acm sigkdd the first society in data mining and knowledge
TRANSCRIPT

Gregory Piatetsky-Shapiro, Chair, SIGKDDGreg James, SIGKDD Webcast Director
ACM SIGKDD The First Society in
Data Mining and Knowledge Discovery
www.KDD.org
Join SIGKDD for free participation in future webcasts, discounts on KDD conferences, …
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 2
Stay Current with Data Mining
Visit www.KDnuggets.comSubscribe to KDnuggets News (free)
Discuss data mining atwww.KDnuggets.com/forums

Web Content Mining
Bing LiuDepartment of Computer Science
University of Illinois at [email protected]
http://www.cs.uic.edu/~liub
ACM SIGKDD Webcast, Nov 29, 2006
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 4
Introduction
The Web is perhaps the single largest and distributed data source in the world that is easily accessible.
Web mining: develop techniques to mine knowledge from the Web and the usage of the Web. It consists of:
Web usage mining: discover user access patterns from usage logs, e.g., clickstreams.
Web structure mining: discover knowledge from hyperlinks.
Web content mining: mine knowledge from page contents.
We focus on Web content mining. Still a very large topic. I will not discuss
Traditional tasks: Web page classification, clustering, etc.

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 5
Roadmap
Introduction
1. Structured data extraction
2. Information integration
3. Opinion mining (information extraction)
Conclusions
Structured data
Unstructured text
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 6
Structured Data Extraction
A large amount of information on the Web is contained in regularly structured data objects.
often data records retrieved from databases.
Such Web data records are important: lists of products and services.Applications: Gather data to provide valued added services
comparative shopping, object search (rather than page search), etc.
Two types of pages with structured data:List pages, and detail pages

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 7
List Page – two lists of products
Two lists
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 8
Detail Page – detailed description

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 9
Extraction Task: an illustration
$19.95 ***** Cookware Lid Rack 22x6 Cabinet Organizersimage 2
$7.95 ***** Cabinet Organizer (Non-skid): White
14.75x9Cabinet Organizers image 2
$7.95 ***** Round Turntable: White 12-in. Cabinet Organizers by Copcoimage 1
$4.95 ***** Round Turntable: White 9-in. Cabinet Organizers by Copcoimage 1
nesting
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 10
Data Model and Solution
Web data model: Nested relations See formal definitions in (Grumbach and Mecca, ICDT-99; Liu, Web Data Mining book 2006)
Solve the problemTwo main types of techniques
Wrapper induction – supervisedAutomatic extraction – unsupervised
Information that can be exploitedSource files (e.g., Web pages in HTML)
Represented as strings or treesVisual information (e.g., rendering information)

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 11
Tree and Visual information
HTML
HEADBODY
TR|TD
TD TD TD TD
TR TR|
TD
TR TRTR|
TD
TR|TD
TR|TD
TABLE P
TR
TD TD TD TD
TD TD TD TD
TABLE
TBODY
data record 1
data record 2
TR|TD
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 12
Wrapper Induction (Muslea et al., Agents-99)
Using machine learning to generate extraction rules.The user marks the target items in a few training pages. The system learns extraction rules from these pages. The rules are applied to extract items from other pages.
Training ExamplesE1: 513 Pico, <b>Venice</b>, Phone 1-<b>800</b>-555-1515E2: 90 Colfax, <b>Palms</b>, Phone (800) 508-1570E3: 523 1st St., <b>LA</b>, Phone 1-<b>800</b>-578-2293E4: 403 La Tijera, <b>Watts</b>, Phone: (310) 798-0008
Output Extraction RulesStart rules: End rules:R1: SkipTo(() SkipTo())R2: SkipTo(-<b>) SkipTo(</b>)

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 13
Automatic Extraction
There are two main problem formulations:Problem 1: Extraction based on a single list page (Liu et al., KDD-03; Liu, Web Data Mining book
2006)
Problem 2: Extraction based on multiple input pages of the same type (list pages or detail pages) (Grumbach and Mecca, ICDT-99).
Problem 1 is more general: Algorithms for solving Problem 1 can solve Problem 2.
Thus, we only discuss Problem 1.
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 14
Automatic Extraction: Problem 1
Data region1
Data region2
Data records

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 15
Solution Techniques
Identify data regions and data recordsBy finding repeated patterns
string matching (treat HTML source as a string)
tree matching (treat HTML source as a tree)
Align data items: Multiple alignmentMany multiple alignment algorithms exist, however, they
tend to make unnecessary commitments in early (often wrong) alignments.
inefficient.
An new algorithm, called Partial Tree Alignment, was proposed to deal with the problems (Zhai and Liu, WWW-05)
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 16
Roadmap
Introduction
1. Structured data extraction
2. Information integration
3. Opinion mining (information extraction)
Conclusions
Structured data
Unstructured text

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 17
Information Integration
The extracted data from different sites need to be integrated to produce a consistent database. Integration means:
Schema match: match columns in different data tables that contain the same type of information (e.g., product names). Data instance match: match values that are semantically identical but represented differently in different Web sites (e.g., “Coke” and “Coca Cola”).
Unfortunately, limited research has been done so far in this extraction context. Much of the research has been focused on the integration of Web query interfaces
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 18
Web Query Interface Integration (Wu et al., SIGMOD-04; Dragut et al., VLDB-06)
united.com airtravel.com delta.com hotwire.com
Global Query Interface

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 19
An Illustration (He and Chang, SIGMOD-03)
Discover synonym attributes (book domain)Author – Writer, Subject – Category
Model Discovery
author name subject categorywriter
S2:writertitlecategoryformat
S3:nametitlekeywordbinding
S1:authortitlesubjectISBN
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 20
Schema Matching as Correlation Mining(He and Chang, KDD-04)
This technique needs a large number of input query interfaces.
Synonym attributes are negatively correlatedthey are alternatives, rarely co-occur.e.g., Author = writer
Group attributes have positive correlationthey often co-occur in query interfacese.g., {Last Name, First Name}

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 21
A Clustering Approach (Wu et al., SIGMOD-04)
1:1 match based on clustering of attributes:
Similarity: linguistic similarity and domain similarity (domain: usually in a drop-down list)
X
1:m mappingsAggregate and is-a types
Bridging effect: “a2” and “c2” might not look similar themselves but they might both be similar to “b3”called the transitive property
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 22
“Bridging” Effect
?A
CB
Observations:- It is difficult to match “Select your vehicle” field, A, with “make” field, B- But A’s instances are similar to C’s, and C’s label is similar to B’s- Thus, C can serve as a “bridge” to connect A and B!
Attribute
Label
Domain value instance

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 23
Instance-Based Matching via Query Probing (Wang et al., VLDB-04)
Both query interfaces and returned results (instances) are considered in matching.
Assumption: A global schema (GS) and a set of instances are given.
The method uses each instance value (IV) of every attribute in GS to probe the underlying database to obtain the count of IV appeared in the returned results.
These counts are used to help matching.
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 24
Query Interface and Result Page
Title?

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 25
Roadmap
Introduction
1. Structured data extraction
2. Information integration
3. Opinion mining (information extraction)
Conclusions
Structured data
Unstructured text
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 26
Information Extraction
We now move to unstructured text on the Web.
A major Web content mining research is to extract specific types of information from text in Web pages.
Factual information, e.g., Extract unreported side effects of drugs from Web pages.
Extract infectious diseases from online news.
Extract economic data from reports of different countries.
Subjective opinionsWe focus on this topic as it is quite unique to the Web. There is also a growing interest in this topic.
It is probably useful to everyone: consumers and organizations.

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 27
Word-of-Mouth on the Web
The Web has dramatically changed the way that people express their opinions. One can
post reviews of products at merchant sites, and express opinions on almost anything in forums, discussion groups, and blogs, which are collectively called the user generated content.
We only focus on mining product reviews here.Extract and summarize opinions in reviews.
Benefits:Potential Customer: No need to read many reviewsProduct manufacturer: market intelligence, product benchmarking.
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 28
Sentiment Classification of Reviews(Turney, ACL-02, Pang et al., EMNLP-02; Dave et al., WWW-03)
Classify reviews based on the overall sentiment expressed by authors, i.e.,
Positive or negative
Related to but different from traditional topic-based text classification.
Here the opinion words (e.g., great, beautiful, bad, etc) are important, not topic words.
Some representative techniquesUse opinion phrases (Turney, ACL-02).
Use traditional text classification method (Pang et al., EMNLP-02),
Use a custom-designed score function (Dave et al., WWW-03).

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 29
Feature-Based Opinion Summarization (Hu and Liu, KDD-04)
Sentiment classification does not find what exactly consumers liked or disliked. You may say that people can read reviews, but
In online shopping, a lot of people write reviews
Time consuming and boring to read all the reviews
How?
Opinion summarization is a natural solution What is an effective summary?
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 30
An Review Example and a Summary
GREAT Camera., Jun 3, 2004 Reviewer: jprice174 from Atlanta,
Ga.I did a lot of research last year before I bought this camera... It kinda hurt to leave behind my beloved nikon 35mm SLR, but I was going to Italy, and I needed something smaller, and digital. The pictures coming out of this camera are amazing. The 'auto' feature takes great pictures most of the time. And with digital, you're not wasting film if the picture doesn't come out. …
….
Summary:
Feature1: picturePositive: 12
The pictures coming out of this camera are amazing. Overall this is a good camera with a really good picture clarity.
…Negative: 2
The pictures come out hazy if your hands shake even for a moment during the entire process of taking a picture.Focusing on a display rack about 20 feet away in a brightly lit room during day time, pictures produced by this camera were blurry and in a shade of orange.
Feature2: battery life…
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 31
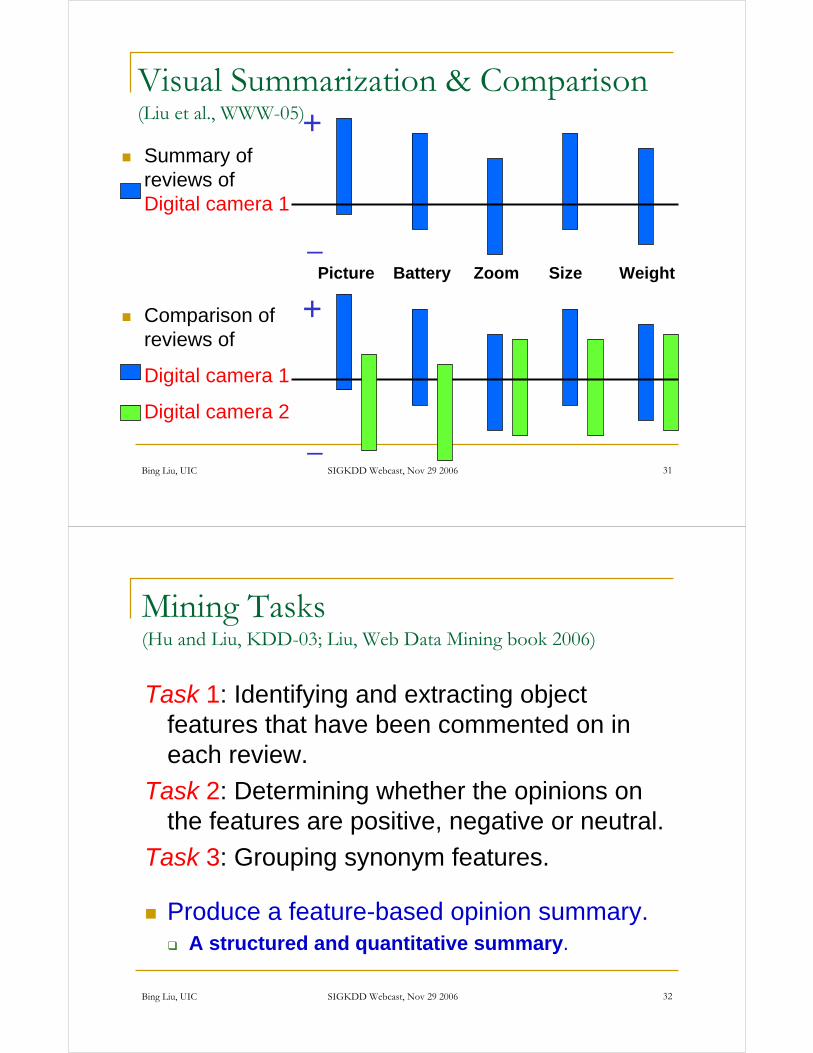
Visual Summarization & Comparison (Liu et al., WWW-05)
Summary of reviews of Digital camera 1
Picture Battery Size WeightZoom
Comparison of reviews of
Digital camera 1
Digital camera 2
+
_
_
+
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 32
Mining Tasks(Hu and Liu, KDD-03; Liu, Web Data Mining book 2006)
Task 1: Identifying and extracting object features that have been commented on in each review.
Task 2: Determining whether the opinions on the features are positive, negative or neutral.
Task 3: Grouping synonym features.
Produce a feature-based opinion summary.A structured and quantitative summary.

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 33
Extraction of Comparative Relations(Jinal and Liu, AAAI-06; Liu, Web Data Mining book 2006)
Opinions are basically evaluations. There is in fact another type of evaluation.
Comparisons: “Car X’s engine is not as good as that of car Y”
Direct opinions: “Car X is great.”but compared to what?
Comparative Sentence MiningIdentify comparative sentences, and
extract comparative relations from them, i.e., who is better than who on what.
See the above references for more info …
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 34
Existing Techniques
Current algorithms are combinations of Natural language processing (NLP) methods, and
Part-of-speech tagging, parsing, etc.
Pre-compiled opinion words and comparative words.
Data mining or machine learning techniques.Pattern mining and supervised learning, etc.
The problems are all very challenging.
Many researchers have worked on the problems recently.
See relevant papers for details.

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 35
Roadmap
Introduction
1. Structured data extraction
2. Information integration
3. Opinion mining (information extraction)
Conclusions
Structured data
Unstructured text
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 36
Conclusions
We Introduced:Structured data extractionInformation integrationOpinion mining (information extraction)
Due to time constraints, many other content mining topics could not be discussed. Although the tasks look quite different, there is a common theme:
Information synthesis: extraction and IntegrationI.e., identify and extract pieces of information items from multiple sources and integrate them in a consistent and coherent manner.

Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 37
Conclusions (Cont’d)
Data extraction and integration fit the model.Extraction of structured data
Integrate them: find synonyms, a very tough problem
Opinion mining and summarization also fit the modelextract product features and opinions
Summarizing the results, which is integration: synonyms
Both problems are very challenging.
In fact, many Web content mining tasks are similar: extraction and integration.
They all need some levels of Natural Language Understanding!
Bing Liu, UIC SIGKDD Webcast, Nov 29 2006 38
Q & A
Questions and Answers will be posted on www.KDnuggets.com/forums, under Webcasts: Web Content Mining forum
A link to the recorded version of this presentation will be posted at www.KDD.org
References of this talk can be found at: http://www.cs.uic.edu/~liub/WCM-Refs.html
Thank you for attending!