adding value through marketing stuart lewis – demonstrating and exploiting repository value
TRANSCRIPT

Addingvalue
throughmarketing
Stuart Lewis – Demonstrating and Exploiting Repository Value

Adding value through marketing
• How can we add value to our repositories?
–Marketing their contents–Understand how search services work
–Marketing items–Measuring the impact

What are we marketing?
The content
NOT
The Service

What is marketing?
• Marketing of items– Making people aware that they exist– Making them recognisable (brand / product
awareness)– Making people want to have them– Making people want to tell other people about
them

Repositories can market themselves
Repository
GoogleYahooMSN
OAIsterIntute
Repository Search
Google Scholar
EThOS

How do search engines find what we have?
• 3 methods1. They crawl our site
• They look at every page by following links and index all of our data
2. We suggest what to index using sitemaps• We provide a list of URLs, the date that they were last changed,
and their relative importance to us
3. They harvest our metadata• They harvest our metadata using OAI-PMH
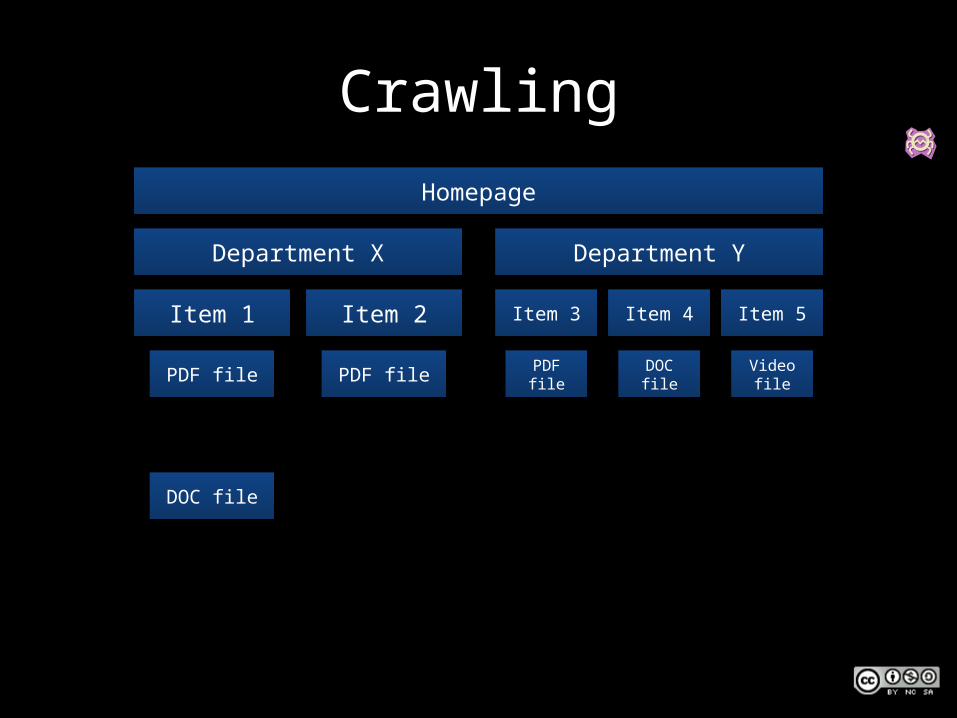
CrawlingHomepage
Department X
Item 1
PDF file
DOC file
Item 2
PDF file
Department Y
Item 3
PDF file
Item 4
DOC file
Item 5
Video file
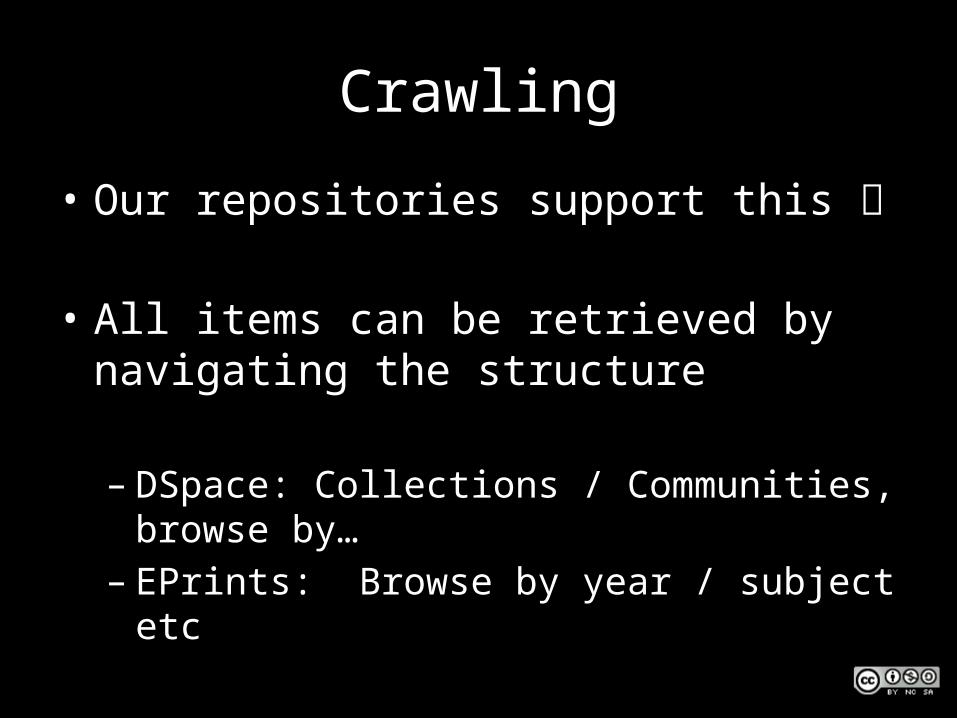
Crawling
• Our repositories support this
• All items can be retrieved by navigating the structure
– DSpace: Collections / Communities, browse by…– EPrints: Browse by year / subject etc

Sitemaps<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url> <loc>http://repository.example.com/</loc><lastmod>2008-12-03</lastmod>
<changefreq>daily</changefreq><priority>0.8</priority>
</url><url>
<loc>http://repository.example.com/item67</loc><lastmod>2008-12-01</lastmod>
<changefreq>monthly</changefreq><priority>1.0</priority>
</url></urlset>

Sitemaps
• Some repositories support this
• All items can be retrieved by navigating the sitemap

OAI-PMH
• Commands can be sent to the repository– Identify– List records– Get record– Get new records since dd-mm-yyyy
– Perform a full harvest first time– Perform subsequent incremental updates

OAI-PMH
• All repositories support this
• All items can be retrieved by harvesting the metadata

Indexing the metadata
• They’ve found our items, how do they index them?1. ‘Traditional search engines’ – Index the text,
using semantic hints2. ‘Specialist search engines’ – Index the text,
helped by embedded metadata3. ‘Metadata search services’ – Index just the
metadata
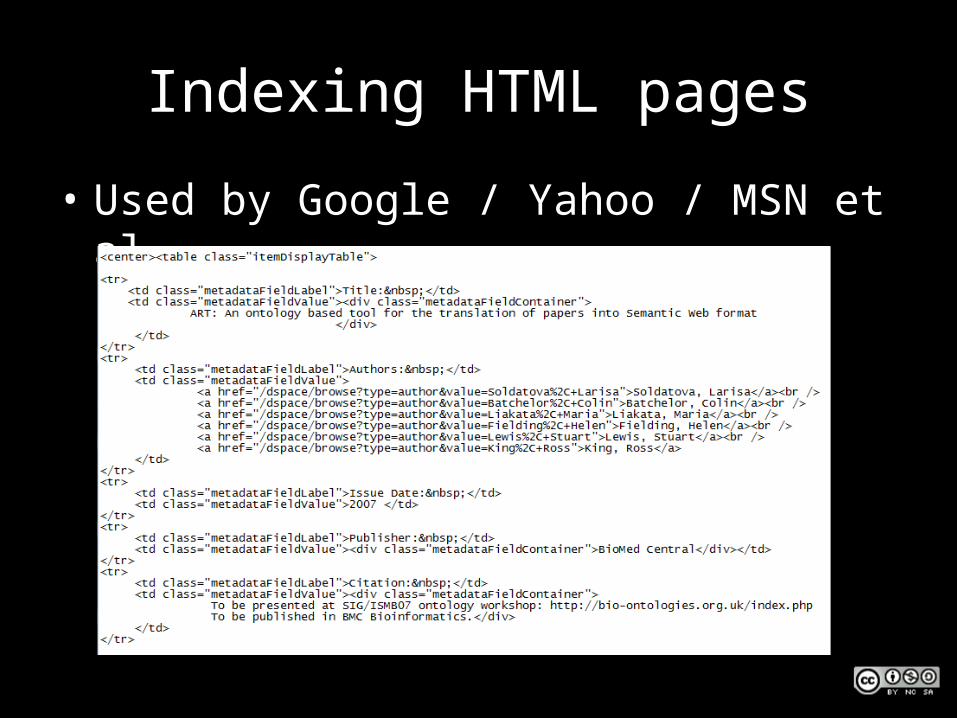
Indexing HTML pages
• Used by Google / Yahoo / MSN et al
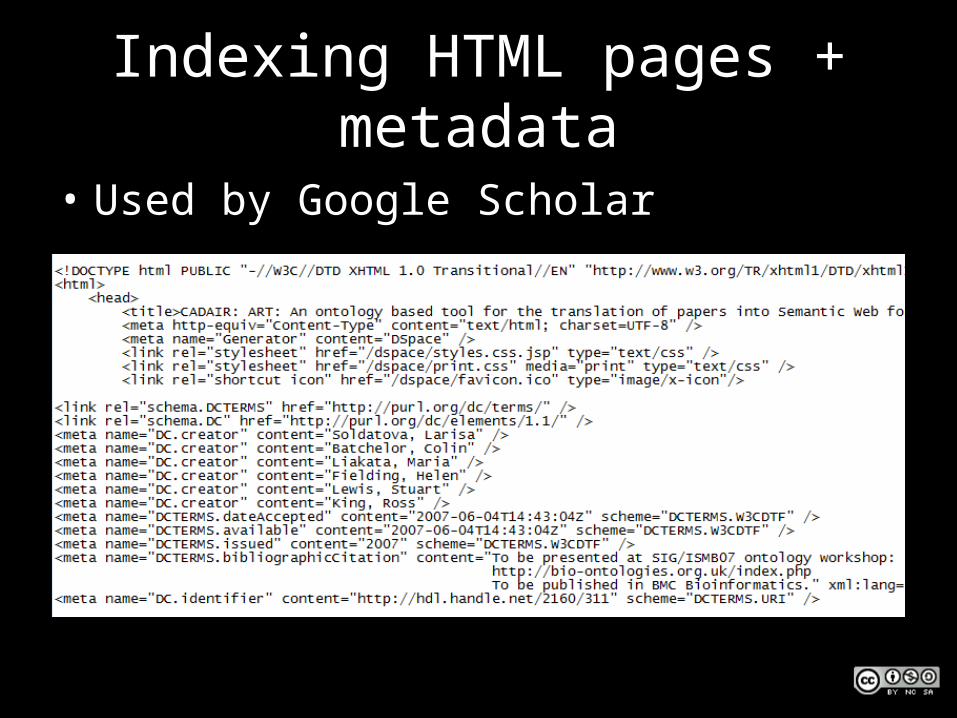
Indexing HTML pages + metadata
• Used by Google Scholar
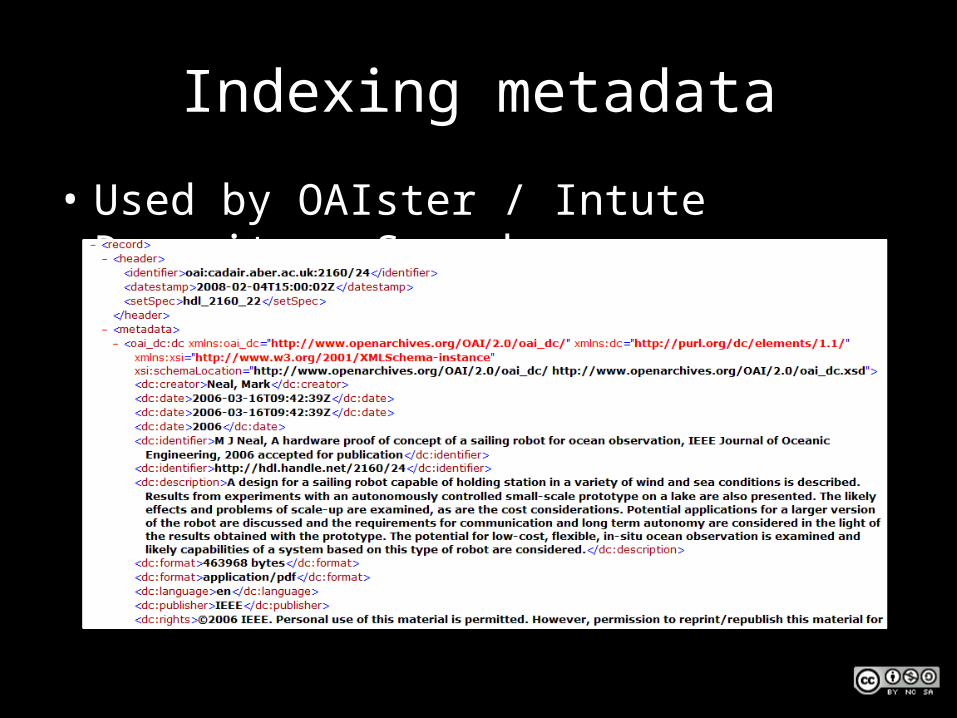
Indexing metadata
• Used by OAIster / Intute Repository Search

How they workGoogle / Yahoo /
MSNGoogle Scholar OAISter / Intute RS /
EThOSCrawl / sitemaps Crawl / sitemaps +
metadataOAI-PMH harvest
Index page + full text Index metadata + full text
Index metadata
Powerful, but doesn’t use the structured metadata
Very powerful as it uses metadata + full text
Limited to metadata only – requires good metadata (e.g.
subject keywords more important)

What about rankings?
• Crawling / indexing / harvesting gets our content into the search engines…
• …but how do rankings work?
• We want good rankings, we need…


How do rankings work?
• To be honest, we don’t really know!– This is intentional to stop spamming
• We know the high-level details such as:– PageRank technology– Hypertext-Matching Analysis
PageRank
PageRank reflects our view of the importance of web pages by considering more than 500 million variables and 2 billion terms. Pages that we believe are important pages receive a higher PageRank and are more likely to appear at the top of the search results.
PageRank also considers the importance of each page that casts a vote, as votes from some pages are considered to have greater value, thus giving the linked page greater value. We have always taken a pragmatic approach to help improve search quality and create useful products, and our technology uses the collective intelligence of the web to determine a page's importance.

Hypertext-Matching Analysis
Our search engine also analyzes page content. However, instead of simply scanning for page-based text (which can be manipulated by site publishers through meta-tags), our technology analyzes the full content of a page and factors in fonts, subdivisions and the precise location of each word.
We also analyze the content of neighboring web pages to ensure the results returned are the most relevant to a user's query.

How do rankings work?
• Some possible conclusions:– One big repository will have a higher page rank
than lots of individual author pages scattered across the web
– Encourage links to items– Edit templates sensibly:• E.g. leave item titles in <title> element
– Ensure good quality metadata• Populate subject tags if possible (more important
where the full text is not available)

Marketing individual items
• Tell people about the items!– Encourage use of RSS feeds• Feeds for individuals -> Facebook• Feeds for research groups -> department web pages

Marketing individual items
• Tell people about the items!– Encourage authors to post messages• Authors know who their potential audiences are• Look for discipline-specific email lists

Marketing individual items
• Tell people about the items!– Encourage people to link to items• Consider adding links to web link sites
– del.icio.us– digg– Citeulike– reddit– facebook– stumbleupon– connotea

Marketing individual items
• Tell people about the items!– Encourage authors to play the system• arXix example…
– Dietrich, JP (2008) Disentangling visibility and self-promotion bias in the arXiv: astro-ph positional citation effect. PUBLICATIONS OF THE ASTRONOMICAL SOCIETY OF THE PACIFIC
– http://arxiv.org/abs/0805.0307v2(869): 801-804

Self-Promotion Bias in Arxiv Deposit Listings
(1) Arxiv provides a daily list of articles deposited. The articles higher on that list are more cited than the articles lower on that list.

Self-Promotion Bias in Arxiv Deposit Listings
(2) Whether an article appears higher on that list does not depend on merit. It depends on what time the article was deposited.

Self-Promotion Bias in Arxiv Deposit Listings
(3) Timing is predictable from time zones and geography, so if these two factors are controlled for, one can also identify which articles were (probably) deliberately timed by their authors so as to appear near the top of the list ("self-promotion").

Self-Promotion Bias in Arxiv Deposit Listings
(4) This study shows that even after one has removed any effect of self-promotion, appearing nearer the top of the list randomly still increases an article's citation count.
(5) Self-promotion itself increases an article's citation count too.http://openaccess.eprints.org/index.php?/archives/444-Self-Promotion-Bias-in-Arxiv-Deposit-Listings.html

But don’t be silly
• Sagi I., Yechiam E., Amusing titles in scientific journals and article citation. Journal of Information Science, 2008;34(5):680-687DOI: 10.1177/0165551507086261
• http://jis.sagepub.com/cgi/content/abstract/34/5/680

But don’t be silly
The present study examines whether the use of humor in scientific article titles is associated with the number of citations an article receives. Four judges rated the degree of amusement
and pleasantness of titles of articles published over 10 years (from 1985 to 1994) in two of the most prestigious journals in psychology, Psychological Bulletin and Psychological Review. We then examined the association between the levels of amusement
and pleasantness and the article's monthly citation average.
The results show that, while the pleasantness rating was weakly
associated with the number of citations, articles with highly
amusing titles (2 standard deviations above average) received
fewer citations.

Search Engine Optimisation (SEO)
• There is a serious point:– Consider SEO tactics e.g.:• Use titles that contain search terms

Marketing individual items
• Tell people about the items!– Encourage authors to blog about their items
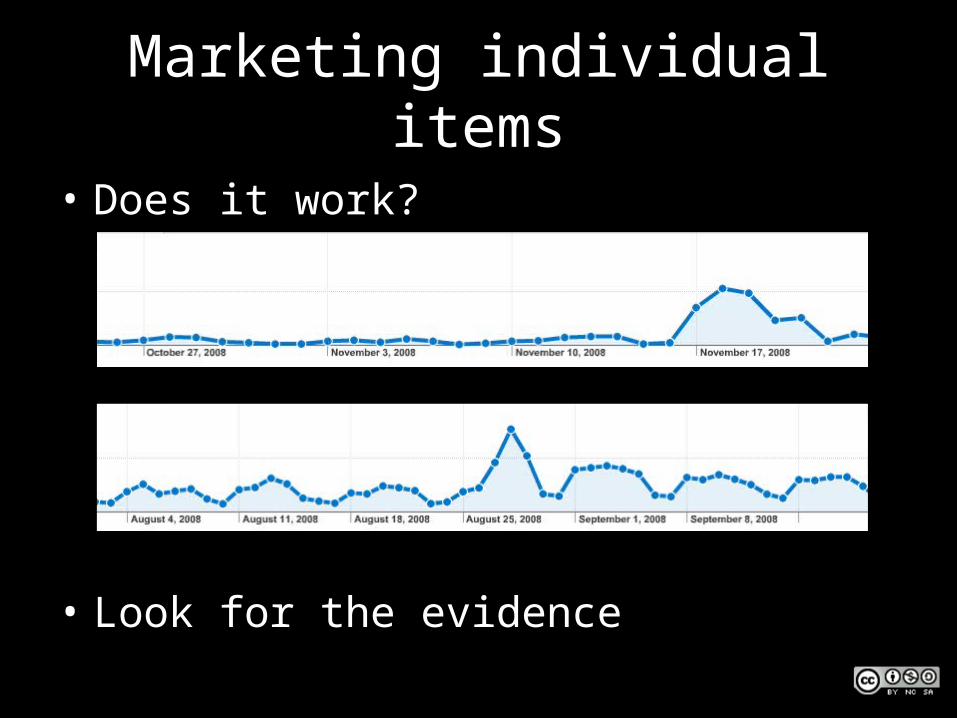
Marketing individual items
• Does it work?
• Look for the evidence

Some conclusions
• Work with the systems• Know and understand the systems• Play the systems• If we / the authors don’t promote the items,
who will?

Coming up next…
• Know what you are aiming for – what do you consider ‘success’ to be? Once you know, work out how you can measure it. Discuss…
• Small group discussion: Demonstrating value: what is a successful repository
• Take some of these ideas and work out how they can help you achieve whatever your definition of a successful repository is

What are we aiming for?
• An example question to ponder:– What is an ideal distribution for repository traffic?

Attributions• Cover image: http://www.flickr.com/photos/evert-jan/314349264/• Shop front: http://www.flickr.com/photos/28526185@N04/2663558632/• Green bottles: http://www.flickr.com/photos/7302101@N08/434693011/