Problem zu vermeiden, sollten Sie statt dessen einen Extrakt benutzen.
Das System benutzt die occurs-Klausel nur als Richtwert, um zu bestimmen, wieviel Speicher zugewiesen werden soll. Wenn zum ersten Mal einer internen Tabelle eine Zeile hinzugefügt wird, dann wird genug Speicher reserviert, um die Anzahl der Zeilen zu speichern, die in der occurs-Klausel angegeben sind. Wenn Sie diesen Speicher verbraucht haben, wird so viel neuer Speicher zugewiesen, wie gebraucht wird.
Alternativ können Sie auch occurs 0 spezifizieren. Das System allokiert dann 8 KB Speicherplatz. Allerdings gibt es keinen Vorteil beim Gebrauch von occurs 0, außer vielleicht, daß es einfacher ist, occurs 0 zu codieren, als die Größe einer internen Tabelle zu schätzen.
Um eine schnelle Ausführung und wenig Speicher zu verbrauchen, wählen Sie bitte den Wert für occurs so, daß der Speicherplatz der durchschnittlichen maximalen Anzahl von Zeilen in der Tabelle entspricht.
Gebrauchen Sie occurs 0 nicht, wenn Sie erwarten, daß die interne Tabelle weniger als 8 KB Speicher benötigt. Wenn Sie das tun, wird das System 8 KB Speicher aus dem Anlagerungsbereich (paging area) zuweisen. Speicher wird verschwendet und das Paging-Verhalten könnte zunehmen, was eine langsamere Ausführung zur Folge hat.
Abhängig von der occurs-Klausel und der Größe der internen Tabelle weist das System entweder aus dem Rollbereich des Programms oder dem Anlagerungsbereich des Systems Speicher zu, evtl. aus beiden Bereichen. Speicherzugriffe im Rollbereich können etwas schneller sein als Zugriffe im Anlagerungsbereich. Speicherzuweisungen im Seitenbereich sind immer eine Seite groß (gewöhnlich 8 KB oder 8192 Byte).
Es gibt zwei Methoden, wie das System Speicherzuweisungen vornimmt. Im ersten Fall ist occursungleich Null, und die Größe der internen Tabelle (berechnet durch occurs , multipliziert mit der Anzahl der Byte pro Zeile) ist kleiner oder gleich 8 KB. (Die Anzahl der Byte pro Zeile können Sie mit der Anweisung describe table erhalten, die im nächsten Kapitel detailliert beschrieben wird,

oder mit der Feldanzeige im Debugger.) Wenn die erste Zeile einer internen Tabelle hinzugefügt wird, wird Speicher aus dem Rollbereich zugewiesen. Die Menge, die zugewiesen wird, entspricht der berechneten Größe der internen Tabelle. Wenn diese Speichermenge überschritten wird, wird erneut eine gleiche Menge zugewiesen, und dieser Prozeß wiederholt sich, bis 8 KB überschritten werden. Wenn das passiert, werden im Folgenden immer 8 KB aus dem Seitenbereich zugewiesen.
Wenn Sie occurs 0 angeben, werden alle Speicherzuweisungen im Seitenbereich vorgenommen. Dann werden immer 8 KB Seiten zugewiesen. Wenn die berechnete Größe der internen Tabelle größer als 8 KB ist, ändert das System den Wert für occurs bei der ersten Speicherzuweisung in Null um. Alle Speicherallokationen werden dann aus dem Seitenbereich vorgenommen. Sie können sich die Änderung von occurs mit der Anweisung describe table nach der ersten Speicherzuweisung ansehen und sich den Wert von sy-toccu anzeigen lassen. Diese Anweisung ist im Kapitel 9 »Zuweisungen, Konvertierungen und Berechnungen« beschrieben.
Daten aus einer internen Tabelle lesen
Zwei Anweisungen werden gewöhnlich benutzt, um Daten aus einer internen Tabelle zu lesen:
■ loop at ■ read table
Benutzen Sie loop at, um mehrere Zeilen einer internen Tabelle zu lesen. Nutzen Sie readtable, um eine einzelne Zeile zu lesen.
Mehrere Zeilen mit der Anweisung loop at lesen
Um einige oder alle Zeilen einer internen Tabelle zu lesen, benutzen Sie die Anweisung loop at.loop at liest den Inhalt einer internen Tabelle, und plaziert eine nach der anderen in dem Arbeitsbereich.
Syntax der Anweisung loop at
Das Folgende ist die Syntax der loop at-Anweisung.
loop at it [into wa] [from m] [to n] [where exp]....endloop
wobei:
■ it der Name der internen Tabelle ist. ■ wa der Name des Arbeitsbereichs ist. ■ m und n sind Ganzzahlliterale, Konstanten oder Variablen, die eine relative Zeilennummer
repräsentieren. Zum Beispiel bedeutet 1 die erste Zeile in der Tabelle, und 2 die zweite und so weiter.

■ exp ist der logische Ausdruck, der die Zeilen begrenzt, die gelesen werden. ■ ... steht für eine beliebige Anzahl von Programm-Code-Zeilen. Diese Programmzeilen
werden für jede gelesene Zeile der internen Tabelle ausgeführt.
Die Zeilen werden einzeln aus der internen Tabelle gelesen und nacheinander im Arbeitsbereich plaziert. Die Programmzeilen zwischen loop at und endloop werden für jede Zeile ausgeführt. Die Schleife endet, wenn die letzte Zeile der internen Tabelle gelesen wurde und die Anweisung, die auf endloop folgt, wird ausgeführt.
Die folgenden Punkte sind zu beachten:
■ wa muß dieselbe Struktur wie die Zeilen des Rumpfs haben. ■ wa kann die Kopfzeile oder jede andere Feldleiste mit derselben Struktur wie die Zeile des
Rumpfs sein. ■ Wenn Sie einen Arbeitsbereich spezifizieren, benutzt das System standardmäßig die Kopfzeile.
Zum Beispiel liest loop at into it die Zeilen der internen Tabelle it, indem es eine nach der anderen in der Kopfzeile it plaziert. Eine äquivalente Anweisung ist loop at it.
■ Wenn from nicht spezifiziert ist, dann wird standardmäßig mit der ersten Zeile begonnen. ■ Wenn to nicht spezifiziert ist, dann wird standardmäßig bis zur letzten Zeile gelesen. ■ Komponenten von it, die in einem logischen Ausdruck spezifiziert werden, soll nicht der
Name der internen Tabelle vorangestellt werden. Zum Beispiel ist where f1 = 'X'korrekt, aber it-f1 = 'X' erzeugt einen Syntaxfehler.
■ exp kann jeder logische Ausdruck sein. Allerdings muß der erste Operand des Vergleichs immer eine Komponente der internen Tabelle sein. Wenn z.B. it eine Komponente f1beinhaltet, dann ist f1 = 'X' korrekt und 'X' = f1 ist nicht korrekt und erzeugt einen Syntaxfehler.
■ Die Zusätze from, to und where können beliebig gemischt werden.
In einer Schleife enthält sy-tabix die relative Zeilennummer des aktuellen Datensatzes. Z.B. bei der Verarbeitung des ersten Datensatzes der internen Tabelle ist der Wert von sy-tabix 1. Bei der Verarbeitung des zweiten Satzes ist sy-tabix 2. Wenn die Schleife verlassen wird, wird der Wert von sy-tabix auf den Wert zurückgesetzt, den sy-tabix hatte, bevor die Schleife begann. Wenn die Schleifen verschachtelt sind, dann bezieht sich der Wert von sy-tabix auf die aktuelle Schleife.
Nach endloop wird sy-subrc Null sein, wenn irgendwelche Zeilen gelesen wurden. Es wird ungleich Null sein, wenn keine Zeile der internen Tabelle gelesen wurde.
Listing 11.4 erweitert das Listing 11.3 um ein loop at und die Ausgabe der Zeilen der internen Tabelle.
Listing 11.4: Dieses Programm fügt drei Zeilen aus der Kopfzeile in eine interne Tabelle it ein und erzeugt dann eine Ausgabe der drei Zeilen.
1 report ztx1104.2 data: begin of it occurs 3,

3 f1(1),4 f2(2),5 end of it.6 it-f1 = 'A'.7 it-f2 = 'XX'.8 append it to it. "appends header line IT to body IT9 it-f1 = 'B'.10 it-f2 = 'YY'.11 append it. "same as line 812 it-f1 = 'C'.13 append it. "the internal table now contains three rows.14 sy-tabix = sy-subrc = 99.15 loop at it. "same as: loop at it into it16 write: / sy-tabix, it-f1, it-f2.17 endloop.18 write: / 'done. sy-tabix =', sy-tabix,19 / ' sy-subrc =', sy-subrc.
Der Programm-Code in Listing 11.4 erzeugt folgende Ausgabe:
1 A XX2 B YY3 C YYdone. sy-tabix = 99sy-subrc = 0
■ Die Zeilen 2 bis 13 sind dieselben wie in Listing 11.3. Es werden drei Zeilen zu einer internen Tabelle hinzugefügt.
■ Zeile 14 erzeugt für sy-tabix und sy-subrc einen zufälligen Wert. ■ Zeile 15 beginnt die Schleife mit dem Lesen der ersten Zeile der internen Tabelle it und fügt
sie in die Kopfzeile it ein. ■ Zeile 16 schreibt den Wert von sy-tabix und die Werte der Komponenten der Kopfzeile aus. ■ Zeile 17 markiert das Ende der Schleife und die Rückkehr zu Zeile 15. ■ Zeile 15 wird wieder ausgeführt. Jetzt wird die zweite Zeile der internen Tabelle in der
Kopfzeile plaziert und der vorherige Inhalt überschrieben. ■ Zeile 16 wird ausgeführt und schreibt wieder die Werte der Kopfzeile aus. ■ Zeile 17 sorgt dafür, daß alle Zeilen der internen Tabelle durchlaufen werden, die gelesen
werden. Wenn die letzte Zeile gelesen wurde, endet die Schleife. ■ In Zeile 18 wird sy-tabix wieder mit dem Wert gefüllt, den es hatte, bevor die Schleife
ausgeführt wurde. Sy-subrc enthält den Wert Null, was bedeutet, daß Zeilen aus der internen Tabelle mit der Anweisung loop at gelesen wurden.
Die Anzahl der gelesenen Zeilen einer internen Tabelle begrenzen
Wenn Sie die Zusätze from, to und where benutzen, dann können Sie die Anzahl der Zeilen begrenzen, die aus einer internen Tabelle gelesen werden.

Listing 11.5: Dieses Programm ist wie Listing 11.4, allerdings werden nur einige der Zeilen gelesen.
1 report ztx1105.2 data: begin of it occurs 3,3 f1(1),4 f2(2),5 end of it.6 it-f1 = 'A'.7 it-f2 = 'XX'.8 append it.9 it-f1 = 'B'.10 it-f2 = 'YY'.11 append it.12 it-f1 = 'C'.13 append it. "it now contains three rows1415 loop at it where f2 = 'YY'. "f2 is right, it-f2 would be wrong here16 write: / sy-tabix, it-f1, it-f2.17 endloop.18 skip.1920 loop at it to 2. "same as: loop at it from 1 to 2.21 write: / sy-tabix, it-f1, it-f2.22 endloop.23 skip.2425 loop at it from 2. "same as: loop at it from 2 to 3.26 write: / sy-tabix, it-f1, it-f2.27 endloop.28 skip.2930 loop at it from 2 where f1 = 'C'.31 write: / sy-tabix, it-f1, it-f2.32 endloop.
Der Programm-Code in Listing 11.5 erzeugt folgende Ausgabe:
2 B YY3 C YY
1 A XX2 B YY

2 B YY3 C YY
3 C YY
■ Die Zeilen 2 bis 13 fügen drei Zeilen in eine interne Tabelle ein. ■ Die Zeilen 15 bis 17 lesen lediglich die Zeilen der internen Tabelle, wo f2 einen Wert gleich 'YY' hat. Nur die Zeilen 2 und 3 erfüllen diese Bedingung.
■ Zeile 18 überspringt eine Zeile in der Ausgabe, das Ergebnis ist eine Leerzeile. ■ In den Zeilen 20 bis 22 werden nur die Zeilen 1 und 2 der internen Tabelle gelesen. ■ In den Zeilen 23 bis 25 werden nur die Zeilen 2 und 3 der internen Tabelle gelesen. ■ Zeile 30 liest ab Zeile 2 der internen Tabelle und sucht alle Zeilen, in denen f1 einen Wert
gleich 'C' hat. Nur die dritte Zeile erfüllt diese Bedingung.
Wenn Sie sicherstellen, daß der Datentyp und die Länge des Feldes in exp dem Feld der internen Tabelle entsprechen, werden keine Konvertierungen ausgeführt. Das Ergebnis ist eine schnellere Schleife. Wenn Konvertierungen benötigt werden, werden diese bei jedem Schleifendurchlauf vollzogen, und das kann die Ausführung signifikant verlangsamen. Nutzen Sie like oder Konstanten, um Konvertierungen zu vermeiden.
Obwohl where nur eine Untermenge des Tabelleninhalts liefert, wird die Tabelle voll gelesen.
Die Anweisungen exit, continue, stop und check
Tabelle 11.1 illustriert die Auswirkungen von exit, continue und check beim Gebrauch innerhalb einer loop at/endloop-Schleife.
Tabelle 11.1: Anweisungen, die die Ausführung in Schleifen für interne Tabelle verändern können.
Anweisung Auswirkung
exit Beendet die Schleife sofort. Die Programmausführung wird unmittelbar nach endloop fortgesetzt.

continue Geht sofort zur endloop-Anweisung und überspringt alle Anweisungen innerhalb der Schleife. Die nächste Zeile der internen Tabelle wird zurückgegeben, und die Ausführung wird am Beginn der Schleife fortgesetzt. Wenn es keine weiteren Zeilen mehr zu holen gibt, dann wird die Programmausführung mit der ersten Anweisung nach endloop fortgesetzt.
check exp Wenn exp wahr ist, wird die Programmausführung fortgesetzt. Wenn exp falsch ist, dann ist das Ergebnis dasselbe wie bei continue.
Eine einzelne Zeile mit der Anweisung read table lesen
Um eine Zeile einer internen Tabelle zu lesen, benutzen Sie die Anweisung read table . readtable liest eine Zeile, die die spezifischen Kriterien erfüllt, und plaziert sie in dem Arbeitsbereich.
Syntax der Anweisung read table
Das Folgende ist die Syntax der read table-Anweisung.
read table it [into wa] [index i | with key keyexp [binary search] ] [comparing cmpexp] [transporting texp].
wobei:
■ it der Name der internen Tabelle ist. ■ wa der Name des Arbeitsbereichs ist. ■ it ist ein Ganzzahlliteral, eine Konstante oder Variable, die eine relative Zeilennummer
repräsentiert. Z.B. 1 bedeutet die erste Zeile der Tabelle, 2 die zweite Zeile und so weiter. ■ keyexp ist ein Ausdruck mit einem Wert, der gefunden werden soll. ■ cmpexp ist ein Vergleichsausdruck, der einen Test in der gefundenen Zeile ausführt. ■ texp ist ein Ausdruck, der die Felder wiedergibt, die in den Arbeitsbereich transportiert
werden sollen, wenn die Zeile gefunden wurde. ■ Wenn sowohl comparing als auch transporting spezifiziert werden, dann muß comparing zuerst definiert werden.
Die folgenden Punkte sind zu beachten:
■ wa muß dieselbe Struktur wie die Zeilen des Rumpfs haben. ■ wa kann die Kopfzeile oder jede andere Feldleiste mit derselben Struktur wie die Zeile des
Rumpfs sein. ■ Wenn Sie einen Arbeitsbereich spezifizieren, benutzt das System standardmäßig die Kopfzeile.
Zum Beispiel liest read table at into it die Zeile der internen Tabelle it, indem es sie in der Kopfzeile it plaziert. Eine gleichwertige Anweisung ist read table it.
Der Zusatz index
Ein index einer Zeile einer internen Tabelle ist die relative Zeilennummer. Z.B. hat die erste Zeile

der Tabelle den Index 1, die zweite den Index 2 und so weiter. Bei der Anweisung read table liest das System die i-te Zeile aus der internen Tabelle und plaziert sie im Arbeitsbereich, wenn index ispezifiziert ist. Z.B. read table it index 7 liest die siebte Zeile einer internen Tabelle und plaziert sie in der Kopfzeile.
Ist der Zugriff erfolgreich (d.h. die i-te Zeile existiert), dann wird sy-subrc Null und sy- tabix i zugewiesen (siehe Listing 11.6).
Listing 11.6: Der Zusatz index in der Anweisung read table ermittelt eine einzelne Zeile über die relative Zeilennummer.
1 report ztx1106.2 data: begin of it occurs 3,3 f1(2) type n,4 f2 type i,5 f3(2) type c,6 f4 type p,7 end of it,8 wa like it.910 it-f1 = '10'. it-f3 = 'AA'. it-f2 = it-f4 = 1. append it.11 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.12 it-f1 = '30'. it-f3 = 'CC'. it-f2 = it-f4 = 3. append it.1314 read table it index 2.15 write: / 'sy-subrc =', sy-subrc,16 / 'sy-tabix =', sy-tabix,17 / it-f1, it-f2, it-f3, it-f4.1819 read table it into wa index 1.20 write: /,21 / 'sy-subrc =', sy-subrc,22 / 'sy-tabix =', sy-tabix,23 / it-f1, it-f2, it-f3, it-f4,24 / wa-f1, wa-f2, wa-f3, wa-f4.2526 read table it index 4.27 write: /,28 / 'sy-subrc =', sy-subrc,29 / 'sy-tabix =', sy-tabix,30 / it-f1, it-f2, it-f3, it-f4,31 / wa-f1, wa-f2, wa-f3, wa-f4.
Der Programm-Code in Listing 11.6 erzeugt folgende Ausgabe:
sy-subrc = 0

sy-tabix = 220 2 BB 2
sy-subrc = 0sy-tabix = 120 2 BB 210 1 AA 1
sy-subrc = 4sy-tabix = 020 2 BB 210 1 AA 1
■ Die Zeilen 2 bis 7 definieren eine interne Tabelle mit einer Kopfzeile. ■ Zeile 8 definiert einen Arbeitsbereich wa wie die Kopfzeile von it.■ Die Zeilen 10 bis 12 fügen der internen Tabelle drei Zeilen hinzu. ■ Zeile 14 liest die zweite Zeile. Weil kein Arbeitsbereich spezifiziert ist, werden die Inhalte in
der Kopfzeile plaziert. Nach dem Lesen wird sy-subrc auf Null gesetzt. Das bedeutet, daß die Zeile existiert und daß sy-tabix mit der Zeilennummer gefüllt wird.
■ Zeile 19 liest Zeile 1 in den Arbeitsbereich wa. Der Inhalt der Kopfzeile ist nach dem Lesen unverändert.
■ Zeile 26 versucht die Zeile 4 der internen Tabelle in die Kopfzeile zu lesen. Es gibt aber keine Zeile 4, also wird sy-subrc auf 4 gesetzt, sy-tabix auf 0, und die Kopfzeile und der Arbeitsbereich bleiben unverändert.
Der Zusatz with key
Wenn with key keyexp spezifiziert wird, findet das System die Zeile, die dem Schlüsselausdruck gleicht und plaziert sie in der Kopfzeile. Tabelle 11.2 beschreibt Schlüsselausdrücke und deren Auswirkungen. Mit dem Gebrauch des Schlüsselausdrucks können Sie eine einzelne Zeile spezifizieren, die gelesen werden soll. Wenn mehr als eine Zeile dem Ausdruck gleicht, wird die erste gefundene (diejenige mit dem niedrigsten Index) zurückgegeben.
Tabelle 11.2: Schlüsselausdrücke und deren Auswirkungen
Schlüsselausdruck Auswirkung
c1 = v1 c2 = v2 ... Lokalisiert die erste Zeile der internen Tabelle, in der die Komponente c1 den Wert v1 und die Komponente c2 den Wert v2 hat und so weiter. v1 ist ein Literal, eine Konstante oder eine Variable.

(f1) = v1 (f2) = v2 Dasselbe wie oben, allerdings ist f1 eine Variable, die den Namen der zu vergleichenden Komponente enthält. Der Wert in f1 muß in Großbuchstaben ausgedrückt sein. Wenn f1 leer ist, wird der Vergleich ignoriert.
= wa wa ist ein Arbeitsbereich, der in seiner Struktur einer internen Tabelle gleicht. Der Schlüsselausdruck lokalisiert die erste Zeile in der internen Tabelle, die exakt dem Inhalt von wa gleicht.
wa wa ist ein Arbeitsbereich und kürzer als die Struktur der internen Tabelle oder mit ihr identisch. Wenn wa n Felder hat, müssen die ersten n Felder der internen Tabelle den Feldern des Arbeitsbereichs gleichen. Der Schlüsselausdruck lokalisiert die erste Zeile in der internen Tabelle, dessen n erste Felder dem Inhalt von wa gleichen. Leerzeichen werden wie zu findende Werte behandelt, sie werden keinem anderen Wert als dem Leerzeichen zugeordnet.
In Release 4 werden notwendige Konvertierungen für die ersten drei Schlüsselausdrücke in der Tabelle 11.2 in derselben Reihenfolge ihres Auftretens ausgeführt wie bei logischen Ausdrücken. In vorherigen Systemen werden Konvertierungen durchgeführt, indem man von dem rechten Wert zu den Datentypen und Längen der Komponente auf der linken Seite konvertiert.
Tabelle 11.3: Werte, die sy-subrc und sy-tabix zugeordnet werden.
Ergebnis sy-subrc sy-tabix
Lesen war erfolgreich 0 Index der gefundenen Zeile
Lesen war nicht erfolgreich, aber eine Zeile mit einem Schlüssel größer als der nachgefragte existiert.
4 Index der Zeile mit dem nächsthöheren Schlüssel
Lesen war nicht erfolgreich, und es wurde keine Zeile mit einem größeren Schlüssel gefunden.
8 Nummer der Zeilen in it+1
Listing 11.7 veranschaulicht den Gebrauch von Schlüsselausdrücken.
Listing 11.7: Beim Gebrauch eines Schlüsselausdruckes können Sie eine Zeile suchen, indem Sie den Wert anstatt des Index spezifizieren.

1 report ztx1107.2 data: begin of it occurs 3,3 f1(2) type n,4 f2 type i,5 f3(2) type c,6 f4 type p,7 end of it,8 begin of w1,9 f1 like it-f1,10 f2 like it-f2,11 end of w1,12 w2 like it,13 f(8).1415 it-f1 = '10'. it-f3 = 'AA'. it-f2 = it-f4 = 1. append it.16 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.17 it-f1 = '30'. it-f3 = 'CC'. it-f2 = it-f4 = 3. append it.1819 read table it with key f1 = '30' f2 = 3.20 write: / 'sy-subrc =', sy-subrc,21 / 'sy-tabix =', sy-tabix,22 / it-f1, it-f2, it-f3, it-f4.2324 f = 'F2'. "must be in uppercase25 read table it into w2 with key (f) = 2.26 write: /,27 / 'sy-subrc =', sy-subrc,28 / 'sy-tabix =', sy-tabix,29 / it-f1, it-f2, it-f3, it-f4,30 / w2-f1, w2-f2, w2-f3, w2-f4.3132 clear w2.33 w2-f1 = '10'. w2-f3 = 'AA'. w2-f2 = w2-f4 = 1.34 read table it with key = w2.35 write: /,36 / 'sy-subrc =', sy-subrc,37 / 'sy-tabix =', sy-tabix,38 / it-f1, it-f2, it-f3, it-f4.3940 w1-f1 = '20'. w1-f2 = 2.41 read table it into w2 with key w1.42 write: /,43 / 'sy-subrc =', sy-subrc,44 / 'sy-tabix =', sy-tabix,45 / it-f1, it-f2, it-f3, it-f4.

Der Programm-Code in Listing 11.7 erzeugt folgende Ausgabe:
sy-subrc = 0sy-tabix = 330 3 CC 3
sy-subrc = 0sy-tabix = 230 3 CC 320 2 BB 2
sy-subrc = 0sy-tabix = 110 1 AA 1
sy-subrc = 0sy-tabix = 210 1 AA 1
■ Die Zeilen 2 bis 7 definieren eine interne Tabelle mit einer Kopfzeile. ■ Zeile 8 definiert einen Arbeitsbereich w1 mit den ersten zwei gleichen Feldern wie die
Kopfzeile it.■ Zeile 9 definiert einen Arbeitsbereich w2, der mit der ganzen Länge der Kopfzeile it gleicht. ■ Die Zeilen 15 bis 17 fügen drei Zeilen der internen Tabelle hinzu. ■ Zeile 19 liest eine Zeile, die den Wert '30' in f1 und 3 in f2 hat. Nach dem Lesen wird sy-subrc auf Null gesetzt. Das bedeutet, daß die Zeile existiert, und daß sy- tabix mit der Zeilennummer gefüllt wird. Da kein Arbeitsbereich spezifiziert ist, wird der Inhalt in der Kopfzeile plaziert.
■ Zeile 25 sucht nach einer Zeile, die den Wert 2 in der f2 Spalte hat. Wird sie gefunden, wird sie in den Arbeitsbereich geschrieben. Der Inhalt der Kopfzeile wird nach dem Lesen unverändert gelassen.
■ Zeile 34 sucht nach einer Zeile, welche die Werte beinhaltet, die in allen Feldern von w2spezifiziert sind. Mit dieser Syntax muß w2 der ganzen Struktur von it gleichen. Der Inhalt der gefundenen Zeile wird in der Kopfzeile plaziert. Felder, die Leerzeichen enthalten, werden in der Tabelle gesucht, es werden nicht alle Werte zugeordnet, wie es bei der Suche mit einem Standardschlüssel gemacht wird (siehe nächster Abschnitt).
■ Zeile 41 sucht nach einer Zeile, welche die Werte beinhaltet, die in allen Feldern von w1spezifiziert sind. Mit dieser Syntax kann w1 kürzer als it sein. Der Inhalt der passenden Zeile wird in der Kopfzeile plaziert. Wie zuvor werden Leerzeichen als zu suchende Werte interpretiert und können nur sich selbst zugeordnet werden.
Der Zusatz binary search
Wenn Sie den Zusatz with key benutzen, sollten Sie auch den Zusatz binary search benutzen. Damit wird erreicht, daß die Suche der Zeile einen binären Suchalgorithmus statt des linearen Lesens der Tabelle verwendet. Dies ergibt dieselbe Ausführungsgeschwindigkeit wie die Suche in einer

Datenbanktabelle mittels eines Index. Zuvor muß allerdings die interne Tabelle in aufsteigender Reihenfolge in den Komponenten, die in dem Schlüsselausdruck spezifiziert sind, sortiert werden. (Siehe nächster Abschnitt über das Sortieren.)
Keine Zusätze
Wenn weder ein Index noch ein Schlüsselausdruck spezifiziert ist, wird die Tabelle von Anfang an nach einer Zeile durchsucht, die dem Standardschlüssel der Kopfzeile entspricht. Der Standardschlüssel ist ein imaginärer Schlüssel, zusammengesetzt aus allen Zeichenfeldern der Kopfzeile (Typen c, d, t, n und x). Ein Leerzeichen in einer Spalte des Standardschlüssels bewirkt, daß alle Werte zueinander passen. Danach werden die Werte von sy-subrc und sys-tabix in der gleichen Art gesetzt wie bei der Anweisung read table mit einem Schlüsselausdruck.
Nur Leerzeichen in einem Standardschlüssel werden alle Werte zuordnen. Das bedeutet, daß Sie die Typen d, t, n und x nicht löschen können und eine Zuordnung erhalten - denn Löschen setzt die Werte auf Null und wandelt sie nicht in Leerzeichen um. Sie müssen Leerzeichen in diese Felder füllen, um eine Zuordnung zu erreichen. Das können Sie erreichen, wenn Sie eine Feldleiste (siehe nächstes Beispiel), ein Unterfeld oder ein Feldsymbol nutzen (siehe vorheriger Abschnitt über Feldsymbole für mehr Information).
Listing 11.8 zeigt ein Beispiel.
Listing 11.8: Dieses Programm findet eine Zeile mit denselben Werten wie sie die Standardschlüsselfelder in der Kopfzeile haben. Leerzeichen in einem Standardschlüsselfeld sorgen dafür, daß die Spalte nicht berücksichtigt wird.
1 report ztx1108.2 data: begin of it occurs 3,3 f1(2) type n, "character field - part of default key4 f2 type i, "numeric field - not part of default key5 f3(2) type c, "character field - part of default key6 f4 type p, "numeric field - not part of default key7 end of it.89 it-f1 = '10'. it-f3 = 'AA'. it-f2 = it-f4 = 1. append it.10 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.11 it-f1 = '30'. it-f3 = 'CC'. it-f2 = it-f4 = 3. append it.1213 sort it by f1 f3.

14 clear it.15 it(2) = ' '. it-f3 = 'BB'.16 read table it binary search.17 write: / 'sy-subrc =', sy-subrc,18 / 'sy-tabix =', sy-tabix,19 / 'f1=', it-f1, 'f2=', it-f2, 'f3=', it-f3, 'f4=', it-f4.2021 clear it.22 it-f1 = '30'. it-f3 = 'AA'.23 read table it binary search.24 write: / 'sy-subrc =', sy-subrc,25 / 'sy-tabix =', sy-tabix,26 / 'f1=', it-f1, 'f2=', it-f2, 'f3=', it-f3, 'f4=', it-f4.
Der Programm-Code in Listing 11.8 erzeugt folgende Ausgabe:
sy-subrc = 0sy-tabix = 2f1= 20 f2= 2 f3= BB f4= 2sy-subrc = 4sy-tabix = 3f1= 30 f2= 0 f3= AA f4= 0
■ Die Zeilen 2 bis 7 definieren eine interne Tabelle mit einer Kopzeile. f1 und f3 sind die Zeichendatentypen und formen damit die Standardschlüssel.
■ Die Zeilen 9 bis 11 fügen drei Zeilen der internen Tabelle hinzu. ■ Zeile 13 sortiert it nach f1 und f3 in aufsteigender Reihenfolge. ■ Zeile 14 löscht den Inhalt der Kopfzeile, indem alle Komponenten in Leerzeichen und Nullen
gesetzt werden. ■ Unter Nutzung eines Unterfeldes schreibt Zeile 15 Leerzeichen in das f1-Feld, so daß alle
Werte zugeordnet werden. Das andere Standardschlüsselfeld (f3) wird mit 'BB' gefüllt. ■ Zeile 16 führt eine binäre Suche für eine Zeile aus, die 'BB' in der Komponente f3 beinhaltet. ■ Nach der Suche zeigt die Ausgabe, daß sy-subrc auf Null gesetzt ist. Das zeigt Ihnen an, daß
ein Wert gefunden wurde, der den Kriterien zugeordnet werden kann. sy-tabix enthält den Wert 2, die relative Zeilennummer der passenden Zeile. Die Kopfzeile wird dann mit der passenden Zeile gefüllt und ausgegeben.
■ Zeile 21 löscht die Kopfzeile. ■ Zeile 22 plaziert '30' und 'AA' in den Standardschlüsselfeldern f1 und f3.■ Zeile 23 führt eine binäre Suche für f1 = '30' und f3 = 'AA' aus. Der Rückgabewert
von sy-subrc ist 4. Das zeigt an, daß eine passende Zeile nicht gefunden wurde und sy-tabix beinhaltet 3 - die Anzahl der Zeilen in der Tabelle. Der Inhalt der Kopfzeile bleibt unverändert wie in Zeile 22.
In diesem Beispiel enthält die interne Tabelle lediglich ein paar Zeilen, so daß die binäre Suche nicht in meßbaren Verbesserungen in der Ausführung resultiert. Es ist hier nur erläutert, um zu zeigen, wie es prinzipiell funktioniert.

Die Anweisung read table kann nur verwendet werden, um eine interne Tabelle zu lesen. Diese Anweisung arbeitet nicht mit Datenbanktabellen. Nutzen Sie dafür select single.
Der Zusatz comparing
Der Zusatz comparing findet Unterschiede im Inhalt des Arbeitsbereichs und der Zeile, die gefunden wurde, bevor sie im Arbeitsbereich plaziert wurde. Benutzen Sie ihn in Verbindung mit index oder with key. Nachdem eine Zeile gefunden wurde und sie denselben Inhalt wie der Arbeitsbereich hat, wird sy-subrc 0 sein. Wenn der Inhalt sich unterscheidet, dann wird sy-subrc 2 sein, und der Inhalt wird mit der gefundenen Zeile überschrieben. Wenn keine Zeile gefunden wird, dann wird sy-subrc größer als 2 sein, und der Inhalt bleibt unverändert.
Tabelle 11.4 beschreibt die Werte für den Vergleichsausdruck (cmpexp in die Syntax für readtable).
Tabelle 11.4: Formen für den Vergleichsausdruck in der Anweisung read table
Cmpexp Beschreibung
f1 f2 ... Nachdem eine Zeile gefunden wurde, wird der Wert von f1 in der gefundenen Zeile mit dem Wert von f1 im Arbeitsbereich verglichen. Dann wird der Wert von f2 mit dem Wert von f2 im Arbeitsbereich verglichen und so weiter. Wenn alle gleich sind, dann wird sy-subrc auf 0 gesetzt. Wenn es irgendeinen Unterschied gibt, dann wird sy-subrc auf 2 gesetzt.
all fields Alle Felder werden verglichen, so wie es für f1 f2 ... beschrieben ist.
no fields Kein Feld wird verglichen. Dieses ist der Standardfall.
Listing 11.9 zeigt ein Beispiel.
Listing 11.9: Der Zusatz comparing setzt den Wert von sy-subrc auf 2, wenn irgendein Feld sich unterscheidet.
1 report ztx1109.2 data: begin of it occurs 3,3 f1(2) type n,

4 f2 type i,5 f3(2) type c,6 f4 type p,7 end of it,8 wa like it.910 it-f1 = '10'. it-f3 = 'AA'. it-f2 = it-f4 = 1. append it.11 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.12 it-f1 = '30'. it-f3 = 'CC'. it-f2 = it-f4 = 3. append it.1314 read table it index 2 comparing f1.15 write: / 'sy-subrc =', sy-subrc,16 / 'sy-tabix =', sy-tabix,17 / it-f1, it-f2, it-f3, it-f4.1819 read table it into wa index 1 comparing f2 f4.20 write: /,21 / 'sy-subrc =', sy-subrc,22 / 'sy-tabix =', sy-tabix,23 / it-f1, it-f2, it-f3, it-f4,24 / wa-f1, wa-f2, wa-f3, wa-f4.2526 it = wa.27 read table it with key f3 = 'AA' comparing all fields.28 write: /,29 / 'sy-subrc =', sy-subrc,30 / 'sy-tabix =', sy-tabix,31 / it-f1, it-f2, it-f3, it-f4,32 / wa-f1, wa-f2, wa-f3, wa-f4.
Der Programm-Code in Listing 11.9 erzeugt folgende Ausgabe:
sy-subrc = 2sy-tabix = 220 2 BB 2
sy-subrc = 2sy-tabix = 120 2 BB 210 1 AA 1
sy-subrc = 0sy-tabix = 110 1 AA 110 1 AA 1

■ In Zeile 14 lokalisiert index 2 die Zeile 2. Bevor die Zeile in die Kopfzeile kopiert wird, wird der Wert von f1 in dem Rumpf mit dem Wert von f1 in der Kopfzeile verglichen. In diesem Fall hat die Kopfzeile immer noch den Wert 3 (unverändert nach dem Hinzufügen der letzen Zeile) und die gefundene Zeile beinhaltet eine 2. Sie sind unterschiedlich, so daß sy-subrcauf 2 gesetzt wird. Der Inhalt der internen Tabelle wird dann in die Kopfzeile geschrieben und der vorhandene Inhalt überschrieben.
■ In Zeile 19 wird die Zeile 1 gefunden. Die Werte von f2 und f4 in Zeile 1 werden dann mit den Komponenten der Kopfzeile mit dem gleichen Namen verglichen. Die Kopfzeile enthält die Zeile 2 (erhalten durch Zeile 14), und somit sind sie unterschiedlich. Als Ergebnis wird sy-subrc auf 2 gesetzt.
■ Zeile 26 kopiert den Inhalt von wa in die Kopfzeile. ■ In Zeile 27 wird nach einer Zeile mit f3 = 'AA' gesucht. Zeile 1 paßt, wie in den Werten
von sy-subrc und sy-tabix in der Ausgabe ersichtlich. Zeile 1 ist schon in der Kopfzeile, deshalb stimmen alle Werte in den Feldern überein und sy-subrc wird auf 0 gesetzt.
Der Zusatz transporting
Der Zusatz transporting beeinflußt die Art, wie Felder von der gefundenen Zeile in den Arbeitsbereich bewegt werden. Wenn der Zusatz angegeben wird, dann werden nur die spezifizierten Komponenten in den Arbeitsbereich bewegt. Wenn keine Zeile gefunden wird, dann macht transporting nichts.
Tabelle 11.5 beschreibt die Werte für den Transportierausdruck (texp in die Syntax für read table).
Tabelle 11.5: Formen für den Transportierausdruck in der Anweisung read table
Cmpexp Beschreibung
f1 f2 ... Nachdem eine Zeile gefunden wurde, wird der Wert von f1 in der gefundenen Zeile in den Arbeitsbereich geschrieben. Dann wird der Wert von f2 in den Arbeitsbereich geschrieben und so weiter. Nur die Komponenten, die nach transporting genannt werden, werden transportiert. Alle anderen Komponenten bleiben unverändert.
all fields Alle Felder werden transportiert. Dies ist der Standardfall, und das Ergebnisist dasselbe wie ohne Ausführung mit dem Zusatz transporting.
no fields Kein Feld wird transportiert. Kein Feld im Arbeitsbereich wird verändert.
Dieser Zusatz ist sinnvoll, wenn Sie lediglich die Existenz einer Zeile in einer internen Tabelle testen wollen, ohne den Inhalt der Kopfzeile zu verändern. Zum Beispiel können Sie, bevor Sie eine Zeile anfügen, bestimmen, ob diese Zeile schon in der internen Tabelle existiert.
Listing 11.10 zeigt ein Beispiel.

Listing 11.10: Die effiziente Art, Zeilen in eine sortierte interne Tabelle einzufügen und die Sortierung zu erhalten
1 report ztx1110.2 data: begin of it occurs 3,3 f1(2) type n,4 f2 type i,5 f3(2) type c,6 f4 type p,7 end of it.89 it-f1 = '40'. it-f3 = 'DD'. it-f2 = it-f4 = 4. append it.10 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.1112 sort it by f1.13 do 5 times.14 it-f1 = sy-index * 10.15 it-f3 = 'XX'.16 it-f2 = it-f4 = sy-index.17 read table it18 with key f1 = it-f119 binary search20 transporting no fields.21 if sy-subrc <> 0.22 insert it index sy-tabix.23 endif.24 enddo.2526 loop at it.27 write: / it-f1, it-f2, it-f3, it-f4.28 endloop.
Der Programm-Code in Listing 11.10 erzeugt folgende Ausgabe:
10 1 XX 120 2 BB 230 3 XX 340 4 DD 450 5 XX 5
■ Die Zeilen 9 und 10 fügen zwei Zeilen in it ein. (Sie sind absichtlich nicht sortiert, um das Beispiel zu verdeutlichen.)
■ Zeile 12 sortiert it aufsteigend nach f1, so daß die folgende Anweisung read table denZusatz binary search benutzen kann.
■ Zeile 13 durchläuft die Schleife 5mal. Jedesmal, wenn die Schleife durchlaufen wird, wird eine

neue Zeile in it erzeugt und in der Kopfzeile plaziert. (Zeilen 14, 15 und 16.) ■ Die Zeilen 17 und 21 bestimmen, ob eine Zeile schon mit denselben Werten für f1 existiert,
die den Werten in der Kopfzeile entspricht. Wenn keine Zeile gefunden wird, dann wird sy-subrc auf einen Wert ungleich 0 und sy-tabix auf den Index der Zeile mit dem nächsten Wert gesetzt, d.h. sy-tabix entspricht der Anzahl der Zeilen plus 1.
Den Inhalt einer internen Tabelle sortieren
Um den Inhalt einer internen Tabelle zu sortieren, nutzen Sie bitte die Anweisung sort. Zeilen können nach einer oder mehreren Spalten in aufsteigender oder absteigender Reihenfolge sortiert werden. Die Sortierreihenfolge selbst kann auch verändert werden.
Syntax der Anweisung sort
Das Folgende ist die Syntax der sort-Anweisung.
sort it [descending] [as text] [by f1 [ascending|descending] [as text] -> f2 ...].
wobei:
■ it der Name der internen Tabelle ist. ■ f1 und f2 Komponenten von it sind. ■ ... für jede beliebige Anzahl von Feldern steht, die optional ascending folgen können.
Die folgenden Punkte sind zu beachten:
■ ascending (aufsteigend) ist die vorgegebene Sortierreihenfolge. ■ Wenn descending (absteigend) nach sort und vor den Komponenten erscheint, wird es die
standardmäßige Sortierreihenfolge und gilt für alle Komponenten. Diese Vorgabe kann für eine Komponente überschrieben werden, wenn nach der Komponente ascending spezifiziert wird.
■ Wenn keine Zusätze angegeben sind, wird die Tabelle nach den Standardschlüsselfeldern (alle Felder vom Datentyp c, n, p, d und t) in aufsteigender Reihenfolge sortiert.
Die Sortierreihenfolge für Zeilen, die denselben Wert haben, ist nicht voraussagbar. Zeilen mit demselben Wert in einer sortierten Spalte können nach dem Sortieren in jeder Reihenfolge erscheinen. Listing 11.11 zeigt Beispiele der Anweisung sort und verdeutlicht auch diesen Punkt.
Listing 11.11: Nutzung der Anweisung sort, um die Zeilen einer internen Tabelle zu sortieren.
1 report ztx1111.2 data: begin of it occurs 5,3 i like sy-index,

4 t,5 end of it,6 alpha(5) value 'CBABB'.78 do 5 times varying it-t from alpha+0 next alpha+1.9 it-i = sy-index.10 append it.11 enddo.1213 loop at it.14 write: / it-i, it-t.15 endloop.1617 skip.18 sort it by t.19 loop at it.20 write: / it-i, it-t.21 endloop.2223 skip.24 sort it by t.25 loop at it.26 write: / it-i, it-t.27 endloop.2829 skip.30 sort it by t i.31 loop at it.32 write: / it-i, it-t.33 endloop.3435 skip.36 sort it by t descending i.37 *same as: sort it descending by t i ascending.38 loop at it.39 write: / it-i, it-t.40 endloop.4142 skip.43 sort it.44 *same as: sort it by t.45 loop at it.46 write: / it-t.47 endloop.
Der Programm-Code in Listing 11.11 erzeugt folgende Ausgabe:

.........1 C2 B3 A4 B5 B
3 A2 B4 B5 B1 C
3 A5 B4 B2 B1 C
3 A2 B4 B5 B1 C
1 C2 B4 B5 B3 A
ABBBC
■ Die Zeilen 2 bis 5 definieren eine interne Tabelle mit zwei Komponenten: i und t. Die occurs-Klausel ist 5, und daher wird die interne Tabelle mit fünf Zeilen gefüllt.
■ Zeile 6 definiert alpha als Datentyp c mit variabler Länge 5 und erhält einen Vorgabewert. ■ Die Zeilen 8 bis 11 fügen der internen Tabelle fünf Zeilen hinzu. Jede Zeile enthält einen
Buchstaben von alpha und den Wert von sy-index, wenn eine Zeile angefügt wird. ■ Die Zeilen 13 bis 15 schreiben den Inhalt der internen Tabelle aus. Die Zeilennummer von sy-tabix erscheint links auf der Ausgabe. Die Zeilen der internen Tabelle sind in ihrer ursprünglichen Reihenfolge, so daß die Werte von sy-index und sy-tabix passen.
■ Zeile 18 sortiert die Zeilen so, daß die Werte von t in aufsteigender Reihenfolge erscheinen. ■ In Zeile 24 wird die interne Tabelle noch einmal mit derselben Anweisung sortiert. Beachten

Sie, daß die relative Reihenfolge der Zeilen mit einem Wert 'B' nicht erhalten bleibt. Wenn Sie wollen, daß die Werte in der Spalte in einer bestimmten Reihenfolge sind, müssen Sie das in der sort-Anweisung spezifizieren. Die Reihenfolge der Zeilen mit identischen Werten wird während der Sortierung nicht erhalten.
■ In Zeile 30 wird die interne Tabelle nach t in aufsteigender Reihenfolge und dann nach i in absteigender Reihenfolge sortiert.
■ In Zeile 36 wird die interne Tabelle nach t in absteigender Reihenfolge und dann nach i in aufsteigender Reihenfolge sortiert.
■ Zeile 37 zeigt eine alternative Syntax, die dasselbe Ergebnis wie Zeile 36 liefert. In dieser Anweisung wird descending direkt hinter it plaziert und wird so die Vorgabe. Die Komponente t wird somit absteigend sortiert und bei der Komponente i wird die Vorgabe mit dem Zusatz ascending überschrieben.
■ Zeile 43 sortiert die interne Tabelle nach den Standardschlüsselfeldern (Datentypen c, n, d, tund x). In diesem Fall gibt es nur ein Feld in dem Standardschlüssel t, so daß die interne Tabelle lediglich nach t in aufsteigender Reihenfolge sortiert wird.
Sortierreihenfolge und der Zusatz as text
Innerhalb des Betriebssystems wird jedes Zeichen, das Sie auf dem Bildschirm sehen, als ein numerischer Wert dargestellt. Während der Sortierung bestimmt der numerische Wert des Zeichens die Sortierreihenfolge. Läuft z.B. ein ABAP/4-Programm in einer ASCII-Umgebung, hat der Buchstabe o einen dezimalen ASCII-Wert von 111 und p einen Wert von 112. Deshalb kommt p nach o in der Sortierreihenfolge. Diese Sortierreihenfolge wird binary sort sequence genannt.
Wenn eine Sprache akzentuierte Zeichen wie á, à oder ähnliche beinhaltet, dann wird ein numerischer Wert für jede Form der akzentuierten Zeichen vorgesehen. Z.B. o und ö (umgelautetes o) sind einzelne und verschiedene Buchstaben, jeder mit einem individuellen numerischen Wert. (In ASCII ist der numerische Wert von ö 246.) Wenn Sie Daten mit akzentuierten Zeichen sortieren, dann sollten die akzentuierten Zeichen mit den nichtakzentuierten Zeichen erscheinen. o und ö sollen z.B. zusammen sein, danach kommt p. Leider folgen die binären Werte der akzentuierten Zeichen denen der nichtakzentuierten nicht aufeinander. Daher muß ein anderer Weg gewählt werden, um die akzentuierten Zeichen richtig zu sortieren.
Der Zusatz as text modifiziert die Sortierreihenfolge so, daß die akzentuierten Zeichen richtig sortiert werden. Mit Zusatz as text wird nicht mehr die binäre Sortierreihenfolge benutzt. Statt dessen bestimmt die Textumgebung die Sortierreihenfolge.
Die Textumgebung ist eine Menge von Zeichen, die mit der Anmeldesprache des Benutzers bei der Anmeldung zusammenhängt. Sie wird bestimmt durch den Sprachschlüssel, den Sie beim Anmelden eingeben, und besteht in erster Linie aus dem Zeichensatz der Sprache und der zugehörigen Reihenfolge. Sie können die Textumgebung zur Laufzeit mit der Anweisung set locale setzen. Diese Anweisung setzt den Wert von sy-langu, d.h. dem aktuellen Zeichensatz und der zugehörigen Reihenfolge der spezifizierten Sprache.
Die folgenden Punkte sind bei dem Zusatz as text zu beachten:

■ Er kann nur mit Feldern vom Datentyp c benutzt werden. ■ Er kann nach sort und vor den Namen der Komponenten spezifiziert werden. In diesem Fall
gilt er für alle Komponenten vom Datentyp c, die beim Sortieren benutzt werden. ■ Er kann auch hinter einer Komponente spezifiziert werden. In diesem Fall gilt er nur für die
Komponente.
Listing 11.12 zeigt ein Beispiel.
Listing 11.12: Um akzentuierte Zeichen zu sortieren, wird der Zusatz as text benötigt.
1 report ztx1112.2 data: begin of it occurs 4,3 t(30),4 end of it.56 it-t = 'Higgle'. append it.7 it-t = 'Hoffman'. append it.8 it-t = 'Höllman'. append it.9 it-t = 'Hubble'. append it.1011 write: / 'sy-langu=', sy-langu.12 sort it. "sorts by default key. t is type c, therefore orts by t.13 loop at it.14 write: / it-t.15 endloop.1617 skip.18 set locale language 'D'. "Equivalent to signing on in German19 write: / 'sy-langu=', sy-langu.20 sort it as text. "as text here applies to all type c components21 *same as: sort it by t as text.22 loop at it.23 write: / it-t.24 endloop.
Der Programm-Code in Listing 11.12 erzeugt folgende Ausgabe:
sy-langu= EHiggleHoffmanHubbleHöllman
sy-langu= D

HiggleHoffmanHöllmanHubble
■ Die Zeilen 6 bis 9 fügen der internen Tabelle vier Zeilen hinzu, von denen die vierte ein öbeinhaltet.
■ Zeile 11 schreibt die aktuelle Anmeldesprache aus. ■ Zeile 12 sortiert it nach dem Standardschlüssel in binärer Sortierreihenfolge gemäß der
aktuellen Anmeldesprache. Die Ausgabe zeigt, daß ö in der sortierten Reihenfolge an letzter Stelle erscheint.
■ set locale in Zeile 18 ändert die Umgebung des Programms; es ist dem Anmelden in Deutsch gleichzusetzen. Sy-langu wird auf D gesetzt, und der deutsche Zeichensatz und die zugehörigen Reihenfolgen werden von nun an in dem Programm benutzt.
■ Zeile 20 benutzt sort mit dem Zusatz as text nach dem Namen der internen Tabelle. Damit gilt as text für alle Komponenten mit dem Datentyp c. In der Ausgabe erscheinen ound ö zusammen.
Nachdem Sie mit as text sortiert haben, benutzen Sie nicht den Zusatz binarysearch bei der Anweisung read table. Die Zeilen werden nicht in binärer Reihenfolge sortiert, so daß eine binäre Suche falsche Ergebnisse liefert. Um binarysearch erfolgreich zu benutzen, sehen Sie bitte in der ABAP/4-Schlüsselwortdokumentation bei den Erläuterungen zur Anweisung convert into sortable nach.
Sortierreihenfolgen variieren je nach Plattform. Wenn sie von einem Betriebssystem zu einem anderen transportiert werden, sind die einzigen sicheren Sortierfolgen A-Z, a-z, und 0-9, aber nicht unbedingt in der Reihenfolge.
Nach dem Sortieren können Sie Duplikate in einer internen Tabelle mit der Anweisung delete adjacent duplicates löschen, wie auch in der ABAP/4-Schlüsselwortdokumentation beschrieben.
Zusammenfassung

■ Eine interne Tabelle ist eine Ansammlung von Zeilen im RAM auf dem Applikationsserver. Sie besteht aus einer Kopfzeile und einem Rumpf. Die Kopfzeile ist optional. Die Kopfzeile ist der implizite Arbeitsbereich einer internen Tabelle.
■ Die Existenz der occurs-Klausel erstellt eine interne Tabelle. ■ Benutzen Sie die Anweisung loop at, um mehrere Zeilen einer internen Tabelle zu erhalten.
Jede Zeile wird einzeln in der Kopfzeile oder einem expliziten Arbeitsbereich plaziert. Benutzen Sie from, to and where, um Zeilen zu spezifizieren, die zurückgegeben werden sollen. In der Schleife beinhaltet sy-tabix die relative Zeilennummer. Nachdem die Schleife durchlaufen ist, wird sy-subrc Null sein, wenn irgendeine Zeile in der Schleife prozessiert wurde.
■ In der Schleife kann die Ausführung durch die Anweisungen exit, continue oder checkverändert werden. exit beendet die Schleife und setzt die Verarbeitung mit der Anweisung nach endloop fort. continue überspringt die verbleibenden Anweisungen der Schleife und fährt sofort mit dem nächsten Schleifendurchlauf fort. check setzt wie continue mit dem nächsten Schleifendurchlauf fort, jedoch erst, wenn ein logischer Ausdruck falsch ist.
■ Benutzen Sie die Anweisung read table, um eine einzelne Zeile einer internen Tabelle zu lokalisieren. Mit dem Zusatz index können Sie eine einzelne Zeile mit der relativen Zeilennummer lokalisieren. Das ist sehr effizient, um eine Zeile zu finden. Mit dem Zusatz with key können Sie eine Zeile mit einem bestimmten Wert finden. comparing stellt fest, ob bestimmte Werte in dem Arbeitsbereich von Werten in der gefundenen Zeile abweichen. transporting verhindert ungewollte und unnötige Zuweisungen von der gefundenen Zeile in den Arbeitsbereich.
■ Die Anweisung sort sortiert eine interne Tabelle nach den Komponenten. Wenn keine Komponenten genannt werden, wird die Tabelle nach den Standardschlüsselfeldern (Datentyp c, n, d, t und x) sortiert.
Erlaubt Nicht erlaubt
Benutzen Sie den Zusatz binary searchmit der Anweisung read table. Es steigert die Ausführung der Suche deutlich.
Benutzen Sie nicht occurs 0 für interne Tabellen, die kleiner als 8 KB sind. Das bedeutet: Zuweisung von zuviel Speicher und langsamerer Ausführung.
Benutzen Sie den Zusatz index mit der Anweisung read table, wenn möglich. Es ist der schnellste Weg, eine Zeile zu finden.
Fragen & Antworten
Frage:In einigen Programmen habe ich einen benutzerdefinierten Datentyp mit der occurs -Klauselgesehen. Der Typ wird dann benutzt, um einen internen Tabellentyp und folglich eine interne Tabelle zu definieren. Dies wird im Listing 11.13 gezeigt. Warum wird dies so gemacht? Können Sie eine interne Tabelle immer mit der Anweisung data definieren? Warum führen Sie die

Anweisung types ein?
Listing 11.13: Definieren einer internen Tabelle mit einem benutzerdefinierten Typ
1 report ztx1113.2 types: begin of my_type,3 f1,4 f2,5 end of my_type,6 t_it type my_type occurs 10.7 data it type t_it.
Antwort:Es gibt keinen Vorteil bei der Nutzung von internen Tabellentypen, wie sie im Listing 11.13 gezeigt werden. Datentypen sind nur sinnvoll, wenn sie mehr als ein Datenobjekt definieren. In diesem Programm wird nur ein Datenobjekt vom Typ t_it definiert. In diesem Fall wäre es einfacher, nicht die Anweisung types zu benutzen und die gesamte Definition mit data zu erzeugen.
Theoretisch sind Datentypen sinnvoll, wenn Sie mehrere Datenobjekte vom gleichen Typ definieren wollen. Listing 11.14 zeigt drei Arten, mehrdimensionale interne Tabellen zu definieren: nur mit der Anweisung data, mit der Anweisung types und mit einer DDIC-Struktur.
Listing 11.14: Die Definition von mehrdimensionalen Tabellen wird mit der Anweisung typesvereinfacht.
1 report ztx1114.23 * Define 3 identical internal tables using DATA only4 data: begin of it_1a occurs 10,5 f1,6 f2,7 end of it_1a,8 it_1b like it_1a occurs 10 with header line,9 it_1c like it_1a occurs 10 with header line.1011 * Define 3 more identical internal tables using TYPES12 types: begin of t_,13 f1,14 f2,15 end of t_,16 t_it type t_ occurs 10.17 data: it_2a type t_it,18 it_2b type t_it,19 it_2c type t_it.2021 * Define 3 more using a DDIC structure

22 data: it_3a like ztx_it occurs 10 with header line,23 it_3b like ztx_it occurs 10 with header line,24 it_3c like ztx_it occurs 10 with header line.
Bei den ersten beiden Methoden ist es Ansichtssache, welche von beiden deutlicher ist. Keine von beiden hat einen entscheidenden Vorteil. Ich glaube, daß die dritte Methode die bevorzugte ist. Sie ist deutlicher. Falls Sie die Definition sehen möchten, brauchen Sie einfach nur auf den Namen der DDIC-Struktur doppelzuklicken. Wenn Sie sich die Struktur anschauen, so sehen Sie etwas, das aussagekräftiger ist als eine ABAP/4-Definition. Zu jedem Datenelement und auch der Struktur selbst gibt es einen kurzen Text. Diese Texte können auch übersetzt werden. Zusätzlich ist die Struktur für die Wiederverwendung in anderen Programmen verfügbar. Meiner Meinung nach ist der Gebrauch einer Struktur der Definition types deutlich überlegen.
Es gibt jedoch einen Aspekt, worin der Datentyp der Struktur überlegen ist. Er kann Definitionen für verschachtelte interne Tabellen enthalten. Nur in diesem Fall würde ich einen Datentyp verwenden. In allen anderen Fällen ist eine Struktur in dem DDIC für a date begin of oder a like der bessere Weg.
Workshop
Der Workshop bietet Ihnen zwei Wege, wie Sie überprüfen können, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen helfen Ihnen, das Erlernte zu vertiefen, während die Übungen Ihnen ermöglichen, es praktisch anzuwenden. Antworten zu den Übungen und Fragen finden Sie im Anhang B »Antworten zu den Kontrollfragen und Übungen«.
Kontrollfragen
1. Was setzt eine Grenze für die maximale Menge an erweitertem Speicher, die eine interne Tabelle zuweisen kann?
2. Warum sollten Sie nicht occurs 0 benutzen, wenn Sie erwarten, daß die interne Tabelle weniger als 8 KB speichert?
3. Können Sie die Anweisung read table benutzen, um Tabellen einer Datenbank zu lesen?
Übung 1
Zeigen und erklären Sie die Umwandlungen, die im Programm ztx1110 auftreten (siehe Listing 11.15).
Listing 11.15: Umwandlungen (Hinweis: Programm->Analyse)
1 report ztx1110.

2 data: begin of it occurs 3,3 f1(2) type n,4 f2 type i,5 f3(2) type c,6 f4 type p,7 end of it.89 it-f1 = '40'. it-f3 = 'DD'. it-f2 = it-f4 = 4. append it.10 it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.1112 sort it by f1.13 do 5 times.14 it-f1 = sy-index * 10. 15 it-f3 = 'XX'. 16 it-f2 = it-f4 = sy-index.17 read table it 18 with key f1 = it-f1 19 binary search 20 transporting no fields.21 if sy-subrc <> 0.22 insert it index sy-tabix.23 endif.24 enddo.2526 loop at it.27 write: / it-f1, it-f2, it-f3, it-f4.28 endloop.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 12
Interne Tabellen, Teil 1
Kapitelziele
Wenn Sie dieses Kapitel durchgearbeitet haben, sind Sie in der Lage:
■ Tabellenrumpf-Operatoren zu erkennen und sie zum Testen auf die Existenz von Daten in einer internen Tabelle zu benutzen sowie den Inhalt zweier interner Tabellen auf Gleichheit zu prüfen
■ die Anzahl von Zeilen in einer internen Tabelle mit Hilfe von describe und sy- tfillzu bestimmen
■ den Inhalt von einer internen Tabelle zu einer anderen mit Hilfe des Tabellenrumpf-Operators und der Anweisungen append lines und insert lines zu kopieren
■ sich interne Tabellen mit Hilfe von editor-call anzusehen und zu modifizieren ■ mit insert und modify-Anweisungen den Inhalt interner Tabellen zu ändern ■ Zeilen aus einer internen Tabelle mit Hilfe von delete, delete . . . where, clear, clear it [], refresh und free zu löschen
■ eine interne Tabelle mit Hilfe von append sorted by und collect zu füllen
Den Inhalt interner Tabellen testen und modifizieren
Benutzen Sie die folgenden Konstrukte, um den Inhalt interner Tabellen zu testen und zu modifizieren:
■ Den Tabellenrumpf-Operator ■ describe table■ append lines■ insert lines

■ editor-call■ insert■ modify■ free■ delete■ clear■ refresh■ append sorted by ■ collect
Der Rumpf einer internen Tabelle wird durch die Syntax it[] dargestellt, wobei it der Name irgendeiner internen Tabelle ist. it[] heißt, »der Rumpf der internen Tabelle it«. Es darf nichts zwischen den eckigen Klammern stehen; sie müssen genauso wie eben gezeigt geschrieben werden. Sie können diese Syntax benutzen, um effiziente Tabellenoperationen, die keine Kopfzeile erfordern, auszuführen. Diese Operationen werden in diesem Kapitel beschrieben.
Wenn eine interne Tabelle keine Kopfzeile hat, ist der interne Tabellenname selbst der Rumpf. Hat zum Beispiel eine interne Tabelle keine Kopfzeile, kann man entweder it[] oder it benutzen, um den Rumpf zu repräsentieren; beide sind gleichwertig.
Informationen über eine interne Tabelle erhalten
Die folgenden gebräuchlichen Informationen kann man über eine interne Tabelle erhalten:
■ ob die interne Tabelle Daten enthält ■ wieviel Zeilen sie enthält
Wie bestimmt man, ob eine interne Tabelle leer ist
Wenn der Rumpf einer internen Tabelle nur Initialwerte (Leerzeichen, Nullen) enthält, ist er leer. Deshalb kann man zur Bestimmung, ob eine interne Tabelle Daten enthält, den Rumpf mit der folgenden Anweisung testen:
if it[] is initial.
Wenn der Test wahr ist, ist die interne Tabelle leer. Wenn der Rückgabewert falsch ist, enthält sie mindestens eine Zeile.
Die Anzahl von Zeilen einer internen Tabelle bestimmen
Um die Anzahl von Zeilen einer internen Tabelle zu bestimmen, wird die Variable sy- tfillbenutzt. Sie wird durch die describe table-Anweisung gesetzt.

Syntax der describe table-Anweisung
Im folgenden wird die Syntax der describe table-Anweisung gezeigt.
describe table it [lines I] [occur j]
wobei:
■ it der Name der internen Tabelle ist. ■ i und j numerische Variable sind.
Mit dieser Anweisung werden die drei Systemvariablen aus Tabelle 12.1 gefüllt.
Tabelle 12.1: Die describe table-Anweisung füllt diese Systemvariablen
Variable Wert
Sy-tfillSy-tlengSy-toccu
Anzahl der Zeilen
Länge einer Zeile in Byte
Aktuelle Wert der occurs-Klausel
Die folgenden Punkte gelten:
■ Wenn der Zusatz lines i spezifiziert wird, wird die Anzahl der Zeilen in sy-tfill und igeschrieben.
■ Wenn der Zusatz occurs j spezifiziert wird, wird die Größe der occurs-Klausel in sy-toccu und j geschrieben.
Es gibt nur eine Instanz, unter welcher sich sy-toccu von der occurs-Klausel in der Table Definition unterscheidet. Wenn nämlich sy-tleng * sy-toccu > 8192 ist und nachdem eine Zeile der internen Tabelle hinzugefügt wurde, wird sy-toccu Null sein. Das zeigt an, daß Speicher in 8 KB-Blöcken für diese interne Tabelle allokiert wurde.

Ein Beispielprogramm, das Informationen über eine interne Tabelle enthält
Listing 12.1 zeigt ein Beispielprogramm, das Informationen über eine interne Tabelle enthält.
Listing 12.1: Die describe table-Anweisung benutzt Systemvariable, um den Tabelleninhalt zu quantifizieren.
1 report ztx1201.2 data: begin of it occurs 3,3 f1 value 'X',4 end of it,5 n type i.67 if it[] is initial.8 write: / 'it is empty'.9 endif.1011 append: it, it, it. "same as writing 'append it' 3 times.1213 if not it[] is initial.14 write: / 'it is not empty'.15 endif.1617 write: / 'number of rows from sy-tabix:', sy-tabix.18 describe table it lines n.19 write: / 'number of rows from sy-tfill:', sy-tfill,20 / 'length of a row from sy-tleng:', sy-tleng,21 / 'occurs value from sy-toccu:', sy-toccu.
Das Programm aus Listing 12.1 produziert die folgende Ausgabe:
it is empty it is not empty number of rows from sy-tabix: 3 number of rows from sy-tfill: 3 length of a row from sy-tleng: 1 occurs value from sy-toccu: 3
■ Zeile 7 vergleicht den Rumpf der internen Tabelle mit Hilfe des Tabellenrumpf- Operators mit Initialwerten. Da die interne Tabelle zu dieser Zeit noch keine Einträge hat, ist der Test wahr.
■ Zeile 11 benutzt den Kettenoperator (:), um drei identische Zeilen an it anzu- hängen. ■ Zeile 13 testet wieder den Rumpf. Dieses Mal wird der Test durch ein logisches not
vorgenommen. Da die interne Tabelle Daten enthält, ist der Test wahr. ■ Hinter jeder append-Anweisung, wird der Wert von sy-tabix auf die Anzahl der Zeilen

der internen Tabelle gesetzt. Zeile 17 schreibt diesen Wert aus. ■ Zeile 18 benutzt die describe-Anweisung, um die Zeilenanzahl zu bestimmen, und schreibt
sie in sy-tfill. It enthält auch die Zeilenlänge und Größe der occurs -Klausel und schreibt sie in sy-tleng und sy-toccu.
Wenn man nur Informationen braucht, ob die Tabelle Daten enthält und nicht, wie viele Zeilen sie hat, sollte man den Rumpfoperator benutzen. Er ist effizienter als die describe table-Anweisung.
Daten von einer internen Tabelle in eine andere kopieren
Wenn zwei interne Tabellen die gleiche Struktur haben, kann man mit der folgenden Anweisung den Inhalt einer internen Tabelle in eine andere duplizieren.
it2[] = it1[].
Zwei interne Tabellen haben die gleiche Struktur, wenn sie 1. die gleiche Anzahl von Komponenten haben und 2. die Datentypen- und Längen jeder Komponente die gleichen sind wie die korrespondierenden Komponenten der anderen internen Tabelle. Nur die Namen der Komponenten müssen nicht übereinstimmen.
Die vorangegangene Anweisung kopiert den Inhalt des Rumpfs von it1 und stellt ihn in den Rumpf von it2. Alle existierenden Einträge in it2 werden überschrieben. Der Inhalt der Kopfzeilen, wenn jede interne Tabelle einen hat, bleibt unverändert. Das ist die wirkungsvollste Methode, um den Tabelleninhalt einer internen Tabelle in eine andere zu überführen.
Teile einer internen Tabelle kopieren
Wenn man nur Teile einer internen Tabelle in eine andere kopieren oder den Inhalt der Zieltabelle nicht verändern will, benutzt man die append lines und insert lines- Anweisungen.
Die append lines-Anweisung

Man benutzt append lines, um Zeilen an die Zieltabelle zu hängen.
Die Syntax von append lines
append lines of it1 [from nf] [to nt] to it2.
wobei:
■ it1 und it2 interne Tabellen ohne Kopfzeilen sind. ■ nf und nt numerische Variable, Literale oder Konstanten sind.
Die folgenden Punkte gelten:
■ Die Strukturen von it1 und it2 müssen passen. ■ nf ist der Index der ersten Zeile, die aus it1 kopiert werden soll. Wenn die from- Ergänzung
nicht angegeben ist, fängt das Kopieren aus der ersten Zeile von it1 an. ■ nt ist der Index der letzten Zeile, die aus it1 kopiert werden soll. Wenn die Ergänzung to
nicht mit angegeben wurde, wird bis zur letzten Zeile von it1 kopiert. ■ Sind weder from noch to angegeben, wird die gesamte Tabelle angehängt. ■ Nachdem die append lines-Anweisung ausgeführt wurde, enthält sy-tabix die Anzahl
der Zeilen in der Tabelle.
append lines ist drei- oder viermal schneller als append to.
Die insert lines-Anweisung
Mit insert lines fügt man Zeilen an anderen Stellen als nur am Ende der Zieltabelle ein.
Die Syntax von insert lines
Nachfolgend sehen Sie die Syntax von insert lines.
insert lines of it1 [from nf] [to nt] into it2 [index nb].
wobei:
■ it1 und it2 interne Tabellen ohne Kopfzeilen sind. ■ nf, nt, und nb numerische Variable, Literale oder Konstanten sein können.

Alle Punkte, die für append lines gelten, gelten auch hier. Der Unterschied ist, daß Zeilen aus it1 in it2 vor Zeilennummer nb eingefügt werden. Wenn der Wert von nb der Anzahl von Zeilen in it2 plus einer entspricht, wird die Zeile an das Ende von it2 gehängt. Ist nb größer, wird die Zeile nicht angehängt, und sy-subrc ist 4. Wenn nb kleiner als 1 ist, tritt ein Laufzeitfehler auf.
Man kann diese Anweisung sowohl innerhalb als auch außerhalb von loop at it2 benutzen. Benutzt man sie außerhalb, muß man mit dem Zusatz index arbeiten, Benutzt man sie innerhalb, ist index optional. Wird es nicht spezifiziert, wird die aktuelle Zeilennummer in it2 angenommen.
Beispielprogramm, das Daten zwischen zwei internen Tabellen kopiert
Listing 12.2 zeigt ein Beispielprogramm, welches Daten von einer internen Tabelle in eine andere kopiert.
Listing 12.2: Dieses Programm kopiert Daten von einer internen Tabelle in eine andere unter Benutzung von append lines und insert lines.
1 report ztx1202.2 data: begin of it1 occurs 10,3 f1,4 end of it1,5 it2 like it1 occurs 10 with header line,6 alpha(10) value 'ABCDEFGHIJ'.78 do 10 times varying it1-f1 from alpha+0 next alpha+1.9 append it1.10 enddo.1112 append lines of it1 from 2 to 5 to it2.13 loop at it2.14 write it2-f1.15 endloop.1617 insert lines of it1 from 8 into it2 index 2.18 skip.19 loop at it2.20 write it2-f1.21 endloop.2223 loop at it2.24 if it2-f1 >= 'E'.25 insert lines of it1 to 1 into it2.26 endif.27 endloop.

2829 skip.30 loop at it2.31 write it2-f1.32 endloop.3334 skip.35 it2[] = it1[].36 loop at it2.37 write it2-f1.38 endloop.
Das Programm aus Listing 12.2 zeigt folgende Ausgabe:
B C D E
B H I J C D E
B A H A I A J C D A E
A B C D E F G H I J
■ Die Zeilen 8 bis 10 füllen it1 mit zehn Zeilen, welche die ersten zehn Buchstaben des Alphabets enthalten.
■ Die Zeile 12 hängt die Zeilen 2 bis 5 von it1 an it2. it2 hat nun vier Zeilen, welche die Buchstaben B bis E enthalten.
■ Auf Zeile 17 ist to nicht mitangegeben, somit wird das Ende von it1 angenommen. Dies wiederum fügt die Zeilen 8, 9, und 10 aus it1 nach it2 vor Zeile 2.
■ Auf Zeile 24, wenn der Buchstabe in it2-f1 größer oder gleich E ist, wird Zeile 1 von it1vor der aktuellen Zeile von it2 eingefügt. (Da kein from angegeben wurde, wird der Anfang von it1 angenommen.) Das bedeutet, vier Zeilen werden eingefügt. In der Ausgabe stehen die 'A' Werte.
■ Zeile 35 kopiert den Inhalt von it1 nach it2, wobei der existierende Inhalt in it2vollständig überschrieben wird.
Zwei interne Tabelleninhalte vergleichen
Mit Hilfe des Tabellenrumpf-Operators können die Inhalte zweier interner Tabellen wie folgt verglichen werden:
if it1[] = it2[].
Um dieses Konstrukt zu benutzen, müssen beide interne Tabellen die gleiche Tabellenstruktur haben. Wenn dies nicht der Fall ist, muß der Inhalt Zeile für Zeile verglichen werden.

Die Anweisung ist wahr, wenn it1 und it2 die gleiche Anzahl an Zeilen enthalten und der Inhalt jeder Zeile identisch ist.
Mit der if-equal to-Anweisung wird in der Regel der Inhalt zweier Tabellen zu verglichen.
Die editor-call-Anweisung
Die editor-call-Anweisung zeigt ähnlich wie der ABAP/4-Quellcode-Editor den Inhalt einer Tabelle an. Das ist nützlich für die Fehlersuche und zudem eine einfache Schnittstelle, die dem Anwender das Eingeben und Modifizieren von Daten in tabellarischer Form erlaubt.
Die Syntax der editor-call-Anweisung
Im folgenden wird die Syntax der editor-call-Anweisung erklärt.
Editor-call for it [title t] [display mode].
wobei:
■ it der Name der internen Tabelle ist. ■ t eine Variable, ein Literal oder eine Konstante ist.
Die folgenden Punkte gelten:
■ it kann nur Typ c Komponenten enthalten. ■ Die maximale Länge einer Zeile beträgt 72 Zeichen. ■ t ist der Text, der in der Titelzeile des Fensters erscheint. ■ Mit dem Zusatz display mode werden die Daten im Editor im Anzeigemodus gezeigt. Der
Anwender kann Suchfunktionen auszuführen und blättern; er kann den Inhalt aber nicht ändern.
Nach Ansehen bzw. Ändern des Inhalts der internen Tabelle über den Editor drücken Sie auf folgende Schaltflächen: Sichern, Zurück, Exit oder Annullieren (Cancel). Wurden Änderungen gemacht, werden Sie aufgefordert zu sichern.
Nachdem die editor-call-Anweisung ausgeführt wurde, wird sy-subrc auf die Werte wie in Tabelle 12.2 gezeigt gesetzt.

Tabelle 12.2: Werte von sy-subrc nach der editor-call-Anweisung
sy-subrc Bedeutung
0
4
Es wurde eine Sicherung durchgeführt. Der Inhalt der internen Tabelle hat sich oder hat sich nicht geändert.
Der Anwender hat keine Sicherung durchgeführt. Der Inhalt der internen Tabelle ist unverändert.
Listing 12.3 zeigt ein Beispielprogramm, das die editor-call-Anweisung benutzt. In diesem Beispiel wird die interne Tabelle mit fünf Zeilen gefüllt und im Editor angezeigt, so daß der Anwender die Daten modifizieren kann. Der Inhalt wird dann ausgeschrieben, ebenso wie eine Nachricht, um anzuzeigen, ob die Daten geändert wurden.
Listing 12.3: Die Benutzung der editor-call-Anweisung, um Daten anzusehen, zu editieren und den Inhalt einer internen Tabelle auf Fehler zu überprüfen
1 report ztx1203.2 data: begin of it occurs 10,3 t(72), "text4 end of it,5 save_it like it occurs 10. "will contain copy of the original67 it-t = 'Name :'. append it.8 it-t = 'Address :'. append it.9 it-t = 'Phone :'. append it.10 it-t = 'Freeform Text '. append it.11 clear it-t with '-'. append it.1213 save_it = it[]. "same as: save_it[] = it[].14 editor-call for it title 'Freeform Entry'.15 if sy-subrc = 4. "user did not perform a save16 write: / 'Data was not changed'.17 elseif save_it[] <> it[]. "user performed a save18 write: / 'Data was changed'.19 else.20 write: / 'Data was not changed'.21 endif.22 write: / sy-uline(72).23 loop at it.24 write: / it-t.

25 endloop.
Werden keine Daten im Editor eingegeben, erzeugt das Programm aus Listing 12.3 die folgende Ausgabe:
Data was not changed -------------------------------------------------------------------Name : Address : Phone : Freeform Text -------------------------------------------------------------------
■ Die Zeilen 2 bis 4 definieren eine interne Tabelle mit einer einzelnen Komponente t und einer Zeichenlänge von 72.
■ Zeile 5 definiert eine zweite interne Tabelle wie die erste. Sie wird dazu benutzt, eine Kopie der Daten von it zu speichern. Sie hat keine Kopfzeile. Die Kopfzeile wurde ausgelassen, weil sie in diesem Programm nicht gebraucht wird.
■ Die Zeilen 7 bis 11 hängen fünf Zeilen von der Kopfzeile an die interne Tabelle. ■ Zeile 13 kopiert den Rumpf von it an den Rumpf von save_it. Da save_it keine
Kopfzeile hat, kann die linke Seite der Zuweisung mit oder ohne Klammern geschrieben werden.
■ Zeile 14 zeigt den Inhalt der internen Tabelle mit dem Titel Freeform Entry im Editor an. ■ Zeile 15 prüft den Wert von sy-subrc, um zu bestimmen, ob der Anwender gesichert hat.
Wenn nicht, werden keine Daten ausgeschrieben und eine Nachricht wird angezeigt. ■ Zeile 17 vergleicht den Inhalt von it mit dem Inhalt der Kopie in save_it. Wenn er
unterschiedlich ist, wird eine Meldung ausgeschrieben. Ist er identisch, schreibt Zeile 20 eine entsprechende Meldung.
■ Zeile 22 schreibt eine 72 Zeichen lange Unterstreichungslinie. ■ Die Zeilen 23 bis 25 geben den neuen Inhalt der internen Tabelle einschließlich der
Anwendermodifikationen aus.
Zeilen in eine interne Tabelle einfügen
Um eine einzelne Zeile in eine interne Tabelle einzufügen, benutzt man die insert- Anweisung.
Syntax der insert-Anweisung
Im folgenden wird die Syntax der insert-Anweisung gezeigt.
insert [wa into] it [index n]
wobei:

■ wa ein Arbeitsbereich mit der gleichen Struktur wie eine Zeile der internen Tabelle it ist. ■ n eine Variable, ein numerisches Literal oder eine Konstante ist.
Die folgenden Punkte gelten:
■ Wenn wa angegeben ist, wird der Inhalt von wa in it eingefügt. wa muß die gleiche Struktur wie it haben.
■ Ist wa nicht angegeben, wird der Inhalt der Kopfzeile in it eingefügt. Hat it keine Kopfzeile, muß wa angegeben werden.
■ Ist index angegeben, wird die neue Zeile vor Zeile n eingefügt. Zeile n wird dann zu n+1.■ Die insert-Anweisung kann innerhalb oder außerhalb von loop at it benutzt werden.
Wird sie außerhalb benutzt, muß index mit angegeben werden. Wird sie innerhalb benutzt, ist index optional. Wird sie nicht angegeben, wird die aktuelle Zeile angenommen.
Listing 12.4 enthält ein Beispielprogramm, das die insert-Anweisung benutzt.
Listing 12.4: Die Anweisung insert wird benutzt, um eine einzelne Zeile in eine interne Tabelle einzufügen.
1 report ztx1204.2 data: begin of it occurs 5,3 f1 like sy-index,4 end of it.56 do 5 times.7 it-f1 = sy-index.8 append it.9 enddo.1011 it-f1 = -99.12 insert it index 3.1314 loop at it.15 write / it-f1.16 endloop.1718 loop at it where f1 >= 4.19 it-f1 = -88.20 insert it.21 endloop.2223 skip.24 loop at it.25 write / it-f1.26 endloop.

Das Programm aus Listing 12.4 erzeugt die folgende Ausgabe:
1299-345
1299-388-488-5
■ Die Zeilen 6 bis 9 hängen fünf Zeilen mit den Nummern 1 bis 5 an it.■ Zeile 11 weist der Komponente it-f1 einen Wert von -99 zu. ■ Zeile 12 fügt die Kopfzeile von it als neue Zeile in den Rumpf von it vor Zeile 3 ein. Die
existierende Zeile 3 wird nun nach dem Einfügen zur Zeile 4. ■ Zeile 18 verarbeitet jetzt diejenigen Zeilen der internen Tabelle, deren Wert von f1 größer
oder gleich 4 ist. Vor jeder Zeile fügt Zeile 20 eine neue Zeile aus der Kopfzeile von it ein. Vor dem Einfügen ändert Zeile 19 die Komponente f1 auf den Wert 88-.
Nachdem jede insert-Anweisung ausgeführt ist, reindexiert das System alle Zeilen unterhalb der neu eingefügten Zeile. Das schafft zusätzlichen Aufwand, wenn man Zeilen nahe am Anfang einer großen internen Tabelle einfügt. Muß man einen Zeilenblock in eine große interne Tabelle einfügen, sollte man besser eine andere Tabelle für die neu einzufügenden Zeilen vorbereiten und dabei mit insert linesarbeiten. Somit werden die Zeilen der Zieltabelle nur einmal reindexiert, nachdem die Anweisung ausgeführt wurde.
Fügt man eine neue Zeile in it innerhalb von loop at it ein, berührt der insert -Befehl nicht sofort die interne Tabelle. Er wird statt dessen erst beim nächsten Schleifendurchgang effektiv. Wird eine Zeile hinter der aktuellen Zeile eingefügt, wird die Tabelle bei endloop reindexiert, sy-tabix wird hochgezählt und der nächste Schleifendurchgang verarbeitet die Zeile, auf die in sy-tabix gezeigt wird. Nehmen Sie zum Beispiel an, wir befinden uns im dritten Schleifendurchgang, und es wird eine neue Zeile vor Zeile 4 eingefügt. Wird endloop ausgeführt, so wird die neue Zeile

zur vierten, die alte Zeile 4 wird 5 und so weiter. sy-tabix wird um 1 hochgezählt, und der nächste Schleifendurchgang verarbeitet den eben zugefügten Satz.
Befindet man sich innerhalb einer Schleife und wird eine Zeile vor der aktuellen Zeile eingefügt, wird die Tabelle wieder bei endloop reindexiert. Dieses Mal jedoch wird sy- tabix um 1 hochgezählt zuzüglich der Zeilen, die vor der aktuellen eingefügt wurden. Beim nächsten Schleifendurchgang wird die Zeile verarbeitet, die der aktuellen Zeile folgt. Nehmen Sie zum Beispiel an, im dritten Schleifendurchgang fügen Sie eine Zeile vor der Zeile 3 ein. Bei endloop wird die neue Zeile zu Zeile 3, Zeile 3 wird Zeile 4 und so weiter. Die Zeile, die gerade verarbeitet wird, hat einen Index von 4. Sy-tabix wird um 2 hochgezählt, was 5 ergibt. Zeile 4 wurde reindexiert zu 5, somit wird Zeile 5 beim nächsten Schleifendurchgang verarbeitet.
Zeilen einer internen Tabelle modifizieren
Um eine Zeile innerhalb einer internen Tabelle zu modifizieren, benutzt man die modify -Anweisung.
Syntax der modify-Anweisung.
modify it [from wa] [index n] [transport c1 c2 . . . [where exp]].
wobei:
■ it der Name einer internen Tabelle mit oder ohne Kopfzeile ist. ■ wa ein Arbeitsbereich mit der gleichen Struktur wie eine Zeile im Rumpf von it ist.■ n eine Variable, ein numerisches Literal oder eine Konstante ist. ■ c1 und c2 Komponenten von it sind.■ exp ein logischer Ausdruck ist, der Komponenten von it mit einbindet.
Die folgenden Punkte gelten:
■ Wenn from wa angegeben wird, wird die Zeile mit dem Inhalt von wa überschrieben. ■ Wenn from wa nicht angegeben wird, wird die Zeile mit dem Inhalt der Kopfzeile
überschrieben.■ Wenn index n angegeben ist, zeigt n die Zeilennummer an, die überschrieben wird. ■ modify it kann innerhalb oder außerhalb von loop at it angegeben werden. Ist es
außerhalb, muß index n angegeben werden. Ist es innerhalb, ist index n optional. Ist es nicht angegeben, wird die aktuelle Zeile modifiziert.
transporting gibt an, welche Komponenten überschrieben werden. Ohne transportingwerden alle überschrieben. Der Rest bleibt unverändert.
Gibt man eine where-Bedingung hinter transporting an, führt das dazu, daß alle Komponenten überschrieben werden, die die where-Klausel erfüllen. Die linke Seite jeder exp-Bedingung muß

eine Komponente von it angeben. Die gleiche Komponente kann hinter transporting und expangegeben werden.
Man kann modify it im Zusammenhang mit where benutzen:
■ innerhalb von loop at it ■ mit dem Zusatz von index
Listing 12.5 zeigt ein Beispielprogramm, das den Inhalt einer internen Tabelle modifiziert.
Listing 12.5: Man benutzt modify, um den Inhalt einer oder mehrerer Zeilen einer internen Tabelle zu überschreiben.
1 report ztx1205.2 data: begin of it occurs 5,3 f1 like sy-index,4 f2,5 end of it,6 alpha(5) value 'ABCDE'.78 do 5 times varying it-f2 from alpha+0 next alpha+1.9 it-f1 = sy-index.10 append it.11 enddo.1213 it-f2 = 'Z'.14 modify it index 4.1516 loop at it.17 write: / it-f1, it-f2.18 endloop.1920 loop at it.21 it-f1 = it-f1 * 2.22 modify it.23 endloop.2425 skip.26 loop at it.27 write: / it-f1, it-f2.28 endloop.2930 it-f2 = 'X'.31 modify it transporting f2 where f1 <> 10.32

33 skip.34 loop at it.35 write: / it-f1, it-f2.36 endloop.
Programm 12.5 zeigt die folgende Ausgabe:
1 A 2 B 3 C 5 Z 5 E
2 A 4 B 6 C 10 Z 10 E
2 X 4 X 6 X 10 Z 10 E
■ Die Zeilen 8 bis 11 addieren fünf Zeilen zu it. Jede Zeile enthält eine sequentielle Nummer und einen Buchstaben aus dem Alphabet.
■ Zeile 13 modifiziert den Inhalt von it-f2 mit dem Wert 'Z'. it-f1 wird nicht verändert, somit bleibt der zuletzt hinzugefügte Wert (5) erhalten.
■ Zeile 14 überschreibt Zeile 4 mit dem Inhalt der Kopfzeile und verändert f1 zu 5 und f2 zu Z.■ Die Zeilen 20 bis 23 verarbeiten alle Zeilen von it und stellen eine Zeile nach der anderen in
die Kopfzeile. Zeile 21 multipliziert den Inhalt der Kopfzeile der Komponente f1 mit 2. Zeile 22 kopiert den Inhalt der Kopfzeile zurück in die aktuelle Zeile des Rumpfes von it und überschreibt ihn.
■ Zeile 30 verändert den Inhalt der Kopfzeile von Komponente f2 durch Zuweisung von 'X'.■ Zeile 31 verändert alle Zeilen im Rumpf, wobei f1 nicht gleich 10 ist. Nur der Wert von f2
wird aus der Kopfzeile kopiert und überschreibt f2-Werte im Rumpf. f1 bleibt unverändert im Rumpf und in der Kopfzeile.
Den Inhalt einer internen Tabelle löschen
Mit den folgenden Anweisungen läßt sich der Inhalt einer internen Tabelle löschen:
■ free■ refresh

■ clear■ delete
Die Benutzung von free, um den Inhalt einer internen Tabelle zu löschen
Mit free löscht man Zeilen aus einer internen Tabelle und gibt den allokierten Speicher wieder frei.
Die Syntax von free
Im folgenden wird die Syntax von free erklärt.
free it.
wobei:
■ it eine interne Tabelle mit oder ohne Kopfzeile ist.
Die folgenden Punkte gelten:
■ Alle Zeilen werden gelöscht, und der gesamte allokierte Speicher, der für den Rumpf der internen Tabelle benutzt wurde, wird deallokiert.
■ Die Kopfzeile, falls vorhanden, bleibt unverändert.
Man benutzt free, wenn die interne Tabelle nicht mehr gebraucht wird.
Obwohl der Speicher für interne Tabellen automatisch nach Beendigung des Programms freigegeben wird, ist es effizienter, den Speicher selbst freizugeben. Der Grund dafür ist, daß, wenn die Ausgabe dem Benutzer angezeigt wird, das Programm technisch noch nicht beendet ist. Alle Ressourcen bleiben allokiert, solange vom Anwender nicht die Schaltfläche Zurück betätigt wird. Erst das setzt den Inhalt der internen Tabelle frei und beendet das Programm. Man kann den internen Tabelleninhalt früher freigeben, indem man die free-Anweisung an das Ende des Programms legt. Der Inhalt der internen Tabelle wird freigesetzt, bevor der Anwender die Liste sieht und nicht erst danach.
Listing 12.6 zeigt, wie die free-Anweisung benutzt wird.

Listing 12.6: Die Benutzung der free-Anweisung, um Zeilen einer internen Tabelle zu löschen und Speicher freizugeben
1 report ztx1206.2 data: begin of it occurs 3,3 f1 like sy-index,4 end of it.56 do 3 times.7 it-f1 = sy-index.8 append it.9 enddo.1011 loop at it.12 write it-f1.13 endloop.1415 free it.16 if it[] is initial.17 write: / 'no rows exist in it after free'.18 endif.
Das Programm erzeugt die folgende Ausgabe:
1 2 3 no rows exist in it after free
Zeile 15 löscht alle Zeilen der internen Tabelle und gibt den Speicher frei.
Die Benutzung von refresh, um den Inhalt einer internen Tabelle zu löschen
Man benutzt refresh, um alle Zeilen einer internen Tabelle zu löschen, läßt aber den Speicher allokiert.
Syntax der refresh-Anweisung
refresh it.
wobei:
■ it eine interne Tabelle mit oder ohne Kopfzeile ist.
Die folgenden Punkte gelten:

■ Alle Zeilen werden gelöscht. Der gesamte Speicher, der vom Rumpf der internen Tabelle benutzt wird, bleibt allokiert.
■ Die Kopfzeile, wenn sie existiert, bleibt unverändert.
Man benutzt refresh, wenn alle Zeilen gelöscht werden sollen, die interne Tabelle aber wieder benutzt werden soll. Schreibt man zum Beispiel einen Verkaufsbericht einer Zweigstelle, wird der Bericht mit allen möglichen Verkaufszahlen gefüllt; die Daten werden verarbeitet und ausgeschrieben. Nach dem refresh-Kommando wird die Tabelle mit Zahlen anderer Zweigstellen gefüllt, ausgeschrieben und so weiter.
Wenn Sie beabsichtigen, die Tabelle sofort nach dem Löschen wieder mit Daten zu füllen, ist refresh geeigneter als free, da unnötige Speicherbelegungen vermieden werden.
Listing 12.7 zeigt, wie die refresh-Anweisung benutzt wird.
Listing 12.7: Mit Hilfe von refresh alle Zeilen einer internen Tabelle löschen
1 report ztx1207.2 data: begin of it occurs 3,3 f1 like sy-index,4 end of it,5 i like sy-index.67 do 3 times.8 i = sy-index.9 do 3 times.10 it-f1 = i * sy-index.11 append it.12 enddo.13 write: / ''.14 loop at it.15 write it-f1.16 endloop.17 refresh it.18 enddo.1920 free it.
Das Programm erzeugt die folgende Ausgabe
1 2 3 2 4 6 3 6 9

■ Zeile 7 beginnt mit einer Schleifenverarbeitung, die dreimal ausgeführt wird. Sie enthält eine verschachtelte innere Schleife.
■ Zeile 8 speichert den aktuellen Wert von sy-index aus der äußeren Schleife. ■ In Zeile 9 fängt die innere Schleife an. ■ In Zeile 10 wird die Anzahl der inneren Schleifendurchläufe mit der Anzahl der äußeren
multipliziert.■ Zeile 11 addiert jede Zeile zu der internen Tabelle. ■ Zeile 13 fängt eine neue Ausgabezeile an. ■ Die Zeilen 14 bis 16 schreiben den Inhalt der internen Tabelle aus. ■ Zeile 17 löscht alle Zeilen aus der internen Tabelle, gibt aber den Speicher nicht frei. Hier wird refresh anstelle von free benutzt, weil die äußere Schleife sich wiederholt und die interne Tabelle sofort wieder gefüllt wird.
■ Zeile 20 löscht alle Zeilen und gibt den Speicher für die interne Tabelle frei, bevor die Liste angezeigt wird. Das macht das Programm effizienter.
Die Benutzung von clear mit einer internen Tabelle
Mit der clear-Anweisung kann man folgendes machen:
■ entweder alle Zeilen einer internen Tabelle löschen und den Speicher belegt lassen ■ oder die Kopfzeile löschen (die Komponenten auf Null oder Leerzeichen setzen)
Die Syntax der clear-Anweisung bei Benutzung einer internen Tabelle
Im folgenden wird die Syntax der clear-Anweisung im Zusammenhang mit der Benutzung einer internen Tabelle gezeigt.
clear it | clear it[]
wobei:
■ it der Name einer internen Tabelle ist.
Die folgenden Punkte gelten:
■ Wenn it eine Kopfzeile hat, löscht clear it[] alle Zeilen. Clear it löscht die Kopfzeile.
■ Wenn it keine Kopfzeile hat, löschen beide alle Zeilen, lassen aber den Speicher allokiert.
Der Effekt von clear auf eine interne Tabelle ist in Tabelle 12.3 zusammengefaßt. Der Effekt von clear variiert, je nachdem, ob die interne Tabelle eine Kopfzeile hat oder nicht.
Tabelle 12.3: Der Effekt von clear auf eine interne Tabelle
Anweisung Wenn it eine Kopfzeile hat Wenn it keine Kopfzeile hat
clear it Löscht die Kopfzeile Löscht alle Zeilen
clear it[] Löscht alle Zeilen Löscht alle Zeilen
Das Programm in Listing 12.8 zeigt den Gebrauch von clear mit einer internen Tabelle.
Listing 12.8: Die clear-Anweisung kann benutzt werden, um eine Kopfzeile oder den Inhalt einer internen Tabelle zu löschen.
1 report ztx1208.2 data: begin of it occurs 3,3 f1,4 end of it.56 it-f1 = 'X'.7 append: it, it.89 clear it. "it has a header line so clears the header line10 write: 'f1=', it-f1.1112 write: / ''.13 loop at it.14 write it-f1.15 endloop.1617 clear it[]. "same as: refresh it.18 loop at it.19 write it-f1.20 endloop.21 write: / 'sy-subrc=', sy-subrc.
Das Programm erzeugt die folgende Ausgabe:
f1=X X sy-subrc= 4
■ Zeile 6 stellt 'X' in die Kopfzeile von it.■ Zeile 7 hängt zwei Zeilen an it; beide haben 'X' in f1 stehen. ■ Zeile 9 löscht die Kopfzeile von it.■ Zeile 10 schreibt Leerzeichen; damit wird angezeigt, daß die Kopfzeile von it frei ist. ■ Die Zeilen 13 bis 15 zeigen in der Ausgabe, daß die interne Tabelle noch Daten enthält.

■ Zeile 17 löscht den Rumpf von it, indem alle Zeilen gelöscht werden, der Speicher aber allokiert bleibt. Der Inhalt der Kopfzeile bleibt unverändert.
■ Die Zeilen 18 bis 20 produzieren keine Ausgabe, weil die interne Tabelle leer ist. ■ Zeile 21 zeigt den Rückgabewert nach der Schleifenverarbeitung. Das bestätigt wiederum, daß
keine Zeilen in der internen Tabelle existieren.
Die Benutzung von delete, um Zeilen aus einer internen Tabelle zu löschen
Mit delete löscht man eine oder mehrere Zeilen aus einer internen Tabelle.
Die Syntax der delete-Anweisung
Im folgenden wird die Syntax der delete-Anweisung gezeigt.
delete it (a) [index n](b) [from i] [to j](c) [where exp]
wobei:
■ n, i oder j numerische Literale, Variable oder Konstante sind. ■ exp ein logischer Ausdruck ist, der die Komponenten von it mit einbindet.
Die folgenden Punkte gelten:
■ Die Ergänzungen, die den Punkten (a), (b) und (c) folgen, sind optional. ■ Es kann nur ein Punkt (a), (b) oder (c) angegeben werden. ■ delete it ohne Zusatz kann nur innerhalb loop at it benutzt werden. In diesem Fall
wird die aktuelle Zeile gelöscht. ■ Wird index n angegeben, wird die n-te Zeile von it gelöscht. ■ Wird from i angegeben, werden Zeilen gelöscht, die mit der i-ten anfangen. ■ Wird to j angegeben, werden Zeilen von der j-ten einschließlich derselben gelöscht. ■ Wird from nicht mit to benutzt, wird from 1 angenommen. ■ Der Ausdruck exp muß eine Komponente von it auf der linken Seite jedes Vergleichs haben.
Hat zum Beispiel it die Komponenten f1 und f2, könnte exp so aussehen: where f1 = 'A' and f2 = 'B'.
Listing 12.9 zeigt ein Beispielprogramm, das Zeilen mit Hilfe der delete-Anweisung aus einer internen Tabelle löscht.
Listing 12.9: Das Löschen von Zeilen kann ebenso mit der delete-Anweisung erfolgen.
1 report ztx1209.

2 data: begin of it occurs 12,3 f1,4 end of it,5 alpha(12) value 'ABCDEFGHIJKL'.67 do 12 times varying it-f1 from alpha+0 next alpha+1.8 append it.9 enddo.1011 loop at it.12 write: / sy-tabix, it-f1.13 endloop.1415 delete it index 5.16 skip.17 loop at it.18 write: / sy-tabix, it-f1.19 endloop.2021 delete it from 6 to 8.22 skip.23 loop at it.24 write: / sy-tabix, it-f1.25 endloop.2627 delete it where f1 between 'B' and 'D'.28 skip.29 loop at it.30 write: / sy-tabix, it-f1.31 endloop.3233 loop at it where f1 between 'E' and 'J'.34 delete it.35 endloop.3637 skip.38 loop at it.39 write: / sy-tabix, it-f1.40 endloop.4142 read table it with key f1 = 'K' binary search.43 write: /, / 'sy-subrc=', sy-subrc, 'sy-tabix=', sy-tabix, / ''.44 if sy-subrc = 0.45 delete it index sy-tabix.46 endif.47

48 skip.49 loop at it.50 write: / sy-tabix, it-f1.51 endloop.5253 free it.
Das Programm erzeugt die folgende Ausgabe:
1 A2 B3 C4 D5 E6 F7 G8 H9 I10 J11 K12 L
1 A2 B3 C4 D5 F6 G7 H8 I9 J10 K11 L
1 A2 B3 C4 D5 F6 J7 K8 L
1 A2 F3 J

4 K5 L
1 A2 K3 L
sy-subrc= 0 sy-tabix= 2
1 A2 L
■ Die Zeilen 7 bis 9 füllen it mit zwölf Zeilen mit Werten von 'A' bis 'L'.■ Die Zeilen 11 bis 13 schreiben den Inhalt der internen Tabelle. ■ Zeile 15 löscht die fünfte Zeile, indem 'E' aus der Tabelle entfernt wird. ■ Zeile 21 löscht die sechste bis achte Zeile, indem G, H und I aus der internen Tabelle entfernt
werden. Die neunte Zeile wird die sechste und so weiter. ■ Zeile 27 löscht Zeilen, die f1-Werte von 'B' bis einschließlich 'D' haben. Das führt dazu,
daß die zweite, dritte und vierte Zeile gelöscht werden. ■ Zeile 33 liest Zeilen, die f1-Werte zwischen 'E' und 'J' haben. Die Zeilen 2 und 3 erfüllen
diese Kriterien. Die delete-Anweisung auf Zeile 34 hat keine Zusätze, somit löscht sie die aktuelle Zeile bei jedem Schleifendurchgang, was dazu führt, daß die zweite und dritte Zeile gelöscht werden.
■ Zeile 42 lokalisiert die Zeile, in der f1 den Wert 'K' hat. Obwohl it nur drei Zeilen enthält, wird binary search der Vollständigkeit halber benutzt.
■ Zeile 45 wird ausgeführt, da sy-subrc Null ist. Es löscht Zeile 2, indem es 'K' aus der internen Tabelle entfernt.
Ähnlich wie Einfügungen berühren Löschungen innerhalb von loop at it die interne Tabelle nicht sofort, werden aber beim nächsten Schleifendurchgang effektiv. Wird eine Zeile hinter der aktuellen Zeile gelöscht, wird die Tabelle bei endloop reindexiert, sy-tabix wird hochgezählt, und der nächste Schleifendurchgang verarbeitet die Zeile, auf die von sy-tabix gezeigt wird. Nehmen wir zum Beispiel an, wir befinden uns im dritten Schleifendurchgang, und Zeile 4 wird gelöscht. Wird endloop ausgeführt, wird also diese Zeile gelöscht, Zeile 5 wird Zeile 4 und so weiter. sy-tabix wird um 1 hochgezählt und der nächste Schleifendurchgang verarbeitet den nächsten Satz.
Befindet man sich innerhalb einer Schleife, und es wird eine Zeile vor der aktuellen gelöscht, wird die Tabelle bei endloop reindexiert. Dieses Mal jedoch wird sy-tabix um 1 hochgezählt abzüglich der Anzahl von Zeilen, die vor der aktuellen gelöscht wurden. Beim nächsten Schleifendurchgang wird die Zeile verarbeitet, die der aktuellen folgt. Angenommen, im dritten Schleifendurchgang wird Zeile 3 gelöscht. Bei endloop wird Zeile 4 zu Zeile 3 und so weiter. Sy-tabix wird mit 0 hochgezählt. Zeile 4 wurde reindexiert zu 3, somit wird sie beim nächsten Schleifendurchgang verarbeitet.

Das Anlegen von Top-Ten-Listen mit Hilfe von append sorted by
Nehmen Sie an, Sie werden gebeten, eine Liste der zehn erfolgreichsten Vertriebsbeauftragten in Ihrer Firma zu erstellen. Das könnten Sie folgendermaßen angehen:
■ Es werden alle Repräsentanten und ihre Verkaufszahlen in einer internen Tabelle erfaßt. ■ Sie werden in absteigender Reihenfolge sortiert. ■ Die ersten zehn werden ausgedruckt.
Das sieht nach einem gangbaren Weg aus. Jedoch kann man mit append sorted by oftmals bessere Ergebnisse erzielen.
Die Syntax von append sorted by
Im folgenden wird die Syntax von append sorted by erklärt.
append [wa to] it sorted by c.
wobei:
■ it der Name einer internen Tabelle ist. ■ wa ein Arbeitsbereich ist, der die gleiche Struktur wie die Zeilen der internen Tabelle hat. ■ c eine Komponente von it ist.
Die folgenden Punkte gelten:
■ Wenn wa nicht angegeben ist, wird die Zeile, die angehängt werden soll, aus der Kopfzeile herausgenommen.
■ Ist wa angegeben, wird die Zeile, die angehängt werden soll, aus dem Arbeitsbereich wagenommen.
■ Es kann nur eine Komponente c angegeben werden.
Die append sorted by-Anweisung nimmt eine Zeile aus dem Arbeitsbereich und fügt sie in der internen Tabelle dort ein, wohin sie der Reihenfolge nach gehört. Sie hat zwei ungewöhnliche Eigenschaften:
■ Die Anzahl der Zeilen, die angehängt werden können, ist durch den Wert der occurs-Klausel begrenzt. Ist die occurs-Klausel zum Beispiel 10, können maximal zehn Zeilen an die interne Tabelle angehängt werden. Nur in diesem Fall limitiert occurs die Anzahl der Zeilen, die einer internen Tabelle hinzugefügt werden können.
■ Sie sortiert nur in absteigender Reihenfolge.

Der Seiteneffekt ist eine »Top n List«, wobei n der Zahl in der occurs-Klausel entspricht.
Mit jedem append durchsucht das System den existierenden Tabelleninhalt, um zu bestimmen, wo die neue Zeile hineinpaßt. Die Sortierreihenfolge ist von c absteigend. Sind weniger Zeilen in der internen Tabelle als mit n in der occurs-Klausel angegeben, steht die Zeile in der Tabelle gemäß der Sortierreihenfolge. Sind n Zeilen in der internen Tabelle, wird die Zeile gemäß der Sortierreihenfolge eingefügt, und die letzte Zeile wird aufgegeben. Existiert der Wert von c in der internen Tabelle, wird die neue Zeile immer an die existierende Zeile mit dem gleichen Wert angehängt. Deshalb, wenn occurs 3 ist und Zeile 3 ein 'X' in c enthält, wird keine neue Zeile angehängt, die ein 'X' in centhält.
Listing 12.10 zeigt ein Beispielprogramm, das eine Liste der drei besten Verkäufer erstellt.
Listing 12.10: Verwendung von append sorted by, um die drei besten Verkäufer herauszufinden
1 report ztx1210.2 data: begin of it occurs 3,3 sales type p decimals 2,4 name(10),5 end of it.67 it-sales = 100.8 it-name = 'Jack'.9 append it sorted by sales.1011 it-sales = 50.12 it-name = 'Jim'.13 append it sorted by sales.1415 it-sales = 150.16 it-name = 'Jane'.17 append it sorted by sales.1819 it-sales = 75.20 it-name = 'George'.21 append it sorted by sales.2223 it-sales = 200.24 it-name = 'Gina'.25 append it sorted by sales.2627 it-sales = 100.28 it-name = 'Jeff'.29 append it sorted by sales.3031 loop at it.

32 write: / it-sales, it-name.33 endloop.
Das Programm erzeugt die folgende Ausgabe:
200.00 Gina 150.00 Jane 100.00 Jack
■ Die Zeilen 2 bis 5 definieren eine interne Tabelle mit dem occurs-Wert von 3. Wenn diese internen Tabelle mit append sorted by gefüllt ist, wird die maximale Anzahl an Zeilen in der internen Tabelle auf drei begrenzt.
■ Die Zeilen 7 und 8 weisen der Kopfzeile Werte zu. ■ Zeile 9 durchsucht it, um die neue Zeile an die richtige Stelle zu setzen. Die interne Tabelle
ist leer, somit wird die Zeile einfach angehängt (s. Abbildung 12.1).
Abbildung 12.1: Es existieren keine Zeilen in der internen Tabelle, somit wird die erste Zeile einfach angehängt.
■ 50 kommt nach 100, wenn die Verkäufe absteigend sortiert werden, also fügt Zeile 13 die neue Zeile hinter der schon existierenden ein (s. Abbildung 12.2).
Abbildung 12.2: Die zweite Zeile wird in der korrekten Sortierfolge eingefügt, somit kommt sie direkt nach der ersten Zeile.
■ 150 kommt vor 100, d.h. Zeile 15 fügt die neue Reihe vor der ersten ein. Die interne Tabelle enthält nun die maximale Zeilenanzahl (s. Abbildung 12.3).

Abbildung 12.3: Diesmal diktiert die Sortierreihenfolge, daß die neue Zeile vor der ersten eingefügt wird.
■ 75 kommt hinter 100, somit fügt Zeile 21 die neue Zeile hinter der zweiten Zeile ein, und die neue Zeile wird Zeile 3. Die dritte Zeile würde zur vierten, die Tabelle kann aber nur drei Zeilen halten, somit wird die vierte ausgelassen (s. Abbildung 12.4).
Abbildung 12.4: Diese Zeile paßt hinter die zweite, somit wird sie dort eingefügt. Die interne Tabelle kann maximal drei Zeilen aufnehmen, somit wird die vierte aufgegeben.
■ 200 kommt vor 150, somit fügt Zeile 25 die Zeile vor der ersten Zeile ein. Der Rest der Zeilen wird nach unten verschoben, und die letzte Zeile wird weggelassen (s. Abbildung 12.5).

Abbildung 12.5: Diesmal soll die neue Zeile zuerst kommen. Die existierenden Zeilen werden nach unten gedrückt, und die letzte Zeile wird aufgegeben.
■ 100 kommt hinter 150, 100 ist aber schon da. Zeile 29 versucht also, die neue Zeile hinter den existierenden Wert von 100 zu setzen. Somit würde daraus Zeile 4, deshalb wird die Zeile nicht eingefügt (s. Abbildung 12.6).
Abbildung 12.6: Die neue Zeile wird allen existierenden Zeilen mit gleichem Wert folgen. Somit wäre sie Zeile 4 und wird deshalb nicht eingefügt.
Vermischen Sie nicht append sorted by mit anderen Anweisungen, die Daten an eine interne Tabelle hängen (wie insert oder append). Wenn sie it mit append sorted by füllen, sollte das auch die einzige Anweisung bleiben. Ein Vermischen dieser Anweisungen bewirkt unvorhersehbare Verhaltensweisen.
Mit append sorted by arbeiten Sie effektiver, wenn Sie einer internen Tabelle eine Zeile nach der anderen anhängen. Wenn Sie die Daten schon in einer

Datenbanktabelle haben und nur die »Top Ten-Werte« finden wollen, ist es ratsam, die Zeilen mit Feldoperationen einzulesen und dann zu sortieren. (Informationen über Feldoperationen finden Sie in Kapitel 13, »Interne Tabellen, Teil2«.)
Eine interne Tabelle mit collect füllen
Mit Hilfe der collect-Anweisung können Sie beim Füllen von internen Tabellen Gesamtsummen bilden.
Die Syntax der collect-Anweisung
collect [wa into] it.
Wobei:
■ it eine interne Tabelle ist. ■ wa ein Arbeitsbereich ist, der die gleiche Struktur wie it hat.
Die folgenden Punkte gelten:
■ Wenn wa into angegeben ist, wird die Zeile, die gesammelt werden soll, aus dem Arbeitsbereich genommen. In diesem Fall wird die Kopfzeile der internen Tabelle ignoriert, sofern es eine bei it gibt.
■ Wenn wa into nicht angegeben ist, muß die interne Tabelle eine Kopfzeile haben. Die Zeile, die gesammelt wird, wird aus der Kopfzeile von it genommen.
Wenn collect ausgeführt wird, formt das System einen Schlüssel aus dem Standardschlüssel des Arbeitsbereichs. Die Standardschlüsselfelder sind die Zeichenfelder (Typ c, n, d, t und x).Somit wird der Schlüssel aus den Werten aller Felder von Typ c, n, d, t und x zusammengesetzt. Es ist dabei egal, ob sie nebeneinander stehen oder voneinander durch andere Felder getrennt sind.
Das System durchsucht den Rumpf der internen Tabelle nach einer Zeile, die den gleichen Schlüssel im Arbeitsbereich hat. Findet es keinen, wird die Zeile ans Ende der Tabelle gehängt. Findet es einen, werden die numerischen Felder (Typ i, p und f) aus dem Arbeitsbereich in die korrespondierenden Felder des gefundenen Satzes hinzugefügt. Listing 12.11 zeigt dies.
Listing 12.11: collect verbindet Zeilen, wie sie der internen Tabelle hinzugefügt werden.
1 report ztx1211.2 data: begin of it occurs 10,3 date type d, " part of default key4 tot_sales type p decimals 2, "not part of default key5 name(10), " part of default key

6 num_sales type i value 1, "not part of default key7 end of it.89 it-date = '19980101'.10 it-tot_sales = 100.11 it-name = 'Jack'.12 collect it.1314 it-date = '19980101'.15 it-tot_sales = 200.16 it-name = 'Jim'.17 collect it.1819 it-date = '19980101'.20 it-tot_sales = 300.21 it-name = 'Jack'.22 collect it.2324 it-date = '19980101'.25 it-tot_sales = 400.26 it-name = 'Jack'.27 collect it.2829 it-date = '19980101'.30 it-tot_sales = 500.31 it-name = 'Jim'.32 collect it.3334 it-date = '19980101'.35 it-tot_sales = 600.36 it-name = 'Jane'.37 collect it.3839 it-date = '19980102'.40 it-tot_sales = 700.41 it-name = 'Jack'.42 collect it.4344 loop at it.45 write: / it-date, it-tot_sales, it-name, it-num_sales.46 endloop.
Das Programm erzeugt die folgende Ausgabe:
19980101 800.00 Jack 3 19980101 700.00 Jim 2

19980101 600.00 Jane 1 19980102 700.00 Jack 1
■ Die Zeilen 2 bis 7 definieren eine interne Tabelle mit vier Komponenten. Zwei sind Zeichentypen (date und name), und zwei sind numerisch (tot_sales und num_sales).Der Standardschlüssel ist somit zusammengesetzt aus den Komponenten date und name.
■ Die Zeilen 9 bis 11 weisen den Kopfzeilenkomponenten date, tot_sales und nameWerte zu. Num_sales hat immer noch den Standardwert 1, zugewiesen in Zeile 6.
■ Zeile 12 durchsucht den Rumpf von it nach einer Zeile, die den gleichen Wert in date und name (den Standardschlüsselfeldern) hat wie in der Kopfzeile. Die interne Tabelle ist leer, somit passen keine Zeilen zueinander. Die Kopfzeile wird somit der internen Tabelle angehängt (s. Abbildung 12.7).
Abbildung 12.7: Wenn der Standardschlüssel nicht im Rumpf gefunden wird, wird die Zeile angehängt. Der Standardschlüssel ist aus allen nicht-numerischen Feldern zusammengesetzt, also ist er in diesem Diagramm die Kombination von date (erstes Feld) und name (drittes Feld).
■ Zeile 17 verhält sich ähnlich wie Zeile 12. Die interne Tabelle hat eine Zeile; die Werte in den date- und name-Feldern passen nicht zueinander, somit wird die Kopfzeile der internen Tabelle angehängt (s. Abbildung 12.8).
Abbildung 12.8: Abermals wird der Standardschlüssel nicht in der Tabelle gefunden, also wird die Zeile angehängt.

■ Zeile 22 durchsucht die interne Tabelle nach einer Zeile, die '19980101' im Datumsfeld (date) enthält und Jack im Namensfeld (name). Zeile 1 paßt, und die numerischen Felder werden zusammengelegt. Das Kopfzeilenfeld tot_sales enthält 2000. Das wird dem tot_sales-Feld in Zeile 1 hinzugefügt und liefert als Resultat 300. Der Wert im Feld num_sales der Kopfzeile wird nun auch dem num_sales- Feld in Zeile 1 mit einem Wert von 2 hinzugefügt. Zeile 1 wird mit diesen Werten aktualisiert. Der Inhalt der Kopfzeile bleibt unverändert (s. Abbildung 12.9).
Abbildung 12.9: Dieses Mal paßt der Standardschlüssel zur ersten Zeile der Tabelle. Die numerischen Felder in diesem Arbeitsbereich werden den korrespondierenden Feldern der ersten Zeile hinzugefügt.
■ Zeile 27 sucht nach einer Zeile mit dem Datum '19980101' und dem Namen 'Jack'.Zeile 1 paßt, somit kann der Inhalt der numerischen Felder (tot_sales und num_sales)der Kopfzeile den numerischen Feldern in der gefundenen Zeile hinzugefügt werden (s. Abbildung 12.10).
Abbildung 12.10: Abermals paßt der Standardschlüssel zur ersten Zeile der Tabelle. Die numerischen Felder in diesem Arbeitsbereich werden den korrespondierenden Feldern der ersten Zeile hinzugefügt.
■ Zeile 32 paßt zu Zeile 2 und addiert '500' zu tot_sales und 1 zu num_sales (s. Abbildung 12.11).

Abbildung 12.11: Dieses Mal paßt der Standardschlüssel zur zweiten Zeile der Tabelle. Die numerischen Felder im Arbeitsbereich werden den korrespondierenden Feldern in der zweiten Zeile hinzugefügt.
■ Auf Zeile 37 passen die Werte in date und name (die Standardschlüsselfelder) der Kopfzeile auf keine Zeile in it, somit wird eine neue Zeile an das Ende der Tabelle angehängt (s. Abbildung 12.12).
Abbildung 12.12: Der Standardschlüssel paßt dieses Mal zu keiner Zeile, deshalb wird eine neue Zeile angehängt.
■ Zeile 42 hängt eine neue Zeile der internen Tabelle an, weil die Werte in date und name zu keiner Zeile in it passen (s. Abbildung 12.13).

Abbildung 12.13: Abermals paßt der Standardschlüssel zu keiner Zeile, so daß noch eine neue Zeile angehängt wird.
Benutzt man collect, um Zeilen einer internen Tabelle hinzuzufügen, sollten alle Zeilen mit collect hinzugefügt werden. Man sollte collect nicht zusammen mit append oder irgendeiner anderen Anweisung mischen, um Daten einer internen Tabelle hinzuzufügen. Das Ergebnis ist nicht voraussehbar. Die einzige Anweisung, die man zum Ändern von internen Tabelleninhalten benutzten kann, die mit collectgefüllt wurden, ist modify ... transporting f1 f2 ..., wobei f1 und f2numerische Felder sind (keine Standardschlüsselfelder).
Zusammenfassung
■ Der Tabellenrumpf-Operator ermöglicht es, die Existenz von Daten zu prüfen, zwei interne Tabellen auf Übereinstimmung zu vergleichen oder eine interne Tabelle zu duplizieren.
■ Die describe table-Anweisung stellt die Anzahl der internen Zeilenanzahl in sy-tfill, die Breite einer Zeile in Byte in sy-tleng und die Größe der occurs -Klausel in sy-toccu.
■ Um Teile einer internen Tabelle von einer zur anderen zu kopieren, benutzt man appendlines of oder insert lines of.
■ editor-call zeigt den Inhalt einer Tabelle in einem Editor an. Das ermöglicht dem Anwender, Daten zu ändern. Gleichzeitig ist es ein gutes Werkzeug, um Fehler zu finden.
■ Mit insert wird eine Zeile an einer beliebigen Stelle innerhalb der internen Tabelle hinzugefügt. Die Position kann mit Hilfe eines Index bestimmt werden, oder man kann damit innerhalb einer Schleife die aktuelle Zeile bearbeiten.
■ modify ändert den Inhalt einer oder mehrerer Zeilen. Die Zeile kann mit Hilfe eines Index

bestimmt werden, oder man kann damit innerhalb einer Schleife die aktuelle Zeile bearbeiten. Benutzt man zusätzlich die where-Klausel, kann der Inhalt vieler Zeilen geändert werden.
■ Mit delete werden eine oder mehrere Zeilen entfernt. Wird delete innerhalb einer Schleife ohne Zusatz benutzt, wird die aktuelle Zeile gelöscht. Man kann auch einen Einzelindex, einen Indexbereich oder die where-Klausel benutzen.
■ clear it löscht die Kopfzeile von it. Gibt es keine Kopfzeile, werden alle Zeilen gelöscht. Clear it[] löscht immer alle Zeilen aus it. Der interne Tabellenspeicher bleibt allokiert.
■ Refresh löscht immer alle Zeilen und läßt den Speicher allokiert. Es entspricht genau dem clear it[]. Man benutzt refresh, wenn man eine interne Tabelle wieder mit Daten füllen will.
■ free it löscht alle Zeilen aus it und setzt den Speicher frei. Es sollte innerhalb des Programms sofort nach der Verarbeitung der internen Tabelle gesetzt werden.
■ Mit append sorted by legt man »Top-Ten-Listen« an, statt Zeile für Zeile anzuhängen und sie dann zu sortieren.
■ Mit Hilfe von collect werden innerhalb einer internen Tabelle Summen ausgegeben, während sie gefüllt wird. Man kann collect auch zum Überprüfen aller Einträge auf Gleichheit benutzen.
Erlaubt Nicht erlaubt
Benutzen Sie die free-Anweisung am Programmende für alle internen Tabellen. Dies gibt Speicher frei, der nicht mehr gebraucht wird, wenn der Anwender sich die Tabelle ansieht.
Benutzen Sie den Tabellenrumpf-Operator, um die Existenz von Daten innerhalb einer Tabelle zu überprüfen.
Benutzen Sie append sorted by, wenn Sie »Top-Ten-Listen« erstellen, solange die Liste noch nicht existiert und nur sortiert werden muß.
Fügen Sie niemals Zeilen für Zeile ein, wenn diese als Gruppe mit dem Befehl insert lines of oder append lines of zusammengefaßtwerden können.
Frage & Antwort
Frage:In diesem Kapitel haben wir viele Möglichkeiten kennengelernt, ähnliche Aufgaben zu lösen. Es hat den Anschein, als ob man in ABAP/4 immer verschiedene Möglichkeiten des Lösungsansatzes hat. Warum wird nicht einfach der beste Weg gezeigt und auf den Rest verzichtet?

Antwort:Es gibt einige Gründe, die für den hier beschriebenen Weg sprechen: 1. Effektivität und 2. das Verstehen des Programm-Codes. An der Datenmenge gemessen ist Effektivität das primäre Ziel der ABAP/4-Programmierung. Sie sollen die effizientesten Möglichkeiten der Anweisungen kennenlernen. Das kann als Ergebnis drastische Leistungssteigerungen nicht nur für Ihr Programm bewirken. Es ist nicht unüblich, Programm-Code nach Übernahme in die Produktion zu überarbeiten. Da Programmierer mehr in existierenden Programm-Codes lesen als neue anlegen, sollte man verschiedene Variationen dieser Anweisungen kennen. Wenn man den SAP-Code nicht versteht, ist man auch nicht in der Lage zu verstehen, wie die Daten an die gegenwärtige Stelle kommen oder wie die Ausgabe funktioniert.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, um Ihr Verständnis für den Stoff zu vertiefen, und im Übungsabschnitt können Sie Erfahrungen sammeln, indem Sie das Erlernte anwenden. Antworten auf die Prüfungsaufgaben und Übungen finden Sie im Anhang B (»Antworten zu Kontrollfragen und Übungen«).
Kontrollfragen
1. Wenn ich innerhalb einer Schleife sy-tabix ändere, ändert das die aktuelle Zeile? Zum Beispiel würden sich die insert, modify und delete-Anweisungen auf die Zeile im Arbeitsbereich auswirken oder auf die Zeile, die über sy-tabix angezeigt wird?
2. Wann gebrauche ich sy-toccu? Warum muß ich den Wert der occurs-Klausel während der Laufzeit wissen?
Übung 1
Lesen Sie den Inhalt von ztxlfa1 in eine interne Tabelle ein (benutzen Sie select into table). Dann ändern Sie die land1-Spalte, so daß die dritte Zeile 'US' enthält ( benutzen Sie modify transporting where). Ändern Sie auch regions, indem Sie alle MA in TX ändern (benutzen Sie modify transporting where).
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 13
Interne Tabellen, Teil 2
Kapitelziele
Wenn Sie dieses Kapitel beendet haben, können Sie:
■ eine interne Tabelle aus einer Datenbanktabelle mit Hilfe der leistungsfähigsten Konstrukte füllen ■ einen Gruppenwechsel mit Hilfe von at und on change of ausführen
Eine interne Tabelle mit Daten aus einer Datenbanktabelle füllen
Häufig stehen in ABAP/4 Daten, die man aus einer oder mehr Datenbanktabellen in eine interne Tabelle einlesen will. In diesem Abschnitt soll der effektivste Weg dahin aufgezeigt werden.
Es gibt zwei Möglichkeiten, eine interne Tabellen mit Daten aus der Datenbanktabelle zu füllen:
■ durch das direkte Einlesen von Zeilen in die interne Tabelle ■ durch Einlesen von einzelnen Zeilen in einen Arbeitsbereich, um sie dann der internen Tabelle
anzuhängen
Direktes Einlesen von Zeilen in eine interne Tabelle
Um Zeilen direkt in eine interne Tabelle einzulesen, benutzt man die Ergänzung into table zur SQL-Anweisung select. Diese Anweisung nimmt die selektierten Zeilen und liest sie in Einzeloperationen, auch als Feldoperation bezeichnet, in die interne Tabelle. Es werden keine Arbeitsbereiche belegt oder benötigt.
Unter einer Feldoperation versteht man Anweisungen, die Befehle an mehrere Zeilen interner Tabellen ausführen, anstatt Einzelsätze zu verarbeiten. Feldoperationen sind immer wirksamer als

Einzelsatzoperationen.
Mit select into table beschreitet man den effizientesten Weg, eine interne Tabelle aus der Datenbank zu füllen.
Die Syntax für den Zusatz into table der select-Anweisung
Die folgende Beschreibung zeigt die Syntax für den Zusatz into table der select- Anweisung.
(a) select * (b) select f1 f2 . . .
from dbtab into [corresponding fields of] table it.
wobei:
■ dbtab der Name der Datenbanktabelle ist. ■ f1 und f2 Felder innerhalb dbtab sind. ■ it der Name der internen Tabelle ist.
Folgende Punkte gelten:
■ it kann eine Kopfzeile haben. ■ andere Zusätze, wie where und order by können auf it folgen. ■ es wird kein endselect mit into table benutzt. select into fängt auch keine
Schleifenverarbeitung an, deshalb wird konsequenter Weise kein endselect benötigt.
Die select into table-Anweisung stellt alle selektierten Zeilen direkt in den Rumpf von it.Existierende interne Tabelleninhalte werden zuerst aufgegeben. Listing 13.1 beinhaltet ein Beispielprogramm mit select into table.
Listing 13.1: Dieses Programm liest direkt aus einer Datenbanktabelle in eine interne Tabelle.
1 report ztx1301.2 tables ztxlfa1.3 data it like ztxlfa1 occurs 23 with header line.45 select * from ztxlfa1 into table it. "don't code an endselect6 loop at it.7 write: / it-lifnr, it-name1.8 endloop.

910 select * from ztxlfa1 into table it11 where lifnr between 'V2' and 'V5'.12 skip.13 loop at it.
14 write: / it-lifnr, it-name1.15 endloop.16 free it.
Das Programm aus Listing 13.1 erzeugt die folgende Ausgabe:
V9 Code Now, Specs Later Ltd. 1000 Parts Unlimited 1010 Industrial Pumps Inc. 1020 Chemical Nation Ltd. 1030 ChickenFeed Ltd. 1050 The Bit Bucket 1060 Memory Lane Ltd. 1070 Flip My Switch Inc. V10 Duncan's Mouse Inc. V6 Anna Banana Ltd. V8 Smile When You Say That Ltd. V11 Weiner Schnittsel Inc. V12 Saurkrouten 1040 Motherboards Inc. 1080 Silicon Sandwich Ltd. 1090 Consume Inc. 2000 Monitors and More Ltd. V1 Quantity First Ltd. V2 OverPriced Goods Inc. V3 Fluffy Bunnies Ltd. V4 Moo like a Cow Inc. V5 Wolfman Sport Accessories Inc. V7 The Breakfast Club Inc.
V2 OverPriced Goods Inc. V3 Fluffy Bunnies Ltd. V4 Moo like a Cow Inc. V5 Wolfman Sport Accessories Inc.
■ Zeile 5 holt alle Datenbankzeilen aus der Tabelle ztxlfa1 und stellt sie direkt in den Rumpf der internen Tabelle it. Die Kopfzeile wird nicht benutzt und ihr Inhalt bleibt unverändert.
■ Zeile 10 ist ähnlich Zeile 5, außer daß sie Kreditorennummern zwischen V2 und V5 bezieht. Der existierende Inhalt von it wird gelöscht, bevor sie gefüllt wird.

Benutzen Sie nie endselect mit der select into table-Anweisung, sonst entsteht ein Syntaxfehler.
Die Sortierung und select into table
Nehmen Sie an, Ihr Programm liest schon Daten in eine interne Tabelle. Wenn diese Daten sortiert werden müssen, benutzt man die sort-Anweisung. Benutzen Sie nicht order by bei der select-Anweisung,auch dann nicht, wenn diese Felder von einem Index unterstützt werden. Messungen zeigen, daß die sort-Anweisung etwas schneller ist. Auch wenn sie vergleichbar wären, wäre sort nach wie vor die bessere Methode.
Benutzen Sie nie order by mit select into table, sondern sort in der internen Tabelle.
Die Felder, die man auswählt, müssen in die interne Tabelle passen
Stellen wir uns folgendes vor:
■ Eine Zeile wird aus dbtab geholt. ■ Eine Zeile wird in der internen Tabelle it allokiert. ■ Die Zeile von dbtab wird Byte für Byte in die neue Zeile in it übertragen.

Abbildung 13.1: Die Datenbanktabelle ztx1302 enthält drei Felder: f1, f2 und f3. f1 ist ein einzelnes Byte, f2 ist zwei Byte lang und f3 ein Byte.
Abbildung 13.2: Der * bewirkt, daß alle Felder nacheinander aus der Datenbanktabelle ztx1302 selektiert werden. Sie passen exakt in jede Zeile von it, da die Struktur von it zur Struktur der Datenbanktabelle paßt.

Abbildung 13.3: In diesem Beispiel werden nur die ersten zwei Felder mit insgesamt drei Byte aus der Datenbanktabelle ztx1302 selektiert. Sie werden Byte für Byte in die ersten drei Byte jeder Zeile von it gestellt.
Abbildung 13.4: Abermals werden die ersten zwei Felder aus der Datenbanktabelle ztx1302 selektiert, aber diemal in unterschiedlicher Reihenfolge, wie sie in der internen Tabelle erscheinen. Daraus entstehen korrupte Daten, wenn sie Byte für Byte in jede Zeile von it gestellt werden. it-f1 empfängt das erste Byte von f2, und it-f2 empfängt das letzte Byte von f2 und ein Byte von f1.
Jede Zeile von dbtab wird Byte für Byte in eine neue Zeile von it übertragen, was der Zuweisung einer Feldleiste an die nächste entspräche. Es gibt nur einen Unterschied zwischen dieser und einer Feldleistenzuweisung: dbtab kann kleiner (in Byte) sein als it, aber nicht länger. Wenn sie länger ist, erfolgt ein Abbruch (short dump) mit der Meldung (Error SAPSQL_SELECT_TAB_TOO_SMALL). Die Datentypen und Längen eines jeden Sendefeldes in dbtab sollten in das Empfangsfeld von it passen. Die übriggebliebenen Felder in it werden mit Initialwerten (Leerzeichen oder Nullen) aufgefüllt. Abbildung 13.1 bis 13.4 zeigen diesen Zusammenhang auf.

Tabelle 13.1 zeigt eine Zusammenfassung der Regeln von select mit into table. Die selektierten Felder müssen in die interne Tabelle passen. Tabelle 13.1 macht Sie mit den Restriktionen bekannt.
Tabelle 13.1: Regeln für die Benutzung von select mit into table
Anweisung Welche Felder werden selektiert? Restriktionen
select * Alle Felder in der Datenbank Die interne Tabelle muß letztlich genauso viele Felder haben wie die Datenbanktabelle, und die Felder müssen mit Feldern der Datenbanktabelle übereinstimmen.
select f1 f1 aus der Datenbanktabelle Die interne Tabelle muß mit einem Feld wie f1 anfangen oder aber ein Feld wie f1 haben.
Listing 13.2 und 13.3 illustrieren dieses Konzept.
Listing 13.2: Was passiert, wenn sich die Tabellenstruktur bei der select into-Anweisungunterscheidet?
1 report ztx1302.2 tables ztxlfa1.3 data begin of it occurs 2.4 include structure ztxlfa1.5 data: invoice_amt type p,6 end of it.78 select * from ztxlfa1 into table it where land1 = 'DE'.9 loop at it.10 write: / it-lifnr, it-land1, it-regio, it-invoice_amt.11 endloop.1213 skip.14 select lifnr land1 regio from ztxlfa1 into table it where land1 = 'DE'.15 loop at it.16 write: / it-mandt, it-lifnr, it-land1, it-regio.17 endloop.18 free it.
Das Programm aus Listing 13.2 zeigt die folgende Ausgabe:
V11 DE 07 0 V12 DE 14 0 V8 DE 03 0

V11 DE 07 V12 DE 14 V8 DE 03
■ Zeile 3 definiert it, als wenn alle Felder der DDIC-Struktur ztxlfa1 plus einem zusätzlichen Feld vorhanden seien.
■ Zeile 8 selektiert alle Felder aus ztxlfa1. Sie füllen den Anfang einer jeden Zeile in it.Invoice_amt ist auf Null gesetzt.
■ Zeile 14 selektiert lifnr, land1 und regio in den ersten Teil einer jeden Zeile von it. Es beginnt allerdings mit mandt und nicht lifnr, da die DDIC-Struktur von ztxlfa1 mit mandtanfängt. Die Ausgabe zeigt, daß die ersten drei Byte von lifnr in it-mandt aufhören, it-lifnr wird drei Byte nach links gerückt und enthält auch land1. regio ist leer.
Listing 13.3: Ihr Programm wird einen Fehler produzieren, wenn Sie versuchen, mehr Felder in die interne Tabelle zu legen, als dafür vorgesehen sind.
1 report ztx1303.2 tables ztxlfa1.3 data: begin of it occurs 23,4 lifnr like ztxlfa1-lifnr, "this is a char 10 field5 land1 like ztxlfa1-land1, "this is a char 3 field6 end of it.78 *The next line causes a short dump. The internal table is too narrow.9 select * from ztxlfa1 into table it.
Das Programm aus Listing 13.3 zeigt die folgende Ausgabe (s. Abbildung 13.5).

Abbildung 13.5: Dieser Abbruch tritt auf, wenn der Report ztx1303 ausgeführt wird. Es wurden mehr Felder selektiert, als in die interne Tabelle passen.
■ Zeile 3 definiert eine interne Tabelle, die zwei Komponenten hat. Die Gesamtlänge von it ist 13 Byte.
■ Zeile 9 selektiert alle Felder aus ztxlfa1 nach it. Die Gesamtlänge aller Felder ist größer als 13 Byte. Somit bricht konsequenterweise das Programm ab.
Die Benutzung von corresponding fields
Wenn sich die Komponenten der internen Tabelle nicht in der gleichen Reihenfolge wie die der Datenbank befinden oder sie nicht dieselben Datentypen und Längen haben, kann man mit der Erweiterung corresponding fields arbeiten. Diese Erweiterung hat den gleichen Effekt wie die movecorresponding-Anweisung für eine Feldleiste: Sie verschiebt Felder aus der Datenbanktabelle in Felder gleichen Namens in den Rumpf der internen Tabelle.

Mit corresponding fields wird eine Zuweisung pro Feld durchgeführt, statt einer einzelnen Zuweisung für die gesamte Zeile. Somit wird unnötiger Aufwand der select -Anweisung produziert. Es sollte nur gebraucht werden, wenn unbedingt nötig.
Die folgenden Punkte gelten:
■ Die Reihenfolge der sendenden und empfangenen Felder ist bedeutungslos. ■ Sendefelder, die kein korrespondierendes Empfangsfeld haben, werden verworfen. ■ Empfangsfelder, die kein korrespondierendes Sendefeld haben, bleiben unverändert.
Listing 13.4 zeigt die Effizienz und Ineffizienz bei Benutzung dieser Ergänzung.
Listing 13.4: Durch corresponding fields werden interne Tabellen aus der Datenbank gefüllt.
1 report ztx1304.2 tables ztxlfa1.3 data: begin of it1 occurs 23,4 lifnr like ztxlfa1-lifnr,5 lifnr_ext like ztxlfa1-lifnr,6 land1 like ztxlfa1-land1,7 end of it1,8 begin of it2 occurs 23,9 lifnr like ztxlfa1-lifnr,10 land1 like ztxlfa1-land1,11 end of it2.1213 * This is efficient usage:14 select lifnr land1 from ztxlfa115 into corresponding fields of table it116 where lifnr between 'V10' and 'V12'.17 loop at it1.18 write: / it1-lifnr, it1-land1.19 endloop.2021 * This is inefficient:22 select * from ztxlfa123 into corresponding fields of table it224 where lifnr between 'V10' and 'V12'.25 skip.26 loop at it1.27 write: / it1-lifnr, it1-land1.28 endloop.2930 * Instead, write:31 select lifnr land1 from ztxlfa1 into table it232 where lifnr between 'V10' and 'V12'.33 skip.34 loop at it2.

35 write: / it2-lifnr, it2-land1.36 endloop.37 free: it1, it2.
Das Programm aus Listing 13.4 hat die folgende Ausgabe:
V10 CC V11 DE V12 DE
V10 CC V11 DE V12 DE
V10 CC V11 DE V12 DE
■ Zeile 14 liest lifnr- und land1-Felder aus der Tabelle ztxlfa1- in lifnr- und land1-Felder der internen Tabelle it1. Die interne Tabelle hat Feld lifnr_ext zwischen lifnr und land1, somit kann man into table nicht benutzen. Wenn it1 die Felder in dieser Reihenfolge erwartet, wäre hier corresponding fields angebracht.
■ Zeile 22 selektiert alle Felder aus Tabelle ztxlfa1 in nur zwei Felder der Tabelle it2. Das ist ineffizient. Statt dessen zeigt Zeile 31, daß, wenn man nur die notwendigen Felder in der korrekten Reihenfolge selektiert, into table benutzt werden kann.
Zeilen hintereinander mit select hinzufügen
select wird benutzt, um Zeilen hintereinander hinzuzufügen. Dafür braucht man einen Arbeitsbereich und eine zweite Anweisung wie append, insert oder collect. Läßt man die Ergänzung tableweg, erzwingt das System, daß die Zeile dem Arbeitsbereich zugewiesen wird. Es ist üblich, Kopfzeilen einer internen Tabelle explizit als Arbeitsbereich zu benutzen. Alternativ wird auch der Standardtabellenarbeitsbereich gebraucht (using tables).
Listing 13.5 zeigt einige Beispiele von select, um Zeilen hintereinander einer internen Tabelle hinzuzufügen.
Listing 13.5: Die Benutzung von select mit der append-Anweisung, um interne Tabellen zu füllen.
1 report ztx1305.2 tables ztxlfa1.3 data it like ztxlfa1 occurs 2 with header line.45 *Do it this way6 select * from ztxlfa1 into it "notice 'table' is omitted so the7 where land1 = 'DE'. "row goes into the header line of it

8 append it.9 endselect.1011 loop at it.12 write: / it-lifnr, it-land1, it-regio.13 endloop.14 refresh it.1516 *Or this way17 select * from ztxlfa1 "no 'into' so the row goes into the18 where land1 = 'DE'. "default table work area19 append ztxlfa1 to it. "and then is appended to it20 endselect.2122 skip.23 loop at it.24 write: / it-lifnr, it-land1, it-regio.25 endloop.26 refresh it.2728 *Not this way29 select * from ztxlfa1 "row goes into default table work area30 where land1 = 'DE'.31 it = ztxlfa1. "then is assigned to the header line32 append it.33 endselect.3435 skip.36 loop at it.37 write: / it-lifnr, it-land1, it-regio.38 endloop.39 free it.
Das Programm aus Listing 13.5 hat folgende Ausgabe:
V11 DE 07V12 DE 14V8 DE 03
V11 DE 07V12 DE 14V8 DE 03
V11 DE 07V12 DE 14V8 DE 03
■ Zeile 6 zeigt keine table-Anweisung vor it, somit werden die Felder aus ztxlfa1 in die

Kopfzeile von it geschrieben. Zeile 8 hängt die Kopfzeile an it.■ Zeile 17 enthält keine into-Klausel, somit wird jede Zeile in den Standardtabellenarbeitsbereich ztxlfa1 geschrieben. Zeile 19 hängt den Arbeitsbereich ztxlfa1 an die interne Tabelle (die Kopfzeile wird nicht benutzt).
■ Zeile 29 plaziert jede Zeile in den Arbeitsbereich ztxlfa1. Zeile 31 schiebt ztxlfa1 in die Kopfzeile von it vor dem Anhängen (append).
into corresponding fields kann man auch dazu benutzen, um Daten in einen Arbeitsbereich zu legen, statt in den Rumpf einer internen Tabelle. Der Effekt ist ähnlich wie bei der move-corresponding-Anweisung, ist aber effizienter. Das Listing 13.6 zeigt, wie.
Listing 13.6: Wie die Ergänzung corresponding fields der select-Anweisung den gleichen Effekt hat wie die move-corresponding-Anweisung
1 report ztx1306.2 tables ztxlfa1.3 data: begin of it occurs 2,4 lifnr like ztxlfa1-lifnr,5 row_id like sy-index,6 land1 like ztxlfa1-land1,7 end of it.89 *Do it this way:10 select lifnr land1 from ztxlfa111 into corresponding fields of it "notice 'table' is omitted12 where land1 = 'DE'.13 append it.14 endselect.1516 loop at it.17 write: / it-lifnr, it-row_id, it-land1.18 endloop.19 refresh it.2021 *Not this way:22 select * from ztxlfa123 where land1 = 'DE'.24 move-corresponding ztxlfa1 to it.25 append it.26 endselect.2728 skip.29 loop at it.30 write: / it-lifnr, it-row_id, it-land1.31 endloop.32 free it.
Das Programm aus Listing 13.6 hat die folgende Ausgabe:

V11 0 DEV12 0 DEV8 0 DE
V11 0 DEV12 0 DEV8 0 DE
■ Auf Zeile 11 wird die table-Ergänzung vor it weggelassen. Somit werden die Zeilen in die Kopfzeile geschrieben. lifnr wird in it-lifnr geschrieben und land1 in it-land1. Zeile 7 hängt die Kopfzeile an it.
■ Zeile 22 schiebt die Zeilen in den Arbeitsbereich ztxlfa1. Zeile 24 benutzt eine ähnliche Anweisung (move corresponding), um den Arbeitsbereich in die Kopfzeile von it zu transferieren. Zeile 25 hängt dann die Kopfzeile an den Rumpf von it. Das Ergebnis ist identisch mit der ersten select-Anweisung, ruft aber eine zusätzliche Anweisung auf, und ist damit nicht so leistungsfähig.
Zusammenfassung von select, internen Tabellen und deren Leistungsfähigkeit
Tabelle 13 enthält eine Liste der verschiedensten Formen des select, wie sie in internen Tabellen benutzt werden, und ihre relative Leistungsfähigkeit. Sie sind in absteigender Reihenfolge von der besten zur schlechtesten Leistungsfähigkeit beschrieben.
Tabelle 13.2: Verschiedene Formen der select-Anweisung, um eine interne Tabelle zu füllen
Anweisung(en) Füllt
select into table it Rumpf
select into corresponding fields of table it Rumpf
select into it Kopfzeile
select into corresponding fields of it Kopfzeile
Der Gebrauch von lfa1-, lfb1-, lfc1- und lfc3- Beispieltabellen
Bevor wir den nächsten Abschnitt betrachten, wäre es hilfreich, sich erstmal mit den Beispieltabellen ztxlfa1, ztxlfb1 und ztxlfc3 vertraut zu machen, da diese für die nächsten Beispiele und Übungen gebraucht werden. Diese Tabellen basieren auf den R/3-Tabellen lfa1, lfb1, lfc1 und lfc3. Sehen Sie sich die Strukturen dieser Tabellen im DDIC noch einmal an, während Sie die

untenstehende Beschreibung lesen.
SAP hat R/3 so konzipiert, daß es als Konglomerat vieler Firmen genutzt werden kann. Während der R/3-Konfiguration wird jeder Firma ein Buchungskreis (company code) zugeteilt. Dieser Code ist ein Teil des Primärschlüssels in vielen Stammdatentabellen, der es dem Konglomerat ermöglicht, die Informationen seiner Firmen in einer Datenbank zu verwalten. Das Management kann so pro Firma individuelle Berichte zur Auswertung schreiben lassen und ebenso konsolidierte Reports über viele Firmen.
Tabelle lfa1 enthält Kreditorenstamminformationen, die konsistent über alle Firmen sind. Ignoriert man mandt, so enthält der Primärschlüssel nur lifnr, die Kreditorennummer. Die Felder von lfa1enthalten zum Beispiel den Kreditornamen, die Adresse, die Telefonnummer, die Landessprache und den Industrieschlüssel (abhängig vom Produkt, wie z.B. die Chemieindustrie, Bauindustrie und so weiter).
Tabelle lfb1 enthält Kreditorenstamminformationen, die spezifisch für eine Firma sind. Ihr Primärschlüssel besteht aus lifnr und bukrs: dem Firmen-Codefeld (s.a. Abb. 13.6). Innerhalb von lfb1 sind auch Firmenkontonummer, Steuerinformationen und vieles mehr gespeichert.
Abbildung 13.6: Die Beziehung zwischen den Primäschlüsseln.
Abbildung 13.6 zeigt die Beziehung zwischen dem Primärschlüssel der Tabellen lfa1 bis lfc3. Sie fangen alle mit lifnr an, und lfa1 benutzt ihn als gesamten Primärschlüssel. Lfb1 benutzt die Kreditorennummer und den Buchungskreis. Lfc1 benutzt die Kreditorennummer, den Buchungskreis und das Fiskaljahr. Lfc3 benutzt die gleichen Felder einschließlich eines speziellen General Ledger (G/L, Hauptbuchhaltung)- Indikators.
Tabelle lfc1 enthält G/L-Geschäftstransaktionen. Jede Zeile enthält die Angaben eines Fiskaljahres eines Kreditors innerhalb einer Firma. Der Primärschlüssel besteht aus lifnr, bukrs, gjahr und dem Fiskaljahr.
Eine Serie von Feldern mit Namen umNNs, umNNh und umNNu wird 16mal innerhalb einer lfc1 Zeile wiederholt. Jeder der ersten zwölf Serien enthält Debitorenbuchungen, Kreditbuchungen und Verkäufe einer Buchungsperiode (normalerweise ein Monat) des Fiskaljahres. Die letzten vier Serien sind beendete Perioden, die für Jahresabschlüsse benutzt werden.

In einem Fiskaljahr gibt es bis zu zwölf oder dreizehn Buchungsperioden. Das wird während der Systemkonfiguration festgelegt. Gibt es 13 Buchungsperioden, gibt es nur drei zusätzliche Abschlußperioden.
Tabelle lfc3 enthält spezielle G/L-Geschäftstransaktionen. Für die Hauptbuchhaltung benutzen alternative Abstimmungskonten spezielle G/Ls. Jede Zeile der Tabelle lfc3 enthält eine Zusammenfassung der G/Ls für das gesamte Fiskaljahr in drei Feldern: saldv, soll1 und habn1.Diese enthalten die Bilanz, die Schuldposten und die Kreditbuchungen des Fiskaljahres. Der Primärschlüssel ist der gleiche wie bei lfc1 einschließlich des speziellen G/L-Indikators: shbkz. Der Wert in diesem Feld zeigt an, welche alternativen Abstimmungskonten benutzt wurden. Viele Stammdatentabellen benutzen ein ähnliches Model für ihre Primärschlüsselstrukturen.
In diesem Buch werden vereinfachte Versionen dieser Tabellen benutzt: ztxlfa1, ztxlfb1, ztxlfc1 und ztxlfc3. Diese werden mit der Setup-Routine angelegt.
Gruppenwechsel
Nachdem eine interne Tabelle mit Daten gefüllt wurde, muß man die Daten meistens auch wieder rausschreiben. Diese Ausgabe wird häufig Zusammenfassungen (wie z.B. Gesamtsummen) am Anfang oder am Ende des Reports haben. Ebenso kann es innerhalb eines Berichts Zwischensummen geben.
Nehmen Sie einmal an, Sie müssen für die Hauptbuchhaltung die Kennzahlen aus der Tabelle ztxlfa1für jeden Kreditor mit Zwischensumme pro Fiskaljahr schreiben und eine Gesamtsumme am Ende des Berichts ausgeben.
Um diese Aufgabe durchzuführen, kann man die Daten in eine interne Tabelle schreiben und dann innerhalb einer Schleife die folgenden Anweisungen benutzen:
■ at first / endat ■ at last / endat ■ at new / endat ■ at end of / endat ■ sum■ on change on / endon
Die erste Anweisung in jedem dieser Anweisungspaare - sum ist ausgenommen - kontrolliert, ob der Programm-Code, der dazwischen liegt, auch ausgeführt wird. Diese Art der Kontrolle wird auch Gruppenwechsel genannt. Der Zweck eines Gruppenwechsels ist es, den Zeilen-Code der dazwischen liegt, unter besonderen Bedingungen (d.h. spezifische Bedingungen innerhalb der Daten) während einer Schleifenverarbeitung auszuführen.

Die at first und at last-Anweisungen
at first und at last werden während der ersten oder letzten Schleifenverarbeitung einer internen Tabelle ausgeführt.
Die Syntax für at first- und at last-Anweisungen
Die folgenden Zeilen beschreiben die Syntax von at first und at last-Anweisungen.
loop at it....at first....endat.at last....endat....endloop.
wobei:
■ it eine interne Tabelle ist. ■ ... einer beliebigen Anzahl an Zeilencode entspricht, der dazwischenliegt (auch Null).
Die folgenden Punkte sind zu beachten:
■ Diese Anweisungen können nur mit loop at benutzt werden; sie können nicht zusammen mit select genutzt werden.
■ at first muß nicht zwingend vor at last stehen. Die Reihenfolge kann variieren. ■ Die Anweisungen können mehrmals in der gleichen Schleife vorkommen. Zum Beispiel können
Sie zweimal at first- und dreimal at last-Anweisungen innerhalb einer Schleife haben, die in beliebiger Reihenfolge stehen können.
■ Die Anweisungen sollten nicht in sich selber verschachtelt sein (d.h. at last sollte nicht innerhalb von at first und endat stehen).
■ Es gibt keine Ergänzungen zu diesen Anweisungen.
Beim ersten Schleifendurchgang werden die Zeilen, die zwischen at first und endat liegen, ausgeführt. Beim letzten Schleifendurchgang werden die Zeilen, die zwischen at last und endatliegen ausgeführt. Kommt at first mehrmals vor, werden sie alle ausgeführt. At last verhält sich ähnlich.
Man benutzt at first, um:
■ Schleifenverarbeitung anzustoßen ■ Gesamtsummen an den Anfang eines Berichts zu setzen

■ Kopfzeilen auszugeben
Man benutzt at last, um:
■ Schleifenverarbeitung anzustoßen ■ Gesamtsummen an das Ende eines Berichts zu setzen ■ Fußzeilen auszugeben
Listing 13.7 zeigt ein Beispielprogramm, das diese Konstrukte benutzt.
Listing 13.7: Die Benutzung von at first, um Kopfzeilen zu schreiben und at last, um die letzte Zeile zu unterstreichen
1 report ztx1307.2 tables ztxlfc3.3 data it like ztxlfc3 occurs 25 with header line.4 select * from ztxlfc3 into table it where shbkz = 'Z'.5 loop at it.6 at first.7 write: / 'Vendor',8 12 'Cpny',9 17 'Year',10 22 'Bal C/F'.11 uline.12 endat.13 write: / it-lifnr,14 12 it-bukrs,15 17 it-gjahr,16 22 it-saldv.17 at last.18 write: / '----------',19 12 '----',20 17 '----',21 22 '-------------------'.22 endat.23 endloop.24 free it.
Das Programm aus Listing 13.7 zeigt die folgende Ausgabe:
Vendor Cpny Year Bal C/F----------------------------------------1000 1000 1995 0.00 1000 1000 1996 5,000.00 1000 1000 1998 4,000.00 1040 4000 1997 0.00 1070 2000 1997 1,000.00

1090 2000 1997 250.50 V1 1000 1992 1,000.00 V1 3000 1990 1,000.00 V1 3000 1994 1,000.00 V4 4000 1997 100.00 V6 2000 1997 1,000.00 V6 4000 1997 0.00 ---------- ---- ---- -------------------
■ Die Zeilen 6 bis 11 werden nur beim ersten Schleifendurchgang bearbeitet. Das Programm schreibt Kopfzeilen, gefolgt von Unterstrichen (Zeile 11).
■ Die Zeilen 13 bis 16 schreiben den Inhalt der Zeile. Sie werden für jede Zeile ausgeführt. ■ Die Zeilen 17 bis 22 werden nur beim letzten Schleifendurchgang benutzt. Dieses Beispiel schreibt
einen Unterstrich am Ende jeder Spalte.
Die Werte von Komponenten sind verschwunden
Zwischen at first und endat oder zwischen at last und endat enthalten die Werte der Komponenten des Arbeitsbereichs keine Daten. Die Standardschlüsselfelder sind mit Sternzeichen (*) aufgefüllt und die numerischen Felder mit Nullen. endat stellt den Inhalt der Werte wieder her, den sie vor at hatten. Änderungen im Arbeitsbereich innerhalb von at und endat gehen verloren.
Listing 13.8 zeigt, daß die Komponenten der Standardschlüsselfelder innerhalb at und endat mit Sternzeichen gefüllt sind und die Nicht-Schlüsselfelder mit Nullen.
Listing 13.8: Der Inhalt der internen Tabellenfelder zwischen at und endat
1 report ztx1308.2 tables ztxlfc3.3 data it like ztxlfc3 occurs 1 with header line.4 select * up to 1 rows from ztxlfc3 into table it.5 loop at it.6 write: / 'Before ''at first'':',7 / it-lifnr, it-bukrs, it-gjahr, it-shbkz, it-saldv,8 it-solll.9 at first.10 write: / 'Inside ''at first'':',11 / it-lifnr, it-bukrs, it-gjahr, it-shbkz, it-saldv,12 it-solll.13 it-lifnr = 'XXXX'.14 endat.15 write: / 'Between ''at first'' and ''at last'':',16 / it-lifnr, it-bukrs, it-gjahr, it-shbkz, it-saldv,17 it-solll.18 at last.19 write: / 'Inside ''at last'':',20 / it-lifnr, it-bukrs, it-gjahr, it-shbkz, it-saldv,

21 it-solll.22 it-lifnr = 'XXXX'.23 endat.24 write: / 'After ''at last'':',25 / it-lifnr, it-bukrs, it-gjahr, it-shbkz, it-saldv,26 it-solll.27 endloop.28 free it.
Das Programm aus Listing 13.8 produziert die folgende Ausgabe.
Before 'at first':1000 1000 1990 A 1,000.00 500.00Inside 'at first':********** **** **** * 0.00 0.00Between 'at first' and 'at last':1000 1000 1990 A 1,000.00 500.00Inside 'at last':********** **** **** * 0.00 0.00After 'at last':1000 1000 1990 A 1,000.00 500.00
■ Zeile 4 selektiert eine Zeile aus ztxlfc3 nach it.■ Innerhalb der Schleife, die in Zeile 5 anfängt, wird der Inhalt der Zeile zuerst ausgeschrieben. Er
wird dann wieder innerhalb von at first und endat geschrieben. Die Ausgabe zeigt, daß die Standardschlüsselfelder Sternzeichen enthalten und der Rest Nullen.
■ Zeile 13 ordnet it-lifnr einen neuen Wert zu. ■ Nach dem endat auf Zeile 14 zeigt die Ausgabe, daß alle Werte im Arbeitsbereich
wiederhergestellt wurden. Änderungen an der Kopfzeile, die innerhalb von at / endat gemacht wurden, sind verloren.
■ In Zeile 18 zeigt at last das gleiche Verhalten. ■ In Zeile 27 steigt die Schleife beim ersten Durchgang aus, um die Ausgabe möglichst einfach zu
halten.
Die Benutzung von at new und at end of
At new- und at end of-Anweisungen dienen dazu, Änderungen in einer Spalte pro Schleifendurchgang ausfindig zu machen. Mit Hilfe dieser Anweisungen kann man Programm-Code am Anfang und Ende einer Gruppe von Sätzen ausführen.
Die Syntax von at new und at end of
Im folgenden wird die Syntax zu at new und at end of erklärt.
Sort by c.Loop at it....

at new c.endat....at end of c....endat....endloop.
wobei:
■ it eine interne Tabelle ist. ■ c eine Komponente von it.■ ... Programmzeilen sein sollen.
Die folgenden Punkte sind zu beachten:
■ Diese Anweisungen können nur innerhalb einer Schleife und nicht zusammen mit select benutzt werden.
■ At new muß nicht zwingend vor at end of stehen. Diese Anweisungen können in beliebiger Reihenfolge stehen.
■ Diese Anweisungen können mehrmals in einer Schleife auftreten. Zum Beispiel können zweimal at new- und dreimal at end of-Anweisungen innerhalb einer Schleife in beliebiger Reihenfolge stehen.
■ Diese Anweisungen sollten nicht ineinander verschachtelt werden (d.h., at end of sollte nicht innerhalb von at new / endat stehen).
■ Es gibt für diese Anweisungen keine Ergänzungen.
Die Benutzung von at new
Jedesmal, wenn sich der Wert von c ändert, werden die Programmzeilen zwischen at new und endatausgeführt. Dieser Block wird ebenso bei jedem Schleifendurchgang ausgeführt, oder wenn sich Werte links von c ändern. Zwischen at und endat werden die numerischen Felder rechts von c auf Null gesetzt. Die nicht numerischen Felder werden mit Sternzeichen (*) gefüllt. Kommt at new mehrfach vor, werden alle ausgeführt. At end of verhält sich ähnlich.
Der Gruppenwechsel wird durch eine sogenannte Kontrollstufe reguliert. Im folgenden Programmausschnitt ist f2 z.B. eine solche Kontrollstufe, weil es in der at new- Anweisung erscheint.
loop at it.at new f2."(ab hier Programm-Code)endat.endloop.
Man sagt, daß der Gruppenwechsel angestoßen wird, wenn sich die Kontrollstufe ändert. Das bedeutet, wenn sich der Inhalt der Kontrollstufe ändert, wird der Programm- Code zwischen at und endat

ausgeführt.
Ein Gruppenwechsel wird auch angestoßen, wenn sich Felder vor der Kontrollstufe in der Struktur ändern. Deshalb sollte man die Struktur der internen Tabelle mit den Feldern beginnen, welche die Kontrollstufe ausmachen. Sie müssen auch nach allen Feldern vor und einschließlich c sortieren.
Zwischen at und endat werden numerische Felder rechts von der Kontrollstufe zu Null, und nicht numerische Felder werden mit Sternzeichen aufgefüllt.
Abbildung 13.7 und 13.8 erläutern den Gebrauch von at new.
Abbildung 13.7: Diese Abbildung zeigt eine Kontrollstufe, die in Gang gesetzt wird, wenn sich der Wert von f1 ändert. Sie zeigt auch, daß f2 ein Sternzeichen innerhalb des Gruppenwechsels (zwischen at und endat) enthält.
Abbildung 13.8: Diese Abbildung zeigt, daß diese Kontrollstufe angestoßen wird, wenn f2 oder f1 sich ändern. Das passiert, weil f1 in der Struktur von it vor f2 kommt.
Dieses Programm bietet ein Arbeitsbeispiel von Abbildung 13.7 und 13.8. Es zeigt den Punkt, an welchem ein Gruppenwechsel angestoßen wird, wenn sich die Kontrollstufe ändert oder Felder sich vor der Kontrollstufe ändern.
Listing 13.9: Der Programm-Code aus Abbildungen 13.7 und 13.8 in einem Beispielprogramm

1 report ztx1309.2 data: begin of it occurs 4,3 f1,4 f2,5 end of it.67 it = '1A'. append it. "Fill it with data8 it = '3A'. append it.9 it = '1B'. append it.10 it = '2B'. append it.1112 sort it by f1. "it now looks like figure 13.713 loop at it.14 at new f1.15 write: / it-f1, it-f2.16 endat.17 endloop.18 skip.19 sort it by f2. "it now looks like figure 13.820 loop at it.21 at new f2.22 write: / it-f1, it-f2.23 endat.24 endloop.25 skip.26 sort it by f1 f2. "it now looks like figure 13.827 loop at it.28 at new f1.29 write: / it-f1.30 endat.31 at new f2.32 write: /4 it-f2.33 endat.34 endloop.35 free it.
Das Programm aus Listing 13.9 zeigt die folgende Ausgabe:
1 *2 * 3 *
1 A 3 A 1 B 2 B

1AB2B3A
■ Zeile 12 sortiert it mit f1. Auf Zeile 14 wird at new beim ersten Schleifendurchgang angestoßen und jedesmal, wenn sich f1 ändert.
■ Zeile 19 sortiert it mit f2. Auf Zeile 20 wird at new beim ersten Durchgang angestoßen oder jedesmal, wenn sich die Werte von f1 oder f2 ändern. Das passiert, weil eine Kontrollstufe angestoßen wird, wenn sich f2 oder irgendein Feld vor f2 ändert.
■ Zeile 26 sortiert it mit f1 und f2. Auf Zeile 28 wird at new jedesmal angestoßen, wenn sich der Wert von f1 ändert, und auf Zeile 31 wird at new jedesmal angestoßen, wenn sich f1 oder f2 ändert.
Die Benutzung von at end of
Die Programmzeilen zwischen at end of und endat werden ausgeführt:
■ wenn sich die Kontrollstufe ändert ■ wenn sich irgendwelche Felder vor der Kontrollstufe ändern ■ wenn es sich um die letzte Zeile einer Tabelle handelt
Listing 13.10 zeigt diese Anweisung.
Listing 13.10: Wie at new und at end of durch Feldänderungen und Kontrollstufenänderungen angestoßen werden.
1 report ztx1310.2 data: begin of it occurs 4,3 f1,4 f2,5 end of it.67 it = '1A'. append it. "Fill it with data8 it = '3A'. append it.9 it = '1B'. append it.10 it = '2B'. append it.1112 sort it by f1.13 loop at it.14 at new f1.15 write: / 'start of:', it-f1.16 endat.17 write: /4 it-f1.

18 at end of f1.19 write: / 'end of:', it-f1.20 endat.21 endloop.22 free it.
Das Programm aus Listing 13.10 zeigt folgendes:
start of: 1 11end of: 1 start of: 2 2end of: 2 start of: 3 3end of: 3
■ Zeile 12 sortiert it mit f1.■ Auf Zeile 14 wird jedesmal, wenn sich f1 ändert, at new angestoßen. ■ Auf Zeile 18 wird at end angestoßen, wenn sich die Kontrollstufe beim Lesen des nächsten
Satzes ändert, oder wenn es sich um die letzte Zeile handelt.
Benutzen Sie nicht Gruppenwechselanweisungen innerhalb einer Schleife mit at it where ...-Konstrukten; das führt zu unvorhersehbaren Ergebnissen.
Die Benutzung von sum
Mit sum werden Gesamtsummen einer Kontrollstufe ausgegeben.
Syntax von sum
Folgende Zeilen zeigen die Syntax der sum-Anweisung.
at first/last/new/end of....sum...endat.

wobei:
■ ... Programmzeilen sein sollen
sum rechnet die Gesamtsumme einer Kontrollstufe aus. Das wird verständlich, wenn man sich folgendes vorstellt:
■ Es findet alle Zeilen, die die gleichen Werte innerhalb einer Kontrollstufe haben und alle Felder links davon.
■ Es summiert jede numerische Spalte rechts der Kontrollstufe. ■ Es stellt die Gesamtsummen in die korrespondierenden Felder des Arbeitsbereichs.
Listing 13.11 soll dies veranschaulichen.
Listing 13.11: Die sum-Anweisung
1 report ztx1311.2 data: begin of it occurs 4,3 f1,4 f2 type i,5 f3 type i,6 end of it.78 it-f1 = 'A'. it-f2 = 1. it-f3 = 10. append it.9 it-f1 = 'B'. it-f2 = 3. it-f3 = 30. append it.10 it-f1 = 'A'. it-f2 = 2. it-f3 = 20. append it.11 it-f1 = 'B'. it-f2 = 4. it-f3 = 40. append it.1213 sort it by f1. "it now looks like figure 13.914 loop at it.15 at new f1.16 sum.17 write: / 'total:', it-f1, it-f2, it-f3.18 endat.19 write: /11 it-f2, it-f3.20 endloop.21 free it.
Das Programm aus Listing 13.11 erzeugt folgende Ausgabe:
total: A 3 301 102 20 total: B 7 703 30 4 40

■ Zeile 13 sortiert it mit f1 aufsteigend. Der Inhalt nach der Sortierung ist in Abbildung 13.9 zu sehen.
■ Beim ersten Schleifendurchgang wird der Programm-Code zwischen Zeile 15 und 18 ausgeführt. Die Kontrollstufe hat den Wert 'A'.
■ Bevor Zeile 16 ausgeführt wird, enthalten die Felder des Arbeitsbereichs rechts von der Kontrollstufe Nullen. Die sum-Anweisung findet alle angrenzenden Zeilen, die ein 'A' in f1haben. Es summiert die numerischen Spalten rechts von der Kontrollstufe und stellt das Ergebnis in den Arbeitsbereich (s.a. Abbildung 13.9).
■ Beim zweiten Schleifendurchgang wird at new nicht angestoßen. ■ Beim dritten Schleifendurchgang enthält f1 'B' und at new (Zeile 15) wird angestoßen. ■ Bevor Zeile 16 ausgeführt wird, enthalten die Felder des Arbeitsbereichs rechts von der
Kontrollstufe Nullen. Die sum-Anweisung findet alle angrenzenden Zeilen, die ein 'B' in f1haben. Es summiert die numerischen Spalten rechts von der Kontrollstufe und stellt das Ergebnis in den Arbeitsbereich (s.a. Abbildung 13.10).
Abbildung 13.9: Die Abbildung zeigt, was in Listing 13.11 passiert. Beim ersten Schleifendurchgang wird der Wechsel angestoßen, und die sum-Anweisung ausgeführt. Alle Zeilen, die die gleichen Werte wie die Kontrollstufe haben, werden gefunden, und die numerischen Felder rechts von der Kontrollstufe werden im Arbeitsbereich aufsummiert.

Abbildung 13.10: Die Abbildung zeigt, was passiert, wenn der Gruppenwechsel zum zweiten Mal angestoßen und die sum-Anweisung ausgeführt wird.
Das Summieren kann in einem Überlauf enden, da die Gesamtsumme in ein Feld gleicher Länge gestellt wird. Ein Überlauf produziert einen Programmabbruch mit der Fehlermeldung SUM_OVERFLOW. Bei der Benutzung von sum vermeiden Sie einen Überlauf, indem Sie die Länge der numerischen Felder erhöhen, bevor Sie die interne Tabelle füllen.
Die Benutzung von on change of
Eine weitere Anweisung für den Gruppenwechsel ist on change of. Sie verhält sich ähnlich at new.
Die Syntax von on change of
Folgende Zeilen zeigen die Syntax von on change of.
On change of v1 [or v2 . . .]....[else.- - -]endon.
wobei:
■ v1 und v2 Variable oder Feldleistennamen sind.

■ ... Programmanweisungen sind. ■ - - - Programmzeilen sind.
Die folgenden Punkte gelten:
■ Wenn sich der Wert der Variablen (v1, v2 und so weiter) von einem Test zum nächsten ändert, werden die Anweisungen, die on change of folgen, ausgeführt.
■ Wenn keine Änderung entdeckt wird und die else-Bedingung zum Tragen kommt, werden die Anweisungen, die auf else folgen, ausgeführt.
on change of unterscheidet sich von at new in den folgenden Punkten:
■ Es kann in jedem Schleifenkonstrukt benutzt werden, nicht nur mit loop at. Zum Beispiel kann es mit select und endselect, do und enddo oder while und endwhile benutzt werden, und auch innerhalb von get events.
■ Ein einzelner on change of kann bei einem Wechsel in einem oder mehreren Feldern nach ofund getrennt durch or angestoßen werden. Diese Felder können elementare Felder oder Feldleisten sein. Befindet man sich innerhalb einer Schleife, müssen diese Felder nicht unbedingt zur Schleife gehören.
■ Wird on change of in einer Schleife benutzt, wird ein Wechsel in einem Feld links von der Kontrollstufe keinen Gruppenwechsel anstoßen.
■ Wird on change of in einer Schleife benutzt, enthalten Felder rechts davon immer noch ihre originalen Werte; sie ändern sich nicht, um Nullen oder Sternzeichen aufzunehmen.
■ Man kann else zwischen on change of und endon benutzen. ■ Man kann es mit loop at it where . . . benutzen. ■ Man kann on change of zusammen mit sum benutzen. Es summiert alle numerischen Felder,
außer diejenigen, die nach of kommen. ■ Alle Werte, die innerhalb von on change of geändert wurden, bleiben nach endon geändert.
Der Inhalt der Kopfzeilen wird nicht wieder so hergestellt wie für at und endat.
Hinter den Kulissen von on change of
Wenn eine Schleife anfängt Befehle abzuarbeiten, legt das System globale Hilfsfelder für jedes Feld an, das in einer on change of-Anweisung vorkommt. Beim Anlegen werden diesen Feldern Standardinitialwerte mitgegeben (Leerzeichen oder Nullen). Sie werden wieder freigesetzt, wenn die Schleifenverarbeitung endet.
Da globale Hilfsfelder nicht außerhalb einer Schleife existieren, kann man on change of nicht außerhalb einer Schleife benutzen.
Jedesmal, wenn on change of ausgeführt wird, wird der Inhalt von ihren Feldern mit dem Inhalt der

globalen Hilfsfelder verglichen. Sind sie unterschiedlich, wird on change of angestoßen, und die Hilfsfelder werden mit den neuen Werten aktualisiert. Bleiben sie gleich, wird der Programm-Code innerhalb von on change of nicht ausgeführt.
Dieses Konzept zeigen die Grafiken in Abbildung 13.11 bis 13.16.
Abbildung 13.11: Dies ist das erste Mal, daß eine Schleife on change of benutzt.
Abbildung 13.12: Wenn on change of angestoßen wird, werden die Hilfsfelder aktualisiert.

Abbildung 13.13: Dies ist der zweite Schleifendurchgang. Der Inhalt der Hilfsfelder paßt, und on change of wird nicht angestoßen.
Abbildung 13.14: Dies ist der dritte Schleifendurchgang. on change of wird angestoßen.
Abbildung 13.15: Hier sind die Hilfsfelder aktualisiert.

Abbildung 13.16: Das ist der vierte Schleifendurchgang. on change of wird nicht angestoßen.
Der Gebrauch von on change of
Listing 13.12.zeigt den Gebrauch von on change of.
Listing 13.12: Die Benutzung von on change of auf zwei verschieden Weisen: innerhalb einer Schleife und innerhalb von select
1 report ztx1312.2 tables ztxlfa1.3 data: begin of it occurs 4,4 f1 type i,5 f2,6 f3 type i,7 f4,8 end of it.910 it-f1 = 1. it-f2 = 'A'. it-f3 = 11. it-f4 = 'W'. append it.11 it-f1 = 3. it-f2 = 'A'. it-f3 = 22. it-f4 = 'X'. append it.12 it-f1 = 1. it-f2 = 'A'. it-f3 = 33. it-f4 = 'Y'. append it.13 it-f1 = 2. it-f2 = 'A'. it-f3 = 44. it-f4 = 'Z'. append it.1415 loop at it.16 on change of it-f2.17 write: / it-f1, it-f2, it-f3, it-f4.18 endon.19 endloop.20 write: / 'End of loop'.2122 * executing the same code again - the aux field still contains 'A'23 loop at it.

24 at first.25 write: / 'Looping without a reset...'.26 endat.27 on change of it-f2.28 write: / it-f1, it-f2, it-f3, it-f4.29 else.30 write: / 'on change of not triggered for row', sy-tabix.31 endon.32 endloop.33 write: / 'End of loop'.3435 *reset the aux field to blanks36 clear it-f2.37 on change of it-f2.38 endon.39 loop at it.40 at first.41 write: / 'Looping after reset...'.42 endat.43 on change of it-f2.44 write: / it-f1, it-f2, it-f3, it-f4.45 endon.46 endloop.47 write: / 'End of loop'.48 free it.4950 select * from ztxlfa1 where land1 = 'US'.51 on change of ztxlfa1-land1.52 write: / 'land1=', ztxlfa1-land1.53 endon.54 endselect.55 write: / 'End of select'.5657 *executing the same select again without a reset works find58 select * from ztxlfa1 where land1 = 'US'.59 on change of ztxlfa1-land1.60 write: / 'land1=', ztxlfa1-land1.61 endon.62 endselect.63 write: / 'End of select'.
In der Version 3.0F und höher erzeugt das Programm folgende Ausgabe:
1 A 11 W End of loop Looping without a reset... on change of not triggered for row 2on change of not triggered for row 3

on change of not triggered for row 4End of loop Looping after reset... 1 A 11 W End of loop land1= US End of select land1= US End of select
■ Die Zeilen 10 bis 13 füllen die interne Tabelle mit Anfangswerten. it-f2 enthält den Wert 'A' in allen vier Zeilen.
■ Zeile 16 schreibt jede Zeile nach der Verarbeitung aus. ■ Die Zeilen 17, 20, 23 und 26 werden beim ersten Schleifendurchgang angestoßen. Das passiert,
weil die Hilfsfelder Nullen oder Leerzeichen enthalten und sich somit von den Werten in der ersten Zeile unterscheiden. Die Werte der ersten Zeile werden in die Hilfsfelder kopiert, die Werte werden von der write-Anweisung ausgeschrieben.
■ Zeile 20 wird nicht angestoßen, da bei allen weiteren Schleifendurchläufen der Wert von it-f2gleich 'A' ist, und das globale Hilfsfeld auch 'A' enthält. Beachten Sie, daß eine Änderung des Wertes links von f2 den Befehl on change of nicht anstößt wie bei at new.
■ Die interne Tabelle wird hinter Zeile 31 nicht mehr benutzt und freigesetzt. Das löscht alle Zeilen und gibt auch wieder Speicher frei.
■ Zeile 33 selektiert alle Zeilen aus ztxlfa1 in der Reihenfolge von land1.■ Obwohl dieser select 23 Zeilen zurückliefert, wie in der letzten Zeile der Ausgabe zu sehen ist,
existieren nur fünf gleiche Werte von land1, die ausgeschrieben werden.
Die Benutzung von on change of
Beim ersten Schleifendurchgang werden die globalen Hilfsfelder mit Initialwerten (Leerzeichen oder Nullen) angelegt. Wenn der erste Wert einer Schleife ein Leerzeichen oder eine Null ist, wird onchange of nicht angestoßen. Listing 13.13 zeigt dieses Problem und liefert eine Lösung.
Listing 13.13: Die erste Zeile von Schleife #1 stößt on change of nicht an.
1 report ztx1313.2 data: begin of it occurs 4,3 f1 type i,4 end of it.56 it-f1 = 0. append it.7 it-f1 = 3. append it.8 it-f1 = 1. append it.9 it-f1 = 2. append it.1011 loop at it. "loop #112 write: / '==new row==', 12 it-f1.13 on change of it-f1.

14 write: / 'f1 changed:', 12 it-f1.15 endon.16 endloop.1718 skip.19 loop at it. "loop #220 write: / '==new row==', 12 it-f1.21 on change of it-f1.22 write: / 'f1 changed:', 12 it-f1.23 else.24 if sy-tabix = 1.25 write: / 'f1 changed:', 12 it-f1.26 endif.27 endon.28 endloop.29 free it.
Das Programm aus Listing 13.13 zeigt die folgende Ausgabe:
==new row== 0 ==new row== 3 f1 changed: 3 ==new row== 1 f1 changed: 1 ==new row== 2 f1 changed: 2
==new row== 0 f1 changed: 0 ==new row== 3 f1 changed: 3 ==new row== 1 f1 changed: 1 ==new row== 2 f1 changed: 2
■ Die Zeilen 6 bis 9 füllen die interne Tabelle mit vier Zeilen. Der Wert von it-f1 in der ersten Zeile ist Null.
■ Auf Zeile 13 stößt der erste Schleifendurchgang on change of nicht an, weil das globale Hilfsfeld eine Null enthält.
■ Die Zeilen 23 bis 24 wurden der Schleife #2 zugeordnet, um den Fehler zu entdecken. Beachten Sie, daß at first nicht zum Entdecken dieses Problems benutzt werden kann, da alle numerischen Felder im Arbeitsbereich innerhalb von at first und endat auf Null gesetzt werden.

In Versionen vor 3.0F setzten nur select- und get-Anweisungen die globalen Hilfsfelder zurück. Wenn Sie diese jedoch selbst zurücksetzen, kann man dazu on change of in jedem Schleifenkonstrukt benutzen. Benutzen Sie diesen Programm-Code, um ein Zurücksetzen (reset) zu bewirken: clear f1. on change of f1. endon. clearschiebt Initialwerte in f1. on change of vergleicht f1 mit den globalen Hilfsfeldern. Unterscheiden sie sich, überschreibt das Entleeren mit on change of sie mit Initialwerten. Gehen Sie so vor, um die Hilfsfelder mit einem beliebigen Wert von f1 zu füllen.
Zusammenfassung
■ Eine Feldoperation ist der effizienteste Weg, eine interne Tabelle aus einer Datenbank zu füllen. Sie liest Zeilen direkt aus der Datenbank in den Rumpf der internen Tabelle, ohne Arbeitsbereiche zu benutzen. Über die into table-Ergänzung bei der select-Anweisung ist das so implementiert.
■ Eine interne Tabelle muß groß genug gewählt werden, um die selektierten Werte aus der Datenbank mit aufzunehmen. Um präziser zu sein, die Breite einer internen Tabellenzeile in Byte muß größer oder gleich der Gesamtzahl an Byte aller selektierten Spalten aus der Datenbank in der internen Tabelle sein. Ist die interne Tabellenzeile breiter, füllen die selektierten Spalten aus der Datenbank die höchstwertigen Byte jeder internen Tabellenzeile. Die übriggebliebenen Byte werden auf Standardwerte gesetzt.
■ Benutzen Sie into corresponding fields, wenn die Felder der internen Tabelle sich in unterschiedlicher Reihenfolge befinden oder untereinander von Feldern getrennt sind, die nicht aus der Datenbanktabelle selektiert wurden.
■ Benutzen Sie at und endat, um die Verarbeitung anzustoßen, die auf einem Wechsel in der Spalte einer internen Tabelle oder irgendeiner Spalte links davon basiert.
■ Benutzen Sie sum mit at und endat oder mit on change of, um Gesamtsummen und Zwischenwerte auszurechnen.
■ Benutzen Sie on change of innerhalb von Schleifen, um die Verarbeitung, die auf einem Wechsel in einer der selektierten Spalten basiert.
Benutzen Sie nicht select und append. Wenn möglich, benutzen Sie select into table. Benutzen Sie nicht order by mit select into table. Benutzen Sie statt dessen sort in der internen Tabelle.
Fragen & Antworten

Frage:Der erste Teil dieses Kapitels schien viel Wert auf Effizienz zu legen. Ich lerne zwar, finde aber alle diese Methoden konfus. Macht das alles wirklich Sinn?
Antwort:Die Erfahrung zeigt, daß Studenten, die von der Pike auf lernen, besser sind. ABAP/4-Programme verarbeiten oft viele Datenmengen, der »einfache Code« erhöht die Verwaltungsarbeit eines Programms. Wenn Sie am Anfang nur einfache Methoden lernen, werden Sie sich schwer wieder davon lösen können. Schlechter Programm-Code geht zu Lasten der Performance Ihres Systems und der Programme.
Workshop
Der Workshop zeigt Ihnen zwei Wege, wie Sie überprüfen können, was Sie in diesem Kapitel gelernt haben. Die Kontrollfrage hilft Ihnen, das Erlernte zu vertiefen, während die Übungen Ihnen ermöglichen, praktisch zu arbeiten. Antworten zu den Übungen und Fragen finden Sie im Anhang B »Antworten zu den Kontrollfragen und Übungen«.
Kontrollfrage
1. Wie sind die Werte der Felder rechts von der Kontrollstufe zwischen at- und endat -Anweisungen?
Übung 1
Kopieren Sie das Programm ztx1110 nach ***e1301. Ändern Sie es dahingehend, daß eine gefundene Zeile mit dem Inhalt der Überschrift überschrieben wird, wenn der Inhalt irgendeines Feldes dieser Reihe von dem abweicht, was in der Überschrift steht. Die Ausgabe sollte folgendermaßen aussehen:
10 1 XX 1 20 2 XX 2 30 3 XX 3 40 4 XX 4 50 5 XX 5
Benutzen Sie den comparing-Zusatz aus der read table-Anweisung.
Übung 2
Das folgende Programm produziert einen Fehler. Beschreiben Sie das Problem, kopieren Sie das Programm nach ***302, und beheben Sie den Fehler.
report zty1302

tables: ztxlfa1.data: begin of it occurs 10,lifnr like ztxlfa1-lifnr,land1 like ztxlfa1-land1,end of it. select * from ztxlfa1 into table it.loop at it.write: / it-lifnr,it-land1.endloop.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 2
Tag 14
Die write-Anweisung
Kapitelziele
Wenn Sie dieses Kapitel beendet haben, sollten Sie in der Lage sein:
■ den Effekt von Datentypen bei der Ausgabe zu verstehen ■ die Formatoptionen der write-Anweisung zu benutzen ■ Konvertierungs-Exits (conversion exits) zu benutzen und ihre Festlegung innerhalb der
Domänen zu erkennen
Standardlängen und Formatierungen
Wenn Sie keine Längenangaben angeben oder Formatierungsoptionen bei der write- Anweisung benutzen, wird das System Standardformate und Standardlängen benutzen, die auf den Datentypen von jeder geschriebenen Variablen basieren. Im folgenden Abschnitt werden diese Standardwerte beschrieben.
Standardlängen
Die Ausgabelänge eines Feldes ist die Anzahl von Zeichen, die zur Anzeige des Feldes gebraucht wird. Die Ausgabelänge wird von einer write-Anweisung benötigt, um Platz auf der Ausgabeliste für ein Feld zu reservieren. Felder, die innerhalb eines Programms mit Hilfe der data-Anweisung definiert werden, haben die Standardausgabelänge wie in Tabelle 14.1 gezeigt.
Tabelle 14.1: ABAP/4-Datentypen bestimmen die Standardformate und Längen.

Daten Ausrichtung Format VorzeichenStandard AusgabeTypenlänge
i rechts Nullen werden unterdrückt abschließend 11
p rechts Nullen werden unterdrückt abschließend 2*Feldlänge oder (2*Feldlänge)+1
f keine Wissenschaftl. Notation führend 22
n rechts Führende Nullen werden angezeigt
keine Feldlänge
c links Führende Leerzeichen werden unterdrückt
Feldlänge
d links Wird von Benutzerstandards be-stimmt
8
t links HH:MM:SS 6
x links 2*Feldlänge
Felder aus dem Data Dictionary haben DDIC-Datentypen wie DEC, CHAR, CURR und so weiter. Sie basieren alle auf ABAP/4-Datentypen und vererben ihre Standardlängen und Formate. Um den ABAP/4-Datentyp zu bestimmen und somit das Standardausgabeformat, schauen Sie in die ABAP/4-Schlüsselwortdokumentation zur tables- Anweisung. Die Hilfe kann man sich ansehen, indem man den Cursor auf die tables- Anweisung innerhalb des Programms positioniert und die F1-Hilfedrückt.
Zur Ergänzung sei gesagt, daß Ausgabelänge und Dezimalstellen von DDIC-Feldern innerhalb der Domäne definiert werden. Diese Felder überschreiben den Standard und sind in Abbildung 14.1 zu sehen.

Abbildung 14.1: Ausgabelänge und Dezimalstellen überschreiben die Standardwerte, die von den Datentypen vererbt werden.
Ausgabelänge und deren Dezimalstellen werden allen Feldern vererbt, die von einer Domäne angelegt werden. Das Beispiel in Abbildung 14.1 zeigt eine Feldlänge von 15, das bedeutet, daß 15 Zeichen in jedem Feld gespeichert werden können, das diese Domäne benutzt. Die Ausgabelänge ist 20, somit ist genügend Platz vorhanden, um Dezimalpunkte, Vorzeichen und Trennzeichen für die Tausendernotation zu setzen.
Gepackte Felder
Die Standardausgabelänge eines Feldes von Typ p entspricht zweimal der definierten Feldlänge. Wenn Dezimalstellen definiert werden, wird die Standardausgabelänge um 1 erhöht, somit ist sie 2*Feldlänge+1. Tabelle 14.2 zeigt ein Beispiel zu Standardausgabelängen von Feldern des Typs p.
Tabelle 14.2: Standardausgabelänge für gepackte Dezimalfelder

Datendefinition Standardausgabelänge
data f1(4) type p. 8
data f2(4) type p decimals 2. 9
data f3(5) type p. 10
data f4(5) type p decimals 3. 11
Standardformat
Das Standardformat ist auf den Datentyp der Variablen zurückzuführen. Tabelle 14.1 zeigt, wie die Ausgabe für jeden ABAP/4-Datentyp formatiert wird. Die Ausgabe von numerischen Feldern (Felder vom Typ p, I und f) ist rechts ausgerichtet, wobei führende Nullen unterdrückt werden, und der Rest ist links ausgerichtet. Zusätzlich gibt es typspezifische Formatierungen.
Standard-Datumsformate
Datumswerte werden entsprechend dem Datumsformat des Benutzerprofils ausgegeben, solange die Ausgabelänge 10 oder größer ist. Die Standardausgabelänge ist 8. Die Länge muß entsprechend auf 10 erhöht werden, um die Trennzeichen zu sehen. Wird eine Variable mit like definiert (z.B. like sy-datum), dann wird die Ausgabelänge von der Domäne genommen.
Standard-Zeitformat
Die Ausgabe der Zeit hat das Format HH:MM:SS, solange die Ausgabelänge 8 oder größer ist. Die Standardausgabelänge ist 6, d.h. auch hier muß die Länge letztlich 8 Zeichen betragen, bevor die Trennzeichen zu sehen sind. Wird auch hier wieder eine Variable mit like definiert (z.B. like sy-uzeit), wird die Ausgabelänge von der Domäne genommen.
Numerische Standardformate
Bürger der Vereinigten Staaten schreiben eine Zahl wie folgt: 1,234.56. In anderen Ländern, wie z.B. in Europa wird die gleiche Nummer folgendermaßen geschrieben: 1.234,56. Die Benutzung von Kommata und Dezimalstellen ist umgekehrt. R/3 ermöglicht jedem Benutzer eine von diesen Einstellungen über Einstellungen im Benutzerprofil bezüglich der Dezimalnotation individuell zu bestimmen (Sie können aus jeder Maske heraus den Menüpfad System->Benutzervorgaben->Eigene Daten auswählen).
Um Änderungen im Benutzerprofil wirksam zu machen, muß man sich im R/3 ab- und

wieder anmelden.
Tabelle 14.3 zeigt die Auswirkungen für numerische Ausgaben durch die Einstellungen für die Dezimalnotation im Benutzerprofil.
Tabelle 14.3: Dezimalnotationseinstellungen
im Benutzerprofil haben Einfluß auf die numerischen
Ausgabeformate.
Einstellung Beispielausgabe
Komma
Periode
1,234.56
1.234,56
Das Standardausgabeformat für Gleitkommavariable (Typ f) entspricht einer wissenschaftlichen Notation. Das kann mit Hilfe einer Ausgabemaske oder mit Konvertierungs-Exits modifiziert werden.
Überlaufformate
Hat man Zahlen, die zu groß sind für die Ausgabefelder, setzt das System ein Sternzeichen (*) in die erste Spalte der Ausgabe, um einen Überlauf anzuzeigen. Vorher versucht das System aber, wenn irgendwie möglich, alle Zeichen darzustellen. Trennzeichen für Tausend werden nur ausgegeben, wenn genügend Platz im Ausgabefeld vorhanden ist. Wenn nicht, werden sie nacheinander gelöscht, und zwar beginnend von links nach rechts im Feld. Handelt es sich um eine positive Nummer und paßt sie in das Ausgabefeld unter Zuhilfenahme des Vorzeichenfeldes, wird das System sie auch benutzen.
Beispielprogramm für Standardeinstellungen
In Listing 14.1 werden Standardlängen und Formate gezeigt. Ebenso wird hier die Handhabung von Zahlen gezeigt, die nahe am Überlauf des Ausgabefeldes stehen.
Listing 14.1: Standardformate und Längen
1 report ztx1401.2 data: t1 type t value '123456',3 t2 like sy-uzeit value '123456',4 d1 type d value '19980201',5 d2 like sy-datum value '19980201',6 f1 type f value '-1234',7 i1 type i value '12345678-',

8 i2 type i value '123456789-',9 i3 type i value '1123456789-',10 i4 type i value '1123456789',11 n1(5) type n value 123,12 p1(5) type p value '123456789-',13 c1(5) type c value 'ABC',14 x1(2) type x value 'A0B0'.1516 write: / t1, 26 'type t: default output length = 6',17 /(8) t1, 26 'type t: increased output length to 8',18 /(12) t1, 26 'type t: increased output length to 12',19 / t2, 26 'type t: default output length = 8 (from domain)',20 / d1, 26 'type d: default output length = 8',21 /(10) d1, 26 'type d: increased output length to 10',22 / d2, 26 'type d: default output length = 10 (from domain)',23 / f1, 26 'type f: default output length = 22',24 / i1, 26 'type i: default output length = 11',25 / i2, 26 'type i: same output length, more digits',26 / i3, 26 'type i: same output length, even more digits',27 /(10) i3, 26 'type i: smaller output length, negative number',28 /(10) i4, 26 'type i: smaller output length, positive number',29 / n1, 26 'type n: default output length = field length',30 / p1, 26 'type p: default output length = 2 * length = 10',31 /(12) p1, 26 'type p: output length increased to 12',32 /(15) p1, 26 'type p: output length increased to 15',33 / c1, 26 'type c: output length = field length (left just)',34 / x1, 26 'type x: default output length = 2 * length = 4'.
Das Programm in Listing 14.1 erzeugt folgende Ausgabe
123456 type t: default output length = 612:34:56 type t: increased output length to 812:34:56 type t: increased output length to 1212:34:56 type t: default output length = 8 (from domain)19980201 type d: default output length = 81998/02/01 type d: increased output length to 101998/02/01 type d: default output length = 10 (from domain)-1.234000000000000E+03 type f: default output length = 2212,345,678- type i: default output length = 11123456,789- type i: same output length, more digits1123456789- type i: same output length, even more digits*23456789- type i: smaller output length, negative number1123456789 type i: smaller output length, positive number00123 type n: default output length = field length123456789- type p: default output length = 2 * length = 10123,456,789- type p: output length increased to 12

123,456,789- type p: output length increased to 15 ABC type c: output length = field length (left just)A0B0 type x: default output length = 2 * length = 4
■ Zeile 16 schreibt eine Variable vom Type t mit der Standardlänge von 6. Es gibt keinen Platz für Trennzeichen, also werden sie nicht geschrieben.
■ Zeile 17 schreibt die gleiche Variable, allerdings mit einer Ausgabelänge von 8. Diese Ausgabelänge wurde der Variablen mit der write-Anweisung übergeben. Die Ausgabelänge überschreibt die Standardausgabelänge und stellt genügend Platz für Trennzeichen zur Verfügung.
■ Zeile 18 zeigt, daß das Ausgabefeld größer als acht Zeichen ist. Das Zeitfeld ist innerhalb des Feldes standardmäßig links ausgerichtet.
■ Zeile 19 erzeugt eine Ausgabe mit der Anweisung like sy-uzeit. Innerhalb der Domäne ist die Ausgabelänge auf acht Zeichen gesetzt. Somit ist die Ausgabelänge für das Feld t2 auch 8, was genügend Platz für Trennzeichen läßt.
■ Zeile 20 schreibt eine Variable vom Typ d mit der Standardlänge von 8. Hier gibt es keinen Platz für Trennzeichen, somit enthält das Feld auch keine. Die Reihenfolge für Jahr/Monat/Tag ist jedoch über die Benutzereinstellungen bestimmt.
■ Zeile 21 schreibt das gleiche Datumsfeld, allerdings mit einer Ausgabelänge von 10, somit ist auch hier jetzt Platz für Trennzeichen.
■ Zeile 22 schreibt Feld d2 aus. Die Länge von d2 wird von der Domäne für sy-datumerhalten.
■ Zeile 24 schreibt eine Ganzzahl (Integer) mit einer Standardlänge von 11. ■ Zeile 25 schreibt eine größere Ganzzahl, aber mit der gleichen Ausgabelänge wie vorher. Das
erste Trennzeichen für Tausend ist gelöscht, so daß ein Extrazeichen geschrieben werden muß. ■ Zeile 26 erhöht die Zahl um 1, somit wird das zweite Trennzeichen gelöscht. ■ Zeile 27 schreibt die gleiche Nummer aus, allerdings wird jetzt die Ausgabelänge um 1
erniedrigt. Der Überlaufanzeiger erscheint als erstes Zeichen im Ausgabefeld. ■ Zeile 28 schreibt die gleiche Nummer mit der gleichen Länge. Dieses Mal aber ist die Zahl
positiv. Das System schiebt die Zahl nach rechts und benutzt ein Vorzeichenfeld, um einen Überlauf zu verhindern.
■ Zeile 29 schreibt ein numerisches Feld, das rechts ausgerichtet ist, mit führenden Nullen zur linken.
■ Zeile 30 schreibt ein gepackt dezimales Feld mit einer Standardausgabelänge ohne Trennzeichen.
■ Die Zeilen 31 und 32 erhöhen die Ausgabelänge auf 12 und 15 mit rechter Ausrichtung und Trennzeichen.
■ Zeile 33 zeigt ein links ausgerichtetes Zeichen in dem Ausgabefeld. ■ Zeile 34 zeigt die Ausgabe eines hexadezimalen Feldes.
Ergänzungen zur write-Anweisung
In diesem Abschnitt werden einige typische Ausgabespezifikationen zur write-Anweisung erklärt.

Die Syntax der write-Anweisung
Im folgenden wird die Syntax der write-Anweisung gezeigt.
write [at] [/p(l)] v1[+o(sl)] (1) under v2 | no-gap(2) using edit mask m | using no edit mask(3) mm/dd/yy | dd/mm/yy (4) mm/dd/yyyy | dd/mm/yyyy(5) mmddyy | ddmmyy | yymmdd(6) no-zero(7) no-sign(8) decimals n(9) round n(10) currency c | unit u (11) left-justified | centered | right-justified
Erklärung:
■ v1 ist ein Literal, eine Variable oder eine Zeichenkette, ■ p, 1 und n sind numerische Literale oder Variable. ■ p enthält die Position der Spezifikation. Sie identifiziert die Ausgabespalte, in welcher das
Ausgabefeld beginnen soll. ■ 1 ist die Längenspezifikation. Sie identifiziert die Länge des Ausgabefeldes, in welches die
Werte geschrieben werden sollen. ■ o ist ein Unterfeld, das nur numerische Literale enthält. ■ s1 ist ein Unterfeld, das nur numerische Literale enthält. ■ m ist für die Druckaufbereitung. ■ c ist ein Währungsschlüssel (Tabelle tcurc).■ u ist eine Meßeinheit (Tabelle t006).■ n ist ein numerisches Literal oder eine Variable.
Die folgenden Punkte tauchen auf:
■ Wenn p oder 1 Variable sind, wird das Wort at verlangt. ■ Ein Schrägstrich (/) fängt eine neue Zeile an, bevor der Wert der Variablen geschrieben wird.
Sind keine Ergänzungen spezifiziert und sollen zwei write-Anweisungen ausgeführt werden (z.B. write: v1, v2.), wird der Wert von v2 in der gleichen Zeile wie v1 erscheinen, allerdings durch ein Freizeichen getrennt. Paßt v2 nicht mehr in die Zeile, wird es auf die nächste Zeile geschrieben. Ist die Ausgabelänge größer als die Zeilenlänge, wird die Ausgabe rechts gekürzt. Ist der Wert rechts ausgerichtet (Variable Typ p), wird vor der Kürzung der Wert so lange nach rechts geschoben, solange es die führenden Nullen zulassen, ohne die Ausgabe zu verkürzen. Trennzeichen werden, wenn nötig, ebenso weggenommen, um das Verkürzen zu vermeiden.

Eine neue Zeile wird während der Ausgabe immer nach dem Start eines »Events« ausgelöst. Events werden in Tag 17 beschrieben.
Die Position spezifizieren
Bezüglich der Syntax im obigen Beispiel spezifiziert p die Ausgabespalte. Der Ausgabewert kann alle Werte einer vorangegangenen write-Anweisung überschreiben. Das Programm in Listing 14.2 zeigt die Effekte einer Serie von write-Anweisungen. Tabelle 14.4 zeigt den kumulativen Effekt jeder write-Anweisung in Folge, um zu verdeutlichen, wie die Ausgabe aussieht.
Listing 14.2: Eine Folge von write-Anweisungen, die den Effekt der Angabe der Spaltenausgabe zeigen soll
1 report ztx1402.2 data f1(4) type p value 1234.3 write: / '----+----1----+--',4 / '12345678901234567'.5 skip.6 write /1 'X'.7 write 'YZ'.8 write 2 'YZ'.9 write 3 'ABC'.10 write 4 f1.11 write 7 f1.12 write 'Z'.
Das Programm hat die folgende Ausgabe:
----+----1----+--12345678901234567
XYA 1 1,234 Z
■ Die Zeilen 3 und 4 schreiben ein Zeilenlineal, das die Formatierung der Spaltausgabe vereinfachen soll.
■ Zeile 6 schreibt ein 'X' am Anfang von Spalte 1. ■ Zeile 7 schreibt 'YZ' mit einem Freizeichen hinter dem 'X'.■ Zeile 8 schreibt 'YZ' auf Spalte 2. Somit werden das Freizeichen und das 'Y', das vorher
geschrieben wurde, überschrieben. ■ Zeile 9 schreibt 'ABC', beginnend in Spalte 3. Das überschreibt die beiden 'Z' und ein

Freizeichen.
■ Zeile 10 schreibt f1, beginnend in Spalte 4. Die Standardausgabelänge von f1 ist 8; das Standardformat ist rechts ausgerichtet, wobei das letzte Zeichen als Vorzeichen reserviert wird. Die drei führenden Leerzeichen (spaces) überschreiben die existierende Ausgabe beginnend in Spalte 5.
■ Zeile 11 schreibt wieder f1, diesmal in Spalte 7. ■ Zeile 12 schreibt 'Z' ein Freizeichen hinter f1. In der Ausgabe stellt sich das als zwei
Leerzeichen dar. Das erste Leerzeichen hinter der 4 ist das Vorzeichenfeld von f1. Dann wird ein Leerzeichen geschrieben und letztlich das 'Z' in Spalte 16.
Tabelle 14.4: Beispiele der write-Anweisungen und korrespondierende
Ausgaben
AnweisungenKumulative Ausgabe----+----1----+--12345678901234567
write 1 'X'. X
write 'YZ'. X YZ
write 2 'YZ'. XYZZ
write 3 'ABC'. XYABC
write 4 f1. XYA 1,234
write 7 f1. XYA 1 1,234
write 'Z'. XYA 1 1,234 Z
Die Längenspezifikation
In der Syntaxbeschreibung für die write-Anweisung spezifiziert o die Ausgabelänge. Das ist die Anzahl von Zeichen auf der Ausgabezeile, die den Ausgabewert beinhalten soll.
Länge und Position sind immer optional. Sie können aber mit einem Literal oder einer Variablen spezifiziert werden. Handelt es sich um eine Variable, muß das Wort at vorangestellt werden. Handelt es sich bei der Position und Länge beide Male um Literale, so ist at optional.
Wenn der Position- und Längenbestimmung ein Schrägstrich (/) vorangestellt wird, kann kein Freiplatz dazwischen sein. Listing 14.3 zeigt Beispiele.
Listing 14.3: Beispiele von der Benutzung der Position- und Längenspezifikation

1 report ztx1403.2 data: f1(4) type p value 1234,3 p type i value 5,4 l type i value 8.56 write: / '----+----1----+--',7 / '12345678901234567'.8 skip.9 write /(2) 'XYZ'.10 write /(4) 'XYZ'.11 write 'ABC'.12 write /5(4) f1.13 write at /p(l) f1.
Das Programm erzeugt die folgende Ausgabe:
----+----1----+--12345678901234567
XYXYZ ABC 12341,234
■ Zeile 6 schreibt die ersten beiden Zeichen von 'XYZ'.■ Zeile 7 schreibt 'XYZ', indem vier Zeichen für die Ausgabe benutzt werden. Es werden
Standardformate benutzt, d.h., der Wert ist linksbündig ausgerichtet und rechts mit führenden Nullen aufgefüllt.
■ Zeile 8 schreibt 'ABC' mit einem Leerzeichen hinter den vorherigen Wert. Der vorherige Wert wurde rechts mit einem Leerzeichen gefüllt. Ein anderes Leerzeichen wurde vor dem Schreiben von 'ABC' hinzugefügt.
■ Zeile 9 schreibt f1 in ein Feld, das vier Zeichen lang ist, beginnend in Spalte 5. ■ Zeile 10 schreibt f1 in ein acht Zeichen langes Feld, beginnend in Spalte 5. Da Variablen
benutzt werden, wird das Wort at verlangt. Standardeinstellungen werden benutzt, d.h. der Wert ist rechtsbündig und führende Nullen werden unterdrückt. Da auch genügend Platz ist, werden ebenso die Trennzeichen mit geschrieben.
Das Arbeiten mit Unter(Sub)feldern
Man kann Subfelder in der write-Anweisung spezifizieren, indem man Offset und Längenspezifikationen sofort hinter dem Wert ohne ein dazwischenliegendes Freizeichen benutzt. (Wenn nötig, sehen Sie sich noch einmal den vorherigen Abschnitt zur write-Anweisung an.) Man kann kein Subfeld mit einem Literal oder einem numerischen Feld (Typ p, i und f) benutzen. Listing 14.4 zeigt Beispiele.

Listing 14.4: Verwendung von Subfeldern
1 report ztx1404.2 data f1(4) type c value 'ABCD'.34 write: / '----+----1----+--',5 / '12345678901234567'.6 skip.7 write / f1(2).8 write / f1+1(2).9 write: /(2) f1+2(1), f1.
Das Programm aus Listing 14.4 erzeugt die folgende Ausgabe:
----+----1----+--12345678901234567
ABBCC ABCD
■ Zeile 7 schreibt das erste und zweite Zeichen von f1.■ Zeile 8 schreibt das zweite und dritte Zeichen von f1.■ Zeile 9 schreibt das dritte Zeichen von f1, beginnend mit einer neuen Zeile in einem Feld, das
zwei Zeichen lang ist. Es ist linksbündig und rechts mit Leerzeichen (blanks) aufgefüllt. Es schreibt dann den gesamten Inhalt von f1 mit einem Zwischenraum davor.
Die Ergänzung under
Indem man under benutzt, zwingt man das erste Zeichen des Feldes dazu, in der gleichen Spalte positioniert zu werden wie das erste Zeichen eines vorher geschriebenen Feldes. Man kann undernicht mit einer expliziten Positionsspezifikation benutzen. Listing 14.5 zeigt Beispiele.
Listing 14.5: Die under-Ergänzung
1 report ztx1405.2 tables: ztxlfa1.34 select * up to 5 rows from ztxlfa1 order by lifnr.5 write: /1 ztxlfa1-lifnr,6 15 ztxlfa1-land1,7 25 ztxlfa1-name1,8 / ztxlfa1-spras under ztxlfa1-land1,9 ztxlfa1-stras under ztxlfa1-name1.10 skip.

11 endselect.
Das Programm aus Listing 14.5 erzeugt die folgende Ausgabe:
1000 CA Parts Unlimited E 111 Queen St.
1010 CA Industrial Pumps Inc. E 1520 Avenue Rd.
1020 CA Chemical Nation Ltd. E 123 River Ave.
1030 CA ChickenFeed Ltd. E 8718 Wishbone Lane
1040 US Motherboards Inc. E 64 BitBus Blvd.
■ Zeile 6 schreibt das Feld land1, beginnend in Spalte 15. ■ Zeile 7 schreibt das Feld name1, beginnend in Spalte 25. ■ Zeile 8 schreibt das Feld spras, beginnend in der gleichen Spalte wie land1. Es wird
konsequenterweise in Spalte 15 geschrieben. ■ Zeile 9 schreibt das Feld stras, beginnend in der gleichen Spalte wie name1. Es wird deshalb
in Spalte 25 geschrieben.
Die no-gap-Ergänzung
Indem man no-gap benutzt, wird die dazwischenliegende Lücke automatisch hinter ein Feld gesetzt, wenn das nachfolgende Feld keine Spaltenspezifikation hat. Listing 14.6. zeigt Beispiele der Benutzung von no-gap.
Listing 14.6: Die Benutzung von no-gap
1 report ztx1406.2 data f1(4) value 'ABCD'.34 write: / f1, f1,5 / f1 no-gap, f1,6 / '''', f1, '''',7 / '''', 2 f1, 6 '''',8 / '''' no-gap, f1 no-gap, ''''.
Das Programm aus Listing 14.6 hat die folgende Ausgabe:
ABCD ABCD

ABCDABCD' ABCD ' 'ABCD''ABCD'
■ Zeile 4 schreibt f1 zweimal auf die gleiche Zeile. Da es keine bestimmte Position für das zweite f1 gibt, wird ein einzelnes leeres Zwischenzeichen davor geschrieben.
■ Zeile 5 schreibt f1 auch zweimal. Die Benutzung von no-gap nach dem ersten writezwingt die zwei Werte dazu, in der Ausgabe ohne Zwischenraum zu erscheinen.
■ Zeile 6 schreibt f1 mit einem einzigen Hochkomma auf jeder Seite. Ohne den Zusatz von no-gap erscheinen Zwischenräume.
■ Zeile 7 schreibt f1, umgeben von je einem Hochkomma. Die Positionsangaben zwingen die Hochkommata, ohne Zwischenräume zu erscheinen.
■ Zeile 8 benutzt no-gap, um die gleiche Ausgabe zu erzwingen.
Ausgabemasken (Edit Masks)
Mit Hilfe von Ausgabemasken kann man:
■ Zeichen der Ausgabe hinzufügen. ■ ein Vorzeichen an den Anfang einen numerischen Feldes stellen. ■ einen Dezimalpunkt künstlich einfügen oder an eine andere Stelle bewegen. ■ Gleitkommazahlen ohne wissenschaftliche Notation anzeigen.
Egal wo in der Ausgabemaske, der Unterstrich (_) hat eine besondere Bedeutung. Am Anfang einer jeden Maske spielen auch V, LL, RR und == eine besondere Rolle. Alle anderen Zeichen werden ohne Änderungen zur Ausgabe gebracht.
Unterstriche innerhalb einer Ausgabemaske werden nacheinander mit den Zeichen aus dem Quellfeld (das Feld, das ausgeschrieben wird) ersetzt. Die Anzahl von Zeichen, die aus dem Quellfeld genommen werden, sind gleich der Anzahl von Unterstrichen in der Ausgabemaske. Wenn es zum Beispiel drei Zeichen in der Ausgabemaske gibt, werden höchstens drei Zeichen aus dem Quellfeld zur Ausgabe kommen. Alle anderen Zeichen in der Ausgabemaske werden in die Ausgabe eingesetzt. Gewöhnlich muß auch die Länge des Ausgabefeldes erhöht werden, um die Extrazeichen anzupassen, die von der Ausgabemaske eingesetzt wurden.
Die Anweisung write (6) 'ABCD' using edit mask '_:__:_' schreibt z.B. A:BC:D.Die Zeichen werden eins nach dem anderen aus dem Quellfeld genommen, während die Zeichen der Ausgabemaske an die von der Maske gekennzeichneten Stellen eingesetzt werden. Die Anweisung write 'ABCD' using edit mask '_:__:_' schreibt nur A:BC, weil die Standardausgabelänge gleich der Länge des Quellfeldes (4) ist.
Gibt es weniger Unterstriche in der Maske als in dem Quellfeld, gehört es zum Standard, das äußerste linke n-Zeichen aus dem Quellfeld zu nehmen, wobei n der Zahl von Unterstrichen in der Ausgabemaske entspricht. Das kann genauso mit den Sonderzeichen LL geschehen. Zum Beispiel,

write 'ABCD' using edit mask 'LL__:_' nimmt die linken drei Zeichen und schreibt AB:C. Benutzt man statt dessen RR, werden die äußersten drei rechten Zeichen genommen, somit schreibt die Anweisung write 'ABCD' using edit mask 'RR__:_' BC:D.
Gibt es mehr Unterstriche als Quellfeldzeichen, hat LL den Effekt, die Ausgabewerte linksbündig zu schreiben und RR rechtsbündig (s.a. Listing 14.7).
Beginnt die Ausgabemaske mit einem V, wenn es sich auf ein numerisches Feld bezieht (Typ i, p und f), wird das Vorzeichen am Anfang dargestellt. Bezieht es sich auf ein Zeichenfeld, ist V die aktuelle Ausgabe.
Listing 14.7: Verschiedene Darstellungen der Ausgabemaske
1 report ztx1407.2 data: f1(4) value 'ABCD',3 f2 type i value '1234-'.45 write: / ' 5. ', f1,6 / ' 6. ', (6) f1 using edit mask '_:__:_',7 / ' 7. ', f1 using edit mask 'LL_:__',8 / ' 8. ', f1 using edit mask 'RR_:__',9 / ' 9. ', f2 using edit mask 'LLV______',10 / '10. ', f2 using edit mask 'RRV______',11 / '11. ', f2 using edit mask 'RRV___,___',12 / '12. ', f2 using edit mask 'LLV___,___',13 / '13. ', f1 using edit mask 'V___'.
Die Ausgabe des Programms aus Listing 14.7 zeigt folgendes:
5. ABCD 6. A:BC:D 7. A:BC 8. B:CD 9. -1234 10. - 1234 11. - 1,234 12. -123,4 13. VABC
■ Zeile 5 gibt f1 ohne Ausgabemaske wieder. ■ Zeile 6 gibt alle Zeichen aus f1 mit Hilfe der Doppelpunkte als Trennzeichen wieder. ■ Es gibt drei Unterstriche in der Ausgabemaske auf Zeile 7, aber 4 Zeichen in f1. Somit werden
die ersten drei Zeichen von f1 in der Ausgabemaske benutzt. ■ Zeile 8 nimmt die letzten drei Zeichen von f1 und übernimmt sie in die Ausgabemaske. ■ Auf Zeile 9 sind sechs Unterstriche in der Ausgabemaske, mehr als die vier Zeichen von f1.
Der Ausgabewert von f1 ist linksbündig mit einem führenden Vorzeichen.

■ Auf Zeile 10 ist der Ausgabewert von f1 rechtsbündig mit einem führenden Vorzeichen. ■ Die Zeilen 10 und 11 zeigen die Kombination von eingefügten Zeichen mit Ausrichtung. Die
eingefügten Zeichen bewegen sich nicht relativ zum Ausgabefeld. ■ Zeile 13 zeigt den Effekt in der Benutzung von V mit einem Zeichenfeld. Das V selbst gehört
mit zur Ausgabe.
Konvertierungs-Exits (conversion exits)
Ein Konvertierungs-Exit ist eine aufgerufene Routine, welche die Ausgabe formatiert. Beginnt die Ausgabemaske mit == gefolgt von vier Zeichen als Kennung, ruft sie einen Funktionsbaustein auf, der die Ausgabe formatiert. Diese vier Zeichen lange Kennung nennt man auch Konvertierungs-Exit oder Konvertierungsroutine. (Funktionsbausteine werden in den Kapiteln der nachfolgenden Tage behandelt, für jetzt genügt es zu wissen, daß sie wie ein Unterprogramm behandelt werden.) Der Name dieses Funktionsbausteins heißt CONVERSION_EXIT_XXXX_OUTPUT, wobei XXXX der Kennung entspricht, die == folgt. Zum Beispiel write '00001000' using edit mask '==ALPHA' ruft den Funktionsbaustein CONVERSION_EXIT_ALPHA_OUTPUT auf. Die write-Anweisung gibt den Wert zuerst an den Funktionsbaustein weiter, der ihn auf irgendeine Weise ändert und den geänderten Wert ausschreibt. Dieser besondere exit (ALPHA) prüft den Wert, um herauszufinden, ob er nur aus Zahlen besteht. Wenn ja, werden führende Nullen ausgelassen und der Wert wird linksbündig ausgerichtet. Werte, die keine numerischen Zeichen enthalten, werden nicht von ALPHA geändert. SAP liefert ca. 60 Konvertierungs-Exits für die verschiedensten Formatierungsaufgaben. Nach dem 19. Tag mit dem Thema »Modularisierung: Funktionsbausteine, Teil 1« werden Sie genügend Wissen haben, um Ihre eigenen Konvertierungs-Exits zu schreiben.
Konvertierungs-Exits sind sehr nützlich bei komplexen Formatierungsarbeiten, die in mehr als einem Programm gebraucht werden. Der Konvertierungs-Exit CUNIT konvertiert automatisch den Code einer Meßeinheit in eine sinnvolle Beschreibung des gegenwärtigen Anmeldemandanten. Zum Beispiel ist in R/3 der Code für eine Materialkiste KI (KI steht für Kiste). CUNIT konvertiert KI ins Englische mit CR. Ist man in Englisch angemeldet, wird write: '1','KI' using edit mask '==CUNIT' CR ausgeben. Bleibt man in Deutsch angemeldet, ändert sich KI nicht. Somit kann man mit einem Standardsatz von Programm-Code, der in der Datenbank gespeichert ist, sinnvolle Konvertierungen in die entsprechende Landesprache machen.

Abbildung 14.2: Beachten Sie den Inhalt des Feldes Konvert.-Routine.
Konvertierungsroutinen (conversion routines) innerhalb einer Domäne
Konvertierungs-Exits können in dem Feld Konvert-Routine abgelegt werden. Dieser exit wird auf alle Felder vererbt, die diese Domäne benutzen und automatisch angepaßt, wenn der Wert ausgeschrieben wird. Abbildung 14.2 zeigt die Domäne ztxlifnr , die den Konvertierungs-Exit ALPHA benutzt. Somit wird jedesmal, wenn ztxlfa1-lifnr geschrieben wird, der Wert erst den Funktionsbaustein CONVERSION_EXIT_ALPHA_OUTPUT durchlaufen, welcher führende Nullen von numerischen Werten ausläßt und linksbündig schreibt.
Ein Konvertierungs-Exit innerhalb einer Domäne kann mit Hilfe von using no edit mask bei der write-Anweisung jederzeit ausgeschaltet werden.
Listing 14.8: Der Gebrauch von Konvertierungs-Exits
1 report ztx1408.2 tables: ztxlfa1, ztxmara.3 data: f1(10) value '0000001000'.4

5 write: / f1,6 / f1 using edit mask '==ALPHA'.78 skip.9 select * from ztxlfa1 where lifnr = '00000010000'10 or lifnr = 'V1'11 order by lifnr.12 write: / ztxlfa1-lifnr, "domain contains convers. exit ALPHA13 / ztxlfa1-lifnr using no edit mask.14 endselect.1516 skip.17 select single * from ztxmara where matnr = 'M103'.18 write: / ztxmara-matnr,19 (10) ztxmara-brgew,20 ztxmara-gewei. "domain contains convers. exit CUNIT21 set locale language 'D'.22 write: / ztxmara-matnr,23 (10) ztxmara-brgew,24 ztxmara-gewei. "domain contains convers. exit CUNIT
Die Ausgabe des Programms erzeugt die folgende Liste:
00000010001000
10000000001000V1V1
M103 50.000 CR M103 50.000 KI
■ Zeile 5 schreibt den Wert von f1.■ Zeile 6 schreibt denselben Wert, ruft aber Konvertierungs-Exit ALPHA auf. ■ Zeile 9 empfängt zwei Sätze aus ztxlfa1 und schreibt das Feld lifnr zweimal (pro Satz
einmal).■ Die Domäne für ztxlfa1-lifnr enthält den Konvertierungs-Exit ALPHA, somit schreibt
Zeile 12 lifnr mit Hilfe des Konvertierungs-Exits. ■ Zeile 13 schreibt lifnr aus, stellt aber den Konvertierungs-Exit ab. Damit wird der aktuelle
Wert der Tabelle ausgeschrieben. ■ Zeile 17 selektiert einen einzelnen Satz aus ztxmara.■ Zeile 20 schreibt gewei (Einheit für Gewicht) mit Hilfe des Konvertierungs-Exit CUNIT aus
der Domäne. ■ Zeile 21 ändert den Text ins Deutsche. Das entspricht einer Anmeldung in Deutsch.

■ Zeile 24 schreibt den gleichen gewei Wert, aber diesmal wird der deutsche mnemonische Name angezeigt.
Anzeige von existierenden Konvertierungs-Exits
Die folgende Prozedur erklärt, wie man sich Konvertierungs-Exits anzeigen lassen kann.
Starten Sie jetzt das ScreenCam »How to Display Existing Conversion Exits«.
1. Aus der Entwicklungsumgebung wählen Sie den Menüpfad Übersicht->Infosystem.
2. Klicken Sie das Pluszeichen bei Programmierung an. Der Baum wird aufgeblättert.
3. Machen Sie das gleiche jetzt für die Funktionsbibliothek. Gehen Sie jetzt für die Funktionsbibliothek ebenso vor.
4. Doppelklicken Sie jetzt auf Funktionsbausteine.
5. Im Feld Funktionsbaustein geben Sie CONVERSION_EXIT_*_OUTPUT ein und drücken auf Ausführen. Es werden alle Funktionsbausteine mit CONVERSION_EXITS für die write-Anweisungaufgelistet.
Arbeiten mit der Datumsformatierung
Datumsformatierungen machen nicht unbedingt das, was man erwartet. Die meisten beziehen ihre Information aus dem Benutzerprofil.
Tabelle 14.5 enthält eine Beschreibung der entsprechenden Formate.
Tabelle 14.5: Ausgabe der Datumsformate
Format Effekt
yy = Jahr (engl. year)
mm = Monat (engl. month)
dd = Tag (engl. day)
mm/dd/yyyydd/mm/yyyy
Schreibt das Datum wie im Benutzerprofil angegeben. Das ist der Standard.

mm/dd/yydd/mm/yy
Schreibt das Datumsformat ebenfalls wie im Benutzerprofil angegeben
mmddyyddmmyy
Schreibt das Datumsformat ohne Trennzeichen
yymmdd Das ist ebenfalls eine Datumsausgabe ohne Trennzeichen
Konvertierungs-Exits IDATE und SDATE geben alternative Datumsformate. Ebenso gibt der Funktionsbaustein RH_GET_DATE_DAYNAME den Namen des Wochentages eines bestimmten Datums und Sprache wieder. Als Alternative zeigt DATE_COMPUTE_DAY eine Zahl an, die den Tag einer Woche repräsentiert.
Listing 14.9 zeigt einige Formate der Datumsausgabe.
Listing 14.9: Die Datumsformate
1 report ztx1409.2 data: f1 like sy-datum value '19981123',3 begin of f2,4 y(4),5 m(2),6 d(2),7 end of f2,8 begin of f3,9 d(2),10 m(2),11 y(4),12 end of f3,13 begin of f4,14 m(2),15 d(2),16 y(4),17 end of f4.1819 write: / f1, "user profile sets format20 / f1 mm/dd/yyyy, "user profile sets format21 / f1 dd/mm/yyyy, "user profile sets format22 / f1 mm/dd/yy, "user profile fmt, display with 2-digit year23 / f1 dd/mm/yy, "user profile fmt, display with 2-digit year24 / f1 mmddyy, "user profile fmt, 2-digit year, no separators25 / f1 ddmmyy, "user profile fmt, 2-digit year, no separators

26 / f1 yymmdd, "yymmdd format, no separators27 / f1 using edit mask '==IDATE',28 /(11) f1 using edit mask '==SDATE'.2930 f2 = f1.31 move-corresponding f2 to: f3, f4.32 write: /(10) f3 using edit mask '__/__/____', "dd/mm/yyyy format33 /(10) f4 using edit mask '__/__/____'. "mm/dd/yyyy format
Das Programm aus Listing 14.9 zeigt die folgende Ausgabe:
1998/11/231998/11/231998/11/2398/11/2398/11/239811239811239811231998NOV231998/NOV/2323/11/199811/23/1998
■ Zeile 2 definiert f1 like sy-datum. Die Ausgabelänge in der Domäne für sy-datum ist10, somit werden die Trennzeichen bei der Ausgabe mitangezeigt.
■ Die Zeilen 19, 20, 21, 22, 23, 24 und 25 machen alle das gleiche: sie schreiben f1 unter Benutzung des Formats aus dem Benutzerprofil heraus, allerdings manchmal mit und manchmal ohne Trennzeichen.
■ Zeile 27 formatiert das Datum unter Zuhilfenahme des Konvertierungs-Exits IDATE .■ Zeile 28 formatiert das Datum unter Zuhilfenahme des Konvertierungs-Exits SDATE.■ Die Zeilen 30 bis 33 zeigen, wie man sein eigenes Ausgabeformat definieren kann. Allerdings
sollt man besser seine eigene Konvertierungsroutine schreiben, was den Vorteil hat, daß auch andere darauf zugreifen könnten.
Der Gebrauch von no-zero und no-sign
Die Benutzung von no-zero unterdrückt führende Nullen, wenn sie im Zusammenhang mit Variablen vom Typ c oder n gebraucht werden. Im Falle eines Nullwertes bleibt die Ausgabe leer.
no-sign unterdrückt auch bei Variablen vom Typ i, p oder f die Ausgabe des Vorzeichens. Mit anderen Worten, negative Zahlen haben kein Vorzeichen und erscheinen positiv.
Listing 14.10 erläutert diese beiden Ergänzungen.

Listing 14.10: Verwendung von no-zero und no-sign.
1 report ztx1410.2 data: c1(10) type c value '000123',3 n1(10) type n value 123,4 n2(10) type n value 0,5 i1 type i value '123-',6 i2 type i value 123.
7 write: / c1, 20 'type c',8 / c1 no-zero, 20 'type c using no-zero',9 / n1, 20 'type n',10 / n1 no-zero, 20 'type n using no-zero',11 / n2, 20 'type n: zero value',12 / n2 no-zero, 20 'type n: zero value using no-zero',13 / i1, 20 'type i',14 / i2 no-sign, 20 'type i using no-sign'.
Das Programm aus Listing 14.10 hat folgende Ausgabe:
000123 type c 123 type c using no-zero 0000000123 type n 123 type n using no-zero 0000000000 type n: zero value type n: zero value using no-zero 123- type i 123 type i using no-sign
Spezifizierung von Dezimalstellen und das Runden
Zwei Anweisungen sind für das Runden zuständig:
■ decimals■ round
Drei Anweisungen werden benutzt für die Anzahl der Dezimalstellen in der Ausgabe:
■ decimals■ currency■ unit
Die Benutzung der Ergänzungen decimals und round
Mit decimals n wird die Anzahl der Dezimalstellen in der Ausgabeliste erhöht bzw. erniedrigt. Wird

die Zahl der Dezimalstellen erniedrigt, wird der Wert vor der Ausgabe gerundet. Der Wert der Quellvariablen wird nicht geändert, nur die Ausgabe erscheint mit dem geänderten Wert. Wird die Zahl der Stellen erhöht, werden Nullen an das Ende des Wertes gehängt. Negative Werte von n rücken die Dezimalstelle nach rechts, multiplizieren die Zahl mit Faktor 10 und runden sie vor der Anzeige.
Durch round n wird die Ausgabe mit Faktor 10 skaliert und dann vor der Anzeige gerundet. Das hat den gleichen Effekt wie das Multiplizieren mit 10**n. Positive n-Werte rücken die Dezimalstelle nach links und negative Werte nach rechts. Das kann sinnvoll sein, wenn man die Ausgabewerte möglichst nahe an Tausend erreichen will.
Der Unterschied zwischen decimals und round ist, daß decimals die Anzahl von Zeichen, die nach dem Dezimalpunkt zu sehen sind, nach n ändert und dann die Rundung vornimmt. Die Anweisung round rückt den Dezimalpunkt nmal nach links oder rechts, pflegt die Zeichen hinter der Dezimalstelle und macht erst danach die Rundung für die Anzeige.
Listing 14.11 illustriert die Benutzung von decimals und round.
Listing 14.11: Die Benutzung von decimals und round
1 report ztx1411.2 data f1 type p decimals 3 value '1575.456'.3 write: / f1, 20 'as-is',4 / f1 decimals 4, 20 'decimals 4',5 / f1 decimals 3, 20 'decimals 3',6 / f1 decimals 2, 20 'decimals 2',7 / f1 decimals 1, 20 'decimals 1',8 / f1 decimals 0, 20 'decimals 0',9 / f1 decimals -1, 20 'decimals -1',10 / f1 round 4, 20 'round 4',11 / f1 round 3, 20 'round 3',12 / f1 round 2, 20 'round 2',13 / f1 round 1, 20 'round 1',14 / f1 round 0, 20 'round 0',15 / f1 round -1, 20 'round -1',16 / f1 round -2, 20 'round -2',17 / f1 round 3 decimals 1, 20 'round 3 decimals 1',18 / f1 round 3 decimals 3, 20 'round 3 decimals 3'.
Das Programm aus Listing 14.11 hat die folgende Ausgabe:
1,575.456 as-is 1,575.4560 decimals 4 1,575.456 decimals 3 1,575.46 decimals 2 1,575.5 decimals 1 1,575 decimals 0

158 decimals -1 0.158 round 4 1.575 round 3 15.755 round 2 157.546 round 1 1,575.456 round 0 15,754.560 round -1 157,545.600 round -2 1.6 round 3 decimals 1 1.575 round 3 decimals 3
Auf Zeile 8 rundet decimals 0 nicht auf, weil der Bruchteil der Zahl kleiner 0,5 ist.
Mit decimals werden Dezimalstellen, die in der Domäne definiert wurden, überschrieben. Ungeachtet dessen, von wo die Dezimalspezifikation herkommt, es wird niemals ein aktueller Dezimalpunkt in der Zahl angezeigt. Die Zahl wird immer als Ganzzahlwert gespeichert. Die decimals-Anweisung ist eine Formatspezifikation einer Zahl, bevor sie beispielsweise in einer write-Anweisung oder in einer Kalkulation benutzt wird.
Der Gebrauch von currency und unit
Currency und unit sind Alternativen, welche die Position eines Dezimalpunktes in einem Feld von Typ p anzeigen. Sie können nicht zusammen mit decimals benutzt werden.
Die DDIC-Typen CURR und QUAN basieren auf dem ABAP/4-Datentyp p (dezimal gepackt).
Die Benutzung von currency
Wird eine Währungssumme ausgeschrieben, sollte man mit der Ergänzung currency arbeiten. Solche Summen werden normalerweise aus einem Feld vom Typ CURR aus einer Datenbanktabelle gelesen.

Anstatt decimals wird mit currency die Anzahl der Dezimalstellen für Währungssummen benutzt. Ähnlich wie decimals, das die Anzahl der Dezimalstellen beschreibt, wird mit currencyein Währungs-Code wie USD (U.S. Dollar), ITL (Italienische Lira) oder DEM (Deutsche Mark) spezifiziert. Das System liest aus der Tabelle TCURX die Zahl der Dezimalstellen, die für diese Währung bei der Anzeige benutzt werden soll. Wird der Währungs-Code nicht in der Tabelle gefunden, wird eine Standardeinstellung von zwei Dezimalstellen benutzt.
Normalerweise ist der Währungs-Code in der gleichen oder einer ähnlichen Datenbanktabelle gespeichert. So ist zum Beispiel der Währungsschlüssel für Felder von Typ CURR (saldv, solllund habn1) in Tabelle ztxlfc3 in dem Feld ztxt001-waers gespeichert. Durch einen Doppelklick auf diese Felder kann man das herausfinden. Wenn Sie z.B. einen Doppelklick auf ztxlfc3-saldv machen, sehen Sie das Anzeigefeld ZTXLFC3-SALDV wie in Abbildung 14.3.
Abbildung 14.3: Ein Doppelklick auf das Feld saldv in Tabelle ztxlfc3 zeigt diese Maske an.
Die Referenztabelle und das Referenzfeld zeigen, daß ztxt001-waers den Währungsschlüssel enthalten.
Die Tabelle ztxt001 selbst enthält alle Attribute des Buchungskreises; ihr Primärschlüssel ist bukrs. Nimmt man den Wert von ztxlfc3-bukrs und sieht in der Zeile in ztxt001 nach einem passenden Eintrag, sieht man, daß waers den Währungsschlüssel enthält. Listing 14.12 soll dies veranschaulichen.
Listing 14.12: Die Benutzung von currency
1 report ztx1412.2 tables: ztxlfc3.
3 data: f1 type p decimals 1 value '12345.6'.4

5 write: / f1,6 / f1 currency 'USD', 'USD', "US Dollars7 / f1 currency 'ITL', 'ITL'. "Italian Lira89 skip.10 select * from ztxlfc3 where gjahr = '1997'11 and saldv >= 10012 order by bukrs.13 on change of ztxlfc3-bukrs.14 select single * from ztxt001 where bukrs = ztxlfc3-bukrs.15 endon.16 write: / ztxlfc3-saldv currency ztxt001-waers, ztxt001-waers.17 endselect.
Das Programm aus Listing 14.12 zeigt folgende Ausgabe:
123,4561,234.56 USD123,456 ITL
100.00 USD100.00 USD 100.00 USD 100.00 USD 100,000 ITL 25,050 ITL 100,000 ITL 100,000 JPY 300,000 JPY 250.50 CAD 200.00 CAD 1,000.00 CAD 100.00 CAD
■ Zeile 5 schreibt den Wert von f1 wie er ist. ■ Zeile 6 schreibt den gleichen Wert, schaut aber zuerst in der Tabelle TCURX nach 'USD', um
die Anzahl der Dezimalstellen zu bestimmen. Der Wert 'USD' befindet sich nicht in dieser Tabelle, somit wird die Ausgabe mit Standardwerten gemacht (zwei Dezimalstellen).
■ Wenn Zeile 7 ausgeführt wird, zeigt Tabelle TCURX an, daß ITL keine Dezimalstellen hat, so daß der Wert ohne Dezimalstellen formatiert wird.
■ Zeile 10 selektiert Sätze aus der Tabelle ztxlfc3 in der Buchungskreisreihenfolge (bukrs).■ Zeile 13 wird jedesmal angestoßen, wenn sich der Buchungskreis ändert. ■ Zeile 14 sieht in der Tabelle ztxt001 nach, um die Währung für diese Gesellschaft zu finden.
Man erhält den Währungsschlüssel aus Feld ztxt001-waers.■ Zeile 16 schreibt das fortlaufende Ergebnis, indem die Zahl der Dezimalstellen benutzt wird,
die vom Währungsschlüsselfeld in ztxt001-waers angezeigt wird.

Das Arbeiten mit unit
Durch die Ergänzung unit wird die Anzahl der Dezimalstellen für Quantitätsfelder angegeben. Einheiten (units) wie cm (Zentimeter) oder lb (engl. Pfund) bestimmen die Anzeige der Dezimalstellen. Der Code, wie zum Beispiel '%' oder 'KM', wird automatisch nach Einsicht in Tabelle t006 spezifiziert. Die Felder decan und andec bestimmen dann, wie viele Dezimalstellen angezeigt werden.
decan gibt die Anzahl von Nullwerten an, die bei Dezimalwerten verkürzt werden. Es entfernt angehängte Nullen; decan wird nie Nullwerte der Dezimalstellen kürzen. Ist zum Beispiel der Wert 12.30 und decan 1, wird die Ausgabe 12.3 sein. Ist der Wert 12.34 und decan 1, ist die Ausgabe 12.34.
andec hängt Nullen dran, nachdem decan angewendet wurde. Die Anzahl der Dezimalzeichen, die angezeigt werden, muß ein Vielfaches von andec sein. Wenn nötig, wird andec die Werte rechts anpassen. Ist andec 0, werden keine Nullen angehängt. Ist der Wert zum Beispiel 12.34, nachdem decan angewendet wurde, und der Wert von andec ist 3, muß es 0, 3, 6, 9 (oder irgendein Vielfaches von 3) an Dezimalzeichen geben. Der Ausgabewert wird mit Nullen aufgefüllt und wird zu 12.340. Ist der Wert nach decan 12.3456, wird daraus 12.345600. Ist der Wert nach decan 12.30 und andec ist 2, wird daraus 12.30.
Tabelle 14.6 zeigt mehrere Beispiele von decan und andec sowie deren Ausgabeformat.
Tabelle 14.6: Wie die Felder von decan und andec die Ausgabe beeinflussen.
Eingabe decan andec Ergebnis
30.1 1 0 30.1
30.1 1 2 30.10
30.1 1 3 30.100
30.1234 1 3 30.123400
30 1 3 30
30 2 0 30
30.1 2 0 30.1
30.11 2 0 30.11
30.11 2 2 30.11
30.11 2 4 30.1100

Die unit-Anweisung wird typischerweise bei Feldern vom Typ QUAN benutzt, die in der Datenbank gespeichert sind. Jedes Feld muß ein Referenzfeld vom Typ UNIT haben. Die Meßeinheit für die Werte in dem Feld QUAN wird dort gespeichert. Abbildung 14.4 zeigt, daß das Referenzfeld fürztxmara-brgew ztxmara-gewei ist.
Abbildung 14.4: Wenn man auf das Feld ztxmara-brgew doppelklickt, sieht man auf einer neuen Bildschirmmaske die Referenztabelle und das Referenzfeld.
Listing 14.13 erklärt die Benutzung dieser Ergänzungen.
Listing 14.13: Verwendung der unit-Ergänzung
1 report ztx1413.2 tables: ztxmara, t006.3 data: f1 type p decimals 4 value '99.0000',4 f2 type p decimals 4 value '99.1234',5 f3 type p decimals 4 value '99.1200',6 f4 type p decimals 1 value '99.1'.78 write: / f1, 'as-is',9 / f1 unit 'ML', 'ml - milliliters decan 3 andec 3',10 / f1 unit '%', '% - percent decan 2 andec 0',11 / f1 unit '"', '" - inches decan 0 andec 3',12 /,13 / f2, 'as-is',14 / f2 unit '%', '%',15 / f3, 'as-is',16 / f3 unit '%', '%',17 / f4, 'as-is',18 / f4 unit '%', '%'.

1920 skip.21 write: /12 'brgew as-is',22 31 'with units',23 48 'ntgew as-is',24 67 'with units',25 79 'units',26 85 'decan',27 91 'andec'.28 uline.29 select * from ztxmara.30 select single * from t006 where msehi = ztxmara-gewei.31 write: /(5) ztxmara-matnr,32 ztxmara-brgew,33 ztxmara-brgew unit ztxmara-gewei,34 ztxmara-ntgew,35 ztxmara-ntgew unit ztxmara-gewei,36 ztxmara-gewei,37 85 t006-decan,38 91 t006-andec.39 endselect.
Das Programm aus Listing 14.13 produziert die folgende Ausgabe:
99.0000 as-is 99.000 ml - milliliters decan 3 andec 3 99.00 % - percent decan 2 andec 0 99 " - inches decan 0 andec 3
99.1234 as-is 99.1234 % 99.1200 as-is 99.12 % 99.1 as-is 99.1 %
brgew as-is w/units ntgew as-is w/units units decan andec ---------------------------------------------------------------------M100 102.560 102.560 100.000 100 M3 0 3 M101 10.100 10.100 10.000 10 PAL 0 0 M102 1.000 1 0.000 0 ROL 0 0 M103 50.000 50 0.000 0 CR 0 0
■ Zeile 8 schreibt f1 ohne die Benutzung von unit.■ Zeile 9 benutzt die Einheit (unit) ML (Milliliter). In Tabelle t006 wird automatisch nach ML
geschaut. Diese Zeile enthält decan 3 und andec 3. decan 3 zwingt das System dazu,

Nullen hinter der dritten Dezimalstelle zu löschen. Andec 3 zwingt die Zahl von Dezimalstellen dazu, ein Vielfaches von 3 zu sein. An dieser Stelle ist es bereits der Fall, somit wird die Ausgabe mit drei Dezimalstellen angezeigt.
■ Zeile 10 formatiert f1 mit dem Prozentzeichen (%), das decan 2 und andec 0 hat. Mit decan 2 bestimmt man, daß anhängende Nullen nach der zweiten Dezimalstelle gelöscht werden. andec 0 zeigt an, daß es keine weiteren Modifikationen gibt, somit gelangen zwei Dezimalstellen zur Ausgabe.
■ Zeile 11 benutzt die Einheit " (Zoll). Decan 0 zeigt an, daß alle Dezimalnullen gekürzt werden sollen. andec 3 zeigt an, daß die Anzahl an Dezimalstellen mit Nullen auf drei ergänzt wird.
■ Zeile 13 bis 18 formatiert f2 bis f4 mit der Einheit %. ■ In Zeile 16 kürzt decan 2 die anhängenden Nullen. ■ In Zeile 18 tut decan 2 gar nichts, weil es keine anhängenden Nullen gibt, die man kürzen
kann. andec ist 0, somit werden keine Nullen am Ende angehängt. ■ Zeile 29 selektiert alle Sätze aus der Tabelle ztxmara.■ Zeile 30 selektiert den Satz aus Tabelle t006, der die Einheit in ztxmara-gewei enthält.
Beachten Sie bitte, daß das normalerweise nicht so gemacht wird, Sie sollen hier lediglich mit decan und andec vertraut gemacht werden.
■ In den Zeilen 32 bis 35 werden die Werte von gewei und ntgew auf zwei Arten geschrieben. Erstens werden sie so geschrieben, wie sie tatsächlich sind. Zweitens werden sie mit der unit-Ergänzung geschrieben, um das Vorher und Nachher zu zeigen.
■ Die Zeilen 37 und 38 geben die decan- und andec-Werte aus, die für jede Zeilenformatierung benutzt wurden.
Ausrichtung
Indem man left-justified, centered und right-justified benutzt, kann man die Ausgabewerte an das Ausgabefeld entsprechend anpassen. Listing 14.14 zeigt das.
Listing 14.14: Die Ausrichtung bei der write-Anweisung
1 report ztx1414.2 data: f1(6) value 'AB'.3 write: / '....+....1',4 / '1234567890',5 / f1,6 / f1 left-justified,7 / f1 centered,8 / f1 right-justified,9 / '....+....1....+....2....+....3....+....4',10 / '1234567890123456789012345678901234567890',11 /(40) f1 left-justified,12 /(40) f1 centered,13 /(40) f1 right-justified.

Das Programm aus Listing 14.14 produziert den folgenden Ausdruck:
....+....11234567890ABABABAB....+....1....+....2....+....3....+....41234567890123456789012345678901234567890ABABAB
■ Die Zeilen 3, 4, 9 und 10 geben ein Zeilenlineal aus, damit man bei der Ausgabe auch die Spaltennummer sieht.
■ Zeile 5 schreibt f1 mit Standardlänge und Format. Die Standardeinstellung für eine Variable vom Typ c ist left-justification mit einer Standardausgabelänge von 6.
■ Zeile 6 produziert die gleiche Ausgabe. ■ Zeile 7 zentriert die Ausgabe mit der Standardlänge von 6. ■ Zeile 8 richtet den Wert mit einer Standardlänge von 6 rechtsbündig aus. ■ Die Zeilen 11, 12 und 13 haben eine Ausgabelänge von 40. Der Wert ist innerhalb dieser Länge
linksbündig, zentriert und rechtsbündig ausgerichtet.
Zusammenfassung
■ Wenn keine besonderen Einstellungen gemacht werden, gilt bei der write-Anweisung immer die Standardeinstellung. Diese Einstellungen geschehen über die ABAP/4-Datentypen. DDIC-Felder basieren auf ABAP/4-Datentypen, die ihre Einstellungen vererben. Zur Ergänzung: Formatspezifikationen wie Dezimalstellen und Ausgabelängen können ebenso über die Domäne spezifiziert werden; das überschreibt die vererbten Felder.
■ Datums- und Zeitfelder werden immer mit Trennzeichen ausgegeben, wenn genügend Platz vorhanden ist. Wenn nicht, werden die Trennzeichen vollständig gelöscht. Bei numerischen Feldern werden die Trennzeichen für Tausender eins nach dem anderen von links nach rechts gelöscht. Sogar das Vorzeichenfeld wird benutzt, wenn es leer ist.
■ Bis auf yymmdd überschreiben alle vom Benutzer angelegten Datumsformate die Standardeinstellungen.
■ Eine Ausgabemaske kann dazu benutzt werden, Zeichen in die Ausgabe zu schreiben. Man kann auch einen Konvertierungs-Exit aufrufen, der mit Hilfe des ABAP/ 4-Codes den Wert formatiert.
■ Mit no-zero werden führende Nullen in Feldern vom Typ n und c unterdrückt. ■ Mit no-sign werden anhängende Vorzeichenfelder aus der Anzeige entfernt. ■ Mit Hilfe von decimals werden die Dezimalstellen definiert, die angezeigt werden. ■ Mit round wird die Position des Dezimalpunktes in dem Wert bestimmt. ■ Mit currency wird die Anzahl der Dezimalstellen bei Währungsfeldern bestimmt. Zuerst

wird in der Tabelle tcurx der Währungs-Code bestimmt, um die Anzahl der Dezimalstellen zu erfahren. Wird der Code nicht gefunden, werden die Standardeinstellungen mit zwei Dezimalstellen benutzt.
■ Mit unit werden Quantitätsfelder formatiert. Die Einheit (unit) wird in Tabelle t006nachgeschlagen. decan bestimmt die Anzahl von Dezimalnullen, die entfernt werden sollen und andec die Anzahl von Nullen, die hinzugefügt werden sollen. Dezimalzahlen, die keine Nullen haben, werden nie entfernt.
■ Mit left-justified, centerd und right-justified werden die Werte der Ausgabelänge des Feldes angepaßt.
Erlaubt Nicht erlaubt
Ermöglichen Sie den Benutzern, Ihre eigenen Datumsformate anzulegen.
Codieren Sie niemals hart decimals2 für Währungen. Benutzen Sie statt dessen die Ergänzung currency.
Benutzen Sie Konvertierungs-Exits für Formatierungsaufgaben, besonders wenn sie komplexer sind.
Codieren Sie niemals Dezimalstellen für Einheiten wie % und ähnliche. Benutzen Sie statt dessen die Ergänzung unit.
Fragen & Antworten
Frage:Es gibt auch Funktionsbausteine mit Namen CONVERSION_EXIT_XXXX_INPUT. Wozu dienen diese?
Antwort:Das INPUT-Funktionsmodul wird jedesmal aufgerufen, wenn ein Wert in ein Feld eingegeben wird. Der INPUT-Konvertierungs-Exit konvertiert die Benutzereingabe in ein neues Format, bevor sie das Programm erhält. Damit soll die Routine von Formatierungsaufgaben entlastet werden.
Frage:Wie lege ich Konvertierungs-Exits an?
Antwort:Wenn Sie gar nicht wissen, wie Sie diese anlegen sollen, sollten Sie zuerst das entsprechende Kapitel lesen. Als Beispiel legen Sie ein Modul mit Namen CONVERSION_EXIT_XXXXX_OUTPUT an, wobei XXXXX irgendein Name sein kann. Es muß einen Importparameter namens INPUT und einen Exportparameter namens OUTPUT geben. Die Originalwerte aus der write-Anweisung werden über den Input-Parameter übergeben. Sie können ihn reformieren und am Ende des Funktionsbausteines an den Output-Parameter übergeben. Ein guter Weg, um anzufangen, ist, einen existierenden Funktionsbaustein zu kopieren.

Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten, Ihr gelerntes Wissen umzusetzen. Im Prüfungsabschnitt werden Fragen gestellt, die Ihnen helfen sollen, Ihr Verständnis für die besprochene Thematik zu vertiefen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie das Gelernte anwenden. Antworten auf die Prüfungsaufgaben und die Übungen finden Sie im Anhang B (Antworten zu Kontrollfragen und Übungen).
Kontrollfragen
6. 1. Was muß man tun, damit Änderungen bei Benutzerstandards wirksam werden?
7. 2. Was passiert, wenn eine Ausgabemaske, die mit V beginnt, einem numerischen Feld oder einem Zeichenfeld zugeordnet wird?
8. 3. Welche Arten von Variablen können die no-sign-Ergänzung benutzen, damit sowohl negative als auch positive Zahlen erscheinen?
Übung 1
Schreiben Sie ein Programm, daß die folgende Ausgabe erzeugt:
....+....1....+....2....+....3....+....4First DecemberJanuaryFirst
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

RückblickIn der vergangenen Woche haben Sie die folgenden Bereiche und Aufgaben bearbeitet:
■ Sie haben feste und variable Datenobjekte mit vor- und benutzerdefinierten Datentypen angelegt.
■ Sie haben die Regeln der ABAP/4-Syntax und die Anweisungen zur Kontrolle des Programmflusses kennengelernt.
■ Sie haben zugewiesene Anweisungen und Konvertierungsregeln entdeckt. ■ Sie haben interne Tabellen definiert und sie mit impliziten und expliziten Arbeitsbereichen
gefüllt.■ Sie haben die select-Anweisung optimiert, um eine interne Tabelle direkt und effizient zu
füllen.■ Sie haben Gruppenwechsel an internen Tabellen ausgeführt. ■ Sie haben die Formatierungsoptionen der write-Anweisung benutzt und die Auswirkung der
Datentypen bei der Ausgabe erfahren. ■ Sie haben conversion exits erarbeitet und ihre Präsenz in der Domäne kennengelernt.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Auf einen Blick Tag 15 Formatierungstechniken, Teil 1 521
Tag 16 Formatierungstechniken, Teil 2 551
Tag 17 Modularisierung: Ereignisse und Unterprogramme 569
Tag 18 Modularisierung: Übergabe von Parametern an Unterprogramme 599
Tag 19 Modularisierung: Funktionsbausteine, Teil 1 627
Tag 20 Modularisierung: Funktionsbausteine, Teil 2 647
Tag 21 Selektionsbilder 677
■ In der drittenWoche erzeugen Sie Reports, die grafische Symbole und Ikonen verwenden, fügen Kopf- und Fußzeilen an Listen an und senden mit Hilfe der new- page print-Anweisung Ausgaben in den Spoolbereich. Dann lernen Sie die Ereignisse initialisation, start-of-selection, end-of-selection, top-of-pageund end-of-page kennen. Sie codieren auch interne und externe Unterprogramme und Funktionsbausteine und übergeben diesen aktuelle und formale Parameter als Wert, als Wert und Resultat und als Referenz. Schließlich errichten Sie Ausnahmen innerhalb von Funktionsbausteinen, um den Rückgabewert von sy-subrc zu setzen und legen mit der select-options-Anweisung Auswahlmasken an.
■ Am 15. Tag verwenden Sie die grafischen Formatierungoptionen der write-Anweisung (assymbol, as icon, as line), drucken Listenausgaben und bearbeiten die Ausgabe der Schleife.
■ Am 16. Tag benutzen Sie die gebräuchlichen Formatierungsanweisungen new-line , new-page, skip, back, position und set blank lines. Mit new-page print senden Sie Ausgaben in den Spoolbereich.
■ Am 17. Tag benutzen Sie die Ereignisse initialisation, start-of-selection und end-of-selection; Sie definieren sowohl interne und externe Unterprogramme als auch globale, lokale und statische Variable sowie Tabellen-Arbeitsbereiche.
■ Am 18. Tag übergeben Sie aktuelle und formale Parameter an Unterprogramme auf drei Arten: als Wert (by value), als Wert und Resultat (by value and result) und als Referenz (by reference). Außerdem übergeben Sie Feldleisten und interne Tabellen an ein

Unterprogramm.■ Am 19. Tag verstehen und verwenden Sie die include-Anweisung, legen Funktionsgruppen
und -bausteine an und definieren Import-, Export- und Changing-Parameter. ■ Am 20. Tag verstehen Sie die Komponenten und die Struktur einer Funktionsgruppe und
definieren darin globale Daten und Unterprogramme. ■ Am 21. Tag codieren Sie Auswahlmasken, die mit dem Benutzer korrespondieren, verwenden
Formatierungselemente, um effiziente und praktikable Auswahlmasken anzulegen, und verwenden diese Masken, um Datenintegrität zu erhalten.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 15
Formatierungstechniken, Teil 1
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, sollten Sie folgendes können:
■ die grafischen Formatoptionen der write-Anweisung (as symbols, icons und lines )benutzen,
■ Listenausgaben erzeugen und diese im Spoolbereich verändern, ■ Kopf- und Fußzeilen anlegen (no standard page heading, top-of-page, end-of-page),
■ die reserve-Anweisung benutzen, um Zeilen in der Ausgabeliste zu gruppieren.
Grafische Formatierung mit Hilfe der write-Anweisung
Um einfache Grafiken zu erzeugen, können die drei Zusätze, wie in Tabelle 15.1 gezeigt, benutzt werden.
Tabelle 15.1: Grafische Formatierungszusätze zur write-Anweisung
Zusatz Effekt
as symbolas iconas line
Zeigt ein schwarz-weißes Symbol an
Zeigt eine bunte Ikone
Zeigt ein Zeichen zum Zeichnen einer Zeile

Die Syntax des grafischen Zusatzes zur write-Anweisung
write n1 (a) as symbol.(b) as icon.(c) as line.
wobei:
■ die Zusätze (a), (b) und (c) exklusiv veränderlich sind. ■ n1 der Name eines Symbols, einer Ikone oder eines line-draw-Zeichens ist.
Die Benutzung von as symbol
Als Symbol bezeichnet man ein einfaches zweifarbiges Bild eines gewöhnlichen Symbols wie das eines Quadrats, Kreises, Ordners oder eines Dokuments. Die meisten Symbole nehmen den Platz eines einzelnen Zeichens in der Ausgabeliste ein, obwohl es auch welche gibt, die zwei Zeichen einnehmen, wie zum Beispiel das Symbol einer links zeigenden Hand (sym_left_hand). Eine Beispielanweisung wäre write sym_left_hand as symbol.
Um Symbole benutzen zu können, müssen die folgenden Anweisungen am Anfang des Programms stehen:
include <symbol>.
oder
include <list>.
Alle Symbole sind druckbar. Das bedeutet, daß diese Symbole im Druck genauso aussehen, wie sie auf dem Bildschirm erscheinen.
Der Name zwischen den spitzen Klammern ist ein sogenanntes include-Programm. Es beinhaltet einen Satz von Anweisungen, die die Namen definieren, die benutzt werden können. Der <symbol> includebeinhaltet nur die Symboldefinitionen. Der <list> include beinhaltet Symbole, Ikonen, Zeichenlinien und Farbdefinitionen. Listing 15.1 zeigt ein Beispielprogramm, das einige Symbole benutzt.
Listing 15.1: Anzeigen von Symbolen
1 report ztx1501.2 include <symbol>.3 tables ztxlfa1.4 write: / sym_plus_box as symbol, 'Vendor Master Tables',5 /4 sym_filled_circle as symbol, 'LFA1',6 /4 sym_filled_circle as symbol, 'LFB1',7 /4 sym_filled_circle as symbol, 'LFC1',8 / sym_plus_box as symbol, 'Customer Master Tables',9 /4 sym_filled_square as symbol, 'KNA1',

10 /4 sym_filled_square as symbol, 'KNB1',11 /4 sym_filled_square as symbol, 'KNC1'.12 skip.13 uline.14 select * up to 5 rows from ztxlfa1.15 write: / ztxlfa1-lifnr,16 ztxlfa1-name1,17 sym_phone as symbol,18 ztxlfa1-telf1.19 endselect.
Das Programm aus Listing 15.1 erzeugt die Ausgabe, wie sie in Abbildung 15.1 zu sehen ist.
■ Die Zeilen 4 bis 11 schreiben eine Liste mit hart codierten Tabellennamen aus. ■ Die Zeilen 14 bis 19 schreiben Kreditorennummern, Namen und Telefonnummern, denen kleine
Telefonsymbole vorangestellt wurden.
Der Gebrauch von as icon
Eine Ikone (icon) ist ähnlich einem Symbol, ist aber ein mehrfarbiges Bild, das in der Ausgabeliste erscheinen kann. Die meisten Ikonen haben zwei Zeichen in der Ausgabeliste, einige auch mehr. Ein Beispiel einer write-Anweisung die Ikonen ausgibt, wäre write icon_led_red as icon.
Um überhaupt Ikonen darstellen zu können, muß eine include-Anweisung am Programmanfang stehen:
include <icon>.
oder
include <list>.
Abbildung 15.1: Dies ist ein Beispiel einer Ausgabenliste mit Symbolen.
Nicht alle Ikonen sind druckbar. Die Vorgehnsweise, die angibt, welche Ikonen gedruckt werden können und welche nicht, folgt später in diesem Kapitel.
Listing 15.2 gibt einige einfache Ikonen aus.
Listing 15.2: Wie man Ikonen der Ausgabeliste hinzufügt.
1 report ztx1502.2 include <icon>.3 tables: ztxmara, ztxmgef.4 data ico like icon_generate.56 write: / 'checkmark', 15 icon_checked as icon,7 / 'red x', 15 icon_incomplete as icon,8 / 'overview', 15 icon_overview as icon,9 / 'time period', 15 icon_period as icon.10 skip.11 uline.

12 skip.13 write: / 'List of Materials with Radioactive Indicators'.14 uline.15 select * from ztxmara.16 clear ico.17 if not ztxmara-stoff is initial.18 select single * from ztxmgef where stoff = ztxmara-stoff.19 if ztxmgef-lagkl = 7.20 ico = icon_generate.21 endif.22 endif.23 write: / ico as icon,24 ztxmara-matnr,25 ztxmara-mtart,26 ztxmara-matkl,27 ztxmara-brgew,28 ztxmara-ntgew,29 ztxmara-gewei.30 endselect.
Das Programm aus Listing 15.2 erzeugt die Ausgabe, die in Abbildung 15.2 zu sehen ist.
■ In den Zeilen 6 bis 9 werden vier verschiedene Ikonen ausgeschrieben. ■ Zeile 4 definiert eine Variable mit Namen ico, die eine Ikone für die Ausgabe enthalten soll. Es
kann irgendein Ikonenname hinter like erscheinen. ■ Zeile 15 selektiert Zeilen aus der Materialstammdatentabelle ztxmara.■ In Zeile 17 wird für Gefahrengüter in der Tabelle ztxmgef die Nummer für jeden Satz
nachgeschaut.■ Zeile 19 bestimmt, ob das Material radioaktiv ist. Wenn ja, wird die Ikone mit Namen icon_generate der Variablen ico zugeordnet.
■ Zeile 23 schreibt den Wert von ico mit Hilfe von as icon, was zur Folge hat, daß der Wert als Ikone interpretiert wird. Zusätzliche Felder aus ztxmara werden ebenso ausgeschrieben.

Abbildung 15.2: Dies ist ein Beispiel einer Ausgabenliste mit Ikonen.
Die Benutzung von as line
Ein Linienzeichen ist ein Zeichen, das benutzt wird, um Linien innerhalb einer Liste zu zeichnen. Man kann damit horizontale oder vertikale Linien, einen Kasten, ein Gitter oder einer Baumstruktur ähnliche Anordnungen zeichnen.
Typischerweise benutzt man für eine horizontale Linie den Befehl sy-uline. Sie wird einfach mit einer Längenbestimmung ausgeschrieben. Um zum Beispiel eine horizontale Linie zu schreiben, die auf Position 5 mit einer Länge von 10 beginnt, würde man folgendermaßen codieren: write 5(10) sy-line. Eine vertikale Linie wird mit sy- vline codiert; zum Beispiel write: sy-vline, 'X'. Es würde eine vertikale Linie beidseitig von 'X' geschrieben werden. Wenn sich Linien in der Ausgabe kreuzen, würde das System die notwendigen Verbindungszeichen einfügen. Zum Beispiel, wenn sich die Ecken einer horizontalen und einer vertikalen Linie kreuzen, würde eine Kastenecke gezeichnet werden. Um die Kontrolle über die Zeichen zum Zeichnen von Linien zu haben, gibt es zusätzliche Zeichenparameter für Linien.
Listing 15.3: Symbole und Zeichenparameter
1 report ztx1503.

2 include <list>.3 tables: ztxlfa1, ztxlfb1, ztxlfc3.4 data: line1 like line_horizontal_line,5 line2 like line_horizontal_line.67 select * from ztxlfa1.8 select single * from ztxlfb1 where lifnr = ztxlfa1-lifnr.9 if sy-subrc = 0.10 write: / sy-vline, sym_open_folder as symbol.11 else.12 write: / sy-vline, sym_folder as symbol.13 endif.14 write: ztxlfa1-lifnr, 30 sy-vline.15 select * from ztxlfb1 where lifnr = ztxlfa1-lifnr.16 select single lifnr from ztxlfb1 into (ztxlfb1-lifnr)17 where lifnr = ztxlfb1-lifnr18 and bukrs > ztxlfb1-bukrs.19 if sy-subrc = 0.20 line1 = line_left_middle_corner.21 line2 = line_vertical_line.22 else.23 line1 = line_bottom_left_corner.24 clear line2.25 endif.26 write: / sy-vline,27 4 line1 as line,28 ztxlfb1-bukrs,29 30 sy-vline.30 select * from ztxlfc3 where lifnr = ztxlfb1-lifnr31 and bukrs = ztxlfb1-bukrs.32 write: / sy-vline,33 4 line2 as line,34 8 line_left_middle_corner as line,35 ztxlfc3-gjahr, ztxlfc3-shbkz,36 30 sy-vline.37 endselect.38 if sy-subrc = 0.39 write 8(2) line_bottom_left_corner as line.40 endif.41 endselect.42 write: /(30) sy-uline.43 endselect.
Das Programm aus Listing 15.3 erzeugt die folgende Ausgabe:

Abbildung 15.3: Beispiel einer Ausgabe mit horizontalen und vertikalen Linien
■ Zeile 2 enthält die Definitionen aller Symbole und Linienzeichen, so daß sie in diesem Programm benutzt werden können.
■ Zeile 4 definiert zwei Variable, die Linienzeichen enthalten können. ■ Zeile 7 liest alle Zeilen aus ztxlfa1.■ Zeile 8 liest ztxlfb1, um zu sehen, ob es Abhängigkeiten zum aktuellen ztxlfa1- Satz gibt. ■ Wenn es Abhängigkeiten gibt, schreibt Zeile 10 eine vertikale Linie und das Symbol eines offenen
Ordners. Werden keine gefunden, wird eine vertikale Linie und ein geschlossener Ordner angezeigt.
■ Zeile 14 schreibt die Kreditorennummer auf der gleichen Zeile und dann eine vertikale Linie auf Position 30.
■ Zeile 15 liest die abhängigen Sätze aus ztxlfb1.■ Zeile 16 führt eine Vorschau aus, um zu bestimmen, ob es noch mehr abhängige Sätze gibt. ■ Gibt es mehr abhängige Sätze, setzt Zeile 19 die Variable line1, um ein Linienzeichen zu setzen,
und die line2-Variable, um eine vertikale Linie aufzunehmen. An dieser Stelle hätte man auch sy-vline anstatt line_vertical_line benutzen können.
■ Zeile 26 schreibt mit Hilfe des Zusatzes as line die line1-Variable aus, so daß der Wert als Linienzeichenparameter interpretiert wird.
■ Die Zeilen 30 bis 37 schreiben die Abhängigkeiten des aktuellen Satzes aus ztxlfb1 aus. ■ Zeile 42 schreibt eine Unterstreichungslinie mit einer Länge von 30 Zeichen.

Anzeigen der verfügbaren Symbole, Ikonen und Zeichenlinien
Führen Sie die Schritte 1 bis 8 aus, um sich die verfügbaren Symbole, Ikonen und Linienzeichen anzeigen zu lassen. Alle Schritte würden eine write-Anweisung auslösen, die die selektierten Gegenstände in eine Liste schreiben würde.
1. Rufen Sie ein Programm im Programmeditor auf.
2. Stellen Sie den Cursor auf eine freie Zeile.
3. Drücken Sie die Schaltfläche Muster. Die Maske Muster einfügen erscheint.
4. Wählen Sie die Option Write aus, und gehen Sie weiter.
5. Es wird eine neue Maske angezeigt: Zusammenstellen einer Write-Anweisung.
6. Wählen Sie Symbol, Ikone oder Linie aus.
7. Stellen Sie den Cursor rechts auf das Eingabefeld und drücken Sie (F4). Das System wird eine Liste der verfügbaren Gegenstände anzeigen.
8. Suchen Sie sich einen Gegenstand aus, und doppelklicken Sie ihn.
9. Drücken Sie auf die Schaltfläche Übernehmen. Sie kommen in den Editor zurück.
Es können nicht alle Ikonen gedruckt werden. Die druckbaren werden in der Liste wie eben beschrieben mit angezeigt.
Listing 15.4: Symbole, Ikonen und Linienzeichen
1 report ztx1504.2 include <list>. "definitions for icons, symbols + line-draw3 tables: ztxlfa1, ztxlfc3.4 data: it like ztxlfc3 occurs 100 with header line,5 ico_l like icon_green_light.6 select * from ztxlfc3 into table it.7 sort it by lifnr bukrs gjahr shbkz.8 loop at it.9 if it-saldv < 1000.10 ico_l = icon_green_light.11 elseif it-saldv between 1000 and 3000.

12 ico_l = icon_yellow_light.13 else.14 ico_l = icon_red_light.15 endif.16 at new lifnr.17 if sy-tabix > 1.18 write: /5(82) sy-uline,19 19 line_bottom_middle_corner as line,20 21 line_bottom_middle_corner as line.21 skip.22 endif.23 write: /5(15) sy-uline,24 /5 sy-vline, sym_documents as symbol,25 it-lifnr, 19 sy-vline,26 /5(82) sy-uline,27 19 line_cross as line,28 21 line_top_middle_corner as line.29 endat.30 write: / ico_l as icon,31 5 sy-vline, it-bukrs, sy-vline,32 it-gjahr, line_left_middle_corner as line no-gap,33 it-shbkz no-gap, line_right_middle_corner as line,34 it-saldv,35 it-solll,36 it-habnl, sy-vline.37 at last.38 write /5(84) sy-uline.39 endat.40 endloop.
Das Programm aus Listing 15.4 erzeugt die Ausgabe, die in Abbildung 15.4 gezeigt wird.

Abbildung 15.4: Beispiel einer Ausgabeliste, die Symbole, Ikonen und Linienzeichen enthält.
Berichtsformatierung und Druckausgabe
In diesem Abschnitt werden die Berichtsformatierungstechniken (Reports) beschrieben:
■ Kontrolle der Seitengröße ■ Berichtstitel, Kopfzeilen (Überschriften) und Fußzeilen ■ Allgemeine Positions- und Formatierungs-Anweisungen
Kontrolle der Seitengröße
Um die Größe der Ausgabeseite zu kontrollieren, kann mit folgenden Zusätzen der report-Anweisunggearbeitet werden:
■ line-size■ line-count
Der Zusatz line-size kontrolliert die Breite der Ausgabeliste; line-count kontrolliert die Zeilen pro Seite.

Die Syntax von line-size und line-count als Zusatz zur report-Anweisung.
Die Syntax des Zusatzes line-size und line-count zur report-Anweisung ist wie folgt:
report line-size i line-count j(k).
wobei:
■ i, j und k numerische Konstanten sind, Variablen folgen nicht. ■ i die Ausgabebreite der Ausgabeliste spezifiziert. ■ j die Anzahl von Zeilen pro Seite der Ausgabeliste ausgibt. ■ k die Anzahl von Zeilen ausgibt, die für die Kopfzeilen/Überschriften und Fußzeilen jeder Seite
reserviert werden müssen. ■ Man i, j und k nicht in Hochkommata einschließen darf.
line-size und line-count
Standardmäßig ist die Breite einer Ausgabeliste gleich der Breite eines auf volle Größe gestellten Fensters. Wenn Ihr Fenster zum Beispiel auf volle Größe eingestellt ist, bevor Sie einen Report starten, wird das System die eingestellte Breite für die Ausgabe benutzen. Ist Ihre Fenstergröße kleiner als das Maximum, wird das System trotzdem die volle Breite benutzen. Es wird aber ein Rollpfeil zum Blättern nach oben und unten eingestellt.
Um diese Einstellungen zu umgehen, kann man die Ausgabebreite mit Hilfe von line- size einstellen. Gültige Werte sind im Bereich von 2 bis 255.
Die meisten Drucker können nicht mehr als 132 Zeichen pro Zeile drucken. Vermeiden Sie darum, breitere Einstellungen in der Ausgabe vorzunehmen.
Die Seitenzahl erscheint rechts oben in der Ausgabeliste: der Standardwert von Zeilen pro Seite ist 60000. Mit line-count wird dieser Standard überschrieben. Um zum Beispiel 55 Zeilen pro Seite anzugeben, codieren Sie report line-count 55. Wenn Sie line-count 0 eingeben, entspricht das dem Maximalwert von 60000.
Normalerweise kann der Benutzer beim Drucken die Zeilenzahl pro Seite angeben.

Man kann den line-count ebenso mitten in einen Report stellen, somit können unterschiedliche Seiten unterschiedliche Ausgabezeilen haben. Dies wird mit Hilfe der new-page-Anweisung gemacht (wird später noch behandelt). Man kann damit auch die Zeilenzahl pro Seite vor der eigentlichen Ausgabe setzen.
line-count wird normalerweise nicht in Reports benutzt, die auch am Bildschirm angesehen werden können. Nehmen Sie zum Beispiel einmal an, R/3 würde die Seitenzahl jedesmal hochzählen, wenn Sie auf Nach Unten Blättern drücken (die Bildtasten auf der Tastatur). Wenn der Anwender einen Report generiert, bis zur Seite 3 blättert und dann die Fenstergröße ändert, ist er dann immer noch auf Seite 3? Offensichtlich macht es Schwierigkeiten, Regeln über Seitenzahlen aufzustellen, wenn man am Bildschirm arbeitet und die Fenstergröße verändern kann. Man kann die Seitenzahl gleich der Fensterhöhe machen, wenn der Report läuft. Verändert der Benutzer aber die Fenstergröße, nachdem der Report generiert wurde, passen die Seitenumbrüche nicht mehr zur Fenstergröße. Der Anwender wird Lücken in der Ausgabe sehen und Anfangsseiten mitten im Fenster. Um diesen Problemen innerhalb eines Reports vorzubeugen, sollten die Standardwerte für line-count benutzt werden.
Listing 15.5 zeigt ein Beispielprogramm, das die Benutzung von line-count und line-size zeigen soll.
Listing 15.5: line-count und line-size
1 report ztx1505 line-size 132 line-count 55.2 tables ztxlfc3.3 select * from ztxlfc3 order by lifnr bukrs gjahr shbkz.4 on change of ztxlfc3-lifnr.5 write / ztxlfc3-lifnr.6 endon.7 on change of ztxlfc3-gjahr.8 write /10 ztxlfc3-bukrs.9 endon.10 write: /20 ztxlfc3-gjahr,11 ztxlfc3-shbkz,12 ztxlfc3-saldv,13 ztxlfc3-solll,14 ztxlfc3-habnl.15 endselect.
Das Programm aus Listing 15.5 erzeugt die Ausgabe, die in Abbildung 15.5 gezeigt wird.

Abbildung 15.5: Der Effekt von line-count
■ Auf Zeile 1 wird durch line-size die Ausgabebreite auf 132 Zeichen begrenzt. Damit wird eine feste Ausgabebreite unabhängig von der Fenstergröße am Bildschirm erzeugt. Der Benutzer kann sich über den Rollbalken am rechten Rand des Fensters die Ausgabe beliebig ansehen.
■ Auf Zeile 1 wird mit line-count die Anzahl der Zeilen pro Seite auf 55 gesetzt. Das schafft ein Problem, wenn der Anwender nach unten blättert. Das würde mit der Standardeinstellung für line-count nicht passieren. Ein anderes Problem könnte beim Drucken auftauchen. Wenn der Drucker nicht exakt 55 Zeilen pro Seite ausdruckt, werden die Seitenumbrüche der Druckausgabe inkorrekt. Also, indem man die Standardwerte für line-count wählt, kann das Problem vermieden werden, da der Anwender die Zeilen pro Seite selbst beim Suchen eines geeigneten Druckers auswählt.
Die Ausgabeliste drucken
Starten Sie jetzt das ScreenCam »How to Print List Output«.
Um die Ausgabe aus Listing 15.5 auszudrucken, lassen Sie zuerst den Report laufen und folgen den Anweisungen.

1. Aus der Ausgabeliste heraus drücken Sie auf Drucken in der Drucktastenleiste. Ist kein Drucksymbol verfügbar, gehen Sie über den Menüpfad System->Liste- >Drucken.
2. Im Feld Ausgabegerät geben Sie einen gültigen Druckernamen ein. Sie erhalten eine Liste der aktuellen Drucker, wenn Sie den Cursor auf das leere Feld stellen und die (F4)-Taste drücken.
3. Haken Sie Sofort Ausgeben an.
4. Drücken Sie auf das Drucksymbol. Sie kommen zur Liste zurück. Eine generierte Spoolnummer erscheint in der Statusleiste.
Der Basisberater kann auch ein Faxgerät als Ausgabegerät definieren. Um einen Bericht zu faxen, nehmen Sie statt des Druckernamens den Namen des Faxgerätes.
Standarddruckereinstellungen sind in Ihrem Benutzerstammsatz definiert. Über den Menüpfad System->Benutzervorgaben->Eigene Daten können Sie Ihre Einstellungen verändern.
Um einen Report gleichzeitig an mehrere Drucker zu schicken, kann von einem Basisberater ein Druckerpool eingerichtet werden. Es muß zuerst der Report RSPO0051 laufen, um den Druckerpool zu initialisieren. Danach muß über die Transaktion SPAD ein Druckerpool eingerichtet werden.
Das Arbeiten mit Spool
Stößt man das Drucken im R/3 an, wird der Ausdruck erst im Spoolbereich des R/3 zwischengespeichert und dann dem Spoolprozeß des Betriebssystems übergeben. Wenn Sie nicht Sofort Ausgeben aktivieren, wird die Druckausgabe im Spoolbereich des R/3-Systems gehalten und nicht dem Betriebssystem übergeben werden. Die Druckausgabe wird dort so lange stehenbleiben, bis sie gelöscht wird, oder erst nach dem Drucken mit der Löschoption (Löschen Nach Ausgabe) verschwinden. Zusätzlich gibt es sogenannte »Aufräumjobs« (periodisch laufende Hintergrundprogramme), die den Spoolbereich regelmäßig aufräumen.
Um sich die Ausgabe im Spool anzusehen, benutzen Sie die folgenden Anweisungen:
Starten Sie jetzt das ScreenCam »Working with the Spool«.

1. Sie können aus jeder Maske heraus den Menüpfad System->Dienste->Ausgabesteuerung benutzen. Das Spool:Anforderungsbild erscheint.
2. Geben Sie die entsprechenden Optionen ein, um Ihre Ausgabe wiederzufinden. Normalerweise ist der Benutzername ausreichend.
3. Drücken Sie auf (Enter). Die Maske Spool: Aufträge erscheint. Haken Sie den Auftrag an, den Sie sich ansehen wollen. Drücken Sie dann auf Anzeigen (oder F6).
4. Um sich mehrere Einträge anzusehen, benutzen Sie den Menüpfad Bearbeiten- >Alles auswählen. Drücken Sie dann auf Anzeige. Es wird der erste Eintrag angezeigt. Um zum nächsten zu kommen, drücken Sie auf Nächster Spoolauftrag. Um sich den vorherigen wieder anzusehen, drücken Sie auf Vorherigen Druckauftrag.
Wenn Sie nicht Löschen Nach Ausgabe anklicken, bleibt die Ausgabe im Spoolbereich. Somit kann man auch noch zu einem späteren Zeitpunkt drucken.
Kopfzeilen und Fußzeilen anlegen
Standardmäßig wird die Überschrift aus den Programmattributen am Anfang des Reports angezeigt. Man kann sich aber auch seine eigenen Überschriften mit den folgenden zwei Methoden schaffen:
■ Standardkopfzeilen■ Mit top_of_page
Das Anlegen von Standardkopfzeilen
Mit Standardkopfzeilen ist es am leichtesten, seine eigenen Reportüberschriften anzulegen. Die folgende Vorgehensweise beschreibt diesen Vorgang.
Diese Vorgehensweise wird nicht funktionieren, wenn Sie Ihr Programm verändern und diese Schritte ausführen, ohne vorher zu speichern. Wenn Sie den Menüpfad wählen, um die Kopfzeile hinzuzufügen, werden Sie statt dessen eine Dialogbox sehen, die Ihnen anzeigt, daß Sie nicht berechtigt sind, ein SAP-Programm zu ändern. Das passiert, wenn Sie vergessen haben, Ihre Programmänderungen zu sichern, da Sie eine temporäre Kopie des Originals laufen lassen, nämlich eine, die Ihre Änderungen enthält. Der Name Ihrer Änderung fängt nicht mit Y oder Z an, so daß R/3 Ihnen keine Änderung erlaubt.
Starten Sie jetzt das ScreenCam »How to Create Standard Report Headers from the List«.
1. Gehen Sie in den ABAP/4-Editor.

2. Wenn Sie Änderungen gemacht haben, sichern Sie Ihren Report. Erinnern Sie sich an die letzte Warnung. Sie müssen sichern, damit die folgenden Schritte auch funktionieren.
3. Führen Sie den Report aus. Sie sehen die Ausgabeliste.
4. Wählen Sie jetzt den Menüpfad System->Liste->Listüberschrift. Am Anfang des Reports sind Eingabefelder - eins für die Überschrift (Kopfzeile) und vier für die Spaltenüberschriften.
5. Geben Sie die Überschriften in den weiß unterlegten Feldern ein.
6. Sichern Sie. In der Statuszeile wird die Nachricht »Geänd. Texte sind beim nächst. Start von XXXX in Sprache DE aktiv« ausgegeben. Das bedeutet, daß Sie Ihre Änderungen sehen werden, wenn Sie ein Programm beim nächsten Mal aufrufen.
7. Gehen Sie wieder zum Editor zurück, und rufen Sie das Programm erneut auf. Sie werden die neuen Kopfzeilen am Anfang des Reports sehen.
Fragen Sie sich jetzt, wo diese Änderungen gespeichert sind? Sie werden es bestimmt selbst herausfinden.
Die Kopfzeilen, die eingegeben wurden, sind innerhalb Ihres Programms als Textelemente gespeichert. Als Textelement bezeichnet man Zeichenketten, die in der Ausgabe mit angezeigt werden. Sie können als Überschrift vorkommen, in der Mitte (als Zeichenkette, die nicht aus der Datenbank kommt) oder am Ende des Reports als Fußnote. SAP bietet mehrsprachige Möglichkeiten in den Programmen, somit kann alles, was übersetzt werden sollte, wie zum Beispiel Reportüberschriften, getrennt vom Quelltext als Textelement gespeichert werden. Diese Texte können übersetzt werden, ohne den Quelltext zu ändern. In diesem Abschnitt befassen wir uns speziell mit Textelementen für den Report und die Spaltenüberschriften. Es gibt aber auch noch andere Textelemente, mit denen wir uns später beschäftigen werden.
Seitdem Standardüberschriften als Textelemente gespeichert sind, kann man sie sich ansehen und modifizieren, wie es in Abbildung 15.6 gezeigt wird (ABAP/4-Textelemente:Ändern Titel/Überschriften).
Mit den folgenden Schritten können Sie sich Standardüberschriften anlegen, ansehen oder ändern.
Starten Sie jetzt das ScreenCam »How to Create Standard Report Headers Via Text Elements«.
1. Aus dem ABAP/4-Editor heraus wählen Sie den Menüpfad Springen->Textelemente->Titel/Überschriften.
2. Gehen Sie in den Änderungsmodus. Geben Sie jetzt Ihre Änderungen bzw. Ihre neuen Überschriften ein.
3. Sichern Sie Ihre Änderungen, und gehen Sie wieder zurück in den ABPA/4-Editor.
4. Führen Sie Ihr Programm aus. Ihre Änderungen sollten jetzt angezeigt werden.

Abbildung 15.6: Diese Maske enthält die Standard-Textelemente für Kopfzeilen und Überschriften.
Zusammenfassend kann man sagen, wenn das Feld Listenüberschrift nicht leer ist, wird es als Überschrift benutzt. Ist es leer, wird das Titelfeld als Kopfzeile/Überschrift benutzt.
Zum SAP-Standard gehört es, daß die Überschrift linksbündig geschrieben wird. Das bedeutet, daß man die Überschrift nicht zentrieren kann. Selbst wenn man versucht, durch Auffüllen mit Freizeichen die Überschrift in die Mitte zu schieben, wird sie linksbündig angezeigt werden.
Textelemente übersetzen
Indem man Textelemente anlegt, ist man in der Lage, diese auch in andere Sprachen zu übersetzen. Normalerweise wird das von jemandem gemacht, der darauf spezialisiert ist. Der nächste Abschnitt soll Ihnen ein wenig Gespür dafür vermitteln.

Starten Sie jetzt das ScreenCam »Translating Title and Headers«.
1. Von der Maske ABAP/4-Textelemente: Ändern Titel/Überschriften gehen Sie über den Menüpfad Springen->Übersetzung in die zu übersetzende Sprache (Zielsprache für die Übersetzung).
2. Wählen Sie als Zielsprache diejenige aus, in der Sie die zu übersetzenden Textelemente haben wollen. Allerdings muß die Sprache, in die Sie übersetzen wollen, auch auf dem System installiert sein. Da neben Deutsch Englisch mit zur Auslieferungssprache gehört, wählen wir an dieser Stelle EN (Englisch) als Zielsprache.
3. Wählen Sie Übersetzen. Sie bekommen ein neues Bild angezeigt: Übersetzung ABAP/4 -Textpool: XXXX ($) von Sprache DE nach EN.
4. Geben Sie jetzt Ihre Übersetzung ein und sichern Sie. Wenn es mehr zu übersetzen gibt, werden Sie in der Maske bleiben, ansonsten kommen Sie in die Maske Übersetzung ABAP/4-Textpool: XXXX ($) von Sprache DE nach EN zurück.
5. Wählen Sie sich jetzt wieder in das R/3 neu ein, und geben Sie als Anmeldesprache EN ein.
6. Lassen Sie Ihr Programm laufen. Sie werden die übersetzten Überschriften sehen. Wenn Sie sich die Programmattribute ansehen, sind Ihre Übersetzungen in der Maske APAB/4: Programmattribute XXXX zu sehen.
Alle Übersetzungen sind in einem Vorschlagspool eingetragen, aus welchem Sie sich vorherige Übersetzungen eines Wortes oder Phrasen holen können. Wenn Sie eine Übersetzung eingeben, die sich von der unterscheidet, die gespeichert ist, wird Sie das System automatisch mit der vorherigen konfrontieren. Sie müssen dann entweder die neue sichern oder zur vorherigen zurückkehren.
Derjenige, der übersetzt, wird normalerweise mit der Transaktion SE63 arbeiten. Diese Transaktion unterstützt einen ganzen Vorrat an Bausteinen zur Übersetzung. Zum Beispiel die Beschreibung der Datenelemente, Indizes, Programmselektionstexte und so weiter. Der Pfad dahin aus der ABAP/4-Workbench ist Hilfsmittel->Übersetzung- >Kurz- und Langtexte.
Variable in Standard-Seitenüberschriften
Man kann bis zu 10 Variable in der Standard-Seitenüberschrift für ein Programm benutzen. Weisen Sie in Ihrem Programm den Variablen sy-tvar0 bis sy-tvar9 Werte zu. Benutzen Sie in Ihren Überschriften die Variablennamen &0 bis &9, um mit den sy- Variablen innerhalb Ihres Programms zu korrespondieren. Wenn Sie zum Beispiel sy- tvar0 ='AA' and sy-tvar1 ='BB' codieren,wird &0 durch AA ersetzt und &1 wird in der Überschrift mit BB ersetzt.

Obwohl jede sy-tvar-Variable bis zu 20 Zeichen lang sein kann, ist die variable Ausgabelänge standardmäßig 2. Das bedeutet zum Beispiel, egal wo &0 in der Überschrift erscheint, werden exakt zwei Leerzeichen für die Variable sy-tvar0 reserviert. Ist der Wert in sy-tvar0 'A', wird auch 'A'angezeigt. Ist der Wert 'AA', wird 'AA' angezeigt. Ist der Wert 'AAA', wird 'AA' angezeigt.
Die Ausgabelänge kann erhöht werden, indem man Punkte ans Ende der Ausgabevariablen stellt. Um zum Beispiel die Ausgabelänge von &0 von 2 auf 4 zu erhöhen, wird &0.. codiert (es wurden zwei Punkte angehängt). Um die Ausgabelänge auf 7 zu erhöhen, müssen 5 Punkte angehängt werden (&0.....).
Listing 15.6 zeigt ein Programm, das die Standard-Seitenüberschriften mit Variablen benutzt. Abbildung 15.7 zeigt, wie man diese Variablen in den Standard-Textelementen codiert.
Listing 15.6: Variable in Standard-Seitenüberschriften
1 report ztx1506.2 tables ztxlfa1.3 parameters: p_land1 like ztxlfa1-land1 default 'US'.4 sy-tvar0 = sy-uname.5 write: sy-datum to sy-tvar1,6 sy-uzeit to sy-tvar2.7 sy-tvar3 = p_land1.8 select * from ztxlfa1 where land1 = p_land1.9 write: / ztxlfa1-lifnr, ztxlfa1-name1.10 endselect.

Abbildung 15.7: Die Maske ABAP/4-Textelemente:Ändern Titel/Überschriften für Programm ztx1506
Das Programm aus Listing 15.6 erzeugt die folgende Ausgabe:
KENGREENWOOD 1998/05/05 19:40:38 ------------------------------------------------Country Code: US ------------------------------------------------1040 Motherboards Inc. 1080 Silicon Sandwich Ltd. 1090 Consume Inc. 2000 Monitors and More Ltd. V1 Quantity First Ltd. V2 OverPriced Goods Inc. V3 Fluffy Bunnies Ltd. V4 Moo like a Cow Inc. V5 Wolfman Sport Accessories Inc. V7 The Breakfast Club Inc.
■ Zeile 3 definiert p_land1 und fragt den Benutzer nach einem Eingabewert.

■ Zeile 4 weist die aktuelle Benutzerkennung sy-tvar0 zu. ■ Die write-Anweisung in Zeile 5 schiebt den Wert von sy-datum in sy-tvar1. Eine normale
Zuweisung (mit =) hätte den Wert ohne Formatierung verschoben. Mit Hilfe von write wird das Feld dazu gezwungen, mit Trennzeichen gemäß dem Benutzerprofil zu formatieren.
■ Zeile 6 formatiert die aktuelle Zeit und schiebt sie in sy-tvar2.■ Zeile 7 weist den Eingabewert der Variablen sy-tvar3 zu. ■ In Abbildung 15.7 zeigt &0......... an, wo der Wert von sy-tvar0 erscheinen wird. Die
Punkte erhöhen die Ausgabelänge der Variablen von 2 auf 12. &1...... zeigt an, wo der Wert von sy-tvar1 erscheinen wird, &2...... zeigt an, wo der Wert von sy- tvar2 erscheinen wird und so weiter. Die Punkte erhöhen die Ausgabelänge auf 10, 8 und 3.
Manuelle Seitenüberschriften anlegen
Standard-Seitenüberschriften sind einfach anzulegen, allerdings unterliegen sie auch einigen Limitierungen. Sie unterliegen der Begrenzung von einer Zeile pro Seitenüberschrift und vier Zeilen für die Spaltenüberschriften. Es kann nur ein Maximum von zehn Variablen benutzt werden, jede mit einer minimalen Länge von zwei Zeichen. Die Überschrift ist immer linksbündig, und die Farben sind Standard und können nicht geändert werden. Manuelle Überschriften jedoch unterliegen nicht solchen Begrenzungen.
Um manuelle Überschriften anzulegen, muß man:
■ die Standard-Seitenüberschriften ausschalten ■ das top-of-page-Ereignis (event) benutzen, um angepaßte Überschriften zu erzeugen
Um die Standard-Überschriften auszuschalten, fügen Sie dem Report am Ende die Anweisung add no standard page heading zu.
Ein Ereignis in ABAP/4 ist wie ein Unterprogramm in anderen Sprachen. Es ist ein Stück unabhängiger Code; es führt irgendwelche Arbeiten durch und kommt dann wieder an den Punkt zurück, von wo das Ereignis aufgerufen wurde. Allerdings wird hier nicht wie in anderen Sprachen der Programmcode geschrieben, der das Ereignis aufruft. Statt dessen stößt das System das Ereignis unter besonderen Bedingungen selbst an.
Das Ereignis top-of-page wird jedesmal beim Schreiben einer write-Anweisung angestoßen. Bevor irgendwelche Werte der Ausgabeliste hinzugefügt werden, verzweigt das System zum Programmcode, der top-of-page folgt und führt ihn aus. Danach kommt es zur write-Anweisung zurück und schreibt die Werte aus.
Listing 15.7 und Abbildung 15.8 zeigen diesen Prozeß.
Listing 15.7: Das Ereignis top-of-page
1 report ztx1507 no standard page heading.2 data f1(5) value 'Init'.3 f1 = 'Title'.4 write: / 'Hi'.

56 top-of-page.7 write: / 'My', f1.8 uline.
Abbildung 15.8: Ausgabe des Programms 15.7
■ Auf Zeile 1 enthält die report-Anweisung den Zusatz no standard page heading, somit wird die Standardüberschrift nicht geschrieben.
■ Zeile 2 definiert f1 mit einer Länge von fünf Zeichen und gibt ihm einen Initialwert 'Init'.■ Zeile 3 weist f1 den Wert 'Title' zu. ■ Die write-Anweisung auf Zeile 4 stößt das Ereignis top-of-page auf Zeile 6 an. Die Zeilen 7
und 8 werden dann ausgeführt, die Zeile My Title wird auf der ersten Zeile der Liste ausgegeben, gefolgt von einer Unterstreichungslinie (ausgeführt durch den Befehl uline auf Zeile 8). Nach der Verarbeitung wird zurück zur write -Anweisung auf Zeile 4 gesprungen und Hiwird auf Zeile 3 der Ausgabeliste herausgeschrieben.
■ Nachdem Zeile 4 ausgeführt wurde, endet das Programm, und die Ausgabe wird angezeigt.
Beachten Sie, daß der Wert von f1, der am Anfang der Seite ausgegeben wird, der Wert der ersten write-Anweisung ist und nicht der Wert vom Anfang des Programms.
Fußzeilen anlegen

Wie schon früher erwähnt, kann ein Benutzer nach der Generierung eines Reports die Fenstergröße verändern. Um mittlere Seitenumbrüche zu vermeiden, bestehen Online-Reports aus einer einzelnen langen virtuellen Seite, somit haben Fußzeilen wenig Sinn, weil es nur eine geben würde.
Hintergrundreports werden normalerweise ausgedruckt und haben somit eine definitive Seitengröße, die sich nach der Reportgenerierung nicht ändert, daher können sie Fußzeilen haben.
Um Fußzeilen anzulegen, braucht man:
■ den line-count-Zusatz der report-Anweisung, um Platz für die Fußzeile zu reservieren ■ das Ereignis end-of-page
Um Platz für die Fußzeile zu reservieren, kann man die report-Anweisung folgendermaßen codieren: line-count n(m). Wobei n die Anzahl von Zeilen pro Seite ist und m die Anzahl an Zeilen, die man für die Fußzeile reservieren muß. Man sollte n nicht hart codieren, da der Anwender selbst über die Anzahl von Zeilen innerhalb des Reports entscheiden sollte. Lassen Sie es der Einfachheit halber weg und schreiben report line-count (m).
Während der Reportverarbeitung enthält sy-pagno die aktuelle Seitenzahl und sy- linno die aktuelle Zeilennummer, die gerade geschrieben wird.
Codieren Sie end-of-page am Ende des Programms, wie in Listing 15.8 gezeigt. Die Anweisungen, die end-of-page folgen, werden vor Beginn jeder neuen Seite ausgeführt. Eine neue Seite wird angefangen, wenn die write-Anweisung ausgeführt wird und die Ausgabe nicht in die aktuelle Seite paßt. Angenommen, Sie haben folgendermaßen codiert report zxx line-count (3), lassen also drei Zeilen für die Fußzeile übrig. Der Anwender hat aber für die Ausgabe 60 Zeilen pro Seite angegeben. Der Fußzeilenbereich enthält also die Zeilen 58 bis 60. Wenn gerade bis zur 57-ten Zeile geschrieben wurde, würde die nächste write-Anweisung einer neuen Zeile das Ereignis end-of-page auslösen, gefolgt von einem Seitenumbruch, dem top-of-page Ereignis, und dann würde die Ausgabe auf die nächste Seite kommen.
Technisch können Ereignisse in beliebiger Reihenfolge und Position im Programm vorkommen. Codieren Sie im Moment wie gezeigt. Ein weiteres Kapitel wird später detaillierter das Codieren von Ereignissen erklären.
Listing 15.8: top-of-page- und end-of-page-Ereignisse
1 report ztx1508 line-count 20(3) no standard page heading.2 do 80 times.3 write: / 'Please kick me', sy-index, 'times'.

4 enddo.56 top-of-page.7 write: / 'CONFIDENTIAL',8 / 'This page begins with number', sy-index.9 uline.1011 end-of-page.12 write: / sy-uline,13 / 'The number of kicks at the top of the next page will be',14 sy-index,15 / 'Copyright 1998 by the ALA (Abuse Lovers Of America)'.
Dieser Teil der Ausgabe zum Listing 15.8 sieht folgendermaßen aus:
CONFIDENTIALThis page begins with number 1------------------------------------------------------------------Please kick me 1 times Please kick me 2 times Please kick me 3 times Please kick me 4 times Please kick me 5 times Please kick me 6 times Please kick me 7 times Please kick me 8 times Please kick me 9 times Please kick me 10 times Please kick me 11 times Please kick me 12 times Please kick me 13 times Please kick me 14 times -------------------------------------------------------------The number of kicks at the top of the next page will be 15 Copyright 1998 by the ALA (Abuse Lovers Of America)CONFIDENTIALThis page begins with number 15-------------------------------------------------------------Please kick me 15 timesPlease kick me 16 timesPlease kick me 17 timesPlease kick me 18 times
■ Zeile 1 unterdrückt die Benutzung von Standard-Seitenüberschriften, da wir manuelle Überschriften anlegen wollen. Die Zahl der Fußzeilen wird auf drei begrenzt. Die Zeilen pro Seite werden auf 20 gesetzt, somit können wir den Fußzeilencode online testen. Normalerweise werden bei einem online-Report keine Zeilen pro Seite angegeben.
■ Beim ersten Schleifendurchgang stößt Zeile 2 das Ereignis top-of-page auf Zeile 6 an, was

bewirkt, daß die Zeilen 7 bis 9 zwei Kopfzeilen ausgeben, gefolgt von einer Unterstreichungslinie. Kontrolliert wird zu Zeile 3 zurückgegangen, und die write-Anweisung schreibt die vierte Zeile in die Ausgabeliste.
■ Nach 14 Schleifendurchgängen stößt die 15. write-Anweisung das Ereignis end- of-page auf Zeile 11 an. Die Zeilen 12 bis 15 werden ausgeführt, die Fußzeilen schreiben. Danach wird die top-of-page-Anweisung auf Zeile 6 ausgeführt, und die Zeilen 7 bis 9 schreiben die Seitenüberschrift an den Anfang der nächsten Seite. Danach wird wieder kontrolliert auf Zeile 3 zurückgegangen, und die write- Anweisung schreibt die vierte Zeile auf Seite 2.
■ Es wird keine Fußzeile am Ende von der letzten Seite geschrieben.
Die reserve -Anweisung
Manchmal möchte man zusammenhängende Informationen ausgeben, die über mehrere Zeilen verteilt sind. Zum Beispiel schreiben Sie den Namen und die Nummer eines Kreditors auf eine Zeile, gefolgt von der Adresse auf der nächsten Zeile und der Telefonnummer auf der gleichen Zeile dahinter. Es macht Sinn, diese Zeilen als Gruppe für die Ausgabe zusammenzuhalten, um zu verhindern, daß diese Informationen über zwei Seiten ausgegeben werden.
Mit Hilfe der reserve-Anweisung kann man Zeilen innerhalb der Ausgabe gruppieren.
Die Syntax der reserve-Anweisung
reserve n lines.
wobei:
■ n ein numerisches Literal oder eine Variable ist.
Wenn die reserve-Anweisung ausgeführt wird, prüft das System, ob n Zeilen auf der aktuellen Seite verfügbar sind. Gibt es weniger als n Zeilen, wird ein Seitenumbruch gemacht. Das stößt das Ereignis end-of-page an (wenn es existiert), gefolgt vom top- of-page-Ereignis (wenn es existiert). Die nächste write-Anweisung fängt am Anfang der nächsten Seite an.
Sind letztlich n Zeilen verfügbar, wenn die reserve-Anweisung ausgeführt wird, passiert nichts.
Listing 15.9 zeigt ein Beispielprogramm, das die reserve-Anweisung benutzt.
Listing 15.9: Die reserve-Anweisung
1 report ztx1509 line-count 18(2) no standard page heading.2 tables ztxlfa1.34 select * from ztxlfa1.5 reserve 3 lines.6 write: / ztxlfa1-lifnr, ztxlfa1-name1,7 / ztxlfa1-stras, ztxlfa1-regio, ztxlfa1-land1,8 / ztxlfa1-telf1.

9 skip.10 endselect.1112 top-of-page.13 write / 'Vendor Report'.14 uline.1516 end-of-page.17 uline.18 write: / 'Report', sy-repid, ' Created by', sy-uname.
Das Programm aus Listing 15.9 zeigt die folgende Ausgabe:
Vendor Report -----------------------------------------------1000 Parts Unlimited 111 Queen St. ON CA416-255-1212
1010 Industrial Pumps Inc. 1520 Avenue Rd. ON CA 416-535-2341
1020 Chemical Nation Ltd. 123 River Ave. ON CA 416-451-7787
-----------------------------------------------Report ZTX1209 Created by KENGREENWOOD
Vendor Report -----------------------------------------------1030 ChickenFeed Ltd. 8718 Wishbone Lane AB CA 393-565-2340
1040 Motherboards Inc. 64 BitBus Blvd. MA US 617-535-0198
Zeile 5 bestimmt, ob es noch Platz für drei neue Zeilen auf der aktuellen Seite gibt. Wenn ja, passiert gar nichts, und Zeile 6 schreibt die Kreditoreninformationen auf die nächsten Zeilen. Wenn nicht, wird das Ereignis end-of-page (Zeilen 15 bis 17) angestoßen und ein Seitenumbruch gemacht. Danach wird das Ereignis top-of-page (Zeilen 11 bis 13) angestoßen, die write-Anweisung auf Zeile 6 wird ausgeführt, und die Zeilen werden an den Anfang der nächsten Seite geschrieben.

Zusammenfassung
■ Mit Hilfe der Zusätze symbol, as icon und as line zur write-Anweisung kann man einfache grafische Ausgaben anlegen. Wenn man diese Zusätze benutzt, muß man innerhalb des Programms die include-Anweisung für die obigen grafischen Symbole benutzen.
■ Benutzt man den line-size Zusatz zur report-Anweisung, wird die Ausgabebreite der Ausgabeliste festgesetzt. Sie kann auch zum Reservieren von Zeilen für die Fußzeilen benutzt werden. Man kann keine Variablen zur report-Anweisung benutzen. Dafür gibt es die new-page-Anweisung, wenn man Attribute zur Laufzeit setzen will.
■ Seitenüberschriften werden mit Hilfe der top-of-page-Anweisung angelegt. ■ Bis zu zehn Variablen können in der Standard-Seitenüberschrift benutzt werden. Die Werte, die sy-tvar0 bis sy-tvar9 zugewiesen werden, ersetzen &0 bis &9 in der Liste. Mit Hilfe von Punkten wird die Ausgabelänge dieser Ersetzungsvariablen erhöht.
■ Um die Standard-Seitenüberschrift zu unterdrücken, wird der no standard page heading-Zusatz zur report-Anweisung benutzt.
■ Wenn man das Ereignis top-of-page im Programm benutzt, wird es bei der ersten Benutzung von write angestoßen. Die Anweisungen, die folgen, werden ausgeführt, und dann wird zur write-Anweisung zurückgekehrt.
■ Mit end-of-page werden Fußzeilen angelegt. Ebenfalls muß line-count zur report -oder new-page-Anweisung mit benutzt werden, um die Anzahl von Zeilen pro Seite anzugeben und Platz für die Fußzeilen zu lassen.
■ Die reserve-Anweisung gruppiert Zeilen in einer Liste.
Fragen & Antworten
Frage:Was ist die bevorzugte Methode, um eigene Überschriften anzulegen? Die Benutzung von sy-tvar-Variablen oder das Ereignis top-of-event?
Antwort:Das Ereignis top-of-event ist flexibler, deshalb benutzen viele Programmierer diese Methode. Benutzen Sie Textsymbole für Ihre Textliterale, können beide übersetzt werden. Es gibt keine Vorteile für sy-tvar-Variable.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten zu zeigen, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen sollen Ihnen helfen, Ihr Verständnis für die behandelten Themen zu erhärten, und der Übungsabschnitt ermöglicht Ihnen, Erfahrung zu sammeln, indem Sie anwenden, was Sie gelernt haben. Alle Antworten finden Sie in Anhang B.
Kontrollfragen
1. Wie heißen die drei grafischen Zusätze zur write-Anweisung? Welche Anweisungen müssen zusätzlich mit eingeschlossen werden, um die grafischen Zusätze zu schreiben? Geben Sie ein Beispiel

einer include-Anweisung.
2. Wie heißen die zwei Zusätze zur report-Anweisung, welche die Größe der Ausgabeseite kontrollieren? Kann die Variable, die für die beiden Zusätze benutzt wird, variabel sein?
Übung 1
Schreiben Sie ein Programm, das die folgenden Symbole anzeigt: Quadrat, Kreis, Diamant, Brillengläser, Schreiber, Hinweis und Ordner.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 16
Formatierungstechniken, Teil 2
Kapitelziele
Nach diesem Kapitel wissen Sie:
■ wie man die Formatierungsanweisungen new-line, new-page, skip, back, positionund set blank lines benutzt
■ wie man die Ausgabe mit dem Befehl new-page print in den Spoolbereich umleitet
Anweisungen für die Ausgabeaufbereitung
Für die Aufbereitung von Listen werden folgende Befehle benutzt:
■ new-line■ new-page■ skip■ back■ position■ set blank lines
Der Befehl new-line
Der Befehl new-line wird benutzt, um die Ausgabe der nächsten write-Anweisung in einer neuen Zeile zu beginnen. Im Gegensatz zu skip oder write / werden hierbei keine Leerzeichen ausgegeben.
Die Syntax für die Anweisung new-line

new-line [no-scrolling]
Der Zusatz no-scrolling fixiert die nächste Zeile auf dem Bildschirm. Horizontales Verschieben (Scrollen) hat dann auf diese Zeile keinen Einfluß.
Das Listing 16.1 zeigt den Einsatz von new-line.
Listing 16.1: Die new-line-Anweisung
1 report ztx1601 line-size 255.2 tables: ztxlfa1, ztxlfc3.3 select * from ztxlfa1.4 new-line no-scrolling.5 write: ztxlfa1-lifnr, ztxlfa1-name1. "this line won't scroll right6 select * from ztxlfc3 where lifnr = ztxlfa1-lifnr.7 write: /14 ztxlfc3-bukrs, ztxlfc3-gjahr, ztxlfc3-shbkz,8 40 ztxlfc3-saldv, ztxlfc3-solll, ztxlfc3-habnl.9 endselect.10 endselect.
Das Programm liefert folgendes Ergebnis:
1000 Parts Unlimited1000 1990 A 1,000.00 500.001000 1991 A 0.00 5,000.001000 1992 A 1,000.00 11,000.001000 1993 A 0.00 10,000.001000 1994 A 0.00 1,000.001000 1995 A 1,000.00 1,150.001000 1995 Z 0.00 9,000.001000 1996 A 1,000.00 50,000.001000 1996 Z 5,000.00 0.001000 1998 Z 4,000.00 0.003000 1998 A 0.00 10,000.001010 Industrial Pumps Inc.1000 1994 A 0.00 1,000.001000 1995 A 0.00 1,500.001000 1996 A 1,500.00 0.001020 Chemical Nation Ltd.1000 1995 A 0.00 2,000.001000 1996 A 0.00 0.001030 ChickenFeed Ltd.1040 Motherboards Inc.1000 1990 A 100.00 3,000.001000 1997 A 100.00 1,500.00

2000 1997 A 0.00 500.002000 1998 A 1,000.00 300.003000 1998 A 0.00 2,400.00
Die Zeilen 7 und 8 gehen über den Bildschirmrand hinaus. Durch Scrollen nach rechts läßt sich der Rest der Zeilen anzeigen. Dabei bleiben durch den Zusatz no-scrolling der Name und die Nummer des Kreditors im Blickfeld.
Die Anweisung new-page
Die Anweisung new-page wird benutzt:
■ um die nächste write-Anweisung auf einer neuen Seite auszugeben. Durch new- page werden aber keine leeren Seiten erzeugt.
■ um Titel und Überschriften ein und auszuschalten. ■ um die Zeilenbreite (line-size) und die Anzahl der Zeilen pro Seite (line-count) zu
verändern.■ um das Ausdrucken der Seite ein- und auszuschalten.
Die Syntax für new-page
new-page [no-title | with-title][no-heading | with-heading][line-count n(m)][line-size k][print on | print off]
■ n, m und k stehen für numerische Variablen oder Literale.
Folgende Punkte sind zu beachten:
■ new-page kann überall im Programm benutzt werden. Es kann sogar vor der ersten write-Anweisung stehen, um die Eigenschaften für die Ausgabe zu setzen. Da hierbei Variablen benutzt werden können, ist diese Anweisung wesentlich flexibler als die report-Anweisungmit den entsprechenden Zusätzen.
■ no-title unterdrückt die Ausgabe der Titelzeile auf den folgenden Seiten. (Die Titelzeile ist die erste Zeile der Standard-Seitenüberschrift). with-title gibt sie wieder aus.
■ no-heading unterdrückt die Ausgabe der Standard-Spaltenüberschrift auf den folgenden Seiten. with-title schaltet ihn wieder ein.
■ line-count setzt die Zeilenanzahl und die Anzahl der reservierten Fußzeilen pro Seite fest. Beide Werte können einzeln oder zusammen festgelegt werden.
■ line-size legt für die folgenden Seiten die Anzahl der Zeichen je Zeile fest. Der Standardwert entspricht der aktuellen Fensterbreite.
■ print-on bewirkt, daß die Ausgabe der nächsten write-Anweisung in den Spoolbereich gestellt wird und nicht in einer Liste erfolgt. Das Ergebnis wird somit nicht auf dem

Bildschirm angezeigt. Der Anwender kann sich aber gegebenenfalls. die Liste mit Hilfe der Spoolverwaltung anzeigen lassen. (Auf die Ansicht und den Ausdruck der Spool wurde in diesem Kapitel schon eingegangen.) print-off bewirkt das Gegenteil.
■ durch darauffolgende new-page-Anweisungen werden keine leeren Seiten erzeugt. ■ durch new-page wird nicht das Ereignis end-of-page ausgelöst. Aus diesem Grund
werden keine Fußzeilen bei new-page ausgegeben.
Wollen Sie einen Seitenwechsel verursachen und das end-of-page-Ereignisanstoßen, programmieren Sie reserve sy-linct lines. sy-linct enthält die aktuelle Seitenzahl pro Seite. Die Ausgabe der nächsten write-Anweisung wird am Anfang der nächsten neuen Seite erscheinen, und das Ereignis end-of-page wird angestoßen; dies bewirkt das Anlegen von Fußzeilen.
Gebrauch von new-page print
Manchmal ist es sinnvoll, daß ein Report eine Liste auf dem Bildschirm ausgibt und gleichzeitig eine Ausgabe in den Spoolbereich leitet. Zum Beispiel kann es wünschenswert sein, daß ein Report zusammengefaßte Daten an die angemeldeten Anwender schickt und die Detaildaten an den Drucker sendet. Hierzu eignet sich new-page print. Die Ausgabe von write-Anweisungen, die nach new-page print ausgeführt werden, erscheint nicht auf dem Bildschirm, sondern erfolgt im Spoolbereich. Umgekehrt wird dieser Effekt durch new-page print off.

Abbildung 16.1: Die Maske der Druckparameter
Jedesmal, wenn die Anweisung new-page print ausgeführt wird,
■ wird dem Anwender das Popup der Druckparameter angezeigt (Abbildung 16.1). Dieses fordert ihn auf, zum Beispiel den Drucker oder das Format festzulegen.
■ wird ein neuer Spoolauftrag angelegt, falls hier die entsprechende Option angekreuzt wird. Ein Spoolauftrag ist eine Liste im Spoolbereich.
Die Syntax für new-page print
new-page print on[no dialog][new section][immediately immedflag][destination destid][copies numcopies][layout layoutid][list name listname]

[sap cover page coverpageflag][cover text title][department dept][receiver recievername][keep in spool keepflag][dataset expiration numdays][line-count linesperpage][line-size numcolumns]
■ die kursiv geschriebenen Bezeichnungen stehen für Variablen bzw. Literale.
Sie sollten folgende Grundsätze beachten:
■ Benutzen Sie no dialog, um die Anzeige der Druckparameter zu unterdrücken. Statt dessen werden die Benutzervorgaben herangezogen.
■ Für den Fall, daß in den Benutzervorgaben kein Drucker angegeben ist, wird die Dialogbox der Druckangaben trotz no dialog angezeigt.
■ new section wird benutzt, um die Seitenzahl wieder bei 1 zu beginnen. ■ Zum sofortigen Ausdruck der Liste setzen Sie in der Druckmaske »Sofort Ausgeben« auf 'X'.
Der Standardwert ist hierbei leer, was bewirkt, daß die Liste im Spoolbereich gehalten wird. ■ Die Drucker-ID wird mit Ausgabegerät festgelegt. ■ Mit Anzahl Ausdrucke legen Sie die Anzahl der auszudruckenden Exemplare fest.
■ Benutzen Sie Aufbereitung, um die Druckaufbereitung zu steuern. Aus der Druckaufbereitung ergeben sich die Anzahl der Zeilen pro Seite und die Anzahl der Zeichen pro Zeile. Die vordefinierten Aufbereitungen können im Popup der Druckparameter mit Hilfe der (F4)-Hilfe im Feld Druckaufbereitung aufgelistet werden.
■ Mit Name legen Sie den Namen der Liste im Spoolbereich fest. Diesen können Sie dann in der Spoolverwaltung benutzen, um Ihre Liste wiederzufinden. (Geben Sie diesen Namen im dritten Feld der Spoolverwaltung an.)
■ Benutzen Sie »SAP_Deckblatt«, um die Ausgabe eines Deckblattes zu steuern. Steht dieser Wert auf leer, wird die Ausgabe des Deckblattes unterdrückt. Durch 'X' wird die Ausgabe aktiviert. Der Wert 'X' übernimmt die aktuelle Druckereinstellung.
■ Mit Abteilung bestimmen Sie den Namen der Abteilung, der auf das Deckblatt gedruckt werden soll
■ Benutzen Sie Empfänger, um auf dem Deckblatt den Empfänger anzugeben. ■ Haken Sie Neuer Spoolauftrag an, um den Spoolauftrag nach dem Ausdruck zu halten. Das
ermöglicht dem Anwender einen weiteren späteren Ausdruck, ohne den Report erneut zu starten.
■ Mit Spool-Verweildauer legen Sie fest, wie viele Tage der Spoolauftrag gehalten werden soll, bevor er automatisch gelöscht wird.
■ Benutzen Sie Zeilen, um die Anzahl der Zeilen pro Seite und die Anzahl der Zeichen pro Zeile zu bestimmen.
Weitere Parameter sind in der ABAP/4-Dokumentation enthalten.

Wird die Druckausgabe direkt mit new-page print on in den Spoolbereich geschickt, können zusätzlich zwei weitere Anweisungen benutzt werden. Die setmargins-Anweisung kontrolliert die Seitenränder, und print-control erlaubt, Druckzeichen direkt an den Drucker zu senden. Mit print-control können beliebige Druckerzeichen wie CPI (character per inch), LPI (lines per inch) oder Fonts gesteuert werden. Diese Anweisungen haben keinen Einfluß auf Listen, die direkt über die Schaltfläche Drukken oder über den Menüpfad gedruckt werden. Sie beeinflussen nur Drucke, die mit new-page print on gedruckt werden. Die ABAP/4-Schlüsselwortdokumentation enthält zusätzliche Details.
Das Listing in 16.2 zeigt die Anwendung der Anweisung new-page print.
Listing 16.2: Die Anweisung new-page print
1 report ztx1602.2 tables ztxlfa1.3 parameters: prt_id like estwo-spooldest obligatory.45 new-page print on6 no dialog7 immediately 'X'8 destination prt_id.910 select * from ztxlfa1.11 write: / ztxlfa1-lifnr.12 endselect.1314 new-page print off.15 write: / sy-dbcnt, 'lines sent to printer', prt_id.
Das Programm in 16.2 erzeugt folgende Liste:
23 lines sent to printer BOS4
■ Zeile 3 veranlaßt den Anwender, einen Drucker anzugeben. Das Feld estwo- spooldestbesitzt eine Fremdschlüsselbeziehung zur Tabelle, die die Drucker-IDs enthält. Somit steht für dieses Eingabefeld die (F4)-Hilfe zur Verfügung. Mit ihrer Hilfe lassen sich alle verfügbaren Drucker auflisten.
■ Zeile 5 steuert die Ausgabe der nächsten write-Anweisungen. No dialog unterdrückt die

Anzeige des Popups für die Druckangaben. Diese Parameter werden aus den Benutzervorgaben und den Angaben der Zeilen 6 bis 8 entnommen. Das 'X' bei Sofort Ausgeben bewirkt, daß die Liste sofort ausgedruckt wird. Zeile 8 leitet die Ausgabe an den im Selektionsbild angegebenen Drucker weiter.
■ Die Ausgabe der Zeile 11 wird direkt an den Drucker übergeben. Sie erscheint nicht auf dem Bildschirm.
■ Zeile 14 hebt die Drucksteuerung wieder auf und gibt die nächsten write-Anweisungenwieder auf dem Bildschirm aus.
Anzeige der ABAP/4-Dokumentation für new-page print
Im Normalfall zeigt die (F1)-Hilfe die Dokumentation für new-page print nicht an. Diese spezielle Dokumentation erhält man wie folgt:
1. Beginnen Sie im ABAP/4-Editor:Einstiegsbild.
2. Wählen Sie den Menüpfad Hilfsmittel->ABAP/4-Schlüsselwortdokumentation aus. Sie sehen die Struktur: ABAP/4-SAP's 4GL Programmsprache.
3. Gehen Sie über den Menüpfad Bearbeiten->Suchen. Das Popup Kapitel Suchen wird angezeigt.
4. Im Suchfeld geben Sie new-page print an.
5. Klicken Sie die Schaltfläche Weiter an. Es wird wieder zur Strukturanzeige zurückgesprungen, wobei der Cursor auf die Zeile new-page print positioniert ist.
6. Dopppelklicken Sie auf diese Zeile. Die Dokumentation wird angezeigt.
Die Anweisung skip
Die Anweisung skip ermöglicht Ihnen:
■ das Erzeugen von Leerzeichen. ■ die aktuelle Ausgabeposition auf der aktuellen Seite nach oben und unten zu verschieben.
Die Syntax der Anweisung skip
skip [n | to line n]
wobei:
■ n eine numerische Variable oder Literal ist.

Ohne jeglichen Zusatz erzeugt skip eine Leerzeile. skip n erzeugt n Leerzeilen. Ist n kleiner als 1, werden keine Leerzeichen generiert. Eine skip-Anweisung am Ende der Seite bewirkt einen Seitenumbruch. skip erzeugt Leerzeilen nach einer write-Anweisung, am Anfang der ersten Seite und am Anfang einer Seite, die durch new-page begonnen wurde. Keine Leerzeilen werden am Anfang einer sonstigen Seite oder am Ende der letzten Seite ausgegeben. Wenn zum Beispiel am Ende einer Seite noch zwei Zeilen zur Verfügung stehen, erzeugt skip 5 zwei Leerzeilen auf der aktuellen Seite. Auf der folgenden Seite werden keine Leerzeilen ausgegeben, da diese nicht die erste Seite sein kann und nicht durch ein new-page erzeugt wurde.
Will man eine Fußzeile auf der letzten Seite des Reports haben, programmiert man skip sy-linct als letzte Programmieranweisung. Diese Anweisung schreibt Fußzeilen. Will man eine neue Seite anstoßen und eine Fußzeile am Ende der aktuellen Seiten haben, programmiert man skip sy-linct statt new-page.
skip to line n bewirkt, daß die nächste Ausgabeposition an den Anfang der n-ten Zeile auf der aktuellen Seite gesetzt wird. skip to line 3 zum Beispiel hat zur Folge, daß die Ausgabe der nächsten write-Anweisung am Anfang der dritten Zeile beginnt. Übersteigt hierbei die Zeilennummer die Anzahl der Zeilen pro Seite, wird diese Anweisung ignoriert.
Das Listing 16.3 zeigt die Anwendung der skip-Anweisung.
Listing 16.3: Die Anweisung skip
1 report ztx1603.2 tables ztxlfa1.3 data n type i.4 select * from ztxlfa1 order by land1.5 on change of ztxlfa1-land1.6 if sy-dbcnt > 1.7 n = sy-linno - 1.8 skip to line n.9 write 35 '*** Last Vendor With This Country Code ***'.10 endif.11 write / ztxlfa1-land1.12 endon.13 write: /4 ztxlfa1-lifnr, ztxlfa1-name1.14 endselect.
Es wird folgende Liste erstellt:

CA1000 Parts Unlimited 1010 Industrial Pumps Inc. 1020 Chemical Nation Ltd. 1030 ChickenFeed Ltd. 1050 The Bit Bucket 1060 Memory Lane Ltd. 1070 Flip My Switch Inc. *** Last Vendor With This Country Code ***CC V9 Code Now, Specs Later Ltd. V10 Duncan's Mouse Inc. *** Last Vendor With This Country Code ***DE V6 Anna Banana Ltd.V11 Wiener Schnitzel Inc. V12 Sauerkraut AG *** Last Vendor With This Country Code ***US V8 Smile When You Say That Ltd.1040 Motherboards Inc.1080 Silicon Sandwich Ltd.1090 Consume Ltd.2000 Monitors and More Ltd.V1 Quality First Ltd.V2 OverPriced Goods Inc.V3 Fluffy Bunnies Ltd.V4 Moo like a Cow Inc.V5 Wolfman Sport Accessories Inc.V7 The Breakfast Club Inc.
Bei Änderung von ztx-land1:
■ Es wird in den Verarbeitungsblock von Zeile 5 bis 12 verzweigt. ■ In Zeile 6 wird mit sy-dbcnt der aktuelle Schleifendurchlauf abgefragt. Bei der
Verarbeitung des ersten Datensatzes steht sy-linno auf 1, so daß nicht in den if-Verarbeitungsblock verzweigt wird.
■ Für die fortlaufenden Datensätze enthält sy-linno in Zeile 7 die aktuelle Zeilennummer. In dieser Zeile wird die nächste write-Anweisung ausgegeben.
■ Zeile 8 setzt die Ausgabeposition auf Zeile n, welche die vorher ausgegebene Zeile darstellt. ■ Zeile 9 kennzeichnet dann in dieser Zeile den letzten Kreditor der jeweiligen Gruppe.
Die Anweisung back
Benutzen Sie die Anweisung back, um die aktuelle Ausgabeposition zurückzusetzen:
■ auf die erste Zeile der aktuellen Seite (nach der top-of-page-Verarbeitung).■ auf die nächste Zeile, nachdem eine reserve-Anweisung ausgeführt wurde.
Syntax für die Anweisung back

Die Syntax für die back-Anweisung ist:
back.
wobei:
■ back, innerhalb des Ereignisses top-of-page ausgeführt, zur ersten Ausgabezeile von top-of-page gesprungen wird.
Wenn Sie in der report-Anweisung no standard page heading festlegen, wird zur ersten Zeile der aktuellen Seite gesprungen. Bei Verwendung der Standardüberschriftzeile wird die Ausgabeposition auf die darauffolgende Zeile gesetzt.
Ein Beispielprogramm sehen Sie im Listing 16.4.
Listing 16.4: Die Anweisung back
1 report ztx1604 no standard page heading.2 data n type i.3 do 4 times.4 write: /(4) sy-index.5 enddo.6 back.7 do 4 times.8 n = sy-index * 10.9 write: /10(4) n.10 enddo.1112 top-of-page.13 write: / 'This was my title'.14 uline.15 back.16 write 6 'is '.17 skip.
Es wird folgende Liste ausgegeben:
This is my title -----------------------1 10 2 20 3 30 4 40
■ Beim ersten Durchlauf stößt Zeile 4 das Ereignis top-of-page (Zeile 12) an.

■ Zeile 13 gibt die Überschriftzeile aus. Zeile 14 unterstreicht diese. ■ Zeile 15 setzt die aktuelle Ausgabeposition auf die erste Zeile der Liste. ■ Zeile 16 überschreibt 'was' mit 'is'.■ Zeile 17 setzt dann die Ausgabeposition eine Zeile weiter. Die zweite Zeile der Liste ist nun
die aktuelle Ausgabezeile. ■ Die Programmsteuerung springt nun zu Zeile 4. Es wird das Zeichen '/' für eine neue Zeile
umgesetzt. Beim ersten Schleifendurchlauf erfolgt somit die Ausgabe in der dritten Zeile. Die folgenden Werte werden in die nächsten Zeilen geschrieben.
■ Zeile 6 springt zur ersten Zeile nach top-of-page zurück (Zeile 2 der Ausgabeliste). ■ Die Schleife von Zeile 7 bis 10 überschreibt die Augabeliste ab Zeile 3. Diese Daten werden
rechts von den schon vorhandenen Daten ab Spalte 10 ausgegeben.
Die Anweisung position
Die Anweisung position wird benutzt, um die Ausgabe auf eine bestimmte Spaltenposition zu setzen. Zum Beispiel wird durch skip to line 2. position 3. write 'Hi' in der dritten Spalte der zweiten Zeile das Wort Hi ausgegeben.
Die Syntax von position
position vl.
wobei:
vl hierbei eine numerische Variable oder Literal ist.
Listing 16.5: Die Anweisung position
1 report ztx1605.2 data n type i.3 do 4 times.4 do 4 times.5 position sy-index.6 write 'A'.7 enddo.8 new-line.9 enddo.1011 skip.12 do 4 times.13 do 4 times.14 position sy-index.15 write 'A'.

16 enddo.17 skip.18 enddo.
Es wird folgende Liste ausgegeben:
AAAAAAAAAAAAAAAA
AAAA
AAAA
AAAA
AAAA
■ Zeile 3 startet eine do-Schleife.■ In dieser Schleife wird in Zeile 4 eine zweite Schleife gestartet. Zeile 5 setzt die
Spaltenposition gleich mit der Anzahl der Schleifendurchläufe. Zeile 6 bewirkt somit, daß viermal der Buchstabe A (Spalte 1 bis 4) in jeweils vier Zeilen ausgegeben wird.
■ Zeile 8 setzt die Ausgabeposition um eine Zeile weiter nach unten. ■ Zeile 11 erzeugt eine Leerzeile. ■ Der Abschnitt zwischen den Zeilen 12 bis 18 entspricht dem Coding zwischen den Zeilen 3 bis
9 mit dem Unterschied, das statt new-line in Zeile 17 skip benutzt wird. Als Ergebnis stehen zwischen den eigentlichen Ausgabezeilen noch zusätzliche Leerzeichen.
Die position-Anweisung, der eine write-Anweisung folgt, entspricht einer einzelnen write-Anweisung (siehe Tag 15).
Die Anweisung set blank lines
Ist das Ergebnis einer write-Anweisung eine Leerzeile, wird ihre Ausgabe im Normalfall unterdrückt. Soll zum Beispiel mit write eine Variable angezeigt werden, deren Inhalt nur aus Leerzeichen besteht, wird hierfür keine Leerzeile ausgegeben. Mit set blank lines läßt sich dieses ändern.
Die Syntax für set blank lines

set blank lines on | off.
Folgendes gilt es zu beachten:
■ Der Standardwert steht auf off. ■ Leerzeichen, die durch die skip-Anweisung erzeugt wurden, werden nicht unterdrückt. ■ Leerzeichen, die durch write / ohne Variable erzeugt wurden, werden nicht unterdrückt.
Zum Beispiel erzeugt write / immer eine Leerzeile, während write / '' nur dann eine Leerzeile erzeugt, wenn set blank lines auf on steht.
Listing 16.6: Die Anweisung set blank lines
1 report ztx1606.2 data: f1, f2, f3.3 write: / 'Text 1'.4 write: / f1, / f2, / f3.5 write: / 'Text 2'.6 skip.78 set blank lines on.9 write: / 'Text 3'.10 write: / f1, / f2, / f3.11 write: / 'Text 4'.1213 set blank lines off.14 skip.15 write: / 'Text 5'.16 write: / f1, / f2, / f3.17 write: / 'Text 6'.
Das Programm ergibt folgende Liste:
Text 1 Text 2
Text 3
Text 4
Text 5 Text 6
■ Zeile 2 definiert drei Variablen. Alle drei haben die Zeichenlänge 1 und einen Standardinitialwert von Leerstellen.

■ Die skip-Anweisung in Zeile 6 erzeugt immer eine Leerzeile. ■ Zeile 8 ermöglicht der write-Anweisung komplette Leerzeilen auszugeben. ■ Aus Zeile 10 ergeben sich drei Leerzeilen. ■ Zeile 13 setzt set blank lines wieder zurück auf off.■ Zeile 14 erzeugt eine Leerzeile. ■ Zeile 16 wird bei der Ausgabe ignoriert.
Zusammenfassung
■ Benutzen Sie new-line, um eine neue Zeile zu beginnen oder eine Zeile auf dem Bildschirm zu fixieren. Horizontales Schieben hat dann auf die nächste ausgegebene Zeile keine Auswirkung mehr.
■ Benutzen Sie new-page, um einen Seitenumbruch zu erzeugen, Titel und Überschriftszeilen ein- und auszublenden, die Zeilenanzahl pro Seite und die Zeichenanzahl pro Zeile für einzelne Seiten zu ändern und die Ausgabe in den Spoolbereich zu leiten.
■ Benutzen Sie skip, um Leerzeilen zu erzeugen. skip to line positioniert die Ausgabe auf eine bestimmte Zeile.
■ Benutzen Sie back, um zum Seitenanfang oder zum Beginn einer Zeilengruppe zu springen. ■ Benutzen Sie position, um die nächste Spalte für die Ausgabe zu bestimmen. ■ Benutzen Sie set blank lines, um bei der Ausgabe von Variablen, die leer sind,
Leerzeilen zu erzeugen.
Erlaubt Nicht erlaubt
Benutzen Sie Symbole und Ikonen in Ihrem Report, um die Lesbarkeit zu verbessern.
Codieren Sie eine Seitengröße nicht hart. Erlauben Sie den Benutzern, sie zu spezifizieren, wenn sie den Report ausdrucken.
Legen Sie keine Reports an, die breiter als 132 Zeichen sind, wenn der Benutzer ihn ausdrucken will. Die meisten Drucker können nicht mehr als 132 Zeichenbreite drucken.
Fragen & Antworten
Frage:Ich verstehe nicht ganz den Unterschied zwischen skip und new-line. Beide bewirken doch, daß die nächste write-Anweisung in einer neuen Zeile beginnt?
Antwort:Der Zweck von skip ist, Leerzeilen zu erzeugen. New-line bewirkt aber, daß die nächste Ausgabe in einer neuen Zeile beginnt, erzeugt dabei aber keine Leerzeilen.

Workshop
Der Workshop versucht auf zwei Arten, das neu erlangte Wissen dieses Kapitels zu festigen. Im Quiz-Abschnitt werden Fragen gestellt, damit Sie den dargestellten Stoff vertiefen können. Der Übungsabschnitt soll Ihnen Praxis im Umgang mit den einzelnen Anweisungen geben. Die Antworten zum Quiz stehen im Anhang B.
Kontrollfragen
1. Welche Anweisung verwenden Sie, um die gleiche Zeile zu überschreiben?
2. Wann würden Sie skip sy-linct statt new-page benutzen, um Fußzeilen auszugeben?
Übung 1
Erläutern Sie den Ablauf des nachstehenden Programms.
Listing 16.7: top-of-page, position und skip
report zty1607.data n type i.do 4 times.do 4 times.position sy-index.write 'A'.enddo.add 1 to n.skip to line n.enddo.
top-of-page.n = sy-linno.
Folgende Liste wird daraufhin angezeigt:
AAAAAAAAAAAAAAAA

Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 17
Modularisierung: Ereignisse und Unterprogramme
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, sind Sie fähig,
■ die verschiedenen Typen der Modularisierungseinheiten in ABAP/4 zu unterscheiden ■ die ABAP/4-Ereignisse zu verstehen ■ die Ereignisse initialization, start-of-selection und end-of-selection zu
benutzen■ interne und externe Unterprogramme zu schreiben ■ globale, lokale und statische Variablen sowie Tabellenarbeitsbereiche zu definieren ■ die Auswirkungen von exit, check und stop innerhalb von Ereignissen und
Unterprogrammen zu verstehen
Modularisierungseinheiten in ABAP/4
Eine Modularisierungseinheit ist wie eine Muschel, in die der Programmcode gelegt werden kann. Sie erlaubt Ihnen, eine Gruppe von Zeilen von dem Rest des Programmcodes zu trennen und zu einer bestimmten Zeit auszuführen. Die Zeilen einer Modularisierungseinheit agieren fast wie ein kleines Programm, das von einem anderen Programm aufgerufen werden kann.
ABAP/4 bietet drei Typen von Modularisierungseinheiten:
■ Ereignisse■ Unterprogramme■ Funktionsbausteine
Dieses Kapitel erklärt Ereignisse und Unterprogramme. Das nächste Kapitel erklärt Funktionsbausteine.

Nutzen Sie Modularisierungseinheiten, um redundanten Programmcode zu vermeiden und Ihr Programm einfacher lesbar zu machen. Nehmen Sie zum Beispiel an, daß Sie eine Reihe von Anweisungen haben, die eine Adresse formatieren, und Sie müssen an verschiedenen Stellen des Programms Adressen formatieren. Anstatt den Programmcode zu duplizieren, können Sie diesen Programmcode in einer Modularisierungseinheit plazieren und diese immer aufrufen, wenn sie eine Adresse formatieren wollen.
Ereignisse
Entgegen dem ersten Anschein sind ABAP/4-Programme ereignisgesteuert. Ein gutes Verständnis von Ereignissen ist der Schlüssel zu einem guten Verständnis von ABAP/4.
Ereignisse definieren
Ein Ereignis ist ein Etikett, das einen Abschnitt vom Programmcode identifiziert. Der Abschnitt vom Programmcode, der mit einem Ereignis assoziiert ist, beginnt mit dem Ereignisnamen und endet, wenn der nächste Ereignisname im Programmcode auftaucht. In Programm 17.1 sind initialization,start-of-selection und end-of- selection die Ereignisnamen. Ereignisnamen sind reservierte Wörter. Sie können keine neuen Ereignisse definieren - Sie können nur die existierenden nutzen.
Listing 17.1: Drei grundlegende Ereignisse
1 report ztx1701.2 initialization.3 write / '1'.45 start-of-selection.6 write / '2'.78 end-of-selection.9 write / '3'.
Der Programmcode in Programm 17.1 erzeugt folgende Ausgabe:
123
■ Zeile 2 identifiziert den Beginn des Ereignisses initialization.■ Zeile 3 ist assoziiert mit dem Ereignis initialization. Wenn dieser Zeile noch mehrere
Zeilen folgen würden, dann würden sie alle zu diesem Ereignis initialization gehören.■ Zeile 4 markiert das Ende des Programmcodes, der zu initialization gehört, und den
Beginn des Ereignisses start-of-selection.

■ Zeile 6 gehört zu dem Ereignis start-of-selection.■ Zeile 8 markiert die untere Grenze des Programmcodes, der zu dem Ereignis start-of-selection gehört und die obere Grenze, die zu dem Ereignis end-of- selectiongehört.
■ Zeile 9 gehört zu dem Ereignis end-of-selection.■ Die untere Grenze des Programmcodes, der zu end-of-selection gehört, wird durch das
Ende des Programms markiert. ■ Wenn Sie dieses Programm ablaufen lassen, dann werden die Ereignisse durch ein
Treiberprogramm ausgelöst. Die folgenden Absätze erklären dieses Konzept im Detail.
Ein Treiberprogramm ist ein Programm, das ein anderes (getriebenes) Programm kontrolliert. SAP liefert Treiberprogramme mit dem R/3-System aus. Sie können das getriebene Programm zur Verfügung stellen. Wenn Sie ein Programm starten, dann wird das Treiberprogramm immer als erstes gestartet und ruft so die Ereignisse in Ihrem Programm auf. Anders ausgedrückt, ein Treiberprogramm startet zuerst und kontrolliert, wenn Ihr Programm die Kontrolle erhält. Das war in allen Programmen so, die Sie bis jetzt geschrieben haben; bisher waren Sie sich dessen nur nicht bewußt. Lesen Sie bitte diesen Absatz sehr sorgfältig. Um es noch einmal zu wiederholen: Wenn Sie Ihr Programm starten, wird zuerst das Treiberprogramm gestartet und kontrolliert Ihr Programm, indem es die Ereignisse darin aufruft.
Der Programmcode, der mit einem Ereignis assoziiert ist, wird durch einen Ausdruck des Treiberprogramms ausgelöst. Ereignisse werden durch das Treiberprogramm mit einer definierten und vorhersagbaren Reihenfolge ausgelöst. Abbildung 17.1 illustriert diesen Punkt.
Abbildung 17.1: Das Treiberprogramm und die Ereignisse, die ausgelöst werden können.
Abbildung 17.1 zeigt einen Pseudo-Programmcode im Treiberprogramm. Die rechte Seite der Abbildung zeigt den richtigen Programmcode. Wenn das Programm ztx1701 ausgeführt wird, startet der Treiber auf der linken Seite der Abbildung zuerst. Das Programm folgt dann dieser Sequenz:
■ Es löst das Ereignis initialization aus. Das resultiert in der Ausführung des Programmcodes, der zu dem Ereignis initialization gehört. Wenn Sie kein Ereignis initialization in Ihrem Programm verwenden, dann überspringt das Treiberprogramm diesen Schritt.

■ Dann wird das Auswahlbild für Ihr Programm gezeigt. (Ein Auswahlbild ist das Bild, das die Eingabefelder der Anweisung parameter enthält.) Wenn Ihr Programm kein Auswahlbild enthält, dann wird dieser Schritt übersprungen.
■ Es löst das Ereignis start-of-selection aus. Das resultiert in der Ausführung des Programmcodes, der zu dem Ereignis start-of-selection gehört. Wenn Sie kein Ereignis start-of-selection in Ihrem Programm verwenden, dann überspringt das Treiberprogramm diesen Schritt.
■ Es löst das Ereignis end-of-selection in Ihrem Programm aus und führt den zugehörigen Programmcode aus. Wenn Sie kein end-of-selection codiert haben, dann wird dieser Schritt übersprungen.
■ Dann wird dem Nutzer die Ausgabeliste gezeigt.
Die Reihenfolge der Ausführung der Ereignisse wird durch das Treiberprogramm bestimmt, nicht durch Ihr Programm. Deshalb können Sie die Ereignisse in jeder beliebigen Reihenfolge codieren, die Reihenfolge der Ausführung bleibt immer dieselbe. Listing 17.2 illustriert diesen Punkt.
Listing 17.2: Ausgelöste Ereignisse, deren Reihenfolge durch das Treiberprgramm bestimmt wird.
1 report ztx1702.2 data f1 type i value 1.34 end-of-selection.5 write: / '3. f1 =', f1.67 start-of-selection.8 write: / '2. f1 =', f1.9 f1 = 99.1011 initialization.12 write: / '1. f1 =', f1.13 add 1 to f1.
Der Programmcode in Listing 17.2 erzeugt folgende Ausgabe:
1. f1 = 12. f1 = 23. f1 = 99
■ Wenn Sie ztx1702 starten, dann startet das Treiberprogramm zuerst. ■ Es löst das Ereignis initialization aus. ■ Der Programmcode, der mit initialization assoziiert ist, wird ausgeführt (Zeile 12 und
13). Der Wert von f1 wird ausgegeben, und 1 wird addiert. Die Kontrolle wird dann an das Treiberprogramm zurückgegeben.
■ Das Treiberprogramm sucht dann das Auswahlbild. Für dieses Programm gibt es kein Auswahlbild, so daß dann das Ereignis start-of-selection gesucht wird. In Zeile 7 wird

es gefunden, und so werden die Zeilen 8 und 9 ausgeführt. Dann wird die Kontrolle an das Treiberprogramm zurückgegeben.
■ Das Treiberprogramm sucht dann das Ereignis end-of-selection. In Zeile 4 wird es gefunden, und die Programmausführung beginnt in Zeile 5. Lediglich die Zeile 5 gehört zu dem Ereignis end-of-selection. Sie wird ausgeführt und die Kontrolle an das Treiberprogramm zurückgegeben.
■ Der Treiber gibt am Ende die Liste für den Benutzer aus.
Dieses Beispiel illustriert, daß die Ereignisse in unterschiedliche Reihenfolge gebracht werden können und sich die Ausführungsreihenfolge trotzdem nicht ändert. Die Ausführungsreihenfolge ist immer initialization, start-of-selection, end-of-selection . Es gibt noch andere Ereignisse; einige erscheinen nach initialization und andere zwischen start-of-selection und end-of-selection.
Programmierer positionieren die Ereignisse in der Reihenfolge, in der sie ausgelöst werden, um die Programme verständlicher zu machen.
Es gibt elf verschiedene Ereignisse in ABAP/4, die in Tabelle 17.1 nach ihrer Auslösung kategorisiert sind.
Tabelle 17.1: ABAP/4-Ereignisse
Kategorie Ereignis
Treiber initializationat selection-screenstart-of-selectiongetend-of-selection
Benutzer at line-selectionat pfnat user-command
Programm top-of-pageend-of-page
Treiberereignisse werden durch das Treiberprogramm ausgelöst. Benutzerereignisse werden durch den Benutzer über die Benutzerschnittstelle ausgelöst. Programmereignisse sind solche, die in dem Programm ausgelöst werden. Dieses Kapitel beschreibt detailliert die Benutzung von initialization, start-of-selection und end-of-selection . Beachten Sie, daß einige dieser Ereignisse zwischen start-of-selection und end-of-selection erscheinen.
In dem vorangegangenen Tag »Formatierungstechniken, Teil 2« haben Sie etwas über die Ereignisse top-of-page und bottom-of-page gelernt. Die Informationen in diesem Tag beziehen sich auch

auf diese Ereignisse, allerdings werden sie durch Anweisungen im Programm ausgelöst und nicht vom Treiber.
Spezielle Überlegungen bei Benutzung von write innerhalb von Ereignissen
Ereignisse haben zwei ungewöhnliche Auswirkungen auf die Anweisung write:
■ Wenn ein Programm ein Auswahlbild hat und Sie die Anweisung write in einem Ereignis vor start-of-selection ausführen, dann werden Sie keine Ausgabe von dieser Anweisung sehen. Haben Sie z.B. die Anweisung parameters in Ihrem Programm, dann wird ein Auswahlfenster erzeugt, in dem der Benutzer die Parameterwerte eingeben kann. Wenn Sie in diesem Programm write in dem Ereignis initialization ausführen, werden Sie keine Ausgabe sehen.
■ Ein neues Ereignis beginnt bei der Ausgabe immer mit einer neuen Zeile. Wenn Sie z.B. die Anweisung write in start-of-selection ausführen, dann wird write in end-of-selection in einer neuen Zeile beginnen. Sie können skip to line benutzen, um in der gleichen Zeile fortzufahren, falls notwendig.
top-of-page auslösen
Dieser Abschnitt beschreibt wie top-of-page in Verbindung mit Treiberprogrammereignissen ausgelöst wird. Wenn Ihr Programm kein Auswahlbild hat, löst die erste write-Anweisung top-of-page aus. Wenn Ihr Programm ein Auswahlbild hat, dann kann top-of-page zweimal ausgelöst werden:
■ von der ersten write-Anweisung, die ausgeführt wird, bevor das Auswahlbild gezeigt wird ■ von der ersten write-Anweisung, nachdem das Auswahlbild gezeigt wurde
Allerdings müssen Sie sich nur Gedanken machen, wenn Sie etwas Ungewöhnliches in top-of-page machen, wie Dateien öffnen oder Daten initialisieren.
Wenn top-of-page zweimal ausgelöst wird, dann werden Sie die Ausgabe der write- Anweisung nur bei dem zweiten Zeitpunkt der Auslösung sehen. Die Ausgabe des ersten Zeitpunktes wird verworfen. Diese doppelte Auslösung führt normalerweise aus folgenden Gründen nicht zu Problemen:
■ Sie können keine Ausgabe durch write sehen, bevor das Auswahlbild gezeigt wird, so daß Sie es normalerweise nicht vorher codieren.
■ Nur das Ereignis top-of-page enthält für gewöhnlich write-Anweisungen, und die Ausgabe von der ersten Auslösung wird verworfen, so daß kein Schaden entsteht, wenn es zweimal ausgelöst wird.

Die Variation write to der Anweisung write wird nicht durch top-of-pageausgelöst.
Vorgabe start-of-selection
Wenn vor der ersten ausführbaren Anweisung in Ihrem Programm kein Ereignisname steht, wird das System zur Laufzeit automatisch start-of-selection vor die erste Zeile des ausführbaren Programmcodes einfügen. Wenn Sie keine Ereignisse programmiert haben oder Sie den Programmcode am Beginn des Programms ohne Ereignis codiert haben, wird start-of-selection angenommen. Listing 17.3 zeigt ein Beispiel mit einem Programm, das sowohl ein Auswahlbild als auch Ereignisse enthält. Es enthält auch ein programmgetriebenes Ereignis - top-of-page.
Listing 17.3: start-of-selection wird automatisch vor der ersten Programmzeile eingefügt.
1 report ztx1703 no standard page heading.2 parameters p1(8).34 write: / 'p1 =', p1.56 initialization.7 p1 = 'Init'.89 end-of-selection.10 write: /(14) sy-uline,11 / 'End of program'.1213 top-of-page.14 write: / 'This is My Title'.15 skip.
Der Programmcode in Listing 17.3 erzeugt folgende Ausgabe:
This is My Titlep1 = INIT --------------End of program
■ Wenn Sie Programm ztx1703 ausführen, startet zuerst das Treiberprogramm. Da es Programmcode am Beginn des Programms ohne ein Ereignis gibt, wird start- of-selection automatisch in Zeile 3 eingefügt.
■ Das Treiberprogramm löst das Ereignis initialization aus. Zeile 7 wird ausgeführt und weist p1 den Wert 'Init' zu. Die Kontrolle wird an das Treiberprogramm zurückgegeben.
■ Da es ein Auswahlbild in diesem Programm gibt, wird dieses nun gezeigt. (Siehe Abb. 17.2) Der Wert, der p1 in Zeile 7 zugewiesen wurde, wird in dem Eingabefeld sichtbar.
■ Der Benuzter drückt Ausführen auf dem Auswahlbild. Die Kontrolle wird an das

Treiberprogramm zurückgegeben, das dann das Ereignis start-of-selection auslöst. ■ Da start-of-selection in Zeile 3 einfügt wurde, wird die Kontrolle an ztx1703
gegeben mit dem Start in Zeile 4. ■ Zeile 4 wird ausgeführt. Da dieses die erste write-Anweisung ist, die nach start- of-selection ausgeführt wird, löst es das Ereignis top-of-page aus. Die Kontrolle wird an Zeile 14 gegeben.
■ Zeile 14 schreibt This is my Title. Zeile 15 schreibt ein Leerzeile. Die Kontrolle kehrt zur Zeile 4 zurück.
■ Zeile 4 schreibt den Wert von p1.■ Der Treiber löst dann das Ereignis end-of-selection aus. Die Kontrolle wird an Zeile 10
übergeben.■ Zeile 10 schreibt eine horizontale Linie für 14 Byte. ■ Zeile 11 schreibt End of program. Die Kontrolle wird an das Treiberprogramm
zurückgegeben.
Sie können eine Bedingung nicht mit einem Ereignis verknüpfen oder ein Ereignis in einer Schleife plazieren. Wenn Sie es dennoch tun, wird ein Syntaxfehler erzeugt. Der Programmcode in Listing 17.4 erzeugt z.B. einen Syntaxfehler.
Listing 17.4: Fügen Sie ein Ereignis weder in einer Schleife noch in einer Bedingung ein.
1 report ztx1704.2 data f1.34 start-of-selection.5 f1 = 'A'.67 if f1 = 'A'.8 end-of-selection.9 write: / f1.10 endif.

Abbildung 17.2: Das Auswahlbild für das Programm ztx1703
Der Programmcode in Listing 17.4 erzeugt einen Syntaxfehler: Die Schachtelung ist nicht korrekt: Vor der Anweisung end-of-selection muß die mit if begonnene Kontrollstruktur durch endifabgeschlossen werden.
Ereignisnamen haben eine höhere Priorität als APAB/4-Anweisungen. Die Anweisung if in Zeile 7 gehört zu dem Ereignis start-of-selection. Die Anweisung endif in Zeile 10 gehört zu dem Ereignis end-of-selection. Sie schließen damit alle offenen Bedingungen und Schleifen in dem Ereignis. Deshalb müßte dieses Programm die Anweisung endif vor dem Ereignis end-of-selection haben. Weil es ein endif in dem Ereignis end-of-selection in Zeile 10 gibt, müßte dieses endif entfernt werden, damit das Programm läuft.
Sie sollten Datendefinitionen nicht in Ereignisse packen. Obwohl das keine Syntaxfehler erzeugt, ist es schlechter Programmierstil. Alle Datendefinitionen sollten zu Beginn des Programms gemacht werden.
Jedes Ereignis hat einen spezifischen Zweck und wird gebraucht, um eine bestimmte Aufgabe zu erfüllen. Ich werde später noch näher darauf eingehen. Wenn Sie keine Ereignisse in Ihrem Programm sehen, erinnern Sie sich daran, daß ein Ereignis immer existiert - start-of-selection.

Ein Ereignis verlassen
Sie können ein Ereignis jederzeit verlassen, wenn Sie eine der folgenden Anweisungen benutzen:
■ exit■ check■ stop
Bitte schauen Sie sich jetzt noch einmal die Funktionalität der Anweisung check an (erläutert am 10. Tag).
Die folgenden Ausführungen beschreiben die Auswirkungen von check und exit, wenn sie außerhalb einer Schleife programmiert werden. Der Effekt der Anweisung stop ist sowohl innerhalb als auch außerhalb einer Schleife der gleiche.
Obwohl zu diesem Zeitpunkt nur drei Ereignisse im Detail besprochen worden sind, ist dieses Kapitel so allgemein geschrieben, daß es auch für die anderen Ereignisse gültig ist.
In allen Ereignissen:
■ verläßt check sofort das aktuelle Ereignis, und der Prozeß fährt mit dem nächsten Ereignis fort (oder mit der nächsten Aktion; wie Anzeige des Auswahlbildes oder der Ausgabe).
■ verläßt stop sofort das aktuelle Ereignis und geht direkt zu dem Ereignis end-of- selection. Die Anweisung stop innerhalb von end-of-selection verläßt das Ereignis. Es erzeugt keine Endlosschleife.
In allen Ereignissen vor start-of-selection:
■ haben exit und check dasselbe Verhalten. Sie verlassen beide sofort das aktuelle Ereignis, und der Prozeß fährt mit dem nächsten Ereignis fort (oder mit der nächsten Aktion; wie Anzeige des Auswahlbildes oder der Ausgabe).
In start-of-selection und Ereignissen, die danach erscheinen,
■ terminiert exit den Bericht und zeigt die Ausgabeliste. Eine einzige Ausnahme existiert: innerhalb von top-of-page verhält sich exit wie check.
■ verläßt check das Ereignis, und der Prozeß fährt mit dem nächsten Ereignis fort (oder mit der nächsten Aktion; wie Anzeige der Ausgabeliste).

Benutzen Sie stop nicht mit folgenden Ereignissen: initialization, atselection- screen output, top-of-page und end-of-page. Technisch kann stop mit top-of- page und end-of-page arbeiten, wenn Sie es unterlassen, danach die Anweisung write in end-of-selection zu benutzen. Im Fall von top-of-page führt write zu einem Programmabbruch; im Fall von end-of-case verlieren Sie Ihre Ausgabe. Es ist sicherer, es überhaupt nicht mit diesen Ereignissen zu verwenden.
check, exit und stop setzen nicht den Wert von sy-subrc. Wenn Sie einen Wert setzen wollen, können Sie einen numerischen Wert zuweisen.
Der Bericht in Listing 17.5 erlaubt Ihnen, die Auswirkungen dieser Anweisungen in verschiedenen Ereignissen auszuprobieren. Kopieren Sie es, und Sie entfernen die Kommentare, um mit den Variationen zu experimentieren.
Listing 17.5: Effekte von exit, check und stop in Ereignissen
1 report ztx1705 no standard page heading line-count 6(2).2 *in events before start-of-selection:3 * - exit and check have the same behavior. They both leave the event4 * and processing continues with the next event or action.5 * - stop goes directly to the end-of-selection event6 * (don't use stop in initialization or at selection-screen output)78 *in start-of-selection and subsequent events:9 * - exit terminates the report and shows the output list10 * exception: top-of-page: exit leaves the event11 * - check leaves the event and processing continues with the next one.12 * - stop goes directly to the end-of-selection event1314 "execute an:15 parameters: exit_sos radiobutton group g1, "exit in start-of-selection16 exit_eos radiobutton group g1, "exit in end-of-selection17 chck_sos radiobutton group g1, "check in start-of-selection18 chck_eos radiobutton group g1, "check in end of selection19 stop_sos radiobutton group g1, "stop in start-of-selection20 stop_eos radiobutton group g1, "stop in end-of-selection21 none radiobutton group g1. "no stop, exit or check22

23 initialization.24 * exit. "exits event25 * check 1 = 2. "exits event26 * stop. "don't do this27 chck_sos = 'X'.2829 at selection-screen output.30 * exit. "exits event31 * check 1 = 2. "exits event32 * stop. "don't do this33 message s789(zk) with 'at selection-screen output'.3435 at selection-screen on radiobutton group g1.36 * exit. "exits event37 * check 1 = 2. "exits event38 * stop. "goes to end-of-selection39 message i789(zk) with 'at selection-screen on rbg'.4041 at selection-screen.42 * exit. "exits event43 * check 1 = 2. "exits event44 * stop. "goes to end-of-selection45 message i789(zk) with 'at selection-screen'.4647 start-of-selection.48 write: / 'Top of SOS'.49 if exit_sos = 'X'.50 exit. "exits report51 elseif chck_sos = 'X'.52 check 1 = 2. "exits event53 elseif stop_sos = 'X'.54 stop. "goes to end-of-selection55 endif.56 write: / 'Bottom of SOS'.5758 end-of-selection.59 write: / 'Top of EOS'.60 if exit_eos = 'X'.61 exit. "exits report62 elseif chck_eos = 'X'.63 check 1 = 2. "exits report64 elseif stop_eos = 'X'.65 stop. "exits report66 endif.67 write: / 'Bottom of EOS'.68 write: / '1',69 / '2',

70 / '3'.7172 top-of-page.73 write: / 'Title'.74 * exit. "exits event and returns to write statement75 * check 'X' = 'Y'. "exits event and returns to write statement76 * stop. "goto end-of-selection - don't write after it77 uline.7879 end-of-page.80 uline.81 * exit. "exits report82 * check 'X' = 'Y'. "exits event and returns to write statement83 * stop. "goto end-of-selection - don't write after it84 write: / 'Footer'.
■ Zeile 15 definiert eine Gruppe von Auswahlknöpfen. Die Wahl eines Knopfes resultiert in der Ausführung der Anweisung, wie in dem Kommentar erwähnt. Z.B. resultiert die Auswahl choosing exit_sos in der Ausführung der Anweisung exit in dem Ereignis start-of-selection.
■ check 1 = 2 ist hart codiert, so daß immer ein negativer Wert zurückgeliefert wird. ■ Vielleicht wollen Sie die Zeilenzahl erhöhen, um die Ausgabe lesbarer zu machen. Sie ist so
gesetzt, daß das Ereignis buttom-of-page ausgelöst wird.
Rückkehr von der Liste
Lassen Sie uns näher die Ereignisse im Zusammenhang mit einem Bericht, der ein Auswahlbild hat, betrachten. (Erinnern Sie sich, daß die Anweisung parameters ein Auswahlbild generiert.)
Wenn der Benutzer einen Bericht ausführt, löst der Treiber initialization aus und zeigt das Auswahlbild. Nach dem Drücken des Ausführen-Knopfes, löst der Treiber die restlichen Ereignisse aus, das Programm endet, und der Benutzer sieht die Liste. Der Benutzer drückt auf Zurück, um zurückzukehren. Der Treiber startet dann die Verarbeitung und beginnt am Anfang der Ereignisliste. Er löst das Ereignis initialization aus, und alle folgenden Ereignisse werden in der normalen Reihenfolge ausgelöst. Das Ergebnis ist, daß der Benutzer nach dem Drücken von Zurück das Auswahlbild sieht. Es gibt allerdings einen Unterschied bei einem Neustart.
Das Auswahlbild hat eine eigene Kopie aller Variablen, die auf dem Auswahlbild angezeigt werden. Das erste Mal, wenn der Bericht gelaufen ist und das Treiberprogramm wieder die Kontrolle erlangt, nachdem das Ereignis initialization beendet ist, werden die Werte der Programmvariablen in die korrespondierenden Variablen des Auswahlbildes kopiert und angezeigt. Der Benutzer kann die Eingabefelder verändern. Wenn der Benutzer auf Ausführen drückt, speichert der Treiber die Werte des Auswahlbildes in zwei Datenbereichen: in einen, der zu dem Auswahlbild gehört und in Ihre Programmvariablen.
Allerdings geschieht dies lediglich beim ersten Aufruf des Programms. Wenn der Benutzer von der

Liste aus auf Zurück drückt, dann wird initialization erneut ausgelöst. Wenn die Kontrolle an den Treiber zurückkehrt, kopiert es nicht die Programmvariablen in den Bildschirmdatenbereich. Statt dessen werden die existierenden Werte aus dem Bildschirmdatenbereich angezeigt, der immer noch die vom Benutzer eingegebenen Werte enthält. Das Ergebnis ist, daß der Benutzer die Werte sieht, die er zuletzt eingegeben hat, unabhängig davon, was sonst in Ihrem Programm passiert ist. Dann, nachdem der Benuzter den Ausführen-Knopf gedrückt hat, werden die Werte vom Bildschirm in den Bildschirmdatenbereich und dann in sein Programm kopiert. Falls Sie z.B. Werte während initialization gesetzt haben, dann werden diese Werte auf dem Auswahlbild angezeigt, wenn Sie das Programm starten. Wenn Sie den Zurück-Knopf auf dem Auswahlbild drücken, wird initialization ausgeführt, aber die gesetzten Werte werden nicht angezeigt. Der Benutzer sieht statt dessen die Werte, die er eingegeben hat.
Unterprogramme
Ein Unterprogramm ist ein wiederverwendbarer Programmcode. Es ist wie ein kleines Programm, das von einem anderen Punkt in Ihrem Programm aufgerufen werden kann. Innerhalb des Programms können Sie Variablen definieren, Anweisungen ausführen, Ergebnisse berechnen und Ausgaben erzeugen. Um ein Unterprogramm zu definieren, benutzen Sie die Anweisung form, um den Start des Unterprogramms anzuzeigen, und Sie benutzen endform, um das Ende des Unterprogramms anzuzeigen. Der Name des Unterprogramms kann nicht länger als 30 Buchstaben sein.
Um ein Unterprogramm aufzurufen, benutzen Sie die Anweisung perform.
Listing 17.6 zeigt ein Beispielprogramm, das ein Unterprogramm definiert und aufruft.
Listing 17.6: Definition und Aufruf eines Unterprogamms
1 report ztx1706.23 write: / 'Before call 1'.4 perform sub1.5 write: / 'Before call 2'.6 perform sub1.7 write: / 'After calls'.89 form sub1.10 write: / 'Inside sub1'.11 endform.
Der Programmcode in Listing 17.6 erzeugt folgende Ausgabe:
Before Call 1Inside sub1Before call 2Inside sub1

After Calls
■ Zeile 3 wird ausgeführt. ■ Zeile 4 gibt die Kontrolle an Zeile 9. ■ Zeile 10 wird ausgeführt. ■ Zeile 11 gibt die Kontrolle wieder an Zeile 4. ■ Zeile 5 wird ausgeführt. ■ Zeile 6 gibt die Kontrolle an Zeile 9. ■ Zeile 10 wird ausgeführt. ■ Zeile 11 gibt die Kontrolle wieder an Zeile 6. ■ Zeile 7 wird ausgeführt.
Es gibt zwei Typen von Unterprogrammen:
■ Interne Unterprogramme ■ Externe Unterprogramme
Listing 17.6 illustriert den Aufruf eines internen Unterprogramms.
Definition und Aufruf interner Unterprogramme
Die Definition von Unterprogrammen wird gewöhnlich am Ende des Programms nach den Ereignissen plaziert. Die Anweisung form definiert das Ende des vorangegangenen Ereignisses und den Beginn des Unterprogramms. Unterprogramme können nicht innerhalb von Ereignissen verwendet werden.
Die Syntax für die form-Anweisung
form s [tables t1 t2 ...][using u1 value(u2) ...][changing c1 value(c2) ...].---endform.
wobei:
■ s der Name des Unterprogramms ist. ■ t1, t2, u1, u2, c1 und c2 sind Parameter. ■ tables erlaubt es, daß interne Tabellen wie Parameter übergeben werden können. ■ Der Zusatz value kann nicht nach tables benutzt werden. ■ De Zusatz value kann für jede Variable angewendet werden, die mit using oder changing
übergeben wird. ■ ... repräsentiert eine beliebige Anzahl von Programmzeilen.
Die folgenden Punkte finden Anwendung:

■ Alle Zusätze sind optional. ■ Wenn Zusätze codiert werden, müssen sie in der hier gezeigten Reihenfolge erscheinen. Wenn
codiert, muß tables zuerst kommen, dann using und zum Schluß changing.■ Jeder Zusatz kann nur einmal spezifiziert werden. Z.B. kann tables nur einmal erscheinen.
Allerdings können mehrere Tabellen hinter tables aufgeführt werden. ■ Benutzen Sie keine Kommata, um Parameter zu trennen. ■ tables erlaubt nur die Übergabe interner Tabellen - keine Datenbanktabellen. ■ Ein Unterprogramm kann ein anderes Unterprogramm aufrufen. ■ Rekursion wird unterstützt. Ein Unterprogramm kann sich selber aufrufen oder ein anderes
Unterprogramm, das dann dieses aufruft. ■ Definitionen von Unterprogrammen können nicht verschachtelt werden. (Sie können ein
Unterprogramm nicht innerhalb eines anderen Programms definieren.)
Syntax für die Anweisung perform
perform a) sb) n of s1 s2 s3 ...[tables t1 t2 ...][using u1 u2 ...][changing c1 c2 ...].
wobei:
■ s, s1, s2, s3 Unterprogrammnamen sind. ■ n ist eine numerische Variable. ■ a) und b) sind gegenseitig exklusiv. ■ tables, using und changing können entweder in a) oder b) erscheinen. ■ Der Zusatz value() kann nicht mit perform benutzt werden.
Wenn Sie Syntax b) nutzen, können Sie ein Unterprogramm aus einer Liste von Unterprogrammen spezifizieren, damit es ausgeführt wird. Wenn n zum Beispiel den Wert 2 hat, dann wird das zweite Unterprogramm in der Liste ausgeführt. Listing 17.7 illustriert diese Syntax.
Listing 17.7: Aufruf einer Serie von Unterprogrammen
1 report ztx1707.2 do 3 times.3 perform sy-index of s1 s2 s3.4 enddo.56 form s1.7 write: / 'Hi from s1'.8 endform.910 form s2.11 write: / 'Hi from s2'.

12 endform.1314 form s3.15 write: / 'Hi from s3'.16 endform.
Der Programmcode in Listing 17.7 erzeugt folgende Ausgabe:
Hi from s1Hi from s2Hi from s3
■ Zeile 2 startet eine Schleife, die dreimal ausgeführt wird. Sy-index ist der Schleifenzähler und wird mit jedem Schleifendurchlauf hochgezählt.
■ Wenn die Zeile 3 das erste Mal ausgeführt wird, dann hat sy-index den Wert 1. Deshalb wird das erste Unterprogramm (s1) ausgeführt.
■ Wenn die Zeile 3 das zweite Mal ausgeführt wird, dann hat sy-index den Wert 2. Deshalb wird das zweite Unterprogramm (s2) ausgeführt.
■ Wenn die Zeile 3 das dritte Mal ausgeführt wird, dann hat sy-index den Wert 3. Deshalb wird das dritte Unterprogramm (s3) ausgeführt.
Ein Unterprogramm verlassen
Sie können ein Unterprogramm jederzeit mit den folgenden Anweisungen verlassen:
■ exit■ check■ stop
Die folgenden Absätze beschreiben die Auswirkung von check und exit, wenn Sie innerhalb eines Unterprogramms, aber außerhalb einer Schleife codiert werden. Der Effekt von stop ist derselbe innerhalb eines Unterprogramms, unabhängig davon, ob es in einer Schleife codiert ist.
In Unterprogrammen:
■ verlassen check und exit sofort das Unterprogramm, und die Verarbeitung fährt mit der nächsten ausführbaren Anweisung nach perform fort.
■ verläßt stop das Unterprogramm sofort und geht direkt zu dem Ereignis end-of-selection.
■ setzen check, exit und stop nicht den Wert von sy-subrc. Wenn Sie den Wert setzen wollen, weisen Sie ihm vor dem Verlassen einen numerischen Wert zu.
Listing 17.8 illustriert den Effekt dieser Anweisungen innerhalb von Unterprogrammen.
Listing 17.8: Auswirkungen von exit, check und stop innerhalb eines Unterprogramms

1 report ztx1708.2 data f1 value 'X'.34 clear sy-subrc.5 perform s1. write: / 'sy-subrc =', sy-subrc.6 perform s2. write: / 'sy-subrc =', sy-subrc.7 perform s3. write: / 'sy-subrc =', sy-subrc.8 perform s4. write: / 'sy-subrc =', sy-subrc.910 end-of-selection.11 write: 'Stopped, sy-subrc =', sy-subrc.12 if sy-subrc = 7.13 stop.14 endif.15 write: / 'After Stop'.1617 form s1.18 do 4 times.19 exit.20 enddo.21 write / 'In s1'.22 exit.23 write / 'After Exit'.24 endform.2526 form s2.27 do 4 times.28 check f1 = 'Y'.29 write / sy-index.30 enddo.31 write / 'In s2'.32 check f1 = 'Y'.33 write / 'After Check'.34 endform.3536 form s3.37 do 4 times.38 sy-subrc = 7.39 stop.40 write / sy-index.41 enddo.42 endform.4344 form s4.45 write: / 'In s4'.46 endform.

Der Programmcode in Programm 17.8 erzeugt folgende Ausgabe:
In s1sy-subrc = 0In s2sy-subrc = 0
Stopped, sy-subrc = 7
■ Zeile 5 übergibt die Kontrolle an Zeile 17. ■ Zeile 18 beginnt die Schleife. Zeile 19 verläßt die Schleife, nicht das Unterprogramm. ■ Zeile 22 verläßt das Unterprogramm. Die Kontrolle kehrt zu Zeile 6 zurück. ■ Zeile 6 übergibt die Kontrolle an Zeile 26. ■ Zeile 28 übergibt die Kontrolle viermal an Zeile 27. ■ Zeile 32 verläßt das Unterprogramm. Zeile 7 übernimmt wieder die Kontrolle. ■ Zeile 7 übergibt die Kontrolle an Zeile 36. ■ Zeile 39 übergibt die Kontrolle direkt an Zeile 10. ■ Die Ausgabe von Zeile 11 beginnt in einer neuen Zeile, weil ein neues Ereignis eingetreten ist. ■ Zeile 13 verläßt das Ereignis und die Liste wird gezeigt.
Definition globaler und lokaler Variablen
Eine globale Variable wird außerhalb eines Unterprogramms mittels der Anweisungen tables oder data definiert. Auf die globale Variable kann von jedem Punkt des Programms aus zugegriffen werden, d.h. innerhalb eines Unterprogramms oder eines Ereignisses. Es ist gute Programmierpraxis, globale Variablen am Anfang eines Programms vor der ersten ausführbaren Programmzeile zu plazieren.
Eine lokale Variable ist eine Variable, die in einem Unterprogramm mit den Anweisungen local,data oder statistics definiert wird. Man sagt, daß sie lokal für das Unterprogramm verfügbar ist. Variablen, die mit local definiert werden, sind von außerhalb des Unterprogramms zugänglich; Variablen, die mit data oder statistics definiert sind, sind nicht zugänglich. Damit sind Variablen, die mit local definiert sind, wenn ein Unterprogramm ein anderes Unterprogramm aufruft, in dem aufrufenden Unterprogramm sichtbar - Variablen, die mit data oder statistics definiert sind, sind es nicht.
Für lokale Variablen, die mit local oder data definiert sind, wird bei jedem Aufruf des Unterprogramms Speicherplatz zugewiesen. Dieser Speicher wird wieder freigegeben, wenn das Unterprogramm endet, so daß alle Werte verlorengehen. Mit der Anweisung statistics bleibt der Speicher erhalten. Diese Eigenschaften werden jetzt detailliert in diesem Kapitel behandelt.
Definition des tables-Arbeitsbereiches
Variablen, die mit der Anweisung tables definiert werden, sind immer global. Die Plazierung der Anweisung tables am Anfang des Programms definiert eine globale Feldleiste. Die Plazierung

derselben Anweisung innerhalb eines Unterprogramms definiert genauso eine globale Feldleiste mit diesem Namen. Deshalb sollten Sie die Anweisung tables möglichst nicht in einem Unterprogramm definieren, weil sie immer global ist; globale Definitionen sollten immer am Anfang des Programms stehen.
Um einen lokalen Tabellenarbeitsbereich in einem Unterprogramm zu definieren, benutzen Sie die Anweisung local statt tables. Die Syntax ist dieselbe wie bei tables, aber es wird eine lokale Feldleiste statt einer globalen erzeugt. Die Variablen, die mit local definiert werden, sind innerhalb des Unterprogramms und in den aufgerufenen Unterprogrammen sichtbar.
Um genau zu sein, eine Variable ist erst ab dem Punkt bekannt, an dem sie definiert wird. Wenn Sie zum Beispiel in Zeile 10 eine Variable definieren, dann können Sie erst ab Zeile 11 oder später auf diese Variable zugreifen, aber nicht in den Zeilen vor Zeile 10. Im Fall einer lokalen Definition, können Sie auf die globale Version dieser Variable überall vor der Definition local zugreifen.
Listing 17.9 illustriert die Anweisung local.
Listing 17.9: Die Anweisung local
1 report ztx1709.2 tables ztxlfa1.34 SELECT SINGLE * FROM ZTXLFA1 WHERE LIFNR = 'V9'.5 write: / '*-----', ztxlfa1-lifnr.6 perform s1.7 write: / '*S1---', ztxlfa1-lifnr.8 perform s2.9 write: / '*S2---', ztxlfa1-lifnr.1011 form s1.12 write: / ' S1-A', ztxlfa1-lifnr.13 local ztxlfa1.14 select single * from ztxlfa1 where lifnr = 'V1'.15 write: / ' S1-B', ztxlfa1-lifnr.16 perform s2.17 write: / ' S1-C', ztxlfa1-lifnr.18 endform.1920 form s2.21 write: / ' S2-A', ztxlfa1-lifnr.

22 select single * from ztxlfa1 where lifnr = 'V2'.23 write: / ' S2-B', ztxlfa1-lifnr.24 endform.
Der Programmcode in Listing 17.9 erzeugt folgende Ausgabe:
* - - - - -V9S1-A V9S1-B V1S2-A V1S2-B V2S1-C V2*S1 - - -V9S2-A V9S2-B V2*S2 - - -V2
■ Zeile 2 definiert einen globalen Arbeitsbereich mit dem Namen ztxlfa1.■ Zeile 4 selektiert einen Satz der Tabelle ztxlfa1 und plaziert ihn in dem globalen
Arbeitsbereich ztxlfa1.■ Zeile 5 schreibt den Wert V9 aus dem globalen Arbeitsbereich ztxlfa1.■ Zeile 6 übergibt die Kontrolle aus Zeile 11. ■ Zeile 12 schreibt den Wert von lifnr aus dem globalen Arbeitsbereich ztxlfa1.■ Zeile 13 definiert eine lokale Feldleiste ztxlfa1. (Es ist gute Programmierpraxis, die
Definitionen am Anfang des Unterprogramms zu plazieren. Für Demonstrationszwecke in diesem Beispiel ist es nach write plaziert, um den Effekt von local zu zeigen.) Ein neuer Speicherbereich mit dem Namen ztxlfa1 wird zugewiesen. Verweise auf ztxlfa1 werden sich ab diesem Punkt in dem Unterprogramm und in aufgerufenen Unterprogrammen auf die lokale Definition von ztxlfa1 und nicht auf die globale Definition beziehen. Die globale Definition ist nun unzugänglich.
■ Zeile 14 selektiert einen Satz und plaziert ihn in dem lokalen Arbeitsbereich ztxlfa1.■ Zeile 15 schreibt den Wert von dem lokalen Arbeitsbereich. Es ist V1.■ Zeile 16 übergibt die Kontrolle an Zeile 20. Der lokale Speicher bleibt zugewiesen und ist
immer noch sichtbar in s2.■ Zeile 21 schreibt von dem lokalen Speicherbereich, der in s1 definiert ist. ■ Zeile 22 selektiert einen neuen Wert in das lokale ztxlfa1.■ Zeile 24 übergibt die Kontrolle an Zeile 17. Der lokale Speicher bleibt zugewiesen und
unverändert.■ Zeile 17 schreibt den Wert und setzt ihn in den lokalen ztxlfa1 mittels s2.■ Zeile 18 übergibt die Kontrolle an Zeile 6. Der lokale Speicher wird freigegeben und der Wert
von V2 verworfen. ■ Zeile 7 schreibt den Wert von lifnr. Er ist jetzt V9 - derselbe Wert, den es hatte, als s1
aufgerufen wurde. ■ Zeile 8 übergibt die Kontrolle an Zeile 20. ■ Vor der Ausführung von Zeile 21 ist keine lokale Definition von ztxlfa1 erzeugt worden.
Deshalb wird die globale ztxlfa1-lifnr ausgeschrieben.

■ Zeile 22 selektiert einen Satz in den globalen Arbeitsbereich ztxlfa1.■ Zeile 23 schreibt V2 aus dem globalen Arbeitsbereich. ■ Zeile 24 übergibt die Kontrolle an Zeile 8. ■ Zeile 9 schreibt V2 aus dem globalen Arbeitsbereich.
Wenn Sie eine lokale Variable mit demselben Namen einer globalen Variable haben, dann hat die lokale Variable innerhalb des Unterprogramms Vorrang. Konsequenterweise haben Sie keinen Zugriff aus dem Unterprogramm auf die globale Variable mit demselben Namen. Alle Verweise zeigen auf die lokale Variable.
Definition von data
Variablen, die am Anfang des Programms mit der Anweisung data definiert sind, sind global. Die Definition von data in einem Unterprogramm ist lokal. Speicher für diese Variablen wird zugewiesen, wenn das Unterprogramm aufgerufen wird und freigegeben, wenn es zurückkehrt. Wie Variablen, die mit local definiert sind, gehen die Werte in data Variablen verloren, wenn das Unterprogramm zurückkehrt.
Benuzten Sie die Anweisung statics, um eine lokale Variable zu definieren, die nicht freigegeben wird, wenn das Unterprogramm endet. Die Syntax für statics ist dieselbe wie für die Anweisung data. Der Speicher für eine statische Variable wird zugewiesen, wenn das Unterprogramm das erste Mal aufgerufen wird, und bleibt erhalten, bis das Unterprogramm endet. Allerdings ist eine statische Variable nur in dem Unterprogramm selbst sichtbar, nicht in Unterprogrammen, die Sie aufruft. Das nächste Mal, wenn das Unterprogramm aufgerufen wird, wird der Speicher für die Variable wieder sichtbar. Der Wert der Variable wird derselbe sein wie bei der letzten Rückkehr aus dem Unterprogramm.
Der Speicher der statischen Variable gehört zu dem Unterprogramm, das den Speicher zugewiesen hat; diese Variable ist von anderen Programmen aus nicht sichtbar. Wenn Sie statische Variablen mit demselben Namen in mehreren Unterprogrammen zuweisen, sind es unterschiedliche Variablen mit eigenem Speicher und eigenen Werten.
Programm 17.10 illustriert Variablen, die data und statics verwenden:
Listing 17.10: data und statics
1 report ztx1710.2 data: f1 type i value 8,3 f2 type i value 9.45 write: / 'before s1:', f1, f2.6 do 3 times.7 perform s1.8 enddo.9 write: / 'after s1:', f1, f2.10

11 form s1.12 data f1 type i value 1.13 STATICS F2 TYPE I VALUE 1.14 write: / 'inside s1:', f1, f2.15 perform s2.16 f1 = f2 = f2 * 2.17 endform.1819 form s2.20 write: ' S2-', f1, f2.21 endform.
Der Programmcode in Programm 17.9 erzeugt folgende Ausgabe:
before s1: 8 9inside s1: 1 1 S2- 8 9inside s1: 1 2 S2- 8 9inside s1: 1 4 S2- 8 9AFTER S1: 8 9
■ Die Zeilen 2 und 3 definieren die globalen Variablen f1 und f2.■ Zeile 7 übergibt die Kontrolle an Zeile 11. ■ Zeile 12 allokiert neuen Speicher für die lokale Variable f1 und weist einen Wert von 1 zu. ■ Zeile 13 allokiert neuen Speicher für die lokale Variable f2 und weist einen Wert von 1 zu. ■ Zeile 15 übergibt die Kontrolle an Zeile 19. ■ Zeile 20 schreibt von den globalen Variablen f1 und f2.■ Zeile 21 gibt die Kontrolle an Zeile 15 zurück. ■ Zeile 17 gibt die Kontrolle an Zeile 6. Der Speicher von f1 wird frei und der Speicher von f2
wird gehalten. Allerdings wird der Speicher erst wieder sichtbar, wenn das Unterprogramm erneut aufgerufen wird.
■ Die Schleife wird durchlaufen, und Zeile 7 übergibt die Kontrolle wieder an Zeile 11. ■ Zeile 12 allokiert neuen Speicher für f1 und weist den Wert 1 zu. ■ Zeile 13 sorgt dafür, daß der vorher allokierte Speicher für f2 wieder in dem Unterprogramm
sichtbar wird. Der Wert von f2 ist 2; derselbe Wert, der beim Verlassen des Unterprogramms vorhanden war.
Zusammenfassung
■ ABAP/4 hat drei Typen von Modularisierungseinheiten: Ereignisse, Unterprogramme und Funktionsbausteine.
■ Ereignisse existieren in allen Programmen. Wenn kein Ereignis codiert ist, wird das Standard-Ereignis start-of-selection automatisch eingefügt. Werte für Parameter, die auf dem Auswahlbild erscheinen, werden oft durch initialization zugewiesen. end-of-selection ist für die Programmbeendigung, Zusammenfassungen oder ungewöhnliche Beendigungsroutinen vorgesehen. Ereignisse werden durch das Treiberprogramm ausgelöst. Der

Treiber startet immer vor Ihrem Programm und kontrolliert, wann die Ereignisse ausgeführt werden. Sie können keine Bedingungen um einen Ereignisnamen herum plazieren. Alle Ereignisse werden immer ausgelöst, wenn der Benutzer von der Liste zurückkehrt. Allerdings werden die Variablen des Auswahlbildes nicht wieder durch den Programmdatenbereich gefüllt.
■ Benutzen Sie exit, check und stop, um ein Ereignis zu verlassen.
Fragen & Antworten
Frage:Was passiert, wenn zwei Ereignisse denselben Namen im gleichen Programm haben?
Antwort:Wenn Sie zwei Ereignisse mit demselben Namen in dem gleichen Programm codiert haben, dann werden beide Ereignisse in der Reihenfolge, in der sie in Ihrem Programm erscheinen, durch das System ausgelöst.
Frage:Wie kann ich einen Ereignisnamen und eine Anweisung unterscheiden?
Antwort:Wenn Sie ein einfaches Wort gefolgt von einem Punkt sehen, ist es in der Regel ein Ereignis. Darüber hinaus haben Ereignisse keine anderen identifizierbaren Eigenschaften als ihren Namen. Sie sind einfach reservierte Wörter, und um eines wiederzuerkennen, müssen Sie sich ihre Namen merken. Genauso wie Sie sich Schlüsselwörter in Anweisungen merken.
Frage:Kann ich das Treiberprogramm sehen? Kann ich den Treiber sehen? Kann ich einen Treiber erzeugen? Was ist der Unterschied zwischen den verfügbaren Treiberprogrammen?
Antwort:Das Treiberprogramm wird logische Datenbank genannt. Sie können das Treiberprogramm wählen, indem Sie die Felder der logischen Datenbank in dem Programmeigenschaftenbild füllen. Wenn Sie keines spezifizieren, dann wird der Standardwert automatisch zugewiesen. Den Treiber wollen Sie nur wählen, wenn Sie Daten aus der Datenbank lesen und Ihrem Programm automatisch zur Verfügung stellen wollen. Die standardmäßigen logischen Datenbanken lesen nicht von der Datenbank - sie lösen nur Ereignisse aus. Unabhängig von dem Treiber, den Sie wählen, werden die Ereignisse in der gleichen relativen Reihenfolge ausgelöst. Auch wenn Sie Ihr eigenes logisches Datenbankprogramm erstellen, können Sie nicht die relative Reihenfolge der Ereignisse oder ihre Namen wechseln, noch können Sie neue erstellen. Um ein Treiberprogramm zu sehen, starten Sie von dem Quellcode-Editor aus. Wählen Sie den Menüpfad Werkzeuge -> Hilfe über.
Drücken Sie den Auswahlknopf der logischen Datenbank, und geben Sie die logische Datenbankidentifikation ein (z.B. KDF). Sie werden dann die Struktur der logischen Datenbank sehen. Wählen Sie den Menüpfad Springen-> Datenbankprogramm, um das Treiberprogramm zu sehen. Erinnern Sie sich, daß der Programmcode für den Treiber in diesem Kapitel ein Pseudocode war, so daß

Sie keine Anweisungen wie trigger initialization sehen werden. Logische Datenbanken sind ein kompliziertes Thema und benötigen mehrere Kapitel zur vollständigen Beschreibung.
Frage:Wenn ich eine Anweisung write in einem Ereignis ausführe, die start-of-selectionvorausgeht, ist dies nur möglich, wenn es kein Auswahlbild gibt. Wenn es ein Auswahlbild gibt, sehe ich keine Ausgabe. Warum?
Antwort:R/3 benutzt einen sogenannten screen context, um Eingaben zu akzeptieren und Ihnen eine Ausgabe anzuzeigen. Sie können sich den screen context als ein Bild vorstellen. Jeder wird in zwei Phasen ausgeführt: die Dialogphase und die Listphase. Die Dialogphase erscheint immer zuerst, gefolgt von der Liste. Die Dialogphase wird benutzt, um dem Benutzer Eingabefelder zu zeigen, wie solche, die durch die Parameteranweisung generiert werden. Die Listphase wird benutzt, um die Ausgabe der Anweisung write zu zeigen. Beide Phasen nutzen denselben screen context, so daß sie sich überschreiben. Die Dialogphase allerdings wartet auf die Benutzereingabe und erlaubt es sich, sich selbst anzuzeigen, bevor die Liste gezeigt wird. Wenn Sie die Anweisung write in dem Ereignis initialization ausführen und das Auswahlbild angezeigt wird, dann überschreibt das Auswahlbild die Ausgabe von write, und die Ausgabe ist verloren. Sie können auf dem Auswahlbild Ausführen wählen, und wenn die Anweisung write ausgeführt ist, überschreibt die Liste das Auswahlbild, und Sie sehen die Ausgabe. Wenn Sie jedoch kein Auswahlbild haben, können die write-Anweisungen, die in dem Ereignis initialization erscheinen, weiter gesehen werden.
Workshop
Der Workshop versucht auf zwei Arten, das neu erlangte Wissen dieses Kapitels zu festigen. Im Quiz-Abschnitt werden Fragen gestellt, damit Sie den dargestellten Stoff vertiefen können. Der Übungsabschnitt soll Ihnen Praxis im Umgang mit den einzelnen Anweisungen geben. Die Antworten zum Quiz stehen im Anhang B.
Kontrollfragen
1. Löst die Variation write to der Anweisung write das Ereignis top-of-page aus?
2. In welchen Ereignissen sollten Sie nicht stop verwenden?
3. Ab welchem Punkt ist eine Variable innerhalb eines Programms bekannt?
Übung 1
Erstellen Sie einen Bericht, der die Eingabeparameter p_land1 akzeptiert. Definieren Sie es wie ztxlfa1-land1. Füllen Sie dieses Feld zur Laufzeit mit dem Vorgabewert US, indem Sie das Ereignis initialization benutzen. Ihr Hauptprogramm sollte eine einzige Anweisung haben, die ein Unterprogramm aufruft, das Sätze von ztxlfa1 selektiert, in denen das Feld land1 dem

Parameter p_land1 gleicht. Innerhalb von select rufen Sie ein anderes Unterprogramm auf, um den Satz auszugeben. Benutzen Sie das Ereignis top-of-page, um einen Berichtstitel zu erzeugen. Schreiben Sie den Wert des Feldes p_land1 in den Titel.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 18
Modularisierung: Übergabe von Parametern an Unterprogramme
Kapitelziele
Wenn Sie sich dieses Kapitel erarbeitet haben, sollten Sie folgendes können:
■ Aktual- und Formalparameter an Unterprogramme übergeben ■ Parameter auf drei verschiedene Arten übergeben: als Referenz (by reference), als Wert
(by value) und als Wert und Resultat (by value and result)■ Feldleisten und interne Tabellen an Unterprogramme übergeben ■ verstehen, wie Variablen zwischen internen und externen Unterprogrammen aufgeteilt werden
Parameterübergabe
Statt mit using tables, local, data und statischen Bezeichnungen Variablen zu definieren, kann man Variable auch mit der form-Anweisung definieren. Diese werden auch als Parameter bezeichnet. Parameter können entweder lokal oder global referenzierende Variable sein. Der Speicher für lokale Parameter wird allokiert, wenn das Unterprogramm aufgerufen wird und wieder freigesetzt, wenn das Unterprogramm beendet ist. Definiert man Variable mit der form-Anweisung, muß die perform-Anweisung Werte an eine dieser Variablen übergeben.
Parameternamen, die zur form-Anweisung gehören, werden auch formale Parameter genannt. Dieser Ausdruck ist recht einfach zu behalten, da »formal« mit »form« anfängt. In der Anweisung form s1 using p1 changing p2 p3 werden zum Beispiel die Parameter p1, p2 und p3 formale Parameter genannt.
Parameternamen, die in der perform-Anweisung vorkommen, werden aktuelle Parameter genannt. Zum Beispiel werden in der Anweisung perform s1 using f1 changing f2 f3 die Parameter f1, f2 und f3 aktuelle Parameter genannt.

Wie Variable als Parametern definiert werden, zeigt Listing 18.1.
Listing 18.1: Parameterübergabe an ein Unterprogramm
1 report ztx1801.2 data: f1 value 'A',3 f2 value 'B',4 f3 value 'C'.56 perform: s1 using f1 f2 f3,7 s2 using f1 f2 f3.89 form s1 using p1 p2 p3.10 write: / f1, f2, f3,11 / p1, p2, p3.12 endform.1314 form s2 using f1 f2 f3.15 skip.16 write: / f1, f2, f3.17 endform.
Das Programm aus Listing 18.1 erzeugt die folgende Ausgabe:
A B CA B C
A B C
■ Zeile 6 übergibt die Kontrolle an Zeile 9. ■ Zeile 9 definiert drei Variable: p1, p2 und p3. Der Wert von f1 wird p1 zugewiesen, der
Wert von f2 an p2 und der Wert von f3 an p3.■ Zeile 10 gibt die Werte von p1, p2 und p3 aus und die globalen Variablen f1, f2 und f3.■ Zeile 12 übergibt die Kontrolle wieder an Zeile 6. ■ Zeile 7 übergibt die Kontrolle an Zeile 14. ■ Zeile 14 definiert drei Variable: f1, f2 und f3. Der Wert von f1 wird an f1 übergeben, der
Wert von f2 wird an f2 übergeben und f3 wird f3 zugewiesen. ■ Zeile 16 schreibt die Werte der Variablen f1, f2 und f3 aus, die auf Zeile 14 mit der form-
Anweisung definiert wurden. ■ Zeile 17 übergibt die Kontrolle wieder an Zeile 7.
Bevor Sie jetzt weitermachen, sehen Sie sich bitte die Syntax der form- und perform-Anweisungen von Tag 17 an (Definieren und Aufrufen interner Unterprogramme).

Erlaubt Nicht erlaubt
Benutzen Sie formale Parameter. Sie sind in der Benutzung effektiver als aktuelle Parameter.
Übergeben Sie interne Tabellen nie als Wert oder als Wert und Resultat, solange sie keine neue Kopie der internen Tabelle brauchen. Wenn möglich, sollten Sie Parameter immer als Referenz übergeben.
Parameter anlegen
Parameter können entweder vom Typ aktuell (auch aktueller oder Aktualparameter genannt) oder formal (Formalparameter) sein. Ein Aktualparameter ist ein formaler Parameter, der einen Datentyp hat, gefolgt von einem Namen in der form-Anweisung. Ein Formalparameter hat keinen Datentyp in seiner Definition in der form-Anweisung. In Listing 18.1 sind alle Parameter formal.
Formale Parameter erlauben es einem, Variable irgendeines Datentyps und Länge zu übergeben. Die formalen Parameter benutzen die Attribute der aktuellen Parameter. Wird zum Beispiel ein 4 Byte langer Ganzzahlwert an einen formalen Parameter p1 übergeben, wird p1 eine 4 Byte lange Ganzzahl.
Die Syntax von Parametern
form s1 using u1 type t value(u2) type tchanging c1 type t value(c2) type t.
wobei:
■ s1 der Name des Unterprogramms ist. ■ u1, u2, c1 und c2 formale Parameter sind. ■ t entweder ein ABAP/4-Datentyp oder ein benutzerdefinierter Datentyp ist.
Die folgenden Punkte gelten:
■ Es kann nur ein Datentyp in der form-Anweisung spezifiziert werden. Eine Länge kann nicht spezifiziert werden.
■ Definiert man einen formalen Parameter mit einem Datentyp einer bestimmten Länge (das sind die Typen d, t, i und f), muß der aktuelle Parameter mit dem Datentyp des formalen Parameters gleich sein. Das ist normalerweise immer der Fall, denn man wird nicht versuchen, Daten in unterschiedliche Datentypen zu übergeben.
Übergibt man eine Variable mit falschen Typ- und Längenwerten an einen Parameter, ergibt das einen Syntaxfehler. Listing 18.2 zeigt, wie man diese Parameter benutzt.

Listing 18.2: Die Benutzung von kategorisierten Parametern
1 report ztx1802.2 data: f1 value 'A',3 f2 type i value 4,4 f3 like sy-datum,5 f4 like sy-uzeit.67 f3 = sy-datum.8 f4 = sy-uzeit.910 perform s1 using f1 f2 f3 f4.1112 form s1 using p1 type c13 p2 type i14 p3 type d15 p4 type t.16 write: / p1,17 / p2,18 / p3,19 / p4.20 endform.
Das Programm aus Listing 18.2 erzeugt die folgende Ausgabe:
AAA419980510164836
■ Die Zeilen 2 bis 5 definieren vier Variable mit verschiedenen Datentypen. f3 ist Typ c Länge 8 mit einer Ausgabelänge von zehn Zeichen (definiert in der Domäne für syst-datum). f4ist Typ c Länge 6 mit einer Ausgabelänge von acht Zeichen (definiert in der Domäne für sy-uzeit).
■ Zeile 10 übergibt die Kontrolle an Zeile 12. ■ Auf Zeile 12 akzeptiert p1 nur aktuelle Parameter von Typ c. f1 ist Typ c Länge 3, somit
wird eine Länge von 3 p1 zugeordnet. Wenn f1 nicht Typ c wäre, würde ein Syntaxfehler erscheinen. p2 hat einen Datentyp fixer Länge; Typ i ist immer vier Zeichen lang; f2 auch, somit passen alle Parameter. p3 und p4 sind auch Datentypen von fixer Länge, wie ihre aktuellen Parameter.
■ Die Zeilen 16 bis 19 schreiben die Werte von p1 bis p4 aus. Beachten Sie, daß die Ausgabelänge der aktuellen Parameter nicht dem formalen Parameter übergeben werden. Die Ausgabelänge der formalen Parameter wird auf den Standardwert des jeweiligen Datentyps gesetzt. Damit wird auch die Ausgabe des Datums und der Zeit ohne Trennzeichen ausgegeben.

Parameter haben drei Vorteile:
■ Sie sind wirksamer, und es wird weniger CPU-Zeit gebraucht, um Speicher für aktuelle Parameter zu allokieren als für formale Parameter.
■ Sie helfen, Programmierfehler zu vermeiden. Da man keine Parameter inkompatibler Typen übergeben kann, wird die Syntaxprüfung entsprechende Fehler aufzeigen.
■ Sie verhindern Laufzeitfehler. Wenn das Programm zum Beispiel formale Parameter akzeptiert und damit arithmetische Operationen ausführt, ist es möglich, Daten an das Unterprogramm zu übergeben. Passiert so etwas während der Laufzeit, wird das Programm abgebrochen.
Die Übergabe von Feldleisten
Feldleisten werden wie andere Parameter übergeben. Will man jedoch auf die Komponenten der Feldleiste innerhalb eines Unterprogramms zugreifen, muß man dem Unterprogramm die Struktur der Feldleiste mit einer von beiden Zusätzen zur form-Anweisung bekannt machen:
■ like x ■ structure x
Das x bezeichnet hierbei eine Feldleiste, eine DDIC-Datenstruktur oder eine Tabelle. Zum Beispiel, form s1 using fs1 structure ztxlfa1 definiert fs1 mit der Struktur der DDIC-Tabelle ztxlfa1.
Kontrolle der Parameter-Übergabe
Es gibt drei Möglichkeiten, Parameter an ein Unterprogramm zu übergeben:
■ by reference (als Referenz) ■ by value (als Wert) ■ by value and result (als Wert und Resultat)
Die Syntax der form-Anweisung bestimmt, wie Variable übergeben werden. Die Syntax für perform tut das nicht. Was das bedeutet, wird im nächsten Abschnitt erklärt. Als erstes sollte man lernen, wie jede dieser Methoden programmiert wird.
Tabelle 18.1 zeigt die Beziehung zwischen der Syntax und der Übergabemethode.
Tabelle 18.1: Zusätze zur form-Anweisung und Übergabemethode
Zusatz Methode

using v1changing v1using value(v1)changing value(v1)
Übergabe als Referenz
Übergabe als Referenz
Übergabe als Wert
Übergabe als Wert und Resultat
Obwohl sich die Syntaxen von form und perform unterscheiden können, sollten sie für die Programmlesbarkeit gleich sein.
Listing 18.3 zeigt, wie man diese Zusätze programmiert.
Listing 18.3: Wie Parameterzusätze programmiert werden.
1 report ztx1803.2 data: f1 value 'A',3 f2 value 'B',4 f3 value 'C',5 f4 value 'D',6 f5 value 'E',7 f6 value 'F'.89 perform s1 using f1 f210 changing f3 f4.1112 perform s2 using f1 f2 f3 f413 changing f5 f6.1415 perform s3 using f1 f2 f3.1617 form s1 using p1 value(p2)18 changing p3 value(p4).19 write: / p1, p2, p3, p4.20 endform.2122 form s2 using p1 value(p2) value(p3) p423 changing value(p5) p6.24 write: / p1, p2, p3, p4, p5, p6.25 endform.2627 form s3 using value(p1)28 changing p2 value(p3).29 write: / p1, p2, p3.

30 endform.
Das Programm aus Listing 18.3 erzeugt die folgende Ausgabe:
A B C DA B C D E FA B C
■ In Zeile 9 werden vier Parameter an das Unterprogramm s1 übergeben. Die Syntax in Zeile 17 bestimmt, wie sie übergeben werden. f1 und f3 werden als Referenz übergeben; f2 als Wert; f4 als Wert und Resultat.
■ Zeile 12 übergibt sechs Parameter an das Unterprogramm s2. f1, f4 und f6 werden als Referenz übergeben; f2 und f3 als Wert; f5 als Wert und Resultat.
■ Zeile 15 übergibt drei Parameter an das Unterprogramm s3. f3 wird als Wert übergeben, f4als Referenz und f5 als Wert und Resultat. Obwohl die perform- Anweisung nur usingspezifiziert, ist es der form-Anweisung erlaubt, sich davon zu unterscheiden. Sie spezifiziert beide, using und changing. Die Syntax der form- Anweisung bestimmt die Methode, wie die Parameter übergeben werden sollen.
Merken Sie sich folgende Punkte:
■ perform und form müssen die gleiche Anzahl an Parametern enthalten. ■ Die Syntaxen der perform- und form-Anweisung können sich unterscheiden. ■ Allein die Syntax der form-Anweisung bestimmt die Methode der Parameterübergabe. ■ Der Zusatz value() kann nicht zusammen mit der perform-Anweisung benutzt werden. ■ using muß vor changing stehen. ■ Der Zusatz using kann nur einmal in einer Anweisung erscheinen. Dasselbe gilt für changing.
Die Methoden zur Parameterübergabe
Tabelle 18.2 beschreibt kurz die drei Methoden der Parameterübergabe.
Tabelle 18.2: Methoden der Parameterübergabe
Methode Beschreibung Vorteil
by reference
(als Referenz)
Übergibt ein Zeichen an die originale Speicherlokation
Sehr effizient

by value
(als Wert)
Allokiert neuen Speicher für die Benutzung innerhalb des Unterprogramms. Der Speicher wird wieder freigegeben, wenn das Unterprogramm beendet ist.
Verhindert Änderungen an übergebenen Variablen
by value and result
(als Wert und Resultat)
Ähnlich der Übergabe by value. Es wird aber der Inhalt des neuen Speichers vor der Rückgabe zurück zum Originalspeicher kopiert.
Erlaubt Änderungen und Rollback
Parameterübergabe als Referenz
Wird ein Parameter als Referenz übergeben, wird für den Wert kein neuer Speicher allokiert. Statt dessen wird ein Zeiger (pointer) zum Originalspeicherplatz übergeben. Alle Verweise zum Parameter sind Verweise an den Originalspeicherplatz. Änderungen an den Variablen innerhalb des Unterprogramms aktualisieren auch sofort die Speicherlokation. Abbildung 18.1 und Listing 18.4 zeigen, wie das funktioniert.
Abbildung 18.1: Wie die Parameterübergabe als Referenz die Originalspeicherbelegung beeinflußt.
Listing 18.4: Effekte durch Parameterübergabe als Referenz
1 report ztx1804.2 data f1 value 'A'.34 perform s1 using f1.5 write / f1.67 form s1 using p1.

8 p1 = 'X'.9 endform.
Das Programm aus Listing 18.4 erzeugt die folgende Ausgabe:
X
■ Zeile 2 allokiert Speicher für Variable f1. Nehmen wir an, der Speicherplatz liegt auf Adresse 1000.
■ Zeile 4 übergibt die Kontrolle an Zeile 7. ■ Zeile 7 zwingt f1, als Referenz übergeben zu werden. Deshalb ist p1 ein Zeiger zur
Speicheradresse 1000. ■ Zeile 8 modifiziert Speicheradresse 1000, was den Speicherplatz für f1 dazu zwingt, sich in x
zu ändern. ■ Zeile 9 übergibt die Kontrolle an Zeile 5. ■ Zeile 5 schreibt den Wert x aus.
Bei internen Unterprogrammen gibt es einen kleinen Unterschied zwischen der Parameterübergabe als Referenz und dem Zugreifen auf globale Variable aus dem Unterprogramm heraus. Beide erlauben es, den Wert der globalen Variablen zu ändern. In externen Unterprogrammen und Funktionsbausteinen (s.a. Kapitel 19) ist die Übergabe als Referenz gebräuchlicher. Die Parameterübergabe an ein Unterprogramm, sei es extern oder intern, ist guter Programmierstil. Es macht die Pflege leichter und erhöht die Lesbarkeit des Programms.
Die Zusätze using f1 und changing f1, beide übergeben f1 als Referenz, sind identisch in der Funktionalität. Der Grund dafür, daß beide existieren, ist die Dokumentation darüber, ob das Unterprogramm einen Parameter ändert oder nicht.
Programmiert man changing mit Parametern, ändert sich das Unterprogramm. Man sollte usingmit Parametern programmieren, die nicht vom Unterprogramm geändert werden. Listing 18.5 beschreibt diesen Punkt.
Listing 18.5: using und changing sind identisch in ihrer Funktion.
1 report ztx1805.2 data: f1 value 'A',3 f2 value 'B'.45 write: / f1, f2.6 perform s1 using f17 changing f2.8 write: / f1, f2.910 form s1 using p111 changing p2.

12 p1 = p2 = 'X'.13 endform.
Das Programm aus Listing 18.5 erzeugt die folgende Ausgabe:
A BX X
f1 und f2 werden beide als Referenz an s1 übergeben. Somit sind p1 und p2 Zeiger auf f1 und f2.Änderungen an p1 und p2 werden sofort in f1 und f2 reflektiert. Dieses Beispiel zeigt nur, daß es möglich ist, irgendeinen Parameter zu ändern, der als Referenz übergeben wurde. Sie sollten Ihre Parameter so programmieren, daß using und changing die Benutzung dieser Parameter ordentlich dokumentiert.
Parameterübergabe als Wert
Wird ein Parameter als Wert übergeben, wird neuer Speicher für diesen Wert allokiert. Der Speicher wird in dem Moment allokiert, in welchem das Unterprogramm aufgerufen wird. Der Speicher wird wieder frei, wenn das Unterprogramm beendet ist. Deshalb sind Referenzen zum Parameter Bezugspunkte zu einem einheitlichen Speicherbereich, der nur innerhalb des Unterprogrammms bekannt ist; der Originalspeicherplatz ist separat. Das Original bleibt unverändert, wenn der Wert des Parameters geändert wird. Abbildung 18.2 und Listing 18.6 zeigen, wie das funktioniert.
Abbildung 18.2: Wie ein Parameter, der als Wert übergeben wurde, unabhängig vom Originalspeicherplatz neuen Speicherplatz allokiert.
Listing 18.6: Effekte bei der Übergabe als Wert
1 report ztx1806.2 data: f1 value 'A'.34 perform s1 using f1.

5 write / f1.67 form s1 using value(p1).8 p1 = 'X'.9 write / p1.10 endform.
Das Programm aus Listing 18.6 erzeugt die folgende Ausgabe:
XA
■ Zeile 2 allokiert Speicherplatz für die Variable f1.■ Zeile 4 übergibt die Kontrolle an Zeile 7. ■ Zeile 7 zwingt f1 als Wert übergeben zu werden. Deshalb bezieht sich p1 auf eine neue
Speicheradresse, die unabhängig von f1 ist. Der Wert von f1 wird automatisch in den Speicherbereich von p1 kopiert.
■ Zeile 8 modifiziert den Speicher für p1. f1 bleibt unverändert. ■ Zeile 9 schreibt den Wert x aus. ■ Zeile 10 übergibt die Kontrolle an Zeile 5. ■ Zeile 5 schreibt den Wert A aus.
Man benutzt die Parameterübergabe als Wert, wenn man eine Kopie der Variablen braucht, die man ändern muß, ohne auf das Original einwirken zu müssen.
Parameterübergabe als Wert und Resultat
Die Parameterübergabe als Wert und Resultat ist ähnlich der Übergabe als Wert. Ähnlich wie als Wert wird neuer Speicherbereich allokiert, der eine unabhängige Kopie der Variablen hält. Der Speicher wird freigegeben, wenn das Unterprogramm endet und Unterschiede auftauchen.
Wenn die endform-Anweisung ausgeführt wird, wird der Wert des lokalen Speichers zurück zum Originalspeicherplatz kopiert. Änderungen an den Parametern innerhalb des Unterprogramms werden im Original wiedergespiegelt, aber nicht, bevor das Unterprogramm zurückkehrt.
Das sieht zunächst nur nach einem kleinen Unterschied aus, aber der Unterschied wird größer. Sie können ändern, egal, ob eine Kopie stattfindet oder nicht.
Die Kopie findet immer statt, solange man das Unterprogramm mit einem der beiden folgenden Anweisungen verläßt:
■ stop■ message ennn
Die stop-Anweisung beendet das Unterprogramm und springt direkt zum Ereignis end-of-

selection. Wenn p1 als Wert und Resultat übergeben wurde, werden Änderungen an p1aufgegeben, bevor end-of-selection angestoßen wird. stop verhält sich wie ein Mini-Rollback für value and result-Parameter. Wenn sie innerhalb eines Unterprogramms benutzt wird, wird der stop-Anweisung normalerweise ein Test auf Abbruchbedingungen innerhalb des Programms vorausgeschickt. Taucht die Abbruchbedingung auf, wird stop ausgeführt. Es hebt die Änderungen der value and result- Variablen auf und stößt die end-of-selection-Anweisung an, welche wiederum Aufräumprozeduren anstößt.
Man benutzt die Übergabe als Wert und Resultat für Parameter, die geändert werden sollen. Es gibt aber auch die Möglichkeit, daß die Änderungen aufgehoben werden sollen, wenn eine Abbruchbedingung im Unterprogramm auftaucht.
Die message-Anweisung und ihre Wirkung auf Unterprogramme werden im Tag 21 beschrieben.
Abbildung 18.3 und Listing 18.7 zeigen Parameter, die als Wert und Resultat übergeben wurden.
Abbildung 18.3: Wie ein Parameter, der als Wert und Resultat übergeben wurde, neuen Speicherplatz unabhängig vom Original allokiert und die Werte wieder zurückkopiert.
Listing 18.7: Effekt der Übergabe als Wert und Resultat
1 report ztx1807.2 data: f1 value 'A'.34 perform: s1 changing f1,5 s2 changing f1.6

7 end-of-selection.8 write: / 'Stopped. f1 =', f1.910 form s1 changing value(p1).11 p1 = 'B'.12 endform.1314 form s2 changing value(p1).
15 p1 = 'X'.16 stop.17 endform.
Das Programm aus Listing 18.7 erzeugt die folgende Ausgabe:
Stopped. f1 = B
■ Zeile 2 allokiert Speicher für die Variable f1.■ Zeile 4 übergibt die Kontrolle an Zeile 9. ■ Zeile 10 zwingt f1, als Wert und Resultat übergeben zu werden. Deshalb bezieht sich p1 auf
die neue Speicheradresse, die unabhängig von f1 ist. Der Wert von f1 wird automatisch in den Speicher von p1 kopiert.
■ Zeile 11 modifiziert den Speicher für p1. f1 bleibt unverändert. ■ Zeile 12 kopiert den Wert von p1 zurück in f1 , setzt p1 frei und übergibt die Kontrolle an
Zeile 5. ■ Zeile 5 übergibt die Kontrolle an Zeile 14. ■ Zeile 14 zwingt f1 zur Übergabe als Wert und Resultat. Neuer Speicherbereich wird für p1
allokiert und der Wert von f1 wird dahinein kopiert. ■ Zeile 15 ändert den Wert von p1 in B.■ Zeile 16 führt die stop-Anweisung aus. Der Speicher für p1 wird frei und der geänderte Wert
ist verloren. Die Kontrolle wird an Zeile 7 übergeben. ■ Zeile 8 schreibt den Wert B aus.
Interne Tabellen als Parameter übergeben
Bitte wiederholen Sie an dieser Stelle das Gelernte über interne Tabellen, besonders die it[]-Syntax.
Man kann eine der beiden folgenden Methoden benutzen, um eine interne Tabelle an ein Unterprogramm zu übergeben:
1. Übergabe mit Kopfzeile
2. Nur Übergabe des Rumpfs

Wenn die interne Tabelle eine Kopfzeile hat, übergibt Methode 1 die Kopfzeile und den Rumpf an das Unterprogramm. Methode 2 übergibt nur den Rumpf an das Unterprogramm.
Wenn die interne Tabelle keine Kopfzeile hat, kann man beide Methoden benutzen. Allerdings verhält sich Methode 1 ein wenig unterschiedlich - sie wird automatisch eine Kopfzeile für die interne Tabelle innerhalb des Unterprogramms anlegen.
An dieser Stelle fragen Sie sich vielleicht: »Warum sollte ich eine interne Tabelle ohne Kopfzeile übergeben wollen?« Meistens braucht man dies auch nicht. Es könnte jedoch einmal erforderlich sein, eine interne Tabelle ohne Kopfzeile zu übergeben. Das kommt bei verschachtelten internen Tabellen vor. Verschachtelte interne Tabellen haben keine Kopfzeile.
Tabelle 18.3 zeigt in einer Zusammenfassung jede dieser Methoden bei internen Tabellen mit oder ohne Kopfzeile.
Tabelle 18.3: Methoden und Ergebnisse bei der Übergabe einer internen Tabelle an ein Unterprogramm
MethodeWenn die interne Tabelle eine Kopfzeile hat
Wenn die interne Tabelle keine Kopfzeile hat
Mit Kopfzeile Übergibt beide Legt eine Kopfzeile innerhalb des Unterprogramms an
Ohne Kopfzeile Übergibt nur den Rumpf Übergibt den Rumpf
Tabelle 18.4 zeigt die Syntax für jede Methode, wie man eine interne Tabelle an ein Unterprogramm übergibt.
Tabelle 18.4: Syntax der Methoden, wie man eine interne Tabelle an ein Unterprogramm übergibt.
Methode Syntax Übergabe
Mit Kopfzeile form s1 tables it Als Referenz

Nur der Rumpf form s1 using it[]form s1 changing it[]form s1 using value(it[])form s1 changing value( it[])
Als Referenz
Als Referenz
Als Wert
Als Wert und Resultat
Wenn die interne Tabelle eine Kopfzeile hat, übergibt die erste Methode in Tabelle 18.4 sowohl die Kopfzeile als auch den Rumpf an das Unterprogramm. Die anderen Methoden übergeben nur den Rumpf.
Wenn die interne Tabelle keine Kopfzeile hat, übergibt die erste Methode in Tabelle 18.4 den Rumpf und legt eine Kopfzeile innerhalb des Unterprogramms an. Die anderen übergeben nur den Rumpf.
Die Komponenten einer internen Tabelle innerhalb des Unterprogramms bekannt machen
Die Übergabe einer internen Tabelle ist allein nicht ausreichend, man muß auch die Struktur der internen Tabelle dem Unterprogramm bekanntgeben. Beschreibt man nicht die Struktur der internen Tabelle in der form-Anweisung, werden die Komponenten innerhalb des Unterprogramms unbekannt bleiben. Somit wird jeder Zugriff auf eine Komponente innerhalb des Unterprogramms mit einem Syntaxfehler enden.
Die Synatx, die man benötigt, hängt von der Methode ab, die man benutzt, um eine interne Tabelle zu übergeben. Tabelle 18.5 zeigt die angemessene Syntax für jede dieser Methoden.
Tabelle 18.5: Syntax, um eine interne Tabelle einem Unterprogramm zu beschreiben
Methode Syntax Gültige Werte für x

Mit Kopfzeile tables it structure xtables it like x
Eine Feldleiste
Eine DDIC-Struktur
Eine DDIC-Tabelle
Eine interne Tabelle mit Kopfzeile
Eine interne Tabelle ohne Kopfzeile
Ein interner Tabellenrumpf (it[])
Ohne Kopfzeile using it[] like x Eine interne Tabelle ohne Kopfzeile
Ein interner Tabellenrumpf (it[])
Der structure-Zusatz erwartet einen Feldleistennamen hinter it. An dieser Stelle kann man den Namen irgendeiner Feldleiste eingeben, DDIC-Strukturen oder Tabellen oder den Namen einer internen Tabelle, die eine Kopfzeile hat.
Der like-Zusatz erwartet einen Tabellenrumpf hinter it. Wenn die interne Tabelle, die man an dieser Stelle bezeichnen will, keine Kopfzeile hat, bezieht sich entweder it oder it[] auf den Rumpf von it. Wenn sie eine Kopfzeile hat, kann sich nur die Syntax von it[] auf den Rumpf von it beziehen.
Wird nur der Rumpf übergeben, braucht man normalerweise einen Arbeitsbereich innerhalb des Unterprogramms, um Sätze aus der internen Tabelle zu empfangen und hinzuzufügen. Um it zu definieren, kann man local, data oder statics benutzen. Ist schon ein globaler Arbeitsbereich verfügbar, kann man auch diesen benutzen, obwohl der Zugriff auf globale Variable aus einem Unterprogramm heraus die Programmpflege schwieriger macht. Entscheidet man sich für die data-Anweisung, um einen Arbeitsbereich zu definieren, ist der Zusatz like line of itabbodyverfügbar. Er definiert eine Feldleiste, die nur den Rumpf einer internen Tabelle benutzt. Das Ergebnisfeld ist genauso wie die Zeile des internen Tabellenrumpfs itabbody. Zum Beispiel definiert data fs like line of it[] eine Feldleiste fs. Sie hat dieselbe Struktur wie eine einzelne Zeile von it.
Eine interne Tabelle mit Kopfzeile übergeben
Wenn eine interne Tabelle eine Kopfzeile hat, und man will sowohl Kopfzeile als auch Rumpf an ein Unterprogramm übergeben, sollte man die Syntax so benutzen, wie es in der ersten Tabellenzeile von Tabelle 18.4 gezeigt wird. Sie übergibt die Kopfzeile und den Rumpf, und beide werden als Referenz übergeben. Änderungen an Kopfzeile oder Rumpf der internen Tabelle innerhalb des Unterprogramms werden sofort im Original reflektiert.

Listing 18.8 zeigt die Syntax.
Listing 18.8: Wie man eine interne Tabelle mit Kopfzeile übergibt
1 report ztx1808.2 * Here, IT is an internal table that has a header line3 * This program shows how to pass both the header line and body.4 tables ztxlfa1.5 data it like ztxlfa1 occurs 5 with header line.67 select * up to 5 rows from ztxlfa1 into table it order by lifnr.8 perform s1 tables it.9 loop at it.10 write / it-lifnr.11 endloop.1213 form s1 tables pt structure ztxlfa1. "uses the field string ztxlfa114 "here, you can use:15 "structure fs "a field string16 "structure ddicst "a ddic structure or table17 "structure it "any internal table with header line18 "like it. "ok if itab doesn't have header line19 "like it[]. "any internal table20 read table pt index 3.21 pt-lifnr = 'XXX'.22 modify pt index 3.23 endform.
Das Programm aus Listing 18.8 erzeugt die folgende Ausgabe:
10001010XXX10301040
■ Zeile 4 definiert einen globalen Arbeitsbereich ztxlfa1. Dieser Arbeitsbereich ist eine Feldleiste, die die gleiche Struktur wie die DDIC-Tabelle ztxlfa1 hat.
■ Zeile 5 definiert die interne Tabelle it mit einer Kopfzeile. ■ Zeile 7 füllt die interne Tabelle mit 5 Zeilen aus Tabelle ztxlfa1.■ Zeile 8 übergibt die Kontrolle an Zeile 13. ■ Zeile 13 zwingt die interne Tabelle, zusammen mit ihrer Kopfzeile übergeben zu werden. Die
Übergabe erfolgt als Referenz, somit ist pt ein Zeiger auf das Original. structure benutzt man, um die Struktur der internen Tabelle dem Unterprogramm bekannt zu machen. Ohne

würde jeder Zugriff auf eine der Komponenten der internen Tabelle einen Syntaxfehler verursachen.
■ Die Zeilen 15 bis 19 zeigen die Möglichkeiten, die Struktur von it innerhalb des Unterprogramms bekannt zu machen.
■ Zeile 20 liest Zeile 3 aus pt und stellt sie in die Kopfzeile. Ohne den Zusatz structure aufZeile 13 würde das zum Syntaxfehler führen.
■ Zeile 21 ändert den Wert von lifnr in der Kopfzeile. Seit die interne Tabelle mit Kopfzeile als Referenz übergeben wurde, modifiziert das den Inhalt der Originalkopfzeile.
■ Zeile 22 überschreibt Zeile 3 aus der Kopfzeile. Seit die interne Tabelle als Referenz übergeben wurde, modifiziert das den Inhalt der internen Originaltabelle.
■ Zeile 23 übergibt die Kontrolle an Zeile 8. ■ Die Zeilen 9 bis 11 schreiben den Inhalt der internen Tabelle. Die Ausgabe zeigt, daß sich der
Inhalt verändert hat.
Hat eine interne Tabelle keine Kopfzeile und man will den Rumpf übergeben und eine Kopfzeile in dem Unterprogramm anlegen, kann man auch die Syntax wie in der ersten Zeile von Tabelle 18.4 benutzen. Diese übergibt den Rumpf als Referenz und legt lokal eine Kopfzeile im Unterprogramm an. Änderungen am Rumpf der internen Originaltabelle innerhalb des Unterprogramms werden sofort im Original reflektiert.
Listing 18.9 zeigt diese Syntax.
Listing 18.9: Wie eine interne Tabelle ohne Kopfzeile an ein Unterprogramm übergeben wird und automatisch eine Kopfzeile anlegt.
1 report ztx1809.2 * Here, an internal table that doesn't have a header line3 * is passed with header line4 tables ztxlfa1.5 data: it like ztxlfa1 occurs 5. "doesn't have a header line67 select * up to 5 rows from ztxlfa1 into table it order by lifnr.8 perform s1 tables it.9 loop at it into ztxlfa1. "need to use a work area because it10 write / ztxlfa1-lifnr. "doesn't have a header line11 endloop.1213 form s1 tables pt structure ztxlfa1. "or you can use:14 " like it15 " like it[]16 read table pt index 3.17 pt-lifnr = 'XXX'.18 modify pt index 3.19 endform.

Das Programm aus Listing 18.9 erzeugt die folgende Ausgabe:
10001010XXX10301040
■ Zeile 4 definiert einen globalen Arbeitsbereich ztxlfa1. Dieser Arbeitsbereich ist eine Feldleiste mit der gleichen Struktur wie die DDIC-Tabelle ztxlfa1.
■ Zeile 5 definiert die interne Tabelle it ohne Kopfzeile. ■ Zeile 7 füllt die interne Tabelle mit fünf Zeilen aus ztxlfa1.■ Zeile 8 übergibt die Kontrolle an Zeile 13. ■ Zeile 13 zwingt den Rumpf der internen Tabelle, übergeben zu werden, und automatisch wird
eine Kopfzeile für it angelegt. Der Rumpf wird als Referenz übergeben, somit ist pt ein Zeiger auf den Originalrumpf und zur lokalen Kopfzeile. structure wird benutzt, um die Struktur der internen Tabelle dem Unterprogramm bekannt zu machen. Ohne würde jeder Zugriff auf eine der Komponenten der internen Tabelle einen Syntaxfehler verursachen.
■ Die Zeilen 14 und 15 zeigen andere Möglichkeiten, die Struktur von it dem Unterprogramm bekannt zu machen.
■ Zeile 16 liest Zeile 3 aus pt und stellt sie in die lokale Kopfzeile. Ohne den structure -Zusatz aus Zeile 13 würde das einen Syntaxfehler verursachen.
■ Zeile 17 ändert den Wert von lifnr in der Kopfzeile. Da die interne Originaltabelle keine Kopfzeile hat, ändert das nichts außerhalb des Unterprogramms.
■ Zeile 18 überschreibt Zeile 3 aus der lokalen Kopfzeile. Da die interne Tabelle als Referenz übergeben wurde, modifiziert das den Inhalt der internen Originaltabelle.
■ Zeile 19 übergibt die Kontrolle an Zeile 8. Der Speicher für die lokale Kopfzeile wird freigesetzt.
■ Die Zeilen 9 bis 11 schreiben den Inhalt der internen Tabelle aus. Da it keine Kopfzeile hat, wird die Feldleiste ztxlfa1 als Arbeitsbereich benutzt. Die Ausgabe zeigt, daß sich der Inhalt geändert hat.
Wenn eine interne Tabelle keine Kopfzeile hat und man will den Rumpf übergeben, ohne automatisch eine Kopfzeile in dem Unterprogramm anzulegen, kann man die Syntax wie in den Zeilen 2 bis 5 der Tabelle 18.4 benutzen. Mit dieser Syntax kann der Rumpf als Referenz, als Wert oder als Wert und Resultat übergeben werden. Wird it als Referenz übergeben, werden Änderungen am Rumpf der internen Tabelle innerhalb des Unterprogramms sofort im Original reflektiert. Wird it als Wert übergeben, wird eine lokale Kopie von it angelegt, was bedeutet, daß Änderungen am Ende des Unterprogramms aufgehoben werden, wenn der lokale Speicher für it freigesetzt wird. Wird it als Wert und Resultat übergeben, werden Änderungen ins Original zurückkopiert, wenn endformausgeführt wird. Eine stop-Anweisung innerhalb des Unterprogramms wird alle Änderungen an itaufheben und die Kontrolle direkt an end- of-selection übergeben.
Listing 18.10 zeigt diese Methode.

Listing 18.10: Wie eine interne Tabelle ohne Kopfzeile an ein Unterprogramm übergeben wird.
1 report ztx1810.2 * Here, an internal table that doesn't have a header line3 * is passed without creating a header line automatically4 tables ztxlfa1.5 data: it like ztxlfa1 occurs 5. "doesn't have a header line67 select * up to 5 rows from ztxlfa1 into table it order by lifnr.8 perform: s1 using it,9 s2 using it,10 s3 using it,11 writeitout tables it.1213 end-of-selection.14 write: / 'In End-Of-Selection'.15 perform writeitout tables it.1617 form s1 using value(pt) like it. "pass by value18 * you can also use: like it[].19 data wa like line of pt.20 * you can also use:21 * data wa like ztxlfa1.22 * data wa like line of pt[].23 * local ztxlfa1. "if you use this, the work area name24 * "will be ztxlfa1, not wa25 read table pt into wa index 1.26 wa-lifnr = 'XXX'.27 modify pt from wa index 1.28 endform.2930 form s2 using pt like it. "pass by reference31 data wa like line of pt.32 read table pt into wa index 2.33 wa-lifnr = 'YYY'.34 modify pt from wa index 2.35 endform.3637 form s3 changing value(pt) like it. "pass by value and result38 data wa like line of pt.39 read table pt into wa index 3.40 wa-lifnr = 'ZZZ'.41 modify pt from wa index 3.42 stop.43 endform.44

45 form writeitout tables it structure ztxlfa1.46 loop at it.47 write / it-lifnr.48 endloop.49 endform.
Das Programm aus Listing 18.10 erzeugt die folgende Ausgabe:
In End-Of-Selection1000YYY102010301040
■ Zeile 4 definiert einen globalen Arbeitsbereich ztxlfa1. Dieser Arbeitsbereich ist eine Feldleiste mit der gleichen Struktur wie die DDIC-Tabelle ztxlfa1.
■ Zeile 5 definiert die interne Tabelle it ohne Kopfzeile. ■ Zeile 7 füllt die interne Tabelle mit fünf Zeilen aus Tabelle ztxlfa1.■ Zeile 8 übergibt die Kontrolle an Zeile 17. ■ Zeile 17 übergibt den Rumpf der internen Tabelle als Wert und legt keine Kopfzeile für it an.
Die Übergabe als Wert legt eine separate Kopie der internen Tabelle an, somit gehört pt zur lokalen Kopie einer internen Tabelle. like wird für die Definition von pt als interne Tabelle gebraucht. Ohne like würde pt eine einfache Variable sein, und ein Syntaxfehler würde auftreten.
■ Zeile 18 zeigt die anderen Möglichkeiten, pt als interne Tabelle zu definieren. ■ Zeile 19 definiert einen lokalen Arbeitsbereich wa, der die gleiche Struktur wie eine Zeile von pt hat. Die Zeilen 20 bis 24 zeigen die anderen Möglichkeiten der Definition eines lokalen Arbeitsbereichs für pt.
■ Zeile 25 liest Zeile 1 aus pt und stellt sie in wa.■ Zeile 26 ändert den Wert von lifnr im Arbeitsbereich wa.■ Zeile 27 überschreibt Zeile 1 von wa. Seit die interne Tabelle als Wert übergeben wurde,
modifiziert dies den Inhalt der lokalen Kopie. Das Original bleibt unverändert. ■ Zeile 28 übergibt die Kontrolle an Zeile 8. Der Speicher für pt wird frei, und die Änderung ist
verloren.■ Zeile 9 übergibt die Kontrolle an Zeile 30. ■ Zeile 30 übergibt den Rumpf der internen Tabelle als Referenz und legt keine Kopfzeile an. pt
bezieht sich jetzt auf das Original. like wird für die Definition von pt als interne Tabelle gebraucht. Ohne like würde pt eine einfache Variable sein, und ein Syntaxfehler würde auftreten.
■ Zeile 31 definiert einen lokalen Arbeitsbereich wa, der dieselbe Struktur wie eine Zeile in pthat.
■ Zeile 32 liest Zeile 2 aus pt und stellt sie in wa.■ Zeile 33 ändert den Wert von lifnr im Arbeitsbereich wa.■ Zeile 34 überschreibt Zeile 2 aus wa. Seit die interne Tabelle als Referenz übergeben wurde,
modifiziert dies den Inhalt des Originals. Das Original wird jetzt geändert.

■ Zeile 35 übergibt die Kontrolle an Zeile 9. ■ Zeile 10 übergibt die Kontrolle an Zeile 37. ■ Zeile 37 übergibt den Rumpf der internen Tabelle als Wert und Resultat und legt keine
Kopfzeile für it an. pt bezieht sich jetzt auf eine Kopie des Originals. like wird gebraucht, um pt als interne Tabelle zu definieren. Ohne like würde pt eine einfache Variable sein und einen Syntaxfehler verursachen.
■ Zeile 38 definiert einen lokalen Arbeitsbereich wa, der die gleiche Struktur wie eine Zeile in pt hat.
■ Zeile 39 liest Zeile 3 aus pt und stellt sie in wa.■ Zeile 40 ändert den Wert von lifnr im Arbeitsbereich wa.■ Zeile 41 überschreibt Zeile 3 aus wa. Da die interne Tabelle als Wert und Resultat übergeben
wurde, modifiziert das den Inhalt der lokalen Kopie. Das Original bleibt bis jetzt unverändert. ■ Zeile 42 überspringt die endform-Anweisung und übergibt die Kontrolle direkt an Zeile 13.
Würde die stop-Anweisung nicht ausgeführt werden, würde die endform- Anweisung die lokale Kopie zwingen, das Original zu überschreiben, und die Änderungen würden beibehalten werden.
■ Zeile 15 übergibt die Kontrolle an Zeile 45. ■ Zeile 45 übergibt die interne Tabelle als Referenz, und eine Kopfzeile wird automatisch
angelegt.■ Die Zeilen 46 bis 48 schreiben den Inhalt der internen Tabelle. Die einzige Änderung ist in
Zeile 2 und wird von s2 ausgeführt.
Externe Unterprogramme definieren und aufrufen
Ein externes Unterprogramm ist ein Programm, das außerhalb des Programms liegt, in dem die perform-Anweisung ausgeführt wird, um das Unterprogrammm aufzurufen. Abbildung 18.4 zeigt ein externes Unterprogramm.
Abbildung 18.4: Illustration eines externen Unterprogramms
Wenn ein perform-Befehl ein externes Unterprogramm aufruft, passiert folgendes:
■ Das externe Programm, welches das Unterprogramm enthält, wird aufgerufen. ■ Das gesamte externe Programm wird einer Syntaxprüfung unterworfen. ■ Die Kontrolle wird dem form-Befehl des externen Programms übergeben. ■ Die Anweisungen innerhalb des externen Unterprogramms werden ausgeführt.

■ Mit endform wird die Kontrolle wieder den Anweisungen übergeben, die dem performfolgen.
Aus zwei Gründen ist die Syntaxprüfung während der Laufzeit bedeutend:
■ Handelt es sich bei dem formalen Parameter um einen aktuellen, würde das bei einem nicht passenden aktuellen Parameter zu einem Laufzeitfehler statt zu einem Synatxfehler führen.
■ Ein Syntaxfehler irgendwo im externen Programm würde einen Laufzeitfehler melden, egal ob innerhalb oder außerhalb des externen Unterprogramms.
Externe Unterprogramme sind internen Unterprogrammen ähnlich:
■ Beiden können Parameter übergeben werden. ■ Beide können mit formalen Parametern umgehen. ■ Beide können Parameter als Wert, als Wert und Resultat und als Referenz übernehmen. ■ Beide erlauben lokale Variablendefinitionen.
Abbildung 18.5 zeigt den Unterschied zwischen externen und internen Unterprogrammen.
Abbildung 18.5: Der Unterschied zwischen internen und externen Unterprogrammen
Im folgenden werden die Unterschiede zwischen externen und internen Unterprogrammen aufgezeigt:
■ Eine globale Variable, die mit der data-Anweisung definiert wurde, ist nur innerhalb des Programms bekannt, in dem sie definiert wurde. In Abbildung 18.5 erscheint zum Beispiel die data f1-Anweisung in beiden Programmen. Damit werden zwei Speicherbereiche mit Namen f1 definiert. Das f1, das innerhalb ztx1811 definiert wurde, ist nur innerhalb des Programms ztx1811 erreichbar. Das f1, das in ztx1812 definiert wurde, ist nur innerhalb ztx1812 erreichbar. Alle Verweise auf f1 innerhalb ztx1812 sind Verweise zum f1, das innerhalb ztx1812 definiert wurde.
■ Eine globale Variable, die den gleichen Namen in beiden Programmen benutzt und mit der tables-Anweisung in beiden Programmen angelegt wurde, ist in beiden Programmen gleich. Eine Änderung dieser Variablen in einem Programm beeinflußt auch das andere. In Abbildung 18.5 wird der Speicher ztxlfa1 zwischen beiden Programmen geteilt. Jede Änderung im Arbeitsbereich wird sofort in beiden Programmen wirksam.
Listing 18.11 und 18.12 zeigen den Aufruf eines externen Unterprogramms.

Listing 18.11: Aufruf des Unterprogramms aus Listing 18.12
1 report ztx1811.2 tables ztxlfa1.3 data f1(3) value 'AAA'.45 ztxlfa1-lifnr = '1000'.6 perform s1(ztx1812).7 write: / 'f1 =', f1,8 / 'lifnr =', ztxlfa1-lifnr.
Listing 18.12: Unterprogramm, das vom Programm in Listing 18.11 aufgerufen wird.
1 report ztx1812.2 tables ztxlfa1.3 data f1(3).45 form s1.6 f1 = 'ZZZ'.7 ztxlfa1-lifnr = '9999'.8 endform.
Das Programm aus Listing 18.11 erzeugt die folgende Ausgabe:
f1 = AAA lifnr = 9999
■ In beiden Programmen definiert Zeile 2 einen globalen Arbeitsbereich ztxlfa1. Dieser Arbeitsbereich wird zwischen beiden Programmen aufgeteilt.
■ In beiden Programmen definiert Zeile 3 eine globale Variable f1. Zwei unabhängige Speicherbereiche werden definiert, einer für jedes Programm.
■ In ztx1811 weist Zeile 5 ztxlfa1-lifnr den Wert 1000 zu. ■ In ztx1811, Zeile 6 wird die Kontrolle an Zeile 5 in ztx1812 übergeben. ■ In ztx1812 weist Zeile 6 ZZZ der globalen Variablen f1 für ztx1812 zu. f1 in ztx1811
bleibt unberührt. ■ In ztx1812 weist Zeile 7 ztxlfa1 den Wert 9999 zu. Das tangiert beide Programme. ■ In ztx1811 übergibt Zeile 8 die Kontrolle an Zeile 6 in ztx1811.■ In ztx1811 schreiben Zeile 7 und 8 die Werte von f1 und ztxlfa1-lifnr aus. f1 bleibt
unverändert und lifnr wurde geändert.

Benutzen Sie die local-Anweisung innerhalb des Unterprogramms, um zu vermeiden, daß Tabellen in Arbeitsbereichen von Programmen gemeinsam benutzt werden.
Zusammenfassung
■ Parameter können auf drei verschiedene Weisen übergeben werden: als Wert, als Wert und Resultat und als Referenz. Die Syntax der form-Anweisung bestimmt, welche Methode benutzt wird.
■ Der Rumpf einer internen Tabelle kann mit Hilfe von using und changing übergeben werden. Der Rumpf (und die Kopfzeile, wenn vorhanden) kann mit der tables -Anweisungübergeben werden. Wenn die interne Tabelle keine Kopfzeile hat, legt tables eine innerhalb des Unterprogramms an.
■ Um auf die Komponenten einer Feldleiste oder eines Unterprogramms zuzugreifen, die innerhalb des Unterprogramms bekannt sind, muß die Struktur in der form-Anweisungdeklariert werden.
■ Externe Unterprogramme sind internen ähnlich. In externen Unterprogrammen werden Variable, die mit data definiert sind, nur innerhalb des Programms bekannt bleiben, in dem sie definiert wurden. Variable, die den gleichen Namen haben und mit tables definiert wurden, sind in beiden Programmen bekannt.
Fragen & Antworten
Frage:Warum muß ich alle Variationen von der Übergabe interner Tabellen mit oder ohne Kopfzeile wissen? Reichen nicht einige Variationen aus, um alle Fälle abzudecken?
Antwort:Wenn Sie nur Programme anlegen, müßten Sie nicht alle Variationen kennen. Die meiste Zeit verbringt man aber damit, Programme zu lesen. Da alle diese Methoden in Programmen vorkommen können, muß man sie beherrschen.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten zu zeigen, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen sollen Ihnen helfen, Ihr Verständnis für die behandelten Themen zu vertiefen, und der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie anwenden, was Sie gelernt haben. Alle Antworten finden Sie in Anhang B.
Kontrollfragen
1. Wie heißen Parameter, die in der form-Anweisung vorkommen?

2. Was passiert, wenn Variable mit falscher Länge und falschem Datentyp an Formalparameter übergeben werden?
3. Wenn man einen Parameter als Referenz übergibt, wird dann neuer Speicher für den Wert angelegt?
4. Welche Auswirkungen haben die Ergänzungen using f1 und changing f1 auf die Art und Weise, wie Parameter übergeben werden?
Übung 1
Lassen Sie das Programm aus Listing 18.13 laufen. Kommentieren Sie die Parameter-Anweisungen aus, und lassen Sie es wieder laufen. Beschreiben Sie die Reihenfolge der Ereignisse, die in jedem Fall auftreten.
Listing 18.13: Beschreiben Sie die Reihenfolge der Ereignisse, die in diesem Programm auftreten.
report ztx1813 no standard page heading.ztx1813 data: flag,ctr type i.
parameters p1.
initialization.flag = 'I'.write: / 'in Initialization'.
start-of-selection.flag = 'S'.write: / 'in Start-Of-Selection',/ 'p1 =', p1.
top-of-page.add 1 to ctr.write: / 'Top of page, flag =', flag, 'ctr =', ctr.uline.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.

Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 19
Modularisierung: Funktionsbausteine, Teil 1
Kapitelziele
Nach diesem Kapitel sind Sie fähig:
■ die include-Anweisung zu verstehen und zu benutzen ■ Funktionsgruppen und -bausteine anzulegen ■ Import-, Export- und Wechselparameter zu definieren
Verwendung der include-Anweisung
Ein Include-Programm ist ein Programm, in welchem der Inhalt so programmiert ist, daß er auch von anderen Programmen benutzt werden kann. Normalerweise ist das Programm in sich nicht komplett. Statt dessen verwenden andere Programme den Code des Include-Programms, indem sie die Zeilen vom Include-Programm zu sich selbst hinüberkopieren. Das Kopieren geschieht während der Laufzeit mit der include -Anweisung. Ein Include-Programm nennt man auch ein included program.
Ein Programm, welches ein anderes enthält, nennt man ein including program.
Syntax für die include-Anweisung
Es folgt die Syntax für die include-Anweisung.
include ipgm.
wobei:
■ ipgm ein Programm vom Typ i ist.

Folgende Punkte gelten:
■ Ein Include-Programm muß vom Typ i sein. Sie spezifizieren den Programmtyp im Typenfeld auf der Maske Programmattribute, wenn Sie das Programm anlegen.
■ Ein Include-Programm kann in ein oder mehrere including programs eingebettet werden. ■ Ein Programm vom Typ i kann keine partiellen oder unvollständigen Anweisungen enthalten.
Die include-Anweisung kopiert den Inhalt des Include-Programms in das including program. Der Code des Include-Programms wird kopiert, wie er ist, und ersetzt die include-Anweisung im Moment der Programmgenerierung. Abbildung 19.1 illustriert die include-Anweisung.
Abbildung 19.1: Eine Illustration der include-Anweisung
In Abbildung 19.1. ist za das including program. Die Include-Programme sind zb und zc. Bei der Generierung von za wird der Quellcode von zb und zc in za mit dem Programm eingesetzt, das unter in der Abbildung gezeigt wird.
Die Listings 19.1 bis 19.3 illustrieren Include-Programme.
Listing 19.1: Ein including-Programm
1 report ztx1901 no standard page heading.2 tables: ztxlfa1, ztxlfb1.3 parameters p_lifnr like ztxlfa1-lifnr obligatory default '1000'.45 include: ztx1902,6 ztx1903.78 top-of-page.9 write: / 'Company Codes for Vendor', p_lifnr.10 uline.

Listing 19.2: Dieses Programm wird in ztx1901 eingeschlossen.
1 ***INCLUDE ZTX1902.2 select single * from ztxlfa1 where lifnr = p_lifnr.
Listing 19.3: Dieses Programm wird ebenfalls in ztx1901 eingeschlossen.
1 ***INCLUDE ZTX1903.2 select * from ztxlfb1 where lifnr = ztxlfa1-lifnr.3 write: / ztxlfb1-bukrs.4 endselect.
Die Programmcodes der Listings 19.1 bis 19.3 erzeugen folgende Ausgabe:
Company Codes for Vendor 1000 ---------------------------------10003000
■ Während der Generierung von ztx1901 kopiert Zeile 5 den Code von Programm ztx1902 zu ztx1901. Der eingefügte Code ersetzt Zeile 5.
■ Ebenfalls während der Generierung von ztx1901 kopiert Zeile 6 den Code von Programm ztx1903 zu ztx1901. Der eingefügte Code ersetzt Zeile 6.
■ Wenn das Programm läuft, verhält sich ztx1901 wie ein einzelnes Programm, als ob die Code-Zeilen der Include-Programme direkt in ztx1901 eingetippt worden wären.
SAP verwendet include-Anweisungen, um Code-Redundanz zu verringern und sehr große Programme in kleinere Einheiten zu unterteilen.
Während Sie sich ein including program anschauen, können Sie sich den Inhalt eines Include-Programms ansehen, indem Sie einfach auf seinen Namen doppelklicken. Wenn Sie zum Beispiel ztx1901 auf der Maske ABAP/4-Editor:Programme Editieren aufbereiten, machen Sie einen Doppelklick auf die Namen ztx1902 oder ztx1903. Das Include-Programm wird sofort angezeigt.

Will man eine Referenzliste aller includes, kann man den Report RSINCL00 laufen lassen. Geben Sie den Programmnamen des Programms ein, das andere Programme enthält, und wählen Sie entsprechend den Selektionsfeldern aus.
Funktionsbausteine
Ein Funktionsbaustein ist die letzte der vier wichtigsten Modularisierungseinheiten in ABAP/4. In folgenden Punkten ähnelt es sehr dem externen Unterprogramm:
■ Beide existieren innerhalb eines externen Programms. ■ Beide ermöglichen Parametern, übergeben bzw. zurückgegeben zu werden. ■ Parameter können als Wert übergeben werden, als Wert und Resultat oder als Referenz.
Die Hauptunterschiede zwischen Funktionsbausteinen und externen Unterprogrammen sind:
■ Funktionsbausteine haben eine spezielle Maske, um Parameter zu definieren - Parameter werden nicht durch ABAP/4-Anweisungen definiert.
■ tables-Arbeitsbereiche werden nicht zwischen Funktionsbausteinen und aufrufenden Programmen geteilt.
■ Zum Aufrufen eines Funktionsbausteins wird eine andere Syntax benötigt als zum Aufrufen eines Unterprogramms.
■ Das Verlassen des Funktionsbausteins erfolgt über die raise-Anweisung anstatt mit check,exit oder stop.
Der Name eines Funktionsbausteins hat eine Länge von minimal drei und maximal 30 Zeichen. Funktionsbausteine von Kunden müssen mit Y_ oder Z_ anfangen. Der Name jedes einzelnen Funktionsbausteins ist einmalig innerhalb des gesamten R/3-Systems.
Funktionsgruppen
Wie bereits erwähnt, ist eine Funktionsgruppe ein Programm, welches Funktionsbausteine enthält. In jedem R/3-System bietet SAP mehr als 5000 vorgefertigte Funktionsgruppen an. Insgesamt enthalten diese mehr als 30000 Funktionsbausteine. Wenn die Funktionalität, die Sie benötigen, nicht bereits durch diese Funktionsgruppen abgedeckt wird, können Sie sich auch Ihre eigenen Funktionsgruppen und -bausteine anlegen.
Jede Funktionsgruppe wird anhand eines vier Zeichen langen »Identifizierers« erkannt, Funktionsgruppen-ID genannt. Wenn Sie Ihre eigene Funktionsgruppe anlegen, müssen Sie sich ein Funktionsgruppen-ID aussuchen, welches mit Y oder Z beginnt. Das ID muß genau vier Zeichen lang sein und darf weder Leerzeichen noch Sonderzeichen enthalten.

In früheren Versionen als 3.0F erlaubt Ihnen das R/3-System, auch weniger als vier Zeichen oder auch Leerzeichen zu verwenden. Trotzdem sollten Sie dies nicht tun, weil die Werkzeuge, die Funktionsbausteine bearbeiten, sich in so einer Funktionsgruppe fehlerhaft verhalten würden.
Um Funktionsgruppen zu illustrieren, werde ich kurz beschreiben, wie man eine Funktionsgruppe und in dieser einen Funktionsbaustein anlegt. Gehen wir davon aus, daß weder die Funktionsgruppe noch der Baustein bisher existiert.
Sie fangen damit an, einen Funktionsbaustein anzulegen. Wenn Sie dies tun, wird Sie das System zuerst nach dem Funktionsgruppen-ID fragen. Dieses ID sagt dem System, wo es den Funktionsbaustein speichern soll.
Wenn Sie die ID bereitstellen, und sie bisher nicht existiert hat, legt das System folgendes an:
■ ein Hauptprogramm ■ ein top include■ ein UXX include■ einen Funktionsbaustein include
Zusammengenommen kennt man diese Komponenten als Funktionsgruppe. Ihre Verbindungen werden in Abbildung 19.2 gezeigt.
Der Name des Hauptprogramms ist saplfgid, wobei fgid Ihr vierbuchstabiges Funktionsgruppen-ID ist. Das System plaziert automatisch zwei include-Anweisungen:
■ include lfgidtop. ■ include ifgiduxx.

Abbildung 19.2: Dies ist die hierarchische Verbindung der Komponenten einer Funktionsgruppe.
Das erste include-Programm - lfgidtop - wird top include genannt. Hier hinein können Sie umfassende Datendefinitionen plazieren, d.h. umfassend zu allen Funktionsbausteinen innerhalb der Gruppe.
Das zweite include-Programm - lfgiduxx - heißt UXX. Sie dürfen UXX nicht verändern. Das System setzt automatisch für jeden Funktionsbaustein, den Sie in dieser Funktionsgruppe anlegen, eine include-Anweisung in das UXX. Für den ersten Funktionsbaustein wird die Anweisung include lfgidu01 in das UXX eingefügt. Wenn Sie einen zweiten Funktionsbaustein anlegen, fügt das System eine zweite Anweisung hinzu: include lfgidu02. Jedesmal, wenn Sie die Gruppe um einen neuen Funktionsbaustein erweitern, fügt das System UXX eine weitere include-Anweisung hinzu. Die Nummer von include ist 01 für den ersten Baustein, 02 für den zweiten und so weiter.
In jedem include, das in UXX vorkommt, steckt der Quellcode für einen Funktionsbaustein.
Der Zugang zur Funktionsbibliothek
Funktionsgruppen werden gespeichert in einer Tabellengruppe innerhalb der Datenbank: in der Funktionsbibliothek. In der Funktionsbibliothek haben Sie auch Zugriff zu den Werkzeugen, mit denen Sie die Funktionsgruppen und -bausteine bearbeiten. Um von der Development Workbench auf die Funktionsbibliothek zuzugreifen, drükken Sie die Schaltfläche Funktionsbibliothek auf der Drucktastenleiste. Der Transaktionscode ist SE37.
Auf jede Komponente einer Funktionsgruppe kann von der Einstiegsmaske der Funktionsbibliothek aus zugegriffen werden (Abb. 19.3.).

Abbildung 19.3: Die Einstiegsmaske Funktionsbibliothek
Um zum Beispiel auf das Hauptprogramm der Funktionsgruppe zuzugreifen, wählen Sie die Option Hauptprogramm und drücken dann auf Anzeigen. Das Hauptprogramm der Funktionsgruppe ztxa wird in Abbildung 19.4. gezeigt.

Abbildung 19.4: Das Hauptprogramm der Funktionsgruppe ztxa
Abbildung 19.5. zeigt die UXX für die Funktionsgruppe ztxa.

Abbildung 19.5: Die UXX für die Funktionsgruppe ztxa
In Abbildung 19.5. können Sie sehen, daß die Funktionsgruppe ztxa zwei Funktionsbausteine enthält: z_tx_1901 und z_tx_1902. Der erste ist aktiv, der zweite nicht (sein Name ist auskommentiert).
Einen Funktionsbaustein aktivieren
Ein Funktionsbaustein muß aktiviert worden sein, bevor er aufgerufen werden kann. Es gibt einen Aktivieren-Knopf auf der Einstiegsmaske Funktionsbibliothek. Wenn Sie diesen anklicken, wird der Funktionsbaustein aktiviert.
Wenn der Funtionsbaustein zuerst angelegt wird, wird die include-Anweisung für ihn im UXX auskommentiert. Wenn man den Baustein aktiviert, entfernt das System den Kommentar aus der include-Anweisung. Dann kann der Funktionsbaustein auch von anderen Programmen aufgerufen werden. Wenn Sie den Code innerhalb des Funktionsbausteins ändern, muß er nicht erneut aktiviert werden. Andererseits würde eine weitere Aktivierung ihm auch nicht schaden.
Wenn Sie es möchten, können Sie einen Funktionsbaustein deaktivieren. Wählen Sie den Menüpfad Funktionsbaustein->Deaktivieren aus der Maske ABAP/4-Funktionsbibliothek:Einstieg. Dadurch wird die include-Anweisung für diesen Funktionsbaustein im UXX auskommentiert.

Alle Funktionsbausteine, die zu einer einzelnen Gruppe gehören, existieren innerhalb eines Hauptprogramms: saplfgid. Daher bewirkt ein Syntaxfehler in irgendeinem dieser Bausteine, daß alle übrigen nicht mehr funktionieren; wenn Sie also einen einzigen ausführen, wird das mit einem Syntaxfehler enden. Die Funktionen Aktivieren und Deaktivieren ermöglichen Ihnen, mit jedem einzelnen Funktionsbaustein zu arbeiten, ohne die anderen zu beeinflussen. Sie können einen Funktionsbaustein deaktivieren, bevor Sie mit ihm arbeiten, können den Code ändern und dann einen Syntaxtest durchführen, bevor Sie ihn wieder reaktivieren. So können die restlichen Bausteine nach wie vor aufgerufen sein, sogar, wenn Sie an einem von ihnen arbeiten.
Datendefinition innerhalb eines Funktionsbausteins
Datendefinitionen innerhalb von Funktionsbausteinen sind ähnlich denen von Unterprogrammen.
Benutzen Sie die data-Anweisung innerhalb eines Funktionsbausteins, um lokale Variablen zu definieren, die jedesmal reinitialisiert werden, wenn der Funktionsbaustein aufgerufen wird. Verwenden Sie die statics-Anweisung zur Definition der lokalen Variablen, die belegt werden, wenn der Funktionsbaustein das erste Mal aufgerufen wird. Der Wert einer statischen Variablen zwischen zwei Aufrufen wird gespeichert.
Definieren Sie Parameter innerhalb der Funktionsschnittstelle, um lokale Definitionen von Variablen anzulegen, die in den Funktionsbaustein über- und von dort zurückgegeben wurden (beachten Sie den folgenden Abschnitt).
Innerhalb eines Funktionsbausteins können Sie die local-Anweisung nicht benutzen. Globalisierte Schnittstellenparameter haben den gleichen Effekt.
Definition der Funktionsschnittstelle
Um Parameter an einen Funktionsbaustein übergeben zu können, müssen Sie eine Funktionsschnittstelle definieren. Die Funktionsschnittstelle ist die Definition der Parameter, die an einen Funktionsbaustein übergeben und von diesem empfangen wurden. Man nennt sie auch einfach Schnittstelle. Von nun an werde ich daher die Funktionsschnittstelle einfach als Schnittstelle bezeichnen.
Um Parameter zu definieren, müssen Sie zu einer der beiden Parameterdefinitions- Masken gehen:
■ Import-/Export-Parameterschnittstelle■ Tabellen-/Ausnahmenschnittstelle
Die Maske Import-/Export-Parameterschnittstelle sehen Sie in Abbildung 19.6. Hier können Sie definieren:
■ Import-Parameter■ Export-Parameter■ Changing-Parameter

Abbildung 19.6: Die Maske der Schnittstelle Import-/Export-Parameter
Die Maske Tabellenparameter/Ausnahmenschnittstelle sehen Sie in Abbildung 19.7. Hier können Sie:
■ interne Tabellenparameter definieren ■ Ausnahmen dokumentieren
Abbildung 19.7: Die Maske der Schnittstelle Tabellenparameter/Ausnahmen
Tragen Sie den Parameternamen in die erste Spalte ein und die Attribute für den Parameter in die übrigen Spalten. Tragen Sie einen Parameter pro Zeile ein.
Import-Parameter sind Variable oder Feldleisten, die Werte enthalten, welche vom aufrufenden Programm in den Funktionsbaustein übergeben wurden. Diese Werte stammen von außerhalb des Funktionsbausteins und werden in ihn importiert.
Export-Parameter sind Variable oder Feldleisten, die Werte enthalten, die vom Funktionsbaustein zurückgegeben werden. Diese Werte stammen aus dem Funktionsbaustein und werden aus ihm exportiert.

Changing-Parameter sind Variable oder Feldleisten, die Werte enthalten, die in den Funktionsbaustein übergeben, vom Code innerhalb des Funktionsbausteins geändert und dann zurückgegeben werden.
Tabellenparameter sind interne Tabellen, die an den Funktionsbaustein übergeben, darin geändert und dann zurückgegeben werden.
Ausnahme ist der Name für einen Fehler, der innerhalb eines Funktionsbausteins auftritt. Ausnahmen werden im folgenden Abschnitt detailliert beschrieben.
Parameter übergeben
Die Methoden, Parameter an Funktionsbausteine zu übergeben, sind jenen sehr ähnlich, mit denen man Parameter an externe Unterprogramme übergibt.
Standardmäßig gilt:
■ Import- und Export-Parameter werden als Wert übergeben. ■ Changing-Parameter werden als Wert und Resultat übergeben. ■ Interne Tabellen werden als Referenz übergeben.
Sie können alle drei Übergabeparameter dazu bringen, als Referenz übergeben zu werden, indem Sie die Checkbox Referenz in der Import-/Export-Parametermaske anhaken (siehe Abb. 19.6).
Das Konzept, einen Export-Parameter als Wert zu übergeben, ist für die meisten Programmierer etwas befremdlich. Bedenken Sie: Als Wert übergeben, wird der Speicher für einen Export-Parameter innerhalb des Funktionsbausteins definiert. Die endfunction-Anweisung kopiert den Wert des Export-Parameters aus dem Funktionsbaustein heraus in die Variable, die dem aufrufenden Programm zugeordnet ist.
Wird die enfunction-Anweisung nicht ausgeführt (wenn Sie z.B. den Funktionsbaustein über die raise-Anweisung verlassen), wird der Wert nicht kopiert, und die Variable des »Aufrufers« bleibt unverändert.
Aktual- und Formalparameter
Funktionsbausteine können, genau wie Unterprogramme, aktuell oder formal sein. Die Aktualisierung verläuft bei Funktionsbausteinen genau wie bei Unterprogrammen. Formalparameter übernehmen alle technischen Charakteristika vom Übergabeparameter. Wenn zum Beispiel der Übergabeparameter vom Typ c ist und die Länge 12 hat und der Parameter des Funktionsbausteins ist formal, erhält er den Typ cund die Länge 12.

Aktualparameter für Funktionsbausteine folgen den gleichen Regeln wie Aktualparameter für Unterprogramme. Es gibt zwei Möglichkeiten, Aktualparameter auf der Maske Import-/Export-Parameter zu spezifizieren:
■ indem man in der Spalte Referenztyp einen ABAP/4-Datentyp spezifiziert ■ indem man in der Spalte Referenzfeld den Namen oder die Komponente einer DDIC-Struktur
spezifiziert
Sie können nicht beide Methoden für einen einzelnen Parameter anwenden; Sie müssen die eine oder die andere benutzen.
Bei der ersten Methode spezifizieren Sie einfach einen ABAP/4-Datentyp in der Spalte Referenztyp. In Abbildung 19.8. sind zum Beispiel p1 und p2 Aktualparameter, die den ABAP/4-Datentyp i (integer) haben. p3 ist ebenfalls aktuell, mit dem Datentyp p. Typ i ist ein Datentyp mit der festgelegten Länge 4. Typ p hat eine variierende Länge und übernimmt seine Länge und die Anzahl der Dezimalstellen von dem Parameter, der ihm übergeben wird.
Bei der zweiten Methode tragen Sie den Namen einer Data Dictionary-Struktur in die Spalte Referenzfeld ein. Die Parameter werden so definiert, als hätten Sie in einem externen Unterprogramm den like-Zusatzin der form-Anweisung verwendet.
Parameter können auch als optional klassifiziert werden, und ihnen können Standardwerte zugewiesen werden. Um einen Import-Parameter optional zu machen, machen Sie ein Häkchen in der Spalte Optional (Abb. 19.7.). Wenn Sie einen Import-Parameter optional machen, müssen Sie ihn in der callfunction-Anweisung nicht aufrufen. Export-Parameter sind immer optional.
Um einem Import-Parameter einen Standardwert zuzuweisen, tragen Sie in die Spalte Vorschlag einen Wert ein, wobei Sie Zeichenwerte mit Apostrophen einschließen müssen. sy-Variablennamen sind auch erlaubt. Wenn Sie einen Vorschlag spezifizieren, macht das System automatisch ein Häkchen in die Spalte Optional.
Alle Parameter, die Sie in der Schnittstelle definieren, erscheinen auch am Anfang des Quellcodes mit einem speziellen Kommentar. Jede Zeile dieses speziellen Kommentars beginnt mit den Zeichen *".Jedesmal, wenn Sie die Schnittstelle ändern, aktualisiert das System automatisch diese speziellen Kommentare, um Ihre Änderungen zu zeigen.

Abbildung 19.8: Die system-generierten Kommentare am Anfang des Quellcodes
Sie dürfen diese Kommentare weder ändern noch löschen; sie werden vom System generiert. Wenn Sie sie ändern, könnte der Funktionsbaustein unter Umständen nicht mehr arbeiten.
In Abbildung 19.8. können Sie sehen, daß p1, p2 und p3 als Wert übergeben werden.
Aufruf von Funktionsbausteinen
Um einen Funktionsbaustein aufzurufen, müssen Sie die Anweisung call function codieren. Sie sehen den Kontrollfluß in Listing 19.4.
Listing 19.4: Das Programm stellt einen einfachen Aufruf eines Funktionsbausteins dar.

1 report ztx1904.23 write: / 'Before Call'.4 call function 'Z_TX_1901'.5 write: / 'After Call'.
Der Code in Listing 19.4. erzeugt folgende Ausgabe:
Before Call Hi from Z_TX_1901 After Call
■ Zeile 4 setzt die Kontrolle an den Anfang des Funktionsbausteins z_tx_1901. In diesem Beispiel existiert der Funktionsbaustein innerhalb der Funktionsgruppe ztxa. saplztxa ist das Hauptprogramm für diese Funktionsgruppe und verhält sich wie der Container für z_tx_1901.
■ Der Code innerhalb des Funktionsbausteins wird ausgeführt.
Die letzte Zeile des Funktionsbausteins gibt die Kontrolle an die call function-Anweisung zurück. Die Verarbeitung wird mit der nächsten Anweisung nach call function fortgesetzt.
Die Syntax für die call function-Anweisung
Es folgt die Syntax für die call function-Anweisung.
call function 'F'[exporting p1 = v1 ... ][importing p2 = v2 ... ][changing p3 = v3 ... ][tables p4 = it ... ][exceptions x1 = n [others = n]].
wobei:
■ F der Name des Funktionsbausteins ist. ■ p1 bis p4 in der Funktionsschnittstelle definierte Parameternamen sind. ■ v1 bis v3 Variablen oder Feldleistennamen sind, die im aufrufenden Programm definiert sind. ■ it eine interne Tabelle ist, die im aufrufenden Programm definiert ist. ■ n ein jegliches integriertes Literal ist; n kann keine Variable sein. ■ x1 der Name einer Ausnahme ist, hochgestellt im Funktionsbaustein.
Folgende Punkte gelten:
■ Alle Zusätze sind optional. ■ call function ist eine einzelne Anweisung. Setzen Sie keine Punkte oder Kommata hinter
Parameter- oder Ausnahmenamen. ■ Der Name des Funktionsbausteins muß in Großbuchstaben codiert sein. Andernfalls würde die

Funktion nicht gefunden werden, und ein Programmabbruch wäre die Folge.
Verwenden Sie die call function-Anweisung, um die Kontrolle an einen Funktionsbaustein zu übergeben und Parameter zu spezifizieren. In Abbildung 19.9 sehen Sie, wie Parameter an einen Funktionsbaustein übergeben und von dort empfangen werden.
Abbildung 19.9: Hier wird gezeigt, wie Parameter an einen Funktionsbaustein übergeben und von dort empfangen werden.
In der call function-Anweisung sind Im- und Exporte immer vom Standpunkt des Programms aus zu sehen. Werte, die von der call function-Anweisung exportiert werden, werden vom Funktionsbaustein importiert und umgekehrt.
Links vom Gleichheitszeichen (=) ist eine Liste von Parameternamen, die in der Funktionsschnittstelle definiert sind. Auf der rechten Seite stehen Variablen, die innerhalb des aufrufenden Programm definiert sind. Zuweisungen nach exporting erfolgen von rechts nach links. Zuweisungen nach importingerfolgen von links nach rechts.
Zuweisungen nach changing und tables erfolgen in beide Richtungen. Vor dem Aufruf erfolgt die Zuweisung von rechts nach links. Die Rückgabe des Wertes erfolgt in umgekehrter Richtung.
Nehmen wir Abbildung 19.9. als ein Beispiel. Wenn Sie den Baustein Z_XXX aufrufen, wird der Wert der Variablen v1 dem Parameter p1 zugewiesen, und der Wert von v2 dem Parameter p2. Kontrollieren Sie dann die Übergaben an den Funktionsbaustein. Umgekehrt wird der Wert von p3 der Variablen v3zugewiesen.
Der Ausdruck Import-Parameter (ohne Hinweis darauf, ob vom Standpunkt des Programms oder des Funktionsbausteins betrachtet) meint immer Parameter, die in den Funktionsbaustein importiert werden. Ebenso gilt der Ausdruck Export-Parameter ohne

konkreten Hinweis immer für den Export aus dem Funktionsbaustein.
Beispiel eines Funktionsbausteins
In diesem Abschnitt zeige ich den Aufruf eines Beispiel-Funktionsbausteins z_tx_div, der lediglich zwei Zahlen teilt und das Ergebnis der Division zeigt.
Listing 19.5. ruft z_tx_div auf und übergibt Parameter. Abbildung 19.7. zeigt die Maske der Import-/Export-Parameter für diesen Funktionsbaustein, und Listing 19.6 zeigt hierfür den Quellcode.
Listing 19.5: Verwendung der call functions-Anweisung mit Parametern
1 report ztx1905.2 parameters: op1 type i default 2, "operand 13 op2 type i default 3. "operand 24 data rslt type p decimals 2. "result56 call function 'Z_TX_DIV'7 exporting8 p1 = op19 p2 = op210 importing11 p3 = rslt.1213 write: / op1, '/', op2, '=', rslt.
Listing 19.6: Der Quellcode für den Funktionsbaustein z_tx_div
1 function z_tx_div.2 *"-----------------------------------------------------------3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(P1) TYPE I DEFAULT 16 *" VALUE(P2) TYPE I7 *" EXPORTING8 *" VALUE(P3) TYPE P9 *"------------------------------------------------------------10 p3 = p1 / p2.11 endfunction.
Der Code in Listing 19.6 wird aufgerufen von der Zeile 6 in Listing 19.5.
Der Code in Listing 19.5 erzeugt diese Ausgabe:
2 / 3 = 0.67

■ In Listing 19.5 definieren die Zeilen 2 und 3 zwei Variablen, op1 und op1. Weil diese definiert sind, die parameters-Anweisung zu verwenden, wird der Benutzer nach Werten für diese Variablen gefragt, wenn das Programm startet.
■ Zeile 4 definiert eine Variable namens rslt vom Typ p mit zwei Dezimalstellen. ■ Zeile 6 übergibt die Kontrolle an den Funktionsbaustein Z_TX_DIV. Der Wert der Variablen op1
wird dem Import-Parameter p1 zugewiesen, und der Wert von op2 dem Import-Parameter p2. In der Export-/Import-Parameter-Maske wird ein Referenztyp für diese Parameter spezifiziert, was sie zu Aktualparametern macht. Weil diese Parameter aktuell sind, erhalten Sie ihre technischen Attribute nicht von p1 und p2. Vielmehr müssen die Datentypen von op1 und op2 zu denen von p1 und p2 passen. op1 und op2 sind als ganze Zahlen definiert, daher passen die Datentypen zueinander. P3 ist Typ p; es ist ein partieller aktueller Parameter. Er erhält seine Länge und die Anzahl der Dezimalstellen von rslt. Die Werte von op1 und op2 werden an den Funktionsbaustein übergeben, und die Kontrolle geht zu Zeile 1 in Listing 19.6.
■ In Listing 19.6 führt die Zeile 10 eine einfache Division aus. ■ Der Funktionsbaustein gibt die Kontrolle zurück an Zeile 6 von Listing 19.5. Der Wert von p3
wird der Variablen rslt zugewiesen. ■ Zeile 13 schreibt das Resultat der Division aus.
Drücken Sie die Schaltfläche Muster auf ABAP/4-Editor:Programm Editieren, um die callfunction-Anweisung automatisch in Ihren Code einzufügen. Sie werden nach dem Namen des Funktionsbausteins gefragt, und Sie codiert automatisch die linke Seite aller Zuweisungen von Schnittstellenparametern für Sie.
Anlegen eines Funktionsbausteins
Gehen Sie wie folgt vor, um einen Funktionsbaustein anzulegen. Als Übung folgen Sie dieser Anweisung, und legen Sie einen Funktionsbaustein an, genau wie z_tx_div. Rufen Sie z_**div auf, und legen Sie es in der Funktionsgruppe z**a ab (denken Sie daran, ** zu ersetzen durch die Zeichen, mit denen Sie Ihre Programme identifizieren).
Starten Sie jetzt das ScreenCam »How to Create a Function Module«.
1. In der ABAP/4-Development Workbench drücken Sie auf Funktionsbibliothek (siehe Abb. 19.3).
2. Tippen Sie den Namen Ihres Funktionsbausteins in das Feld Funktionsbaustein. Der Name muß mit Y_oder Z_ beginnen.
3. Drücken Sie Anlegen. Die Maske Funktionsgruppe Eingeben erscheint.
4. Tippen Sie den Namen einer Funktionsgruppe in das entsprechende Feld. Der Name muß vier Zeichen lang sein und mit Y oder Z anfangen.

5. Tippen Sie ein S in das Applikationsfeld. Dieses Feld wird benutzt, um anzuzeigen, welche Funktionsebene den Funktionsbaustein benutzt. Unsere Funktionalität wird von keiner Funktionsebene benutzt, sie ist nur ein Beispiel (S zeigt an, daß der Funktionsbaustein eine Funktionalität enthält, die von der Basis benötigt wird).
6. Geben Sie eine Kurzbeschreibung des Funktionsbausteins in das Feld Kurztext ein. Die Inhalte dieses Felds können betrachtet werden, wenn man eine Liste der Funktionsbausteine anzeigt.
7. Sichern Sie.
8. Wenn die Funktionsgruppe nicht schon existiert, werden Sie informiert und gefragt, ob Sie sie jetzt anlegen wollen. Drücken Sie auf Ja. Die Dialogbox Funktionsgruppe Anlegen öffnet sich. Geben Sie eine Beschreibung in das Feld Kurzbeschreibung ein und sichern Sie. Die Maske Objektkatalogeintrag erscheint. Drücken Sie auf Lokales Objekt.
9. Wählen Sie Quelltext. Fbaustein:Editieren wird angezeigt (Abbildung 19.8).
10. Tippen Sie den Quellcode in Ihren Funktionsbaustein. Ändern Sie unter keinen Umständen die system-generierten Kommentarzeilen! Es könnte sein, daß Ihr Funktionsbaustein nicht mehr arbeitet.
11. Sichern Sie. Die Nachricht Programm xxx wurde gesichert erscheint am unteren Bildschirmrand.
12. Drücken Sie auf Zurück. Sie kommen wieder zur Maske Funktionsbibliothek:Einstieg.
13. Wenn Sie Import- oder Export-Parameter definieren möchten, wählen Sie die Option Schnittstelle. Tippen Sie die Namen Ihrer Parameter in die erste Spalte und, fügen Sie alle anderen gewünschten Charakteristika hinzu. Dann sichern Sie und drücken Zurück.
14. Um schließlich Ihren Funktionsbaustein zu aktivieren, drücken Sie Aktivieren auf der Drucktastenleiste.

Abbildung 19.10: Fbaustein anlegen:Verwaltungsmaske
Jetzt ist es an der Zeit, ein ABAP/4-Programm zu schreiben, um Ihren Funktionsbaustein aufzurufen und auszuprobieren. Legen Sie ein Programm an, wie es in Listing 19.5 gezeigt wird. Denken Sie daran, in Ihrem Programm den Namen Ihres Funktionsbausteins in Großbuchstaben zu codieren. Wenn Sie dies nicht machen, erhalten Sie einen Programmabbruch, weil das System den Baustein nicht finden kann.
Benutzen Sie den Object Browser, um die von Ihnen angelegten Funktionsbausteine aufzulisten.
Zusammenfassung
■ Sie können die include-Anweisung verwenden, um Ihren Code in kleinere Abschnitte einzuteilen. Include-Programme haben den Programmtyp i. Ihr Code wird anstelle der include-Anweisung in das including program kopiert und ersetzt diese komplett.

■ Funktionsbausteine sind Modularisierungs-Einheiten mit einzigartigen Namen, die von jedem Programm im gesamten R/3-System aufgerufen werden können. Sie beinhalten Code, der von mehr als einem Programm verwendet wird.
■ Eine Funktionsgruppe ist eine Sammlung von Programmen und hat eine vordefinierte Struktur. Die Namen aller Programme innerhalb der Gruppe enthalten alle eine vier Zeichen lange Funktionsgruppen-ID.
■ Die Schnittstelle eines Funktionsbausteins enthält sowohl die Definitionen für Import-, Export- und Changing-Parameter als auch die Dokumentation der Ausnahmen, die im Funktionsbaustein vorkommen.
■ Aktuelle und formale Parameter können spezifiziert werden, und sie können als Referenz, als Wert oder als Wert und Resultat übergeben werden.
Erlaubt Nicht erlaubt
Verwenden Sie die Übergabe als Referenz für Import-Parameter. Seien Sie vorsichtig bei der Benutzung für Export-Parameter. Die Werte von Parametern, die als Referenz übergeben werden, ändern sich sofort im aufrufenden Programm. Wenn Sie Export-Parameter ändern, bevor Sie die raise-Anweisung ausgeben, kehren Sie zwar zurück, aber die Werte werden schon vom aufrufenden Programm geändert sein.
Ändern Sie nicht die system-generierten Kommentare am Beginn des Quellcodes für den Funktionsbaustein.
Dokumentieren Sie alle Ausnahmen in der Funktionsschnittstelle und alle Parameter in der Komponente Dokumentation dieses Bausteins.
Importieren Sie keine Werte vom Funktionsbaustein, die Sie nicht benötigen. Vermeiden Sie einfach unnötige Importe von der call function-Anweisung.
Sichern Sie Ihre Testdaten, damit Sie Ihr Funktionsmodul nach Modifikationen mit denselben Daten abermals testen können.
Verwenden Sie nicht stop, exit oder checkinnerhalb eines Funktionsbausteins. (check und exit sind in Ordnung, wenn sie sich innerhalb einer Schleife in einem Funktionsbaustein befinden.)
Fragen & Antworten
Frage:Wie kann ich entscheiden, ob ich include, ein internes oder externes Unterprogramm oder einen Funktionsbaustein in mein Programm einfügen soll?
Antwort:Wenn der Code nicht von anderen Programmen benutzt wird, verwenden Sie ein internes Unterprogramm. Wenn der Code für andere Programme nützlich sein könnte, nehmen Sie einen Funktionsbaustein. Sie sollten keine externen Unterprogramme anlegen. Diese wurden in den vergangenen Kapiteln nur behandelt, damit Sie wissen, wie Sie sie benutzen können, da immer noch viele im R/3-System in Gebrauch sind. Auch Funktionsbausteine sind einfacher zu verstehen, wenn Sie wissen, wie externe Unterprogramme arbeiten. Verwenden Sie Funktionsbausteine anstelle von externen Unterprogrammen. include sollten

Sie benutzen, um Ihre Programmstruktur zu vereinfachen und ähnliche Komponenten zu gruppieren. include sollte nicht verwendet werden als Behälter für wiederverwendbaren Code, der in verschiedenen Programmen verwendet wird. Sie könnten zum Beispiel Ihre gesamten Datendeklarationen in ein include packen, Ihre Ereignisse in ein zweites, Ihre Unterprogramme in ein drittes und Ihre Aufrufe von Funktionsbausteinen in ein viertes.
Frage:Wie entscheide ich, in welche Funktionsgruppe ich einen neuen Funktionsbaustein stelle? Wann sollte ich eine neue anlegen, und wann eine bereits existierende benutzen?
Antwort:Stellen Sie Funktionsbausteine mit ähnlicher Funktionalität in dieselbe Funktionsgruppe. So könnten Sie zum Beispiel alle Funktionsbausteine, die sich mit Abwertung beschäftigen, in einer Funktionsgruppe zusammenfassen, in einer anderen alle Bausteine mit Kalenderfunktionen, und wieder in einer anderen diejenigen, welche externe Kommunikationsschnittstellen anbieten.
Workshop
Der Workshop bietet Ihnen zwei Möglichkeiten zu zeigen, was Sie in diesem Kapitel gelernt haben. Die Kontrollfragen sollen Ihnen helfen, Ihr Verständnis für die behandelten Themen zu vertiefen, und der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie anwenden, was Sie gelernt haben. Alle Antworten finden Sie in Anhang B.
Kontrollfragen
1. Richtig oder falsch: Ein Import-Parameter mit einem Vorschlag ist immer optional?
2. Richtig oder falsch: Alle Export-Parameter sind optional?
Übung 1
Benutzen Sie die Funktion Test in der Funktionsbibliothek, um den Funktionsbaustein POPUP_WITH_TABEL_DISPLAY zu testen. Wenn Sie dies getan haben, schauen Sie sich das folgende Programm an, und sagen Sie sein Verhalten voraus.
report ztx1910.data: begin of it occurs 5,data(10),end of it,result(10).
perform: fill_table tables it,call_fm tables it changing result.write: / 'Result=', result.
form fill_table tables it like it.

move 'Select' to it-data. append it.move 'One' to it-data. append it. move 'Option' to it-data. append it.endform.form call_fm tables it changing result.call function 'POPUP_WITH_TABLE_DISPLAY'importingendpos_col = 30endpos_row = 30startpos_col = 1startpos_row = 1titletext = 'Look Ma, a Window'exportingchoise = resulttablesvaluetab = it.endform.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 20
Modularisierung: Funktionsbausteine, Teil 2
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, können Sie:
■ die Komponenten und Struktur eines Funktionsbausteins verstehen ■ globale Daten und Unterprogramme innerhalb einer Funktionsgruppe definieren
Globale Daten für Funktionsbausteine definieren
Es können zwei Typen globaler Daten für Funktionsbausteine definiert werden:
■ Datendefinitionen, die in den top include plaziert werden, sind von allen Funktionsbausteinen und Unterprogrammen innerhalb der Gruppe zugreifbar. Dieser Typ globaler Daten bleibt über den Aufruf von Funktionsbausteinen erhalten.
■ Datendefinitionen innerhalb der Schnittstelle sind nur innerhalb des Funktionsbausteins bekannt. Wenn die Schnittstelle als globale Schnittstelle definiert ist, sind die Parameterdefinitionen auch innerhalb aller Unterprogramme bekannt, die der Funktionsbaustein aufruft. Dieser Typ globaler Daten bleibt nicht über den Aufruf von Funktionsbausteinen erhalten.
Auf Datendefinitionen, die globalen Daten, die innerhalb des top include definiert sind, kann von allen Funktionsbausteinen aus zugegriffen werden. Das ist analog zu globalen Datendefinition zu Beginn eines ABAP/4-Programms.
Auf Datendefinitionen, die Parameter, die innerhalb einer globalen Schnittstelle definiert werden, kann von allen Unterprogrammen aus zugegriffen werden, die vom Funktionsbaustein aufgerufen werden. Das ist analog zu Variablen, die mit der locals- Anweisung innerhalb einer Unterprogramm definiert werden.

Auf Datendefinitionen, die Parameter, die innerhalb einer lokalen Schnittstelle definiert werden, kann von Unterprogrammen aus, die vom Funktionsbaustein aufgerufen werden, nicht zugegriffen werden. Das ist analog zu Variablen, die innerhalb einer Unterprogramm mit der data-Anweisung definiert werden. Der Vorgabewert für Schnittstellen ist lokal.
Um eine Schnittstelle global zu machen, wählen Sie im Fenster Funktionsbaustein ändern: Import/Export Parameter den Menüpfad Bearbeiten->Parameter globalisieren. Um sie wieder lokal zu machen, wählen Sie den Menüpfad Bearbeiten->Parameter lokalisieren.
Wenn ein Parameter in zwei Funktionsbausteinen mit demselben Namen innerhalb einer Gruppe existiert und beide Schnittstellen global sind, muß die Datendefinition dieser beiden Parameter gleich sein.
Globale Daten, die innerhalb des top include definiert sind, werden angelegt, wenn ein Programm den ersten Aufruf irgendeines Funktionsbausteins der Gruppe macht. Sie bleiben so lange angelegt, wie das aufrufende Programm aktiv bleibt. Jeder nachfolgende Aufruf eines Funktionsbaustein aus derselben Gruppe sieht die vorigen Werte innerhalb des Bereichs der globalen Daten. Die Werte im Bereich der globalen Daten bleiben bis zum Ende des aufrufenden Programms erhalten.
Globale Daten, die durch eine global erstellte Schnittstelle definiert sind, werden jedesmal wieder initialisiert, wenn der Funktionsbaustein aufgerufen wird.
Die Listings 20.1 bis 20.4 veranschaulichen die »Lebensdauer« von globalen Daten, die innerhalb des top include definiert werden.
Listing 20.1: Dieses Programm veranschaulicht die »Lebensdauer« von globalen Daten.
1 report ztx2001.2 parameters parm_in(10) default 'XYZ' obligatory.3 data f1(10) value 'INIT'.45 perform: call_fm12,6 call_fm13.7 write: / 'f1 =', f1.89*_____________________________________________________________________10 form call_fm12.11 call function 'Z_TX_2002'12 exporting13 p_in = parm_in

14 exceptions15 others = 1.16 endform.1718*_____________________________________________________________________19 form call_fm13.20 call function 'Z_TX_2003'21 importing22 p_out = f123 exceptions24 others = 1.25 endform.
Listing 20.2: Das ist das Quellprogramm des ersten Funktionsbausteins, der von Listing 20.1 aufgerufen wird.
1 function z_tx_2002.2 *"------------------------------------------------------------3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(P_IN)6 *"------------------------------------------------------------7 g1 = p_in.8 endfunction.
Listing 20.3: Das ist das Quellprogramm des zweiten Funktionsbausteins, der von Listing 20.1 aufgerufen wird.
1 function z_tx_2003.2 *"------------------------------------------------------------3 *"*"Local interface:4 *" EXPORTING5 *" VALUE(P_OUT)6 *"------------------------------------------------------------7 p_out = g1.8 endfunction.
Listing 20.4: Dies ist das top include für die Funktionsgruppe ztxb - ztxb enthält die Funktionsbausteine, die in den Listings 20.2 und 20.3 gezeigt werden.
1 function-pool ztxb.2 data g1(10).
Die Programmzeilen in den Listings 20.1 bis 20.4 erzeugen diese Ausgabe:

f1 = XYZ
■ In Listing 20.1 übergibt Zeile 5 die Kontrolle an Zeile 10, und Zeile 11 ruft den Funktionsbaustein z_tx_2002 auf, welcher in der Funktionsgruppe xtxb vorkommt. Der Wert von parm_in wird an p_in übergeben. Die Kontrolle geht an Zeile 1 von Listing 20.2.
■ In Listing 20.2 überträgt Zeile 7 den Wert von p_in in die globale Variable g1. g1 ist im topinclude in Zeile 2 von Listing 20.4 definiert. Das macht sie für alle Funktionsbausteine sichtbar, und der Wert bleibt zwischen den Aufrufen von Funktionsbausteinen dieser Gruppe erhalten. Die Kontrolle geht an Zeile 11 von Listing 20.1 zurück.
■ In Listing 20.1 übergibt Zeile 16 die Kontrolle an Zeile 5, dann an Zeile 6 und dann an Zeile 19. Zeile 20 ruft den Funktionsbaustein z_tx_2003 auf, welcher ebenfalls in der Funktionsgruppe ztxb vorkommt. Die Kontrolle geht an Zeile 1 von Listing 20.3 über.
■ In Listing 20.3 überträgt Zeile 7 den Wert der globalen Variablen g1 an p_out. g1 enthält nach wie vor den Wert, der ihr vom vorigen Funktionsbaustein zugewiesen wurde. Die Kontrolle kehrt zum rufenden Programm zurück und der Wert wird ausgegeben.
Eine interne Tabelle an einen Funktionsbaustein übergeben
Die Übergabe einer internen Tabelle an einen Funktionsbaustein folgt den gleichen Regeln wie die Übergabe einer internen Tabelle an ein Unterprogramm. Es gibt zwei Methoden der Übergabe:
■ über den tables-Teil der Schnittstelle. Das ist gleichbedeutend mit der Möglichkeit, sie mittels des tables-Zusatzes zur perform-Anweisung zu übergeben.
■ über den importing- oder changing-Teil der Schnittstelle. Ersteres ist gleichbedeutend mit using bei der perform-Anweisung, und letzteres ist gleichbedeutend mit changing bei perform.
Um eine interne Tabelle zurückzuerhalten, die innerhalb eines Funktionsbausteins definiert ist, benutzen Sie eine der folgenden Schnittstellenteile:
■ den tables-Teil der Schnittstelle ■ den exporting-Teil der Schnittstelle
Eine interne Tabelle mit tables übergeben
Wenn Sie den tables-Teil der Schnittstelle benutzen, können Sie die interne Tabelle zusammen mit der Kopfzeile übergeben. Wenn sie keine Kopfzeile hat, wird automatisch einer innerhalb des Funktionsbausteins angefordert werden. Tables-Parameter werden immer als Referenz übergeben.
Um diese Methode zu nutzen, wählen Sie im Fenster Funktionsbibliothek: Eingangsbild den Auswahlknopf Schnittstelle Tabellenparameter/Ausnahmen und drücken dann die Schaltfläche Ändern. Sie werden das Fenster Tabellenparameter/Ausnahmen sehen. In der oberen Hälfte des Fensters unter der Spalte Tabellenparameter geben Sie die Namen von internen Tabellenparametern ein.

Wenn die interne Tabelle von strukturiertem Typ ist, können Sie optional in der Spalte Ref. Struktur eine DDIC-Struktur eingeben. Nur DDIC-Strukturnamen können hier eingegeben werden. Wenn Sie keine DDIC-Struktur hier eingeben, werden Sie nicht in der Lage sein, irgendeine Komponente der internen Tabelle innerhalb des Funktionsbausteins anzusprechen. Versuchten Sie es, wird dies einen Syntaxfehler verursachen.
Wenn die interne Tabelle keinen strukturierten Typ hat, können Sie statt dessen einen ABAP/4-Datentyp in der Spalte Referenztyp angeben.
Eine interne Tabelle mit exporting/importing und changing übergeben
Wenn Sie den exporting/importing oder changing-Teil der Schnittstelle benutzen, können Sie nur den Tabellenrumpf einer internen Tabelle übergeben. Jedoch ermöglichen es Ihnen diese Teile der Schnittstelle, zu wählen, ob Sie den internen Tabellenrumpf als Wert (Vorgabewert) oder durch Referenz übergeben. Wenn Sie diese Methode nutzen, müssen Sie table in der Spalte Referenztyp angeben.
Die Abbildungen 20.1 und 20.2 sowie die Listings 20.5 und 20.6 erläutern die Wege, interne Tabellen an einen Funktionsbaustein zu übergeben.
Listing 20.5: Dieses Programm übergibt interne Tabellen an einen Funktionsbaustein.
1 report ztx2005.2 tables ztxlfa1.3 data: it_a like ztxlfa1 occurs 3, "doesn't have a header line4 it_b like ztxlfa1 occurs 3. "doesn't have a header line5 select * up to 3 rows from ztxlfa1 into table it_a.67 call function 'Z_TX_2006'8 exporting9 it1 = it_a[]10 importing11 it2 = it_b[]12 tables13 it4 = it_a14 changing15 it3 = it_a[]16 exceptions17 others = 1.1819 write: / 'AFTER CALL',20 / 'IT_A:'.21 loop at it_a into ztxlfa1.22 write / ztxlfa1-lifnr.

23 endloop.24 uline.25 write / 'IT_B:'.26 loop at it_b into ztxlfa1.27 write / ztxlfa1-lifnr.28 endloop.
Abbildung 20.1: Die Maske mit den Import/Export-Parametern zeigt, wie der Rumpf einer internen Tabelle übergeben wird.
Abbildung 20.2: Die Maske Tabellenparameter/Ausnahmen zeigt, wie eine interne Tabelle zusammen mit ihrer Kopfzeile übergeben wird.
Listing 20.6: Dies ist das Quellprogramm für den Funktionsbaustein, der aus Listing 20.5 aufgerufen wird.
1 function z_tx_2006.2 *"------------------------------------------------------------

3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(IT1) TYPE TABLE6 *" EXPORTING7 *" VALUE(IT2) TYPE TABLE8 *" TABLES9 *" IT4 STRUCTURE LFA110 *" CHANGING11 *" VALUE(IT3) TYPE TABLE12 *"------------------------------------------------------------13 data wa like lfa1.14 write / 'IT1:'.15 loop at it1 into wa.16 write / wa-lifnr.17 endloop.18 loop at it3 into wa.19 wa-lifnr = sy-tabix.20 modify it3 from wa.21 endloop.22 uline.23 write: / 'IT4:'.24 loop at it4.25 write / it4-lifnr.26 endloop.27 uline.28 it2[] = it1[].29 endfunction.
Das Programm in den Listings 20.5 und 20.6 erzeugt diese Ausgabe:
------------IT1:100010101020------------IT4:100010101020------------AFTER CALL IT_A:123------------

IT_B:100010101020
In Listing 20.5 sind it_a und it_b interne Tabellen ohne Kopfzeilen.
Zeile 5 legt drei Zeilen in it_a ab.
■ Zeile 8 übergibt den Tabellenrumpf von it_a an it1 als Wert, an it3 als Wert und Ergebnis, und an it4 als Referenz mit Kopfzeile (it4 wird eine Kopfzeile innerhalb des Funktionsbausteins erfordern).
■ In Listing 20.6 und innerhalb des Funktionsbausteins, sind it1 und it3 unabhängige Kopien von it_a. Zeile 13 definiert einen Arbeitsbereich, der für it1 und it3 benutzt wird, da sie keine Kopfzeilen haben.
■ Die Zeilen 15 bis 17 geben den Inhalt von it1 mittels des Arbeitsbereichs wa aus. ■ Die Zeilen 18 bis 21 ändern den Inhalt von it3. Diese Tabelle wurde als Wert und Ergebnis
übergeben, also wird das Original geändert werden, wenn die endfunction -Anweisungausgeführt wird.
■ Die Zeilen 24 bis 26 geben den Inhalt von it4 aus. Beachten Sie, daß Zeile 25 auf eine Komponente von it zugreift. Dies ist nur möglich, weil die Spalte: Ref. Struktur auf dem Fenster Tabellenparameter/Ausnahmen den Namen einer DDIC-Struktur lfa1 enthält. Dies definiert die Struktur von it innerhalb des Funktionsbausteins. Wenn die Spalte Ref. Struktur leer wäre, würde ein Syntaxfehler in Zeile 25 auftreten.
■ Zeile 28 kopiert den Inhalt von it1 nach it2.■ Zeile 29 kopiert den Inhalt von it3 zurück nach it_a im aufrufenden Programm und die
Kontrolle kehrt zum Aufrufer zurück. ■ In Listing 20.5 zeigen die Zeilen 21 bis 23, daß der Inhalt von it_a durch den
Funktionsbaustein geändert wurde. ■ Die Zeilen 26 bis 28 zeigen, daß der Inhalt von it_a durch den Funktíonsbaustein nach it_b
kopiert wurde.
Unterprogramme in einer Funktionsgruppe definieren
Sie können interne und externe Unterprogramme aus Funktionsbausteinen heraus aufrufen. Aufrufe von externen Unterprogrammen sind für Funktionsbausteine wie für Reports gleich. Interne Unterprogramme sollten mit einem speziellen include definiert werden: dem F01.
F01 wird in die Funktionsgruppe eingeschlossen, indem das Hauptprogramm editiert wird und die Anweisung include lfgidF01 eingefügt wird. Anschließend wird es durch Doppelklick auf den Namen vom include automatisch erzeugt. Darin können Sie Unterprogramme anlegen, auf die von allen Funktionsbausteinen innerhalb der Gruppe zugegriffen werden kann. Es gibt allerdings einen einfacheren Weg.

Der einfachste Weg F01 zu definieren ist, wenn Sie Ihren Unterprogrammaufruf programmieren und dann auf den Unterprogrammnamen in der perform-Anweisung doppelklicken. Das folgende Verfahren veranschaulicht diesen Vorgang.
Starten Sie jetzt das ScreenCam »How to Create Subroutines within a Function Group«.
1. Starten Sie vom Fenster Funktionsbibliothek:Eingangsbild.
2. Wählen Sie den Auswahlknopf Quelltext.
3. Drücken Sie die Schaltfläche Ändern. Das Fenster Funktionsbaustein ändern erscheint.
4. Tippen Sie eine perform-Anweisung in das Quellprogramm des Funktionsbausteins ein. Zum Beispiel perform sub1.
5. Doppelklicken Sie auf den Unterprogrammnamen. In diesem Beispiel würden Sie auf sub1doppelklicken. Das Dialogfenster Objekt Anlegen erscheint und fragt Sie, ob Sie das Unterprogramm anlegen möchten.
6. Drücken Sie die Schaltfläche Ja. Das Dialogfenster Anlegen Unterprogramm erscheint. Der Unterprogrammname erscheint im Feld Unterprogramm. Der Include-Name lfgidf01 erscheint im Auswahlkästchen Include, und der Auswahlknopf auf der linken Seite ist automatisch gedrückt.
7. Drücken Sie die Schaltfläche Fortsetzen (der grüne OK-Haken). Ein Warnung-Dialogfenster erscheint und zeigt an, daß das Hauptprogramm geändert wird und eine include lfgidf01-Anweisungeingefügt wird.
8. Drücken Sie die Schaltfläche Fortsetzen (der grüne OK-Haken). Sie sehen das Dialogfenster Editor Verlassen, welches anzeigt, daß Ihr Quellprogramm geändert wurde und Sie fragt, ob Sie die Änderungen sichern möchten.
9. Drücken Sie die Schaltfläche Ja. Das Fenster Funktionsbaustein Editor wird angezeigt. Sie ändern nun F01. Programmieren Sie hier das Unterprogramm.
10. Wenn Sie Ihr Unterprogramm fertig programmiert haben, drücken Sie Sichern und dann Zurück. Sie kehren nun zurück zum Quellprogramm des Funktionsbausteins, wo Sie begonnen haben.
Einen Funktionsbaustein freigeben
Die Funktion Freigeben fügt der Schnittstelle eines Funktionsbausteins eine Schutzebene hinzu, indem sie sie vor Änderungen schützt. Wenn Sie Ihren Funktionsbaustein abschließend getestet haben, wollen Sie ihn vielleicht freigeben um anzuzeigen, daß es für andere Entwickler sicher ist, ihn in ihren Programmen zu benutzen. Indem Sie dies tun, versprechen Sie im wesentlichen, die Schnittstellenparameter in keiner Weise so zu ändern, daß das Probleme in irgendeinem Programm verursachen könnte, das Ihren Funktionsbaustein aufruft. Sie versprechen die Schnittstellenstabilität.

Zum Beispiel sollten Sie nach dem Freigeben eines Funktionsbausteins keinen Pflichtparameter hinzufügen, die Vorschlagswerte ändern oder einen Parameter entfernen. Falls Sie das dennoch täten, könnten bestehende Aufrufe von Ihrem Funktionsbaustein scheitern oder anders arbeiten.
Nach dem Freigeben können Sie immer noch die Schnittstelle ändern, Sie benötigen aber einen zusätzlichen Schritt, um dies zu tun.
Um einen Funktionsbaustein freizugeben, benutzen Sie das folgende Verfahren.
Starten Sie jetzt das ScreenCam »How to Release a Function Module«.
1. Beginnen Sie im Fenster Funktionsbibliothek:Eingangsbild
2. Wählen Sie den Auswahlknopf Schnittstelle.
3. Drücken Sie die Schaltfläche Ändern. Das Fenster: FBaustein Ändern wird angezeigt. Drücken Sie auf die Registerkarte Verwaltung. In der unteren rechten Ecke des Fensters, am unteren Rand der Gruppe Allgemeine Daten, werden Sie Nicht Freigegeben sehen.
4. Wählen Sie den Menüpfad Funktionsbaustein->Freigabe->Freigeben. Die Meldung Freigegeben erscheint am unteren Fensterrand in der Statuszeile. In der unteren rechten Ecke des Fensters ändert sich Nicht Freigegeben zu Freigegeben Für Kunden, gefolgt vom aktuellen Datum.
Wenn Sie versuchen, die Schnittstelle zu ändern, nachdem der Funktionsbaustein freigegeben wurde, sind die Eingabefelder auf dem Schnittstellenfenster inaktiv. Die Meldung Funktionsbaustein Wurde Schon Freigegeben wird ebenfalls am unteren Fensterrand erscheinen. Wenn Sie jedoch die Schnittstelle ändern wollen, brauchen Sie bloß die Schaltfläche Anzeigen<->Ändern zu drücken, und es ist Ihnen erlaubt, sie so zu ändern, wie Sie das wollen. Vergessen Sie aber nicht, daß Sie keine Änderungen machen sollten, die verursachen können, daß bestehende Programme abnormal beenden oder andere Ergebnisse liefern.
Gibt man versehentlich einen Funktionsbaustein frei und will dies rückgängig machen, geht man in den Anzeigemodus Funktionsbaustein->Freigabe->Freigabe zurücknehmen.
Einen Funktionsbaustein testen
Wenn Sie einen Funktionsbaustein testen wollen, ohne ein ABAP/4-Programm zu schreiben, können Sie dies tun, indem Sie die Testumgebung innerhalb der Funktionsbibliothek benutzen. Benutzen Sie das

folgende Verfahren, um mit der Testumgebung zu arbeiten.
Starten Sie jetzt das ScreenCam »How to Use the Test Environment for Function Modules«.
1. Beginnen Sie am Fenster Funktionsbibliothek:Eingangsbild. Tippen Sie den Namen des Funktionsbausteins, den Sie testen wollen, in das Feld Funktionsbaustein ein.
2. Drücken Sie die Schaltfläche Einzeltest. Sie werden das Fenster Funktionsbausteine testen sehen (gezeigt in Abb. 20.3).
3. Tippen Sie die Parameter ein, die Sie für den Test versorgen wollen. Um eine interne Tabelle zu füllen, doppelklicken Sie auf den Namen der internen Tabelle. Es wird ein Fenster gezeigt, das Ihnen ermöglicht, Daten in die interne Tabelle einzugeben. (Wenn Sie eine Ref. Struktur für die interne Tabelle angegeben haben, werden die Spalten der Struktur angezeigt werden.) Tippen Sie Ihre Daten ein und drücken Sie die Entertaste. Sie werden zum Fenster Testumgebung Für Funktionsbausteine zurückkehren.
Abbildung 20.3: Die Testumgebung für Funktionsbausteine

4. Drücken Sie die Schaltfläche Ausführen auf der Anwendungssymbolleiste, um den Funktionsbaustein auszuführen. Sie werden das Fenster Funktionsbaustein testen:Ergebnisse sehen (siehe Abb. 20.4). Die Ausgabe von write-Anweisungen innerhalb des Funktionsbausteins erscheinen zuerst. In Abbildung 20.4 ist You passed A das Ergebnis einer write-Anweisung in dem Funktionsbaustein. Weiterhin wird die für die Ausführung des Funktionsbausteins benötigte Zeit angezeigt (in Mikrosekunden). Anschließend werden die Werte der Parameter gezeigt, und die changing- und tables-Parameterhaben zwei Werte: vorher und nachher. Für changing-Parameter wird der »Vorher«-Wert zuerst angezeigt, und der »Nachher«- Wert erscheint darunter. Für tables-Parameter erscheint der »Nachher«-Inhalt über dem »Vorher"(Original)-Inhalt. In Abbildung 20.4 enthielt die interne Tabelle it zwei Zeilen nach der Ausführung und drei Zeilen vorher. Um die Vorher- und Nachher-Inhalte der internen Tabelle zu sehen, doppelklicken Sie auf eine Zeile.
Abbildung 20.4: Der Testfunktionsbaustein: hier werden die Vorher- und Nachher-Ergebnisse der changing- und tables-Parameter gezeigt.

Um Testdaten und/oder Ergebnisse zu sichern, sichern Sie entweder in der Maske der Testumgebung oder in der Ergebnis-Maske. Um Ihre gesicherten Ergebnisse zurückzuholen, drücken Sie auf die Schaltfläche der entsprechenden Maske. Es können auch Testsequenzen mit der Schaltfläche Testsequenz gebildet werden.
Existierende Funktionsbausteine finden
Wie zuvor schon gesagt, liefert SAP mehr als 5000 vordefinierte Funktionsgruppen, die mehr als 30000 Funktionsbausteine enthalten. Oft ist die von Ihnen benötigte Funktionalität bereits durch diese durch SAP gelieferten Funktionsbausteine abgedeckt - Sie müssen lediglich den richtigen zu finden. Um einen existierenden Funktionsbaustein zu finden, benutzen Sie das Repository Information System. Das folgende Verfahren zeigt Ihnen wie.
Starten Sie jetzt das ScreenCam »How to Search for Function Modules«.
1. Ausgehend vom Fenster ABAP/4-Enwicklungs-Workbench, wählen Sie den Menüpfad Übersicht->Infosystem. Sie sehen das Fenster ABAP/4 Repository Information System, abgebildet in Abbildung 20.5.

Abbildung 20.5: Das ABAP/4-Infosystem
2. Klappen Sie die Zeile Programmierung auf, indem Sie auf das Pluszeichen (+) links davon klicken. Ein Unterbaum wird darunter angezeigt.
3. Klappen Sie die Zeile Funktionsbibliothek auf, indem sie auf das Pluszeichen (+) links davon klicken. Ein Unterbaum wird darunter angezeigt. Ihr Bildschirm sollte nun wie auf Abbildung 20.6 aussehen.
Abbildung 20.6: Das Infosystem aufgeklappt
4. Doppelklicken Sie auf die Zeile Funktionsbausteine. Das Fenster ABAP/4 Repository Info System:Funktionsbausteine, wird angezeigt. Ihr Bildschirm sollte nun wie in Abbildung 20.7 aussehen. Dieses ist ein Auswahlfenster, in welchem Sie Suchkriterien eingeben können, um Funktionsbausteine zu suchen. Alle Felder ignorieren Groß-/Kleinschreibung mit der Ausnahme des Kurztextfeldes, welches Groß-/ Kleinschreibung unterscheidet!

Abbildung 20.7: Das Infosystem:Funktionsbaustein mit Selektionsmöglichkeiten
5. Um einen Funktionsbaustein zu suchen, können Sie entweder Worte oder Zeichenfolgen in den Suchfeldern eingeben. Benutzen Sie + und * als Wildcard-Zeichen. + steht für irgendein Einzelzeichen und * steht für irgendeine Zeichenfolge. Als Beispiel geben Sie *DATE* in das Funktionsbausteinfeld ein. Dieses wird alle Funktionsbausteine finden, die die Zeichen DATE irgendwo in ihrem Namen enthalten. Oder Sie geben *Date* oder *date* im Kurzbeschreibungsfeld ein (nur eine Zeichenfolge ist in diesem Feld erlaubt).
6. Um mehr als einen Wert einzugeben, nach dem gesucht werden soll, drücken Sie den Pfeil am Ende des Feldes. Das Fenster: Mehrfachauswahl wird angezeigt (siehe Abb. 20.8). Die Werte, die Sie auf diesem Bild eingeben, werden mit ODER zusammengefaßt. Tippen Sie mehrere Suchkriterien hier ein. Diese Werte sind als included Werte bekannt, oder einfach als die »includes«. (Hier wird der Ausdruck anders gebraucht als bei der Bezeichnung von Include-Parameter.)
7. Drücken Sie die Schaltfläche: Optionen, um Auswahloperatoren wie gleich, nicht gleich, größer als, kleiner als usw. einzutragen. Sie werden das Fenster: Pflegen Auswahloptionen, sehen, wie in Abbildung 20.9 gezeigt. Um Muster oder Muster Ausschließen eingeben zu können, muß Ihr Wert ein Musterzeichen enthalten: entweder + oder *. Drücken Sie die Schaltfläche Übernehmen, um zum Fenster: Mehrfachauswahl zurückzukehren.

Abbildung 20.8: Mehrfachselektionen
Abbildung 20.9: Nach Initialwert selektieren
8. Auf dem Fenster: Mehrfachauswahl drücken Sie die Schaltfläche: Komplexe Suche. Das Fenster: Mehrfachauswahl wird wieder angezeigt, aber diesmal gibt es einen Rollbalken auf der rechten Seite, und Bereichsfelder erscheinen (siehe Abb. 20.10). Um Werte einzugeben, die von der Suche

ausgeschlossen werden sollen, scrollen Sie nach unten und geben sie in der Gruppe ein mit dem Titel ...Aber nicht (siehe Abb. 20.11). Diese Werte werden Ausschlußwerte genannt oder einfacher, excludes.
Abbildung 20.10: Mehrfachselektionen mit Rollbalken rechts der Intervalleingaben

Abbildung 20.11: Die ...Aber-nicht-Selektion
9. Drücken sie die Schaltfläche: Übernehmen, um Ihre Auswahlkriterien zurück in das Auswahlfenster zu übernehmen. Sie kehren zurück zum Fenster: ABAP/4 Repository Information System, und wenn Sie mehrfache Auswahlkriterien eingegeben haben, ist der Pfeil am Ende der Zeile grün, um anzuzeigen, daß mehr als ein Auswahlkriterium existiert (siehe Abb. 20.12).

Abbildung 20.12: Repository-Infosystem: Funktionsbaustein
10. Um die Suche zu beginnen, drücken Sie die Schaltfläche Ausführen. Die Suchergebnisse werden bestimmt, als ob für alle include-Kriterien getrennte Suchen durchgeführt und dann die Ergebnisse mit ODER zusammengeführt worden wären. Weiterhin, wenn excludes angegeben wurden, werden diese ein Eintrag nach dem anderen angewendet. Angenommen, Sie haben zum Beispiel in dem Kurzbeschreibungsfeld die includes *Date* und *date* und die excludes *Update* und *update* angegeben. Es werden alle Beschreibungen gefunden, die *Date* enthalten, und dann werden alle Beschreibungen, die *date* enthalten, mit ODER mit der ersten Ergebnismenge zusammengeführt. Dann werden alle Beschreibungen, die *Update* enthalten, entfernt, und dann werden alle, die *update* enthalten, entfernt. Das Ergebnis wird die Zeichenfolgen »Date« oder »date« ohne »Update« und »update« enthalten. Sie sehen die Ergebnisse im Fenster Funktionsbausteine (siehe Abb. 20.13). Die Anzahl gefundener Funktionsbausteine wird in der Titelzeile in Klammern angezeigt.

Abbildung 20.13: Funktionsbausteine

Abbildung 20.14: Fbausteine anzeigen: Dokumentation
11. Um einen Funktionsbaustein anzuzeigen, machen Sie darauf einen Doppelklick. Das Fenster Funktionsbausteine anzeigen:Dokumentation, wird angezeigt (siehe Abb. 20.14). Dieses Fenster zeigt Ihnen alle Schnittstellenparameter und ihre Dokumentation. Um eine ergänzende Dokumentation zu sehen, doppelklicken Sie auf einen Parameternamen (siehe Abb. 20.15). Um zur Schnittstellendokumentation zurückzukehren, drücken Sie die Schaltfläche Zurück. Um zur Funktionsbausteinliste zurückzukehren, drücken Sie erneut die Schaltfläche Zurück.
Abbildung 20.15: Ergänzende Informationen für einen Parameter
12. Um einen Funktionsbaustein zu testen, setzen Sie Ihren Mauszeiger darauf, und drücken Sie die Schaltfläche Test/Ausführen (sie sieht wie ein kleiner Schraubenschlüssel aus). Es wird Ihnen das Fenster Testumgebung für diesen Funktionsbaustein gezeigt.
Nicht alle Parameter haben zusätzliche Dokumentation. Wenn Sie auf Parameter ohne weitere Dokumentation doppelklicken, passiert gar nichts.
Die Anzahl der Funktionsbausteine kann beim Suchen mit Hilfe der Suchkriterien

innerhalb der Selektionsmaske erhöht oder erniedrigt werden. Der Standardwert ist 500.
Die Komponenten Ihrer Funktionsgruppe untersuchen
Nachdem Sie Ihren ersten Funktionsbaustein angelegt haben, benutzen Sie das folgende Verfahren, und nehmen Sie sich ein paar Minuten Zeit, um die Bestandteile der Funktionsgruppe zu untersuchen. Sie sollten die Struktur verstehen, die Sie gerade angelegt haben.
Starten Sie jetzt das ScreenCam »Exploring the Components of Your Function Group«.
1. Beginnen Sie auf dem Fenster Funktionsbibiliothek:Eingangsbild. Wenn es nicht schon da ist, tippen Sie den Namen Ihres Funktionsbausteins in das Feld Funktionsbaustein.
2. Wählen Sie den Auswahlknopf Verwaltung und drücken Sie dann die Schaltfläche Ändern. Das Fenster Funktionsbaustein ändern wird angezeigt (siehe Abb. 20.16). Gehen Sie in Verwaltung. Am oberen Fensterrand im Feld Funktionsgruppe können Sie die ID der Funktionsgruppe sehen, zu der dieser Funktionsbaustein gehört. In der unteren rechten Ecke im Feld Programm können Sie den Namen des Hauptprogramms für diese Funktionsgruppe sehen. Im Feld Include befindet sich der Name des Include, welches das Quellprogramm für den Funktionsbaustein enthält. Das letzte Feld zeigt den Status des Funktionsbausteins: Aktiv oder Nicht aktiv. Drücken Sie die Schaltfläche Zurück, um zum Fenster Funktionsbibliothek:Eingangsbild zurückzukehren.

Abbildung 20.16: Verwaltungsmaske für Funktionsbausteine
3. Wählen Sie Import/Export-Parameter an.
4. Wählen Sie Ausnahmen. Hier können Sie interne Tabellenparameter und Ausnahmenamen eingeben oder ändern.
5. Wählen Sie Dokumentation. Hier können Sie eine kurze Beschreibung für jeden Parameter und Ausnahme in der Schnittstelle eingeben.
6. Wählen Sie Quellprogramm.
7. Wählen Sie Springen:Globale Daten. Das Fenster Funktionsbaustein:Editor wird angezeigt. Diesmal editieren Sie jedoch das top include. Beachten Sie den Namen des top include in der Titelzeile. Er entspricht der Namenskonvention lfgidtop , wobei fgid der Name Ihrer Funktionsgruppe ist. Hier können Sie globale Variablen und Tabellenarbeitsbereiche definieren, die allen Funktionsbausteinen innerhalb der Funktionsgruppe zugänglich sind. Wenn Ihr Funktionsbaustein die message-Anweisungbenutzt, können Sie auch die Standard-Meldungsklasse definieren (in der function-pool-Anweisung). Drücken Sie die Schaltfläche Zurück, um zurückzukehren.

8. Wählen Sie Springen:Rahmenprogramm. Das Fenster Funktionsbaustein:Editor wird angezeigt. Diesmal editieren Sie das Hauptprogramm (siehe Abb. 20.17). Beachten Sie, daß der Name in der Titelleiste mit sapl beginnt, gefolgt von Ihrer Funktionsgruppen-ID. Die zwei include-Anweisungen konstituieren das top include und das UXX in das Hauptprogramm. Doppelklickt man auf das UXX, wird das include-Quellprogramm angezeigt - es enthält die Anweisungen, die die Funktionsbausteine in die Gruppe einschließen. Ihre Namen werden in Kommentaren am Ende jeder include-Anweisung angezeigt. Sie dürfen das UXX nicht verändern. Doppelklickt man auf eine der include-Anweisungen, wird das Quellprogramm für einen Funktionsbaustein innerhalb der Gruppe angezeigt. Drücken Sie die Schaltfläche Zurück, um zurückzukehren.
Abbildung 20.17: Rahmenprogramm
Um Funktionsbausteine zu kopieren oder zu löschen, benutzen Sie die entsprechende Schaltfläche in der Einstiegsmaske der Funktionsbibliothek.

Fehler in Funktionsbausteinen finden und beheben
Der einfachste Weg, Fehler in einem Funktionsbaustein zu beheben, ist, eine Syntaxprüfung durchzuführen, wenn Sie den Funktionsbaustein bearbeiten. Sie können dies im Fenster: Funktionsbaustein editieren tun, indem Sie die Schaltfläche: Prüfen auf der Drucktastenleiste drücken. Bis jetzt haben Sie nur einen Funktionsbaustein angelegt, also wissen Sie noch nicht, wo Sie nachsehen müssen, wenn er nicht funktioniert.
Wenn Sie aber viele Funktionsbausteine angelegt haben, geraten Sie vielleicht in die Lage, daß, wenn Sie einen oder mehrere Funktionsbausteine in einer Gruppe aufrufen, das System Ihnen sagt, dasß irgendwo ein Syntaxfehler sei. Die Fehlermeldung, die Sie gegebenenfalls sehen, erscheint in einem SAP R/3-Dialogfenster, so wie es in Abbildung 20.18 gezeigt ist.
Abbildung 20.18: Ein Syntaxfehler innerhalb eines Funktionsbausteins während der Laufzeit
Innerhalb dieses SAP R/3-Dialogfensters befindet sich genug Information, um die exakte Lage und den Grund des Fehlers zu bestimmen. In Abbildung 20.18 enthält das erste Feld den Programmnamen lztxau02. Dies ist das Include-Programm, das den Fehler enthält. Das zweite Feld sagt Ihnen, daß der Fehler in Zeile 10 auftritt. Am unteren Rand des Dialogfensters ist der genaue Fehler. In diesem Fall heißt der Fehler ":" expected after "P2".
Um den Fehler zu beheben, benutzen Sie das folgende Verfahren.
Starten Sie jetzt das ScreenCam »How to Fix an Error in a Function Module«.
1. Beginnen Sie mit dem Fenster ABAP/4 Editor:Eingangsbild (Transaktion SE38).
2. Im Feld Programm tippen Sie den Programmnamen des ersten Feldes des Dialogfensters ein, in diesem Fall lztxau02.
3. Drücken Sie die Schaltfläche Ändern. Dies wird Ihnen das Quellprogramm des Funktionsbausteins zeigen, der den Fehler enthält.

4. Drücken Sie die Schaltfläche Prüfen auf der Drucktastenleiste. Sie sollten denselben Fehler sehen, der am unteren Rand des SAP-R/3-Dialogfensters angezeigt wurde.
5. Korrigieren Sie den Fehler. Oft können Sie einfach die Schaltfläche Korrigieren drücken, und das System wird den Fehler automatisch für Sie korrigieren.
Den Rückgabewert von sy-subrc setzen
Normalerweise setzt das System automatisch bei der Rückkehr von einem Funktionsbaustein den Wert von sy-subrc auf Null. Benutzen Sie eine der zwei Anweisungen, um sy-subrc auf einen Wert ungleich Null zu setzen:
■ raise■ message ... raising
Die raise-Anweisung
Benutzen Sie die raise-Anweisung, um den Funktionsbaustein zu verlassen und den Wert von sy-subrc bei der Rückkehr zu setzen.
Syntax der raise-Anweisung
Das Folgende ist die Syntax für die raise-Anweisung.
raise xname.
wobei:
■ xname der Name der auszulösenden Ausnahme ist.
Es gelten die folgenden Punkte:
■ xname kann irgendein Name sein, den Sie erfinden. Er muß nicht irgendwo vorher definiert sein. Er kann bis zu 30 Zeichen lang sein. Alle Zeichen sind erlaubt außer " ' . , und :.
■ Schließen Sie xname nicht in Hochkommata ein. ■ xname darf keine Variable sein.
Wenn die raise-Anweisung ausgeführt wird, kehrt die Kontrolle unmittelbar zu der callfunction-Anweisung zurück und ein Wert wird sy-subrc zugewiesen, basierend auf den Ausnahmen, die Sie dort aufgelistet haben. Werte, die export-Parametern zugewiesen sind, werden nicht zum rufenden Programm zurückkopiert. Die Listings 20.7 und 20.8 sowie Abbildung 20.19 illustrieren diesen Sachverhalt.

Der Code in Listing 20.8 ist nur ein Beispiel; normalerweise wäre an dieser Stelle ein Code, der reale Prozesse ausführt.
Abbildung 20.19: Beispiel einer raise-Anweisung
Listing 20.7: Wie man den Wert von sy-subrc aus einem Funktionsbaustein heraus setzt.
1 report ztx2007.2 parameters parm_in default 'A'.3 data vout(4) value 'INIT'.4 call function 'Z_TX_2008'5 exporting 6 exname = parm_in7 importing 8 pout = vout9 exceptions10 error_a = 111 error_b = 412 error_c = 413 others = 99.14 write: / 'sy-subrc =', sy-subrc,15 / 'vout =', vout.
Listing 20.8: Dies ist der Funktionsbaustein, der von Listing 20.7 aufgerufen wird.
1 function z_tx_2008.2 *"------------------------------------------------------------3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(EXNAME)6 *" EXPORTING7 *" VALUE(POUT)8 *" EXCEPTIONS

9 *" ERROR_A10 *" ERROR_B11 *" ERROR_C12 *" ERROR_X13 *"------------------------------------------------------------14 pout = 'XXX'.15 case exname.16 when 'A'. raise error_a.17 when 'B'. raise error_b.18 when 'C'. raise error_c.19 when 'X'. raise error_x.20 endcase.21 endfunction.
Die Programme in den Listings 20.7 und 20.8 erzeugen diese Ausgabe, wenn Sie einen Wert A für parm_in angeben:
sy-subrc = 1 vout = INIT
■ In Listing 20.7 übernimmt Zeile 4 den Wert von parm_in und übergibt ihn an den Funktionsbaustein z_tx_2007. Die Kontrolle geht an Zeile 1 von Listing 20.8 über.
■ In Listing 20.8 weist Zeile 14 einen Wert dem Parameter pout zu. Dieser Parameter wird als Wert übergeben, so daß die Änderung nur die lokale Definition von pout betrifft. Das Original wurde noch nicht geändert.
■ In Listing 20.8 prüft Zeile 15 den Wert, der mittels des Parameters exname übergeben wird. Der Wert ist B, so daß Zeile 17 - raise error_b - ausgeführt wird. Die Kontrolle geht an Zeile 9 von Listing 20.7 über. Da die raise-Anweisung ausgeführt wurde, wird der Wert von pout nicht in das rufende Programm zurückkopiert, so daß der Wert von vout unverändert bleiben wird.
■ In Listing 20.7 durchsucht das System die Zeilen 10 bis 13, bis es einen Treffer für die Ausnahme findet, die durch die gerade ausgeführte raise-Anweisung benannt wurde. In diesem Fall sucht es nach error_b. Es paßt Zeile 11.
■ In Zeile 11 wird der Wert auf der rechten Seite des Gleichheitsoperators sy-subrc zugewiesen. Die Kontrolle geht dann an Zeile 20 über.
Der Spezialname others in Zeile 13 von Listing 20.7 gilt für alle Ausnahmen, die nicht explizit im exceptions-Zusatz benannt sind. Würde zum Beispiel Zeile 7 der Listing 20.8 ausgeführt, würde die Ausnahme error_x gesetzt. Diese Ausnahme ist in Listing 20.7 nicht genannt, also wird othersausgeführt, und der Wert von sy-subrc wird auf 99 gesetzt. Sie können beliebige Nummern für Ausnahmerückkehrwerte programmieren.

Wird nicht others codiert und eine Ausnahme (exeption) taucht innerhalb des Funktionsbausteins auf, die nicht in der exeption-Anweisung erwähnt ist, bricht das Programm ab, und es kommt zum Laufzeitfehler RAISE_EXEPTION.
Wenn ein export-Parameter als Wert übergeben wird, bleibt sein Wert nach einem raiseunverändert im rufenden Programm, sogar wenn ein Wert innerhalb des Funktionsbausteins zugewiesen wurde, bevor die raise-Anweisung ausgeführt wurde. Falls der Parameter durch Referenz übergeben wurde, wird er im rufenden Programm geändert (der Auswahlknopf Referenz ist im Fenster: Export/Import-Parameter gesetzt). Dieser Effekt wird in Listing 20.7 gezeigt. Der Wert von pout wird im Funktionsbaustein geändert und wird, falls eine raise-Anweisung ausgeführt wird, nicht in das rufende Programm zurückkopiert.
Check, exit und stop haben innerhalb von Funktionsbausteinen die gleiche Bedeutung wie in externen Unterprogrammen. Sie sollten jedoch nicht in Funktionsbausteinen benutzt werden. Statt dessen sollte mit der raise-Anweisunggearbeitet werden, weil sie es dem rufenden Programm ermöglicht, den Rückgabewert von sy-subrc zu nutzen.
Die message ... raising-Anweisung benutzen
Die message ... raising-Anweisung besitzt zwei Betriebsarten:
Wenn die nach raising genannte Ausnahme nicht durch die call function-Anweisungbehandelt wird und others nicht programmiert ist, wird eine Meldung an den Benutzer gesendet.
Wenn die nach raising genannte Ausnahme durch die call function-Anweisung behandelt wird, wird keine Meldung an den Benutzer gesendet. Statt dessen kehrt die Kontrolle zur callfunction-Anweisung zurück, und die Ausnahme wird in derselben Weise behandelt wie für die raise-Anweisung.
Syntax für die message ... raising-Anweisung
Das Folgende ist die Syntax für die message ... raising-Anweisung.
message tnnn(cc) [with v1 v2 ...] raising xname
wobei:
■ t der Meldungstyp (e, w, i, s, a, oder x) ist. ■ nnn die Meldungsnummer ist.

■ (cc) die Meldungsklasse ist. ■ v1 und v2 Werte sind, die in den Meldungstext eingefügt werden. ■ xname der Name der auszulösenden Ausnahme ist.
Es gelten folgende Punkte:
■ xname ist eine Ausnahme, wie sie für die raise-Anweisung beschrieben wurde. ■ Wenn die Meldungsklasse hier nicht angegeben wird, muß sie in der function- pool-
Anweisung im top include für die Funktionsgruppe mittels des message-id- Zusatzes angegeben werden.
■ Die folgenden sy-Variablen werden gesetzt: sy-msgid, sy-msgty, sy-msgno, und sy-msgv1 bis sy-msgv4. Diese können innerhalb des rufenden Programms untersucht werden (nach der Rückkehr).
Wenn die message ... raising-Anweisung ausgeführt wird, hängt der Kontrollfluß vom Meldungstyp ab und davon, ob die Ausnahmebedingung durch das rufende Programm behandelt wird (spezifiziert in der Ausnahmeliste im rufenden Programm).
■ Wenn die Ausnahmebedingung durch den Rufenden behandelt wird, kehrt die Kontrolle zum Rufenden zurück. Die Werte der sy-msg-Variablen werden gesetzt. Die Werte der export-Parameter, als Werte übergeben, werden nicht zurückgegeben.
■ Wenn die Ausnahmebedingung nicht durch den Rufenden behandelt wird, das gilt auch für die Meldungstypen e, w, und a, wird der Funktionsbaustein verlassen und das rufende Programm sofort beendet. Die Meldung wird angezeigt, und die Ausgabeliste erscheint leer. Wenn der Benutzer die Entertaste drückt, wird die leere Liste entfernt, und der Benutzer kehrt zurück zum Fenster, von wo aus das Programm gestartet wurde.
■ Wenn die Ausnahmebedingung nicht durch den Rufenden behandelt wird, das gilt ebenso für den Meldungstyp i, wird die Meldung dem Benutzer in einem Dialogfenster gezeigt. Wenn der Benutzer die Entertaste drückt, kehrt die Kontrolle zum Funktionsbaustein zu der der message-Anweisung folgenden Anweisung zurück. Der Funktionsbaustein setzt die Verarbeitung fort, und die Kontrolle kehrt an der endfunction-Anweisung zum rufenden Programm zurück. Die Werte der sy-msg- Variablen sind gesetzt, und die Werte der als Wert übergebenen export-Parameter werden zurückgegeben.
■ Wenn die Ausnahmebedingung nicht durch den Rufenden behandelt wird, gleiches gilt für den Meldungstyp s, wird die Meldung in einem Systembereich gespeichert. Die Kontrolle setzt an der der message-Anweisung folgenden Anweisung innerhalb des Funktionsbausteins fort. Der Funktionsbaustein setzt die Verarbeitung fort, und an der endfunction-Anweisung kehrt die Kontrolle zum rufenden Programm zurück. Die Werte der sy-msg-Variablen sind gesetzt, und die Werte der als Werte übergebenen export-Parameter werden zurückgegeben. Wenn die Liste angezeigt wird, erscheint die Meldung in der Statusleiste am unteren Listenrand.
■ Wenn die Ausnahmebedingung nicht durch den Rufenden behandelt wird, das gilt auch für den Meldungstyp x, wird der Funktionsbaustein verlassen, und das rufende Programm wird sofort beendet. Ein Programmabbruch (auch Short dump oder Kurzdump genannt) wird erzeugt und dem Benutzer angezeigt.
Die Listings 20.9 und 20.10 illustrieren den Effekt der message ... raising-Anweisung.

Listing 20.9: Die message ... raising-Anweisung benutzen
1 report ztx2009.2 parameters: p_etype default 'E', "enter message types E W I S A X3 p_handle default 'Y'. "if Y, handle the exception4 data vout(4) value 'INIT'.56 if p_handle = 'Y'.7 perform call_and_handle_exception.8 else.9 perform call_and_dont_handle_exception.10 endif.11 write: / 'sy-subrc =', sy-subrc,12 / 'vout =', vout,13 / 'sy-msgty', sy-msgty,14 / 'sy-msgid', sy-msgid,15 / 'sy-msgno', sy-msgno,16 / 'sy-msgv1', sy-msgv1.1718*_____________________________________________________________________19 form call_and_handle_exception.20 call function 'Z_TX_2010'21 exporting22 msgtype = p_etype23 importing24 pout = vout25 exceptions26 error_e = 127 error_w = 228 error_i = 329 error_s = 430 error_a = 531 error_x = 632 others = 7.33 endform.3435*_____________________________________________________________________36 form call_and_dont_handle_exception.37 call function 'Z_TX_2010'38 exporting39 msgtype = p_etype40 importing41 pout = vout.42 endform.

Listing 20.10: Das Quellprogramm des von Listing 20.9 aufgerufenen Funktionsbausteins
1 function z_tx_2010.2 *"------------------------------------------------------------3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(MSGTYPE)6 *" EXPORTING7 *" VALUE(POUT)8 *" EXCEPTIONS9 *" ERROR_E10 *" ERROR_W11 *" ERROR_I12 *" ERROR_S13 *" ERROR_A14 *" ERROR_X15 *"------------------------------------------------------------16 pout = 'XXX'.17 case msgtype.18 when 'E'. message e991(zz) with 'Error E' raising error_e.19 when 'W'. message e992(zz) with 'Error W' raising error_w.20 when 'I'. message e993(zz) with 'Error I' raising error_i.21 when 'S'. message e994(zz) with 'Error S' raising error_s.22 when 'A'. message e995(zz) with 'Error A' raising error_a.23 when 'X'. message e996(zz) with 'Error X' raising error_x.24 endcase.25 endfunction.
Wenn die vorbelegten Parameterwerte benutzt werden, erzeugt das Programm in den Listings 20.9 und 20.10 folgende Ausgabe:
sy-subrc = 1 vout = INIT sy-msgty E sy-msgid ZZ sy-msgno 991 sy-msgv1 Error E
■ In Listing 20.9 ist Zeile 6 wahr, wenn die vorbelegten Werte benutzt werden, also geht die Kontrolle an das Unterprogramm call_and_handle_exception über.
■ Zeile 20 übergibt die Kontrolle an Zeile 1 von Listing 20.10. ■ In Listing 20.10 weist Zeile 16 dem lokalen Parameter pout einen Wert zu. Dieser Wert ist
definiert als zu übergebender Wert, so daß der Wert von vout im rufenden Programm noch nicht geändert wird.
■ Zeile 18 der case-Anweisung ist wahr, und die message ... raising-Anweisung wird ausgeführt. Diese löst die Ausnahme error_e aus.
■ Die Ausnahme error_e wird durch das rufende Programm behandelt, so daß die Meldung dem

Benutzer nicht angezeigt wird. Die Kontrolle kehrt zu Zeile 25 von Listing 20.9 zurück. Der Wert von vout wird nicht geändert; den sy-msg-Variablen werden Werte zugewiesen.
■ In Listing 20.9 weist Zeile 26 sy-subrc den Wert 1 zu. ■ Zeile 33 gibt die Kontrolle an Zeile 11 zurück, und die Werte werden ausgegeben.
Versuchen Sie das Programm ztx2009 auszuführen. Indem Sie für p_handle einen Wert von Nangeben, werden Sie die erzeugten Fehlermeldungen sehen.
Ausnahmen in der Schnittstelle definieren
Wann immer Sie eine Ausnahme in einem Funktionsbaustein auslösen, sollten Sie den Namen in der Funktionsbaustein-Schnittstelle dokumentieren. Die Ausnahmenamen werden auch automatisch am Anfang des Quellprogramms des Funktionsbausteins innerhalb der vom System generierten Kommentare erscheinen. Das folgende Verfahren beschreibt, wie Sie Ihre Ausnahmen dokumentieren.
Starten Sie jetzt das ScreenCam »How to Document Exceptions in the Function Module Interface«.
1. Beginnen Sie mit dem Fenster: Funktionsbibliothek: Eingangsbild.
2. Tippen Sie Ihren Funktionsbausteinnamen in das Feld Funktionsbaustein, wenn er dort nicht schon steht.
3. Wählen Sie Ausnahmen.
4. In der unteren Hälfte des Fensters, in dem Ausnahmenbereich, tippen Sie die Namen der Ausnahmen ein, die im Quellprogramm des Funktionsbausteins vorkommen.
5. Drücken Sie die Schaltflächen Sichern und Zurück. Sie kehren zurück zum Fenster Funktionsbibliothek:Eingangsbild.
Die call function-Anweisung automatisch einfügen
Anstatt daß Sie die call function-Anweisung in Ihr Quellprogramm eintippen, kann das System dies auch automatisch für Sie erledigen. Wenn Sie so verfahren, werden die Ausnahmennamen, die Sie in der Schnittstelle dokumentiert haben, ebenso automatisch in Ihr Programm eingefügt.
Starten Sie nun das ScreenCam »How to Insert a call function Statement into Your ABAP/4 Program«.
Um die Effekte Ihrer Ausnahmendokumentation zu sehen, erzeugen Sie ein ABAP/4- Programm. Anstatt die call function-Anweisung selbst zu programmieren, benutzen Sie das folgende Verfahren, um automatisch die call function-Anweisung zu erzeugen:
1. Beginnen Sie im Fenster ABAP/4-Editor:Programm ändern.

2. Positionieren Sie Ihren Mauszeiger innerhalb des Quellprogramms auf die Zeile nach derjenigen, auf welcher die call function-Anweisung erscheinen soll.
3. Drücken Sie die Schaltfläche Muster auf der Anwendungssymbolleiste. Das Dialogfenster Muster einfügen erscheint.
4. Der Auswahlknopf Call Function sollte bereits ausgewählt sein. Falls nicht, wählen Sie ihn jetzt.
5. Tippen Sie den Namen Ihres Funktionsbausteins in das Eingabefeld rechts von Call Function.
6. Drücken Sie die Schaltfläche Weiter (der grüne Haken). Sie kehren zurück zum Fenster Programm Editieren. Eine call function-Anweisung wird im Quellprogramm über der Zeile erscheinen, wo Sie Ihren Mauszeiger positioniert haben. Die Anweisung wird in derselben Spalte beginnen, in der Ihr Mauszeiger stand. Die Parameter und Ausnahmen, die Sie in der Schnittstelle benannt haben, werden erscheinen. Wenn ein Parameter in der Schnittstelle als optional gekennzeichnet ist, wird er auskommentiert sein, und der Vorbelegungswert wird rechts davon erscheinen.
7. Geben Sie die Werte rechts von den Gleichheitszeichen ein. Sie können beliebig die Anweisungszeilen ändern oder Zeilen nach dem importing-Zusatz entfernen, wenn Sie diese Rückgabewerte nicht benötigen.
Eine leere importing-Klausel führt zu einem Syntaxfehler. Wenn keine Parameternamen dem Wort importing folgen, oder wenn sie alle auskommentiert sind, muß man das Wort importing zurücknehmen. Das Gleiche gilt für exporting.
Zusammenfassung
■ Globale Variablen können auf zwei Ebenen definiert werden. Wenn sie im top includedefiniert werden, sind sie global für alle Funktionsbausteine innerhalb der Gruppe und behalten ihre Werte zwischen Aufrufen von Funktionsbausteinen innerhalb der Gruppe, solange das rufende Programm ausgeführt wird. Indem die Schnittstelle globalisiert wird, sind Parameter innerhalb von aus dem Funktionsbaustein aufgerufenen Unterprogrammen sichtbar.
■ Innerhalb einer Funktionsgruppe definierte Unterprogramme werden in dem F01 includeprogrammiert.
■ Funktionsbausteine können freigegeben werden, um anzuzeigen, daß die Schnittstelle stabil ist und keine bedeutenden Änderungen mehr daran gemacht werden. Sie werden daher zur allgemeinen Verfügbarkeit freigegeben, und es ist sicher, sie in produktiven Programmen zu benutzen.
■ Die Testumgebung bietet einen bequemen Weg, um Funktionsbausteine auszuführen, ohne irgendein ABAP/4-Programm zu schreiben.

■ Existierende Funktionsbausteine können mit der Hilfe des Repository Information System gefunden werden.
Fragen & Antworten
Frage:Warum würden Sie einen Import-Parameter durch Referenz übergeben? Wenn Sie sowohl Import- als auch Export-Parameter als durch Referenz zu übergeben spezifizieren, sind sie dann nicht dasselbe? Warum gibt es diese Möglichkeit?
Antwort:Eine Übergabe durch Referenz ist schneller als eine Übergabe als Wert. Sie sollten diese aus Performance-Gründen benutzen. Jedoch bieten die Begriffe »Import« und »Export« wichtige Dokumentation bezüglich der Rolle, die jeder Parameter innerhalb des Funktionsbausteins spielt. Sie sollten keine Import- Parameter ändern, sie sollten immer übergeben werden, ohne daß sie durch den Funktionsbaustein geändert werden. Ebenso sollten Sie keine Werte durch Export-Parameter in den Funktionsbaustein übergeben. Der Wert eines Export-Parameters sollte immer aus dem Funktionsbaustein stammen.
Workshop
Der Übungsteil bietet Ihnen zwei Wege zu vertiefen, was Sie in diesem Kapitel gelernt haben. Die Fragen sollen Ihnen helfen, Ihr Verständnis des abgehandelten Stoffes zu festigen und der Übungsabschnitt ermöglicht Ihnen, Erfahrungen zu sammeln, indem Sie anwenden, was Sie gelernt haben. Sie können Antworten zu den Fragen und Übungen im Anhang B finden.
Kontrollfragen
1. Wenn ein Parameter mit demselben Namen in zwei Funktionsbausteinen innerhalb einer Gruppe existiert und beide Schnittstellen global sind, müssen die Datendefinitionen dieser beiden Parameter identisch sein?
2. Wenn Sie versehentlich einen Funktionsbaustein freigeben und die Freigabe zurücknehmen wollen, welchen Menüpfad können Sie nutzen?
3. Wenn Sie others nicht programmieren und eine Ausnahme innerhalb des Funktionsbausteins ausgelöst wird, die nicht im exceptions-Zusatz aufgeführt ist, was passiert dann?
4. Check, exit und stop haben dieselbe Wirkung in Funktionsbausteinen wie in externen Unterprogrammen. Sollten sie innerhalb von Funktionsbausteinen benutzt werden?
Übung 1
Kopieren Sie den Funktionsbaustein z_tx_div, und modifizieren Sie ihn, um die zero_divide-

Ausnahme auszulösen, wenn der Wert von p2 Null ist. (Um einen Funktionsbaustein zu kopieren, benutzen Sie die Schaltfläche Kopieren im Fenster Funktionsbibliothek: Eingangsbild).
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Woche 3
Tag 21
Selektionsbilder
Kapitelziele
Nachdem Sie dieses Kapitel durchgearbeitet haben, sollten Sie:
■ Selektionsbilder programmieren können, die mit dem Benutzer interagieren ■ Fremdschlüssel verstehen, die bei der Prüfung der Benutzereingaben helfen können ■ verstehen, wie Matchcodes in ABAP/4-Programmen verwendet werden ■ Formatierungselemente benutzen, um effiziente, gut gestaltete Selektionsbilder zu erzeugen ■ Selektionsbilder benutzen, um die Datenintegrität zu gewährleisten ■ Meldungen benutzen, um effektiv zu kommunizieren
Ereignisgesteuerte Programmierung
In der heutigen Zeit mit der Verbreitung des World Wide Web und all seinen Folgen muß ein Programm so angelegt sein, daß es mit dem Endbenutzer interagieren und kommunizieren kann. Dies wird in ABAP/4 mit Ereignissen erreicht, die durch die Benutzeraktionen ausgelöst werden.
Auszuführende Programmblöcke werden durch Ereignisschlüsselwörter definiert und werden dementsprechend ausgeführt, wenn bestimmte bedeutende Ereignisse eintreten.
Standardmäßig ist das Ereignis start-of-selection allen Ereignissen in ABAP/4 zugewiesen. In Ihren Programmen können Sie einen Prozeßblock definieren und diesen Block an ein Ereignisschlüsselwort hängen.
Für allgemein leicht lesbare Programme ist es üblich, aufeinanderfolgende Prozeßblökke in der Reihenfolge zu definieren, in der sie höchstwahrscheinlich durch das Ausführen des Selektionsbildes aufgerufen werden. Zudem ist es üblich, die wichtigsten Ereignisse für das Programmieren der Selektionsbilder zu verwenden. Diese Ereignisse sind die folgenden:

■ das initialization-Ereignis■ das at selection-screen-Ereignis■ das at user-command-Ereignis
Das initialization-Ereignis
Das folgende Programm zeigt die Syntax für das initialization-Ereignis:
report ywhatyr.tables: marc, mvke...data: p_year for sy-datum.initialization.if sy-datum ge '01012000'p_year = '2000'.else.p_year = 'Yesteryear'.endif.
Wenn in diesem Beispiel das Programm ausgeführt wird, für das ein Selektionsbild definiert ist, wird dieser initialization-Prozeßblock ausgeführt und das Parameterfeld p_year wirdgleich einem Wert gesetzt, der vom Systemdatum zum Zeitpunkt der Ausführung abhängt. Dieser Block ist es, in dem Sie die Anfangswerte Ihres Selektionsbildes definieren, basierend auf den benötigten Kriterien, der die Datenintegrität der Benutzereingaben gewährleistet. Einige Beispiele enthalten das Setzen von Titelleisten, indem Textelemente graphischen Benutzeroberflächen (GUI) zugewiesen werden, sowie den Status von Funktionscodes.
Sie haben nun gesehen, wie das initialization-Ereignis funktioniert, es ist also nun an der Zeit, sich einige Anwendungen der at selection-screen- und at user-command -Ereignisse genauer anzusehen.
Das at selection-screen-Ereignis
Das at selection-screen-Ereignis wird nach der Benutzereingabe auf dem aktiven Selektionsbild ausgeführt. Dies kann eintreten, wenn der Benutzer eine Funktionstaste drückt oder auf eine Schaltfläche klickt, oder ebenso durch eine Menge anderer Elemente, die der Anwender benutzen kann. Im Zuge der Datengültigkeitsprüfungen können durch das at selection-screen-Ereignis Warnmeldungen, GUI-Statusänderungen oder sogar Dialogfenster aufgerufen werden. Sie werden später noch mehr solche Beispiele sehen, wenn Sie das Formatieren von Selektionsbildern und die mit den bildformatierenden Elementen verbundenen Ereignisse betrachten. Jetzt wollen wir uns jedoch eine Schaltfläche auf einem Selektionsbild ansehen und wie mit dieser die Ereignisse at selection-screen und at user-command im nächsten Beispiel benutzt werden.
Das at user-command-Ereignis

Schaltflächen sowie viele andere ereignisgesteuerte Selektionsbildoptionen können sehr nützlich sein, für die Interaktion mit dem Benutzer oder zur Prüfung von Benutzereingaben. Im nächsten Abschnitt werden Sie erforschen, wie Schaltflächen zu benutzen sind, um das at user-command-Ereignis auszulösen, und Sie betrachten ein Beispiel, wie Schaltflächen benutzt werden können, um Benutzereingaben auszuwerten.
Syntax für das Selektionsbild Schaltflächenereignis
Das folgende Programm zeigt die Syntax für das Selektionsbild Schaltflächenereignis:
selection-screen pushbutton example1 user-command 1234.
Wenn diese Anweisung zusammen mit der at selection-screen-Anweisung benutzt wird, ist dies ein ausgezeichneter Weg, mit dem Benutzer zu interagieren, wenn er Daten eingibt. Die Syntax ist ähnlich der eines Selektionsbildes Kommentar, mit dem Unterschied, daß hier Daten übergeben werden, wenn der Benutzer die Schaltfläche drückt. Indem die Schaltfläche gedrückt wird, wird sccrfields-ucomm im at selection-screen -Ereignis ausgelöst, und die Eingabefelder werden eingelesen. Diese Daten können dann geprüft und dem Benutzer kann eine Meldung geschickt werden, abhängig vom Zweck der Schaltfläche. Dieses ist ein Beispiel dafür, wie Sie zwei Schaltflächen benutzen können, um die Sprache zu bestimmen, in der selektierte Daten ausgegeben werden sollen.
Das folgende Programm zeigt die Syntax für zwei Schaltflächen, die benutzt werden, um eine Sprache auszuwählen:
selection-screen pushbutton 10(20) text-003 user-command engl.selection-screen pushbutton 50(20) text-004 user-command germ.
at selection-screen.at user-command.case sy-ucomm.when 'engl'.lang-english = 'Y'.when 'germ'.lang-german = 'Y'.endcase.
In diesem Beispiel können Sie mit einer case-Anweisung prüfen, welche der zwei Schaltflächen durch den Benutzer gedrückt wurden (siehe Abb. 21.1). Wenn der Benutzer das at user-command Ereignis auslöst, enthält das Feld sy-ucomm den eindeutigen vierstelligen Namen des Objektes, das der Benutzer ausgewählt hat. Auf diese Weise können Sie verschiedene Datengültigkeitsprüfungen programmieren oder Benutzereingaben steuern, basierend auf der Kombination von eingegebenen Daten und Objekten, in diesem Fall Schaltflächen, die der Benutzer ausgewählt hat.
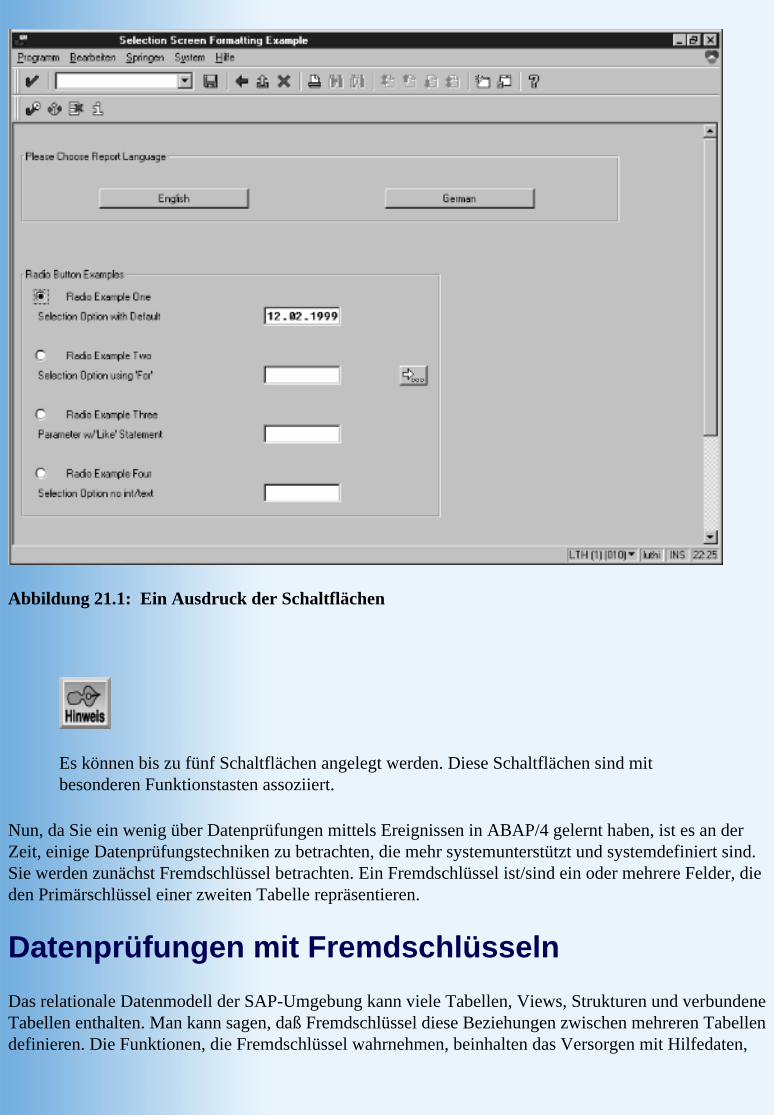
Abbildung 21.1: Ein Ausdruck der Schaltflächen
Es können bis zu fünf Schaltflächen angelegt werden. Diese Schaltflächen sind mit besonderen Funktionstasten assoziiert.
Nun, da Sie ein wenig über Datenprüfungen mittels Ereignissen in ABAP/4 gelernt haben, ist es an der Zeit, einige Datenprüfungstechniken zu betrachten, die mehr systemunterstützt und systemdefiniert sind. Sie werden zunächst Fremdschlüssel betrachten. Ein Fremdschlüssel ist/sind ein oder mehrere Felder, die den Primärschlüssel einer zweiten Tabelle repräsentieren.
Datenprüfungen mit Fremdschlüsseln
Das relationale Datenmodell der SAP-Umgebung kann viele Tabellen, Views, Strukturen und verbundene Tabellen enthalten. Man kann sagen, daß Fremdschlüssel diese Beziehungen zwischen mehreren Tabellen definieren. Die Funktionen, die Fremdschlüssel wahrnehmen, beinhalten das Versorgen mit Hilfedaten,

Erzeugen von Dictionary-Objekten; das aber, worauf Sie sich hierkonzentrieren werden, liegt in dem Bereich der Datenprüfungen. Denn schließlich ist es eines der Hauptziele, wenn Selektionsbilder definiert werden, die Datenintegrität mit Hilfe der sehr bedeutsamen Fremdschlüssel zu erhalten.
Ein Fremdschlüsselfeld ist per Definition auf Werte beschränkt, die mit jenen des Primärschlüssels der Prüftabelle des Eingabefeldes korrespondieren. So wird die Beziehung zwischen den zwei Tabellen hergestellt. Eine Tabelle, FORKEY1, kann als Fremdschlüssel- (oder abhängige) Tabelle gedacht werden, hauptsächlich weil sie Fremdschlüsselfelder enthält, die Primärschlüsselfeldern in CHECK1 zugewiesen sind, welches seinerseits als Prüf- (oder Referenz-) Tabelle bezeichnet wird.
Das Fremdschlüsselfeld und der Primärschlüssel der zugefügten Tabelle müssen sich die gleiche Domäne teilen, und eine Wertetabelle für diese Domäne muß auch angegeben werden. Das erweitert auf eine Art die Datenintegrität, die normalerweise in der Tabelle unterstützt wird.
Einige Prüftabellen können mehrere Primärschlüsselfelder enthalten. In diesen Fällen müssen Zuweisungen für jedes Feld gemacht werden, wenn man eine Fremdschlüsselbeziehung aufbaut. Es gibt folgende drei Optionen:
■ Benutzen Sie einen partiellen Fremdschlüssel. In diesem Fall werden einige Felder nicht berücksichtigt, wenn gültige Werte für Eingaben im Fremdschlüsselfeld geprüft werden. Bestimmte Felder sind in diesem Fall als generisch gekennzeichnet und werden so vom System bei der Prüfung ignoriert.
■ Benutzen Sie einen festen Fremdschlüssel. Damit eine Eingabe im Feld gültig ist, muß der Wert dem der Konstante in der Prüftabelle entsprechen.
■ Erzeugen Sie eine Feld-zu-Feld-Zuweisung. Dies ist die gründlichste der drei Auswahlmöglichkeiten. Jedes Primärschlüsselfeld in der Prüftabelle wird mit einem Feld in der Fremdschlüsseltabelle in Beziehung gesetzt, und alle Schlüsselfelder werden dann benutzt, um gültige Eingaben in der Fremdschlüsseltabelle zu bestimmen.
Grundsätzlich ähnelt die Art, wie ein Fremdschlüssel arbeitet, der einer direkten select -Anweisung für die Prüftabelle des Feldes mit dem Fremdschlüssel. Genauer gesagt, wenn ein Fremdschlüsselfeld gefüllt wird, wird die select-Anweisung, die vom SAP-System bei der Definition des Fremdschlüssels erzeugt wurde, vom Programm gesendet. Wenn die Tabelle einen Wert für diese Selektion zurückgibt, ist die Eingabe gültig. Wenn der Satz nicht gefunden wird, ist die Feldeingabe ungültig.
Das folgende Programm zeigt die Syntax für eine vom System generierte select-Anweisung:
select * from table_1 where table_1-exam1 = fk_exam1 and table_1-exam2 = fk_exam2.
Dieses Programmstück zeigt ein Beispiel einer vom System generierten select-Anweisung, die

aufgerufen wird, wenn Daten in das Feld mit der Fremdschlüsseldefinition eingegeben werden. In diesem Szenario ist eine Eingabe in dieses Bildschirmfeld nur zulässig, wenn die select-Anweisung gültige Daten von der Prüftabelle liefert, indem die Dateneingaben in den Feldern fk_exam1 und fk_exam2als Schlüssel benutzt werden.
Beim Anlegen von Fremdschlüsselbezeichnungen muß auf Kardinalität geachtet werden. Die Kardinalität eines Fremdschlüssels, zusammen mit seinem Typ, verweist auf die semantischen Attribute des Fremdschlüssels. Jede Kardinalität eines Fremdschlüssels dieser Art von Einträgen ist optional. Die Kardinalität sollte jedoch nicht überbewertet werden, da diese Einträge praktisch sind und nötig werden, wenn man verschiedene Aggregattypen wie Hilfe, Views o.ä. anlegen will.
Kardinalität ist eine Beschreibung der Beziehung zwischen einem oder mehreren Datenelementen zu einem oder mehreren anderen Datenelementen. Wenn ein Fremdschlüssel, der zwei Tabellen verbindet, definiert worden ist, verweist ein Satz der Fremdschlüsseltabelle auf einen Satz der Prüftabelle. Diese Beziehung wird geschaffen, indem Felder einer Tabelle (der Fremdschlüsseltabelle) den Primärschlüsselfeldern der anderen Tabelle (der Prüftabelle) zugewiesen werden.
Die Beziehung existiert nur, wenn die Fremdschlüsselfelder vom selben Datentyp und derselben Länge sind wie die korrespondierenden Primärschlüsselfelder. Eine Prüf- oder Elterntabelle ist diejenige Tabelle, auf welche durch den Fremdschlüssel selbst verwiesen wird. Diese ist gewöhnlich eine Wertetabelle, kann aber auch eine Tabelle sein, die aus einer Untermenge des Inhalts einer Wertetabelle besteht. Eine Wertetabelle bestimmt die gültigen Werte, die zu einer Datenelementen-Domäne gehören.
In manchen Fällen wird ein fester Fremdschlüssel am besten für Ihre Anforderungen passen. Dies ist dann der Fall, wenn alle gültigen Eingaben im Eingabefeld einen bestimmten Wert im Schlüsselfeld der zugehörigen Prüftabelle enthalten. Während der Abfrage mit der select-Anweisung wird das feste Feld gegen das Primärschlüsselfeld geprüft, das den festen Wert enthält.
Hält man sich an die SAP-Namenskonventionen (d.h., daß eigene Objekte mit Y oder Z beginnen müssen), kommt man nicht in Namenskonflikte.
Datenprüfungen mit Matchcodes
Ein anderer nützlicher Weg, zur Gewährleistung der Datenintegrität während der Benutzereingabe, ist

sogenannte Matchcodes zu benutzen. Ein Matchcode ist ein Objekt, das benutzt wird, um Datensätze im SAP-Data Dictionary zu finden. Genauer gesagt: Matchcodes greifen auf ähnliche Weise auf Datensätze zu wie ein Index, in dem alle Schlüsselfelder keine Mußfelder sind, aber sie unterscheiden sich von Indizes, da Matchcodes mehr als eine Tabelle im Selektionsbereich enthalten können.
So funktioniert das: Zuerst wird ein Matchcode-Objekt mit geeigneten Primär- und Sekundärtabellen definiert und signifikante Felder bestimmt. Dieses Objekt identifiziert dann alle möglichen Wege zu den benötigten Datensätzen. Als nächstes werden Matchcode-IDs erzeugt, indem auf einen Weg abgebildet wird, der durch das Matchcode-Objekt definiert worden ist. Die einzigen Datenfelder, die in dieser ID erlaubt sind, basieren vollständig auf dem Matchcode-Objekt. Mindestens eine ID muß für jedes Matchcode-Objekt definiert sein. Matchcode-Objekte werden als Pooltabelle abgespeichert, welche automatisch für jede Matchcode-ID erzeugt wird, die Sie definieren.
Ein Datenpool ist eine logisch zusammengefaßte Tabelle, welche von SAP benutzt wird, um intern Steuerdaten zu speichern. Diese Daten, für welche eine externe Verwendung nicht sinnvoll ist, werden als Anzahl von Datenbanktabellen für eine SAP- Tabelle abgebildet.
Ein Matchcode kann auf zwei verschiedene Arten aktualisiert (zusammengestellt) werden:
■ physikalisch. In dieser Einstellung werden Daten in einer separaten Tabelle im SAP-System gespeichert. Die Änderungstypen A, P und S werden als physische Tabellen abgelegt.
■ logisch. Diese Option erzeugt Matchcode-Daten temporär während des Zugriffs auf den Matchcode. Dieser Zugriff wird durch einen Datenbankview gebildet. In dieser Hinsicht ist die logische Methode diesselbe wie eine transparente Speicherung. Diese beinhaltet nur die Änderungstypen I und K.
In der folgenden Aufgabe werden Sie lernen, zwölf einfachen Schritten zu folgen, um Matchcode-Objekte zu erzeugen und zu pflegen. Beginnen Sie mit dem Fenster Data Dictionary, gezeigt in Abbildung 21.2, und vervollständigen Sie die folgenden Schritte:
1. Geben Sie einen Namen für Ihr neues Objekt ein.
2. Geben Sie beschreibenden Text ein, wenn Sie Ihre Primärtabelle auf dem Fenster Eigenschaften, gezeigt in Abbildung 21.3, eingeben, und drücken Sie die Schaltfläche Sichern. Die Primärtabelle repräsentiert die Hauptquelltabelle für die nachfolgende Feldsuche. Sekundärtabellen können ebenfalls an dieser Stelle gepflegt werden, indem Sie auf die Primärtabelle doppelklicken oder die Schaltfläche Tabellen drücken. Diese Tabellen müssen mit der Primärtabelle durch Fremdschlüssel verbunden sein.

Abbildung 21.2: Die Einstiegsmaske des Data Dictionary

Abbildung 21.3: Matchcode-Objekte pflegen
3. Hier haben Sie die Option, den Matchcode als logisches Objekt zu erzeugen oder ihn in einen Transportauftrag aufzunehmen. Nachdem Sie dies getan haben, klikken Sie auf die Schaltfläche Sichern (siehe Abb. 21.4).
4. Wie die Statusleiste anzeigt, werden die Mußschlüsselfelder automatisch übernommen (siehe Abb. 21.5). Wenn Sie wollen, können Sie die Schaltfläche Felder drükken und alle Selektionsfelder pflegen, die Sie möchten. An dieser Stelle müssen Sie auf den grünen Pfeil klicken, um zurück zum Fenster Matchcode-Objekt Pflegen (Eigenschaften) zu gelangen.
5. Der nächste Schritt im Erfassungsprozeß ist, das Matchcode-Objekt zu aktivieren. Der Status des Objektes ist Neu und Gesichert (siehe Abb. 21.6).
6. Der Status wird nun auf Aktiv und Gesichert gesetzt. Danach müssen Sie eine Matchcode-ID erzeugen, oder Ihr Objekt wird unvollständig sein (siehe Abb. 21.7). Um dies zu tun, klicken Sie die Schaltfläche Matchcode(MC-)IDs. Sollte Ihr Bild nicht so aussehen, wie in Abbildung 21.2. gezeigt, gehen Sie über den Menüpfad Dictionary:Einstieg Hilfsmittel->Matchcode-Objekte->Anlegen.

Abbildung 21.4: Objektkatalogeintrag

Abbildung 21.5: Matchcode-Objekte pflegen (Felder)

Abbildung 21.6: Matchcode-Attribute vor der Aktivierung

Abbildung 21.7: Matchcode-Objekte nach der Aktivierung
7. Das System wird Sie aufforden, eine neue ID zu erzeugen, wenn es noch keine gibt (siehe Abb. 21.8). Um dies zu tun, klicken Sie auf die Schaltfläche Ja.
Abbildung 21.8: Aufforderung zum Anlegen eines Objekts
8. In dem Fenster Matchcode-ID, gezeigt in Abbildung 21.9, geben Sie eine Matchcode-ID-Nummer ein, gültige Eingabebereiche sind alle Buchstaben des Alphabets und jede Nummer. Sie können auch auf den Abwärtspfeil drücken, um einen Bereich gültiger Eingaben zu sehen.

Abbildung 21.9: Dialogbox zum Anlegen einer ID
9. Lassen Sie uns einige mögliche Eingaben betrachten (siehe Abb. 21.10). Wie Sie sehen können, zeigt dieses Fenster einige Matchcode-IDs und zu jeder eine Kurzbeschreibung. Wählen Sie eine aus, und klicken Sie auf den grünen Pfeil.
Abbildung 21.10: Matchcode-Trefferliste
10. Folgen Sie diesen Schritten, die wir gelernt haben, um Selektionsfelder für diese Matchcode-ID zu pflegen, vergewissern Sie sich, einen Änderungstyp eingegeben zu haben, und klicken Sie auf Sichern (siehe Abb. 21.11). Ich werde Änderungstypen nochmals später in diesem Abschnitt besprechen. An dieser Stelle können Sie weitere Selektionskriterien eingeben, indem Sie die Schaltfläche Selektionskriterien drücken.

Abbildung 21.11: Pflege der Attribute
11. Im Fenster Selektionskriterien Pflegen können Sie Felder und Selektionskriterien für Ihre Matchcode-IDs eingeben und pflegen. Hier ist ein Beispiel für eine Anforderung einer Materialnummer, die nicht größer ist als der Wert 8888 (siehe Abb. 21.12). Wenn Sie fertig sind, klicken Sie auf Sichern und auf den grünen Pfeil, um zurückzukehren.

Abbildung 21.12: Pflege der Attribute
12. Nun müssen Sie nur noch Ihre Matchcode-ID aktivieren, und dann können Sie Ihr neues Objekt benutzen (siehe Abb. 21.13).

Abbildung 21.13: Das Generieren des Matchcode
Die Index-Untermaske muß nicht gepflegt werden, da ihr Inhalt nur zur Dokumentation existiert. Lassen Sie die Felder leer, und ignorieren Sie die Warnung im Log bei der Aktivierung.
In diesen zwölf einfachen Schritten haben Sie einen Matchcode erzeugt, den Sie nun für die Erhaltung der Datenintegrität benutzen können. Sie lernten, wie die Primärschlüssel Ihnen helfen, mögliche Werte verbundener Tabellen zu prüfen, und Sie kennen jetztdas Konzept zusammengefaßter Datenfelder (Pool). Erinnern Sie sich, die Weise, in welcher die Matchcode-Daten abgelegt werden, hängt vom Änderungstyp ab, der während der Erstanlage ausgewählt wurde. Hier ist eine Beschreibung jeder dieser fünf Typen:
■ I - wird durch die in den Eigenschaften angegebene Datenbank gepflegt. ■ S - wird durch die Datenbankschnittstelle gepflegt. ■ A - wird automatisch durch das Systemprogram SAPMACO gepflegt. ■ P - wird durch ein Anwendungsprogramm gepflegt.

■ K - wird auch durch ein Anwendungsprogramm gepflegt.
Syntax für das Benutzen eines Matchcodes
Das Folgende ist die Syntax für das Benutzen von Matchcodes für die Eingabeprüfung von Parametern auf Selektionsbildern:
tables: saptabparameter: example like saptab-field matchcode object exam.select single field from saptab where field = example.
Dieses Beispiel benutzt das Matchcode-Object exam, welches schon mit einer Matchcode-ID definiert wurde, um die Dateneingabe für das Parameterfeld example zu prüfen. Dieses Objekt exam enthält die Beziehungsdaten, die nötig sind, um die Integrität der Benutzereingabe zu gewährleisten.
Selektionsbilder formatieren
Nachdem Sie nun einige Werkzeuge erforscht haben, um Eingabedaten in ABAP/4 zu prüfen, lassen Sie uns einige Zeit darauf verwenden, mehr über das effektive Gestalten von Selektionsbildformaten zu lernen. Wenn Eingabebilder für das Anwenden auf Datenberichten definiert werden, können verschiedene Selektionselemente kombiniert werden, um Datenintegrität zu gewährleisten und dennoch leicht zu benutzen zu sein. Diese Elemente schließen Standardeingabefelder ein wie Selektionsoptionen und Parameter und auch andere wie Auswahlfelder, Auswahlknöpfe, und Schaltflächen. Der folgende Abschnitt wird jedes Element einzeln betrachten und einige Beispiele dafür geben, wo sie am besten eingesetzt werden. Sie werden die Möglichkeit haben, sie in Übung 1 am Ende des Kapitels zu kombinieren.
selection-screen-Anweisungen benutzen
Selektionsbildelemente können in zusammenhängende Einheiten, auch Blöcke genannt, kombiniert werden. Diese logischen Blöcke sind im wesentlichen eine kosmetische Bildeigenschaft, welche die Kombination von Bildeingabelementen einschließt und mit einem beschreibenden Rahmentitel versehen werden kann.
Syntax für den selection-screen-Block mit Rahmen
Das Folgende ist die Syntax für einen selection-screen-Block mit Rahmen:
selection-screen begin of block block0 with frame title text-000.
Zusätzlich zu der block-Anweisung können Selektionsbilder durch Benutzen von formatierenden Elementen gestaltet werden, wie die folgenden selection-screen-Anweisungen:
■ selection-screen comment - Diese Anweisung wird einen Kommentar auf dem

Selektionsbild erzeugen. ■ selection-screen uline - Diese Anweisung wird einen Unterstrich an einer bestimmten
Stelle in einer bestimmten Länge auf dem Bild erzeugen. ■ selection-screen position - Diese Anweisung ist ein sehr nützliches Werkzeug, das
einen Kommentar für das nächste Parameterfeld auf dem Bild erzeugt. Dies gilt sowohl für selection-options als auch für parameters.
■ selection-screen begin-of-line und selection-screen end-of-line - Alle Eingabefelder, die zwischen diesen zwei Anweisungen liegen, werden nebeneinander auf derselben Zeile plaziert.
■ selection-screen skip n - Diese Anweisung erzeugt eine Leerzeile für n Zeilen auf dem Selektionsbild.
Die meisten Elemente des vorangegangenen Abschnitts sind von kosmetischer Art; im nächsten Abschnitt werden Sie auf einige der Selektionsbildelemente stoßen, die mehr für das Bearbeiten von Dateneingaben geeignet sind.
Selektionsbild Parameter
Die parameter-Anweisung auf dem Selektionsbild erzeugt eine Datenstruktur in dem Programm, das die zur Laufzeit vom Benutzer in das Parameterfeld eingegebenen Daten enthält.
Parameter können am besten benutzt werden, wenn das Eingabefeld einen Einzelwert erfordert, im Gegensatz zu Wertebereichen. Der gültige Wertebereich kann vom Benutzer bestimmt werden, indem er auf den Abwärtspfeil klickt oder die (F4)-Taste drückt, wenn der Cursor in dem von der parameter-Anweisung generierten Feld steht. Diese Wertetabelle kann vom Programmierer gepflegt werden, um kundeneigene Werte für spezielle Transaktionen oder Berichte aufzunehmen. Der direkteste Weg um eine (F4)-Hilfe zu erzeugen ist, eine Prüftabelle der Felddomäne im ABAP/4 Dictionary zuzuweisen.
Eine Domäne beschreibt die Eigenschaften von Feldern einer Tabelle. Sie definiert den Bereich von gültigen Datenwerten für ein Feld und für bestimmte Eigenschaften des Feldes.
Domänen bestimmen die Attribute wie Typ, Länge und mögliche Fremdschlüsselbezeichnungen. Ändert man eine Domäne, ändern sich die Attribute aller Datenelemente, die zur Domäne gehören, da Datenelemente einer Domäne ihre Eigenschaften vererben.
Um eine Domäne anzusehen oder zu bearbeiten, starten Sie im Fenster Data Dictionary (siehe Abb. 21.14). Wählen Sie den zu Domänen gehörenden Auswahlknopf, und wählen Sie die Schalftläche für die Bearbeitung, die Sie ausführen wollen.

Abbildung 21.14: Die Dictionary-Einstiegsmaske
In diesem Beispiel haben Sie den Anzeigemodus gewählt (siehe Abb. 21.15). Wie Sie sehen können, werden die Domänen-Charakteristika auf dem Bild angezeigt.
Zusammen mit der parameter-Anweisung können Sie Schlüsselwörter anwenden, die die Eingaben mit gewissen Optionen einschränken. Diese drei Schlüsselwörter sind die folgenden:
■ lower case - Wenn Sie dieses Schlüsselwort in der Selektionsanweisung anenden, werden die im Eingabefeld in Kleinbuchstaben eingegebenen Werte nicht automatisch in Großbuchstaben umgewandelt, was bei allen Eingabefelder in ABAP/4 zur Laufzeit geschieht.
■ Obligatory - Dieses Schlüsselwort verbietet leere Eingabefelder. ■ Default - Dieser Ausdruck liefert einen Anfangswert für den Parameter.

Abbildung 21.15: Domänenanzeige
Textelemente für Maskenelemente sollten gepflegt werden, um den Anwender zu vernünftigen Eingaben zu zwingen. Diese Textelemente sind von Sprachschlüsseln abhängig und erscheinen in der Anmeldesprache.
Um Textelemente für Ihr Selektionsbild zu pflegen, wählen Sie den Menüpfad Springen->Textelemente im ABAP/4-Editor. Sie können alle drei Texttypen für Ihr Programm von hier aus pflegen. Wir werden nun ein Beispiel zur Pflege von Textsymbolen sehen (siehe Bild 21.16).
Abbildung 21.17 zeigt das Bild, das Ihnen ermöglicht die Textsymbole zu pflegen, die Sie in Ihrem Programm erzeugt haben. Wenn Sie mehr hinzufügen möchten, geben Sie eine Nummer und einenText ein, und klicken Sie die Schaltfläche Sichern. Beachten Sie auch die Option Verwendungsnachweis, welche wirklich sehr brauchbar ist.

Selektionsbild checkbox
Parameter können als Datenfelder angelegt werden, die nur einen Eingabewert enthalten, und sie können auch als Auswahlfelder angelegt werden. Wenn Parameter die Form von Auswahlfeldern annehmen, werden sie als Typ C angelegt und enthalten den Wert X, wenn sie ausgewählt sind, und ein Leerzeichen, wenn nicht ausgewählt. Eine gute Anwendung des checkbox-Parameters ist, den Benutzer aufzufordern, anzugeben, ob er/sie eine bestimmte Komponente eines Berichts angezeigt haben möchte.
Abbildung 21.16: Textsymbole Einstieg

Abbildung 21.17: Pflege von Textsymbolen
Die Syntax der checkbox
Das Folgende ist die Syntax für einen Parameter, der als Auswahlfeld erscheint:
parameters: testparm as checkbox default 'X'.
In diesem Beispiel wird der Anfangswert auf ausgewählt gesetzt, oder X für die logische Verarbeitung im Programm. Auswahlfelder schließen sich im Gegensatz zu Auswahlknöpfen nicht gegenseitig aus, so daß der Benutzer so viele Felder auswählen kann, wie auf dem Selektionsbild erzeugt worden sind.
Wie Sie gelernt haben, wird am besten die parameter-Anweisung benutzt, wenn ein Einzeleingabewert gefordert ist. Wenn die angeforderte Eingabe besser als Wertebereich dargestellt werden kann, ist die select-options-Anweisung effektiver.
Die select-options-Anweisung erzeugt eine interne Selektionstabelle, die die Eingabe für die zugehörigen Eingabefelder enthält.
Selektionsbild select-options

Die select-options-Anweisung wird ähnlich der parameters-Anweisung benutzt, indem sie Selektionskriterien für ein Datenbankfeld erzeugt. Der Hauptunterschied zwischen den beiden ist, daß die select-options-Anweisung zwei Eingabefelder erzeugt, ein VON- und ein BIS-Feld, im Gegensatz zu einer einfachen Einzelfeldeingabe.
Syntax für select-options
Die Syntax für diese Anweisung ist wie folgt:
select-options ex sele for table-field default 'VALUELOW' to 'VALUEHI'.
Die select-options-Anweisung zeigt eine Zeile, die gewöhnlich zwei Felder für Eingabedaten hat. Durch die no-intervals-Klausel in der select-options-Syntax kann sie auf nur ein Feld reduziert werden. Wenn Ihr Programm zum Beispiel kein BIS-Feld zur Eingabe in der select-options-Anweisungszeile erfordert, Sie dennoch die select-options -Anweisung benutzen wollen, würden Sie diese no-intervals-Klausel benutzen. Diese Klausel sowie auch die no-extension-Klausel werden im Beispiel am Ende dieses Abschnitts noch eingehend behandelt. Jetzt jedoch werden wir das Format der internen select-options-Selektionstabelle besprechen.
Diese interne Tabelle wird mit dem folgenden Feldformat gefüllt, wenn der Benutzer auf den Pfeil rechts vom BIS-Feld der select-options klickt. Das Klicken auf diesen Pfeil bringt ein Mehrfachselektionseingabebild zum Vorschein, welches die interne Selektionstabelle füllt. Diese Tabelle enthält dann die Schlüsseleigenschaften der Eingabedaten, einschließlich SIGN, OPTION , LOW-Wert und HIGH-Wert. Diese Eigenschaften der select-options-Anweisung können folgende Bedingungen haben:
■ SIGN - kann INCLUSIVE bedeuten, welches der Vorgabewert ist, oder EXCLUSIVE, welches im Fenster Komplexe Selektionen angekreuzt werden kann.
■ OPTION - kann die Werte annehmen BT (zwischen), CP (enthält Muster), EQ (gleich) und GE(größer oder gleich).
■ LOW - enthält den Eingabewert des VON-Feldes. ■ HIGH - enthält den Eingabewert des BIS-Feldes.
Diese mehrfache select-option kann ausgeschlossen werden, indem die no-extension -Klausel benutzt wird.
Selektionsbild Auswahlknöpfe (Optionen)
Zusätzlich zum Feld parameters und select-options, ist das Selektionsbild die radiobutton -Anweisung eine gute Möglichkeit, während der Benutzereingabe zur Laufzeit Datenintegrität zu

gewährleisten. Um Parameter als Auswahlknöpfe zu erzeugen, müsen Sie mit der radiobuttongroup-Klausel definieren.
Syntax für eine radiobutton group
Das Folgende ist die Syntax für eine radiobutton-Parametergruppe:
selection-screen begin of block rad_blk with frame title text-000.parameters: rad_ex1 radiobutton group one,rad_ex2 radiobutton group one,rad_ex3 radiobutton group one.selection-screen end of block rad_blk.
Dieses Beispiel erzeugt eine Gruppe von drei Parametern als Auswahlknöpfe. Wie Sie sehen können, werden diese Auswahlknöpfe in einen Block auf dem Bild gruppiert. Dies ist gute Programmierpraxis, da es dem Benutzer zu erkennen hilft, daß sie alle zur selben Eingabeanforderungsgruppe gehören. Diese Parameter werden am besten benutzt, um einen Einzelwert aus einer Mehrfachoption auszuwählen und müssen mindestens zwei Knöpfe pro Gruppe enthalten.
Nur einer dieser drei Beispielknöpfe kann zur Laufzeit ausgewählt werden aufgrund seiner Zugehörigkeit zur Gruppe Eins. Die Datenintegrität ist gewährleistet, weil dies ein guter Weg ist, eine einzige aus sich gegenseitig ausschließenden Eingaben des Benutzers auszuwählen. Dieser Sachverhalt wird am Beispiel eines einfachen Selektionsbildes, das viele Selektionsbildelemente integriert, die Sie gerade gelernt haben, noch genauer dargestellt.
Beispielprogramm für ein Selektionsbild
Das Folgende ist ein Beispielprogramm für ein Selektionsbild, das aus den meisten vorkommenden Grundelementen besteht:
report YJACOBJX message-id Y6.* Database Table Definitionstables: mara. selection-screen skip 1.selection-screen begin of block block0 with frame title text-000.selection-screen skip 1.selection-screen begin of line.selection-screen pushbutton 10(20) text-003 user-command engl.selection-screen pushbutton 50(20) text-004 user-command germ.selection-screen end of line.selection-screen end of block block0.* Selection parametersselection-screen skip 2.selection-screen begin of block block1 with frame title text-001no intervals.selection-screen begin of line.

parameters: p_ex1 radiobutton group rad1 .selection-screen comment 5(30) text-ex1.selection-screen end of line.parameters: p_jdate1 type d default sy-datum.selection-screen skip 1.selection-screen begin of line.parameters: p_ex2 radiobutton group rad1 .selection-screen comment 5(30) text-ex2.selection-screen end of line.select-options: s_jdate2 for mara-laeda. selection-screen skip 1.selection-screen begin of line.parameters: p_ex3 radiobutton group rad1.selection-screen comment 5(20) text-ex3.selection-screen end of line.parameters: p_jdate3 like mara-laeda. selection-screen skip 1.selection-screen begin of line.parameters: p_ex4 radiobutton group rad1 .selection-screen comment 5(30) text-ex4.selection-screen end of line.select-options: s_jdate4 for mara-laeda no-extension no intervals.selection-screen end of block block1.selection-screen skip.selection-screen begin of block block2 with frame title text-002no intervals.selection-screen begin of line.parameters: P_ex5 as checkbox.selection-screen comment 5(30) text-ex5.selection-screen end of line. selection-screen skip.selection-screen begin of line.parameters: P_ex6 as checkbox.selection-screen comment 5(30) text-ex6.selection-screen end of line.selection-screen skip.selection-screen begin of line.parameters: P_ex7 as checkbox.selection-screen comment 5(30) text-ex7.selection-screen end of line.selection-screen end of block block2.* AT selection-screen.AT selection-screen.if ( p_ex1 = 'X' ) and( ( p_jdate1 = 'IEQ?' ) or ( p_jdate1 is initial ) ).message E017 with 'Selection Option with Default field has no value'.elseif ( p_ex1 = 'X' ) andnot ( ( p_jdate1 = 'IEQ?' ) or ( p_jdate1 is initial ) ).

message I017 with 'We are now using Example 1'.endif.if ( p_ex2 = 'X' ) and( ( s_jdate2 = 'IEQ?' ) or ( s_jdate2 is initial ) ).message E017 with 'Selection Option using for field has no value'.elseif ( p_ex2 = 'X' ) andnot ( ( s_jdate2 = 'IEQ?' ) or ( s_jdate2 is initial ) ).message I017 with 'And now Example 2 is selected'.endif.if ( p_ex3 = 'X' ) and( ( p_jdate3 = 'IEQ?' ) or ( p_jdate3 is initial ) ).message E017 with 'Parameter w/ like statement field has no value'.elseif ( p_ex3 = 'X' ) andnot ( ( p_jdate3 = 'IEQ?' ) or ( p_jdate3 is initial ) ).message I017 with 'We are now using Example 3'.endif.if ( p_ex4 = 'X' ) and( ( s_jdate4 = 'IEQ?' ) or ( s_jdate4 is initial ) ).message E017 with 'Selection Option with no interval has no value'.elseif ( p_ex4 = 'X' ) andnot ( ( s_jdate4 = 'IEQ?' ) or ( s_jdate4 is initial ) ).message I017 with 'We are now using Example 4'.endif.if p_ex5 = 'X'.perform get_price_data.else.message I017 with 'No Pricing Data selected'.endif.if p_ex6 = 'X'.perform get_cost_data.else.message I017 with 'No Costing Data selected'.endif.if p_ex7 = 'X'.perform get_revenue_data.else.message I017 with 'No Revenue Data selected'.endif.form get_cost_data....endform.form get_revenue_data....endform.form get_price_data....endform.

Da Auswahlknöpfe sich gegenseitig ausschließen, empfiehlt es sich, sie alle in denselben Prozeßblock auf dem Selektionsbild zusammenfassen. Beachten Sie in Abbildung 21.18, wie jede Gruppe von Feldelementen voneinander getrennt wurde, damit nur solche Felder enthalten sind, die für diesen Entscheidungsblock wichtig sind.
Wie Sie in Abbildung 21.19 sehen können, ist es schwieriger, den angeforderten Datenfeldern zu folgen, wenn sie nicht in Selektionsbildblöcken zusammengefaßt sind.
Parameter, die mit der like-Klausel definiert sind, erscheinen mit einem Abwärtspfeil, welcher angeklickt werden kann, um ein Listenfenster mit gültigen Werten zu sehen (siehe Abb. 21.20).
Abbildung 21.18: Selektionsmaske mit Entscheidungsblock

Abbildung 21.19: Selektionsmaske ohne Block

Abbildung 21.20: Parametereingabe mit Pfeil nach unten
Wir können nun auf unsere Auswahl klicken und den grünen Prüfknopf drücken (siehe Abb. 21.21). Dies wird dieses Parameterfeld mit dem von Ihnen ausgewählten Wert füllen. Das kann für einen Bentzer sehr hilfreich sein, um mit Ihren Selektionsanforderungen vertrauter zu werden.
Wenn Sie eine select-option erzeugen ohne die no-extension-Klausel zu benutzen, haben Sie die Möglichkeit mehrfache Selektionen einzugeben oder einen Bereich von Selektionen. Um mehrfache Selektionen oder einen Bereich von Selektionen einzugeben, klicken Sie einfach auf die Schaltfläche mit dem weißen Pfeil (siehe Abb. 21.22).

Abbildung 21.21: Ein gültiges Datum wählen
Abbildung 21.22: Erweiterte Selektionsoptionen
An dieser Stelle können Sie all Ihre Selektionskriterien eingeben und auf die Schaltfläche Kopieren klicken (siehe Abb. 21.23).

Abbildung 21.23: Selektionseingaben
Wie Sie sehen können, ändert der Pfeil seine Farbe und ist nun grün (siehe Abb. 21.24). Das folgt aus der Tatsache, daß Sie mehrfache Selektionen für dieses Feld ausgewählt haben, und diese Eingaben die Selektionstabelle zur Laufzeit füllen werden.

Abbildung 21.24: Selektionseingaben mit grünem Pfeil
Wenn Sie die no-extensions- und no-intervals-Klauseln in der select-options-Anweisung benutzen, erhalten Sie ein Eingabefeld, das ähnlich einem Parameterfeld arbeitet, einschließlich einem Abwärtspfeil, um gültige Eingaben zu sehen (siehe Abb. 21.25).

Abbildung 21.25: Selektionsmaske ohne Erweiterung oder Intervalle
Seien Sie vorsichtig im Benutzen von Vorgabewerten für select-options-Felder. Wie Sie in Abbildung 21.26 sehen können, erlaubt das Feld Ihnen nicht, gültige Eingaben zu sehen, wenn Sie ein select-option-Feld mit einem Vorgabewert füllen.

Abbildung 21.26: select-option mit Standardwert
Die folgende Abbildung zeigt ein Beispiel einer Datenprüfroutine, welche eine Informationsmeldung in Form eines Dialogfensters benutzt, das rein informativ ist und das Programm lediglich anhält. Das ist sehr geeignet, um den Status der Ereignisse in der Datenverarbeitung anzuzeigen (Abb. 21.27).
Abbildung 21.27: Popup für Datenvalidierungen
Sie können aber auch den Fehlertyp eines Meldungstextes benutzen. Dieser Meldungstyp bringt eine Textmeldung in die Statusleiste des Programms. Hauptsächlich wird er benutzt, um Daten bei der Ersteingabe zu prüfen (siehe Abb. 21.28).

Abbildung 21.28: Fehlermeldungen in der Statuszeile
Das besprochene Beispiel zeigt Ihnen viele Elemente von Selektionsbildern, kombiniert in effizientem und einfachem Format. Bitte schauen Sie sich den Programmcode an, der dieses Selektionsbild in den Abschnitten vor diesem visuellem Durchgang erzeugt hat.
Erlaubt Nicht erlaubt
Pflegen Sie die Selektionsmaskenelemente für die Arbeiten, die hierzu am besten passen.
Vergessen Sie nicht, Plausibilitätsprüfungen durchzuführen.
Bauen Sie die Selektionsmasken so auf, daß der Anwender den Anforderungen leichter folgen kann.
Wie im letzen Beispiel erwähnt, ist es gute Praxis, Meldungsanweisungen als Eingabeprüfwarnungen zur Laufzeit zu benutzen.
Die Meldungsanweisung benutzen
Meldungen werden in der Tabelle T100 gepflegt und gespeichert und können von der ABAP Workbench aus erreicht werden. Ein effektiver Programmierer gibt Meldungen aus, die erläuternd sind und dem

Benutzer helfen, den Programmfluß zu verstehen.
Jeder individuellen Meldungsanweisung kann ein Meldungstyp zugewiesen werden, der verschiedene Auswirkungen auf die Ausgabe des Programms hat.
■ S - Erfolg; diese Meldung wird auf dem folgenden Bild in der Statuszeile angezeigt. ■ A - Abbruch; die laufende Transaktion wird angehalten, und eine Meldung wird angezeigt, bis der
Benutzer sie bestätigt. ■ E - Fehler; der Benutzer muß Daten eingeben, um fortzufahren. ■ W - Warnung; der Benutzer kann entweder die Eingabedaten modifizieren oder (Enter) drücken,
um fortzufahren. ■ I - Information; der Benutzer muß (Enter) drücken, um am selben Punkt im Programm
fortzufahren.
Sie müssen eine message-id-Reportanweisung am Anfang des Programms angeben.
Syntax für die message-id-Anweisung
Das Folgende ist die Syntax für eine message-id-Anweisung in einem Report:
report example line-count 65 line-size 132 message-id fs.
Diese Zwei-Zeichen-ID und eine dreiziffrige Meldungsnummer, zusammen mit der Sprache, bestimmen die Meldungsklasse. SAP hat es Ihnen erleichtert, Meldungsanweisungen in Ihr Programm aufzunehmen, indem Sie das insert-Kommando im ABAP/4-Editor benutzen.
Abbildung 21.29 ist ein Schnellzugang, indem Sie auf die Meldungs-ID-Nummer im ABAP/4-Editor doppelklicken.
Lassen Sie uns mit dem Object Browser starten, und wählen Sie Andere Objekte am unteren Rand der Liste (siehe Abb. 21.30). Sie können zum Fenster Individuelle Meldungen Pflegen springen, indem Sie auf die Meldungs-ID-Nummer im ABAP/4-Editor doppelklicken.

Abbildung 21.29: Der Object Browser

Abbildung 21.30: Andere Objekt-Entwicklungsmaske

Abbildung 21.31: Pflege der Nachrichtenklasse

Abbildung 21.32: Individuelle Pflege der Nachrichten
Als nächstes geben Sie eine Meldungsklasse ein und klicken auf die Ikone für die Aktion, die Sie durchführen wollen. In diesem Beispiel klicken Sie auf den Erzeugen-Modus (siehe Abb. 21.31).
Nun sehen Sie das Fenster Meldungsklasse Pflegen; hier ist es, wo sie die Eigenschaften der Meldungsklasse eingeben können, die Sie editieren (siehe Abb. 21.32). Klikken Sie die Schaltfläche Meldungen, um individuelle Meldungen zu pflegen.
Sie sind nun im Editor-Modus, welcher mit einem Eintrag in der Liste der Meldungstextelemente übereinstimmt. Nachdem die notwendigen Änderungen erledigt wurden, klicken Sie auf die Schaltfläche Sichern, und Sie können Ihre Nachricht benutzen.
Erlaubt Nicht erlaubt
Benutzen Sie Nachrichten, die dem Anwender helfen, Daten vernünftig einzugeben.
Vergessen Sie nicht, die richtige message-id an den Anfang ihres Platzes zu stellen.

Nutzen Sie existierende Nachrichtenklassen, bevor Sie eigene anlegen.
Zusammenfassung
■ ABAP/4 ist eine ereignisgesteuerte Programmiersprache, und Sie können aus dieser Tatsache Nutzen ziehen, indem Sie die at selection-screen- und initialization -Ereignissebenutzen, ebenso wie das at user-command-Ereignis, um Benutzereingaben mit einer Anzahl von Techniken zu prüfen.
■ Fremdschlüssel können benutzt werden, um die Integrität von Eingabedaten zu prüfen, indem die Primärschlüssel einer Prüftabelle benutzt werden.
■ Matchcodes benutzen logisch zusammengefaßte Daten (Pool), um Benutzereingaben zu prüfen, basierend auf spezifizierten Selektionskriterien in Verbindung mit Selektionsbildparametern und Selektionsoptionen.
■ Meldungen können benutzt werden, um den Status des Programms mitzuteilen und die Gültigkeit der eingegebenen Daten, und ebenso, um mit dem Benutzer so zu interagieren, daß Daten effektiver verarbeitet werden können.
■ Textelemente sollten für Selektionsbildelemente gepflegt sein, damit der Benutzer ein gutes Verständnis für die Verwendungsmöglichkeiten der verschiedenen Selektionskriterienfeldobjekte bekommt.
Mit ABAP/4 können Sie bestehende logische Datenbankselektionsbilder anpassen und ändern, damit Sie Ihren speziellen Bedürfnissen genügen.
Fragen & Antworten
Frage:Was passiert, wenn ein Primärschlüsselfeld zu einer Prüftabelle hinzugefügt wird, nachdem ein Fremdschlüssel definiert worden ist?
Antwort:Zusätzliche Felder, die zum Primärschlüssel einer Fremdschlüsselprüftabelle hinzugefügt werden, werden als generisch gekennzeichnet und daher vom System ignoriert, wenn Daten geprüft werden, die in das Fremdschlüsselfeld eingegeben werden.
Frage:Ist es möglich, Variablen, wie Systemfehlermeldungen oder Rückgabewerte, in einen Meldungstext einzufügen?
Antwort:Ja. Wenn Sie ein kaufmännisches Und (&; Ampersand) an die Stelle im Meldungstext einfügen, an der die Variable erscheinen soll, und die Meldung aufrufen und die Variable übergeben, ähnlich einer performAnweisung.
Workshop

Der Übungsteil bietet Ihnen zwei Wege zu vertiefen, was Sie in diesem Kapitel gelernt haben. Die Fragen sollen Ihnen zu helfen, Ihr Verständnis des abgehandelten Stoffes zu festigen. Der Übungsabschnitt ermöglicht Ihnen, Erfahrung zu sammeln, indem Sie anwenden, was Sie gelernt haben. Die Antworten zu den Fragen und Übungen finden Sie in Anhang B.
Kontrollfragen
1. Wie funktionieren die zwei Arten von Matchcode-Zusammenstellung im Hinblick auf die Speicherung der Matchcode-Daten?
2. Wenn Sie die Charakteristika einer Domäne ändern, ändern sich die Charakteristika der verbundenen Datenelemente in gleicher Weise?
3. Was ist die Grundregel für das Anlegen einer Fremdschlüsselbeziehung?
Übung 1
Erzeugen Sie einen Selektionsbildreport, der alle Komponenten einer bill of materials in mehreren Sprachen auflistet. Konstruieren Sie Felder für Selektionen für einen Bereich von Material- und Anlagenkombinationen. Benutzen Sie von den Elementen, die wir in diesem Kapitel kennengelernt haben, diejenigen, die für diese Aufgaben am besten passen.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

RückblickIn der vergangenen und zugleich letzten Woche haben Sie die folgenden Aufgaben erfüllt:
■ Reports erzeugt, die grafische Symbole und Ikonen verwenden ■ Listen Kopf- und Fußzeilen angehängt ■ die Druckausgabe mit new-page print in den Spoolbereich gesandt ■ die Ereignisse initialisation, start-of-selection, end-of-selection, top-of page und end-of-page kennengelernt
■ sowohl interne und externe Unterprogramme als auch Funktionsbausteine codiert, und diesen aktuelle und formale Parameter als Wert, als Wert und Resultat sowie als Referenz übergeben
■ Ausnahmen innerhalb eines Funktionsbausteins errichtet, um den Rückgabewert von sy-subrc zu setzen
■ Auswahlmasken mit der select-options-Anweisung angelegt.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Tag A
Anhang:Namenskonventionen
Programm-Namenskonventionen
Es gibt zwei Programmtypen:
■ Reports (Berichte) ■ Dialogprogramme
Jeder Programmtyp hat seine eigenen Namenskonventionen: Tabelle A.1 enthält die Zeichen, die nicht in Programmnamen erlaubt sind.
Tabelle A.1: Ungültige Zeichen für Programmnamen
Zeichen Beschreibung
. Punkt
, Komma
Leerzeichen
() Klammern
' Einfaches Anführungszeichen
" Anführungszeichen
= Gleichheitszeichen
* Sternzeichen
_ Unterstrich

% Prozent
ÄäÖöÜüß Umlaute und das »scharfe s«
Namenskonventionen für Reports
Kundenberichtsnamen müssen der Konvention Yaxxxxxx oder Zaxxxxxx folgen, wobei:
■ das erste Zeichen ein Y oder Z sein muß. ■ das zweite Zeichen die Anwendung bezeichnen soll. ■ bei SAP R/3-Versionen kleiner als 4.0 der Programmname auf zehn Zeichen begrenzt war. Seit
Version 4.0 darf der Programmname größer sein.
Das zweite Zeichen ist die Kurzform der Anwendung (s.a. Tabelle A.2). So würde zum Beispiel ein Treasuryreport der Namenskonvention Z5xxxxxx folgen, während die Logistikberichte Z21xxxxxheißen.
Jedes Anwendungsgebiet kann über einen Code gekennzeichnet werden. Jeder Code hat zwei gebräuchliche Fassungen, eine lange und eine kurze. Es gibt ebenso einen Code für logische Datenbanknamen. Diese Codes werden in Tabelle A.2 gezeigt.
Tabelle A.2: Codes für den Anwendungsbereich im R/3
Anwendungsgebiet Lange Fassung Kurze Fassung
Finanzwesen FI 1
Materialwirtschaft MM 2
Vertrieb SD 3
Produktionsplanung PP 4
Treasury TR 5
Qualitätsmanagement QM 6
Projektsystem PS 7
Instandhaltung PM 8
Warehouse Management WM 9
Personalwirtschaft HR 10
Controlling CO 12
Prozeßindustrie PI 13

Investment Management IM 14
Logistik LO 21
Anwendungsübergreifende Funktionen CA 23
Namenskonventionen für Dialogprogramme
Kundeneigene Dialogprogramme haben die Namenskonventionen SAPMYxxx oder SAPMZxxx,wobei:
■ Die ersten vier Zeichen SAPM sein müssen. ■ Das fünfte Zeichen ein Y oder Z sein muß. ■ Die letzten Stellen irgendwelche Zeichen enthalten können.
SAP-eigene Programme haben die Namenskonvention SAPMaxxx, wobei a das Kurzzeichen des Anwendungsgebiets ist.
Kundennamensräume
Das R/3-System enthält viele Typen von Entwicklungsobjekten. Will man ein eigenes anlegen, muß man es im Kundenamensraum anlegen. Diese Namenskonventionen werden in Tabelle A.3 gezeigt und beziehen sich auf Version 3.0F. Änderungen in neueren Releases sind vorbehalten.
Tabelle A.3: Kundennamensräume für alle R/3-Entwicklungsobjekte
Objekt-TypMaximaleLänge
Namenskonvention Bemerkung
ABAP/4 QUERY
Query
Funktionsbereich
Sachgruppe
2
4
3
*
*
*
Append-Strukturen
Append-Struktur
Append-Struktur-Felder
10
10
Y*Z*
YY*ZZ*

Applikation Logs
Objekt
Sub-Objekt
4
10
Y* oder Z*
Y* oder Z*
Bereichsmenüs 4 Y*Z*
Berechtigungen
Berechtigung
Berechtigungsklasse
Berechtigungsgruppe
Berechtigungsobjekt
12
4
30
10
*
Y*Z*
Y*Z*
Y*Z*
Nicht an 2. Position erlaubt
CATT 8 Y*Z*
Änderungsbelegobjekt 10 Y* oder Z*
Codepage 4 9*
Datenelemente
Datenelement
Datenelement-Zusatz
10
4
Y*Z*
*
Wenn der Kunde das Datenelement anlegt
SAP-Zusatz 4 9* Wenn SAP das Datenelement anlegt
Datenmodelle
Datenmodell
Einheit
10
10
Y*Z*
Y*Z*
Entwicklungsklasse 4 Y*Z*
Dialog-Module 30 Y*Z*RP_*
RH_INFOTYP_9*

Dokumentationsmodul
Allgemeiner Text (TX)
Testlauf-Beschreibung
Hauptkapitel
IMG
Kapitel
Bemerkungen
Release Information
Struktur
Online-Text
28
20
20
20
20
26
20
12
28
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Domänen 10 Y*Z*
Weiterentwicklungen
Weiterentwicklung
Erweiterungsprojekt
8
8
Y*Z*
*
Funktionscodes
Funktionscode
Menü-Exit
4
4
Y*Z*
+*
Funktionsbibliothek
Funktionsgruppe
User-Exit-Fkts.gruppe
Funktionsbaustein
Field exit
User exit
4
4
30
30
30
30
Y*Z*
XZ*
Y_*Z_*
Field_exit_*
Field_exit_*_x
Exit_pppppppp_nnn

Konvertierungs-Exit Conversion_exit_xxxx_input
Conversion_exit_xxxx_output
GUI-Status 8 *
IDOCs
Segment-Typ
Basis-IDOC-Typ
Erweiterter Typ
IDOC-Typ
7
8
8
8
Z1*
Y*Z*
*
Y*Z*
Includes (DDIC)
Customizing Includes
10 CI_* Nur bei SAP angelegten Tabellen
Includes (Programm)
Include
Include für User Exits
8
8
Y*Z*
ZffffUnn
Ffff=Funktionsgruppe
Info-Typen 4 9*
Sperrobjekt 10 EY*EZ*
Logische Datenbank 3 Y*aZ*a a=Anwendungsgebiet
Logistik Info.System
Ereignis
Einheit
2
2
Y*Z*
Y*Z*
Transportobjekte 10 Y*Z*
Matchcodes
Matchcode-ID
Matchcode-Objekt
1
4
0-9
Y*Z*

Nachrichten
Nachrichtenklasse
Nachrichtennummer
2
3
Y*Z*
*
Module Pools
Dialog
Screen
Info-Typ
Unterprogramm
Update-Pgr.
8
8
8
8
8
SAPDY*SAPDZ*
SAPMY*SAPMZ*
MP9*
SAPFY*SAPFZ*
SAPUY*SAPUZ*
Nummernkreisobjekt 10 Y*Z*
Parameter Ids 3 Y*Z*
Drucker-Macros - Y*Z*9*
Relation IDs
R/3 Analyzer Identifier
2
20
Y*Z*
Y*Z*
Reports
Report-Name
Report-Kategorie
Varianten
Transportierbar, Global
Transportierbar, Lokal
Nicht Transportierbar
8
4
14
14
14
Y*Z*
Y*Z*
X*CUS&*
Y*
Z*

Report Writer
Report
Report-Gruppe
Bibliothek
Standard-Layout
8
4
3
7
*
*
*
*
Erstes Zeichen nicht 0-9
Erstes Zeichen nicht 0-9
Erstes Zeichen nicht 0-9
Erstes Zeichen nicht 0-9
SAPScript
Layout-Set
Form
Standard-Text-ID
Standard-Text-Name
Stil
Screens
12
16
4
32
8
4
*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
9*
>0
Screen Exits für Kunden Dialogprogramme
Spool
Layout Type
Font Group
Device Type
Page Format
System Barcode
16
8
8
8
8
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Y*Z*
Standardaufgabe 8 9*
Standard Roll 8 9*
Strukturen (DDIC) 10 Y*Z*
SYSLOG-Nachrichten-ID 2 Y*Z*

Tabellen
Feldnamen
Index-Namen
Transparent-, Pool-, Cluster-Namen
Pool-Name
Tabellenpool-Name
Tabellen-Clustername
10
3
10
10
10
*
Y*Z*
Y*Z
T9**
P9*
PA9*PB9*PS9*
HRT9*HRP9*
HRI9*
Y*Z*
Y*Z*
Für Pool-Tabelle im ATAB-Pool für Kunden Info-Typen
Titlebars 3 *
Transactionscodes 4 Y*Z*
Typgruppe 5 Y*Z*
Benutzerprofile 12 * _ (Unterstrich) nicht an zweiter Position erlaubt
Views
View Cluster
View Name
Help View
10
10
10
Y*Z*
*
H_Y*H_Z*
View Maintenance Data
View Content
Table Content
-
-
reserved in TRESC
reserved in TRESC
Workflow-Objekt-Typ 10 Y*Z*
Sie werden bemerkt haben, daß es ein paar SAP-Objekte innerhalb des Kundennamensbereiches gibt. Diese Objekte wurden vor der Erstellung der Namenskonventionen angelegt. Eine Liste dieser

Ausnahmen kann man in Tabelle TDKZ finden.
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

Tag B
Anhang:Antworten zu den Kontrollfragen und Übungen
Kapitel 1
Antworten zu den Kontrollfragen
1. SM04 (Menüpfad: System->Status)
2. S000
3. S001
4. Drei. Es gibt nur eine Datenbank pro R/3-System.
5. Drei: zwei für den Applikationsserver und einen für den Datenbankserver.
6. Open SQL ist der SAP-eigene ANSI SQL-Dialekt. Er ist eine Untermenge und Variationen von ANSI SQL.
7. Open SQL hat drei Vorteile:
■ Der Code ist portierbar. ■ Er unterstützt Pufferung von Tabellen. ■ Er unterstützt automatisches Mandanten-Handling.
8. Die Datenbankschnittstelle der Arbeitsprozesse implementiert Open SQL.
9. Wenn ein Programm ausgeführt wird, wird ein neuer Rollbereich allokiert und wieder deallokiert, wenn das Programm beendet ist. Der Rollbereich enthält den Wert der Variablen dieses Programms

und den aktuellen Programmzeiger.
10. Der Benutzerkontext wird jedesmal allokiert, wenn sich ein Benutzer einwählt und wieder deallokiert, wenn er sich abmeldet. Er enthält Informationen über den Benutzer, wie z.B. seine Berechtigungen, Profileinstellungen und die TCP/IP-Adresse.
11. Ein Roll-Out erfolgt jedesmal, wenn ein Dialogschritt beendet ist. Er setzt den Dialogprozeß frei, damit dieser andere Aufgaben wahrnehmen kann. Somit verbraucht das Programm keine CPU-Zeit, während es auf andere Anwendereingaben wartet.
Antwort zu Übung 1
In den Abbildungen 1.28 und 1.31 enthält das erste Feld nicht den Typ CLNT; deshalb ist die Tabelle mandantenunabhängig. Open SQL-Anweisungen wirken auf alle Zeilen innerhalb der Tabelle. In den Abbildungen 1.29 und 1.30 ist das erste Tabellenfeld Typ CLNT; deshalb ist die Tabelle mandantenabhängig. Open SQL-Anweisungen wirken somit nur auf Tabelleninhalte, welche die Mandantennummer des Anmeldemandanten enthalten.
Kapitel 2
Antworten zu den Kontrollfragen
1. Sie allokiert einen Standard-Arbeitsbereich für die Tabelle und gibt dem Programm Zugriff auf die Datenbanktabelle des gleichen Namens.
2. Der Standard-Arbeitsbereich ist der Speicherbereich, der von der tables-Anweisung allokiert wird. Dieser Speicherbereich hat den gleichen Namen und die gleiche Struktur wie die Tabelle in der tables-Anweisung. Die select-Anweisung benutzt sie standardmäßig, solange es keine into-Klausel gibt.
3. In den Standard-Tabellenarbeitsbereich
4. In die gleiche Zeile wie die Ausgabe der vorherigen write-Anweisung
5. Sy-subrc
6. Sy-dbcnt
7. Zeile 4 wird 30mal ausgeführt, jedesmal wenn eine Zeile gelesen wird.
8. Keinmal. Zeile 4 wird nicht ausgeführt, wenn die Tabelle leer ist.
Antworten zu den Programmierübungen

1. Dieser Report zeigt alle Kreditorennummern und Firmencodes aus Tabelle ztxlfb1 an, wobei die Firmencodes größer oder gleich 3000 sind. Beachten Sie, daß bukr ein Zeichenfeld ist. Schreibt man den Wert 5000 nicht in Einzelanführungszeichen, wird das System den Wert automatisch in Vergleichszeichen konvertieren. Es gibt keinen Unterschied in der Programmausgabe, ob man die Anführungszeichen nun spezifiziert oder nicht. Es gehört jedoch zu einem guten Programmierstil und macht das Programm effizienter, wenn man Konvertierungen vermeidet.
1 report ztz0201.2 tables ztxlfb1.3 select * from ztxlfb1 where bukrs >= '3000'4 order by bukrs lifnr descending.5 write: / ztxlfb1-bukrs, ztxlfb1-lifnr.6 endselect.7 if sy-subrc <> 0.8 write / 'Keine Datensätze gefunden'.9 endif.
2. Wie hier gezeigt, wird der Test für sy-subrc hinter endselect gelegt.
1 report ztz0202.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr like 'W%'.4 write / ztxlfa1-lifnr.5 endselect. 6 if sy-subrc <> 0.7 write / 'Keine Datensätze gefunden'.8 endif.
3. Es fehlt ein Punkt am Ende der tables-Anweisung, und die Kreditorennummer muß linksseitig mit Nullen aufgefüllt werden, da es sich um ein Zeichenfeld in der Datenbank handelt (dies wird noch ausführlicher im Kapitel über Konvertierungen behandelt).
1 report ztz0203.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr > '0000001050'.4 write / ztxlfa1-lifnr.5 endselect.
4. In der letzten Zeile steht Keine Datensätze gefunden, obwohl dort Sätze gefunden werden. Das Problem liegt in Zeile 6. Der Test sollte auf Gleichheit und nicht auf Ungleichheit lauten.
1 report ztz0204.2 tables ztxlfa1.

3 select * from ztxlfa1 where lifnr > '0000001050'.4 write / ztxlfa1-lifnr.5 endselect.6 if sy-dbcnt = 0.7 write / 'Keine Datensätze gefunden'.8 endif.
5. Die write-Anweisung sollte innerhalb der select-Schleife liegen.
1 report ztz0205.2 tables ztxlfa1.3 select * from ztxlfa1 where lifnr > '0000001050'.4 write / ztxlfa1-lifnr.5 endselect.6 if sy-subrc <> 0.7 write / 'Keine Datensätze gefunden'.8 endif.
6. In Bezug auf das Originalprogramm wird Tabelle ztxlfc3 nicht benutzt. Die Definition kann daher aus Zeile 2 entfernt werden. into ztxlfa1 auf Zeile 4 wird nicht gebraucht, da ztxlfa1der Standardarbeitsbereich ist. Die Zeilen 5 und 6 können zusammengefaßt werden. Der zweite Ausdruck, der sy-dbcnt auf Zeile 8 benutzt, ist redundant und kann entfernt werden. Zeile 12 braucht keinen Arbeitsbereich und kann ebenfalls entfernt werden. Konsequenterweise müssen die Zeilen 13 und 14 geändert werden, um ztxlfb1 zu schreiben, und Zeile 3 wird nicht länger gebraucht. Die Zeilen 13 und 14 können zusammengefaßt werden. Das vereinfacht das Programm.
1 report ztz0206.2 tables: ztxlfa1, ztxlfb1.34 select * from ztxlfa1.5 write: / ztxlfa1-lifnr,6 ztxlfa1-name1.7 endselect.8 if sy-subrc <> 0.9 write / 'Keine Datensätze in ztxlfa1 gefunden'.10 endif.11 uline.12 select * from ztxlfb1.13 write: / ztxlfb1-lifnr,14 ztxlfb1-bukrs.15 endselect.16 if sy-subrc <> 0.17 write / 'Keine Datensätze gefunden'.18 endif.

7. Der Syntaxfehler stammt von der endselect-Anweisung auf Zeile 5. Er sollte entfernt werden. Man kann den Fehler auch beseitigen, indem man das Wort single aus der select-Anweisung von Zeile 3 entfernt. Das ist allerdings nicht sehr wirksam, da nur eine Zeile gelesen wird. Der Vergleichsoperator auf Zeile 3 ist auch nicht richtig. Er sollte = sein.
1 report ztz0207.2 tables ztxlfa1.3 select single * from ztxlfa1 where lifnr = '0000001000'.4 write / ztxlfa1-lifnr.5 if sy-subrc <> 0.6 write / 'Keine Datensätze gefunden'.7 endif.
Kapitel 3
Antworten zu den Kontrollfragen
1. Die Domäne gibt einem Feld seine technischen Eigenschaften, wie z.B. Datentyp und Länge.
2. Das Datenelement enthält den Domänennamen, Feldkennung für Masken und Listen und die Dokumentation für die (F1)-Hilfe.
3. Anwendungsdaten sind Daten, die von den R/3-Anwendungen wie z.B. SD (Vertrieb) benutzt werden. Es gibt zwei Typen: Stammdaten und Bewegungsdaten. Ein Beispiel für Anwendungsdaten sind Bestellungen (ein Beispiel für Bewegungsdaten) oder Kreditoreninformationen (ein Beispiel für Stammdaten). Es gibt auch Systemdaten, wie z.B. Konfigurationsdaten oder DDIC-Metadaten, in Ergänzung zu den Anwendungsdaten.
4. Nein, die Stelle des Dezimalpunktes ist Teil der Feldbeschreibung. Es wird in der Domäne gespeichert, nicht in dem Wert.
5. SE16, SE17, SM30 und SM31. SE16 ist die gebräuchlichste, und SE17 kann nicht zur Aktualisierung von Daten benutzt werden.
6. Eine Transparente Tabelle hat eine n-zu-1-Beziehung mit einer Datenbanktabelle. Pool- und Cluster-Tabellen haben eine Mehrfachbeziehung zu den Datenbanktabellen.
Antwort zu Übung 1
Die Lösung steht in Bezug zur Tabelle ztzlfa1 im R/3-System.
Antwort zu Übung 2

Um die Lösung für Tabelle ***kna1 zu sehen, sehen Sie sich die Tabelle ztxkna1 im R/3-System an. Es folgt die Lösung für den Report:
1 report ztz0302.2 tables ztzkna1.3 select * from ztzkna1.4 write: / ztzkna1-kunnr, ztzkna1-name1,5 ztzkna1-cityc, ztzkna1-regio,6 ztzkna1-land1.7 endselect.8 if sy-subrc <> 0.9 write / 'No rows found'.10 endif.
Kapitel 4
Antworten zu den Kontrollfragen
1. Beide müssen die gleiche Domäne benutzen.
2. Geben Sie innerhalb zt1 .INCLUDE im Namensfeld ein und zs1 als Datenelement und zwar an der Stelle in der Tabelle, wo die Struktur mit eingeschlossen werden soll.
3. Eine Texttabelle bietet Beschreibungen für viele Sprachen und zwar für Programmcode, der in einer Prüftabelle enthalten ist.
4. mandt, spras, f1 und f2.
5. Jedes Feld vom Typ CURR muß auf ein Währungsschlüsselfeld (Typ CUKY) Bezug nehmen.
Antwort zu Übung 1
Für diese Lösung sehen Sie sich Tabelle ztzt005 online im R/3-System an.
Antwort zu Übung 2
Für diese Lösung sehen Sie sich Tabelle ztzt005s online im R/3-System an. Vergessen Sie nicht, die Kardinalität und Fremdschlüssel-Feldtypen der Fremdschlüsselbeziehung mit denen, die online beschrieben sind, zu vergleichen.
Antwort zu Übung 3
Für diese Lösung sehen Sie sich Tabelle ztzlfa1 online im R/3-System an. Vergessen Sie nicht, die

Kardinalität und Fremdschlüssel-Feldtypen der Fremdschlüsselbeziehung mit denen, die online beschrieben sind, zu vergleichen.
Antwort zu Übung 4
Für diese Lösung sehen Sie sich Tabelle ztzkna1 online im R/3 System an. Vergessen Sie nicht, die Kardinalität und Fremdschlüssel-Feldtypen der Fremdschlüsselbeziehung mit denen, die online beschrieben sind, zu vergleichen.
Antwort zu Übung 5
Für diese Lösung sehen Sie sich die Tabellen ztzt005h und ztz005g online im R/3- System an. Vergessen Sie nicht, die Kardinalität und Fremdschlüssel-Feldtypen der Fremdschlüsselbeziehung mit denen, die online beschrieben sind, zu vergleichen.
Antwort zu Übung 6
Für diese Lösung sehen Sie sich Struktur ***tel und die Tabellen ztzlfa1 und ztzkna1 onlineim R/3-System an.
Antwort zu Übung 7
Für diese Lösung sehen Sie sich Tabelle ztzkna1 online im R/3-System an.
Kapitel 5
Antworten zu den Kontrollfragen
1. Nein. Sie können keinen Index an eine select-Anweisung binden. Der Optimierer wird immer einen Index zur Laufzeit wählen.
2. Ja, aber Sie müssen sich einen Änderungsschlüssel von der SAP holen. Dies geschieht über das OSS (Online Service System).
3. Ja, Sie können das Laufzeitanalyse-Werkzeug benutzen, um die Unterschiede zu messen.
Antwort zu Übung 1
Führen Sie Transaktion SE12 aus, und sehen Sie sich die Tabellen an. Sehen Sie sich auch die technischen Einstellungen an.
Datenart:

MARA: APPL0-Stammdaten, Transparente Tabellen (s. Abb. 5.21)
LFA1: APPL0-Stammdaten, Transparente Tabellen (s. Abb.5.22)
KNA1: APPL0-Stammdaten, Transparente Tabellen (s. Abb.5.23)
Größenkategorie:
MARA: 4 Datensätze werden erwartet: 57000 bis 46000000 (s. Abb. 5.21)
LFA1: 3 Datensätze werden erwartet: 11000 bis 44000 (s. Abb. 5.22)
KNA1: 3 Datensätze werden erwartet: 9600 bis 38000 (s. Abb. 5.23)
Folgende Abbildungen sollen zur Erklärung helfen:
Abbildung B.1: a1.pcx

Abbildung B.2: a2.pcx

Abbildung B.3: a3.pcx
Die Größenkategorie bestimmt die wahrscheinliche Menge an Speicherplatz für eine Tabelle in der Datenbank. Die (F4)-Hilfe zum Feld Größenkategorie zeigt die Eingabemöglichkeiten. Komplikationen kann es geben, wenn der maximale Speicherplatz nicht ausreicht, der für diese Tabelle angegeben wurde.
Kapitel 6
Antwort zur Kontrollfrage
1. Ja. Jede Änderung in der Domäne verlangt eine Reaktivierung. Die Tabelle sollte auch reaktiviert werden. Ebenso sollte eine Konsistenzprüfung gemacht werden.
Antwort zu Übung 1
1. Der schnellste Weg, eine Datenbanktabelle zu löschen, ist der, auf der Betriebssystemebene im Datenbanksystem den Befehl drop table abzusetzen.

Kapitel 7
Antworten zu den Kontrollfragen
Die Lösungen sind wie folgt:
1. Die richtige Definition ist 'Don''t bite.'. Sie sollte in Einzelanführungszeichen gesetzt sein und erfordert zwei Anführungszeichen in der Mitte.
2. Die richtige Definition ist '+2.2E03'. Der Exponent ist E, nicht F, und Dezimalzahlen sind nicht als Exponent erlaubt.
3. Die Definition ist richtig.
4. Die richtige Definition ist '00000F'. Es sollte kein führendes x geben. Es muß eine gerade Anzahl von Zeichen existieren, und sie müssen in Großbuchstaben sein.
5. Die richtige Definition ist '-9.9'. Numerische Literale, die Dezimalzahlen beinhalten, müssen in Einzelanführungszeichen eingeschlossen sein, und das Vorzeichen muß führen.
6. Gleitkommawerte können den Wert 1E+308 nicht überschreiten.
7. H ist kein gültiges hexadezimales Zeichen. Gültige Zeichen sind A-F und 0-9.
8. Die Definition ist richtig. Es ist ein einfaches Anführungszeichen präsent. Wenn man es schreiben würde, würde es so ' " ' aussehen.
9. Die Definition ist richtig. Ein doppeltes Anführungszeichen, eingeschlossen von einfachen, ist präsent. Wenn es ausgeschrieben wird, ist die Ausgabe ' " '.
Die Lösungen sind wie folgt:
1. Die richtige Definition ist data st_f1(5) type c. Es sollte kein Schrägstrich in der Variablendefinition auftauchen. Der Unterstrich sollte statt dessen benutzt werden.
2. Die richtige Definition ist data f1 type c.
3. Die richtige Definition ist data f1(29) type c. Es sollte kein Freizeichen zwischen dem Feldnamen und der Längenspezifikation sein.
4. Variable sollten nicht mit einer numerischen Zahl beginnen, und eine Längenangabe ist bei type inicht erlaubt. Die richtige Definition ist data a1 type i.

5. Die richtige Definition ist data per_cent type p decimals 1 value '55.5'. Ein Schrägstrich sollte nicht im Variablennamen vorkommen. Im Wert ist eine Dezimalzahl spezifiziert, aber die decimals-Ergänzung fehlt. Der Wert enthält eine Dezimalzahl, ist aber nicht in Anführungszeichen eingeschlossen.
6. Die Definition ist richtig. f1 kann drei Zeichen haben, weil (L*2)-1 = (2*2) -1 = 3 ist.
Antwort zu Übung 1
report ztz0707.parameters: p_date like sy-datum default sy-datum, p_field1 type c, chckbox1 as checkbox, chckbox2 as checkbox, radbut1 radiobutton group g1 default 'X', radbut2 radiobutton group g1.
Kapitel 8
Antworten zu den Kontrollfragen
1. Die eine vordefinierte Konstante heißt SPACE. Das Äquivalent dazu als Literal ist ' '.
2. Die Anweisungstypen, die benutzt werden können, sind data- und structure-Typen.Benutzerdefinierte werden im Data Dictionary angelegt, um die Pflege zu unterstützen und Redundanz zu verringern.
Antwort zu Übung 1
types: dollar(16) type p decimals 2,point(16) type p decimals 0. "credit card points
data: begin of usd_amount,hotel type dollar,rent_car type dollar,plane type dollar,food type dollar,end of usd_amount,begin of amex_pt,hotel type p decimals 2,rent_car type point,plane type point,food type point,end of amex_pt.

Antwort zu Übung 2
Output:
1 3 4 59 8 7 6
Kapitel 9
Antworten zu den Kontrollfragen
1. Man kann eq oder = benutzen. Zum Beispiel: move vara to varb. ist das gleiche wie varv= vara. oder varb eq vara.
2. Operatoren und Operanden müssen mit Leerzeichen in der Reihenfolge getrennt werden, wie die Variablen verarbeitet werden.
Antwort zu Übung 1
1. sperz2. konzs3. fdpos4. msgid5. matkl
Zwei Dinge sind falsch im Programm: erstens die Tabellendeklaration von ztxt005t und zweitens die Einzelanführungszeichen vor der Variablen land1. Deklarieren Sie die Tabelle, und entfernen Sie die Einzelanführungszeichen vor der land1-Variablen.
Kapitel 10
Antworten zu den Kontrollfragen
1. Die Antwort lautet folgendermaßen:
case v1.when 5. write 'Die Nummer ist fünf.'.when 10. write 'Die Nummer ist zehn.'.when others. write 'Die >Nummer ist nicht fünf oder zehn.'.endcase.

2. Die Zeichenkettenoperatoren sind CP (contains pattern) und NP (does not contain pattern).
3. Die drei Kontrollanweisungen sind exit, continue und check:
■ Die exit-Anweisung wird benutzt, um die Weiterverarbeitung innerhalb von loop-,select-, do- und while-Anweisungen zu verhindern und innerhalb von Unterprogrammen mit form.
■ Die continue-Anweisung wird dazu benutzt, um alle Anweisungen in der aktuellen Schleife zu überspringen und ans Ende der Schleife zu gehen. Continue kann mit loop-, select-,do- und while-Anweisungen benutzt werden.
■ Die check-Anweisung ist ähnlich der continue-Anweisung, kann aber logische Ausdrücke enthalten.
Antwort zu Übung 1
report ztz1001. data: l1(2) type c. do 20 times. write / sy-index. do 10 times. l1 = sy-index. write l1. enddo.enddo.
Die Konvertierung erscheint im Programm wie folgt:
I --> C ZTX1001 000060 L1 = SY-INDEX.
Kapitel 11
Antworten zu den Kontrollfragen
1. Der Basisberater setzt die Werte für den Speicher, der für interne Tabellen allokiert werden kann. Vergrößern Sie den Speicher, wird Ihr Programm Speicher aus dem Arbeitsprozeß abziehen.
2. Wenn Sie das machen, wird das System 8 KB große Blöcke aus dem Paging-Bereich allokieren. Speicher wird verschwendet, und das Paging-Verhalten würde ansteigen, was eine schlechte Systemantwortzeit bedeuten würde.
3. Die read table-Anweisung kann nur benutzt werden, um interne Tabellen zu lesen. Es geht nicht mit Datenbanktabellen. Benutzen Sie statt dessen select single .

Antwort zu Übung 1
In früheren Systemen wurden Konvertierungen ausgeführt, indem der rechtsstehende Wert in den Datentyp und die Länge der linksstehenden Komponente konvertiert wurde.
Abbildung B.4: b_fig04.pcx
Auf Zeile 9 und 10 wurde von c nach n konvertiert und dann von p nach I (Parameter nach Ganzzahl).
Auf Zeile 16 gab es eine Konvertierung von p nach I.
Kapitel 12
Anworten zu den Kontrollfragen
1. Ihre Änderung an sy-tabix wird ignoriert und die Anweisungen arbeiten mit den Zeilen des

Arbeitsbereichs. sy-tabix verhält sich wie sy-index: in beiden Anweisungen wirken sich Änderungen nicht auf die Schleifenoperationen aus. Außerdem wird der Wert von sy-tabix am Ende eines Schleifendurchgangs zurückgesetzt, so daß der nächste Durchgang läuft, als ob es nie eine Änderung gegeben hätte.
2. Sy-toccu sagt aus, ob die interne Tabelle ganz im Paging-Bereich liegt (Rückgabewert Null). Wenn der Wert Null ist, ist sie vollständig im Paging-Bereich. Dies macht in einem Produktionssystem keinen Sinn, aber während der Entwicklung könnte es sinnvoll sein zur Bestätigung Ihrer Erwartung, wie Speicherplatz der internen Tabelle zugewiesen wird. Wenn Sie zum Beispiel die interne Tabelle im Rollbereich erwarten, aber sy-toccu Null enthält (und damit anzeigt, daß sie in der paging area ist), schauen Sie aus einem anderen Blickwinkel auf Ihre occurs-Klausel, um zu entscheiden, ob sie korrekt ist.
Antwort zu Übung 1
report ztz1201.tables ztxlfa1.data it like ztxlfa1 occurs 23 with header line.
select * from ztxlfa1 into table it. "Kein endselect programmierenloop at it.write: / sy-tabix, it-land1, it-regio.endloop.uline.it-land1 = 'US'. modify it index 3 transporting land1.it-regio = 'TX'. modify it transporting regio where regio = 'MA'.loop at it.write: / sy-tabix, it-land1, it-regio.endloop.free it.
Kapitel 13
Antworten zur Kontrollfrage
1. Numerische Felder (Typ i, p und f) werden mit Nullen gefüllt. Die restlichen Felder rechts vom Kontrollevel werden mit Sternzeichen gefüllt.
Anwort zu Übung 1
report ztz1301.data: begin of it occurs 3,f1(2) type n,f2 type i,

f3(2) type c,f4 type p,end of it.
it-f1 = '40'. it-f3 = 'DD'. it-f2 = it-f4 = 4. append it.it-f1 = '20'. it-f3 = 'BB'. it-f2 = it-f4 = 2. append it.
sort it by f1.do 5 times.
it-f1 = sy-index * 10. it-f3 = 'XX'. it-f2 = it-f4 = sy-index.read table it with key f1 = it-f1 binary search comparing f2 f3 f4transporting no fields.if sy-subrc = 2.modify it index sy-tabix.elseif sy-subrc <> 0.insert it index sy-tabix.endif.enddo.
loop at it.write: / it-f1, it-f2, it-f3, it-f4.endloop.
Antwort zu Übung 2
Dies ist ein wirkungsvoller Weg, das Problem zu beheben:
report ztz1302.tables: ztxlfa1.data: begin of it occurs 10,lifnr like ztxlfa1-lifnr,land1 like ztxlfa1-land1,end of it. select lifnr land1 from ztxlfa1 into table it.loop at it.write: / it-lifnr,it-land1.endloop.
Kapitel 14

Antworten zu den Kontrollfragen
1. Sie müssen sich vom R/3-System ab- und dann wieder darin anmelden, bevor die Änderungen an den Benutzerstandards wirksam werden.
2. Eine Editiermaske, die mit einem V beginnt und einem numerischen Feld angeschlossen ist (Typen i, p und f), bewirkt, daß das Anmeldefeld am Beginn angezeigt wird. Wenn sie zu einem Zeichenfeld gehört, ist ein V die aktuelle Ausgabe.
3. Die no-sign-Ergänzung unterdrückt die Ausgabe des Vorzeichens, wenn sie mit Variablen der Typen i, p oder f benutzt wird. Mit anderen Worten, negative Zahlen haben kein Vorzeichen und erscheinen, als seien sie positiv.
Antwort zu Übung 1
1 report ztz1401.2 write: / '....+....1....+....2....+....3....+....4',3 / 'First',4 40 'December',5 /16 'January',6 /30 'First'.
Kapitel 15
Antworten zu den Kontrollfragen
1. Die drei grafischen Ergänzungen sind symbols, icon und line. Das Programm sollte für jede Ergänzung eine include-Anweisung haben, include <...>, um sie zu benutzen. Zum Beispiel:
include <symbol> for symbols,include <icon> for icons,include <line> for lines.
2. Die beiden Anweisungen, die mit der report-Anweisung verwendet werden, sind line sizeund line count. Die Variablen für diese Anweisungen müssen numerisch sein, weil sie die Größe der Seite kontrollieren.
Antwort zu Übung 1
report ztz1501.include <symbol>.write: /4 sym_filled_square as symbol, 'square',

/4 sym_filled_diamond as symbol, 'diamond',/4 sym_filled_circle as symbol, 'circle',/4 sym_glasses as symbol, 'glasses',/4 sym_pencil as symbol, 'pencil',/4 sym_phone as symbol, 'phone',/4 sym_note as symbol, 'note',/4 sym_folder as symbol, 'folder'.
Abbildung B.5: a5.pcx
Kapitel 16
Antworten zu den Kontrollfragen
1. Die back-Anweisung kann benutzt werden, um an den Anfang der laufenden Ausgabeposition zurückzukehren.
2. Verwenden Sie skip sy-linct anstatt new-page, wenn Sie eine neue Seite anlegen und eine Fußzeile für die laufende Zeile haben wollen.

Antwort zu Übung 1
Zeile 3 beginnt mit do loop. Beim ersten Durchgang löst die write-Anweisung in Zeile 6 das top-of-page-Ereignis aus. Der Wert von sy-linno enthält immer den Wert der laufenden Zeilennummer der Liste. An diesem Punkt wird sie der Zeile zugefügt, die der Überschrift der Standardseite folgt. Zeile 13 fügt diesen Wert der Variablen n zu. Die Kontrolle kehrt zurück zu Zeile 6 und A wird ausgeschrieben. Bei jedem erfolgreichen Schleifendurchgang erhöht Zeile 8 den Wert von n, und Zeile 9 setzt die laufende Ausgabezeile. Das führt dazu, daß die Zeilen nacheinander ausgeschrieben werden, und zwar angefangen mit der Zeile, die der Standardüberschrift folgt.
Zeile 4 beginnt mit einem verschachtelten do loop. Bei jedem Durchgang setzt Zeile 5 die laufende Ausgabenposition gleich mit der laufenden Schleifenwiederholung. Beim ersten Durchgang wird die laufende Ausgabeposition auf 1 gesetzt, beim zweiten Mal dann auf 2 und so weiter. Dadurch schreibt Zeile 6 den Buchstaben A vier Mal in die Spalten 1 bis 4.
Kapitel 17
Antworten zu den Kontrollfragen
1. Nein.
2. Benutzen Sie stop nicht in den folgenden Ereignissen: initialization, at select-screen output, top-of-page und end-of-page. Technisch kann es funktionieren mit top-of-page und end-of-page, wenn Sie es unterlassen, die write-Anweisungen hinter end-of-selection auszugeben.
3. Eine Variable ist innerhalb eines Programms nur bekannt, nachdem sie definiert wurde. Wenn Sie zum Beispiel eine Variable in Zeile 10 definieren, können Sie auf diese in Zeile 11 und später zurückgreifen, nicht aber in den Zeilen 1 bis 9. Bei einer lokalen Definition können Sie vor der Definition überall auf die globale Version der Variablen zugreifen.
Antwort zu Übung 1
REPORT ZTZ1701 NO STANDARD PAGE HEADING.TABLES ZTXLFA1.PARAMETERS P_LAND1 LIKE ZTXLFA1-LAND1.
INITIALIZATION.P_LAND1 = 'US'.
START-OF-SELECTION.PERFORM CREATE_REPORT.

FORM CREATE_REPORT.SELECT * FROM ZTXLFA1 WHERE LAND1 = P_LAND1.PERFORM WRITE_REC.ENDSELECT.ENDFORM.
FORM WRITE_REC.WRITE: / ZTXLFA1-LIFNR, ZTXLFA1-NAME1, ZTXLFA1-LAND1.ENDFORM.
TOP-OF-PAGE.FORMAT COLOR COL_HEADING.WRITE: / 'Vendors with Country Code', P_LAND1.ULINE.
Kapitel 18
Antworten zu den Kontrollfragen
1. Parameternamen, die in der form-Anweisung auftauchen, heißen formale Parameter. Diesen Namen kann man sich leicht merken, weil »formal« mit »form« beginnt. In der Anweisung form s1 using p1 changing p2 p3 heißen zum Beispiel die Parameter p1, p2 und p3 formale Parameter.
2. Wenn Sie eine Variable mit falschem Datentyp oder falscher Datenlänge an einen aktuellen Parameter übergeben, erzeugen Sie einen Syntaxfehler.
3. Neuer Speicherplatz wird dem Wert nicht zugewiesen. Statt dessen wird ein Zeiger auf die originale Speicheradresse übergeben. Alle Referenzen zum Parameter sind Referenzen zur originalen Speicheradresse. Änderungen an der Variablen innerhalb des Unterprogramms aktualisiert die originale Speicheradresse auf der Stelle.
4. Die Ergänzungen using f1 und changing f1 übergeben beide f1 als Referenz - sie sind identisch in ihrer Funktion. Der Grund, warum beide existieren, besteht darin, daß sie - richtig benutzt - dokumentieren können, ob das Unterprogramm einen Parameter ändern wird oder nicht.
Antwort zu Übung 1
Die folgende Ausgabe wird generiert:
Top of page, flag = S ctr = 1--------------------------------in Start-Of-Selectionp1 =

Der Abschnitt Initialisierung wird nicht ausgeführt, weil es keine Selektionskriterien im Programm gibt. Das Ereignis start-of-selection wird ausgeführt. Wenn das Programm bei der ersten write-Anweisung anlangt, wird die Kontrolle an das Ereignis top-of-page übergeben. Wenn dieses Ereignis komplett ist, kehrt die Kontrolle zu start-of-selection zurück.
Kapitel 19
Antworten zu den Kontrollfragen
1. Richtig. Sie müssen niemals den Wert für einen Import-Parameter definieren, der einen Vorschlagwert hat.
2. Richtig. Sie müssen niemals Parameter codieren, die vom Funktionsbaustein exportiert werden.
Antwort zu Übung 1
Wenn das Programm ausgeführt wird, wird die interne Tabelle gefüllt und der Funktionsbaustein aufgerufen. Ein Popup-Fenster mit dem Inhalt der internen Tabelle erscheint. Je nachdem, welcher Eintritt vom Anwender gewählt wurde, erfolgt dann der Ausdruck mit der write-Anweisung.
Kapitel 20
Antworten zu den Kontrollfragen
1. Die Datendefinitionen beider Parameter müssen identisch sein.
2. Verwenden Sie den Menüpfad: Freigabe -> Freigabe zurücknehmen.
3. Das Programm wird abgebrochen, daraus resultiert ein Short Dump (Programmabbruch) mit dem Laufzeitfehler RAISE_EXCEPTION.
4. Sie sollten nicht innerhalb von Funktionsbausteinen verwendet werden. Statt dessen sollten Sie die raise-Anweisung benutzen, weil Sie hiermit sofort den Wert von sy-subrc setzen können.
Antwort zu Übung 1
1 function z_tz_div.2 *"------------------------------------------------------------3 *"*"Local interface:4 *" IMPORTING5 *" VALUE(P1) TYPE I DEFAULT 16 *" VALUE(P2) TYPE I

7 *" EXPORTING8 *" VALUE(P3) TYPE P9 *" EXCEPTIONS10 *" ZERO_DIVIDE11 *"------------------------------------------------------------12 if p2 = 0.13 raise zero_divide.14 endif.15 p3 = p1 / p2.16 endfunction.
Kapitel 21
Antworten zu den Kontrollfragen
1. Die zwei Arten der Matchcode-Zusammenstellung sind physikalisch und logisch. Physikalisch bedeutet, daß die Daten in einer separaten Tabelle gespeichert sind. Logisch bedeutet, die Daten werden über Views angesprochen, was dasselbe ist wie transparentes Speichern.
2. Ja, Änderungen an den Charakteristika einer Domäne verändern auch die der zugehörigen Datenelemente, weil Datenelemente einer Domäne alle Eigenschaften einer Domäne übernehmen.
3. Die erste Regel, eine Fremdschlüsselverbindung zu etablieren, ist, eine Verbindung zwischen verschiedenen Tabellen zu definieren.
Antwort zu Übung 1
report ztz2101.tables: mara, t001w. * Selection parameters for BOMsselection-screen begin of line.selection-screen comment (33) text-bom.parameters: bom like mara-matnr,spras like t002-spras.selection-screen end of line.selection-screen skip 1.Select-options: matnr for mara-matnr,werks for t001w-werks.

Abbildung B.6: a6.pcx
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH.Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X

StichwortverzeichnisA
ABAP/4 Workbench ❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Debugger❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Editor❍ Ihr erstes ABAP/4®-Programm ❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Hilfe-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Interpreter❍ Die Entwicklungsumgebung
ABAP/4-Programm-Editor❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Reports❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Syntax❍ Ihr erstes ABAP/4®-Programm
ABAP/4-Syntaxelemente❍ Datendefinitionen in ABAP/4®, Teil 1
Abbruch❍ Interne Tabellen, Teil 2
add-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
add-corresponding-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
Aktivierungsprotokoll❍ Das Data Dictionary ®, Teil 4
Aktual- und Formalparameter ❍ Modularisierung: Funktionsbausteine, Teil 1
Aktualparameter❍ Modularisierung: Übergabe von Parametern an Unterprogramme
aktuelle Parameter ❍ Modularisierung: Übergabe von Parametern an Unterprogramme

als Referenz ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
als Wert ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
als Wert und Resultat ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Ändern des Datentyps ❍ Das Data Dictionary ®, Teil 1
Änderungsbelege❍ Das Data Dictionary ®, Teil 4
Angepaßte Fremdschlüssel ❍ Das Data Dictionary ®, Teil 2
Anlegen des Fremdschlüssels ❍ Das Data Dictionary ®, Teil 2
Anlegen des Fremdschüssels ❍ Das Data Dictionary ®, Teil 2
Anlegen einer transparenten Tabelle ❍ Das Data Dictionary ®, Teil 1 ❍ Das Data Dictionary ®, Teil 1
Anlegen eines Datenelements ❍ Das Data Dictionary ®, Teil 1
Anlegen eines Funktionsbausteins ❍ Modularisierung: Funktionsbausteine, Teil 1
Anlegen von Tabellen ❍ Das Data Dictionary ®, Teil 1
Anmeldemandant❍ Die Entwicklungsumgebung
Annullieren (Cancel) ❍ Ihr erstes ABAP/4®-Programm
ANSI-SQL❍ Die Entwicklungsumgebung
Anweisung constants ❍ Datendefinition in ABAP/4®, Teil 2
Anweisung set locale ❍ Interne Tabellen
Anweisung type-pools ❍ Datendefinition in ABAP/4®, Teil 2
AnzeigenÄndern-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
append lines-Anweisung ❍ Interne Tabellen, Teil 1

append sorted by ❍ Interne Tabellen, Teil 1
append sorted by-Anweisung ❍ Interne Tabellen, Teil 1
append-Anweisung❍ Interne Tabellen
APPL0❍ Das Data Dictionary ®, Teil 3
APPL1❍ Das Data Dictionary ®, Teil 3
APPL2❍ Das Data Dictionary ®, Teil 3
Applikationsserver❍ Die Entwicklungsumgebung
Arbeitsbereich❍ Die Entwicklungsumgebung
Arbeitsprozeß❍ Die Entwicklungsumgebung ❍ Die Entwicklungsumgebung
Arbeitsprozesse❍ Die Entwicklungsumgebung
Architektur des Applikationsservers ❍ Die Entwicklungsumgebung
as icon ❍ Formatierungstechniken, Teil 1
as line ❍ Formatierungstechniken, Teil 1
as symbol ❍ Formatierungstechniken, Teil 1
as text-Zusatz ❍ Interne Tabellen
assign❍ Zuweisungen, Konvertierungen und Berechnungen
at❍ Interne Tabellen, Teil 2
at end of ❍ Interne Tabellen, Teil 2
at end of-Anweisung ❍ Interne Tabellen, Teil 2
at first-Anweisung ❍ Interne Tabellen, Teil 2

at last-Anweisung ❍ Interne Tabellen, Teil 2
at new ❍ Interne Tabellen, Teil 2
At new-Anweisung ❍ Interne Tabellen, Teil 2
at selection-screen-Ereignis ❍ Selektionsbilder
at user-command-Ereignis ❍ Selektionsbilder
Aufruf von Funktionsbausteinen ❍ Modularisierung: Funktionsbausteine, Teil 1
Aus dem Puffer einfügen-Schaltfläche ❍ Ihr erstes ABAP/4®-Programm
Ausgabelängenfeld❍ Das Data Dictionary ®, Teil 1
Ausgabemasken❍ Die write-Anweisung
Auslieferungsklasse❍ Das Data Dictionary ®, Teil 1
Ausnahme❍ Modularisierung: Funktionsbausteine, Teil 1
Ausrichtung❍ Zuweisungen, Konvertierungen und Berechnungen ❍ Die write-Anweisung
Ausschneiden und Einfügen ❍ Ihr erstes ABAP/4®-Programm
Ausschneiden-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
Automatische Mandantenpflege ❍ Die Entwicklungsumgebung
Automatische Tabellenhistorie ❍ Das Data Dictionary ®, Teil 4
automatische Tabellenhistorie ❍ Das Data Dictionary ®, Teil 4
B
back-Anweisung❍ Formatierungstechniken, Teil 2
Basis

❍ Die Entwicklungsumgebung Basis-Verwaltungs-Werkzeuge
❍ Die Entwicklungsumgebung Batch-Programme
❍ Das Data Dictionary ®, Teil 2 Befehlsfeld
❍ Die Entwicklungsumgebung ❍ Die Entwicklungsumgebung ❍ Ihr erstes ABAP/4®-Programm
Beispieltabellen❍ Interne Tabellen, Teil 2
Benutzerkontext❍ Die Entwicklungsumgebung
Berechnungen❍ Zuweisungen, Konvertierungen und Berechnungen
Berichtsformatierung❍ Formatierungstechniken, Teil 1
Betriebssystem❍ Die Entwicklungsumgebung
Bewegungsdaten❍ Das Data Dictionary ®, Teil 3
binary search-Zusatz ❍ Interne Tabellen
binary sort sequence ❍ Interne Tabellen
Browser❍ Das Data Dictionary ®, Teil 1
by reference ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
by value ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
by value and result ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
bypassing buffer ❍ Das Data Dictionary ®, Teil 3
C
call function-Anweisung ❍ Modularisierung: Funktionsbausteine, Teil 1 ❍ Modularisierung: Funktionsbausteine, Teil 2

case sensitive ❍ Datendefinitionen in ABAP/4®, Teil 1
case-Anweisung❍ Allgemeine Kontrollanweisungen
changing❍ Modularisierung: Funktionsbausteine, Teil 2
Changing-Parameter❍ Modularisierung: Funktionsbausteine, Teil 1
char2❍ Datendefinition in ABAP/4®, Teil 2
check❍ Modularisierung: Ereignisse und Unterprogramme
check-Anweisung❍ Allgemeine Kontrollanweisungen
checkbox-Zusatz❍ Datendefinitionen in ABAP/4®, Teil 1
clear-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen ❍ Interne Tabellen, Teil 1
Client-Server❍ Die Entwicklungsumgebung
Client-Server-Konfigurationen❍ Die Entwicklungsumgebung
Clustertabellen❍ Das Data Dictionary ®, Teil 1 ❍ Das Data Dictionary ®, Teil 1
collect-Anweisung❍ Interne Tabellen, Teil 1
comparing-Zusatz❍ Interne Tabellen
compute-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
continue-Anweisung❍ Allgemeine Kontrollanweisungen
conversion exits ❍ Die write-Anweisung
conversion routines ❍ Die write-Anweisung
corresponding fields ❍ Interne Tabellen, Teil 2
currency-Ergänzung

❍ Die write-Anweisung Customizing Daten
❍ Das Data Dictionary ®, Teil 3 Customizing-Tabellen
❍ Das Data Dictionary ®, Teil 1
D
Data Browser ❍ Ihr erstes ABAP/4®-Programm
Data Dictionary ❍ Ihr erstes ABAP/4®-Programm
data-Anweisung❍ Ihr erstes ABAP/4®-Programm ❍ Datendefinitionen in ABAP/4®, Teil 1 ❍ Modularisierung: Ereignisse und Unterprogramme
Datenart❍ Das Data Dictionary ®, Teil 3
Datenbankadministrator❍ Das Data Dictionary ®, Teil 3
Datenbankschnittstelle❍ Die Entwicklungsumgebung
Datenbankserver❍ Die Entwicklungsumgebung
Datenbank-Utility❍ Das Data Dictionary ®, Teil 4
Datenbrowser❍ Das Data Dictionary ®, Teil 1
Datenbrowser-Hilfsmittel❍ Das Data Dictionary ®, Teil 1
Datenelemente❍ Das Data Dictionary ®, Teil 1
Datenkonvertierungen❍ Zuweisungen, Konvertierungen und Berechnungen
Datenmodellierer❍ Ihr erstes ABAP/4®-Programm
Datenobjekte❍ Datendefinitionen in ABAP/4®, Teil 1
Datenprüfungen mit Fremdschlüsseln ❍ Selektionsbilder
Datentypen

❍ Datendefinitionen in ABAP/4®, Teil 1 Datentypfeld
❍ Das Data Dictionary ®, Teil 1 Datentypzeichen
❍ Datendefinitionen in ABAP/4®, Teil 1 Datumsberechnungen
❍ Zuweisungen, Konvertierungen und Berechnungen Datumsformatierung
❍ Die write-Anweisung DB Space
❍ Das Data Dictionary ®, Teil 3 DBA
❍ Das Data Dictionary ®, Teil 3 DDIC
❍ Ihr erstes ABAP/4®-Programm DDIC-Objekte
❍ Das Data Dictionary ®, Teil 1 decimals-Ergänzung
❍ Die write-Anweisung Default-Prüftabelle
❍ Das Data Dictionary ®, Teil 2 Defaultwerte
❍ Zuweisungen, Konvertierungen und Berechnungen Definition von Variablen
❍ Datendefinitionen in ABAP/4®, Teil 1 delete-Anweisung
❍ Interne Tabellen, Teil 1 describe table-Anweisung
❍ Interne Tabellen, Teil 1 Dezimalpunkt
❍ Das Data Dictionary ®, Teil 1 Dialogprogramme
❍ Ihr erstes ABAP/4®-Programm Dialogschritt
❍ Die Entwicklungsumgebung Dispatcher
❍ Die Entwicklungsumgebung do ... varying/enddo
❍ Allgemeine Kontrollanweisungen do-Anweisung
❍ Allgemeine Kontrollanweisungen

Domäne❍ Das Data Dictionary ®, Teil 1 ❍ Das Data Dictionary ®, Teil 1 ❍ Das Data Dictionary ®, Teil 1
Doppeln-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
Druckausgabe❍ Formatierungstechniken, Teil 1
Drucken❍ Ihr erstes ABAP/4®-Programm
Drucktastenleiste❍ Die Entwicklungsumgebung ❍ Ihr erstes ABAP/4®-Programm
Dynamische Zuweisungen ❍ Zuweisungen, Konvertierungen und Berechnungen
E
Edit Masks ❍ Die write-Anweisung
editor-call-Anweisung❍ Interne Tabellen, Teil 1
Editorfunktionen❍ Ihr erstes ABAP/4®-Programm
Einrichten der Prüftabelle ❍ Das Data Dictionary ®, Teil 2
Einzelsatzpuffer TABLP ❍ Das Data Dictionary ®, Teil 3
Einzelsatzpufferung❍ Das Data Dictionary ®, Teil 3
elseif❍ Allgemeine Kontrollanweisungen
endat❍ Interne Tabellen, Teil 2
endform❍ Modularisierung: Ereignisse und Unterprogramme
Endlosschleife❍ Allgemeine Kontrollanweisungen
end-of-page-Ereignis❍ Formatierungstechniken, Teil 2
end-of-selection

❍ Modularisierung: Ereignisse und Unterprogramme ❍ Modularisierung: Ereignisse und Unterprogramme
Enter❍ Ihr erstes ABAP/4®-Programm
Entwicklungsobjekt❍ Ihr erstes ABAP/4®-Programm
Entwicklungsobjekte❍ Ihr erstes ABAP/4®-Programm
Entwicklungsumgebung❍ Ihr erstes ABAP/4®-Programm
Ereignis❍ Modularisierung: Ereignisse und Unterprogramme
Ereignis verlassen ❍ Modularisierung: Ereignisse und Unterprogramme
Ergänzung (siehe auch Zusatz) ❍ Die write-Anweisung
Erste Seite ❍ Ihr erstes ABAP/4®-Programm
Existierende Funktionsbausteine finden ❍ Modularisierung: Funktionsbausteine, Teil 2
exit❍ Modularisierung: Ereignisse und Unterprogramme
exit-Anweisung❍ Allgemeine Kontrollanweisungen
exporting/importing❍ Modularisierung: Funktionsbausteine, Teil 2
Export-Parameter❍ Modularisierung: Funktionsbausteine, Teil 1
Extent❍ Das Data Dictionary ®, Teil 3 ❍ Das Data Dictionary ®, Teil 3
Externe Unterprogramme ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
externe Unterprogramme ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
F
F01 include ❍ Modularisierung: Funktionsbausteine, Teil 2
F1-Hilfe

❍ Ihr erstes ABAP/4®-Programm ❍ Das Data Dictionary ®, Teil 1
F4-Hilfe❍ Das Data Dictionary ®, Teil 2
Fehler in Funktionsbausteinen ❍ Modularisierung: Funktionsbausteine, Teil 2
Feld anhängen ❍ Das Data Dictionary ®, Teil 1
Feld einfügen ❍ Das Data Dictionary ®, Teil 1
Felder löschen ❍ Das Data Dictionary ®, Teil 1
Feldleiste❍ Datendefinition in ABAP/4®, Teil 2
Feldleiste mit Hilfe der data-Anweisung definiert ❍ Datendefinition in ABAP/4®, Teil 2
Feldnamenspalte❍ Das Data Dictionary ®, Teil 1
Feldsymbol❍ Zuweisungen, Konvertierungen und Berechnungen
Feld-zu-Feld-Zuweisung❍ Selektionsbilder
feste Fremdschlüssel ❍ Selektionsbilder
field-symbol-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
form❍ Modularisierung: Ereignisse und Unterprogramme
formale Parameter ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Formalparameter❍ Modularisierung: Übergabe von Parametern an Unterprogramme
form-Anweisung❍ Modularisierung: Ereignisse und Unterprogramme
free-Anweisung❍ Interne Tabellen, Teil 1
Fremdschlüssel❍ Das Data Dictionary ®, Teil 2
Fremdschlüsselbeziehung❍ Das Data Dictionary ®, Teil 2
Fremdschlüsselfeld

❍ SelektionsbilderFremdschlüsselüberprüfung
❍ Das Data Dictionary ®, Teil 2 FüllByte
❍ Zuweisungen, Konvertierungen und Berechnungen Funktionsbaustein freigeben
❍ Modularisierung: Funktionsbausteine, Teil 2 Funktionsbaustein testen
❍ Modularisierung: Funktionsbausteine, Teil 2 Funktionsbausteine
❍ Modularisierung: Funktionsbausteine, Teil 1 Funktionsbibliothek
❍ Ihr erstes ABAP/4®-Programm ❍ Modularisierung: Funktionsbausteine, Teil 1
Funktionsgruppen❍ Modularisierung: Funktionsbausteine, Teil 1
Funktionsschlüssel❍ Die Entwicklungsumgebung
Funktionsschnittstelle❍ Modularisierung: Funktionsbausteine, Teil 1
Fußzeilen❍ Formatierungstechniken, Teil 1
G
Generischer Fremdschlüssel ❍ Das Data Dictionary ®, Teil 2
Generischer Puffer ❍ Das Data Dictionary ®, Teil 3
Gepackte Felder ❍ Die write-Anweisung
Gleitkommaliterale❍ Datendefinitionen in ABAP/4®, Teil 1
Globale Daten definieren ❍ Modularisierung: Funktionsbausteine, Teil 2
globale Variable ❍ Modularisierung: Ereignisse und Unterprogramme
goto-Anweisung❍ Allgemeine Kontrollanweisungen
Grafische Formatierung ❍ Formatierungstechniken, Teil 1

Größenkategorien❍ Das Data Dictionary ®, Teil 3
Gruppenwechsel❍ Interne Tabellen, Teil 2
H
Hexadezimalliteral❍ Datendefinitionen in ABAP/4®, Teil 1
Hilfe❍ Ihr erstes ABAP/4®-Programm
Hypertext❍ Das Data Dictionary ®, Teil 1
I
if-Anweisung❍ Allgemeine Kontrollanweisungen
if-equal to-Anweisung ❍ Interne Tabellen, Teil 1
Ihr erstes Programm ❍ Ihr erstes ABAP/4®-Programm
Ikone❍ Formatierungstechniken, Teil 1
Ikonen❍ Formatierungstechniken, Teil 1
Import-Parameter❍ Modularisierung: Funktionsbausteine, Teil 1
in❍ Die Entwicklungsumgebung
In den Puffer kopieren-Schaltfläche ❍ Ihr erstes ABAP/4®-Programm
include chain ❍ Das Data Dictionary ®, Teil 2
include F01 ❍ Modularisierung: Funktionsbausteine, Teil 2
include-Anweisung❍ Modularisierung: Funktionsbausteine, Teil 1
included program ❍ Modularisierung: Funktionsbausteine, Teil 1
Include-Programm

❍ Modularisierung: Funktionsbausteine, Teil 1 Include-Strukturen
❍ Das Data Dictionary ®, Teil 2 including program
❍ Modularisierung: Funktionsbausteine, Teil 1 Index
❍ Das Data Dictionary ®, Teil 3 index-Zusatz
❍ Interne Tabellen Inhalt einer internen Tabelle löschen
❍ Interne Tabellen, Teil 1 initialization
❍ Modularisierung: Ereignisse und Unterprogramme ❍ Modularisierung: Ereignisse und Unterprogramme
initialization-Ereignis❍ Selektionsbilder
Initialwerte❍ Interne Tabellen, Teil 1
insert lines-Anweisung ❍ Interne Tabellen, Teil 1
insert-Anweisung❍ Interne Tabellen, Teil 1
interne Tabelle ❍ Interne Tabellen
interne Tabelle mit einer Kopfzeile ❍ Interne Tabellen
interne Tabelle mit Kopfzeile übergeben ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
interne Tabelle übergeben ❍ Modularisierung: Funktionsbausteine, Teil 2
Interne Tabellen als Parameter übergeben ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
interne Unterprogramme ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
interner Unterprogramme ❍ Modularisierung: Ereignisse und Unterprogramme
into table-Zusatz ❍ Interne Tabellen, Teil 2
K

Kardinalität❍ Das Data Dictionary ®, Teil 2 ❍ Selektionsbilder
Kettenoperator❍ Ihr erstes ABAP/4®-Programm
Kommentare❍ Ihr erstes ABAP/4®-Programm
Komponenten einer internen Tabelle ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Komponenten Ihrer Funktionsgruppe ❍ Modularisierung: Funktionsbausteine, Teil 2
Konsistenzprüfungen❍ Das Data Dictionary ®, Teil 4
Konstanten❍ Datendefinition in ABAP/4®, Teil 2
Konstanter Fremdschlüssel ❍ Das Data Dictionary ®, Teil 2
Konvertierungs-Exits❍ Die write-Anweisung
Konvertierungsregeln❍ Zuweisungen, Konvertierungen und Berechnungen
Konvertierungsroutinen❍ Die write-Anweisung
Kopfzeilen und Fußzeilen ❍ Formatierungstechniken, Teil 1
Kopieren einer internen Tabelle ❍ Interne Tabellen, Teil 1
Kundenentwicklungsobjekte❍ Ihr erstes ABAP/4®-Programm
Kundenprogramme❍ Ihr erstes ABAP/4®-Programm
L
Längenanpassung❍ Zuweisungen, Konvertierungen und Berechnungen
Laufzeitanalysator❍ Ihr erstes ABAP/4®-Programm
Laufzeitobjekt❍ Ihr erstes ABAP/4®-Programm
Leerzeichen

❍ Formatierungstechniken, Teil 2 Leerzeile
❍ Formatierungstechniken, Teil 2 letzte Seite
❍ Ihr erstes ABAP/4®-Programm lfa1
❍ Interne Tabellen, Teil 2 lfb1
❍ Interne Tabellen, Teil 2 lfc1
❍ Interne Tabellen, Teil 2 lfc3
❍ Interne Tabellen, Teil 2 line-count-Zusatz zur report-Anweisung
❍ Formatierungstechniken, Teil 1 line-draw
❍ Formatierungstechniken, Teil 1 Lines In Lists Option
❍ Die Entwicklungsumgebung line-size-Zusatz zur report-Anweisung
❍ Formatierungstechniken, Teil 1 Linienzeichen
❍ Formatierungstechniken, Teil 1 Literal
❍ Datendefinitionen in ABAP/4®, Teil 1 local-Anweisung
❍ Modularisierung: Ereignisse und Unterprogramme lokale Objekte
❍ Ihr erstes ABAP/4®-Programm lokale Parameter
❍ Modularisierung: Übergabe von Parametern an Unterprogramme lokale Variable
❍ Modularisierung: Ereignisse und Unterprogramme loop at-Anweisung
❍ Interne Tabellen Löschen einer überarbeiteten Version
❍ Das Data Dictionary ®, Teil 4 lower case-Zusatz
❍ Datendefinitionen in ABAP/4®, Teil 1
M

Mandantenanmeldeverfahren❍ Die Entwicklungsumgebung
mandt Feld ❍ Das Data Dictionary ®, Teil 3
Markieren-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
Matchcode-ID❍ Selektionsbilder
Matchcode-Objekte❍ Selektionsbilder
Matchcodes❍ Selektionsbilder
Meldungsanweisung❍ Selektionsbilder
Mengenfelder❍ Das Data Dictionary ®, Teil 2
Menüleiste❍ Die Entwicklungsumgebung
message ... raising-Anweisung ❍ Modularisierung: Funktionsbausteine, Teil 2
message-id-Anweisung❍ Selektionsbilder
modify-Anweisung❍ Interne Tabellen, Teil 1
Modularisierungseinheiten❍ Modularisierung: Ereignisse und Unterprogramme
Modus❍ Ihr erstes ABAP/4®-Programm
move❍ Zuweisungen, Konvertierungen und Berechnungen
move-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
move-corresponding-Anweisung❍ Zuweisungen, Konvertierungen und Berechnungen
Muster-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
N
nächste Seite

❍ Ihr erstes ABAP/4®-Programm Namenskonventionen
❍ Das Data Dictionary ®, Teil 1 nametab
❍ Das Data Dictionary ®, Teil 4 new-line-Anweisung
❍ Formatierungstechniken, Teil 2 new-page print
❍ Formatierungstechniken, Teil 2 new-page print off
❍ Formatierungstechniken, Teil 2 new-page print-Anweisung
❍ Formatierungstechniken, Teil 2 new-page-Anweisung
❍ Formatierungstechniken, Teil 2 no standard page heading
❍ Formatierungstechniken, Teil 1 no-gap-Ergänzung
❍ Die write-Anweisung no-sign-Ergänzung
❍ Die write-Anweisung no-zero-Ergänzung
❍ Die write-Anweisung Numerische Datentypen
❍ Datendefinitionen in ABAP/4®, Teil 1 Numerische Literale
❍ Datendefinitionen in ABAP/4®, Teil 1
O
Objektaktivierung❍ Das Data Dictionary ®, Teil 1
occurs-Zusatz❍ Interne Tabellen
on change of-Anweisung ❍ Interne Tabellen, Teil 2
Open SQL ❍ Die Entwicklungsumgebung
Operatoren für Zeichenketten ❍ Allgemeine Kontrollanweisungen

P
Parameter anlegen ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Parameter übergeben ❍ Modularisierung: Funktionsbausteine, Teil 1
Parameter-Beschriftung❍ Datendefinitionen in ABAP/4®, Teil 1
parameters-Anweisung❍ Datendefinitionen in ABAP/4®, Teil 1
Parameterübergabe❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Parameterübergabe als Referenz ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Parameterübergabe als Wert ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Parameterübergabe als Wert und Resultat ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
partielle Fremdschlüssel ❍ Selektionsbilder
perform❍ Modularisierung: Ereignisse und Unterprogramme
perform-Anweisung❍ Modularisierung: Ereignisse und Unterprogramme ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
perform-Befehl❍ Modularisierung: Übergabe von Parametern an Unterprogramme
persönliches Kennzeichen ❍ Ihr erstes ABAP/4®-Programm
Pooltabellen❍ Das Data Dictionary ®, Teil 1 ❍ Das Data Dictionary ®, Teil 1
Portierbarkeit❍ Die Entwicklungsumgebung
position-Anweisung❍ Formatierungstechniken, Teil 2
Präsentationsserver❍ Die Entwicklungsumgebung
Primärschlüssel❍ Das Data Dictionary ®, Teil 1
Primärschlüsselfelder

❍ Das Data Dictionary ®, Teil 1 Programmattribute
❍ Ihr erstes ABAP/4®-Programm Programmattributmaske
❍ Ihr erstes ABAP/4®-Programm Programmlaufzeitobjekt
❍ Das Data Dictionary ®, Teil 4 Programmnamenskonventionen
❍ Ihr erstes ABAP/4®-Programm Programmpuffer
❍ Datendefinitionen in ABAP/4®, Teil 1 Prüfen der Fremdschüsselbeziehung
❍ Das Data Dictionary ®, Teil 2 Prüfen-Schaltfläche
❍ Ihr erstes ABAP/4®-Programm Prüffeld
❍ Das Data Dictionary ®, Teil 2 Prüftabelle
❍ Das Data Dictionary ®, Teil 2 ❍ Das Data Dictionary ®, Teil 2 ❍ Das Data Dictionary ®, Teil 2
Puffer Auslagerung ❍ Das Data Dictionary ®, Teil 3
Puffern einer Tabelle ❍ Das Data Dictionary ®, Teil 3
Puffern von Daten ❍ Die Entwicklungsumgebung
Puffer-Synchronisation❍ Das Data Dictionary ®, Teil 3
Puffertechniken❍ Das Data Dictionary ®, Teil 3
Puffertypen❍ Das Data Dictionary ®, Teil 3
Q
Quelltexteditor❍ Ihr erstes ABAP/4®-Programm
R

R/3-Anwenderschnittstelle❍ Die Entwicklungsumgebung
R/3-Anwendungsgebiete❍ Die Entwicklungsumgebung
R/3-Basis❍ Die Entwicklungsumgebung
R/3-Bibliothek-Hilfe❍ Das Data Dictionary ®, Teil 1
R/3-Bibliothekshilfe❍ Ihr erstes ABAP/4®-Programm
R/3-Data Dictionary ❍ Ihr erstes ABAP/4®-Programm
R/3-Development Workbench ❍ Ihr erstes ABAP/4®-Programm
R/3-Instanz❍ Die Entwicklungsumgebung
R/3-System❍ Die Entwicklungsumgebung
R/3-Systemarchitektur❍ Die Entwicklungsumgebung
radiobutton group ❍ Selektionsbilder
radiobutton group g-Zusatz ❍ Datendefinitionen in ABAP/4®, Teil 1
radiobutton group-Klausel ❍ Selektionsbilder
radiobutton-Anweisung❍ Selektionsbilder
raise-Anweisung❍ Modularisierung: Funktionsbausteine, Teil 2
raising❍ Modularisierung: Funktionsbausteine, Teil 2
RDBMS❍ Die Entwicklungsumgebung ❍ Die Entwicklungsumgebung
read table-Anweisung ❍ Interne Tabellen
refresh-Anweisung❍ Interne Tabellen, Teil 1
Release-Stände❍ Das Data Dictionary ®, Teil 1

Reports❍ Formatierungstechniken, Teil 1
Reports (Berichte) ❍ Ihr erstes ABAP/4®-Programm
Repository Information System ❍ Modularisierung: Funktionsbausteine, Teil 2
Repository-Suchwerkzeug❍ Ihr erstes ABAP/4®-Programm
reserve-Anweisung❍ Formatierungstechniken, Teil 1
Roll Out ❍ Die Entwicklungsumgebung
Rollbereich❍ Die Entwicklungsumgebung ❍ Datendefinitionen in ABAP/4®, Teil 1
Roll-In❍ Die Entwicklungsumgebung
round-Ergänzung❍ Die write-Anweisung
Rumpf einer internen Tabelle ❍ Interne Tabellen
S
SAP-Dokumentation❍ Das Data Dictionary ®, Teil 1
SAP-Domäne❍ Das Data Dictionary ®, Teil 1
SAPGUI❍ Die Entwicklungsumgebung
Schaltflächen❍ Ihr erstes ABAP/4®-Programm
Schaltflächenereignis❍ Selektionsbilder
Schleifenmechanismus❍ Allgemeine Kontrollanweisungen
Schlüsselausdruck❍ Interne Tabellen
Schlüsselfelder❍ Das Data Dictionary ®, Teil 2
Schlüsselfelder einer Texttabelle

❍ Das Data Dictionary ®, Teil 2 Schlüsselkandidaten
❍ Das Data Dictionary ®, Teil 2 Schnittstelle
❍ Modularisierung: Funktionsbausteine, Teil 1 Schnittstellenmenü
❍ Die Entwicklungsumgebung Screen- und Menu-Painter
❍ Ihr erstes ABAP/4®-Programm Screen-Interpreter
❍ Die Entwicklungsumgebung SE16
❍ Das Data Dictionary ®, Teil 1 SE17
❍ Das Data Dictionary ®, Teil 1 Seitengröße
❍ Formatierungstechniken, Teil 1 sekundären Index löschen
❍ Das Data Dictionary ®, Teil 3 Sekundärindizes
❍ Das Data Dictionary ®, Teil 3 select
❍ Interne Tabellen, Teil 2 select into table
❍ Interne Tabellen, Teil 2 select into table-Anweisung
❍ Interne Tabellen, Teil 2 select single-Anweisung
❍ Ihr erstes ABAP/4®-Programm select-Anweisung
❍ Ihr erstes ABAP/4®-Programm selection-screen-Anweisung
❍ Selektionsbilderselection-screen-Block
❍ Selektionsbilderselect-options-Anweisung
❍ SelektionsbilderSelektionsbild Auswahlknöpfe (Optionen
❍ SelektionsbilderSelektionsbild checkbox
❍ Selektionsbilder

Selektionsbild select-options ❍ Selektionsbilder
Selektionsbilder formatieren ❍ Selektionsbilder
Selektive Indizes ❍ Das Data Dictionary ®, Teil 3
Server-Konfigurationen❍ Die Entwicklungsumgebung
set blank lines ❍ Formatierungstechniken, Teil 2
set blank lines-Anweisung ❍ Formatierungstechniken, Teil 2
short dump ❍ Interne Tabellen, Teil 2
skip-Anweisung❍ Formatierungstechniken, Teil 2
SM30❍ Das Data Dictionary ®, Teil 1
SM31❍ Das Data Dictionary ®, Teil 1
sort-Anweisung❍ Interne Tabellen ❍ Interne Tabellen, Teil 2
Sortierung❍ Interne Tabellen, Teil 2
SPACE❍ Datendefinition in ABAP/4®, Teil 2
Speicherparameter❍ Das Data Dictionary ®, Teil 4
Spool❍ Formatierungstechniken, Teil 1
SQL-Anweisungen❍ Die Entwicklungsumgebung
SQL-Trace Tool ❍ Ihr erstes ABAP/4®-Programm
SQL-Trace-Werkzeug❍ Das Data Dictionary ®, Teil 3
Stammdaten❍ Das Data Dictionary ®, Teil 3
Standard-Anfangswerte❍ Zuweisungen, Konvertierungen und Berechnungen

Standardeinstellungen❍ Die write-Anweisung
Standardformat❍ Die write-Anweisung
Standardkopfzeilen❍ Formatierungstechniken, Teil 1
Standardlängen❍ Die write-Anweisung
Standardschlüsselfelder❍ Interne Tabellen, Teil 1
Stapel-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
start-of-selection❍ Modularisierung: Ereignisse und Unterprogramme ❍ Modularisierung: Ereignisse und Unterprogramme
statics-Anweisung❍ Modularisierung: Ereignisse und Unterprogramme
Statusleiste❍ Die Entwicklungsumgebung
stop❍ Modularisierung: Ereignisse und Unterprogramme
Struktur❍ Ihr erstes ABAP/4®-Programm
Strukturen im Data Dictionary ❍ Das Data Dictionary ®, Teil 2
Strukturierte Typen ❍ Datendefinition in ABAP/4®, Teil 2
Subfelder❍ Die write-Anweisung
Suchen❍ Ihr erstes ABAP/4®-Programm
Suchen und Ersetzen ❍ Ihr erstes ABAP/4®-Programm
sum❍ Interne Tabellen, Teil 2
sum-Anweisung❍ Interne Tabellen, Teil 2
sy❍ Zuweisungen, Konvertierungen und Berechnungen
Sy -Felder ❍ Ihr erstes ABAP/4®-Programm

sy-dbcnt❍ Ihr erstes ABAP/4®-Programm ❍ Ihr erstes ABAP/4®-Programm
sy-fdpos❍ Allgemeine Kontrollanweisungen
Symbole❍ Formatierungstechniken, Teil 1 ❍ Formatierungstechniken, Teil 1
Symbolleiste❍ Die Entwicklungsumgebung ❍ Ihr erstes ABAP/4®-Programm
syst❍ Ihr erstes ABAP/4®-Programm ❍ Zuweisungen, Konvertierungen und Berechnungen
Systemvariable❍ Ihr erstes ABAP/4®-Programm
Systemvariablen❍ Zuweisungen, Konvertierungen und Berechnungen
Systemvariablen suchen ❍ Zuweisungen, Konvertierungen und Berechnungen
syst-Struktur❍ Ihr erstes ABAP/4®-Programm
sy-subrc❍ Ihr erstes ABAP/4®-Programm
sy-tfill❍ Interne Tabellen, Teil 1
T
Tabelle❍ Ihr erstes ABAP/4®-Programm
Tabelle kopieren ❍ Das Data Dictionary ®, Teil 1
Tabellenmandantenabhängig
■ Die Entwicklungsumgebung mandantenunabhängig
■ Die Entwicklungsumgebung Tabellen löschen
❍ Das Data Dictionary ®, Teil 1 Tabellenarbeitsbereich

❍ Ihr erstes ABAP/4®-Programm Tabellencluster
❍ Das Data Dictionary ®, Teil 1 Tabellenindizes
❍ Das Data Dictionary ®, Teil 3 Tabellenkomponenten
❍ Das Data Dictionary ®, Teil 1 Tabellenmodifizierung
❍ Das Data Dictionary ®, Teil 1 Tabellenparameter
❍ Modularisierung: Funktionsbausteine, Teil 1 Tabellenpflege erlaubt
❍ Das Data Dictionary ®, Teil 1 Tabellenpool
❍ Das Data Dictionary ®, Teil 1 Tabellenrumpf-Operator
❍ Interne Tabellen, Teil 1 Tabellentypen
❍ Das Data Dictionary ®, Teil 1 tables-Anweisung
❍ Ihr erstes ABAP/4®-Programm tables-Anweisung zur Definition einer Feldleiste
❍ Datendefinition in ABAP/4®, Teil 2 tables-Arbeitsbereiches
❍ Modularisierung: Ereignisse und Unterprogramme tables-Feldleiste
❍ Datendefinition in ABAP/4®, Teil 2 Tablespace
❍ Das Data Dictionary ®, Teil 3 Task Handler
❍ Die Entwicklungsumgebung Technische Einstellungen
❍ Das Data Dictionary ®, Teil 3 Teilfelder
❍ Zuweisungen, Konvertierungen und Berechnungen Temporäre Version vom aktiven Objekt
❍ Das Data Dictionary ®, Teil 4 Textelement
❍ Formatierungstechniken, Teil 1 Texttabelle
❍ Das Data Dictionary ®, Teil 2

Texttabelle einrichten ❍ Das Data Dictionary ®, Teil 2
Titelleiste❍ Die Entwicklungsumgebung
top include ❍ Modularisierung: Funktionsbausteine, Teil 1
top-of-page❍ Formatierungstechniken, Teil 1 ❍ Modularisierung: Ereignisse und Unterprogramme
top-of-page-Ereignis❍ Formatierungstechniken, Teil 1
top-of-page-event❍ Formatierungstechniken, Teil 1
Transaktion❍ Die Entwicklungsumgebung
Transaktion SE63 ❍ Formatierungstechniken, Teil 1
Transaktionscode❍ Die Entwicklungsumgebung
transparente Tabellen ❍ Das Data Dictionary ®, Teil 1
transporting❍ Interne Tabellen, Teil 1
transporting-Zusatz❍ Interne Tabellen
Treiberprogramm❍ Modularisierung: Ereignisse und Unterprogramme
Typ des Fremdschlüsselfelds ❍ Das Data Dictionary ®, Teil 2
Typenkonvertierung❍ Zuweisungen, Konvertierungen und Berechnungen
Typenpool❍ Datendefinition in ABAP/4®, Teil 2
types-Anweisung❍ Datendefinition in ABAP/4®, Teil 2
Typgruppe❍ Datendefinition in ABAP/4®, Teil 2
Typgruppe anlegen ❍ Datendefinition in ABAP/4®, Teil 2
U

Übergabe des Rumpfs ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Übergabe mit Kopfzeile ❍ Modularisierung: Übergabe von Parametern an Unterprogramme
Übergabeparameter❍ Modularisierung: Funktionsbausteine, Teil 1
under-Ergänzung❍ Die write-Anweisung
unit-Ergänzung❍ Die write-Anweisung
Unterfelder❍ Die write-Anweisung
Unterprogramm verlassen ❍ Modularisierung: Ereignisse und Unterprogramme
Unterprogramme❍ Modularisierung: Ereignisse und Unterprogramme
Unterprogramme in einer Funktionsgruppe definieren ❍ Modularisierung: Funktionsbausteine, Teil 2
USER-Klassen❍ Das Data Dictionary ®, Teil 3
UXX❍ Modularisierung: Funktionsbausteine, Teil 1
V
Variablen❍ Datendefinitionen in ABAP/4®, Teil 1
Variablen vom Typ char ❍ Datendefinition in ABAP/4®, Teil 2
varying-Zusatz❍ Allgemeine Kontrollanweisungen
Verketten-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
Versionen einer Tabelle ❍ Das Data Dictionary ®, Teil 4
Verwendungsnachweis-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
Volle Pufferung ❍ Das Data Dictionary ®, Teil 3
vorherige Seite

❍ Ihr erstes ABAP/4®-Programm
W
Währungsfelder❍ Das Data Dictionary ®, Teil 2
Weiter Suchen ❍ Ihr erstes ABAP/4®-Programm
Wertetabelle❍ Das Data Dictionary ®, Teil 2
where-Klausel❍ Ihr erstes ABAP/4®-Programm
while-Anweisung❍ Allgemeine Kontrollanweisungen
Widerrufen-Schaltfläche❍ Ihr erstes ABAP/4®-Programm
with key-Zusatz ❍ Interne Tabellen
Work Process/WP ❍ Die Entwicklungsumgebung
Workbench Organizer ❍ Ihr erstes ABAP/4®-Programm
Workflow-System❍ Die Entwicklungsumgebung
write-Anweisung❍ Allgemeine Kontrollanweisungen ❍ Die write-Anweisung
Z
Zeichenkettenliterale❍ Datendefinitionen in ABAP/4®, Teil 1
Zeichenkettenoperatoren❍ Allgemeine Kontrollanweisungen
Zeichenlinien❍ Formatierungstechniken, Teil 1
Zeile einfügen-Schaltfläche ❍ Ihr erstes ABAP/4®-Programm
Zeile merken-Schaltfläche ❍ Ihr erstes ABAP/4®-Programm
Zeile verschieben-Schaltfläche

❍ Ihr erstes ABAP/4®-Programm Zurück und Exit
❍ Ihr erstes ABAP/4®-Programm zusammengesetzter Fremdschlüssel
❍ Das Data Dictionary ®, Teil 2 Zusatz Ankreuzfeld
❍ Datendefinitionen in ABAP/4®, Teil 1 Zusatz Auswahlknopf
❍ Datendefinitionen in ABAP/4®, Teil 1 Zusatz Kleinbuchstaben
❍ Datendefinitionen in ABAP/4®, Teil 1 Zusatz like
❍ Datendefinitionen in ABAP/4®, Teil 1 Zusätze (siehe auch: Ergänzungen)
❍ Datendefinitionen in ABAP/4®, Teil 1 Zuweisung von DDIC-Datentypen zu ABAP/4-Datentypen
❍ Datendefinitionen in ABAP/4®, Teil 1 Zuweisungsanweisung
❍ Zuweisungen, Konvertierungen und Berechnungen Zwei interne Tabelleninhalte vergleichen
❍ Interne Tabellen, Teil 1 Zwischenablage
❍ Ihr erstes ABAP/4®-Programm
Ein Imprint des Markt&Technik Buch- und Software-Verlag GmbH. Elektronische Fassung des Titels: ABAP/4® in 21 Tagen, ISBN: 3-8272-2016-X