achieving high utilization with software-driven...
TRANSCRIPT

Achieving High Utilization with Software-Driven WAN
Chi-Yao Hong (UIUC) Srikanth Kandula Ratul Mahajan
Microsoft
Ming Zhang Vijay Gill Mohan Nanduri Roger Wattenhofer
Tuesday, August 13, 13
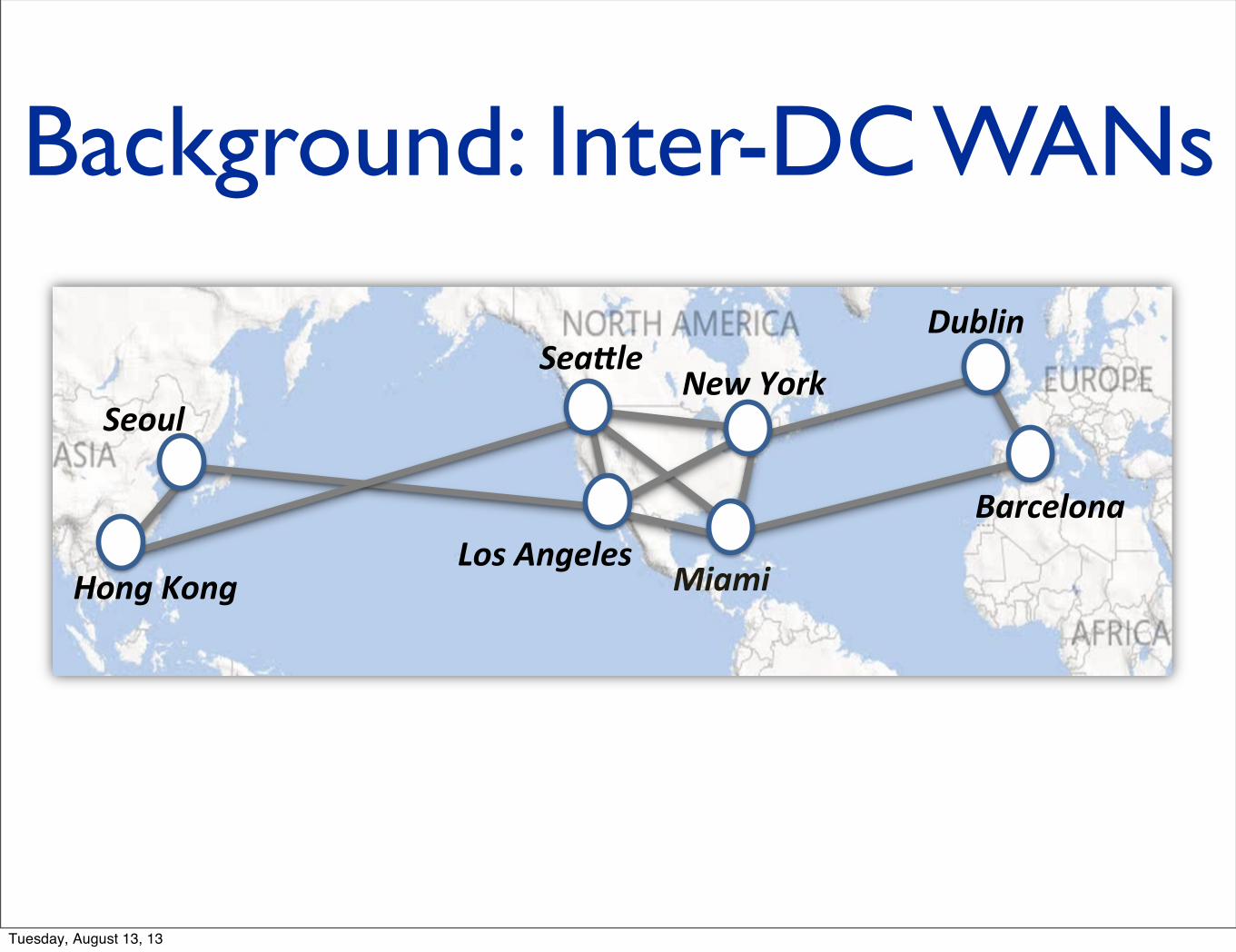
Background: Inter-DC WANs
Hong%Kong%
Seoul%
Sea,le%
Los%Angeles%
New%York%
Miami%
Dublin%
Barcelona%
Tuesday, August 13, 13

Background: Inter-DC WANs
Hong%Kong%
Seoul%
Sea,le%
Los%Angeles%
New%York%
Miami%
Dublin%
Barcelona%
Inter-DC WANs are critical
Tuesday, August 13, 13

Background: Inter-DC WANs
Hong%Kong%
Seoul%
Sea,le%
Los%Angeles%
New%York%
Miami%
Dublin%
Barcelona%
Inter-DC WANs are critical
Inter-DC WANsare highly expensive
Tuesday, August 13, 13

Two key problems
Poor efficiency average utilization over time of busy links is only 30-50%
Poor sharing little support for
flexible resource sharing
Tuesday, August 13, 13

Two key problems
Poor efficiency average utilization over time of busy links is only 30-50%
Poor sharing little support for
flexible resource sharing
Why?
Tuesday, August 13, 13

One cause of inefficiency:lack of coordination
Norm. traffic rate
Time (~ one day)
mean
Tuesday, August 13, 13

One cause of inefficiency:lack of coordination
Background traffic
Non-background traffic
Norm. traffic rate
Time (~ one day)Tuesday, August 13, 13

One cause of inefficiency:lack of coordination
Background traffic
Non-background traffic
Norm. traffic rate
Time (~ one day)
peak before rate adaptation
peak after rate adaptation
> 50% peak reduction
Tuesday, August 13, 13

Another cause of inefficiency:local, greedy resource allocation
MPLS TE (Multiprotocol Label Switching Traffic Engineering) greedily selects shortest path fulfilling capacity constraint
Tuesday, August 13, 13

Local, greedy resource allocation hurts efficiency
Flow Src → Dst
A 1→6B 3→6C 4→6
1 2 3
4
567
flow arrival order: A, B, C each link can carry at most one flow
MPLS-TETuesday, August 13, 13

Local, greedy resource allocation hurts efficiency
Flow Src → Dst
A 1→6B 3→6C 4→6
1 2 3
4
567
flow arrival order: A, B, C each link can carry at most one flow
MPLS-TETuesday, August 13, 13
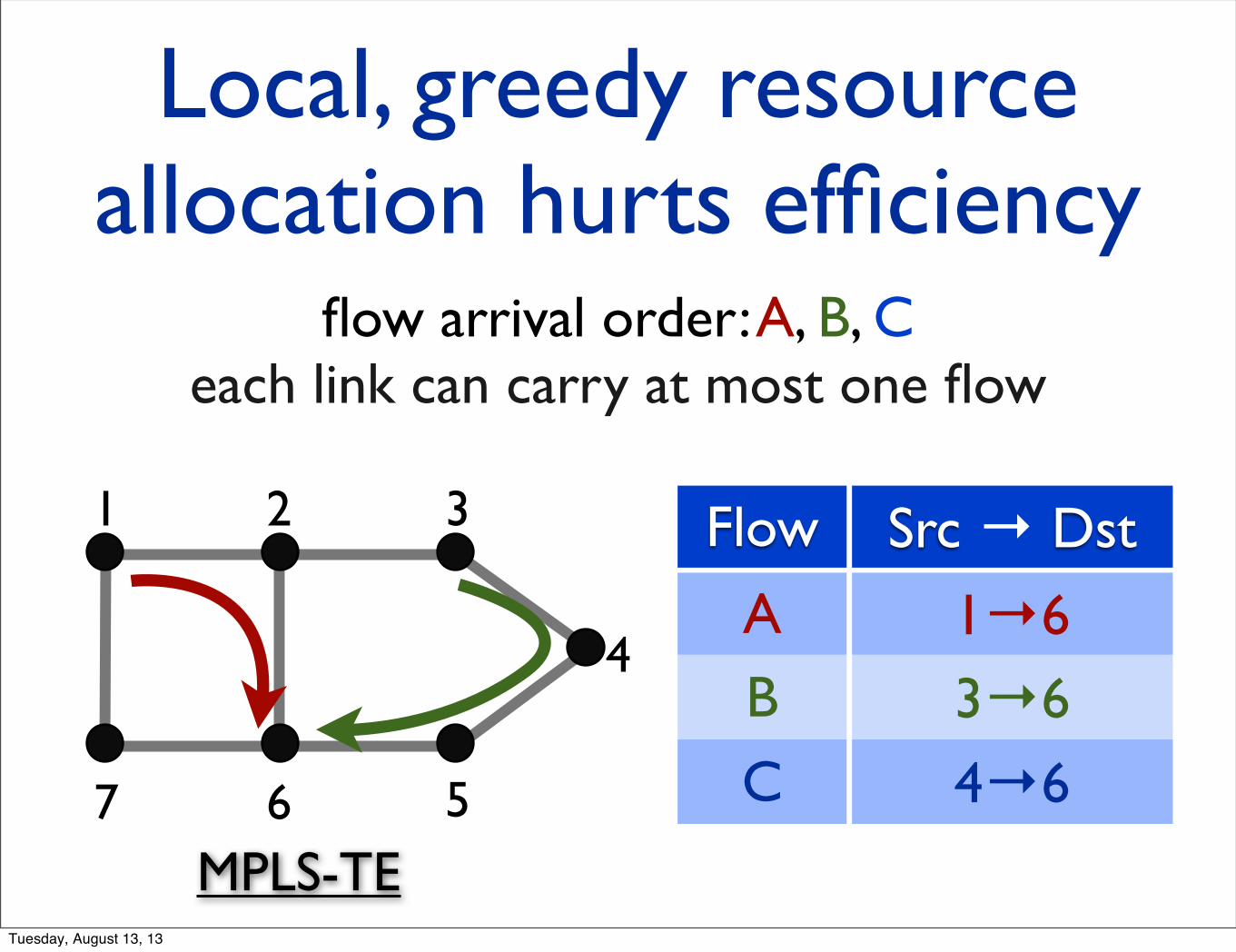
Local, greedy resource allocation hurts efficiency
Flow Src → Dst
A 1→6B 3→6C 4→6
1 2 3
4
567
flow arrival order: A, B, C each link can carry at most one flow
MPLS-TETuesday, August 13, 13

Local, greedy resource allocation hurts efficiency
Flow Src → Dst
A 1→6B 3→6C 4→6
1 2 3
4
567
flow arrival order: A, B, C each link can carry at most one flow
MPLS-TETuesday, August 13, 13

1 2 3
567
1 2 3
567Optimal
Local, greedy resource allocation hurts efficiency
flow arrival order: A, B, C each link can carry at most one flow
MPLS-TETuesday, August 13, 13

Poor sharing
Tuesday, August 13, 13

Poor sharing
• When services compete today, they can get higher throughput by sending faster
Tuesday, August 13, 13

Poor sharing
• Mapping services onto different queues at switches helps, but # services ≫ # queues
(4 - 8 typically)
• When services compete today, they can get higher throughput by sending faster
(hundreds)
Tuesday, August 13, 13

Poor sharing
• Mapping services onto different queues at switches helps, but # services ≫ # queues
(4 - 8 typically)
• When services compete today, they can get higher throughput by sending faster
Borrowing the idea of edge rate limiting, we can have better sharing without many queues
(hundreds)
Tuesday, August 13, 13

Our solution
Tuesday, August 13, 13

SWAN
Our solution
: Software-driven WAN
Tuesday, August 13, 13

SWAN
Our solution
: Software-driven WAN
• high utilization
• flexible sharing
Tuesday, August 13, 13

System flow
WANswitchesHosts
Tuesday, August 13, 13

System flow
WANswitches
SWAN controllertraffic
demandtopology,
traffic
Hosts
Tuesday, August 13, 13

System flow
WANswitches
SWAN controllertraffic
demandtopology,
traffic
[global optimization for high utilization]
Hosts
Tuesday, August 13, 13
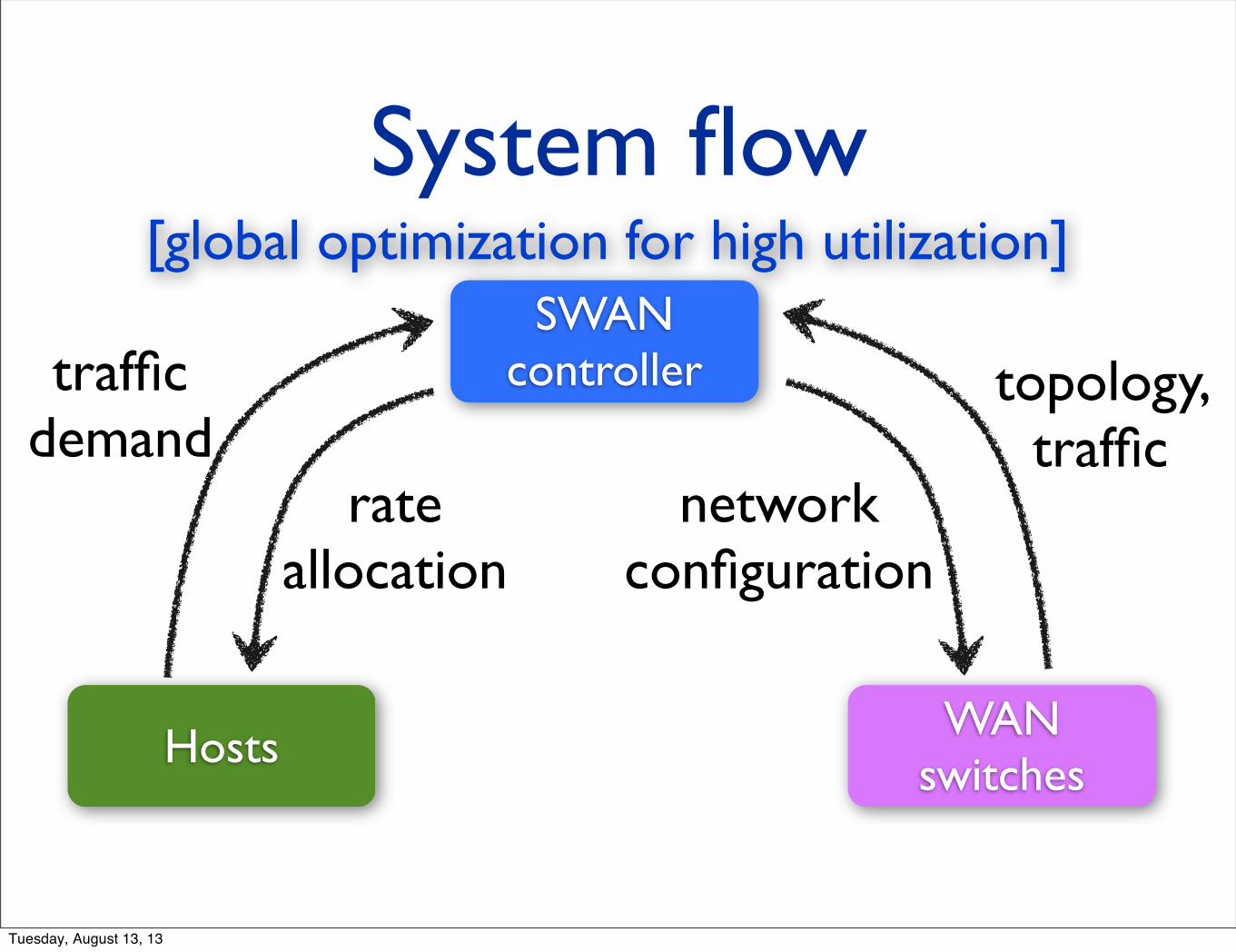
System flow
WANswitches
rate allocation
network configuration
SWAN controllertraffic
demandtopology,
traffic
[global optimization for high utilization]
Hosts
Tuesday, August 13, 13

System flow
WANswitches
rate allocation
network configuration
[rate limiting] [forwarding plane update]
SWAN controllertraffic
demandtopology,
traffic
[global optimization for high utilization]
Hosts
Tuesday, August 13, 13

Challenges
• scalable allocation computation
• congestion-free data plane update
• working with limited switch memory
Tuesday, August 13, 13

Challenge #1: How to compute allocation in a time-efficient manner?
Tuesday, August 13, 13

Computing resource allocation
Path-constrained, multi-commodity flow problem
• allocate higher-priority traffic first
• ensure weighted max-min fairness within a class
Solving at the granularity of {DC pairs, priority class}-tuple
• split the allocation fairly among service flows
Tuesday, August 13, 13

But computing max-min fairness is hard
[Danna, Mandal, Singh; INFOCOM’12]
State-of-the-art takes minutes at our target scaleAs it needs to solve a long sequence of LPs:
# LPs = O(# saturated edges)
Tuesday, August 13, 13

Approximated max-min fairness
Max demand
0
α
MCF solverMaximize throughputPrefer shorter paths
upper & lower bounds
Tuesday, August 13, 13

Approximated max-min fairness
Max demand
0
α
MCF solverMaximize throughputPrefer shorter paths
upper & lower bounds
freeze saturated flow rates
Tuesday, August 13, 13

Approximated max-min fairness
Max demand
0
α
α2
...MCF solver
Maximize throughputPrefer shorter paths
freeze saturated flow rates
upper & lower bounds
Tuesday, August 13, 13

Performance
Theoretical bound:
Empirical efficiency (with α = 2):
• only 4% of flows deviate over 5% from their fair share rate
• sub-second computational time
Tuesday, August 13, 13

Fairness: SWAN vs. MPLS TE
0 1 2 3 4
0 100 200 300 400 500 600
0 1 2 3 4
0 100 200 300 400 500 600
Flow goodput[versus
max-min fair rate]
Flow index[increasing order of demand]
SWAN; α=2
MPLS TE
Tuesday, August 13, 13

Challenge #2:Congestion-free update
How to update forwarding plane without causing transient congestion?
Tuesday, August 13, 13

Congestion-free update is hard
initial state target state
AB
B
A
Tuesday, August 13, 13

Congestion-free update is hard
initial state target state
AB
B
A
A
B✘
Tuesday, August 13, 13

Congestion-free update is hard
initial state target state
AB
B
A
A
B✘ ✘B
A
Tuesday, August 13, 13

In fact, congestion-free update sequence might not exist!
Tuesday, August 13, 13

Idea
Leave a small amount of scratch capacity on each link
Tuesday, August 13, 13

A=2/3
B=2/3
B=2/3
A=2/3
Slack = 1/3 of link capacity ...Init. state target state
Tuesday, August 13, 13

A=2/3
B=2/3
B=2/3
A=2/3
Slack = 1/3 of link capacity ...
B=1/3A=2/3
B=1/3
Init. state target state
Tuesday, August 13, 13

A=2/3
B=2/3
B=2/3
A=2/3
Slack = 1/3 of link capacity ...
B=1/3
B=1/3
A=2/3
B=1/3A=2/3
B=1/3
Init. state target state
Tuesday, August 13, 13

A=2/3
B=2/3
B=2/3
A=2/3
Slack = 1/3 of link capacity ...
B=1/3
B=1/3
A=2/3
B=1/3A=2/3
B=1/3
Does slack guarantee that congestion-free update always exists?
Init. state target state
Tuesday, August 13, 13

Yes!With slack :
• we prove there exists a congestion-free update in steps
one step = multiple updates whose order can be arbitrary
Tuesday, August 13, 13

Yes!With slack :
• we prove there exists a congestion-free update in steps
one step = multiple updates whose order can be arbitrary
It exsits, but how to find it?
Tuesday, August 13, 13

Congestion-free update: LP-based solution
• rate variable: step
flow path
Tuesday, August 13, 13

Congestion-free update: LP-based solution
• rate variable: step
flow path
• input: and • output: ...
Tuesday, August 13, 13

Congestion-free update: LP-based solution
• rate variable: step
flow path
• input: and • output: ...
• congestion-free constraint:
∀i,j on a linklink capacity
Tuesday, August 13, 13

Utilizing all the capacity
non-background is congestion-free
background has bounded congestion
using 90% capacity (s = 10%)
using 100% capacity (s = 0%)
Tuesday, August 13, 13

0.01%
0.1%
1%
10%
0 100 200 300
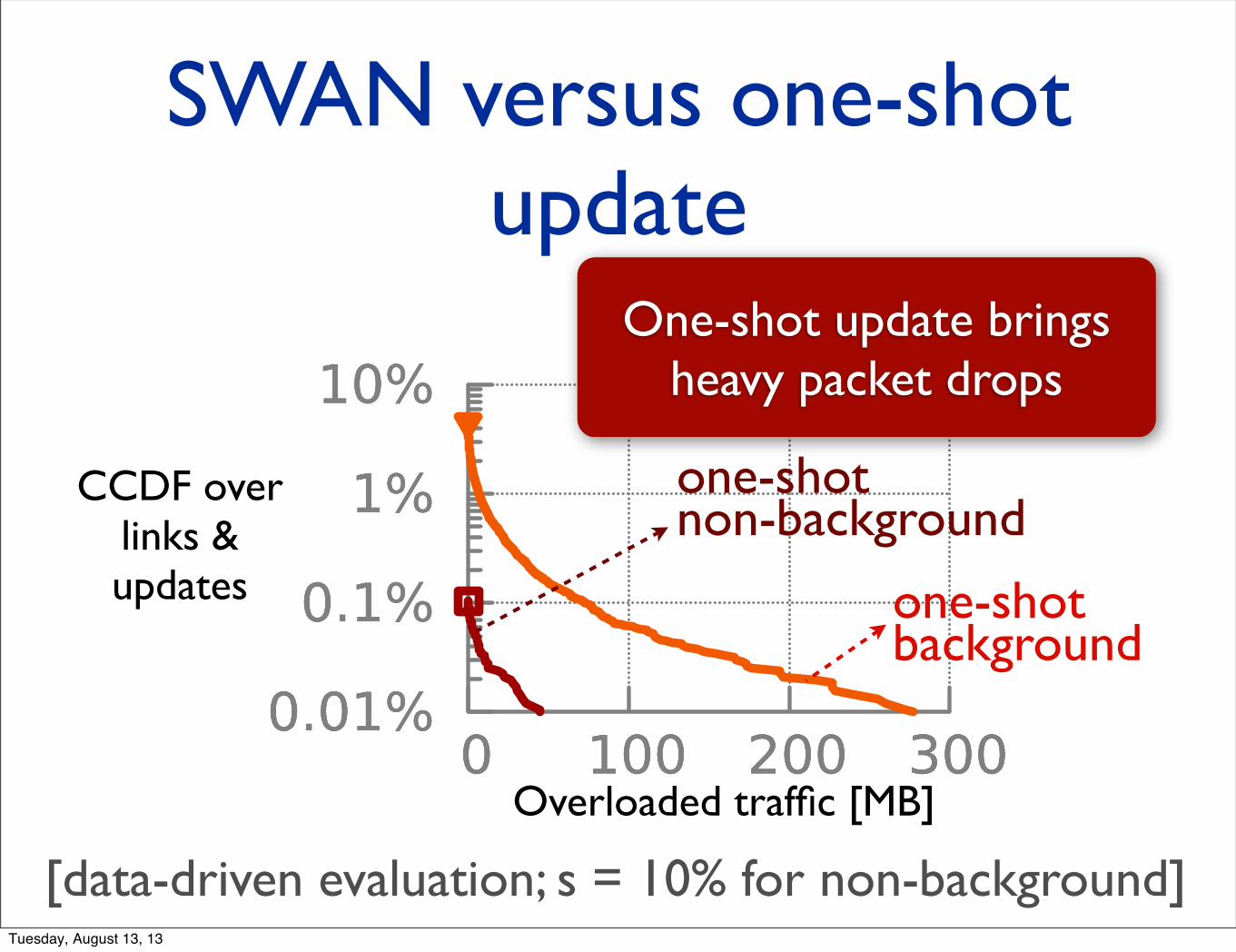
SWAN versus one-shot update
0.01%
0.1%
1%
10%
0 100 200 300
CCDF over links & updates
Overloaded traffic [MB]
[data-driven evaluation; s = 10% for non-background]Tuesday, August 13, 13
0.01%
0.1%
1%
10%
0 100 200 300
SWAN versus one-shot update
0.01%
0.1%
1%
10%
0 100 200 300
CCDF over links & updates
Overloaded traffic [MB]
0.01%
0.1%
1%
10%
0 100 200 300
One-shot update brings heavy packet drops
one-shotnon-background
one-shot background
[data-driven evaluation; s = 10% for non-background]Tuesday, August 13, 13

0.01%
0.1%
1%
10%
0 100 200 300
SWAN versus one-shot update
0.01%
0.1%
1%
10%
0 100 200 300
CCDF over links & updates
Overloaded traffic [MB]
0.01%
0.1%
1%
10%
0 100 200 300
one-shot background
0.01%
0.1%
1%
10%
0 100 200 300
SWAN background
SWANnon-background: congestion-free
background: much better than one-shot
[data-driven evaluation; s = 10% for non-background]Tuesday, August 13, 13

Working with limited switch memory
Challenge #3
Tuesday, August 13, 13

Why does switch memory matter?
Tuesday, August 13, 13

Why does switch memory matter?
How many we need?
• 50 sites = 2,500 pairs • 3 priority classes• static k-shortest path routing [by data-driven analysis]
Tuesday, August 13, 13

Why does switch memory matter?
How many we need?
• 50 sites = 2,500 pairs • 3 priority classes• static k-shortest path routing [by data-driven analysis]
it requires 20K rules to fully use network capacity
Tuesday, August 13, 13

Why does switch memory matter?
Commodity switches has limited memory:• today’s OpenFlow switch: 1-4K rules• next generation: 16K rules
How many we need?
• 50 sites = 2,500 pairs • 3 priority classes• static k-shortest path routing [by data-driven analysis]
it requires 20K rules to fully use network capacity
[Broadcom Trident II]
Tuesday, August 13, 13

Hardness
Finding the set of paths with a given size that carries the most traffic is NP-complete
[Hartman et al., INFOCOM’12]
Tuesday, August 13, 13

Heuristic: Dynamic path set adaptation
Tuesday, August 13, 13

Heuristic: Dynamic path set adaptation
Observation: • working path set ≪ total needed paths
Tuesday, August 13, 13

Heuristic: Dynamic path set adaptation
• important ones that carry more traffic and provide basic connectivity
• 10x fewer rules than static k-shortest path routing
Path selection:
Observation: • working path set ≪ total needed paths
Tuesday, August 13, 13

Heuristic: Dynamic path set adaptation
• important ones that carry more traffic and provide basic connectivity
• 10x fewer rules than static k-shortest path routing
Path selection:
Rule update:• multi-stage rule update • with 10% memory slack, typically 2 stages needed
Observation: • working path set ≪ total needed paths
Tuesday, August 13, 13

Overall workflowCompute resource
allocation
Tuesday, August 13, 13

Overall workflowCompute resource
allocationif enough gain
Compute rule update plan
if not
Tuesday, August 13, 13

Overall workflowCompute resource
allocationif enough gain
Compute rule update plan
if not
Compute congestion-free update plan
Tuesday, August 13, 13

Overall workflowCompute resource
allocation
Notify services with decrease allocation
if enough gain
Compute rule update plan
if not
Compute congestion-free update plan
Tuesday, August 13, 13

Overall workflowCompute resource
allocation
Notify services with decrease allocation
if enough gain
Compute rule update plan
if not
Compute congestion-free update plan
Update network
Tuesday, August 13, 13

Overall workflowCompute resource
allocation
Notify services with decrease allocation
if enough gain
Compute rule update plan
if not
Compute congestion-free update plan
Update network
Notify services with increase allocation
Tuesday, August 13, 13

Evaluation platforms
Arista
Cisco N3K
Blade
Server
Prototype• 5 DCs across 3 continents;
10 switches
Tuesday, August 13, 13

Evaluation platforms
Arista
Cisco N3K
Blade
Server
Prototype• 5 DCs across 3 continents;
10 switches
Data-driven evaluation• 40+ DCs across 3
continents, 80+ switches• G-scale: 12 DCs, 24 switches
Tuesday, August 13, 13

Prototype evaluation
0 0.2 0.4 0.6 0.8
1
0 1 2 3 4 5 6Interactive
ElasticElasticBackground
Time [minute]
Goodput(normalized & stacked)
Traffic: (∀DC-pair) 125 TCP flows per class
Tuesday, August 13, 13

Prototype evaluation
0 0.2 0.4 0.6 0.8
1
0 1 2 3 4 5 6Interactive
ElasticElasticBackground
Time [minute]
Goodput(normalized & stacked)
0 0.2 0.4 0.6 0.8
1
0 1 2 3 4 5 6Interactive
ElasticElasticBackground
(impractical) optimal line
High utilization SWAN’s goodput:
98% of an optimal method
dips due to rate adaptation
Traffic: (∀DC-pair) 125 TCP flows per class
Tuesday, August 13, 13

Prototype evaluation
0 0.2 0.4 0.6 0.8
1
0 1 2 3 4 5 6Interactive
ElasticElasticBackground
Time [minute]
Goodput(normalized & stacked)
0 0.2 0.4 0.6 0.8
1
0 1 2 3 4 5 6Interactive
ElasticElasticBackground
(impractical) optimal line
High utilization SWAN’s goodput:
98% of an optimal method
Flexible sharing Interactive protected;
background rate-adapted
dips due to rate adaptation
Traffic: (∀DC-pair) 125 TCP flows per class
Tuesday, August 13, 13

Data-driven evaluation of 40+ DCs
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
Goodput[versus optimal]
Tuesday, August 13, 13

Data-driven evaluation of 40+ DCs
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
Goodput[versus optimal]
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
99.0%Near-optimal total goodput
under a practical setting
Tuesday, August 13, 13

Data-driven evaluation of 40+ DCs
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
Goodput[versus optimal]
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
99.0%
58.3%
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
SWAN carries ~60% more traffic than MPLS-TE
Tuesday, August 13, 13

Data-driven evaluation of 40+ DCs
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
Goodput[versus optimal]
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
99.0%
58.3%
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
0 0.2 0.4 0.6 0.8
1
SWANSWAN
w/o RateControl
MPLSTE
70.3%
SWAN w/o rate control still carries 20% more traffic than MPLS TE
Tuesday, August 13, 13

SWAN: Software-driven WAN
Tuesday, August 13, 13

SWAN: Software-driven WAN
✔ High utilization and flexible sharing via global rate and route coordination
Tuesday, August 13, 13

SWAN: Software-driven WAN
✔ High utilization and flexible sharing via global rate and route coordination
✔ Scalable allocation via approximated max-min fairness
Tuesday, August 13, 13

SWAN: Software-driven WAN
✔ High utilization and flexible sharing via global rate and route coordination
✔ Congestion-free update in bounded stages
✔ Scalable allocation via approximated max-min fairness
Tuesday, August 13, 13

SWAN: Software-driven WAN
✔ High utilization and flexible sharing via global rate and route coordination
✔ Congestion-free update in bounded stages
✔ Scalable allocation via approximated max-min fairness
✔ Using commodity switches with limited memory
Tuesday, August 13, 13

Conclusion
Achieving high utilization itself is easy, but coupling it with flexible sharing and change management is hard
Tuesday, August 13, 13

Conclusion
Achieving high utilization itself is easy, but coupling it with flexible sharing and change management is hard
Approximating max-min fairness with low
computational time
Tuesday, August 13, 13
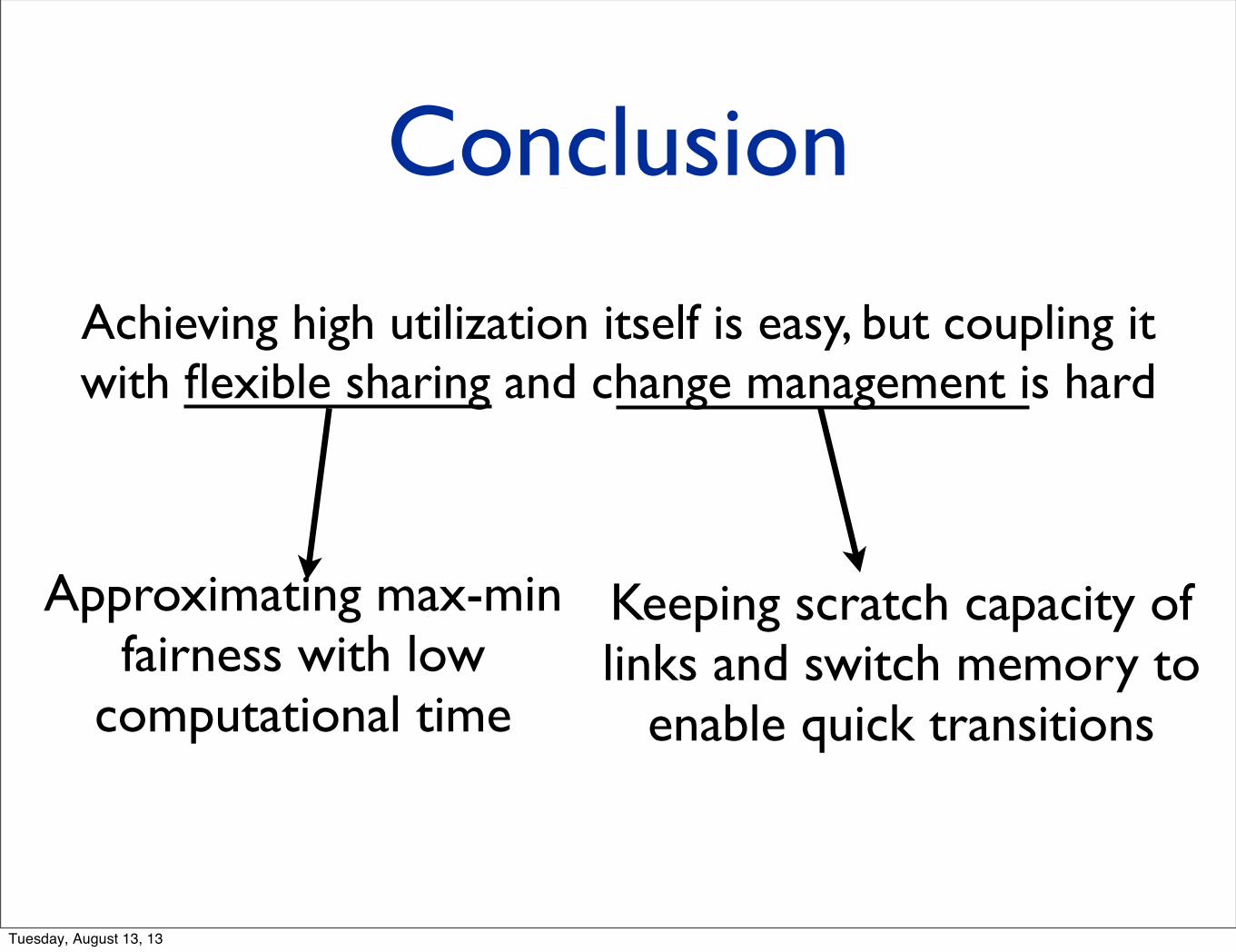
Conclusion
Achieving high utilization itself is easy, but coupling it with flexible sharing and change management is hard
Approximating max-min fairness with low
computational time
Keeping scratch capacity of links and switch memory to
enable quick transitions
Tuesday, August 13, 13

Chi-Yao Hong (UIUC) Srikanth Kandula Ratul Mahajan
MicrosoftMing Zhang Vijay Gill Mohan Nanduri Roger Wattenhofer
on the job market!
Thanks!
Tuesday, August 13, 13

SWAN versus B4SWAN B4
high utilization yes yes
scalable rate and route computation
bounded error heuristic
congestion-free update in bounded steps no
using commodity switches with limited # forwarding
rules yes no
Tuesday, August 13, 13

Demo Video: SWAN achieves high utilization
Tuesday, August 13, 13

Demo Video: SWAN provides flexible sharing
Tuesday, August 13, 13

Controller crashes• Run stateless backup instances
Failure handlingLink and switch failures
• SWAN controller performs one-time global recomputation
• Network agent notifies SWAN controller
• During the recovery, data plane will still operate
Controller bugs
• Work in progress
Tuesday, August 13, 13

Demo Video: SWAN handles link failures gracefully
Tuesday, August 13, 13

SWAN controllerGlobal allocation at {SrcDC, DstDC, ServicePriority}-level
• map flows to priority queues at switches (via DSCP bits)
• support a few priorities (e.g., background < elastic < interactive)
Dst
30%
50%
20%
Src
Label-based forwarding (“tunnels”)
• by tagging VLAN IDs
• SWAN controller globally computes how to split traffic at ingress switches
Tuesday, August 13, 13

Link-level fairness !=network-wide fairness
S1
S2
S3
D1
D2
D3
1/2
1/2
1/2
1/2
Link-level
S1
S2
S3
D1
D2
D3
2/3
1/3
1/3
2/3
Network-wide
Tuesday, August 13, 13

Time for network update
Tuesday, August 13, 13

How much stretch capacity is needed?
s max steps
50% 130% 3
10% 9
0% ∞
goodput
79%91%
100%
100%[data-driven evaluation]
✔
99th pctl.
12
3
6
>
>>
>>
Tuesday, August 13, 13

if not
Our heuristic: dynamic path selection Solve rate allocation
if can fit in memory
Greedily select important paths
Solve again with selected paths
fin.
Using 10x fewer paths than static k-shortest path routing
Tuesday, August 13, 13

old rules
newrules
Rule update with memory constraints
Option #1:
Fully utilize all the switch memory
Rule update may disrupt traffic
switch memory
?
Tuesday, August 13, 13

old rules
newrules
Rule update with memory constraints
Option #2:
Leave 50% slack [Reitblatt et al.; SIGCOMM’12]
Waste a halfswitch memory
switch memory
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
# stages bound:f(memory slack)
Tuesday, August 13, 13

Multi-stage rule update
switch memory
active rules
# stages bound:f(memory slack)
When slack=10%, 2 stages for 95% of time
Tuesday, August 13, 13