accelerating random walks wei dept. of computer science cornell university (joint work with bart...
Post on 21-Dec-2015
218 views
TRANSCRIPT

Accelerating Random Walks
Wei WeiDept. of Computer Science
Cornell University
(joint work with Bart Selman)

Introduction
This talk deals with gathering new information to accelerate search and reasoning.
Although the method proposed can to be generalized to other search problems, we focus on SAT problem in this talk.

Boolean Satisfiability Problem
Boolean Satisfiability Problem (SAT) asks if a Boolean expression can be made true by assigning Boolean values to its variables.
The problem is well-studied in AI community with direct application in reasoning, planning, CSP etc.
Does statement s hold in world A (represented by a set of clauses)?
A ᅣ s (¬s) ^ A unsatisfiable

SAT
SAT (even 3SAT) is NP-complete. Best theoretical bound so far is O(1.334N) for 3SAT (Schoening 1999)
In practice, there are two different kinds of solvers DPLL (Davis, Logemann and Loveland 1962) Local Search (Selman et al 1992)

DPLL
(x1 x2 x3) (x1 x2 x3) (x1 x2 x3) DPLL was first proposed as a simple depth-first
tree search. x1
x2
FT
T
null
F
solution
x2

DPLL
Recently (since late 90’s), many improvements: Randomization, restart, out-of-order backtracking, and clause learning

Local Search
The idea: Start with a random assignment. And make local changes to the assignment until a solution is reached
Pro: often efficient in practice. Sometimes the only feasible way for some problems
Con: Cannot prove nonexistence of solutions. Hard to analyze theoretically

Local Search
Initially, pure hill-climbing greedy search:
Procedure GSATStart with a random truth assignmentRepeat
s:= set of neighbors of current assignment that satisfies most clauses
pick an assignment in s randomly and move to that new assignment
Until a satisfying assignment is found

Local Search, cont.
Later, other local search schemes used: Simulated annealing Tabu search Genetic algorithm Random Walk and its variants the most
successful so far

Unbiased (Pure) Random Walk for SAT
Procedure Random-Walk (RW)Start with a random truth assignmentRepeat
c:= an unsatisfied clause chosen at randomx:= a variable in c chosen at randomflip the truth value of x
Until a satisfying assignment is found

Random Walk algorithms
Random walk algorithm (e.g. Walksat) offer significant improvement on performance over hill-climbing algorithms.
ID Vars clauses GSAT+w Walksat
Ssa7552-038 1501 3575 129 2.3
Ssa7552-158 1363 3034 90 2
Ssa7552-159 1363 3032 14 0.8
Ssa7552-160 1391 3126 18 1.5

New approached to speed up random walks
Next, we’ll discuss how to use new knowledge to improve random walk algorithm STAGE – use more state information Long distance link discovery – transform the
search space

I) STAGE algorithmBoyan and Moore 1998
Idea: more features of the current state may help local search
Task: to incorporate these features into improved evaluation functions, and help guide search

Method
The algorithm learns function V: the expected outcome of a local search algorithm given an initial state.
Can this function be learned successfully?
x
y
x
V(x)

Features
State feature vector: problem specific
Example: for 3SAT, following features are useful:
1. % of clauses currently unsat (=obj function)
2. % of clauses satisfied by exactly 1 variable
3. % of clauses satisfied by exactly 2 variables
4. % of variables set to their naïve setting

Learner
Fitter: can be any function approximator; polynomial regression is used in practice.
Training data: generated on the fly; every LS trajectory produces a series of new training data.
Restrictions on LS: it must terminate in poly-time; it must be Markovian.
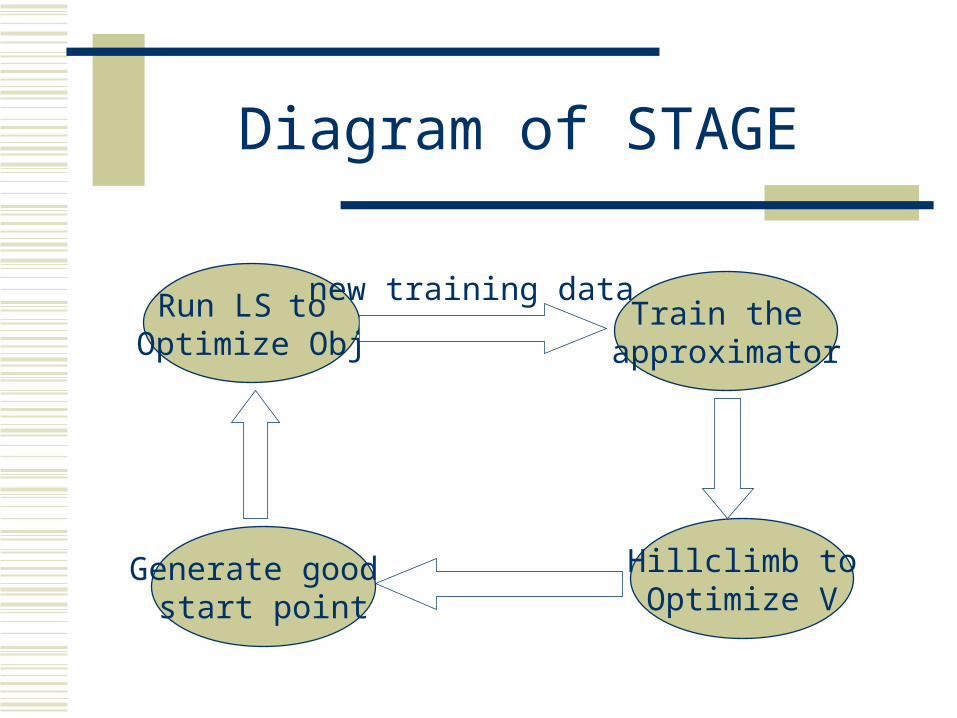
Diagram of STAGE
Run LSto Optimize Obj
Train the approximator
new training data
Hillclimb toOptimize V
Generate good start point

Results
Works on many domain, such as bin-packing, channel routing, SAT
Standard LS
STAGE +LS
Binpacking 109.38 104.77
Channel Routing 22.35 12.42
SAT(par32) 15.22 4.43
Table gives average solution quality

Discussion
Is the learned function a good approximation to V? – Somewhat unclear.
(“worrisome”: performance is not improved when authors used quadratic regression to replace linear regression. Learning does help however.)
Why not learn a better objective function and search on that function directly (clause weighing, adding clauses)?

Method
The algorithm learns function V: the expected outcome of a local search algorithm given an initial state
x
y
x
V(x)

II) Long-distance Link Discovery
Random walk-style methods are successful on hard randomly generated instances, as well as on a number of real-world benchmarks.
However, they are generally less effective in highly structured domains compared to backtrack methods such as DPLL.
Key issue: random walk needs O(N2) flips to propagate dependencies among variables, while in unit-propagation in DPLL takes only O(N).

Overview
Random Walk Strategies
- unbiased random walk
- biased random walk Chain Formulas
- binary chains
- ternary chains Practical Problems Conclusion and Future Directions

Unbiased (Pure) Random Walk for SAT
Procedure Random-Walk (RW)Start with a random truth assignmentRepeat
c:= an unsatisfied clause chosen at randomx:= a variable in c chosen at randomflip the truth value of x
Until a satisfying assignment is found

Unbiased RW on any satisfiable 2SAT Formula
Given a satisfiable 2SAT formula with n variables, a satisfying assignment will be reached by Unbiased RW in O(n2) steps with high probability. (Papadimitriou, 1991)
Elegant proof! (next)

Given a satisfiable 2-SAT formula F.RW starts with a random truth assignment A0.Consider an unsatisfied clause: (x_3 or (not x_4))A0 must have x_3 False and x_4 True (both “wrong”)
A satisfying truth assignment, T, must have x_3 True or x_4 False (or both)
Now, “flip” truth value of x_3 or x_4.With (at least) 50% chance, Hamming distance tosatisfying assignment T is reduced by 1. I.e., we’re moving the right direction! (of course, with 50%(or less) we are moving in the wrong direction… doesn’t matter!)

We have an unbiased random walk with a reflecting barrier at distance N from T (max Hamming distance) and an absorbing barrier (satisfying assignment) at distance 0.
We start at a Hamming distance of approx. ½ N.
Property of unbiased random walks: after N^2 flips, with high probability, we will hit the origin (the satisfying assignment). (Drunkards walk)
So, O(N^2) randomized algorithm (worst-case!) for 2-SAT.
T A0T A0

Unfortunately, does not work for k-SAT withk>= 3.
Reason: example unsat clause: (x_1 or (not x_4) or x_5) now only 1/3 chance (worst-case) of making the right flip!

Unbiased RW on 3SAT Formulas
Random walk takes exponential number of steps to reach 0.
T A0

Comments on RW
1) Random Walk is highly “myopic” does not take into account any gradient of the objective function (= number of unsatisfied clauses)!
Purely “local” fixes.
2) Can we make RW practical for SAT?
Yes --- inject greedy bias into walk
biased Random Walk.

Biased Random Walk (1st minimal greedy bias)
Procedure Random-Walk-with-Freebie (RWF)Start with random truth assignmentRepeat
c:= an unsatisfied clause chosen at random
if there exist a variable x in c with break value = 0 // greedy biasflip the value of x (a “freebie” flip)
else x:= a variable in c chosen at random // pure walkflip the value of x
Until a satisfying assignment is found
break value == # of clauses that become unsatisfied because of flip.

Biased Random Walk(adding more greedy bias)
Procedure WalkSatRepeat
c:= an unsatisfied clause chosen at random
if there exist a variable x in c with break value = 0 // greedy biasflip the value of x (freebie move)
else with probability p // pure walk
x:= a variable in c chosen at random flip the value of x
with probability (1-p)x:= a variable in c with smallest break value // more greedy
biasflip the value of x
Until a satisfying assignment is found
Note: tune parameter p.

Chain Formulas
To better understand the behavior of pure and biased RW procedures on SAT instances, we introduce Chain Formulas.
These formulas have long chains of dependencies between variables.
They effectively demonstrate the extreme properties of RW style algorithms.

Binary Chains
Consider formulas 2-SAT chain, F2chain
x1 x2
x2 x3
…
xn-1 xn
xn x1 Note: Only two satisfying assignments ---TTTTTT … and FFFFFF…

Binary Chains
Walk is exactly balanced.

Binary Chains
We obtain the following theoremTheorem 1. With high probability, the RW procedure takes n2) steps to find a satisfying assignment of F2chain.
DPLL algorithm’s unit propagation mechanism finds an assignment for F2chain in linear time.
Greedy bias does not help in this case: both RWF and WalkSat takes n2) flips to reach a satisfying assignment on these formulas.

Speeding up Random Walks on Binary Chains
Pure binary chain Binary chain with redundancies (implied clauses)
Aside: Note small-world flavor (Watts & Strogatz 99, Kleinberg 00).

Results: Speeding up Random Walks on Binary Chains
*: empirical results**: theoretical proof available
Pure binary chain
Chain with
redundancies
RW (n2)** (n2)**
RWF (n2)** (n1.2)*
WalkSat (n2)* (n1.1)*
Becomesalmost likeunit prop.
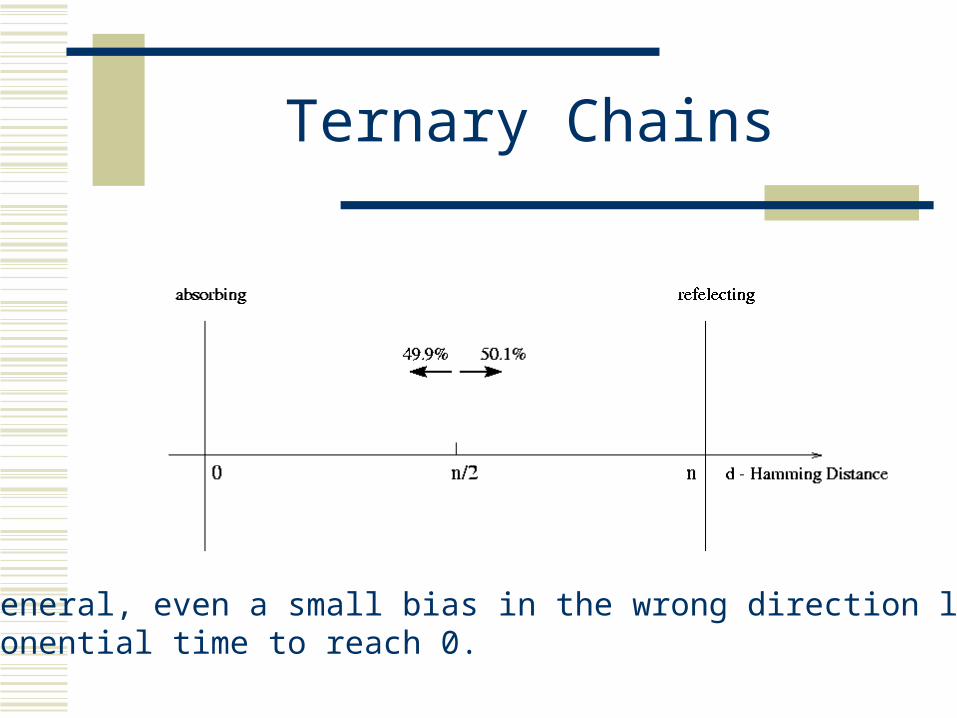
Ternary Chains
In general, even a small bias in the wrong direction leads to exponential time to reach 0.

Ternary Chains
Consider formulas F3chain, low(i)
x1
x2
x1 x2 x3
…
xlow(i) xi-1 xi
…
xlow(n) xn-1 xn Note: Only one satisfying assign.: TTTTT…
*These formulas are inspired by Prestwich [2001]

Ternary Chains
long link
short link
medium link
Effect of X1 and X2 needs to propagate through chain.
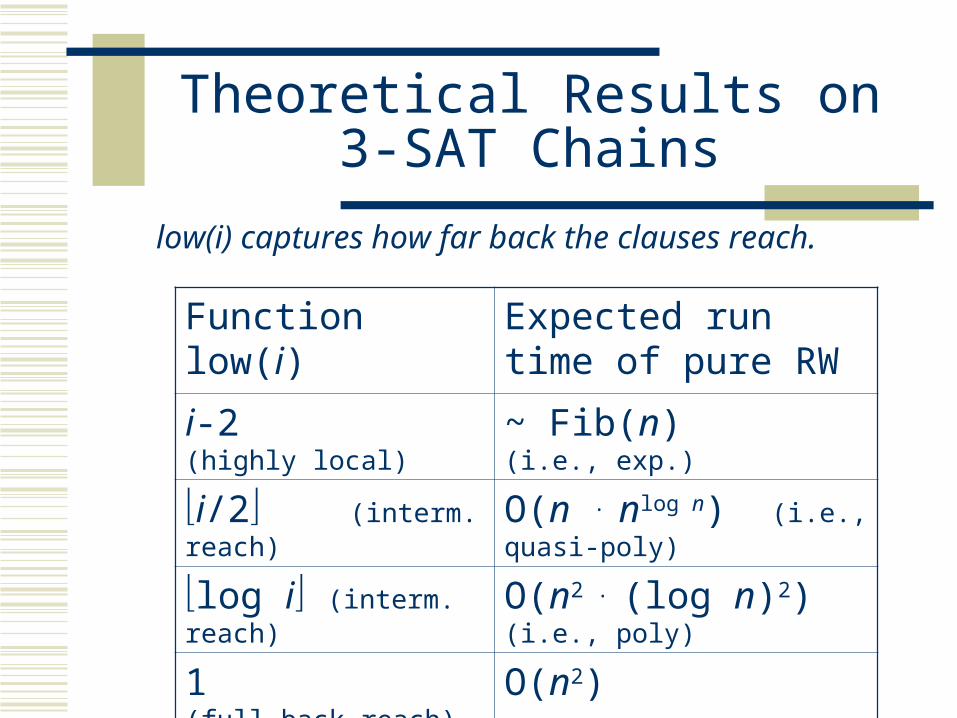
Theoretical Results on 3-SAT Chains
Function low(i) Expected run time of pure RW
i-2 (highly local) ~ Fib(n) (i.e., exp.)
i/2 (interm. reach) O(n . nlog n) (i.e., quasi-poly)
log i (interm. reach) O(n2 . (log n)2) (i.e., poly)
1 (full back reach) O(n2)
low(i) captures how far back the clauses reach.

Proof
The proofs of these claims are quite involved, and are available at http://www.cs.cornell.edu/home/selman/weiwei.pdf
Here, just the intuitions. Each RW process on these formulas can be
decomposed into a series of decoupled, simpler random walks.

Simple case: single “0”
111101 … 111111
111101
111001
1/3
101101
1/3
111111
1/3
zi
?Exp. # steps decomposes:Exp # steps from 111011 + Exp # steps from 111101
Zi is the assignment with all 1’s except for ith position 0.

Recurrence Relations
Our formula structure gives us:
E(f(zi)) = (E(f(zlow(i)) + E(f(zi) + 1) * 1/3
+ (E(f(zi-1) + E(f(zi) + 1) * 1/3
+ 1 * 1/3
E(f(zi)) = E(f(zlow(i)) + E(f(zi-1) + 3

Recurrence Relations
Solving this recurrence for different low(i)’s, we get
Function low(i) E(f(zi))
i-2 Fib(i)
i/2 ilog i
log i i . (log i)2
1 i
This leads to the complexity results for the overall RW.

Decompose: multiple “0”s
110101010101
110001010001
100001
111001110001
101001111001
111111111101
110101010101
110001100001
111001110001
110101
010001
101001111001111101111111
110111010111
110111100111
111111110111
111101
111001
101001111001111101111111
110111 111111
111101 111111
Start
Sat assign.

Results for RW on 3-SAT chains.
Function low(i) Expected Running time of pure RW
i-2 ~ Fib(n)
i/2 O(n . nlog n)
log i O(n2 . (log n)2)
1 O(n2)

Recap Chain Formula Results
Adding implied constraints capturing long-range dependencies speeds random walk on 2-Chain to near linear time.
Certain long-range dependencies in 3-SAT lead to poly-time convergence of random walks.
Can we take advantage of these results on practical problem instances? Yes! (next)

Results on Practical Benchmarks
Idea: Use a formula preprocessor to uncover long-range dependencies and add clauses capturing those dependencies to the formula.
We adapted Brafman’s formula preprocessor to do so. (Brafman 2001)
Experiments on recent verification benchmark.
(Velev 1999)

Empirical Results
SSS-SAT-1.0 instances (Velev 1999). 100 total. level of redundancy added (20% near optimal)
Formulas(redun. level)
<40 sec <400 sec <4000 sec
= 0.0 15 26 42
= 0.2 85 98 100
= 1.0 13 33 64

Conclusions
We introduced a method for speeding up random walk style SAT algorithms based on the addition of constraints that capture long range dependencies.
On a binary chain, we showed how by adding implied clauses, biased RW becomes almost as effective as unit-propagation.

Conclusions, Cont.
In our formal analysis of ternary chains, we showed how the performance of RW varies from exponential to polynomial depending on the range of dependency links. We identified the first subclass of 3-SAT problems solvable in poly-time by unbiased RW
We gave a practical validation of our approach.

Future Directions
It seems likely that many other dependency structures could speed up random walk style methods.
It should be possible to develop preprocessor to uncover other dependencies. For example, in graph coloring problem we have:
x1 x4 , x2 x5 , x3 x6, …
x1 x4 x7 x10, …

The end.