adb introduction
TRANSCRIPT

An Evolution in Database
Technology
Introduction to Associative
Technology

THE CEO PROBLEM
• Too many disparate Databases and data sources
• Lack of timely information & Incorrect information
• Potential Loss of control of the business
• Sky rocketing cost for storage
• Lack of Enterprise reporting
• Lack of knowledge & support capabilities
• Overly complex systems
Contributing issues :

STATEMENT OF THE MARKET
“The business's demand for access to the vast resources of big data gives information managers an opportunity to alter the way the enterprise uses information. IT leaders must educate their business counterparts on the challenges while ensuring some degree of control and coordination so that the big-data opportunity doesn't become big-data chaos, which may raise compliance risks, increase costs and create yet more silos.
Today's information management disciplines and technologies are simply not up to the task of handling all these dynamics. Information managers must fundamentally rethink their approach to data by planning for all the dimensions of information management.”
-Mark Beyer, research vice president at Gartner

PYRAMID OF KNOWLEDGE
SQL FILESMain
Frame
Trade
FeedSocial VideoNOSQL EXCEL
Multiple Data Sources
Information Technology
Computer Science
Hardware Software (Cir. 1971)
Knowledge
Information
Security Level - Critical
Security Level - Important
Security Level - fractured

STATE OF THE MARKET
Explosion of data, exponentially increasing monthly
Security & regulatory compliance
Government, banking & healthcare
Need to aggregate, analyze and deliver quickly
Big data is difficult, expensive and time consuming
Data projects are costly and good talent is hard to find
Needs; ease of use, reduce cost and increase analytic
capabilities
Goal; to deliver insight for business units, customers, and
partners
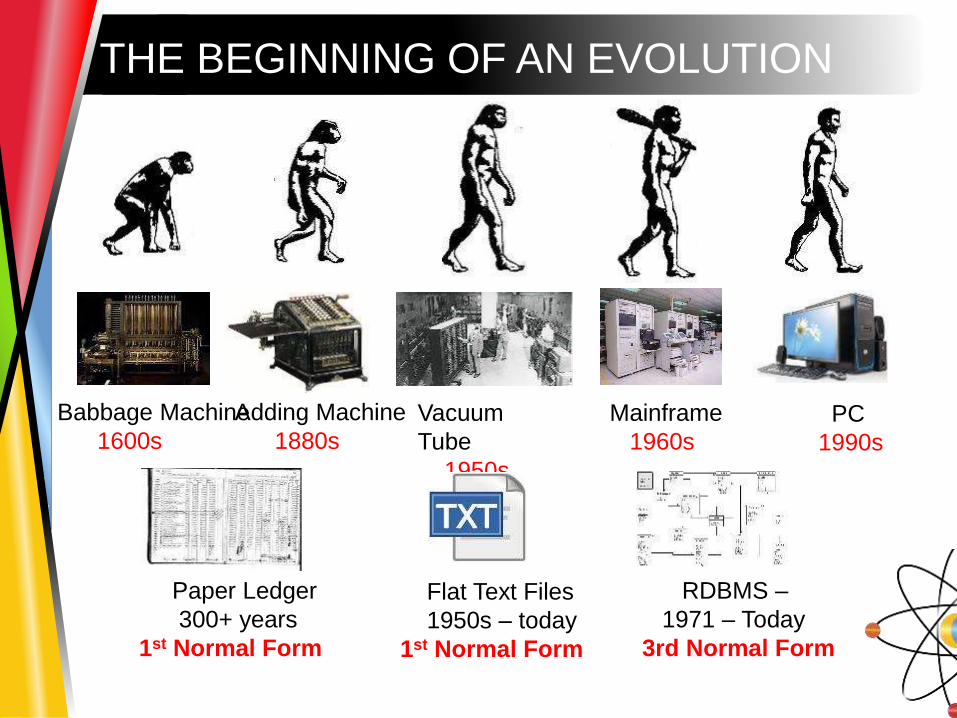
THE BEGINNING OF AN EVOLUTION
Babbage Machine
1600s
Adding Machine
1880s
Vacuum
Tube
1950s
Mainframe
1960sPC
1990s
Paper Ledger
300+ years
1st Normal Form
Flat Text Files
1950s – today
1st Normal Form
RDBMS –
1971 – Today
3rd Normal Form

FORMS OF DATA NORMALIZATION
First Normal Form
First normal form [1] deals with the "shape" of a record type
all occurrences of a record type must contain the same number of fields
Second Normal Form (MongoDB, Raven DB)
Second and third normal forms [2, 3, 7] deal with the relationship between non-key and key fields
Third Normal Form (SQL, NO SQL, Hadoop, Casandra , Mumps, etc.)
Third normal form is violated when a non-key field is a fact about another non-key field
Forth Normal Form (None)
a record type should not contain two or more independent multi-valued facts about an entity
the record must satisfy third normal form
Fifth Normal Form (None)
Fourth and fifth normal forms both deal with combinations of multivalued facts
One difference is that the facts dealt with under fifth normal form are not independent
Sixth Normal Form (None)
A relvar R [table] is in sixth normal form (abbreviated 6NF) if and only if it satisfies no nontrivial join dependencies at all
Some authors use the term sixth normal form differently, namely, as a synonym for Domain/key normal form (DKNF)
(N) Normal Form ( Associative or Vector based)
PARDIGMN Advance in Information Storage and Retrieval

ANALOGY OF ASSOCIATION
F
FIR
E-
Bi-directional
Pointers
addresses
I R E--
Alphabet has 26 Characters
Associations
x0000456
7
x0000456
8
x0000456
9
x0000457
0
x0001 x0002 x0003
AtomicDB logical
Record
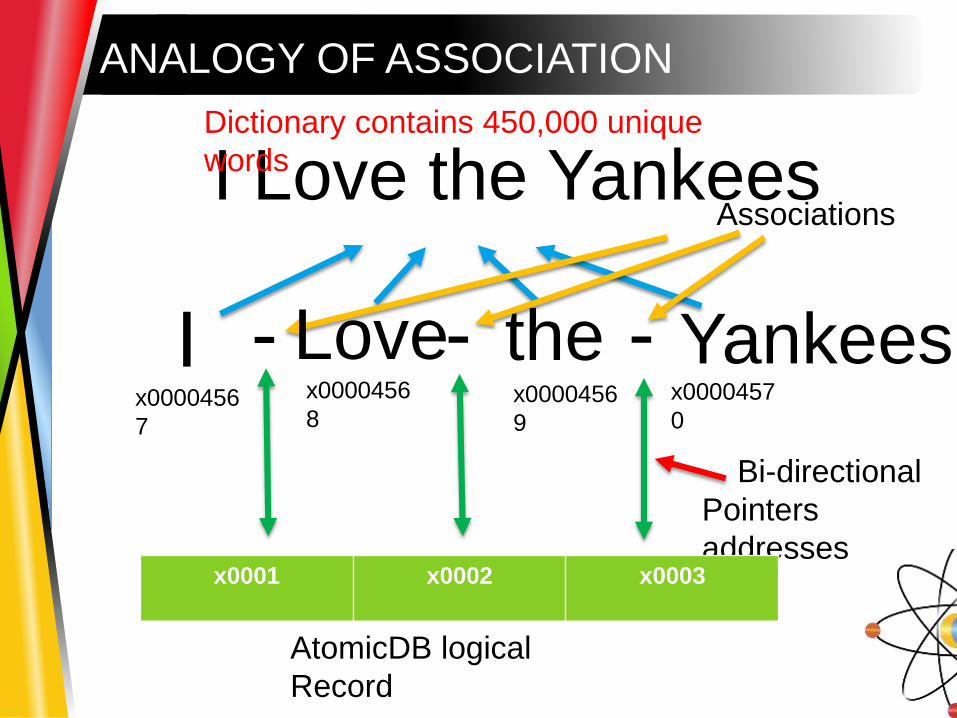
ANALOGY OF ASSOCIATION
I
I Love the Yankees
-
Bi-directional
Pointers
addresses
the Yankees--
Dictionary contains 450,000 unique
words
Associations
x0000456
7
x0000456
9
x0000457
0
x0001 x0002 x0003
AtomicDB logical
Record
x0000456
8
Love

Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
DataAssociative Pointer
AtomicDB Manages The Pointer (Associations)
It Does NOT Manage the Data
Welcome to the FUTURE – the (N) NORMAL FORM

SINGLE INSTANCE STORAGE
Data projects are costly and good talent is
hard to find
1991
2001
1986
2001
2012
1993
1991
1998
Lawyer
Teacher
Mother
Mother
Musician
Engineer
Lawyer
Chef
Robert
John
Jeff
Bill
Andre
John
Alex
Bill
Jones
Smith
Jones
Heart
Stone
Jefferson
Washingto
n
Smith
Susan
Susan
Amanda
Amanda
Sally
Summer
Deborah
Brittney

SINGLE INSTANCE STORAGE
(POINTERS)
Data projects are costly and good talent is
hard to find
1991
1986
2001
2012
1993
1998
Teacher
Mother
Musician
Engineer
Lawyer
Chef
Robert
Jeff
Bill
Andre
John
Alex
Jones
Smith
Heart
Stone
Jefferson
Washingto
n
Susan
Amanda
Sally
Summer
Deborah
Brittney
Information gets contextualized based on associations
Works like the human brain

TECHNICAL - MAPPING TABLES TO
Order Item Quantity Qualifiers Order ID
B7784 2 Red PO090311-72
B7196 3 Brown PO090311-72
B7208 4 Red PO090311-72
B7791 3 Green PO090311-72
B7844 1 Orange PO090311-73
B7863 5 Blue PO090311-74
Order ID
PO090311-72
PO090311-72
PO090311-72
PO090311-72
PO090311-73
PO090311-74
Table Name
Mapping 2-D tables to an ‘n’-D Associative Model enables unbounded extension
and evolution of the data sets, and automatically creates uniqueness (4th normal
form) where replicated values are unified, all record relations are automatically
cross-referenced and where their values (or labels) and their associations become
attributes of the tokens representing them. These tokens (shown next as paired
values) are actually four values, representing >1018th item indexing.
Order Item
B7784
B7196
B7208
B7791
B7844
B7863
Quantity
2
3
4
3
1
5
Qualifiers
Red
Brown
Red
Green
Orange
Blue
Order Item Quantity Qualifiers Order ID 1,0 ORDER ITEM
B77841,3
B77911,4
B72081,2
B71961,1
B78441,5
B78631,6
2,4 3,1 4,1
2,2 3,1 4,1
2,3 3,3 4,1
2,1 3,5 4,2
2,3 3,2 4,1
2,5 3,4 4,3
2,0 QUANTITY
4*2,4
2*2,2
1*2,1
5*2,5
3*2,3
1,3 3,1 4,1
1,4 3,1 4,1
1,3 3,4 4,3
1,5 3,5 4,2
1,1
3,2
4,1
1,4
3,3
3,0 QUALIFIERS
GREEN3,3
BLUE3,4
BROWN3,2
ORANGE3,5
RED3,1
1,1 2,3 4,1
1,4 2,3 4,1
1,6 2,3 4,3
1,5 2,1 4,2
1,2
2,2
4,1
2,4
1,3
4,0 ORDER ID
PO090311-744,3
PO090311-734,2
PO090311-724,1
1,5 2,1 3,5
1,6 2,5 3,4
1,1
2,2
3,1
1,2 1,3 1,4
2,3 2,4
3,2 3,3
Each table is algorithmically analyzed and column names are extracted. Associative
Contexts are auto generated and initially given the column names as attributes.
(These names are often abbreviations whose meaning is known only to the original
developer but in an Associative Model they can be changed later to ‘friendlier’names without affecting query operations)
Then the data sets in each column are auto-assimilated as members of the
corresponding Contexts and value duplication is removed, fusing replicated data.
A ‘schema’ qualifying or mapping the meaning of the inter-relationships between
Contexts can be utilized as an import filter or policy, constraining the assimilation
and coordinating the nature of each item’s relationship to every other item.
Accordingly, for each item, reference tokens representing each other row related
item are bilaterally added as associative attributes of each item, thus creating a
fully indexed and cross-referenced model where every item is now associatively
connected to each and every other related item, and where that connection is a
logical address that references where each item is in memory or in storage.

PROCESSING A REQUEST
Get 1 , 0 / whose .2 , 0 / = “3” AND .3 , 0 / = “Brown” As Answer
3*2,31,1
3,2
4,1
1,4
3,3
BROWN3,21,1 2,3 4,1
PO090311-724,1
1,1
2,2
3,1
1,2 1,3 1,4
2,3 2,4
3,2 3,3
Get Order Item/ whose .Quantity/ = “3” and .Qualifiers/ = “Brown” ...
14
Get Token/ whose .Token/ = “Value” AND .Token/ = “Value” ...
Each and every data set of interest can be found from a generic query that gets
populated at run time, and since everything is interrelated during assimilation,
queries consist only of Boolean vector operations amongst sets of Tokens.
The User visible text is mapped through the Token Space query template.
4*2,4
2*2,2
1*2,1
2,0 QUANTITY
5*2,5
1,3 3,1 4,1
1,4 3,1 4,1
1,3 3,4 4,3
1,5 3,5 4,2
3*2,31,1
3,2
4,1
1,4
3,3
B77841,3
B77911,4
B72081,2
B71961,1
1,0 ORDER ITEM
B78441,5
2,4 3,1 4,1
2,2 3,1 4,1
2,3 3,3 4,1
2,1 3,5 4,2
2,3 3,2 4,1
B78632,5 3,4 4,3
1,6
1,1 1,4
B71962,3 3,2 4,1
GREEN3,3
BLUE3,4
BROWN3,2
3,0 QUALIFIERS
ORANGE3,5
1,1 2,3 4,1
1,4 2,3 4,1
1,6 2,3 4,3
1,5 2,1 4,2
RED3,11,2
2,2
4,1
2,4
1,3
BROWN3,21,1 2,3 4,11,1
3 , 2
PO090311-744,3
PO090311-734,2
4,0 ORDER ID
1,5 2,1 3,5
1,6 2,5 3,4
PO090311-724,1
1,1
2,2
3,1
1,2 1,3 1,4
2,3 2,4
3,2 3,33*2,3
1,1
3,2
4,1
1,4
3,3
2 , 31 , 0
This text to token process is enabled algorithmically and directly maps the alpha /
numeric items from the user, through the Context mapping to the related Tokens.
From the users perspective, either graphically or using some ‘query like’ model, a
context of interest is selected, followed by points of reference.
The associative attributes of the items represented by the points of reference
tokens (2,3 and 3,2) are pulled by index from the system storage and filtered by
the Context of interest (1,0), then pooled in a Boolean operation whose result is
the token (1,1) representing the answer to the user’s query.
The result items’ associative attributes can be read to provide access to all
related items in the system storage. Please note: Unlike a table based system
where every record has to be read and compared to the ‘where’ criteria, only the
criteria ‘items’ need to be read from storage & their attributes ‘pooled’ to get the
answer
A comparison of the processing efficiencies of tables vs tokens is revealing:
For the table example of 100 million records,100 million reads were needed and
each of those reads involved compare operations and record copies for matches.
Here, with the same data set, only four reads were required to get the answer.

REPRESENTING RESULTS
3*2,31,1
3,2
4,1
1,4
3,3
BROWN3,21,1 2,3 4,1
PO090311-724,1
1,1
2,2
3,1
1,2 1,3 1,4
2,3 2,4
3,2 3,3
Get Order Item/ whose .Quantity/ = 3 AND .Qualifiers/ = “Brown” ... as Answer
Show Answer, .Quantity/, .Qualifiers/, .Order ID/
15
1 , 0
2 , 0
3 , 0
4 , 0
1 , 1
2 , 3
3 , 2
4 , 1
B71962,3 3,2 4,1
1,1
ORDER ITEM QUANTITY QUALIFIERS ORDER ID
B7196 3 Brown PO090311-72
Get 1 , 0 / whose .2 , 0 / = 3 and .3 , 0 / = “Brown” As Answer
Show Answer, .2 , 0 /, .3 , 0 /, .4 , 0 /
The ability to access, process and resolve relationships entirely in token space
with all names, labels and values stored as attributes, enables huge advantages
such as multi-lingual, generic user interfaces that populate themselves from the
data sets, cross-referenced and filtered by user and activity profiles.
In the final step involving presenting the answer to the user, the tokens’namespace attributes are read and substituted for the tokens in the user interface /
report.
Once the result items’ values and names / labels are presented for the user, the
associative attributes of the items are always kept available, enabling browsing
from any represented item to any or all of its associated items.
The result set is maintained programmatically as a collection of tokens, so they,
and all their relations can be mapped and presented using available visualization;
in grids, node graphs, 3-D fly throughs, pie charts and bar graphs, tab delimited
text, or in whatever customized way the user community wants.
All items can be manipulated generically since they all have an identical
embodiment with their data (as attributes) being the only difference

HOW IT WORKS
Traditional
Data Base Records
Traditional
Documents
Repositories
1. Traditional repositories
can be decomposed
to a set of information
nodes
2. These are attributed with
indexes of the set of related
information nodes and are
managed as individual items
or objects in an Associative
Model.
3. They are managed as index
and content nodes in a
Virtual Information Layer.

DISPARATE SYSTEMS CO-EXISTENCE
500 + RDBMS
Oracle, DB2, MS
SQL, TXT, Media …
Associative
DB
Staging
Connectivity Hub
Application A Application BApplication AApplication
B
Data Cleansing
Data Normalization
Application C
Associative
DB
Reporting
Intranet
Monitoring
Business
Intelligence
Storage, Licences fees, Agility
Production DW/ DBBi-Directional
ONE SOURCE
Allows for No Business Risk
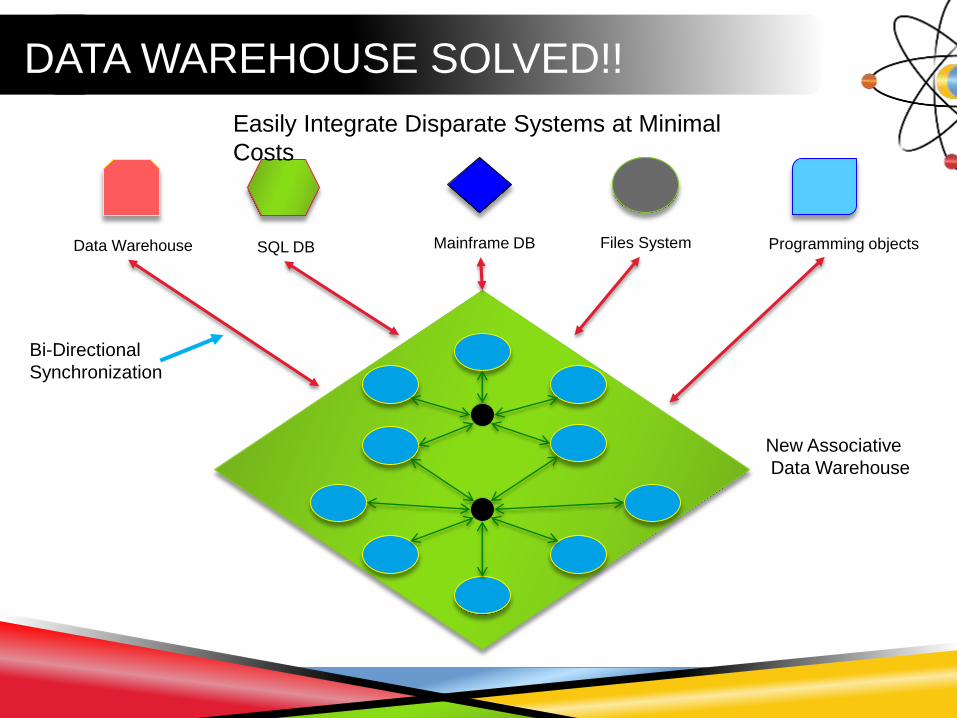
DATA WAREHOUSE SOLVED!!
Data Warehouse SQL DB Programming objectsMainframe DB Files System
New Associative
Data Warehouse
Easily Integrate Disparate Systems at Minimal
Costs
Bi-Directional
Synchronization

SIMPLE ANALOGIES
“It has been estimated that the vocabulary of English includes roughly one million words” – Merriam Webster. Every word is made of a tiny universe of only 26 characters.
Relations Database Management Systems (RDBMS) as well as any 3rd normal form NO-SQL solutions create and manage artificial structures producing tremendous overhead and misuse of resources.
Costly operations such as deletes are non existent in AtomicDB
Fastest operation in computer science is a pointer reference

VECTOR BASED INFORMATION MATRIX
Courtesy of Dr. Ashis Banerjee PHD

THE BRAIN – VECTOR BASED
Courtesy of UC Berkeley

ATOMICDB ADVANTAGES
Performance beyond comparison
1000X faster than SQL on READS (supports case sensitivity if needed)
10X ++ faster on WRITES ( in parallel mode)
Little to no support staff
No Tables, No Views, No whitespaces, No duplicates, No Indexes
Significantly reduce costs in hardware and storage
1/3 the DISK SPACE usage
Easy data analysis, quickly extract real value from your data
Associate Anything to Anything and combine data in all conceivable ways
50-75% reduction in development costs, 80% reduction in development time
Only 6 Instructions in full API, one line of code access to your data, No queries to write
Object oriented design
Aggregating data from heterogeneous systems is now simple
DOD verified Security Model
PARDIGM Shift in Data Storage and Retrieval

Login Instruction
AppName.Login (“Host”, “User Name”, “Password”, Return As, Flags)
Get Instruction
AppName.Get (Model(s), Concept(s), Item(s), ReturnAs, Flags
Add Instruction
AppName. Add( Model(s), Concept(s), Item(s), SendAs, Flags)
Import Instruction
AppName. Import( Model(s), Concept(s), Item(s), ReturnAs, Flags)
Associate Instruction
AppName.Associate (Model(s), Item(s), Items(s), SendAs, Flags)
Modify Instruction
AppName.Modify (Model(s), Concept(s), Items(s), SendAs, Flags)
FILTERING VS QUERYING

WHY ATOMICDB?
Performance beyond comparison
Robust and scalable
Low cost
Unique, non-invasive architecture
Easy to implement
Easy to maintain
Complimentary strategy
Reduces costs over other big data systems
Proven by the US military (US NAVY)
Connectivity Factory™ supports over 500 + financial sources &
data standards

WHO IS ATOMIC DATABASE CORP?
Founded in 2011, headquartered in New York
Presence in Switzerland, England, Canada, France, UAE, Saudi
Arabia and Australia
Private Company with 18 Permanent Individuals
Experienced Management Team (Citigroup, Pfizer, Merrill, META
Group, BEA, Plumtree, City of NY, AuthenWare)
Outstanding Board of Advisors
R&D, Production and Support 50% in USA, Canada & 50% in
Switzerland
Market Innovator w/ Most Comprehensive Database System
Proven Scalability & Rapid Market Expansion

An Evolution in Database
Technology
Thank You, Now Let’s Get to a Live
Demo